

A Latent-Factor-Model-Based Approach for Traffic Data Imputation with Road Network Information


Abstract
:1. Introduction
- Because the interpolation-based approach only considers the neighboring data of missing values and ignores the overall relevant data, the imputation accuracy of the interpolation-based approach is low;
- Because it is difficult to fit the non-linear changes of traffic data by linear functions, the imputation accuracy of regression-based approaches is low when they are used to impute non-linear traffic data;
- In real applications, many other forms information can be used to improve the accuracy of traffic data imputation, such as the road network structure, road conditions, etc. However, most of the current matrix-factorization-based approaches do not consider this information, which reduces their imputation accuracy.
- In the proposed approach, the adjacent matrix of road distance is proposed to represent the spatial information of the road network, which can be combined with original traffic data. This is an innovative mechanism to add auxiliary information to original traffic data;
- The LFM-based data imputation algorithm is employed to impute the missing traffic data in the combined traffic data, so as to accurately impute the missing traffic data;
- The real traffic dataset METR-LA is used to evaluate the performance of the proposed approach. The experimental results indicate that the proposed approach can achieve accurate traffic data imputation in different data missing patterns and with limited amount of traffic data.
2. Related Works
2.1. Interpolation-Based Approaches
2.2. Regression Based Approaches
2.3. Matrix-Factorization-Based Approaches
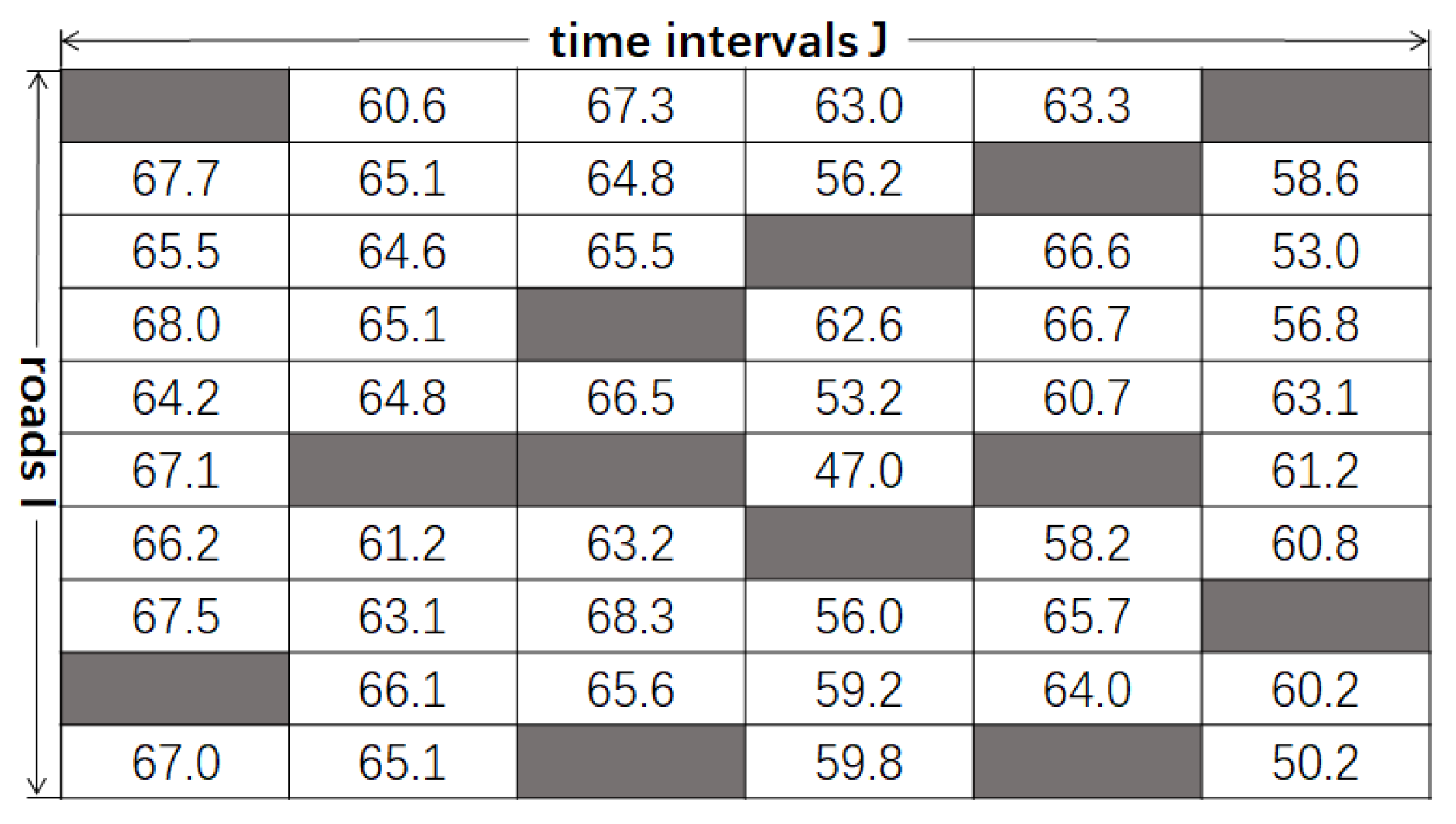
3. The Problem Description
- Roadside facilities can continuously collect the traffic data of their roads. However, the traffic data of the roads without roadside facilities are all missing;
- GPS data of cars can be used to calculate the traffic data of roads passed by cars. However, it is hard for all roads of a road network to have cars with GPS at the same time, so the traffic data of the roads without cars with GPS are missing;
- Due to the network failure, when the collected data are uploaded to the database, the traffic data of all roads in some time intervals are missing.
4. LFM-Based Traffic Data Imputation Approach
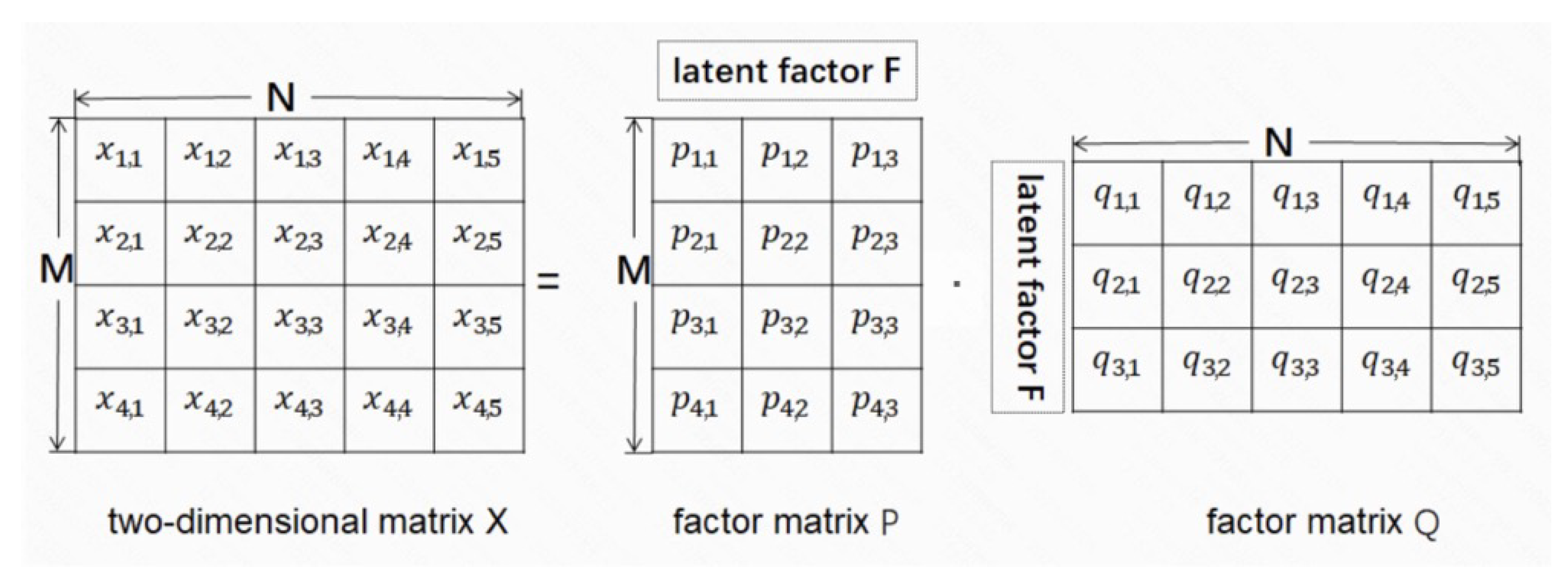
4.1. LFM-Based Factorization
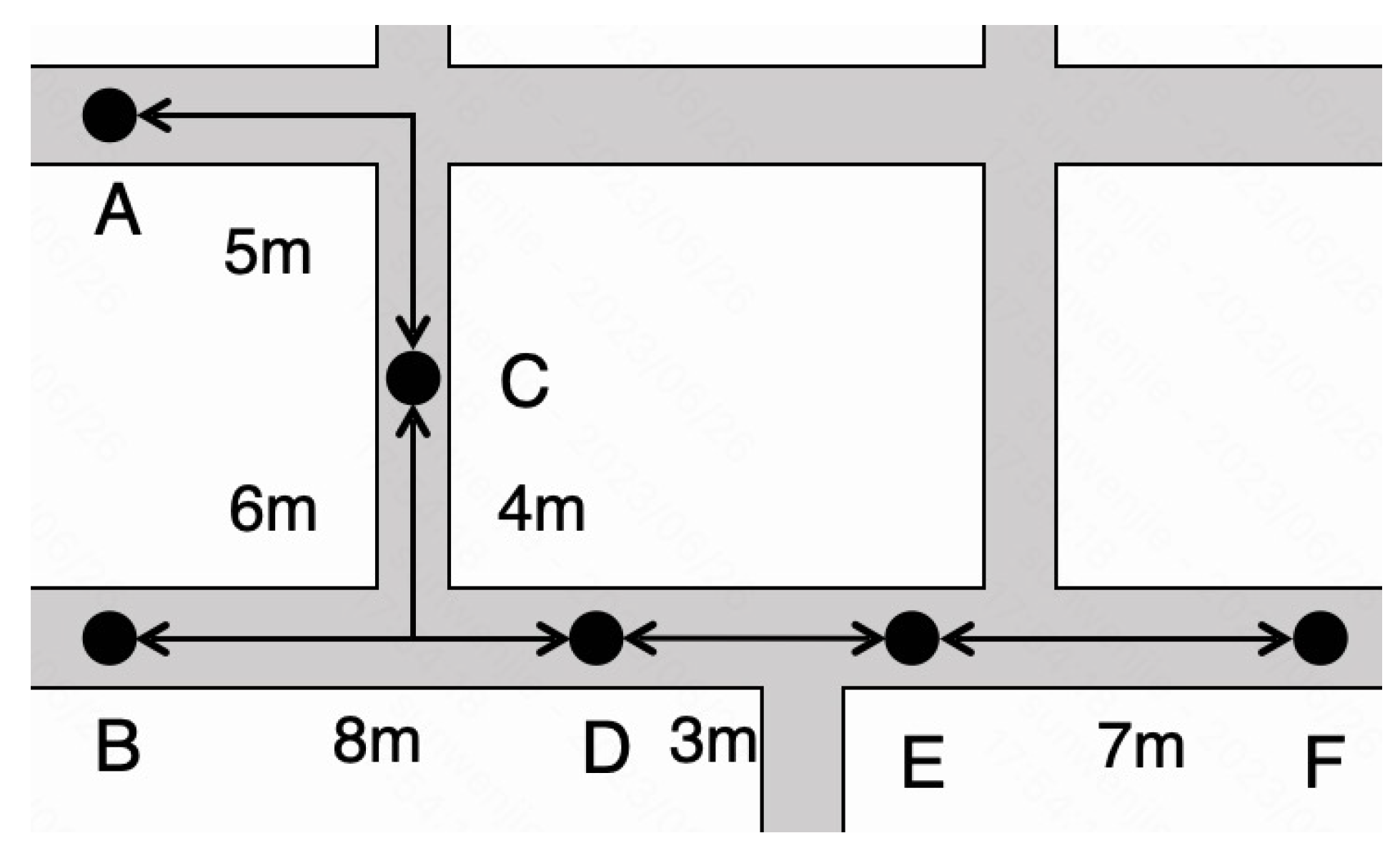
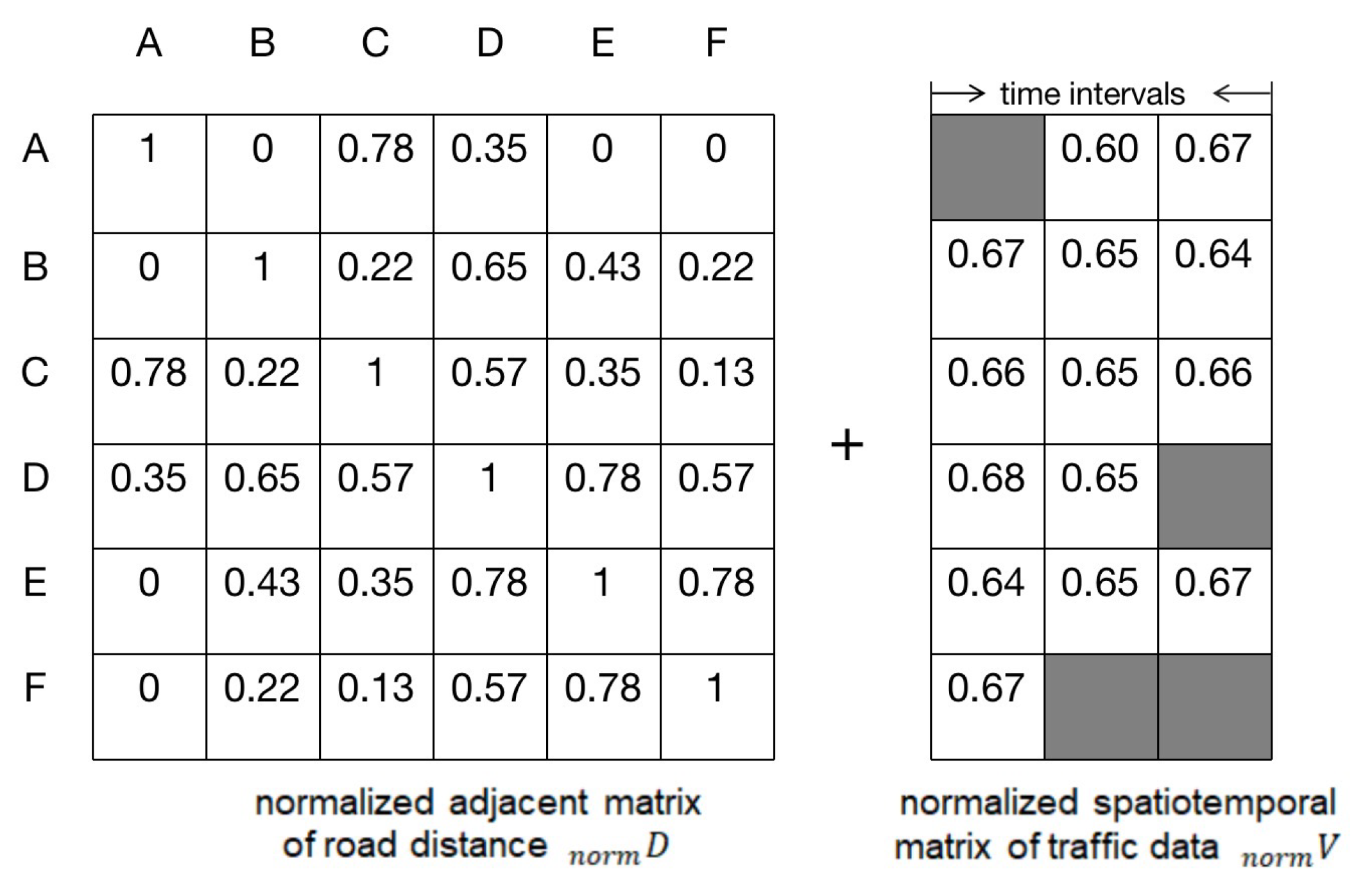
4.2. The Construction of the Adjacent Matrix of Road Distance
4.3. The Combination of the Adjacent Matrix of Road Distance and the Spatiotemporal Matrix of Traffic Data
4.4. The Process of LFM-Based Data Imputation Algorithm
- According to the length M and width N of the matrix and the number of latent factors F, two factor matrices, and , are generated with random values; the Cartesian product of P and Q can construct the matrix , whose size is the same as matrix .
- According to the value difference between the existing elements in and the corresponding elements of , the values of the factor matrices are alternatively updated by gradient descent algorithm. The objective function of the factor matrices update is shown in Equation (6)where is the regularization part and is the parameter to control the regularization.
