Land Cover Heterogeneity Effects on Sub-Pixel and Per-Pixel Classifications



Abstract
:
1. Introduction
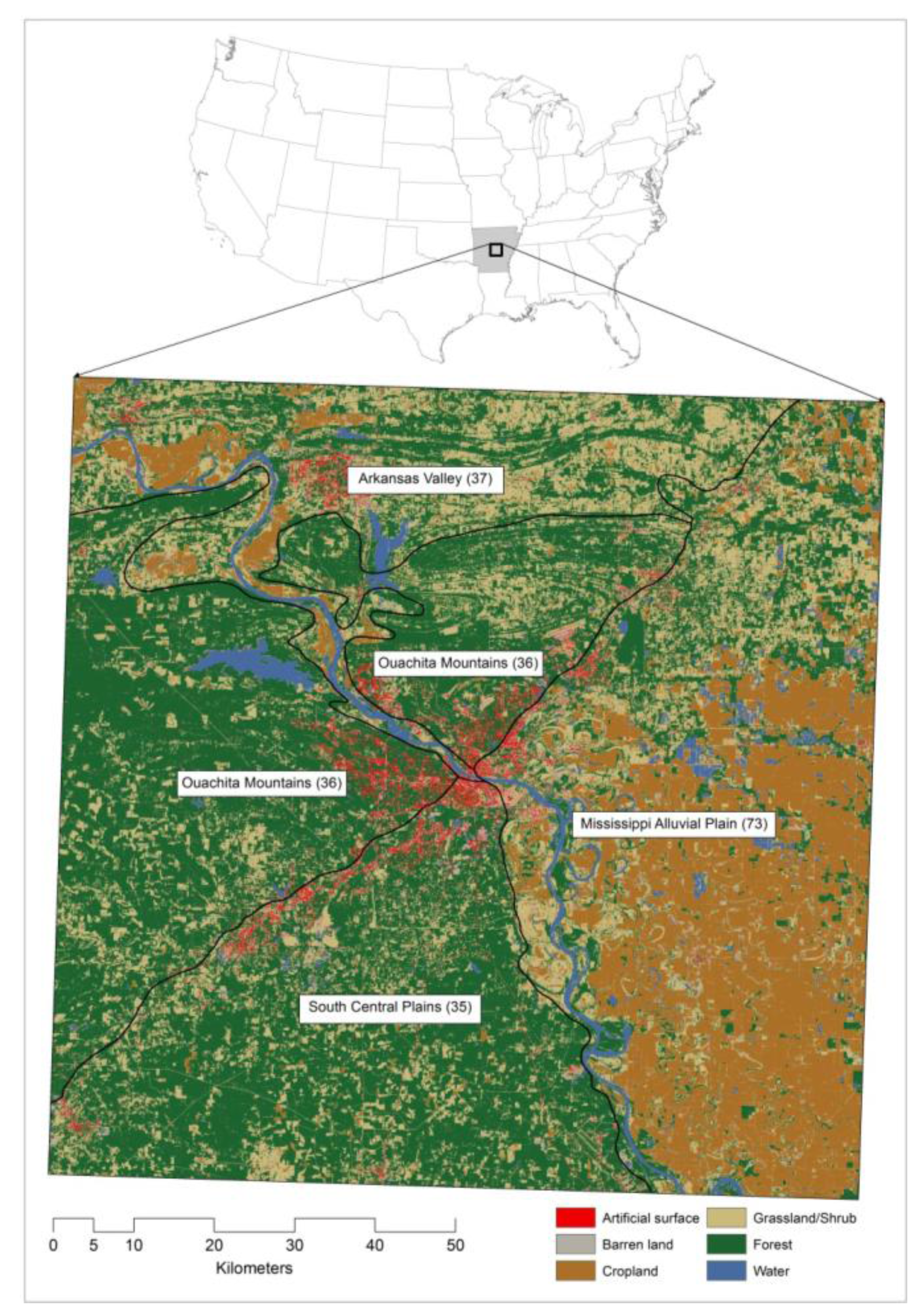
2. Study Area
3. Data
4. Methodology
4.1. Classification

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Definition |
|---|---|
| Cropland (CR) | Areas used for the production of crops, such as corn, soybeans, vegetables, tobacco and cotton. This class also includes fallow cropland. |
| Artificial surface (AR) | Construction materials, such as asphalt, concrete and rooftops. |
| Barren (BA) | Areas of bedrock, bare soil, quarries and any accumulation of earthen material. |
