

GPT-Based Text-to-SQL for Spatial Databases
Abstract
1. Introduction
2. Related Work
3. Method
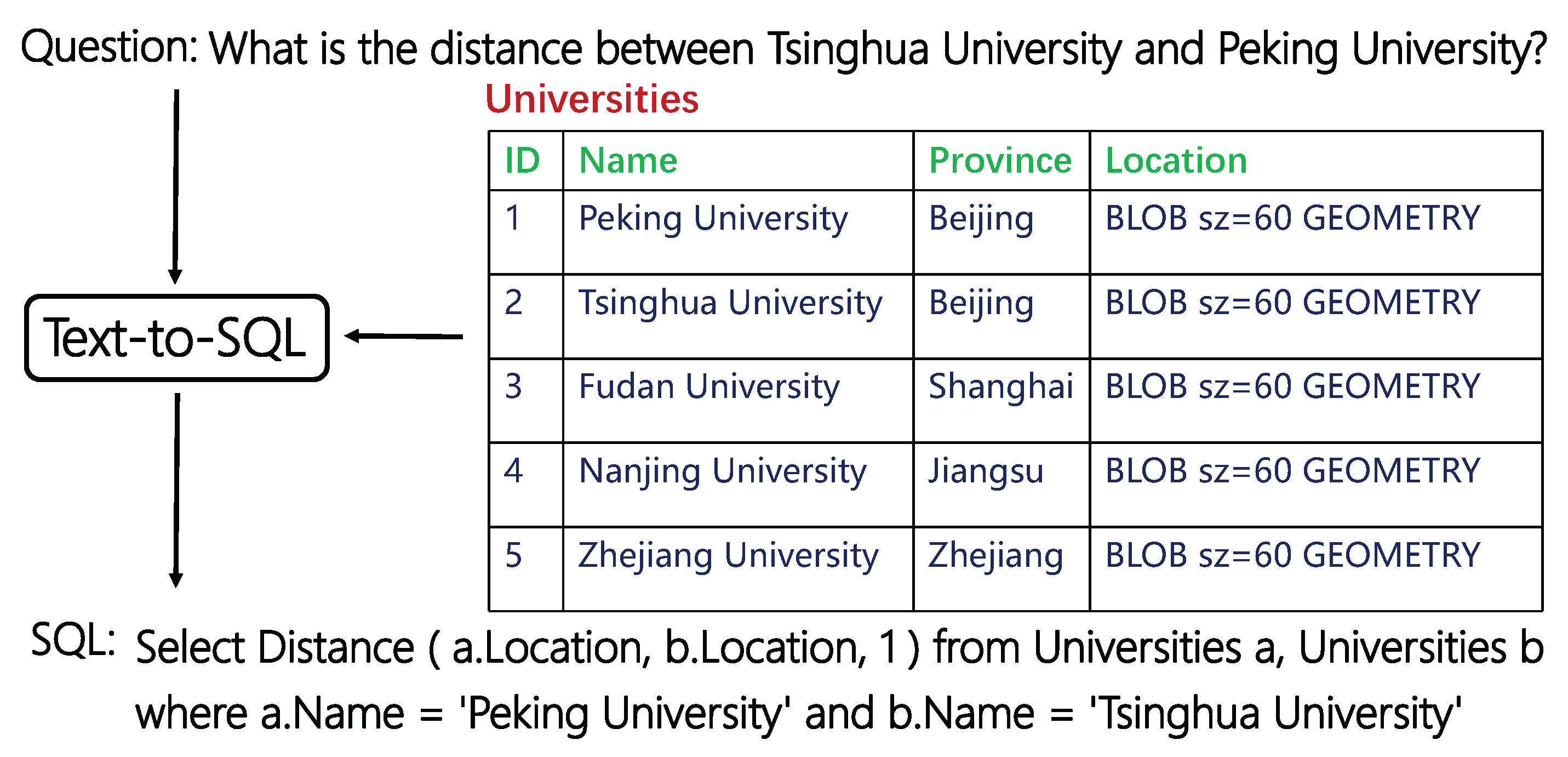
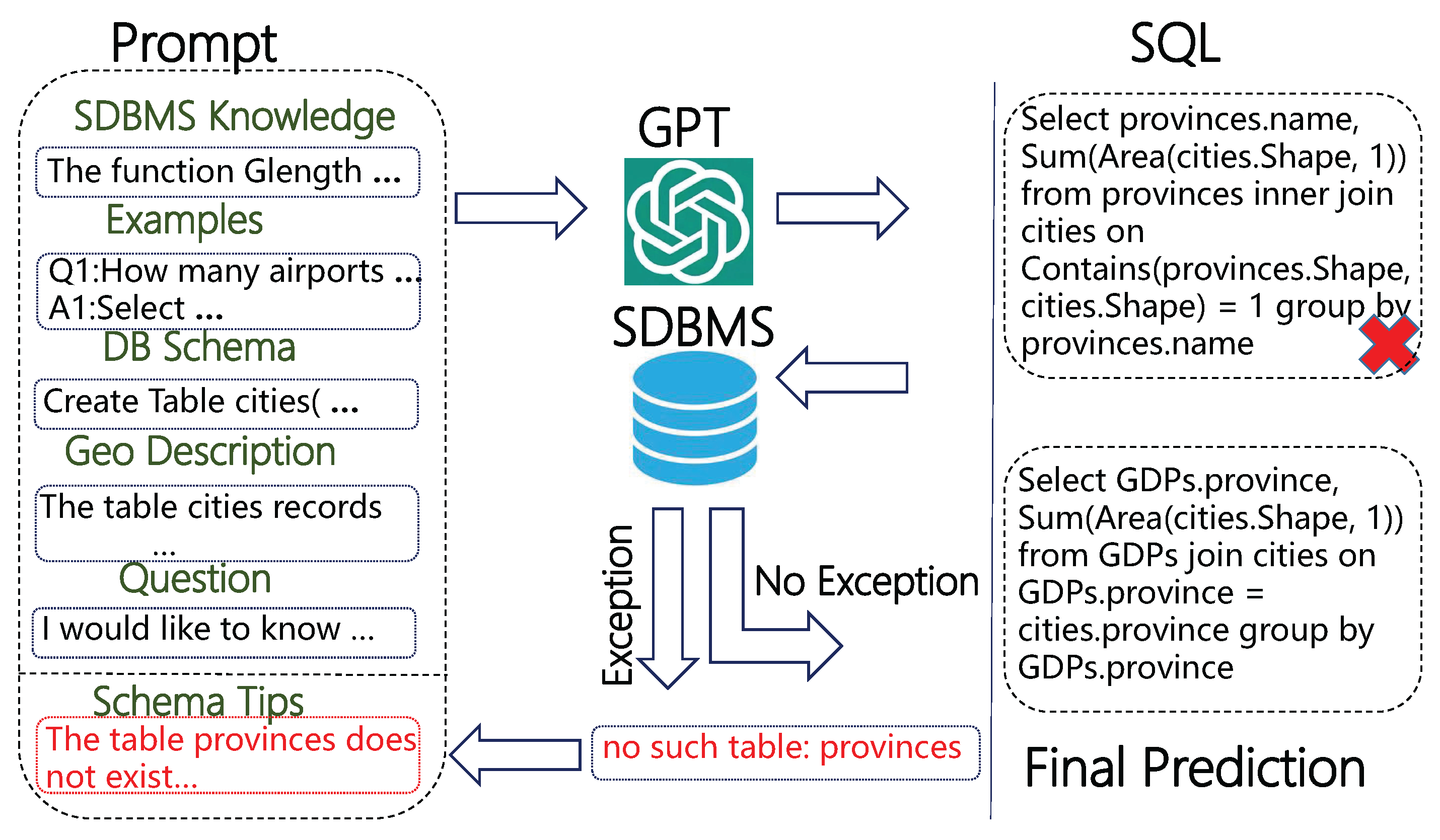
3.1. Overall Framework

3.2. SDBMS Knowledge
3.3. Examples
3.4. Database Schema
3.5. Geographic Descriptions
3.6. Question
3.7. Schema Tips
- When the exception feedback is “no such table: t”, we extract the table name ‘t’ and append the following sentence, “The table ‘t’ does not exist in the database and should not be used.”, to the prompt.
