
Mining Type-β Co-Location Patterns on Closeness Centrality in Spatial Data Sets


Abstract
:1. Introduction
1.1. Motivation
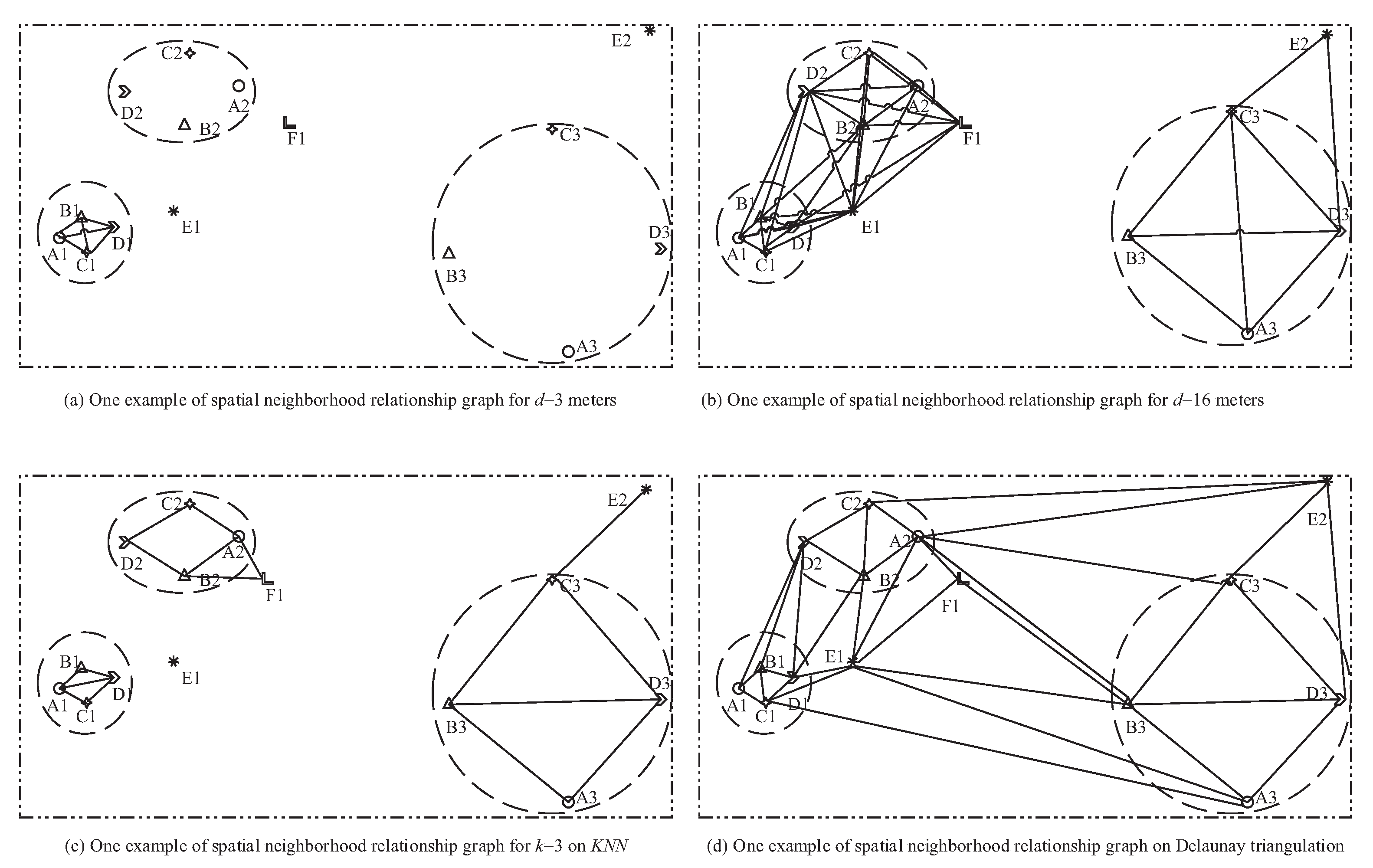
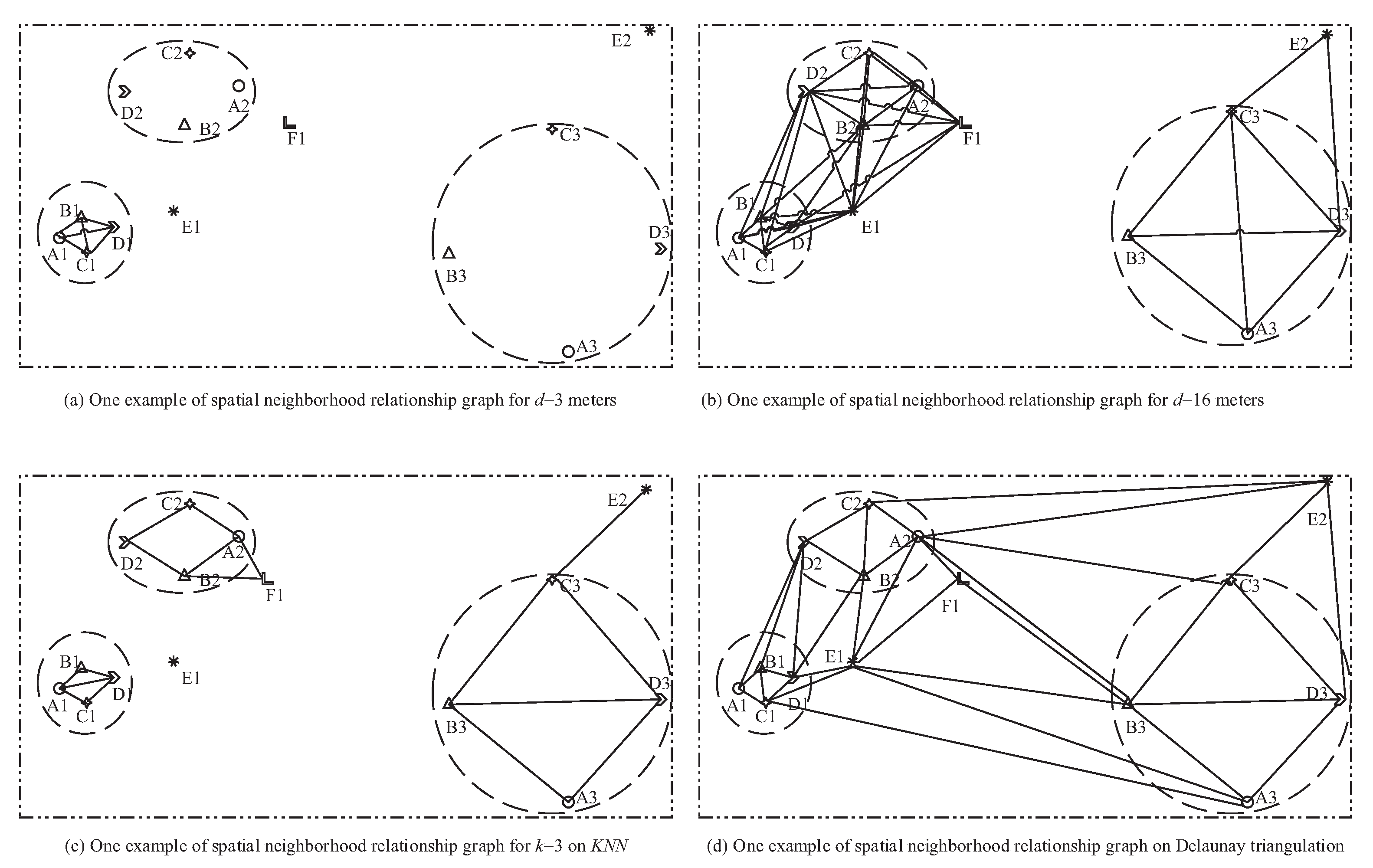
- It is difficult to build a model to generate neighbor relationships to adapt data sets with different distribution densities. To obtain neighbor relationships satisfied to densities, many scholars have proposed different solutions. Figure 1 shows some representative approaches on distance thresholds, such as KNN and the Delaunay triangulation. For example, it is intuitive that A1 and B1 are neighbors of each other in a dense region, and so are A3 and B3 in a sparse zone. On the contrary, it is intuitive that B2 and D1 are not neighbors of each other while B3 and D3 are. As a result, it is not friendly to determine an optimal distance threshold to generate neighbor relationships even for experimental users because (a) too small of a distance threshold may underestimate the prevalence of patterns in sparse regions (e.g., Figure 1a) while (b) a too big one may overestimate the prevalence of patterns in dense zones (e.g., Figure 1b). For example, A1 and D1 should not be considered to be neighbors of each other, while D1 and E1 can be considered to be neighbors of each other in Figure 1d. Furthermore, neighbor relationships in different density areas can overlap but not split. This is the biggest difference between co-location pattern mining and transaction-based association analysis. For example, D1 and E1 can be neighbors of each other in a dense zone, and so can B2 and E1 in a sparse region. Thus, this statement is not friendly to classical clustering.
- The instance of a pattern should be a co-occurrence, and then it would be perfect to integrate and extend the traditional co-occurrences such as the clique, star, and so on [8]. For example, {A2, B2, C2, D2} is suggested to not be an instance of {A, B, C, D}, while the instance is based on the clique in Figure 1a. However, the correlation in {A2, B2, C2, D2} is also strong. Furthermore, {A, B, C, D} selectively occurs in other regions of Figure 1. If instances of patterns are based on the clique, {A, B, C, D} can be prevalent only in Figure 1b when the prevalence threshold is 1. This cannot meet the expectation that the features in {A, B, C, D} are strongly correlated. Furthermore, the same users may be interested in patterns with different correlations in different data sets, let alone different users. To obtain expected patterns, users always have to resize either the parameter of neighbor relationships generation or prevalence threshold in traditional co-location pattern mining models. It inevitably leads to redundancy. For example, to obtain {A, B, C, D} in Figure 1, the prevalence threshold should be reduced to 1/3 if the neighbor relationships is as Figure 1a, or the distance threshold should be increased to 16 m such as in Figure 1b when the prevalence threshold is 1.
