

Convolutional Neural Network-Based Deep Learning Approach for Automatic Flood Mapping Using NovaSAR-1 and Sentinel-1 Data




Abstract
1. Introduction
2. Materials and Methods
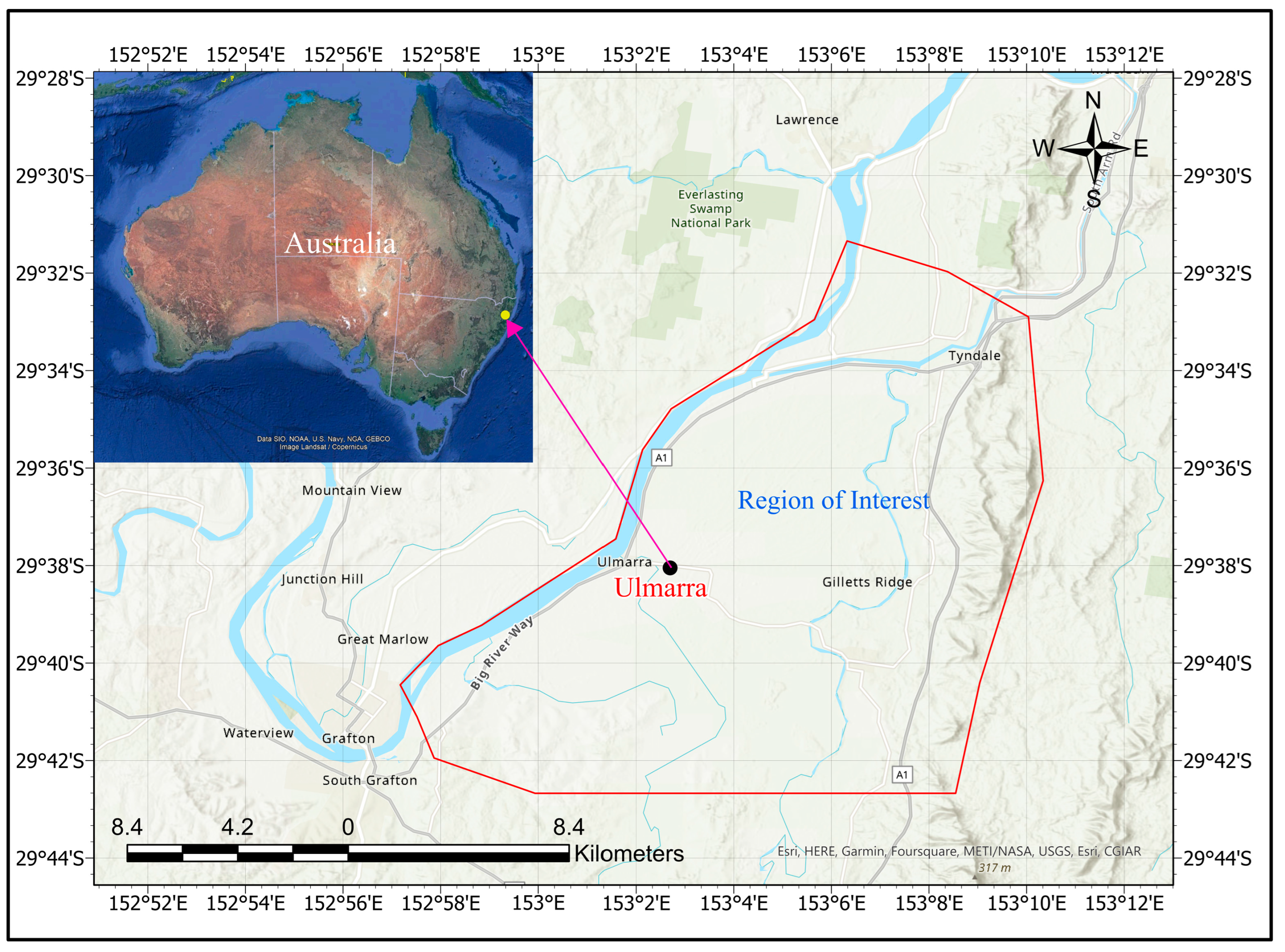
2.1. Study Area
2.2. Dataset
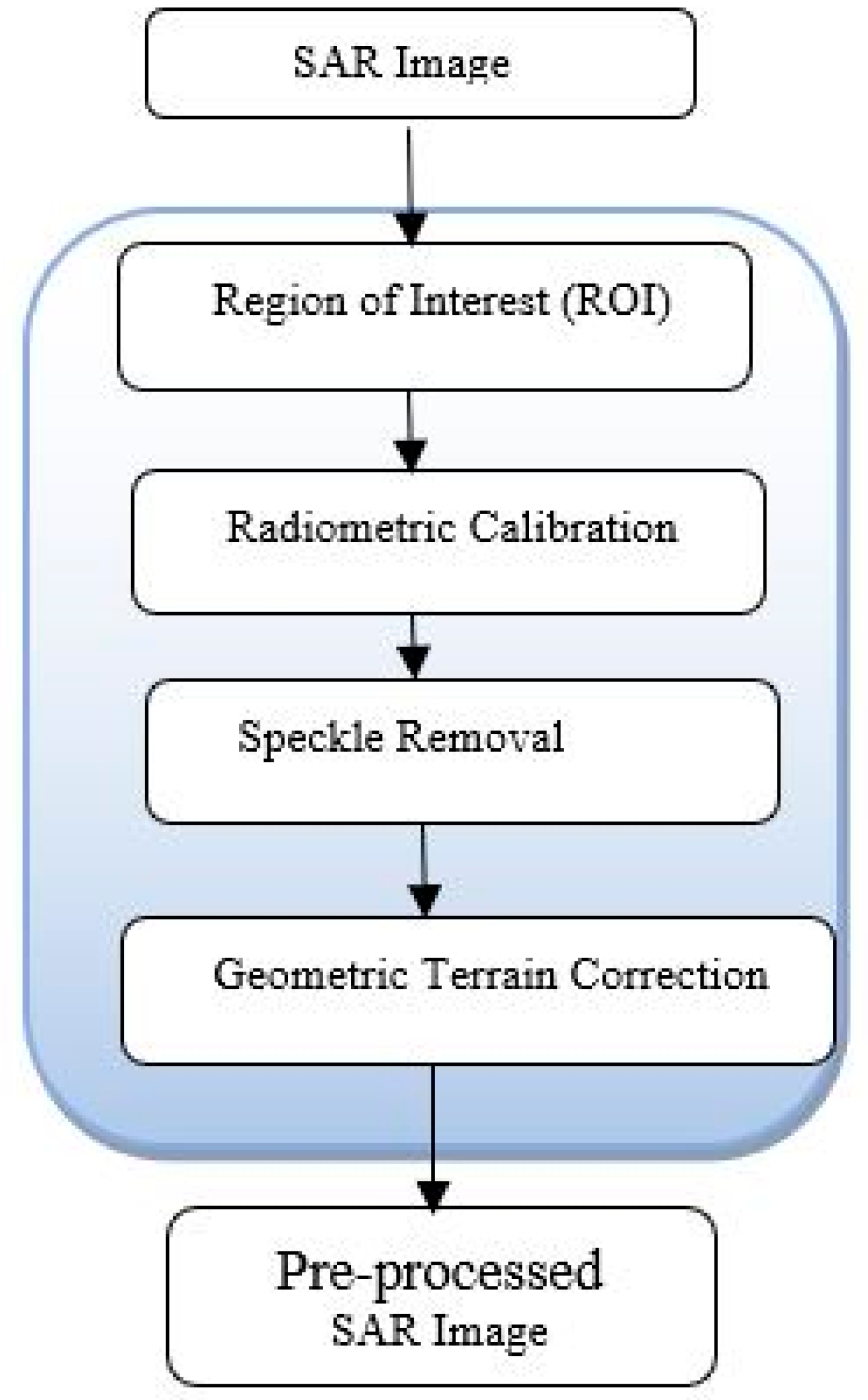
2.3. Image Pre-Processing
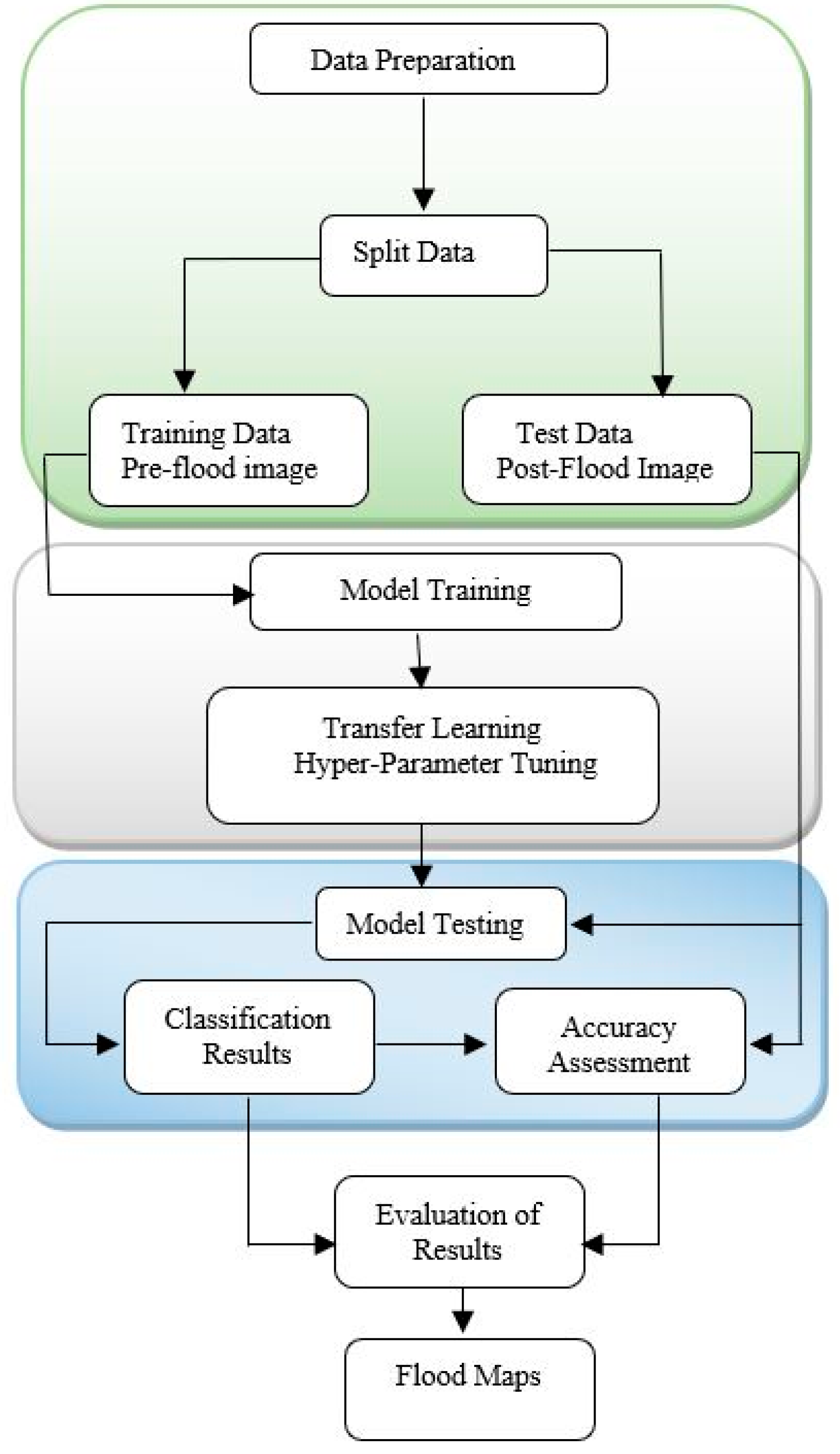
