
A Lightweight Object Detection Method in Aerial Images Based on Dense Feature Fusion Path Aggregation Network

 , , ,
, , ,
Abstract
:1. Introduction
- The aerial images are generally of a large size, leading to the result that the size of targets is small relative to the imagery, which is easy to produce missed detection.
- RSIs are often interfered with by external causes, such as shadows, similar instances and complex backgrounds, making it hard to distinguish texture rules between objects and false objects.
- When some instances are placed side by side in RSIs, Non-Maximum Suppression (NMS) will filter bounding boxes of different objects, resulting in missed detection.
- This article proposes an object detection method for aerial images. This method is not only lightweight but can also carry out accurate and efficient detection work in RSIs.
- In order to strengthen the ability of the model to detect small and medium-sized objects, semantic and location information in feature maps is fused by the Feature Reuse Module (FRM), which can enrich feature information extracted from the backbone.
- A Dense Feature Fusion Path Aggregation Network (DFF-PANet) by using Cross Stage Residual Dense Block (CSRDB) has been designed to handle the problem of external interference caused by complex and changeable RSIs better.
- This study uses the DOTA and the HRSC2016 datasets for experiments to validate the model we put forward and then analyzes the effects of every improvement we suggested through a series of comparative and ablation experiments.
2. Related Works
2.1. Object Detection Algorithms
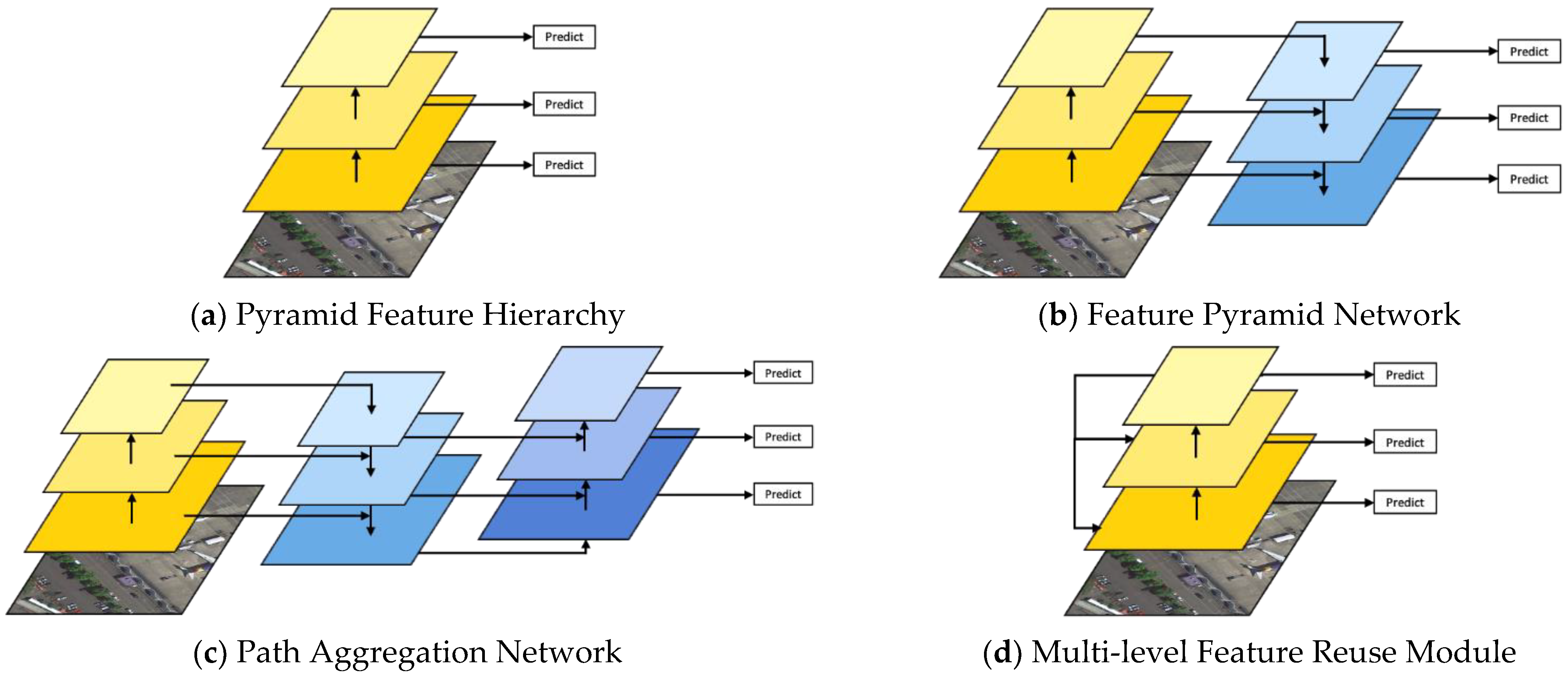
