

Geometry and Topology Correction of 3D Building Models with Fragmented and Disconnected Components

Abstract
1. Introduction
2. Data
2.1. Data Generation and Characteristics
2.2. Data Limitations
3. Methodology
3.1. Duplicate Point Removal Methods
3.1.1. Vertex Map-Based Duplicate Removal
| Algorithm 1 Duplicate vertex removal algorithm using a vertex map |
|
3.1.2. KD-Tree-Based Duplicate Removal
3.2. Spatial Partitioning-Based Connected Mesh Clustering
| Algorithm 2 Spatial partitioning-based DFS for connected mesh clustering |
|
| Algorithm 3 Creationof the spatial grid |
|
4. Experimental Results and Discussion
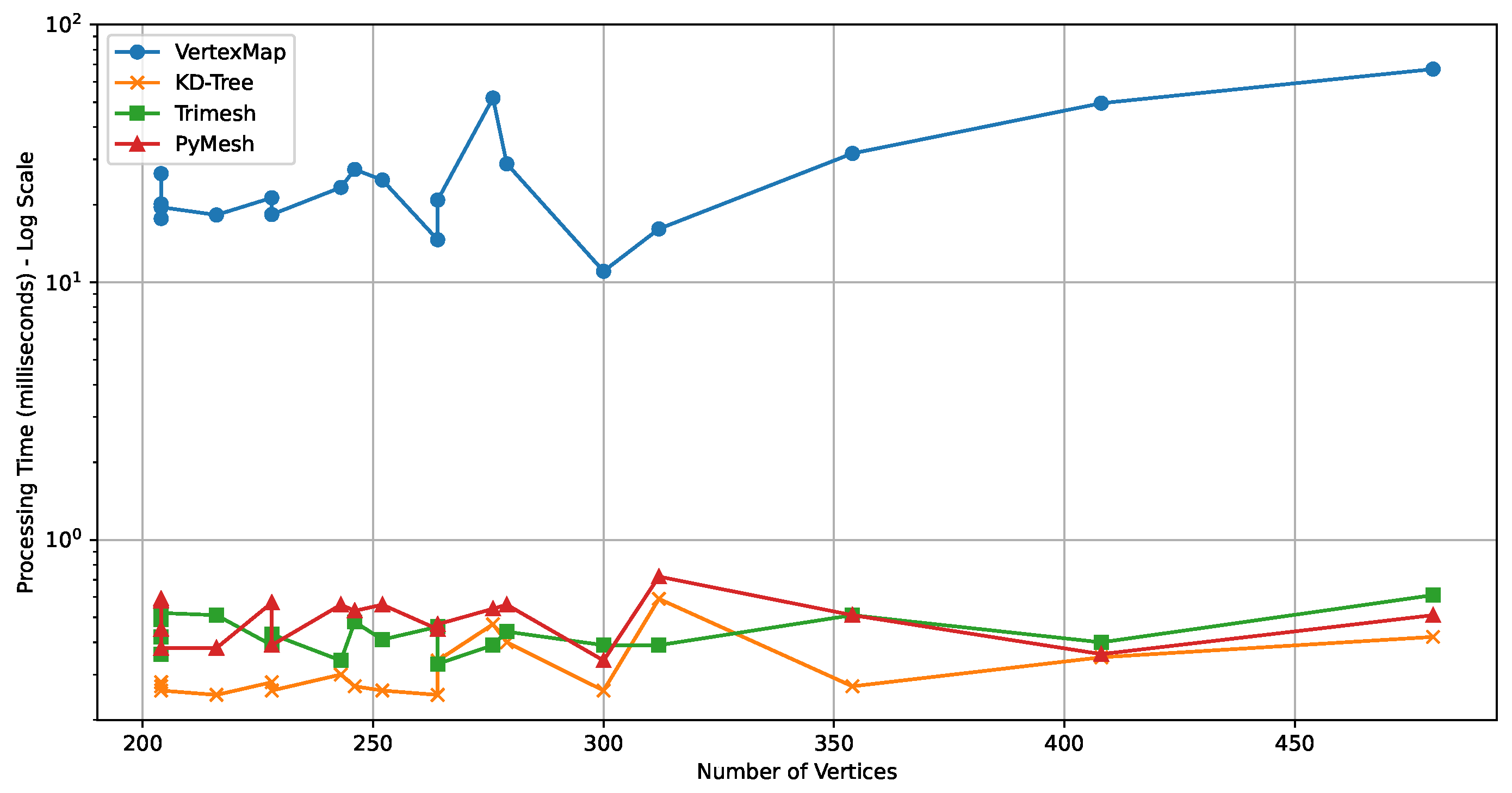
4.1. Experimental Results of Duplicate Point Removal Methods
4.2. Experimental Results of Mesh Clustering Using Spatial DFS
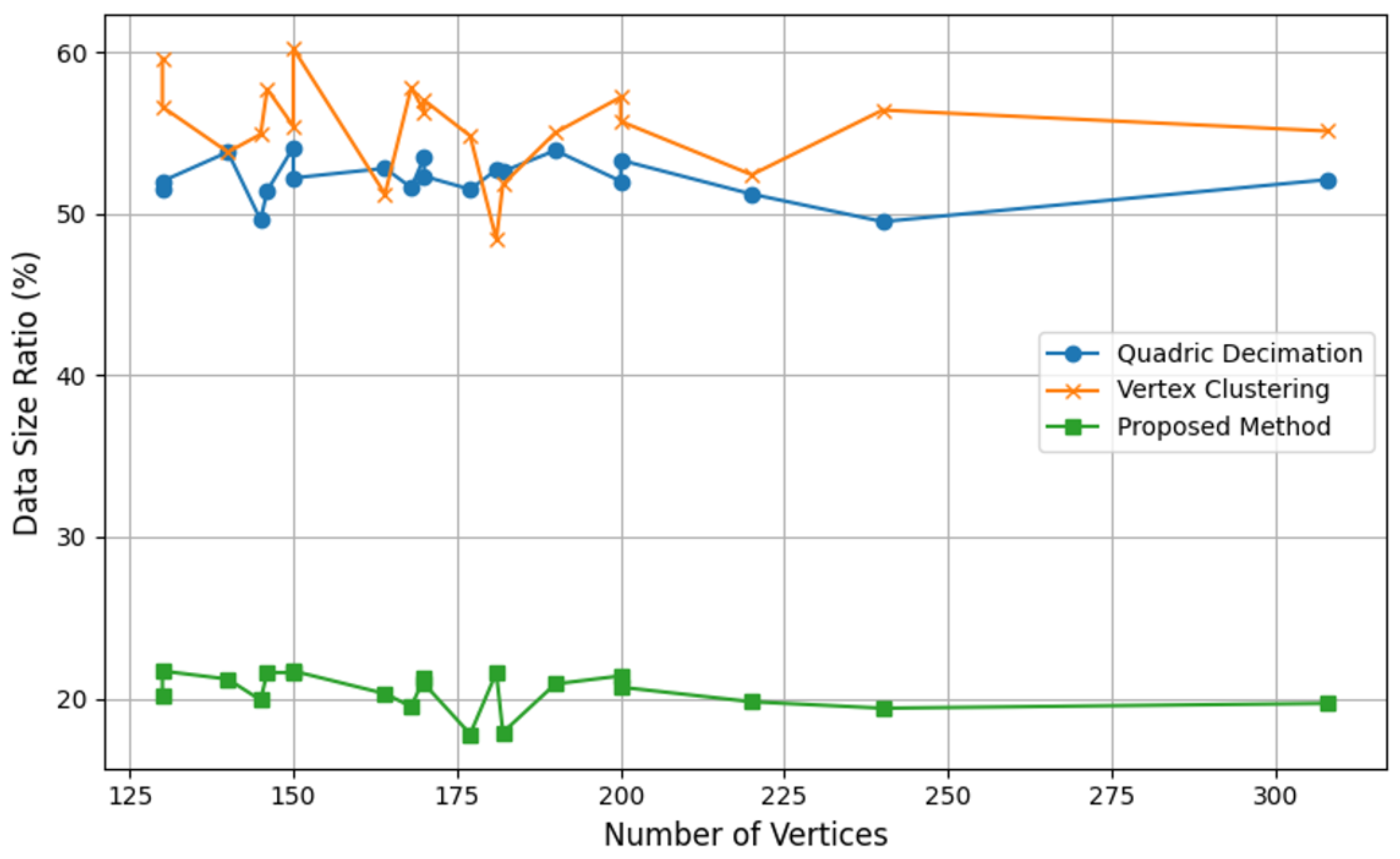
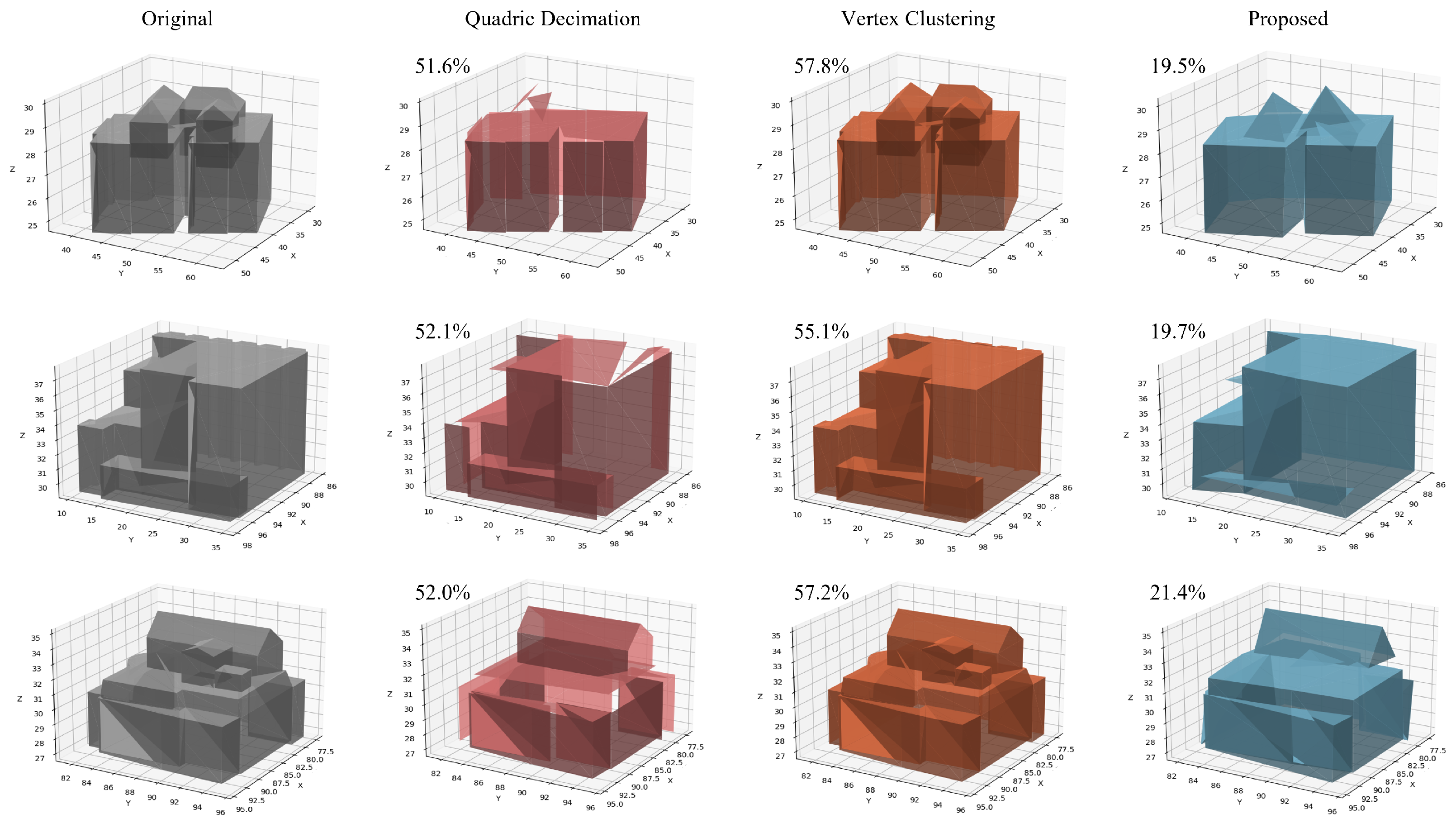
4.3. Comparative Evaluation of Mesh Simplification
4.4. Discussion
5. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lee, A.; Lee, K.W.; Kim, K.H.; Shin, S.W. A geospatial platform to manage large-scale individual mobility for an urban digital twin platform. Remote Sens. 2022, 14, 723. [Google Scholar] [CrossRef]
- Gröger, G.; Plümer, L. CityGML–Interoperable semantic 3D city models. ISPRS J. Photogramm. Remote. Sens. 2012, 71, 12–33. [Google Scholar] [CrossRef]