- Since traditional models check the prevalence of patterns are generally on features’ instance appearance ratios, it inevitably loses instance topology on the spatial neighbor relationships. For example, it can be acknowledged that {B, C, D} is more correlated than {B, D, E} even if the instances of each corresponding feature have appeared in the two patterns with an adaptive definition of pattern instances. The correlation between a feature and the other ones in a pattern can be evaluated from the topology of the pattern’s instances. Understandably, if the instances of a feature in a pattern always have a higher center in the topology, the feature has a stronger correlation with the other features in the pattern than the other ones have. How can the spatial neighbor relationships be transmitted and accumulated to the interesting patterns? This problem needs to be studied urgently. For example, B and C are more likely to be in the center of the topology than A and D in {A, B, C, D} in Figure 1.
1.2. Overall Solution
- Based on that the distances between an instance and its neighbors tend to be similar, a robust way is introduced to generate neighbor relationships. This method is friendly to different distribution densities of spatial data sets. It absorbs the advantages of distance threshold and nearest neighbors.
- A co-occurrence based on closeness centrality is proposed to integrate the clique and the star. It is an extension of instances of the traditional co-location pattern. It can be flexibly scaled with setting the threshold according to the user’s interests. Some interesting patterns are no longer ignored, while spatial neighbor relationships and prevalence patterns need not be sacrificed to redundancy.
- An extended co-location pattern, called type- co-location pattern, is proposed on the closeness centrality. Since the closeness centrality carries the topology of instances, whether a feature is in the center of the topology of a type- co-location pattern can be evaluated.
- Some properties are demonstrated to prune candidate patterns. Our algorithms that were proven to be valid and comprehensive are proposed. Furthermore, they are put to the test using both real and synthetic data sets. The findings of the trial reveal that the framework is more adaptable to the needs of users in comparison with some other algorithms.
