1. Introduction
Archaeological sites are the remains of ancient human activities, which contain rich humanistic and social information and the law of civilization advancement. Archaeological site texts refer to the texts describing the information of archaeological sites, which is a significant carrier of site attribute information. Formally, it is often recorded discretely in various formats, for example, archaeological excavation reports, archaeological excavation briefings and archaeological dictionaries and encyclopedia entries in an unstructured manner. As far as quantity, with the consistent advancement in archaeological work, the textual data in archaeology are increasing, and more and more information on archaeological sites is being accumulated. In terms of content, the degree of detail varies in different types of archaeological site texts, but they all describe the basic information on the site (including name, location, dynasty, cultural type and other key elements), which is an important data hotspot for archaeological research and analysis. As a rule, the content of archaeological site texts primarily incorporates two perspectives: time and space. As the archaeologist Sqaulding said in his published book in 1960, “In short, archaeology is a science that concentrates on the form, time and spatial distribution of ancient remains” [
1]. For archaeology, time and space are essential characteristics of coexisting with the form of remains [
2]. The mutual contents contained in various archaeological site texts mentioned above are the descriptions of essential spatio-temporal information about the site. In archaeological texts, time information is a depiction of the site’s historical period, which may be described as one or more dynasties or some cultural types to which the site belongs. Such descriptions of time are not uniform and might be precise or vague, so determining the period of the remains from the archaeological site text is a vital and fundamental assignment. Spatial information of the site’s geographical location may be unequivocally described as an identified coordinate, an administrative region name or even a vague relative location. Therefore, it also expected to be recognized, interpreted and expressed uniformly in the information extraction. This paper concentrates on the extraction method of the sites’ spatio-temporal information.
Archaeological site texts are the basis for archaeological site research, which contains rich information and research value. Therefore, in order to realize the effective utilization of archaeological site texts, it is especially critical to integrate and use the information on archaeological sites and mine the key and valuable knowledge of archaeology. The traditional method of manual identification to obtain site information from voluminous documents is time-consuming and inefficient, and the results of data structuralization may differ due to the inconsistent levels of various staff, which is inapplicable for information extraction from massive site texts. To date, the problem has received scant attention in the research literature, so there are few studies that have researched archaeological site texts. Therefore, how to extract unified site information from a large number of scattered, detailed or brief unstructured archaeological site texts is the crux of realizing the digitization and comprehensive utilization of archaeological site texts. In recent years, with the increasing development of artificial intelligence technology, information extraction methods and applications for natural language have made great progress. According to Cowie, Information Extraction can be defined as follows: ‘Information Extraction (IE) is the name given to any process which selectively structures and combines data which is found, explicitly stated or implied, in one or more texts’ [