2.4. Data Preparation and Labelling
2.4.1. Data Augmentation and Generation of Training Datasets
2.5. CNN Implementation and System Specification
2.6. CNN Deep Learning Models
2.6.1. U-Net Model
2.6.2. PSPNet Model (Pyramid Scene Parsing Network)
2.6.3. DeepLabV3 Model
2.7. Convolutional Backbones
2.7.1. CNN Model Training
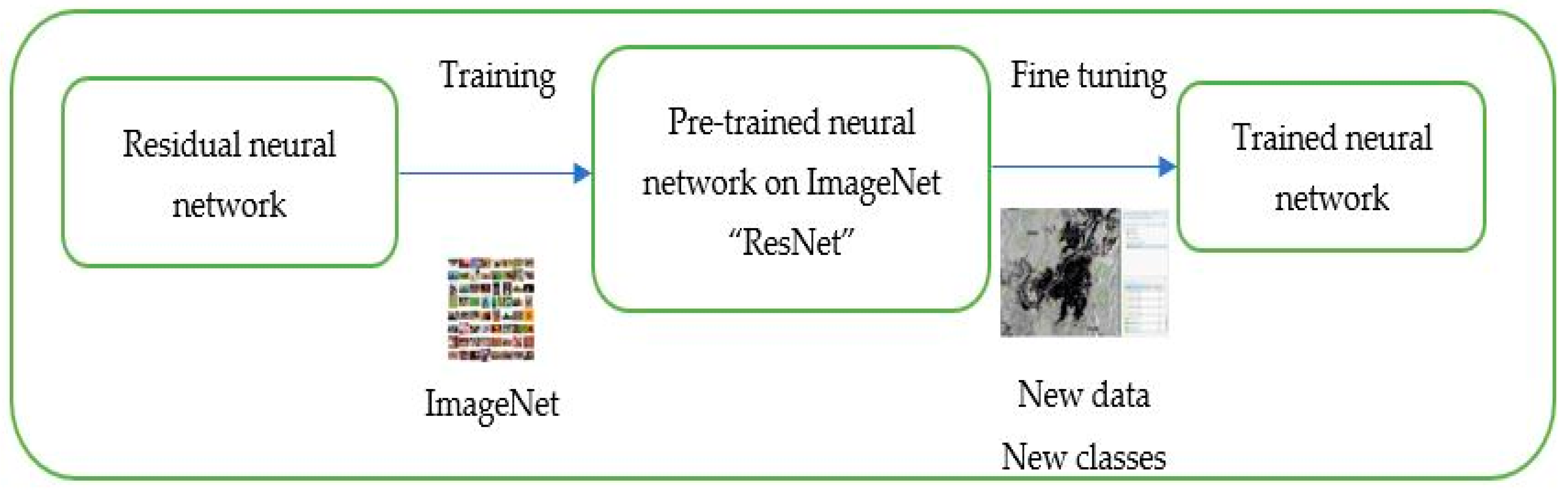
2.7.2. Transfer Learning
2.7.3. Neural Network Hyper-Parameter Tuning
2.8. Accuracy Assessment and Confusion Matrix
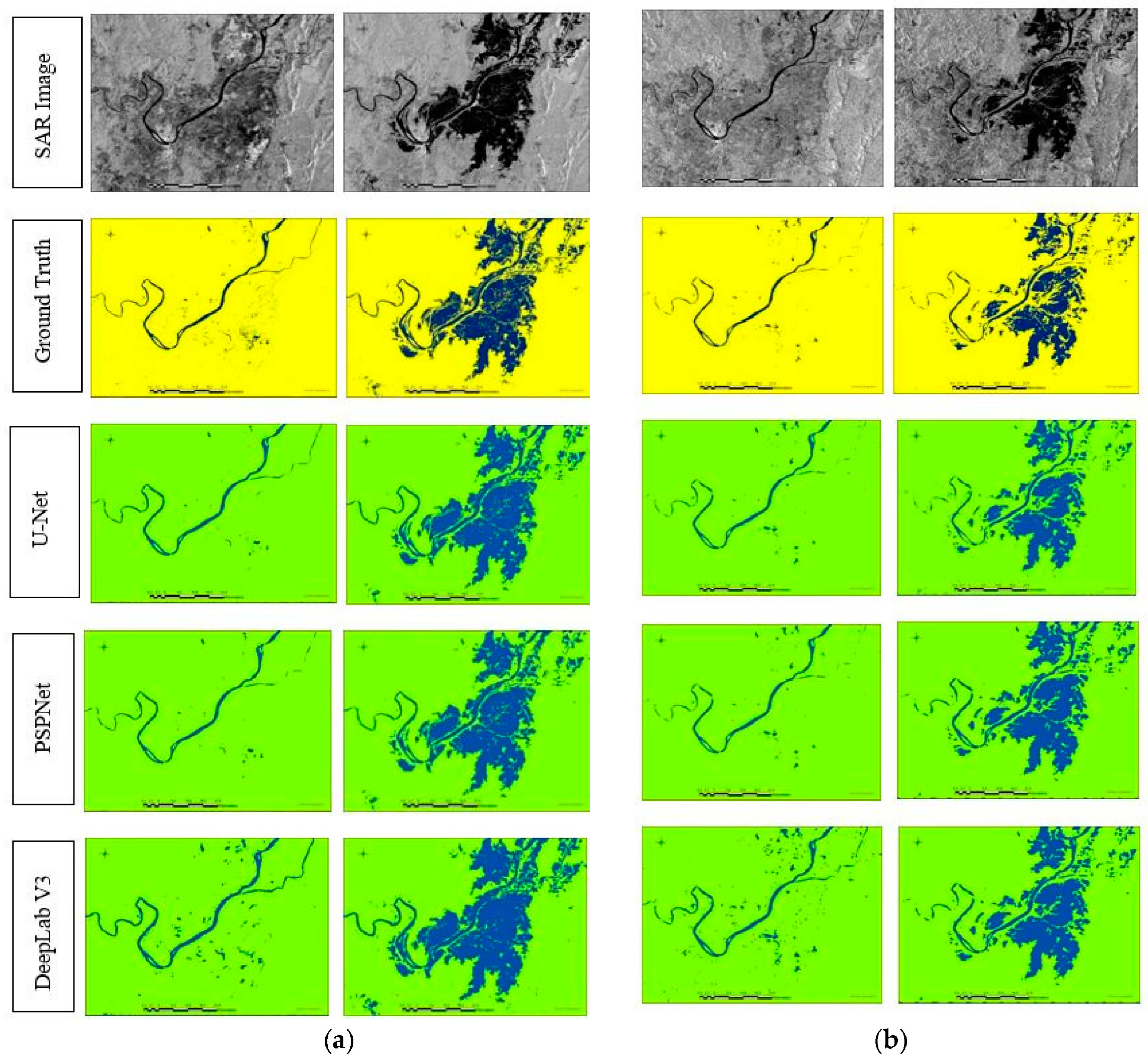
3. Results
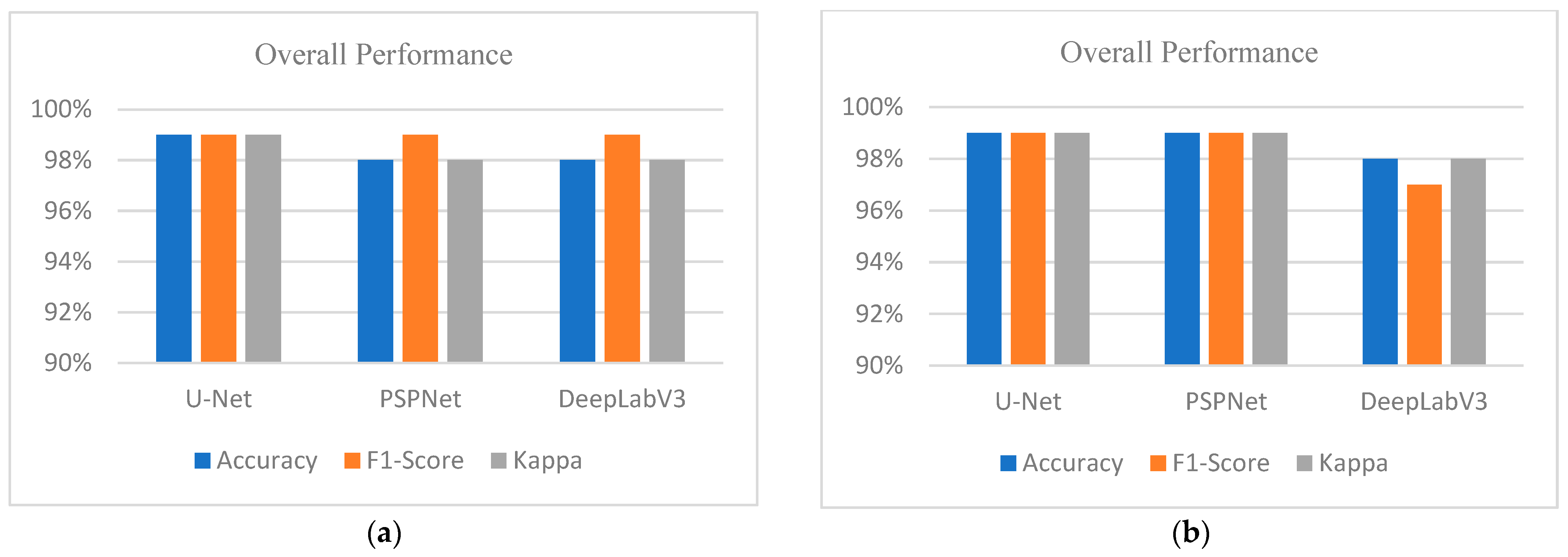
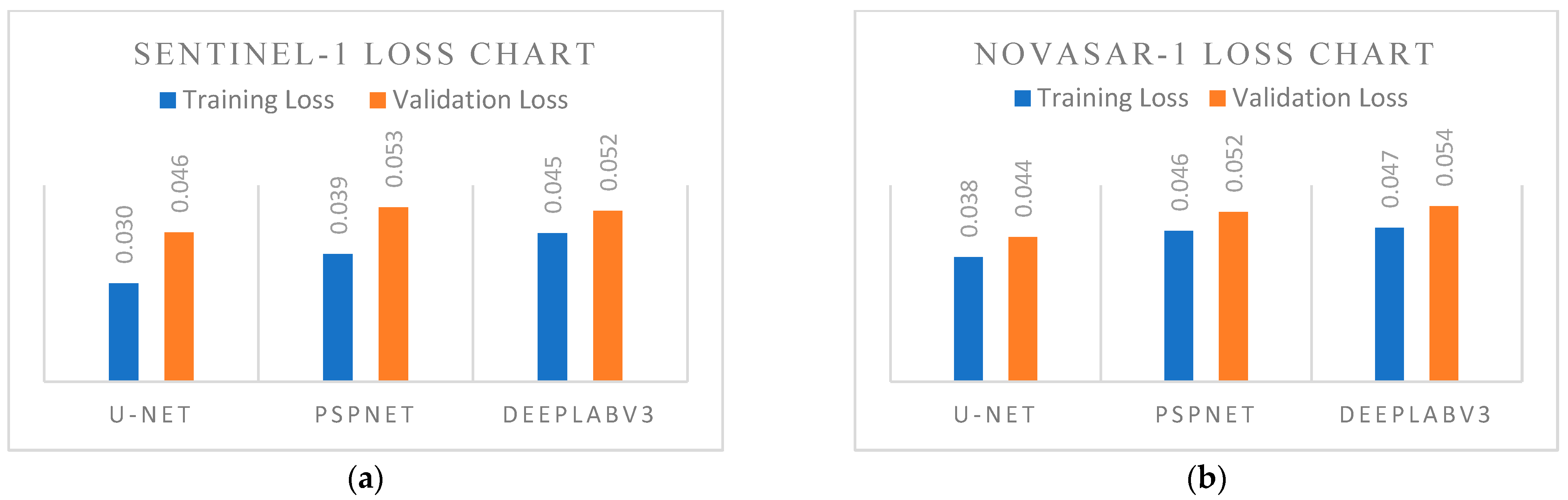
3.1. Training Data Comparison for Binary Classification
