
Towards Measuring Shape Similarity of Polygons Based on Multiscale Features and Grid Context Descriptors



Abstract
1. Introduction
2. Methodology
2.1. Workflow of the Shape Similarity Measurement
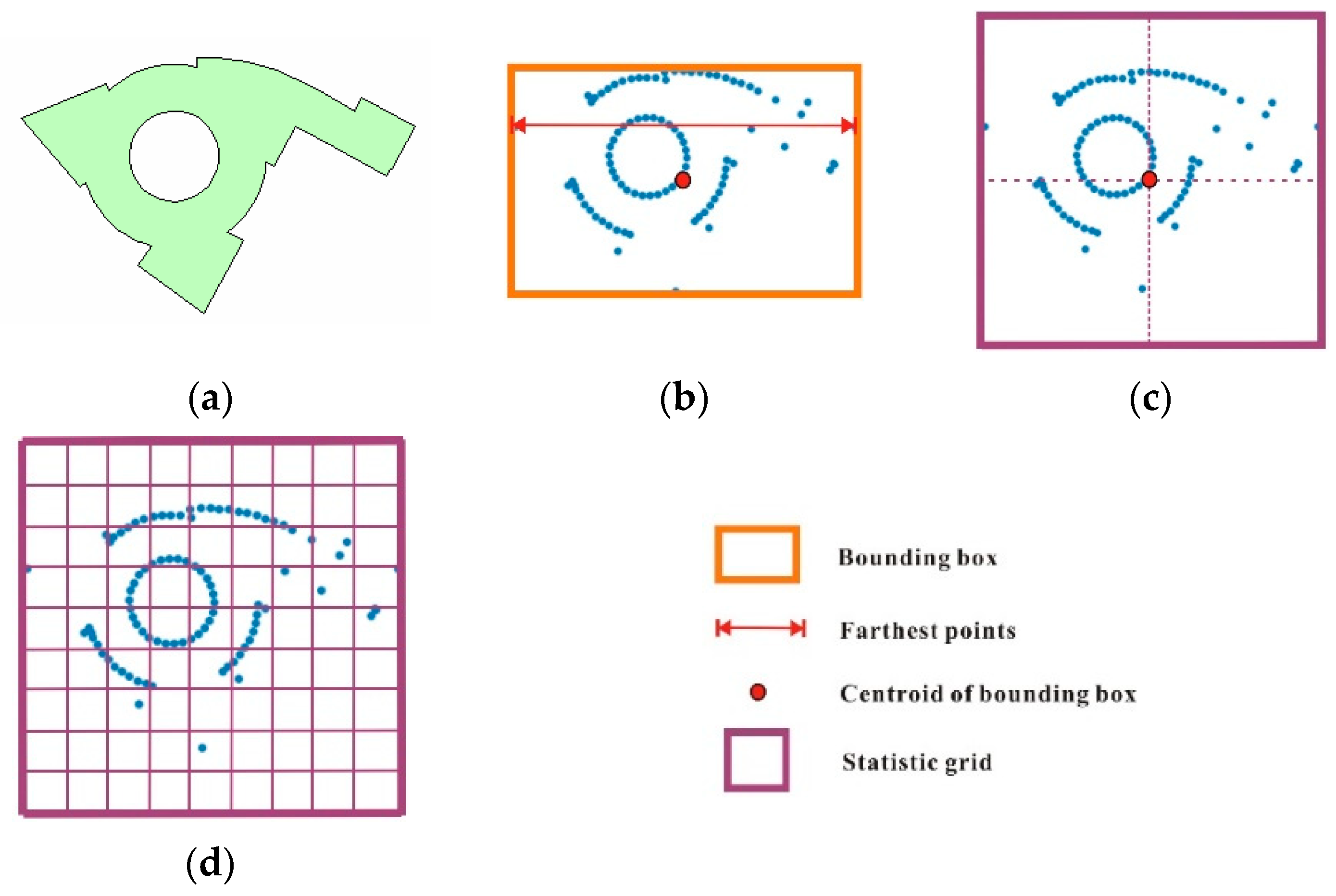
2.1.1. Generation of Multiscale Statistic Features
2.1.2. Derivation of Grid Context Information
2.2. Calculation of the Similarity
2.2.1. Extraction of Multiscale Texture Features
2.2.2. Calculation of the Shape Similarity
3. Experimental Results
3.1. Test of the Sensitivity to Contour Variation
3.2. Similar Polygon Retrieval Test
3.3. Comparison with the Turning Function and Fourier Descriptor Methods
4. Discussion
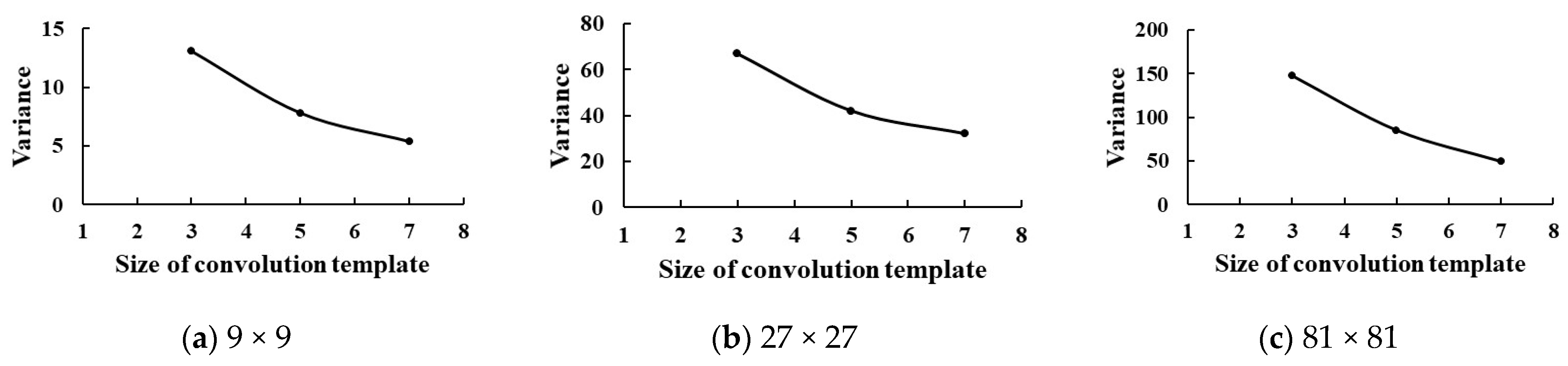
4.1. Optimal Parameter Selection for the Contour Diffusion Method
4.1.1. Size of the Convolution Template
4.1.2. Interpolation Points
4.2. Limitation of the Similarity Cross-Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Xu, Y.; Xie, Z.; Chen, Z.; Wu, L. Shape similarity measurement model for holed polygons based on position graphs and Fourier descriptors. Int. J. Geogr. Inf. Sci. 2017, 31, 253–279. [Google Scholar] [CrossRef]
- Yan, X.; Ai, T.; Yang, M.; Yin, H. A graph convolutional neural network for classification of building patterns using spatial vector data. ISPRS J. Photogramm. Remote Sens. 2019, 150, 259–273. [Google Scholar] [CrossRef]
- Chen, Z.; Zhu, R.; Xie, Z.; Wu, L. Hierarchical model for the similarity measurement of a complex holed-region entity scene. ISPRS J. Photogramm. Remote Sens. 2017, 6, 388. [Google Scholar] [CrossRef]
- Wang, X.; Burghardt, D. A typification method for linear building groups based on stroke simplification. Geocarto Int. 2019, 1–20. [Google Scholar] [CrossRef]
- Kurnianggoro, L.; Wahyono; Jo, K.H. A survey of 2D shape representation: Methods, evaluations, and future research directions. Neurocomputing 2018, 300, 1–16. [Google Scholar] [CrossRef]
- Yan, X.; Ai, T.; Yang, M.; Tong, X. Graph convolutional autoencoder model for the shape coding and cognition of buildings in maps. Int. J. Geogr. Inf. Sci. 2021, 35, 490–512. [Google Scholar] [CrossRef]
- Clementini, E.; di Felice, P. A global framework for qualitative shape description. Geoinformatics 1997, 1, 11–27. [Google Scholar] [CrossRef]
- Freeman, H.; Saghri, A. Generalized chain codes for planar curves. In Proceedings of the 4th International Joint Conference on Pattern Recognition, Kyoto, Japan, 7–10 November 1978; pp. 701–703. [Google Scholar]
