






Flexible Trip-Planning Queries


Abstract
1. Introduction
- Location-based social networks, in which users can send and receive messages from people living in an area of interest, such as [2];
- Location-based services (LBSs), where a user’s current location is used as real time contextual information in the delivery of services [5];
- Collaborative mapping services such as OpenStreetMap [6] and Google map maker enabling crowdsourcing georeferenced contents.
2. Materials and Methods
2.1. Related Work
- Approaches for best routing to relevant resources, which require to identify the relevant territorial resources belonging to categories of interest declared in the query [11];
- The modelling of the visiting priority of the distinct types of spatial objects, both resources and VGSs, thanks to the application of a prioritized aggregation operator [26];
- The ranking of the different retrieved routes by taking into account both the priorities and the flexible constrains.
2.2. Background Notions
2.2.1. Flexible Spatial Conditions
- Flexible Geometric conditions for evaluating degrees of satisfaction of geometric relationships between pairs of spatial objects defined on the domain of some spatially derived attributes (area, ellipticity, etc.). These conditions can be expressed by means of linguistic values such as bigger, smaller, more circular, much longer, etc.: for example to retrieve and rank the European nations with a territory bigger than Italy;
- Flexible Topological conditions for evaluating degrees of satisfaction of topological relationships between pairs of spatial objects such as very overlapped, meeting, almost South, East, etc.: for example to retrieve the nations sharing a border with Italy, and to rank them based on the length of the shared border;
- Flexible directional conditions expressed by linguistic values such as almost South, East, South-West, etc., for computing degrees of satisfactions depending on the directional relationships between pairs of spatial objects: for example to retrieve and rank European nations that are North-East of Italy;
- Flexible Metric conditions expressed by linguistic values such as close, far, very far, etc., for computing degrees of satisfactions depending on the distance between pairs of spatial objects: for example to retrieve and rank European nations depending on their distance to Italy.
2.2.2. Prioritized Aggregation Operator
2.3. Semantics of Flexible Trip-Planning Queries
AND possibly in_neighbourhood (“baby sitter”)
2.4. Graph-Based Algorithm for Flexible Trip-Planning-Query Evaluation
sop <key [OR key]*>p+1]*.
2.4.1. Ranked Route Definition
∀ vi−1, vi ∧ i = 1,…M ∃ ei−1, i = (vi−1, vi, s_ranki−1,i) ∧ s_rank i−1,i > 0
∀p > 1 RSVp = RSV(<v0, …,vp>): = (RSV(<v0,…, vp−1>) + min(op. r_ranki, s_rank p−1, p)) * min(op.r_rankp, s_rank p−1, p)
= (RSVp−1+ min(op. r_rankp, s_rank p−1, p)) * min(op.r_rank p, s_rank p−1, p),
2.4.2. “in_neighbourhood” Definition
2.4.3. Definition of “close”
2.4.4. Graph-Based Algorithm for Query Evaluation
- There exists only one root vertex v0 = (u.default, 0, 1) that identifies the reference geographic area with maximum |O1| departing edges (branches) and no incoming edge;
- There exist a number of vertices vi, named leaf, with no departing branches and at least an incoming branch: ∃ei−1,I | vi ∈ ei−1, i ∧ ¬ ∃ ei,i+1 | vi ∈ ei, i+1;
- All other vertexes have both at least an incoming branch and a departing branch;
- The maximum depth of a branch from root to a leaf is equal–smaller than N, the number of query conjuncts.