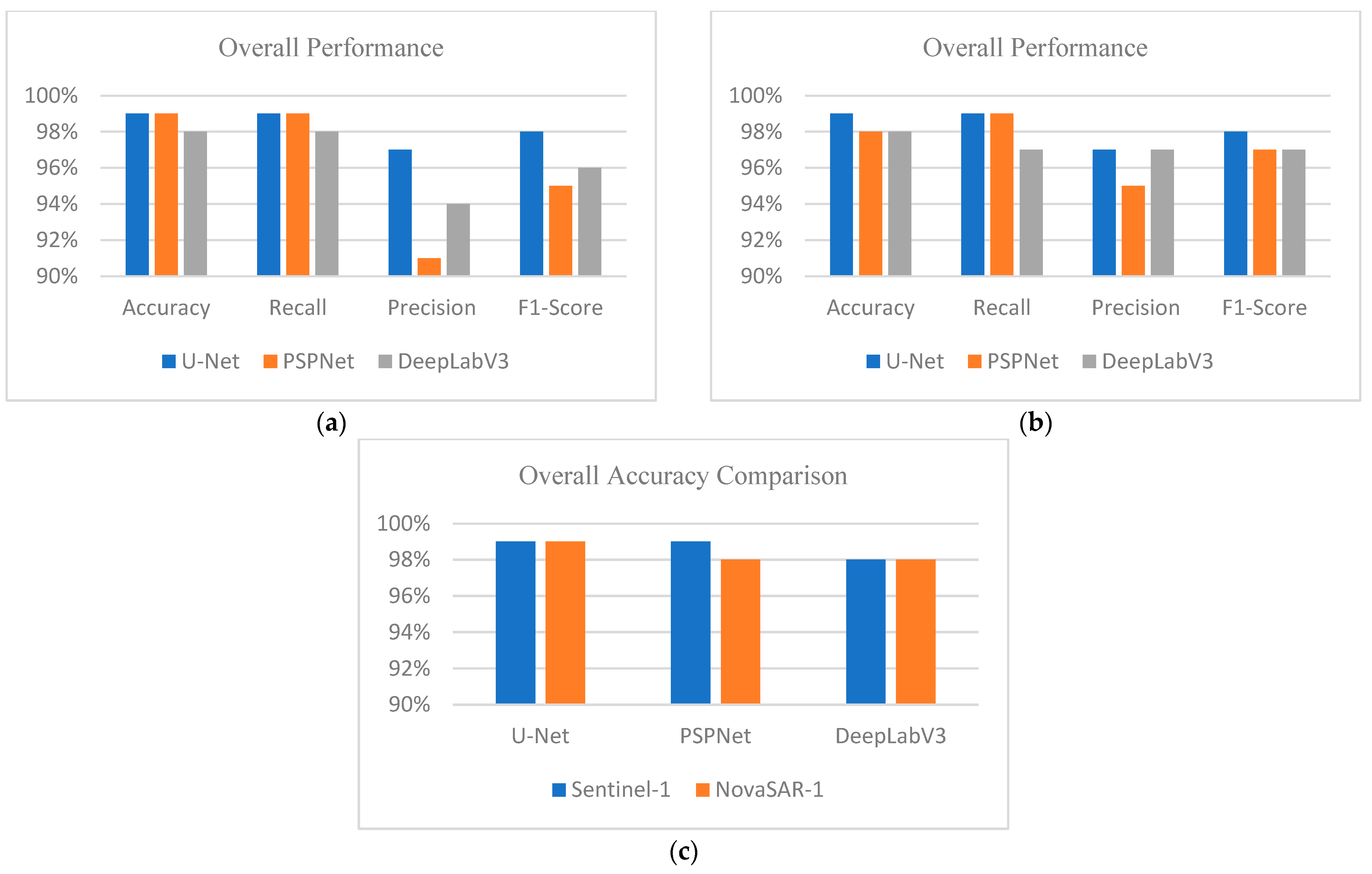
3.2. Test Data Analysis for Binary Classification
3.3. Training Data Comparison for Multi-Classification
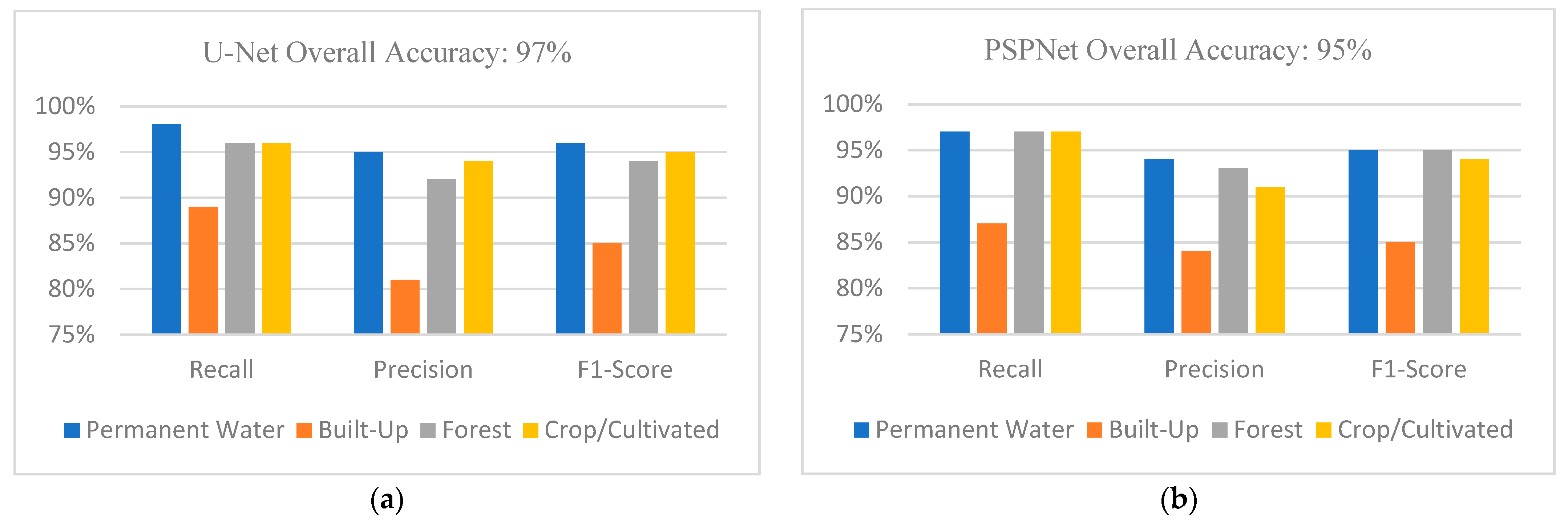
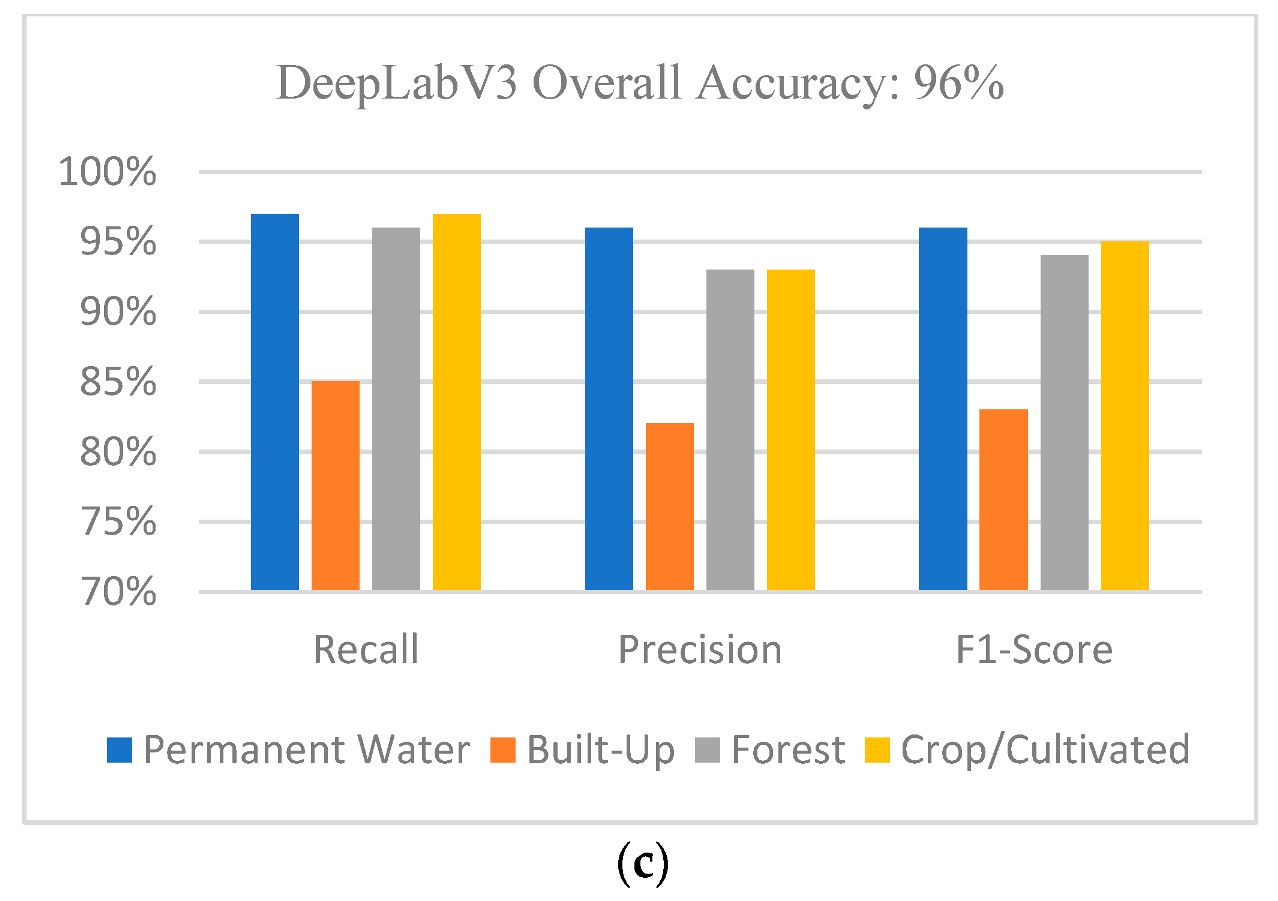
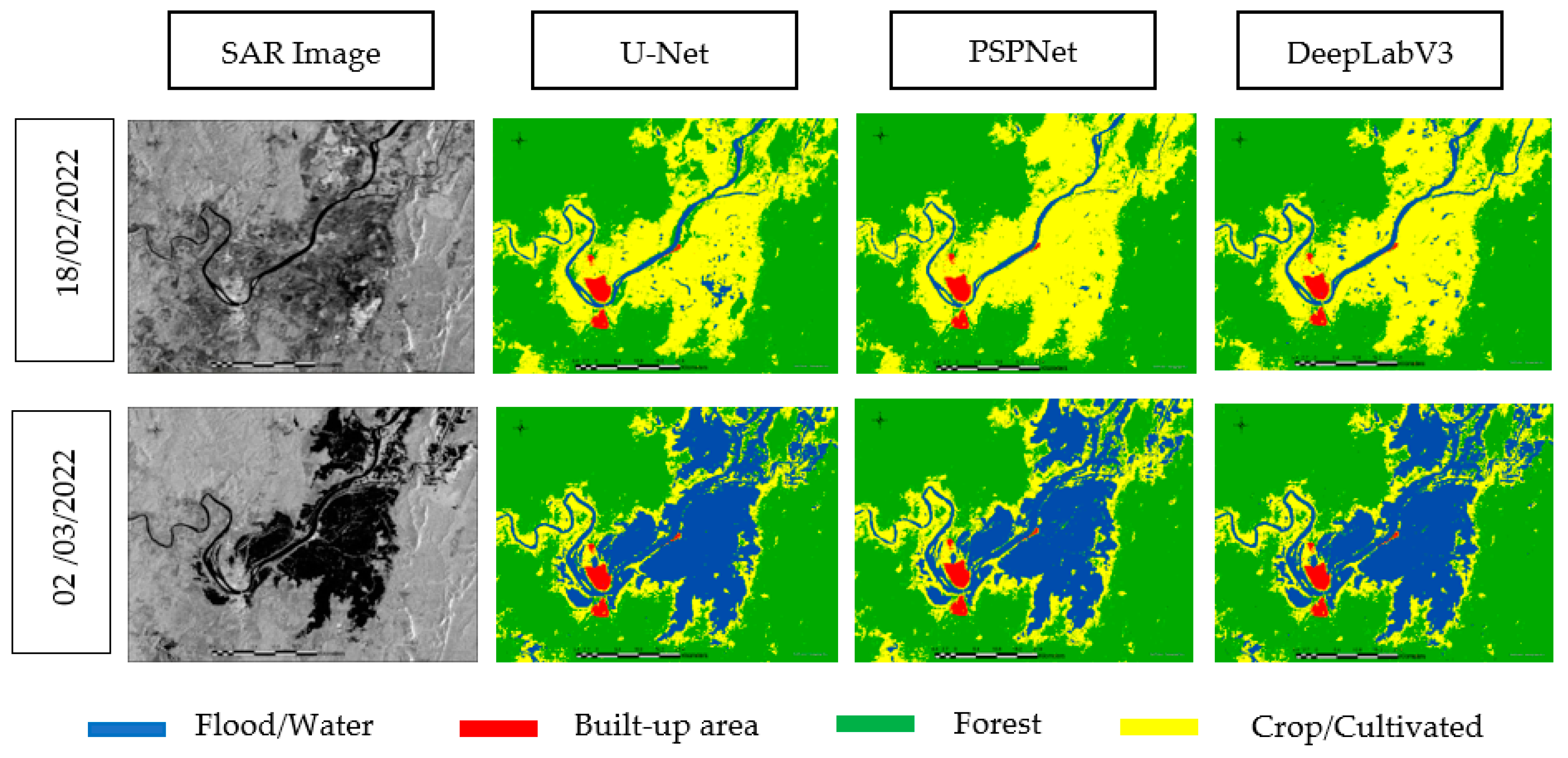
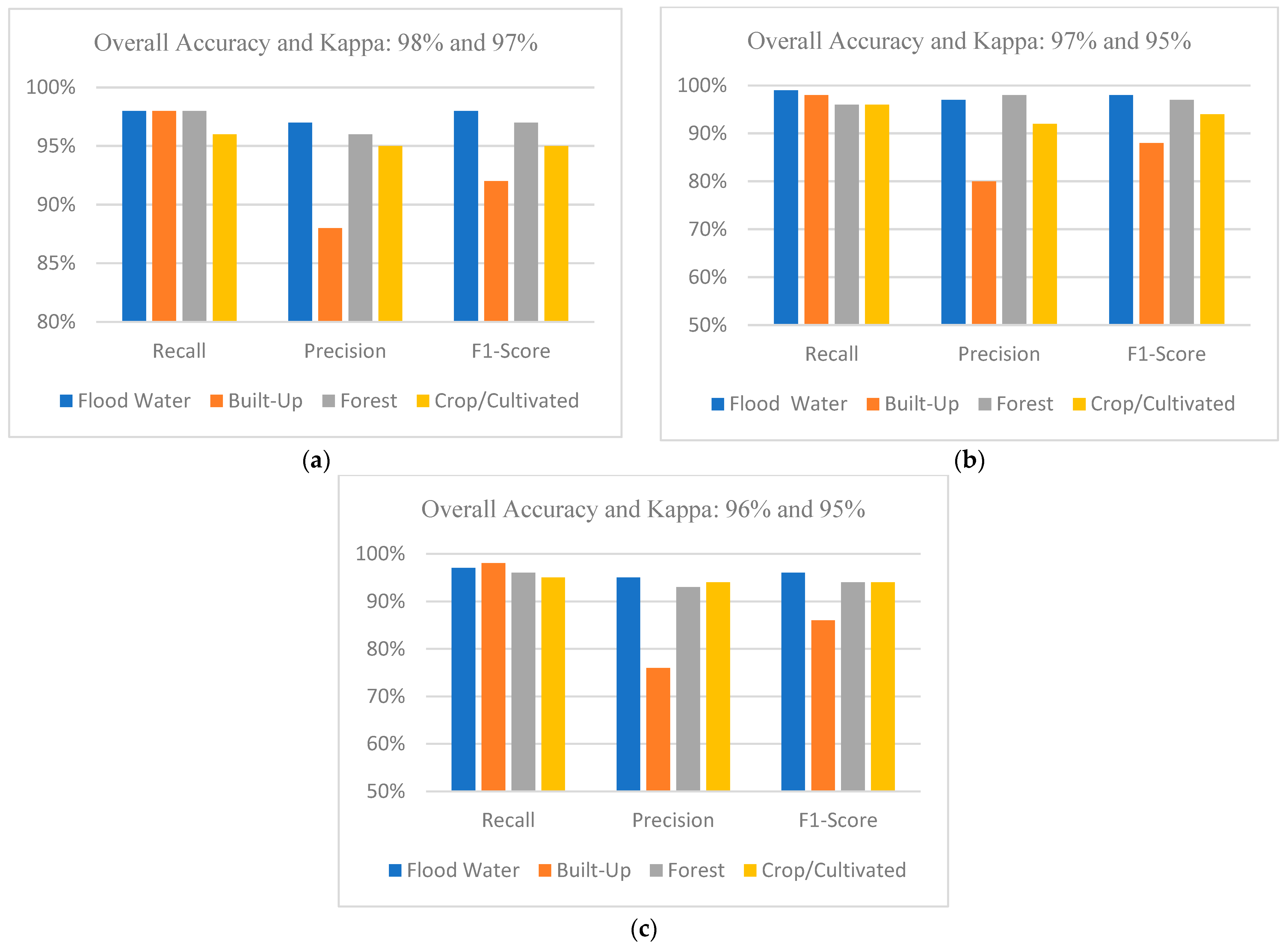
3.4. Test Data Analysis for Multi-Classification
3.5. Hyper-Parameter Tuning Results
3.6. Impact of Class Structure
4. Discussion
5. Conclusions
- The adopted workflow can produce comparable or even superior results to some previous SAR and optical flood-based studies. The method not only speeds up inferencing but also does not depend on many ancillary data from other sources.
