
Joint Promotion Partner Recommendation Systems Using Data from Location-Based Social Networks



Abstract
1. Introduction
- Innovative recommendation system: The proposed recommendation system is the first to exploit LBSN datasets to help POI owners search for suitable joint-promotion partners. Compared to existing approaches (which rely on questionnaire surveys), the proposed method produces results more swiftly, and these results are more accurate and more representative.
- High adaptability of JPPRS to different LBSNs: The proposed method uses six factors to calculate the collaboration suitability score of two businesses, and the data fields needed to calculate these factors are available in most LBSN datasets. In other words, the proposed method can be applied to most LBSN datasets.
- Excellent commercial potential of JPPRS: The proposed method was designed to take into account the needs of recommendation system suppliers and the needs of POI owners once the system is online. Thus, the realization algorithm of the JPPRS is very simple and fast so that the system can be easily realized in the backend of websites. In other words, this approach meets the needs of commercialization.
2. Related Work
2.1. Overview of Existing Social Networks and LBSNs
2.2. Recommendation Systems Using Data Acquired from LBSNs
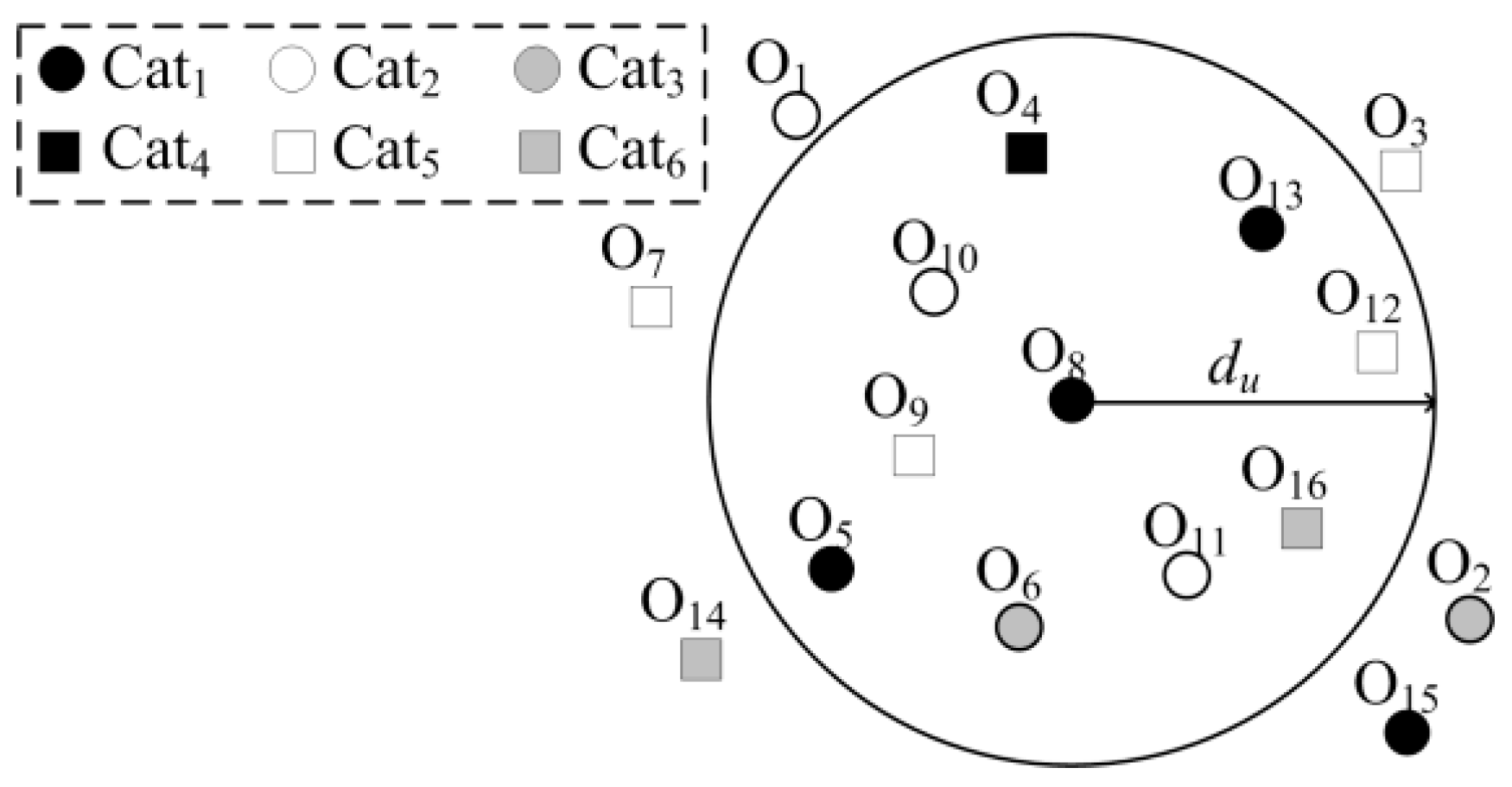
3. Definitions
4. Methodology
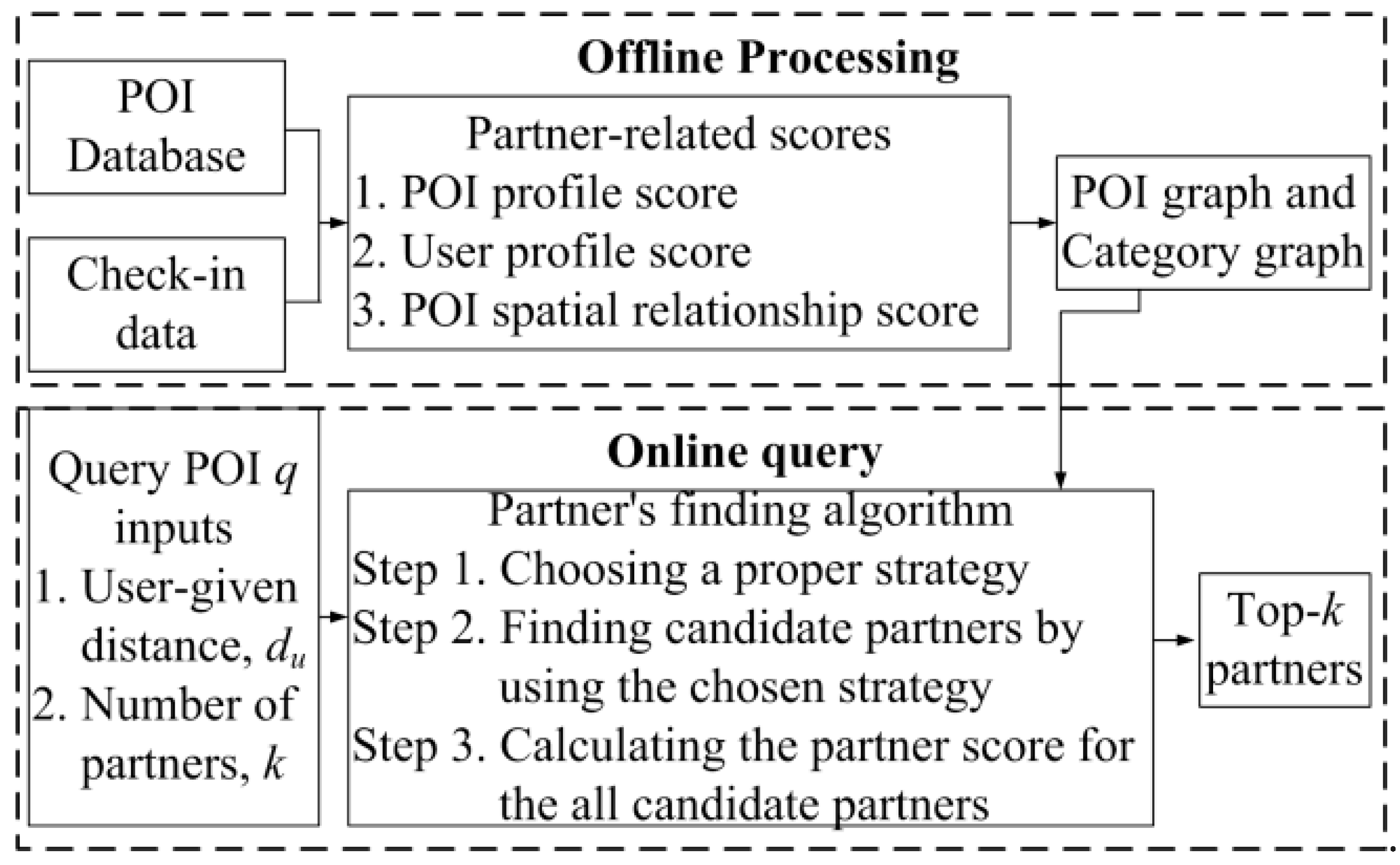