3]. The existing body of research on information extraction suggests that this technology is meaningful and promising. By analyzing the existing research on archaeological text information extraction, it is observed that these studies are basically oriented to English corpus, while Chinese studies are generally based on rules, which has poor portability and high implementation cost. The research on Chinese information extraction in archaeological site texts, which is limited by problems such as corpus annotation and Chinese word segmentation. At the same time, there are some deficiencies in these studies, such as singular data sources, fragmented construction processes and so on.
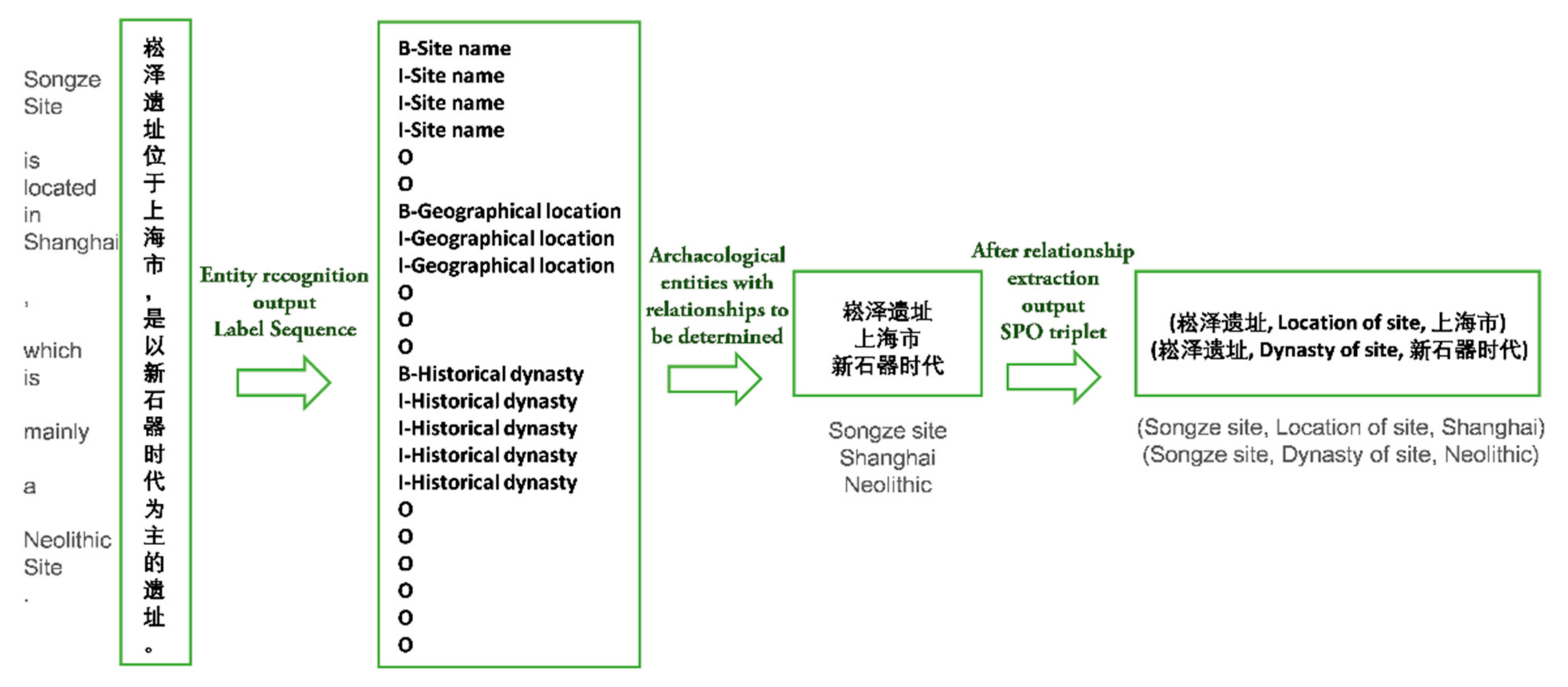
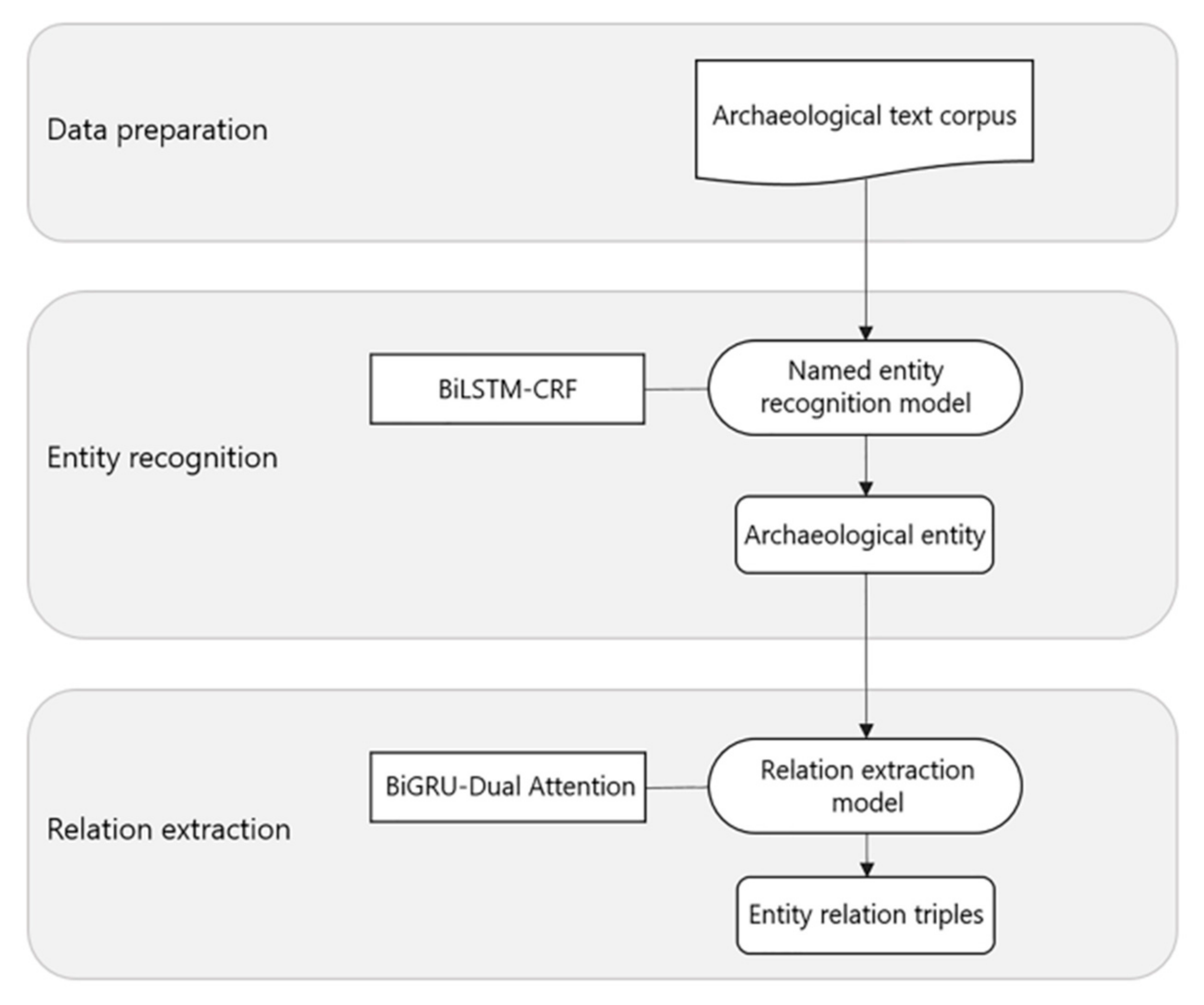
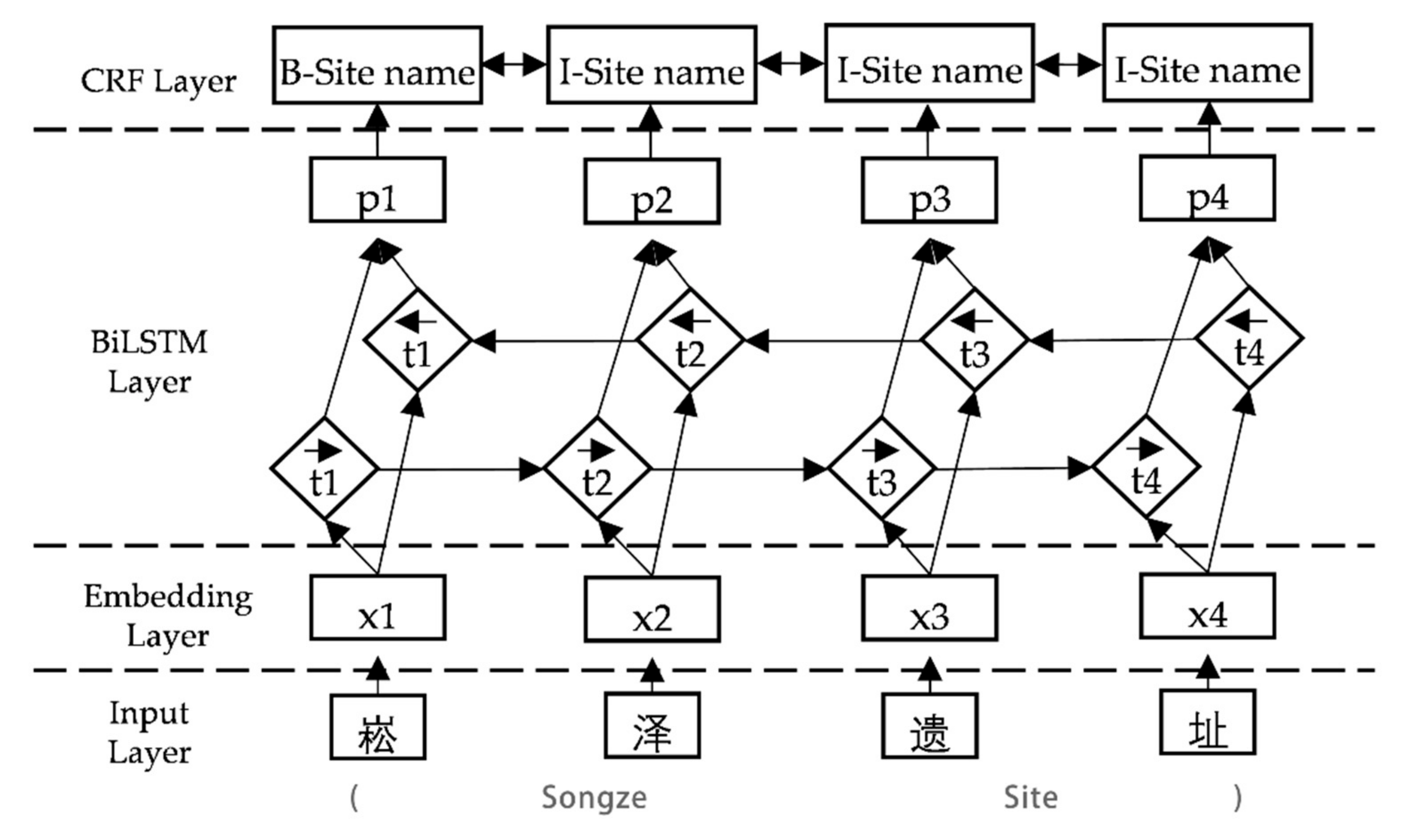
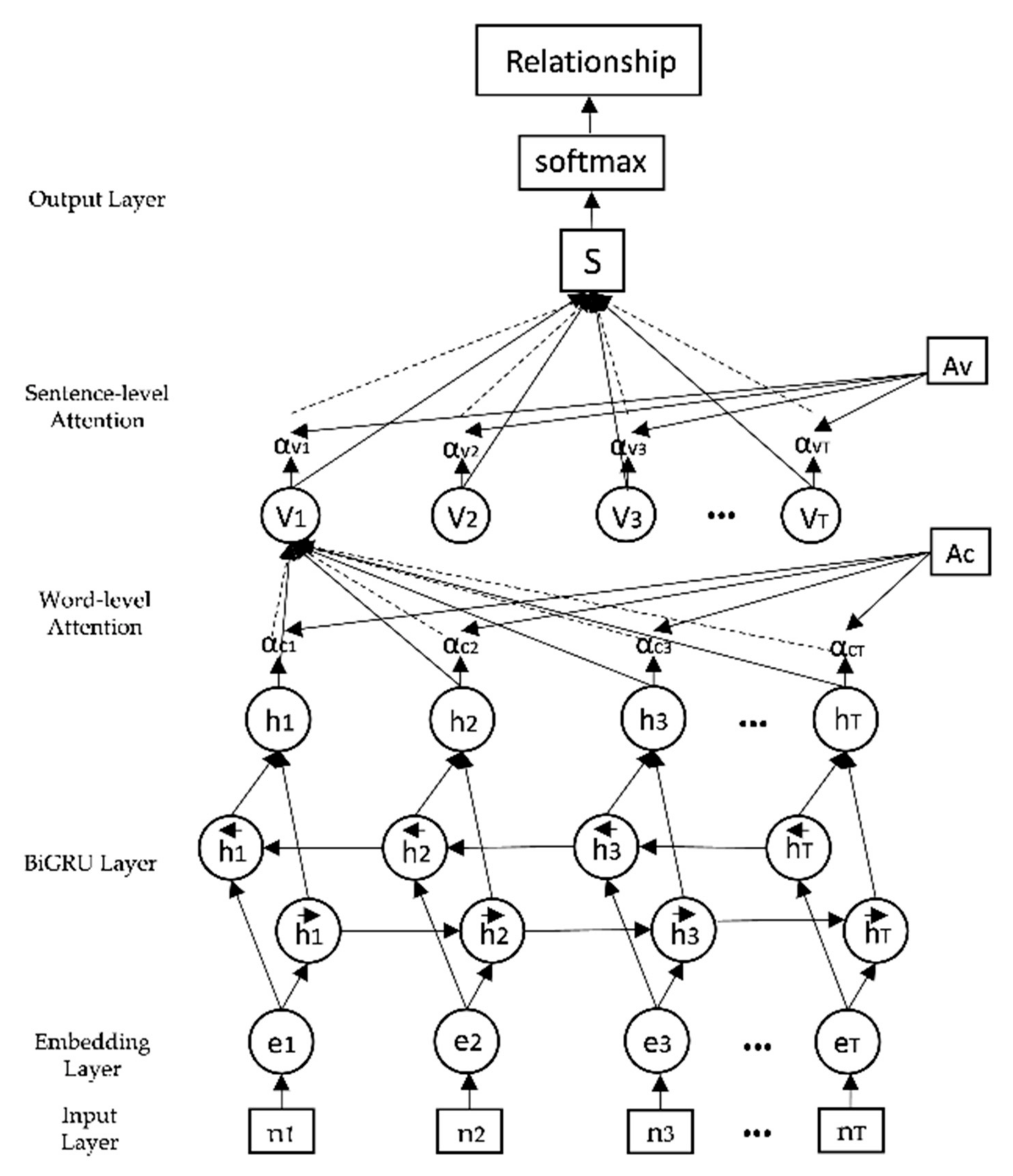
Under this foundation, this paper focuses on the extraction of spatio-temporal information from archaeological site texts. The information extraction experiment is mainly divided into two parts: entity recognition and relationship extraction. Their main goal is to recognize entities from texts and extract semantic relationships between entities. For a given input sentence, entity recognition involves both entity segmentation and the entity type. Relationship extraction aims to identify the semantic relations between symmetric entity pairs from unstructured archaeological site texts and to express them according to the structured form of a triplet (e1, r, e2), where e1 and e2 represent the first entity and the second entity, respectively, and r represents the relationship type between them. Finally, the temporal and spatial information of the site will also be presented in this form. In traditional natural language processing, entity recognition and relationship extraction are two independent tasks. The entity recognition model in this paper, named the Bidirectional Long Short-Term Memory with Conditional Random Fields (BiLSTM-CRF), combines the content of the application in natural language processing [
4] and performs some research on data preprocessing and data analysis. Through the application of the BiLSTM-CRF model, it is able to effectively remember the context information and obtain the dependency relationship between adjacent tags, so as to obtain the optimal labeling results of an archaeological entity. In the relationship extraction task, the Bidirectional Gated Recurrent Units with Dual Attention (BiGRU-Dual Attention) model taken in this study is a mixed methodology based on previous studies [
5,
6]. For the task of Chinese relationship extraction, Chinese words, as the most basic unit in Chinese, contain a large amount of important semantic information. Therefore, the word-level information in Chinese training examples is very important for Chinese relationship extraction. With good optimization effect, the introduction of an attention mechanism can fully extract the context information of archaeological texts, so as to strengthen the extraction effect. The word-level attention mechanism and sentence-level attention mechanism in the model can better allocate weight, eliminate noise and improve the recognition accuracy of entity relationship extraction. By taking advantage of a neural network, the BiGRU-Dual Attention model can solve the problems of low accuracy and poor stability of traditional relationship extraction models. The main purpose is to reduce the work of manual processing and open up new directions and ideas of archaeological analysis.