- When the exception feedback is “no such column: c”, we extract the column name ‘c’ and its corresponding table name ‘t’, and append the following sentence, “The column ‘c’ does not exist in the table ‘t’ and should not be used.”, to the prompt.
- When the exception feedback is “ambiguous column name: c”, we append the following sentence, “Columns in multiple tables may have the same name, so ambiguity should be avoided.”, to the prompt.
4. Experiment
4.1. Experiment Dataset
4.2. Experiment Methods
- SSpa: We have named our method SSpa, which consists of six components. Among them, the examples, database schema, and question are common components of GPT-based methods for relational databases in Text-to-SQL tasks, while the SDBMS knowledge, geographic descriptions, and schema tips represent the innovative aspects of our method.
- DAIL-SQL: DAIL-SQL, developed by Alibaba Group, is a highly effective and efficient method designed to optimize the application of GPT models in Text-to-SQL tasks. Notably, equipped with GPT-4, DAIL-SQL achieved first place on the Spider leaderboard with an execution accuracy of 86.6%, setting a new benchmark. DAIL-SQL is an excellent representative of GPT-based methods for relational databases in Text-to-SQL tasks, consisting mainly of examples, database schema, and question. Hence, we use DAIL-SQL as our baseline method.
- SSpa-SDBMS: Compared to the SSpa method, SSpa-SDBMS removes the SDBMS knowledge component while retaining the geographic descriptions and schema tips.
- SSpa-Geo: Compared to the SSpa method, SSpa-Geo removes the geographic descriptions component while retaining the SDBMS knowledge and schema tips.
- SSpa-Tips: Compared to the SSpa method, SSpa-Tips removes the schema tips component while retaining the SDBMS knowledge and geographic descriptions.
4.3. Evaluation Metrics
5. Results
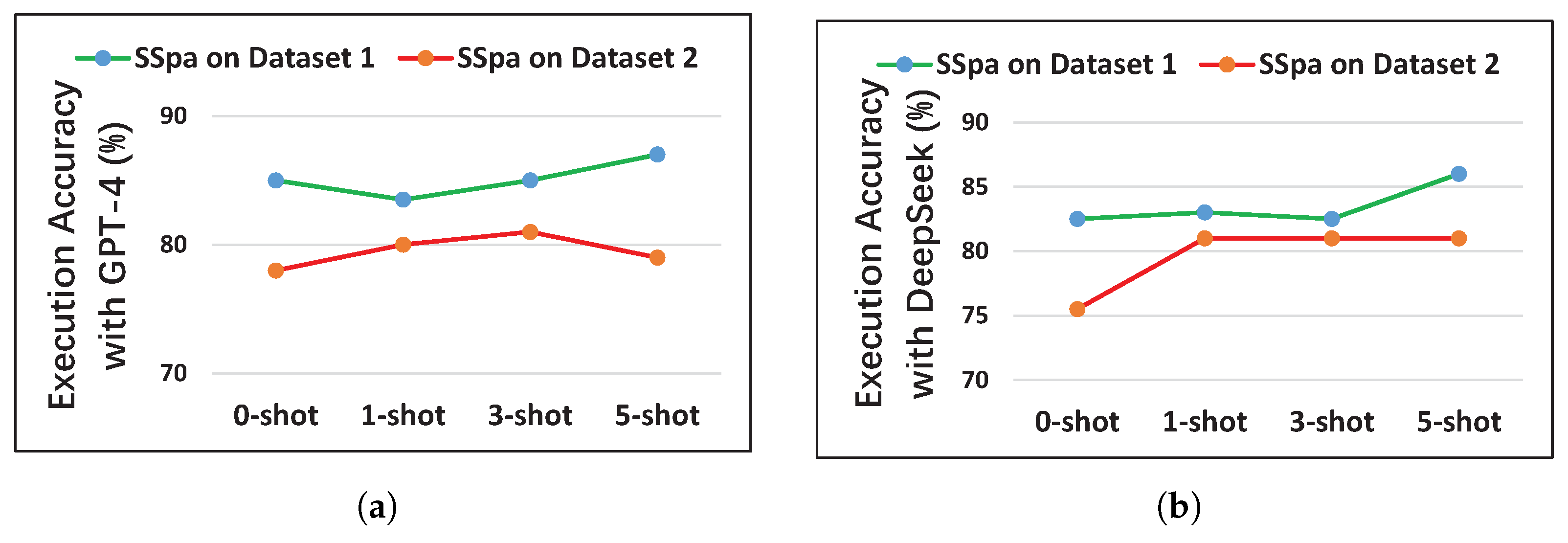
5.1. Performance Evaluation of Each Method
5.2. Effect of Each Component in the Prompt
6. Limitations
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Leszczynski, A.; Crampton, J. Introduction: Spatial Big Data and Everyday Life. Big Data Soc. 2016, 3, 1–6. [Google Scholar] [CrossRef]
- Liu, M.; Wang, X.; Xu, J. NALSD: A Natural Language Interface for Spatial Databases. In Proceedings of the 18th International Symposium on Spatial and Temporal Data, Calgary, AB, Canada, 23–25 August 2023; pp. 175–179. [Google Scholar]
- Liu, M.; Wang, X.; Xu, J.; Lu, H. NALSpatial: An Effective Natural Language Transformation Framework for Queries over Spatial Data. In Proceedings of the 31st ACM International Conference on Advances in Geographic Information Systems, Hamburg, Germany, 13–16 November 2023; p. 4. [Google Scholar]
