Machine Learning Approaches to Bike-Sharing Systems: A Systematic Literature Review




Abstract
1. Introduction
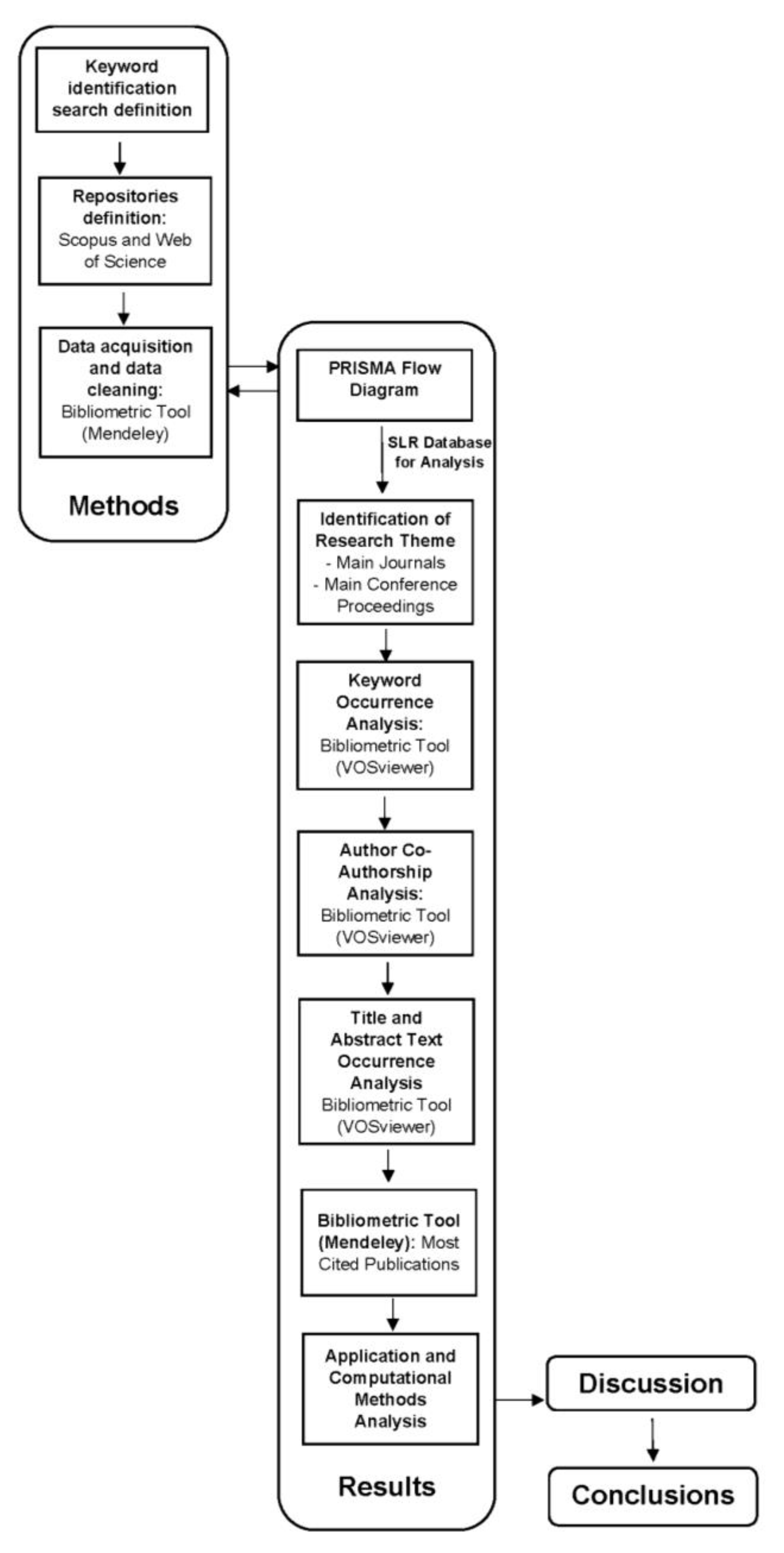
2. Method
2.1. Keyword Identification and Search
2.2. Repositories
2.3. Bibliometric Analysis
2.4. Bibliometric Research Tool for Network Analysis
3. Results
3.1. PRISMA Flow Diagram
3.2. Identification of Research Themes
3.2.1. Main Journals
3.2.2. Main Conference Proceedings
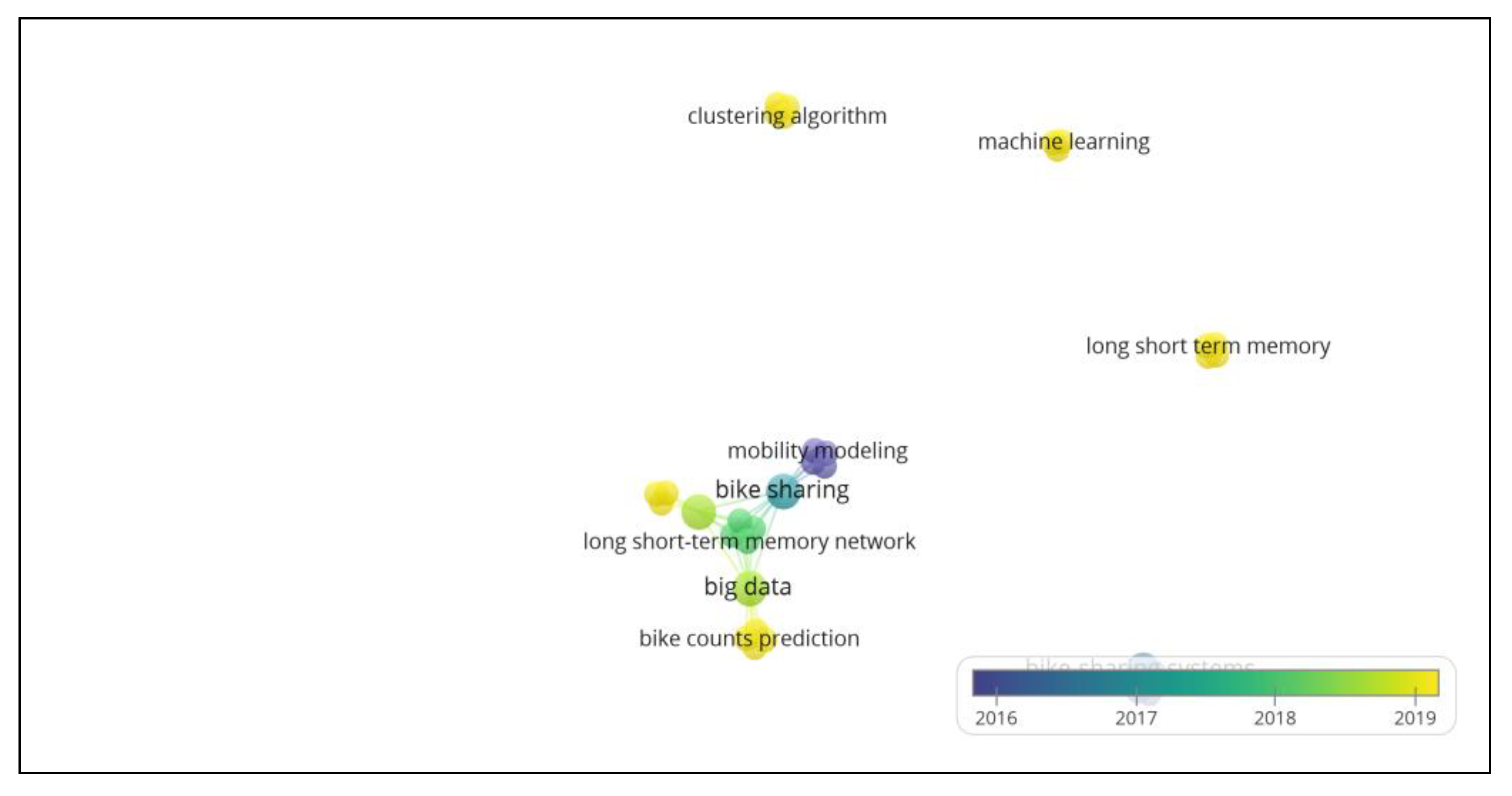
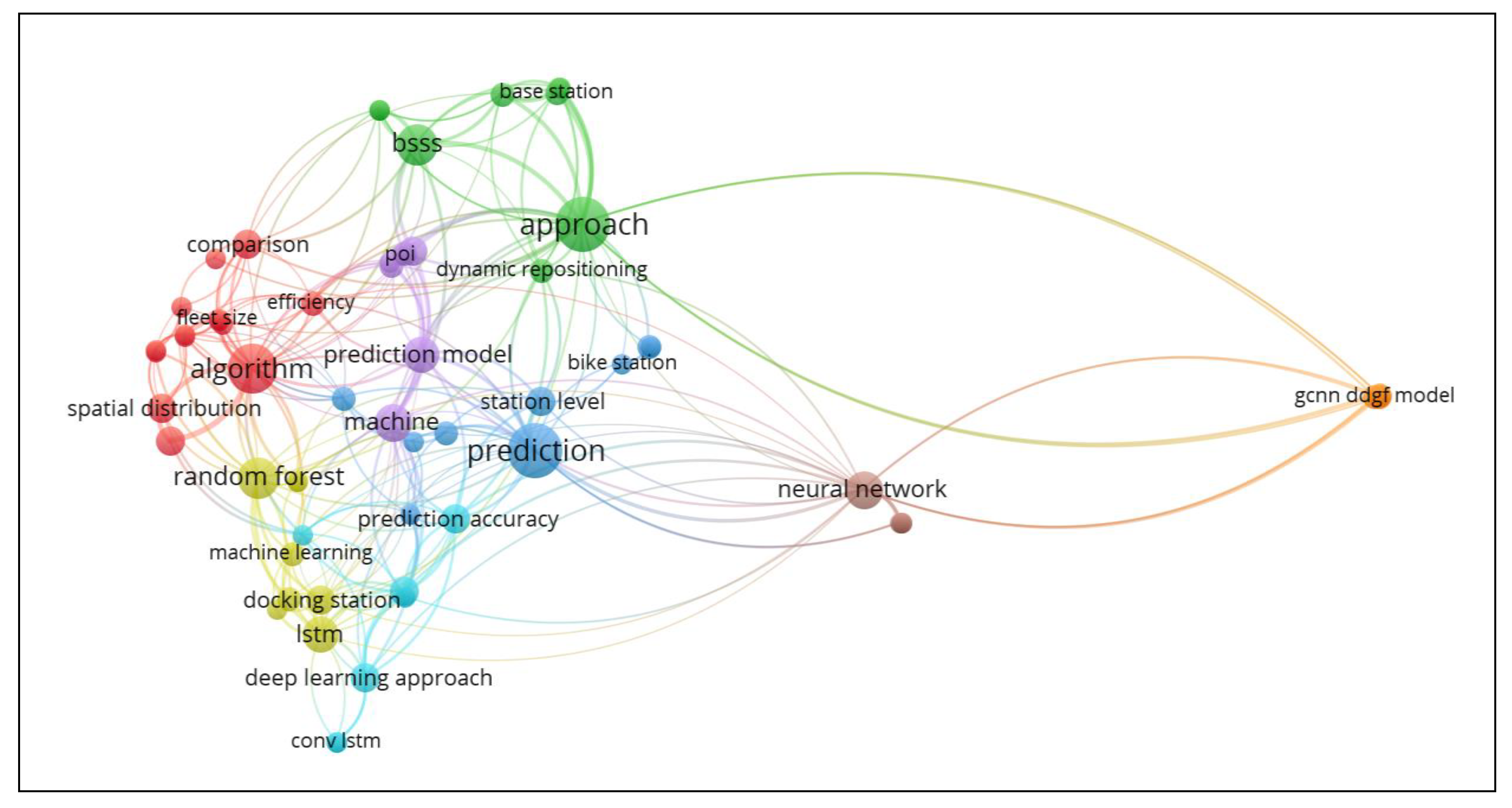
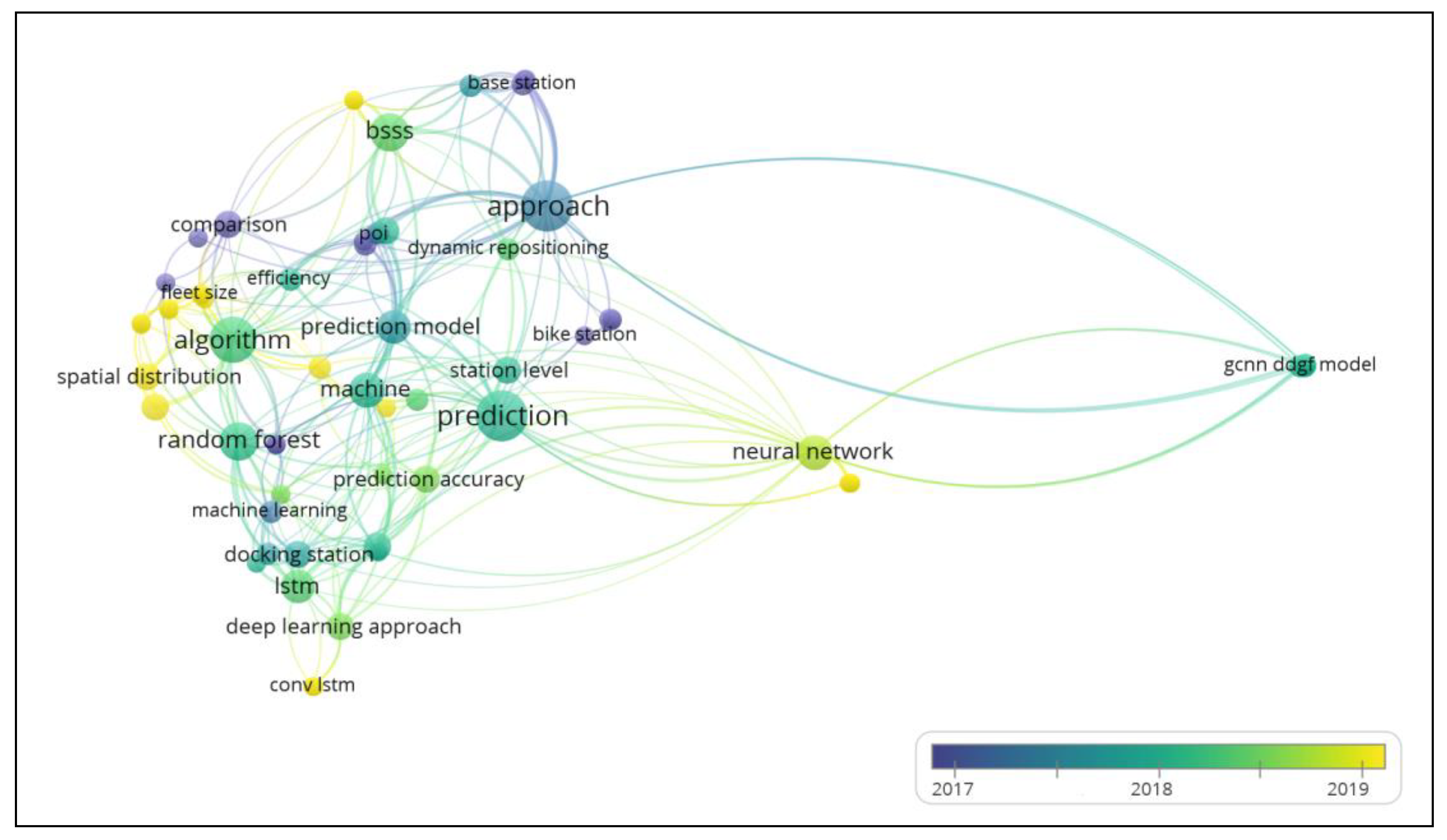
3.3. Keyword Occurrence Analysis
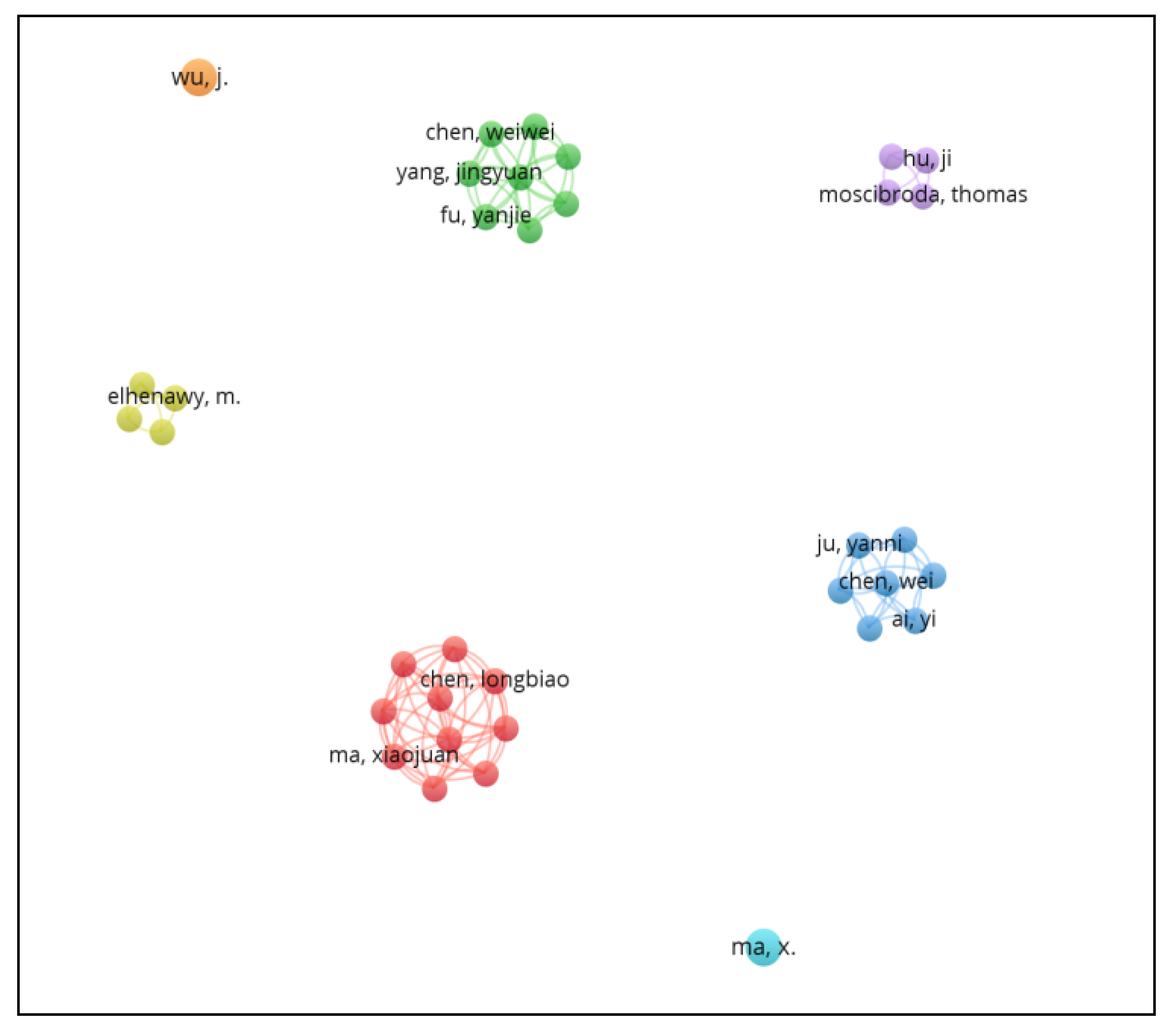
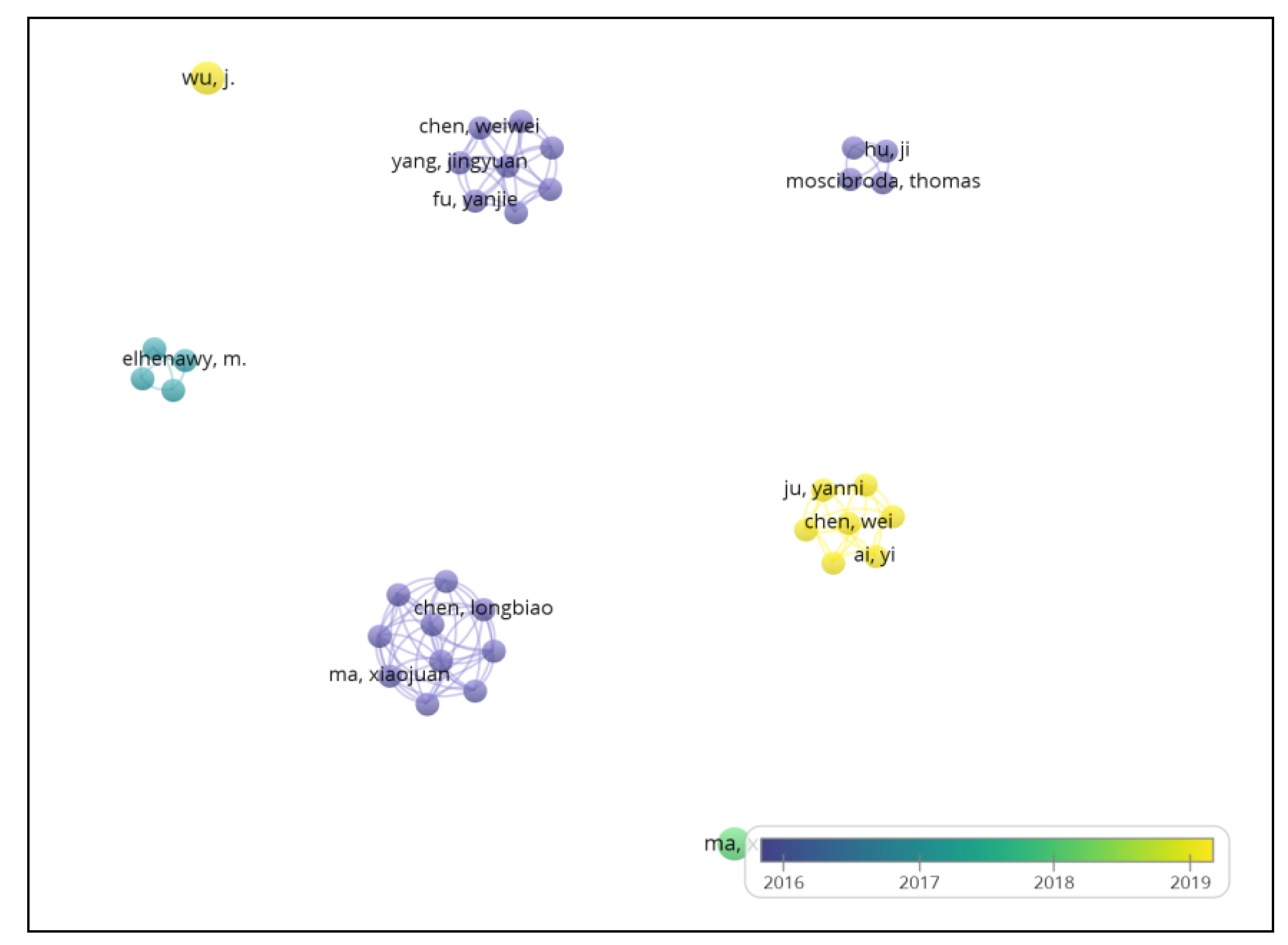
3.4. Author Co-Authorship Analysis
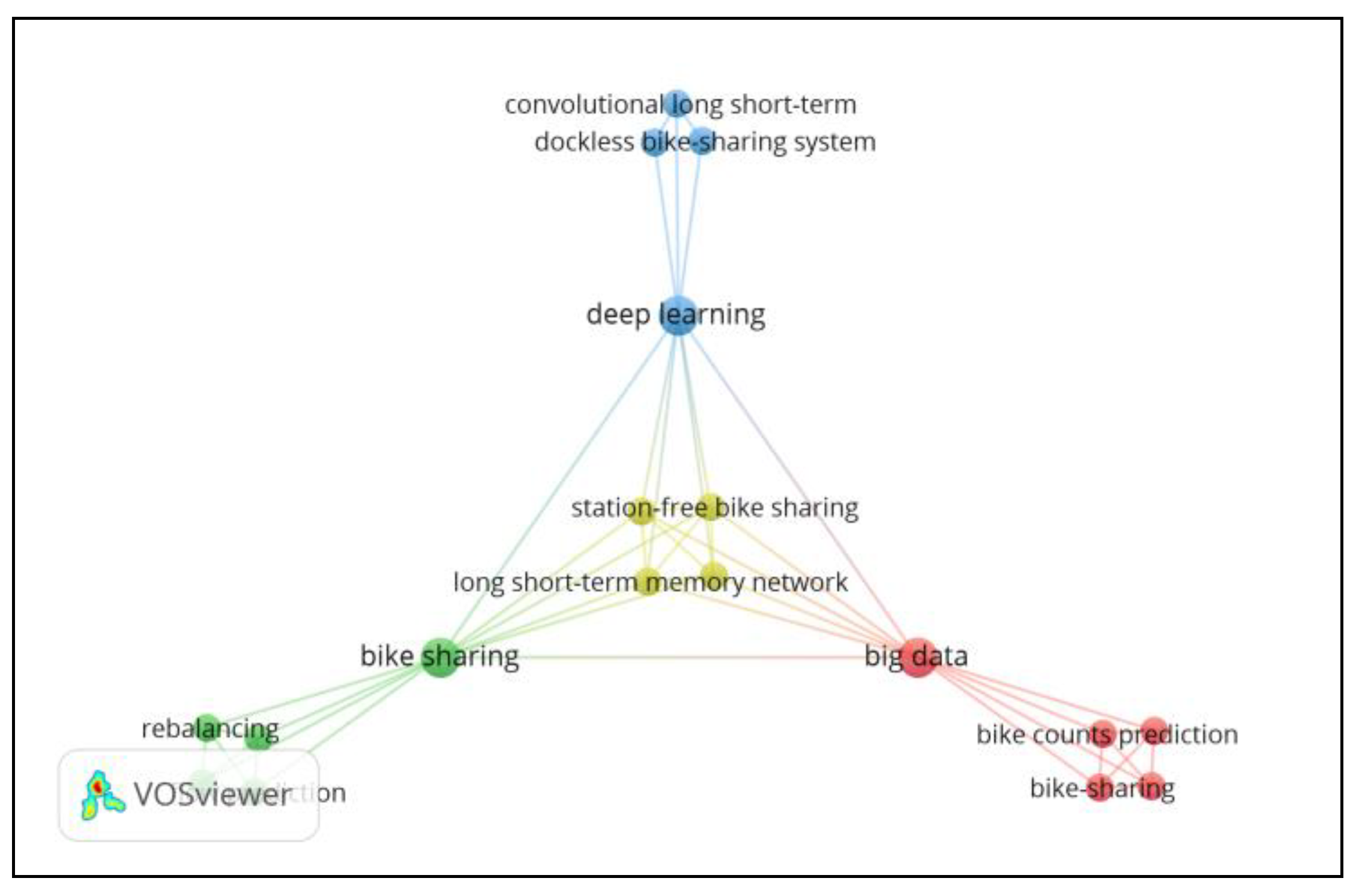
3.5. Title and Abstract Text Occurrence Analysis
3.6. Most Cited Publications
3.7. Application and Method Analysis
4. Discussion
4.1. Research Question Discussion
4.2. Research Gap Discussion
4.3. Study Limitation Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Inter-Agency and Expert Group on Sustainable Development Goal Indicators, Report of the Inter-Agency and Expert Group on Sustainable Development Goal Indicators (E/CN.3/2016/2/Rev.1), Annex IV. 2016. Available online: https://sustainabledevelopment.un.org/content/documents/11803Official-List-of-Proposed-SDG-Indicators.pdf (accessed on 7 June 2020).
- United Nations. Habitat III New Urban Agenda: Quito Declaration on Sustainable Cities and Human Settlements for All. Habitat III Conference, no. October 2016; p. 24. Available online: http://www.eukn.eu/news/detail/agreed-final-draft-of-the-new-urban-agenda-is-now-available/ (accessed on 7 June 2020).
- OECD. Greening Household Behaviour; OECD: Paris, France, 2011. [Google Scholar]
- Klopp, J.M.; Petretta, D.L. The urban sustainable development goal: Indicators, complexity and the politics of measuring cities. Cities 2017, 63, 92–97. [Google Scholar] [CrossRef]
- Meddin, R.; DeMaio, P.J. The Meddin Bike-Sharing World Map. Google Maps. 2020. Available online: https://bikesharingworldmap.com/#/all/2.3/-1.57/33.92/ (accessed on 3 October 2020).
- Chen, C.; Ma, J.; Susilo, Y.; Liu, Y.; Wang, M. The promises of big data and small data for travel behavior (aka human mobility) analysis. Transp. Res. Part C Emerg. Technol. 2016, 68, 285–299. [Google Scholar] [CrossRef] [PubMed]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G.; The PRISMA Group. Preferred reporting items for systematic reviews and meta-analyses: The PRISMA statement. PLoS Med. 2009, 6, e1000097. [Google Scholar] [CrossRef] [PubMed]
- Pickering, C.; Byrne, J. The benefits of publishing systematic quantitative literature reviews for PhD candidates and other early-career researchers. High. Educ. Res. Dev. 2014, 33, 534–548. [Google Scholar] [CrossRef]
- Petticrew, M.; Roberts, H. Systematic Reviews in the Social Sciences: A Practical Guide; Blackwell Publishing Ltd.: Oxford, UK, 2008. [Google Scholar]
- Roscoe, P.B.; Mead, M.; Mead, M. Supporting Materials. In The Mountain Arapesh; Routledge: Abingdon, UK, 2019; pp. 93–158. [Google Scholar]
- Van Eck, N.J.; Waltman, L. Software survey: VOSviewer, a computer program for bibliometric mapping. Scientometrics 2010, 84, 523–538. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Zhang, D.; Wang, L.; Yang, D.; Ma, X.; Li, S.; Wu, Z.; Pan, G.; Nguyen, T.-M.-T.; Jakubowicz, J. Dynamic Cluster-Based over-Demand Prediction in Bike Sharing Systems. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; pp. 841–852. [Google Scholar] [CrossRef]
- Liu, J.; Li, Q.; Qu, M.; Chen, W.; Yang, J.; Xiong, H.; Zhong, H.; Fu, Y. Station Site Optimization in Bike Sharing Systems. In Proceedings of the IEEE International Conference on Data Mining, ICDM, Atlantic City, NJ, USA, 14–17 November 2015; pp. 883–888. [Google Scholar] [CrossRef]
- Ai, Y.; Li, Z.; Gan, M.; Zhang, Y.; Yu, D.; Chen, W.; Ju, Y. A deep learning approach on short-term spatiotemporal distribution forecasting of dockless bike-sharing system. Neural Comput. Appl. 2019, 31, 1665–1677. [Google Scholar] [CrossRef]
- Ashqar, H.I.; Elhenawy, M.; Almannaa, M.H.; Ghanem, A.; Rakha, H.A.; House, L. Modeling Bike Availability in A Bike-Sharing System Using Machine Learning. In Proceedings of the 5th IEEE International Conference on Models and Technologies for Intelligent Transportation Systems, MT-ITS 2017, Naples, Italy, 26–28 June 2017; pp. 374–378. [Google Scholar] [CrossRef]