- One of the findings of this study suggests that training a different pre-flood dataset and testing post-flood water characteristics over the same area may not influence results negatively given the efficiency of the CNN models, thus encouraging the training of a new model on new data in a short time.
- As we have seen in our experiment, the depth of a convolutional backbone vis-a-vis the hyper-parameter setup can determine the training time and model accuracy.
- To improve computational efficiency and reduce training time when training with a deeper neural network, we recommend the use of small batch sizes as large batch sizes can make CNN models difficult to train, especially on machines with low computational power.
- It is also worth pointing out that despite the 50 m low spatial resolution of dual-polarised ScanSAR_195 km_HV NovaSAR-1 imagery, it is suitable for large area monitoring, especially for flood mapping.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ASL | Active Self Learning |
| ASPP | Atrous Spatial Pyramid Pooling |
| CFR | Conditional Random Field |
| CNN | Convolutional Neural Network |
| CSIRO | Commonwealth Scientific and Industrial Organisation |
| DEM | Digital Elevation Model |
| DNN | Deep Neural Network |
| DPK | Deep Learning Package |
| EMD | ESRI Model Definition |
| ESRI | Environmental Systems Research Institute |
| FN | False Negative |
| FP | False positive |
| FPN | Feature Pyramid Network |
| GF-3 | Gaofen-3 |
| GPU | Graphic Processing Unit |
| GRD | Ground Range Detected |
| HV | Horizontal Vertical |
| IFP | Image Formation Process |
| IW | Interferometric Wide |
| MDFD | Multi Depth Flood Detection |
| NNs | Neural Networks |
| OA | Overall Accuracy |
| P | Precision |
| PSPNet | Pyramid Scene Parsing Network |
| R | Recall |
| RAM | Random Access Memory |
| RF | Random Forest |
| RGB | Red Green Blue |
| ROI | Region of Interest |
| SAR | Synthetic Aperture Radar |
| SCD | ScanSAR |
| SNAP | Sentinel Application Platform |
| SRTM | Shuttle Radar Topographic Mission |
| SSTL | Surrey Satellite Technology Limited |
| SVM | Support Vector Machine |
| TN | True Negative |
| TP | True Positive |
| UTM | Universal Transverse Mercator |
| VV | Vertical Vertical |
| WGS | World Geodetic System |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Location | Sensing Date | Image Name |
|---|---|---|
| Ulmarra | 17 April 2021 | NovaSAR_01_21984_scd_29_210417_005131_HH_HV |
| Ulmarra | 5 March 2022 | NovaSAR_01_32067_scd_220305_121059_HH_HV |
| Location | Sensing Date | Image Name |
|---|---|---|
| Ulmarra | 18 February 2022 | S1A_IW_GRDH_1SDV_20220218T190635_20220218T190700_041971_04FF93_F972 |
| Ulmarra | 2 March 2022 | S1A_IW_GRDH_1SDV_20220302T190635_20220302T190700_042146_050598_23F0 |
References
- Delforge, D.; Below, R.; Speybroeck, N. Natural Hazards and Disasters: An overview of the First Half of 2022. Centre for Research on the Epidemiology of Disasters (CRED) Institute of Health & Society (IRSS), UCLouvain, 2022, Issue 68. Available online: https://www.cred.be/publications (accessed on 24 April 2023).
- Hallegatte, S.; Vogt-Schilb, A.; Bangalore, M.; Rozenberg, J. Unbreakable: Building the Resilience of the Poor in the Face of Natural Disasters; World Bank: Washington, DC, USA, 2016. [Google Scholar]
- Rahman, M.R.; Thakur, P.K. Detecting, mapping, and analysing of flood water propagation using synthetic aperture radar (SAR) satellite data and GIS: A case study from the Kendrapara District of Orissa State of India. Egypt. J. Remote Sens. Space Sci. 2017, 21, S37–S41. [Google Scholar] [CrossRef]
- Nemni, E.; Bullock, J.; Belabbes, S.; Bromley, L. Fully Convolutional Neural Network for Rapid Flood Segmentation in Synthetic Aperture Radar Imagery. Remote Sens. 2020, 12, 2532. [Google Scholar] [CrossRef]
- Anusha, N.; Bharathi, B. Flood detection and flood mapping using multi-temporal synthetic aperture radar and optical data. Egypt. J. Remote Sens. Space Sci. 2020, 23, 207–219. [Google Scholar] [CrossRef]
- Melack, J.M.; Hess, L.L.; Sippel, S. Remote Sensing of Lakes and Floodplains in the Amazon Basin. Remote Sens. Rev. 1994, 10, 127–142. [Google Scholar] [CrossRef]
- Chen, P.; Liew, S.C.; Lim, H. Flood detection using multitemporal Radarsat and ERS SAR data. In Proceedings of the 20th Asian Conference of Remote Sensing, Hong Kong, China, 22–25 November 1999. [Google Scholar]
- Vanama, V.S.K.; Rao, Y.S.; Bhatt, C.M. Change detection-based flood mapping using multi-temporal Earth Observation satellite images: 2018 flood event of Kerala, India. Eur. J. Remote Sens. 2021, 54, 42–58. [Google Scholar] [CrossRef]
- Fabris, M.; Battaglia, M.; Chen, X.; Menin, A.; Monego, M.; Floris, M. An Integrated InSAR and GNSS Approach to Monitor Land Subsidence in the Po River Delta (Italy). Remote Sens. 2022, 14, 5578. [Google Scholar] [CrossRef]
- Lazos, I.; Papanikolaou, I.; Sboras, S.; Foumelis, M.; Pikridas, C. Geodetic Upper Crust Deformation Based on Primary GNSS and INSAR Data in the Strymon Basin, Northern Greece—Correlation with Active Faults. Appl. Sci. 2022, 12, 9391. [Google Scholar] [CrossRef]
- Shen, G.; Fu, W.; Guo, H.; Liao, J. Water Body Mapping Using Long Time Series Sentinel-1 SAR Data in Poyang Lake. Water 2022, 14, 1902. [Google Scholar] [CrossRef]
- Dasgupta, A.; Grimaldi, S.; Ramsankaran, R.; Pauwels, V.; Walker, J.; Chini, M.; Hostache, R.; Matgen, P. Flood Mapping Using Synthetic Aperture Radar Sensors from Local to Global Scales. Glob. Flood Hazard Appl. Model. Mapp. Forecast. 2018, 33, 55–77. [Google Scholar] [CrossRef]
- Townsend, P.A. Relationships between forest structure and the detection of flood inundation in forest wetlands using C-band SAR. Int. J. Remote Sens. 2002, 23, 443–460. [Google Scholar] [CrossRef]
- Wang, Y.; Hess, L.L.; Filoso, S.; Melack, J.M. Understanding the radar backscattering from flooded and non-flooded Amazonian Forest: Results from canopy backscatter modelling. Remote Sens. Environ. 1995, 54, 324–332. [Google Scholar] [CrossRef]
- Yang, C.; Zhou, C.; Wan, Q. Proceedings of the Deciding the flood extent with Radarsat SAR data and Image Fusion. Proceedings of 20th Asian Conference of Remote Sensing, Hong Kong, China, 22–25 November 1999. [Google Scholar]
- Pulvirenti, L.; Chini, M.; Pierdicca, N.; Boni, G. Use of SAR Data for Detecting Floodwater in Urban and Agricultural Areas: The Role of the Interferometric Coherence. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1532–1544. [Google Scholar] [CrossRef]