- Wang, X.; Liu, M.; Xu, J.; Lu, H. NALMO: Transforming Queries in Natural Language for Moving Objects Databases. GeoInformatica 2023, 27, 427–460. [Google Scholar] [CrossRef]
- Liu, J.; Shen, D.; Zhang, Y.; Dolan, B.; Carin, L.; Chen, W. What Makes Good In-Context Examples for GPT-3? In Proceedings of the 3rd Workshop on Knowledge Extraction and Integration for Deep Learning Architectures, Dublin, Ireland, 26–27 May 2022; pp. 100–114. [Google Scholar]
- Guo, C.; Tian, Z.; Tang, J.; Wang, P.; Wen, Z.; Yang, K.; Wang, T. Prompting GPT-3.5 for Text-to-SQL with De-semanticization and Skeleton Retrieval. In Proceedings of the Trends in Artificial Intelligence—20th Pacific Rim International Conference on Artificial Intelligence, Jakarta, Indonesia, 15–19 November 2023; pp. 262–274. [Google Scholar]
- Pourreza, M.; Rafiei, D. DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction. In Proceedings of the 37th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2024; pp. 36339–36348. [Google Scholar]
- Zelle, J.M.; Mooney, R.J. Learning to Parse Database Queries using Inductive Logic Programming. In Proceedings of the Thirteenth National Conference on Artificial Intelligence, Portland, OR, USA, 4–8 August 1996; pp. 1050–1055. [Google Scholar]
- Tang, L.R.; Mooney, R.J. Automated Construction of Database Interfaces: Intergrating Statistical and Relational Learning for Semantic Parsing. In Proceedings of the 2000 Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora, Hong Kong, China, 7–8 October 2000; pp. 133–141. [Google Scholar]
- Iyer, S.; Konstas, I.; Cheung, A.; Krishnamurthy, J.; Zettlemoyer, L. Learning a Neural Semantic Parser from User Feedback. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 963–973. [Google Scholar]
- Zhong, V.; Xiong, C.; Socher, R. Seq2SQL: Generating Structured Queries from Natural Language Using Reinforcement Learning. arXiv 2017, arXiv:1709.00103. [Google Scholar] [CrossRef]
- Yu, T.; Zhang, R.; Yang, K.; Yasunaga, M.; Wang, D.; Li, Z.; Ma, J.; Li, I.; Yao, Q.; Roman, S.; et al. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3911–3921. [Google Scholar]
- Min, Q.; Shi, Y.; Zhang, Y. A Pilot Study for Chinese SQL Semantic Parsing. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 3652–3658. [Google Scholar]
- Wang, L.; Zhang, A.; Wu, K.; Sun, K.; Li, Z.; Wu, H.; Zhang, M.; Wang, H. DuSQL: A Large-Scale and Pragmatic Chinese Text-to-SQL Dataset. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, Online, 16–20 November 2020; pp. 6923–6935. [Google Scholar]