2.2. Feature Pyramid
3. Method
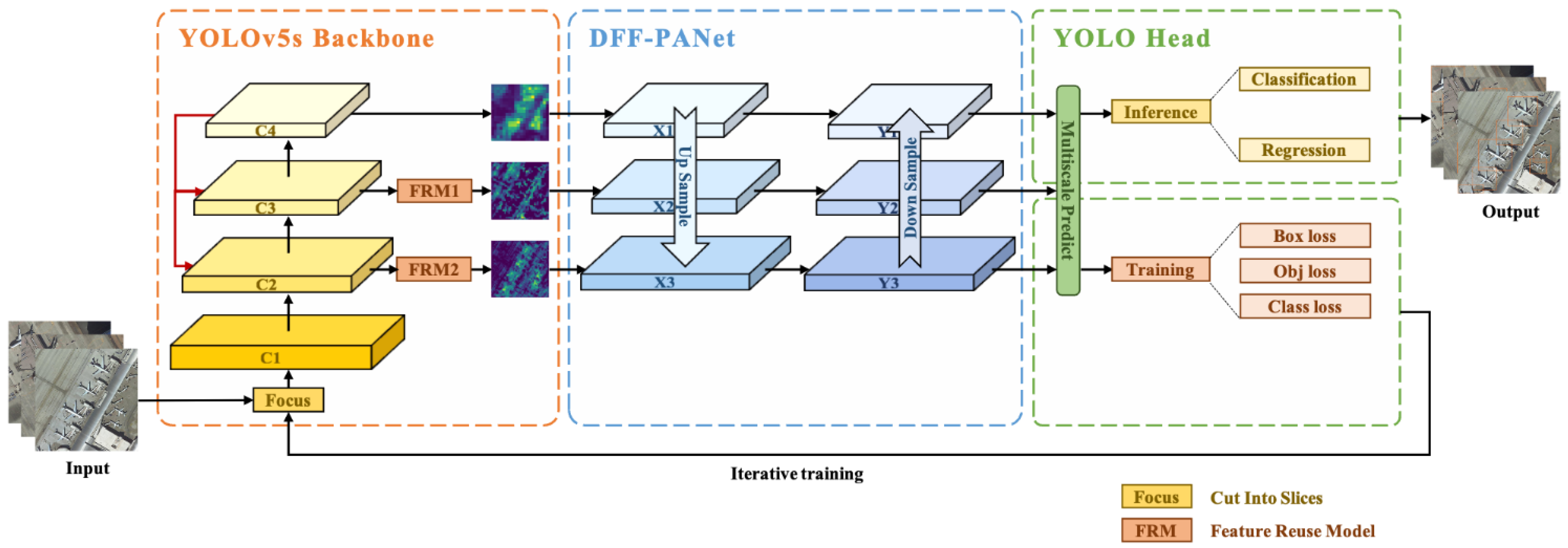
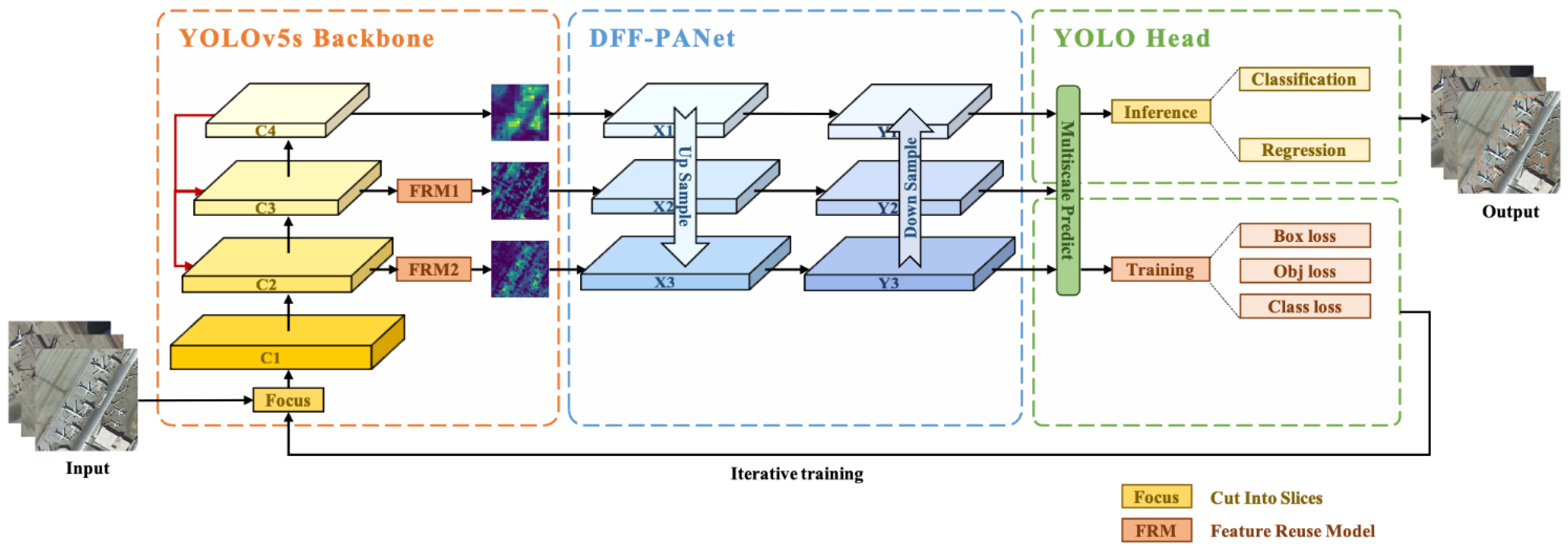
3.1. Overall Network Structure
3.2. YOLOv5s Backbone
- Conversion strategy: Firstly, the 1 × 1 convolutional layer is used to reduce the dimension of each source layer. Next, upsampling by bilinear interpolation, the scale is transformed to a scale of the same size as the convolution to be fused, thus generating the source layer with a transformed resolution ( and , respectively). It is worth noting that BatchNorm normalization [31] and ReLU [32] activation function are added to every conv1 × 1 convolutional layer to handle the issue of gradient disappearance and gradient explosion during backpropagation.
- Feature reuse: After the process of conversion strategy Ti, new feature maps are generated ( and , respectively). For reusing, there are two separate methods to merge new feature maps with , concatenation and element sum operation. Concatenation operation is often used for image detection, which can fuse the extracted convolutional features and preserve the information while increasing the dimension. The element sum operation is often used for image classification, which can increase the image information and preserve the dimension while increasing the information. Therefore, we use the concatenation operation to reuse feature information of the backbone so that the reused features are used as the input of DFF-PANet.
- Feature fusion: After is generated, it is sent to DFF-PANet (it will be introduced in Section 3.3) with the pyramid feature map of the previous layer for feature fusion, and the next pyramid feature map is generated.