In summary, the specific objective of this study was to rapidly and automatically identify and obtain the target information from a large amount of unstructured archaeological site texts by using new technology, thus greatly reducing the preprocessing time of archaeological information extraction. In addition, data for this study were collected from multiple carriers as comprehensively as possible, which provides new ideas and methods for the spatio-temporal information study of archaeological sites. The information extraction of archaeological site text makes an important contribution to the storage, management, utilization and sharing of archaeological knowledge and maximizes the value of archaeological site text.
2. Related Work
As referenced above, information extraction is the key technology of automatically extracting information from archaeological site texts. Around the early 1960s, the research of information extraction technology arose, and this technique empowers rapidly procuring target information from plentiful unstructured texts, bringing about a higher utilization of information. Information extraction methods generally include rule-based, statistics-based and deep-learning-based methods [
7]. The exemplary LaSIE-II (Large Scale Information Extraction) system depends on semantic rules to realize information extraction [
8]. However, this rule-based method has its own restrictions, such as the process of making rules manually being complex and the universality being poor. Consequently, the later research gradually turned to a statistics-based method. In a study conducted by Chambers, it was shown that the statistical learning algorithm can learn the rules from plain texts and perform the information extraction task without knowing the template structure in advance [
9]. In the subsequent studies, researchers found that a method based on statistics is more viable than the previous method, but the cost of labor and time is extremely high since it additionally requires manual annotation with professional knowledge. Lately, the neural network models based on deep learning can automatically obtain feature information from a large number of texts, which provides direct support for the information extraction techniques. The model based on deep learning enormously outperforms the conventional methods in efficiency and accuracy and subsequently became applied broadly and gradually occupied the mainstream in information extraction tasks. Several studies of deep-learning-based information extraction have yielded fruitful outcomes. Qiu et al. proposed an Att-BiLSTM-CRF model based on an attention mechanism to effectively extract information entities in geoscience reports [
10]. Zhang et al. implemented the structured course of geological entity information by utilizing a deep neural network [
11]. Zhao combined the attention mechanism with the labeling and filtering layer in the Bidirectional Gated Recurrent Units (Bi-GRU) model, which significantly affects the relationship extraction of requirement text in the software industry [
12]. From the current state of research, neural networks and CRF methods have become the de facto standard representing some of the best options for information extraction methods.
