
Crowdsourcing of Popular Toponyms: How to Collect and Preserve Toponyms in Spoken Use


Abstract
1. Introduction
2. Background and Related Work
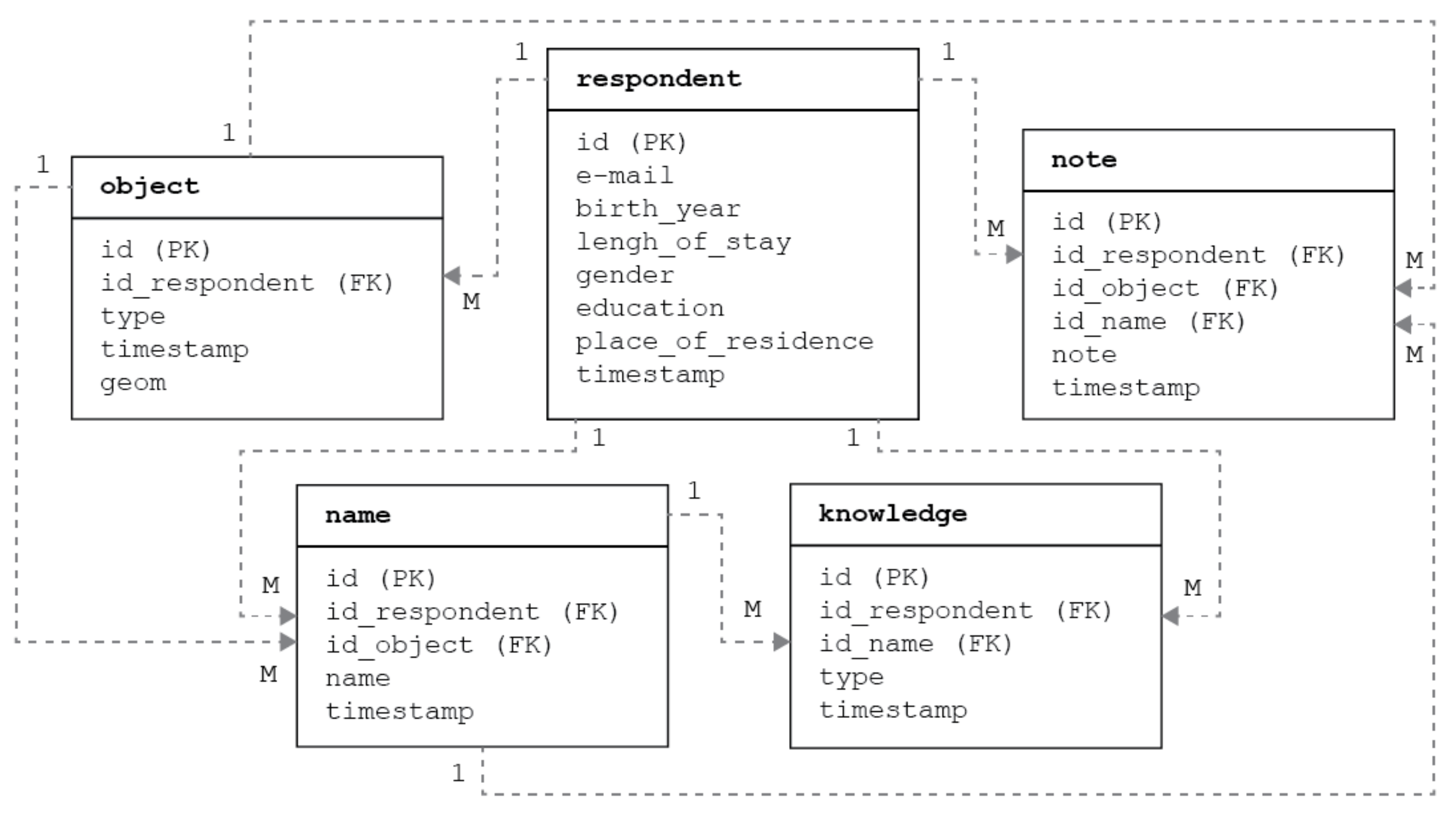
3. Methods
- The collection phase: involving as many respondents as possible and collecting as many toponyms as possible, including the micro-social ones, used only by a very small group of the population (Section 4), i.e., collecting information on the linguistic and geographical aspects of the toponyms;
- The knowledge determination phase: determination of the degree of knowledge of the names collected in the first phase among the inhabitants of the studied territory (Section 5), i.e., collecting the information concerning the social aspect of the toponyms.
