1. Introduction
Unmanned Aerial Vehicles (UAVs) play an important role in many fields, such as aerial photography, disaster rescue, power inspection, etc. [
1]. No matter what field it is used in, a user’s basic requirement of their UAV that allows it to perform tasks is for it to be able to find a sequence of points or a continuous polyline from a starting point to an end point; such a sequence of points or polylines is called a path from the start point to the end point. This kind of strategy of selecting an optimal or better flight path in the mission area, with reference to a certain parameter index such as the shortest flight time consumption or the lowest work cost, is called UAV path planning [
2].
In the context of the big data and information age, the operational environment for drones is becoming increasingly complex, particularly in low-altitude airspace below 1000 m. There are not only UAVs and static targets in this airspace but also other moving entities, such as civil aircraft and birds [
3,
4]. Additionally, electromagnetic and radar fields may also be present [
5,
6,
7], posing potential threats to UAVs. The complexity of the UAV path-planning scenario translates into data complexity, with diverse data sources and organization methods. Massive, multivariate, and heterogeneous data in the absence of a unified organization method are difficult for drones to handle, and it is difficult to carry out unified management and expression. UAV path planning requires traversing an entire map to select an optimal path [
8]. Since UAVs have to consider factors such as battery life and safety during flight, it is necessary to consider the cost of passage to make a balanced choice between the length of a path and safety [
9,
10]. According to research, the application of UAVs in civilian fields has expanded to nearly a hundred different areas [
11], and the trend towards increasingly complex scenarios and diversified purposes is evident. Therefore, it is crucial to study intelligent UAV path-planning methods in complex environments.
There are three main types of existing path-planning environment frameworks: local single-scale grid systems [
12,
13], longitude–latitude systems [
14,
15], and global subdivision grid systems [
16]. Both the local single-scale grid systems and the longitude–latitude systems have had early applications and represent traditional path-planning environmental frameworks. The local single-scale grid systems are similar to grids [
17], but they are not identical. These systems’ advantage is in their relatively straightforward modeling process courtesy of their localized and single-scale nature. This simplicity has made them popular for path planning in simulated environments. However, the local system requires the establishment of a new local grid coordinate system based on the real environment each time the path-planning algorithm is applied in real-world scenarios. Consequently, this process consumes time and resources. On the other hand, the longitude–latitude system is fundamentally a vector description, essentially describing objects through a series of connected points. If sampling is sufficiently detailed, this system can effectively describe obstacle contours. An airspace environment as described by a longitude–latitude system is typically obstacle-free, with any point in the entire environment being reachable unless it is an obstacle. Yet, this system has difficulty describing regional characteristics, especially geospatial elements within geographic characteristics. In summary, local single-scale grid systems and longitude and latitude systems are inefficient when serving as environmental organization frameworks for path-planning problems. Moreover, vector descriptions can be computationally complex and time consuming when performing UAV path-planning tasks. The global subdivision grid system is founded on dividing the earth’s global space into adjustable grids, constituting a global and multi-scale grid system. The path-planning environment’s raster and vector data can both be stored and organized in this system, aligning with the data’s spatiotemporal attributes. Consequently, the global subdivision grid system can be considered a more advanced form of data organization, especially when solving problems that require environmental discretization. It is worth mentioning that the global subdivision grid system is not so suitable for solving vectorization problems. Existing path-planning methods, such as the classic A* algorithm [
2], are best-first searches, meaning that they are formulated in terms of weighted graphs: starting from a specific starting node of a graph, they aim to find a path to a given goal node with the smallest cost (least distance travelled, shortest time, etc.). They execute this by maintaining a tree of paths originating at the start node and extending those paths one edge at a time until the specified termination criterion is satisfied. They primarily considers feasibility (obstacle avoidance) and distance factors (securing the shortest distance while bypassing obstacles). These algorithms struggle to incorporate airspace traffic costs during flight and, consequently, cannot balance a UAV’s choice between flight distance and safety. How to incorporate the traffic cost into the consideration of the loss function is a scientific issue that interests many researchers [
9].
These algorithms rely on the excellent feature representation ability of deep neural networks, the self-supervised learning ability of the reinforcement learning agent, and powerful high-dimensional information perception, understanding, and nonlinear processing capabilities. They are model-independent and suitable for location environment decision-making problems. Though deep reinforcement learning (DRL)’s development began in the late 1980s, it was not until 2009 that scholars combined the
Q-Learning algorithm with drone applications.
Q-learning is a model-free reinforcement learning algorithm used to determine the value of an action in a particular state. It does not require a model of the environment (hence being “model-free”), and it can handle problems with stochastic transitions and rewards without requiring adaptations. Donghua and others [
18] proposed a flight-path-planning algorithm based on the multi-agent
Q-Learning algorithm. However, traditional reinforcement-learning algorithms, constrained by their strategy representation ability, could only tackle simple, low-dimensional decision-making issues. The introduction of deep reinforcement learning broke this limitation, with Mnih et al. [
19,
20] combining a Convolutional Neural Network and
Q-Learning to craft the DQN algorithm model for visual-perception-based control tasks. Rowell et al. [
21] designed a reward function of the DQN algorithm model to increase rewards and punishments based on multi-objective improved distance advantage, function rewards, no-fly penalties, target rewards, and route penalties. UAVs trained using the DQN algorithm demonstrated superior threat avoidance, real-time planning, and reliable route generation prowess compared to traditional obstacle avoidance algorithms. However, most of the current schemes that incorporate the traffic cost into the loss function have improved this classic algorithm. Jun et al. used the Bellman–Ford algorithm to make a balanced choice between distance and safety in a complex environment considering the safety of UAVs [
9]; Wei et al. made improvements to the A* algorithm so that UAVs could consider more factors in path planning [
10]. Shorakaei et al.’s work represents a significant effort in refining path-planning methods for UAVs [
22]. They adopted Jun et al.’s definition of traffic cost and improved genetic algorithms. Their improvement made to the algorithm was the consideration of traffic cost, a critical aspect often overlooked in traditional approaches. In their approach, instead of exclusively focusing on the shortest path or simplest route, the factors of potential traffic within an airspace and safety factors were also considered. The result was a more balanced and realistic path for UAVs that, while being potentially slightly longer or more complex, minimizes the risk of collisions or other safety issues. This is a testament to how novel algorithms and strategies, combined with traditional principles, can pave the way for safer, more efficient UAV operations. Yet, the full potential of deep reinforcement learning in such scenarios remains largely untapped, inviting further exploration in future work.
In summary, classic path-planning algorithms (such as A*) and non-learning-based intelligent algorithms (such as genetic algorithms) have been applied to task scenarios that consider traffic costs; however, the research field of combining deep-reinforcement-learning-based path-planning methods with task scenarios that consider traffic costs has not yet been fully explored. Therefore, to address both the inefficiencies of traditional environmental organization frameworks and problems in data association and representation, such as those relating to single-scale grid systems and latitude and longitude systems, we chose the global subdivision grid system. As it is a typical representative of the global subdivision grid system and due to its unique segmentation method and coding rules, GeoSOT (geographical coordinate grid subdivision by one-dimension-integer and two to
n th power) [
23] can effectively serve as an environmental organization framework for path-planning problems. This paper proposes a GeoSOT-based modeling method. Building upon this, a deep-reinforcement-learning grid model was constructed, incorporating passage cost in the reward mechanism to realize UAV path planning in complex scenarios in which passage cost is considered. It would be valuable to include a comparison with other baseline algorithms commonly used in UAV path planning, such as A*.
