
Formalizing Parameter Constraints to Support Intelligent Geoprocessing: A SHACL-Based Method

 ,
,  , , , ,
, , , , 
Abstract
:1. Introduction
1.1. Existing Methods of Formalizing Parameter Constraints
1.2. Research Question in This Study
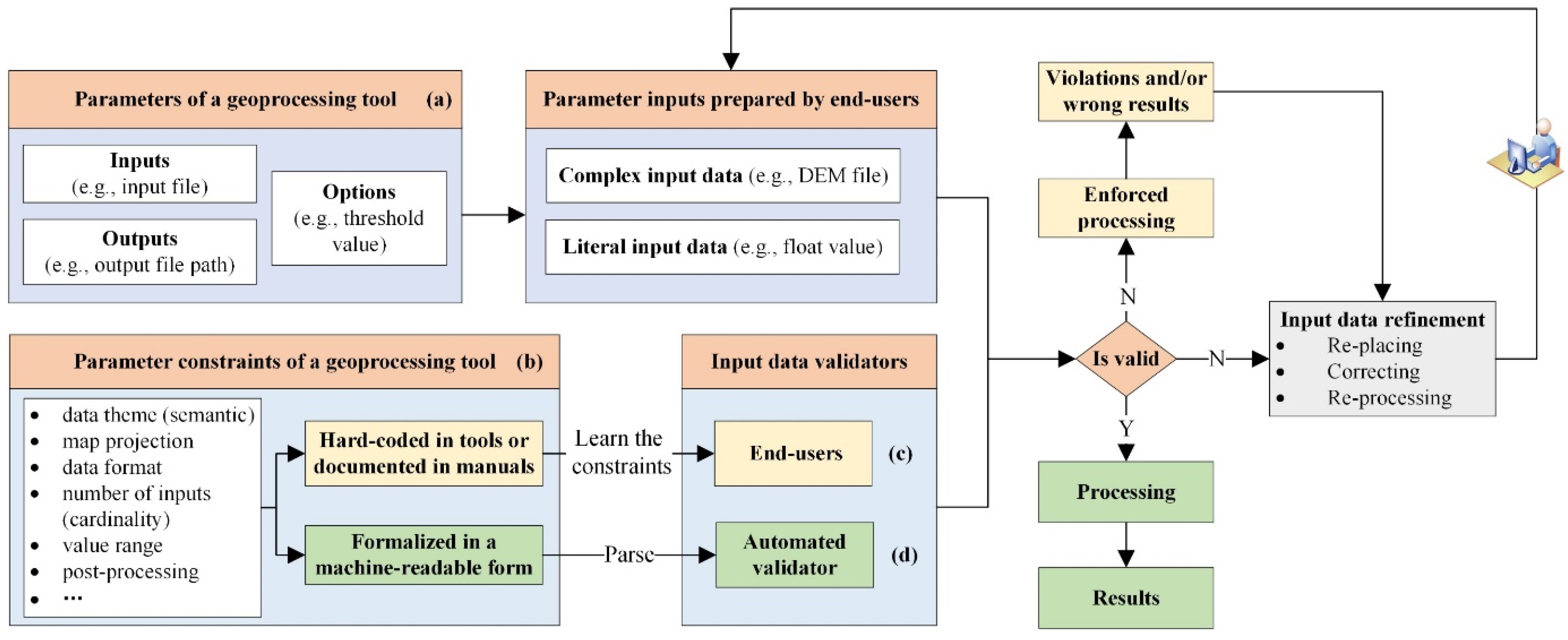