- Gan, Y.; Chen, X.; Huang, Q.; Purver, M.; Woodward, J.R.; Xie, J.; Huang, P. Towards Robustness of Text-to-SQL Models against Synonym Substitution. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, 1–6 August 2021; pp. 2505–2515. [Google Scholar]
- Gan, Y.; Chen, X.; Purver, M. Exploring Underexplored Limitations of Cross-Domain Text-to-SQL Generalization. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 8926–8931. [Google Scholar]
- Shaw, P.; Chang, M.-W.; Pasupat, P.; Toutanova, K. Compositional Generalization and Natural Language Variation: Can a Semantic Parsing Approach Handle Both? In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, 1–6 August 2021; pp. 922–938. [Google Scholar]
- Li, J.; Hui, B.; Qu, G.; Yang, J.; Li, B.; Li, B.; Wang, B.; Qin, B.; Geng, R.; Huo, N.; et al. Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs. In Proceedings of the 37th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023; pp. 42330–42357. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Guo, J.; Zhan, Z.; Gao, Y.; Xiao, Y.; Lou, J.-G.; Liu, T.; Zhang, D. Towards Complex Text-to-SQL in Cross-Domain Database with Intermediate Representation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 4524–4535. [Google Scholar]
- Choi, D.; Shin, M.C.; Kim, E.; Shin, D.R. RYANSQL: Recursively Applying Sketch-Based Slot Fillings for Complex Text-to-SQL in Cross-Domain Databases. Comput. Linguist. 2021, 47, 309–332. [Google Scholar] [CrossRef]
- Hwang, W.; Yim, J.; Park, S.; Seo, M. A Comprehensive Exploration on WikiSQL with Table-Aware Word Contextualization. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Yin, P.; Neubig, G.; Yih, W.-t.; Riedel, S. TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 8413–8426. [Google Scholar]
- Herzig, J.; Nowak, P.K.; Müller, T.; Piccinno, F.; Eisenschlos, J. TAPAS: Weakly Supervised Table Parsing via Pre-Training. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 4320–4333. [Google Scholar]
- Yu, T.; Wu, C.-S.; Lin, X.V.; Wang, B.; Tan, Y.C.; Yang, X.; Radev, D.R.; Socher, R.; Xiong, C. Grappa: Grammar-Augmented Pre-Training for Table Semantic Parsing. In Proceedings of the 9th International Conference on Learning Representations, Online, 3–7 May 2021. [Google Scholar]
- Li, J.; Wang, W.; Ku, W.-S.; Tian, Y.; Wang, H. SpatialNLI: A spatial Domain Natural Language Interface to Databases Using Spatial Comprehension. In Proceedings of the 27th ACM International Conference on Advances in Geographic Information Systems, Chicago, IL, USA, 5–8 November 2019; p. 10. [Google Scholar]
