



Exploration of an Open Vocabulary Model on Semantic Segmentation for Street Scene Imagery


Abstract
1. Introduction
2. Data and Task
2.1. Dataset
2.1.1. Cityscapes
2.1.2. Additional Test Datasets
2.2. Task Definition
2.2.1. Traditional Semantic Segmentation
2.2.2. Open Vocabulary Semantic Segmentation
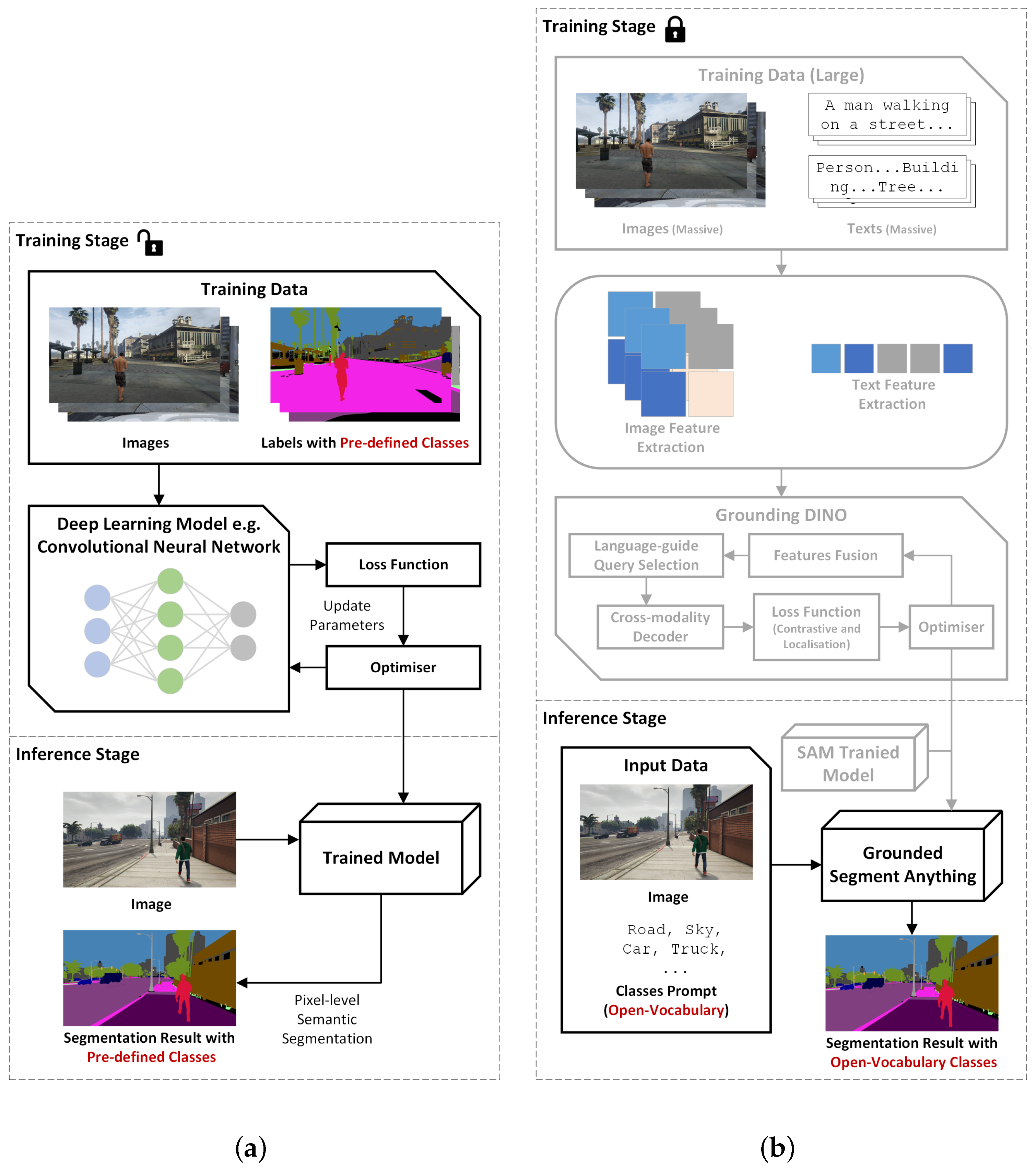
3. Methodology
3.1. Framework of Implementation and Evaluation of Grounded SAM
3.2. Prompt Design
- Prompt : Designed to address confusions not related to the visual level. This prompt aims to rectify errors arising from textual misunderstandings or misclassifications that do not stem from visual similarities.
- Prompt : Tailored to confusions at the visual level. This prompt is particularly focused on addressing the challenges in distinguishing visually similar categories, such as trains and buses.
- Prompt : A combination prompt, developed to tackle both textual and visual confusions. This prompt incorporates elements from both and to provide a more comprehensive solution to the segmentation errors.
3.3. Experimental Setting
3.4. Evaluation Metrics
- Precision and Recall are common metrics used for classification tasks [41]. Precision is the proportion of positive predictions that are true positives, i.e., how many of the positive predictions are correct. Recall is the proportion of all true samples that are correctly predicted, which assesses the model’s ability to identify positive samples and how many positive samples are missed.where is the number of true samples that are predicted as positive. is the number of false samples that are predicted as positive. is false negative samples.
- Intersection over Union (IoU) is typically used in segmentation tasks. It expresses the ratio of the intersection to the combination of predicted results and ground truth for a single class [42]. Mean IoU is the average value of IoU for all classes.where C means the number of classes.
