
Quantifying the Effect of Socio-Economic Predictors and the Built Environment on Mental Health Events in Little Rock, AR

Abstract
1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Data & Pre-Processing
2.3. Methods
2.3.1. Poisson Generalized Linear Model
2.3.2. Random Forest
2.3.3. Spatial Econometric Models
3. Results
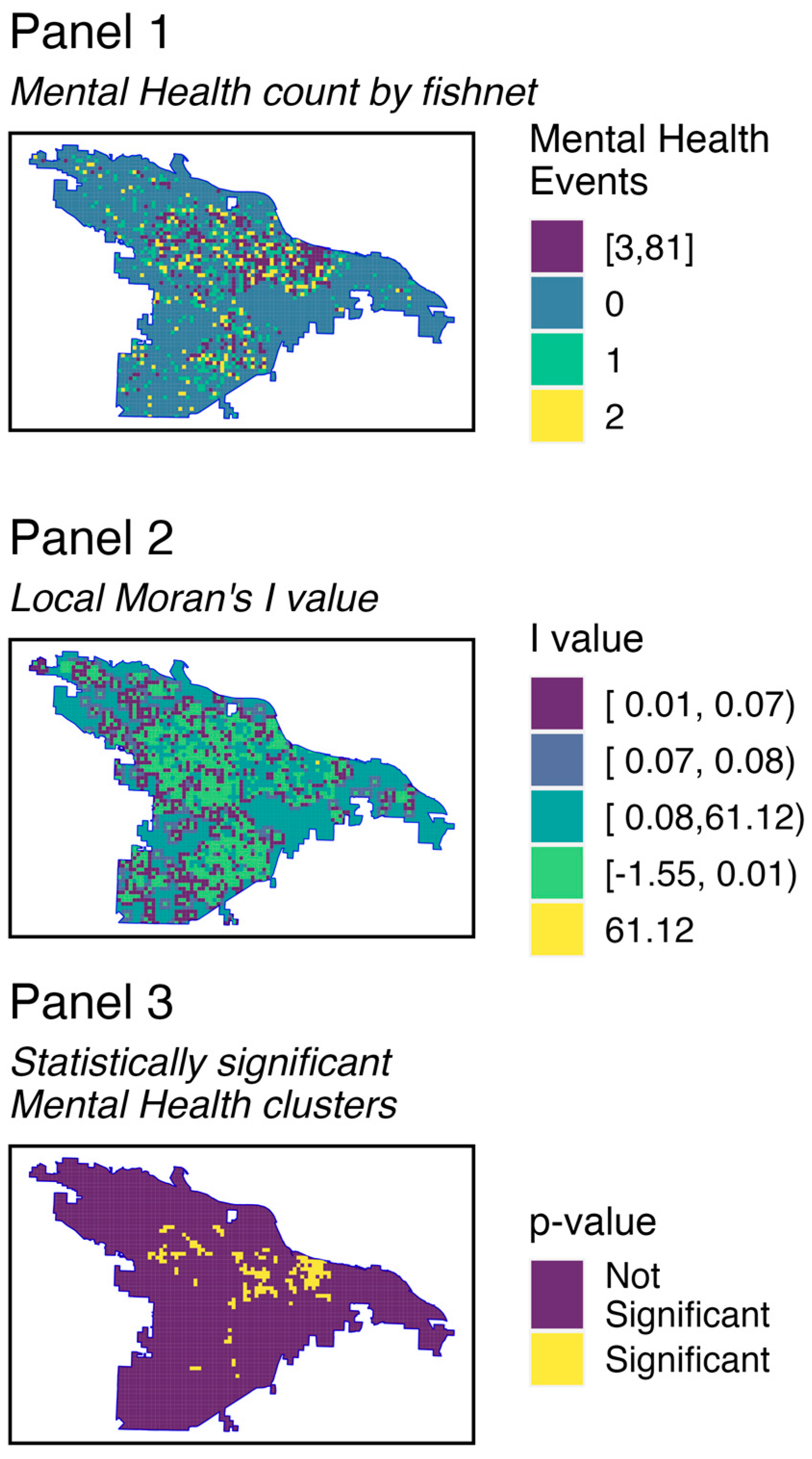
3.1. Evidence of Spatial Clustering
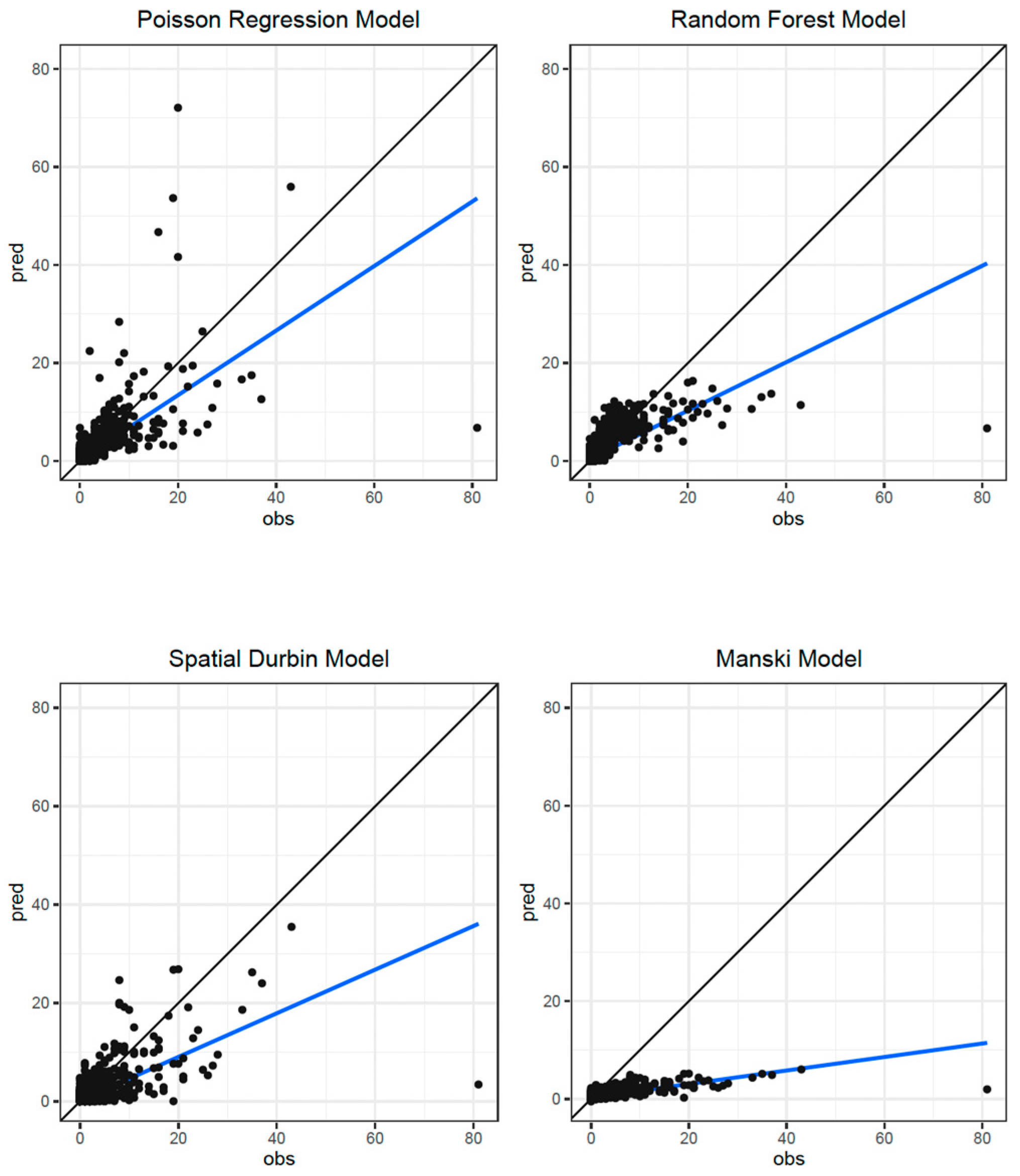
3.2. Model Comparison
3.2.1. Model Performance
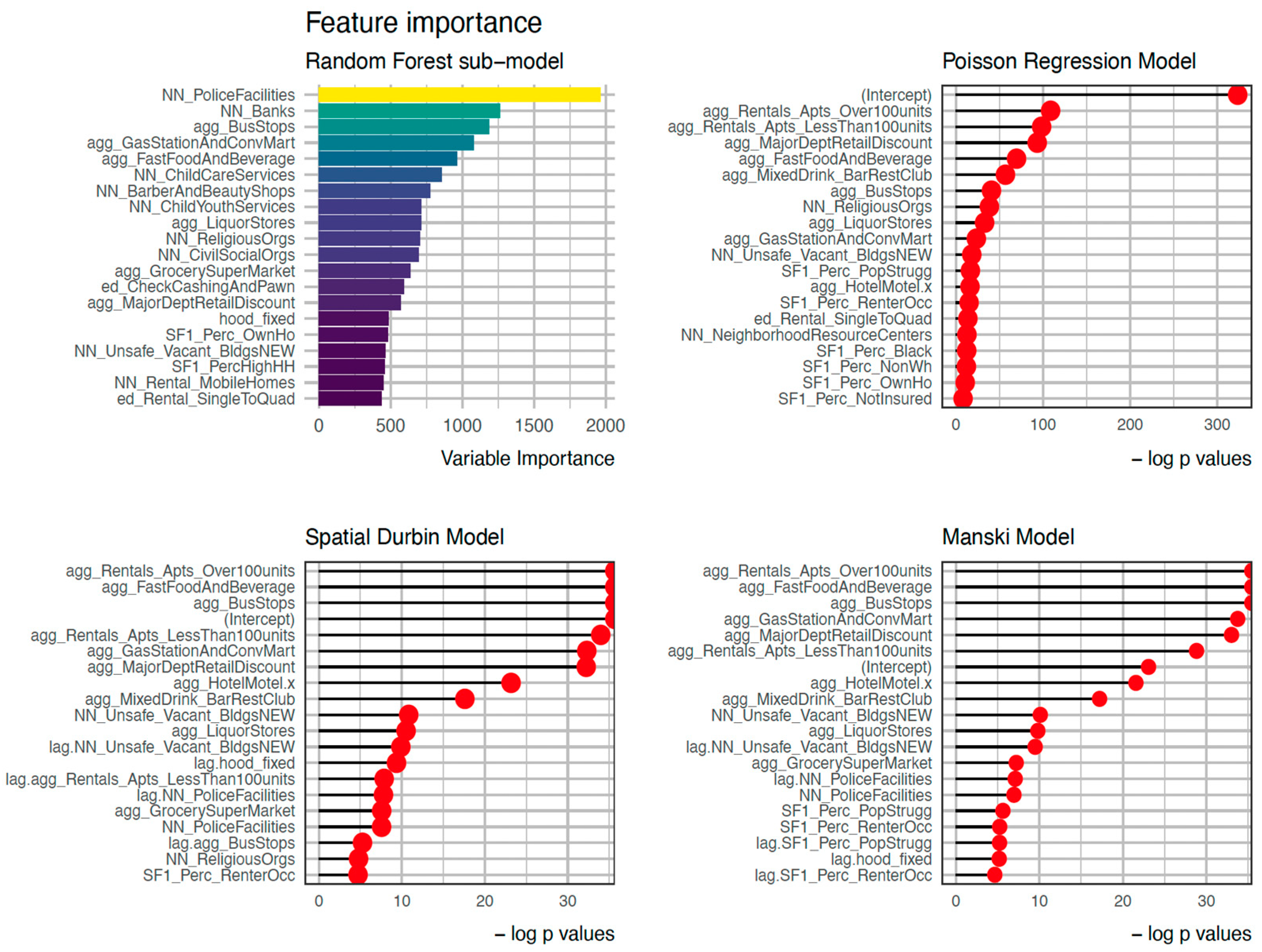
3.2.2. Feature Importance
4. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Perry, W.L.; Mcinnis, B.; Price, C.C.; Smith, S.; Hollywood, J.S. Predictive Policing: Forecasting Crime for Law Enforcement; National Institute of Justice: Washington, DC, USA, 2013. [Google Scholar]
- Weisburd, D. The Law of Crime Concentration and the Criminology of Place. Criminology 2015, 53, 133–157. [Google Scholar] [CrossRef]
- Levin, A.; Rosenfeld, R.; Deckard, M. The Law of Crime Concentration: An application and recommendations for future research. J. Quant. Criminol. 2017, 33, 635–647. [Google Scholar] [CrossRef]
- Brantingham, P.J.; Brantingham, P.L.; Song, J.; Spicer, V. Crime hot spots, crime corridors and the journey to crime: An expanded theoretical model of the generation of crime concentrations. In Geographies of Behavioural Health, Crime, and Disorder; Lersch, K., Chakraborty, J., Eds.; (GeoJournal Library); Springer: Cham, Switzerland, 2020; Volume 126. [Google Scholar]
- NIJ Real-Time Crime Forecasting Challenge. Available online: https://nij.ojp.gov/funding/real-time-crime-forecasting-challenge (accessed on 5 May 2023).
