



Learning Daily Human Mobility with a Transformer-Based Model

Abstract
1. Introduction
2. Literature Review
2.1. Conventional Methods for Mobility Generation/Prediction
2.2. Machine-Learning Based Methods
2.3. Position of This Study
- The self-attention mechanism is used to create vector representations for various urban areas. The representing vectors (and thus the model outputs) vary with urban and societal attributes, enabling the model to make predictions for a new setting of urban and built environments.
- The constructed transformer model shows excellent generation power and high prediction power. Examinations of the transformer components suggest that the model seems to learn the spatial structure of the city and the temporal relationships between movements.
- Our analyses show that the generated mobility patterns could be different from reality even though several aggregated statistics are reproduced.
3. Datasets and Preprocessing
3.1. The Person Trip Survey Data
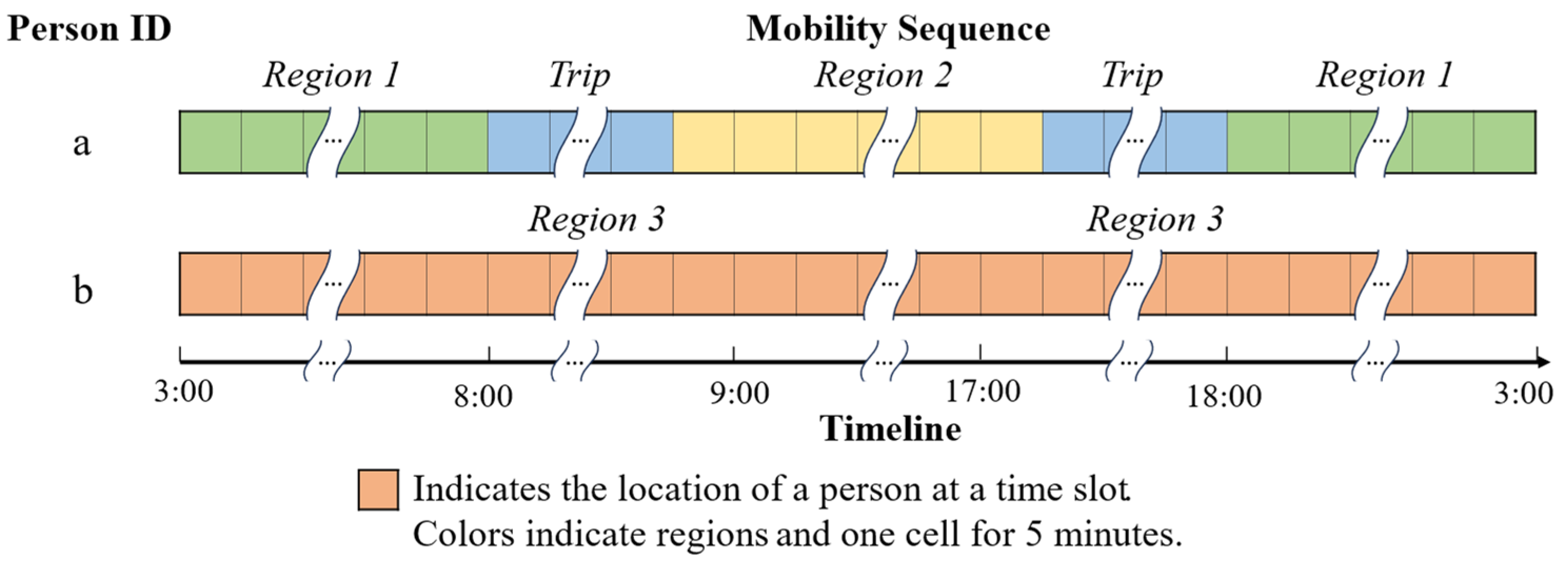
3.2. Construction of Daily Mobility Sequences
3.3. Spatial Datasets and Data Preprocessing
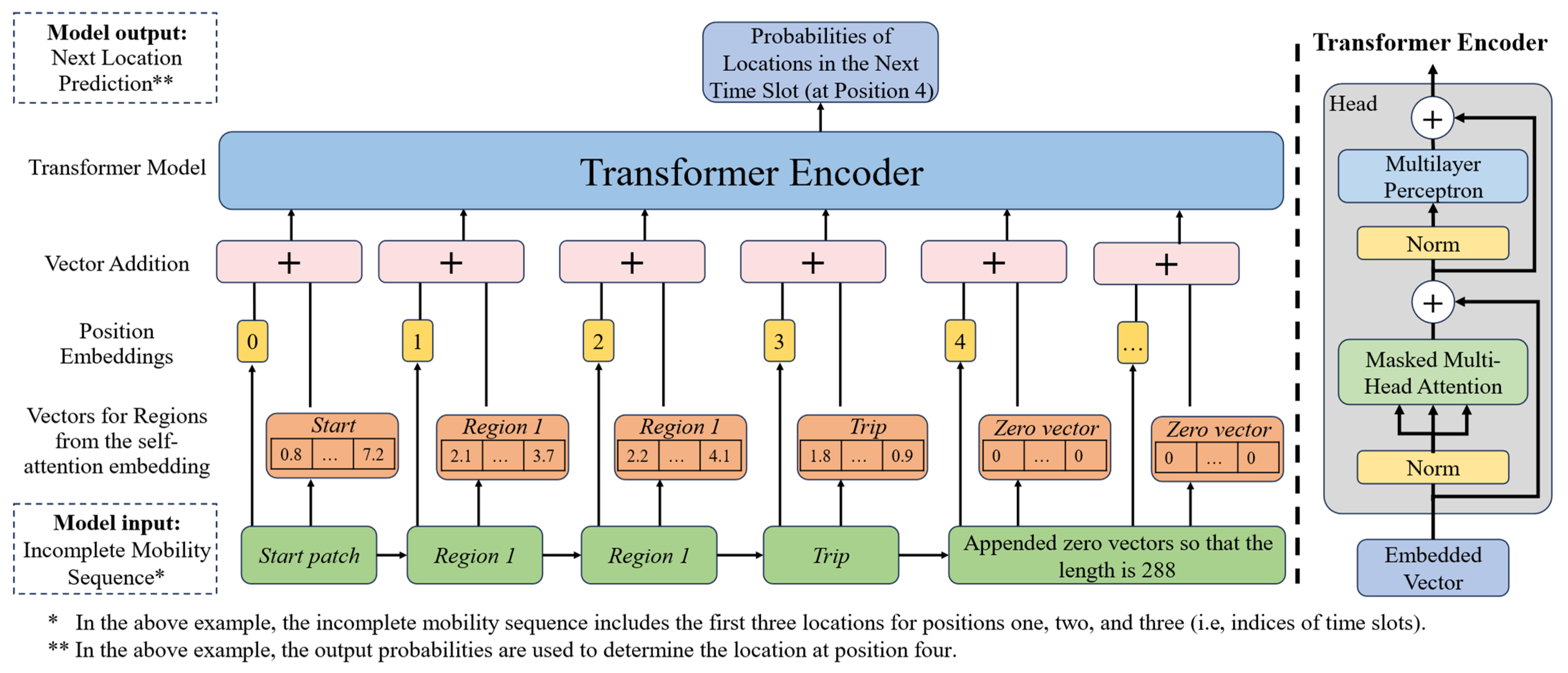
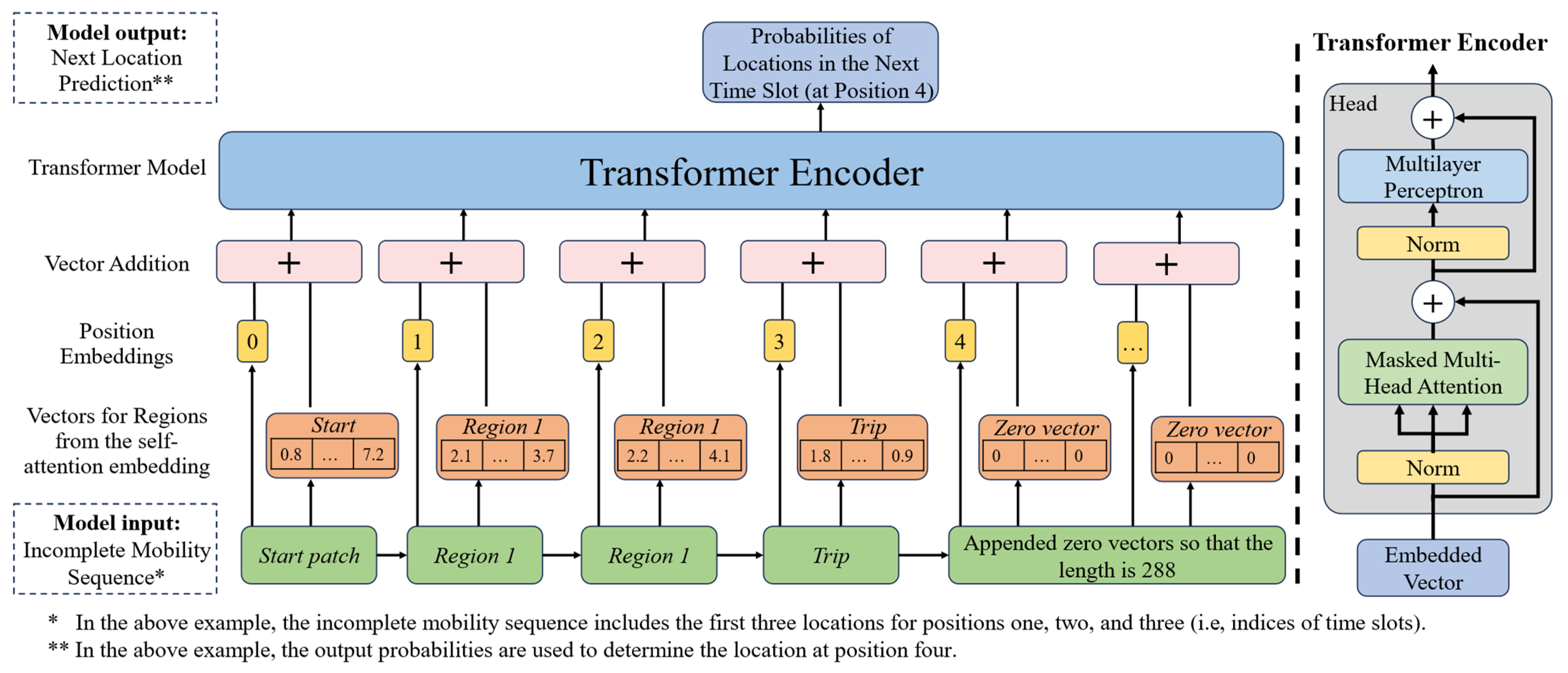
4. A Transformer-Based Model for Mobility Generation and Prediction
4.1. The Self-Attention Mechanism for Embedding
4.2. The GPT Model
5. Experiments and Results
5.1. Setup and Evaluation Metrics
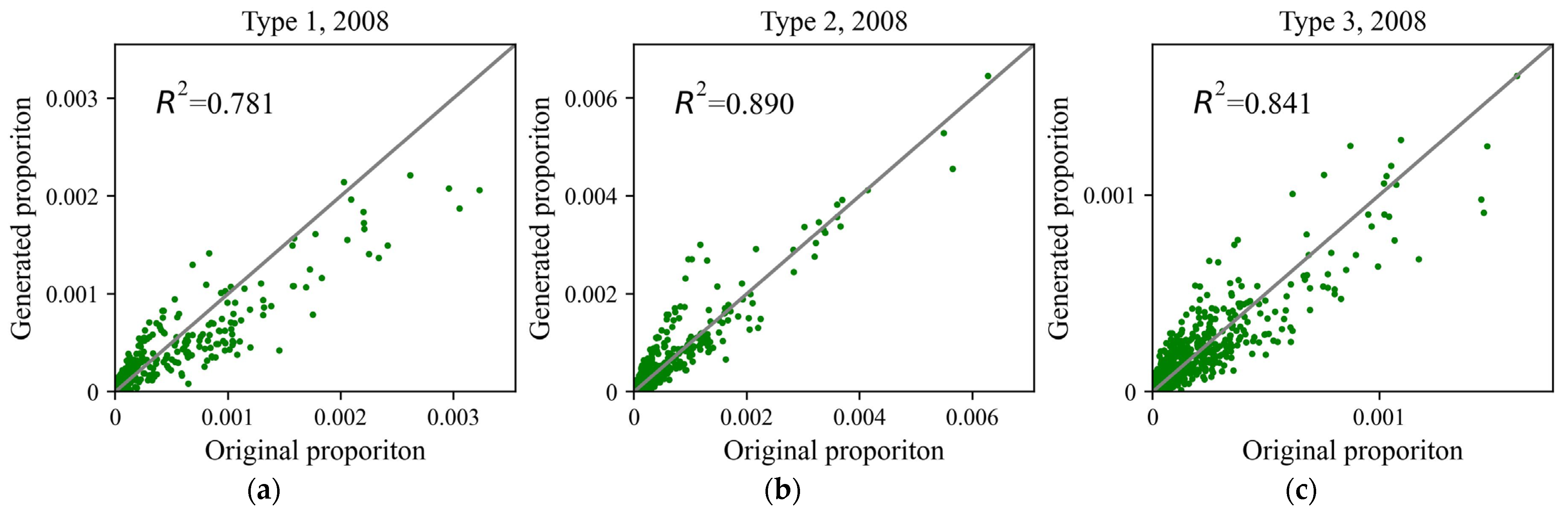
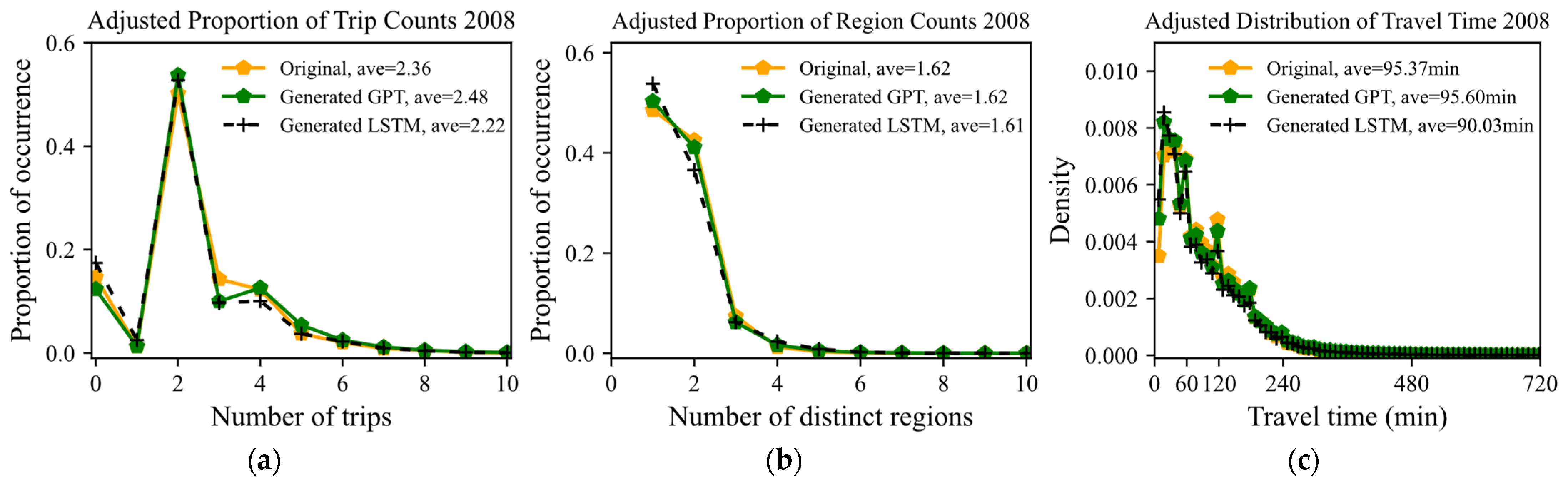
5.2. Evaluation of the Generation Power
5.3. Evaluation of the Prediction Power
5.4. Interpretation of the Transformer Model
5.4.1. Spatial Similarity of Regions
5.4.2. Temporal Relationship of Daily Mobility
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A