4. Experimental Results
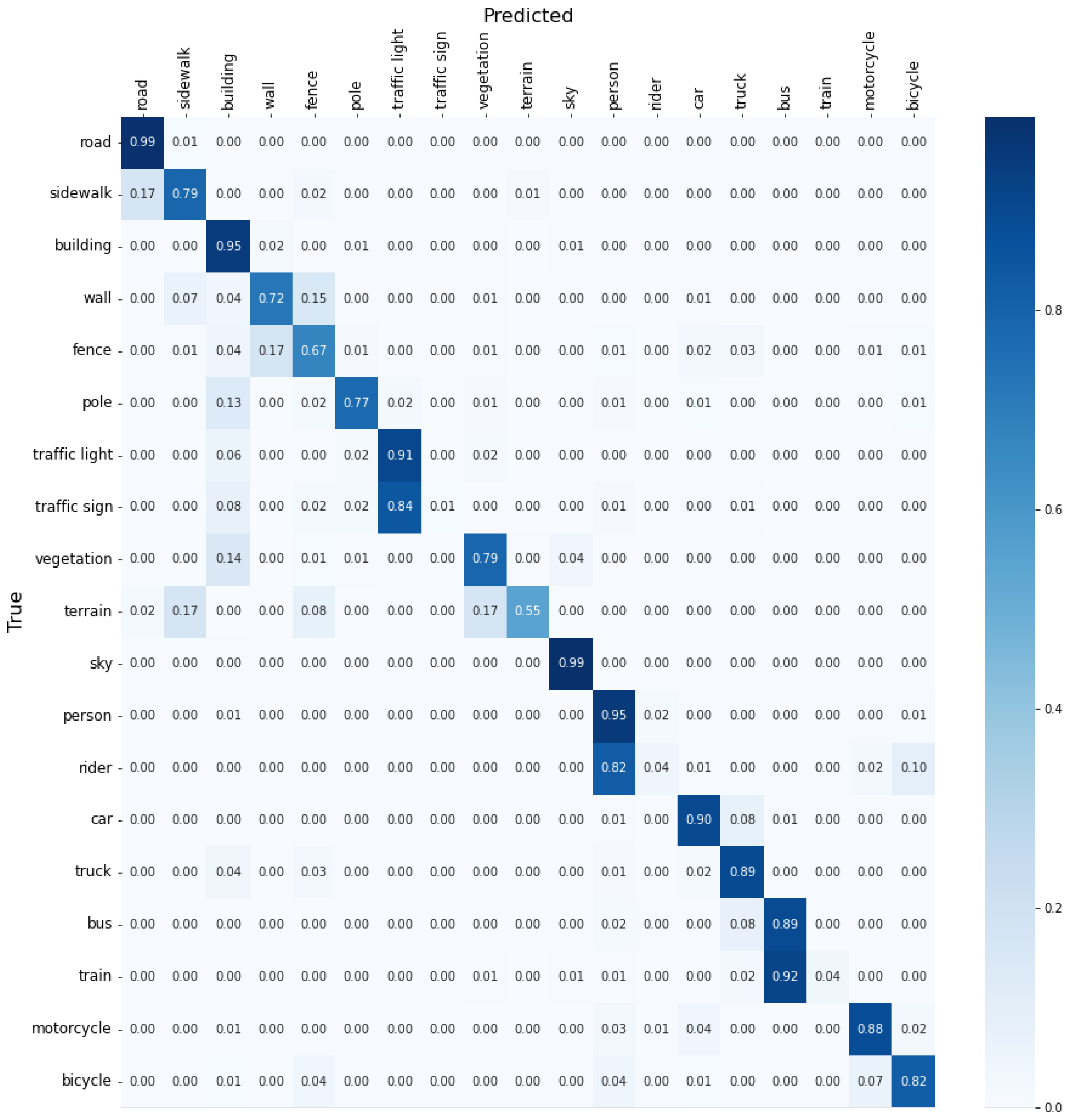
4.1. Results for Individual Category Segmentation
4.2. Result for Multi-Category Segmentation
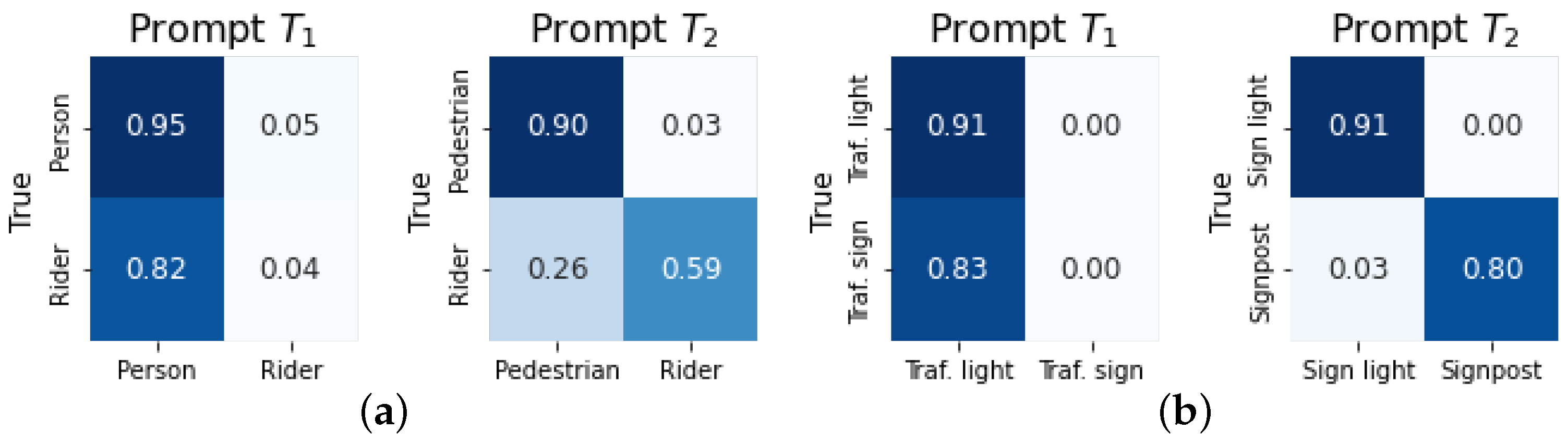
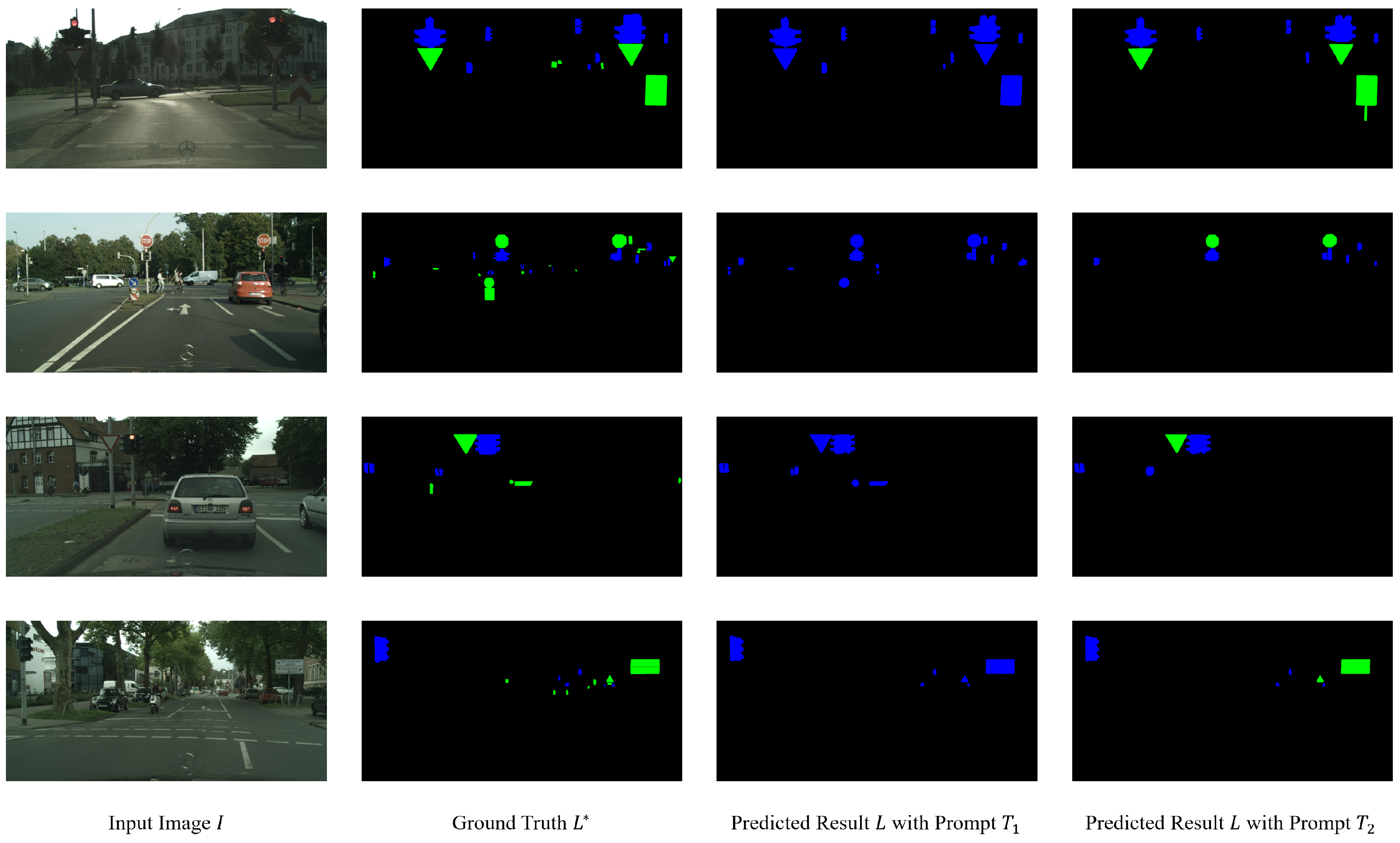
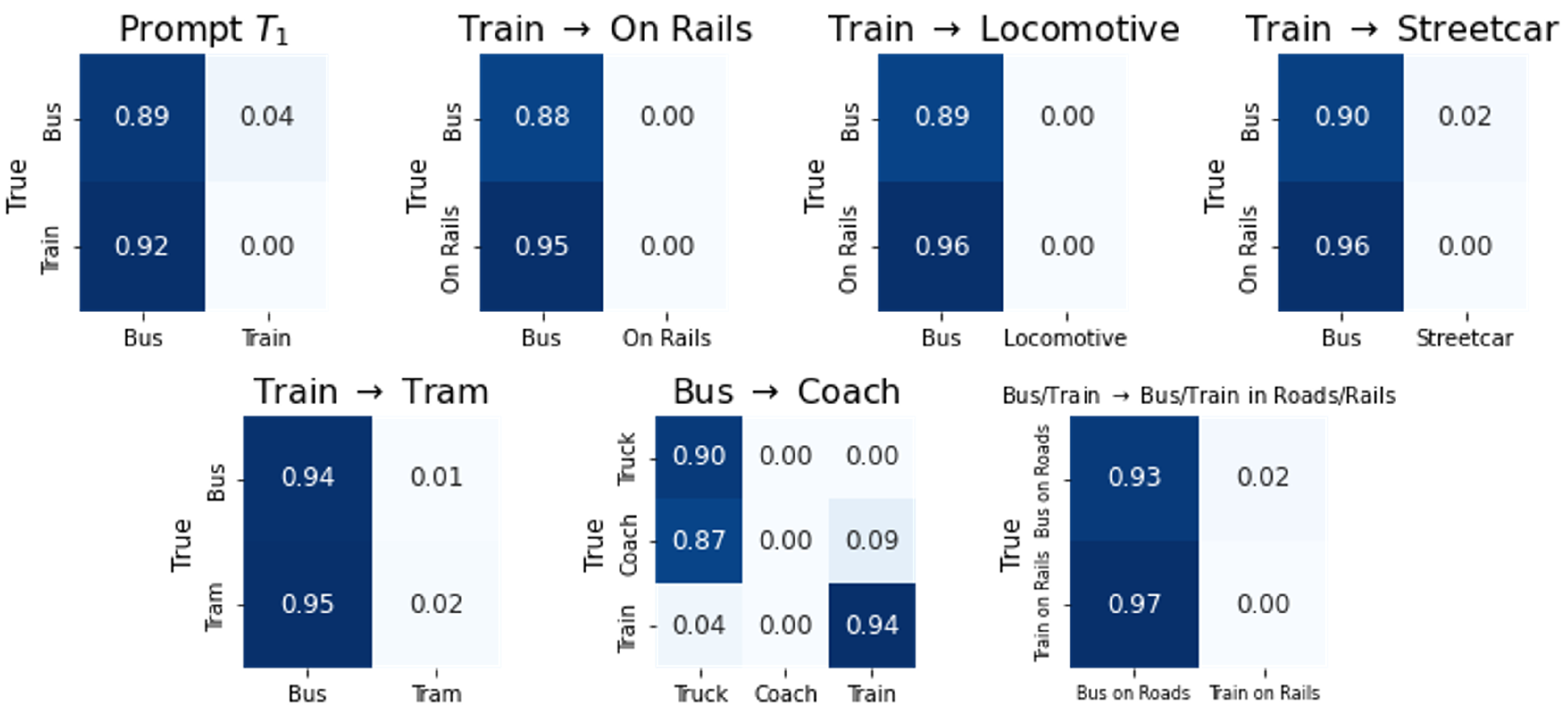
4.3. Improvements in Addressing Textual Similarity
4.4. Improvements in Addressing Visual Similarity
4.5. Comprehensive Results
5. Discussion
5.1. Overall Performance of Open Vocabulary Models
5.2. Impact of Text Input Refinement on Results
5.3. Comparison with Other SOTA Models
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, F.; Zhou, B.; Liu, L.; Liu, Y.; Fung, H.H.; Lin, H.; Ratti, C. Measuring human perceptions of a large-scale urban region using machine learning. Landsc. Urban Plan. 2018, 180, 148–160. [Google Scholar] [CrossRef]
- Biljecki, F.; Ito, K. Street view imagery in urban analytics and GIS: A review. Landsc. Urban Plan. 2021, 215, 104217. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, M.; Wang, M.; Huang, J.; Thomas, F.; Rahimi, K.; Mamouei, M. An interpretable machine learning framework for measuring urban perceptions from panoramic street view images. Iscience 2023, 26. [Google Scholar] [CrossRef] [PubMed]
- Kang, Y.; Zhang, F.; Gao, S.; Lin, H.; Liu, Y. A review of urban physical environment sensing using street view imagery in public health studies. Ann. GIS 2020, 26, 261–275. [Google Scholar] [CrossRef]
- Guan, F.; Fang, Z.; Zhang, X.; Zhong, H.; Zhang, J.; Huang, H. Using street-view panoramas to model the decision-making complexity of road intersections based on the passing branches during navigation. Comput. Environ. Urban Syst. 2023, 103, 101975. [Google Scholar] [CrossRef]
- Feng, D.; Haase-Schütz, C.; Rosenbaum, L.; Hertlein, H.; Glaeser, C.; Timm, F.; Wiesbeck, W.; Dietmayer, K. Deep multi-modal object detection and semantic segmentation for autonomous driving: Datasets, methods, and challenges. IEEE Trans. Intell. Transp. Syst. 2020, 22, 1341–1360. [Google Scholar] [CrossRef]
- Jongwiriyanurak, N.; Zeng, Z.; Wang, M.; Haworth, J.; Tanaksaranond, G.; Boehm, J. Framework for Motorcycle Risk Assessment Using Onboard Panoramic Camera (Short Paper). In Proceedings of the 12th International Conference on Geographic Information Science (GIScience 2023). Schloss Dagstuhl-Leibniz-Zentrum für Informatik, Leeds, UK, 12–15 September 2023. [Google Scholar]
- Li, Z.; Ning, H. Autonomous GIS: The next-generation AI-powered GIS. Int. J. Digit. Earth 2023, 16, 4668–4686. [Google Scholar] [CrossRef]
- Roberts, J.; Lüddecke, T.; Das, S.; Han, K.; Albanie, S. GPT4GEO: How a Language Model Sees the World’s Geography. arXiv 2023, arXiv:2306.00020. [Google Scholar]