2. Related Work
2.1. Traditional Definitions and Lemmas
2.2. Review
3. Spatial Mutual Neighbor Relationship Graph
3.1. Segmentation
3.2. Problem Statement
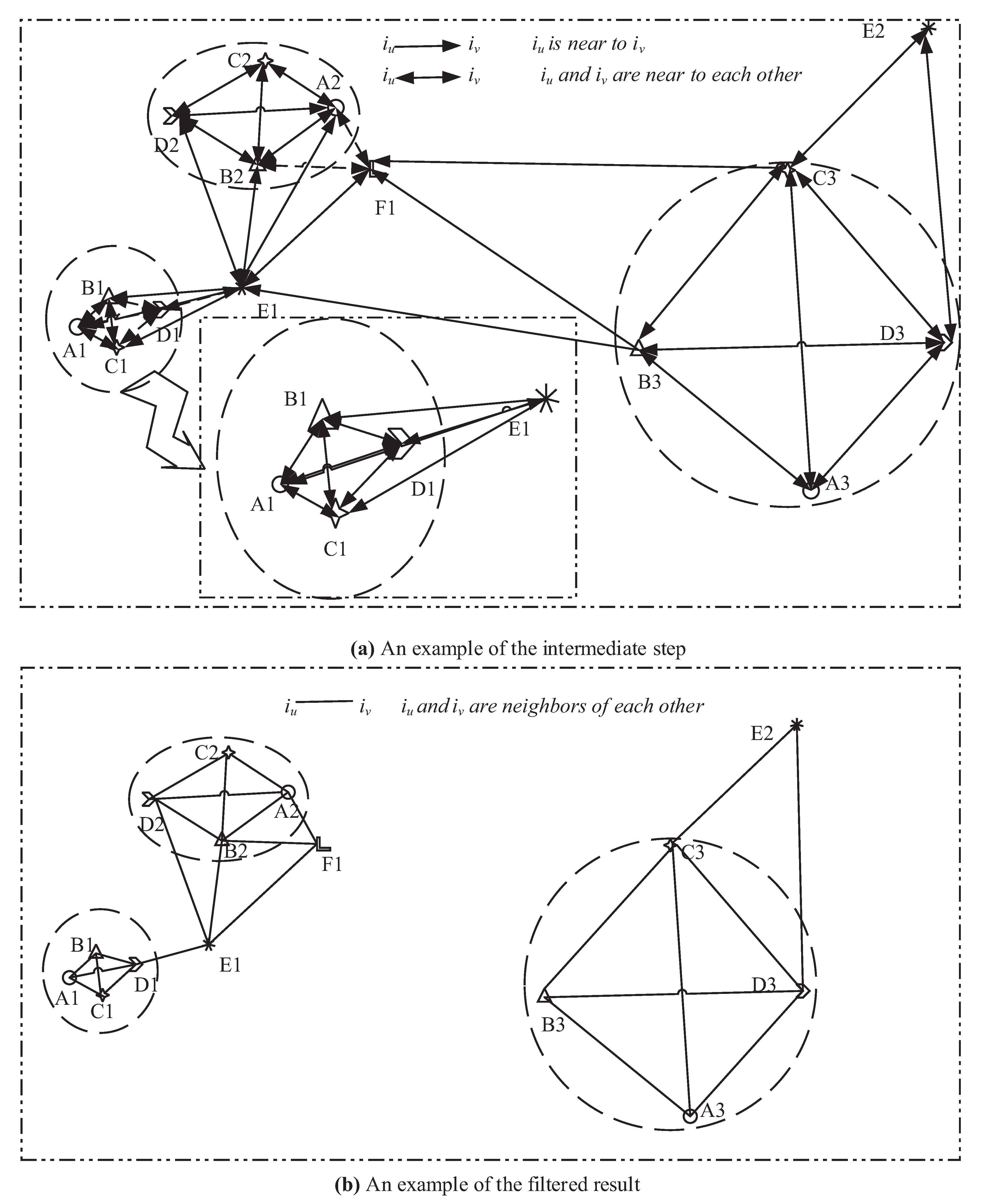
3.3. Generating Mutual Neighbor Relationship Graph on KD-Tree
| Algorithm 1 Generating mutual neighbor relationship graph on KD-Tree. |
| Require:D, F, I, . |
| Ensure: |
| 1: |
| 2: tree = KD-Tree(D) |
| 3: for do |
| 4: //Definition 7. |
| 5: end for |
| 6: for do |
| 7: for do |
| 8: if then |
| 9: //Definition 8. |
| 10: end if |
| 11: end for |
| 12: end for |
| 13: return G = (I,E) //Definition 9. |
4. Prevalence Check on Closeness Centrality
4.1. Definitions and Theorems
4.2. Type- Co-Location Pattern Mining
| Algorithm 2 Mining type- co-location patterns (-CPM) |
| Require:D (the given data set), F (the feature set), I (the instance set with location information), the elastic coefficient to generate mutual neighbor relationships, the threshold for closeness centrality, (the given prevalence threshold). |
| Ensure: (type- co-location patterns with closeness centrality of each feature). |
| 1: G = Algorithm 1 (D, ) //Generate spatial mutual neighbor relationship graph. |
| 2: //Get shortest path lengths between instance pairs. |
| 3: for do |
| 4: for do |
| 5: if then |
| 6: //Theorem 1. |
| 7: end if |
| 8: end for |
| 9: end for |
| 10: //Theorem 2. |
| 11: for do |
| 12: if then |
| 13: |
| 14: for do |
| 15: //Definition 17/ 18 and Lemma 2. |
| 16: end for |
| 17: //Definition 15. |
| 18: end if |
| 19: end for |
| 20: return |
5. Experiment Analysis
5.1. Precision, Accuracy, and Recall
5.2. Efficiency
5.3. Density Response
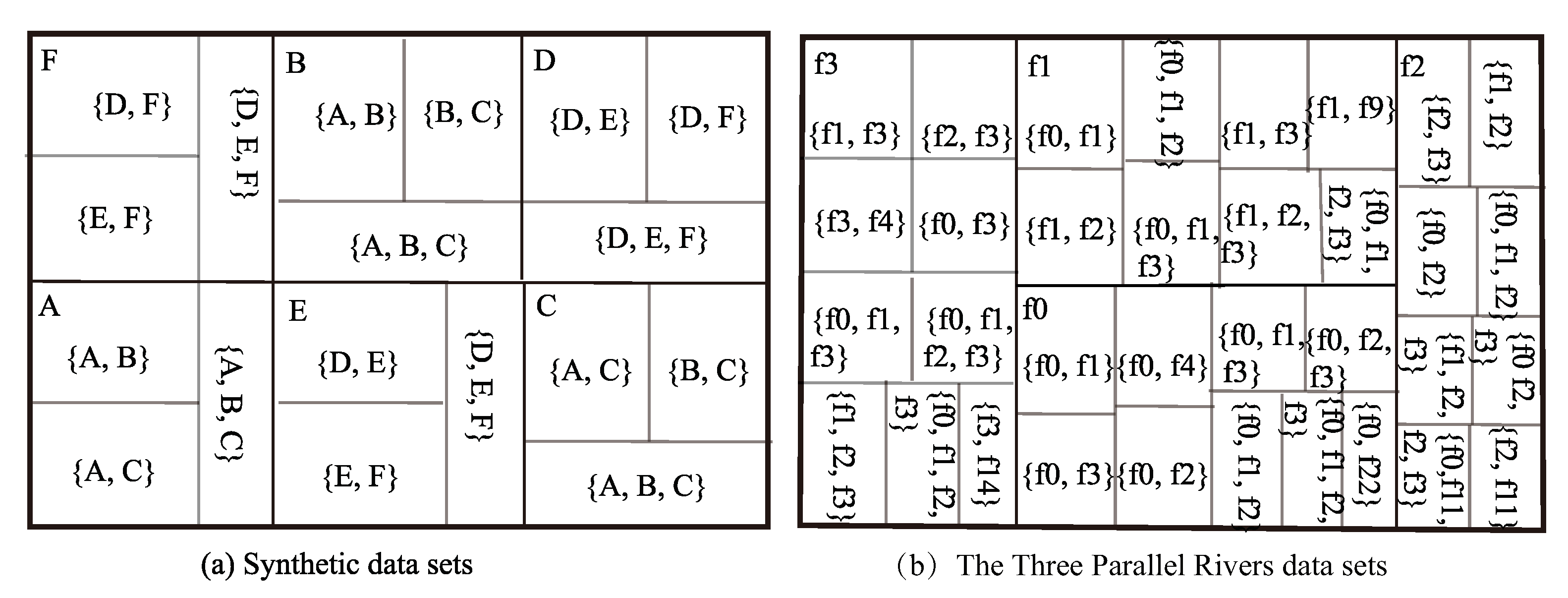
5.4. Feature Closeness Centrality
6. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| k-nearest neighbors | |
| Co-location table instance | |
| Participation index | |
| Inside radius | |
| Outer radius limited by | |
| Directed neighbors limited by | |
| Mutual neighbors limited by | |
| Closeness centrality | |
| The minimum closeness centrality | |
| Type- co-location instance | |
| Type- participation ratio | |
| Type- participation index | |
| Type- co-location patterns | |
| Approximate type- co-location patterns | |
| Closeness centrality of a feature | |
| Extended closeness centrality of a feature | |
