1. Introduction
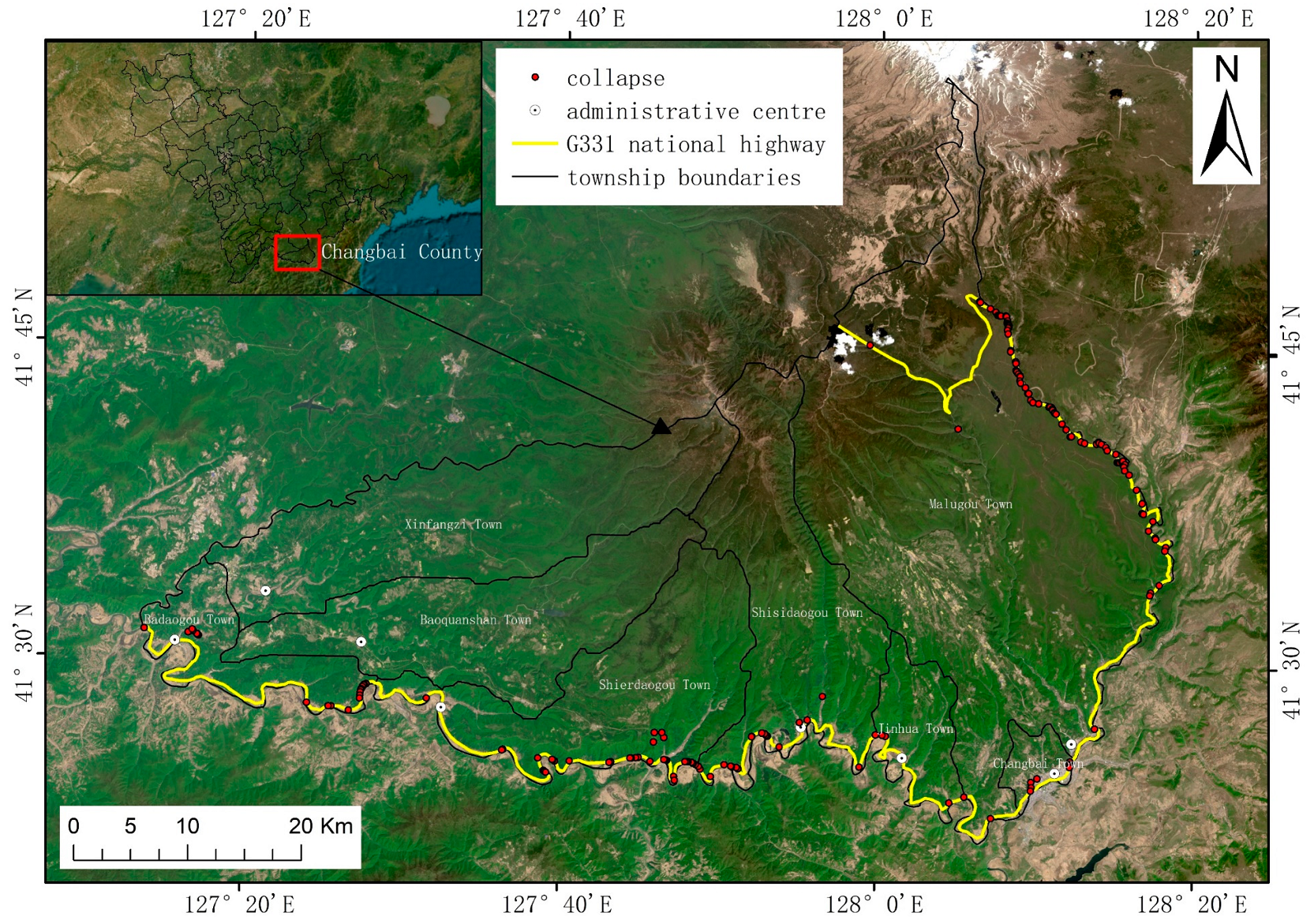
The G331 national highway is located in Changbai Korean Autonomous County, Baishan City, Jilin Province, China (hereinafter referred to as Changbai County). It is close to the border between China and Korea; therefore, it is in an important strategic position and has a profound impact on China’s geopolitical security [
1]. The G331 national highway is a tourist route that leads to the Changbai Mountain scenic spot, and this attracts a large number of tourists and vehicles throughout the year. As other roads are far from the border, the special geographical location of the G331 national highway determines that its existence holds significant importance regarding national defense. The existence of this solution has resolved the geographical obstacles hindering the transportation of combat-ready materials by the Chinese army and improved the speed of responses to border emergencies.
The geological disasters along the G331 national highway in Changbai County are frequently influenced by human engineering activities. Among these activities, collapse disasters, also known as landslide disasters, are the most severe [
2]. Collapse is a kind of geological phenomenon that the rock and soil mass on the steep slope is separated from the parent rock and accumulated at the foot of the slope under the action of gravity. Roads are an important type of infrastructure for economic development. The destruction of roads caused by collapses or landslides will affect the economic development of Changbai County. It also causes loss of life and property for tourists and residents [
3]. The lack of information on the risks associated with collapse disasters and a reliable basis for decision-making hinders work on prevention and control in this study area. Prevention and control work is often carried out blindly and lacks focus, making it impossible to effectively utilize funds for disaster prevention and mitigation. The safety of local people’s lives and property is difficult to guarantee, and meeting the needs of economic development is challenging.