- Wang, X.; Fang, M.; Zeng, Z.; Cheng, T. Where would i go next? large language models as human mobility predictors. arXiv 2023, arXiv:2308.15197. [Google Scholar]
- Mai, G.; Huang, W.; Sun, J.; Song, S.; Mishra, D.; Liu, N.; Gao, S.; Liu, T.; Cong, G.; Hu, Y.; et al. On the opportunities and challenges of foundation models for geospatial artificial intelligence. arXiv 2023, arXiv:2304.06798. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the 38th International Conference on Machine Learning, Virtual Event, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Li, J.; Li, D.; Xiong, C.; Hoi, S. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 12888–12900. [Google Scholar]
- Li, J.; Li, D.; Savarese, S.; Hoi, S. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In Proceedings of the 40th International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 19730–19742. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Siam, M.; Gamal, M.; Abdel-Razek, M.; Yogamani, S.; Jagersand, M.; Zhang, H. A comparative study of real-time semantic segmentation for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 587–597. [Google Scholar]
- Badue, C.; Guidolini, R.; Carneiro, R.V.; Azevedo, P.; Cardoso, V.B.; Forechi, A.; Jesus, L.; Berriel, R.; Paixao, T.M.; Mutz, F.; et al. Self-driving cars: A survey. Expert Syst. Appl. 2021, 165, 113816. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3213–3223. [Google Scholar]
- Liu, X.; Deng, Z.; Yang, Y. Recent progress in semantic image segmentation. Artif. Intell. Rev. 2019, 52, 1089–1106. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; proceedings, part III 18. Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018; Proceedings 4. Springer: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Kang, Y.; Cho, N.; Yoon, J.; Park, S.; Kim, J. Transfer learning of a deep learning model for exploring tourists’ urban image using geotagged photos. ISPRS Int. J. Geo-Inf. 2021, 10, 137. [Google Scholar] [CrossRef]
- Liu, S.; Zeng, Z.; Ren, T.; Li, F.; Zhang, H.; Yang, J.; Li, C.; Yang, J.; Su, H.; Zhu, J.; et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv 2023, arXiv:2303.05499. [Google Scholar]
- Li, L.H.; Zhang, P.; Zhang, H.; Yang, J.; Li, C.; Zhong, Y.; Wang, L.; Yuan, L.; Zhang, L.; Hwang, J.N.; et al. Grounded language-image pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10965–10975. [Google Scholar]
- Minderer, M.; Gritsenko, A.; Stone, A.; Neumann, M.; Weissenborn, D.; Dosovitskiy, A.; Mahendran, A.; Arnab, A.; Dehghani, M.; Shen, Z.; et al. Simple open-vocabulary object detection with vision transformers. arXiv 2022, arXiv:2205.06230. [Google Scholar]