References
- Kapp, A.; Hansmeyer, J.; Mihaljević, H. Generative Models for Synthetic Urban Mobility Data: A Systematic Literature Review. ACM Comput. Surv. 2023, 56, 93:1–93:37. [Google Scholar] [CrossRef]
- Ahmed, B. The Traditional Four Steps Transportation Modeling Using a Simplified Transport Network: A Case Study of Dhaka City, Bangladesh. Int. J. Adv. Sci. Eng. Technol. Res. 2012, 1, 19–40. [Google Scholar]
- Mladenovic, M.; Trifunovic, A. The Shortcomings of the Conventional Four Step Travel Demand Forecasting Process. J. Road Traffic Eng. 2014, 60, 5–12. [Google Scholar]
- Mo, B.; Zhao, Z.; Koutsopoulos, H.N.; Zhao, J. Individual Mobility Prediction: An Interpretable Activity-Based Hidden Markov Approach. arXiv 2021, arXiv:2101.03996. [Google Scholar]
- Wang, W.; Osaragi, T. Daily Human Mobility: A Reproduction Model and Insights from the Energy Concept. ISPRS Int. J. Geo-Inf. 2022, 11, 219. [Google Scholar] [CrossRef]
- Rasouli, S.; Timmermans, H. Activity-Based Models of Travel Demand: Promises, Progress and Prospects. Int. J. Urban Sci. 2014, 18, 31–60. [Google Scholar] [CrossRef]
- Bhat, C.R.; Guo, J.Y.; Srinivasan, S.; Sivakumar, A. Comprehensive Econometric Microsimulator for Daily Activity-Travel Patterns. Transp. Res. Rec. 2004, 1894, 57–66. [Google Scholar] [CrossRef]
- Nurul Habib, K.; El-Assi, W.; Hasnine, M.S.; Lamers, J. Daily Activity-Travel Scheduling Behaviour of Non-Workers in the National Capital Region (NCR) of Canada. Transp. Res. Part A Policy Pract. 2017, 97, 1–16. [Google Scholar] [CrossRef]
- Liu, P.; Liao, F.; Huang, H.-J.; Timmermans, H. Dynamic Activity-Travel Assignment in Multi-State Supernetworks under Transport and Location Capacity Constraints. Transp. A Transp. Sci. 2016, 12, 572–590. [Google Scholar] [CrossRef]