3.3. Dense Feature Fusion Path Aggregation Network (DFF-PANet)
- Dense connection layer: In this module, the dense connection layer is composed of 6 convolution layers for dense connection, with a growth rate of 32. represents the output of the first convolution. represents the output of any intermediate convolution. In this essay, . represents the output of the last convolution. In this essay, . Taking any intermediate convolution as an example, the output of the convolution is concatenated by the previous layer of RDB and all convolutions in RDB, then calculated by the convolutional layer and the ReLU activation function, finally, the output is obtained. It is noteworthy that all convolutions in RDB refer to the convolutions from the first convolution to the previous convolution of this convolution. Its mathematical expression can be represented as:where represents the ReLU activation function. represents the weight of the -th convolutional layer. The dense connection layer makes CBS and the output of each layer directly connected to all subsequent layers, which not only retains feedforward features but also extracts local dense features.
- Local feature fusion: All features in RDB are locally fused by concatenating. In addition, the 1 × 1 convolutional layer is introduced to reduce the dimension and adaptively control the output information. Its mathematical expression can be expressed as:where represents the 1 × 1 convolutional layer in RDB. Local feature fusion can adaptively fuse the previous convolutional features and all the convolutional features in the current RDB.
- Local residual learning: Local residual learning can promote the information flow between feature information before RDB and local dense features processed by RDB. The mathematical expression of the final output of RDB can be expressed as follows:where represents the feature information after local feature fusion. Local residual learning not only contains features before RDB but also local dense features after RDB.
3.4. YOLO Head
3.4.1. Inference
3.4.2. Training
- (1)
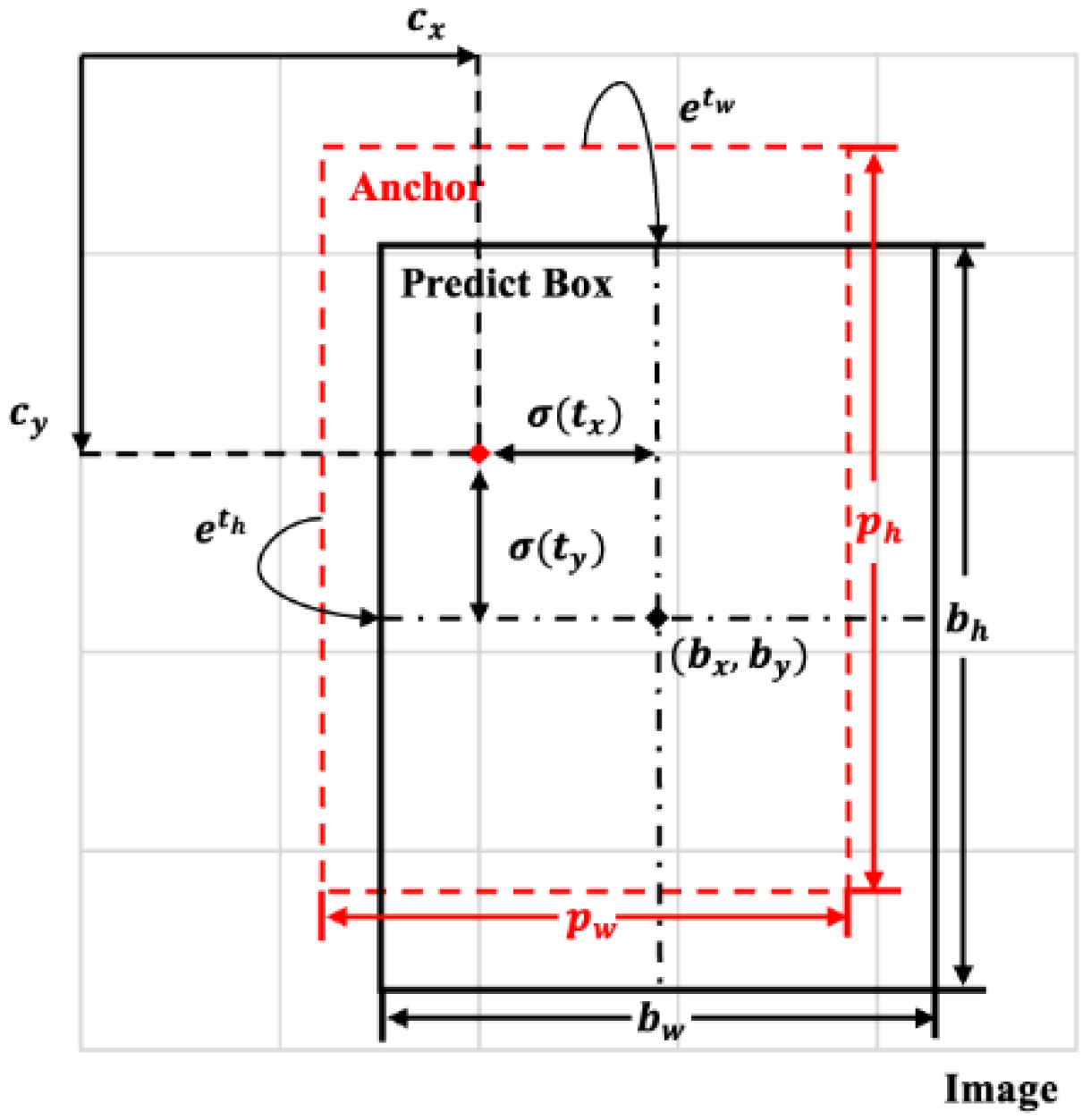
- Bounding box regression loss functionCIoU Loss [35] is introduced to calculate the position loss of the prediction box and the ground truth box. Its mathematical expression can be expressed aswhere and are the width and height of the prediction box , respectively. are are the width and height of the ground truth box , respectively. Nt is the number of objects. is the weight coefficient. is the distance of aspect ratio between prediction box and ground truth box.