The main unique contributions of this paper are as follows:
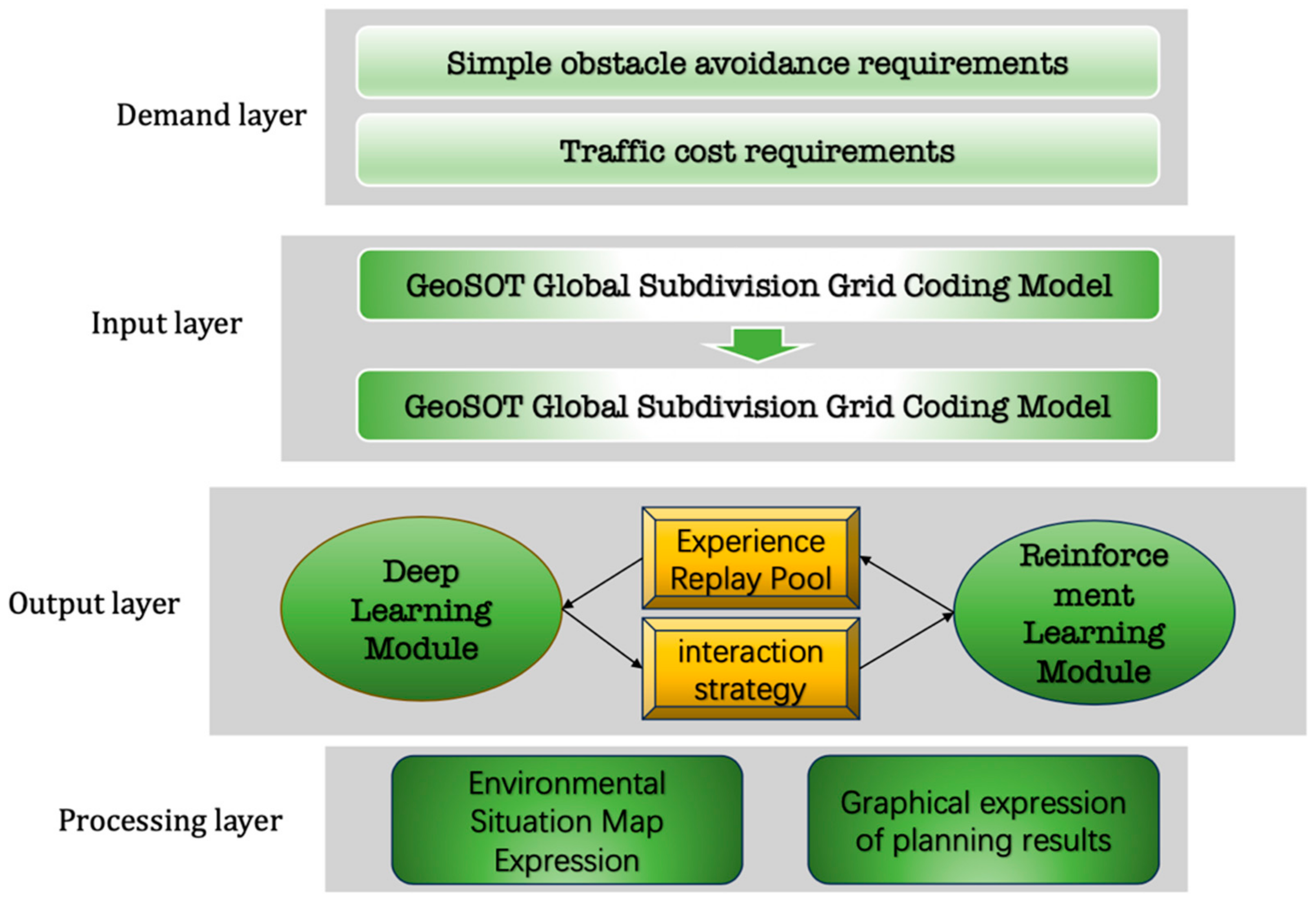
In the context of the intelligent development of UAVs and industries, in view of the inefficiency of the traditional environmental organization framework, the difficulty of data association and expression, and the consideration of traffic costs in UAV path planning, a set of deep-reinforcement-learning grid models with a unified global space framework was established.
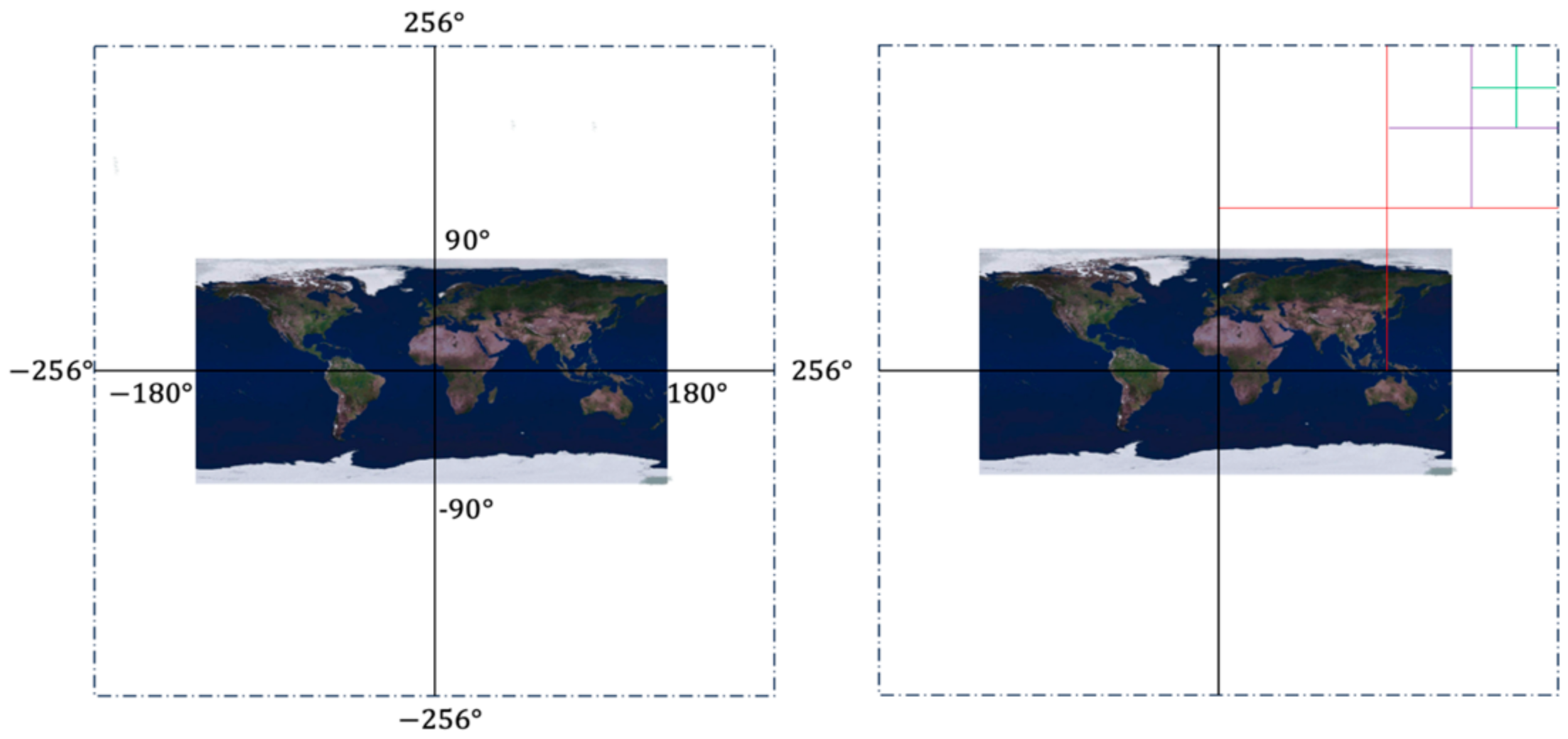
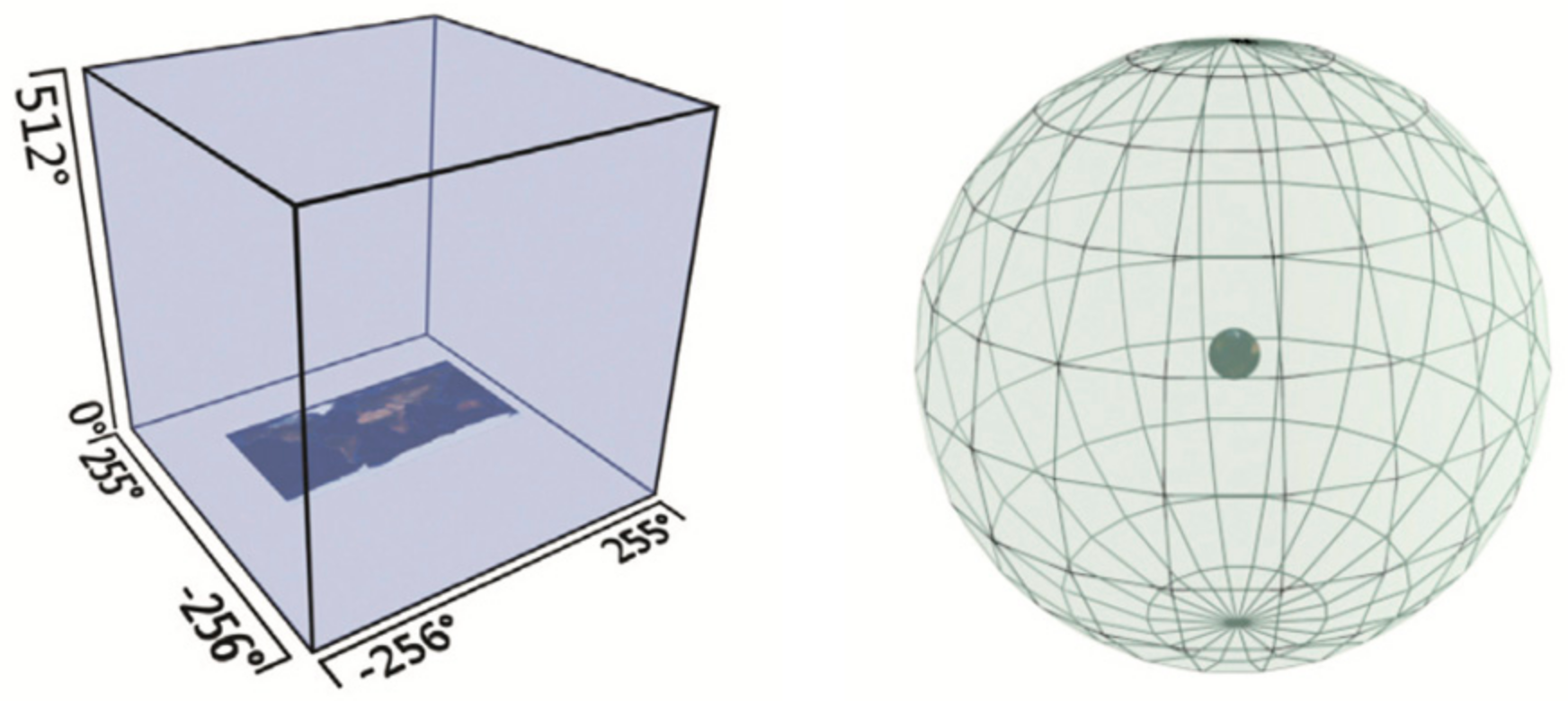
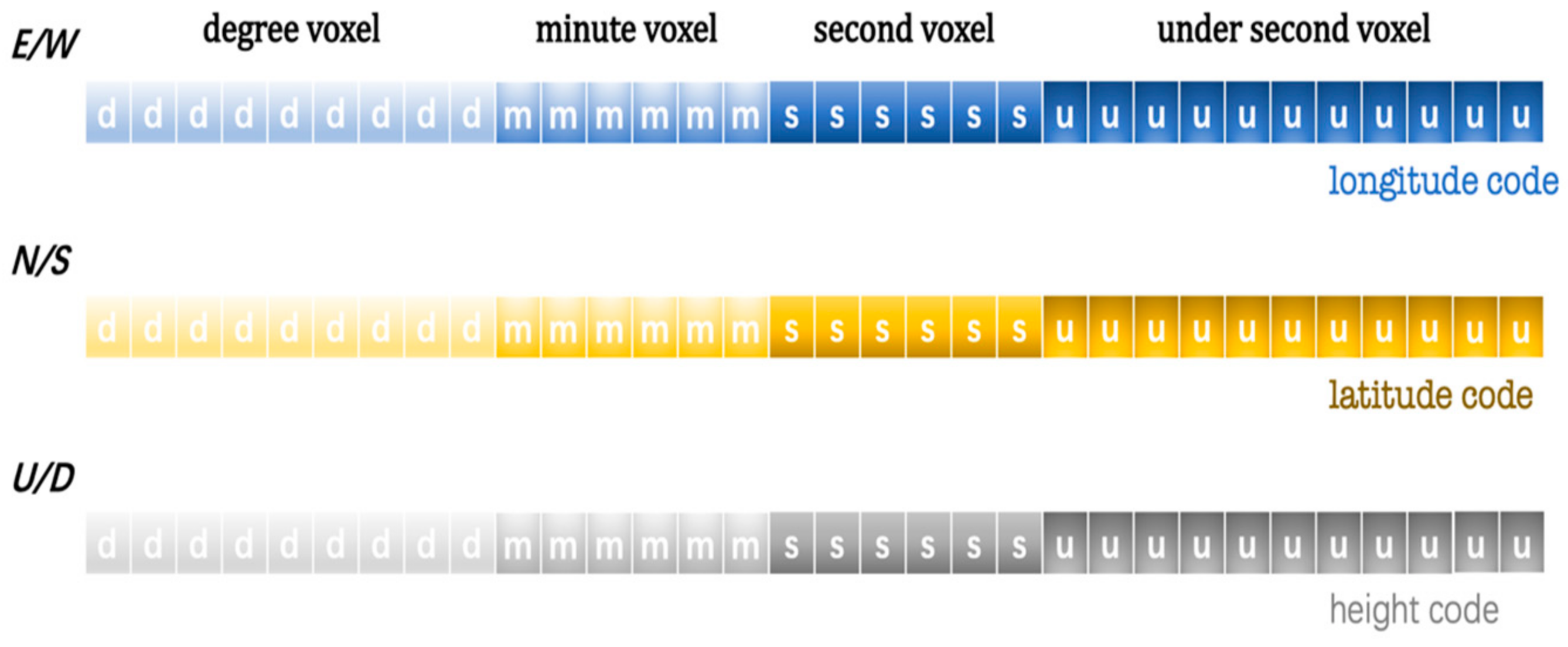
Building upon the GeoSOT global subdivision coding model and local location recognition system, we introduce a modeling method grounded in an airspace grid. Additionally, the low-altitude airspace environment and dynamic targets of UAV flight are gridded and encoded so that the gridded airspace environment data can be better stored and managed.
The Nature DQN algorithm is integrated to devise a specialized application method tailored to specific scene requirements, including reinforcement learning framework construction, neural network model construction, reward mechanism improvement, etc. This culminates in the design of a path-planning experiment for specific application scenarios to validate the robustness of the model and its superiority over classical algorithms in typical scenarios.
