
Discovering Spatio-Temporal Co-Occurrence Patterns of Crimes with Uncertain Occurrence Time



Abstract
:1. Introduction
2. Related Work
2.1. Discovery of Uncertain Co-Occurrence Patterns Based on the Expected Distance
2.2. Discovery of Uncertain Co-Occurrence Patterns Based on the Possible World
2.3. Critical Analysis of Existing Studies
3. Methodology
3.1. Modeling the Temporal Probability Density Function of Crime Events
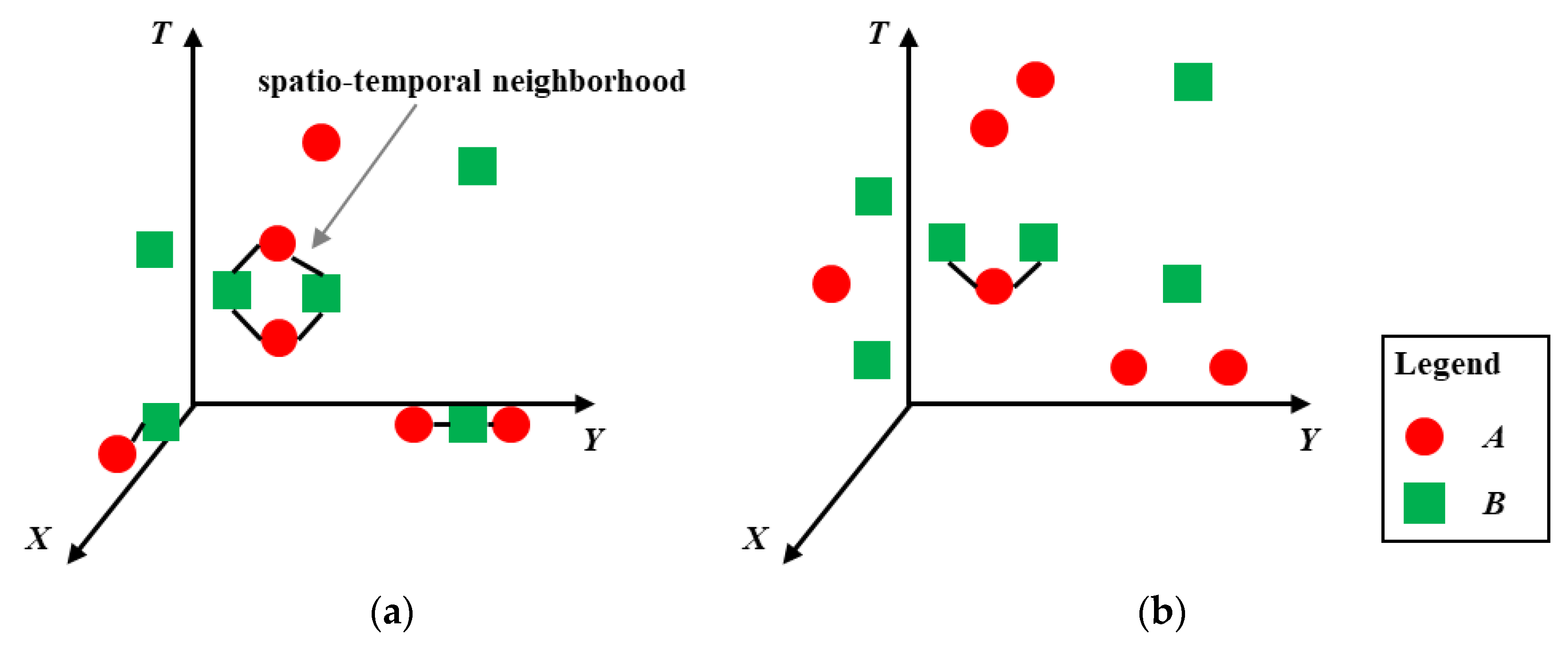
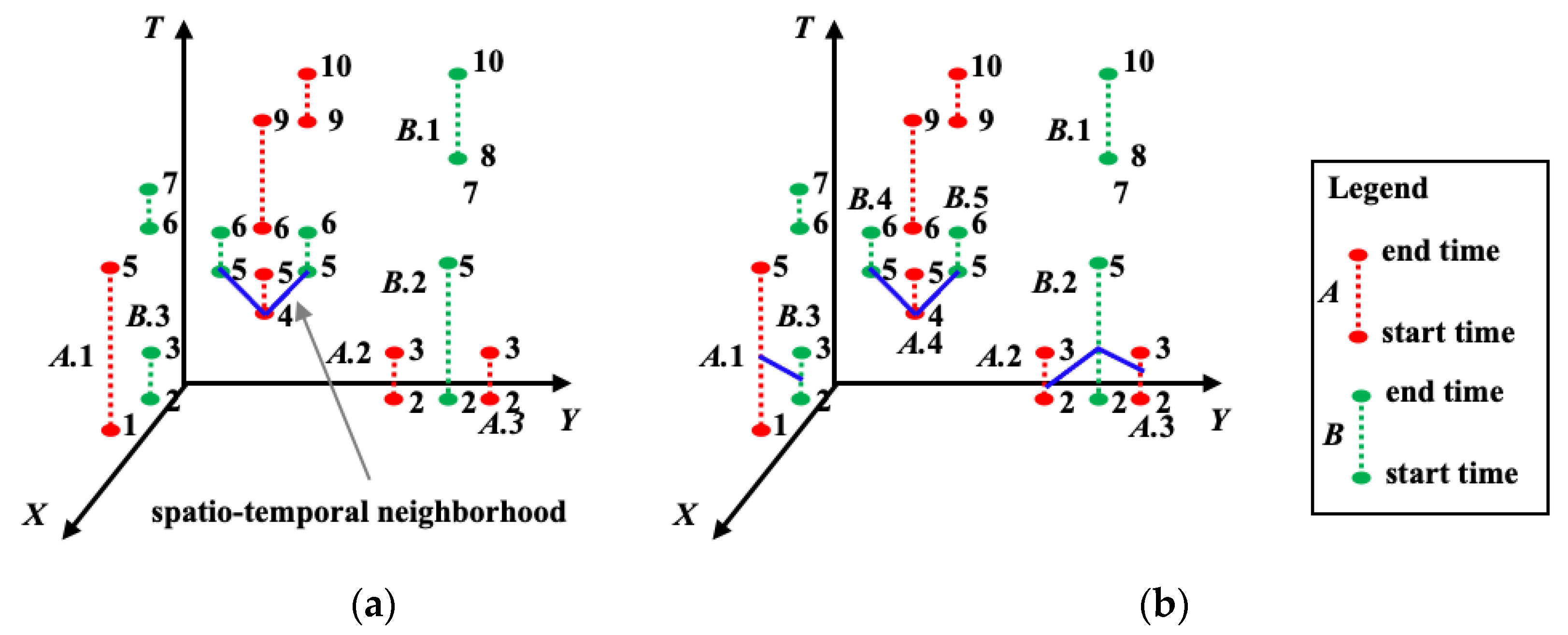
3.2. Constructing the Spatio-Temporal Neighborhood Relationship among Crime Events
3.3. Identifying Uncertain Spatio-Temporal Co-Occurrence Patterns of Crimes
4. Experimental Comparisons and Analysis
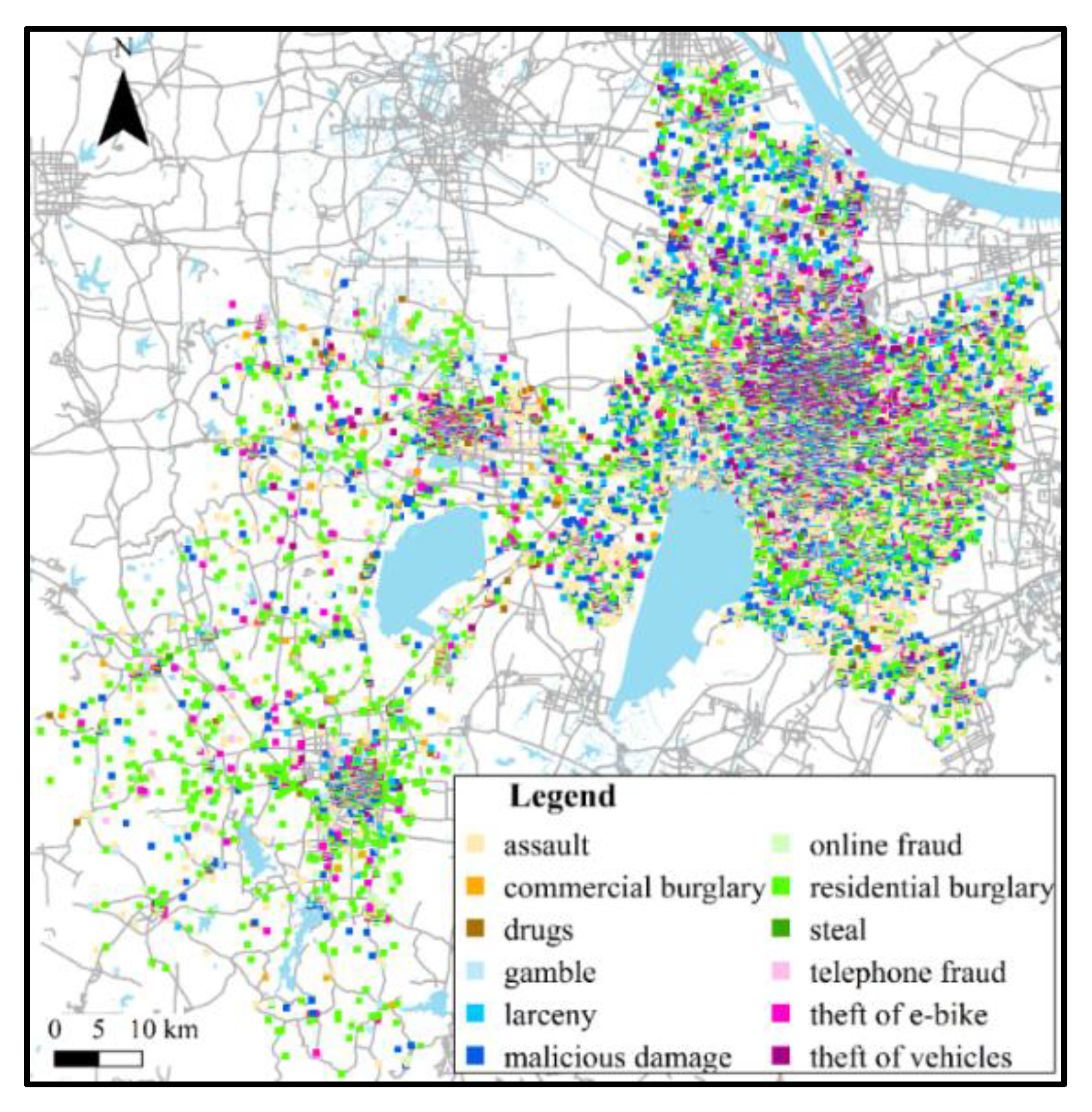
4.1. Real-World Crime Dataset Description
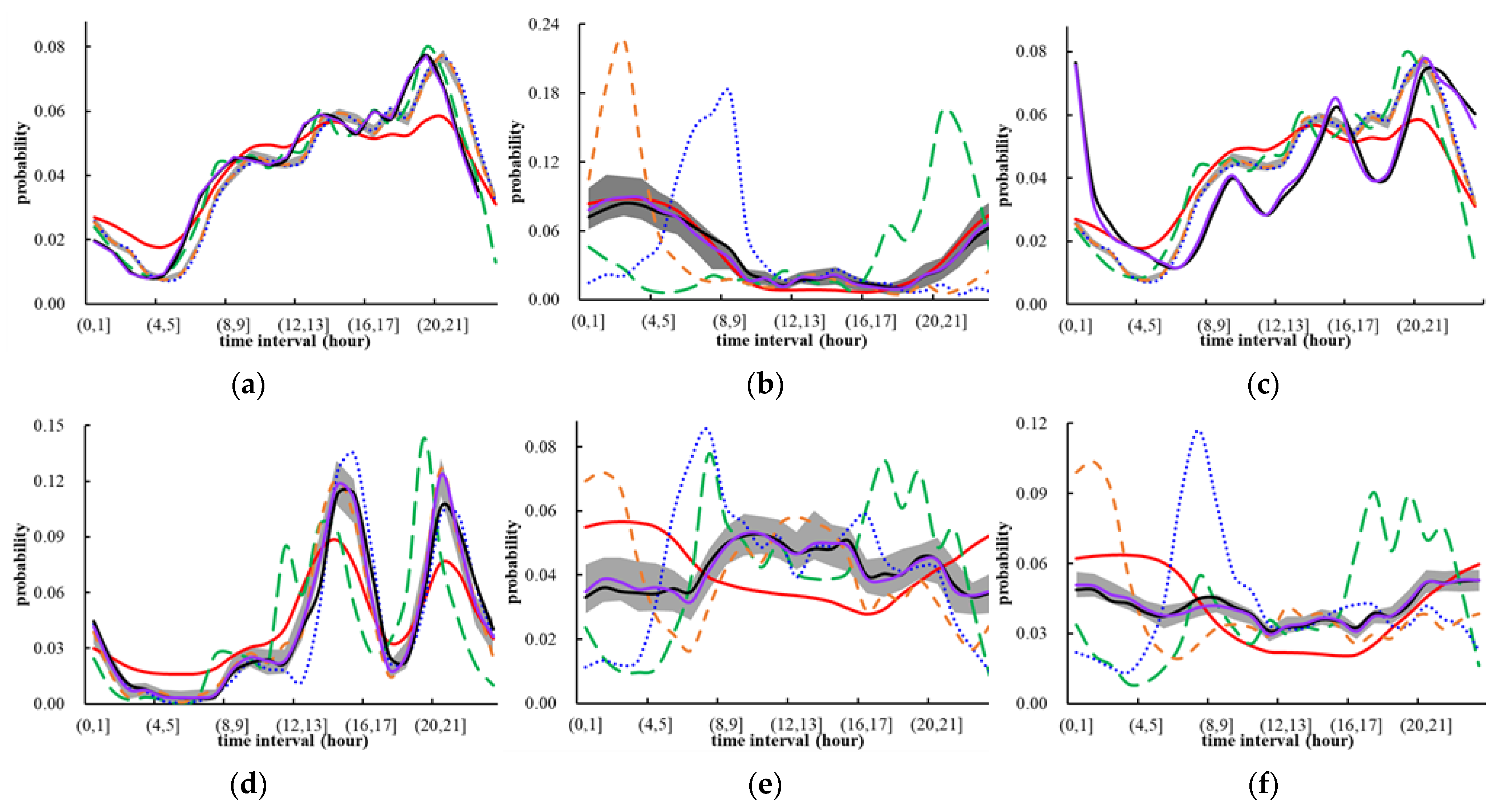
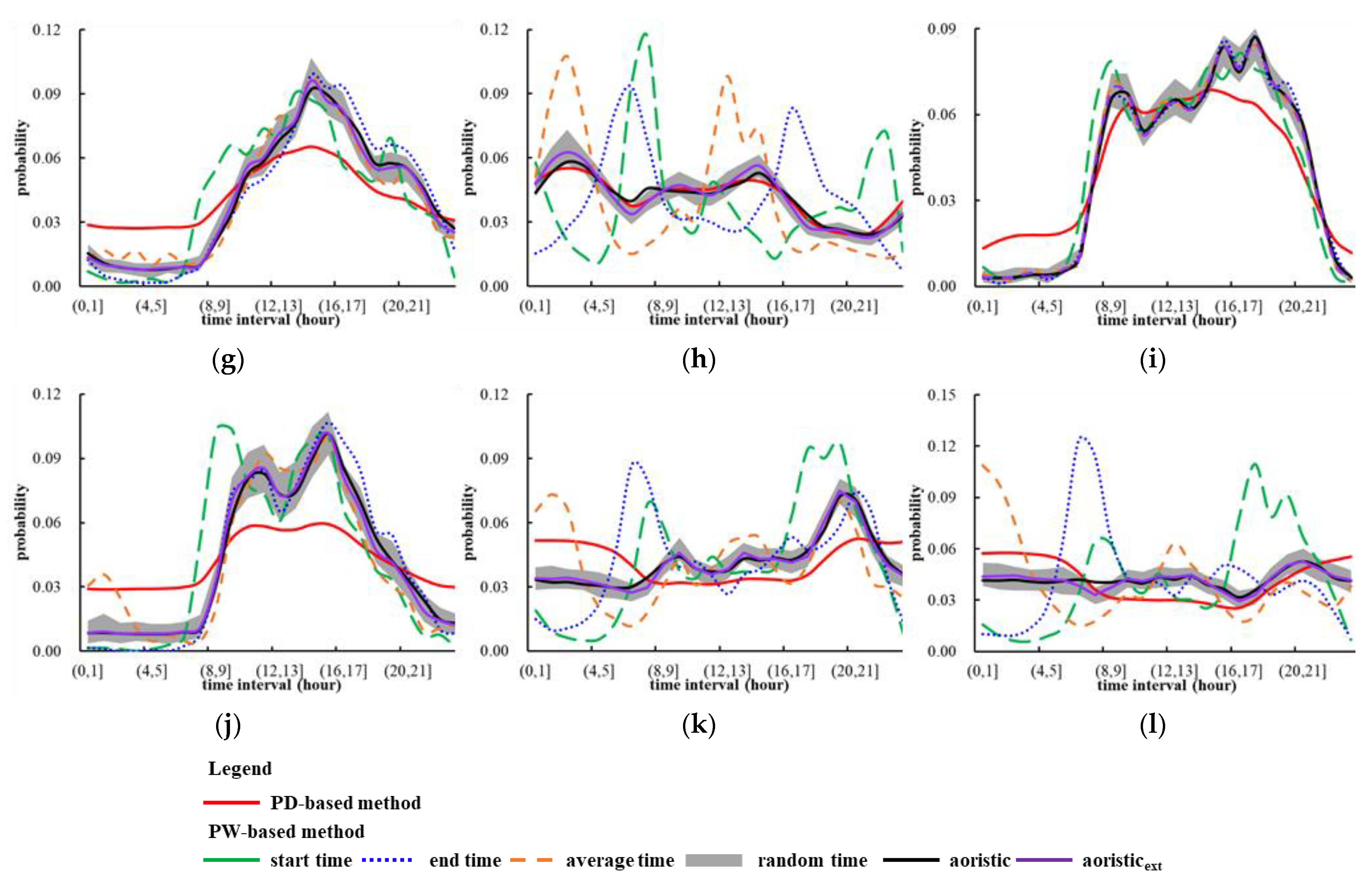
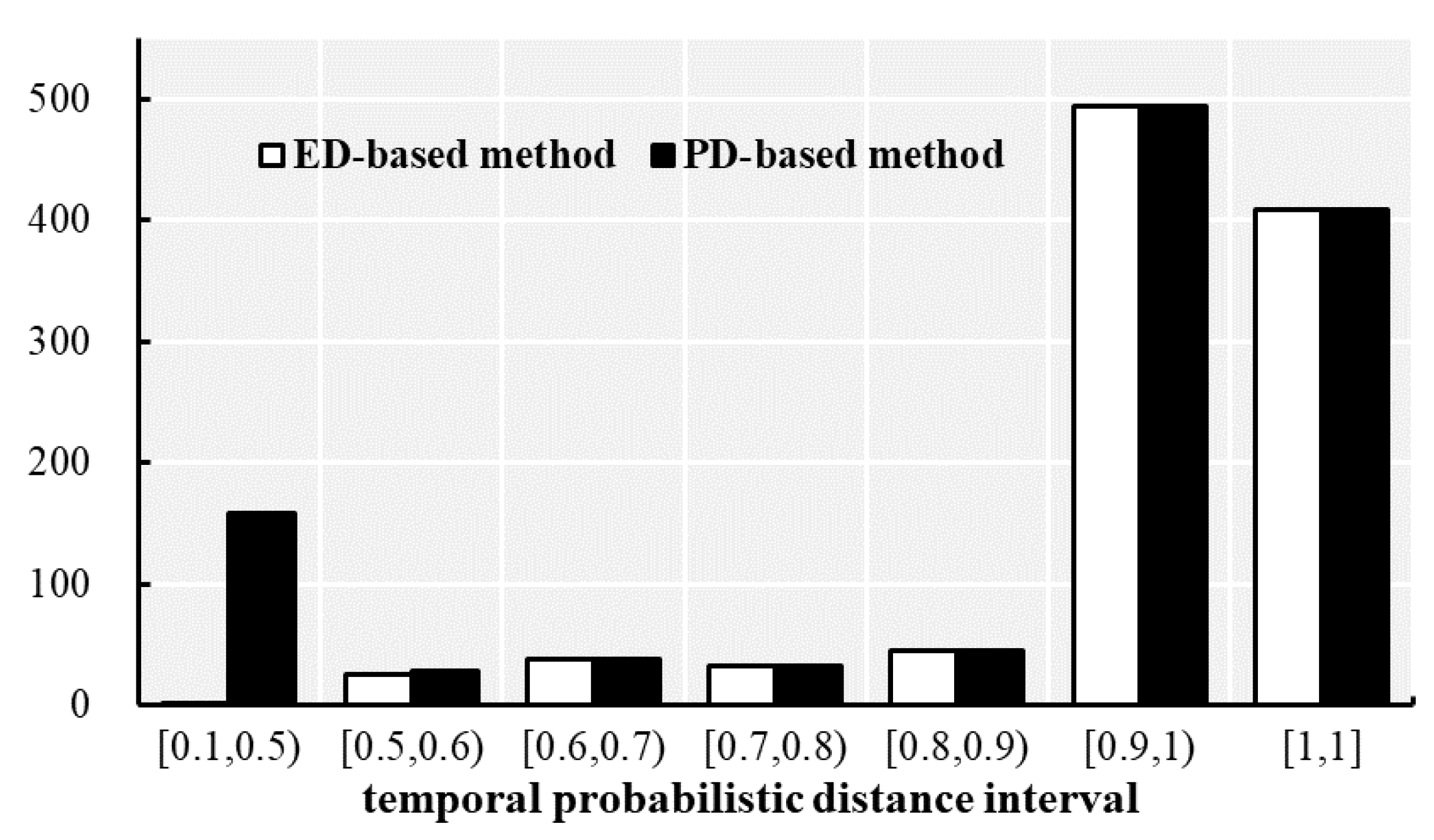
4.2. Experimental Comparisons of Crime Occurrence Time Modeling
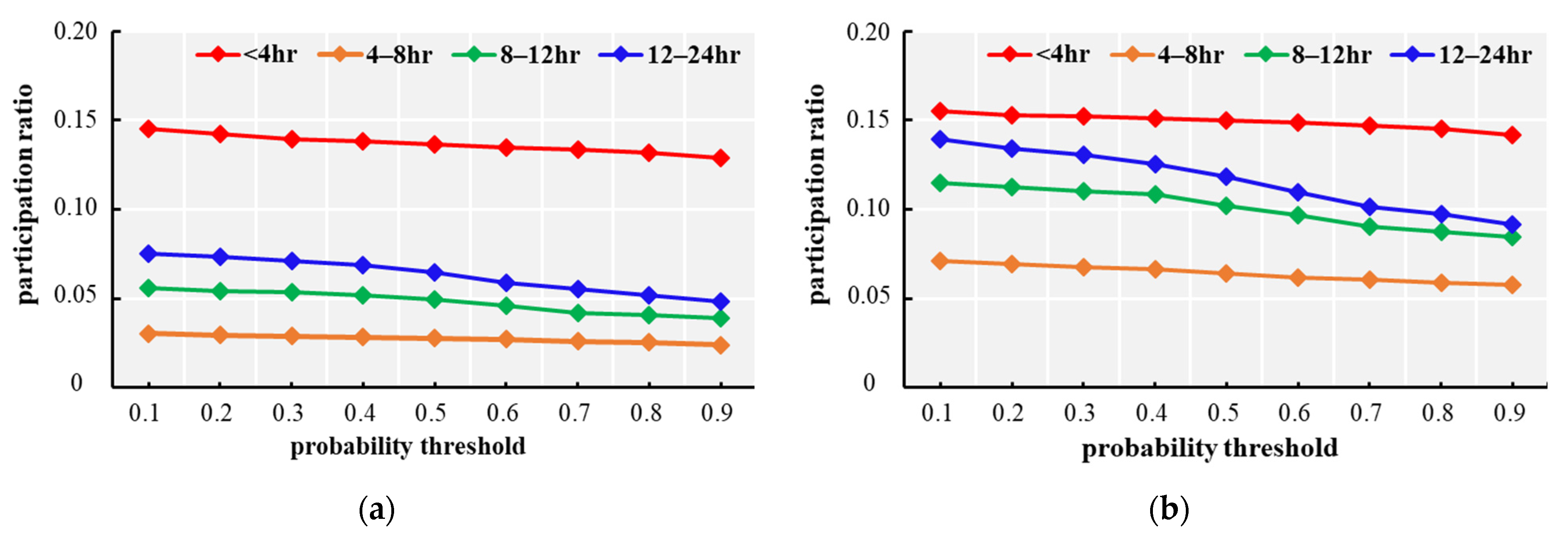
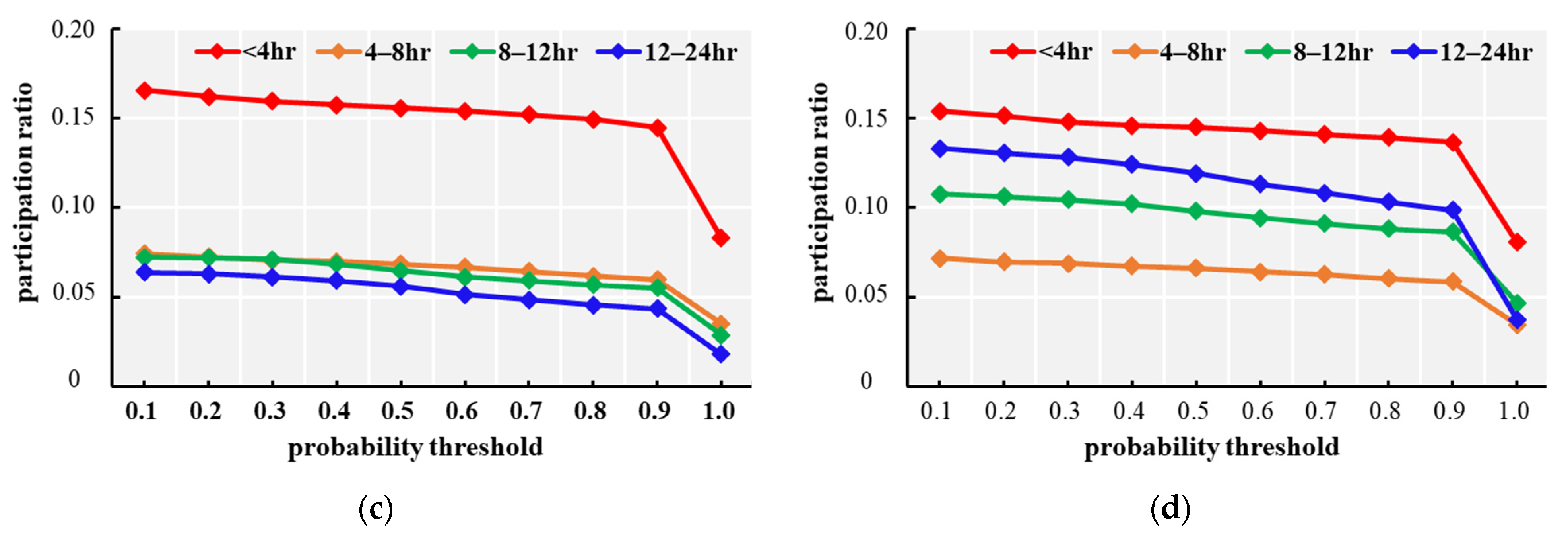
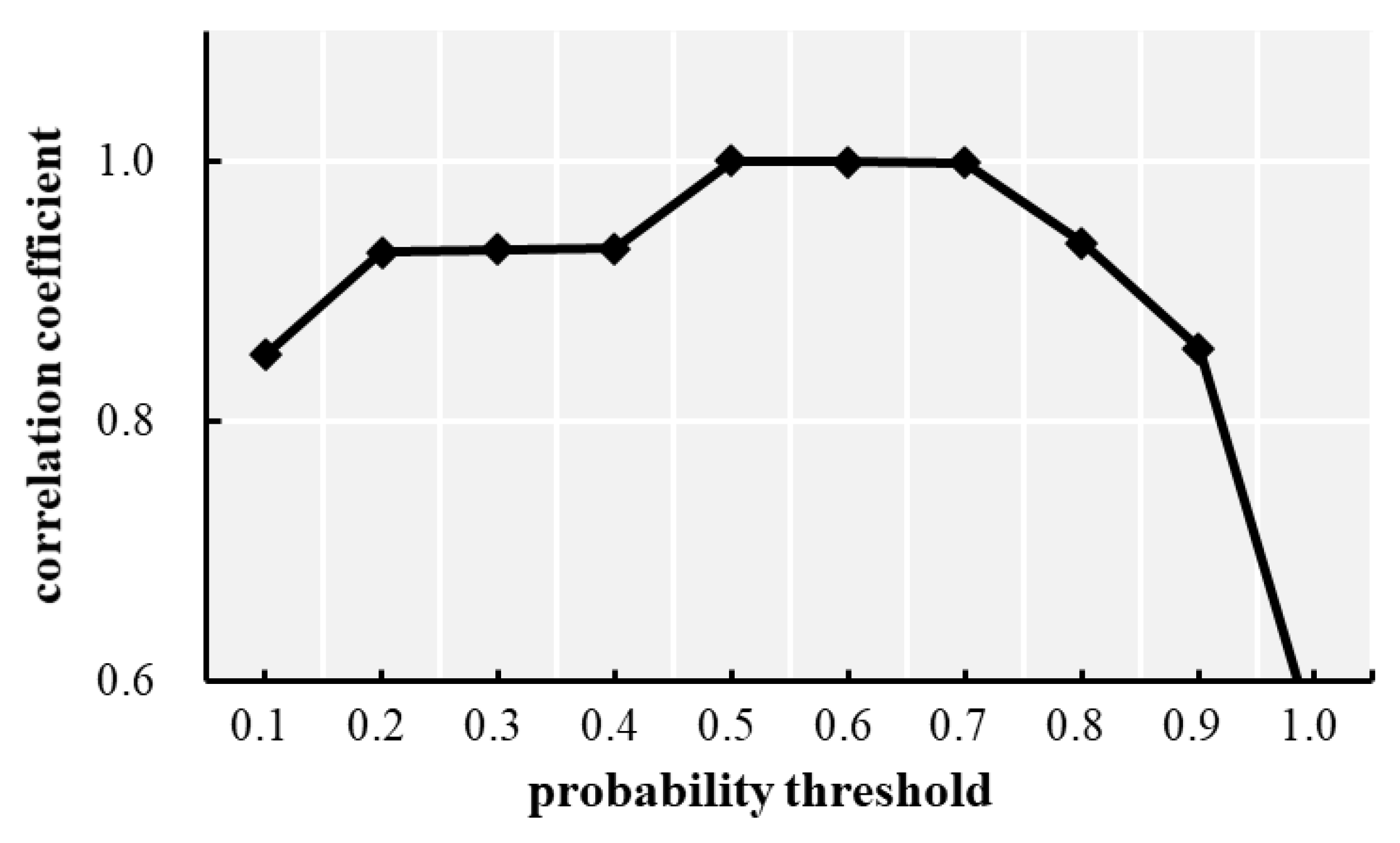
4.3. Analysis of USTCPs Discovered in the Crime Dataset
5. Conclusions and Future Work
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- He, Z.; Deng, M.; Xie, Z.; Wu, L.; Chen, Z.; Pei, T. Discovering the joint influence of urban facilities on crime occurrence using spatial co-location pattern mining. Cities 2020, 99, 160612. [Google Scholar] [CrossRef]
- Barnum, J.; Caplan, J.; Piza, E. The crime kaleidoscope: A cross-jurisdictional analysis of place features and crime in three urban environments. Appl. Geogr. 2017, 79, 203–211. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.L.; Zhang, H. Could Crime Risk Be Propagated across Crime Types? ISPRS Int. J. Geo Inf. 2019, 8, 203. [Google Scholar] [CrossRef] [Green Version]
