
RDQS: A Geospatial Data Analysis System for Improving Roads Directionality Quality

 ,
,  ,
,  ,
,
Abstract
:1. Introduction
- We present RDNN, a road directionality neural network model that detects arrows’ directionality in map images across map providers with high accuracy.
- We conduct a series of experiments to measure and evaluate the accuracy of the detection model using a real-world maps dataset.
- We publish our training and test datasets used to train and evaluate the neural network to make it available for future works in this area.
- We present RDQS, a road directionality quality system that utilizes and integrates this model, along with other components, to assess the quality of maps and report discrepancies in road directionality.
- We conduct experiments utilizing this system to automatically scan thousands of locations in six major regions to identify and report discrepancies in road directionality discovered by our method.
1.1. Related Work
1.1.1. Road Segment Detection System
1.1.2. Road Network Graphs Using Routing API
1.1.3. Road Network Detection Using Probabilistic and Graph Theoretical Methods
1.1.4. Vision-Based Traffic Light and Arrow Detection
1.1.5. Arrow Detection in Medical Images
1.1.6. Arrow Detection in Handwritten Diagrams
1.1.7. State-of-the-Art Deep Learning Models in Computer Vision
1.1.8. Additional Related Work
1.1.9. Comparisons to Other Work
2. Materials and Methods