| Forest (FO) | All trees over 5 m, including low-density trees in urban areas. |
| Grassland/Shrub (GR) | Areas with >80% coverage of graminoid or herbaceous vegetation; or areas with >20% coverage of shrubs less than 5 m high. |
| Water (WA) | Areas of open water with <25% coverage of any other class. |
4.2. Validation
4.3. Statistical Analyses
5. Results and Discussion
5.1. Land Cover Map and Accuracy
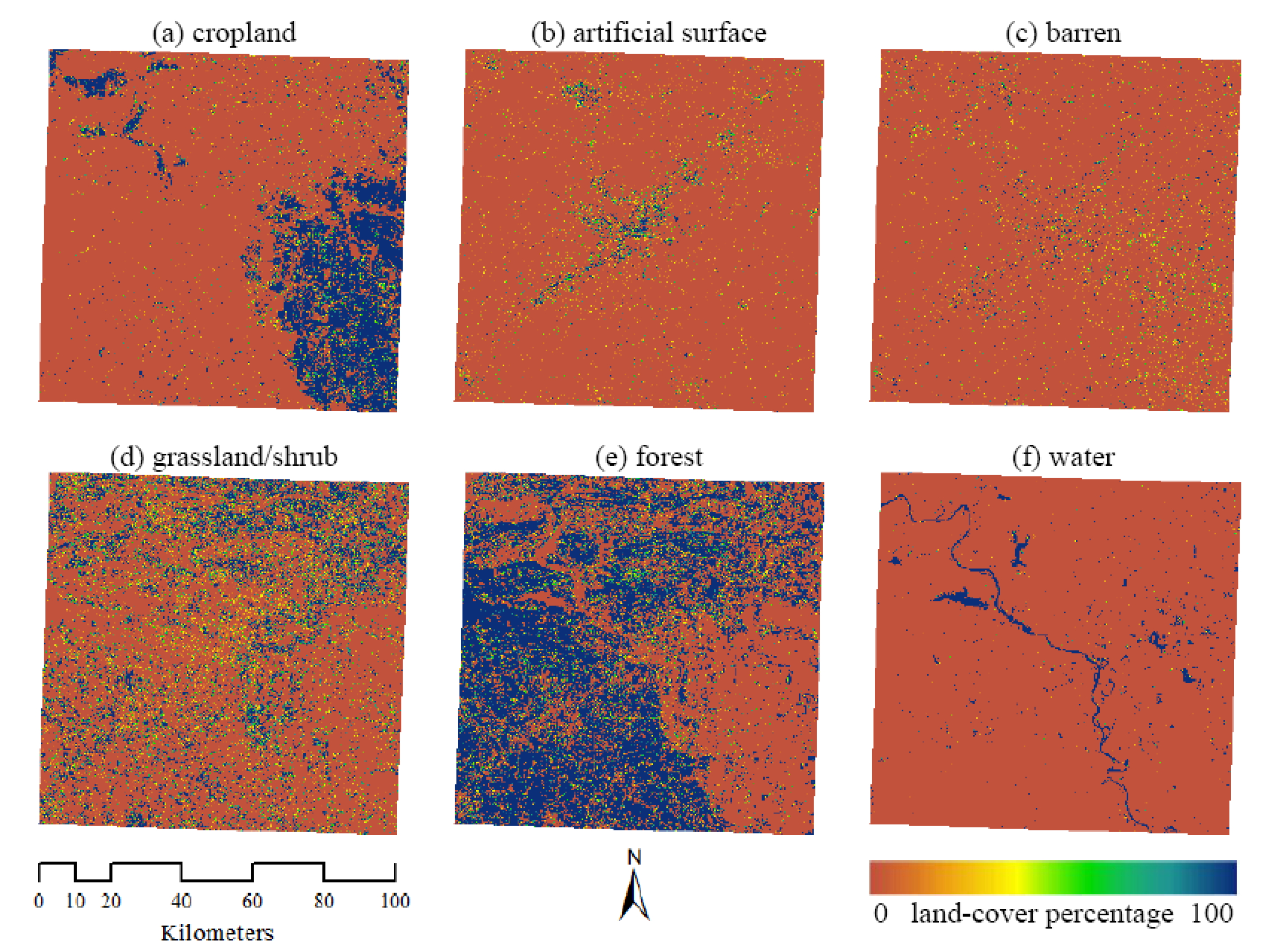
| Land Cover Class | Referenced Percentage | |||||||
|---|---|---|---|---|---|---|---|---|