- Giustarini, L.; Hostache, R.; Matgen, P.; Schumann, G.; Bates, P.D.; Mason, D.C. A change detection approach to flood mapping in urban areas using TerraSAR-X. IEEE Trans. Geosci. Remote Sens. 2013, 51, 2417–2430. [Google Scholar] [CrossRef]
- Li, Y.; Martinis, S.; Wieland, M.; Schlaffer, S.; Natsuaki, R. Urban Flood Mapping Using SAR Intensity and Interferometric Coherence via Bayesian Network Fusion. Remote Sens. 2019, 11, 2231. [Google Scholar] [CrossRef]
- Chini, M.; Pelich, R.; Pulvirenti, L.; Pierdicca, N.; Hostache, R.; Matgen, P. Sentinel-1 InSAR coherence to detect floodwater in urban areas: Houston and hurricane harvey as a test case. Remote Sens. 2019, 11, 107. [Google Scholar] [CrossRef]
- Hess, L.L.; Melack, J.M.; Simonett, D.S. Radar detection of flooding beneath the forest canopy—A review. Int. J. Remote Sens. 1990, 11, 1313–1325. [Google Scholar] [CrossRef]
- Oberstadler, R.; Honsch, H.; Huth, D. Assessment of the mapping capabilities of ERS-1 SAR data for flood mapping: A case study of Germany. Hydrol. Process. 1997, 10, 1415–1425. [Google Scholar] [CrossRef]
- Kundus, P.; Karszenbaum, H.; Pultz, T.; Paramuchi, G.; Bava, J. Influence of flood conditions and vegetation status on the radar back scatter of wetland ecosystem. Can. J. Remote Sens. 2001, 27, 651–662. [Google Scholar] [CrossRef]
- Kang, W.; Xiang, Y.; Wang, F.; Wan, L.; You, H. Flood Detection in Gaofen-3 SAR Images via Fully Convolutional Networks. Sensors 2018, 18, 2915. [Google Scholar] [CrossRef] [PubMed]
- Begoli, E.; Bhattacharya, T.; Kusnezov, D. The need for uncertainty quantification in machine-assisted medical decision making. Nat. Mach. Intell. 2019, 1, 20–23. [Google Scholar] [CrossRef]
- Wang, X.; He, Y. Learning from uncertainty for big data: Future analytical challenges and strategies. IEEE Syst. Man Cybern. Mag. 2016, 2, 26–31. [Google Scholar] [CrossRef]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N.; Prabhat. Deep learning and process understanding for data-driven Earth system science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef] [PubMed]
- Hoeser, T.; Bachofer, F.; Kuenzer, C. Object Detection and Image Segmentation with Deep Learning on Earth Observation Data: A Review-Part II: Applications. Remote Sens. 2020, 12, 3053. [Google Scholar] [CrossRef]
- Rittenbach, A.; Walters, J.P. A Deep Learning Based Approach for Synthetic Aperture Radar Image Formation. arXiv 2021, arXiv:2001.08202. Volume 1. [Google Scholar] [CrossRef]
- Chang, Y.; Anagaw, A.; Chang, L.; Wang, Y.; Hsiao, C.; Lee, W. Ship detection based on YOLOv2 for SAR imagery. Remote Sens. 2019, 11, 786. [Google Scholar] [CrossRef]
- Zhao, B.; Sui, H.; Xu, C.; Liu, J. Deep Learning Approach for Flood Detection Using SAR Image: A Case Study in Xianxiang. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2022, XLIII-B3-2022, 1197–1202. [Google Scholar] [CrossRef]
- Tong, X.; Luo, X.; Liu, S.; Xie, H.; Chao, W.; Liu, S.; Liu, S.; Makhinova, A.; Jiang, Y. An approach for flood monitoring by the combined use of Landsat 8 optical imagery and COSMO-SkyMed radar imagery. ISPRS J. Photogramm. Remote Sens. 2018, 136, 144–153. [Google Scholar] [CrossRef]
- Isikdogan, F.; Bovik, A.C.; Passalacqua, P. Surface Water Mapping by Deep Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4909–4918. [Google Scholar] [CrossRef]
- Chen, Y.; Fan, R.; Yang, X.; Wang, J.; Latif, A. Extraction of Urban Water Bodies from High-Resolution Remote-Sensing Imagery Using Deep Learning. Water 2018, 10, 585. [Google Scholar] [CrossRef]
- Yang, L.; Tian, S.; Yu, L.; Ye, F.; Qian, J.; Qian, Y. Deep Learning for Extracting Water Body from Landsat Imagery. Int. J. Innov. Comput. Inf. Control 2015, 11, 1913–1929. [Google Scholar]
- Lamovec, P.; Mikoš, M.; Oštir, K. Detection of Flooded Areas using Machine Learning Techniques: Case Study of the Ljubljana Moor Floods in 2010. Disaster Adv. 2013, 6, 4–11. [Google Scholar]
- Tanim, A.H.; McRae, C.B.; Tavakol-Davani, H.; Goharian, E. Flood Detection in Urban Areas Using Satellite Imagery and Machine learning. Water 2022, 14, 1140. [Google Scholar] [CrossRef]
- Bioresita, F.; Puissant, A.; Stumpf, A.; Malet, J.P. A Method for Automatic and Rapid Mapping of Water Surfaces from Sentinel-1 Imagery. Remote Sens. 2018, 10, 217. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Tegegne, A. Applications of Convolutional Neural Network for Classification of Land Cover and Groundwater Potentiality Zones. J. Eng. 2022, 2022, 1–8. [Google Scholar] [CrossRef]
- Brownlee, J. What is Deep Learning? Machine Learning Mastery. Machinelearningmastery 2019. Available online: https://machinelearningmastery.com/what-is-deep-learning/ (accessed on 5 May 2022).
- Chen, X.; Lin, X. Big Data Deep Learning: Challenges and Perspectives. Access IEEE 2014, 2, 514–525. [Google Scholar] [CrossRef]
- Zhang, Q.; Yang, Z.; Zhao, W.; Yu, X.; Yin, Z. Polarimetric SAR Landcover Classification Based on CNN with Dimension Reduction of Feature. In Proceedings of the IEEE 6th International Conference on Signal and Image Processing (ICSIP), Nanjing, China, 22–24 October 2021; pp. 331–335. [Google Scholar] [CrossRef]
- Li, H.; Lu, J.; Tian, G.; Huijin, Y.; Zhao, J.; Li, N. Crop Classification Based on GDSSM-CNN Using Multi-Temporal RADARSAT-2 SAR with Limited Labeled Data. Remote Sens. 2022, 14, 3889. [Google Scholar] [CrossRef]
- Iino, S.; Ito, R.; Doi, K.; Imaizumi, T.; Hikosaka, S. CNN-based generation of high-accuracy urban distribution maps utilising SAR satellite imagery for short-term change monitoring. Int. J. Image Data Fusion 2018, 9, 1–17. [Google Scholar] [CrossRef]
- Wu, C.; Yang, X.; Wang, J. Flood Detection in Sar Images Based on Multi-Depth Flood Detection Convolutional Neural Network. In Proceedings of the 6th Asia-Pacific Conference on Synthetic Aperture Radar (APSAR), Xiamen, China, 26–29 November 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Wu, H.; Song, H.; Huang, J.; Zhong, H.; Zhan, R.; Teng, X.; Qiu, Z.; He, M.; Cao, J. Flood Detection in Dual-Polarization SAR Images Based on Multi-Scale Deeplab Model. Remote Sens. 2022, 14, 5181. [Google Scholar] [CrossRef]
- Katiyar, V.; Tamkuan, N.; Nagai, M. Flood Area Detection Using SAR Images with Deep Neural Network during, 2020 Kyushu Flood Japan. In Proceedings of the 41st Asian Conference on Remote Sensing (ACRS2020), Huzhou, China, 9–11 November 2020. [Google Scholar]
- Bhardwaj, A.; Saini, O.; Chatterjee, R. Separability Analysis of Back-Scattering Coefficient of NovaSAR-1 S-Band SAR Datasets for Different Land Use Land Cover (LULC) Classes. 2021. Available online: https://doi.org/10.21203/rs.3.rs-854337/v1 (accessed on 3 March 2022).