- Golmohammadi, J.; Xie, Y.; Gupta, J.; Farhadloo, M.; Li, Y.; Cai, J.; Detor, S.; Roh, A.; Shekhar, S. An Introduction to spatial data mining. In The Geographic Information Science and Technology Body of Knowledge, 4th ed.; Wilson, J.P., Ed.; UCGIS: Ithaca, New York, USA, 2020. [Google Scholar]
- Ratcliffe, J.H. Aoristic signatures and the spatio-temporal analysis of high volume crime patterns. J. Quant. Criminol. 2002, 18, 23–43. [Google Scholar] [CrossRef]
- Martin, B.; Anton, B. Evaluating temporal analysis methods using residential burglary data. ISPRS Int. J. Geo Inf. 2016, 5, 148. [Google Scholar]
- Lu, Y.; Wang, L.; Zhang, X. Mining frequent co-location patterns from uncertain data. J. Front. Comp. Sci. Technol. 2009, 3, 656–664. [Google Scholar]
- Wang, L.; Wu, P.; Chen, H. Finding probabilistic prevalent colocations in spatially uncertain data sets. IEEE Trans. Knowl. Data Eng. 2013, 25, 790–804. [Google Scholar] [CrossRef]
- Liu, Z.; Huang, Y. Mining co-locations under uncertainty. In Proceedings of the 13th International Conference on Advances in Spatial and Temporal Databases, Munich, Germany, 21–23 August 2013; pp. 429–446. [Google Scholar]
- Tobler, W.R. A computer movie simulating urban growth in the Detroit region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- Chen, K.; Deng, M.; Shi, Y. A temporal directed graph convolution network for traffic forecasting using taxi trajectory data. ISPRS Int. J. Geo-Inf. 2021, 10, 624. [Google Scholar] [CrossRef]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. In Proceedings of the 20th International Conference on Very Large Data Base, Santiago, Chile, 12–15 September 1994; pp. 487–499. [Google Scholar]
- Yoo, J.S.; Shekhar, S. A joinless approach for mining spatial colocation patterns. IEEE Trans. Knowl. Data Eng. 2006, 18, 1323–1337. [Google Scholar]
- Cai, J.; Deng, M.; Guo, Y.; Xie, Y.; Shekhar, S. Discovering regions of anomalous spatial co-locations. Int. J. Geogr. Inf. Sci. 2021, 35, 974–998. [Google Scholar] [CrossRef]