- Wang, W.; Li, J.; Ku, W.-S.; Wang, H. Multilingual Spatial Domain Natural Language Interface to Databases. GeoInformatica 2024, 28, 29–52. [Google Scholar] [CrossRef]
- Hong, Z.; Yuan, Z.; Zhang, Q.; Chen, H.; Dong, J.; Huang, F.; Huang, X. Next-Generation Database Interfaces: A Survey of LLM-Based Text-to-SQL. arXiv 2024, arXiv:2406.08426. [Google Scholar]
- Liu, X.; Shen, S.; Li, B.; Ma, P.; Jiang, R.; Zhang, Y.; Fan, J.; Li, G.; Tang, N.; Luo, Y. A Survey of NL2SQL with Large Language Models: Where Are We, and Where Are We Going? arXiv 2024, arXiv:2408.05109. [Google Scholar] [CrossRef]
- Shi, L.; Tang, Z.; Zhang, N.; Zhang, X.; Yang, Z. A Survey on Employing Large Language Models for Text-to-SQL Tasks. arXiv 2024, arXiv:2407.15186. [Google Scholar] [CrossRef]
- Dong, X.; Zhang, C.; Ge, Y.; Mao, Y.; Gao, Y.; Chen, L.; Lin, J.; Lou, D. C3: Zero-Shot Text-to-SQL with ChatGPT. arXiv 2023, arXiv:2307.07306. [Google Scholar]
- Zhang, H.; Cao, R.; Chen, L.; Xu, H.; Yu, K. ACT-SQL: In-Context Learning for Text-to-SQL with Automatically-Generated Chain-of-Thought. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; pp. 3501–3532. [Google Scholar]
- Gao, D.; Wang, H.; Li, Y.; Sun, X.; Qian, Y.; Ding, B.; Zhou, J. Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation. Proc. Vldb Endow. 2024, 17, 1132–1145. [Google Scholar] [CrossRef]
- Wu, H.; Shen, Z.; Hou, S.; Liang, J.; Jiao, H.; Qing, Y.; Zhang, X.; Li, X.; Gui, Z.; Guan, X.; et al. AutoGEEval: A Multimodal and Automated Evaluation Framework for Geospatial Code Generation on GEE with Large Language Models. ISPRS Int. J.-Geo-Inf. 2025, 14, 256. [Google Scholar] [CrossRef]
- Hou, S.; Jiao, H.; Shen, Z.; Liang, J.; Zhao, A.; Zhang, X.; Wang, J.; Wu, H. Chain-of-Programming (CoP): Empowering Large Language Models for Geospatial Code Generation Task. Int. J. Digit. Earth 2025, 18, 2509812. [Google Scholar] [CrossRef]
- Hou, S.; Liang, J.; Zhao, A.; Wu, H. GEE-OPs: An Operator Knowledge Base for Geospatial Code Generation on the Google Earth Engine Platform Powered by Large Language Models. Geo-Spat. Inf. Sci. 2025, 1–22. [Google Scholar] [CrossRef]
- Hou, S.; Shen, Z.; Zhao, A.; Liang, J.; Gui, Z.; Guan, X.; Li, R.; Wu, H. GeoCode-GPT: A Large Language Model for Geospatial Code Generation. Int. J. Appl. Earth Obs. Geoinf. 2025, 138, 104456. [Google Scholar] [CrossRef]
- Hou, S.; Zhao, A.; Liang, J.; Shen, Z.; Wu, H. Geo-FuB: A Method for Constructing An Operator-Function Knowledge Base for Geospatial Code Generation with Large Language Models. Knowl.-Based Syst. 2025, 319, 113624. [Google Scholar] [CrossRef]