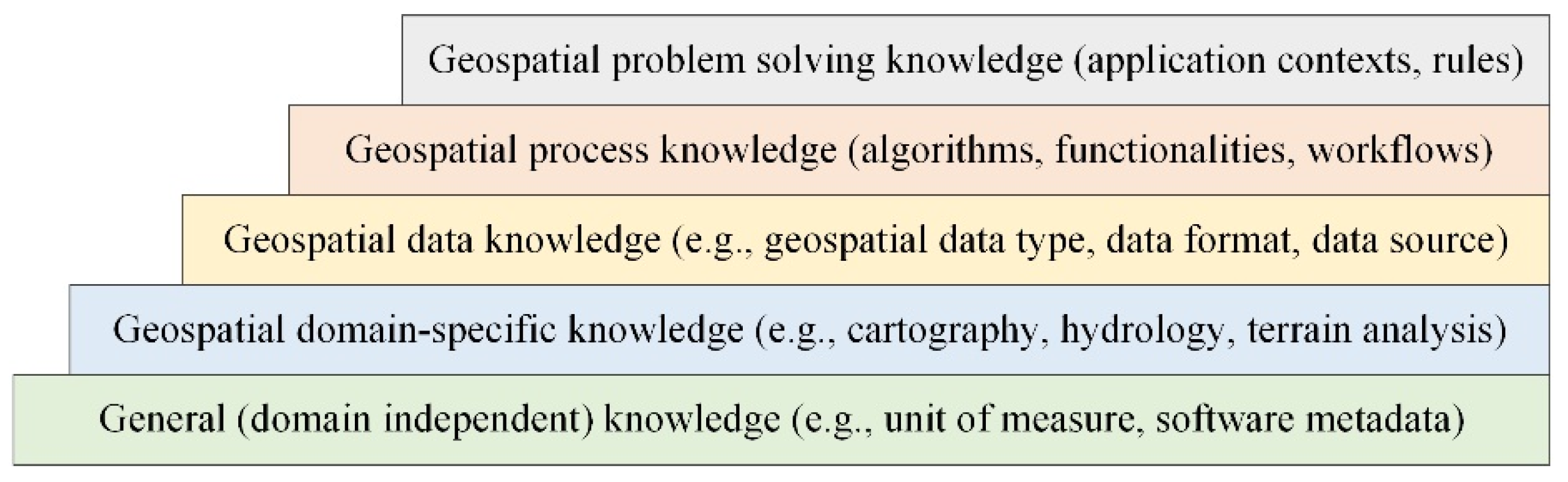
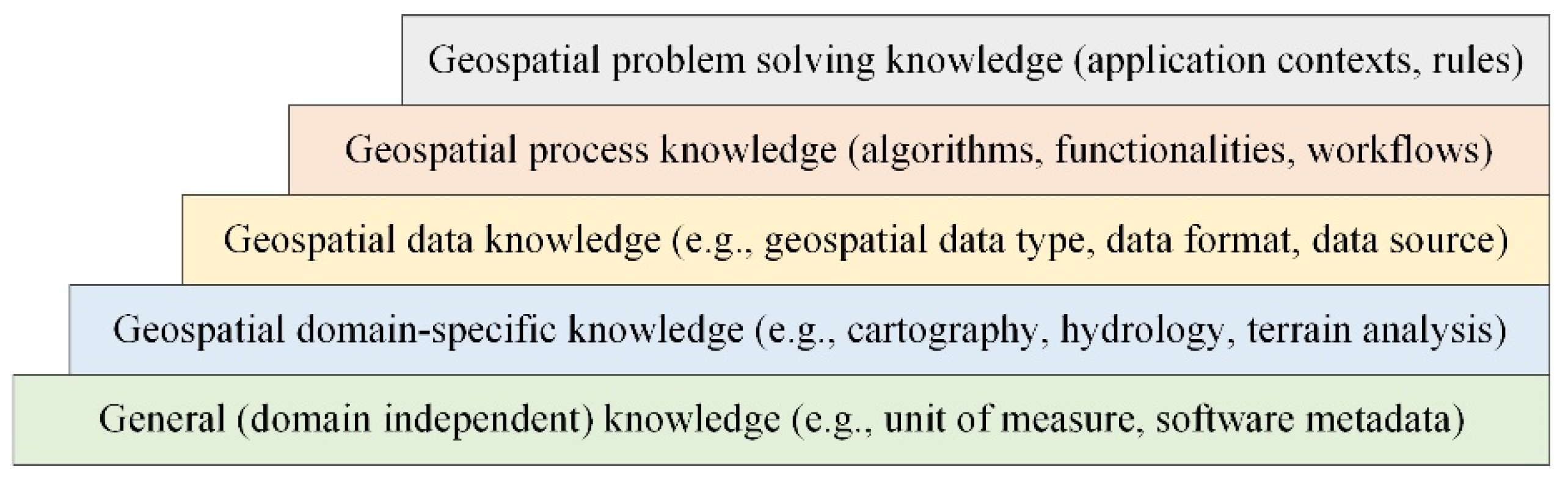
2. Parameter Constraints of Geoprocessing Tools
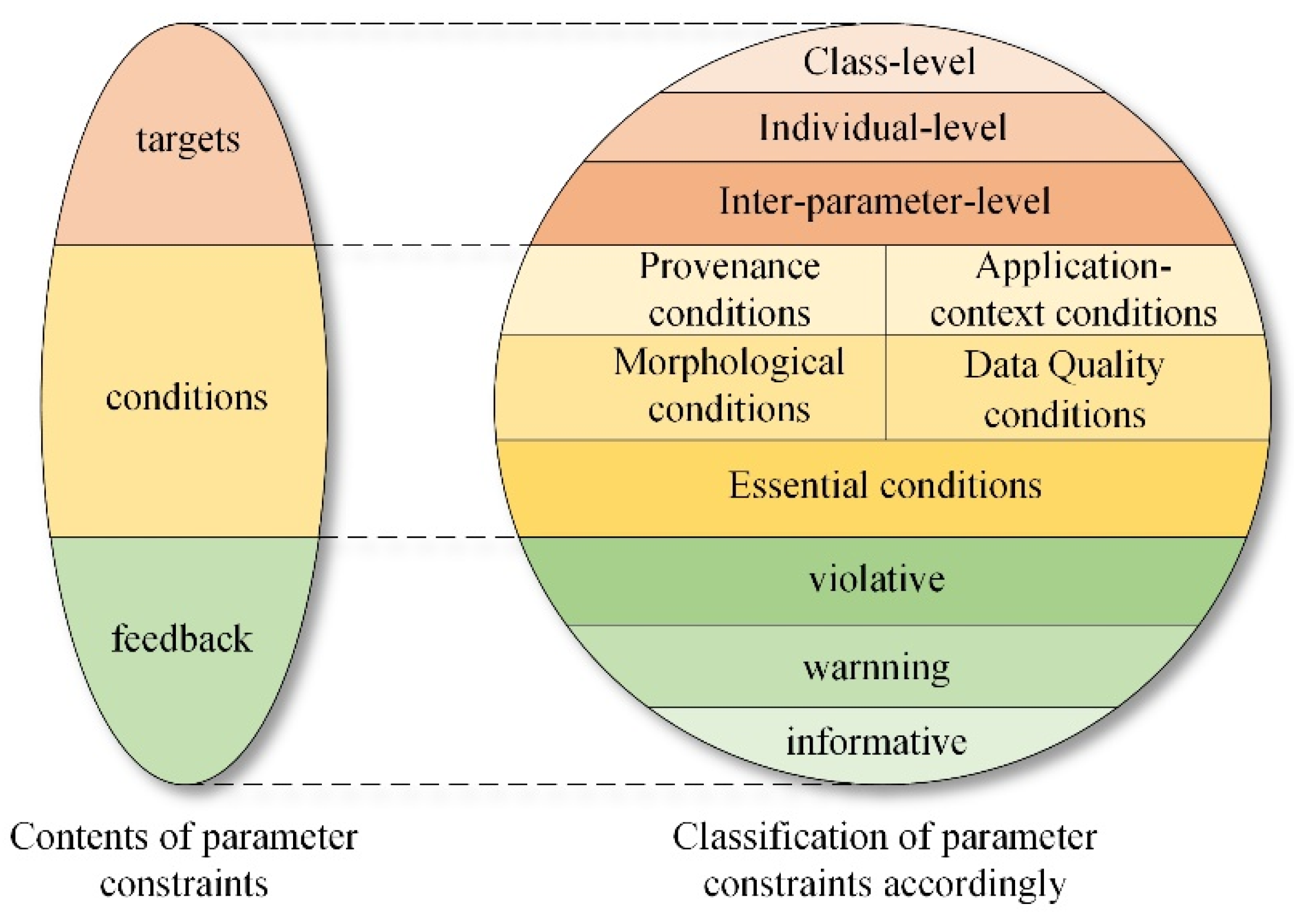
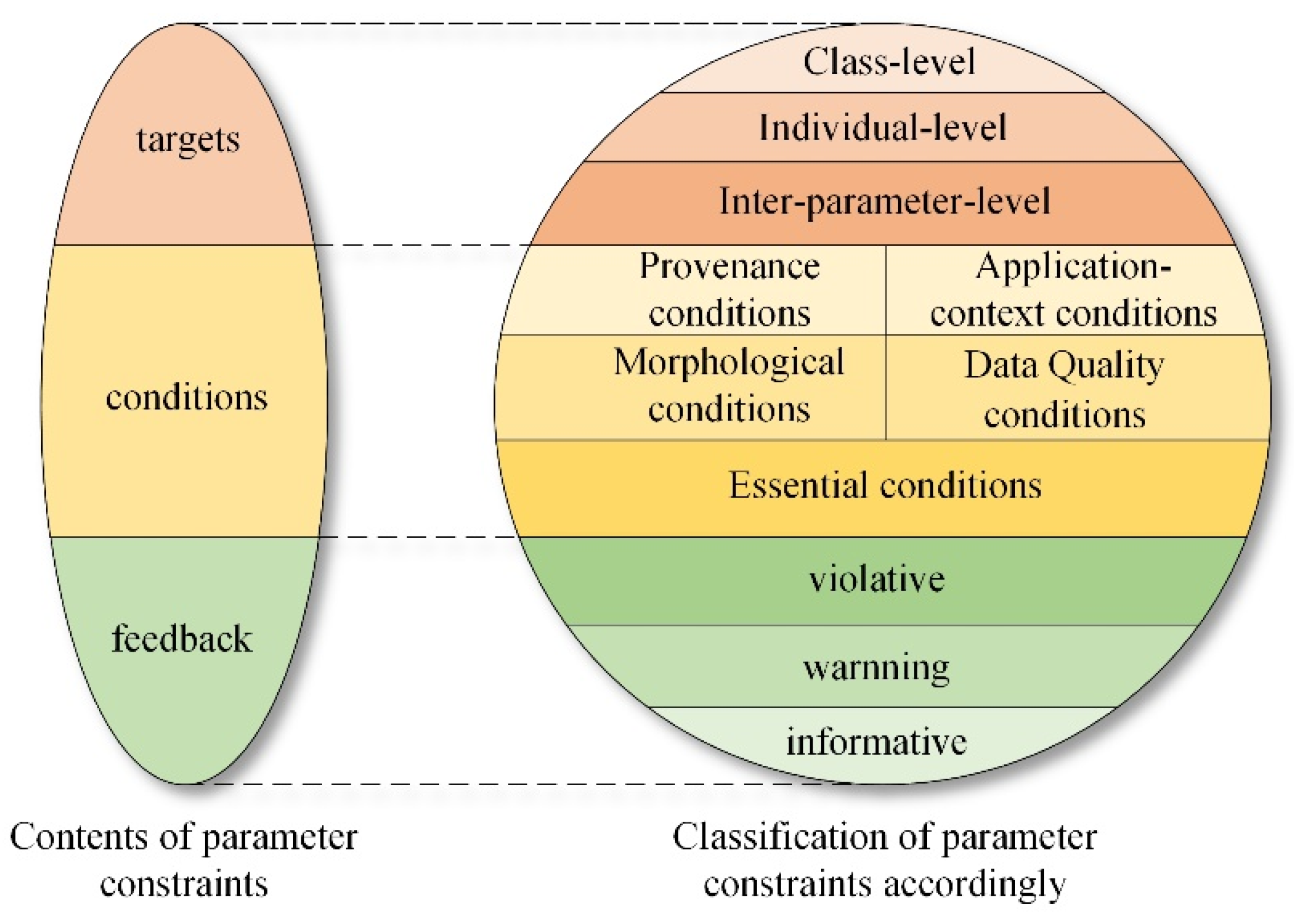
2.1. Target-Oriented Classification of Parameter Constraints