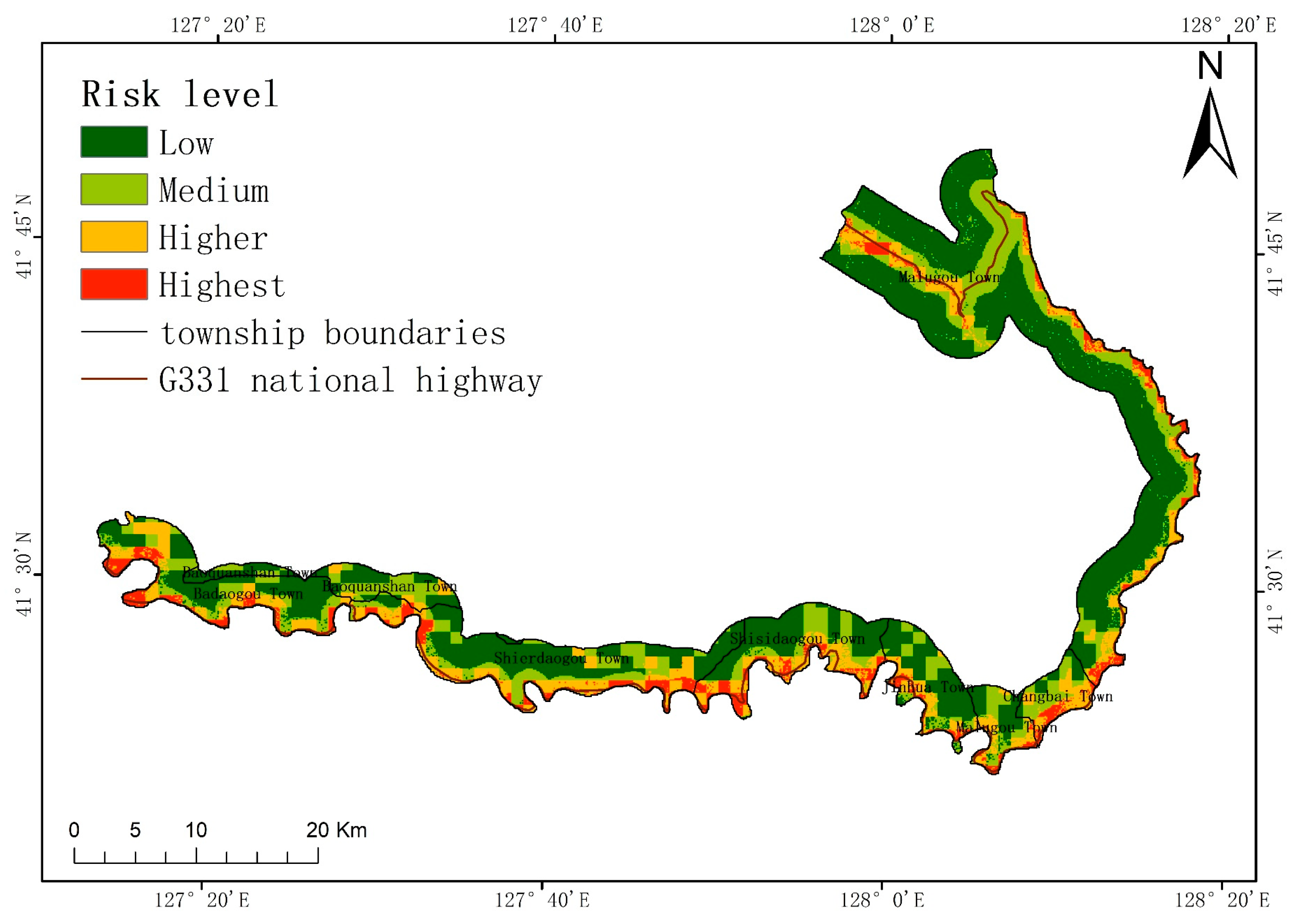
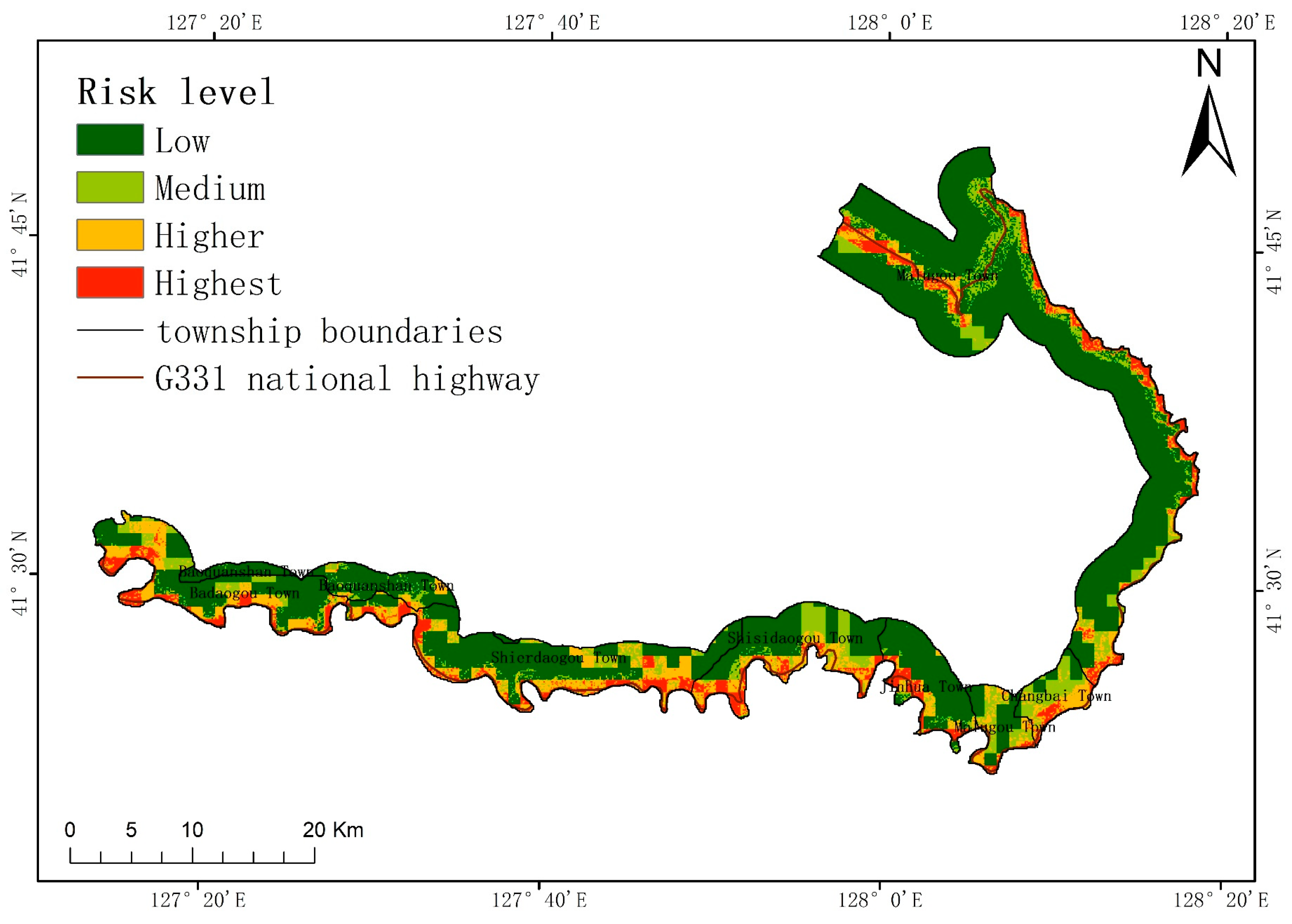
In this paper, a coupling model is used to quantify the risk of collapse in the study area and create a collapse risk map. This provides a reliable foundation for the Changbai County government to develop a plan for preventing collapse disasters and implement an early warning system for such disasters. While minimizing economic investment in disaster prevention and mitigation, it can also achieve a better protection effect and reduce economic losses. The study area currently faces the problem of blind and non-targeted prevention and control strategies for its collapse disasters. Improving these strategies can enable defense work to proceed smoothly and effectively, and protect the safety of people’s lives and property in order to meet the economic development needs of Changbai County.