- Zareian, A.; Rosa, K.D.; Hu, D.H.; Chang, S.F. Open-vocabulary object detection using captions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14393–14402. [Google Scholar]
- Du, Y.; Wei, F.; Zhang, Z.; Shi, M.; Gao, Y.; Li, G. Learning to prompt for open-vocabulary object detection with vision-language model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 14084–14093. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2023; pp. 4015–4026. [Google Scholar]
- Ren, T.; Liu, S.; Zeng, A.; Lin, J.; Li, K.; Cao, H.; Chen, J.; Huang, X.; Chen, Y.; Yan, F.; et al. Grounded sam: Assembling open-world models for diverse visual tasks. arXiv 2024, arXiv:2401.14159. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging properties in self-supervised vision transformers. In Proceedings of the Pr IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 9650–9660. [Google Scholar]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. Bdd100k: A diverse driving dataset for heterogeneous multitask learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2636–2645. [Google Scholar]
- Abu Alhaija, H.; Mustikovela, S.K.; Mescheder, L.; Geiger, A.; Rother, C. Augmented reality meets computer vision: Efficient data generation for urban driving scenes. Int. J. Comput. Vis. 2018, 126, 961–972. [Google Scholar] [CrossRef]
- Richter, S.R.; Vineet, V.; Roth, S.; Koltun, V. Playing for data: Ground truth from computer games. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. Springer: Cham, Switzerland, 2016; pp. 102–118. [Google Scholar]
- Szeliski, R. Computer Vision: Algorithms and Applications; Springer Nature: Cham, Switzerland, 2022. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Nag, S.; Adak, S.; Das, S. What’s there in the dark. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 2996–3000. [Google Scholar]
- Hoyer, L.; Dai, D.; Wang, H.; Van Gool, L. MIC: Masked image consistency for context-enhanced domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 11721–11732. [Google Scholar]
- Hoyer, L.; Dai, D.; Van Gool, L. Hrda: Context-aware high-resolution domain-adaptive semantic segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 372–391. [Google Scholar]
- Hoyer, L.; Dai, D.; Van Gool, L. Daformer: Improving network architectures and training strategies for domain-adaptive semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9924–9935. [Google Scholar]
- Zhang, P.; Zhang, B.; Zhang, T.; Chen, D.; Wang, Y.; Wen, F. Prototypical pseudo label denoising and target structure learning for domain adaptive semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12414–12424. [Google Scholar]