- Shekhar, S.; Jiang, Z.; Ali, R.Y.; Eftelioglu, E.; Tang, X.; Gunturi, V.M.; Zhou, X. Spatiotemporal data mining: A computational perspective. ISPRS Int. J. Geo-Inf. 2015, 4, 2306–2338. [Google Scholar] [CrossRef]
- Nakaya, T.; Yano, K. Visualising crime clusters in a space-time cube: An exploratory data-analysis approach using space-time kernel density estimation and scan statistics. Trans. GIS 2010, 14, 223–239. [Google Scholar] [CrossRef]
- Koperski, K.; Han, J. Discovery of spatial association rules in geographic information databases. In Proceedings of the 4th International Symposium on Spatial Databases, Berlin, Germany, 6–9 August 1995; pp. 47–66. [Google Scholar]
- Huang, Y.; Shekhar, S.; Xiong, H. Discovering colocation patterns from spatial data sets: A general approach. IEEE Trans. Knowl. Data Eng. 2004, 16, 1472–1485. [Google Scholar] [CrossRef] [Green Version]
- Celik, M.; Shekhar, S.; Rogers, J.P.; Shine, J.A.; Yoo, J.S. Mixed-drove spatio-temporal co-occurrence pattern mining: A summary of results. In Proceedings of the 6th International Conference on Data Mining, Hong Kong, China, 18–22 December 2006; pp. 119–128. [Google Scholar]
- Celik, M. Partial spatio-temporal co-occurrence pattern mining. Knowl. Inf. Syst. 2015, 44, 27–49. [Google Scholar] [CrossRef]
- Qian, F.; Yin, L.; He, Q.; He, J. Mining spatio-temporal co-location patterns with weighted sliding window. In Proceedings of the 2009 IEEE International Conference on Intelligent Computing and Intelligent Systems, Shanghai, China, 20–22 November 2009; pp. 181–185. [Google Scholar]
- Cai, J.; Deng, M.; Liu, Q.; Chen, Y.; He, Z.; Tang, J. A statistical method for detecting spatiotemporal co-occurrence patterns. Int. J. Geogr. Inf. Sci. 2019, 33, 967–990. [Google Scholar] [CrossRef]
- Mohan, P.; Shekhar, S.; Shine, J.A.; Rogers, J.P. Cascading spatio-temporal pattern discovery. IEEE Trans. Knowl. Data Eng. 2011, 24, 1977–1992. [Google Scholar] [CrossRef]
- Dalvi, N.; Dan, S. Management of probabilistic data: Foundations and challenges. In Proceedings of the 26th ACM Sigmod-Sigact-Sigart Symposium on Principles of Database Systems, Beijing, China, 11–13 June 2007; pp. 1–12. [Google Scholar]