3. Results
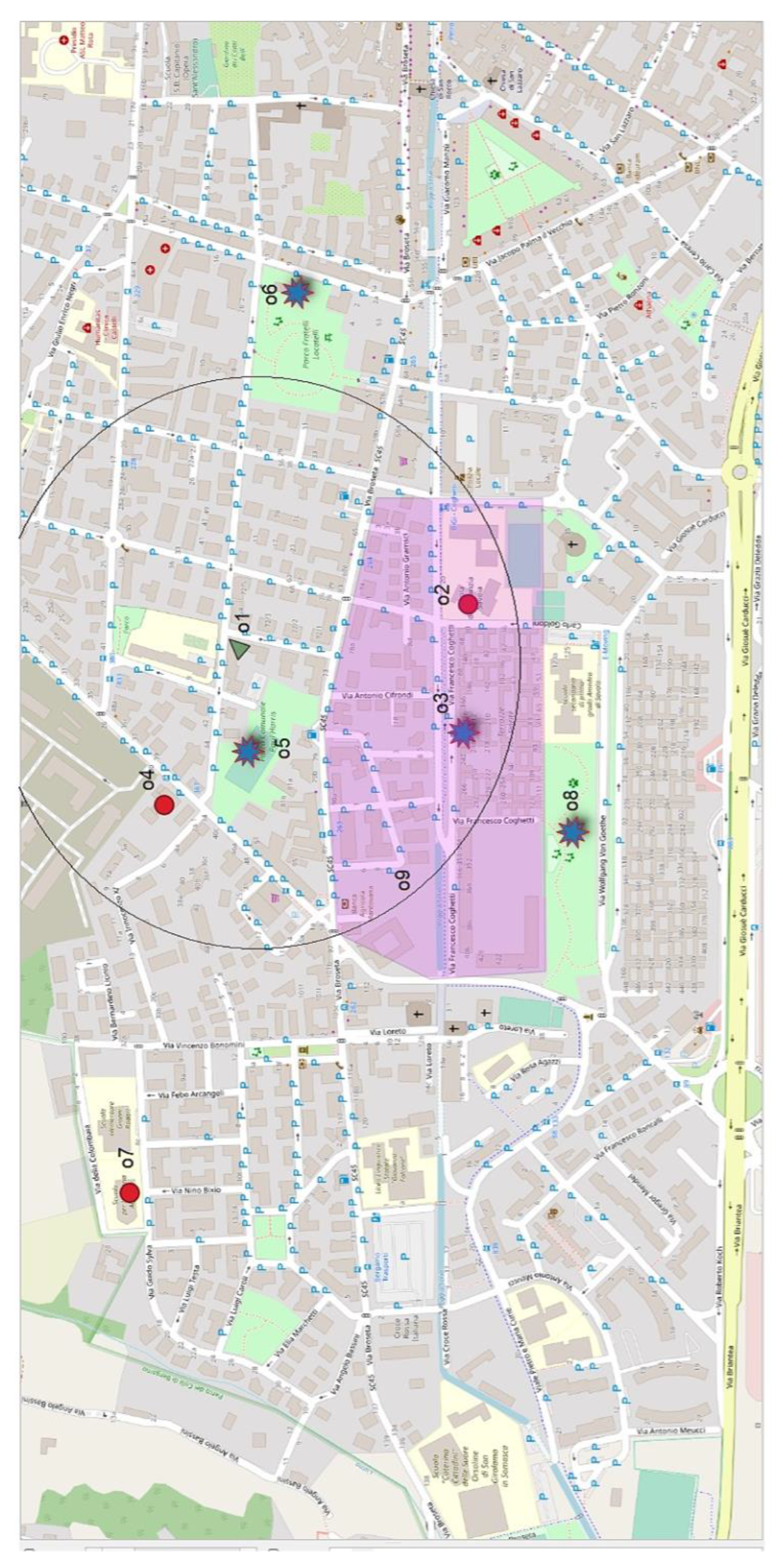
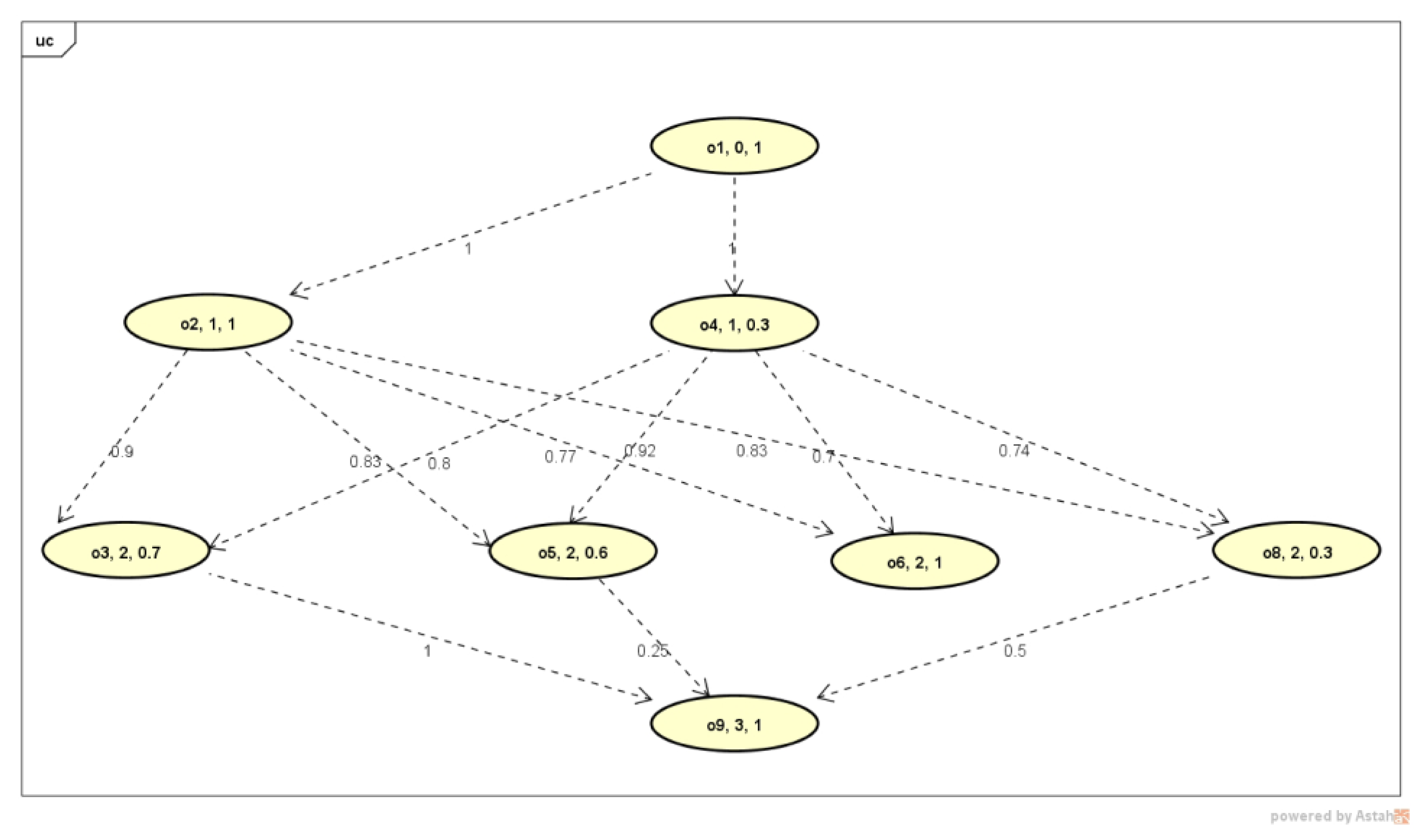
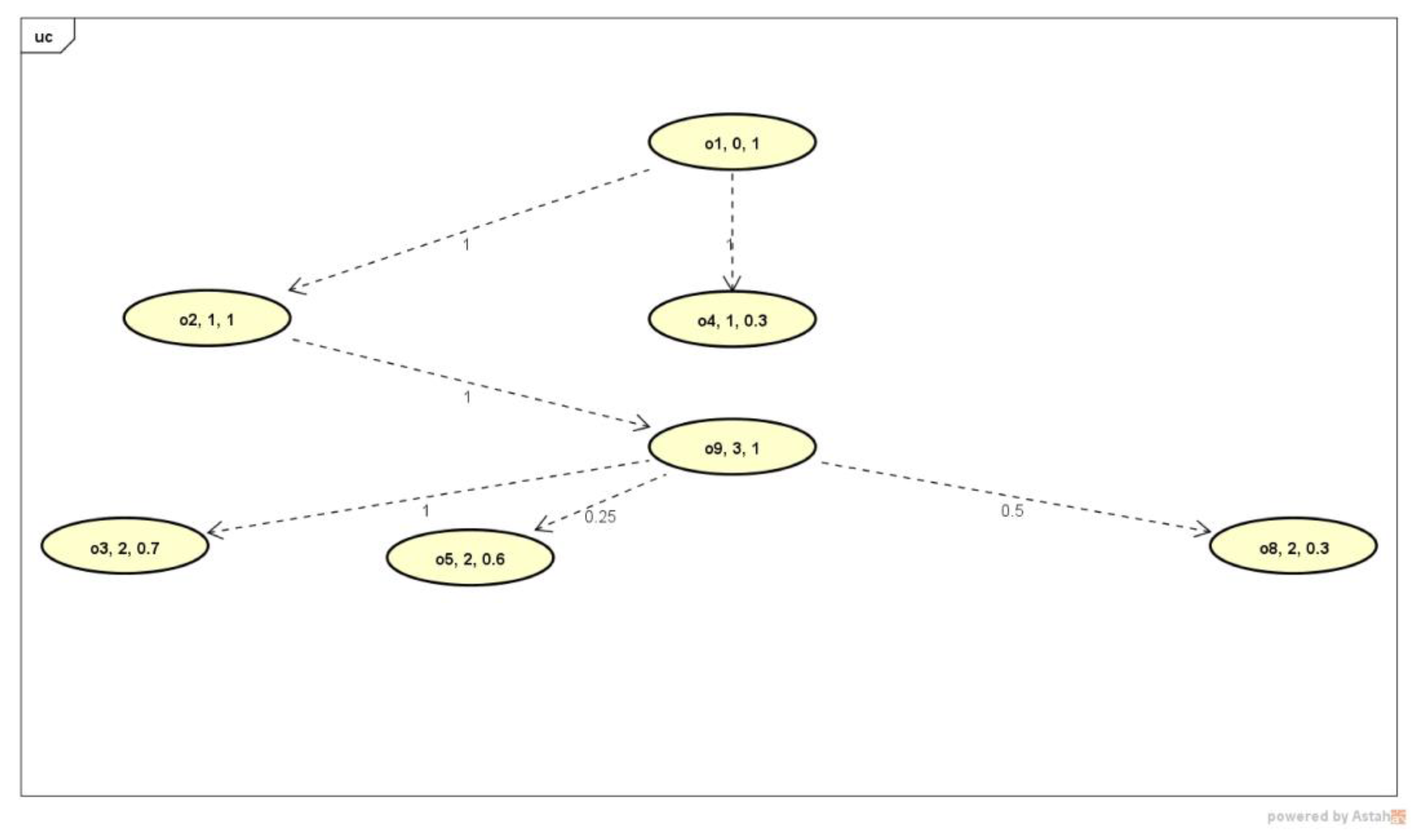
3.1. Running Example of Flexible Trip-Planning-Query Evaluation
AND possibly in neighbourhood
(“recreation centre” OR “library”)
3.2. SO-GREAT System Design and Implementation
3.2.1. User Requirements for Strengthening Local Communities
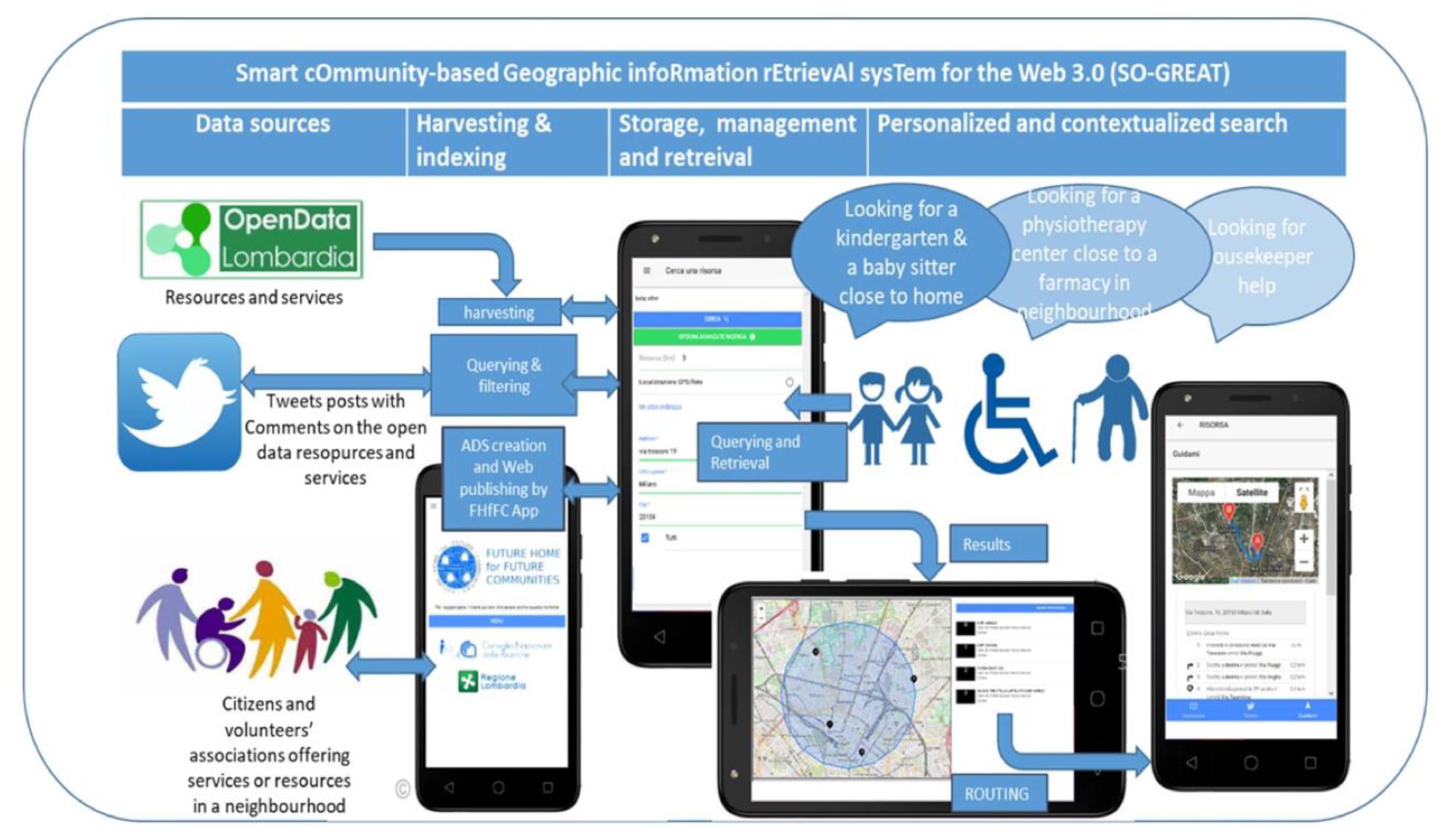
3.2.2. The SO-GREAT System Architecture
- Heterogeneity of the resources and services as far as their semantics, structure, and formats go;
- Missing or implicit geolocation, often encoded by a postal address;
- Short descriptions of the resource facilities: in most cases just metadata are available, such as the type of resource, name, and postal address, while information on comments and ratings from users who experienced the resource/services can help evaluate their trustfulness.
- The possibility to enrich the descriptions of the resources and services with comments collected from social network posts; thus, a harvesting of posts about the resources was a preliminary function.