- Li, G.; Kang, G.; Liu, W.; Wei, Y.; Yang, Y. Content-consistent matching for domain adaptive semantic segmentation. In Proceedings of the European Conference on Computer Vision, Virtual Event, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 440–456. [Google Scholar]
- Zhu, Y.; Sapra, K.; Reda, F.A.; Shih, K.J.; Newsam, S.; Tao, A.; Catanzaro, B. Improving semantic segmentation via video propagation and label relaxation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8856–8865. [Google Scholar]
- Bulo, S.R.; Porzi, L.; Kontschieder, P. In-place activated batchnorm for memory-optimized training of dnns. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5639–5647. [Google Scholar]
- Yin, W.; Liu, Y.; Shen, C.; Hengel, A.v.d.; Sun, B. The devil is in the labels: Semantic segmentation from sentences. arXiv 2022, arXiv:2202.02002. [Google Scholar]
- Meletis, P.; Dubbelman, G. Training of convolutional networks on multiple heterogeneous datasets for street scene semantic segmentation. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1045–1050. [Google Scholar]
- Yang, G.; Zhao, H.; Shi, J.; Deng, Z.; Jia, J. Segstereo: Exploiting semantic information for disparity estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 636–651. [Google Scholar]
- Kong, S.; Fowlkes, C. Pixel-wise attentional gating for parsimonious pixel labeling. arXiv 2018, arXiv:1805.01556. [Google Scholar]
- Takikawa, T.; Acuna, D.; Jampani, V.; Fidler, S. Gated-scnn: Gated shape cnns for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5229–5238. [Google Scholar]
- Ghiasi, G.; Fowlkes, C.C. Laplacian pyramid reconstruction and refinement for semantic segmentation. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part III 14. Springer: Cham, Switzerland, 2016; pp. 519–534. [Google Scholar]
- Lin, G.; Shen, C.; Van Den Hengel, A.; Reid, I. Efficient piecewise training of deep structured models for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3194–3203. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Pre-Defined Classes from Cityscapes () | |||
|---|---|---|---|---|
| Road | Road | Road | Road | |
| Sidewalk | Sidewalk | Sidewalk | Sidewalk | |
| Building | Building | Building | Building | |
| Wall | Wall | Wall | Wall | |
| Fence | Fence | Fence | Fence | |
| Pole | Pole | Pole | Pole | |
| Traffic Light | Signal Light | Traffic Light | Signal Light | |
| Traffic Sign | Signpost | Traffic Sign | Signpost | |
| Vegetation | Vegetation | Vegetation | Vegetation | |
| Terrain | Terrain | Terrain | Terrain | |
| Sky | Sky | Sky | Sky | |
| Person | Pedestrian | Person | Pedestrian | |
| Rider | Rider | Rider | Rider | |
| Car | Car | Car | Car | |
| Truck | Truck | Truck | Truck | |