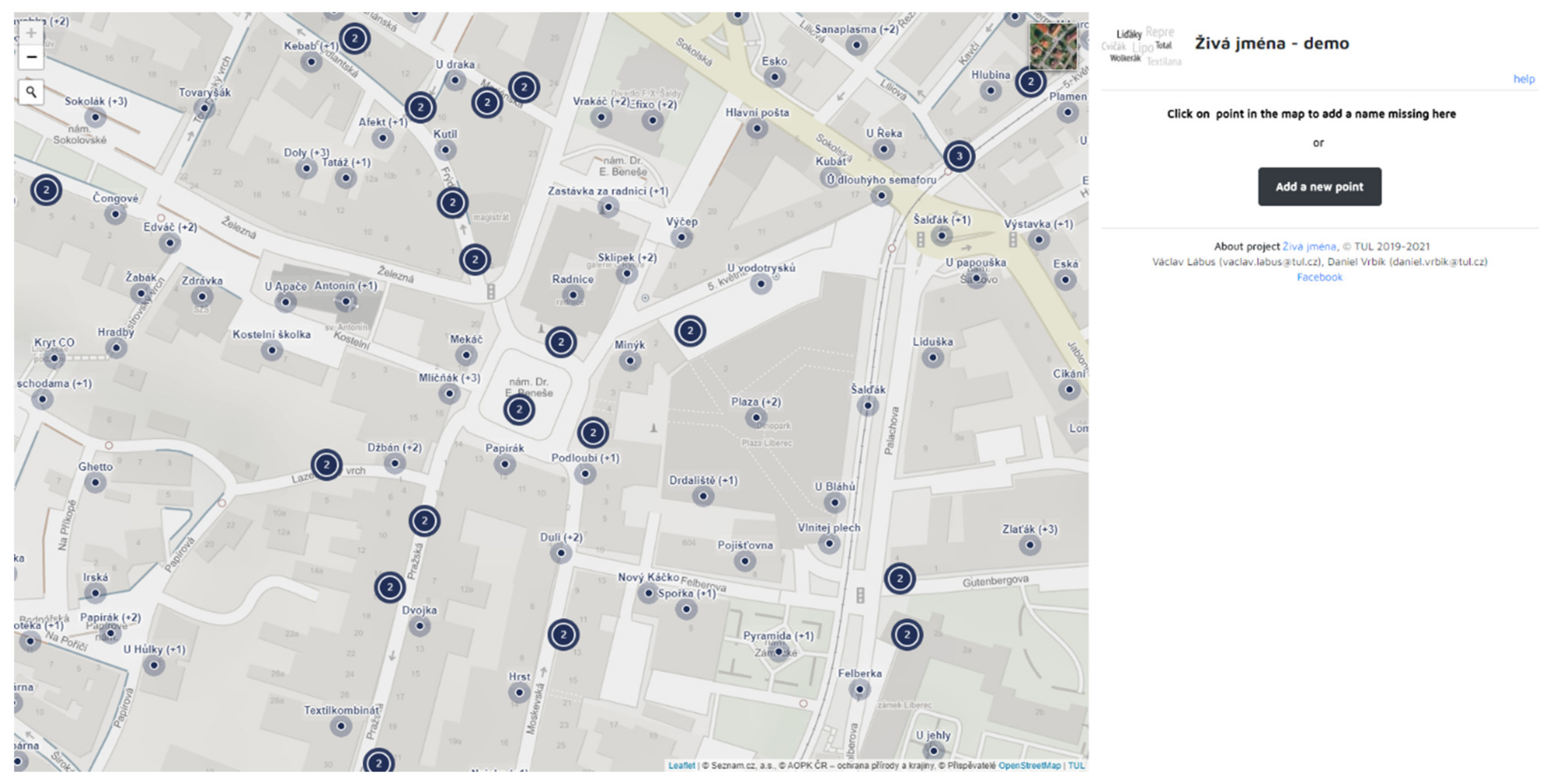
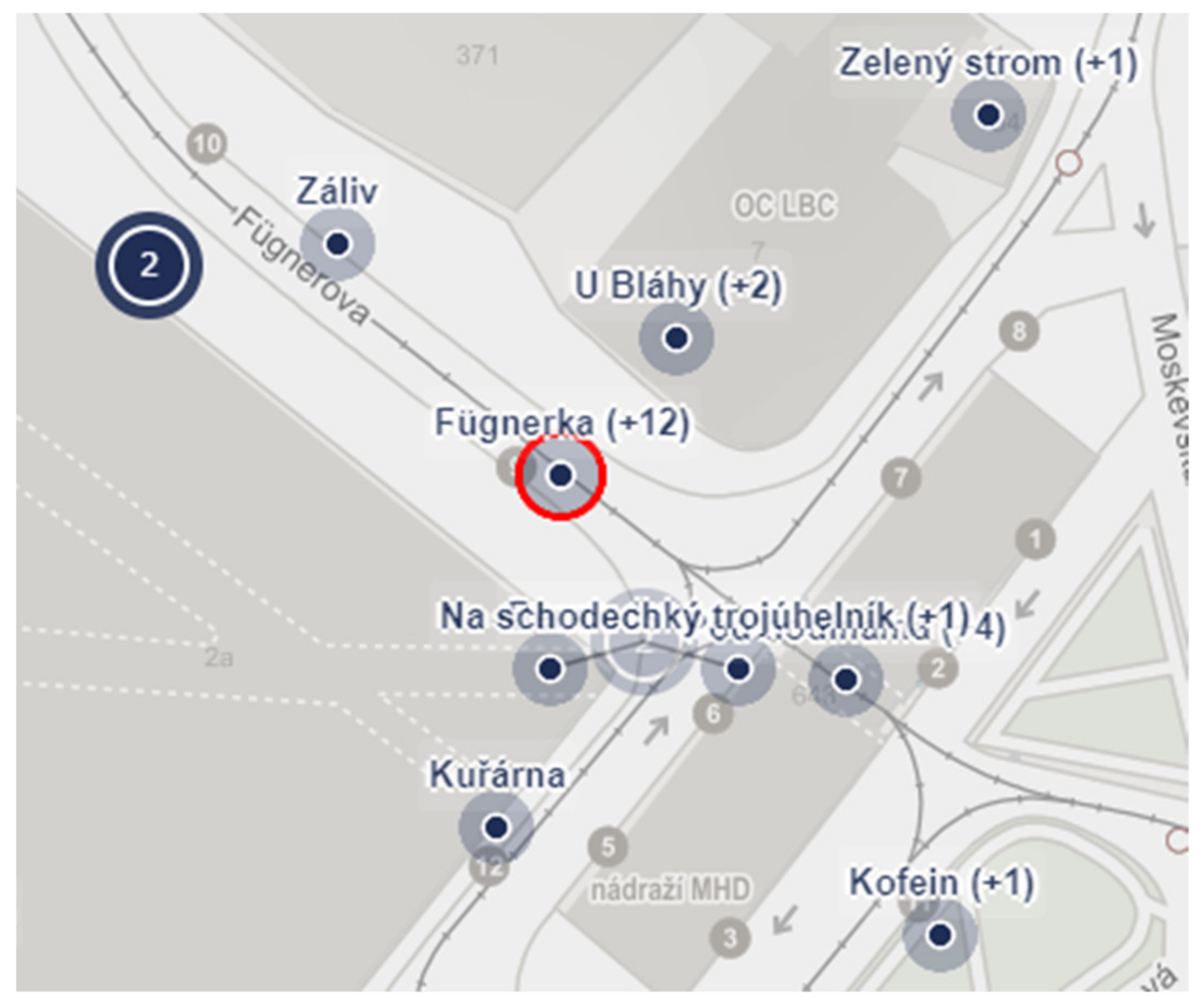
4. Phase 1—Methodology of Collecting the Toponyms
- They may inspire the respondents to add more names to the objects in the map, or to add the names to the other objects that are missing;
- They may inspire the addition of other variations of the name to places that already have their names, or the addition of other relevant information (notes);
- This allows you to show your knowledge to others in the community;
- This is a proactive approach that helps to eliminate the stress of being the first;
- This approach allows a limited validation of the data by other respondents.