- Lum, K.; Isaac, W. To predict and serve? Significance 2016, 13, 14–19. [Google Scholar] [CrossRef]
- Sampson, R.J. Great American City: Chicago and the Enduring Neighborhood Effect; The University of Chicago Press: Chicago, IL, USA, 2012. [Google Scholar]
- Shaw, C.; McKay, H. Juvenile Delinquency in Urban Areas; University of Chicago Press: Chicago, IL, USA, 1942. [Google Scholar]
- Kubrin, C.E. Social disorganization theory: Then, now, and in the future. In Handbook on Crime and Deviance; Krohn, M.D., Lizotte, A.J., Hall, G.P., Eds.; Springer: New York, NY, USA, 2009. [Google Scholar]
- Eck, J.E.; Weisburd, D. Crime places in crime theory. In Crime and Place, Monsey; Eck, J.E., Weisburd, D., Eds.; Criminal Justice Press: New York, NY, USA; Police Executive Research Forum: Washington, DC, USA, 1995. [Google Scholar]
- Pratt, T.C.; Cullen, F.T. Assessing macro-level predictors and theories of crime: A meta-analysis. In Prisons and Prisoners; Tonry, M., Bucerius, S., Eds.; University of Chicago: Chicago, IL, USA, 2005. [Google Scholar]
- Cohen, L.; Felson, M. Social change and crime rate trends: A routine activity approach. Am. Sociol. Rev. 1979, 44, 588–608. [Google Scholar] [CrossRef]
- Brantingham, P.J.; Brantingham, P.L. Crime pattern theory. In Environmental Criminology and Crime Analysis; Wortley, R., Mazerolle, L., Eds.; Willan: Sullompton, UK, 2008. [Google Scholar]
- Brantingham, P.L.; Brantingham, P.J. Criminality of place: Crime generators and crime attractors. Eur. J. Crim. Policy Res. 1995, 3, 5–26. [Google Scholar] [CrossRef]
- Rocek, D.W.; Bell, R. Bars, blocks, and crimes. J. Environ. Syst. 1981, 11, 35–47. [Google Scholar] [CrossRef]
- Madensen, T.D.; Eck, J.E. Violence in bars: Exploring the impact of place manager decision-making. Crime Prev. Community Saf. 2008, 10, 111–125. [Google Scholar] [CrossRef]
- Rahnow, R.; Corcoran, J. Crime and bus stops: An examination of using transit smart card and crime data. Urban Anal. City Sci. 2021, 48, 706–723. [Google Scholar]
- Stucky, T.D.; Smith, S.L. Exploring the conditional effects of bus stops on crime. Secur. J. 2017, 30, 290–309. [Google Scholar] [CrossRef]
- Groff, E.; McCord, E.S. The role of neighborhood parks as crime generators. Secur. J. 2012, 25, 1–24. [Google Scholar] [CrossRef]
- Boessen, A.; Hipp, J.R. Parks as crime inhibitors or generators: Examining parks and the role of their nearby context. Soc. Sci. Res. 2018, 76, 186–201. [Google Scholar] [CrossRef] [PubMed]
- Tillyer, M.S.; Wilcox, P.; Walter, R.J. Crime generators in context: Examining ‘place in neighborhood’ propositions. J. Quantiative Criminol. 2021, 37, 517–546. [Google Scholar] [CrossRef]