| Cropland | Artificial | Barren | Grass-Land/Shrub | Forest | Water | Total | ||
| Estimated percentage | Cropland | 12.65 | 0.05 | 0.78 | 0.91 | 0.44 | 0.18 | 15.00 |
| 12.40 | 0.04 | 0.73 | 0.88 | 0.38 | 0.08 | 14.51 | ||
| Artificial | 0.01 | 4.87 | 0.78 | 0.62 | 0.37 | 0.04 | 6.68 | |
| 0.06 | 5.87 | 1.15 | 1.09 | 0.51 | 0.07 | 8.75 | ||
| Barren | 0.38 | 2.33 | 6.01 | 1.17 | 0.61 | 0.31 | 10.81 | |
| 0.50 | 1.80 | 5.78 | 0.90 | 0.58 | 0.33 | 9.88 | ||
| Grassland/Shrub | 1.61 | 0.65 | 0.37 | 17.93 | 1.58 | 0.19 | 22.33 | |
| 1.67 | 0.25 | 0.22 | 17.56 | 1.35 | 0.21 | 21.24 | ||
| Forest | 0.09 | 0.59 | 0.25 | 2.94 | 29.11 | 0.24 | 33.22 | |
| 0.11 | 0.52 | 0.29 | 3.13 | 29.29 | 0.21 | 33.54 | ||
| Water | 0.04 | 0.00 | 0.13 | 0.28 | 0.21 | 11.30 | 11.95 | |
| 0.04 | 0.01 | 0.15 | 0.28 | 0.22 | 11.37 | 12.07 | ||
| Total | 14.78 | 8.48 | 8.32 | 23.84 | 32.32 | 12.26 | 100.00 | |
| 14.78 | 8.48 | 8.32 | 23.84 | 32.32 | 12.26 | 100.00 | ||
| Overall accuracy (%) | 81.87 | Kappa (%) | 76.99 | |||||
| 82.28 | 77.54 | |||||||
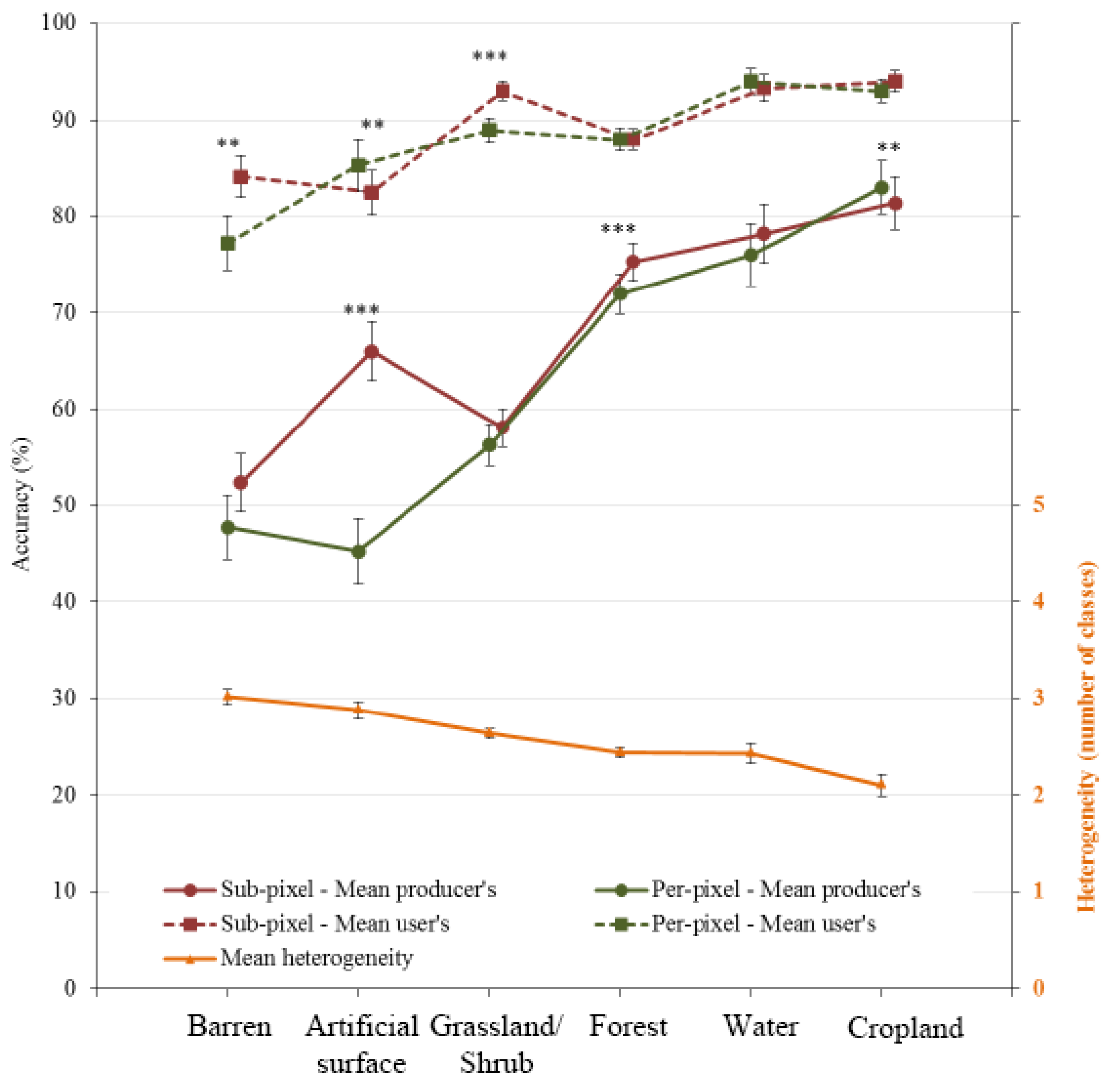
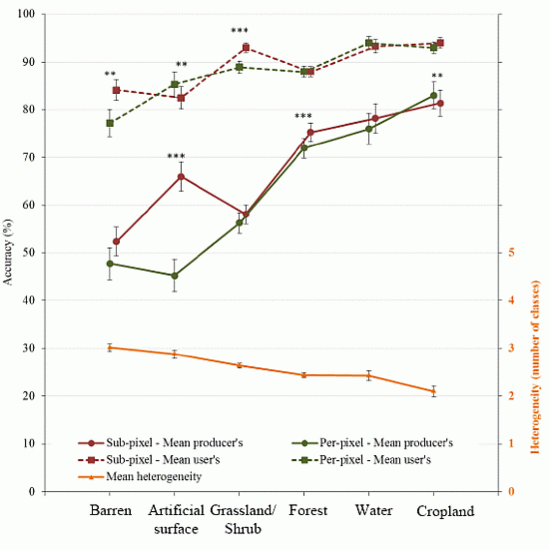
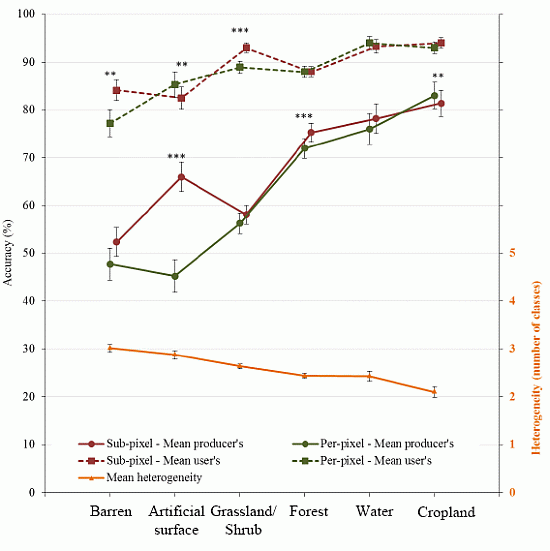
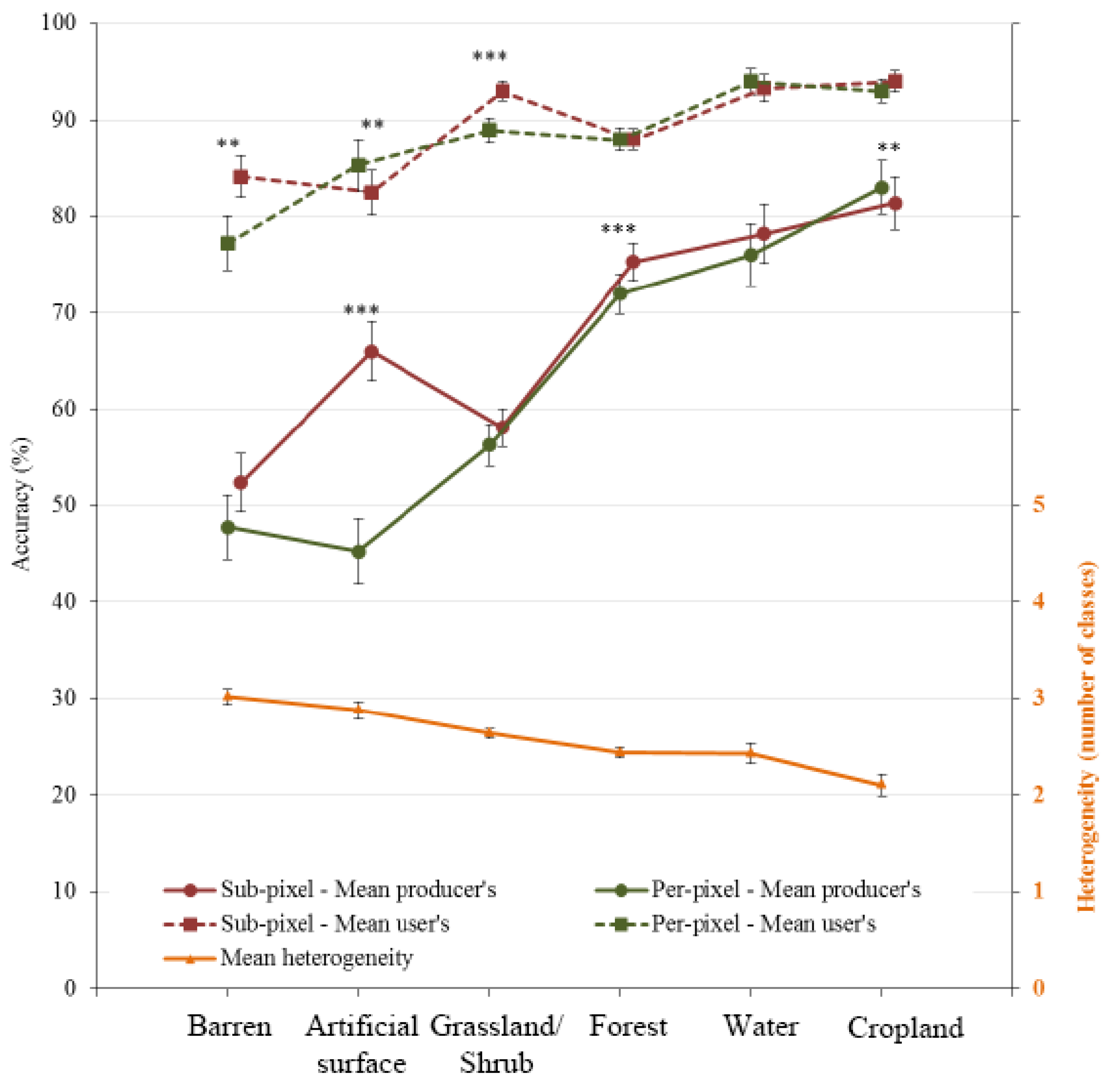
5.2. Heterogeneity and Its Effect on Classification Accuracy
6. Conclusion
Author Contributions
Conflicts of Interest
References
- Turner, B.L.; Lambin, E.F.; Reenberg, A. The emergence of land change science for global environmental change and sustainability. PNAS 2007, 104, 20666–20671. [Google Scholar] [CrossRef]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Congalton, R.G. Accuracy Assessment of Remotely Sensed Data: Future Needs and Directions. In Proceedings of the Pecora 12: Land Information from Space-Based Systems, Sioux Fals, SC, USA, 24–26 August 1994; pp. 383–388.