- Yang, Z.; Hu, J.; Shu, Y.; Cheng, P.; Chen, J.; Moscibroda, T. Mobility Modeling and Prediction in Bike-Sharing Systems. In Proceedings of the 14th Annual International Conference on Mobile Systems, Applications, and Services—MobiSys ’16, Singapore, 26–30 June 2016; pp. 165–178. [Google Scholar] [CrossRef]
- Liu, L.; Sun, L.; Chen, Y.; Ma, X. Optimizing fleet size and scheduling of feeder transit services considering the influence of bike-sharing systems. J. Clean. Prod. 2019, 236, 117550. [Google Scholar] [CrossRef]
- Chen, L.; Ma, X.; Nguyen, T.M.T.; Pan, G.; Jakubowicz, J. Understanding bike trip patterns leveraging bike sharing system open data. Front. Comput. Sci. 2017, 11, 38–48. [Google Scholar] [CrossRef]
- Duan, Y.; Wu, J. Optimizing Rebalance Scheme for Dock-Less Bike Sharing Systems with Adaptive User Incentive. In Proceedings of the IEEE International Conference on Mobile Data Management, Hong Kong, China, 10–13 June 2019; pp. 176–181. [Google Scholar] [CrossRef]
- Jiang, J.; Lin, F.; Fan, J.; Lv, H.; Wu, J. A Destination Prediction Network Based on Spatiotemporal Data for Bike-Sharing. Complexity 2019, 2019. [Google Scholar] [CrossRef]
- Wang, B.; Kim, I. Short-Term Prediction for Bike-Sharing Service Using Machine Learning. Transp. Res. Procedia 2018, 34, 171–178. [Google Scholar] [CrossRef]
- Chen, P.-C.; Hsieh, H.-Y.; Sigalingging, X.K.; Chen, Y.-R.; Leu, J.-S. Prediction of Station Level Demand in a Bike Sharing System Using Recurrent Neural Networks. In Proceedings of the 2017 IEEE 85th Vehicular Technology Conference (VTC Spring), Sydney, Australia, 4–7 June 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Zhou, Y.; Huang, Y. Context Aware Flow Prediction of Bike Sharing Systems. In Proceedings of the 2018 IEEE International Conference on Big Data, Big Data 2018, Seattle, WA, USA, 10–13 December 2018; pp. 2393–2402. [Google Scholar] [CrossRef]
- Pan, Y.; Zheng, R.C.; Zhang, J.; Yao, X. Predicting bike sharing demand using recurrent neural networks. Procedia Comput. Sci. 2019, 147, 562–566. [Google Scholar] [CrossRef]
- Liu, X.; Gherbi, A.; Li, W.; Cheriet, M. Multi features and multi-time steps LSTM based methodology for bike sharing availability prediction. Procedia Comput. Sci. 2019, 155, 394–401. [Google Scholar] [CrossRef]
- Zhou, X. Understanding Spatiotemporal Patterns of Biking Behavior by Analyzing Massive Bike Sharing Data in Chicago. PLoS ONE 2015, 10, e0137922. [Google Scholar] [CrossRef] [PubMed]
- Caggiani, L.; Camporeale, R.; Ottomanelli, M.; Szeto, W.Y. A modeling framework for the dynamic management of free-floating bike-sharing systems. Transp. Res. Part C Emerg. Technol. 2018, 87, 159–182. [Google Scholar] [CrossRef]
- Ghosh, S.; Varakantham, P.; Adulyasak, Y.; Jaillet, P. Dynamic repositioning to reduce lost demand in bike sharing systems. J. Artif. Intell. Res. 2017, 58, 387–430. [Google Scholar] [CrossRef]
- Sarkar, A.; Lathia, N.; Mascolo, C. Comparing cities’ cycling patterns using online shared bicycle maps. Transportation 2015, 42, 541–559. [Google Scholar] [CrossRef]
- Yang, Z.; Chen, J.; Hu, J.; Shu, Y.; Cheng, P. Mobility Modeling and Data-Driven Closed-Loop Prediction in Bike-Sharing Systems. IEEE Trans. Intell. Transp. Syst. 2019, 20, 4488–4499. [Google Scholar] [CrossRef]
- Lin, L.; He, Z.; Peeta, S. Predicting station-level hourly demand in a large-scale bike-sharing network: A graph convolutional neural network approach. Transp. Res. Part C Emerg. Technol. 2018, 97, 258–276. [Google Scholar] [CrossRef]
- Xu, C.; Ji, J.; Liu, P. The station-free sharing bike demand forecasting with a deep learning approach and large-scale datasets. Transp. Res. Part C Emerg. Technol. 2018, 95, 47–60. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, L.; Liu, Y.; Yang, X. Short-term Prediction of Bike-sharing Usage Considering Public Transport: A LSTM Approach. In Proceedings of the IEEE Conference on Intelligent Transportation Systems, Maui, HI, USA, 4–7 November 2018; pp. 1564–1571. [Google Scholar] [CrossRef]
- Du, Y.; Deng, F.; Liao, F. A model framework for discovering the spatio-temporal usage patterns of public free-floating bike-sharing system. Transp. Res. Part C Emerg. Technol. 2019, 103, 39–55. [Google Scholar] [CrossRef]
- Zhao, Y.; Dai, L.; Peng, L.; Song, Y.; Zhou, Z. Analysis of Spatial Distribution of China’s Station-Free Bike-Sharing by Clustering Algorithms. In Proceedings of the ACM International Conference Proceeding Series, Nice, France, 21–25 October 2019; pp. 15–19. [Google Scholar] [CrossRef]