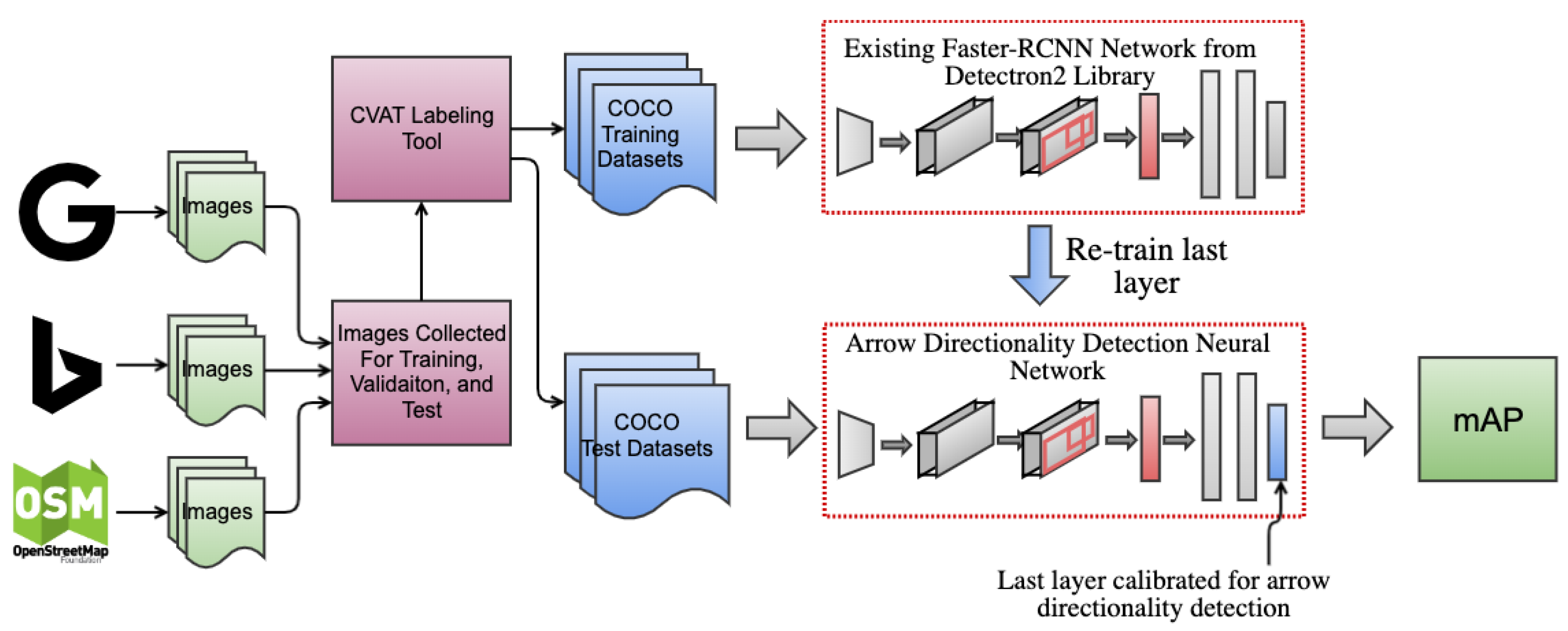
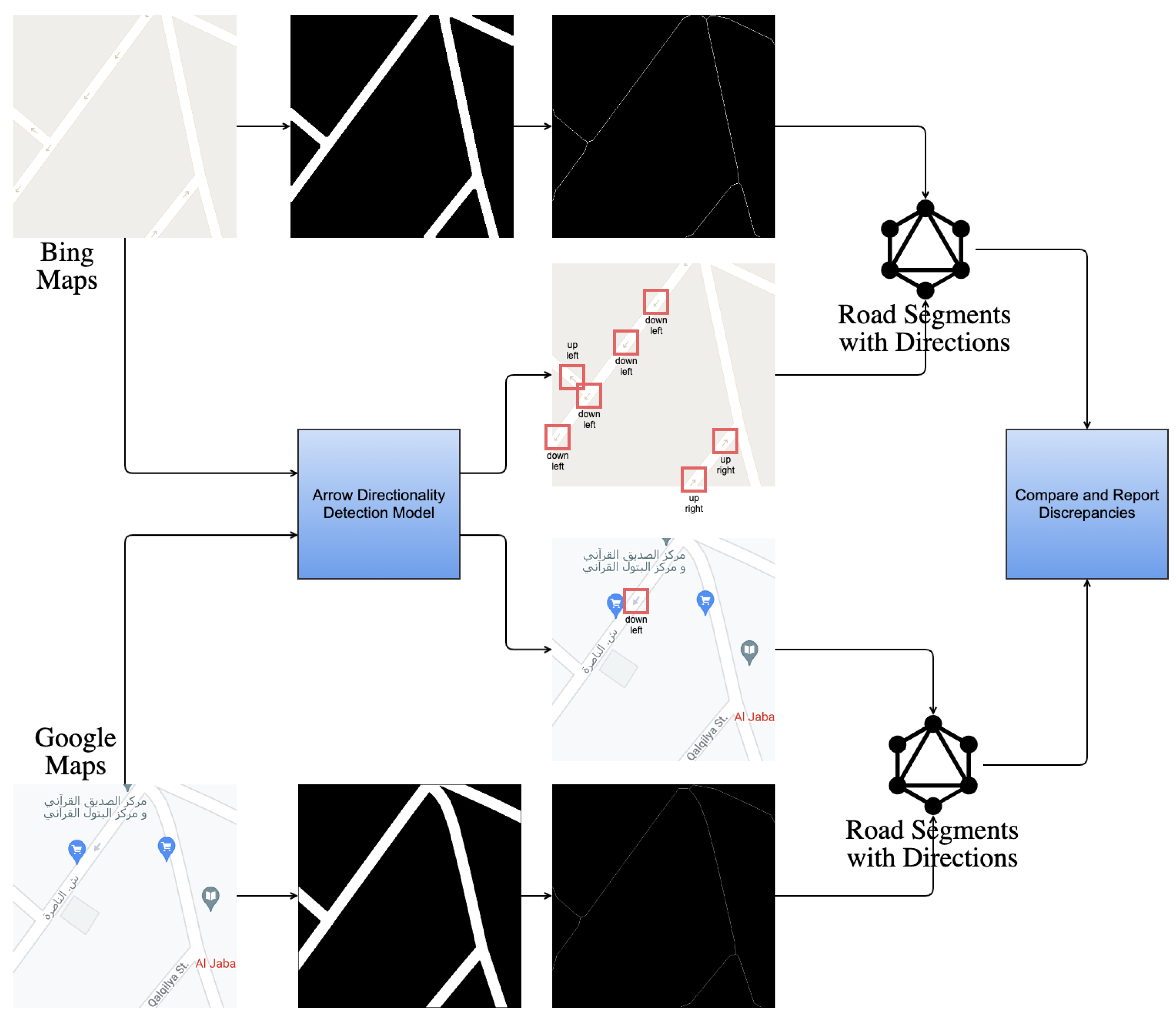
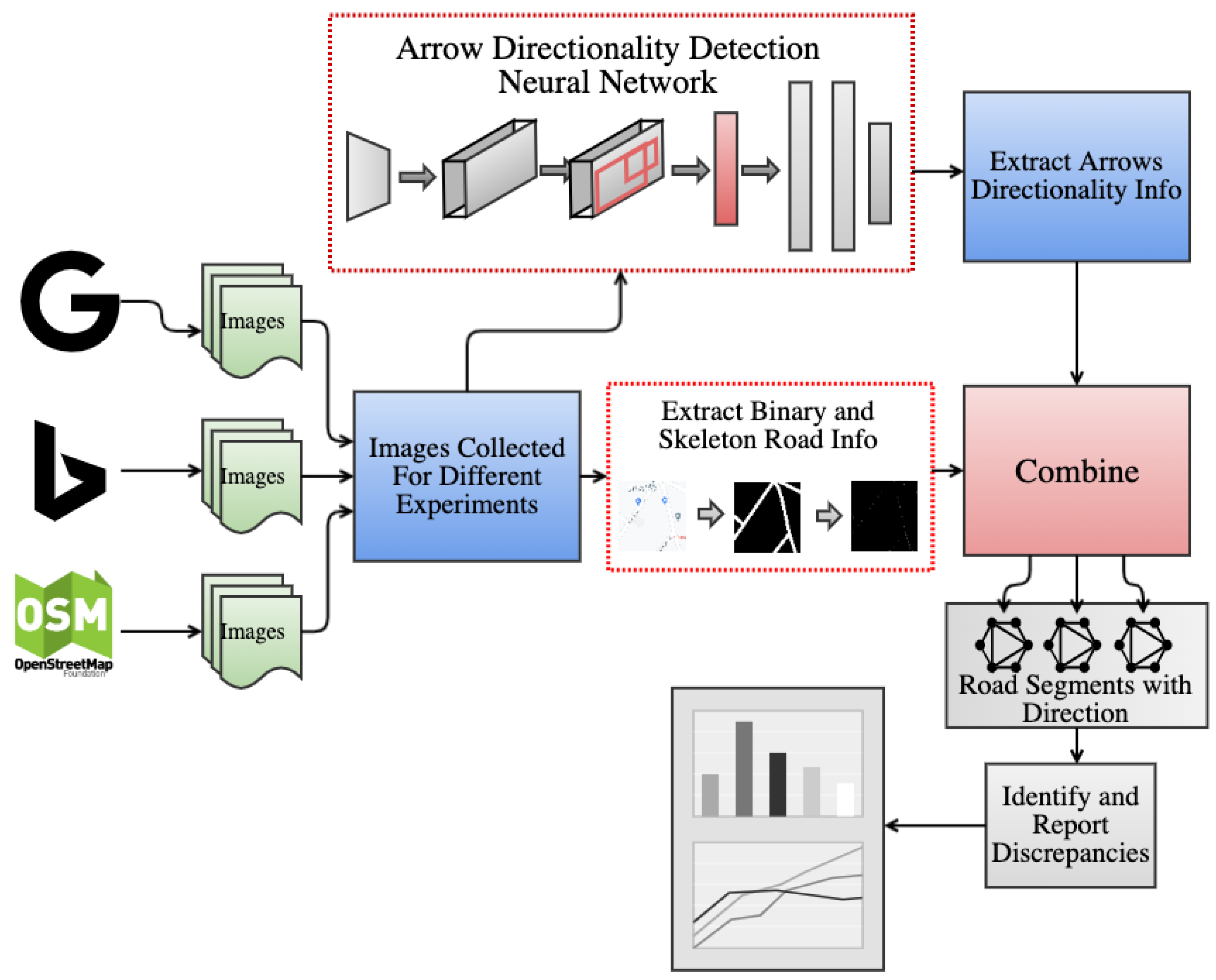
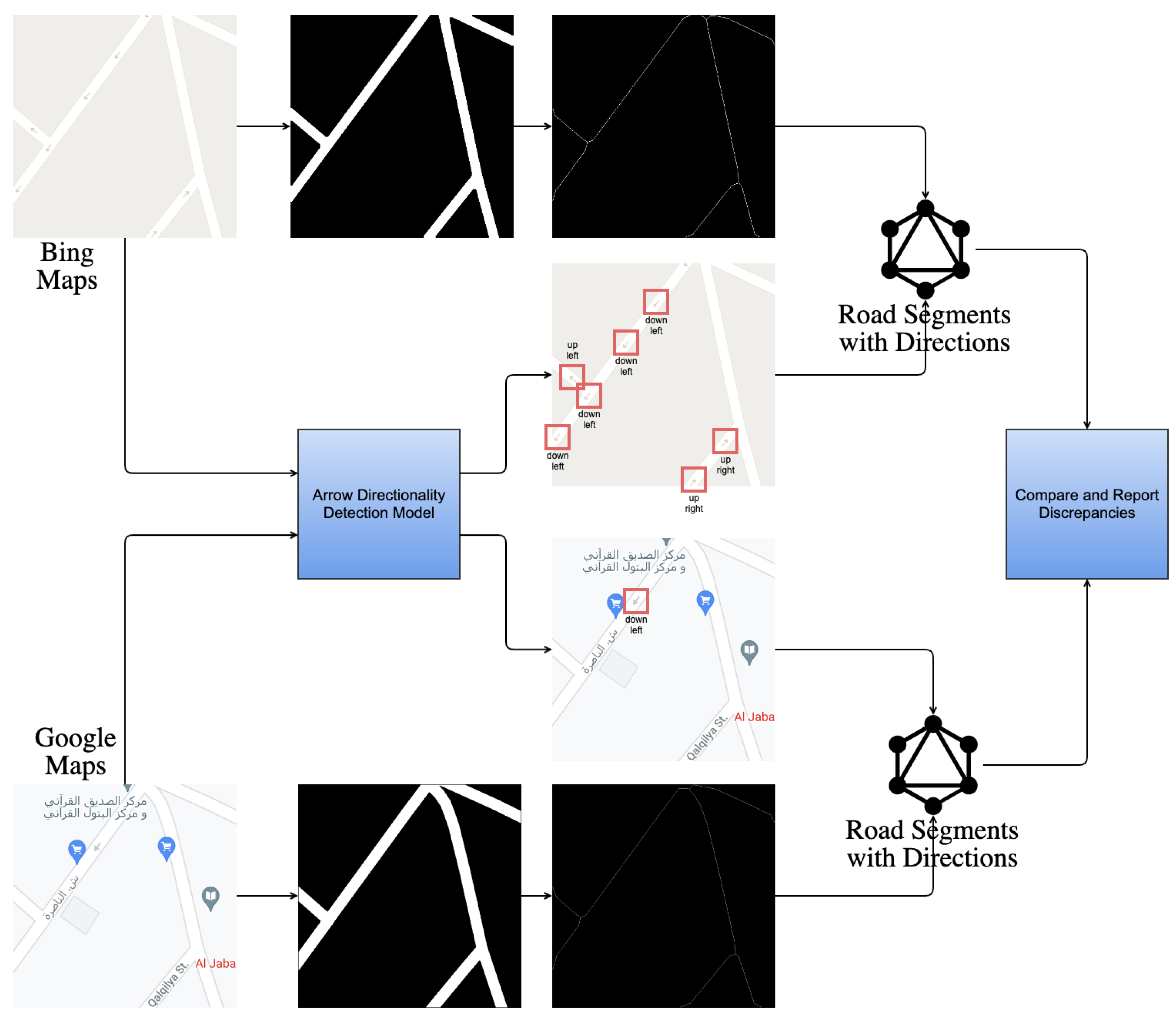
2.1. System Architecture
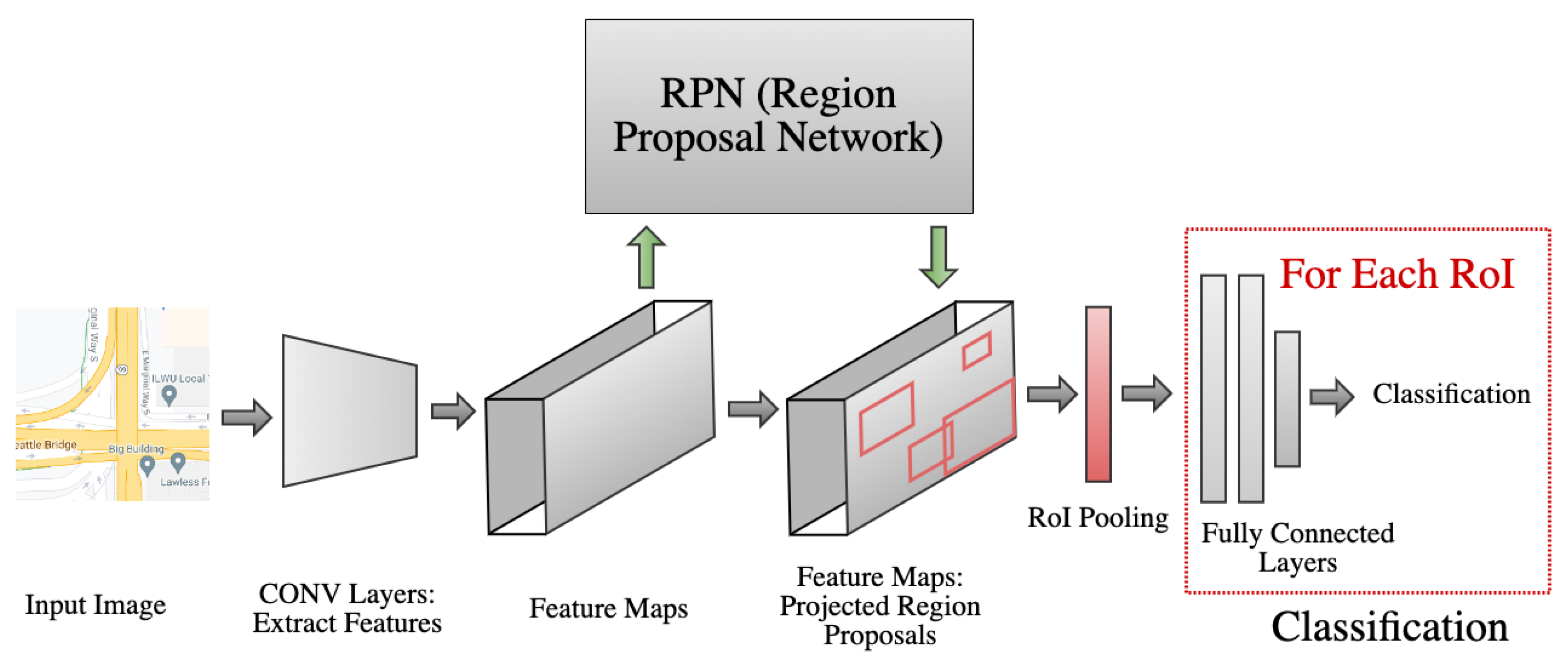
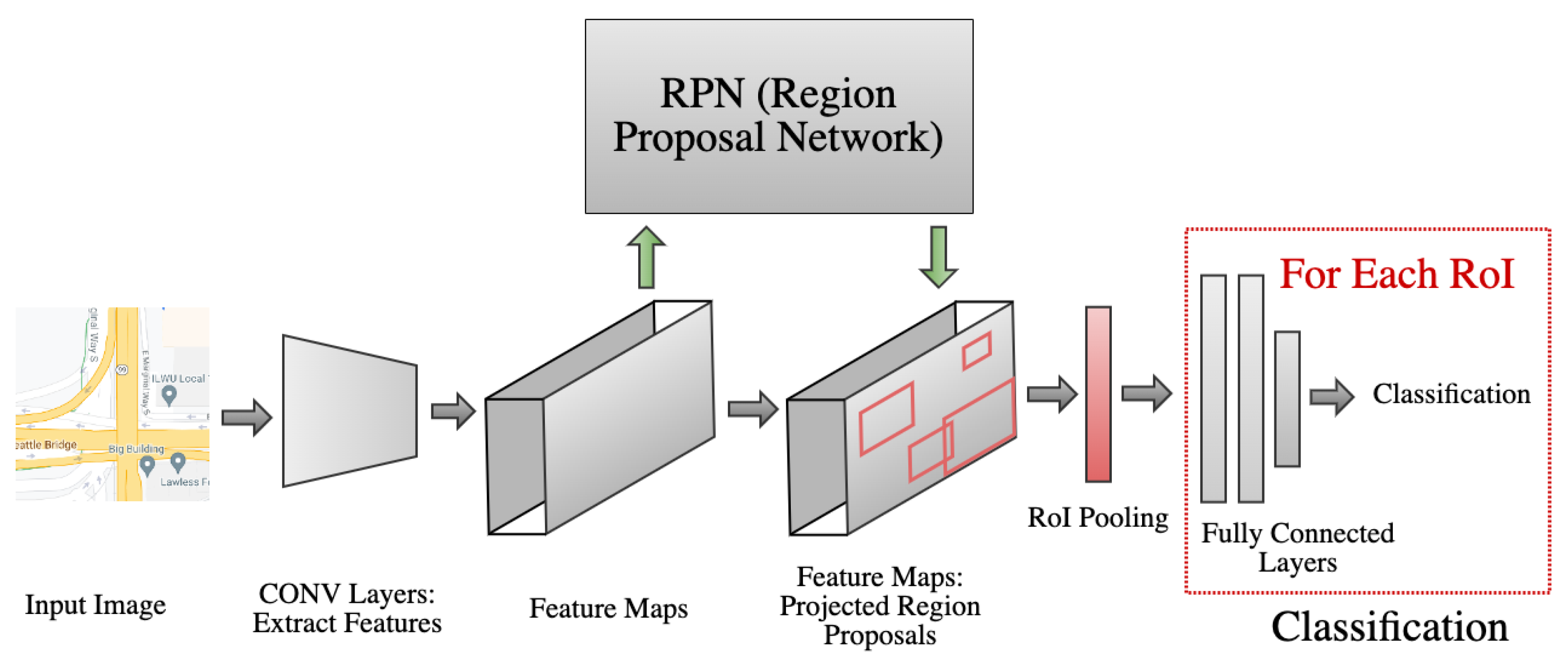
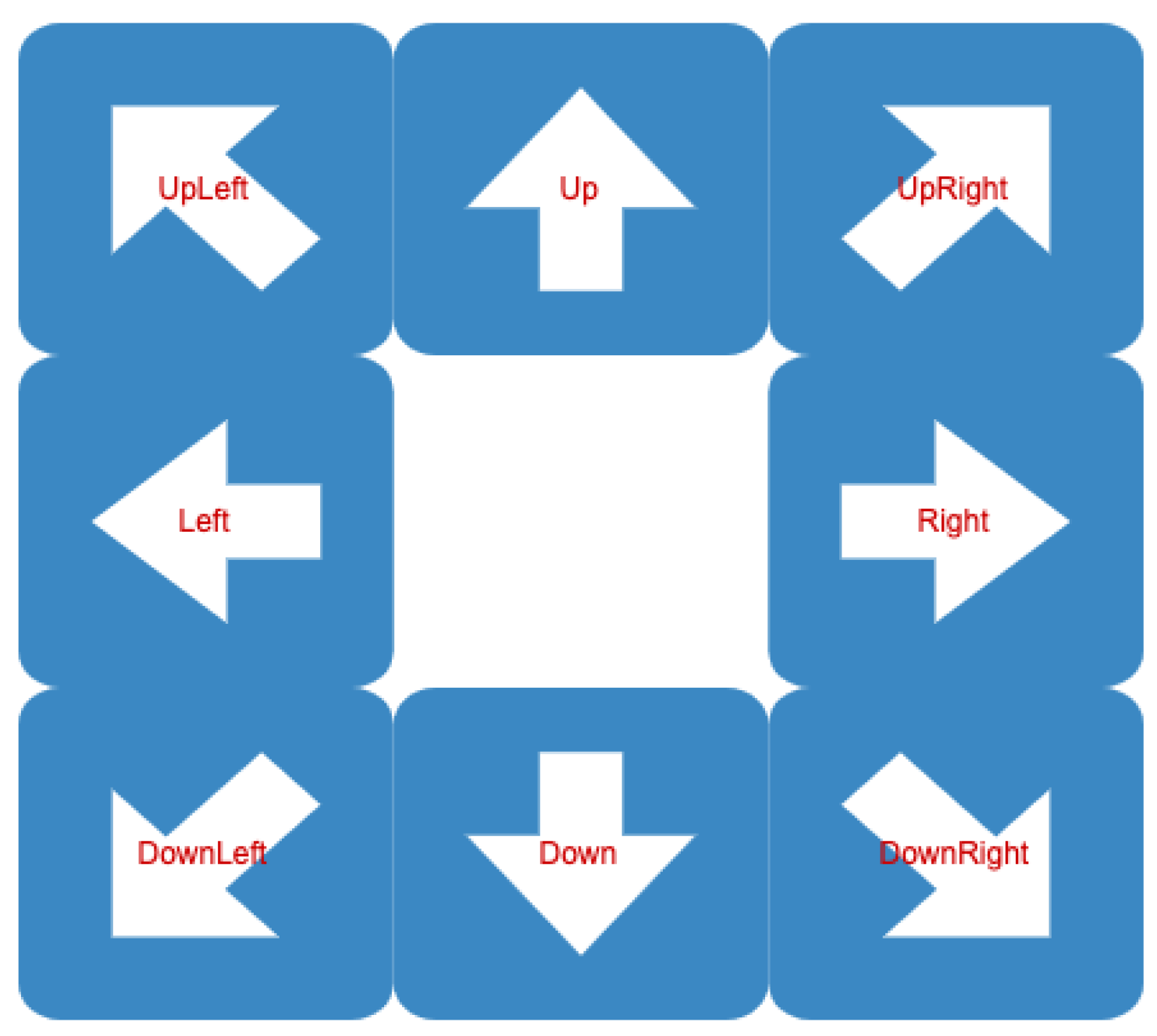
2.2. Road-Directionality Neural Network Model Overview
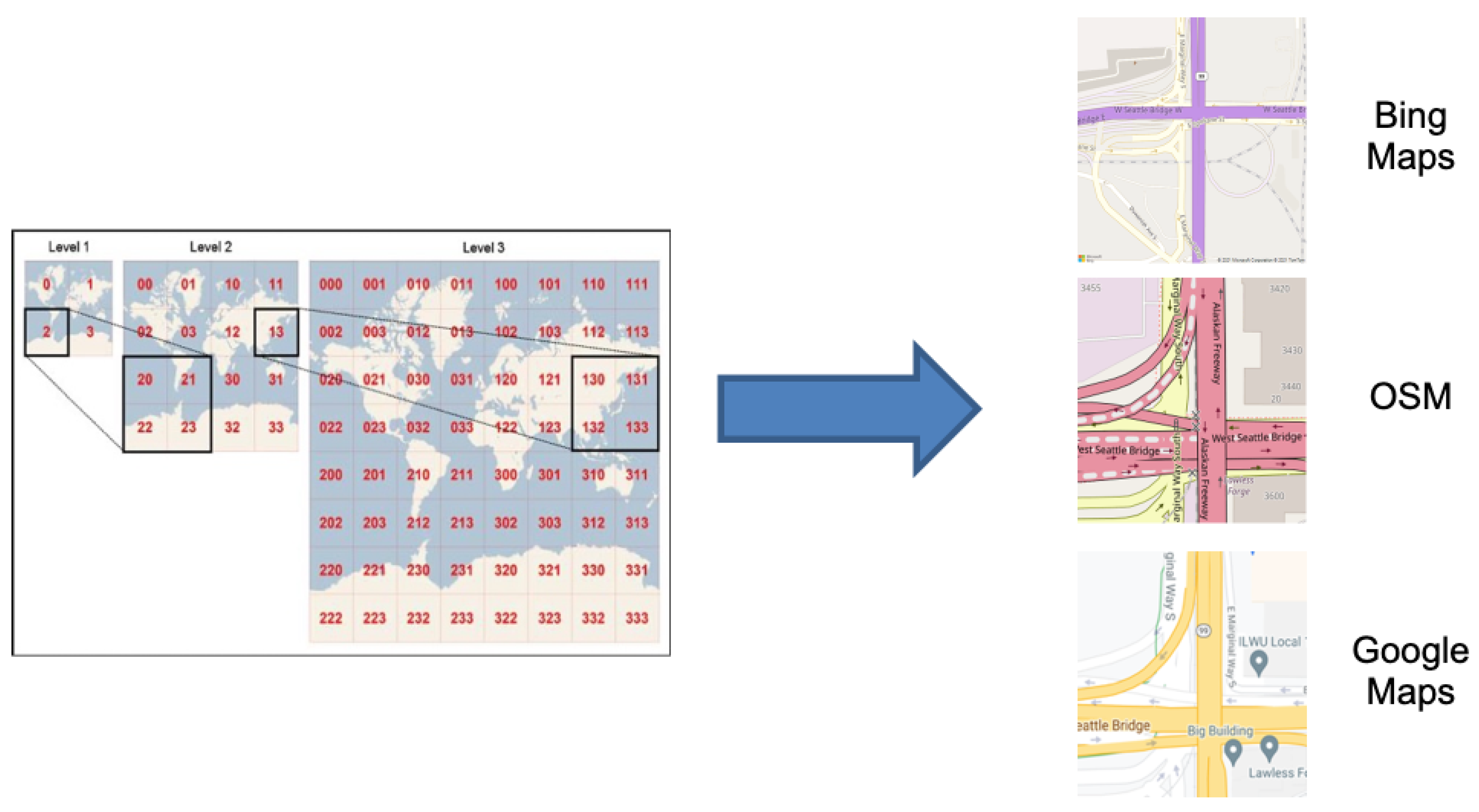
2.3. Data Gathering
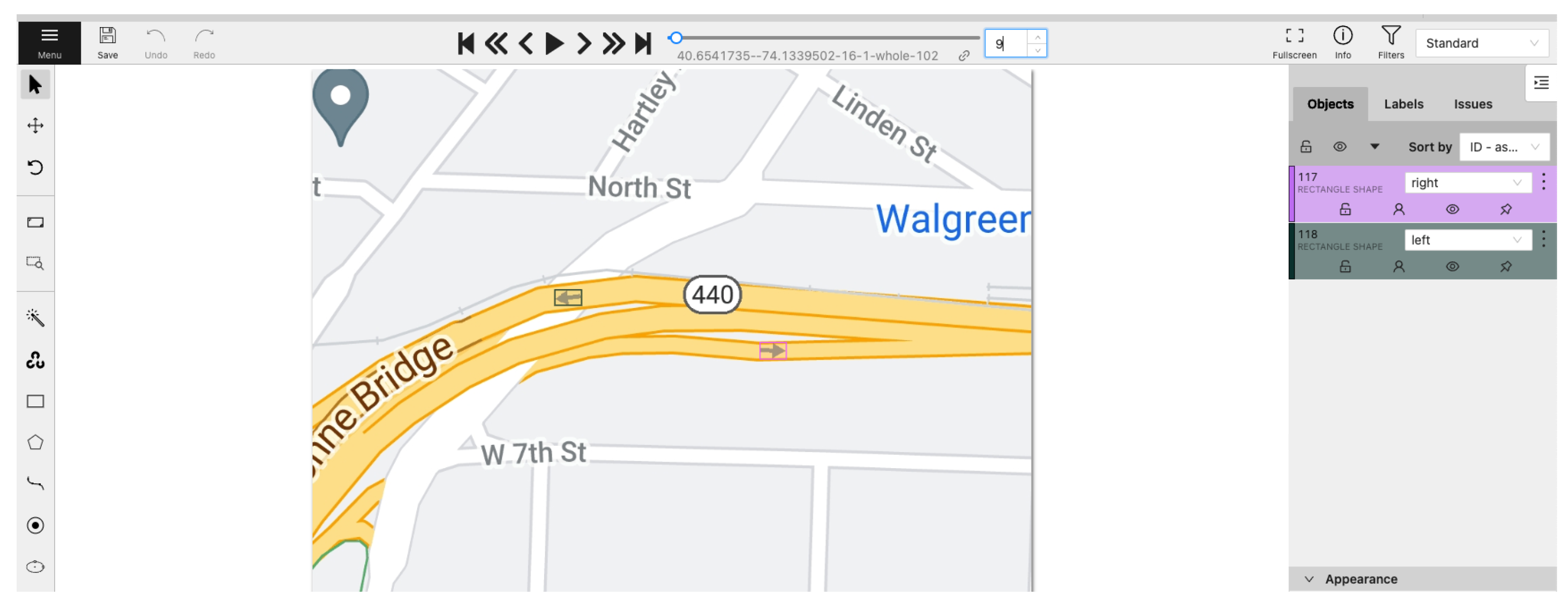
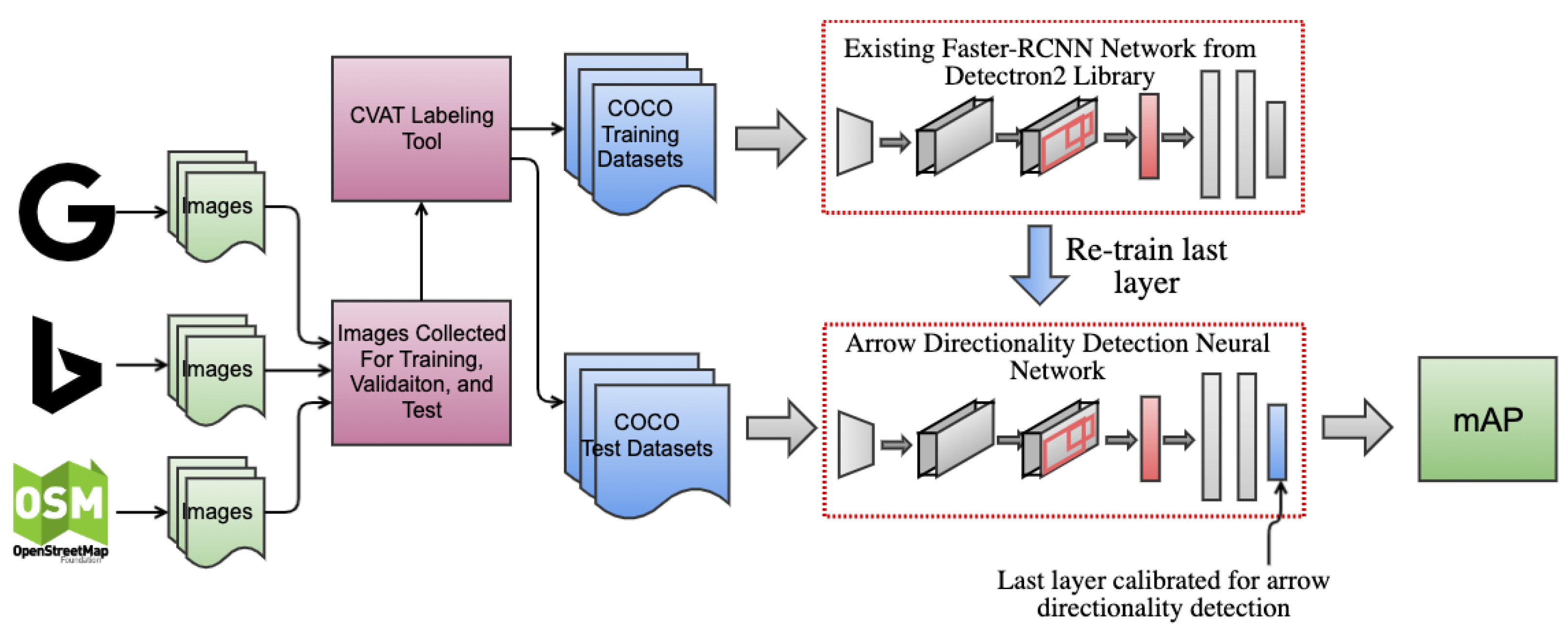
2.4. Data Preparation and Labelling
2.5. Hardware Requirements
3. Results and Discussion
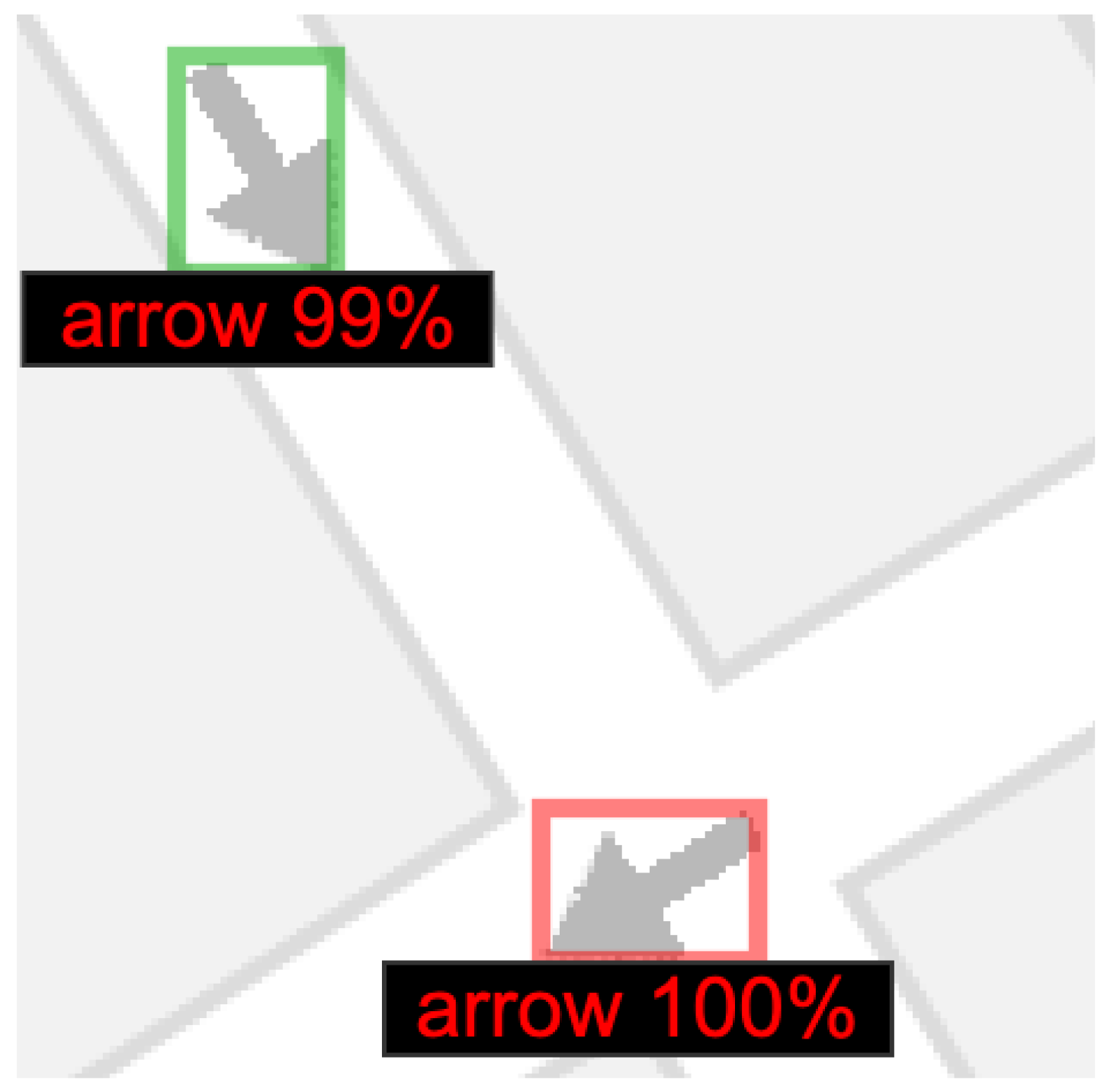
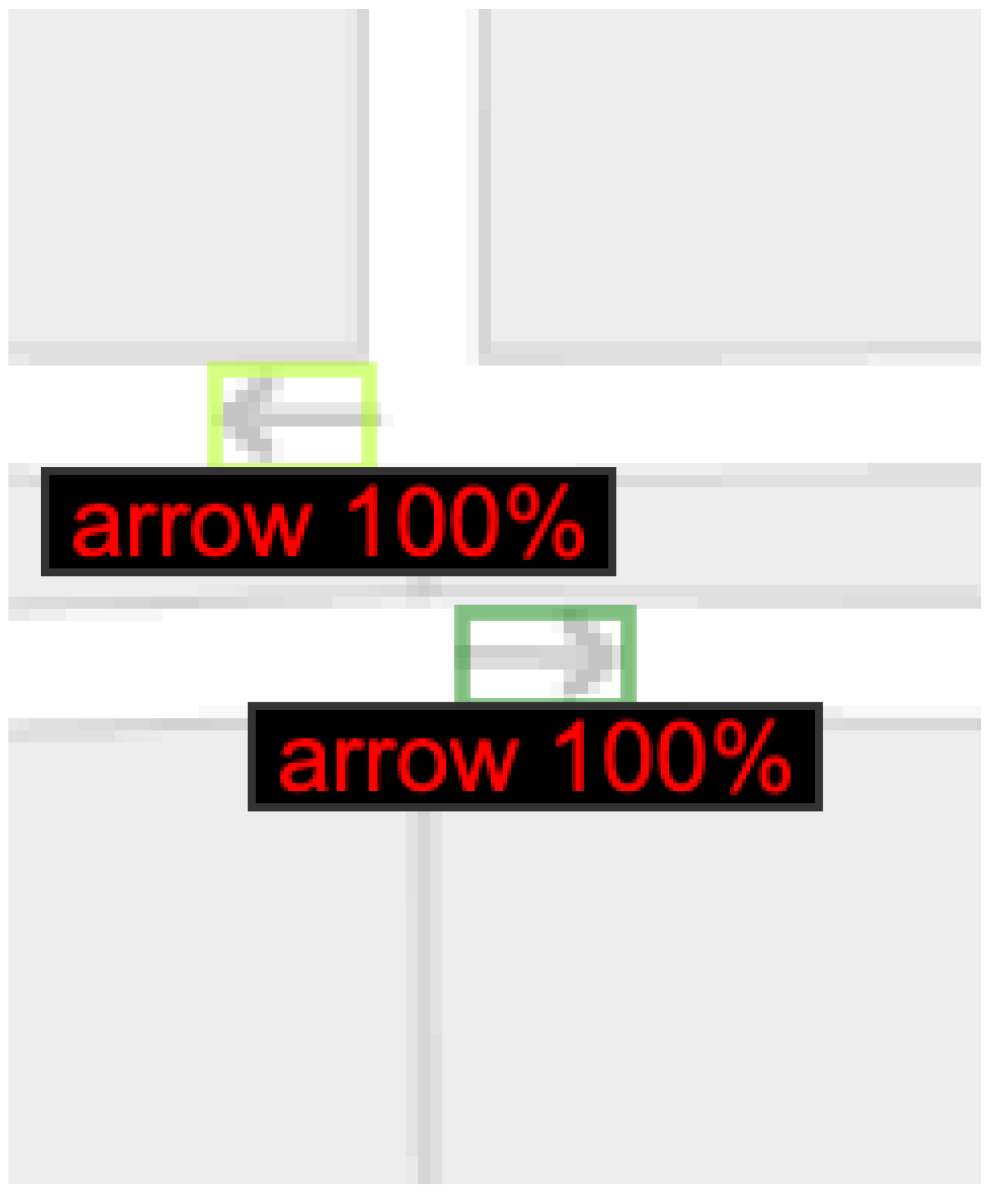
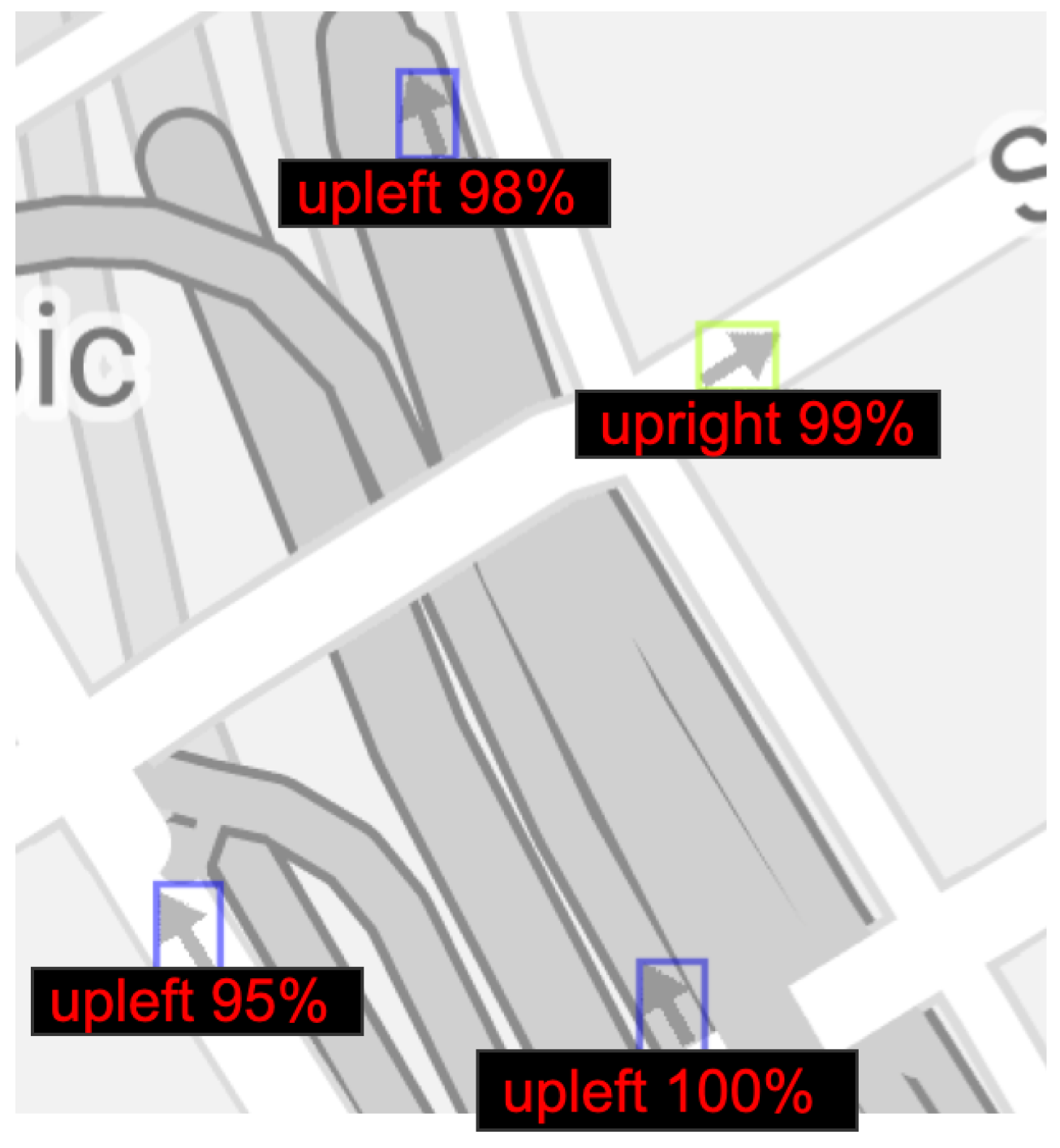
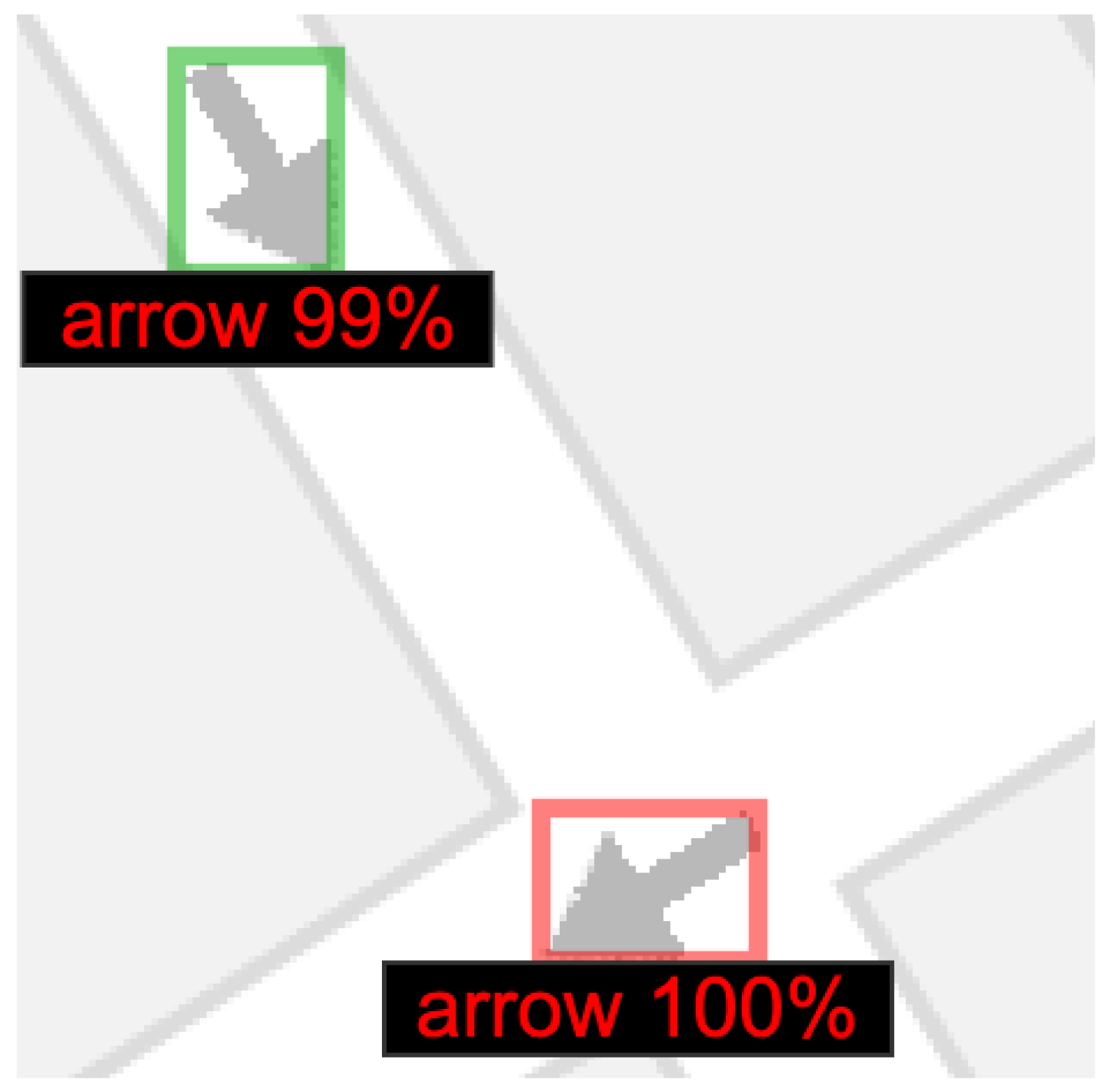
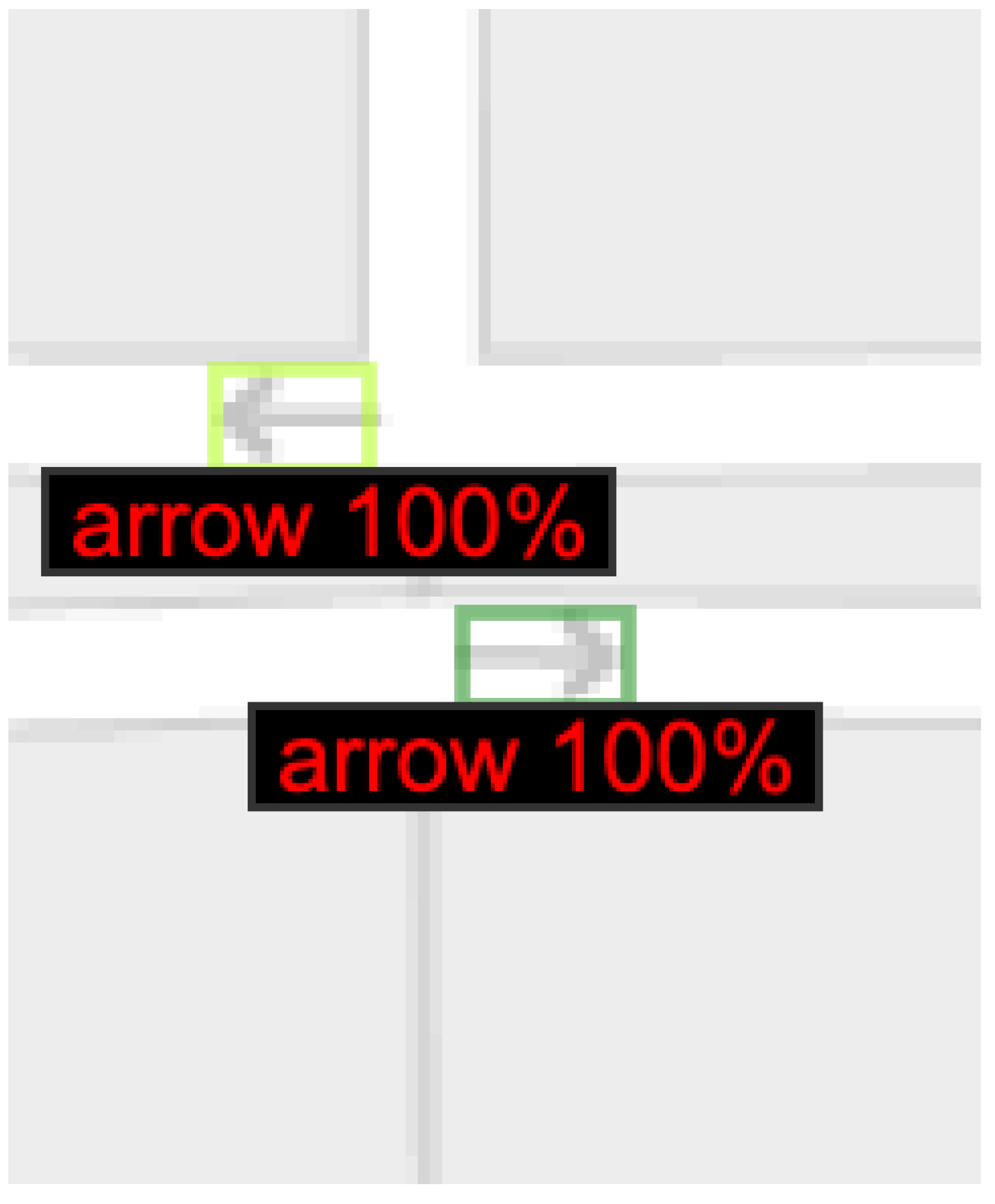
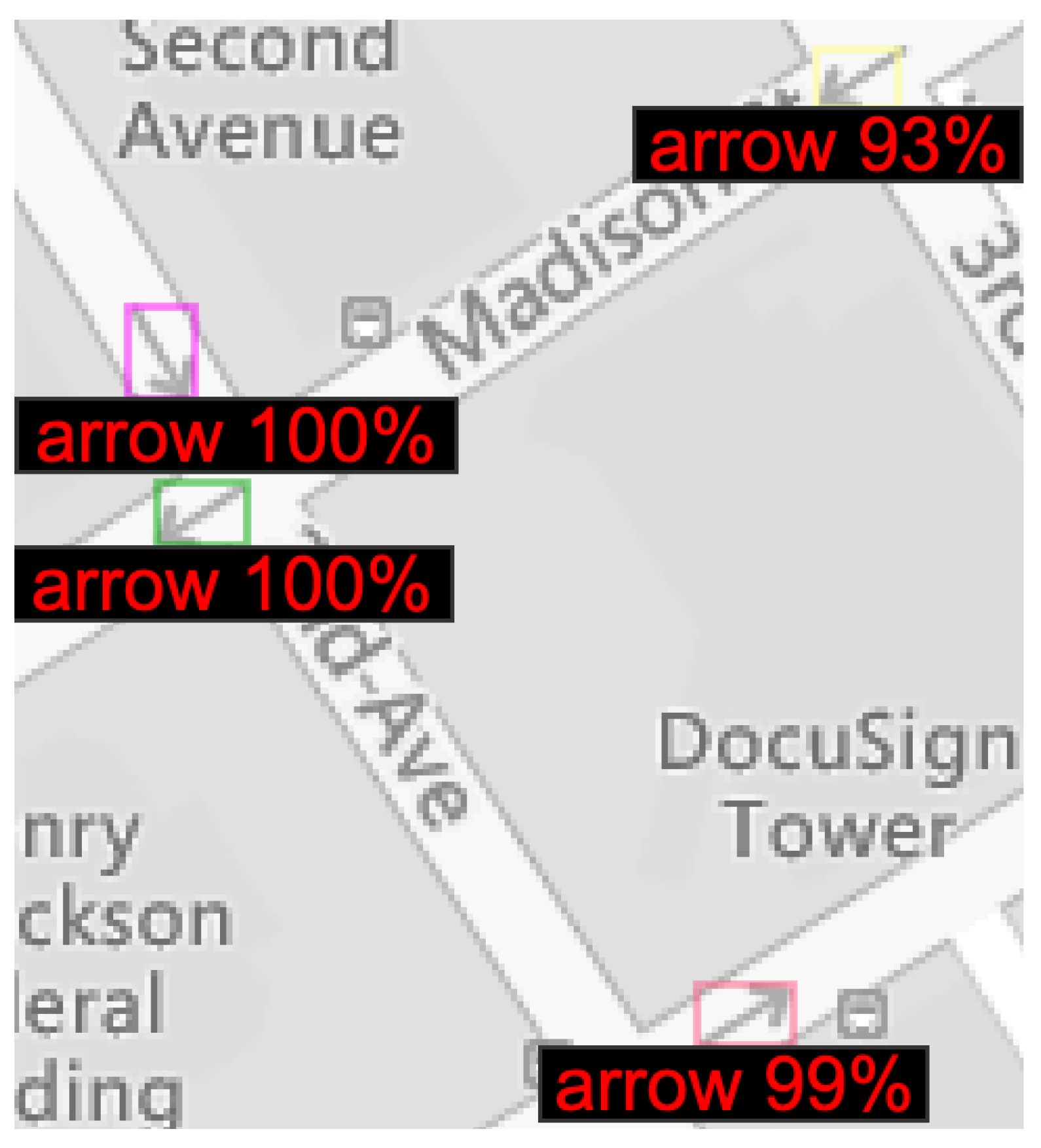
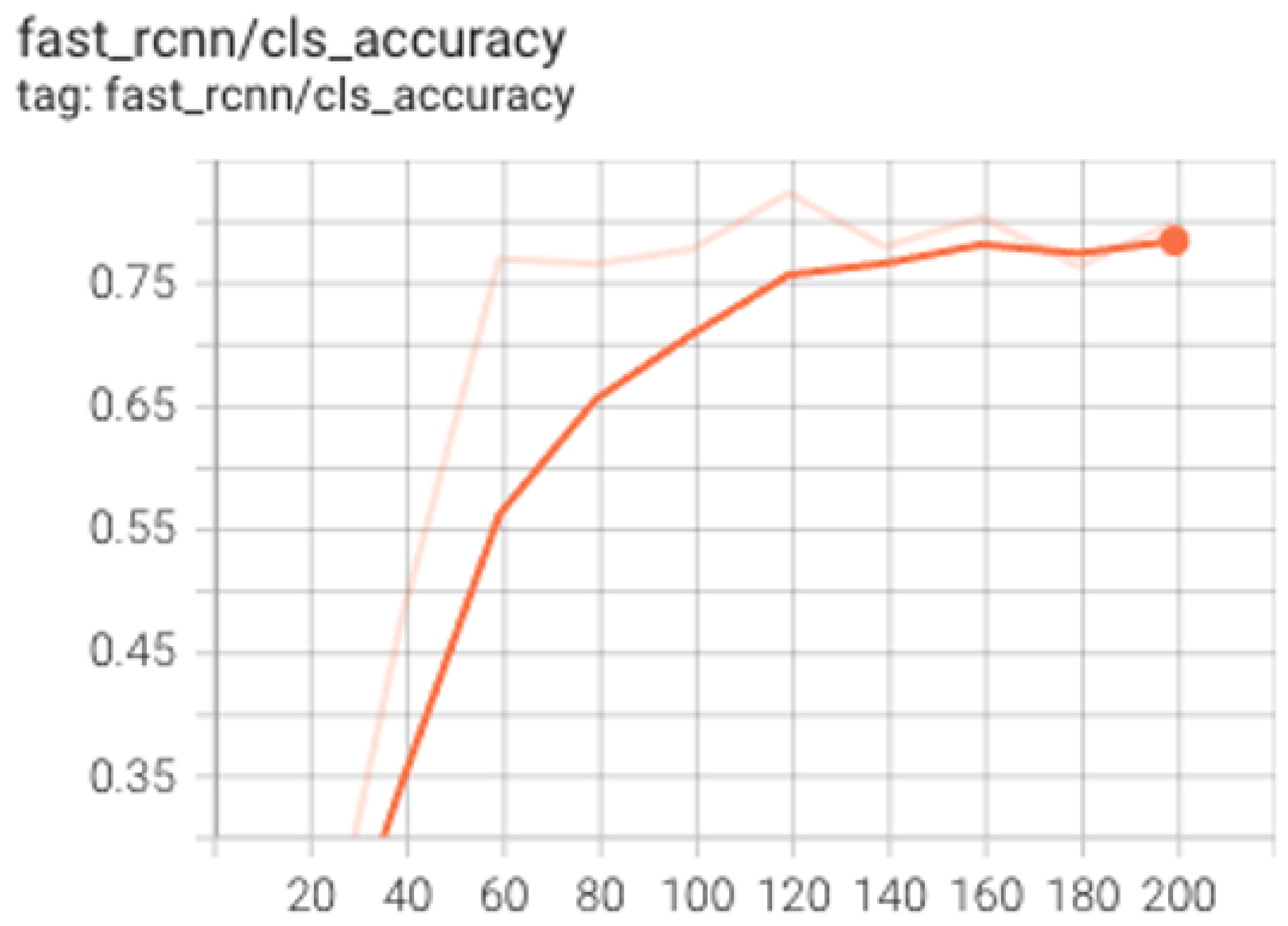
3.1. Experiment #1: Arrow Detection
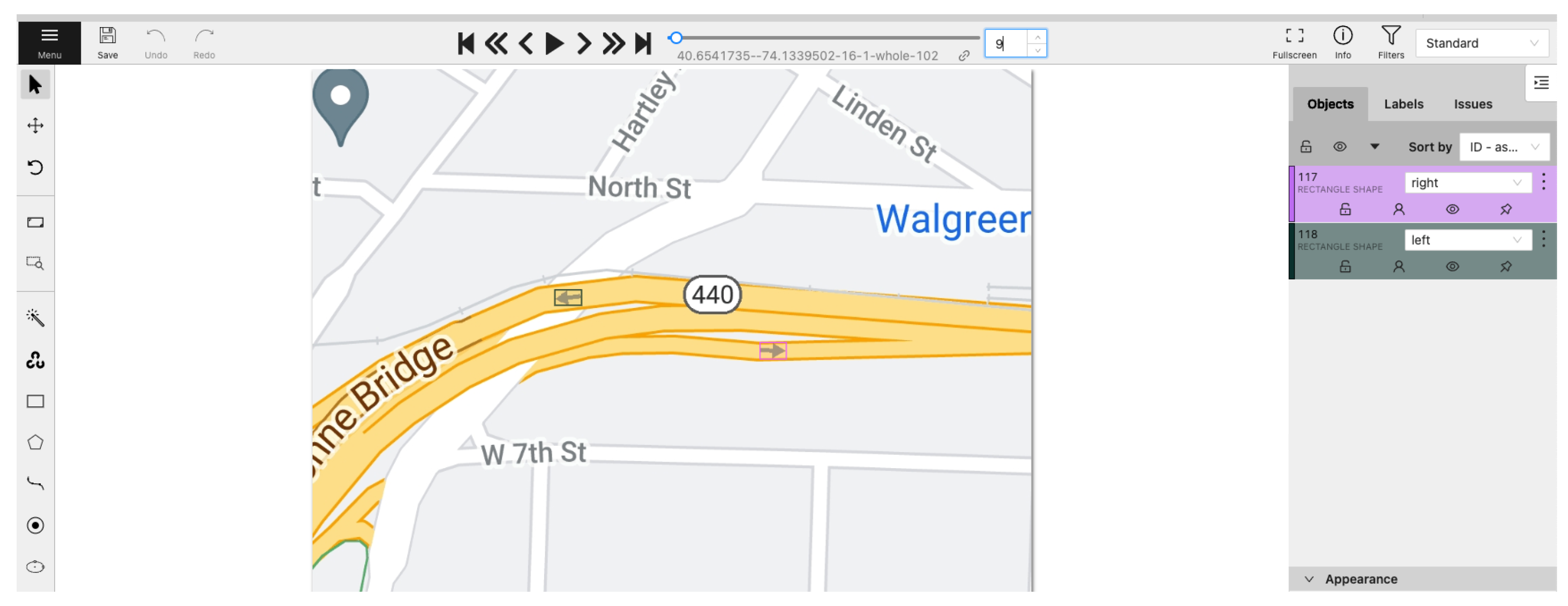
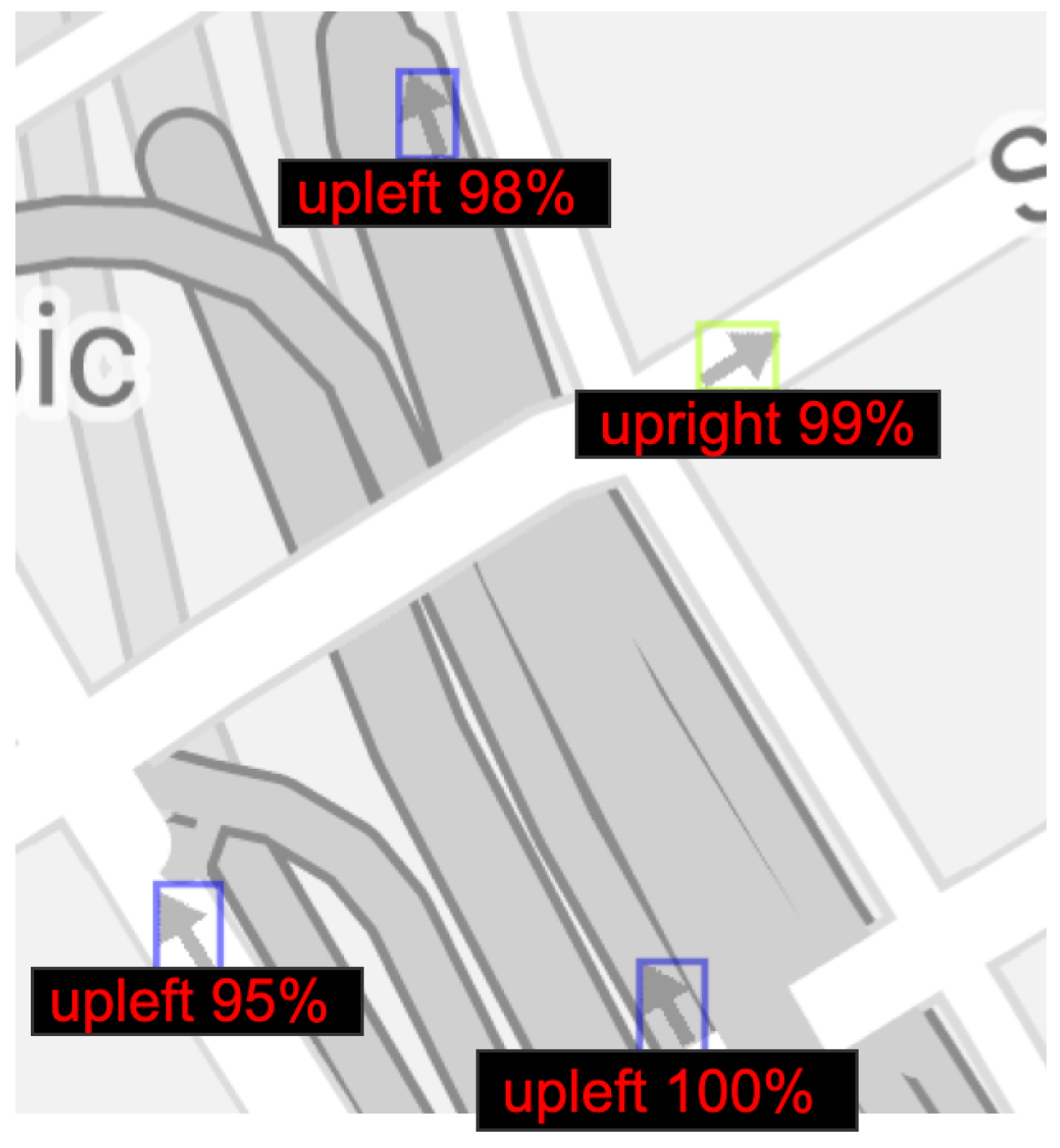
3.2. Experiment #2: Arrow Directionality Detection
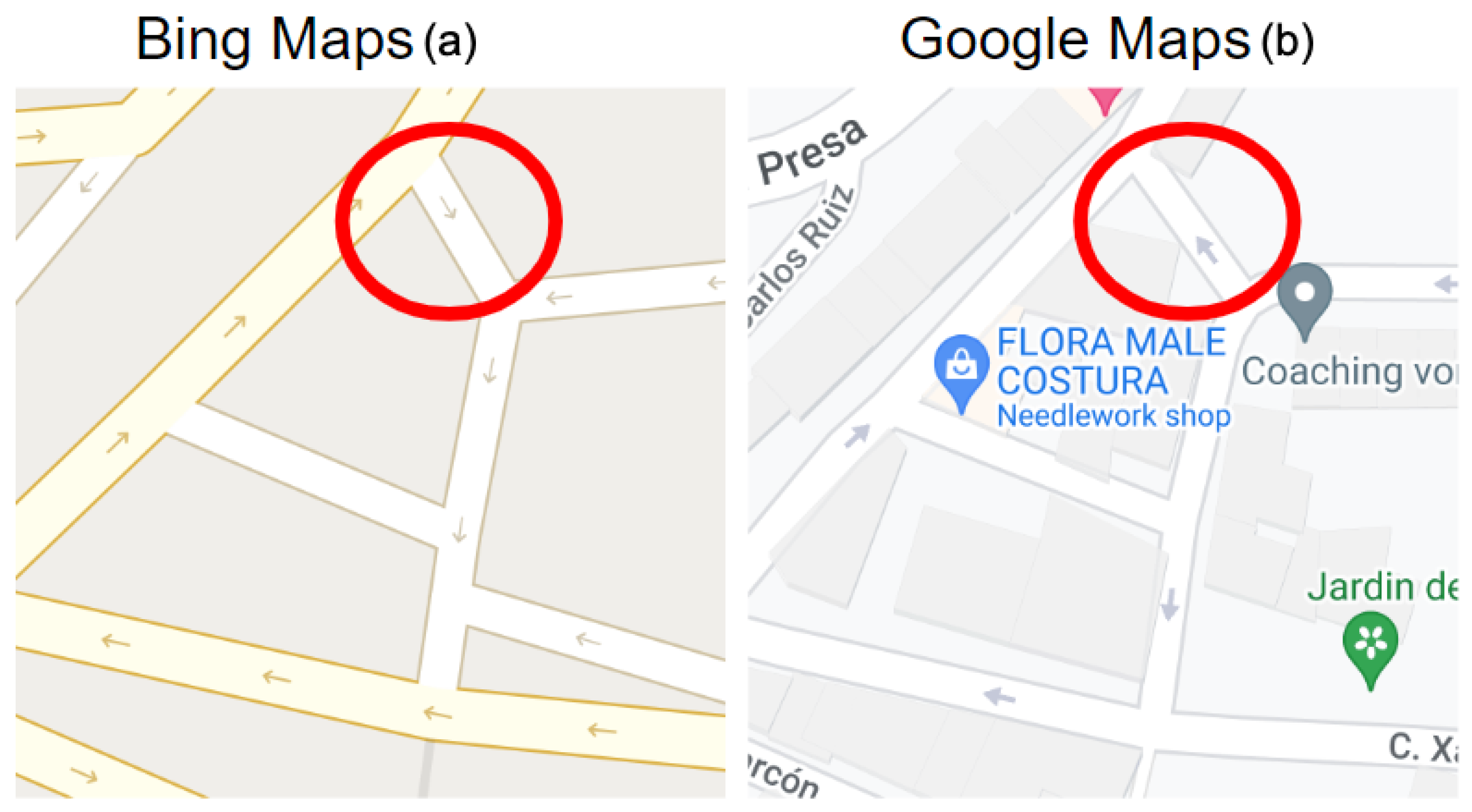
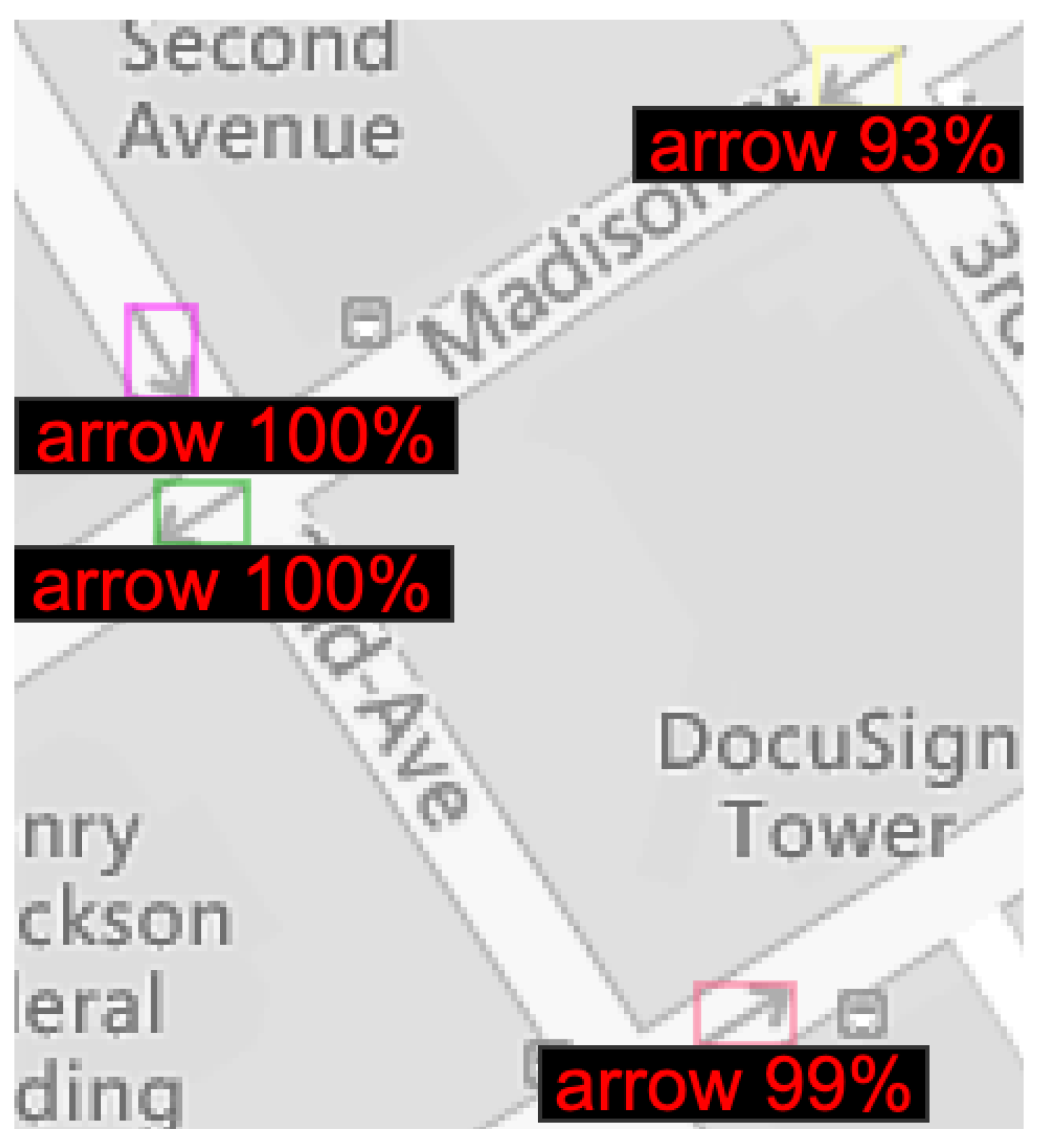
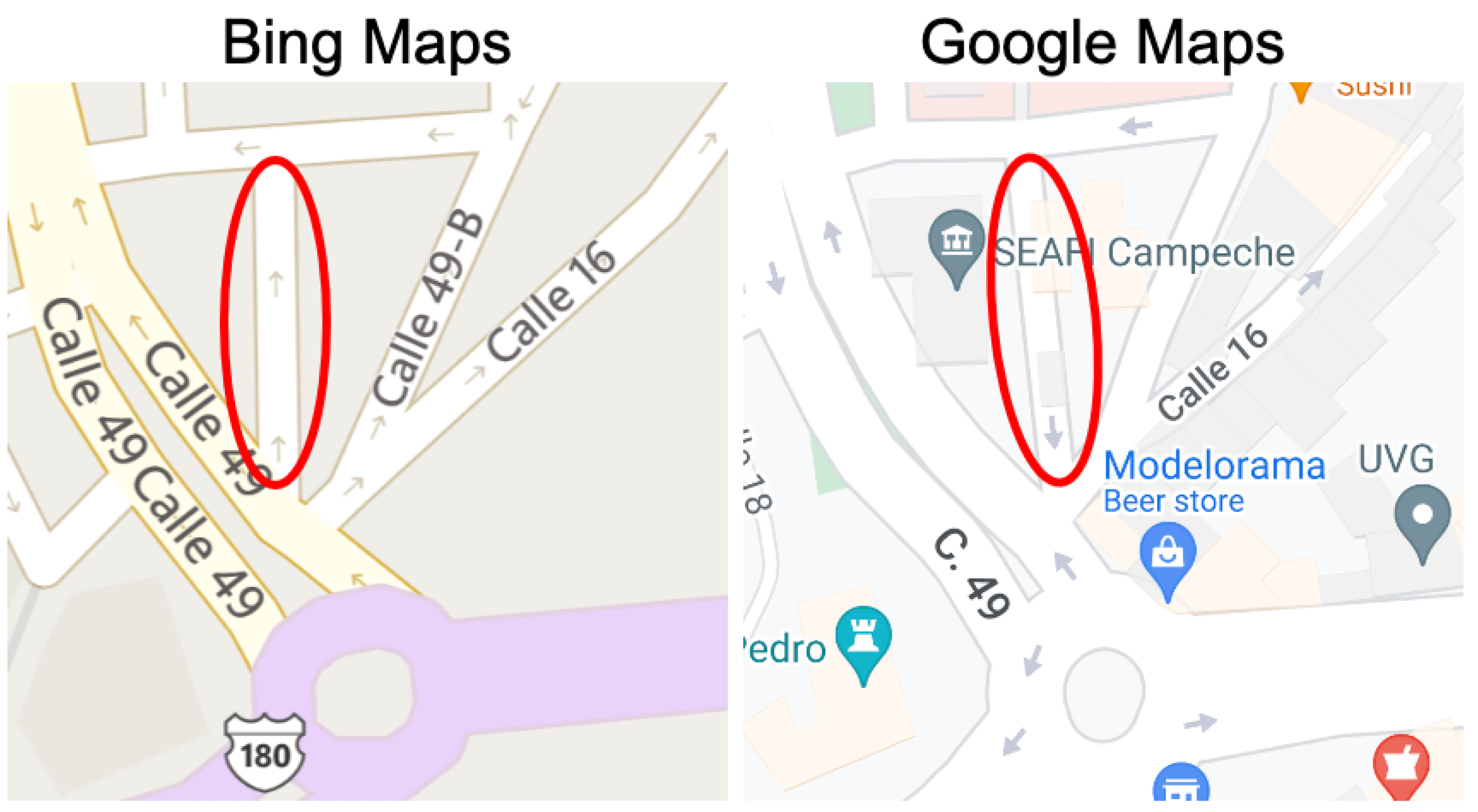
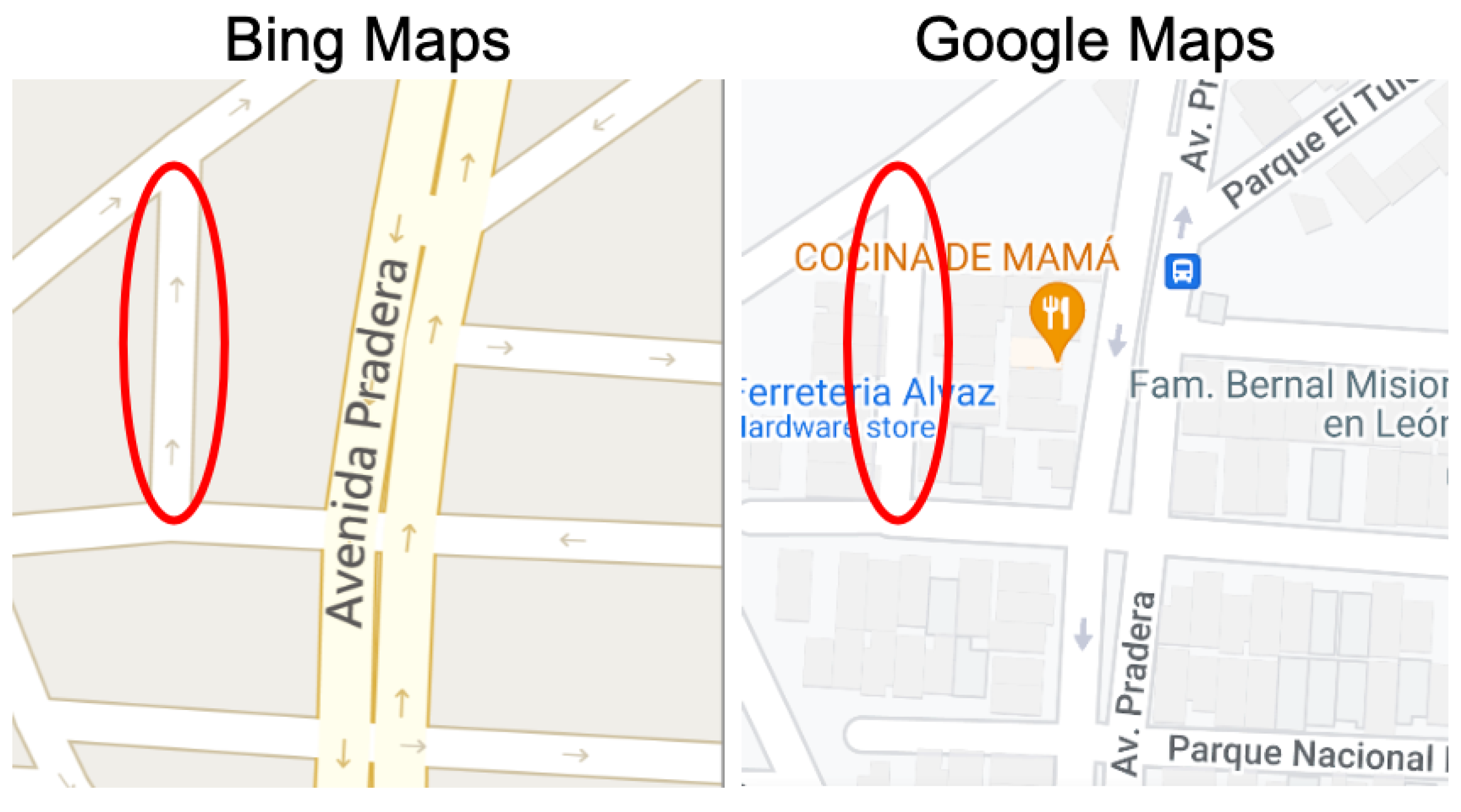
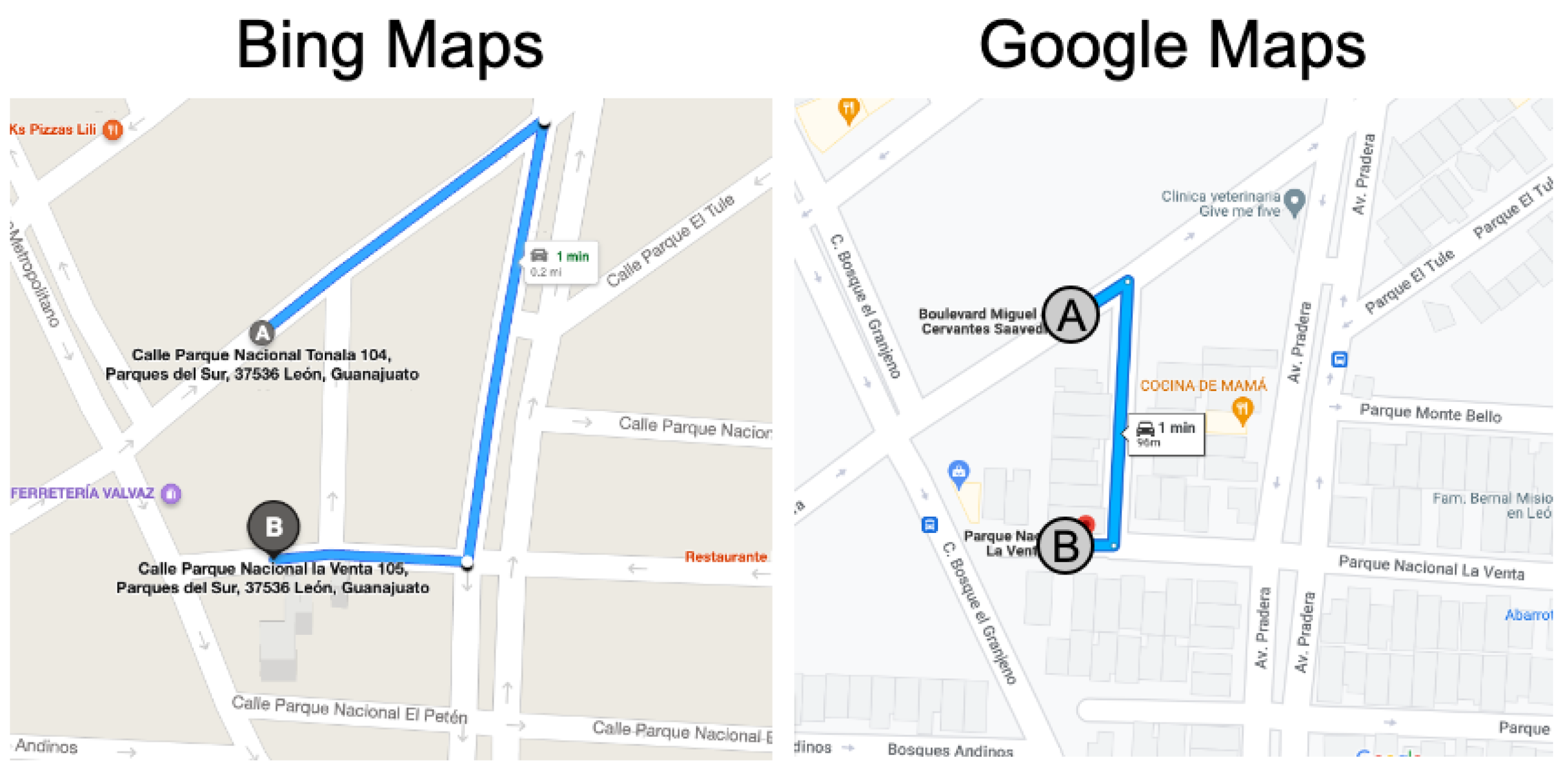
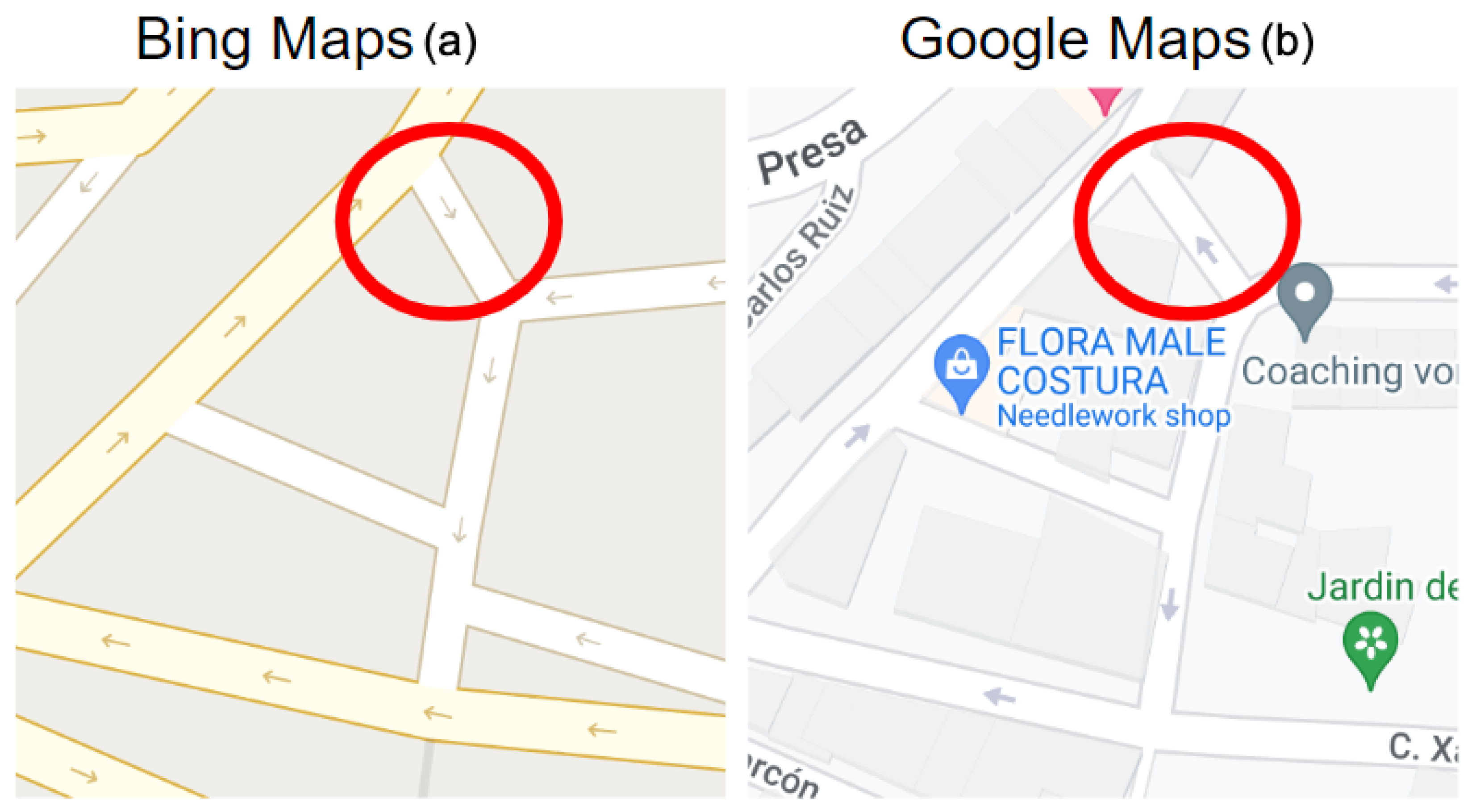
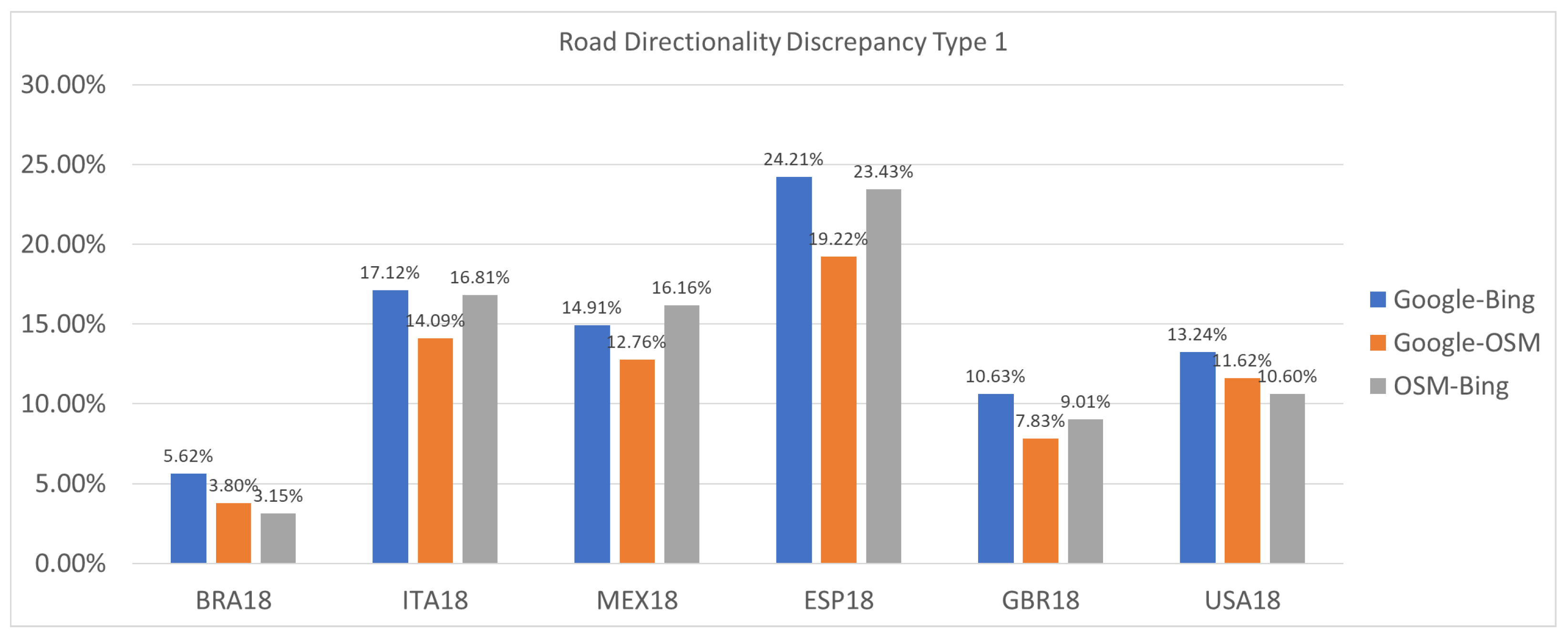
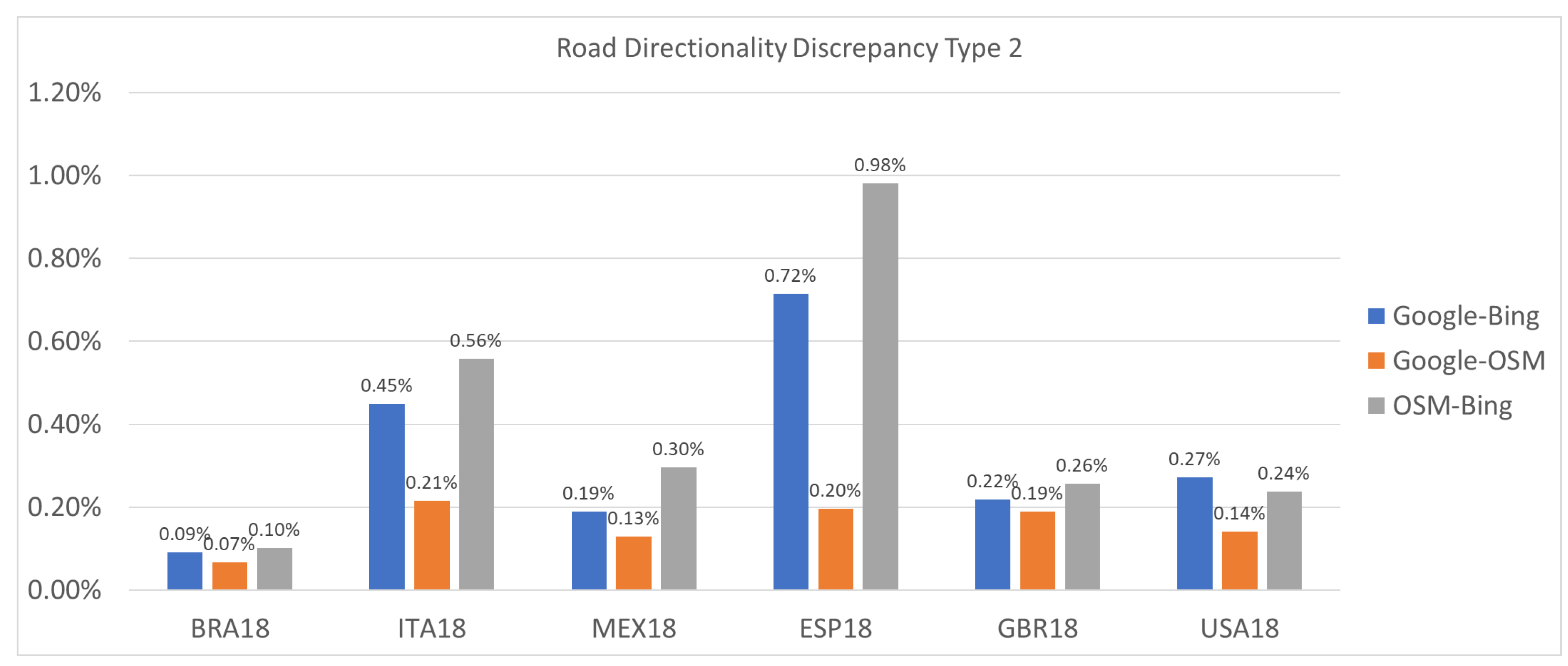
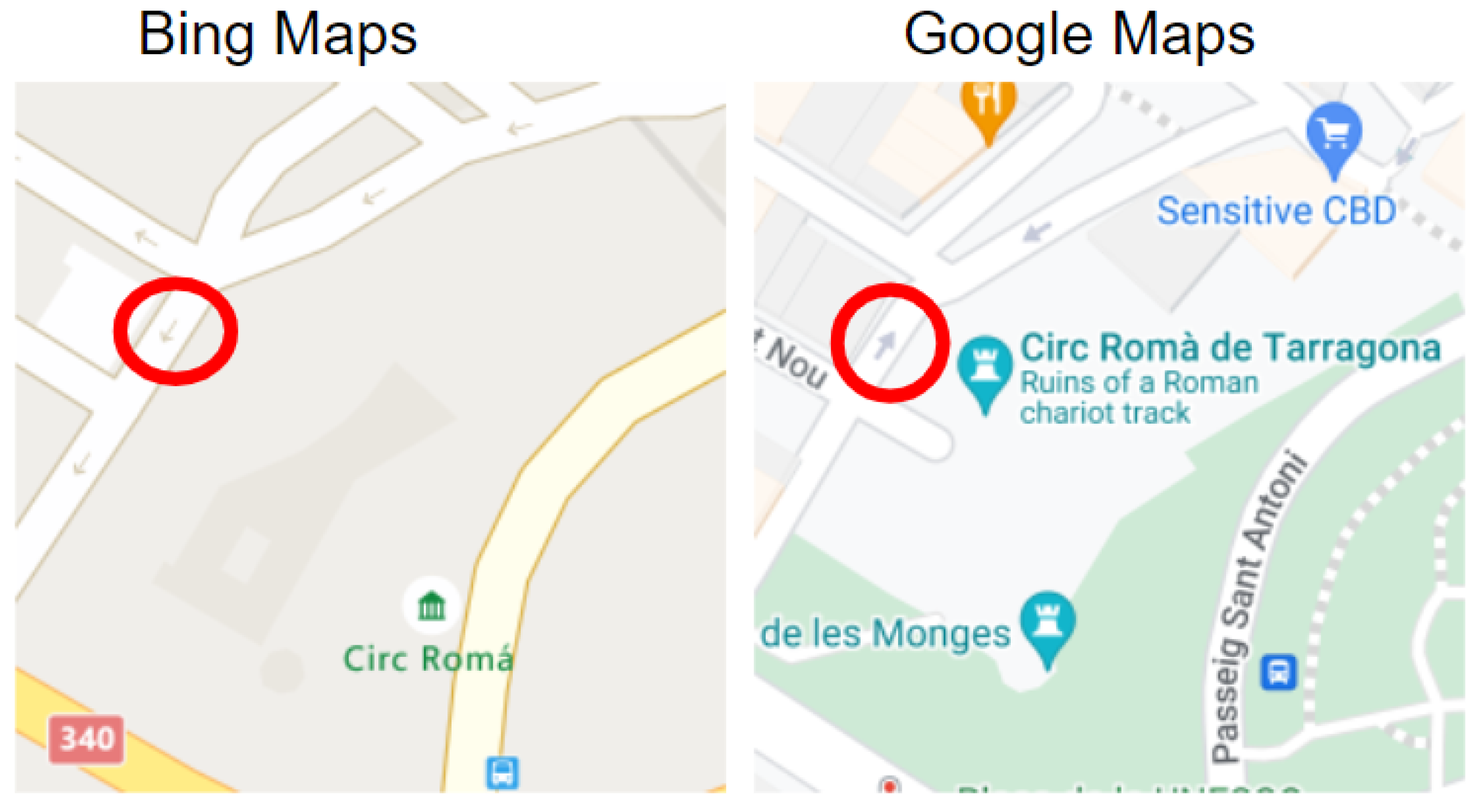