| -CPM | The algorithm mining type- co-location patterns |
| RCMA | The regional co-location mining algorithm |
| SGCT_K | A sparse-graph and condensed tree-based maximal co-location algorithm with a |
| Kernel function | |
| True positive pattern set | |
| False positive pattern set | |
| True negative pattern set | |
| False negative pattern set |
References
- Wang, X.; Lei, L.; Wang, L.; Yang, P.; Chen, H. Spatial co-location pattern discovery Incorporating Fuzzy Theory. IEEE Trans. Fuzzy Syst. 2021, 30, 2055–2072. [Google Scholar] [CrossRef]
- Wang, L.Z.; Fang, Y.; Zhou, L. Preference-Based Spatial Co-Location Pattern Mining; Big Data Management Series; Springer: Singapore, 2022. [Google Scholar] [CrossRef]
- Darwin, C. The Origin of Species; Manchester University Press: Manchester, UK; New York, NY, USA, 1998. [Google Scholar]
- Li, J.; Adilmagambetov, A.; Jabbar, M.M.; Zane, O.R.; Osornio-Vargas, A.; Wine, O. On discovering co-Location patterns in datasets: A case study of pollutants and child cancers. Geoinformatica 2016, 20, 651–692. [Google Scholar] [CrossRef]
- Tran, V.; Wang, L.; Chen, H.; Xiao, Q. MCHT: A maximal clique and hash table-based maximal prevalent co-location pattern mining algorithm. Expert Syst. Appl. 2021, 175, 114830–114850. [Google Scholar] [CrossRef]
- Wang, L.; Bao, X.; Zhou, L.; Chen, H. Mining maximal sub-prevalent co-location patterns. World Wide Web 2019, 22, 1971–1997. [Google Scholar] [CrossRef]
- Sundaram, V.M.; Thnagavelu, A.; Paneer, P. Discovering co-location patterns from spatial domain using a delaunay approach. Procedia Eng. 2012, 38, 2832–2845. [Google Scholar] [CrossRef]
- Hu, Z.; Wang, L.; Tran, V.; Chen, H. Efficiently mining spatial co-location patterns utilizing fuzzy grid cliques. Inf. Sci. 2022, 592, 361–388. [Google Scholar] [CrossRef]
- Zhang, X.; Zhu, J.; Wang, Q.; Zhao, H. Identifying influential nodes in complex networks with community structure. Knowl. Based Syst. 2013, 42, 74–84. [Google Scholar] [CrossRef]
- Huang, Y.; Xiong, H.; Shekhar, S.; Pei, J. Mining confident co-location rules without a support threshold. In Proceedings of the 2003 ACM Symposium, San Diego, CA, USA, 10–12 June 2003; pp. 497–502. [Google Scholar]
- Batal, I.; Hauskrecht, M. A concise representation of association rules using minimal predictive rules. In Proceedings of the Machine Learning and Knowledge Discovery in Databases ECML PKDD 2010, Berlin/Heidelberg, Germany, 20–24 September 2010; pp. 87–102. [Google Scholar]