- Li, D.; Zhao, Y.; Li, Y. Time-Series Representation and Clustering Approaches for Sharing Bike Usage Mining. IEEE Access 2019, 7, 177856–177863. [Google Scholar] [CrossRef]
- Guo, Y.; Shen, X.; Ge, Q.; Wang, L. Station Function Discovery: Exploring Trip Records in Urban Public Bike-Sharing System. IEEE Access 2018, 6, 71060–71068. [Google Scholar] [CrossRef]
- Feng, Y.; Wang, S. A Forecast for Bicycle Rental Demand Based on Random Forests and Multiple Linear Regression. In Proceedings of the16th IEEE/ACIS International Conference on Computer and Information Science, ICIS 2017, Wuhan, China, 24–26 May 2017; pp. 101–105. [Google Scholar] [CrossRef]
- Bacciu, D.; Carta, A.; Gnesi, S.; Semini, L. An experience in using machine learning for short-term predictions in smart transportation systems. J. Log. Algebr. Methods Program. 2017, 87, 52–66. [Google Scholar] [CrossRef]
- Ashqar, H.I.; Elhenawy, M.; Rakha, H.A. Modeling bike counts in a bike-sharing system considering the effect of weather conditions. Case Stud. Transp. Policy 2019, 7, 261–268. [Google Scholar] [CrossRef]
- Wu, X.; Lyu, C.; Wang, Z.; Liu, Z. Station-Level Hourly Bike Demand Prediction for Dynamic Repositioning in Bike Sharing Systems. Smart Innov. Syst. Technol. 2019, 149, 19–27. [Google Scholar] [CrossRef]
- Ma, X.; Yu, H.; Wang, Y.; Wang, Y. Large-Scale Transportation Network Congestion Evolution Prediction Using Deep Learning Theory. PLoS ONE 2015, 10, e0119044. [Google Scholar] [CrossRef]
- Zhao, Z.; Chen, W.; Wu, X.; Chen, P.C.V.; Liu, J. LSTM network: A deep learning approach for short-term traffic forecast. IET Image Process. 2017, 11, 68–75. [Google Scholar] [CrossRef]
- Félix, R.; Cambra, P.; Moura, F. Build it and give ‘em bikes, and they will come: The effects of cycling infrastructure and bike-sharing system in Lisbon. Case Stud. Transp. Policy 2020, 8, 672–682. [Google Scholar] [CrossRef]
- Liao, F. Modeling duration choice in space-time multi-state supernetworks for individual activity-travel scheduling. Transp. Res. Part C Emerg. Technol. 2016, 69, 16–35. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Journals | No. | Quartile Rank | Publisher Country | Field | Publisher |
|---|---|---|---|---|---|
| Transportation Research Part C: Emerging Technologies | 5 | Q1 | United Kingdom | Transportation Computer science Engineering | Elsevier Ltd. |
| IEEE Access | 2 | Q1 | United States of America | Computer science Engineering | Institute of Electrical and Electronic Engineers Inc |
| Journal of Transport Geography | 1 | Q1 | United Kingdom | Transportation Environmental science | Elsevier Ltd. |
| Transportation | 1 | Q1 | The Netherlands | Transportation Engineering | Kluwer Academic Publishers |
| Journal of Artificial Intelligence Research | 1 | Q1 | United States America | Computer science | Morgan Kaufmann Publishers, Inc. |
| Neural Computing and Applications | 1 | Q2 | Germany | Computer science | Springer Verlag |
| Computing | 1 | Q2 | Germany | Computer science Mathematics | Springer Verlag |
| Journal of Logical and Algebraic Methods in Programming | 1 | Q1 | The Netherlands | Computer science Mathematics | Elsevier BV |
| Journal of Urbanism | 1 | Q1 | United Kingdom | Environmental science | Taylor and Francis Inc. |
| PLoS ONE | 1 | Q1 | United States America | Computer science | Public Library of Science |
| Frontiers of Computer Science | 1 | Q2 | Germany | Computer science Mathematics | Springer Verlag |
| Case Studies on Transport Policy | 1 | Q2 | The Netherlands | Transportation | Elsevier BV |
| Complexity | 1 | Q1 | Egypt | Multidisciplinary | Hindawi Limited |
| Smart Innovation, Systems and Technologies | 1 | Q2 | Germany | Computer science Multidisciplinary | Springer Verlag |
| Journal of Cleaner Production | 1 | Q1 | The Netherlands | Engineering | Elsevier BV |
| Applied Intelligence | 1 | Q2 | The Netherlands | Computer science | Kluwer Academic Publishers |
| Conference Proceedings | No. | Publisher Country | Field |
|---|---|---|---|
| Procedia Computer Science | 2 | The Netherlands | Computer science |
| Transportation Research Procedia | 1 | The Netherlands | Transportation |
| ACM International Conference Proceeding Series (ICPS) | 1 | United States of America | Computer science |