- Yu, D.; Ji, S.; Liu, J.; Wei, S. Automatic 3D building reconstruction from multi-view aerial images with deep learning. ISPRS J. Photogramm. Remote. Sens. 2021, 171, 155–170. [Google Scholar] [CrossRef]
- Ren, Y.; Li, X.; Jin, F.; Li, C.; Liu, W.; Li, E.; Zhang, L. Extracting Regular Building Footprints Using Projection Histogram Method from UAV-Based 3D Models. ISPRS Int. J.-Geo-Inf. 2024, 14, 6. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote. Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Lee, A. A Camera Control Method for a Planetary-Scale 3D Map based on a Game Engine with Floating Point Precision Limitation. IEEE Access 2024, 12, 100240–100250. [Google Scholar] [CrossRef]
- Tyagi, N.; Singh, J.; Singh, S.; Sehra, S.S. A 3D Model-Based Framework for Real-Time Emergency Evacuation Using GIS and IoT Devices. ISPRS Int. J.-Geo-Inf. 2024, 13, 445. [Google Scholar] [CrossRef]
- Gao, R.; Yan, G.; Wang, Y.; Yan, T.; Niu, R.; Tang, C. Construction of a Real-Scene 3D Digital Campus Using a Multi-Source Data Fusion: A Case Study of Lanzhou Jiaotong University. ISPRS Int. J.-Geo-Inf. 2025, 14, 19. [Google Scholar] [CrossRef]
- Verma, V.; Kumar, R.; Hsu, S. 3D building detection and modeling from aerial LIDAR data. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; IEEE: New York, NY, USA, 2006; Volume 2, pp. 2213–2220. [Google Scholar]