- Huang, Y.; Shekhar, S.; Xiong, H. Discovering colocation patterns from spatial data sets: A general approach. IEEE Trans. Knowl. Data Eng. 2004, 16, 1472–1485. [Google Scholar] [CrossRef]
- Yao, X.; Chen, L.; Peng, L.; Chi, T. A co-location pattern-mining algorithm with a density-weighted distance thresholding consideration. Inf. Sci. 2017, 396, 144–161. [Google Scholar] [CrossRef]
- Zhao, J.; Wang, L.; Bao, X.; Tan, Y. Mining co-location patterns with spatial distribution characteristics. In Proceedings of the 2016 International Conference on Computer, Information and Telecommunication Systems (CITS), Kunming, China, 6–8 July 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Feng, Q.; Chiew, K.; He, Q.; Huang, H. Mining regional co-location patterns with KNNG. J. Intell. Inf. Syst. 2014, 42, 485–505. [Google Scholar]
- Tran, V.; Wang, L.; Chen, H. A spatial co-location pattern mining algorithm without distance thresholds. In Proceedings of the 2019 IEEE International Conference on Big Knowledge (ICBK), Beijing, China, 10–11 November 2019; pp. 242–249. [Google Scholar] [CrossRef]
- Wang, J.; Wang, L.; Wang, X. Mining prevalent co-Location patterns based on global topological relations. In Proceedings of the 2019 20th IEEE International Conference on Mobile Data Management (MDM), Hong Kong, China, 10–13 June 2019; pp. 210–215. [Google Scholar] [CrossRef]
- Yao, X.; Wang, D.; Peng, L.; Chi, T. An adaptive maximal co-location mining algorithm. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 5551–5554. [Google Scholar] [CrossRef]
- Tantrum, J.; Murua, A.; Stuetzle, W. Hierarchical model-based clustering of large datasets through fractionation and refractionation. Inf. Syst. 2004, 29, 315–326. [Google Scholar] [CrossRef]
- Zhou, G.; Li, Q.; Deng, G.; Yue, T.; Zhou, X. Mining co-location patterns with clusetering items from spatial data sets. ISPRS—Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, XLII-3, 2505–2509. [Google Scholar] [CrossRef]
- Qian, F.; Yin, L.; He, Q.; He, J. Mining spatio-temporal co-location patterns with weighted sliding window. In Proceedings of the 2009 IEEE International Conference on Intelligent Computing and Intelligent Systems, Shanghai, China, 20–22 November 2009; Volume 3, pp. 181–185. [Google Scholar] [CrossRef]