| ACM International Joint Conference on Pervasive and Ubiquitous Computing (Proceedings of the 2016) | 1 | United States of America | Engineering |
| 5th IEEE International Conference on Models and Technologies for Intelligent Transportation Systems (MT-ITS) | 1 | United States of America | Engineering |
| IEEE Vehicular Technology Conference (2017) | 1 | United States of America | Computer science Engineering |
| IEEE Conference on Intelligent Transportation Systems, Proceedings (ITSC 2018) | 1 | United States of America | Computer science Engineering |
| IEEE International Conference on Big Data, Big Data (2018 Proceedings) | 1 | United States of America | Computer science Mathematics |
| IEEE International Conference on Mobile Data Management (2019 Proceedings) | 1 | United States of America | Computer science |
| 2017 IEEE/ACIS 16th International Conference on Computer and Information Science (ICIS) | 1 | United States of America | Computer science Engineering |
| IEEE International Conference on Data Mining | 1 | United States of America | Engineering |
| Annual International Conference on Mobile Systems, Applications, and Services (14th Proceedings) | 1 | United States of America | Computer science Engineering |
| SIAM International Conference on Data Mining (SDM 2018) | 1 | United States of America | Computer science |
| Keyword | Occurrences | Link Strength |
|---|---|---|
| big data | 2 | 10 |
| bike-sharing | 2 | 10 |
| deep learning | 2 | 9 |
| long short-term memory networks | 1 | 6 |
| sharing mobility | 1 | 6 |
| station-free bike-sharing | 1 | 6 |
| travel demand forecasting | 1 | 6 |
| bike-sharing systems | 2 | 5 |
| cycling | 1 | 5 |
| data mining | 1 | 5 |
| demand analysis | 1 | 5 |
| smart-card data | 1 | 5 |
| trip chaining | 1 | 5 |
| bike counts prediction | 1 | 4 |
| bike-sharing systems | 1 | 4 |
| bike-sharing | 1 | 4 |
| flow prediction | 1 | 4 |
| machine learning | 1 | 4 |
| mobility modelling | 1 | 4 |
| random forest | 1 | 4 |
| rebalancing | 1 | 4 |
| sharing economy | 1 | 4 |
| taxi | 1 | 4 |
| travel mode choice | 1 | 4 |
| urban computing | 1 | 4 |
| clustering algorithm | 1 | 3 |
| convolutional long short-term memory network | 1 | 3 |
| dock less bike-sharing system | 1 | 3 |
| long short-term memory | 1 | 3 |
| recurrent neural networks | 1 | 3 |
| shared bike demand prediction | 1 | 3 |
| short-term spatiotemporal distribution forecasting | 1 | 3 |
| spatial distribution | 1 | 3 |
| station-free bike-sharing system | 1 | 3 |
| time-series forecasting | 1 | 3 |
| Author | Documents | Link Strength |
|---|---|---|
| Chen, Longbiao | 1 | 9 |
| Jakubowicz, Jérémie | 1 | 9 |
| Li, Shijian | 1 | 9 |
| Ma, Xiaojuan | 1 | 9 |
| Nguyen, Thi Mai Trang | 1 | 9 |
| Pang, Gang | 1 | 9 |
| Wang, Leye | 1 | 9 |
| Wu, Zhaohui | 1 | 9 |
| Yang, Dingqi | 1 | 9 |
| Zhang, Daqing | 1 | 9 |
| Chen, Weiwei | 1 | 7 |
| Fu, Yanjie | 1 | 7 |
| Li, Qiao | 1 | 7 |
| Liu, Junming | 1 | 7 |
| Qu, Meng | 1 | 7 |
| Xiong, Hui | 1 | 7 |
| Yang, Jingyuan | 1 | 7 |
| Zhong, Hao | 1 | 7 |
| Ai, Yi | 1 | 6 |
| Chen, Wei | 1 | 6 |
| Gan, Mi | 1 | 6 |
| Ju, Yanni | 1 | 6 |
| Li, Zongping | 1 | 6 |
| Yu, Daben | 1 | 6 |
| Zhang, Yunpeng | 1 | 6 |
| Elhenawy, M. | 1 | 3 |
| Ghanem, A. | 1 | 3 |
| House, L. | 1 | 3 |
| Hu, Ji | 1 | 3 |
| Moscibroda, Thomas | 1 | 3 |
| Rakha, H. A. | 1 | 3 |
| Shu, Yuanchao | 1 | 3 |
| Yang, Zidong | 1 | 3 |
| Ma, X. | 2 | 0 |
| Wu, J. | 2 | 0 |
| Term | Occurrences | Relevance |
|---|---|---|
| gcnn model | 2 | 2.08 |
| gcnnrec ddgf | 2 | 2.08 |
| gcnnreg ddgf | 2 | 2.08 |
| gcnnreg ddgf model | 2 | 2.08 |
| lstm nns | 4 | 1.77 |
| sharing bike | 4 | 1.71 |
| deep learning approach | 4 | 1.17 |
| recurrent neural network | 3 | 1.11 |
| gru | 2 | 1.07 |
| clustering algorithm | 4 | 0.86 |
| conv lstm | 2 | 0.83 |
| prediction model | 6 | 0.60 |
| random forest | 8 | 0.49 |
| No. | Author(s) | Year | Article Title | Publication (Journal/Conference Proceeding) | No. of Citations |
|---|---|---|---|---|---|
| 1 | Yang, Z., Hu, J., Shu, Y., (...), Chen, J., Moscibroda, T. | 2016 | Mobility Modeling and Prediction in Bike-Sharing Systems | Annual International Conference on Mobile Systems, Applications, and Services (14th Proceedings) | 60 |
| 2 | Chen, L., Zhang, D., Wang, L., (...), Nguyen, T.-M.-T., Jakubowicz, J. | 2016 | Dynamic Cluster-Based Over-Demand Prediction in Bike Sharing Systems | ACM International Joint Conference on Pervasive and Ubiquitous Computing (2016 Proceedings) | 57 |