- (2)
- Confidence loss functionwhere is the number of channels of the prediction layer, the default is 3. is the prediction vector. is the real vector. is the width of the prediction layer. is the height of the prediction layer.
- (3)
- Classification loss functionwhere is the channels number of the prediction layer, the default is 3. is the prediction probability distribution of each category. is the real probability distribution of each category. is the number of objects. is the number of categories.
3.5. Pseudo-Code of Network Structure
| Algorithm 1: A lightweight object detection method. | |
| Input: | , refers to the input image. |
| Step 1: | , is sent into the backbone to gain feature maps . |
| Step 2: | , refers to the feature maps to be sent into the DFF-PANet for feature fusion. for k in range (1,4) do if then continue else: if : if if end if end for |
| Step 3: | is sent into DFF-PANet, three feature maps of different sizes are generated. |
| Output: | return |
4. Experiments
4.1. Dataset
4.1.1. DOTA Dataset
4.1.2. HRSC2016 Dataset
4.2. Network Training
4.2.1. Parameter Setting
4.2.2. Evaluation Criteria
4.3. Experimental Results
4.3.1. Experimental Results on the DOTA Dataset
4.3.2. Experimental Results on the HRSC2016 Dataset
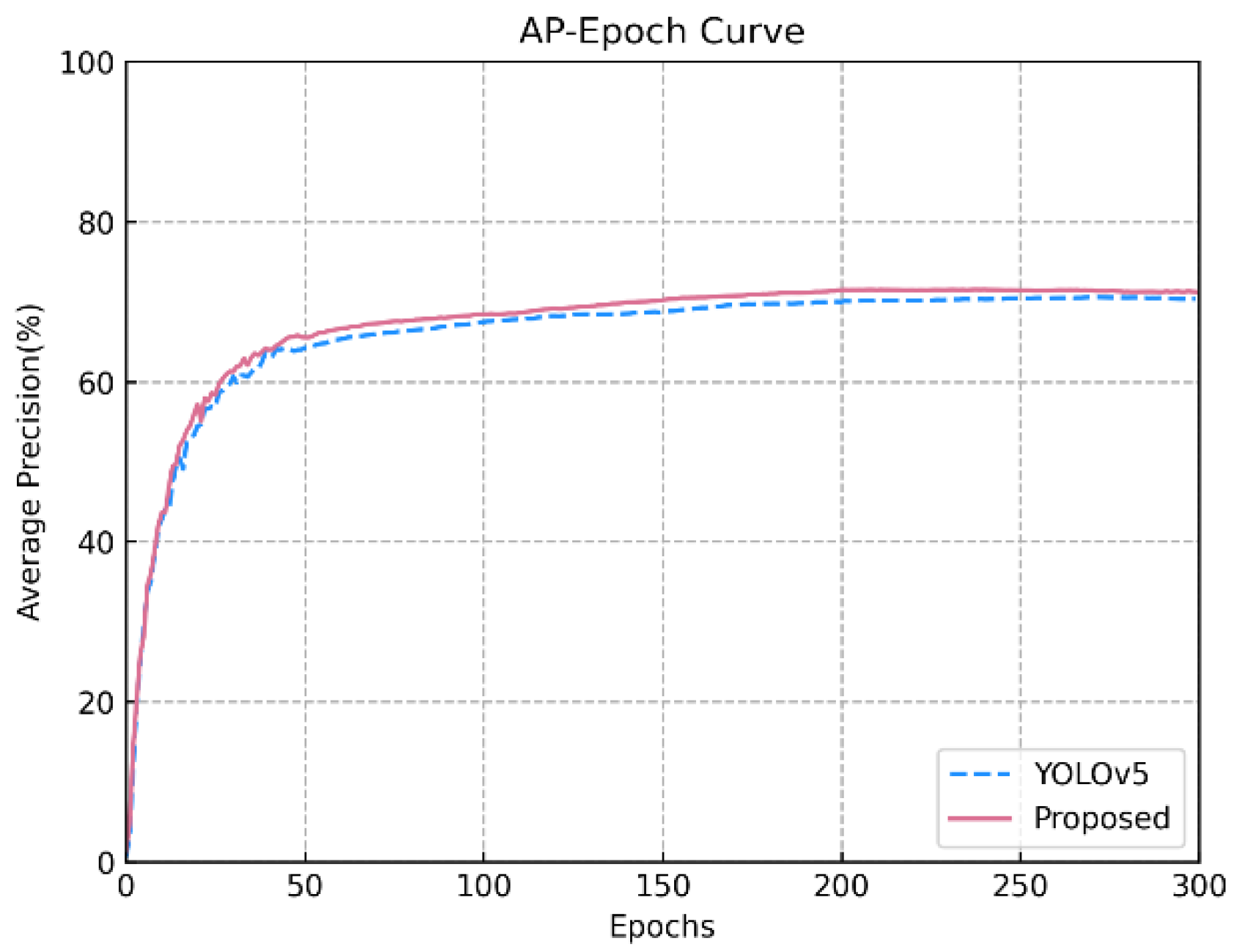
4.4. Visualization Results
4.5. Ablation Study
- Feature Reuse Module (FRM): To demonstrate the validity of the FRM, we added the FRM based on the baseline. With the help of the FRM, the network arrived at 70.8% mAP, which was 0.4% higher than the baseline. Moreover, the experimental result was higher than those without the FRM. It is because before using FRM, low-level feature maps lack rich semantic information, which leads to insufficient detection ability of small instances. While adding FRM, the position information in low-level feature maps can fully mix with semantic information in high-level ones, thereby enhancing the feature reuse ability of the backbone to promote the problem of insufficient feature extraction ability of the network.