| Bus | Bus | Bus | Bus | |
| Train | Train | Tram/... | Tram | |
| Motorbike | Motorbike | Motorbike | Motorbike | |
| Bike | Bike | Bike | Bike |
| Prompt T | Class | Class |
|---|---|---|
| Bus | Train | |
| (Train → On Rails) | Bus | On Rails |
| (Train → Locomotive) | Bus | Locomotive |
| (Train → Streetcar) | Bus | Streetcar |
| (Train → Tram) | Bus | Tram |
| (Bus → Coach) | Coach | Train |
| (Bus → Bus on Roads and Train → Train on Rails) | Bus on Roads | Train on Rails |
| Dataset | Road | S.walk | Build. | Wall | Fence | Pole | T.Light | T.Sign | Veget. | Terrain | Sky | Person | Rider | Car | Truck | Bus | Train | M.bike | Bike |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision in % | |||||||||||||||||||
| Cityscapes val. | 81.34 | 13.58 | 78.16 | 5.77 | 41.88 | 79.45 | 80.33 | 55.06 | 86.19 | 1.99 | 57.09 | 74.72 | 22.85 | 95.69 | 49.87 | 71.01 | 12.64 | 53.80 | 79.04 |
| BDD100K val. | 78.74 | 12.02 | 71.77 | 26.62 | 25.97 | 42.31 | 72.90 | 25.60 | 61.33 | 4.77 | 87.52 | 61.72 | 15.67 | 61.73 | 44.39 | 54.07 | 1.20 | 31.60 | 83.02 |
| KITTI | 91.16 | 26.87 | 78.48 | 16.30 | 30.70 | 78.68 | 76.80 | 23.64 | 83.73 | 14.05 | 94.33 | 73.10 | 43.61 | 96.23 | 24.20 | 70.20 | 60.04 | 56.54 | 59.96 |
| GTA5 | 88.61 | 18.33 | 75.20 | 17.57 | 5.01 | 62.08 | 80.45 | 18.97 | 76.27 | 3.08 | 99.63 | 69.64 | 38.57 | 19.33 | 20.41 | 59.12 | 18.30 | 31.66 | 71.24 |
| Recall in % | |||||||||||||||||||
| Cityscapes val. | 97.04 | 69.03 | 88.21 | 65.71 | 66.85 | 33.95 | 69.37 | 57.28 | 70.15 | 55.49 | 95.52 | 83.05 | 61.52 | 87.05 | 92.73 | 92.23 | 85.17 | 80.78 | 73.36 |
| BDD100K val. | 94.46 | 73.08 | 92.70 | 93.44 | 73.23 | 75.35 | 84.19 | 71.11 | 79.75 | 52.41 | 95.70 | 86.07 | 85.77 | 89.99 | 92.39 | 96.77 | 13.36 | 71.94 | 85.88 |
| KITTI | 92.89 | 69.93 | 86.38 | 51.57 | 67.14 | 47.61 | 69.78 | 66.74 | 77.20 | 59.02 | 95.55 | 72.00 | 70.49 | 88.26 | 79.33 | 88.73 | 93.15 | 85.42 | 63.60 |
| GTA5 | 84.02 | 74.41 | 88.43 | 80.29 | 57.83 | 66.78 | 68.16 | 62.96 | 75.56 | 45.23 | 90.14 | 89.88 | 96.99 | 90.38 | 88.84 | 97.81 | 85.45 | 91.96 | 92.13 |
| IoU in % | |||||||||||||||||||
| Cityscapes val. | 79.37 | 12.80 | 70.77 | 5.60 | 34.68 | 31.21 | 59.30 | 39.03 | 63.07 | 1.96 | 55.60 | 64.83 | 19.99 | 83.77 | 48.0 | 67.00 | 12.36 | 47.70 | 61.42 |
| BDD100K val. | 75.27 | 11.51 | 67.93 | 26.14 | 23.72 | 37.16 | 64.13 | 23.19 | 53.07 | 4.57 | 84.21 | 56.11 | 15.27 | 57.77 | 42.83 | 53.11 | 1.11 | 28.13 | 73.05 |
| KITTI | 85.22 | 24.08 | 69.84 | 14.13 | 26.69 | 42.17 | 57.63 | 21.15 | 67.13 | 12.80 | 90.36 | 56.92 | 36.87 | 85.31 | 22.77 | 64.45 | 57.50 | 51.57 | 44.64 |