4.1. Framework of Joint Promotion Partner Recommendation Systems (JPPRS)
4.2. Offline Processing
4.2.1. POI Profile Score (PPS)
4.2.2. User Profile Score (UPS)
4.2.3. POI Spatial Relationship Score (SRS)
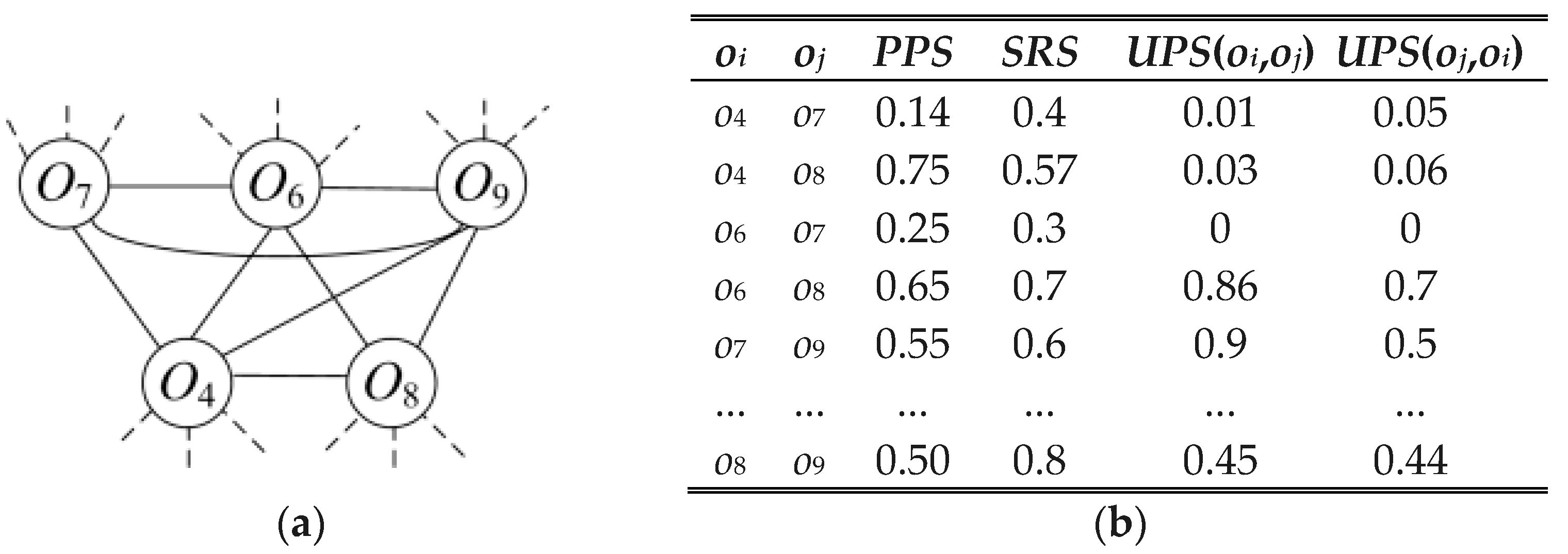
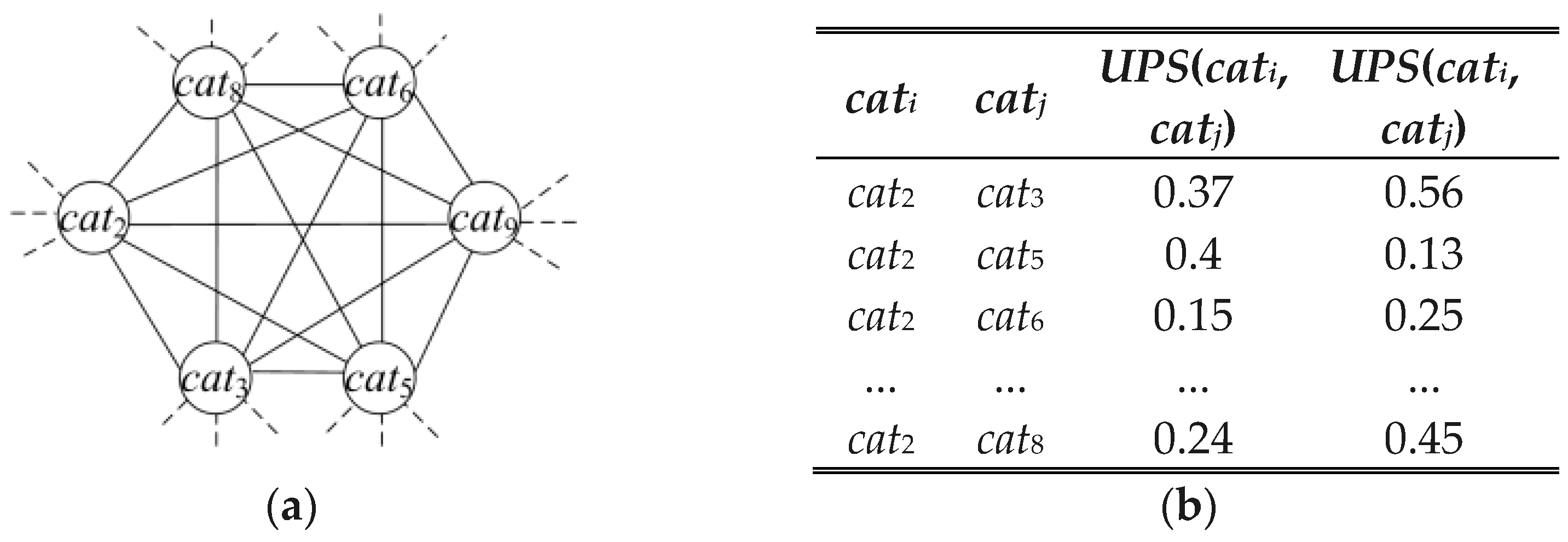