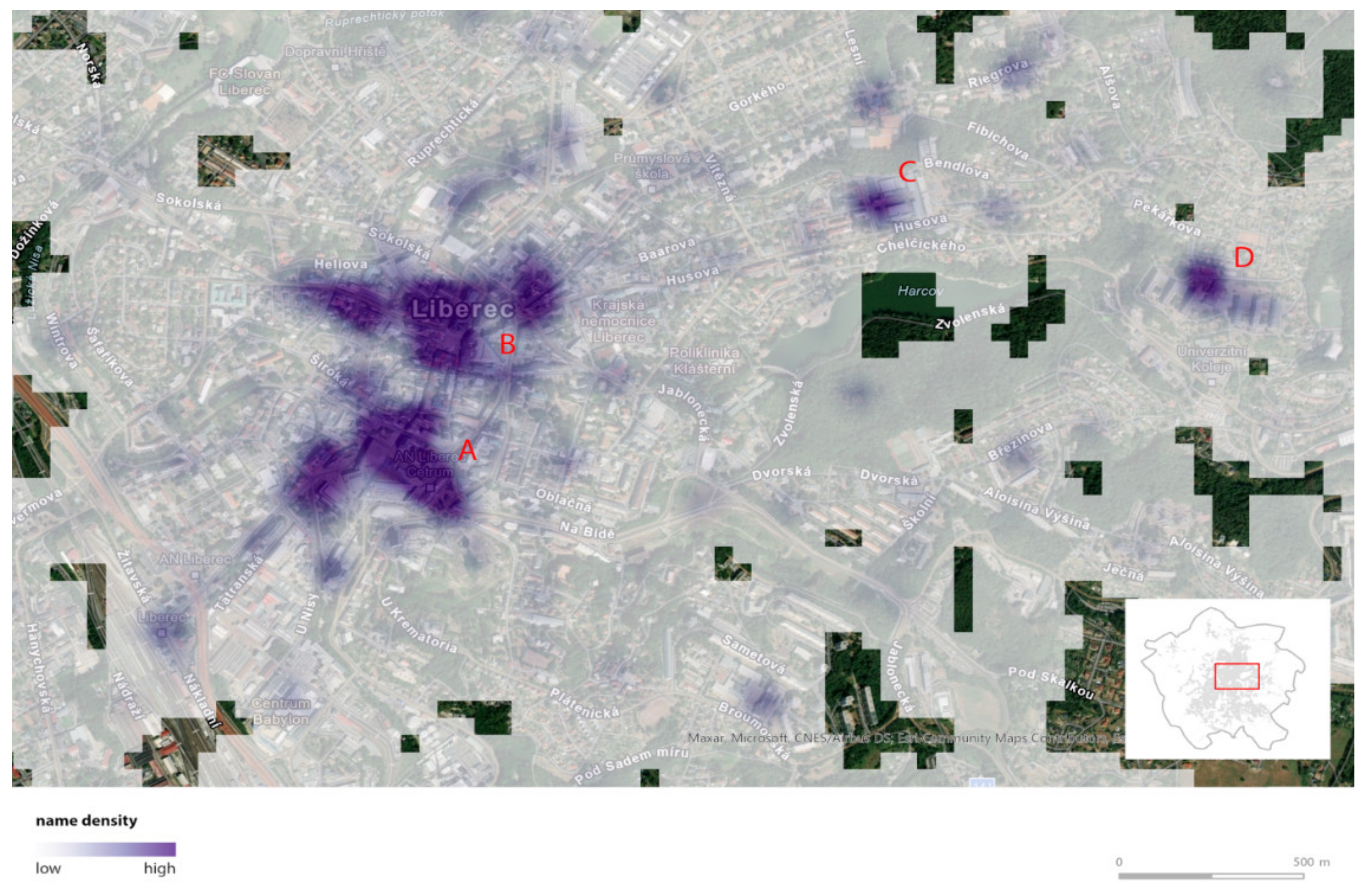
Results of Collecting of Toponyms
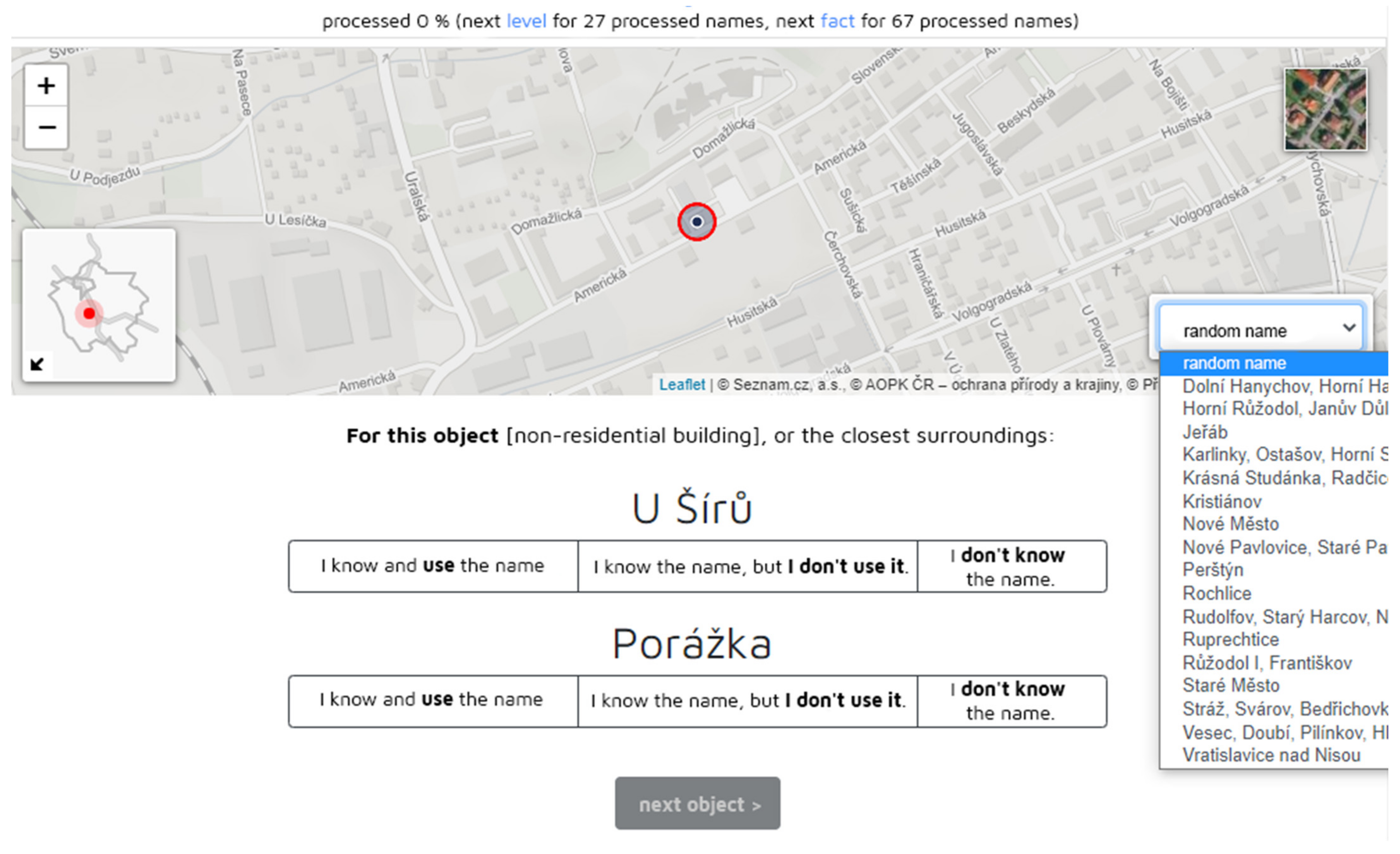
5. Phase 2—Methodology of Determining the Knowledge of the Toponyms Collected
- I know and use the name.
- I know the name, but I don’t use it.
- I don´t know the name.
- An order number in the list of participants ordered by their activity, plus a hierarchic badge system—depending on the number of the names processed, the respondent can see his/her position in the list of respondents and strive for the next, higher position and a new badge. There are ten levels and the intervals between them are not linear. You can proceed faster at the beginning since you are motivated to go through a larger part of the database. The higher number of the names processed, the longer the interval between the levels. The logic behind this is that the people who find this process interesting at the beginning, will persist in doing it. In addition, the respondents who go through all the names are awarded with a certificate.