- Caplan, J.M.; Kennedy, L.W.; Miller, J. Risk terrain modeling: Brokering criminological theory and GIS methods for crime forecasting. Justice Q. 2011, 28, 360–381. [Google Scholar] [CrossRef]
- Andresen, M.A.; Curman, A.S.; Linning, S.J. The trajectories of crime at places: Understanding the patterns of disaggregated crime types. J. Quant. Criminol. 2017, 33, 427–449. [Google Scholar] [CrossRef]
- Hodgkinson, T.; Andresen, M.A. Understanding the spatial patterns of police activity and mental health in a Canadian city. J. Contemp. Crim. Justice 2019, 35, 221–240. [Google Scholar] [CrossRef]
- Koziarski, J. The effect of the COVID-19 pandemic on mental health calls for police service. Crime Sci. 2021, 10, 22. [Google Scholar] [CrossRef]
- Koziarski, J.; Ferguson, L.; Huey, L. Shedding light on the dark figure of police mental health calls for service. Polic. A J. Policy Pract. 2022, 16, 696–706. [Google Scholar] [CrossRef]
- Lersch, K.M.; Christy, A. The geography of mental health: An examination of police calls for service. In Geographies of Behavioural Health, Crime, and Disorder; Lersch, K., Chakraborty, J., Eds.; (GeoJournal Library); Springer: Cham, Switzerland, 2020; Volume 126. [Google Scholar]
- Lersch, K.M. COVID-19 and mental health: An examination of 911 calls for service. Polic. A J. Policy Pract. 2020, 14, 1112–1126. [Google Scholar] [CrossRef]
- Vaughan, A.D.; Hewitt, A.N.; Hodkinson, T.; Andresen, M.A.; Verdun-Jones, S. Temporal patterns of Mental Health Act calls to the police. Polic. A J. Policy Pract. 2019, 13, 172–185. [Google Scholar] [CrossRef]
- Vaughan, A.D.; Ly, M.; Andresen, M.A.; Wuschke, K.; Hodgkinson, T.; Campbell, A. Concentrations and specializatoin of mental health-related calls for police service. Vict. Offenders 2018, 13, 1153–1170. [Google Scholar] [CrossRef]
- Gotway, C.A.; Stroup, W.W. A generalized linear model approach to spatial data analysis and prediction. J. Agric. Biol. Environ. Stat. 1997, 2, 157–178. [Google Scholar] [CrossRef]
- Wang, X.; Brown, D.E. The spatio-temporal modeling for criminal incidents. Secur. Inform. 2012, 1, 2. [Google Scholar] [CrossRef]
- Wheeler, A.P.; Steenbeek, W. Mapping the risk terrain for crime using machine learning. J. Quant. Criminol. 2021, 37, 445–480. [Google Scholar] [CrossRef]
- Harris, C.T.; Drawve, G.; Thomas, S.; Datta, J.; Steinman, H. Innovative data in communities and crime research: An example at the intersection of racial segregation, neighborhood permeability, and crime. J. Crime Justice 2022, 45, 609–626. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing. In R Foundation for Statistical Computing; R Core Team: Vienna, Austria, 2022; Available online: https://www.R-project.org/ (accessed on 2 March 2023).