- The ability to enable the creation of VGSs by volunteers willing to offer some kind of help in their neighbourhood. This possibility can contribute to improve the reciprocal knowledge and cohesion of a local community. Nevertheless, it is necessary to preserve the privacy of both the authors and users to be compliant with privacy regulations in force.
- The possibility to search and retrieve both local open data resources and VGSs in an integrated way, so as to provide the comprehensive knowledge of both the authoritative resources and volunteers’ services offered in the neighbourhood of a user.
- The possibility to express flexible queries expressing both user preferences and priorities in order to identify the most convenient route through a set of relevant retrieved resources and VGSs.
- The possibility to use the system from different mobile phones and tablets, thus asking for a cross-platform implementation also including mobile computing facilities such as off-line creation of VGSs and detection of geographic location by the GPS receiver.
- Open Data from the Lombardy regional authority are harvested by a focused crawler developed in Java that can be customized to specific categories of users: in the case study, information was collected on resources and services of interest for families with children, elderly people, and people with disabilities. The user categories were associated with resource types based on the results of the requirement analysis. Lexical analysis and indexing in full-text were applied relying on Lucene library [29]. The mapping between user categories and resource types can be flexibly customized using a look-up table that can be configured before starting the harvesting, associating a set of resources’ types of possible interest with each user category. Moreover, since the explicit geo-reference of resources is rarely available, it was necessary to apply geographic information retrieval indexing functions to identify it: geo-parsing was firstly performed by applying Name Entity Recognition techniques and Part of Speech Tagging to detect postal addresses [9] and, secondly, geocoding was performed to associate geographic coordinates using the “nominatim” geocoding functionality of the OpenStreetMap project [6].
- Tweets expressing comments on one of the collected open data resources or services are collected, indexed, and stored in the database so as to be able to retrieve them when an expansion of a retrieved resource or service is demanded by the user. This is an annotation approach, performed by running periodic queries with the names of the collected resources using the Standard Tweeter API searches against the free archive of recent Tweets [30]. The filtering functions were developed in Java so that posts retrieved using a resource name were selected if their georeference was close to that of the resource. This was implemented in order to try to reduce ambiguities, since many resources have similar names and it was assumed reasonable that they were visited by users in their neighbourhood. All filtered Tweets associated with a given resource or service are considered as a unique document and are indexed in full text by adding a significance score based on the frequency of occurrences of terms.