2.2. Conditions-Oriented Classification of Parameter Constraints
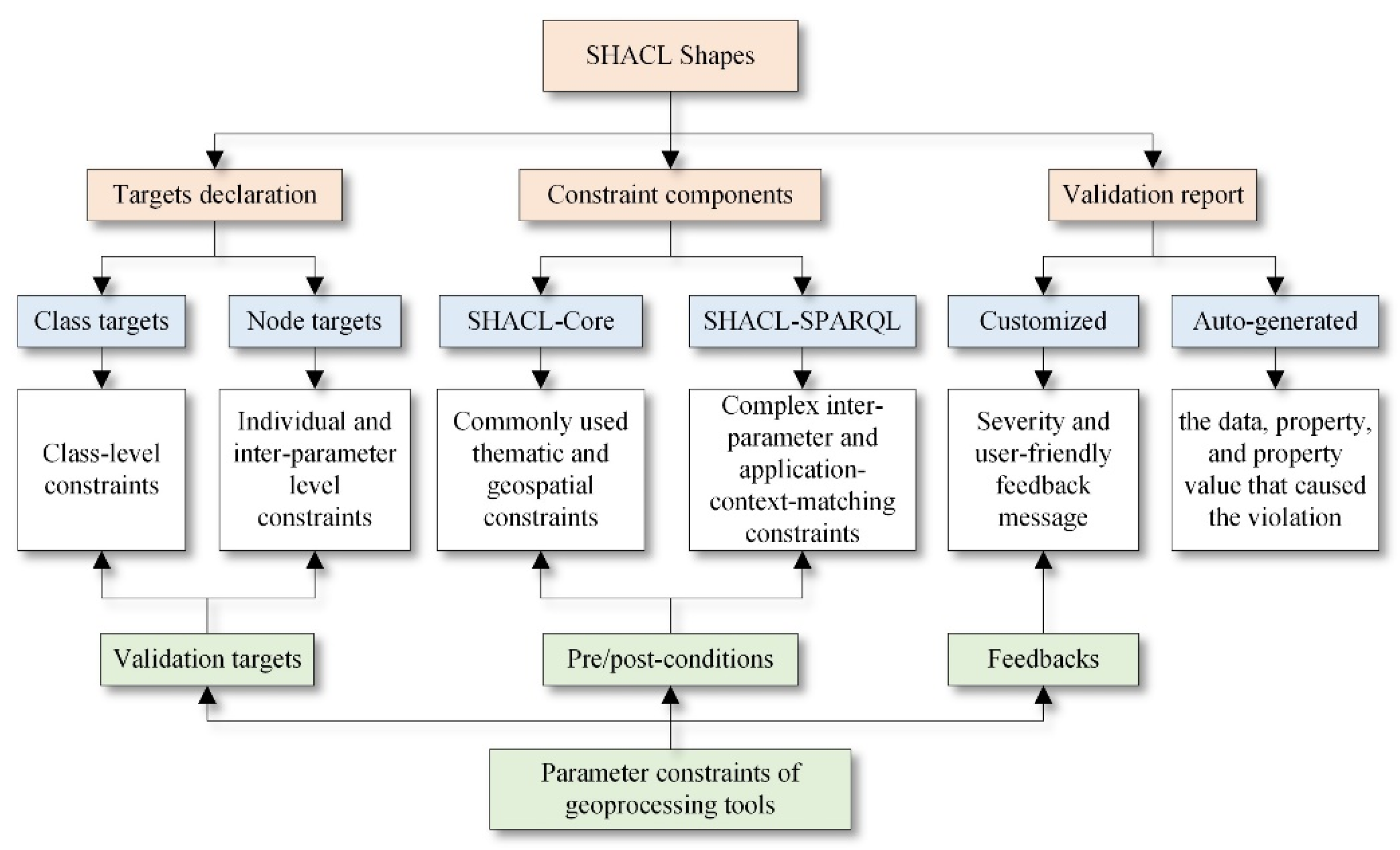
3. SHACL-Based Formalization of Parameter Constraints
3.1. Basic Idea and the High-Level RDF Constraint Language-SHACL
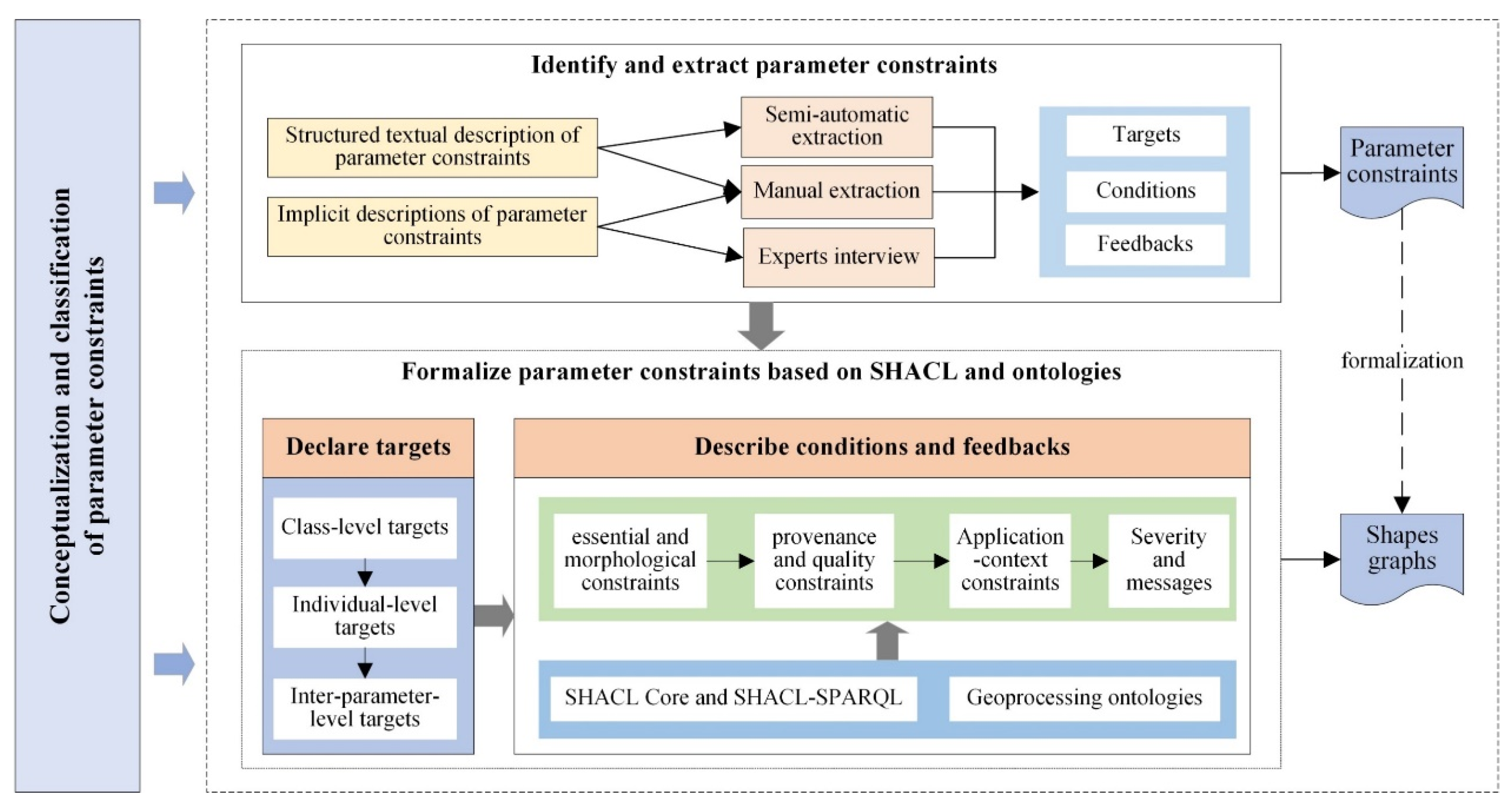
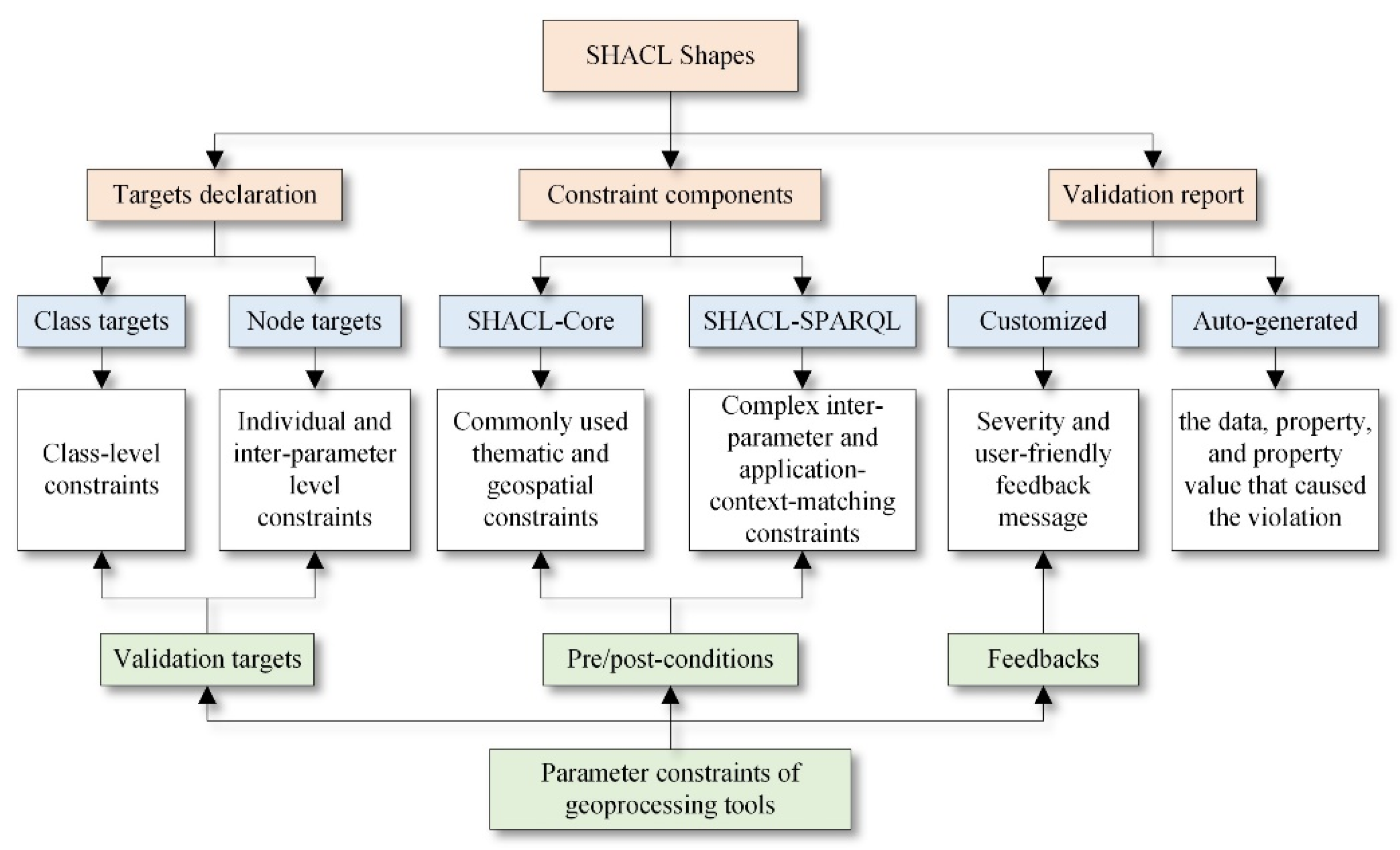