- Jiang, B.; Pei, J.; Member, S. Clustering uncertain data based on probability distribution similarity. IEEE Trans. Knowl. Data Eng. 2013, 25, 751–763. [Google Scholar] [CrossRef]
- Wang, Z.; Lu, B.; Ying, F.; Kong, M.; Tang, M. Research of mining algorithms for uncertain spatio-temporal co-occurrence pattern. In Proceedings of the 9th International Conference on Knowledge and Smart Technology, Chonburi, Thailand, 1–4 February 2017; pp. 12–17. [Google Scholar]
- Ngai, W.K.; Kao, B.; Chui, C.K.; Chen, R.; Chau, M.; Yip, K.Y. Efficient clustering of uncertain data. In Proceedings of the 6th International Conference on Data Mining, Hong Kong, China, 18–22 December 2006; pp. 436–445. [Google Scholar]
- Gullo, F.; Ponti, G.; Tagarelli, A.; Greco, S. A hierarchical algorithm for clustering uncertain data via an information-theoretic approach. In Proceedings of the 8th IEEE International Conference on Data Mining, Washington, WA, USA, 15–19 December 2008; pp. 821–826. [Google Scholar]
- Zhao, Z.; Yan, D.; Ng, W. Mining probabilistically frequent sequential patterns in large uncertain databases. IEEE Trans. Knowl. Data Eng. 2014, 26, 1171–1184. [Google Scholar] [CrossRef]
- Ahmed, A.U.; Ahmed, C.F.; Samiullah, M.; Adnan, N.; Leung, K.S. Mining interesting patterns from uncertain databases. Inf. Sci. 2016, 354, 60–85. [Google Scholar] [CrossRef]
- Sun, L.; Cheng, R.; Cheung, D.W.; Cheng, J. Mining uncertain data with probabilistic guarantees. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, WA, USA, 25–28 July 2010; pp. 273–282. [Google Scholar]
- Ashby, M.P.; Bowers, K.J. A comparison of methods for temporal analysis of aoristic crime. Crime Sci. 2013, 2, 1. [Google Scholar] [CrossRef] [Green Version]
- Oswald, L.; Leitner, M. Evaluating temporal approximation methods using burglary data. ISPRS Int. J. Geo-Inf. 2020, 9, 386. [Google Scholar] [CrossRef]