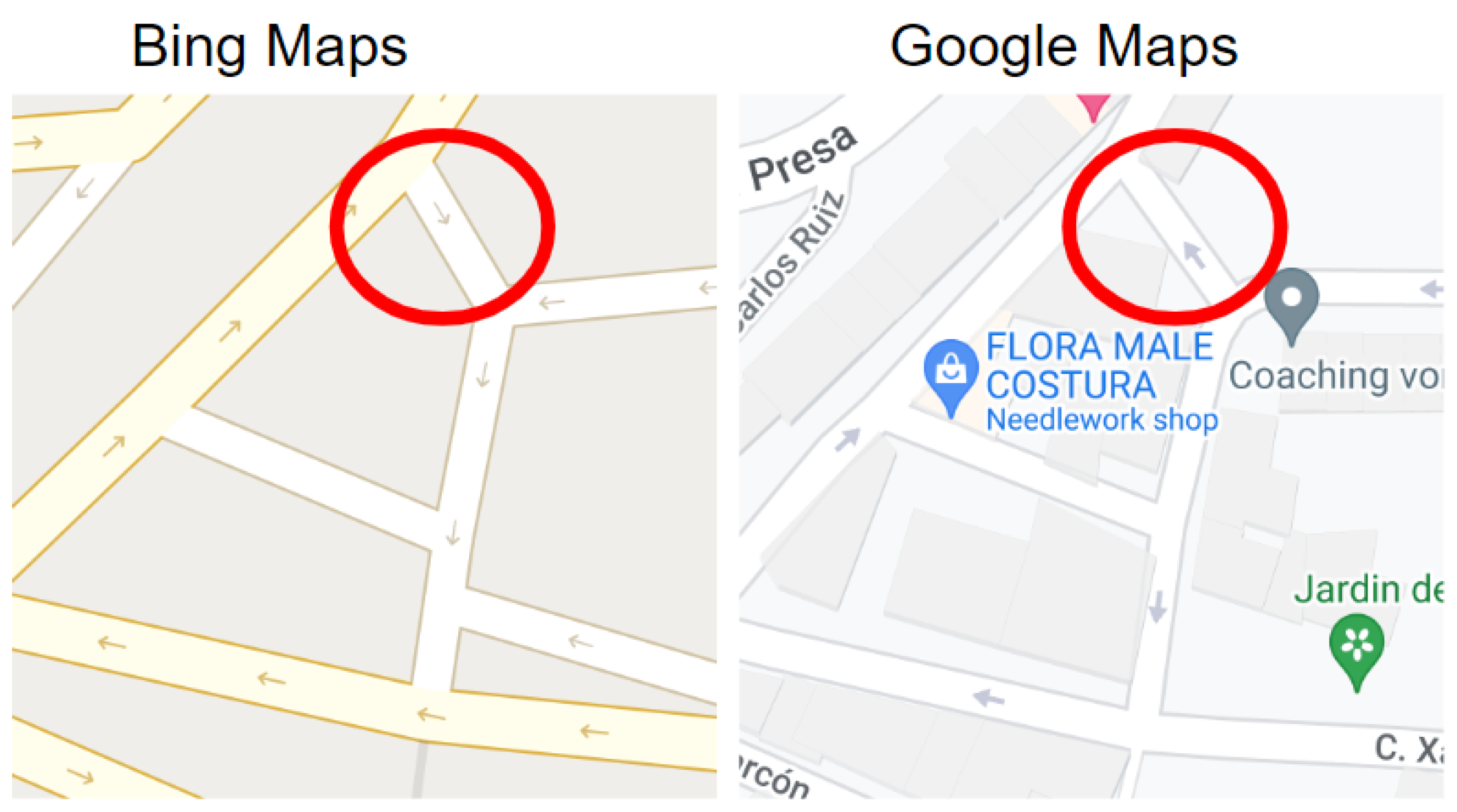
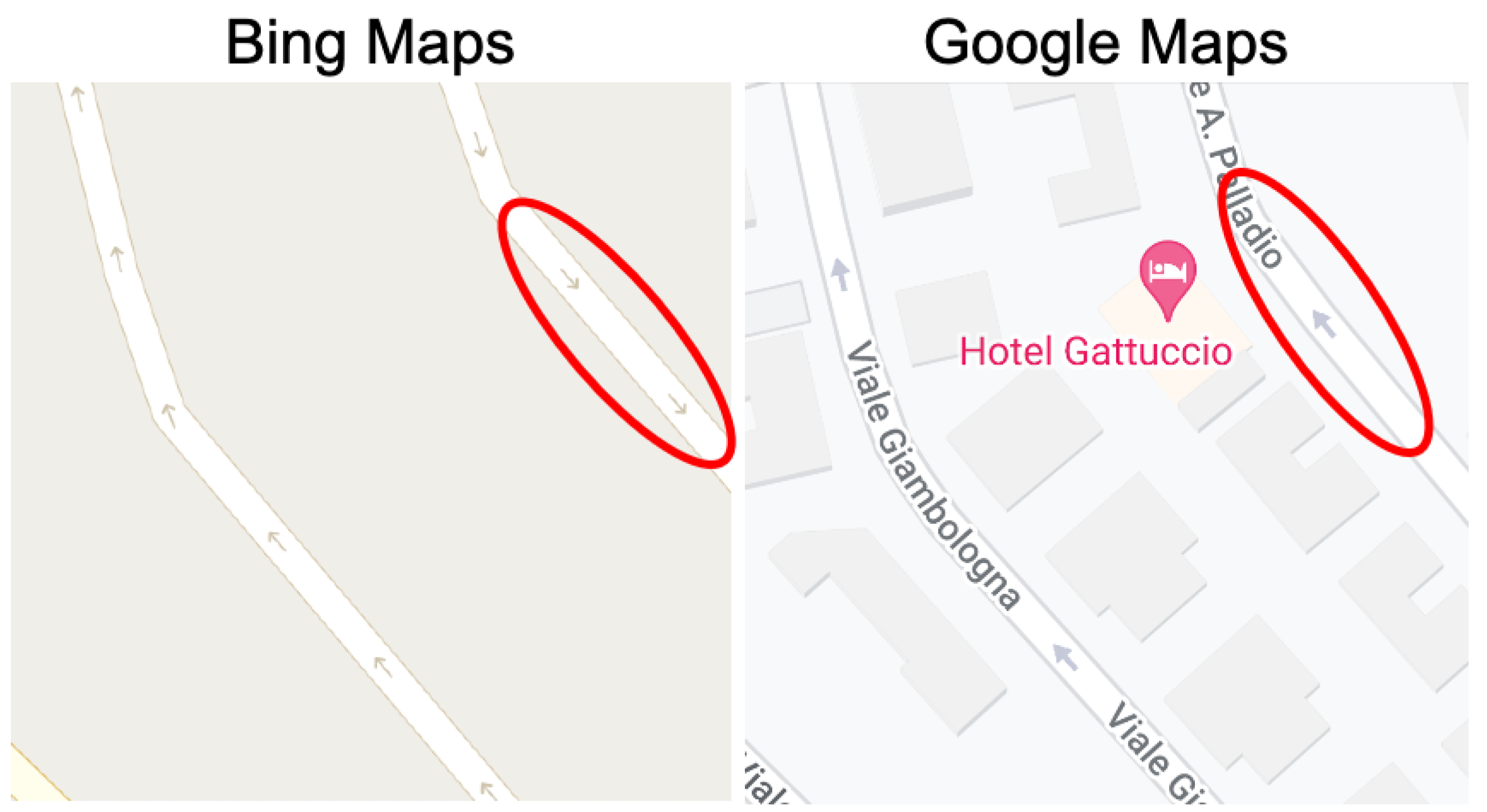
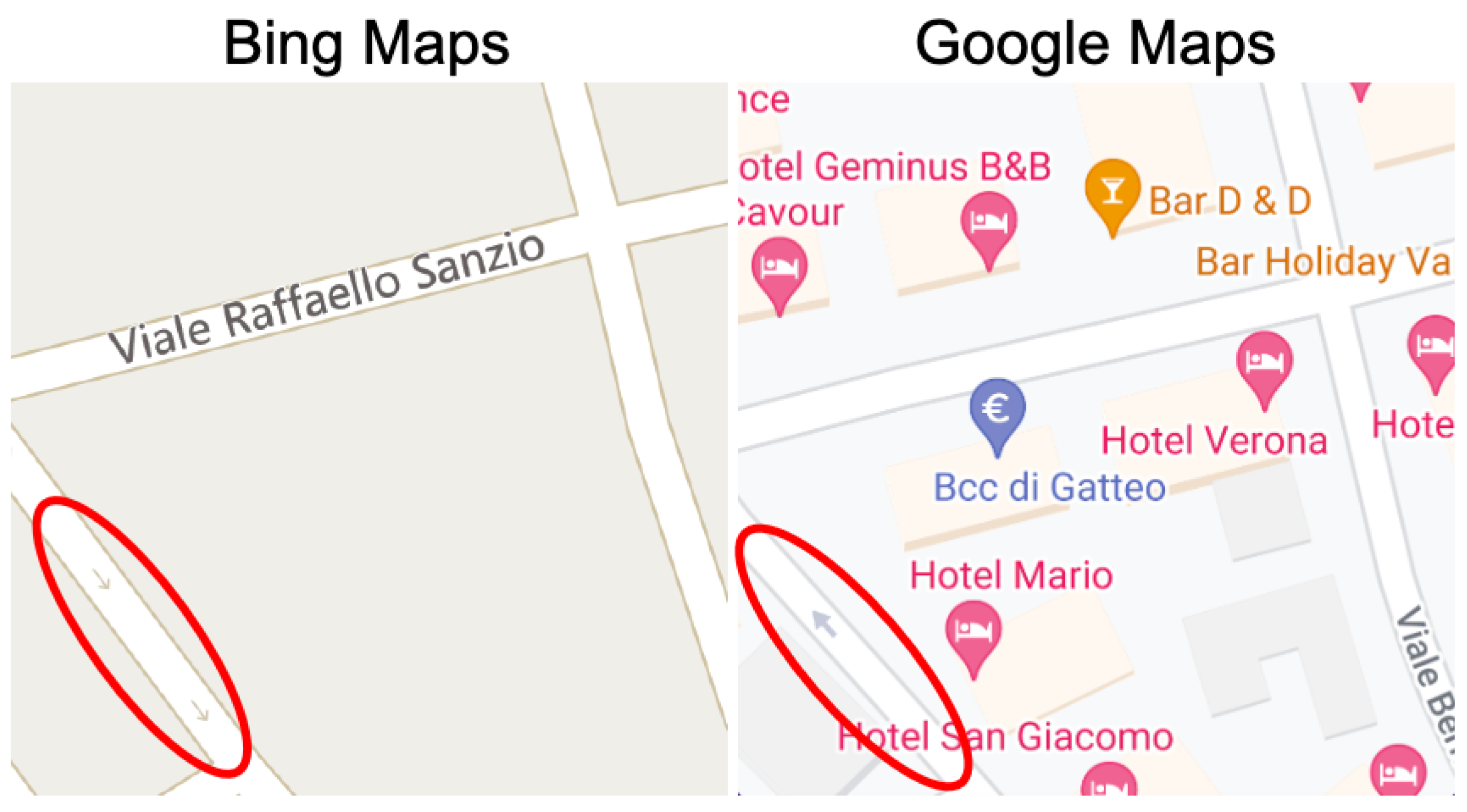
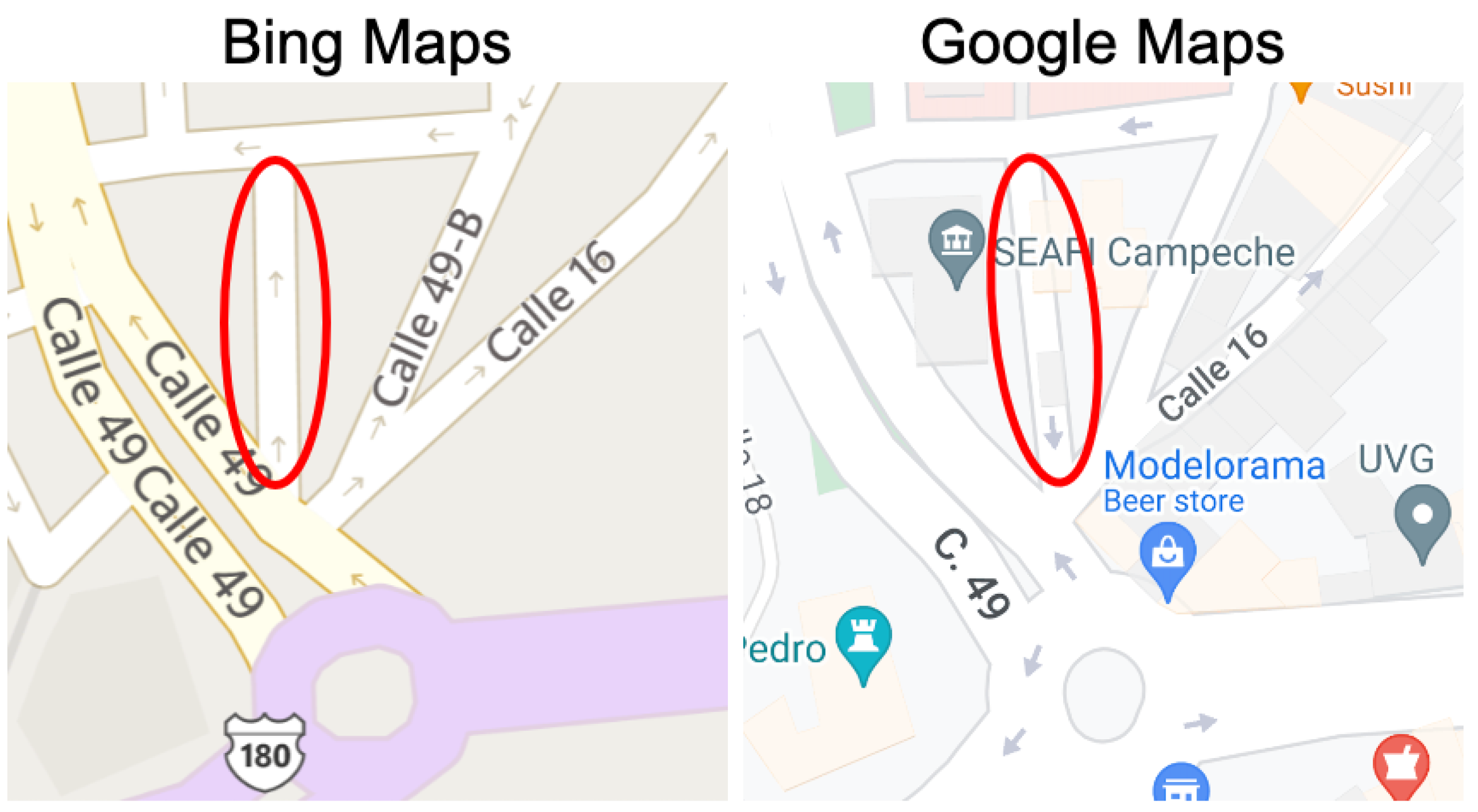
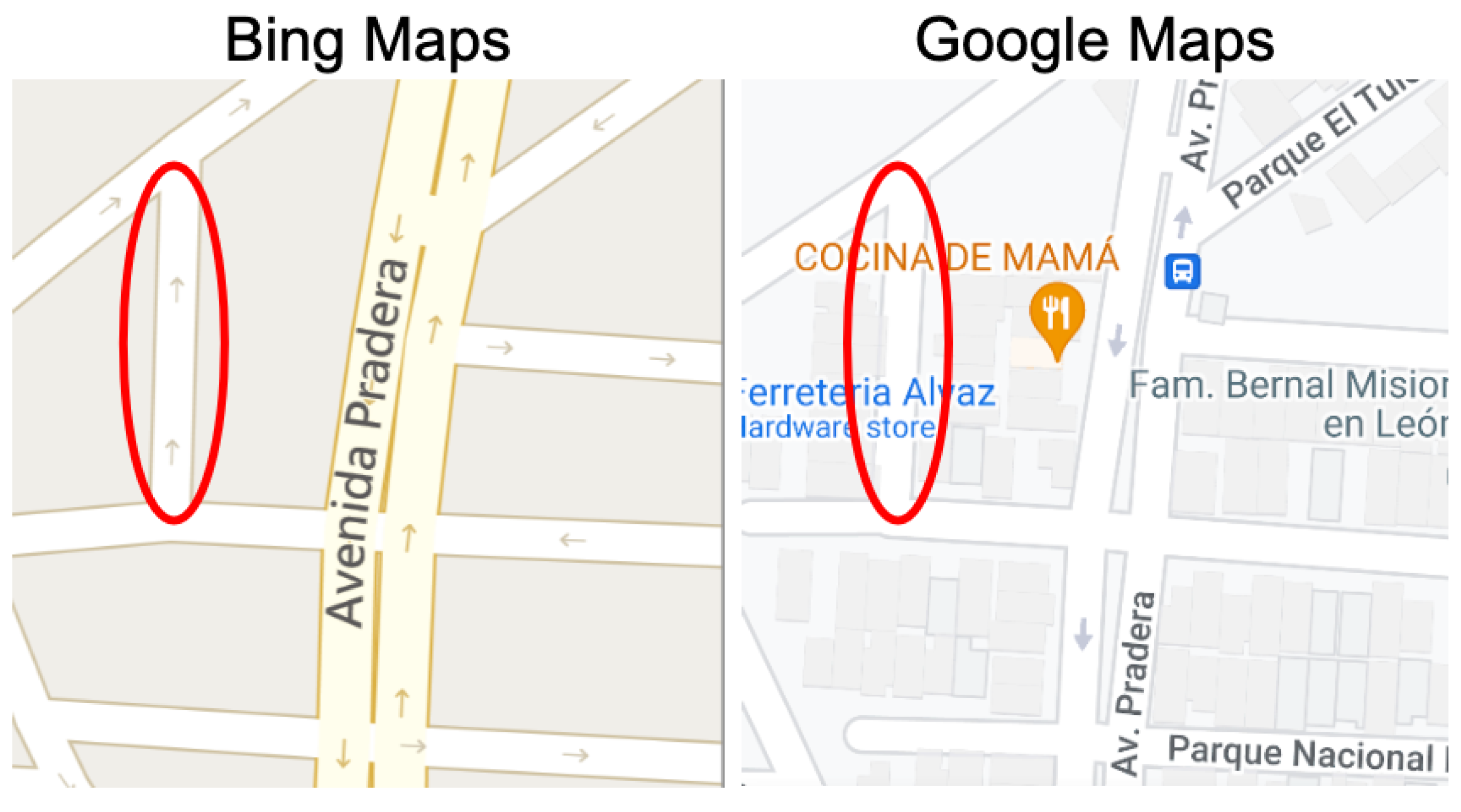
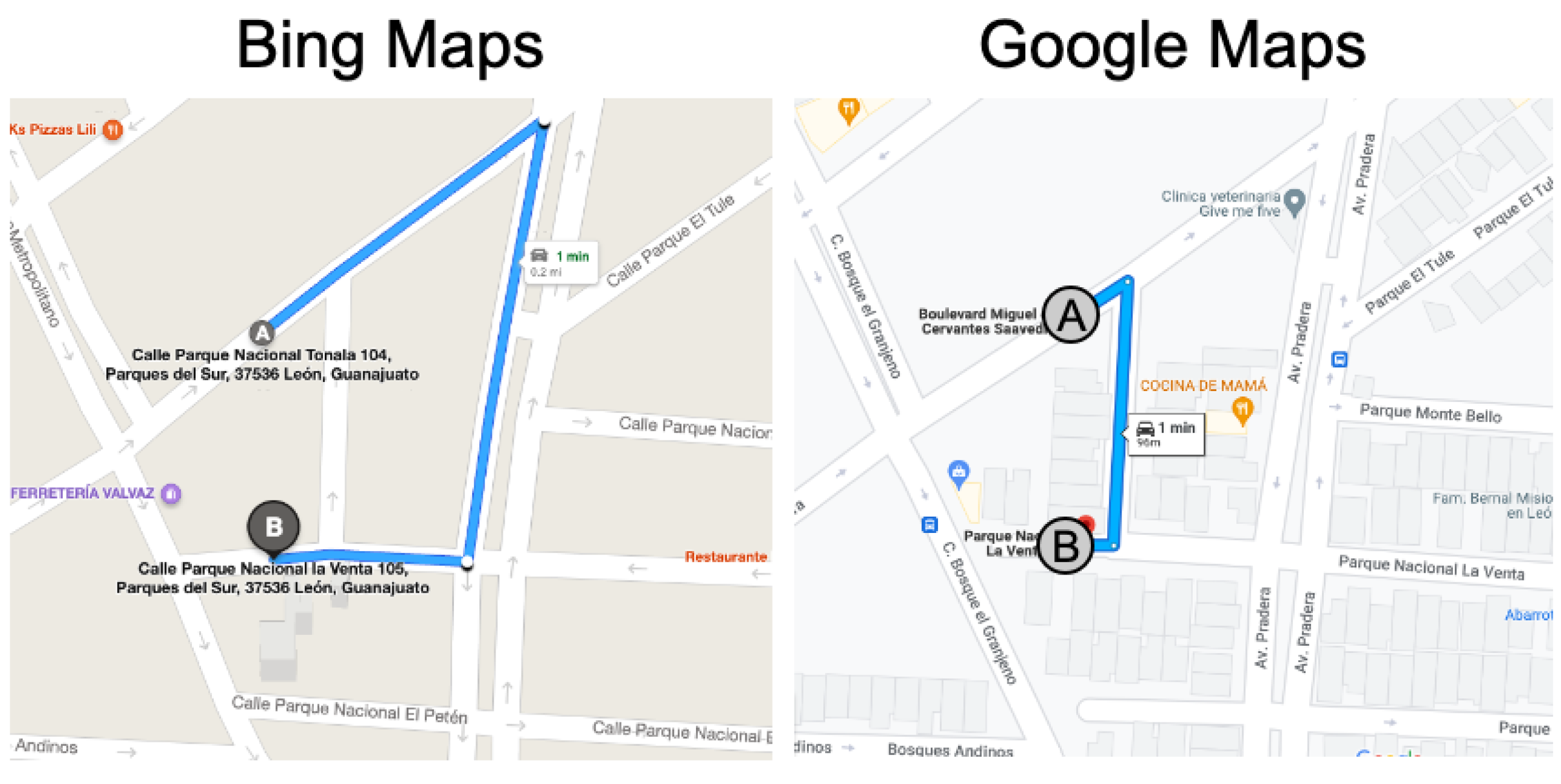
3.3. Experiment #3: Detecting Discrepancies in Road Directions across Map Providers
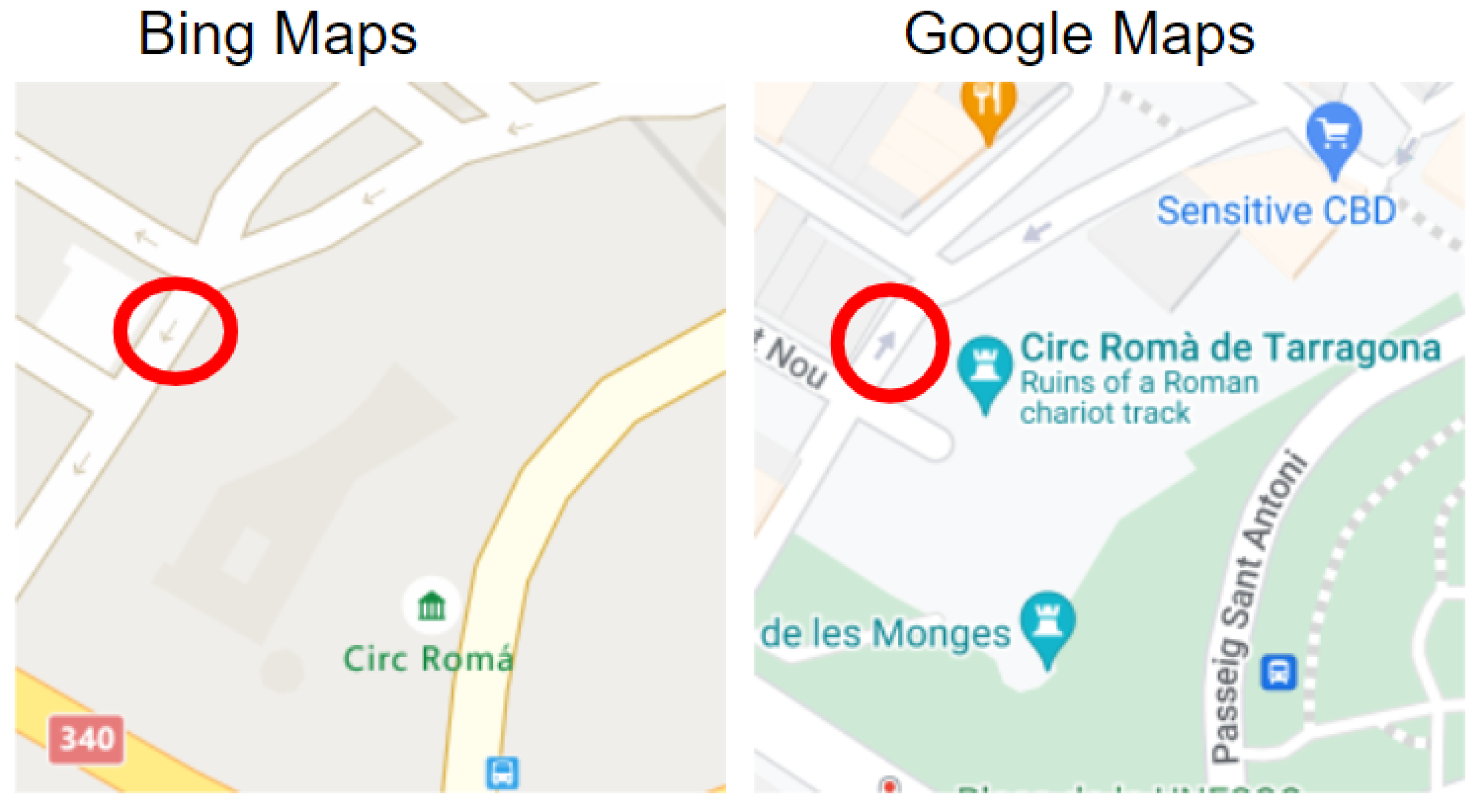
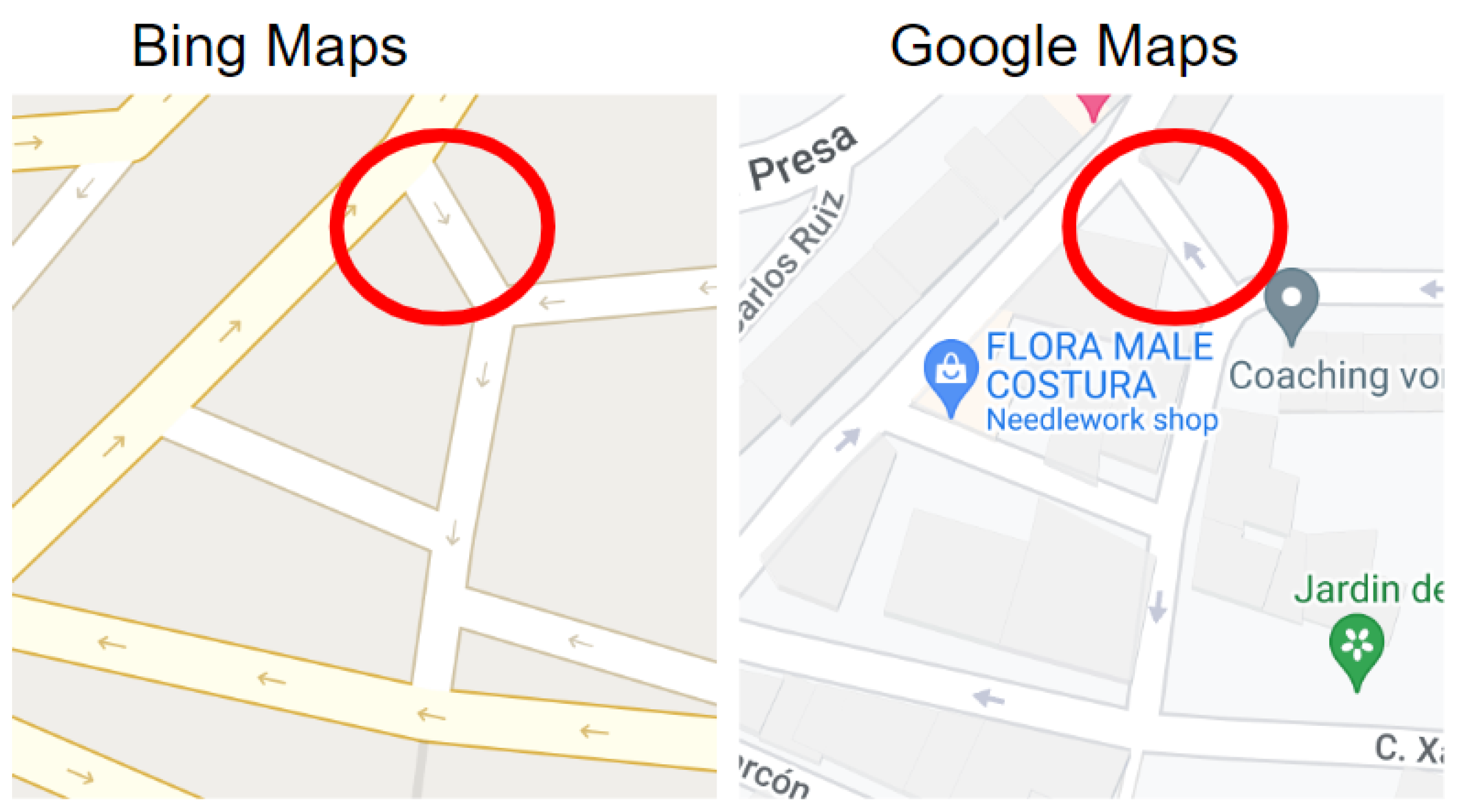
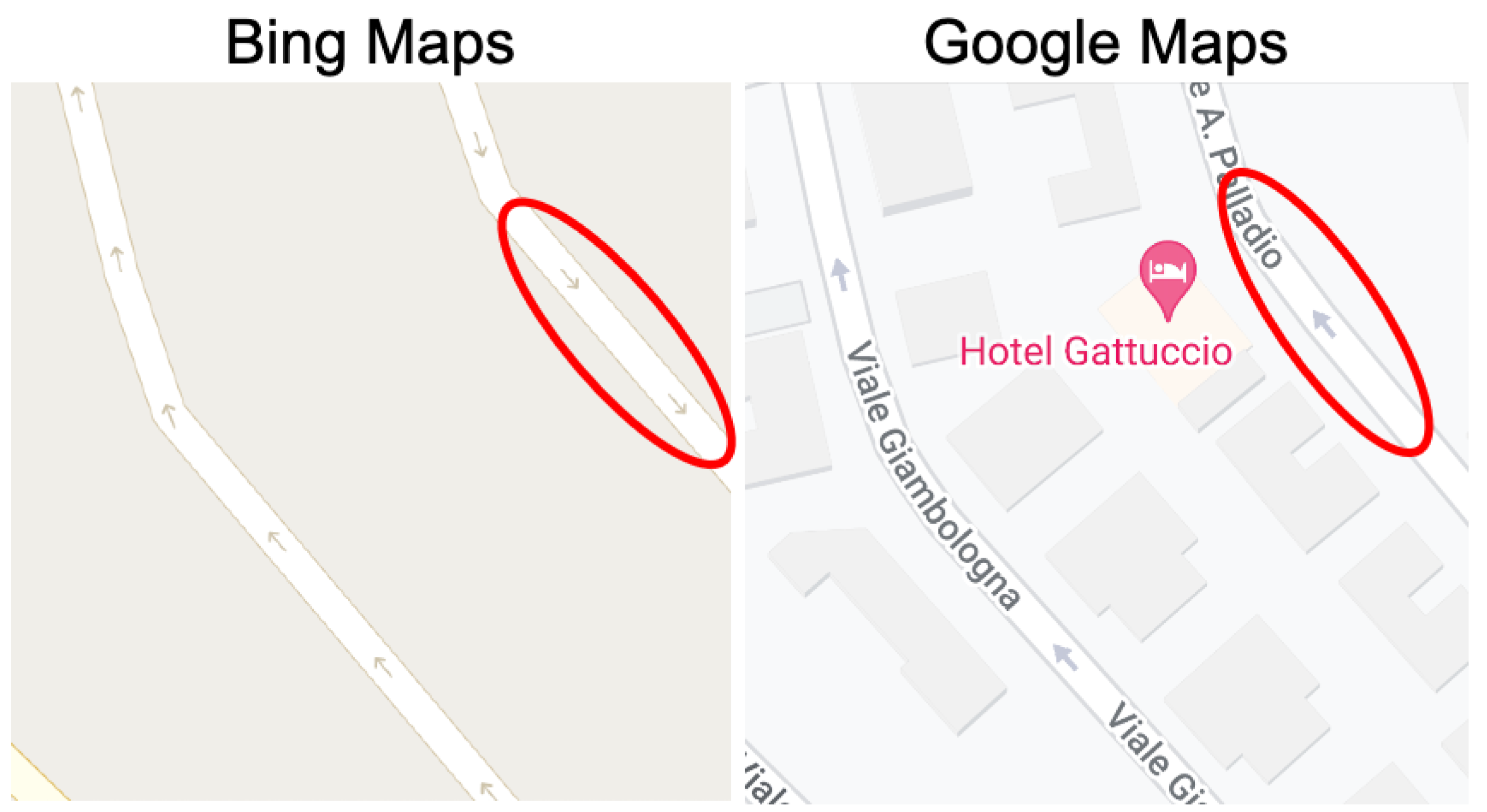
- Type 1 (Weak Discrepancy): This is defined when one provider has arrows indicating a specific direction for a road segement while the other provider is missing any arrows info for the same road segment;
- Type 2 (Strong Discrepancy): This occurs when both providers have arrows for a road segment but their directions do not match, indicating a conflicting road direction.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- 9 Things to Know about Google’s Maps Data: Beyond the Map. Available online: https://cloud.google.com/blog/products/maps-platform/9-things-know-about-googles-maps-data-beyond-map (accessed on 4 April 2022).
- Ciepluch, B.; Jacob, R.; Mooney, P.; Winstanley, A.C. Comparison of the accuracy of OpenStreetMap for Ireland with Google Maps and Bing Maps. In Proceedings of the Ninth International Symposium on Spatial Accuracy Assessment in Natural Resuorces and Enviromental Sciences, Leicester, UK, 20–23 July 2010; p. 337. [Google Scholar]