- Arkin, E.M.; Chew, L.P.; Huttenlocher, D.P.; Kedem, K.; Mitchell, J.S.B. An efficiently computable metric for comparing polygonal shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 13, 209–216. [Google Scholar] [CrossRef]
- Elghazal, A.; Basir, O.; Belkasim, S. Farthest point distance: A new shape signature for Fourier descriptors. Signal. Proc. Image Commun. 2009, 24, 572–586. [Google Scholar] [CrossRef]
- Huang, M.; Lin, J.; Chen, N.; An, W.; Zhu, W. Reversed sketch: A scalable and comparable shape representation. Pattern Recognit. 2018, 80, 168–182. [Google Scholar] [CrossRef]
- Yasseen, Z.; Verroust-Blondet, A.; Nasri, A. Shape matching by part alignment using extended chordal axis transform. Pattern Recognit. 2016, 57, 115–135. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Teague, M.R. Image analysis via the general theory of moments. J. Opt. Soc. Am. 1980, 70, 920–930. [Google Scholar] [CrossRef]
- Lu, G.; Sajjanhar, A. Region-based shape representation and similarity measure suitable for content-based image retrieval. Multimed. Syst. 1999, 7, 165–174. [Google Scholar] [CrossRef]
- Belongie, S.; Malik, J.; Puzicha, J. Shape matching and object recognition using shape contexts. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 509–522. Available online: https://ieeexplore.ieee.org/document/993558 (accessed on 14 February 2021). [CrossRef]
- Žunić, J.; Hirota, K.; Rosin, P.L. A Hu moment invariant as a shape circularity measure. Pattern Recognit. 2010, 43, 47–57. [Google Scholar] [CrossRef]
- Fu, Z.; Fan, L.; Yu, Z.; Zhou, K. A moment-based shape similarity measurement for areal entities in geographical vector data. ISPRS J. Photogramm. Remote Sens. 2018, 7, 208. [Google Scholar] [CrossRef]
- Xu, Y.; Xie, Z.; Chen, Z.; Xie, M. Measuring the similarity between multipolygons using convex hulls and position graphs. Int. J. Geogr. Inf. Sci. 2020, 1–22. [Google Scholar] [CrossRef]
- Wagemans, J.; Elder, J.H.; Kubovy, M.; Palmer, S.E.; Peterson, M.A.; Singh, M.; von der Heydt, R. A century of Gestalt psychology in visual perception: I. Perceptual grouping and figure-ground organization. Psychol. Bull. 2012, 138, 1172. [Google Scholar] [CrossRef]
- Shapiro, L.G.; Stockman, G.C. Computer Vision; Prentice Hall: Hoboken, NJ, USA, 2001. [Google Scholar]
- Julesz, B.; Gilbert, E.N.; Victor, J.D. Visual discrimination of textures with identical third-order statistics. Biol. Cybern. 1978, 37, 137–140. [Google Scholar] [CrossRef]