The application area of information extraction has gradually expanded with the development of its technology. The early research mainly focused on the study of textual information extraction tasks in general-purpose domains, such as the recognition of people’s names and organizations’ names [
13,
14]. On the basis of constant optimization in the general domain over the years, it has promoted the development of information extraction from texts towards more fields, which includes medicine, the military, agriculture and so on [
15,
16,
17]. Simultaneously, information extraction has also developed towards a higher stage, such as relationship extraction, event extraction and other more complicated tasks [
18,
19]. Nowadays, it is observed that information extraction technology has also been explored and applied in history and humanities. For example, Sprugnoli proposed a neural method with manual annotation, which was applied in the place name recognition of English historical tourism texts [
20]. What is more, Pettersson et al. put forward an online tool named HistSearch, which could effectively extract useful information from historical texts in a short time [
21]. On the basis of the study on English archaeological reports at the previous stage, Vlachidis et al. developed the named entity recognition system of Dutch archaeological gray documents, which was able to achieve the semantic annotation of archaeological reports and automatically generate metadata [
22]. With reference to the existing literature and codes, they are mostly for the English corpus and usually use word vectors for training.
The study of Chinese text information extraction mainly paid attention to named entity recognition at the initial stage. After that, it was gradually expanded to the tasks on the relationship and event extraction. In the interim, the field of information extraction was gradually expanded to a larger scope. In terms of the data mining of Chinese archaeological texts, it started relatively late, while it has also obtained some research results. For example, Zhang took advantage of the domain knowledge to carry out the extraction of data from archaeological texts [
23]. However, it is difficult for this pattern-based method to learn enough text patterns, and would be mixed with a large number of meaningless word sequences. For the work adopting this method, it usually needs to be combined with complex verification and filtering. Lu made the proposal of a creative design platform for Changsha kiln cultural relics and extracted the text features of Changsha kiln cultural relic elements by using the BiLSTM-CRF model [
24]. As a result, it achieved the construction of Changsha kiln cultural knowledge base. Based on deep learning technology, the platform realized the redesign of cultural relics elements, which promoted the integrated development of culture and technology. By combining Chinese word segmentation with entity recognition, Zhang effectively realized information extraction from archaeological text data [
25]. However, he only carried out experiments on the data of Liangzhu site, which was lacking popularization and universality. Through the use of information extraction technology, Liu adopted the BiLSTM-CRF model to identify the entities such as person name, location name and time in the Twenty-Four Histories [
26]. After that, he constructed the knowledge graph and stored the extracted knowledge through the neo4j graph database, which realized the semantic retrieval function. However, it still requires a lot of manual work involved in the classification of single and complex sentences when training dependent syntactic analysis models, which makes the model construction lack sufficient automation. Collectively, these studies indicate that information extraction technology based on deep learning has been studied in the field of Chinese archaeological site texts, but few studies have been able to draw on systematic research in the whole process. Meanwhile, such studies remain narrow in focus, dealing only with a specific object without generality. In addition, deep learning is the mainstream method at present, and its achievements have been remarkable.
To summarize, the study of information extraction has gone through decades from pattern recognition to machine learning to deep learning, from general field to professional domain, from regular standard text to ordinary text, and its achievements are remarkable. Based on the above analysis, the research on information extraction in Chinese Archaeology represented by named entity recognition and relationship extraction has made great progress, but it still has broad room for improvement in technology and methods. Firstly, compared with the general field, archaeological texts are rich in resources, but the information contained is complex. There are a large number of proprietary entities in the archaeological field, and it is difficult to identify them, so the research of information extraction focuses on its effectiveness and automation. In addition, archaeological texts put forward higher requirements for the accuracy of relationship extraction because of their complex syntax and the dense distribution of entity pairs with abundant overlapping relationships. Therefore, in view of the high complexity and domain specificity of Chinese archaeological texts, this paper uses natural language processing and deep learning methods to study entity recognition and relationship extraction in Chinese archaeological site texts. Moreover, it is hoped that this method can realize the processing of multi-source text data, complete the establishment from corpus to knowledge graph and truly complete the transformation from unstructured to structured data. According to the practical needs of archaeology, the named entity recognition is accomplished by the BiLSTM-CRF model, and the entity relationship extraction is completed by the BiGRU-Dual Attention model. Finally, the methods and techniques applicable to the archaeological site texts were experimentally tested, and the information extraction model for archaeological site text was constructed. The above study provides a new method for information acquisition in archaeology, which has important research value and application significance for promoting archaeological informatization.
4. Experimental Results
4.1. Experimental Setup
As referenced in
Section 3.2, this study has identified four archaeological entities, including site name, cultural type, geographical location and historical dynasties. Next, the named entity recognition experiment is carried out with the above manually labeled corpus. A total of 21,800 corpora was selected from the texts of 800 sites as the experimental corpus of the named entity recognition experiment. Among them, 80% are used for the training corpus, 10% for the verification corpus and 10% for the test corpus. The statistics of entities in the datasets are shown in
Table 2.
As far as the named entity recognition task of archaeological site text, experiments were conducted based on the Pytorch deep learning framework, and the parameter settings of the model in training are shown in
Table 3.
On the basis of entity recognition, the relationship extraction of archaeological entities is carried out. For the entity relationship extraction in the field of archaeological texts, 8120 corpora are selected from the results of entity recognition, of which 80% are selected as training corpora, 10% as verification corpora and 10% as test corpora. The entity relationship involved are divided into four categories, including the Culture of the site, the Location of the site, the Dynasty of the site and None. The statistics of the relationships in the datasets are shown in
Table 4.
In this paper, the BiGRU-Dual Attention model for archaeological texts is constructed based on the Tensorflow deep learning framework, and the parameter settings of the model in training are shown in
Table 5.
Evaluation is a necessary work in the fields of machine learning, natural language processing, information retrieval and so on, and the evaluation metrics are usually as follows: precision, recall and F1 value. Therefore, the information extraction model for archaeological site texts in this study uses the precision P, recall R and F1 value as the evaluation index. It can be calculated as follows:
where true positives represent data that are truly predicted, false positives represent data that are incorrectly predicted and false negatives represent the data that should be correctly predicted but have not been predicted.
4.2. Entity Recognition Results
The BiLSTM-CRF entity recognition model was trained using the labeled archaeological site text. In order to evaluate the effectiveness of the BiLSTM-CRF entity recognition model in archaeological site texts, comparative experiments were conducted on a Hidden Markov Model (HMM, an early classical statistical model), a BiLSTM model with the same experimental data. The experimental results are shown in
Table 6.
From the analysis of the comparative experiment, the effect of the BiLSTM-CRF model constructed in this paper is superior to other methods, with a precision rate of 94.51%, a recall rate of 82.10% and an F1 value of 87.87%. This indicates that it has good adaptability in the entity recognition task of archaeological site text and can effectively carry out abstract modeling of archaeological texts. In terms of the three metrics, the model in this paper outperforms the HMM model, with an improvement in precision, in recall and in F1 value. It illustrates that the performance of the model relying on a neural network is obviously better than the early statistical model, with a significant improvement. The model in this paper improves the precision, the recall and the F1 value compared with BiLSTM, indicating that the addition of a CRF layer can effectively improve the recognition of relevant entities in the texts of archaeological sites.
In the following, further analysis about the recognition result of the BiLSTM-CRF model for various types of entities is shown in
Table 7.
It can be seen that this model can comparatively accurately recognize four types of entities in the archaeological site text, of which the F1 values of the geographical location and cultural type are above 90%. From the analysis of the experimental results, it can be observed that the precision of cultural type entities is the highest. This may be related to the clear identification of “culture” and “type” in Chinese archeological site texts, which is helpful to improve the recognition capacity of the model. Conversely, the description of historical dynasty is more complex in Chinese, so the model has difficulty finding a general rule expression, bringing about a relatively poor recognition result.