- Bandil, A.; Girdhar, V.; Chau, H.; Ali, M.; Hendawi, A.; Govind, H.; Cao, P.; Song, A. GeoDart: A System for Discovering Maps Discrepancies. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 19–22 April 2021; pp. 2535–2546. [Google Scholar] [CrossRef]
- Basiri, A.; Jackson, M.; Amirian, P.; Pourabdollah, A.; Sester, M.; Winstanley, A.; Moore, T.; Zhang, L. Quality assessment of OpenStreetMap data using trajectory mining. Geo-Spat. Inf. Sci. 2016, 19, 56–68. [Google Scholar] [CrossRef]
- A Geospatial Method for Detecting Map-Based Road Segment Discrepancies. Available online: http://faculty.washington.edu/mhali/Publications/Publications.htm (accessed on 10 March 2021).
- Bandil, A.; Girdhar, V.; Dincer, K.; Govind, H.; Cao, P.; Song, A.; Ali, M. An interactive system to compare, explore and identify discrepancies across map providers. In Proceedings of the 28th International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 3–6 November 2020; pp. 425–428. [Google Scholar]
- Unsalan, C.; Sirmacek, B. Road Network Detection Using Probabilistic and Graph Theoretical Methods. IEEE Trans. Geosci. Remote Sens. 2012, 50, 4441–4453. [Google Scholar] [CrossRef]
- John, V.; Zheming, L.; Mita, S. Robust traffic light and arrow detection using optimal camera parameters and GPS-based priors. In Proceedings of the 2016 Asia-Pacific Conference on Intelligent Robot Systems (ACIRS), Tokyo, Japan, 20–22 July 2016; pp. 204–208. [Google Scholar] [CrossRef]