3.2. Overall Design of the Proposed Method
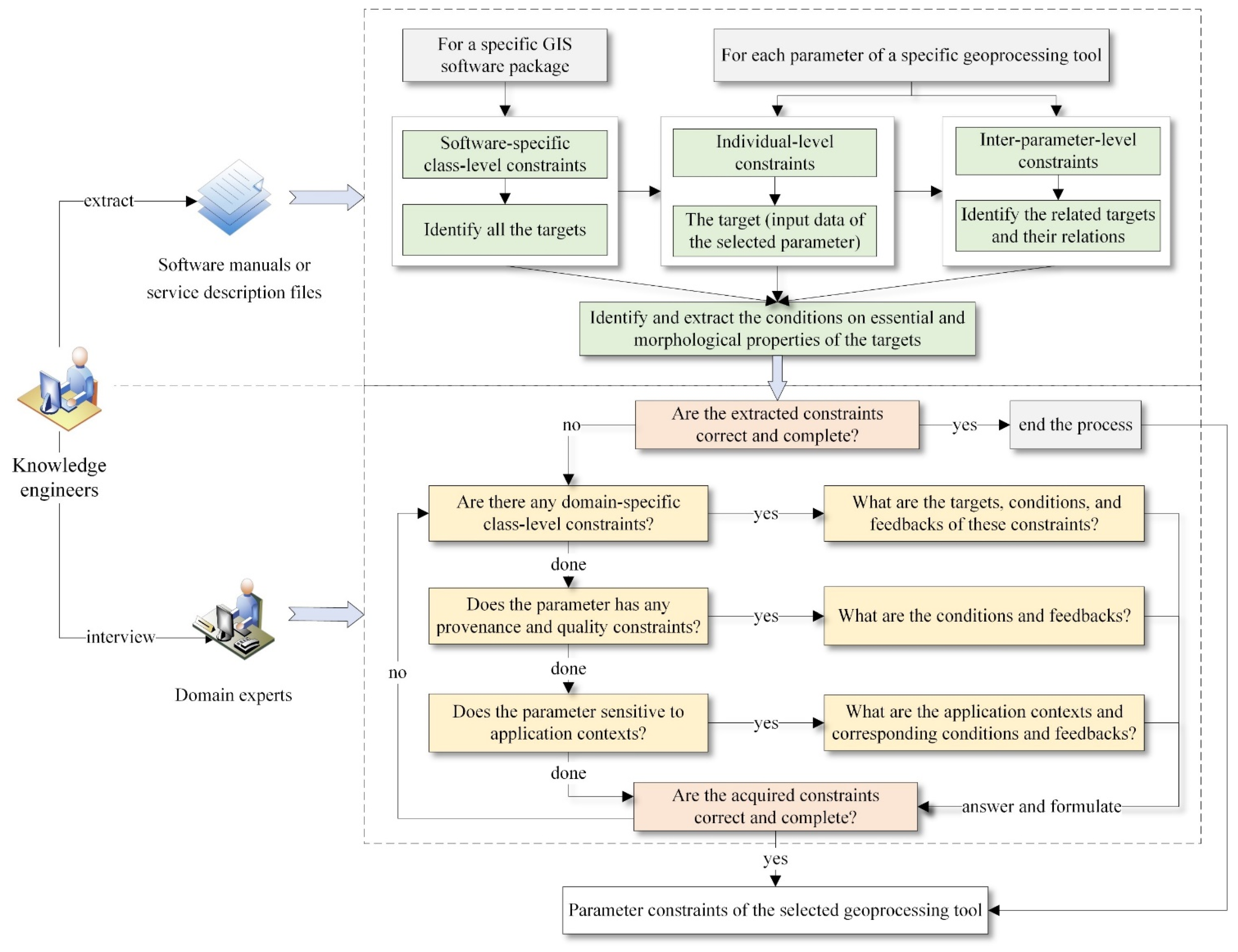
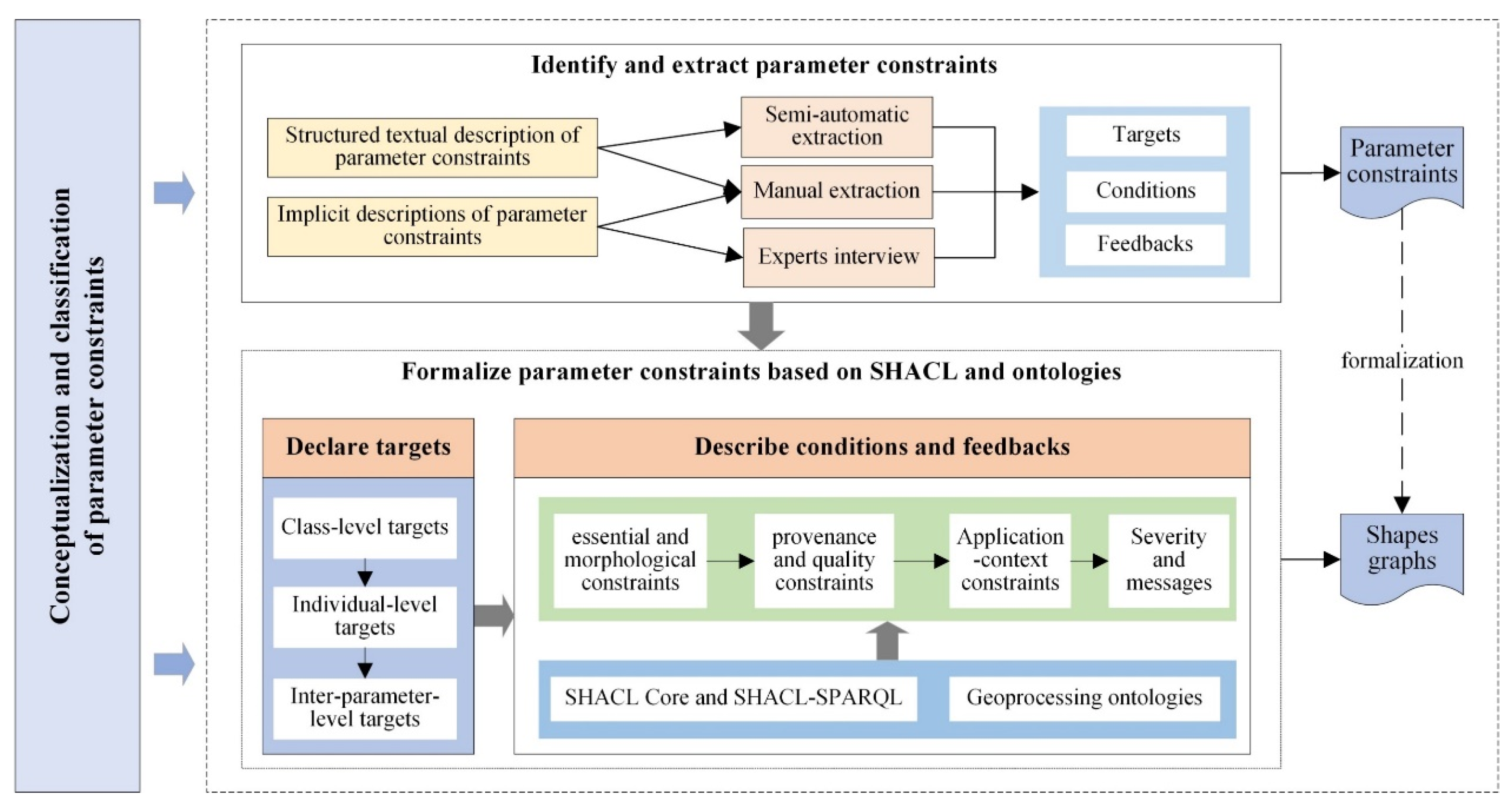
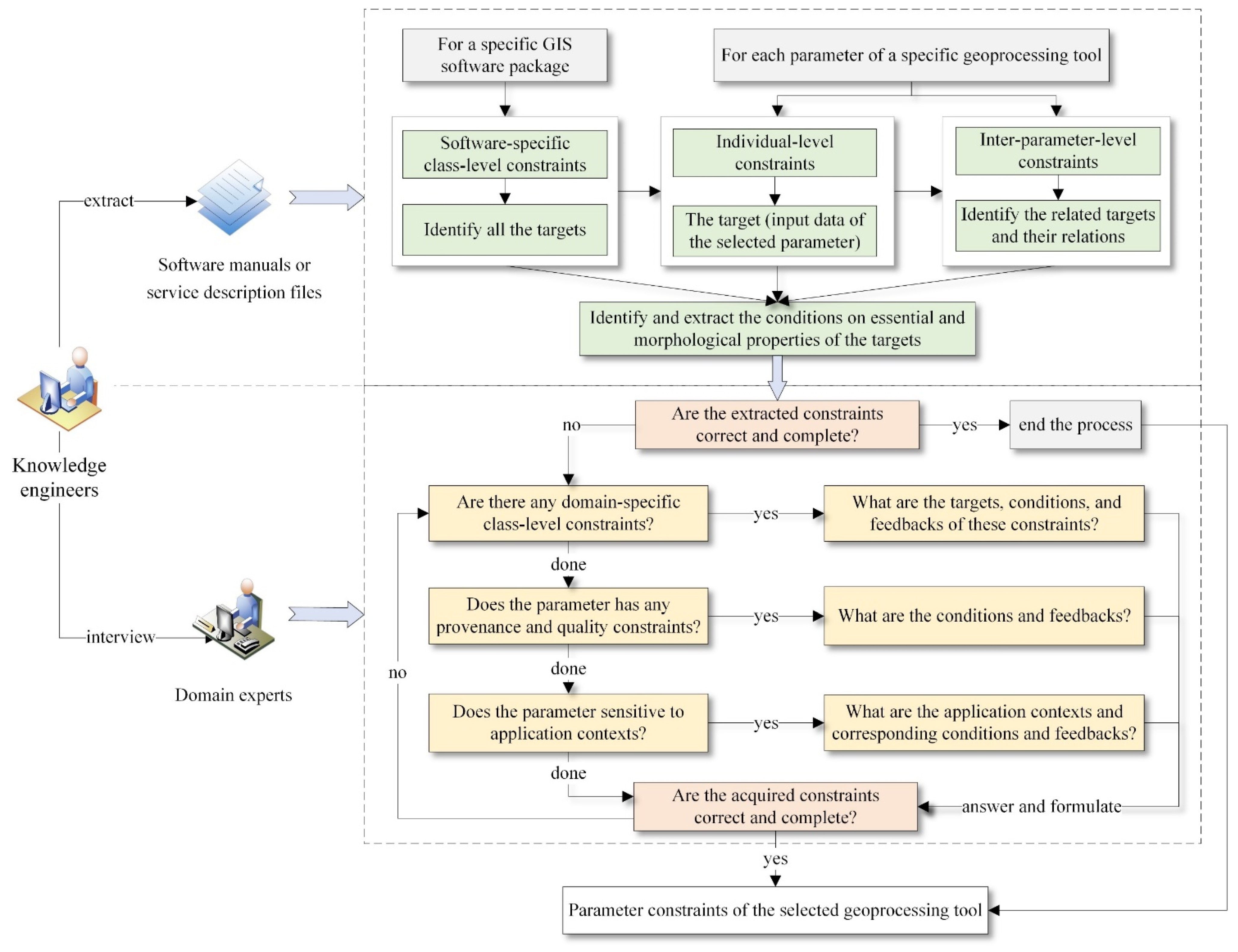
3.3. Identification and Acquisition of Parameter Constraints
- How many types of constraints could a specific parameter have?