4.2.4. POI Graph and Category Graph
4.3. Online Query
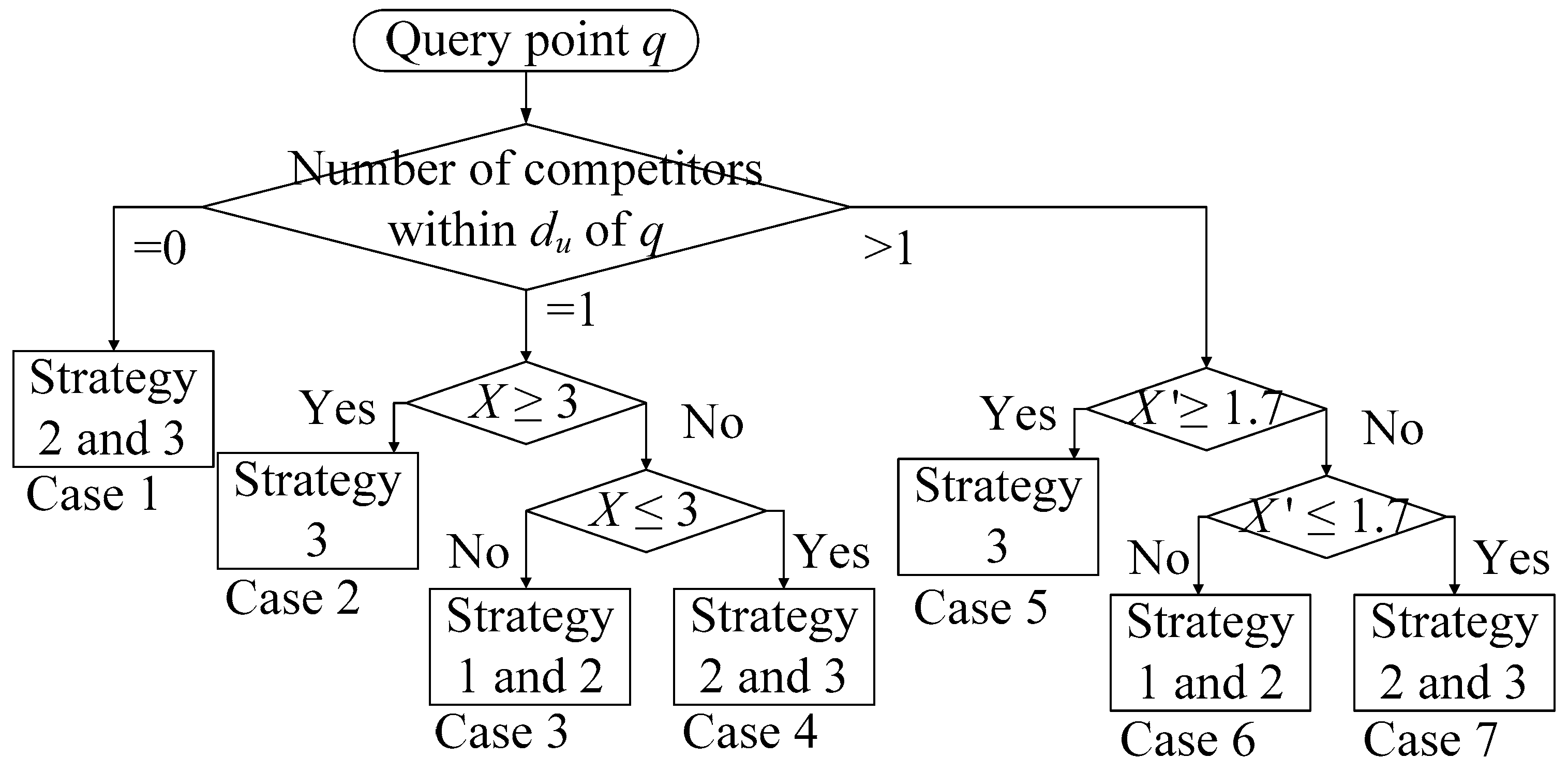
4.3.1. Promotion Strategy Selection
4.3.2. Finding Candidate Partners
4.3.3. Partner Score Calculation
4.3.4. Partners Finding Speed Up Algorithm
5. Experiments