The remainder of this paper is organized as follows: The second section elucidates the method employed, and the third section describes a typical experiment conducted on the deep-reinforcement-learning grid model, which was mainly based on the model’s principle and the improved method proposed above, in order to carry out a relatively sufficient application verification experiment. Finally, we conclude our findings and suggest potential directions for future research.
3. Results
The two experiments discussed in this section were carried out using the same hardware and software environment. The key configurations are as follows:
Hardware environment:
CPU—Intel(R)Core(TM)i5-10400F CPU@2.90GHz;
GPU—NVIDIA GeForce GTX 1650, 4GB;
Memory—16 GB 2933 MHz;
Hard disk—UMIS RPJTJ256MEE1OWX, 256 GB.
Software environment:
Operating system—Windows 10 64bit;
Graphics card driver—nvldumdx.dll 30.0.14.7239 and CUDA 11.0;
Languages and Compilers—Python 3.8 and Spyder 4.1.5;
Main dependent libraries—OpenCV-Python 4.5.5.62, Matplotlib 3.3.2, Mayavi 4.7.2, Numpy 1.22.3, and Torch 1.7.1;
Map-processing software—ArcGIS 10.7 and Cesium 1.7.5.
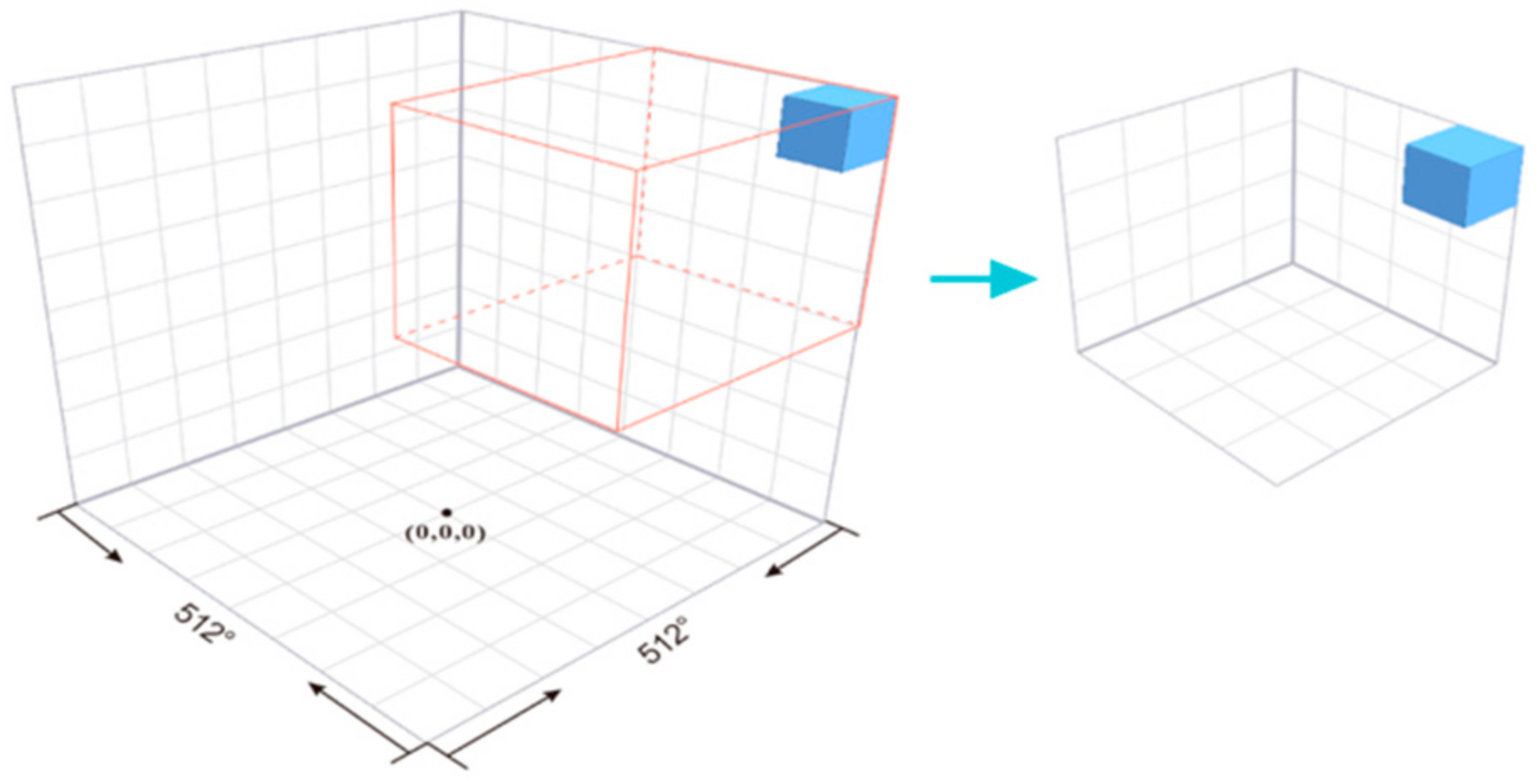
According to the workflow of the deep-reinforcement-learning grid model, the first step for a specific application is to start from the demand layer and clarify the specific needs in the UAV path-planning process. In the mission area, the GeoSOT grid map of the mission area must first be given, and then the geographical elements in the mission area should be expressed in a grid. After these steps are completed, path planning can be carried out. The method of gridding the task area and elements within the area has been given in Part 2. In this model, the real world is abstracted, and each individual space is designated as a toll, so this method is practical.