- Repeat Step (2) until the above objective function is minimized, and the two matrices and are considered to be the same. The missing elements of can be found in .
| Algorithm 1 LFM-based data imputation algorithm |
Require: The combined matrix ; Number of latent factors F; Error threshold ; Ensure: Full matrix
|
5. Experiments and Analysis
5.1. The Data Set and General Settings of Experiments
5.2. The Experimental Results and Analysis
5.2.1. The Accuracy of Different Traffic Data Imputation Approaches
- ARIMA: The Autoregressive Integrated Moving Average is a popular time series traffic data prediction and imputation approach. It uses the temporal relationships of data to predict or impute the missing data [46].
- Mean interpolation, which uses the mean of temporal neighboring data around the missing data to achieve the imputation [47].
- HaLRTC: High-accuracy low-rank tensor completion was proposed by Liu et al. in 2009. The HaLRTC algorithm applies the Alternating Direction Multiplier Method (ADMM) to the process of low-rank tensor completion for missing data imputation [48].
- LRTC-TNN: Low-rank tensor completion and truncated nuclear norm was proposed by Chen et al. in 2020. As with HaLRTC, LRTC-TNN is also based on low-rank tensor completion, and uses a truncated nuclear norm to improve the imputation accuracy of missing data [21].
5.2.2. The Imputation Accuracy of the Proposed Approach under Different Amounts of Collected Traffic Data
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, Y. Automobile Production Increased by 84.2% Year on Year. 2022. Available online: https://epaper.scdaily.cn/shtml/scrb/20220317/271173.shtml (accessed on 7 June 2023).
- Beijing Municipal Commission of Tarnsport. 2022. Available online: http://jtw.beijing.gov.cn/ (accessed on 7 June 2023).
- Ks, A.; Me, B.; Ma, B. Intelligent Transportation Systems in a Developing Country: Benefits and Challenges of Implementation. Transp. Res. Procedia 2021, 55, 1373–1380. [Google Scholar]
- Ait Ouallane, A.; Bakali, A.; Bahnasse, A.; Broumi, S.; Talea, M. Fusion of engineering insights and emerging trends: Intelligent urban traffic management system. Inf. Fusion 2022, 88, 218–248. [Google Scholar] [CrossRef]
- Barceló, J.; Kuwahara, M.; Miska, M. Traffic Data Collection and Its Standardization. In Traffic Data Collection and Its Standardization; Springer: New York, NY, USA, 2010; pp. 1–10. [Google Scholar] [CrossRef]
- Sathish, S.; Ramachandra Rao, K. Real Time Vehicle Tracking and Driver Behaviour Analysis Using GPS/GSM/GPRS Technology. Int. J. Comput. Appl. 2015, 115. [Google Scholar]
- Wang, Y.; Wang, Y. Real-time traffic flow prediction using GPS-enabled floating car data. Transp. Res. Part Emerg. Technol. 2015, 308–321, 60. [Google Scholar]
- Li, Y.; Li, Z.; Li, L. Missing traffic data: Comparison of imputation methods. IET Intell. Transp. Syst. 2014, 8, 51–57. [Google Scholar] [CrossRef]
- Li, L.; Li, Y.; Li, Z. Efficient missing data imputing for traffic flow by considering temporal and spatial dependence. Transp. Res. Part Emerg. Technol. 2013, 34, 108–120. [Google Scholar] [CrossRef]
- Qu, L.; Zhang, Y.; Hu, J.; Jia, L.; Li, L. A BPCA based missing value imputing method for traffic flow volume data. In Proceedings of the 2008 IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008; pp. 985–990. [Google Scholar] [CrossRef]
- Chan, R.K.C.; Lim, J.M.Y.; Parthiban, R. A neural network approach for traffic prediction and routing with missing data imputation for intelligent transportation system. Expert Syst. Appl. 2021, 171, 114573. [Google Scholar] [CrossRef]