- Müller, P.; Zeng, G.; Wonka, P.; Van Gool, L. Image-based procedural modeling of facades. ACM Trans. Graph. 2007, 26, 85. [Google Scholar] [CrossRef]
- Jiang, Y.; Dai, Q.; Min, W.; Li, W. Non-watertight polygonal surface reconstruction from building point cloud via connection and data fit. IEEE Geosci. Remote. Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Skrzypczak, I.; Oleniacz, G.; Leśniak, A.; Zima, K.; Mrówczyńska, M.; Kazak, J.K. Scan-to-BIM method in construction: Assessment of the 3D buildings model accuracy in terms inventory measurements. Build. Res. Inf. 2022, 50, 859–880. [Google Scholar] [CrossRef]
- Lo, S. A new mesh generation scheme for arbitrary planar domains. Int. J. Numer. Methods Eng. 1985, 21, 1403–1426. [Google Scholar] [CrossRef]
- George, P.; Borouchaki, H.; Laug, P. An efficient algorithm for 3D adaptive meshing. Adv. Eng. Softw. 2002, 33, 377–387. [Google Scholar] [CrossRef]
- Cignoni, P.; Callieri, M.; Corsini, M.; Dellepiane, M.; Ganovelli, F.; Ranzuglia, G. Meshlab: An open-source mesh processing tool. In Proceedings of the Eurographics Italian Chapter Conference, Salerno, Italy, 2–4 July 2008; Volume 2008, pp. 129–136. [Google Scholar]
- Shewchuk, J.R. Delaunay refinement algorithms for triangular mesh generation. Comput. Geom. 2002, 22, 21–74. [Google Scholar] [CrossRef]