- To create VGSs offered by registered citizens or voluntary associations the FHfFC Web application was developed in Ionic [31] an open-source mobile user interface toolkit for building cross-platform native web applications. Users willing to create a VGS must register and must indicate an area where they are willing to provide the service, a valid email address to be contacted by potentially interested users, and designate their as one of the available predefined types of services (babysitter, care-giver, nurse, house keeper, etc.). These VGSs may also contain free text and images and are categorized in predefined classes and geo-located to indicate the geographic scope where the service can be provided. The richer the description of the VGS is the more likely it is that its semantic relevance score is high when it is retrieved. Additionally, the more the VGS is commented in a filtered Tweet, the more information is available to the user to assess its trustfulness.
3.2.3. The Data Model and Find Routes Function
- (family, <“kinder garden”, “school”, “recreation center for children”, “library”, “Childhood Social Offer Unit”, “playground”>, 500 mt);
- (”disabled people”, <“Rehabilitation Structure”, “hospital”, “library, “nursing service”>, 200 mt );
- (elderly people, <”recreation center for elderly”, “hospital”, “library, “park”>, 500 mt);
- (Any, <Any>, 5000 mt)
- Register_User: it allows a user to register by filling the information in the user profile. When registering, a user can choose the category of interest uc, can specify the geolocation of u.home, by drawing a polygon, and can specify a personal maximum distance u.uc.δ; alternatively one can accept to share the GPS location detected by the smart device that is used at run time as value of u.home. Having a personal profile, the query log is locally stored and used for auto completion;
- Create_VGS: it allows a registered user to create VGSs. In this case, the user can create several VGSs of distinct type: it is required that the registered user has a valid email to create VGSs. In this case, u.uc.δ delimits the area around u.home in which the VGS can be performed;
- Access_Object: it allows accessing the content of a retrieved object, i.e., to see the description of a resource or VGS;
- Expand_Object: it allows expanding the content of an object with the content of the associated Tweet M. This way one can see the text of all comments on the selected resource or VGS;
- Find_Routes: it allows a user to formulate a trip-planning query and to retrieve a ranked list of convenient routes for visiting the relevant retrieved objects:
3.2.4. The Personalized Keyword Search
(o.H.v ∪ (∪TH)) ∩ (u.uc.<H1.v,…Hk.v>) ≠ ∅
4. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Available online: www.searchenginewatch.com/2014/05/07/google-local-searches-lead-50-of-mobile-users-to-visit-stores-study/ (accessed on 28 February 2023).
- Available online: https://nextdoor.com/ (accessed on 28 February 2023).
- Jones, C.B.; Purves, R.S. Geographical information retrieval (editorial article). Int. J. Geogr. Inf. Sci. 2008, 22, 219–228. [Google Scholar] [CrossRef]
- Purves, R.S.; Clough, P.; Jones, C.B.; Hall, M.H.; Murdock, V. Geographic Information Retrieval: Progress and Challenges in Spatial Search of Text. Found. Trends Inf. Retr. 2018, 12, 164–318. [Google Scholar] [CrossRef]
- Reichenbacher, T.; De Sabbata, S.; Purves, R.S.; Fabrikant, S.I. Assessing geographic relevance for mobile search: A computational model and its validation via crowdsourcing. J. Assoc. Inf. Sci. Technol. 2016, 67, 2620–2634. [Google Scholar] [CrossRef]
- Available online: www.openstreetmap.org/about (accessed on 28 February 2023).
- Bordogna, G.; Frigerio, L.; Rampini, A. Retrieval of visiting paths through relevant resources and services for enabling smart communities. In Proceedings of the 35th Annual ACM Symposium on Applied Computing, Brno, Czech Republic, 30 March–3 April 2020; pp. 714–716. [Google Scholar]
- Huang, Y.W.; Jing, N.; Rundensteiner, E.A. Integrated query processing strategies for spatial path queries. In Proceedings of the 13th International Conference on Data Engineering, Birmingham, UK, 7–11 April 1997; pp. 477–486. [Google Scholar]
- Bordogna, G.; Ghisalberti, G.; Psaila, G. Geographic information retrieval: Modeling uncertainty of user’s context. Fuzzy Sets Syst. 2012, 196, 105–124. [Google Scholar] [CrossRef]