- Lu, H.; Han, J.; Feng, L. Stock movement prediction and n-dimensional inter-transaction association rules. In Proceedings of the SIGMOD Workshop, Research Issues on Data Mining and Knowledge Discovery, Washington, WA, USA, 13 June 1998; pp. 1–7. [Google Scholar]
- Wang, Z.; Hong, Z. Construction, detection, and interpretation of crime patterns over space and time. ISPRS Int. J. Geo-Inf. 2020, 9, 339. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, X.; Zhang, X.; Cui, Y. Self-adapted mixture distance measure for clustering uncertain data. Knowl. Based Syst. 2017, 126, 33–47. [Google Scholar] [CrossRef]
- Wiegand, T.; Moloney, K.A. Handbook of Spatial Point-Pattern Analysis in Ecology; CRC Press: Boca Raton, FL, USA, 2013; pp. 94–98. [Google Scholar]
- Yue, H.; Zhu, X.; Ye, X.; Guo, W. The local colocation patterns of crime and land-use features in Wuhan, China. ISPRS Int. J. Geo-Inf. 2017, 6, 307. [Google Scholar] [CrossRef] [Green Version]
- Felson, M.; Poulsen, E. Simple indicators of crime by time of day. Int. J. Forecast. 2003, 19, 595–601. [Google Scholar] [CrossRef]
- Xu, C.; Liu, L.; Zhou, S.; Ye, X.; Jiang, C. The spatio-temporal patterns of street robbery in DP peninsula. Acta Geogr. Sinica 2013, 68, 1714–1723. [Google Scholar]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; Chapman and Hall: Boca Raton, FL, USA, 1986; p. 46. [Google Scholar]
- Zhang, X.; Liu, H.; Zhang, X. Novel density-based and hierarchical density-based clustering algorithms for uncertain data. Neural Netw. 2017, 93, 240–255. [Google Scholar] [CrossRef]
- Shekhar, S.; Huang, Y. Discovering spatial co-location patterns: A summary of results. In Proceedings of the International Symposium on Spatial and Temporal Databases, Redondo Beach, CA, USA, 12–15 July 2001; pp. 236–256. [Google Scholar]
- National Bureau of Statistics of China. China Population Census Yearbook 2020; China Statistics Press: Beijing, China, 2020.