- Biljecki, F.; Ledoux, H.; Du, X.; Stoter, J.; Soon, K.H.; Khoo, V. The most common geometric and semantic errors in CityGML datasets. In Proceedings of the ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Athens, Greece, 20–21 October 2016; Volume IV-2/W1. [Google Scholar]
- Rashidan, H.; Abdul Rahman, A.; Musliman, I.A.; Buyuksalih, G. Triangular mesh approach for automatic repair of missing surfaces of lod2 building models. Int. Arch. Photogramm. Remote. Sens. Spat. Inf. Sci. 2022, 46, 281–286. [Google Scholar] [CrossRef]
- Ju, T. Fixing geometric errors on polygonal models: A survey. J. Comput. Sci. Technol. 2009, 24, 19–29. [Google Scholar] [CrossRef]
- Shewchuk, J.R. Triangle: Engineering a 2D quality mesh generator and Delaunay triangulator. In Proceedings of the Workshop on Applied Computational Geometry, Philadelphia, PA, USA, 27–28 May 1996; Springer: Berlin/Heidelberg, Germany, 1996; pp. 203–222. [Google Scholar]
- Tautges, T.J.; Blacker, T.; Mitchell, S.A. The whisker weaving algorithm: A connectivity-based method for constructing all-hexahedral finite element meshes. Int. J. Numer. Methods Eng. 1996, 39, 3327–3349. [Google Scholar] [CrossRef]
- Ministry of Land, Infrastructure and Transport Spatial Information Industry Promotion Institute. VWorld. 2025. Available online: https://www.vworld.kr/v4po_main.do (accessed on 25 February 2025).