Existing collapse risk research methods mainly include qualitative methods and quantitative methods [
4]. The qualitative research method involves experts selecting the influencing factors of geological disasters based on their experience and evaluating the impact of these factors on the occurrence of geological disasters. This research method is often considered more subjective [
5]. For example, the analytic hierarchy process [
6], expert evaluation method [
7], and fuzzy set integration method [
8] are common qualitative research methods. The quantitative research method establishes a mathematical relationship between geological disasters and indicators using specific data, resulting in findings with a relatively high accuracy [
9]. However, this research method is easily affected by the challenges of data collection, and the efficiency of data collection will impact the research progress [
10]. Common quantitative research methods include the information quantity method [
11], the logistic regression method [
12], the frequency ratio method [
13], the weight of evidence method [
14], and so on. The information quantity method can identify the optimal combination of influencing factors that contribute significantly to the occurrence of collapse disasters in order to achieve an effective risk assessment of collapse disasters on roads [
15,
16,
17]. With the rise of artificial intelligence, an increasing number of scholars have started utilizing machine learning models [
18]. The most commonly used models are artificial neural networks [
19], support vector machines [
20], and random forest models [
21]. Machine learning algorithms can be applied regardless of the dimension or type of data, making them widely applicable [
22]. The random forest method combines the results of multiple classification trees. It effectively avoids the discontinuity of the predicted value in decision trees and reduces sensitivity to the training dataset so that the predicted value is smoother, thus preventing model overfitting and improving its stability [
23,
24,
25].
Previous studies lack a uniform standard for assessing collapse disaster risks, and various scholars have different interpretations of the concept of a risk and what it entails. Gao [
26] believes that a risk in this context refers to the potential loss of life, property, and economic activities resulting from geological disasters occurring in a specific area and at a specific time. Xiong [
27] believes that the risk of geological disasters is a combination of geological and social attributes and is determined by sensitivity and vulnerability. Sui [