- Santosh, K.C.; Wendling, L.; Antani, S.; Thoma, G.R. Overlaid Arrow Detection for Labeling Regions of Interest in Biomedical Images. IEEE Intell. Syst. 2016, 31, 66–75. [Google Scholar] [CrossRef]
- Schäfer, B.; Keuper, M.; Stuckenschmidt, H. Arrow R-CNN for handwritten diagram recognition. Int. J. Doc. Anal. Recognit. (IJDAR) 2021, 24, 3–17. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.-Y.; Girshick, R. Detectron2. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 17 May 2022).
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 11976–11986. [Google Scholar]
- Yu, T.; Huang, H.; Jiang, N.; Acharya, T.D. Study on Relative Accuracy and Verification Method of High-Definition Maps for Autonomous Driving. ISPRS Int. J. Geo-Inf. 2021, 10, 761. [Google Scholar] [CrossRef]
- Ma, J.; Sun, Q.; Zhou, Z.; Wen, B.; Li, S. A Multi-Scale Residential Areas Matching Method Considering Spatial Neighborhood Features. ISPRS Int. J. Geo-Inf. 2022, 11, 331. [Google Scholar] [CrossRef]
- Alghanim, A.; Jilani, M.; Bertolotto, M.; McArdle, G. Leveraging Road Characteristics and Contributor Behaviour for Assessing Road Type Quality in OSM. ISPRS Int. J. Geo-Inf. 2021, 10, 436. [Google Scholar] [CrossRef]
- Koukoletsos, T.; Haklay, M.; Ellul, C. An automated method to assess data completeness and positional accuracy of OpenStreetMap. In Proceedings of the GeoComputation, London, UK, 20–22 July 2011. [Google Scholar]