4.3. Relationship Extraction Results
In the experiment of entity relationship extraction, the precision P, recall R and F1 value are also used to evaluate the performance of the model. In order to verify the function of the BiGRU-Dual Attention model in precision and recall, the experimental result of relationship extraction from archaeological text entities is analyzed and compared with the BiLSTM-Attention model. The results are shown in
Table 8.
The experimental results demonstrate that the BiGRU-Dual Attention model achieves better function than the BiLSTM-Attention model without increasing the complexity of the model. The BiGRU-Dual Attention model shows some improvement in performance, with progress in precision, in recall, and in F1 value. Meanwhile, it can be seen that the use of dual attention mechanism has a positive impact on improving the model performance and achieve higher precision in relationship extraction. In order to further analyze the difference in the extraction effect of various entity relationships, the evaluation results of different relationships are analyzed, as shown in
Table 9.
Combined with the entity distribution of the labeled sample data set, it can be seen from
Table 4 that the site location relationship accounts for the largest proportion in the test set, while the None relationship accounts for the least proportion. Relatively speaking, the relationship categories with a large amount of data has a higher recall rate during the test. From the above analysis, it can be seen that in the task of text relationship extraction, compared with the improvement of the model algorithm, the quality of the corpus is additionally vital. The higher the quality of the deep learning model’s training and learning sets, the more accurate the model recognition effect will be. In terms of effectiveness and feasibility, the comprehensive experimental results show that the BiGRU-Dual Attention model has a positive impact on relationship extraction in Chinese archaeological site texts.
The purpose of the above experiment is to demonstrate the feasibility of the application of information extraction in the field of archaeological site texts and aims to find a suitable method. Through the reflection on the test results, it can assist with enhancing the datasets and models in the follow-up research. Generally speaking, the BiLSTM-CRF model can effectively identify the four types of entities which relate to the spatio-temporal information of sites. However, it has low recall, which is caused by the changeability of sentence patterns in Chinese archaeological site texts. Later, we will add the entity-labeled corpus to improve the recognition ability of the model. On the basis of the entity recognition experiment, it is found that the BiGRU-Dual Attention model performs well in the task of archaeological site relationship extraction, which further enhances the training efficiency of the experiment. Furthermore, the reason for incorrect entity relationship recognition is mainly related to the lack of an annotation corpus, resulting in the lack of the relationship extraction ability of the model. In future research, the corpus of relational annotated texts will be expanded. We hope to improve the extraction ability of the model to provide a reference for constructing the knowledge graph of archaeological sites.
4.4. Application Example
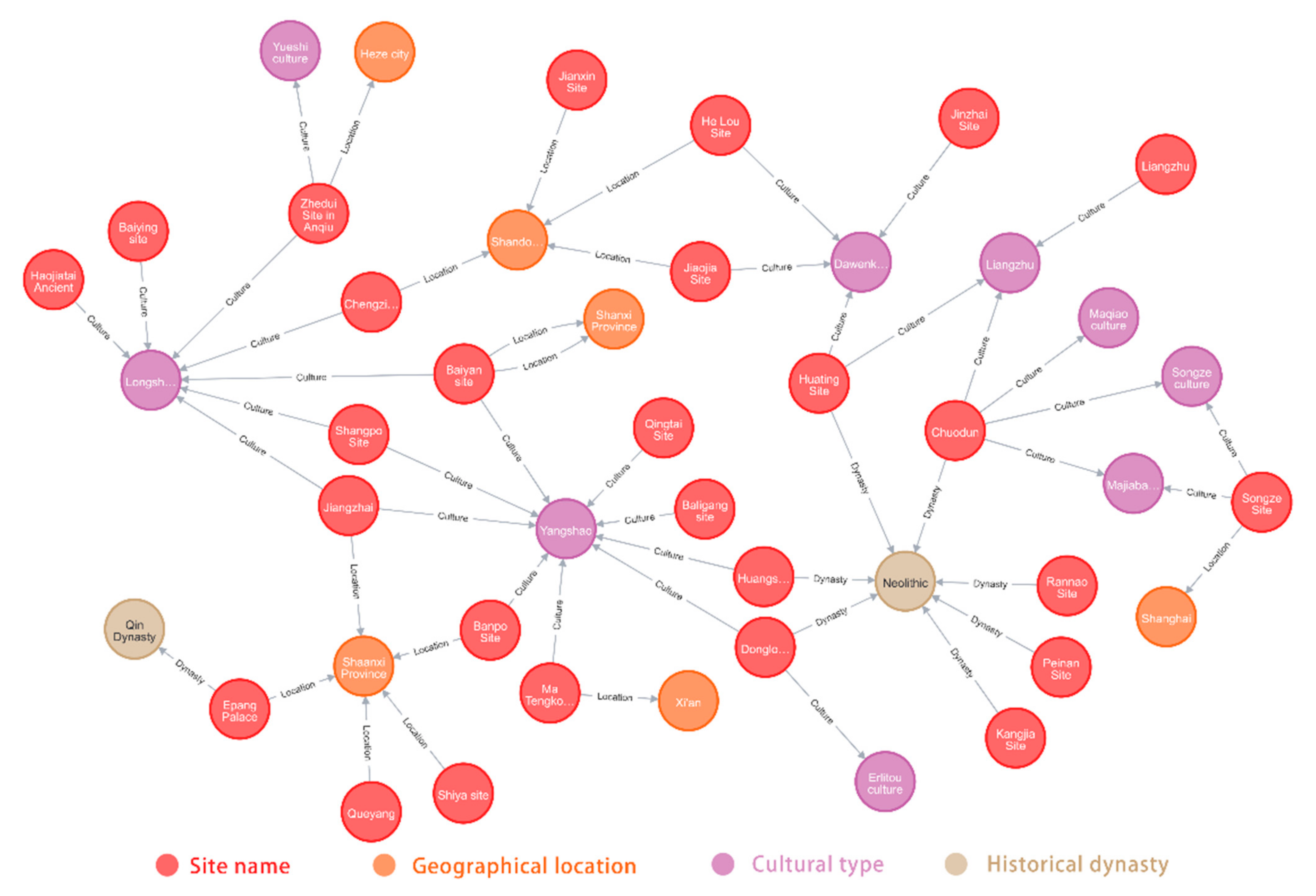
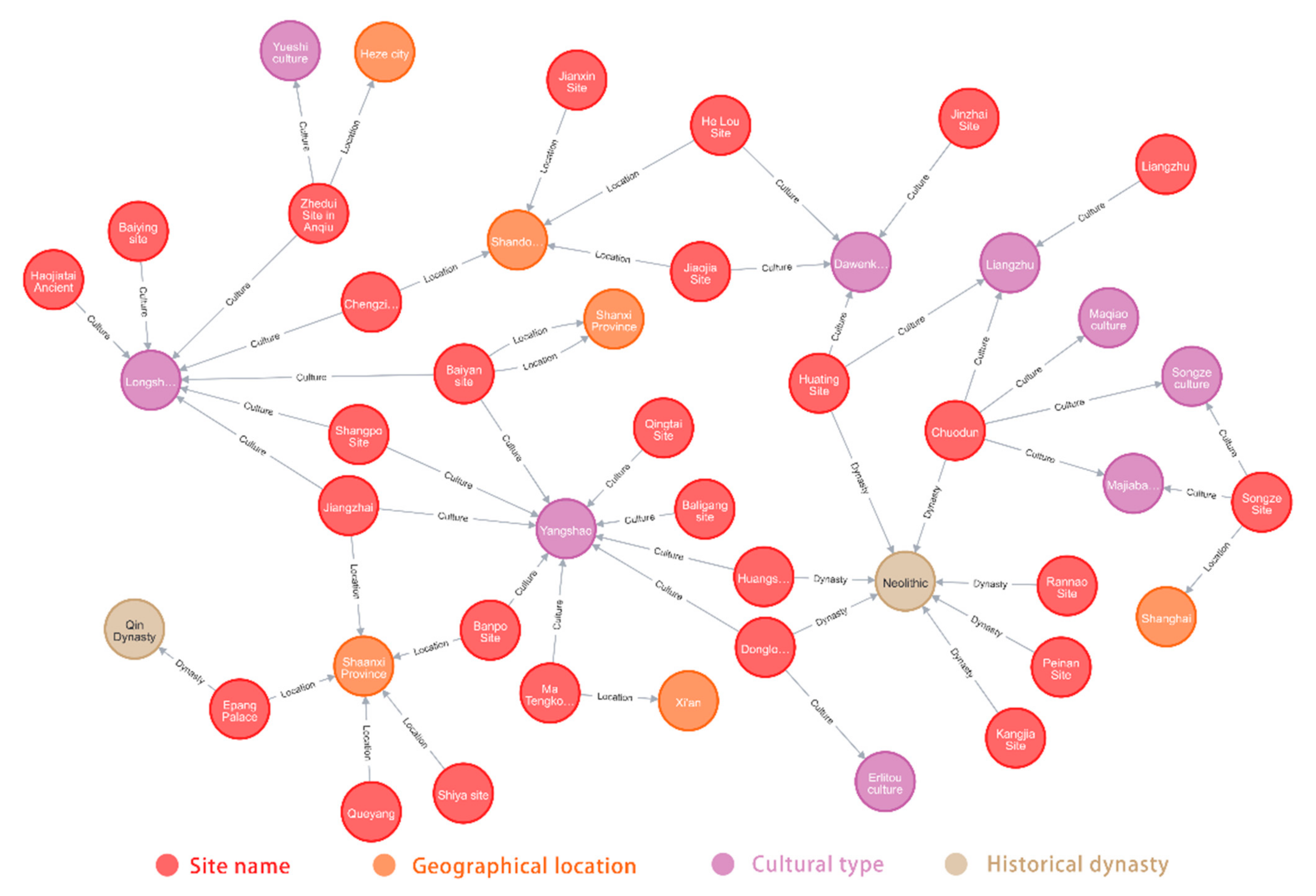
Under the advancement of computers and the Internet over the years, it can be seen that knowledge graph technology has drawn extensive attention. Knowledge graphs have natural advantages for the analysis, display and utilization of the results of information extraction. As the structured semantic knowledge base, knowledge graphs can effectively process, handle and integrate massive amounts of information. Information extraction based on structured triples is an important step in the process of constructing knowledge graphs. After the above information extraction experiment, we obtain the triples from the archaeological site texts. By storing the triples in the relational database, we can obtain a basic knowledge graph and complete the transformation from unstructured texts to structured texts. In line with the knowledge graph construction process, the development and storage of archaeological site knowledge graphs are realized based on Neo4j. The graph contains 3318 nodes and 8120 edges in total.
Figure 5 shows a partial knowledge graph of archaeological sites. Fundamentally, this paper aims to extract structured spatio-temporal information from various archaeological textual data and formalize them with a unified triplet representation. They support graphical query language access, so that deep knowledge can be obtained. The introduction of knowledge graphs is relatively new, and few studies have explored their application in the field of archaeology. In the future, we envisage linking archaeological site knowledge from different resources, and the utilization of these interrelated knowledge will further strengthen the discovery of archaeological knowledge. By constructing the archaeological site knowledge graph, it not only enriches archaeological site knowledge but also popularizes archaeology for the public. Meanwhile, it can establish the foundation for subsequent applications such as the semantic search for archaeological knowledge and intellectual question and answering.