- Miller, E.J.; Roorda, M.J. Prototype Model of Household Activity-Travel Scheduling. Transp. Res. Rec. 2003, 1831, 114–121. [Google Scholar] [CrossRef]
- Drchal, J.; Čertický, M.; Jakob, M. Data-Driven Activity Scheduler for Agent-Based Mobility Models. Transp. Res. Part C Emerg. Technol. 2019, 98, 370–390. [Google Scholar] [CrossRef]
- Allahviranloo, M.; Recker, W. Daily Activity Pattern Recognition by Using Support Vector Machines with Multiple Classes. Transp. Res. Part B Methodol. 2013, 58, 16–43. [Google Scholar] [CrossRef]
- Hesam Hafezi, M.; Sultana Daisy, N.; Millward, H.; Liu, L. Framework for Development of the Scheduler for Activities, Locations, and Travel (SALT) Model. Transp. A Transp. Sci. 2022, 18, 248–280. [Google Scholar] [CrossRef]
- Hafezi, M.H.; Liu, L.; Millward, H. Learning Daily Activity Sequences of Population Groups Using Random Forest Theory. Transp. Res. Rec. 2018, 2672, 194–207. [Google Scholar] [CrossRef]
- Huang, D.; Song, X.; Fan, Z.; Jiang, R.; Shibasaki, R.; Zhang, Y.; Wang, H.; Kato, Y. A Variational Autoencoder Based Generative Model of Urban Human Mobility. In Proceedings of the 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), San Jose, CA, USA, 28–30 March 2019; pp. 425–430. [Google Scholar]
- Sakuma, Y.; Tran, T.P.; Iwai, T.; Nishikawa, A.; Nishi, H. Trajectory Anonymization through Laplace Noise Addition in Latent Space. In Proceedings of the 2021 Ninth International Symposium on Computing and Networking (CANDAR), Matsue, Japan, 23–26 November 2021; pp. 65–73. [Google Scholar]
- Blanco-Justicia, A.; Jebreel, N.M.; Manjón, J.A.; Domingo-Ferrer, J. Generation of Synthetic Trajectory Microdata from Language Models. In Privacy in Statistical Databases; Domingo-Ferrer, J., Laurent, M., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 172–187. [Google Scholar]