- Personal statistics—based on the answers, the respondents can see how many names and which parts of the territory they actually know.
- Interesting facts—after every 6% of the names processed, the application will show an interesting fact or facts about the toponyms or history. This is internal motivation, which stimulates curiosity [46].
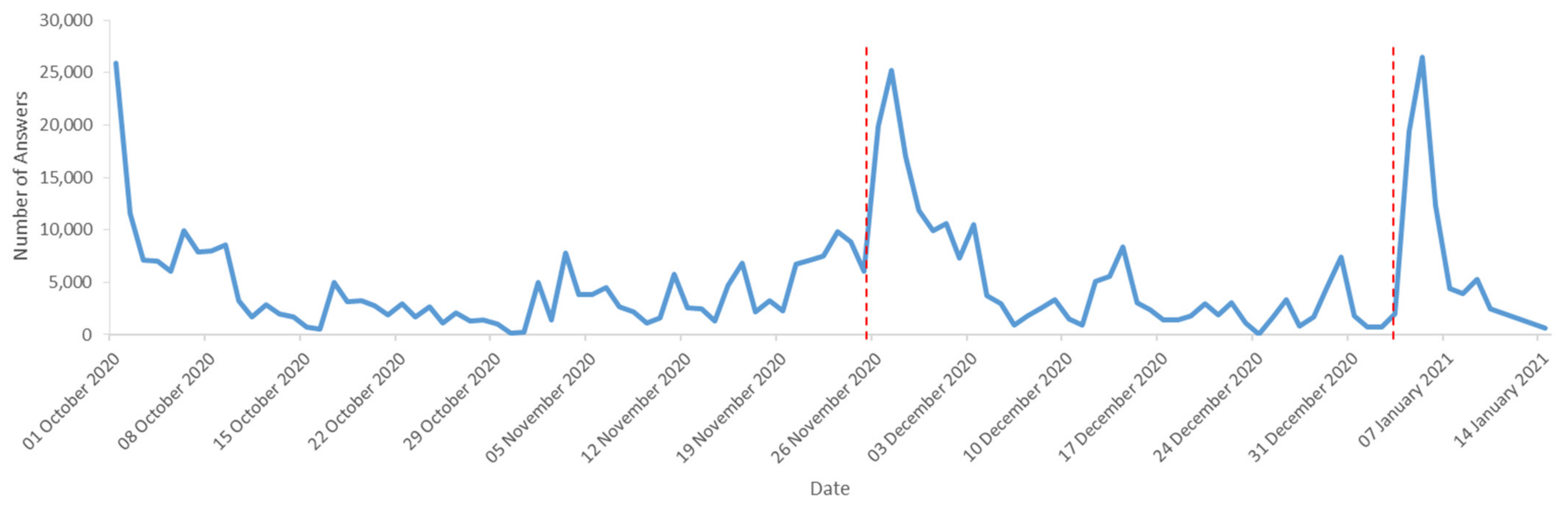
- A contest—the respondents actively participating from 1 October to 31 December 2020 could participate in a raffle, where their chances of winning depended on their activity (the more processed names, the higher the chances of victory). Another condition for the participation in the raffle was processing at least 3% of the database content (ca. 100 names) and filling in the demographic data.