- McGwire, K.C.; Fisher, P. Spatially Variable Thematic Accuracy: Beyond the Confusion Matrix. In Spatial Uncertainty in Ecology: Implications for Remote Sensing and GIS Applications; Hunsaker, C.T., Goodchild, M.F., Friedl, M.A., Case, T.J., Eds.; Springer-Verlag: New York, NY, USA, 2001; pp. 308–329. [Google Scholar]
- Foody, G.M. Local characterization of thematic classification accuracy through spatially constrained confusion matrices. Int. J. Remote Sens. 2005, 26, 1217–1228. [Google Scholar] [CrossRef]
- Comber, A.; Fisher, P.; Brunsdon, C.; Khmag, A. Spatial analysis of remote sensing image classification accuracy. Remote Sens. Environ. 2012, 127, 237–246. [Google Scholar] [CrossRef]
- Hubert-Moy, L.; Cotonnec, A.; le Du, L.; Chardin, A.; Perez, P. A comparison of parametric classification procedures of remotely sensed data applied on different landscape units. Remote Sens. Environ. 2001, 75, 174–187. [Google Scholar] [CrossRef]
- Strahler, A.H.; Woodcock, C.E.; Smith, J.A. On the nature of models in remote sensing. Remote Sens. Environ. 1986, 20, 121–139. [Google Scholar] [CrossRef]
- Yu, Q.; Gong, P.; Tian, Y.Q.; Pu, R.; Yang, J. Factors affecting spatial variation of classification uncertainty in an image object-based vegetation mapping. Photogramm. Eng. Remote Sensing 2008, 74, 1007–1018. [Google Scholar] [CrossRef]
- Fahsi, A.; Tsegaye, T.; Tadesse, W.; Coleman, T. Incorporation of digital elevation models with landsat-tm data to improve land cover classification accuracy. Forest Ecol. Manage. 2000, 128, 57–64. [Google Scholar] [CrossRef]
- Smith, J.H.; Stehman, S.V.; Wickham, J.D.; Yang, L.M. Effects of landscape characteristics on land-cover class accuracy. Remote Sens. Environ. 2003, 84, 342–349. [Google Scholar] [CrossRef]
- Lechner, A.M.; Stein, A.; Jones, S.D.; Ferwerda, J.G. Remote sensing of small and linear features: Quantifying the effects of patch size and length, grid position and detectability on land cover mapping. Remote Sens. Environ. 2009, 113, 2194–2204. [Google Scholar] [CrossRef]
- Smith, J.H.; Wickham, J.D.; Stehman, S.V.; Yang, L. Impacts of patch size and land-cover heterogeneity on thematic image classification accuracy. Photogramm. Eng. Remote Sensing 2002, 68, 65–70. [Google Scholar]
- Aplin, P. On scales dynamics in observing the environment. Int. J. Remote Sens. 2006, 27, 2123–2140. [Google Scholar] [CrossRef]
- Weng, Q.; Lu, D. Landscape as a continuum: An examination of the urban landscape structures and dynamics of Indianapolis city, 1991–2000, by using satellite images. Int. J. Remote Sens. 2009, 30, 2547–2577. [Google Scholar] [CrossRef]
- Foody, G.M.; Doan, H.T.X. Variability in soft classification prediction and its implications for sub-pixel scale change detection and super resolution mapping. Photogramm. Eng. Remote Sensing 2007, 73, 923–933. [Google Scholar] [CrossRef]
- Lo, C.P.; Choi, J. A hybrid approach to urban land use/cover mapping using Landsat 7 Enhanced Thematic Mapper Plus (ETM+) images. Int. J. Remote Sens. 2004, 25, 2687–2700. [Google Scholar] [CrossRef]
- Cross, A.M.; Settle, J.J.; Drake, N.A.; Paivinen, R.T.M. Subpixel measurement of tropical forest cover using AVHRR data. Int. J. Remote Sens. 1991, 12, 1119–1129. [Google Scholar] [CrossRef]
- Shao, Y.; Lunetta, R.S. Sub-pixel mapping of tree canopy, impervious surfaces, and cropland in the Laurentian Great Lakes Basin using MODIS time-series data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 4, 336–347. [Google Scholar] [CrossRef]