- Clausi, D.A. An analysis of co-occurrence texture statistics as a function of grey level quantization. Can. J. Remote Sens. 2002, 28, 45–62. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I.H. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 1973, 6, 610–621. [Google Scholar] [CrossRef]
- Ulaby, F.T.; Kouyate, F.; Brisco, B.; Williams, T.L. Textural information in SAR images. IEEE Trans. Geosci. Remote Sens. 1986, 24, 235–245. [Google Scholar] [CrossRef]
- Gadkari, D. Image Quality Analysis Using GLCM. Master’s Thesis, University of Central Florida, Orlando, FL, USA, 2004. [Google Scholar]
- Fu, Z.; Qin, Q.; Luo, B.; Wu, C.; Sun, H. A local feature descriptor based on combination of structure and texture information for multispectral image matching. IEEE Geosci. Remote Sens. Lett. 2018, 16, 100–104. [Google Scholar] [CrossRef]
- LaMar, E.; Hamann, B.; Joy, K.I. Multiresolution Techniques for Interactive Texture-Based Volume Visualization; IEEE: San Francisco, CA, USA, 1999. [Google Scholar]
- Wang, Z.; Müller, J.C. Line generalization based on analysis of shape characteristics. Cartogr. Geogr. Inf. Syst. 1998, 25, 3–15. [Google Scholar] [CrossRef]
- Ai, T.; Cheng, X.; Liu, P.; Yang, M. A shape analysis and template matching of building features by the Fourier transform method. Comput. Environ. Urban. Syst. 2013, 41, 219–233. [Google Scholar] [CrossRef]
- Fan, H.; Zipf, A.; Fu, Q.; Neis, P. Quality assessment for building footprints data on OpenStreetMap. Int. J. Geogr. Inf. Sci. 2014, 28, 700–719. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. ACM SIGMOBILE Mob. Comput. Commun. Rev. 1948, 5, 3–55. [Google Scholar] [CrossRef]
- Jackson, I. Gestalt—A learning theory for graphic design education. Int. J. Art Des. Educ. 2008, 27, 63–69. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Shape Similarity | Original Polygon | Tolerance | ||||
|---|---|---|---|---|---|---|
| 3 m | 10 m | 20 m | 35 m | |||
 |  |  |  |  | ||
| Original polygon |  | 1.00 | 0.90 | 0.82 | 0.75 | 0.72 |
| 3 m |  | 0.90 | 1.00 | 0.85 | 0.77 | 0.76 |
| 10 m |  | 0.82 | 0.85 | 1.00 | 0.77 | 0.78 |
| 20 m |  | 0.75 | 0.77 | 0.77 | 1.00 | 0.91 |
| 35 m |  | 0.72 | 0.76 | 0.78 | 0.91 | 1.00 |
| Shape Similarity | Original Polygon | Tolerance | ||||
|---|---|---|---|---|---|---|
| 5 km | 10 km | 15 km | 20 km | |||
 |  |  |  |  | ||
| Original polygon |  | 1.00 | 0.90 | 0.86 | 0.80 | 0.78 |
| 5 km |  | 0.90 | 1.00 | 0.86 | 0.79 | 0.77 |
| 10 km |  | 0.86 | 0.86 | 1.00 | 0.82 | 0.80 |