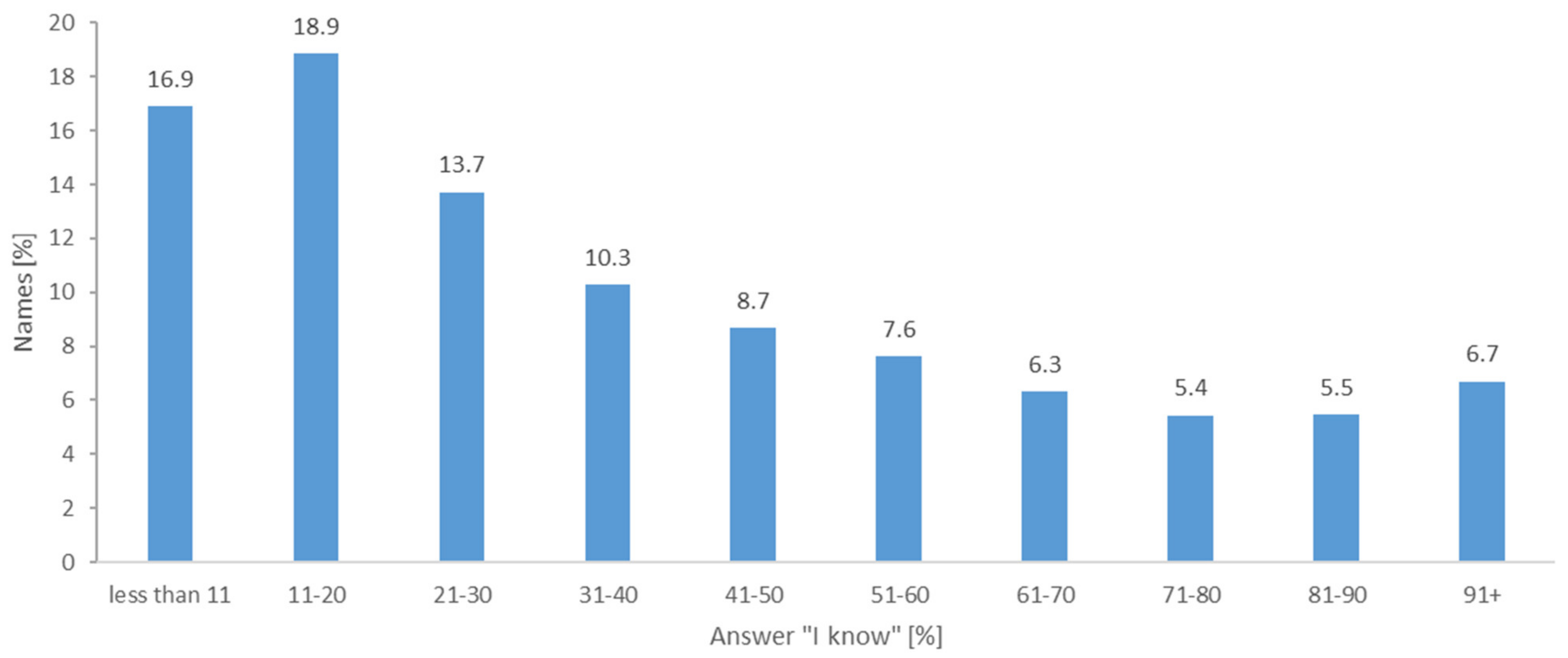
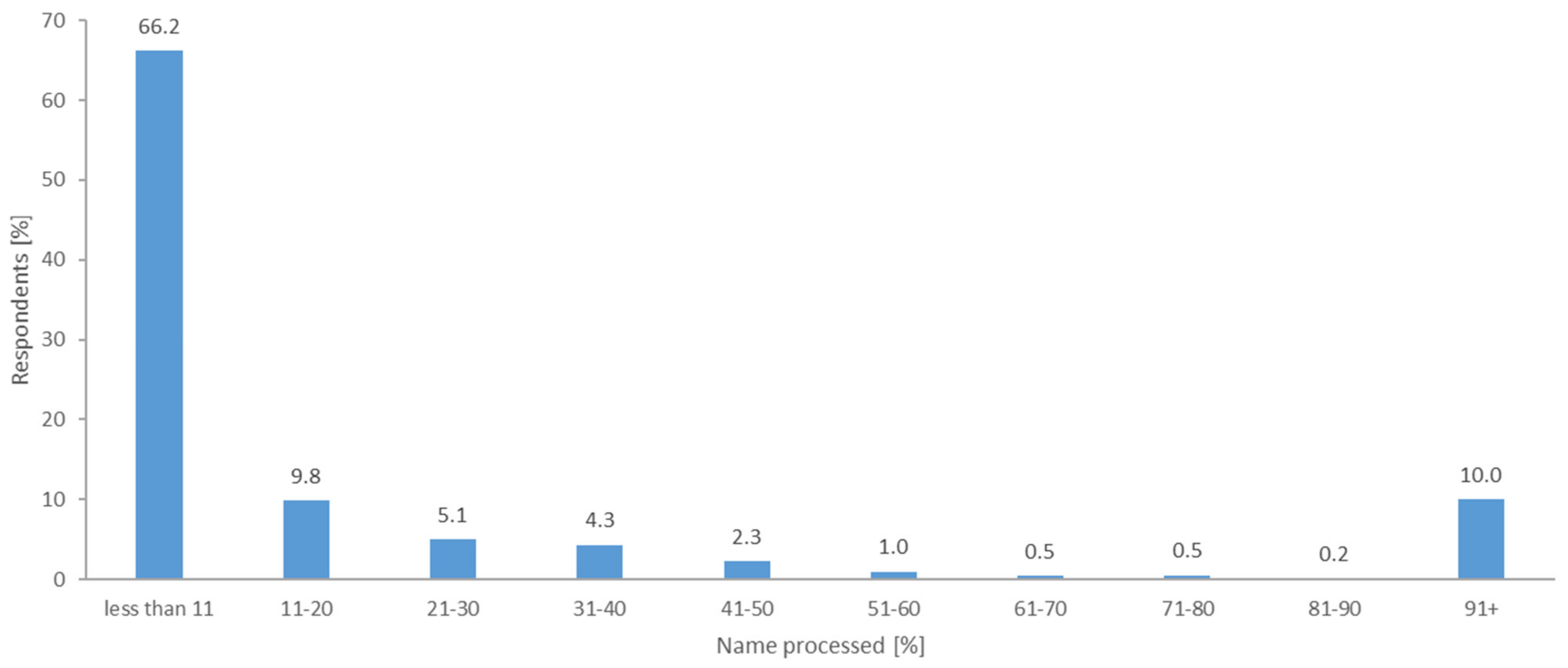
Results of Determining the Knowledge of the Toponyms Collected
6. Discussion
6.1. Main Findings
6.2. Implications for Future Practice
6.3. Research Limitations and Possible Modification
- The first option is to repeatedly display to the respondents the names they have already assessed and evaluate whether they are consistent in the answers. Unfortunately, this method may not be accurate since a name that respondents did not know the first time may seem familiar to them the second time and they may identify it as known but not used by them.