- Pingel, T. The Raster Data Model. In The Geographic Information Science & Technology Body of Knowledge, 3rd Quarter 2018 ed.; Wilson, J.P., Ed.; University Consortium for Geographic Information Science: Washington, DC, USA, 2018. [Google Scholar] [CrossRef]
- Montgomery, D.C.; Peck, E.A.; Vining, G.G. Introduction to Linear Regression Analysis, 4th ed.; Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Breinman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning: With Applications in R; Springer Publishing Company, Incorporated: New York, NY, USA, 2014. [Google Scholar]
- Elhorst, J. Spatial Econometrics: From Cross-Sectional Data to Spatial Panels; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Anselin, L. Local indicators of spatial association—Lisa. Geogr. Anal. 1995, 27, 93–115. [Google Scholar] [CrossRef]
- Bivand, R.S.; Pebesma, E.J.; Gomez-Rubio, V.; Pebesma, E.J. Applied Spatial Dataanalysis with R; Springer: Berlin/Heidelberg, Germany, 2008; Volume 747248717. [Google Scholar]
- Pebesma, E.J.; Bivard, R. Spatial Data Science; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Boots, B. Spatial pattern, analysis of. In International Encyclopedia of the Social & Behavioral Sciences; Smelser, N.J., Baltes, P.B., Eds.; Pergamon: Oxford, UK, 2001; pp. 14818–14822. [Google Scholar]
- De Jong, P.; Sprenger, C.; Veen, F. On extreme values of moran’s i and geary’s c ( spatial autocorrelation). Geogr. Anal. 1984, 16, 17–24. [Google Scholar] [CrossRef]
- Bivand, R.; Wong, D.W.S. Comparing implementations of global and local indicators of spatial association. TEST 2018, 27, 716–748. [Google Scholar] [CrossRef]
- Lum, C.; Koper, C.S. Evidence-Based Policing: Translating Research into Practice; Oxford University Press: Oxford, UK, 2017. [Google Scholar]
- Helfgott, J.B.; Hickman, M.J.; Labossiere, A.P. A descriptive evaluation of the Seattle police department’s crisis response team officer/mental health partnership pilot program. Int. J. Law Psychiatry 2016, 44, 109–122. [Google Scholar] [CrossRef]
- Lee, S.J.; Thomas, P.; Doulis, C.; Bowles, D.; Henderson, K.; Keppich-Arnold, S.; Perez, E.; Stafrace, S. Outcomes achieved by and police and clinician perspectives on a joint police officer mental health clinician mobile response unit. Int. J. Ment. Health Nurs. 2015, 24, 538–546. [Google Scholar] [CrossRef]
- Shapiro, G.K.; Cusi, A.; Kirst, M.; O’Campo, P.; Nakhost, A.; Stergiopoulos, V. Co-responding police-mental health programs: A review. Adm. Policy Ment. Health Ment. Health Serv. Res. 2015, 42, 606–620. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Potential Community Protective Factors X-Y Coordinates | Source |
|---|---|
| Banks | Little Rock City |
| Childcare Services | InfoGroup |
| Child/Youth Services | InfoGroup |
| Civic/Social Organizations | InfoGroup |
| Grocery Stores | Little Rock City |
| High Schools (Public) | LRSD Website |
| Hospitals | InfoGroup |
| Neighborhood Resource Centers | Little Rock City |
| Police/Fire Facilities | Little Rock City |
| Religious Organizations | InfoGroup |
| Potential Community Risk Factors X-Y coordinates | Source |
| Barber and Beauty Shops | Little Rock City |
| Bus Stops | MetroPlan |
| Check Cashing and Pawn Shops | Little Rock City |
| Fast-Food and Beverage Restaurants | Little Rock City |
| Gas Stations and Convenience Stores | Little Rock City |
| Hotels and Motels | Little Rock City |
| Liquor Stores | AR Alcohol Beverage Control |
| Major Dept. Discount Stores | Little Rock City |
| Mixed Drink-Bar, Restaurants, and Clubs | AR Alcohol Beverage Control |
| Rental Mobile Homes | Little Rock City |
| Rental Single to Quad | Little Rock City |
| Rental Apartments < 100 units | Little Rock City |
| Rental Apartments > 100 units | Little Rock City |
| Tattoo Piercing | Little Rock City |
| Unsafe and Vacant Buildings | Little Rock City |
| Crime (Antisocial behavior of community) X-Y coordinates | Source |