- Berke, A.; Doorley, R.; Larson, K.; Moro, E. Generating Synthetic Mobility Data for a Realistic Population with RNNs to Improve Utility and Privacy. In Proceedings of the 37th ACM/SIGAPP Symposium on Applied Computing, Virtual Event, 25–29 April 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 964–967. [Google Scholar]
- Badu-Marfo, G.; Farooq, B.; Patterson, Z. Composite Travel Generative Adversarial Networks for Tabular and Sequential Population Synthesis. IEEE Trans. Intell. Transp. Syst. 2022, 23, 17976–17985. [Google Scholar] [CrossRef]
- Rao, J.; Gao, S.; Kang, Y.; Huang, Q. LSTM-TrajGAN: A Deep Learning Approach to Trajectory Privacy Protection. In Proceedings of the International Conference Geographic Information Science, Seattle, WA, USA, 3–6 November 2020. [Google Scholar]
- Jiang, W.; Zhao, W.X.; Wang, J.; Jiang, J. Continuous Trajectory Generation Based on Two-Stage GAN. In Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on Educational Advances in Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; AAAI Press: Washington, DC, USA, 2023; Volume 37, pp. 4374–4382. [Google Scholar]
- Cao, C.; Li, M. Generating Mobility Trajectories with Retained Data Utility. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 2610–2620. [Google Scholar]
- Solatorio, A.V. GeoFormer: Predicting Human Mobility Using Generative Pre-Trained Transformer (GPT). In Proceedings of the 1st International Workshop on the Human Mobility Prediction Challenge, Hamburg, Germany, 13 November 2023; pp. 11–15. [Google Scholar]