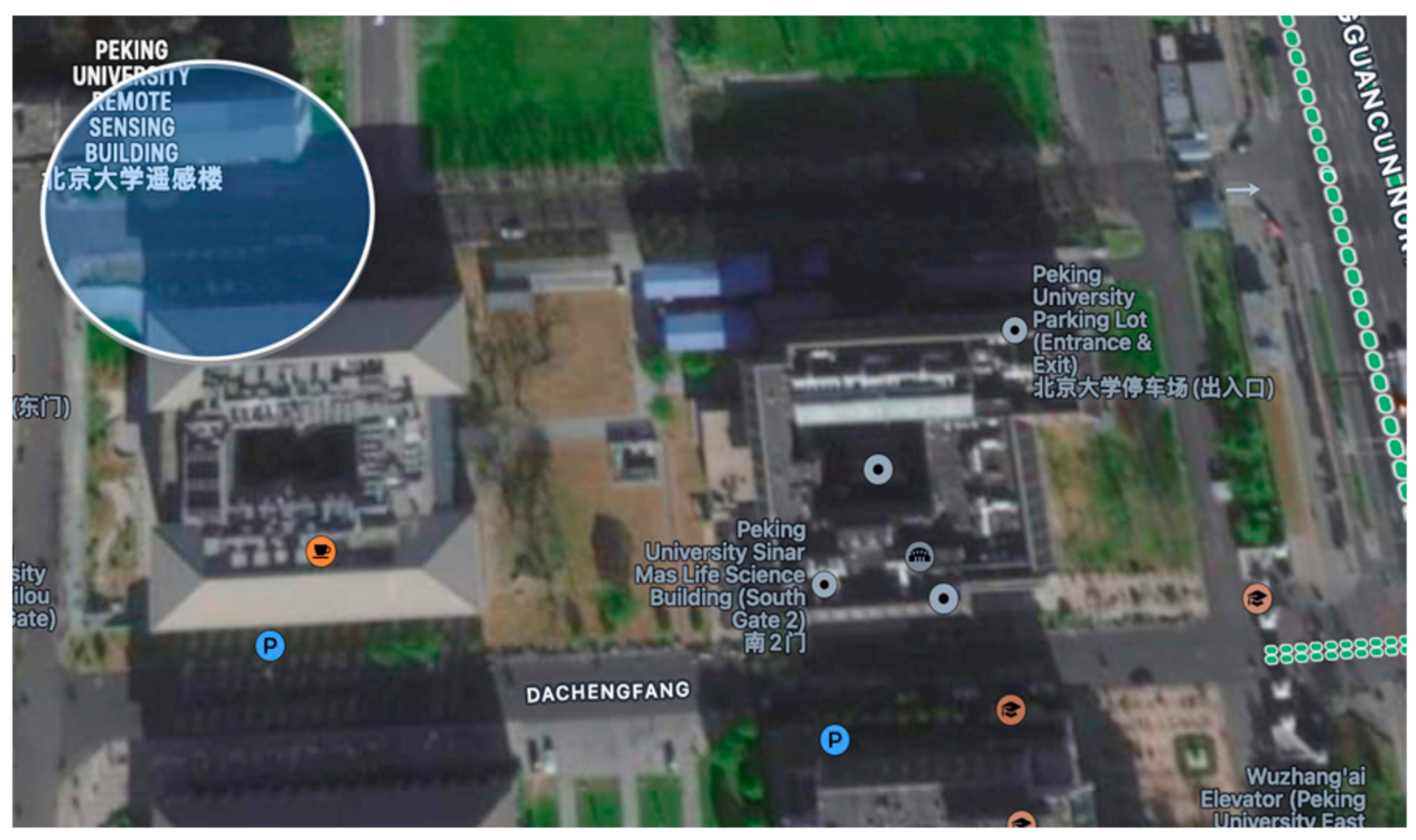
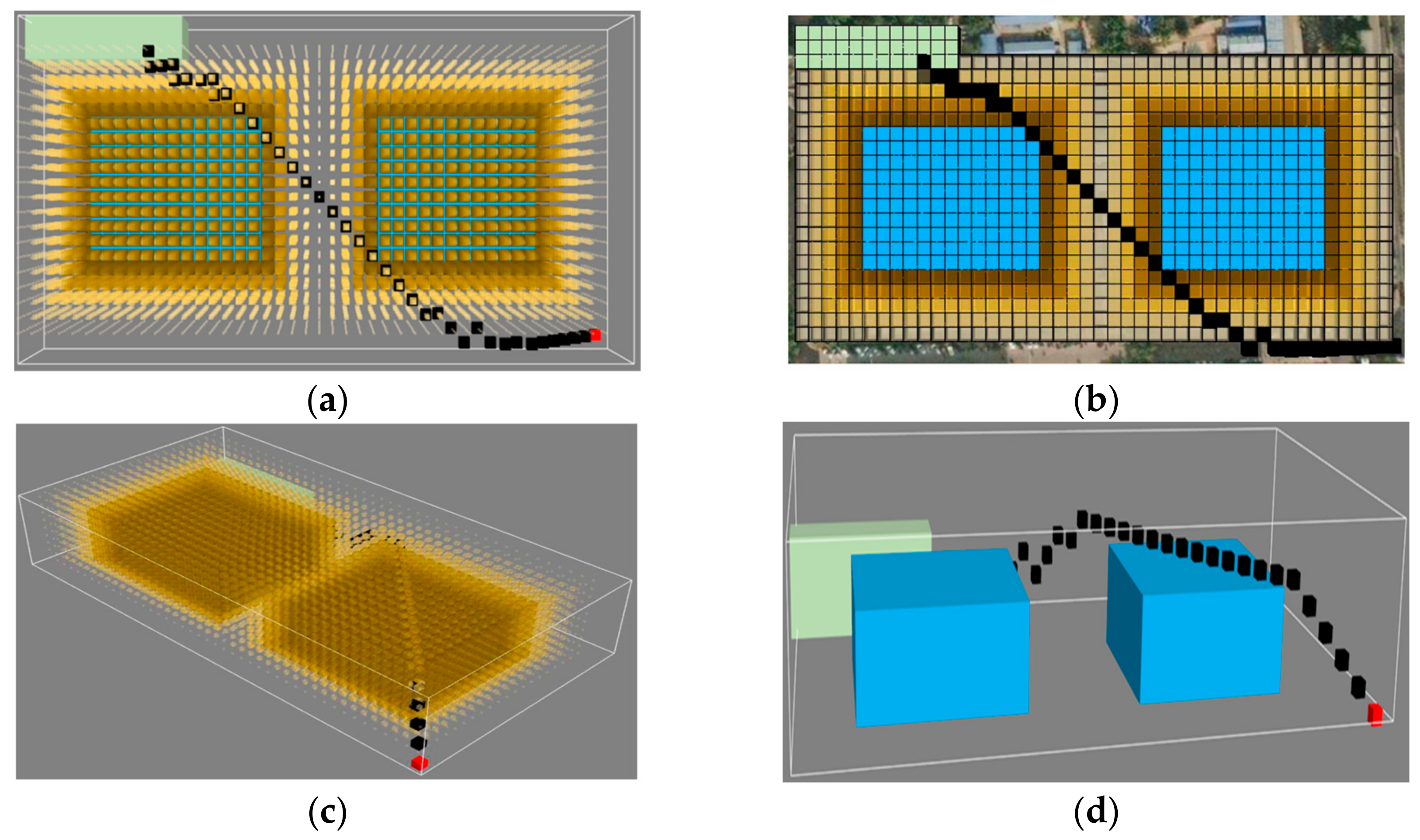
Taking the UAV 3D scene path-planning data from the East Gate of the Peking University Remote Sensing Building as the background, there is clearly a requirement for obstacle avoidance. The starting point of this task scene is a point near the East Gate of Peking University. The selected latitude and longitude coordinates are about (116.3219° E, 39.9966° N, 0 m) and (116.3189° E, 39.9991° N, 0 m); the task area is shown in
Figure 13 below.
Based on the size of the current mission area, the 23rd level grid (with a scale of approx. 8 m near the equator and 4 m near the mission area) of GeoSOT was utilized to partition the environment. Considering the UAV’s flight altitude, only the Lui Che Woo Building and Jinguang Life Science Building are taller structures in the area, so they were treated as obstacles.
The latitude/longitude coordinates of the lower right and upper left corners of the Lui Che Woo Building are approximately (116.3200° E, 39.9981° N, 0 m) and (116.3192° E, 39.9987° N, 0 m). Similarly, for the Jinguang Life Sciences Building, these coordinates are (116.3214° E, 39.9981° N, 0 m) and (116.3214° E, 39.9981° N, 0 m). The obstacle area is depicted in
Figure 14.