- Brovelli, M.A.; Minghini, M.; Molinari, M.E. An Automated GRASS-Based Procedure to Assess the Geometrical Accuracy of the OpenStreetMap Paris Road Network. In Proceedings of the ISPRS Congress, Prague, Czech Republic, 12–19 July 2016. [Google Scholar]
- Brovelli, M.A.; Minghini, M.; Molinari, M.; Mooney, P. Towards an automated comparison of OpenStreetMap with authoritative road datasets. Trans. GIS 2017, 21, 191–206. [Google Scholar] [CrossRef]
- Jackson, S.P.; Mullen, W.; Agouris, P.; Crooks, A.; Croitoru, A.; Stefanidis, A. Assessing completeness and spatial error of features in volunteered geographic information. ISPRS Int. J. Geo-Inf. 2013, 2, 507–530. [Google Scholar] [CrossRef]
- Ludwig, I.; Voss, A.; Krause-Traudes, M. A Comparison of the Street Networks of Navteq and OSM in Germany. In Advancing Geoinformation Science for a Changing World; Springer: Berlin/Heidelberg, Germany, 2011; pp. 65–84. [Google Scholar]
- Zielstra, D.; Hochmair, H.H. Using free and proprietary data to compare shortest-path lengths for effective pedestrian routing in street networks. Transp. Res. Rec. 2012, 2299, 41–47. [Google Scholar] [CrossRef]
- Vokhidov, H.; Hong, H.G.; Kang, J.K.; Hoang, T.M.; Park, K.R. Recognition of Damaged Arrow-Road Markings by Visible Light Camera Sensor Based on Convolutional Neural Network. Sensors 2016, 16, 2160. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Cham, Switerland, 2014; pp. 740–755. [Google Scholar]