- Corrias, R.; Gjoreski, M.; Langheinrich, M. Exploring Transformer and Graph Convolutional Networks for Human Mobility Modeling. Sensors 2023, 23, 4803. [Google Scholar] [CrossRef]
- Lee, M.; Holme, P. Relating Land Use and Human Intra-City Mobility. PLoS ONE 2015, 10, e0140152. [Google Scholar] [CrossRef]
- Kim, H.; Sohn, D. The Urban Built Environment and the Mobility of People with Visual Impairments: Analysing the Travel Behaviours Based on Mobile Phone Data. J. Asian Archit. Build. Eng. 2020, 19, 731–741. [Google Scholar] [CrossRef]
- Lee, B.A.; Oropesa, R.S.; Kanan, J.W. Neighborhood Context and Residential Mobility. Demography 1994, 31, 249–270. [Google Scholar] [CrossRef] [PubMed]
- Osaragi, T.; Kudo, R. Enhancing the Use of Population Statistics Derived from Mobile Phone Users by Considering Building-Use Dependent Purpose of Stay. In Geospatial Technologies for Local and Regional Development; Kyriakidis, P., Hadjimitsis, D., Skarlatos, D., Mansourian, A., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 185–203. [Google Scholar]
- Wang, W.; Osaragi, T. Generating and Understanding Human Daily Activity Sequences Using Time-Varying Markov Chain Models. Travel Behav. Soc. 2024, 34, 100711. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Content |
|---|---|
| Areas subject to survey | Tokyo, Kanagawa, Saitama, Chiba, and Southern Ibaraki prefectures |
| Survey time and day | A total of 24 h on weekdays in October 1978, 1988, 1998, and 2008 excluding Monday and Friday |
| Object of survey | Persons over the age of 5 living in the above areas |
| Sampling | Random sampling based on census data |
| Valid data | A total of 588,352 persons, 667,937 persons, 883,043 persons, and 594,314 persons in 1978, 1988, 1998, and 2008, respectively |