- Dense Feature Fusion Path Aggregation Network (DFF-PANet): To certify the validity of the DFF-PANet, the neck of the baseline was replaced by the DFF-PANet. As is apparently shown in the table, the network reached 71.3% mAP, which was 0.9% higher than the baseline after adding the DFF-PANet. It is because of the strong feature fusion ability of residual dense blocks in the DFF-PANet. After obtaining the local dense features, it retains the accumulated feature information through global feature fusion to improve the network performance.
- Proposed Method: When both the FRM and the DFF-PANet were added to the model, the method we put forward was obtained. We reached 71.5% mAP, which was 1.1% higher than the baseline. Our improved method also reached the highest F1-Score. It displays that the FRM and the DFF-PANet are both effective modules to improve the network performance; they both enhance the detection ability of the model to a certain extent.
5. Discussion
- Model method: We compared our proposed model with different versions of YOLOv5 models on the DOTA datasets, namely, YOLOv5n (nano), YOLOv5s (small) and YOLOv5m (medium). The experimental results are shown in Table 9. As can be seen from Table 9, the method proposed by us has certain improvements on different versions of YOLOv5 models, which increased 1.6%, 1.1% and 0.9%, respectively.
- Lightweight model: Currently, designing a network structure that can balance detection accuracy and model parameters at the same time is the mainstream direction in object detection algorithms. Although most network structures achieve high accuracy, they usually require a large amount of calculation, and it is difficult to achieve good detection performance with a small amount of calculation. In this study, the YOLOv5s model used by us achieves a balance between detection accuracy and model parameters. The model parameters are only 9.2 M, and the inference time is 4.6 ms, meeting the requirements of real-time detection (more than 30 frames; that is, the inference time is less than 33.3 ms). Therefore, it can be deployed on front-end devices, such as mobile terminals [52]. Table 9 shows that the number of parameters in YOLOv5s is nearly 13 M less than that in YOLOv5m, which greatly reduces the model parameters. Compared with YOLOv5n, although the model parameters are 6.1 M more than it, the detection accuracy is improved by 3%. Therefore, compared with YOLOv5n, the increased number of parameters is acceptable.
- Model accuracy: Comparative analysis of the dataset and the ablation experiments mentioned above shows that our proposed method has excellent performance for instances of different sizes or with many external interference factors. However, as can be seen from the data in Table 5, the detection accuracy of objects, such as Ground track field (GTF), Basketball court (BC) and Soccer ball field (SBF), still lags behind first place. Our method does not achieve a satisfactory result when dealing with such objects. It may be because such objects are sometimes in the same background, and their texture information is similar; the feature information cannot be clearly identified by the model, leading to the low detection performance of objects. In future work, we hope to improve the model in this aspect.
6. Conclusions
- (1)
- First, we use the Feature Reuse Module (FRM) to reuse feature maps in the backbone; this module can enhance the detection ability of the network for small and medium-sized targets via fusing semantic information and location information.
- (2)
- After that, we designed the Dense Feature Fusion Path Aggregation Network (DFF-PANet) to better handle the issue of external interference factors in RSIs.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| A2S-Det | Self-Adaptive Anchor Selection |
| AFANet | Adaptive Feature Aggregation Network |
| BCEWithLogitsLoss | Binary Cross Entropy With Logits Loss |
| CF2PN | Cross-Scale Feature Fusion Pyramid Network |
| CIoU | Complete Intersection over Union |
| CNNs | Convolutional Neural Networks |
| CSPDarknet53 | Cross Stage Partial Darknet 53 |
| CSRDB | Cross Stage Residual Dense Block |
| DFF-PANet | Dense Feature Fusion Path Aggregation Network |
| DOTA | Dataset of Object deTection in Aerial images |
| DPM | Deformable Parts Model |
| FLOPs | Floating Point Operations |
| FRM | Feature Reuse Module |
| HOG | Histogram of Oriented Gradients |
| ICN | Image Cascade and Feature Pyramid Network |
| IoU | Intersection over Union |
| M2Det | Multi-level and Multi-scale Detector |
| MFPNet | Multi-Feature Pyramid Network |
| MS COCO | Microsoft Common Objects in Context |
| MSE-DenseNet | Multi-scale SELU DenseNet |
| NMS | Non-Maximum Suppression |
| Pascal VOC | Pascal Visual Object Classes |
| P-R curve | Precision-Recall curve |
| R-CNN | Region-Convolutional Neural Network |
| R-DFPN | Rotation-Dense Feature Pyramid Network |
| RDB | Residual Dense Block |
| RoI | Region of Interest |
| RoI Trans. | RoI Transformer |
| RRPN | Rotation Region Proposal Networks |
| RPN | Region Proposal Networks |
| RSIs | Remote Sensing Images |