| Agg. Assault: Household Member | LRPD |
| Agg. Assault | LRPD |
| Battery: 1st degree | LRPD |
| Battery: 2nd Degree | LRPD |
| Breaking or Entering Vehicle | LRPD |
| Burglary: Residential | LRPD |
| Burglary: Commercial | LRPD |
| Domestic Battering | LRPD |
| Drugs Narcotics | LRPD |
| Rape | LRPD |
| Robbery | LRPD |
| Robbery (Aggravated) | LRPD |
| Runaways | LRPD |
| Terroristic Act | LRPD |
| Theft of Property: Misdemeanor | LRPD |
| Theft of Property: Felony | LRPD |
| Population Metrics extrapolated from census track data | Source |
| Population Density | ACS |
| Percent Black | ACS |
| Percent Non-White | ACS |
| Percent Hispanic | ACS |
| Percent Under 18 | ACS |
| Percent College Educated | ACS |
| Percent Less than High School Degree | ACS |
| Percent in Poverty (under 18) | ACS |
| Percent Population Struggling | ACS |
| Percent Single Parent Households | ACS |
| Percent Female Headed Households | ACS |
| Percent Non-Married Households | ACS |
| Percent on Public Insurance | ACS |
| Percent Not Insured | ACS |
| Percent Home Ownership | ACS |
| Percent Renter Occupied Households | ACS |
| Model | MAPE Mean (SD) | MAE Mean (SD) | RMSE Mean (SD) |
|---|---|---|---|
| Poisson GLM | 1.311 (0.031) | 0.910 (0.270) | 2.917 (1.589) |
| Random Forest | 1.306 (0.035) | 0.868 (0.171) | 2.190 (0.901) |
| Spatial Durbin | 1.316 (NA) | 0.636 (NA) | 2.135 (NA) |
| Manski Model | 1.302 (NA) | 0.771 (NA) | 2.583 (NA) |
| Model | R2 Mean (SD) | Log Deviance Mean (SD) |
|---|---|---|
| Poisson GLM | 0.393 (0.152) | 0.614 (0.051) |
| Random Forest | 0.382 (0.058) | 0.584 (0.040) |
| Spatial Durbin | 0.474 (NA) | 0.710 (NA) |
| Manski Model | 0.437 (NA) | 0.612 (NA) |
| Poisson GLM | Random Forest | Spatial Durbin | Manski |
|---|---|---|---|
| agg Rentals Apts Over100 units | NN PoliceFacilities | agg Rentals Apts Over100 units | agg Rentals Apts Over100 units |
| agg Rentals Apts LessThan100 units | NN Banks | agg FastFoodAndBeverage | agg FastFoodAndBeverage |
| agg MajorDeptRetailDiscount | agg BusStops | agg BusStops | agg BusStops |
| agg FastFoodAndBeverage | agg GasStationAndConvMart | agg Rentals Apts LessThan100 units | agg GasStationAndConvMart |
| agg MixedDrink BarRestClub | agg FastFoodAndBeverage | agg GasStationAndConvMart | agg MajorDeptRetailDiscount |
| agg BusStops | NN ChildCareServices | agg MajorDeptRetailDiscount | agg Rentals Apts LessThan100 units |
| NN ReligiousOrgs | NN BarberAndBeautyShops | agg HotelMotel.x | agg HotelMotel.x |
| agg LiquorStores | NN ChildYouthServices | agg MixedDrink BarRestClub | agg MixedDrink BarRestClub |
| agg GasStationAndConvMart | agg LiquorStores | NN Unsafe Vacant BldgsNEW | NN Unsafe Vacant BldgsNEW |
| NN Unsafe Vacant BldgsNEW | NN ReligiousOrgs | agg LiquorStores | agg LiquorStores |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ek, A.; Drawve, G.; Robinson, S.; Datta, J. Quantifying the Effect of Socio-Economic Predictors and the Built Environment on Mental Health Events in Little Rock, AR. ISPRS Int. J. Geo-Inf. 2023, 12, 205. https://doi.org/10.3390/ijgi12050205
Ek A, Drawve G, Robinson S, Datta J. Quantifying the Effect of Socio-Economic Predictors and the Built Environment on Mental Health Events in Little Rock, AR. ISPRS International Journal of Geo-Information. 2023; 12(5):205. https://doi.org/10.3390/ijgi12050205
Chicago/Turabian StyleEk, Alfieri, Grant Drawve, Samantha Robinson, and Jyotishka Datta. 2023. "Quantifying the Effect of Socio-Economic Predictors and the Built Environment on Mental Health Events in Little Rock, AR" ISPRS International Journal of Geo-Information 12, no. 5: 205. https://doi.org/10.3390/ijgi12050205
APA StyleEk, A., Drawve, G., Robinson, S., & Datta, J. (2023). Quantifying the Effect of Socio-Economic Predictors and the Built Environment on Mental Health Events in Little Rock, AR. ISPRS International Journal of Geo-Information, 12(5), 205. https://doi.org/10.3390/ijgi12050205