- Yang, B.; Kang, Y.; Yuan, Y.; Huang, X.; Li, H. ST-LBAGAN: Spatio-temporal learnable bidirectional attention generative adversarial networks for missing traffic data imputation. Knowl.-Based Syst. 2021, 215, 106705. [Google Scholar] [CrossRef]
- Suga, S.; Fujimori, R.; Yamada, Y.; Ihara, F.; Takamura, D.; Hayashi, K.; Kurihara, S. Traffic information interpolation method based on traffic flow emergence using swarm intelligence. Artif. Life Robot. 2023, 28, 367–380. [Google Scholar] [CrossRef]
- Ma, X.; Luan, S.; Ding, C.; Liu, H.; Wang, Y. Spatial Interpolation of Missing Annual Average Daily Traffic Data Using Copula-Based Model. IEEE Intell. Transp. Syst. Mag. 2019, 11, 158–170. [Google Scholar] [CrossRef]
- Li, L.; Chen, X.; Li, Z.; Zhang, L. Freeway Travel-Time Estimation Based on Temporal–Spatial Queueing Model. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1536–1541. [Google Scholar] [CrossRef]
- Soriguera, F.; Robuste, F. Requiem for Freeway Travel Time Estimation Methods Based on Blind Speed Interpolations Between Point Measurements. IEEE Trans. Intell. Transp. Syst. 2011, 12, 291–297. [Google Scholar] [CrossRef]
- Rodrigues, F.; Henrickson, K.; Pereira, F.C. Multi-Output Gaussian Processes for Crowdsourced Traffic Data Imputation. IEEE Trans. Intell. Transp. Syst. 2019, 20, 594–603. [Google Scholar] [CrossRef]
- Li, Z.; Yu, H.; Zhang, G.; Wang, J. A Bayesian vector autoregression-based data analytics approach to enable irregularly-spaced mixed-frequency traffic collision data imputation with missing values. Transp. Res. Part Emerg. Technol. 2019, 108, 302–319. [Google Scholar] [CrossRef]
- Li, L.; Zhang, J.; Wang, Y.; Ran, B. Missing Value Imputation for Traffic-Related Time Series Data Based on a Multi-View Learning Method. IEEE Trans. Intell. Transp. Syst. 2019, 20, 2933–2943. [Google Scholar] [CrossRef]
- Tan, H.; Feng, G.; Feng, J.; Wang, W.; Zhang, Y.J.; Li, F. A tensor-based method for missing traffic data completion. Transp. Res. Part Emerg. Technol. 2013, 28, 15–27. [Google Scholar] [CrossRef]
- Chen, X.; Yang, J.; Sun, L. A nonconvex low-rank tensor completion model for spatiotemporal traffic data imputation. Transp. Res. Part Emerg. Technol. 2020, 117, 102673. [Google Scholar] [CrossRef]
- Li, M.; Sheng, L.; Song, Y.; Song, J. An enhanced matrix completion method based on non-negative latent factors for recommendation system. Expert Syst. Appl. 2022, 201, 116985. [Google Scholar] [CrossRef]
- Liang, Y.; Zhao, Z.; Sun, L. Memory-augmented dynamic graph convolution networks for traffic data imputation with diverse missing patterns. Transp. Res. Part Emerg. Technol. 2022, 143, 103826. [Google Scholar] [CrossRef]
- Wang, P.; Hu, T.; Gao, F.; Wu, R.; Guo, W.; Zhu, X. A Hybrid Data-Driven Framework for Spatiotemporal Traffic Flow Data Imputation. IEEE Internet Things J. 2022, 9, 16343–16352. [Google Scholar] [CrossRef]
- Chang, G.; Zhang, Y.; Yao, D. Missing data imputation for traffic flow based on improved local least squares. Tsinghua Sci. Technol. 2012, 17, 304–309. [Google Scholar] [CrossRef]
- Chen, Y.; Lv, Y.; Wang, F.Y. Traffic Flow Imputation Using Parallel Data and Generative Adversarial Networks. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1624–1630. [Google Scholar] [CrossRef]
- Chen, Y.; Chen, X.M. A novel reinforced dynamic graph convolutional network model with data imputation for network-wide traffic flow prediction. Transp. Res. Part Emerg. Technol. 2022, 143, 103820. [Google Scholar] [CrossRef]
- Huang, T.; Chakraborty, P.; Sharma, A. Deep convolutional generative adversarial networks for traffic data imputation encoding time series as images. Int. J. Transp. Sci. Technol. 2021, 12, 1–18. [Google Scholar] [CrossRef]