- Tang, M.; Wang, Z. Research of spatial co-location pattern mining based on segmentation threshold weight for big dataset. In Proceedings of the 2015 2nd IEEE International Conference on Spatial Data Mining and Geographical Knowledge Services (ICSDM), Fuzhou, China, 8–10 July 2015; pp. 49–54. [Google Scholar] [CrossRef]
- Dai, B.R.; Lin, M.Y. Efficiently mining dynamic zonal co-location patterns based on maximal co-locations. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining Workshops, Vancouver, BC, Canada, 11 December 2011; pp. 861–868. [Google Scholar] [CrossRef]
- Agarwal, P.; Verma, R.; Gunturi, V.M.V. Discovering spatial regions of high correlation. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW), Barcelona, Spain, 12–15 December 2016; pp. 1082–1089. [Google Scholar] [CrossRef]
- Zeng, X.; Li, Z.; Wang, J.; Li, X. High utility co-location patterns mining from spatial dataset with time interval. In Proceedings of the 2019 IEEE 4th International Conference on Image, Vision and Computing (ICIVC), Xiamen, China, 5–7 July 2019; pp. 628–636. [Google Scholar] [CrossRef]
- Yang, P.; Wang, L.; Wang, X.; Fang, D. An effective approach on mining co-Location patterns from spatial databases with rare features. In Proceedings of the 2019 20th IEEE International Conference on Mobile Data Management (MDM), Hong Kong, China, 10–13 June 2019; pp. 53–62. [Google Scholar] [CrossRef]
- Chan, H.K.H.; Long, C.; Yan, D.; Wong, R.C.W. Fraction-score: A new support measure for co-location pattern mining. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE), Macao, China, 8–11 April 2019; pp. 1514–1525. [Google Scholar] [CrossRef]
- Fang, Y.; Wang, L.; Zhou, L. Mining spatial co-location patterns with key features. J. Data Acquis. Process. 2018, 33, 692–703. [Google Scholar]
- Hou, W.; Li, D.; Xu, C.; Zhang, H.; Li, T. An advanced k nearest neighbor classification algorithm based on KD-tree. In Proceedings of the 2018 IEEE International Conference of Safety Produce Informatization (IICSPI), Chongqing, China, 10–12 December 2018; pp. 902–905. [Google Scholar] [CrossRef]
- Shee, S.C. Tabular algorithms for the shortest path and longest path. Nanta Math. 1977, 10, 100–105. [Google Scholar]
- Shekhar, S.; Huang, Y. Discovering spatial co-location patterns: A summary of results. Lect. Notes Comput. Sci. 2001, 2121, 236–256. [Google Scholar] [CrossRef]