- For each type of parameter constraint, from where could their contents be obtained?
- How do we identify the targets, conditions, and feedback of the constraints?
- How do we acquire the constraints completely and efficiently?
3.4. Formalizing Parameter Constraints Based on SHACL and Ontologies
- Reusable constraints should be formalized at the very beginning of the stage. This includes not only the class-level constraints, but also constraints on commonly-used data properties (e.g., the map projection) that exist in many parameters.
- Constraints that can be easily described using the SHACL Core should be formalized before those using SHACL-SPARQL. As SHACL-SPARQL is a trade-off between usability and flexibility, it is comparatively more difficult to understand, write, and maintain than SHACL Core. SHACL-SPARQL is only suitable for complex constraints such as the inter-parameter and application-context-matching constraints.
3.4.1. Target Declarations of Parameter Constraints

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
|
|
3.4.2. Formalization of Constraint Conditions and Feedback
|
|
|
4. Application Case
4.1. Case Design
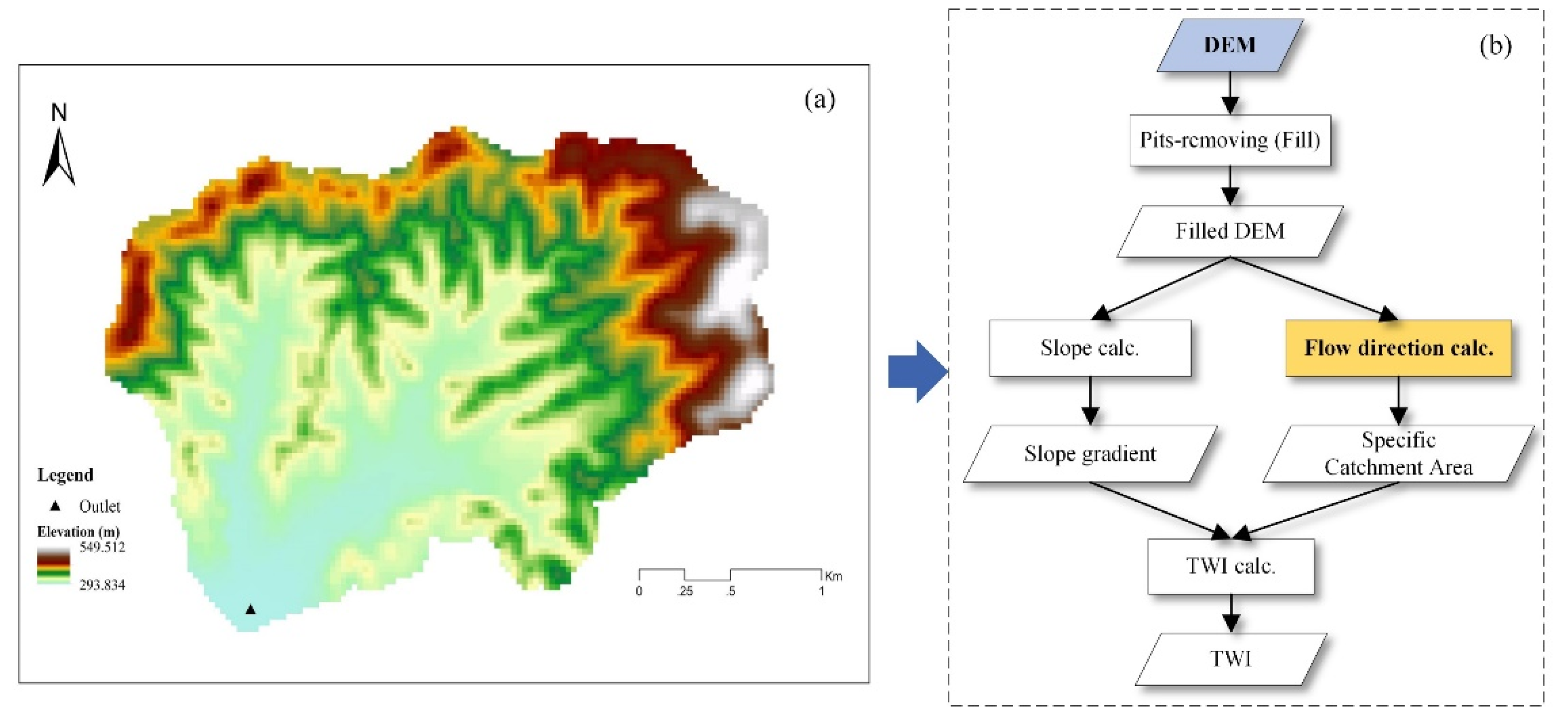
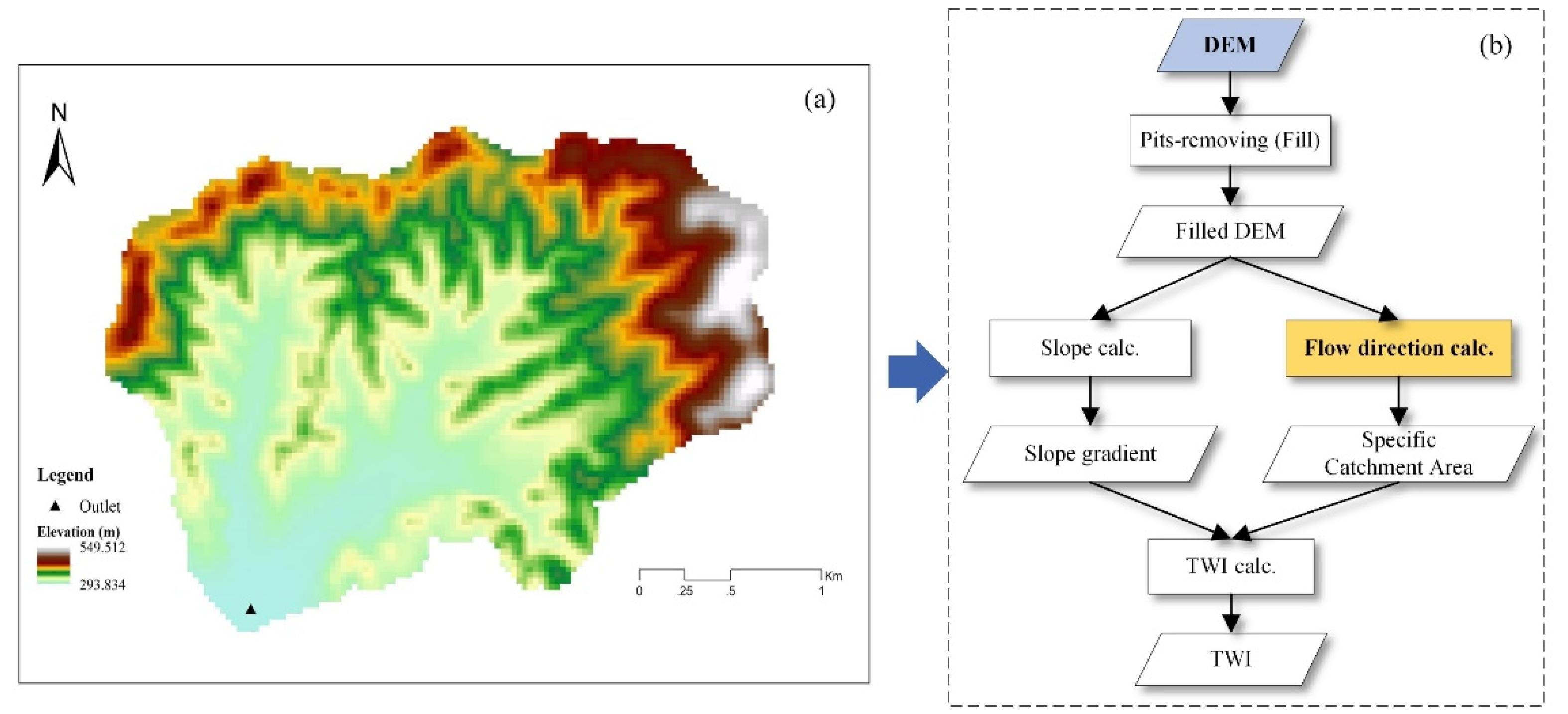
4.1.1. The Flow Direction Tool and Its Parameter Constraints
4.1.2. Extraction and Formalization of Parameter Constraints of the Flow Direction Tool
4.1.3. Application Context and Input Data of the Tool
|
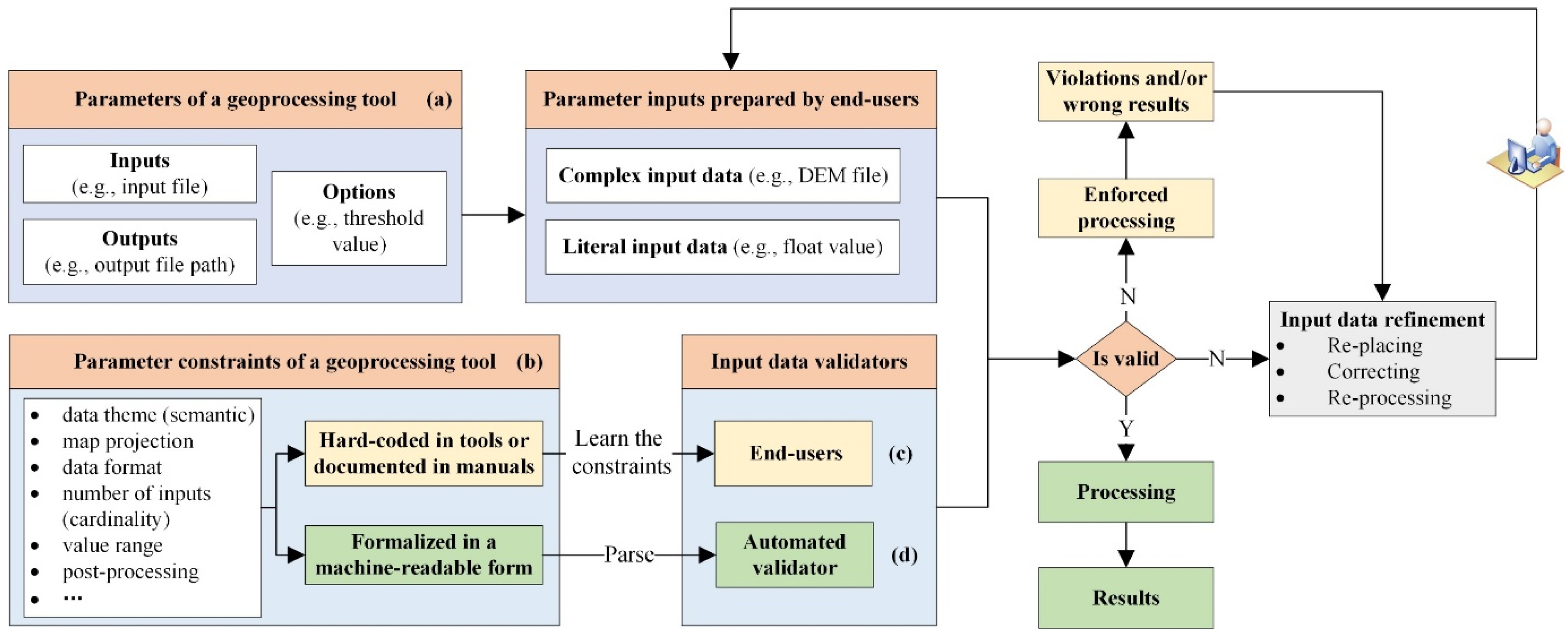
4.2. SHACL-Based Input Data Validation and the Results
5. Evaluation and Discussion
5.1. Evaluation Method
5.2. Evaluation Results and Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Di, L.; Zhao, P.; Yang, W.; Yue, P. Ontology-driven automatic geospatial-processing modeling based on web-service chaining. In Proceedings of the sixth Annual NASA Earth Science Technology Conference, College Park, MD, USA, 27–29 June 2006; pp. 27–29. [Google Scholar]
- Lutz, M. Ontology-Based Descriptions for Semantic Discovery and Composition of Geoprocessing Services. GeoInformatica 2007, 11, 1–36. [Google Scholar] [CrossRef]
- Hofer, B.; Mäs, S.; Brauner, J.; Bernard, L. Towards a knowledge base to support geoprocessing workflow development. Int. J. Geogr. Inf. Sci. 2016, 31, 694–716. [Google Scholar] [CrossRef]
- Scheider, S.; Nyamsuren, E.; Kruiger, H.; Xu, H. Geo-analytical question-answering with GIS. Int. J. Digit. Earth 2020, 14, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Sudmanns, M.; Tiede, D.; Lang, S.; Baraldi, A. Semantic and syntactic interoperability in online processing of big Earth observation data. Int. J. Digit. Earth 2017, 11, 95–112. [Google Scholar] [CrossRef] [Green Version]
- Kruiger, H.; Kasalica, V.; Meerlo, R.; Lamprecht, A.L.; Simon, S. Loose programming of GIS workflows with geo-analytical concepts. Trans. GIS 2020, 25, 424–449. [Google Scholar] [CrossRef]
- Fitzner, D. Formalizing Cross-Parameter Conditions for Geoprocessing Service Chain Validation. In Emerging Methods and Multidisciplinary Applications in Geospatial Research; IGI Global: Hershey, PA, USA, 2011; pp. 282–300. [Google Scholar]
- Cruz, S.A.B.; Monteiro, A.M.V.; Santos, R. Automated geospatial Web Services composition based on geodata quality requirements. Comput. Geosci. 2012, 47, 60–74. [Google Scholar] [CrossRef]