- Weng, Q.; Rajasekar, U.; Hu, X. Modeling urban heat islands and their relationship with impervious surface and vegetation abundance by using ASTER images. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4080–4089. [Google Scholar] [CrossRef]
- Ngigi, T.G.; Tateishi, R.; Gachari, M. Global mean values in linear spectral unmixing: Double fallacy! Int. J. Remote Sens. 2009, 30, 1109–1125. [Google Scholar] [CrossRef]
- Van Oort, P.A.J.; Bregt, A.K.; de Bruin, S.; de Wit, A.J.W.; Stein, A. Spatial variability in classification accuracy of agricultural crops in the dutch national land-cover database. Int. J. Geogr. Inf. Sci. 2004, 18, 611–626. [Google Scholar] [CrossRef]
- Omernik, J. Ecoregions of the conterminous united states. Ann. Assoc. Am. Geogr. 1987, 77, 118–125. [Google Scholar] [CrossRef]
- Jawarneh, R.N.; Julian, J.P. Development of an accurate fine-resolution land cover timeline: Little rock, Arkansas, USA (1857–2006). Appl. Geogr. 2012, 35, 104–113. [Google Scholar] [CrossRef]
- Richards, J.A.; Jia, X. Remote Sensing Digital Image Analysis: An Introduction; Springer-Verlag: Berlin, Germany, 1999. [Google Scholar]
- Wang, F. Fuzzy supervised classification of remote sensing images. IEEE Trans. Geosci. Remote Sens. 1990, 28, 194–201. [Google Scholar] [CrossRef]
- Fry, J.; Xian, G.; Jin, S.; Dewitz, J.; Homer, C.; Yang, L.; Barnes, C.; Herold, N.; Wickham, J. Completion of the 2006 national land cover database for the conterminous United States. Photogramm. Eng. Remote Sensing 2011, 77, 858–864. [Google Scholar]
- U.S. Department of Agriculture National Agriculture Imagery Program (NAIP) Information Sheet. Available online: http://www.fsa.usda.gov/Internet/FSA_File/naip_2010_infosheet.pdf (accessed on 10 November 2013).
- Atmospheric Correction Module User’s Guide. Available online: https://www.exelisvis.com/portals/0/pdfs/envi/Flaash_Module.pdf (accessed on 10 November 2013).
- Ozesmi, S.L.; Bauer, M.E. Satellite remote sensing of wetlands. Wetl. Ecol. Manag. 2002, 10, 381–402. [Google Scholar] [CrossRef]
- Adkins, Z. Naip 2008 Absolute Ground Control: From the Ground up; Naip 2008 Absolute Ground Control: From the Ground up: Washington, DC, USA, 2009. [Google Scholar]
- Campbell, J.B.; Wynne, R.H. Introduction to Remote Sensing, 5th ed.; The Guilford Press: New York, NY, USA, 2011; p. 667. [Google Scholar]
- Powell, R.; Roberts, D.A.; Dennison, P.E.; Hess, L.L. Sub-pixel mapping of urban land cover using multiple endmember spectral mixture analysis: Manaus, Brazil. Remote Sens. Environ. 2007, 106, 253–267. [Google Scholar] [CrossRef]
- Song, C. Spectral mixture analysis for subpixel vegetation fractions in the urban environment: How to incorporate endmember variability? Remote Sens. Environ. 2005, 95, 248–263. [Google Scholar] [CrossRef]
- Pontius, R.G.; Cheuk, M.L. A generalized cross-tabulation matrix to compare soft-classified maps at multiple resolutions. Int. J. Geogr. Inf. Sci. 2006, 20, 1–30. [Google Scholar] [CrossRef]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Thomlinson, J.R.; Bolstad, P.V.; Cohen, W.B. Coordinating methodologies for scaling landcover classifications from site-specific to global: Steps toward validating global map products. Remote Sens. Environ. 1999, 70, 16–28. [Google Scholar] [CrossRef]
- Wilkinson, G.G. Results and implications of a study of fifteen years of satellite image classification experiments. IEEE Trans. Geosci. Remote Sens. 2005, 43, 433–440. [Google Scholar] [CrossRef]