- Bordogna, G.; Bovenzi, G.; Ghisalberti, G.; Psaila, G. Uncertainty Reduction in Location-Based Retrieval of Georeferenced Web Resources by Moving Users. In Proceedings of the Web Intelligence and Intelligent Agent Technology, IEEE/WIC/ACM International Conference, Milan, Italy, 15–18 September 2009; pp. 163–166. [Google Scholar]
- Li, F.; Cheng, D.; Hadjieleftheriou, M.; Kollios, G.; Teng, S.H. On Trip Planning Queries in Spatial Databases. In Advances in Spatial and Temporal Databases, LNCS 3633; Medeiros, C.B., Egenhofer, M., Bertino, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 273–290. [Google Scholar]
- Doherty, A.R.; Gurrin, C.; Jones, G.J.F.; Smeaton, A.F. Retrieval of Similar Travel Routes Using GPS Tracklog Place Names. In Proceedings of the SIGIR GIR’06, Seattle, WA, USA, 10 August 2006. [Google Scholar]
- Adelfio, M.D.; Samet, H. Itinerary Retrieval: Travelers, like Traveling Salesmen, Prefer Efficient Routes. In Proceedings of the 8th ACM SIGSPATIAL Workshop on Geographic Information Retrieval (GIR’14), Dallas, TX, USA, 4–7 November 2014. [Google Scholar]
- Li, Y.; Yang, W.; Dan, W.; Xie, Z. Keyword-aware dominant route search for various user preferences. In Proceedings of the International Conference on Database Systems for Advanced Applications, Hanoi, Vietnam, 20–23 April 2015; pp. 207–222. [Google Scholar]
- Zeng, Y.; Chen, X.; Cao, X.; Qin, S.; Cavazza, M.; Xiang, Y. Optimal route search with the coverage of users’ preferences. In Proceedings of the 24th International Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 2118–2124. [Google Scholar]
- Li, W.; Cao, J.; Guan, J.; Yiu, M.L.; Zhou, S. Retrieving routes of interest over road networks. In Proceedings of the International Conference on Web-Age Information Management, Nanchang, China, 3–5 June 2016; pp. 109–123. [Google Scholar]
- Li, W.; Cao, J.; Guan, J.; Yiu, M.L.; Zhou, S. Efficient Retrieval of Bounded-Cost Informative Routes. IEEE Trans. Knowl. Data Eng. 2017, 29, 2182–2196. [Google Scholar] [CrossRef]
- Thatcher, J. From Volunteered Geographic Information to Volunteered Geographic Services. In Crowdsourcing Geographic Knowledge: Volunteered Geographic Information (VGI) in Theory and Practice; Sui, D.Z., Elwood, S., Goodchild, M.F., Eds.; Springer: Dordrecht, The Netherlands, 2013. [Google Scholar] [CrossRef]
- Mountain, D.; MacFarlane, A. Geographic information retrieval in a mobile environment: Evaluating the needs of mobile individuals. J. Inf. Sci. 2007, 33, 515–530. [Google Scholar] [CrossRef]
- Bordogna, G.; Pagani, M.; Pasi, G.; Psaila, G. Managing uncertainty in location-based queries. Fuzzy Sets Syst. 2009, 160, 2241–2252. [Google Scholar] [CrossRef]
- Petry, F.E. Fuzzy Databases; Springer: Boston, MA, USA, 1996. [Google Scholar]
- Kacprzyk, J.; Zadrożny, S.; Ziołkowski, A. FQUERY III+: A human-consistent database querying system based on fuzzy logic with linguistic quantifiers. Inf. Syst. 1989, 14, 443–453. [Google Scholar] [CrossRef]
- Bosc, P.; Prade, H. An Introduction to the Fuzzy Set and Possibility Theory-Based Treatment of Flexible Queries and Uncertain or Imprecise Databases. In Uncertainty Management in Information Systems; Motro, A., Smets, P., Eds.; Springer: Boston, MA, USA, 1997. [Google Scholar]
- Thulasiraman, K.; Swamy, M.N.S. Graphs: Theory and Algorithms; John Wiley & Sons: New York, NY, USA, 1992. [Google Scholar]
- Pereira, C.; Dragoni, M.; Pasi, G. Multidimensional relevance: Prioritized aggregation in a personalized Information Retrieval setting. Inf. Process. Manag. 2012, 48, 340–357. [Google Scholar] [CrossRef]
- Yager, R.R. Prioritized Aggregation operators. Int. J. Approx. Reason. 2008, 48, 263–274. [Google Scholar] [CrossRef]
- Bordogna, G.; Psaila, G. Fuzzy-Spatial SQL. In Flexible Querying Answering Systems; Springer: Berlin/Heidelberg, Germany, 2004; pp. 307–319. [Google Scholar]
- Hu, Q.; Liu, Q.; Wang, X.; Tung, A.K.H.; Goyal, S.; Yang, J. DocRicher: An Automatic Annotation System for TextDocuments Using Social Media. In Proceedings of the SIGMOD/PODS’15: International Conference on Management of Data, Melbourne, Australia, 31 May–4 June 2015. [Google Scholar] [CrossRef]
- Available online: https://lucene.apache.org/core/ (accessed on 28 February 2023).