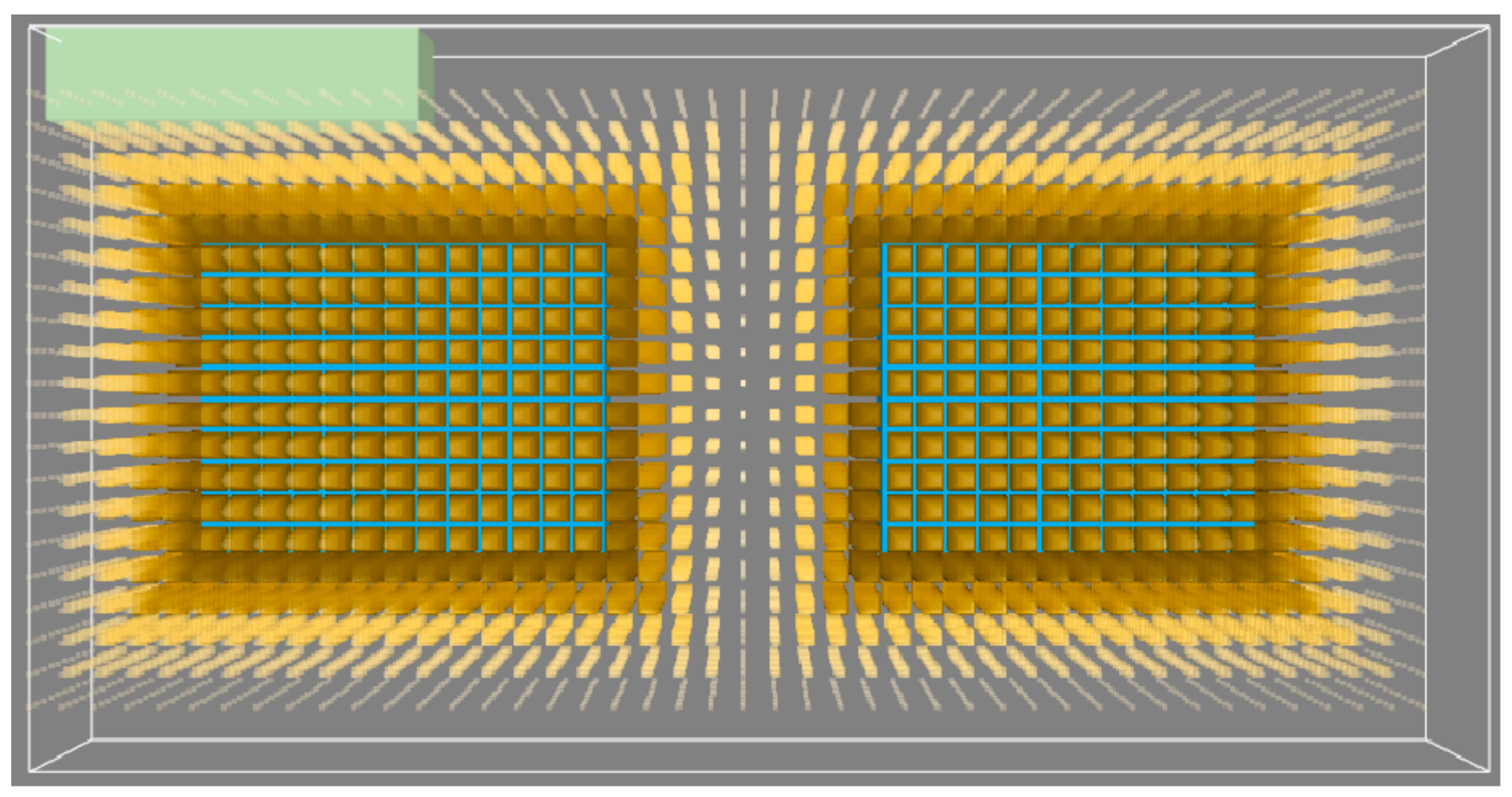
From a two-dimensional perspective, in this experiment, we assigned the remote sensing building as the upper left corner of the task area, used the 23rd-level grid of GeoSOT-3D as a standard, and gridded the task area into a
cuboid area. Among them, the elevations of the Remote Sensing Building, the Lui Che Woo Building, and the Jinguang Life Science Building are all five GeoSOT-3D level-23 grid side lengths. The top view of the task area after division is shown in
Figure 15.
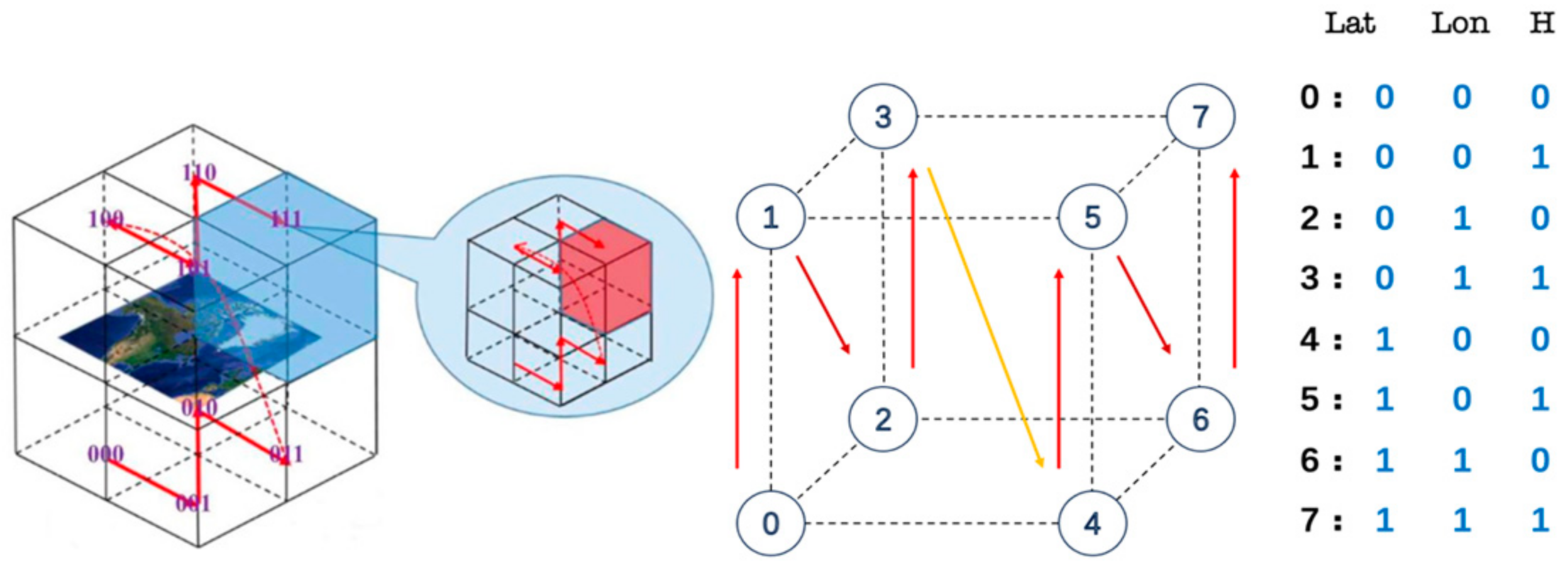
The task area grid set belongs to the same parent grid at the 16th level of GeoSOT-3D. According to the local grid position identification system, this parent grid can be used as a new 0-level subdivision unit, and the grid of this area can be recoded. After encoding, the grid code length of each grid was reduced from 69 bits to 21 bits (7 bits for longitude + 7 bits for latitude + 7 bits for height).
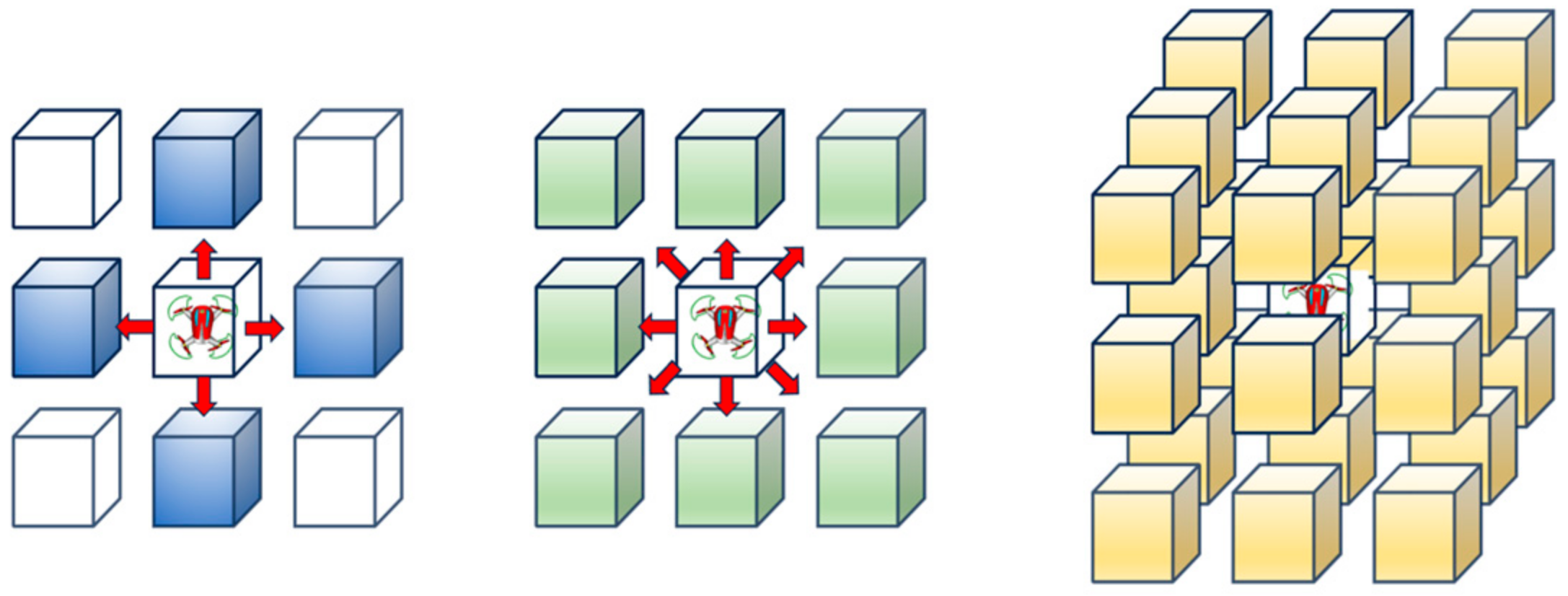
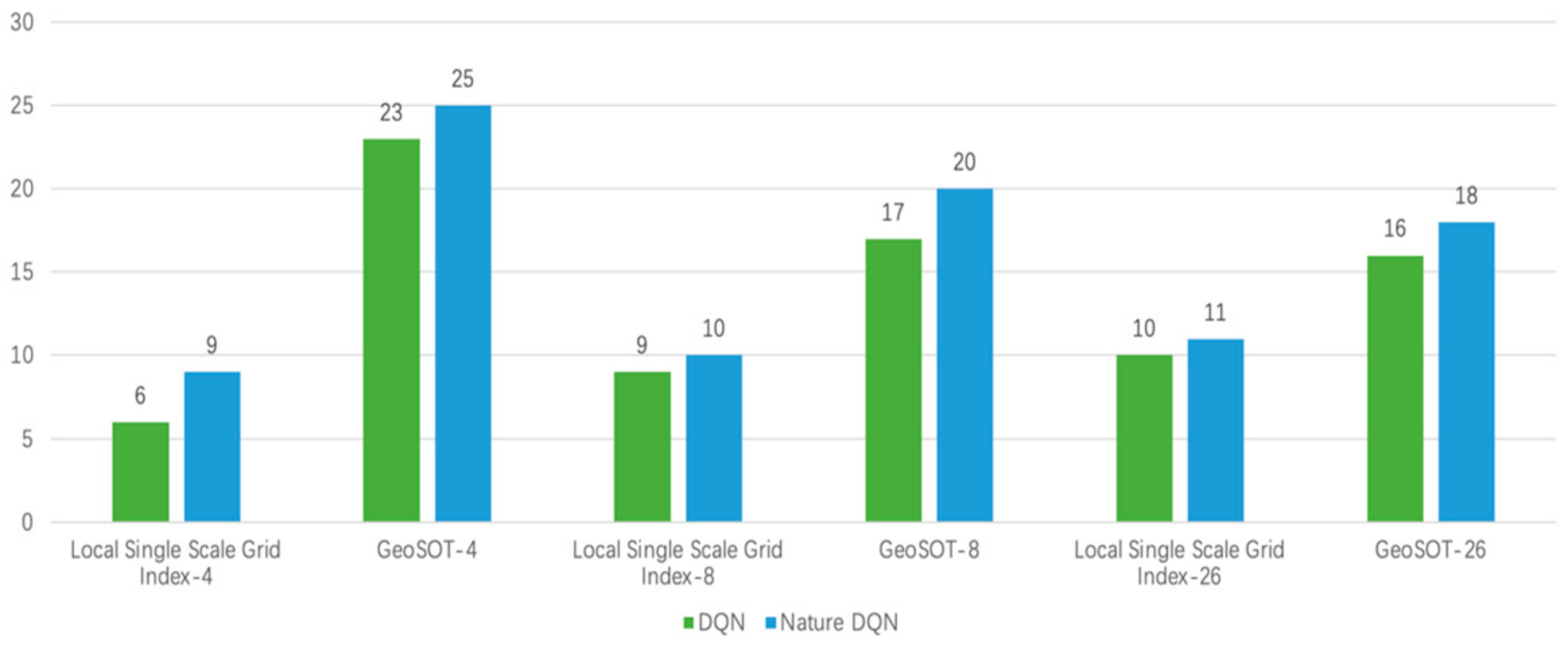
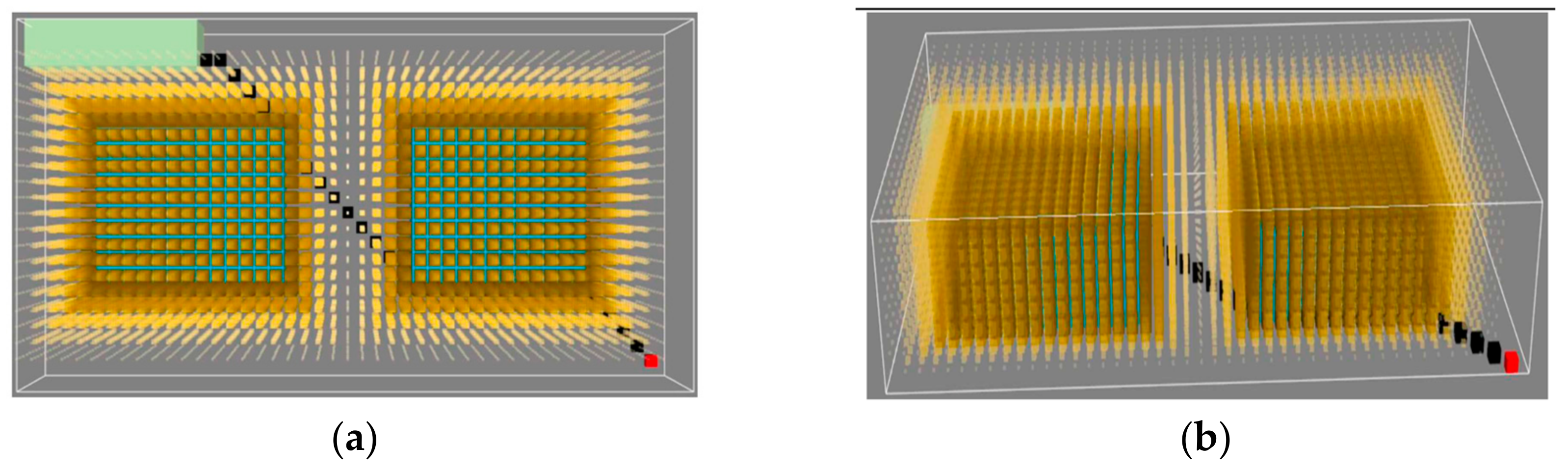
Experiment 1 was conducted to validate the proposed GeoSOT-based deep-reinforcement-learning approach for UAV path planning in comparison to using local single-scale grid indices as inputs. The deep RL algorithm employs DQN and Nature DQN, with the UAV exploring via 4-neighborhood, 8-neighborhood, and 26-neighborhood navigation policies, and the reward function R uses Formula (4). Each experimental group was repeated 30 times, measuring the success rate of the UAV reaching the target area.
The neural network parameters were initialized randomly. The discount factor was used to measure the importance of future rewards in the current state; a larger discount factor means that the agent pays more attention to future rewards, while a smaller discount factor means that the agent pays more attention to immediate rewards. The exploration rate determines the probability of exploring new actions; a higher exploration rate helps to discover better strategies, but it may render the agent unable to converge for a long time, while a lower exploration rate may cause the agent to fall into a local optimal solution. Based on experience gained from related works [
12], the following key hyperparameters (listed in
Table 1) were used:
The experimental results are shown in
Figure 16.
The task success rate data are organized as shown in
Table 2 below:
The experimental results show that no matter what flying method the UAV adopts, the deep-reinforcement-learning algorithm adopts DQN or Nature DQN. The GeoSOT local grid position coding system has a greater success rate for the task success rate than the local grid index as the input of the neural network. This improvement indicates that the input method makes the algorithm more likely to converge, and its anti-interference ability is stronger, that is, the training is more stable.