- Goodchild, M.F.; Biging, G.S.; Congalton, R.G.; Langley, P.G.; Chrisman, N.R.; Davis, F.W. Final Report of the Accuracy Assessment Task Force; National Center for Geographic Information and Analysis (NCGIA): Santa Barbara, CA, USA, 1994. [Google Scholar]
- Wickham, J.D.; Stehman, S.V.; Fry, J.A.; Smith, J.H.; Homer, C.G. Thematic accuracy of the NLCD 2001 land cover for the conterminous United States. Remote Sens. Environ. 2010, 114, 1286–1296. [Google Scholar] [CrossRef]
- Weng, Q.; Hu, X.; Liu, H. Estimating impervious surfaces using linear spectral mixture analysis with multitemporal ASTER images. Int. J. Remote Sens. 2009, 30, 4807–4830. [Google Scholar] [CrossRef]
- Wu, C.; Murray, A.T. Estimating impervious surface distribution by spectral mixture analysis. Remote Sens. Environ. 2003, 84, 493–505. [Google Scholar] [CrossRef]
- Hu, X.; Weng, Q. Estimating impervious surfaces from medium spatial resolution imagery: A comparison between fuzzy classification and LSMA. Int. J. Remote Sens. 2011, 32, 5645–5663. [Google Scholar] [CrossRef]
- Stefanov, W.L.; Ramsey, M.S.; Christensen, P.R. Monitoring urban land cover change: An expert system approach to land cover classification of semiarid to arid urban centers. Remote Sens. Environ. 2001, 77, 173–185. [Google Scholar] [CrossRef]
- Lu, D.; Weng, Q. Spectral mixture analysis of the urban landscape in Indianapolis with Landsat ETM+ imagery. Photogramm. Eng. Remote Sens. 2004, 70, 1053–1062. [Google Scholar] [CrossRef]
- Foody, G.M.; Cox, D.P. Sub-pixel land cover composition estimation using a linear mixture model and fuzzy membership functions. Int. J. Remote Sens. 1994, 15, 619–631. [Google Scholar] [CrossRef]
- Foody, G.M. Sub-pixel Methods in Remote Sensing. In Remote Sensing Image Analysis: Including the Spatial Domain; Jong, S.M.D., Meer, F.D.V.D., Eds.; Springer: Dordrecht, The Netherlands, 2006; Volume 5, pp. 37–49. [Google Scholar]
- Weng, Q. Remote sensing of impervious surfaces in the urban areas: Requirements, methods, and trends. Remote Sens. Environ. 2012, 117, 34–49. [Google Scholar] [CrossRef]
- Nichol, J.E.; Wong, M.S.; Corlett, R.; Nochol, D.W. Assessing avian habitat fragmentation in urban areas of Hong Kong (Kowloon) at high spatial resolution using spectral unmixing. Landscape Urban Plan. 2010, 95, 54–60. [Google Scholar] [CrossRef]
- Small, C. Estimation of urban vegetation abundance by spectral mixture analysis. Int. J. Remote Sens. 2001, 22, 1305–1334. [Google Scholar] [CrossRef]
- Berezowski, T.; Chormański, J.; Batelaan, O.; Canters, F.; van de Voorde, T. Impact of remotely sensed land-cover proportions on urban runoff prediction. Int. J. Appl. Earth Obs. Geoinf. 2012, 16, 54–65. [Google Scholar] [CrossRef]
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Tran, T.V.; Julian, J.P.; De Beurs, K.M. Land Cover Heterogeneity Effects on Sub-Pixel and Per-Pixel Classifications. ISPRS Int. J. Geo-Inf. 2014, 3, 540-553. https://doi.org/10.3390/ijgi3020540
Tran TV, Julian JP, De Beurs KM. Land Cover Heterogeneity Effects on Sub-Pixel and Per-Pixel Classifications. ISPRS International Journal of Geo-Information. 2014; 3(2):540-553. https://doi.org/10.3390/ijgi3020540
Chicago/Turabian StyleTran, Trung V., Jason P. Julian, and Kirsten M. De Beurs. 2014. "Land Cover Heterogeneity Effects on Sub-Pixel and Per-Pixel Classifications" ISPRS International Journal of Geo-Information 3, no. 2: 540-553. https://doi.org/10.3390/ijgi3020540
APA StyleTran, T. V., Julian, J. P., & De Beurs, K. M. (2014). Land Cover Heterogeneity Effects on Sub-Pixel and Per-Pixel Classifications. ISPRS International Journal of Geo-Information, 3(2), 540-553. https://doi.org/10.3390/ijgi3020540