- Jiang, Y.; Yang, C. Is ChatGPT a Good Geospatial Data Analyst? Exploring the Integration of Natural Language into Structured Query Language within a Spatial Database. ISPRS Int. J.-Geo-Inf. 2024, 13, 26. [Google Scholar] [CrossRef]
- Nan, L.; Zhao, Y.; Zou, W.; Ri, N.; Tae, J.; Zhang, E.; Cohan, A.; Radev, D. Enhancing Text-to-SQL Capabilities of Large Language Models: A Study on Prompt Design Strategies. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; pp. 14935–14956. [Google Scholar]
- Chang, S.; Fosler-Lussier, E. How to Prompt LLMs for Text-to-SQL: A Study in Zero-Shot, Single-Domain, and Cross-Domain Settings. arXiv 2023, arXiv:2305.11853. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| question: What is the total area of the three northeastern provinces? |
| questionCHI: 东三省的总面积是多少? |
| evidence: The three northeastern provinces refer to Liaoning, Jilin, and Heilongjiang. |
| evidenceCHI: 东三省指辽宁省, 吉林省, 黑龙江省. |
| name: Liaoning is represented by the name ‘辽宁省’, Jilin is represented by the name |
| ‘吉林省’, and Heilongjiang is represented by the name ‘黑龙江省’. |
| nameCHI: 辽宁省以‘辽宁省’ 为名称表示, 吉林省以‘吉林省’ 为名称表示, 黑龙江省以‘黑 |
| 龙江省’ 为名称表示. |
| SQL: Select Sum (Area (Shape, 1)) from cities where province in ( ‘辽宁省’, ‘吉林省’, ‘黑 |
| 龙江省’) |
| Name | Tables | Columns | PKs | FKs | Qs | Rs | SQLs |
|---|---|---|---|---|---|---|---|
| Ada1 | 6 | 53 | 6 | 1 | 56 | 7 | 90 |
| Ada2 | 6 | 49 | 6 | 0 | 56 | 7 | 56 |
| Edu1 | 3 | 26 | 3 | 3 | 44 | 0 | 93 |
| Edu2 | 3 | 22 | 3 | 0 | 44 | 0 | 44 |
| Tourism | 6 | 57 | 6 | 2 | 33 | 1 | 33 |
| Traffic1 | 11 | 55 | 11 | 4 | 67 | 26 | 81 |
| Traffic2 | 11 | 51 | 11 | 3 | 67 | 26 | 67 |
| Dataset 1 | Dataset 2 | |||||||
|---|---|---|---|---|---|---|---|---|
| Method | 0-Shot | 1-Shot | 3-Shot | 5-Shot | 0-Shot | 1-Shot | 3-Shot | 5-Shot |
| DAIL-SQL | 44.5 | 52.5 | 59.5 | 65.5 | 34.0 | 47.0 | 59.0 | 57.5 |
| SSpa | 85.0 | 83.5 | 85.0 | 87.5 | 78.0 | 80.0 | 81.0 | 79.0 |
| SSpa-SDBMS | 50.0 | 56.0 | 61.5 | 70.5 | 38.0 | 48.0 | 65.5 | 73.0 |
| SSpa-Geo | 80.5 | 77.5 | 78.0 | 77.5 | 75.0 | 71.0 | 71.5 | 68.5 |
| SSpa-Tips | 79.0 | 80.0 | 83.5 | 82.5 | 74.5 | 77.5 | 78.0 | 75.5 |
| Dataset 1 | Dataset 2 | |||||||
|---|---|---|---|---|---|---|---|---|
| Method | 0-Shot | 1-Shot | 3-Shot | 5-Shot | 0-Shot | 1-Shot | 3-Shot | 5-Shot |
| DAIL-SQL | 50.5 | 63 | 65.5 | 70.5 | 38.0 | 57.5 | 62.5 | 65.5 |
| SSpa | 82.5 | 83 | 82.5 | 86 | 75.5 | 81 | 81 | 81 |
| SSpa-SDBMS | 51.5 | 65 | 72 | 78.5 | 41 | 65.5 | 76.5 | 77.5 |
| SSpa-Geo | 79.5 | 79 | 79 | 79 | 72 | 76 | 74.5 | 73.5 |
| SSpa-Tips | 80.5 | 81 | 80.5 | 83.5 | 68.5 | 77 | 78.5 | 76.5 |