- CVAT. Available online: https://cvat.org/ (accessed on 4 February 2022).
- Bing Maps Tile System. Available online: https://docs.microsoft.com/en-us/bingmaps/articles/bing-maps-tile-system?redirectedfrom=MSDN (accessed on 5 March 2022).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Methodlogy | Builds RNG | Detects Arrows | Multi-Directionality | Arrow Source | Compares Providers |
|---|---|---|---|---|---|---|
| Road Segment [5] | Binarization | NO | NO | NO | N/A | YES |
| Routing API [6] | Uses Routing APIs | YES | NO | NO | N/A | YES |
| Satellite Road Network [7] | Probabilistic Methods | YES | NO | NO | N/A | NO |
| Traffic Light [8] | CNN | NO | YES | YES | Traffic Lights | NO |
| Medical Images [9] | Template Comparison | NO | YES | NO | Medical Images | NO |
| Arrow R-CNN [10] | Arrow RCNN | NO | YES | NO | Flowcharts | NO |
| RDNN (this paper) | Faster RCNN | YES | YES | YES | Online Maps | YES |
| Provider: | Google Maps | Bing Maps | OSM |
|---|---|---|---|
| AP50 | 97.9% | 88.7% | 99.6% |
| AR50 | 100% | 90.1% | 100% |
| F1 Score | 98.9% | 89.3% | 99.8% |
| Provider: | Google Maps | Bing Maps | OSM |
|---|---|---|---|
| AP50 | 91.8% | 90.7% | 95.3% |
| AR50 | 92.1% | 91.3% | 95.8% |
| F1 Score | 91.9% | 91.0% | 95.5% |
| Comparison | Total Discrepancies Reported | True Positives | Precision |
|---|---|---|---|