| 3 | Zhou, X. | 2015 | Understanding Spatiotemporal Patterns of Biking Behavior by Analyzing Massive Bike Sharing Data in Chicago | PloS ONE | 54 |
| 4 | Caggiani, L., Camporeale, R., Ottomanelli, M., Szeto, W.Y. | 2018 | A Modeling Framework for the Dynamic Management of Free-Floating Bike-Sharing Systems | Transportation Research Part C: Emerging Technologies | 53 |
| 5 | Ghosh, S., Varakantham, P., Adulyasak, Y., Jaillet, P. | 2017 | Dynamic Repositioning to Reduce Lost Demand in Bike Sharing Systems | Journal of Artificial Intelligence Research | 43 |
| 6 | Lin, L., He, Z., Peeta, S. | 2018 | Predicting Station-Level Hourly Demand in a large-scale Bike-Sharing Network: A Graph Convolutional Neural Network Approach | Transportation Research Part C: Emerging Technologies | 36 |
| 7 | Liu, J., Li, Q., Qu, M., (...), Zhong, H., Fu, Y. | 2016 | Station Site Optimization in Bike Sharing Systems | IEEE International Conference on Data Mining (2015 Proceedings) | 35 |
| 8 | Xu, C., Ji, J., Liu, P. | 2018 | The Station-Free Sharing Bike Demand Forecasting with a Deep Learning Approach and Large-Scale Datasets | Transportation Research Part C: Emerging Technologies | 23 |
| 9 | Bordagaray M., dell’Olio L., Fonzone A., Ibeas Á. | 2016 | Capturing the Conditions That Introduce Systematic Variation in Bike-Sharing Travel Behavior Using Data Mining Techniques | Transportation Research Part C: Emerging Technologies | 23 |
| 10 | Sarkar, A., Lathia, N., Mascolo, C. | 2015 | Comparing Cities’ Cycling Patterns Using Online Shared Bicycle Maps | Transportation | 22 |
| 11 | Ai, Y., Li, Z., Gan, M., (...), Chen, W., Ju, Y. | 2019 | A Deep Learning Approach on Short-Term Spatiotemporal Distribution Forecasting of Dockless Bike-Sharing System | Neural Computing and Applications | 15 |
| 12 | Cagliero, L., Cerquitelli, T., Chiusano, S., Garza, P., Xiao, X. | 2017 | Predicting Critical Conditions in Bicycle Sharing Systems | Computing | 13 |
| 13 | Du, Y., Deng, F., Liao, F. | 2019 | A Model Framework for Discovering the Spatio-Temporal Usage Patterns of Public Free-Floating Bike-Sharing System | Transportation Research Part C: Emerging Technologies | 12 |
| 14 | Ashqar, H.I., Elhenawy, M., Almannaa, M.H., (...), Rakha, H.A., House, L. | 2017 | Modeling Bike Availability in a Bike-Sharing System Using Machine Learning | IEEE International Conference on Models and Technologies for Intelligent Transportation Systems (5th Proceedings) | 12 |
| 15 | Feng, Y., Wang, S. | 2017 | A Forecast for Bicycle Rental Demand Based on Random Forests and Multiple Linear Regression | IEEE/ACIS International Conference on Computer and Information Science (16th Proceedings) | 10 |
| 16 | Bacciu, D., Carta, A., Gnesi, S., Semini, L. | 2017 | An Experience in Using Machine Learning for Short-Term Predictions in Smart Transportation Systems | Journal of Logical and Algebraic Methods in Programming | 6 |
| 17 | Wang, B., Kim, I. | 2018 | Short- Term Prediction for Bike-Sharing Service Using Machine Learning | Transportation Research Procedia | 5 |
| 18 | Chen, P.-C., Hsieh, H.-Y., Sigalingging, X.K., Chen, Y.-R., Leu, J.-S. | 2017 | Prediction of Station Level Demand in a Bike Sharing System Using Recurrent Neural Networks | IEEE Vehicular Technology Conference, 2016 | 5 |
| 19 | Chen, L., Ma, X., Nguyen, T.-M.-T., Pan, G., Jakubowicz, J. | 2017 | Understanding Bike Trip Patterns Leveraging Bike Sharing System Open Data | Frontiers of Computer Science | 5 |
| 20 | Ashqar, H.I., Elhenawy, M., Rakha, H.A. | 2019 | Modeling Bike Counts in a Bike-Sharing System Considering the Effect of Weather Conditions | Case Studies on Transport Policy | 4 |
| 21 | Zhou, Y., Huang, Y. | 2019 | Context Aware Flow Prediction of Bike Sharing Systems | IEEE International Conference on Big Data, Big Data (2018 Proceedings) | 3 |
| 22 | Jiang, J., Lin, F., Fan, J., Lv, H., Wu, J. | 2019 | A Destination Prediction Network Based on Spatiotemporal Data for Bike-Sharing | Complexity | 3 |
| 23 | Pan, Y., Zheng, R.C., Zhang, J., Yao, X. | 2019 | Predicting Bike Sharing Demand Using Recurrent Neural Networks | Procedia Computer Science | 3 |
| 24 | Wu, X., Lyu, C., Wang, Z., Liu, Z. | 2019 | Station-Level Hourly Bike Demand Prediction for Dynamic Repositioning in Bike Sharing Systems | Smart Innovation, Systems and Technologies | 2 |