- National Bureau of Statistics of China. China Population Statistical Yearbook 2017; China Statistics Press: Beijing, China, 2017.
- The Supreme People’s Procuratorate of China. Procuratorial Yearbook of China 2017; China Procuratorate Press: Beijing, China, 2017.
- Becker, G.S. Crime and punishment: An economic approach. J. Polit. Econ. 1968, 76, 169–217. [Google Scholar] [CrossRef] [Green Version]
- Cohen, L.E.; Felson, M. Social change and crime rate trends: A routine activity approach. Am. Soc. Rev. 1979, 44, 588–608. [Google Scholar] [CrossRef]
- Cai, J.; Kwan, M.P. Discovering co-location patterns in multivariate spatial flow data. Int. J. Geogr. Inf. Sci. 2022, 36, 720–748. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Type of Crime | Number of Events | Percentage of Events with Time Span | |||
|---|---|---|---|---|---|---|
| <4 h | 4–8 h | 8–12 h | 12–24 h | |||
| 1 | Assault | 11,403 | 0.974 | 0.007 | 0.015 | 0.005 |
| 2 | Commercial Burglary | 1284 | 0.250 | 0.177 | 0.390 | 0.183 |
| 3 | Drugs | 1698 | 0.785 | 0.057 | 0.036 | 0.122 |
| 4 | Gambling | 1397 | 0.890 | 0.054 | 0.019 | 0.037 |
| 5 | Larceny | 3349 | 0.540 | 0.130 | 0.162 | 0.168 |
| 6 | Malicious Damage | 8040 | 0.508 | 0.096 | 0.186 | 0.209 |
| 7 | Online Fraud | 3471 | 0.729 | 0.116 | 0.051 | 0.104 |
| 8 | Residential Burglary | 8065 | 0.353 | 0.288 | 0.248 | 0.111 |
| 9 | Stealing | 2108 | 0.970 | 0.020 | 0.007 | 0.003 |
| 10 | Telephone Fraud | 2117 | 0.667 | 0.148 | 0.038 | 0.148 |
| 11 | Theft of E-bike | 6353 | 0.468 | 0.185 | 0.199 | 0.148 |
| 12 | Theft of Vehicles | 5639 | 0.330 | 0.154 | 0.243 | 0.273 |
| USTCPs | PD-Based Method | PW-Based Method | ED-Based Method | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Probability Threshold | Start Time | Average Time | End Time | Random Time | Aoristic | Aoristicext | |||||
| 0.1 | 0.5 | 0.8 | 0.9 | ||||||||
| {Assault, Larceny} | 0.17 | 0.16 | 0.15 | 0.15 | 0.16 | 0.16 | 0.16 | 0.16 | 0.16 | 0.16 | 0.16 |