28] believes that landslide risk is a measure used to describe the potential for slope damage to some extent; their research content includes hazard analyses, vulnerability analyses of the people affected by hazards, and risk zoning. Chang [
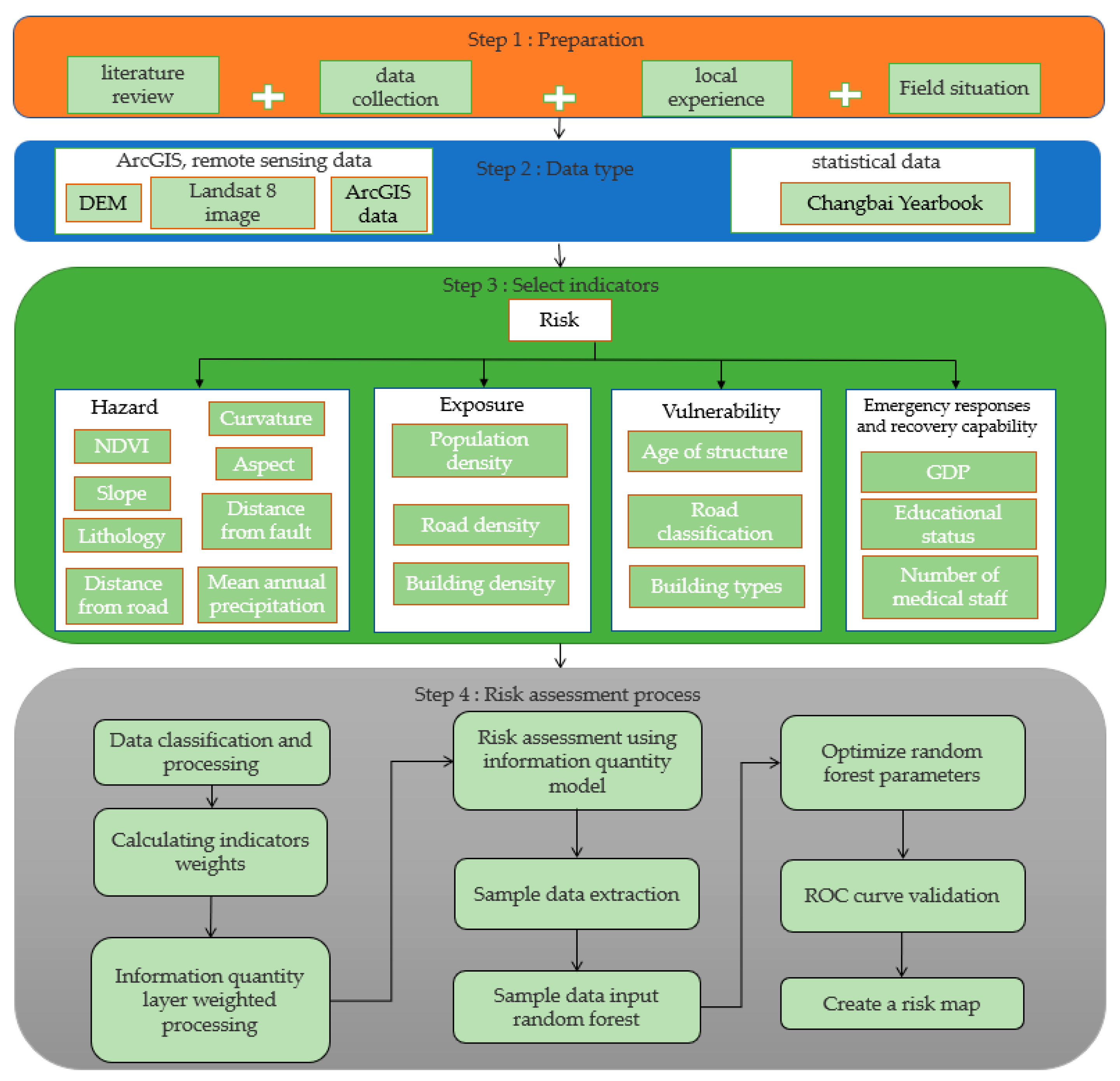
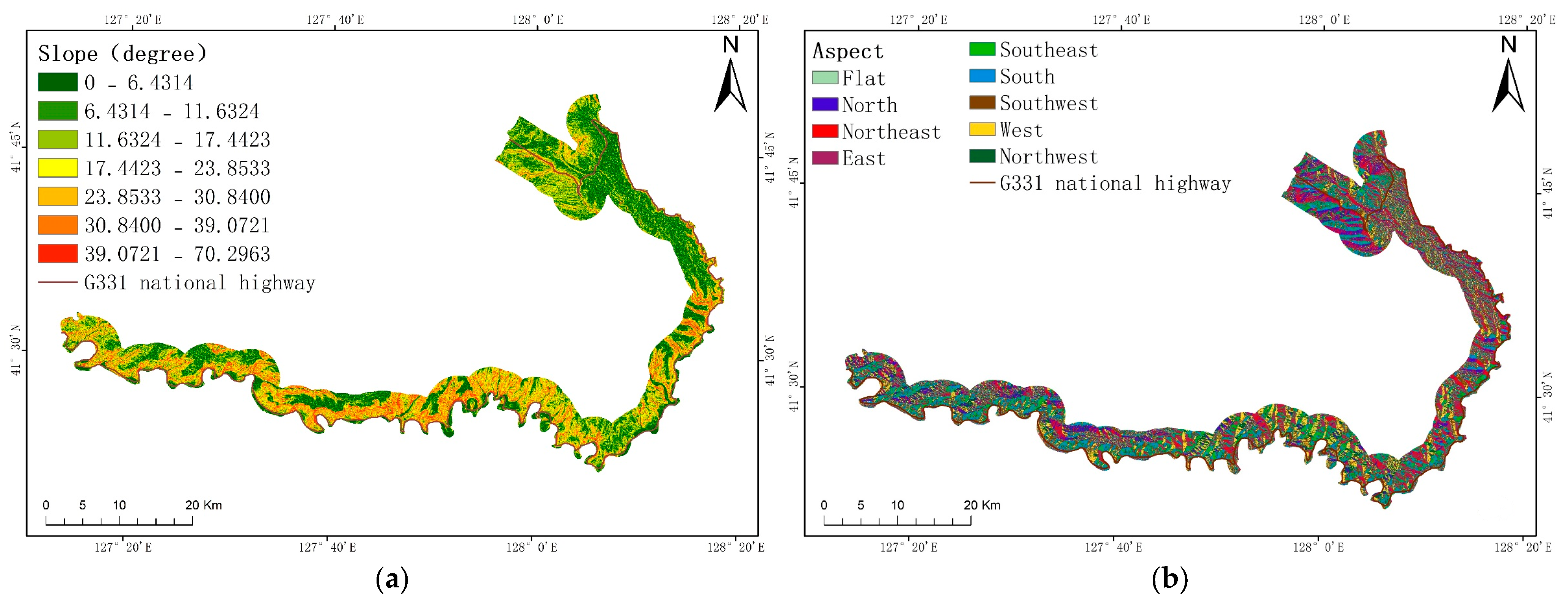
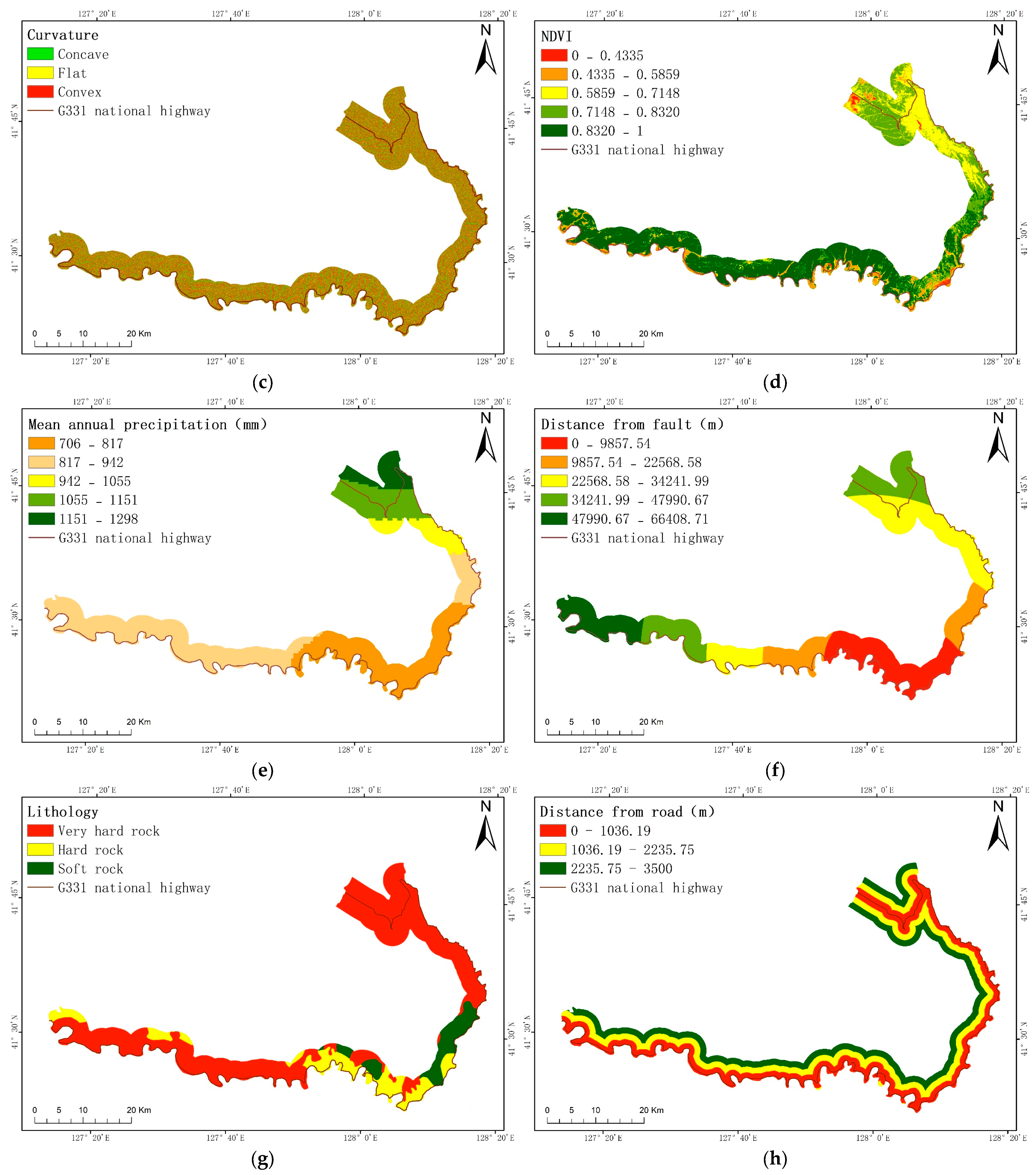
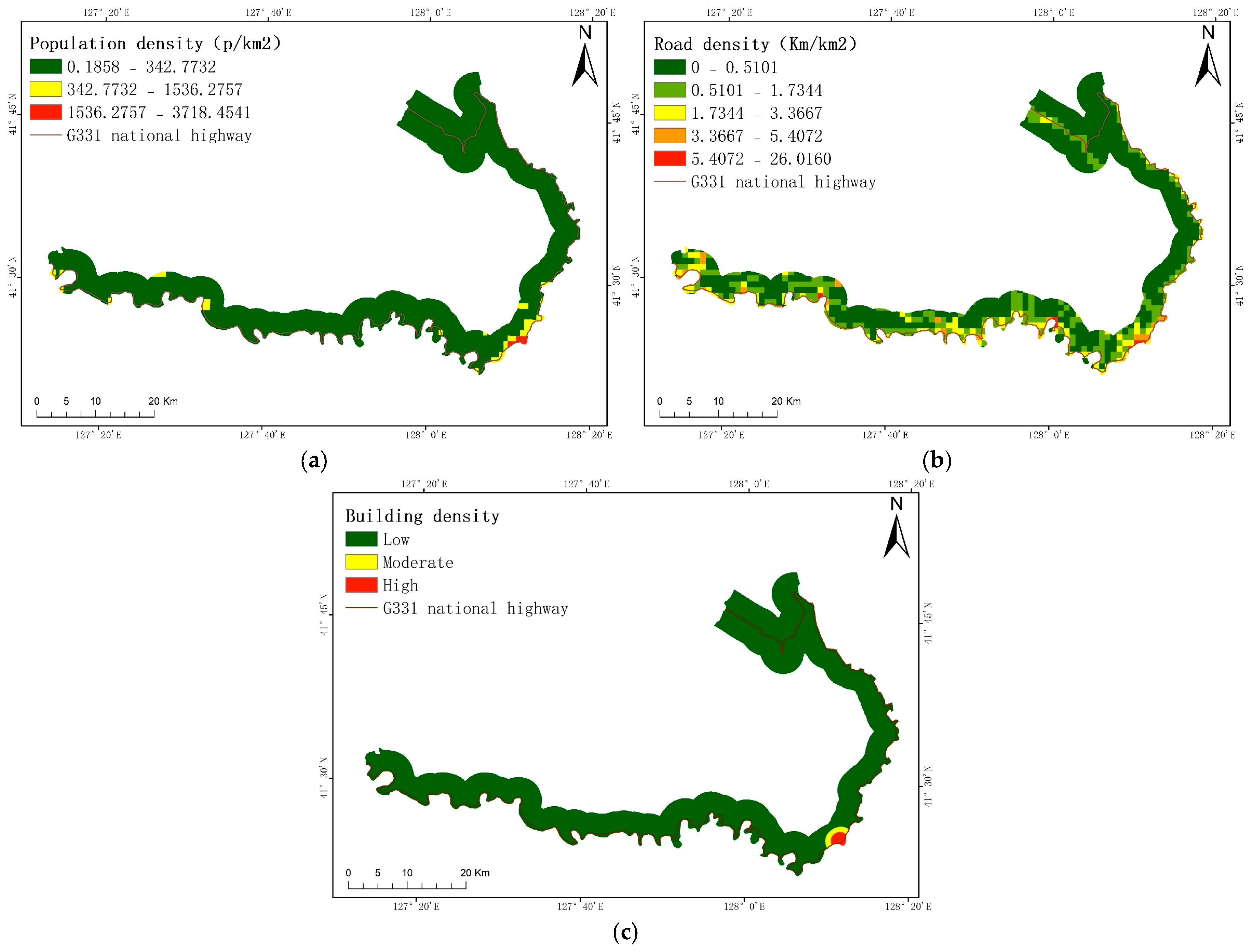
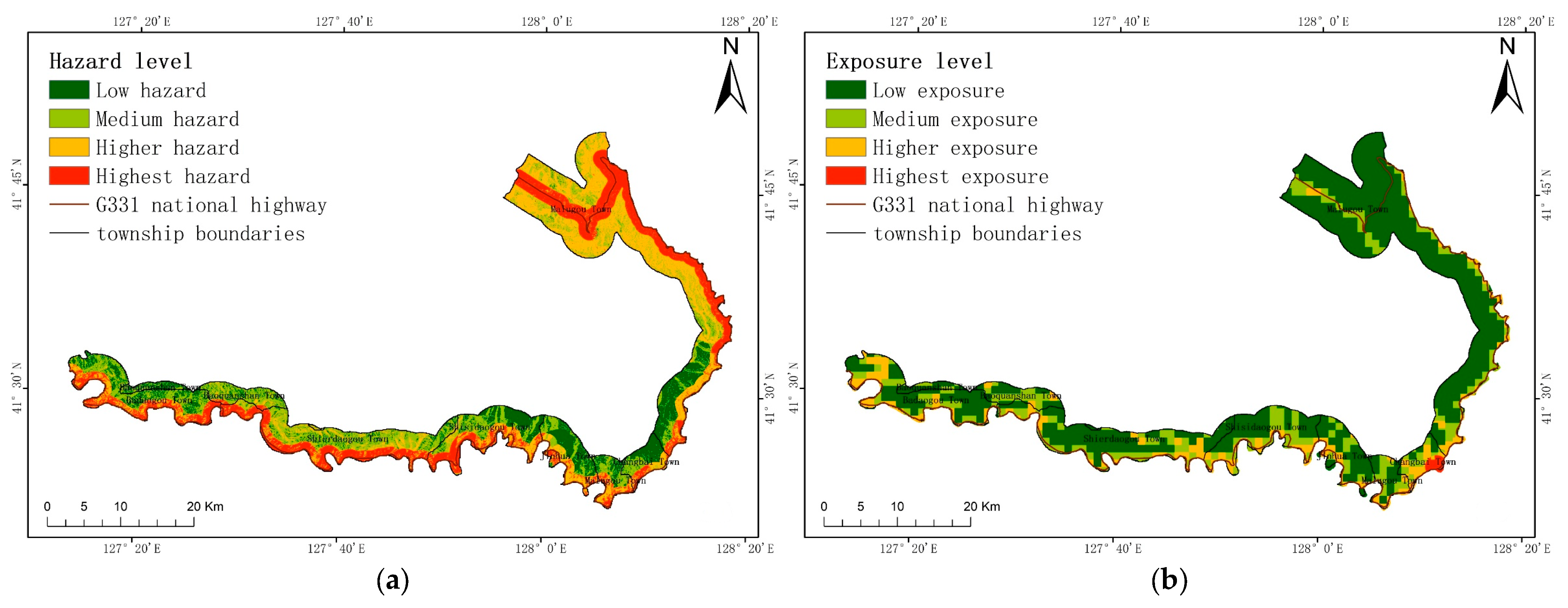
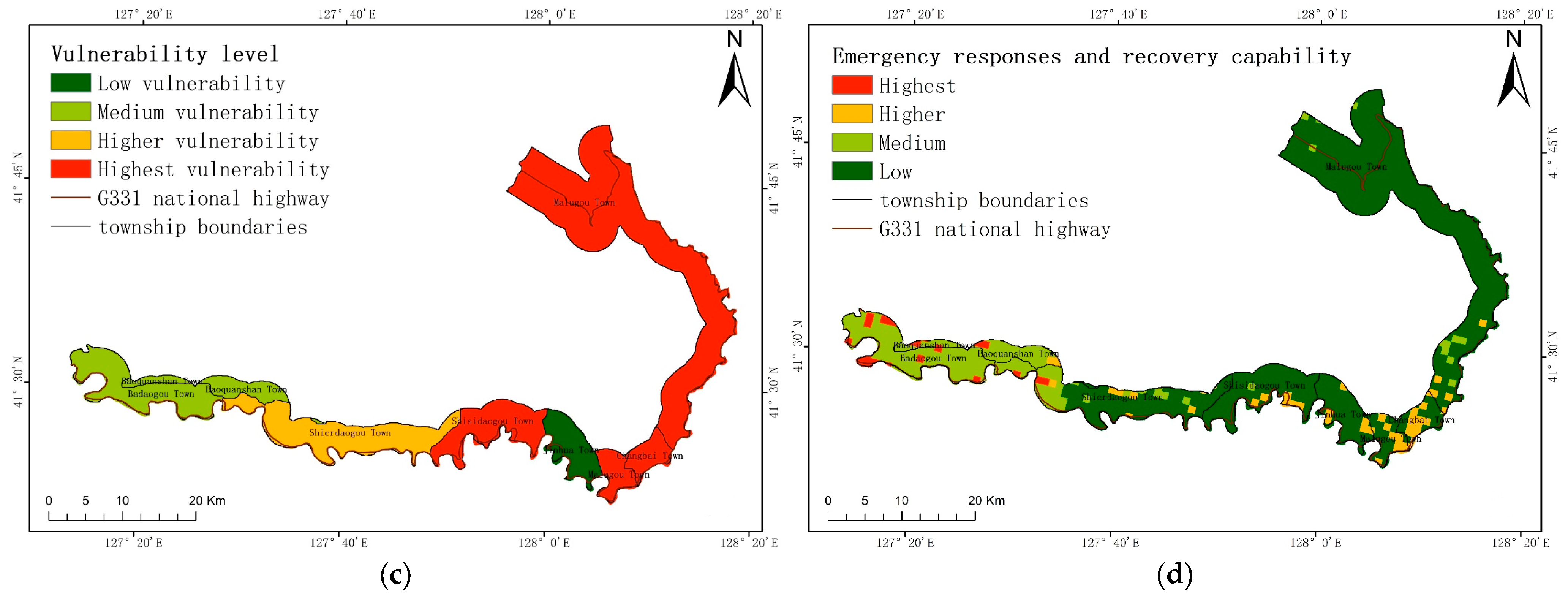
29] considered that risk is the product of hazards, vulnerability, and exposure, which can be expressed as a multiplication of these three factors. On the basis of hazards, vulnerability, and exposure, this study also considers emergency responses and recovery capabilities to ensure that the evaluation results are more scientific and standardized. In this paper, the research area is the G331 national highway in Changbai County. The information quantity method, random forest method, variation coefficient method, entropy weight method, and other methods are primarily employed to create a collapse risk map along the G331 national highway. This map will assist future decision-makers and establishes a theoretical foundation for disaster prevention in the studied area.
6. Discussion
6.1. Comparison with Other Evaluation Methods
There are three main methods for assessing collapse risk. The first uses mathematical statistics. After collecting and processing data, this method establishes a probability model, analyzes the data using this model, calculates the probability distribution and risk value, and finally categorizes the risk level based on the risk value. Such methods have specific requirements regarding the data’s quality and sources. The second method is the scene simulation method [
50,
51]. After collecting data, this method establishes a three-dimensional model and simulates the scene of a collapse using simulation technology. Such methods typically require corresponding software, which can often be costly and will result in increased research expenses. And, due to data processing and model accuracy, the simulation results may not meet expectations. Such methods are frequently employed in small-scale risk assessments. The third category is the index system method [
52,
53]. This method selects indicators by referring to the research of other scholars and then establishes an index system. It calculates and evaluates each layer of indicators, and then integrate them according to specific methods or standards to determine various levels of risk. This method has a certain level of subjectivity in selecting indices and calculating weights, which can impact the evaluation results.