- Lee, A.; Jang, I. Implementation of an open platform for 3D spatial information based on WebGL. ETRI J. 2019, 41, 277–288. [Google Scholar] [CrossRef]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Chen, J.; Clarke, K.C.; Freundschuh, S. Rapid 3d modeling using photogrammetry applied to google earth. In Proceedings of the 19th International Research Symposium on Computer-Based Cartography Albuquerque. Cartography and Geographic Information Society, Albuquerque, NM, USA, 14–16 September 2016; pp. 14–16. [Google Scholar]
- GharehTappeh, Z.S.; Peng, Q. Simplification and unfolding of 3D mesh models: Review and evaluation of existing tools. Procedia CIRP 2021, 100, 121–126. [Google Scholar] [CrossRef]
- Li, Z.; Zhao, Z.; Gao, W.; Jiao, L. An Algorithm for Simplifying 3D Building Models with Consideration for Detailed Features and Topological Structure. ISPRS Int. J.-Geo-Inf. 2024, 13, 356. [Google Scholar] [CrossRef]
- Cai, Y.; Fan, L. An efficient approach to automatic construction of 3D watertight geometry of buildings using point clouds. Remote. Sens. 2021, 13, 1947. [Google Scholar] [CrossRef]
- Sade, B.; Oya, S.; Lee, J.H. Non-watertight dural reconstruction in meningioma surgery: Results in 439 consecutive patients and a review of the literature. J. Neurosurg. 2011, 114, 714–718. [Google Scholar] [CrossRef] [PubMed]
- Bondy, J.A.; Murty, U.S.R. Graph Theory; Springer Publishing Company, Incorporated: Princeton, NJ, USA, 2008. [Google Scholar]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed]
- Ram, P.; Sinha, K. Revisiting kd-tree for nearest neighbor search. In Proceedings of the 25th Acm Sigkdd International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1378–1388. [Google Scholar]
- Dawson-Haggerty Trimesh. 2019. Available online: https://trimesh.org/ (accessed on 28 February 2025).
- Zhou, Q. PyMesh: Geometry Processing Library for Python. 2016. Available online: https://pymesh.readthedocs.io/ (accessed on 28 February 2025).
- Cormen, T.H.; Leiserson, C.E.; Rivest, R.L.; Stein, C. Introduction to Algorithms; MIT Press: Cambridge, MA, USA, 2022. [Google Scholar]
- Sedgewick, R.; Wayne, K. Algorithms; Addison-Wesley Professional: Boston, MA, USA, 2011. [Google Scholar]
- Garland, M.; Heckbert, P.S. Surface simplification using quadric error metrics. In Proceedings of the 24th Annual Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 3–8 August 1997; pp. 209–216. [Google Scholar]
- Weibel, R.; Burgardt, D.; Shashi, S.; Hui, X. On-the-Fly Generalization; Springer: Berlin/Heidelberg, Germany, 2008; pp. 339–344. [Google Scholar]
- Zhou, Q.Y.; Park, J.; Koltun, V. Open3D: A modern library for 3D data processing. arXiv 2018, arXiv:1801.09847. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Vertices | Vertices After Removal | Ratio (%) | Processing Time (ms) | |||
|---|---|---|---|---|---|---|
| Vertex Map | KD-Tree | Trimesh | PyMesh | |||
| 480 | 73 | 15.2 | 67.21 | 0.42 | 0.61 | 0.51 |
| 354 | 82 | 23.2 | 49.55 | 0.35 | 0.40 | 0.36 |
| 312 | 78 | 25.0 | 31.63 | 0.27 | 0.51 | 0.51 |
| 216 | 50 | 23.1 | 16.11 | 0.59 | 0.39 | 0.72 |