| Content of data | Personal attributes, locations and times of departure and arrival, purposes of trips, etc. |
| Land Use Type | Subtype | Description |
|---|---|---|
| Farm and forest | Farmland | Wet, dry, swampy lotus fields and rice fields. |
| Other farmland | The land used for growing wheat, upland rice, vegetables, grassland, etc. | |
| Forest | The land densely populated with perennial vegetation. | |
| Empty | Empty | Wastelands or land with cliffs, rocks, perennial snow, etc. |
| Building | Buildings | Residential or urban areas where buildings are densely built up. |
| Other constructions | The land for an athletic field, airport, baseball field, school, harbor area, etc. | |
| Road | Road | Road or railway. |
| Water | River and lake | Artificial lakes, natural lakes, ponds, fish farms, etc. |
| Waterfront | Areas of sand, rubble, and rock bordering the beach. | |
| Sea area | Including hidden rocks and mudflats in the sea. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, W.; Osaragi, T. Learning Daily Human Mobility with a Transformer-Based Model. ISPRS Int. J. Geo-Inf. 2024, 13, 35. https://doi.org/10.3390/ijgi13020035
Wang W, Osaragi T. Learning Daily Human Mobility with a Transformer-Based Model. ISPRS International Journal of Geo-Information. 2024; 13(2):35. https://doi.org/10.3390/ijgi13020035
Chicago/Turabian StyleWang, Weiying, and Toshihiro Osaragi. 2024. "Learning Daily Human Mobility with a Transformer-Based Model" ISPRS International Journal of Geo-Information 13, no. 2: 35. https://doi.org/10.3390/ijgi13020035
APA StyleWang, W., & Osaragi, T. (2024). Learning Daily Human Mobility with a Transformer-Based Model. ISPRS International Journal of Geo-Information, 13(2), 35. https://doi.org/10.3390/ijgi13020035