- Qi, K.; Gui, Z.; Li, Z.; Guo, W.; Wu, H.; Gong, J. An extension mechanism to verify, constrain and enhance geoprocessing workflows invocation. Trans. GIS 2015, 20, 240–258. [Google Scholar] [CrossRef]
- Wiemann, S.; Karrasch, P.; Bernard, L. Ad-hoc combination and analysis of heterogeneous and distributed spatial data for environmental monitoring—Design and prototype of a web-based solution. Int. J. Digit. Earth 2018, 11, 79–94. [Google Scholar] [CrossRef] [Green Version]
- Hofer, B.; Brauner, J.; Jackson, M.; Granell, C.; Rodrigues, A.; Nüst, D.; Wiemann, S. Descriptions of Spatial Operations—Recent Approaches and Community Feedback. Int. J. Spat. Data Infrastruct. Res. 2015, 10, 124–137. [Google Scholar]
- Hou, Z.-W.; Qin, C.-Z.; Zhu, A.-X.; Liang, P.; Wang, Y.-J.; Zhu, Y.-Q. From Manual to Intelligent: A Review of Input Data Preparation Methods for Geographic Modeling. ISPRS Int. J. Geo-Inf. 2019, 8, 376. [Google Scholar] [CrossRef] [Green Version]
- Martin, D.; Burstein, M.; Hobbs, J.; Lassila, O.; McDermott, D.; McIlraith, S.; Narayanan, S.; Paolucci, M.; Parsia, B.; Payne, T. OWL-S: Semantic markup for web services. W3C Memb. Submiss. 2004, 22, 2004–2007. [Google Scholar]
- Roman, D.; Keller, U.; Lausen, H.; Bruijn, J.D.; Stollberg, M.; Polleres, A.; Feier, C.; Bussler, C.; Fensel, D. Web Service Modeling Ontology. Appl. Ontol. 2005, 1, 77–106. [Google Scholar]
- Lutz, M.; Lucchi, R.; Friis-Christensen, A.; Ostländer, N. A rule-based description framework for the composition of geographic information services. In Proceedings of the International Conference on GeoSpatial Sematics, Mexico City, Mexico, 29–30 November 2007; pp. 114–127. [Google Scholar]
- Xing, H.; Chen, J.; Wu, H.; Hou, D. A Web Service-Oriented Geoprocessing System for Supporting Intelligent Land Cover Change Detection. ISPRS Int. J. Geo-Inf. 2019, 8, 50. [Google Scholar] [CrossRef] [Green Version]
- Tao, J.; Sirin, E.; Bao, J.; McGuinness, D.L. Integrity Constraints in OWL. In Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2010, Atlanta, GA, USA, 11–15 July 2010. [Google Scholar]
- Bosch, T.; Acar, E.; Nolle, A.; Eckert, K. The role of reasoning for rdf validation. In Proceedings of the 11th International Conference on Semantic Systems, SEMANTICS ’15, New York, NY, USA, 16 September 2015; pp. 33–40. [Google Scholar]
- Gayo, J.E.L.; Prud’hommeaux, E.; Boneva, I.; Kontokostas, D. Validating RDF Data; Morgan & Claypool: San Rafael, CA, USA, 2018; Volume 7. [Google Scholar]
- Patel-Schneider, P. Using Description Logics for RDF Constraint Checking and Closed-World Recognition. In Proceedings of the AAAI15: Twenty-Ninth Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Shu, Y. A Practical Approach to Modelling and Validating Integrity Constraints in the Semantic Web. Knowl.-Based Syst. 2018, 153, 29–39. [Google Scholar] [CrossRef]
- Hofer, B.; Papadakis, E.; Mäs, S. Coupling Knowledge with GIS Operations: The Benefits of Extended Operation Descriptions. ISPRS Int. J. Geo-Inf. 2017, 6, 40. [Google Scholar] [CrossRef]
- Scheider, S.; Ballatore, A.; Lemmens, R. Finding and sharing GIS methods based on the questions they answer. Int. J. Digit. Earth 2018, 12, 594–613. [Google Scholar] [CrossRef] [Green Version]
- Harris, S.; Seaborne, A. SPARQL 1.1 Query Language. Available online: https://www.w3.org/TR/sparql11-query/ (accessed on 13 December 2019).