| SGD | Stochastic Gradient Descent |
| SSD | Single Shot MultiBox Detector |
| SVM | Support Vector Machine |
| YOLO | You Only Look Once |
References
- Fu, G.; Liu, C.J.; Zhou, R.; Sun, T.; Zhang, Q.J. Classification for High Resolution Remote Sensing Imagery Using a Fully Convolutional Network. Remote Sens. 2017, 9, 498. [Google Scholar] [CrossRef] [Green Version]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional Neural Networks for Large-Scale Remote-Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 645–657. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.; Fang, L.Y.; Ghamisi, P. Deformable Convolutional Neural Networks for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1254–1258. [Google Scholar] [CrossRef]
- Wu, X.W.; Sahoo, D.; Hoi, S.C.H. Recent advances in deep learning for object detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Zhou, P.C.; Han, J.W. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Qu, Z.; Zhu, F.; Qi, C. Remote Sensing Image Target Detection: Improvement of the YOLOv3 Model with Auxiliary Networks. Remote Sens. 2021, 13, 3908. [Google Scholar] [CrossRef]
- Zhang, J.M.; Jin, X.K.; Sun, J.; Wang, J.; Sangaiah, A.K. Spatial and semantic convolutional features for robust visual object tracking. Multimed. Tools Appl. 2020, 79, 15095–15115. [Google Scholar] [CrossRef]
- Li, X.; Hu, W.M.; Shen, C.H.; Zhang, Z.F.; Dick, A.; Van den Hengel, A. A Survey of Appearance Models in Visual Object Tracking. ACM Trans. Intell. Syst. Technol. 2013, 4, 1–48. [Google Scholar] [CrossRef] [Green Version]
- Cao, C.; Wu, J.; Zeng, X.; Feng, Z.; Huang, Z. Research on Airplane and Ship Detection of Aerial Remote Sensing Images Based on Convolutional Neural Network. Sensors 2020, 20, 4696. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway Township, NJ, USA, 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Everingham, M.; Eslami, S.; Gool, L.V.; Williams, C.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Zitnick, C.L. Microsoft COCO: Common Objects in Context; Springer International Publishing: Cham, Switzerland, 2014. [Google Scholar]
- Yuan, Z.; Liu, Z.; Zhu, C.; Qi, J.; Zhao, D. Object Detection in Remote Sensing Images via Multi-Feature Pyramid Network with Receptive Field Block. Remote Sens. 2021, 13, 862. [Google Scholar] [CrossRef]
- Huang, W.; Li, G.; Chen, Q.; Ju, M.; Qu, J. CF2PN: A Cross-Scale Feature Fusion Pyramid Network Based Remote Sensing Target Detection. Remote Sens. 2021, 13, 847. [Google Scholar] [CrossRef]
- Zhu, H.; Zhang, P.; Wang, L.; Zhang, X.; Jiao, L. A multiscale object detection approach for remote sensing images based on MSE-DenseNet and the dynamic anchor assignment. Remote Sens. Lett. 2019, 10, 959–967. [Google Scholar] [CrossRef]
- Zhang, H.; Wu, J.; Liu, Y.; Yu, J. VaryBlock: A Novel Approach for Object Detection in Remote Sensed Images. Sensors 2019, 19, 5284. [Google Scholar] [CrossRef] [Green Version]
- Zhang, T.; Zhang, J.; Guo, C.; Chen, H.; Zhou, D.; Wang, Y.; Xu, A. A survey of image object detection algorithm based on deep learning. Telecommun. Sci. 2020, 36, 92–106. [Google Scholar]
- Wei, L.; Cui, W.; Hu, Z.; Sun, H.; Hou, S. A single-shot multi-level feature reused neural network for object detection. Vis. Comput. 2021, 37, 133–142. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), London, UK, 1 July 2017. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K. P Dollár Focal Loss for Dense Object Detection. In Proceedings of the IEEE Transactions on Pattern Analysis & Machine Intelligence, Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Computer Society, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. Int. J. Comput. Vis. 2020, 128, 642–656. [Google Scholar] [CrossRef] [Green Version]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF international conference on computer vision, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Francis, B., David, B., Eds.; Microtome Publishing: Brookline, MA, USA; pp. 448–456.
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011; Geoffrey, G., David, D., Miroslav, D., Eds.; Microtome Publishing: Brookline, MA, USA; pp. 315–323.
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual Dense Network for Image Super-Resolution. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Sun, Z.; Leng, X.; Lei, Y.; Xiong, B.; Ji, K.; Kuang, G. BiFA-YOLO: A Novel YOLO-Based Method for Arbitrary-Oriented Ship Detection in High-Resolution SAR Images. Remote Sens. 2021, 13, 4209. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Ding, J.; Xue, N.; Xia, G.S.; Bai, X.; Yang, W.; Yang, M.Y.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M. Object detection in aerial images: A large-scale benchmark and challenges. arXiv 2021, arXiv:2102.12219. [Google Scholar]
- Liu, Z.; Yuan, L.; Weng, L.; Yang, Y. A high resolution optical satellite image dataset for ship recognition and some new baselines. In Proceedings of the International conference on pattern recognition applications and methods, Porto, Portugal, 24–26 February 2017; SciTePress: Beijing, China, 2017. [Google Scholar]