| 25 | Duan, Y., Wu, J. | 2019 | Optimizing Rebalance Scheme for Dock-less Bike Sharing Systems with Adaptive User Incentive | IEEE International Conference on Mobile Data Management (2019 Proceedings) | 2 |
| 26 | Zhang, C., Zhang, L., Liu, Y., Yang, X. | 2018 | Short-Term Prediction of Bike-Sharing Usage Considering Public Transport: A LSTM Approach | IEEE Conference on Intelligent Transportation Systems, Proceedings (ITSC 2018) | 2 |
| 27 | Liu, L., Sun, L., Chen, Y., Ma, X. | 2019 | Optimizing Fleet Size and Scheduling of Feeder Transit Services Considering the Influence of Bike-Sharing Systems | Journal of Cleaner Production | 1 |
| 28 | Zhou, X., Wang, M., Li, D. | 2019 | Bike-Sharing or Taxi? Modeling the Choices of Travel Mode in Chicago Using Machine Learning | Journal of Transport Geography | 1 |
| 29 | Xu, H., Duan, F., Pu, P. | 2019 | Dynamic Bicycle Scheduling Problem Based on Short-Term Demand Prediction | Applied Intelligence | 1 |
| 30 | Zhao, Y., Dai, L., Peng, L., Song, Y., Zhou, Z. | 2019 | Analysis of Spatial Distribution of China’s Station-Free Bike-Sharing by Clustering Algorithms | ACM International Conference Proceeding Series | 1 |
| 31 | Li, D., Zhao, Y., Li, Y. | 2019 | Time-Series Representation and Clustering Approaches for Sharing Bike Usage Mining | IEEE Access | 1 |
| 32 | Liu, X., Gherbi, A., Li, W., Cheriet, M. | 2019 | Multi Features and Multi-Time Steps LSTM Based Methodology for Bike Sharing Availability Prediction | Procedia Computer Science | 1 |
| 33 | Guo, Y., Shen, X., Ge, Q., Wang, L. | 2018 | Station Function Discovery: Exploring Trip Records in Urban Public Bike-Sharing System | IEEE Access | 1 |
| 34 | Liu, K., Wang, P., Zhang, J., Fu, Y., Das, S.K. | 2018 | Modelling the Interaction Coupling of Multi-View Spatiotemporal Contexts for Destination Prediction | SIAM International Conference on Data Mining (SDM 2018) | 1 |
| 35 | Zhou, M., Ding, J., Fang, H. | 2018 | Performance Modelling and Analysis of a Station-Free Bike Sharing System | International Conference on Intelligent Autonomous Systems (ICoIAS 2018) | 1 |
| No. | Author(s) | Application | Methods |
|---|---|---|---|
| 1 | Yang, Z., Hu, J., Shu, Y., (...), Chen, J., Moscibroda, T. | Build a spatiotemporal dynamic network to evaluate and predict station and city bike demand. | Random forest |
| 2 | Chen, L., Zhang, D., Wang, L., (...), Nguyen, T.-M.-T., Jakubowicz, J. | Weight a correlation network to model the relationship among bike stations and dynamically group neighbouring stations with similar bike usage patterns into clusters. Use Monte Carlo simulation to predict the over-demand probability of each cluster. | Weighted correlation network and Monte Carlo simulation (WCN-MC), auto-regressive integrated moving average (ARIMA), Bayesian Monte Carlo (B-MC), artificial neural network (ANN), Static clustering Monte Carlo (SC-MC), common contextual factor-based clustering Monte Carlo (CCF-MC) |
| 3 | Zhou, X. | Detect and visualise spatiotemporal bike flow clusters. Analyse station over-demand patterns across the city using hierarchical clustering to understand spatial distribution of stations with different temporal use signatures, biking behaviour and mobility patterns. | Community detection clustering, hierarchical clustering |
| 4 | Caggiani, L., Camporeale, R., Ottomanelli, M., Szeto, W.Y. | Spatiotemporal clustering, first grouping the data simultaneously by creating a cluster tree and second minimising the average squared distance between points in the same cluster. Forecast the trend of available bikes in each spatiotemporal cluster to understand how many bikes have to be repositioned to improve user satisfaction and system attraction. | Hierarchical clustering, K-means, nonlinear autoregressive neural network prediction |
| 5 | Ghosh, S., Varakantham, P., Adulyasak, Y., Jaillet, P. | Dynamic repositioning of bikes in conjunction with the routing solution and a scalable solution for the real-world large-scale bike-sharing systems. | Lagrange dual decomposition (LDD) |
| 6 | Lin, L., He, Z., Peeta, S. | Six types of GCNN models and seven benchmark models built and compared on a Citi Bike dataset from New York City to make spatiotemporal correlations patterns between stations and to predict station-level hourly demand in a large-scale bike-sharing network. | Graph convolutional neural network with data-driven graph filter (GCNN-DDGF) |