| GTA5 | 75.83 | 17.24 | 68.46 | 16.84 | 4.83 | 47.43 | 58.48 | 17.07 | 61.18 | 2.97 | 89.84 | 64.58 | 38.11 | 18.94 | 19.90 | 58.35 | 17.74 | 30.81 | 67.15 |
| Prompt | Road | S.walk | Build. | Wall | Fence | Pole | T.Light | T.Sign | Veget. | Terrain | Sky | Person | Rider | Car | Truck | Bus | Train | M.bike | Bike | Total |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision in % | ||||||||||||||||||||
| 98.09 | 86.35 | 91.87 | 46.49 | 51.47 | 80.96 | 23.54 | 90.35 | 96.90 | 66.94 | 88.38 | 74.97 | 17.70 | 97.15 | 29.71 | 65.46 | 45.77 | 47.14 | 86.70 | 67.68 | |
| 98.08 | 88.71 | 91.66 | 46.58 | 48.33 | 81.70 | 69.91 | 85.22 | 97.34 | 64.01 | 89.76 | 88.26 | 56.44 | 97.10 | 31.95 | 61.03 | 42.22 | 48.04 | 84.18 | 72.13 | |
| 98.07 | 86.67 | 91.69 | 51.05 | 49.63 | 80.41 | 23.69 | 54.50 | 96.96 | 62.68 | 89.1 | 74.93 | 21.76 | 97.12 | 38.11 | 56.95 | 0.00 | 49.82 | 86.46 | 63.66 | |
| 98.18 | 87.92 | 91.72 | 49.17 | 48.91 | 82.15 | 69.03 | 83.59 | 97.44 | 65.42 | 90.02 | 87.92 | 56.13 | 97.14 | 28.70 | 58.33 | 0.06 | 47.97 | 84.39 | 69.69 | |
| Recall in % | ||||||||||||||||||||
| 98.76 | 78.71 | 94.80 | 72.08 | 67.16 | 77.44 | 90.73 | 0.96 | 78.52 | 55.08 | 99.39 | 95.25 | 4.31 | 89.76 | 89.37 | 88.95 | 4.03 | 88.34 | 81.76 | 71.34 | |
| 99.02 | 77.92 | 95.06 | 70.54 | 68.24 | 74.33 | 91.16 | 80.22 | 78.41 | 56.84 | 99.39 | 89.51 | 58.81 | 90.70 | 89.87 | 90.05 | 4.06 | 87.88 | 83.88 | 78.20 | |
| 98.81 | 77.9 | 91.5 | 70.37 | 64.02 | 76.89 | 91.26 | 0.47 | 78.52 | 55.79 | 99.38 | 95.15 | 5.17 | 89.37 | 89.48 | 90.34 | 0.00 | 86.53 | 82.31 | 70.70 | |
| 98.92 | 79.05 | 95.04 | 71.46 | 68.18 | 73.32 | 91.30 | 79.54 | 79.02 | 60.03 | 99.40 | 89.44 | 57.78 | 90.54 | 75.31 | 89.82 | 0.03 | 87.92 | 83.85 | 77.37 | |
| IoU in % | ||||||||||||||||||||
| 96.90 | 70.00 | 87.47 | 39.40 | 41.12 | 65.50 | 22.99 | 0.96 | 76.60 | 43.30 | 87.90 | 72.28 | 3.59 | 87.46 | 28.70 | 60.54 | 3.85 | 44.38 | 72.65 | 52.93 | |
| 97.14 | 70.89 | 87.49 | 38.99 | 39.46 | 63.72 | 65.48 | 70.42 | 76.77 | 43.07 | 89.27 | 79.99 | 40.45 | 88.31 | 30.84 | 57.17 | 3.85 | 45.05 | 72.46 | 61.10 | |
| 96.93 | 69.56 | 84.49 | 42.02 | 38.81 | 64.76 | 23.17 | 0.47 | 76.63 | 41.88 | 88.61 | 72.17 | 4.36 | 87.07 | 36.47 | 53.68 | 0.00 | 46.24 | 72.91 | 52.64 | |
| 97.14 | 71.31 | 87.53 | 41.10 | 39.82 | 63.25 | 64.77 | 68.80 | 77.42 | 45.57 | 89.53 | 79.65 | 39.80 | 88.19 | 26.23 | 54.71 | 0.02 | 45.01 | 72.59 | 60.65 | |
| Method | mIoU |
|---|---|
| Dataset: BDD100K (val) | |
| NiseNet [43] | 53.5 |
| Grounded SAM with | 39.1 |
| Grounded SAM with | 40.4 |
| Grounded SAM with | 38.2 |
| Grounded SAM with | 39.2 |
| Dataset: GTA5 | |
| MIC [44] | 75.9 |
| HRDA [45] | 73.8 |
| DAFormer [46] | 68.3 |