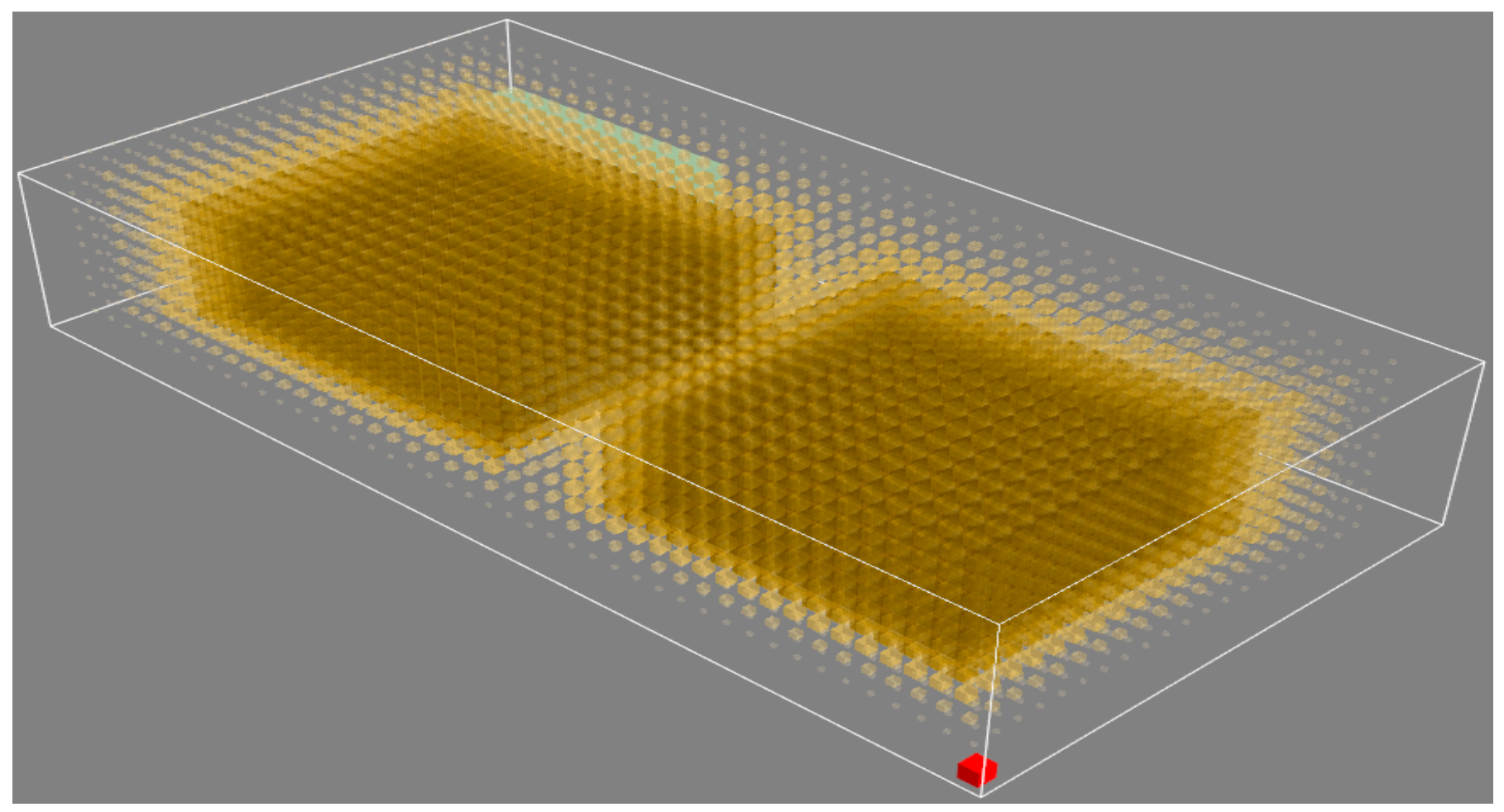
Experiment 2 involved the meticulous process of assigning traffic costs for potential obstacles within the task region along with the adjoining airspace grids. In line with the aforementioned approach, the traffic cost for any grid containing a physical obstacle was set to 1, with a safe distance defined as five grid lengths (N = 5). The traffic cost of the first layer of the outsourced grid for obstacles is 5∕6 ≈ 0.83, the traffic cost of the second layer of the outsourced grid is 4∕6 ≈ 0.67, and the traffic cost of the third layer of the outsourced grid is 3∕6 = 0.50. The traffic cost of the fourth layer of the outsourced grid is 2∕6 ≈ 0.33, the traffic cost of the fifth layer of the outsourced grid is 1∕6 ≈ 0.17, and the traffic cost of the airspace grid outside the safe distance is 0.
The color depth and grid size were used to represent the size of the outsourced grid traffic cost (the darker the color and the larger the grid, the greater the traffic cost). A 3D image of the task area after the traffic cost has been set is shown in
Figure 17.
In Experiment 2, the Nature DQN algorithm was used, employing the reward mechanism R as designated in Formula (6) for setting purposes, and the parameter initialization method of the neural network was randomly initialized. The experiment was divided four times, the deep-reinforcement-learning grid model proposed in this paper was used three times, and the adjustable parameter
μ was set to 0, 0.4, and 0.5, respectively. When
μ = 0, this means that the reward function does not consider the third item; that is, the UAV does not consider the traffic cost at all. When
μ is 0.4 and 0.5, this means that the traffic cost is considered, and the degree of consideration is different. The fourth experiment involved the classic A* algorithm. The hyperparameter settings of the first three experiments are shown in
Table 3 below.
The results of the four experiments are as follows:
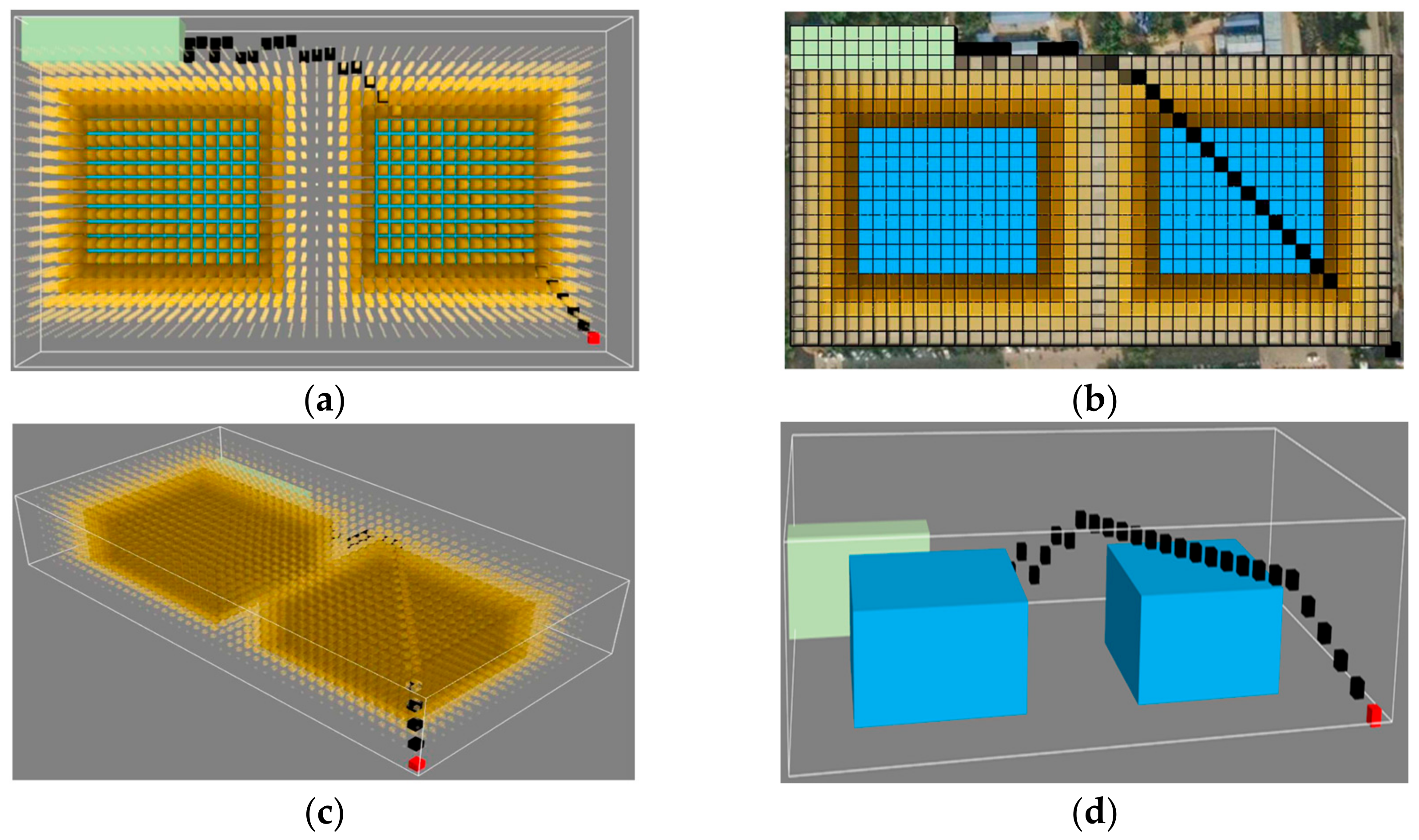
The result of
μ = 0 is shown in
Figure 18a–d are the top views and three-dimensional views of the test results.
In the above results, it can be seen that without considering the traffic cost, some of the grids in the planned path are connected to the surfaces of obstacles, for which the number is 12, which is undoubtedly a safety hazard for UAV flight. Similarly, the results of
μ = 0.4 and
μ = 0.5 are also shown in the figure below.
Figure 19,
Figure 20 and
Figure 21 represent the results of the second and third experiments, respectively.
According to the above results, when μ = 0.4 is adjusted, the UAV has already begun to consider the impact of the traffic cost when planning the path and no longer flies close to the surface of an obstacle, which effectively increases the safety of the UAV’s flight process. When adjusting μ = 0.5, the UAV chooses a grid flight with a higher altitude and lower traffic cost, which more effectively increases the safety of the UAV’s flight.
The results of Experiment 4 show that the A* algorithm makes the UAV choose to fly close to the ground, and a considerable part of the grid is adjacent to obstacles, which is also a safety hazard for UAV flight.