| 204 | 50 | 24.5 | 11.03 | 0.26 | 0.39 | 0.34 |
| 300 | 72 | 24.0 | 28.83 | 0.40 | 0.44 | 0.56 |
| 408 | 96 | 23.5 | 51.90 | 0.47 | 0.39 | 0.54 |
| 204 | 44 | 21.6 | 14.24 | 0.27 | 0.41 | 0.66 |
| 204 | 50 | 24.5 | 13.70 | 0.28 | 0.35 | 0.30 |
| 204 | 58 | 28.4 | 14.62 | 0.25 | 0.46 | 0.45 |
| 228 | 60 | 26.3 | 20.85 | 0.34 | 0.33 | 0.47 |
| 276 | 56 | 20.3 | 24.94 | 0.26 | 0.41 | 0.56 |
| 276 | 70 | 25.4 | 27.41 | 0.27 | 0.48 | 0.53 |
| 252 | 62 | 24.6 | 23.34 | 0.30 | 0.34 | 0.56 |
| 279 | 60 | 21.5 | 21.28 | 0.28 | 0.39 | 0.57 |
| 246 | 66 | 26.8 | 18.32 | 0.26 | 0.43 | 0.39 |
| 243 | 58 | 23.9 | 18.25 | 0.25 | 0.51 | 0.38 |
| 228 | 60 | 26.3 | 17.68 | 0.28 | 0.36 | 0.45 |
| 264 | 66 | 25.0 | 20.14 | 0.28 | 0.42 | 0.58 |
| 264 | 60 | 22.7 | 26.41 | 0.27 | 0.49 | 0.59 |
| Algorithm | Accuracy (%) | Average Time (ms) |
|---|---|---|
| DFS | 100 | 164.63 |
| Spatial DFS | 100 | 23.96 |
| BFS | 100 | 415.64 |
| Union-Find | 100 | 162.12 |
| Original | Quadric Decimation | Vertex Clustering | Proposed Method | ||||
|---|---|---|---|---|---|---|---|
| Vertex | Triangles | Vertex | Triangles | Vertex | Triangles | Vertex | Triangles |
| 164 | 82 | 106 | 24 | 50 | 76 | 26 | 24 |
| 146 | 76 | 92 | 22 | 52 | 76 | 26 | 22 |
| 145 | 81 | 88 | 24 | 52 | 72 | 21 | 24 |
| 170 | 84 | 111 | 25 | 59 | 84 | 30 | 24 |
| 177 | 93 | 112 | 27 | 55 | 93 | 22 | 26 |
| 181 | 92 | 117 | 27 | 48 | 84 | 33 | 26 |
| 200 | 104 | 127 | 31 | 70 | 104 | 34 | 31 |
| 200 | 100 | 130 | 30 | 67 | 100 | 32 | 30 |
| 220 | 118 | 138 | 35 | 71 | 106 | 32 | 35 |
| 182 | 92 | 117 | 27 | 54 | 88 | 22 | 27 |
| 190 | 92 | 125 | 27 | 63 | 92 | 33 | 26 |
| 168 | 88 | 106 | 26 | 60 | 88 | 24 | 26 |
| 150 | 72 | 99 | 21 | 51 | 72 | 27 | 21 |
| 150 | 76 | 96 | 22 | 60 | 76 | 27 | 22 |
| 130 | 68 | 82 | 20 | 50 | 68 | 21 | 19 |
| 308 | 160 | 196 | 48 | 98 | 160 | 44 | 48 |
| 140 | 68 | 92 | 20 | 44 | 68 | 24 | 20 |
| 170 | 88 | 109 | 26 | 62 | 85 | 29 | 25 |
| 130 | 68 | 83 | 20 | 47 | 65 | 24 | 19 |
| 240 | 136 | 146 | 40 | 85 | 127 | 34 | 39 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Published by MDPI on behalf of the International Society for Photogrammetry and Remote Sensing. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, A. Geometry and Topology Correction of 3D Building Models with Fragmented and Disconnected Components. ISPRS Int. J. Geo-Inf. 2025, 14, 198. https://doi.org/10.3390/ijgi14050198
Lee A. Geometry and Topology Correction of 3D Building Models with Fragmented and Disconnected Components. ISPRS International Journal of Geo-Information. 2025; 14(5):198. https://doi.org/10.3390/ijgi14050198
Chicago/Turabian StyleLee, Ahyun. 2025. "Geometry and Topology Correction of 3D Building Models with Fragmented and Disconnected Components" ISPRS International Journal of Geo-Information 14, no. 5: 198. https://doi.org/10.3390/ijgi14050198
APA StyleLee, A. (2025). Geometry and Topology Correction of 3D Building Models with Fragmented and Disconnected Components. ISPRS International Journal of Geo-Information, 14(5), 198. https://doi.org/10.3390/ijgi14050198