| Dataset 1 | Dataset 2 | |||||||
|---|---|---|---|---|---|---|---|---|
| Method | 0-Shot | 1-Shot | 3-Shot | 5-Shot | 0-Shot | 1-Shot | 3-Shot | 5-Shot |
| SSpa | 1 | 2 | 2 | 8 | 1 | 3 | 7 | 8 |
| SSpa-Tips | - | - | - | - | - | - | - | - |
| SSpa-SDBMS | 2 | 0 | 3 | 3 | 1 | 3 | 4 | 4 |
| SSpa-Geo | 2 | 2 | 2 | 7 | 2 | 3 | 4 | 6 |
| Dataset 1 | Dataset 2 | |||||||
|---|---|---|---|---|---|---|---|---|
| Method | 0-Shot | 1-Shot | 3-Shot | 5-Shot | 0-Shot | 1-Shot | 3-Shot | 5-Shot |
| SSpa | 1 | 2 | 2 | 3 | 1 | 1 | 7 | 8 |
| SSpa-Tips | - | - | - | - | - | - | - | - |
| SSpa-SDBMS | 1 | 3 | 7 | 5 | 1 | 5 | 8 | 9 |
| SSpa-Geo | 2 | 4 | 3 | 5 | 1 | 2 | 7 | 12 |
| Dataset 1 | Dataset 2 | |||||||
|---|---|---|---|---|---|---|---|---|
| Method | 0-Shot | 1-Shot | 3-Shot | 5-Shot | 0-Shot | 1-Shot | 3-Shot | 5-Shot |
| DAIL-SQL | 9 | 8 | 10 | 11 | 6 | 7 | 11 | 11 |
| SSpa | 32 | 31 | 32 | 31 | 31 | 30 | 32 | 32 |
| SSpa-Geo | 27 | 16 | 13 | 13 | 32 | 17 | 12 | 11 |
| Dataset 1 | Dataset 2 | |||||||
|---|---|---|---|---|---|---|---|---|
| Method | 0-Shot | 1-Shot | 3-Shot | 5-Shot | 0-Shot | 1-Shot | 3-Shot | 5-Shot |
| DAIL-SQL | 10 | 16 | 15 | 16 | 6 | 18 | 17 | 18 |
| SSpa | 31 | 33 | 33 | 33 | 31 | 34 | 33 | 33 |
| SSpa-SDBMS | 13 | 21 | 23 | 24 | 10 | 23 | 31 | 31 |
| SSpa-Geo | 29 | 23 | 19 | 19 | 28 | 22 | 20 | 18 |
| SSpa-Tips | 30 | 31 | 31 | 31 | 27 | 32 | 31 | 30 |
| Dataset 1 | Dataset 2 | |||||||
|---|---|---|---|---|---|---|---|---|
| Model | 0-Shot | 1-Shot | 3-Shot | 5-Shot | 0-Shot | 1-Shot | 3-Shot | 5-Shot |
| GPT-4 | 73 | 57 | 49 | 36 | 86 | 66 | 35 | 19 |
| DeepSeek | 66 | 38 | 32 | 21 | 78 | 35 | 17 | 14 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the International Society for Photogrammetry and Remote Sensing. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Guo, L.; Liang, Y.; Liu, L.; Huang, J. GPT-Based Text-to-SQL for Spatial Databases. ISPRS Int. J. Geo-Inf. 2025, 14, 288. https://doi.org/10.3390/ijgi14080288
Wang H, Guo L, Liang Y, Liu L, Huang J. GPT-Based Text-to-SQL for Spatial Databases. ISPRS International Journal of Geo-Information. 2025; 14(8):288. https://doi.org/10.3390/ijgi14080288
Chicago/Turabian StyleWang, Hui, Li Guo, Yubin Liang, Le Liu, and Jiajin Huang. 2025. "GPT-Based Text-to-SQL for Spatial Databases" ISPRS International Journal of Geo-Information 14, no. 8: 288. https://doi.org/10.3390/ijgi14080288
APA StyleWang, H., Guo, L., Liang, Y., Liu, L., & Huang, J. (2025). GPT-Based Text-to-SQL for Spatial Databases. ISPRS International Journal of Geo-Information, 14(8), 288. https://doi.org/10.3390/ijgi14080288