5. Discussion and Conclusions
The archaeological site text is chosen as the research object in this study. Considering the issue of rich information with scattered knowledge in the field of Chinese archaeological site texts, its features and its application requirements are taken as the starting point. We utilize the information extraction method to extract the spatio-temporal information from the archaeological site text. The results show that it is suitable for relevant tasks. Compared with other existing studies, we explore the text of more data sources and naturally integrate them together. This study has obtained multi-source data, such as archaeological books, excavation reports and online texts. It has the benefit of obtaining higher-quality information and good coverage of archaeological site fields, which is vital for knowledge discovery and acquisition. We prove that information extraction technology is suitable for the field of Chinese archaeology, rather than only discussing a single text object. Compared with Zhang [
25], under the same evaluation metrics, the P, R and F1 of our information extraction experiment are marginally lower, essentially in light of the fact that the input data in his study are semi-structured, while our input data are structured and come from various sources. The performance of the named entity recognition model is similar to that of Liu [
26] but with higher precision and low recall. With the continuous emergence of new entities, to guarantee the quality of named entity recognition, we need to maintain dictionaries. When dictionaries are not detailed or domain rules are not complete, there are often the characteristics of high precision and low recall. Simultaneously, it is also observed that there is an unbalanced distribution of entity relations in the text of archaeological sites. In a text, there are often more descriptions of location and less descriptions of culture or dynasty. Therefore, in the case of model algorithm adaptation, effective data augmentation is expected to make the distribution of entity relations balanced, so as to improve the overall effect of information extraction. Nowadays, various information sharing media provide useful knowledge, so it is difficult to establish a final and complete knowledge base. However, different knowledge sources can complement each other. Compared with the method of description flow used by Zhang [
23], triplets can connect knowledge from different sources and publish them in a unified way. At the same time, we introduced knowledge graphs and conducted a preliminary exploration. It allows users to make complex queries in the knowledge graph to promote knowledge connection and sharing. On this basis, it is able to provide data support for relevant scholars and provide new ideas for traditional information retrieval.
The study of the spatio-temporal information extraction method and its effectiveness verification of Chinese archaeological site texts is conducted in this paper. By fully using the multi-source and heterogeneous archaeological site text data on the Internet, this study conducts data annotation, which preliminarily completes the construction of the Chinese archaeological site corpus. Since there is no public annotation dataset or corpus in the field of Chinese archaeology, through the analysis of Chinese archaeological site texts, this study makes an appropriate definition of entity relationship hierarchy about site spatial-temporal information. Based on this, it establishes the data foundation for knowledge extraction of archaeological sites. By relying on the deep learning method that does not need manual feature extraction, the BiLSTM-CRF, named the entity recognition model, and the BiGRU-Dual Attention relationship extraction model are constructed to extract the spatial-temporal information on the site. After that, this study conducted comparative experiments, which obtained relatively good experimental results. These results show the possibility of applying this information extraction method to archaeological site texts. To further verify the extraction results of entity relationship triples of archaeological sites, an example of a knowledge graph was completed. Therefore, a new method is provided for the storage and display of traditional archaeological site knowledge. According to the results of the study, it can promote the relevant research of spatio-temporal information mining on sites and provide the basis for the construction of knowledge graphs in archaeology. Moreover, it is of great reference value for promoting the innovation of archaeological research methods and the exploration of archaeological problems in the information age. In the follow-up work, it is intended to annotate more archaeological site entities (including excavated artifacts, site area and so on) to expand the corpus, which tries to perfect the construction of knowledge graphs in the Chinese archaeological field and enrich the connotation of knowledge. In the meantime, we will continue to develop and research semantic search, intelligent Q&A and other upper-level applications based on the Chinese archaeological site knowledge graph.