- In the second method, it would be possible to display to the respondents several totally fictitious but meaningful names. Respondents should not know them.
- The third method is based on the statistical analysis of respondents’ answers. It is possible to compare whether a particular respondent often appears among those who know little known names (for instance, applying the Kendall´s tau method). Thus, it would be a matter of determining the degree of agreement between the respondents. In this way it would be possible to identify a respondent whose answers fall outside the group. However, determining the borderline at which the respondent’s agreement with others is insufficient is very subjective. In addition, in the case of the low involvement of a particular respondent, the results of the statistical evaluation will not be accurate enough.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pires, M. Investigating Non-Universal Popular Urban Toponyms. Onoma 2007, 131–154. [Google Scholar] [CrossRef]
- Balode, L. Unofficial urbanonyms of Latvia: Tendencies of derivation. In Names and Their Environment, Proceedings of the 25th International Congress of Onomastic Sciences, Glasgow, UK, 25–29 August 2014; Hough, C., Izdebska, D., Eds.; University of Glasgow: Glasgow, UK, 2016; Volume 1, pp. 69–79. [Google Scholar]
- Český Statistický úřad: Veřejná Databáze. Available online: https://vdb.czso.cz/vdbvo2/faces/cs/index.jsf?page=profil-uzemi&uzemiprofil=31588&u=__VUZEMI__43__563889# (accessed on 1 March 2021).
- Tom, A.; Denis, M. Language and Spatial Cognition: Comparing the Roles of Landmarks and Street Names in Route Instructions. Appl. Cognit. Psychol. 2004, 18, 1213–1230. [Google Scholar] [CrossRef]
- David, J.; Mácha, P. Názvy Míst. Paměť, Identita, Kulturní Dědictví; Host: Brno, Czech Republic; University of Ostrava: Ostrava, Czech Republic, 2014; pp. 71–72. [Google Scholar]
- Lynch, K. The Image of the City; The MIT Press: Cambridge, MA, USA, 1960. [Google Scholar]
- Ainiala, T. Names in society. In The Oxford Handbook of Names and Naming; Hough, C., Ed.; Oxford University Press: Oxford, UK, 2016; p. 373. [Google Scholar]
- Dunn, C.E. Participatory GIS—a People’s GIS? Prog. Hum. Geogr. 2007, 31, 616–637. [Google Scholar] [CrossRef]
- Goodchild, M.F. Citizens as Sensors: The World of Volunteered Geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef]
- Sieber, R.; Robinson, P.; Johnson, P.; Corbett, J. Doing Public Participation on the Geospatial Web. Ann. Am. Assoc. Geogr. 2016, 106, 1–17. [Google Scholar] [CrossRef]
- Crooks, A.; Hudson-Smith, A.; Croitoru, A.; Stefanidis, A. The evolving GeoWeb. In GeoComputation; CRC Press: Boca Raton, FL, USA, 2014; pp. 69–96. ISBN 978-1-4665-0328-1. [Google Scholar]
- Hogerwerf, J. Toponymic data and map production in the Netherlands: From field work to crowd sourcing. In Eleventh United Nations Conference on the Standardization of Geographical Names; UNGEGN: New York, NY, USA, 2018; E/CONF.105/87/CRP.87. [Google Scholar]
- Rampl, G. Crowdsourcing and GIS-Based Methods in a Field Name Survey in Tyrol. 2014, pp. 1–7. Available online: https://unstats.un.org/unsd/geoinfo/UNGEGN/docs/28th-gegn-docs/WP/WP16_Field%20name%20survey%20in%20Tyrol.pdf (accessed on 1 March 2021).
- Castellote, J.; Huerta Guijarro, J.; Pescador, J.; Brown, M. Towns Conquer: A gamified application to collect geographical names (vernacular names/toponyms). In Proceedings of the AGILE International Conference, Leuven, Belgium, 14–17 May 2013; Available online: https://nottingham-repository.worktribe.com/output/1003559/towns-conquer-a-gamified-application-to-collect-geographical-names-vernacular-namestoponyms (accessed on 1 March 2021).
- Názvy Míst. Available online: https://www.nazvymist.cz/ (accessed on 1 March 2021).
- Southall, H.; Aucott, P.; Fleet, C.; Pert, T.; Stoner, M. GB1900: Engaging the Public in Very Large Scale Gazetteer Construction from the Ordnance Survey “County Series” 1:10,560 Mapping of Great Britain. J. Map Geogr. Libr. 2017, 13, 7–28. [Google Scholar] [CrossRef]
- Perdana, A.; Ostermann, F. A Citizen Science Approach for Collecting Toponyms. ISPRS Int. J. Geo Inf. 2018, 7, 222. [Google Scholar] [CrossRef]
- Pánek, J. From Mental Maps to GeoParticipation. Cartogr. J. 2016, 53, 300–307. [Google Scholar] [CrossRef]
- Waze Mobile. Available online: https://www.waze.com/cs/ (accessed on 1 March 2021).