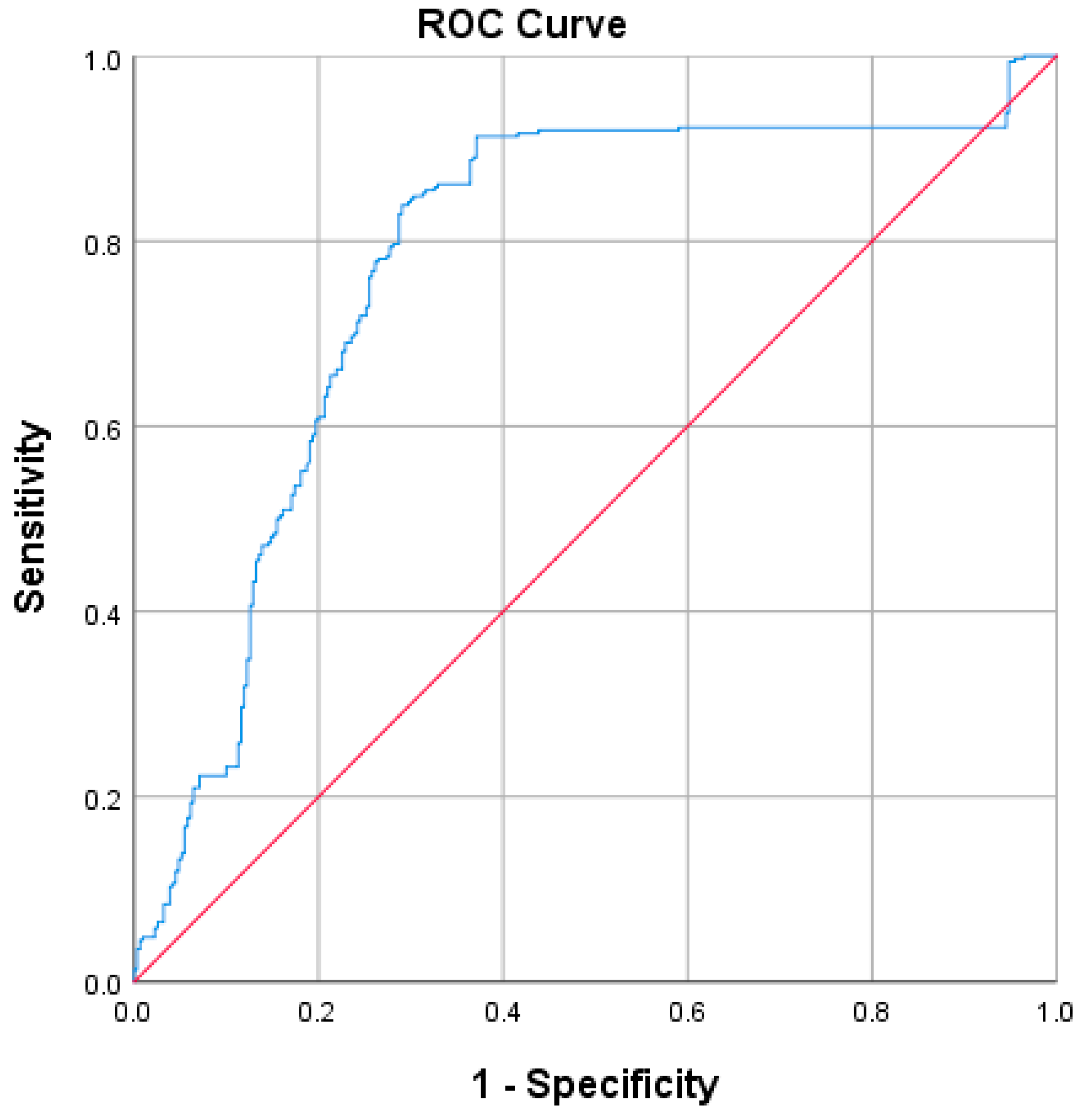
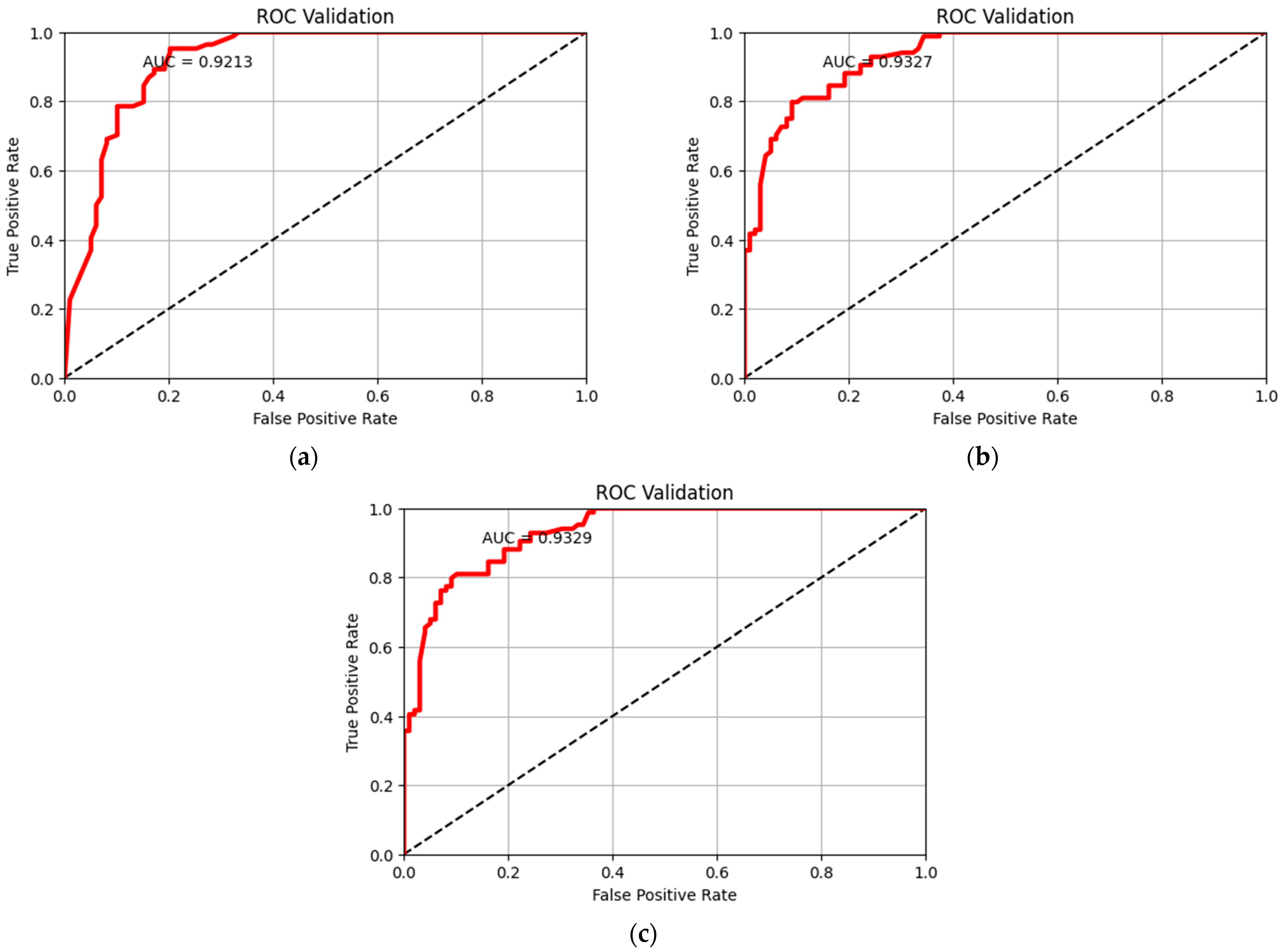
Based on the index system method, this study integrates remote sensing data, statis-tical data, and raster data to minimize the subjectivity in selecting indices. The subjectivity of the weight calculation was reduced via qualitative weight calculation method. Finally, a random forest model was optimized using GridSearchCV for our risk assessment. By using the autonomous learning and self-adjusting characteristics of machine learning, the possible subjectivity in this research was further weakened. After minimizing the subjectivity, a risk map was obtained.
6.2. Comparison with Others’ Studies
In previous studies, assessments of collapse risks have utilized various research methods, which vary depending on the research objectives and geographical locations. When conducting research on regional objects such as highways, railways, or historical relics, the index system and mathematical statistics methods are usually employed. When studying individual collapses, the scene simulation method is usually chosen. However, when selecting the index system method, various scholars have enhanced their approaches from different perspectives. In order to examine the relationship between landslides and the surrounding environment, Zhao utilized the spatial case-based reasoning method to assess the risk of landslides in Lushan County [
39]. In order to eliminate the error of subjective weighting, Gao utilized a weight-based generalized objective function to evaluate vulnerability. This was combined with a Gaussian process classification model to assess hazard levels, and subsequently conduct a risk assessment [
26]. Chang utilized the empirical model developed by Wischmeier to compute the intensity of rainfall for a hazard assessment. This approach allowed their study to examine the influence of rainfall on landslides. Subsequently, their risk assessment was conducted by considering three key factors: hazard, exposure, and vulnerability [
29]. Sui studied a specific landslide at Shiyantan in Mayang County. They determined the threshold of landslide risk level in China using the ALARP method and discussed the acceptable range of risks to life and economic risk [
30]. Karma Tempa evaluated the assets of the AH-48 highway using a system independently developed by Bhutan. He then assessed the risk of the AH-48 highway from three perspectives: asset value, threat value, and vulnerability value [
54]. Zheng incorporated railway management into the evaluation system and assessed the risk of the Chengdu–Kunming railway using the analytic hierarchy process and triangular fuzzy number method [
55]. In this study, the index system method was selected to collect remote sensing data, statistical data, and raster data. On the basis of hazard, exposure and vulnerability, emergency responses and recovery capability were also considered. The entropy weight method and the variation coefficient method were combined to eliminate subjective errors in our weight calculation process. Additionally, our random forest model’s hyperparameters were adjusted using GridSearchCV to generate a risk map. The model eliminated subjective errors from