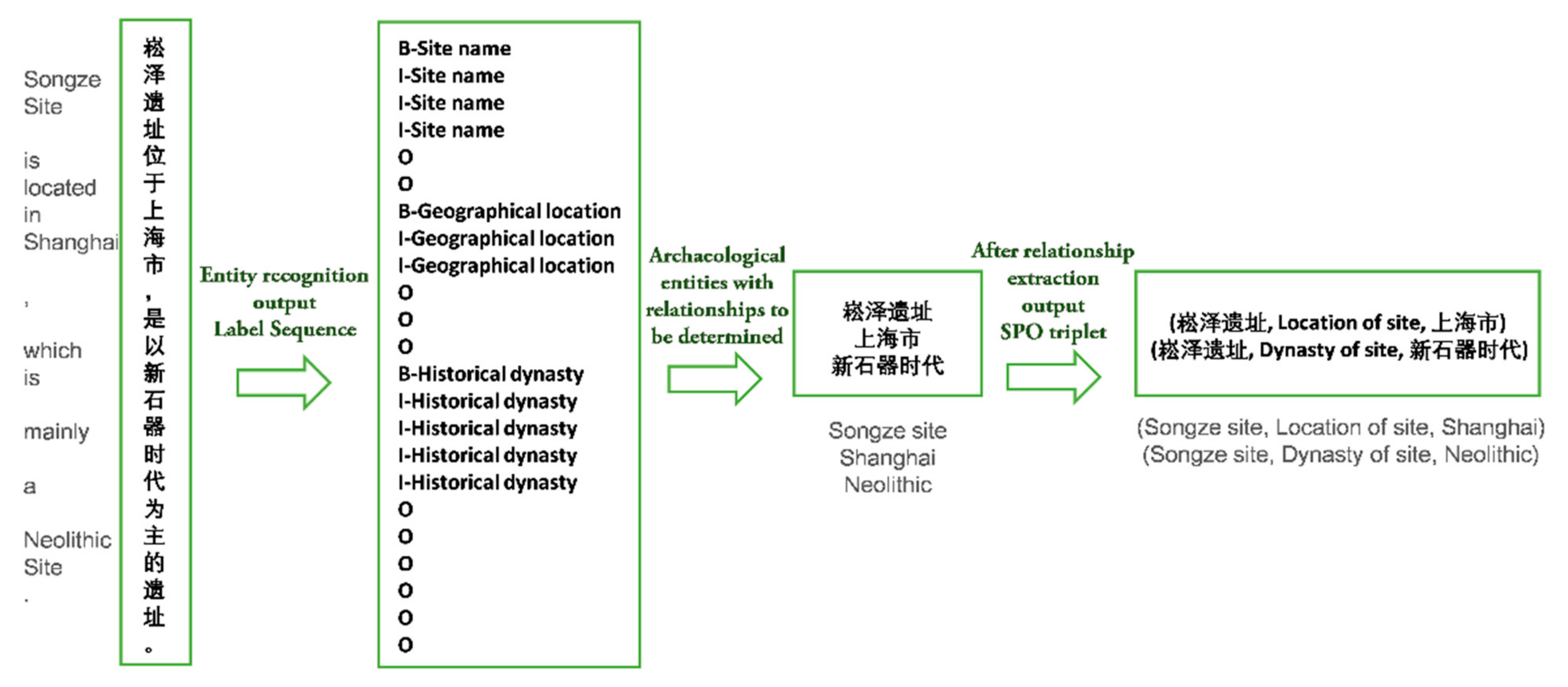
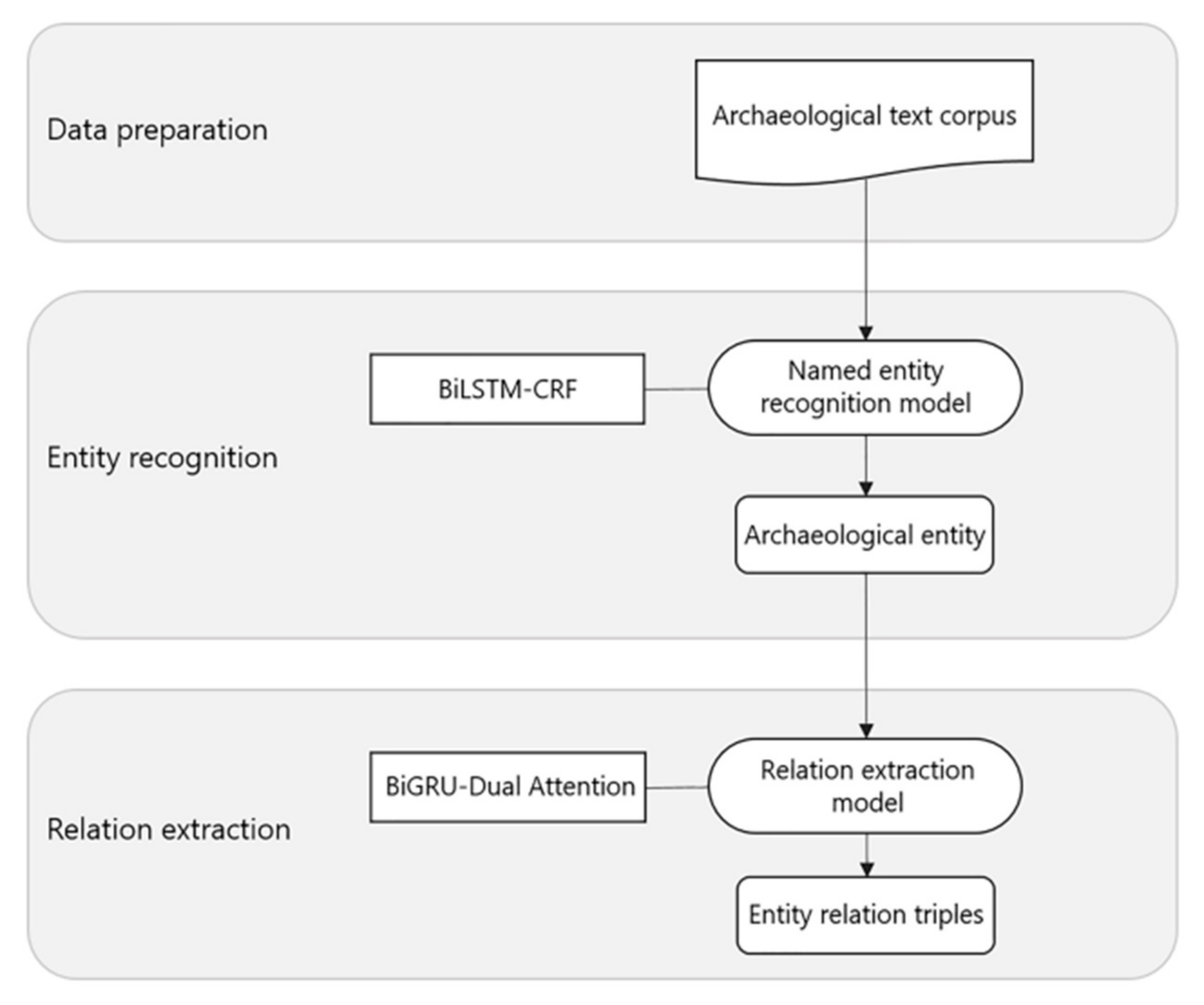
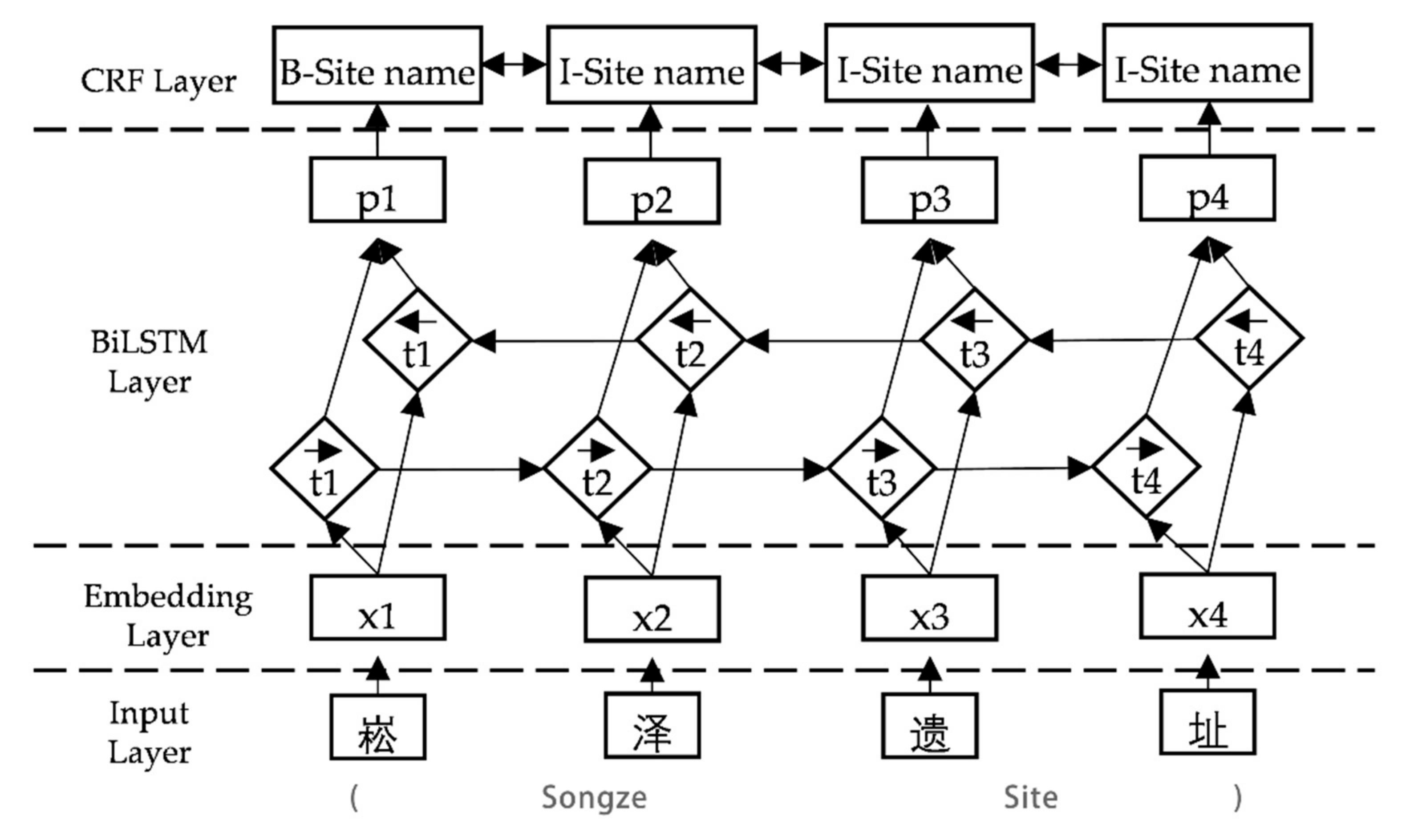