- SETI@home. Available online: https://setiathome.berkeley.edu (accessed on 1 March 2021).
- Pánek, J.; Ivan, I.; Macková, L. Comparing Residents’ Fear of Crime with Recorded Crime Data—Case Study of Ostrava, Czech Republic. ISPRS Int. J. Geo Inf. 2019, 8, 401. [Google Scholar] [CrossRef]
- Olteanu-Raimond, A.-M.; Hart, G.; Foody, G.M.; Touya, G.; Kellenberger, T.; Demetriou, D. The Scale of VGI in Map Production: A Perspective on European National Mapping Agencies. Trans. GIS 2017, 21, 74–90. [Google Scholar] [CrossRef]
- Howe, J. The Rise of Crowdsourcing. WIRED, 6 June 2006; 1–4. [Google Scholar]
- Haklay, M. Geographic citizen science: An overview. In Geographic Citizen Science Design: No One Left Behind; Skarlatidou, A., Haklay, M., Eds.; UCL Press: London, UK, 2021; pp. 15–37. [Google Scholar] [CrossRef]
- Goodchild, M.F.; Glennon, J.A. Crowdsourcing geographic information for disaster response: A research frontier. Int. J. Digit. Earth 2010, 3, 231–241. [Google Scholar] [CrossRef]
- Cartwright, W. Neocartography: Opportunities, Issues and Prospects. S. Afr. J. Geomat. 2012, 1, 14–31. [Google Scholar]
- Surowiecki, J. The Wisdom of Crowds; Anchor: New York, NY, USA, 2004; ISBN 978-0385721707. [Google Scholar]
- Haklay, M. Citizen science and volunteered geographic information: Overview and typology of participation. In Crowdsourcing Geographic Knowledge: Volunteered Geographic Information (VGI) in Theory and Practice; Sui, D.Z., Elwood, S., Goodchild, M.F., Eds.; Springer: New York, NY, USA, 2013; ISBN 978-94-007-4586-5. [Google Scholar]
- UNGEGN. The Benefits of Geographical Names Standardization; UNGEGN: New York, NY, USA, 2015; pp. 1–39. [Google Scholar]
- Ordnance Survey Press Office. Do You Know Where to Find Your Nuncle Dicks or Your Deadman’s Head? Available online: https://www.ordnancesurvey.co.uk/newsroom/blog/know-find-nuncle-dicks-deadmans-head (accessed on 13 April 2021).
- Geospatial World. OS Embarks on a Vernacular Geography Project. Available online: https://www.geospatialworld.net/news/os-embarks-on-a-vernacular-geography-project/ (accessed on 13 April 2021).
- Shetland Amenity Trust. Shetland Place Names Project. Available online: https://www.shetlandamenity.org/shetland-place-names-project (accessed on 13 April 2021).
- Meitheal Logainm.Ie. Available online: https://meitheal.logainm.ie/en/ (accessed on 13 April 2021).
- Šrámek, R. Úvod do Obecné Onomastiky; Masaryk University: Brno, Czech Republic, 1999. [Google Scholar]
- Český Statistický Úřad: Informační Společnost v Číslech. 2020. Available online: https://www.czso.cz/documents/10180/122362632/06100420.pdf/1273f88b-7e14-4555-b58b-3087658409e0?version=1.4 (accessed on 1 March 2021).
- Brown, G.; Pullar, D.V. An evaluation of the use of points versus polygons in public participation geographic information systems using quasi-experimental design and Monte Carlo simulation. Int. J. Geogr. Inf. Sci. 2012, 26, 231–246. [Google Scholar] [CrossRef]
- Wikimedia Foundation. Editor Survey Report—April 2011. Available online: https://wikimediafoundation.org/w/index.php?title=File%3AEditor_Survey_Report_-_April_2011.pdf&page=1 (accessed on 1 March 2021).
- SimilarWeb. 2020. Available online: https://www.similarweb.com/top-websites/czech-republic/category/reference-materials/maps/ (accessed on 1 March 2021).
- Jay, C.; Dunne, R.; Gelsthorpe, D.; Vigo, M. To sign up, or not to sign up? Maximizing citizen science contribution rates through optional registration. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; ACM: New York, NY, USA, 2016; pp. 1827–1832. [Google Scholar]
- Jackson, C.B.; Crowston, K.; Østerlund, C. Did They Login?: Patterns of Anonymous Contributions in Online Communities. Proc. ACM Hum. Comput. Interact. 2018, 2, 1–16. [Google Scholar] [CrossRef]
- Coleman, D.; Georgiadou, Y. Volunteered Geographic Information: The Nature and Motivation of Produsers. Int. J. Spat. Data Infrastruct. Res. 2009, 332–358. [Google Scholar] [CrossRef]
- Eveleigh, A.; Jennett, C.; Lynn, S.; Cox, A.L. “I want to be a captain! I want to be a captain!”: Gamification in the old weather citizen science project. In Proceedings of the First International Conference on Gameful Design, Research, and Applications, Toronto, ON, Canada, 2–4 October 2013; ACM: New York, NY, USA, 2013; pp. 79–82. [Google Scholar] [CrossRef]
- Zeng, Z.; Tang, J.; Wang, T. Motivation Mechanism of Gamification in Crowdsourcing Projects. J. Conserv. Sci. 2017, 1, 71–82. [Google Scholar] [CrossRef]
- Bowser, A.; Hansen, D.; He, Y.; Boston, C.; Reid, M.; Gunnell, L.; Preece, J. Using gamification to inspire new citizen science volunteers. In Proceedings of the First International Conference on Gameful Design, Research, and Applications, Toronto, ON, Canada, 2–4 October 2013; ACM: New York, NY, USA, 2013; pp. 18–25. [Google Scholar]
- Hamari, J.; Koivisto, J.; Sarsa, H. Does gamification work?—A literature review of empirical studies on gamification. In Proceedings of the 2014 47th Hawaii International Conference on System Sciences, Waikoloa, HI, USA, 6–9 January 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 3025–3034. [Google Scholar]
- Morschheuser, B.; Hamari, J.; Koivisto, J. Gamification in crowdsourcing: A review. In Proceedings of the 2016 49th Hawaii International Conference on System Sciences, Koloa, HI, USA, 5–8 January 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 4375–4384. [Google Scholar]
- Krško, J. Všeobecnolingvistické Aspekty Onymie. Matej Bel University: Banska Bystrica, Slovakia, 2016. [Google Scholar]
- Lábus, V.; Vrbík, D. Toponyma v Krajině a Možnosti Jejich Výzkumu; Technical University of Liberec: Liberec, Czech Republic, 2018. [Google Scholar]
- Nielsen, J. The 90-9-1 rule for participation inequality in social media and online communities. In Nielsen Norman Group Evidence-Based User Experience Research, Training, and Consulting; Nielsen Norman Group: Fremont, CA, USA, 2006; Available online: https://www.nngroup.com/articles/participation-inequality/ (accessed on 1 March 2021).