| 7 | Liu, J., Li, Q., Qu, M., (...), Zhong, H., Fu, Y. | Bike-sharing network optimisation approach of station site allocation in terms of the bike usage as well as the required rebalancing efforts by considering multiple influential factors: environment and complex public transportation networks. | Artificial neural network (ANN) |
| 8 | Xu, C., Ji, J., Liu, P. | Predict the bike-sharing trip gap, production and attraction: mobility pattern of the station-free bike-sharing at a citywide scale and development of dynamic demand forecasting models to predict the travel demand of station-free bike-sharing using the deep learning approach. | Long short-term memory neural networks (LSTM NNs) |
| 9 | Bordagaray M., dell’Olio L., Fonzone A., Ibeas Á. | Algorithm to classify trips of bike-sharing system (BSS) users in well-defined usage types by mining smart-card transactions, and spatiotemporal distribution and travel behaviour within public systems. | Rule-based classification, logistic regression (binary regression) |
| 10 | Sarkar, A., Lathia, N., Mascolo, C. | Model granular behavioural patterns on spatiotemporal variations and bike station redistribution. | Hierarchical clustering |
| 11 | Ai, Y., Li, Z., Gan, M., (...), Chen, W., Ju, Y. | A deep learning approach to address the spatiotemporal dependences, including the number of bicycles in the area, distribution uniformity, usage distribution and time of day. | Convolutional long short-term memory network (conv-LSTM) |
| 12 | Cagliero, L., Cerquitelli, T., Chiusano, S., Garza, P., Xiao, X. | Station performance occupancy-level prediction. | Bayesian classifier, L3 classifiers |
| 13 | Du, Y., Deng, F., Liao, F. | Model framework to explore the spatiotemporal usage patterns of free-floating shared bikes using the usage data to explore the impact of factors on the frequency in different districts. | Random forest, hierarchical clustering |
| 14 | Ashqar, H.I., Elhenawy, M., Almannaa, M.H., (...), Rakha, H.A., House, L. | Univariate and multivariate models for availability prediction of shared bikes at the station. | Random forest, least-squares boosting and partial least-squares regression (PLSR) |
| 15 | Feng, Y., Wang, S. | Multiple regression analysis has a great improvement when a random forest model is used to predict the demand for bicycle rental. | Multiple linear regression, random forest |
| 16 | Bacciu, D., Carta, A., Gnesi, S., Semini, L. | Compare machine learning techniques to predict and infer whether there is in use a bike that could be, with high probability, returned at the station where the user is waiting. | Gausian support vector machine (SVM) classifier, time series, random forest |
| 17 | Wang, B., Kim, I. | Short-term forecast for docking station usage with two RNN techniques and random forest (RF) to compare performance. | Recurrent neural networks (RNNs) (long short-term memory network (LSTM) and gated recurrent unit (GRU)), random forest |
| 18 | Chen, P.-C., Hsieh, H.-Y., Sigalingging, X.K., Chen, Y.-R., Leu, J.-S. | Predict both rental and return demand for every station at once, which is efficient for online balancing strategies. | Recurrent neural network (RNN) |
| 19 | Chen, L., Ma, X., Nguyen, T.-M.-T., Pan, G., Jakubowicz, J. | Approach to infer the spatiotemporal bike trip patterns from the public station feeds. | Sparse regularisation, weighted regularisation |
| 20 | Ashqar, H.I., Elhenawy, M., Rakha, H.A. | Quantify the effect of several variables (month of the year, day of the week, time of the day and various weather conditions) on the mean of bike counts for the Bay Area BSS network. Prediction model for the bike counts at each station over time as it is one of the key tasks in making the rebalancing operation more efficient. | Poisson regression model (PRM), negative binomial regression model (NBRM), random forest, Bayesian information criterion (BIC) |
| 21 | Zhou, Y., Huang, Y. | Context-aware framework to predict bike flows for both existing stations and new stations that incorporates spatiotemporal, network and environmental contexts in a synergistic manner. | Fuzzy logic (FL)-based adaptive neuro-fuzzy inference system for enhancing traveling comfort (FLC), auto-regression moving average (ARMA), artificial neural network (ANN), bipartite clustering |
| 22 | Jiang, J., Lin, F., Fan, J., Lv, H., Wu, J. | Prediction network based on spatiotemporal data. | Long short-term memory network (LSTM), convolutional neural network (CNN), candidate generation model (CGM), naïve Bayesian |