- Yoo, J.S.; Shekhar, S. A joinless approach for mining Spatial colocation patterns. IEEE Trans. Knowl. Data Eng. 2006, 18, 1323–1337. [Google Scholar] [CrossRef]
- Graham, R.L.; Hell, P. On the history of the minimum spanning tree problem. Ann. Hist. Comput. 1985, 7, 43–57. [Google Scholar] [CrossRef]
- Wang, L.; Bao, X.; Chen, H.; Cao, L. Effective lossless condensed representation and discovery of spatial co-location patterns. Inf. Sci. 2018, 436, 197–213. [Google Scholar] [CrossRef]
- Buckland, M.K.; Gey, F.C. The relationship between Recall and Precision. J. Assoc. Inf. Sci. Technol. 2010, 45, 12–19. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
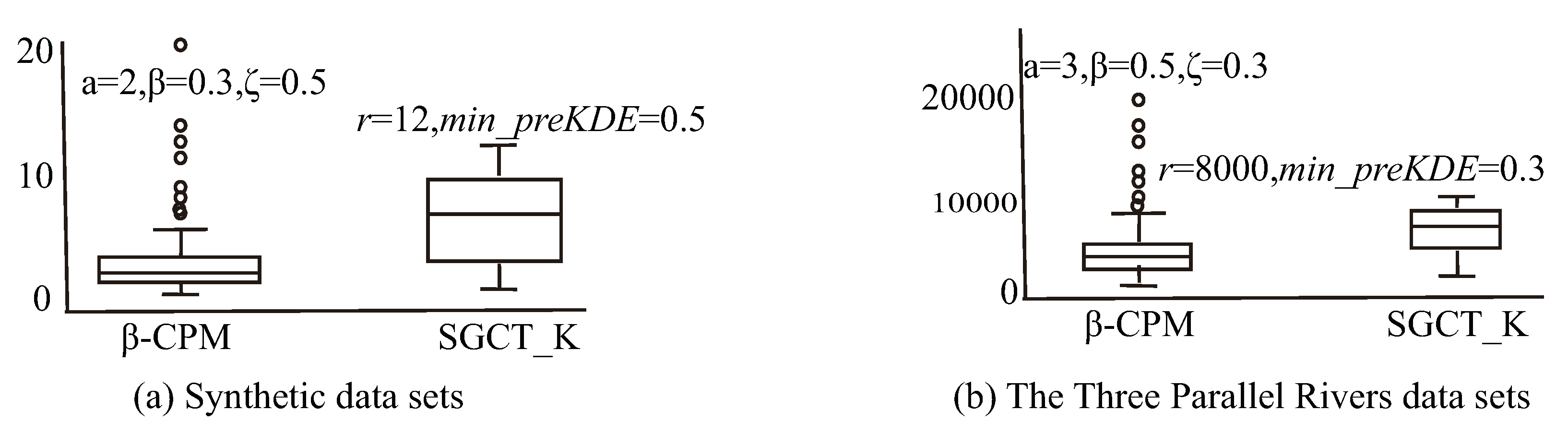{kind=link}
{kind=link}
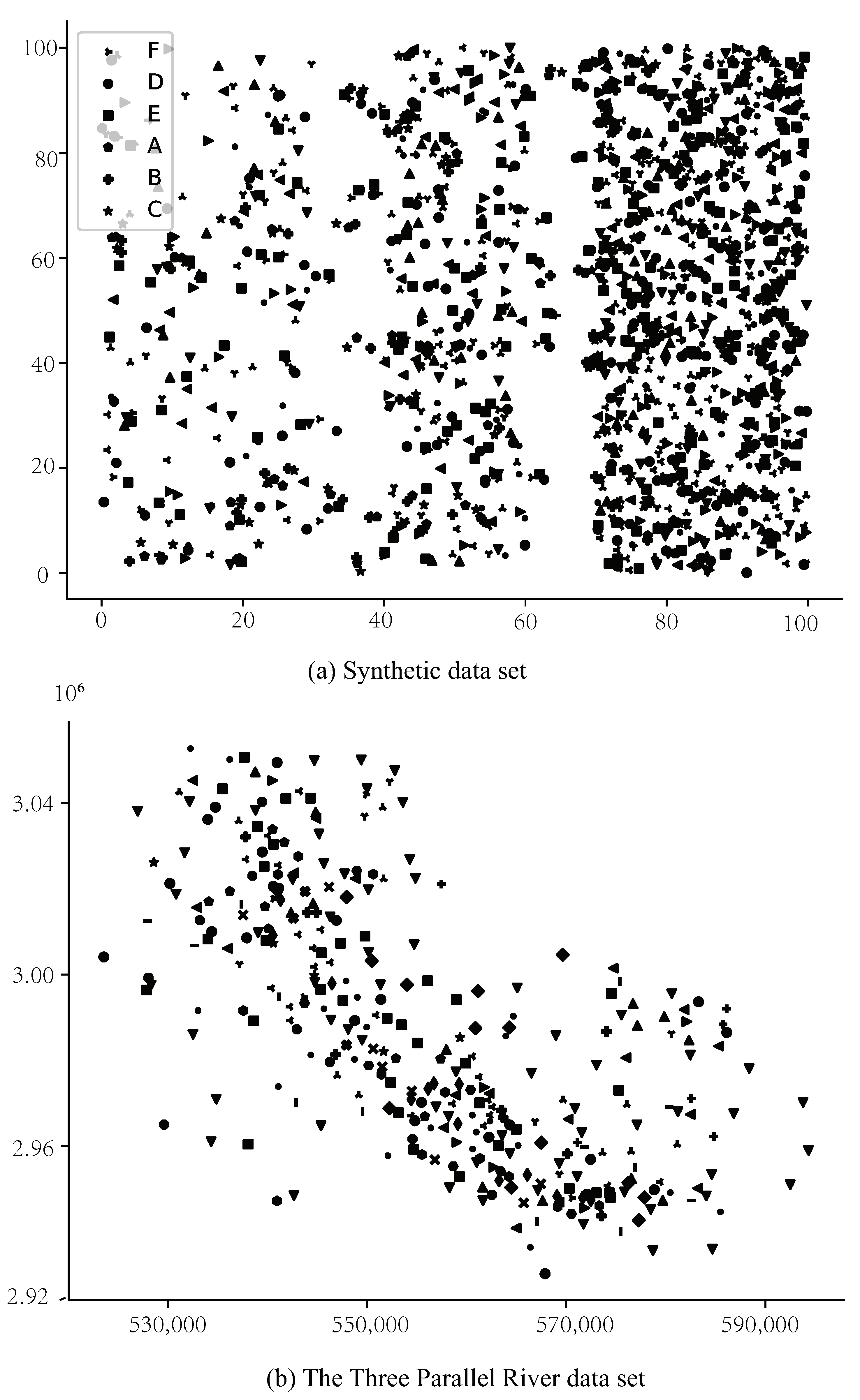
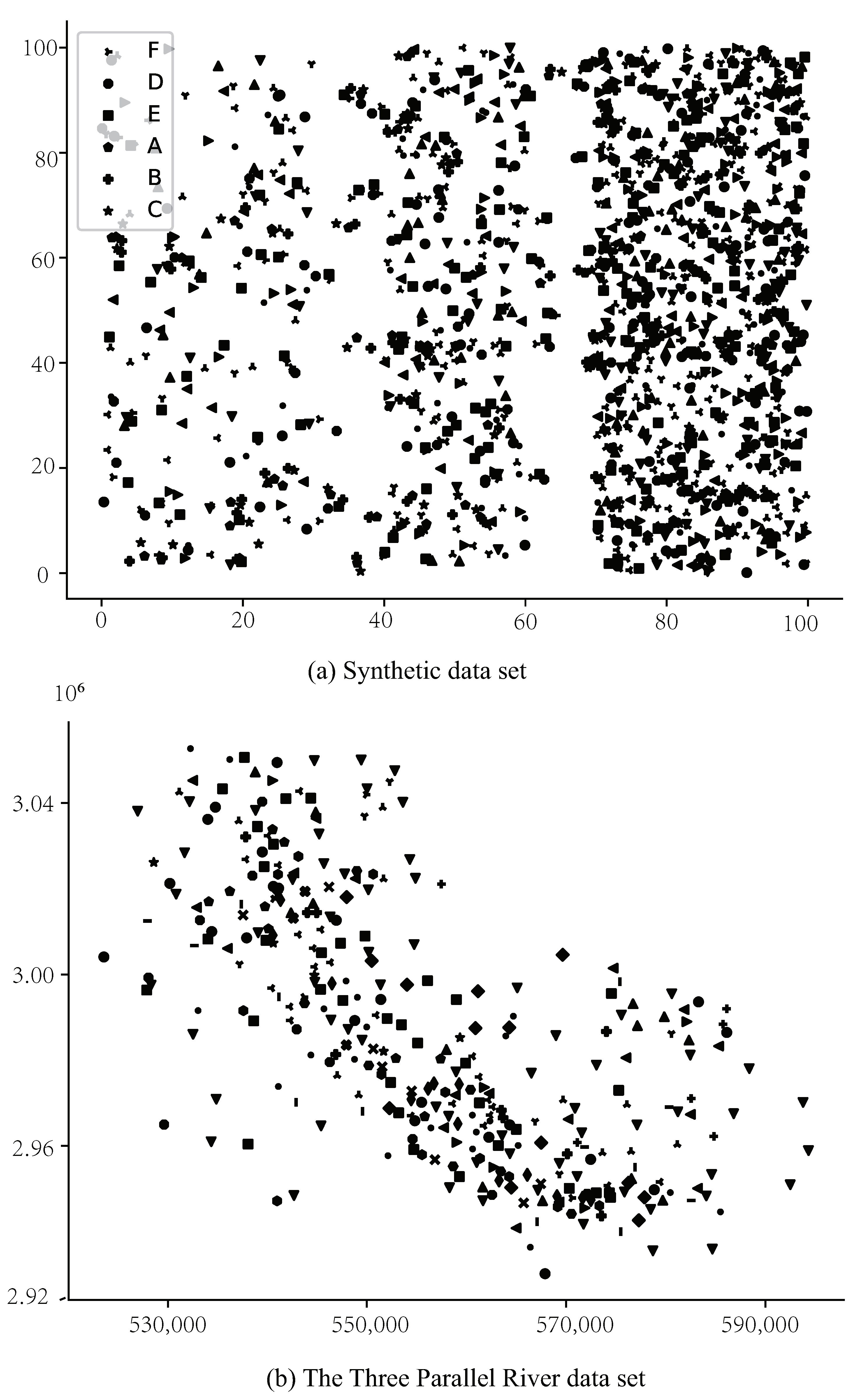
| Data Sets | Feature Count | Instance Count | Distribution Densities |
|---|---|---|---|
| Synthetic data set | 16 | 1515 | Density ratios of 3:8:13 |
| The Three Parallel Rivers data set | 31 | 337 | More different densities |
| Algorithms | Synthetic Data Set | The Three Parallel Rivers Data Sets |
|---|---|---|
| RCMA | 3,492,173,294 ( = 0.5, = 0.5, = 0.05) | ( = 0.5, = 0.2, = 0.05) |
| SGCT_K | 6,408,119 (r = 12, = 0.3) | 1,129,484 (r = 8000, = 0.3) |
| -CPM | 208,859 ( = 2, = 0.3, = 0.5) | 136,428 ( = 3, = 0.5, = 0.5) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, M.; Wang, L.; Wu, P.; Tran, V. Mining Type-β Co-Location Patterns on Closeness Centrality in Spatial Data Sets. ISPRS Int. J. Geo-Inf. 2022, 11, 418. https://doi.org/10.3390/ijgi11080418
Zou M, Wang L, Wu P, Tran V. Mining Type-β Co-Location Patterns on Closeness Centrality in Spatial Data Sets. ISPRS International Journal of Geo-Information. 2022; 11(8):418. https://doi.org/10.3390/ijgi11080418
Chicago/Turabian StyleZou, Muquan, Lizhen Wang, Pingping Wu, and Vanha Tran. 2022. "Mining Type-β Co-Location Patterns on Closeness Centrality in Spatial Data Sets" ISPRS International Journal of Geo-Information 11, no. 8: 418. https://doi.org/10.3390/ijgi11080418
APA StyleZou, M., Wang, L., Wu, P., & Tran, V. (2022). Mining Type-β Co-Location Patterns on Closeness Centrality in Spatial Data Sets. ISPRS International Journal of Geo-Information, 11(8), 418. https://doi.org/10.3390/ijgi11080418