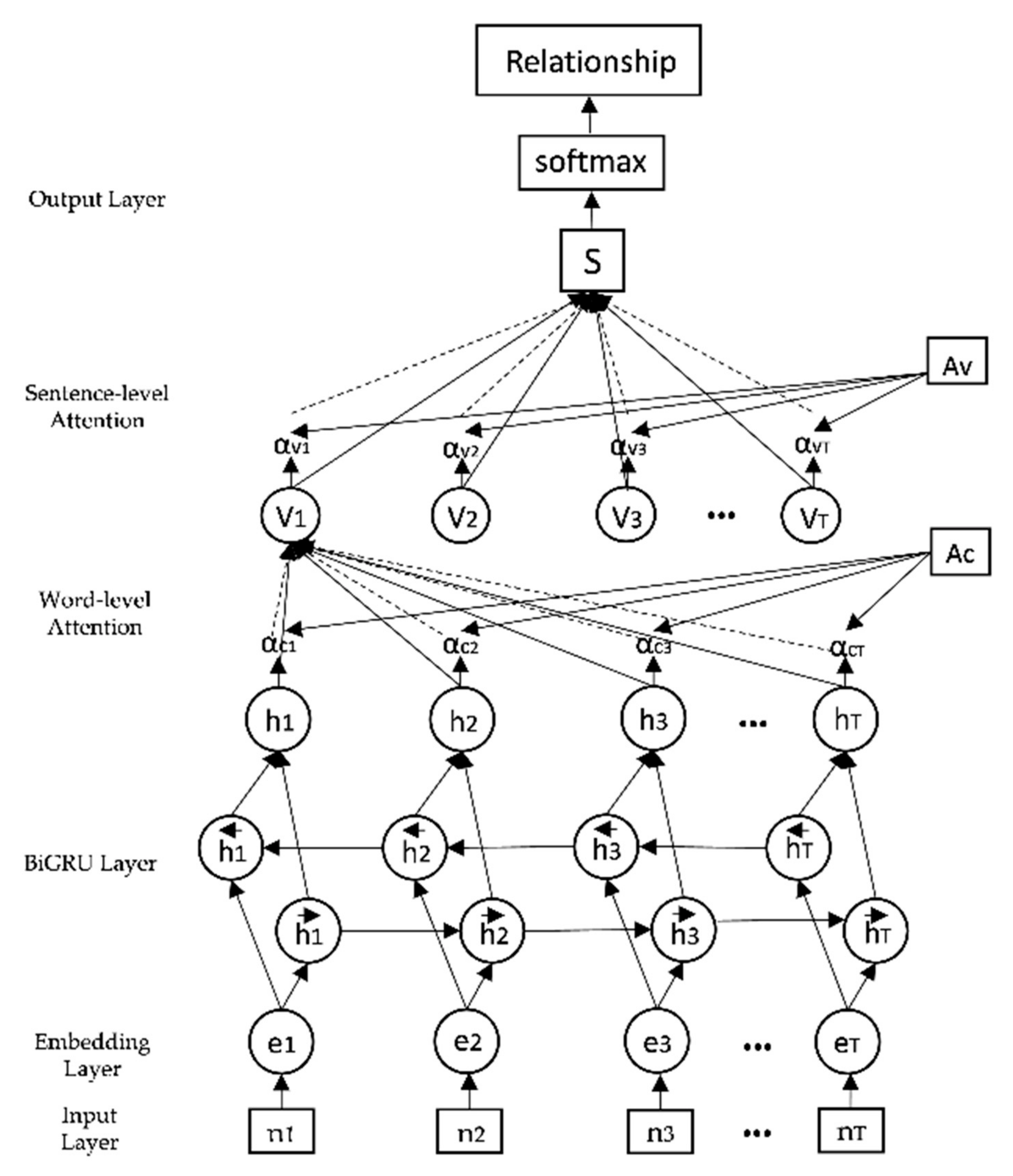

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}