| 23 | Pan, Y., Zheng, R.C., Zhang, J., Yao, X. | Prediction of bike-renting in different areas of a city during a future period based on historical, weather and time data. | Community detection clustering, recurrent neural network (RNN), long short-term memory network (LSTM) |
| 24 | Wu, X., Lyu, C., Wang, Z., Liu, Z. | Prediction accuracy of the hourly bike number change at the station level. | Random forest (RF), gradient boosting regression tree (GBRT) and neural network (NN) |
| 25 | Duan, Y., Wu, J. | Rebalancing the dock-less bike-sharing systems. | Markov decision process (MDP), deep reinforcement learning (DRL) |
| 26 | Zhang, C., Zhang, L., Liu, Y., Yang, X. | Prediction approach to historical usage and real-time passengers of public transport and neural networks to establish the connection among them. | Long short-term memory (LSTM) |
| 27 | Liu, L., Sun, L., Chen, Y., Ma, X. | Optimisation of fleet size and schedules of feeder buses that connect metro and residential areas in the context of bike-sharing systems. | Non- dominated sorting genetic algorithm -II (NSGA-II), customised multi-objective optimisation algorithm based on particle swarm optimisation (MPSO) |
| 28 | Zhou, X., Wang, M., Li, D. | Spatiotemporal model for travel choices between two transport alternatives. | Logistic regression, regularised linear models with stochastic gradient descent (SGD) learning, nonlinear algorithms, K-nearest neighbours (K-NN), support vector machine (SVM), Gaussian naïve Bayes, decision tree (DT), neural network, random forest (RF) |
| 29 | Xu, H., Duan, F., Pu, P. | Dynamic bicycle scheduling (DBS) model based on short-term demand prediction. | K-means, random forest (RF), enhanced genetic algorithm (E-GA) |
| 30 | Zhao, Y., Dai, L., Peng, L., Song, Y., Zhou, Z. | Model characteristics of the spatial distribution of shared traffic resources through the relationship between the density of bicycle distribution and the geographical location. | K-means (KM), ant colony (ACO), fuzzy C-means (FCM), mean shift (MS) |
| 31 | Li, D., Zhao, Y., Li, Y. | Dimension reduction in count series data to enhance performance with clustering, classification and prediction. | Time series, hierarchical clustering, K-Means (KM), K-medoids, K-shape |
| 32 | Liu, X., Gherbi, A., Li, W., Cheriet, M. | Rebalance bikes efficiently among different bike-sharing dockers. | Long short-term memory (LSTM), recurrent neural network (RNN), deep neural network (DNN) |
| 33 | Guo, Y., Shen, X., Ge, Q., Wang, L. | Station function method validated by the analysis of spatiotemporal characteristics on traffic patterns for station clusters and evaluated by the comparison of clustering results with the data of point of interests and station names. | K-means (KM), latent dirichlet allocation (LDA) |
| 34 | Liu, K., Wang, P., Zhang, J., Fu, Y., Das, S.K. | Multi-view model that can learn the relationship of the spatial and temporal views and substantially enhance the predictive performances. | Multiple additive regression trees (MART), RankBoost (RB), LambdaMART (LM), ListNet (LN), RankNet (RN) |
| 35 | Zhou, M., Ding, J., Fang, H. | Performance analysis for station-free bike-sharing systems to evaluate the travel time, capacity planning and utilisation. | Monte Carlo (MC), continuous time Markov chain (CTMC), performance evaluation process algebra (PEPA) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Albuquerque, V.; Sales Dias, M.; Bacao, F. Machine Learning Approaches to Bike-Sharing Systems: A Systematic Literature Review. ISPRS Int. J. Geo-Inf. 2021, 10, 62. https://doi.org/10.3390/ijgi10020062
Albuquerque V, Sales Dias M, Bacao F. Machine Learning Approaches to Bike-Sharing Systems: A Systematic Literature Review. ISPRS International Journal of Geo-Information. 2021; 10(2):62. https://doi.org/10.3390/ijgi10020062
Chicago/Turabian StyleAlbuquerque, Vitória, Miguel Sales Dias, and Fernando Bacao. 2021. "Machine Learning Approaches to Bike-Sharing Systems: A Systematic Literature Review" ISPRS International Journal of Geo-Information 10, no. 2: 62. https://doi.org/10.3390/ijgi10020062
APA StyleAlbuquerque, V., Sales Dias, M., & Bacao, F. (2021). Machine Learning Approaches to Bike-Sharing Systems: A Systematic Literature Review. ISPRS International Journal of Geo-Information, 10(2), 62. https://doi.org/10.3390/ijgi10020062