| Google Maps vs. Bing Maps | 4 | 3 | 75% |
| Google Maps vs. OSM | 1 | 0 | 0% |
| Bing Maps vs. OSM | 8 | 3 | 37.5% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salama, A.; Hampshire, C.; Lee, J.; Sabour, A.; Yao, J.; Al-Masri, E.; Ali, M.; Govind, H.; Tan, M.; Agrawal, V.; et al. RDQS: A Geospatial Data Analysis System for Improving Roads Directionality Quality. ISPRS Int. J. Geo-Inf. 2022, 11, 448. https://doi.org/10.3390/ijgi11080448
Salama A, Hampshire C, Lee J, Sabour A, Yao J, Al-Masri E, Ali M, Govind H, Tan M, Agrawal V, et al. RDQS: A Geospatial Data Analysis System for Improving Roads Directionality Quality. ISPRS International Journal of Geo-Information. 2022; 11(8):448. https://doi.org/10.3390/ijgi11080448
Chicago/Turabian StyleSalama, Abdulrahman, Cordel Hampshire, Josh Lee, Adel Sabour, Jiawei Yao, Eyhab Al-Masri, Mohamed Ali, Harsh Govind, Ming Tan, Vashutosh Agrawal, and et al. 2022. "RDQS: A Geospatial Data Analysis System for Improving Roads Directionality Quality" ISPRS International Journal of Geo-Information 11, no. 8: 448. https://doi.org/10.3390/ijgi11080448
APA StyleSalama, A., Hampshire, C., Lee, J., Sabour, A., Yao, J., Al-Masri, E., Ali, M., Govind, H., Tan, M., Agrawal, V., Maresov, E., & Prakash, R. (2022). RDQS: A Geospatial Data Analysis System for Improving Roads Directionality Quality. ISPRS International Journal of Geo-Information, 11(8), 448. https://doi.org/10.3390/ijgi11080448