| 15 km |  | 0.80 | 0.79 | 0.82 | 1.00 | 0.86 |
| 20 km |  | 0.78 | 0.77 | 0.80 | 0.86 | 1.00 |
| Reference Building Footprints | Template Building Footprints | Recognition Correct? | |||||
|---|---|---|---|---|---|---|---|
 |  |  |  |  |  | ||
 | 0.76 | 0.46 | 0.31 | 0.40 | 0.55 | 0.40 | Yes |
 | 0.47 | 0.78 | 0.43 | 0.58 | 0.65 | 0.62 | Yes |
 | 0.79 | 0.33 | 0.38 | 0.36 | 0.53 | 0.37 | Yes |
 | 0.25 | 0.44 | 0.70 | 0.76 | 0.60 | 0.28 | Yes |
 | 0.41 | 0.90 | 0.43 | 0.54 | 0.63 | 0.65 | Yes |
 | 0.57 | 0.54 | 0.65 | 0.87 | 0.74 | 0.44 | Yes |
 | 0.52 | 0.54 | 0.66 | 0.89 | 0.71 | 0.42 | Yes |
 | 0.37 | 0.47 | 0.76 | 0.66 | 0.46 | 0.35 | Yes |
 | 0.54 | 0.56 | 0.65 | 0.88 | 0.74 | 0.44 | Yes |
 | 0.41 | 0.78 | 0.41 | 0.54 | 0.64 | 0.61 | Yes |
 | 0.79 | 0.42 | 0.30 | 0.42 | 0.53 | 0.45 | Yes |
 | 0.63 | 0.58 | 0.46 | 0.68 | 0.88 | 0.50 | Yes |
 | 0.86 | 0.42 | 0.43 | 0.53 | 0.68 | 0.50 | Yes |
 | 0.44 | 0.66 | 0.35 | 0.29 | 0.54 | 0.67 | Yes |
 | 0.75 | 0.52 | 0.42 | 0.40 | 0.53 | 0.47 | Yes |
 | 0.75 | 0.36 | 0.31 | 0.40 | 0.50 | 0.43 | Yes |
 | 0.47 | 0.51 | 0.65 | 0.81 | 0.67 | 0.39 | Yes |
 | 0.64 | 0.33 | 0.36 | 0.28 | 0.47 | 0.41 | Yes |
 | 0.52 | 0.75 | 0.38 | 0.48 | 0.63 | 0.60 | Yes |
 | 0.50 | 0.57 | 0.46 | 0.56 | 0.74 | 0.56 | Yes |
| Shape Similarity | Polygon A | Polygon B | Polygon C | |
|---|---|---|---|---|
 |  |  | ||
| Polygon A |  | 1 | 0.51 | 0.50 |
| Polygon B |  | 0.51 | 1 | 0.43 |
| Polygon C |  | 0.50 | 0.43 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, H.; Zhao, Z.; Li, W. Towards Measuring Shape Similarity of Polygons Based on Multiscale Features and Grid Context Descriptors. ISPRS Int. J. Geo-Inf. 2021, 10, 279. https://doi.org/10.3390/ijgi10050279
Fan H, Zhao Z, Li W. Towards Measuring Shape Similarity of Polygons Based on Multiscale Features and Grid Context Descriptors. ISPRS International Journal of Geo-Information. 2021; 10(5):279. https://doi.org/10.3390/ijgi10050279
Chicago/Turabian StyleFan, Hongchao, Zhiyao Zhao, and Wenwen Li. 2021. "Towards Measuring Shape Similarity of Polygons Based on Multiscale Features and Grid Context Descriptors" ISPRS International Journal of Geo-Information 10, no. 5: 279. https://doi.org/10.3390/ijgi10050279
APA StyleFan, H., Zhao, Z., & Li, W. (2021). Towards Measuring Shape Similarity of Polygons Based on Multiscale Features and Grid Context Descriptors. ISPRS International Journal of Geo-Information, 10(5), 279. https://doi.org/10.3390/ijgi10050279