| ProDA [47] | 57.5 |
| CCM [48] | 49.9 |
| Grounded SAM with | 53.1 |
| Grounded SAM with | 56.2 |
| Grounded SAM with | 51.4 |
| Grounded SAM with | 53.6 |
| Dataset: KITTI | |
| Deeplabv3+ + SDCNet [49] | 72.8 |
| MapillaryAI [50] | 69.6 |
| SIW [51] | 68.9 |
| AHiSS [52] | 61.2 |
| SegStereo [53] | 59.1 |
| APMoE-seg [54] | 48.0 |
| Grounded SAM with | 45.4 |
| Grounded SAM with | 50.6 |
| Grounded SAM with | 45.2 |
| Grounded SAM with | 50.3 |
| Method | Road | S.walk | Build. | Wall | Fence | Pole | T.Light | T.Sign | Veget. | Terrain | Sky | Person | Rider | Car | Truck | Bus | Train | M.bike | Bike | Total |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LRR [56] | 97.7 | 79.9 | 90.7 | 44.4 | 48.6 | 58.6 | 68.2 | 72.0 | 92.5 | 69.3 | 94.7 | 81.6 | 60.0 | 94.0 | 43.6 | 56.8 | 47.2 | 54.8 | 69.7 | 69.7 |
| Deeplabv2 [26] | 97.9 | 81.3 | 90.3 | 48.8 | 47.4 | 49.6 | 57.9 | 67.3 | 91.9 | 69.4 | 94.2 | 79.8 | 59.8 | 93.7 | 56.5 | 67.5 | 57.5 | 57.7 | 68.8 | 70.4 |
| Piecewise [57] | 98.0 | 82.6 | 90.6 | 44.0 | 50.7 | 51.1 | 65.0 | 71.7 | 92.0 | 72.0 | 94.1 | 81.5 | 61.1 | 94.3 | 61.1 | 65.1 | 53.8 | 61.6 | 70.6 | 71.6 |
| PSP-Net [24] | 98.2 | 85.8 | 92.8 | 57.5 | 65.9 | 62.6 | 71.8 | 80.7 | 92.4 | 64.5 | 94.8 | 82.1 | 61.5 | 95.1 | 78.6 | 88.3 | 77.9 | 68.1 | 78.0 | 78.8 |
| Deeplabv3+ [28] | 98.2 | 84.9 | 92.7 | 57.3 | 62.1 | 65.2 | 68.6 | 78.9 | 92.7 | 63.5 | 95.3 | 92.3 | 62.8 | 95.4 | 85.3 | 89.1 | 80.9 | 64.6 | 77.3 | 78.8 |
| GSCNN [55] | 98.3 | 86.3 | 93.3 | 55.8 | 64.0 | 70.8 | 75.9 | 83.1 | 93.0 | 65.1 | 95.2 | 85.3 | 67.9 | 96.0 | 80.8 | 91.2 | 83.3 | 69.6 | 80.4 | 80.8 |
| Grounded SAM | 97.1 | 70.9 | 87.5 | 39.0 | 39.5 | 63.7 | 65.5 | 70.4 | 76.8 | 43.1 | 89.3 | 80.0 | 40.5 | 88.3 | 30.8 | 57.2 | 3.9 | 45.1 | 72.5 | 61.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, Z.; Boehm, J. Exploration of an Open Vocabulary Model on Semantic Segmentation for Street Scene Imagery. ISPRS Int. J. Geo-Inf. 2024, 13, 153. https://doi.org/10.3390/ijgi13050153
Zeng Z, Boehm J. Exploration of an Open Vocabulary Model on Semantic Segmentation for Street Scene Imagery. ISPRS International Journal of Geo-Information. 2024; 13(5):153. https://doi.org/10.3390/ijgi13050153
Chicago/Turabian StyleZeng, Zichao, and Jan Boehm. 2024. "Exploration of an Open Vocabulary Model on Semantic Segmentation for Street Scene Imagery" ISPRS International Journal of Geo-Information 13, no. 5: 153. https://doi.org/10.3390/ijgi13050153
APA StyleZeng, Z., & Boehm, J. (2024). Exploration of an Open Vocabulary Model on Semantic Segmentation for Street Scene Imagery. ISPRS International Journal of Geo-Information, 13(5), 153. https://doi.org/10.3390/ijgi13050153