- Bosch, T.; Eckert, K. Requirements on RDF Constraint Formulation and Validation. In Proceedings of the the 14th DCMI InternationalConference on Dublin Core and Metadata Applications (DC 2014), Austin, TX, USA, 12–15 October 2014; pp. 95–108. [Google Scholar]
- Kontokostas, D.; Westphal, P.; Auer, S.; Hellmann, S.; Lehmann, J.; Cornelissen, R.; Zaveri, A. Test-driven evaluation of linked data quality. In Proceedings of the the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014. [Google Scholar]
- Knublauch, H.; Kontokostas, D. Shapes Constraint Language (SHACL). Available online: https://www.w3.org/TR/shacl/ (accessed on 20 November 2019).
- Mendel-Gleason, G.; Feeney, K.; Brennan, R. Ontology Consistency and Instance Checking for Real World Linked Data. In Proceedings of the the 2nd Workshop on Linked Data Quality co-located with 12th Extended Semantic Web Conference (ESWC 2015), Portorož, Slovenia, 1 June 2015. [Google Scholar]
- Poveda-Villalón, M.; Gómez-Pérez, A.; Suárez-Figueroa, M. OOPS! (OntOlogy Pitfall Scanner!): An On-line Tool for Ontology Evaluation. Int. J. Semant. Web Inf. Syst. IJSWIS 2014, 10, 7–34. [Google Scholar] [CrossRef] [Green Version]
- Lindsay, J.B. WhiteboxTools User Manual. Available online: https://jblindsay.github.io/wbt_book/preface.html (accessed on 4 July 2020).
- Lu, Y.; Qin, C.-Z.; Zhu, A.-X.; Qiu, W. Application-matching knowledge based engine for a modelling environment for digital terrain analysis. In Proceedings of the GeoInformatics, Hong Kong, China: The Chinese University of Hong Kong, Hong Kong, China, 15–17 June 2012. [Google Scholar]
- Sun, K.; Zhu, Y.; Pan, P.; Hou, Z.; Wang, D.; Li, W.; Song, J. Geospatial data ontology: The semantic foundation of geospatial data integration and sharing. Big Earth Data 2019, 3, 269–296. [Google Scholar] [CrossRef] [Green Version]
- Peng, Y.; Wei, Y.; Di, L.; He, L.; Gong, J.; Zhang, L. Sharing geospatial provenance in a service-oriented environment. Comput. Environ. Urban Syst. 2011, 35, 333–343. [Google Scholar]
- Di, L.; Yue, P.; Ramapriyan, H.K.; King, R.L. Geoscience Data Provenance: An Overview. IEEE Trans. Geosci. Remote Sens. 2013, 51, 5065–5072. [Google Scholar] [CrossRef]
- Servigne, S.; Ubeda, T.; Puricelli, A.; Laurini, R. A Methodology for Spatial Consistency Improvement of Geographic Databases. GeoInformatica 2000, 4, 7–34. [Google Scholar] [CrossRef]
- Liang, P.; Qin, C.-Z.; Zhu, A.-X.; Hou, Z.-W.; Fan, N.-Q.; Wang, Y.-J. A case-based method of selecting covariates for digital soil mapping. J. Integr. Agric. 2020, 19, 2–11. [Google Scholar] [CrossRef]
- Qin, C.; Wu, X.; Jiang, J.; Zhu, A.-X. Case-based knowledge formalization and reasoning method for digital terrain analysis—Application to extracting drainage networks. Hydrol. Earth Syst. Sci. 2016, 20, 3379–3392. [Google Scholar] [CrossRef] [Green Version]
- Frank, A.U. Tiers of ontology and consistency constraints in geographical information systems. Int. J. Geogr. Inf. Sci. 2001, 15, 667–678. [Google Scholar] [CrossRef]
- Smith, M.J.D.; Goodchild, M.F.; Longley, P.A. Geospatial Analysis—A Comprehensive Guide to Principles, Techniques and Software Tools, 6th ed.; The Winchelsea Press: Winchelsea, UK, 2018. [Google Scholar]
- Hutchinson, M.F. Adding the Z Dimension. In The Handbook of Geographic Information Science; Wilson, J.P., Fotheringham, A.S., Eds.; Blackwell Publishing Ltd.: Hoboken, NJ, USA, 2008. [Google Scholar]
- Tomaszuk, D. RDF Validation: A Brief Survey. In Proceedings of the International Conference: Beyond Databases, Ustroń, Poland, 30 May–2 June 2017. [Google Scholar]
- Wiharja, K.; Pan, J.Z.; Kollingbaum, M.J.; Deng, Y. Schema aware iterative Knowledge Graph completion. J. Web Semant. 2020, 65, 100616. [Google Scholar] [CrossRef]
- Gayo, J.E.L.; Prud’hommeaux, E.; Solbrig, H.R.; Boneva, I. Validating and describing linked data portals using shapes. arXiv 2017, arXiv:1701.08924 [cs.DB]. [Google Scholar]
- Bosch, T.; Eckert, K. Guidance, please! towards a framework for RDF-based constraint languages. In Proceedings of the 2015 International Conference on Dublin Core and Metadata Applications, São Paulo, Brazil, 1–4 September 2015; pp. 95–111. [Google Scholar]
- Knublauch, H. SHACL and OWL Compared. Available online: https://spinrdf.org/shacl-and-owl.html (accessed on 2 November 2019).
- Albrecht, J. Universal Analytical GIS Operations: A Task-Oriented Systematization of Data Structure-Independent GIS Functionality. In Geographic Information Research: Transatlantic Perspectives; Onsrud, H., Craglia, M., Eds.; Taylor & Francis: Abingdon, UK, 1998; pp. 577–591. [Google Scholar]
- Miles, A.; Bechhofer, S. Simple Knowledge Organization System. Available online: https://www.w3.org/TR/2009/REC-skos-reference-20090818/ (accessed on 6 May 2021).
- Brauner, J. Formalizations for Geooperators-Geoprocessing in Spatial Data Infrastructures; Technische Universität Dresden: Dresden, Germany, 2015. [Google Scholar]
- Battle, R.; Kolas, D. GeoSPARQL: Enabling a Geospatial Semantic Web. Semant. Web J. 2012, 3, 355–370. [Google Scholar] [CrossRef]
- Qin, C.; Zhu, A.X.; Pei, T.; Li, B.; Zhou, C.; Yang, L. An adaptive approach to selecting a flow-partition exponent for a multiple-flow-direction algorithm. Int. J. Geogr. Inf. Sci. 2007, 21, 443–458. [Google Scholar] [CrossRef]
- Rampi, L.P.; Knight, J.F.; Lenhart, C.F. Comparison of Flow Direction Algorithms in the Application of the CTI for Mapping Wetlands in Minnesota. Wetlands 2014, 34, 513–525. [Google Scholar] [CrossRef]
- Wilson, J.P. Environmental Applications of Digital Terrain Modeling; Wiley-Blackwell: Oxford, UK, 2018. [Google Scholar]
- Wang, Y.-J.; Qin, C.-Z.; Zhu, A.-X. Review on algorithms of dealing with depressions in grid DEM. Ann. Gis 2019, 25, 83–97. [Google Scholar] [CrossRef] [Green Version]
- International Organization for Standardization. Ergonomic Requirements for Office Work with Visual Display Terminals (VDTs)—Part 11: Guidance on Usability. ISO 9241-11: 1998; International Organization for Standardization: Geneva, Switzerland, 1998. [Google Scholar]
- Huang, Z. Usability of tourism websites: A case study of heuristic evaluation. New Rev. Hypermedia Multimed. 2020, 26, 55–91. [Google Scholar] [CrossRef]
- Nielsen, J. Designing Web Usability: The Practice of Simplicity; New Riders Publishing: Indianapolis, IN, USA, 2000. [Google Scholar]
- Nielsen, J. Usability 101: Introduction to Usability. Available online: https://www.nngroup.com/articles/usability-101-introduction-to-usability/ (accessed on 1 April 2021).