- Khayati, M.; Lerner, A.; Tymchenko, Z.; Cudré-Mauroux, P. Mind the gap: An experimental evaluation of imputation of missing values techniques in time series. Proc. VLDB Endow. 2020, 13, 768–782. [Google Scholar] [CrossRef]
- Tak, S.; Woo, S.; Yeo, H. Data-Driven Imputation Method for Traffic Data in Sectional Units of Road Links. IEEE Trans. Intell. Transp. Syst. 2016, 17, 1762–1771. [Google Scholar] [CrossRef]
- Bae, B.; Kim, H.; Lim, H.; Liu, Y.; Han, L.D.; Freeze, P.B. Missing data imputation for traffic flow speed using spatio-temporal cokriging. Transp. Res. Part Emerg. Technol. 2018, 88, 124–139. [Google Scholar] [CrossRef]
- Deb, R.; Liew, A.W.C. Missing value imputation for the analysis of incomplete traffic accident data. Inf. Sci. 2016, 339, 274–289. [Google Scholar] [CrossRef]
- Wang, S.; Mao, G. Fundamental Limits of Missing Traffic Data Estimation in Urban Networks. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1191–1203. [Google Scholar] [CrossRef]
- Shaoxu, S.; Yu, S.; Aoqian, Z.; Lei, C.; Jianmin, W. Enriching Data Imputation under Similarity Rule Constraints. IEEE Trans. Knowl. Data Eng. 2018, 32, 275–287. [Google Scholar]
- Rekatsinas, T.; Chu, X.; Ilyas, I.F.; Ré, C. HoloClean: Holistic Data Repairs with Probabilistic Inference. Proc. VLDB Endow. 2017, 10, 1190–1201. [Google Scholar] [CrossRef]
- Breve, B.; Caruccio, L.; Deufemia, V.; Polese, G. RENUVER: A Missing Value Imputation Algorithm based on Relaxed Functional Dependencies. In Proceedings of the 25th International Conference on Extending Database Technology, EDBT 2022, Edinburgh, UK, 29 March–1 April 2022. [Google Scholar]
- Kaur, M.; Singh, S.; Aggarwal, N. Missing traffic data imputation using a dual-stage error-corrected boosting regressor with uncertainty estimation. Inf. Sci. 2022, 586, 344–373. [Google Scholar] [CrossRef]
- Haliduola, H.N.; Bretz, F.; Mansmann, U. Missing data imputation using utility-based regression and sampling approaches. Comput. Methods Programs Biomed. 2022, 226, 107172. [Google Scholar] [CrossRef]
- Templeton, G.F.; Kang, M.; Tahmasbi, N. Regression imputation optimizing sample size and emulation: Demonstrations and comparisons to prominent methods. Decis. Support Syst. 2021, 151, 113624. [Google Scholar] [CrossRef]
- Crambes, C.; Henchiri, Y. Regression imputation in the functional linear model with missing values in the response. J. Stat. Plan. Inference 2019, 201, 103–119. [Google Scholar] [CrossRef]
- Jia, X.; Dong, X.; Chen, M.; Yu, X. Missing data imputation for traffic congestion data based on joint matrix factorization. Knowl.-Based Syst. 2021, 225, 107114. [Google Scholar] [CrossRef]
- Nie, T.; Qin, G.; Sun, J. Truncated tensor Schatten p-norm based approach for spatiotemporal traffic data imputation with complicated missing patterns. Transp. Res. Part Emerg. Technol. 2022, 141, 103737. [Google Scholar] [CrossRef]
- Chen, X.; He, Z.; Sun, L. A Bayesian tensor decomposition approach for spatiotemporal traffic data imputation. Transp. Res. Part Emerg. Technol. 2019, 98, 73–84. [Google Scholar] [CrossRef]
- de, M.; Goulart, J.; Kibangou, A.; Favier, G. Traffic data imputation via tensor completion based on soft thresholding of Tucker core. Transp. Res. Part Emerg. Technol. 2017, 85, 348–362. [Google Scholar] [CrossRef]
- Hidas, P.; Hoogendoorn, S.P. Impact of spatial network structure on traffic flow. Transp. Res. Part Methodol. 2011, 1582–1597, 45. [Google Scholar]