- Available online: https://developer.twitter.com (accessed on 28 February 2023).
- Available online: https://ionicframework.com/ (accessed on 28 February 2023).
- Available online: https://www.mongodb.com/ (accessed on 28 February 2023).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| A°∩B° = 1 | A°∩B+ = 0.5 | A°∩B− = 0 | |
| A+∩B° = 0.5 | A+∩B+ = 0.25 | A+∩B− = 0 | |
| A−∩B° = 0 | A−∩B+ = 0 | A−∩B− = 0 | |
| A°∩B° = 1 |  | A°∩B+ = 0.5 |  |
| A+∩B+ = 0.25 |  | A−∩B+ = 0 |  |
| V Set of Vertexes | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Query Keyword | Retrieved Resources and VGSs | p | r_rank | ||||||
| u.home | o1 “user home” | 0 | 1 | ||||||
| “Kinder garden” | o2 “Scuola infanzia Coghetti” | 1 | 1 | ||||||
| o4 “Scuola privata Virgo… “ | 1 | 0.3 | |||||||
| o7 “Scuola dell’infanzia Sylva” | 1 | 1 | |||||||
| “Library OR recreation center” | o3 “Biblioteca Coghetti” | 2 | 0.7 | ||||||
| o5 “Centro Sportivo Diaz” | 2 | 0.6 | |||||||
| o6 “Ludoteca Locatelli” | 2 | 1 | |||||||
| o8 “Giardinetto Scuri” | 2 | 0.3 | |||||||
| Baby sitter | o9 “Sig.ra Clelia” | 3 | 1 | ||||||
| E Set of Edges | |||||||||
| s_rank | o1 | o2 | o3 | o4 | o5 | o6 | o7 | o8 | o9 |
| o1 | 1 | 1 | 0 | ||||||
| o2 | 0.90 | 0.83 | 0.77 | 0.83 | |||||
| o3 | 1 | ||||||||
| o4 | 0.80 | 0.92 | 0.70 | 0.74 | |||||
| o5 | 0.25 | ||||||||
| o6 | 0 | ||||||||
| o7 | |||||||||
| o8 | 0.50 | ||||||||
| o9 | |||||||||
| Objects | Dist (Mt) | Closeness | |
|---|---|---|---|
| o2 | o3 | 165 | 0.90 |
| o2 | o5 | 311 | 0.83 |
| o2 | o6 | 436 | 0.77 |
| o2 | o8 | 317 | 0.83 |
| o4 | o3 | 378 | 0.80 |
| o4 | o5 | 132 | 0.92 |
| o4 | o6 | 636 | 0.70 |
| o4 | o8 | 520 | 0.74 |
| Ranked Routes | RSV |
|---|---|
| o1–o2–o3–o9 | 2.40 |
| o1–o2–o6 | 1.77 |
| o1–o2–o5–o9 | 1.75 |
| o1–o2–o8–o9 | 1.45 |
| o1–o4–o5–o9 | 1.05 |
| o1–o4–o6 | 1.00 |
| o1–o4–o8–o9 | 0.75 |
| o1–o4–o3–o9 | 0.72 |
| Ranked Routes | RSV |
|---|---|
| o1–o2–o9–o3 | 2.7 |
| o1–o2–o9–o8 | 2.3 |
| o1–o2–o9–o5 | 2.2 |
| o1–o4 | 0.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bordogna, G.; Carrara, P.; Frigerio, L.; Lella, S. Flexible Trip-Planning Queries. ISPRS Int. J. Geo-Inf. 2023, 12, 204. https://doi.org/10.3390/ijgi12050204
Bordogna G, Carrara P, Frigerio L, Lella S. Flexible Trip-Planning Queries. ISPRS International Journal of Geo-Information. 2023; 12(5):204. https://doi.org/10.3390/ijgi12050204
Chicago/Turabian StyleBordogna, Gloria, Paola Carrara, Luca Frigerio, and Simone Lella. 2023. "Flexible Trip-Planning Queries" ISPRS International Journal of Geo-Information 12, no. 5: 204. https://doi.org/10.3390/ijgi12050204
APA StyleBordogna, G., Carrara, P., Frigerio, L., & Lella, S. (2023). Flexible Trip-Planning Queries. ISPRS International Journal of Geo-Information, 12(5), 204. https://doi.org/10.3390/ijgi12050204