- Sun, W.; Zhang, X.; Zhang, T.; Zhu, P.; Gao, L.; Tang, X.; Liu, B. Adaptive Feature Aggregation Network for Object Detection in Remote Sensing Images. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; IEEE: Piscataway Township, NJ, USA, 2020. [Google Scholar]
- Xiao, Z.; Wang, K.; Wan, Q.; Tan, X.; Xu, C.; Xia, F. A2S-Det: Efficiency Anchor Matching in Aerial Image Oriented Object Detection. Remote Sens. 2021, 13, 73. [Google Scholar] [CrossRef]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic Ship Detection in Remote Sensing Images from Google Earth of Complex Scenes Based on Multiscale Rotation Dense Feature Pyramid Networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-Oriented Scene Text Detection via Rotation Proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef] [Green Version]
- Azimi, S.M.; Vig, E.; Bahmanyar, R.; Körner, M.; Reinartz, P. Towards Multi-class Object Detection in Unconstrained Remote Sensing Imagery. In Computer Vision—ACCV 2018; Springer International Publishing: Cham, Switzerland, 2019. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning RoI Transformer for Detecting Oriented Objects in Aerial Images. arXiv 2018, arXiv:1812.00155. [Google Scholar]
- Zhang, Y.; Sheng, W.; Jiang, J.; Jing, N.; Mao, Z. Priority Branches for Ship Detection in Optical Remote Sensing Images. Remote Sens. 2020, 12, 1196. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Guo, W.; Zhu, S.; Yu, W. Toward arbitrary-oriented ship detection with rotated region proposal and discrimination networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1745–1749. [Google Scholar] [CrossRef]
- Yang, X.; Hou, L.; Zhou, Y.; Wang, W.; Yan, J. Dense label encoding for boundary discontinuity free rotation detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Liao, M.; Zhu, Z.; Shi, B.; Xia, G.; Bai, X. Rotation-sensitive regression for oriented scene text detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Qian, W.; Yang, X.; Peng, S.; Guo, Y.; Yan, J. Learning modulated loss for rotated object detection. arXiv 2019, arXiv:1911.08299. [Google Scholar]
- Ming, Q.; Zhou, Z.; Miao, L.; Zhang, H.; Li, L. Dynamic anchor learning for arbitrary-oriented object detection. arXiv 2020, arXiv:2012.04150. [Google Scholar]
- Yang, X.; Liu, Q.; Yan, J.; Li, A.; Zhang, Z.; Yu, G. R3det: Refined single-stage detector with feature refinement for rotating object. arXiv 2019, arXiv:1908.05612. [Google Scholar]
- Qing, Y.; Liu, W.; Feng, L.; Gao, W. Improved Yolo network for free-angle remote sensing target detection. Remote Sens. 2021, 13, 2171. [Google Scholar] [CrossRef]
- Luo, R.; Chen, L.; Xing, J.; Yuan, Z.; Wang, J. A Fast Aircraft Detection Method for SAR Images Based on Efficient Bidirectional Path Aggregated Attention Network. Remote Sens. 2021, 13, 2940. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Presence of Anchor Box | Stages | Detection Method | Advantages | Disadvantages |
|---|---|---|---|---|
| Object detection algorithms based on anchor-box | One-stage/Regression-based object detection algorithms | YOLO [10] | Object detection task is transformed into a regression problem, which highly speeds up the detection. | The position is not accurate, and the detection effect of small and dense instances is not efficient. |
| SSD [22] | Multi-scale detection is realized by using feature layers of different scales extracted from the backbone, and the speed of detection is fast. | Due to the deep convolutional layer, the extracted features may be lost for smaller targets. | ||
| RetinaNet [25] | Focal loss is introduced to solve the issue of positive and negative sample imbalance effectively. | Detection speed is average. | ||
| Two-stage/Region-based object detection algorithms | R-CNN [26] | Extract and learn features from CNNs automatically and accelerate feature extraction. | It takes a long time to acquire regional targets. Furthermore, feature extraction is complex. | |
| Fast R-CNN [27] | Detection efficiency is greatly improved, and training speed is significantly enhanced. | End-to-end detection is preliminarily implemented and restricted by selective search algorithms. | ||
| Faster R-CNN [28] | Region Proposal Network (RPN) is used rather than selective search algorithms to improve detection speed. | The training is divided into two stages, the region generation stage and the detection stage, which is slow and cannot satisfy the requirement of real-time. | ||
| Object detection algorithms based on anchor-free | - | CornerNet [29] | By predicting the upper left and lower right corner of the object, object detection is regarded as key point detection, and the speed of detection is improved. | Easy to generate error anchor boxes. |
| - | FCOS [30] | Many positive samples are obtained, and the problem of poor learning ability caused by a small number of positive samples are alleviated. | Semantic ambiguity may occur due to the overlapping of ground truth boxes during detection. |
| Network Module | Input | Output | Operation | ||
|---|---|---|---|---|---|
| Backbone | Focus | Slice | |||
| Extract Feature | Convolution | ||||