- Conejo, R.; Guzmán, E.; Pérez-de-la-Cruz, J.-L. Knowledge-based validation for hydrological information systems. Appl. Artif. Intell. 2007, 21, 803–830. [Google Scholar] [CrossRef]
- Shu, Y.; Liu, Q.; Taylor, K. Semantic validation of environmental observations data. Environ. Modell. Softw. 2016, 79, 10–21. [Google Scholar] [CrossRef]
- Yu, J.; Taylor, P.; Cox, S.J.D.; Walker, G. Validating observation data in WaterML 2.0. Comput. Geosci. 2015, 82, 98–110. [Google Scholar] [CrossRef]
- Tan, W.-S.; Liu, D.; Bishu, R. Web evaluation: Heuristic evaluation vs. user testing. Int. J. Ind. Ergon. 2009, 39, 621–627. [Google Scholar] [CrossRef]
- Maguire, M.; Isherwood, P. A Comparison of User Testing and Heuristic Evaluation Methods for Identifying Website Usability Problems. In Proceedings of the International Conference of Design, User Experience, and Usability, Cham, Switzerland, 4–8 July 2018; pp. 429–438. [Google Scholar]

| Number of Inputs for Validation | Under OWA and NUNA | Under CWA and UNA | ||
|---|---|---|---|---|
| Is Valid | Reason | Is Valid | Reason | |
| no input (incomplete input) | true | infer that there might have one or more unknown inputs | false | missing required input |
| only one input (as the required) | true | it exactly has one required input | true | it exactly has one required input |
| two different inputs (too many inputs) | true | infer that the two inputs are the same entity with different names * | false | can only have one input, but provided two different inputs |
| Constraint Types (Based on Validation Targets) | Subtypes | Description |
|---|---|---|
| Class-level constraints | - | the constraints on a group of targets (e.g., the instances of a target class or subjects/objects of a target predicate). |
| Individual-level constraints | parameter-level | constraints on the input data of each parameter as a whole. |
| data-level | constraints on each input data property. | |
| Inter-parameter-level constraints | equivalent constraints | inputs of two (or more) given parameters must conform to the same conditions: e.g., the coordinate reference system. |
| dependency constraints | conditions on the inputs of a parameter are determined by the properties of input data of another parameter. |
| Constraint Types (Based on Data Properties) | Description |
|---|---|
| Essential constraints | Constraints on essential properties such as data theme and spatial/temporal coverage that distinguish the dataset from others. |
| Morphological constraints | Constraints on morphological properties that describe the internal structure and external shape of the data, such as CRS and data format. |
| Provenance constraints | Constraints on provenance information that indicate where and how the data are collected and derived from, such as data sources, processing algorithms and steps, etc. They are important to ensure the usability and reliability of input data [33,34]. |
| Quality constraints | Constraints on data quality attributes such as outliers, coverage completeness, accuracy, and results of consistencies verified by geographic databases in structural, geometric, and topo-semantic levels [8,35]. |
| Application-context-matching constraints | Constraints on input data or its properties determined by the specific natural or social application context of the geoprocessing tool, such as suitable value range |
| No. | Example Shapes | Description |
|---|---|---|
| 1 | data:RasterDataShape a sh:NodeShape; sh:targetClass data:RasterData; | declare data:RasterData as the target class explicitly |
| 2 | data:RasterData a sh:NodeShape, rdfs:Class. | declare data:RasterData as the target class implicitly |
| 3 | data:ParameterShape a sh:NodeShape; sh:targetSubjectsOf process:hasData; | declare the subjects (parameters) of predicate process:hasData as the targets |
| 4 | data:DataShape a sh:NodeShape; sh:targetObjectsOf process:hasData; | declare the objects (input data) of predicate process:hasData as the targets |
| Parameter | Constraint Types and Properties | Constraint Conditions |
|---|---|---|
| in_surface_raster | Essential: data theme | semantically equal to Filled-DEM or Hydrologically-corrected DEM |
| Morphological: cardinality | only 1 | |
| Morphological: value type | string | |
| Morphological: data type | grid raster | |
| Morphological: CRS | must be projected | |
| Provenance: pre-processing tool | should be arcgis:Fill | |
| flow_direction_type | Morphological: cardinality | at most 1 |
| Morphological: value type | string | |
| Morphological: value range | only D8, MFD, Dinf are allowed | |
| Application-context-matching constraints | see Listing 5 |
| Usability Heuristic | Evaluation Criteria | Explanation |
|---|---|---|
| Correctness |
| The ability of the validator to correctly detect all the invalid input data based on the formalized constraints. This is a restrictive criterion. |
| Completeness (coverage) |
| The number of parameter constraint types the method is able to formalize. Only consider the constraints that have been explicitly mentioned in the design of the method under evaluation. |
| Error prevention |
| The ability to define the severity and friendly feedback messages to facilitate end-user-understand and deal with input data violations |
| Flexibility and extendibility |
| The ability to formalize parameter constraints for different tasks in different contexts, including those that have not been pre-defined in the method. |
| Learnability |
| Whether the method under evaluation has provided means to facilitate the intended users to learn, understand, and use the method (not only the underlying language). |
| Standard and consistency |
| Whether the method follows a standard for constraints to ensure the constraints formalized by different users have consistent style and meaning. |
| Efficiency of use |
| The ability to reduce time and efforts expended in the formalization of parameter constraints. The tools must support the formalization of parameter constraints directly, not only general rules or SPARQL queries. |
| Usability Heuristic | Evaluation Criteria * | Features Count of the Formalization Methods | ||
|---|---|---|---|---|
| Inference-Oriented Methods | SPARQL-Based Methods | The Proposed SHACL-Based Method | ||
| correctness | (1) |
|
|
|
| Completeness (coverage) | (2) (3) |
|
|
|
| Error prevention | (4) (5) |
|
|
|
| Flexibility and extendibility | (6) (7) |
|
|
|
| Learnability | (8) (9) (10) |
|
|
|
| Standard and consistency | (11) |
|
|
|
| Efficiency of use | (12) (13) (14) |
|
|
|
| Usability score | 12 | 9 | 20 | |
| Method | Example of Formalized Constraints |
|---|---|
| the SPARQL-based method [22] | geop:Project dt:has_expression “ASK WHERE { geod:in_dataset dt:has_geometry ?g. ?g dt:hasSRS ?SRS. FILTER (?SRS!= ”“). }”. geop:Project dt:has_message “Your input dataset–(@{geod:in_dataset.rdf:type.?}) does not have a defined coordinate reference system”. |
| the proposed SHACL-based method | dt:SRSShape a sh:NodeShape; sh:targetObjectsOf dt:has_geometry; sh:property [ sh:path dt:hasSRS; sh:minLength 1; sh:message “Your input dataset does not have a defined coordinate reference system” @en; ]. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, Z.-W.; Qin, C.-Z.; Zhu, A.-X.; Wang, Y.-J.; Liang, P.; Wang, Y.-J.; Zhu, Y.-Q. Formalizing Parameter Constraints to Support Intelligent Geoprocessing: A SHACL-Based Method. ISPRS Int. J. Geo-Inf. 2021, 10, 605. https://doi.org/10.3390/ijgi10090605
Hou Z-W, Qin C-Z, Zhu A-X, Wang Y-J, Liang P, Wang Y-J, Zhu Y-Q. Formalizing Parameter Constraints to Support Intelligent Geoprocessing: A SHACL-Based Method. ISPRS International Journal of Geo-Information. 2021; 10(9):605. https://doi.org/10.3390/ijgi10090605
Chicago/Turabian StyleHou, Zhi-Wei, Cheng-Zhi Qin, A-Xing Zhu, Yi-Jie Wang, Peng Liang, Yu-Jing Wang, and Yun-Qiang Zhu. 2021. "Formalizing Parameter Constraints to Support Intelligent Geoprocessing: A SHACL-Based Method" ISPRS International Journal of Geo-Information 10, no. 9: 605. https://doi.org/10.3390/ijgi10090605
APA StyleHou, Z.-W., Qin, C.-Z., Zhu, A.-X., Wang, Y.-J., Liang, P., Wang, Y.-J., & Zhu, Y.-Q. (2021). Formalizing Parameter Constraints to Support Intelligent Geoprocessing: A SHACL-Based Method. ISPRS International Journal of Geo-Information, 10(9), 605. https://doi.org/10.3390/ijgi10090605