| {Assault, Malicious Damage} | 0.29 | 0.28 | 0.27 | 0.26 | 0.28 | 0.28 | 0.28 | 0.28 | 0.28 | 0.28 | 0.28 |
| {Assault, Residential Burglary} | 0.24 | 0.22 | 0.21 | 0.20 | 0.22 | 0.22 | 0.22 | 0.22 | 0.22 | 0.23 | 0.22 |
| {Assault, Theft of E-bike} | 0.25 | 0.23 | 0.22 | 0.22 | 0.24 | 0.23 | 0.24 | 0.23 | 0.24 | 0.24 | 0.23 |
| {Assault, Theft of Vehicles} | 0.18 | 0.17 | 0.15 | - | 0.17 | 0.17 | 0.16 | 0.17 | 0.17 | 0.17 | 0.16 |
| {Commercial Burglary, Stealing} | 0.17 | 0.17 | 0.17 | 0.16 | 0.16 | 0.17 | 0.17 | 0.17 | 0.17 | 0.17 | 0.17 |
| {Drugs, Stealing} | 0.18 | 0.17 | 0.16 | 0.16 | 0.17 | 0.17 | 0.17 | 0.17 | 0.17 | 0.17 | 0.17 |
| {Larceny, Malicious Damage} | 0.20 | 0.18 | 0.17 | 0.16 | 0.19 | 0.18 | 0.18 | 0.18 | 0.19 | 0.19 | 0.18 |
| {Larceny, Online Fraud} | 0.19 | 0.17 | 0.16 | 0.15 | 0.17 | 0.17 | 0.17 | 0.17 | 0.17 | 0.17 | 0.17 |
| {Larceny, Theft of Vehicles} | 0.22 | 0.19 | 0.17 | 0.17 | 0.20 | 0.19 | 0.20 | 0.19 | 0.20 | 0.20 | 0.19 |
| {Larceny, Theft of E-bike} | 0.21 | 0.19 | 0.17 | 0.16 | 0.19 | 0.19 | 0.19 | 0.19 | 0.19 | 0.19 | 0.19 |
| {Malicious Damage, Online Fraud} | 0.21 | 0.19 | 0.18 | 0.17 | 0.19 | 0.19 | 0.20 | 0.19 | 0.20 | 0.20 | 0.19 |
| {Malicious Damage, Residential Burglary} | 0.28 | 0.25 | 0.23 | 0.22 | 0.25 | 0.25 | 0.25 | 0.25 | 0.26 | 0.26 | 0.25 |
| {Malicious Damage, Stealing} | 0.17 | 0.16 | 0.15 | 0.15 | 0.16 | 0.16 | - | - | - | - | 0.16 |
| {Malicious Damage, Telephone Fraud} | 0.15 | - | - | - | - | - | - | - | - | - | - |
| {Malicious Damage, Theft of E-bike} | 0.35 | 0.33 | 0.30 | 0.29 | 0.33 | 0.33 | 0.33 | 0.33 | 0.33 | 0.33 | 0.33 |
| {Malicious Damage, Theft of Vehicles} | 0.31 | 0.28 | 0.25 | 0.24 | 0.28 | 0.28 | 0.28 | 0.28 | 0.28 | 0.28 | 0.28 |
| {Online Fraud, Stealing} | 0.15 | - | - | - | - | - | - | - | - | - | - |
| {Online Fraud, Telephone Fraud} | 0.17 | - | - | - | 0.16 | - | - | - | - | - | - |
| {Online Fraud, Theft of E-bike} | 0.23 | 0.21 | 0.19 | 0.19 | 0.22 | 0.21 | 0.21 | 0.21 | 0.22 | 0.21 | 0.21 |