| FRM | FRM1 | Fusion | |||
| FRM2 | Fusion | ||||
| DFF-PANet | Top-down path | Fusion | |||
| Bottom-up path | Fusion | ||||
| YOLO Head | Inference | Classification | - | ||
| Regression | - | ||||
| Training | Box loss | Complete Loss (CIoU) | |||
| Obj loss | BCEWithLogitsLoss | ||||
| Class loss | BCEWithLogitsLoss | ||||
| Input Size | Batch Size | Momentum | Weight Decay | Learning Rate | Epoch |
|---|---|---|---|---|---|
| 640 × 640 | 16 | 0.9 | 0.0005 | 0.01 | 300 |
| PL | Plane | LV | Large vehicle | SBF | Soccer ball field |
| BD | Baseball diamond | SH | Ship | BA | Roundabout |
| BR | Bridge | TC | Tennis court | HA | Harbor |
| GTF | Ground track field | BC | Basketball court | SP | Swimming pool |
| SV | Small vehicle | ST | Storage tank | HC | Helicopter |
| Model | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Two-stage: | ||||||||||||||||
| R-DFPN [40] | 80.9 | 65.8 | 33.8 | 58.9 | 55.8 | 50.9 | 54.8 | 90.3 | 66.3 | 68.7 | 48.7 | 51.8 | 55.1 | 51.3 | 35.9 | 57.9 |
| Faster R-CNN [28] | 80.2 | 77.6 | 32.9 | 68.1 | 53.7 | 52.5 | 50.0 | 90.4 | 75.1 | 59.6 | 57.0 | 49.8 | 61.7 | 56.5 | 41.9 | 60.5 |
| RRPN [41] | 88.5 | 71.2 | 31.7 | 59.3 | 51.9 | 56.2 | 57.3 | 90.8 | 72.8 | 67.4 | 56.7 | 52.8 | 53.1 | 51.9 | 53.6 | 61.0 |
| ICN [42] | 81.4 | 74.3 | 47.7 | 70.3 | 64.9 | 67.8 | 70.0 | 90.8 | 79.1 | 78.2 | 53.6 | 62.9 | 67.0 | 64.2 | 50.2 | 68.2 |
| RoI Trans. [43] | 88.6 | 78.5 | 43.4 | 75.9 | 68.8 | 73.7 | 83.6 | 90.7 | 77.3 | 81.5 | 58.4 | 53.5 | 62.8 | 58.9 | 47.7 | 69.6 |
| One-stage: | ||||||||||||||||
| SSD [22] | 57.9 | 32.8 | 16.1 | 18.7 | 0.1 | 36.9 | 24.7 | 81.2 | 25.1 | 47.5 | 11.2 | 31.5 | 14.1 | 9.1 | 0.0 | 29.9 |
| YOLOV2 [11] | 76.9 | 33.9 | 22.7 | 34.9 | 38.7 | 32.0 | 52.4 | 61.7 | 48.5 | 33.9 | 29.3 | 36.8 | 36.4 | 38.3 | 11.6 | 39.2 |
| RetinaNet [25] | 88.3 | 77.8 | 47.5 | 59.1 | 73.8 | 63.5 | 77.7 | 90.4 | 78.6 | 65.9 | 48.7 | 61.8 | 68.9 | 71.6 | 38.2 | 67.5 |
| AFANet [38] | 89.4 | 73.9 | 47.3 | 59.9 | 64.5 | 67.3 | 82.9 | 90.7 | 66.3 | 72.3 | 67.6 | 62.2 | 76.8 | 60.5 | 52.8 | 69.0 |
| A2S-Det [39] | 89.6 | 77.9 | 46.4 | 56.5 | 75.9 | 74.8 | 86.1 | 90.6 | 81.1 | 83.7 | 50.2 | 60.9 | 65.3 | 69.8 | 50.9 | 70.6 |
| YOLOv5 | 91.6 | 75.5 | 46.0 | 61.4 | 68.1 | 85.5 | 87.8 | 93.0 | 65.9 | 69.6 | 57.2 | 58.6 | 83.9 | 61.6 | 50.6 | 70.4 |
| Ours | 92.1 | 73.5 | 49.0 | 63.7 | 69.1 | 85.8 | 87.9 | 93.6 | 65.9 | 71.2 | 52.6 | 61.4 | 83.5 | 63.6 | 59.0 | 71.5 |
| Method | Precision and Recall (%) | AP Values (%) | Times (ms) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | AP50 | AP75 | APS | APM | APL | - | |
| YOLOv5 | 79.0 | 65.9 | 71.9 | 70.4 | 44.9 | 17.7 | 41.7 | 55.6 | 3.3 |
| Proposed | 77.2 | 67.0 | 72.8 | 71.5 | 45.9 | 18.4 | 43.0 | 56.8 | 4.6 |
| Model | mAP | Inference Time (ms) |
|---|---|---|
| Two-stage: | ||
| RRPN [41] | 79.1 | 285.7 |
| R2PN [45] | 79.6 | - |
| RoI Trans. [43] | 86.2 | 166.7 |
| DCL [46] | 89.5 | - |
| One-stage: | ||
| RetinaNet [25] | 80.8 | - |
| RRD [47] | 84.3 | - |
| RSDet [48] | 86.5 | - |
| DAL [49] | 89.0 | 29.4 |
| R3Det [50] | 89.3 | 83.3 |
| RepVGG-YOLO [51] | 91.5 | 45.5 |
| YOLOv5 | 92.4 | 2.9 |
| Ours | 93.3 | 4.0 |
| Model | FRM | DFF-PANet | Params (M) | FLOPs (B) | Precision (%) | Recall (%) | F1-Score (%) | mAP@.5 (%) |
|---|---|---|---|---|---|---|---|---|
| Baseline | - | - | 7.1 | 16.4 | 79.0 | 65.9 | 71.9 | 70.4 |
| A | ✓ | 8.4 | 17.8 | 75.0 | 68.2 | 71.4 | 71.0 (+0.6) | |
| B | ✓ | 7.8 | 20.9 | 80.4 | 65.8 | 72.4 | 71.3 (+0.9) | |
| C | ✓ | ✓ | 9.2 | 22.2 | 77.2 | 67.0 | 72.8 | 71.5 (+1.1) |
| Model | Size (Pixels) | Time (ms) | Params (M) | FLOPs (B) | mAP (%) |
|---|---|---|---|---|---|
| YOLOv5n | 640 | 2.1 | 1.9 | 4.7 | 66.9 |
| YOLOv5n + FRM + DFF-PANet | 640 | 2.9 | 3.1 | 9.0 | 68.5 |
| YOLOv5s | 640 | 3.3 | 7.1 | 16.4 | 70.4 |
| YOLOv5s + FRM + DFF-PANet (*) | 640 | 4.6 | 9.2 | 22.2 | 71.5 |
| YOLOv5m | 640 | 7.6 | 21.2 | 51.4 | 72.4 |
| YOLOv5m + FRM + DFF-PANet | 640 | 8.9 | 22.2 | 53.5 | 73.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, L.; Rao, X.; Li, Y.; Zuo, X.; Qiao, B.; Lin, Y. A Lightweight Object Detection Method in Aerial Images Based on Dense Feature Fusion Path Aggregation Network. ISPRS Int. J. Geo-Inf. 2022, 11, 189. https://doi.org/10.3390/ijgi11030189
Zhou L, Rao X, Li Y, Zuo X, Qiao B, Lin Y. A Lightweight Object Detection Method in Aerial Images Based on Dense Feature Fusion Path Aggregation Network. ISPRS International Journal of Geo-Information. 2022; 11(3):189. https://doi.org/10.3390/ijgi11030189
Chicago/Turabian StyleZhou, Liming, Xiaohan Rao, Yahui Li, Xianyu Zuo, Baojun Qiao, and Yinghao Lin. 2022. "A Lightweight Object Detection Method in Aerial Images Based on Dense Feature Fusion Path Aggregation Network" ISPRS International Journal of Geo-Information 11, no. 3: 189. https://doi.org/10.3390/ijgi11030189
APA StyleZhou, L., Rao, X., Li, Y., Zuo, X., Qiao, B., & Lin, Y. (2022). A Lightweight Object Detection Method in Aerial Images Based on Dense Feature Fusion Path Aggregation Network. ISPRS International Journal of Geo-Information, 11(3), 189. https://doi.org/10.3390/ijgi11030189