two aspects: multi-source data and combined weights. This optimized machine learning model was used to generate the risk map, resulting in more accurate evaluation results. In this study, the more commonly used natural breakpoint method was selected as the threshold. In future research, the risk level threshold should be determined using a more scientific method, as the risk map will consequently be more accurate. Or, by utilizing a deep learning model, the results could be made more accurate.
6.3. The Social Impact of Our Research Results
The research results reported here are beneficial for developing geological disaster prevention plans and implementing geological disaster warning projects in the study area. When formulating plans for geological disaster prevention and control, different measures can be developed based on different levels of risk. In areas with higher elevation, collapses are often more likely to occur, and there are often more disaster-exposed people in these regions. Greater manpower and material resources are needed when formulating prevention and control measures. In urban planning, it is important to avoid constructing buildings in areas with the higher and highest risk levels. This is to prevent reductions in the vegetation coverage and to minimize the probability of collapses. At the same time, this can also reduce the loss of economic assets and personal safety when collapses occur in these regions. When conducting emergency evacuations, it is important to ensure that the layout of emergency material warehouses and emergency corridors in higher and highest risk areas is more rational. When a collapse occurs, emergency materials can reach the affected areas more quickly, and the evacuation of affected people will be expedited. Shelters should also be constructed in areas with a low level of risk. These results are also applicable in other countries. However, it is necessary to consider the local natural environment and human factors when selecting data indicators; the corresponding local data should be selected.
6.4. Limitations
The study area is located on the Chinese border. When collecting data, it was necessary to aggregate statistics into larger units in order to accurately represent the variations in values. Some of the data grid units provided by the relevant departments are large. As a result, it was not possible to fully cover the entire research area.
Collecting data on vulnerability, emergency responses and recovery capability indicators was too difficult. This led to the selection of township-level units for producing data maps of criterion layers. This further affected the accuracy of our vulnerability and emergency responses and recovery capability maps. If these indicators used smaller statistical units, for example, statistical units within a community, the quality of evaluation would be improved.
The random forest program runs automatically. Once it starts running, there are too few parts that can be debugged manually. This model is more suitable for solving classification problems. Its effectiveness in solving regression problems is not as high as that in solving classification problems.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}