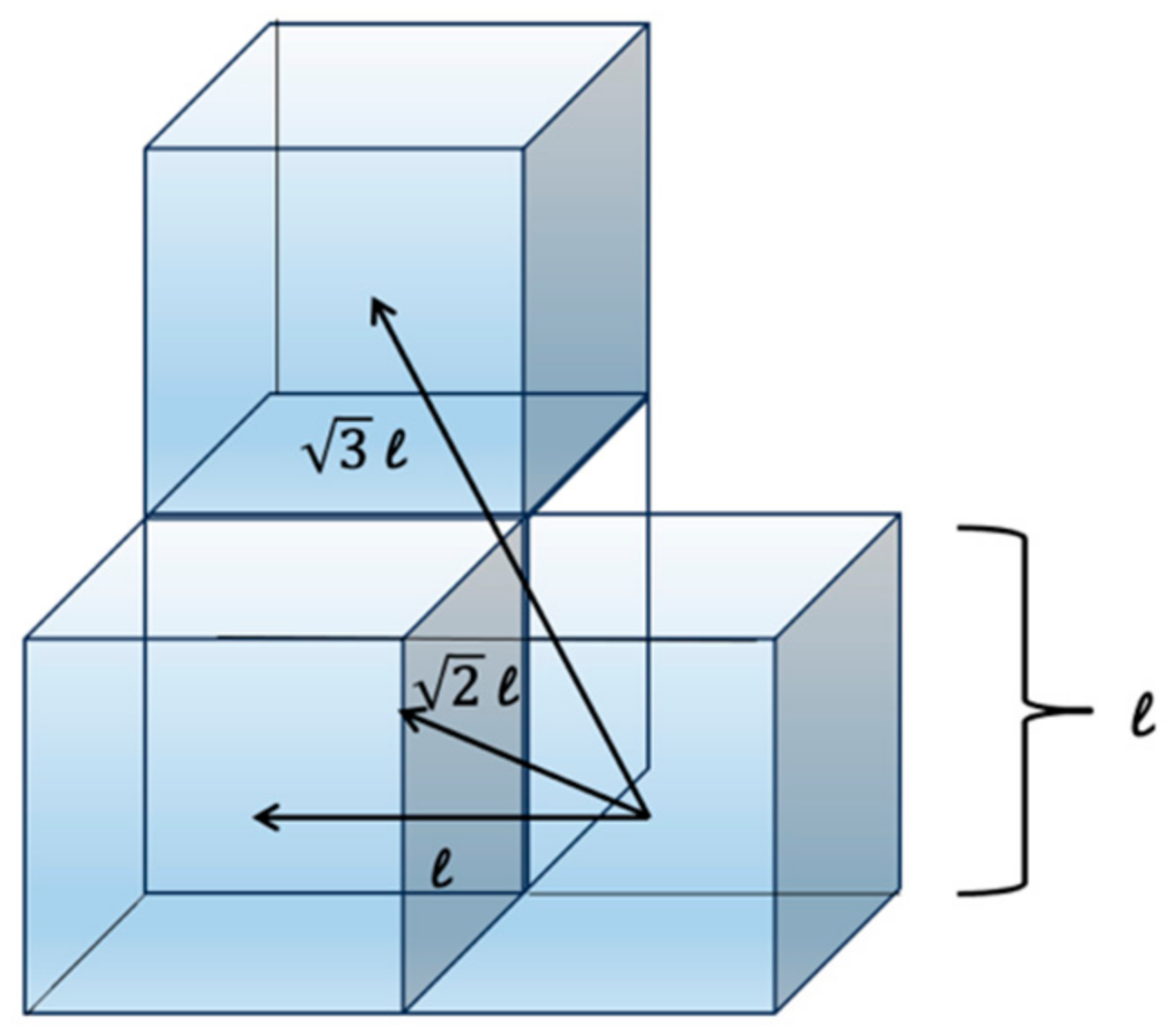
For the calculation of the path length, the side length of a single grid is, the length of flying in a straight direction corresponds to
, the length of flying along a grid in a diagonal direction corresponds to
, and the length along the diagonal section of a body is
. The length of flying along a grid is as shown in
Figure 22 below.
The experimental results are shown in
Table 4 below.
4. Discussion
Experiment 1 indicated that the GeoSOT local grid location encoding system achieved a higher success rate for task completion compared to when local grid indexes were used as neural network inputs. The reason for this result is that the process of establishing the local single-scale grid system involved greater randomness, and the relationships between local grid indexes were not strong enough to effectively characterize the UAV’s state. This lack of valid “contextual” relationships between UAVs limited what the neural network could learn each round. In contrast, the process of establishing the local grid location identification system was non-random, with grid-to-grid relationships following a spatiotemporal z-curve filling pattern. This enabled the encoding of spatial locations as representations with richer “contextual” information. This prior structure enables more efficient learning in the complex path-planning task compared to the use of local grid indices alone.
Experiment 2 provides valuable insights into the performance of the proposed deep-reinforcement-learning grid model. When the traffic cost is not considered (μ = 0), the Nature DQN algorithm plans some UAV flight paths adjacent to building surfaces, posing safety risks. By adjusting μ to 0.4, the UAV chooses higher-altitude grids, effectively avoiding proximity to buildings. At μ = 0.5, the path-planning safety is further enhanced. As a result of the A* algorithm, the UAV chooses to fly close to obstacles and the ground, and a considerable part of the grid is adjacent to obstacles, which is also a serious safety hazard. The deep-reinforcement-learning grid model proposed in this paper performs better than A* in terms of safety for the demand improvement method considering the traffic cost. When μ = 0.5, the total path traffic cost of the planned flight path was reduced by 61.71% compared with the A* algorithm and did not exist in the grid adjacent to the building. At the same time, the experimental results show that the degree of consideration of the UAV’s flight with respect to the traffic cost can be adjusted by adjusting μ; that is, the two factors of the flight distance and safety of the UAV can be controlled degrees of importance. At the same time, the first three sets of experimental results of Experiment 2 show that adjusting μ can regulate the degree to which the drone considers the traffic cost; the larger the value of μ, the greater the impact of the traffic cost on the drone’s path planning, and the more likely it is the drone will choose a grid with a low traffic cost.
The deep-reinforcement-learning grid model put forth in this research is well suited to the increasing intelligentization of UAV path planning in the big data era. By leveraging grid encodings, it can effectively represent fundamental environmental data traits. Further integration with deep RL produced a comprehensive depiction of spatialized information like surroundings and route outputs. This grid-based DRL approach has significant foreseeable potential for civilian use cases, such as deliveries and aerial photography. It could furnish UAVs with an intelligent obstacle avoidance technique that efficiently structures environmental data while accounting for diverse influencing factors.
Concurrently, when experimenting with and applying this method, the relevant requirements of the Civil Aviation Administration of China’s “Interim Measures for the Administration of Commercial Operation of Civil Unmanned Aerial Vehicle” should be followed to ensure flight safety and prevent accidents. Specifically, in this study, the research team obtained the proper registrations and approvals as mandated, and flights were conducted according to the rules and ethical standards for unmanned aerial systems. Ensuring compliance with civil aviation regulations and operating unmanned aerial vehicles responsibly are essential for advancing scientific understanding while protecting public safety.
Looking ahead, this model can enable drones to make better contextual decisions and fly along safer trajectories. By organizing spatial knowledge and optimizing policies through experience, the deep RL grid paradigm promises the continued advancement of intelligent UAV navigation amidst complex real-world settings. Its strengths in fusing environmental encodings with adaptive learning make it an impactful contribution towards the future of AI-enabled flight planning systems.
5. Conclusions
This research makes effective use of the advancements in artificial intelligence and big data to tackle new complexities in UAV path planning. Recognizing the growing interdependence between UAV trajectory optimization and AI, this paper underscores their combined development.
The designed deep-reinforcement-learning grid model can fully express the basic characteristics of environmental data information through grids and is coupled with a deep reinforcement learning model to provide a comprehensive presentation of various types of information, such as environmental situations and path results under a spatial distribution.
Grounded in related challenges, a unified deep reinforcement learning model has been proposed within a GeoSOT global spatial framework tailored for UAVs. This novel integration harnesses GeoSOT’s capabilities in unified spatial data organization and expression along with the end-to-end solution proficiencies of deep RL.
The resulting paradigm constitutes a new approach to UAV path planning, which has been validated through scene implementations. GeoSOT’s spatial knowledge representation and deep RL’s learning capacities prove highly complementary. This harmony allows the model to address associated obstacles in the planning process. This paper provides a new investigation of the combined application of a deep-reinforcement-learning model for UAV path planning and the global subdivision grid coding system, in which some existing problems are solved or alleviated, but there are still some aspects worth exploring, such as the generalizability of deep reinforcement learning models. This paper defines the state of an unmanned aerial vehicle (UAV) as the spatial encoding of its location, which lacks generalizability. Subsequent research should consider including some property characterizations of a UAV’s neighboring grids in a given state, such as passability, enabling the neural network to learn the spatial features of the UAV’s current spatial location and neighboring properties. Through massive data training, deep-reinforcement-learning models may gain generalizability. In new, unknown environments, good predictive performance can be achieved by observing a UAV’s spatial location and neighboring features.
The deep-reinforcement-learning (DRL) grid model put forth in this research is well suited to the increasing intelligentization of UAV path planning in the big data era. By leveraging grid encodings, it can effectively represent fundamental environmental data traits. Further integration with deep RL produced a comprehensive depiction of spatialized information like surroundings and route outputs.
Overall, by leveraging AI innovations and a multi-faceted spatial framework, this research enables sophisticated UAV navigation. It lays the groundwork for continued advancement at the intersection of intelligent systems and robotics. The proposed model delivers robust and generalizable solutions, unlocking the potential of AI-empowered UAV path planning in the big data era.
It is foreseeable that the proposed deep-reinforcement-learning grid model will have the following application scenarios in the future. The first is civilian scenarios, such as express delivery, aerial photography, etc., in which the proposed model can provide UAVs with an intelligent obstacle avoidance method that can efficiently organize environmental data and consider the influence of many factors in an environment; the second is military scenarios, such as rescue in disaster areas, the selection of strike targets, etc., in which the proposed model can provide UAVs with path planning in rapidly changing complex scenes. Of course, this model still needs to be tested further in various conditions, and the criterion of wind direction and strength must be taken into account, both of which are worth exploring in future research.
Looking ahead, this model can enable drones to make better contextual decisions and fly along safer trajectories. By organizing spatial knowledge and optimizing policies through experience, the deep RL grid paradigm promises the continued advancement of intelligent UAV navigation amidst complex real-world settings. Its strengths in fusing environmental encodings with adaptive learning make the proposed model an impactful contribution towards the future of AI-enabled flight planning systems.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}