- Vrbík, D. Crowdsourcing of Local Spatial and Historical Knowledge. GI Forum 2016, 2, 109–122. [Google Scholar] [CrossRef][Green Version]
- Zachte, E. Distribution of Article Edits over Registered Editors: Wikipedia Statistics—Tables—English. 2017. Available online: https://stats.wikimedia.org/EN/TablesWikipediaEN.htm (accessed on 25 October 2017).
- Raddick, M.J.; Bracey, G.; Gay, P.L.; Lintott, C.J.; Murray, P.; Schawinski, K.; Szalay, A.S.; Vandenberg, J. Galaxy Zoo: Exploring the Motivations of Citizen Science Volunteers. Astron. Educ. Rev. 2010, 9, 1. [Google Scholar] [CrossRef]
- Lotfian, M.; Ingensand, J.; Brovelli, M.A. A Framework for Classifying Participant Motivation That Considers the Typology of Citizen Science Projects. ISPRS Int. J. Geo Inf. 2020, 9, 704. [Google Scholar] [CrossRef]
- Zheng, H.; Li, D.; Hou, W. Task Design, Motivation, and Participation in Crowdsourcing Contests. Int. J. Electron. Commer. 2011, 15, 57–88. [Google Scholar] [CrossRef]
- Enge, E. Mobile vs. Desktop Usage in 2019. 2019. Available online: https://www.perficient.com/insights/research-hub/mobile-vs-desktop-usage-study (accessed on 1 March 2021).
- Moor, T.D.; Rijpma, A.; López, M.P. Dynamics of Engagement in Citizen Science: Results from the “Yes, I Do!”-Project. Citiz. Sci. Theory Pract. 2019, 4, 38. [Google Scholar] [CrossRef]
- Goodchild, M.F. Putting research into practise. In Quality Aspects of Spatial Data Mining; Stein, A., Shi, W., Bijker, W., Eds.; CRC Press: Boca Raton, FL, USA, 2009; pp. 345–356. [Google Scholar]
- Haklay, M. How Good Is Volunteered Geographical Information? A Comparative Study of OpenStreetMap and Ordnance Survey Datasets. Environ. Plan. B Plan. Des. 2010, 37, 682–703. [Google Scholar] [CrossRef]
- Koukoletsos, T. A Framework for Quality Evaluation of VGI Linear Datasets. Ph.D. Thesis, University College London, London, UK, 2012. Available online: http://discovery.ucl.ac.uk/1359907/11/1359907.pdf (accessed on 6 August 2017).
- Lábus, V.; Vrbík, D. Poznámky k tzv. objektové fixaci toponym. Linguist. Brun. 2019, 15–26. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Motivation (Example) | At the Beginning (%) n = 120 | In the Meantime (%) n = 79 |
|---|---|---|
| patriotism (“This project delighted the heart of the Liberec citizen.”) | 23 | 5 |
| general/professional interest in the topic (“I am interested in the history and present state of Liberec.”/“My philological education and former interest in toponomastics.”) | 23 | 1 |
| knowledge development (“It was interesting to browse and explore the popular place names.”/“Presentation of interesting facts that gave me new angles of view of various places.”) | 20 | 22 |
| curiosity (“What kind of project is this?”/“Curiosity related to names used for concrete places.”) | 16 | 19 |
| altruism (“Using my knowledge to help the project.”) | 15 | 15 |
| verification of knowledge (“I was wondering how many names I actually know.”) | 13 | 13 |
| finishing the work (“When I get into something, I want to make it to the end.”) | 2 | 27 |
| fun (“It was adventurous and I liked it.”) | 0 | 15 |
| game (“And the levels were motivating too.”) | 0 | 11 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vrbík, D.; Lábus, V. Crowdsourcing of Popular Toponyms: How to Collect and Preserve Toponyms in Spoken Use. ISPRS Int. J. Geo-Inf. 2021, 10, 303. https://doi.org/10.3390/ijgi10050303
Vrbík D, Lábus V. Crowdsourcing of Popular Toponyms: How to Collect and Preserve Toponyms in Spoken Use. ISPRS International Journal of Geo-Information. 2021; 10(5):303. https://doi.org/10.3390/ijgi10050303
Chicago/Turabian StyleVrbík, Daniel, and Václav Lábus. 2021. "Crowdsourcing of Popular Toponyms: How to Collect and Preserve Toponyms in Spoken Use" ISPRS International Journal of Geo-Information 10, no. 5: 303. https://doi.org/10.3390/ijgi10050303
APA StyleVrbík, D., & Lábus, V. (2021). Crowdsourcing of Popular Toponyms: How to Collect and Preserve Toponyms in Spoken Use. ISPRS International Journal of Geo-Information, 10(5), 303. https://doi.org/10.3390/ijgi10050303