| {Online Fraud, Theft of Vehicles} | 0.26 | 0.23 | 0.21 | 0.20 | 0.23 | 0.23 | 0.23 | 0.23 | 0.23 | 0.23 | 0.23 |
| {Residential Burglary, Theft of E-bike} | 0.25 | 0.23 | 0.21 | 0.20 | 0.23 | 0.23 | 0.23 | 0.23 | 0.23 | 0.23 | 0.23 |
| {Residential Burglary, Theft of Vehicles} | 0.20 | 0.18 | 0.16 | 0.15 | 0.18 | 0.18 | 0.18 | 0.18 | 0.18 | 0.18 | 0.18 |
| {Stealing, Telephone Fraud} | 0.18 | 0.16 | 0.16 | 0.15 | 0.16 | 0.16 | 0.16 | 0.16 | 0.17 | 0.17 | 0.16 |
| {Stealing, Theft of E-bike} | 0.22 | 0.20 | 0.19 | 0.19 | 0.20 | 0.20 | 0.20 | 0.20 | 0.20 | 0.21 | 0.20 |
| {Stealing, Theft of Vehicles} | 0.21 | 0.20 | 0.19 | 0.19 | 0.20 | 0.20 | 0.20 | 0.20 | 0.20 | 0.20 | 0.20 |
| {Telephone Fraud, Theft of E-bike} | 0.19 | 0.17 | 0.15 | - | 0.17 | 0.17 | 0.17 | 0.17 | 0.17 | 0.17 | 0.17 |
| {Telephone Fraud, Theft of Vehicles} | 0.18 | 0.16 | - | - | 0.16 | 0.16 | 0.16 | - | 0.16 | 0.17 | 0.16 |
| {Theft of E-bike, Theft of Vehicles} | 0.38 | 0.34 | 0.31 | 0.30 | 0.35 | 0.35 | 0.35 | 0.34 | 0.35 | 0.35 | 0.35 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Cai, J.; Deng, M. Discovering Spatio-Temporal Co-Occurrence Patterns of Crimes with Uncertain Occurrence Time. ISPRS Int. J. Geo-Inf. 2022, 11, 454. https://doi.org/10.3390/ijgi11080454
Chen Y, Cai J, Deng M. Discovering Spatio-Temporal Co-Occurrence Patterns of Crimes with Uncertain Occurrence Time. ISPRS International Journal of Geo-Information. 2022; 11(8):454. https://doi.org/10.3390/ijgi11080454
Chicago/Turabian StyleChen, Yuanfang, Jiannan Cai, and Min Deng. 2022. "Discovering Spatio-Temporal Co-Occurrence Patterns of Crimes with Uncertain Occurrence Time" ISPRS International Journal of Geo-Information 11, no. 8: 454. https://doi.org/10.3390/ijgi11080454
APA StyleChen, Y., Cai, J., & Deng, M. (2022). Discovering Spatio-Temporal Co-Occurrence Patterns of Crimes with Uncertain Occurrence Time. ISPRS International Journal of Geo-Information, 11(8), 454. https://doi.org/10.3390/ijgi11080454