- ESRI ArcGIS Pro. Release 3.0. June 2022. Available online: https://pro.arcgis.com/en/pro-app/latest/help/analysis/image-analyst/deep-learning-in-arcgis-pro.htm (accessed on 20 August 2022).
- Reina, G.; Panchumarthy, R.; Thakur, S.; Bastidas, A.; Bakas, S. Systematic Evaluation of Image Tiling Adverse Effects on Deep Learning Semantic Segmentation. Front. Neurosci. 2020, 14, 65. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Akiyama, T.; Junior, J.; Gonçalves, W.; Bressan, P.; Eltner, A.; Binder, F.; Singer, T. Deep learning applied to water segmentation. ISPRS—Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, XLIII-B2-2020, 1189–1193. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Chen, L.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Liu, F.; Lin, G.; Shen, C. CRF learning with CNN features for image segmentation. Pattern Recognit. 2015, 48, 2983–2992. [Google Scholar] [CrossRef]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFS. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Szegedy, C.; Wei, L.; Yangqing, J.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Cheng, G.; Wang, Y.; Xu, S.; Wang, H.; Xiang, S.; Pan, C. Automatic Road Detection and Centerline Extraction via Cascaded End-to-End Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3322–3337. [Google Scholar] [CrossRef]
- Abd-Elrahman, A.; Britt, K.; Liu, T. Deep Learning Classification of High-Resolution Drone Images Using the ArcGIS Pro Software. FOR374/FR444, 10/2021. EDIS 2021, 2021, 5. [Google Scholar] [CrossRef]
- Wei, W. Using U-Net and PSPNet to explore the reusability parameters of CNN parameters. arXiv 2020, arXiv:2008.03414. [Google Scholar]
- Zhang, G.; Lei, T.; Cui, Y.; Jiang, P. A Dual-Path and Lightweight Convolutional Neural Network for High-Resolution Aerial Image Segmentation. ISPRS Int. J. Geo-Inf. 2019, 8, 582. [Google Scholar] [CrossRef]
- Sara El Amrani, A. Flood Detection with a Deep Learning Approach Using Optical and SAR Satellite Data. Master’s Thesis, Leibniz Universität Hannover, Hanover, Germany, 2019. [Google Scholar]
- Yang, X.; Li, X.; Ye, Y.; Lau, K.R.Y.; Zhang, X.; Huang, X. Road Detection and Centerline Extraction Via Deep Recurrent Convolutional Neural Network U-Net. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7209–7220. [Google Scholar] [CrossRef]
- Cao, Z.; Diao, W.; Zhang, Y.; Yan, M.; Hu, H.; Sun, X.; Fu, K. Semantic Labeling for High-Resolution Aerial Images Based on the DMFFNet. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1021–1024. [Google Scholar]
- Kunang, Y.; Nurmaini, S.; Stiawan, D.; Bhakti, Y.; Yudho, B. Deep learning with focal loss approach for attacks classification. TELKOMNIKA (Telecommun. Comput. Electron. Control) 2021, 19, 1407–1418. [Google Scholar] [CrossRef]
- Hoeser, T.; Kuenzer, C. Object Detection and Image Segmentation with Deep Learning on Earth Observation Data: A Review-Part I: Evolution and Recent Trends. Remote Sens. 2020, 12, 1667. [Google Scholar] [CrossRef]
- Commonwealth Scientific and Industrial Research Orgnisation. CSIRO NovaSAR-1 National Facility Datahub. Available online: https://data.novasar.csiro.au/#/home (accessed on 30 March 2022).
- European Commission European Space Agency. Copernicus Open Access Hub. Available online: https://www.esa.int/Applications/Observing_the_Earth/Copernicus/Europe_s_Copernicus_programme (accessed on 30 March 2022).













| Sensor | NovaSAR-1 | NovaSAR-1 | Sentinel-1 | Sentinel-1 |
|---|---|---|---|---|
| Band Used | S-dual polarised (HHHV) | S-dual polarised (HHHV) | C-dual polarised (VVVH) | C-dual polarised (VVVH) |
| Spatial Resolution (m) | 50 | 50 | 5 × 20 | 5 × 20 |
| Date | 17 April 2021 | 5 March 2022 | 18 February 2022 | 3 March 2022 |
| Product Type | SCD | SCD | GRD | GRD |
| Remark | Pre-flood for training | Post-flood for testing | Pre-flood for training | Post-flood tor testing |
| Category/Dataset | Sentinel-1 | NovaSAR-1 |
|---|---|---|
| Binary Class | Water Non-Water | Water Non-Water |
| Image tiles for Training and Validation | 2120 | 2196 |
| Image tiles for Validation | ||
| Multi-Class | Water Built-up Forest Cropland/Cultivated | Not Applicable |
| Image tiles for Training and Validation | 1980 |
| Model + Backbone | Batch Size | Epochs | Learning Rate | Overall Accuracy |
|---|---|---|---|---|
| Unet+ Resnet 18 | 2 | 29/50 | 7.5858 × 10−6 | 99% |
| Unet+ Resnet 18 | 4 | 23/50 | 6.3096 × 10−6 | 99% |
| Unet+ Resnet 18 | 8 | 30/50 | 7.5858 × 10−6 | 99% |
| Unet+ Resnet 18 | 16 | 49/50 | 2.5119 × 10−6 | 96% |
| Unet+ Resnet 34 | 2 | 17/50 | 6.3096 × 10−6 | 99% |
| Unet+ Resnet 34 | 16 | 34/50 | 6.3096 × 10−6 | 96% |
| Unet+ Resnet 34 | 32 | 49/50 | 3.6308 × 10−6 | 97% |
| PSPN + Resnet 18 | 2 | 19/50 | 3.9811 × 10−3 | 99% |
| PSPN + Resnet 18 | 4 | 32/50 | 1.0965 × 10−3 | 99% |
| PSPN + Resnet 34 | 2 | 17/50 | 2.2909 × 10−3 | 99% |
| PSPN + Resnet 34 | 8 | 28/50 | 7.5858 × 10−4 | 99% |
| PSPN + Resnet 34 | 4 | 46/50 | 6.3096 × 10−4 | 99% |
| PSPN + Resnet 50 | 2 | 20/50 | 1.0000 × 10−2 | 99% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Andrew, O.; Apan, A.; Paudyal, D.R.; Perera, K. Convolutional Neural Network-Based Deep Learning Approach for Automatic Flood Mapping Using NovaSAR-1 and Sentinel-1 Data. ISPRS Int. J. Geo-Inf. 2023, 12, 194. https://doi.org/10.3390/ijgi12050194
Andrew O, Apan A, Paudyal DR, Perera K. Convolutional Neural Network-Based Deep Learning Approach for Automatic Flood Mapping Using NovaSAR-1 and Sentinel-1 Data. ISPRS International Journal of Geo-Information. 2023; 12(5):194. https://doi.org/10.3390/ijgi12050194
Chicago/Turabian StyleAndrew, Ogbaje, Armando Apan, Dev Raj Paudyal, and Kithsiri Perera. 2023. "Convolutional Neural Network-Based Deep Learning Approach for Automatic Flood Mapping Using NovaSAR-1 and Sentinel-1 Data" ISPRS International Journal of Geo-Information 12, no. 5: 194. https://doi.org/10.3390/ijgi12050194
APA StyleAndrew, O., Apan, A., Paudyal, D. R., & Perera, K. (2023). Convolutional Neural Network-Based Deep Learning Approach for Automatic Flood Mapping Using NovaSAR-1 and Sentinel-1 Data. ISPRS International Journal of Geo-Information, 12(5), 194. https://doi.org/10.3390/ijgi12050194