- Acun, F.; Gol, E.A. Traffic Prediction on Large Scale Traffic Networks Using ARIMA and K-Means. In Proceedings of the 2021 29th Signal Processing and Communications Applications Conference (SIU), Istanbul, Turkey, 9–11 June 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Sefidian, A.M.; Daneshpour, N. Missing value imputation using a novel grey based fuzzy c-means, mutual information based feature selection, and regression model. Expert Syst. Appl. 2019, 115, 68–94. [Google Scholar] [CrossRef]
- Liu, J.; Musialski, P.; Wonka, P.; Ye, J. Tensor completion for estimating missing values in visual data. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2114–2121. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Size | Missing Patterns | Pattern Names |
|---|---|---|
| Spatiotemporal matrix: | In roads | Removal of certain roads |
| Roads: 20 | GPS | Random removal |
| Time intervals: 325 | In time intervals | Removal of certain time intervals |
| Missing Patterns | Missing Rates | ARIMA | MEAN | HaLRTC | LRTC-TNN | OUR |
|---|---|---|---|---|---|---|
|
Removal of certain roads | 20% | N/A | N/A | 6.74/6.67 | 5.67/5.01 | 3.45/3.13 |
| 40% | N/A | N/A | 7.73/7.78 | 6.73/7.89 | 3.56/3.17 | |
| 50% | N/A | N/A | 8.76/6.08 | 7.01/8.07 | 3.56/3.40 | |
| 70% | N/A | N/A | 9.26/10.89 | 8.45/9.77 | 4.77/5.06 | |
|
Random removal | 20% | 8.50/3.56 | 9.70/3.19 | 5.83/3.47 | 4.65/3.06 | 3.43/3.26 |
| 40% | 8.67/9.88 | 20.51/19.83 | 6.76/6.83 | 5.12/4.90 | 3.87/3.45 | |
| 50% | 10.66/11.20 | 25.05/26.89 | 7.30/8.07 | 5.50/5.41 | 5.73/5.70 | |
| 70% | 12.45/13.37 | 36.37/36.09 | 8.89/10.76 | 6.53/7.04 | 5.70/6.00 | |
|
Removal of certain time intervals | 20% | 6.49/7.07 | 10.48/11.14 | 8.79/9.69 | 6.93/6.19 | 3.47/3.01 |
| 40% | 8.45/7.98 | 20.76/21.52 | 10.19/10.27 | 7.59/8.50 | 3.80/3.47 | |
| 50% | 10.04/11.89 | 25.73/21.24 | 12.37/10.11 | 8.61/7.97 | 3.77/3.64 | |
| 70% | 12.09/11.17 | 36.33/35.85 | 14.34/16.94 | 8.41/8.45 | 5.46/4.77 |
| Missing Patterns | Missing Rates | 5 Time Intervals | 10 Time Intervals | 15 Time Intervals |
|---|---|---|---|---|
| Removal of certain roads | 3.78/3.47 | 3.57/3.26 | 3.45/3.13 | |
| 3.90/3.26 | 3.84/3.29 | 3.56/3.17 | ||
| 4.07/3.56 | 3.85/3.37 | 3.56/3.40 | ||
| 5.90/4.89 | 5.98/4.98 | 5.77/5.06 | ||
| Random removal | 4.03/3.47 | 3.56/3.34 | 3.43/3.26 | |
| 4.13/3.98 | 3.93/3.67 | 3.88/3.45 | ||
| 5.89/5.04 | 5.57/4.84 | 5.43/4.73 | ||
| 6.04/5.13 | 5.83/5.02 | 5.70/5.00 | ||
| Removal of certain time points | 3.73/3.47 | 3.24/3.12 | 3.23/3.01 | |
| 3.86/3.89 | 3.78/3.27 | 3.80/3.39 | ||
| 4.01/3.78 | 3.90/3.43 | 3.77/3.37 | ||
| 5.74/4.88 | 5.38/4.65 | 5.46/4.77 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, X.; Sun, W.; Song, C.; Cai, Z.; Guo, L. A Latent-Factor-Model-Based Approach for Traffic Data Imputation with Road Network Information. ISPRS Int. J. Geo-Inf. 2023, 12, 378. https://doi.org/10.3390/ijgi12090378
Su X, Sun W, Song C, Cai Z, Guo L. A Latent-Factor-Model-Based Approach for Traffic Data Imputation with Road Network Information. ISPRS International Journal of Geo-Information. 2023; 12(9):378. https://doi.org/10.3390/ijgi12090378
Chicago/Turabian StyleSu, Xing, Wenjie Sun, Chenting Song, Zhi Cai, and Limin Guo. 2023. "A Latent-Factor-Model-Based Approach for Traffic Data Imputation with Road Network Information" ISPRS International Journal of Geo-Information 12, no. 9: 378. https://doi.org/10.3390/ijgi12090378
APA StyleSu, X., Sun, W., Song, C., Cai, Z., & Guo, L. (2023). A Latent-Factor-Model-Based Approach for Traffic Data Imputation with Road Network Information. ISPRS International Journal of Geo-Information, 12(9), 378. https://doi.org/10.3390/ijgi12090378