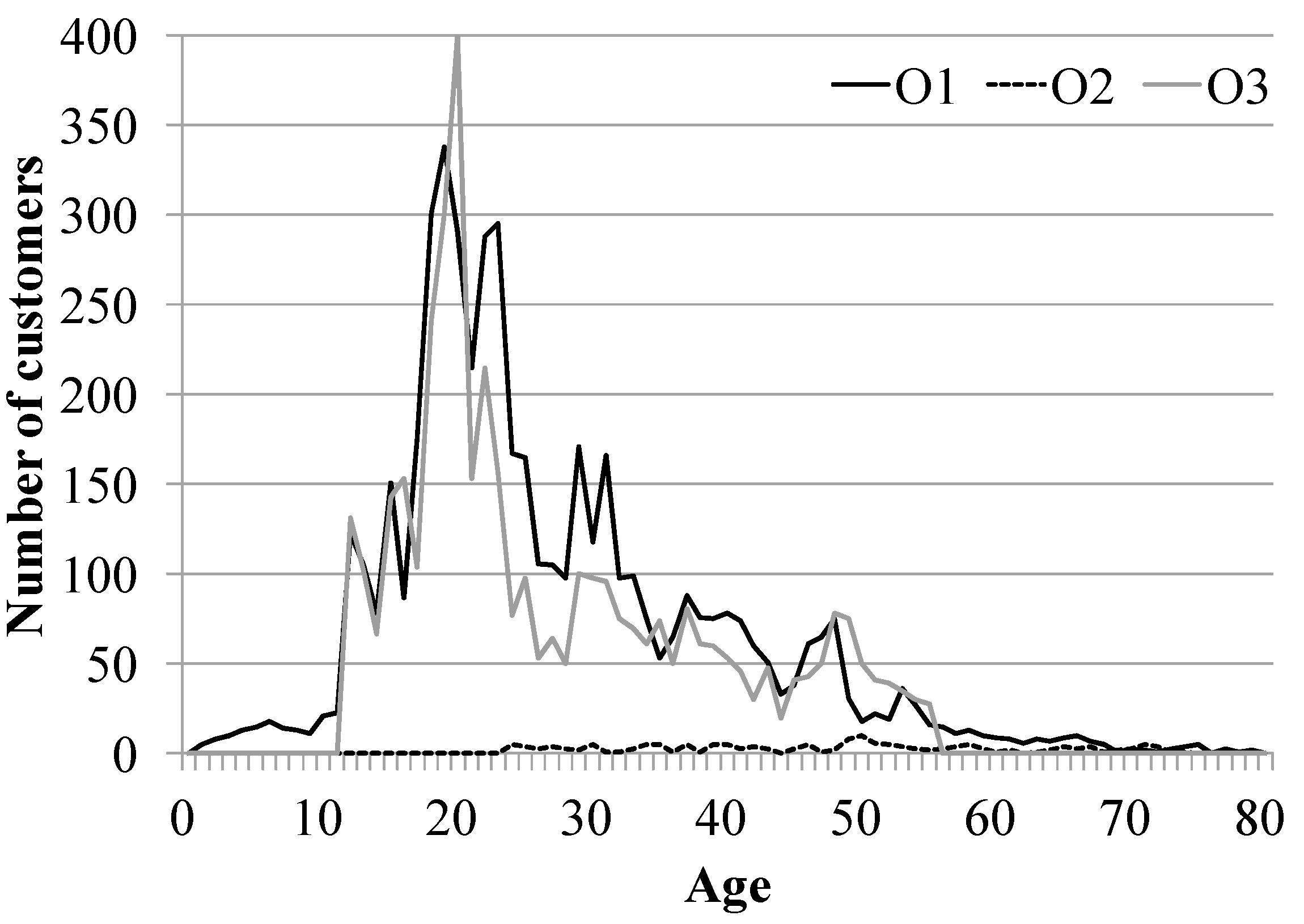
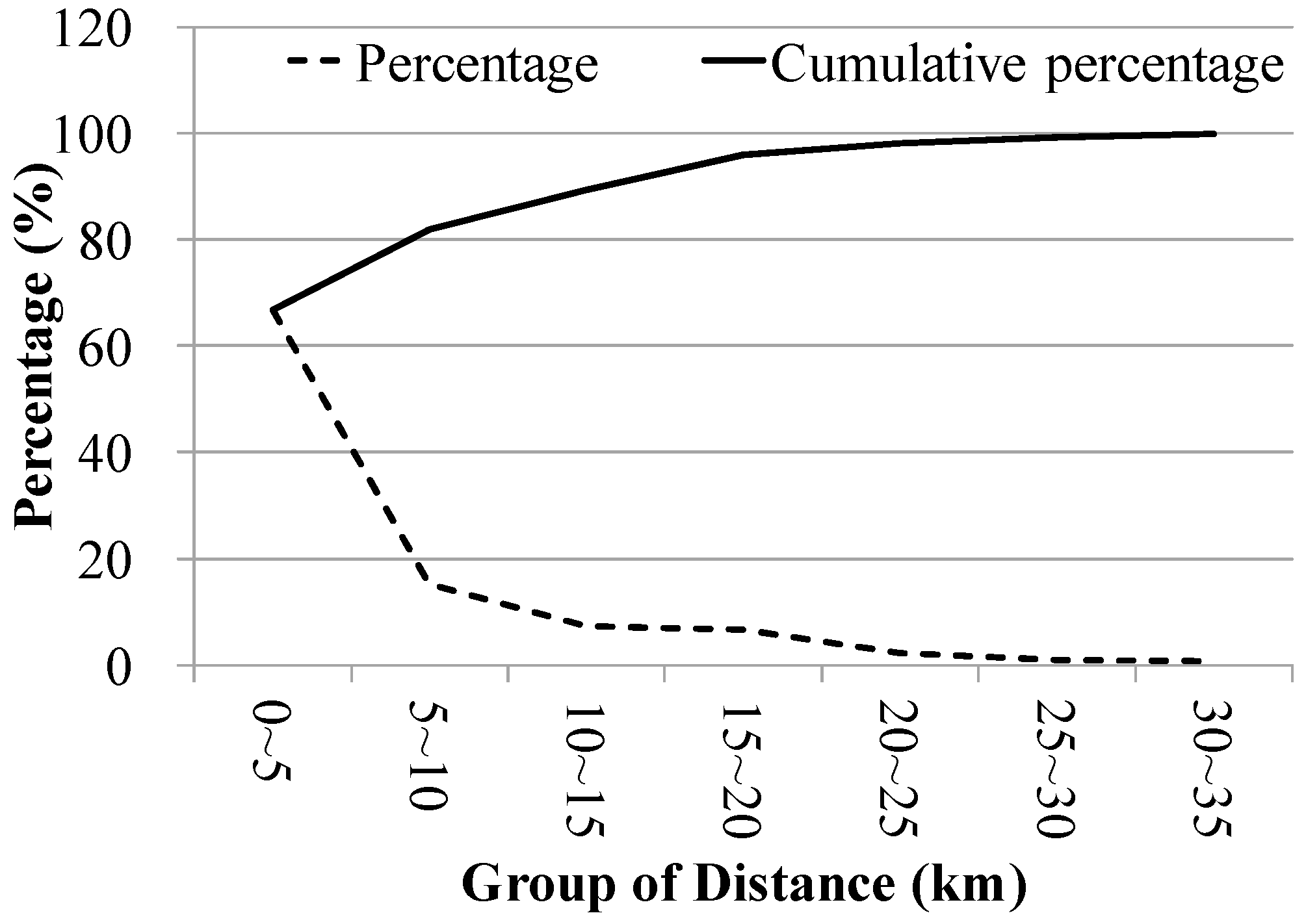
5.1. Experiment Settings
5.2. Conditions of Algorithm under Different Response Strategies
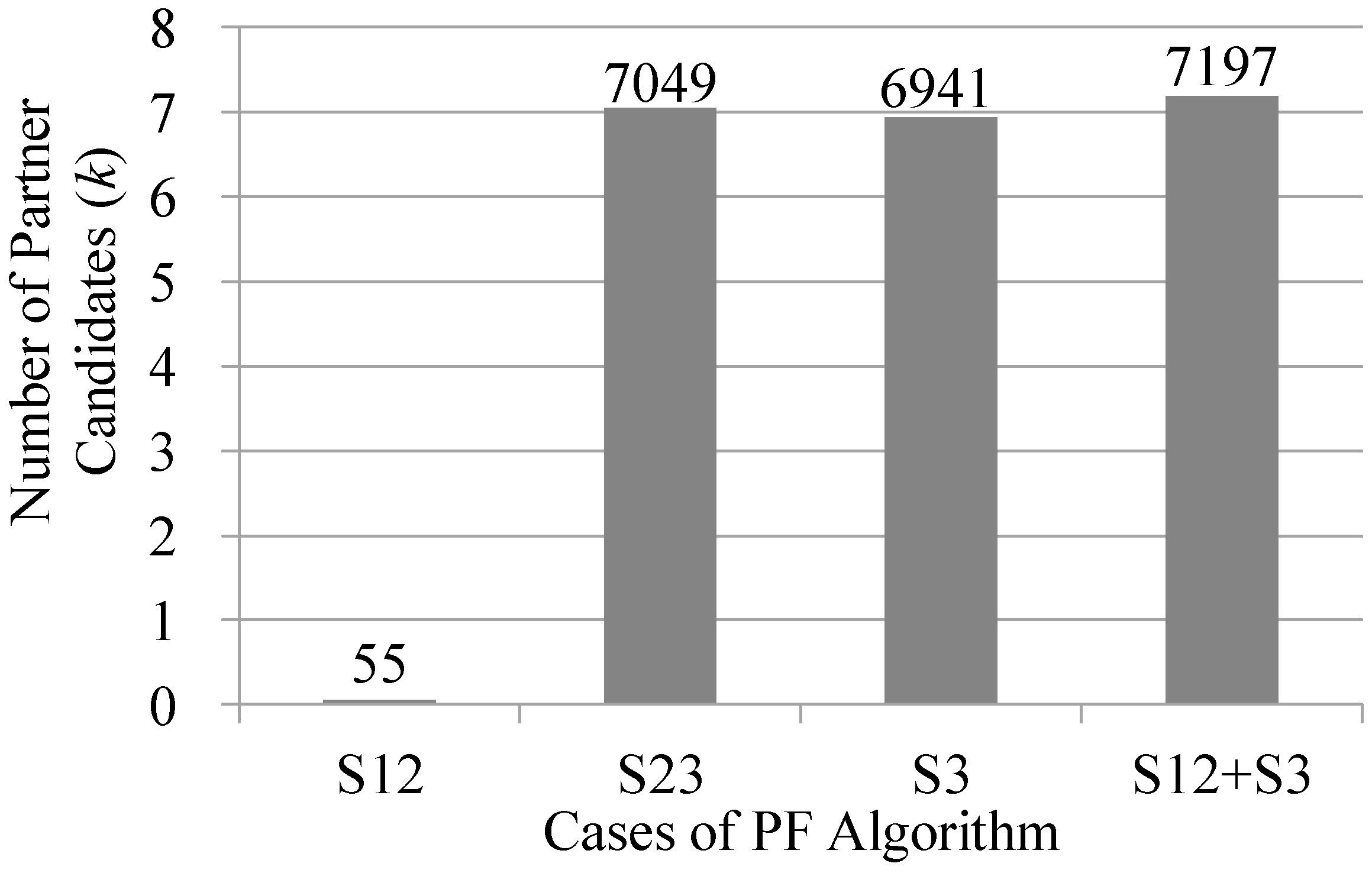
5.2.1. Numbers of Candidate Partners Identified by Different Response Strategies
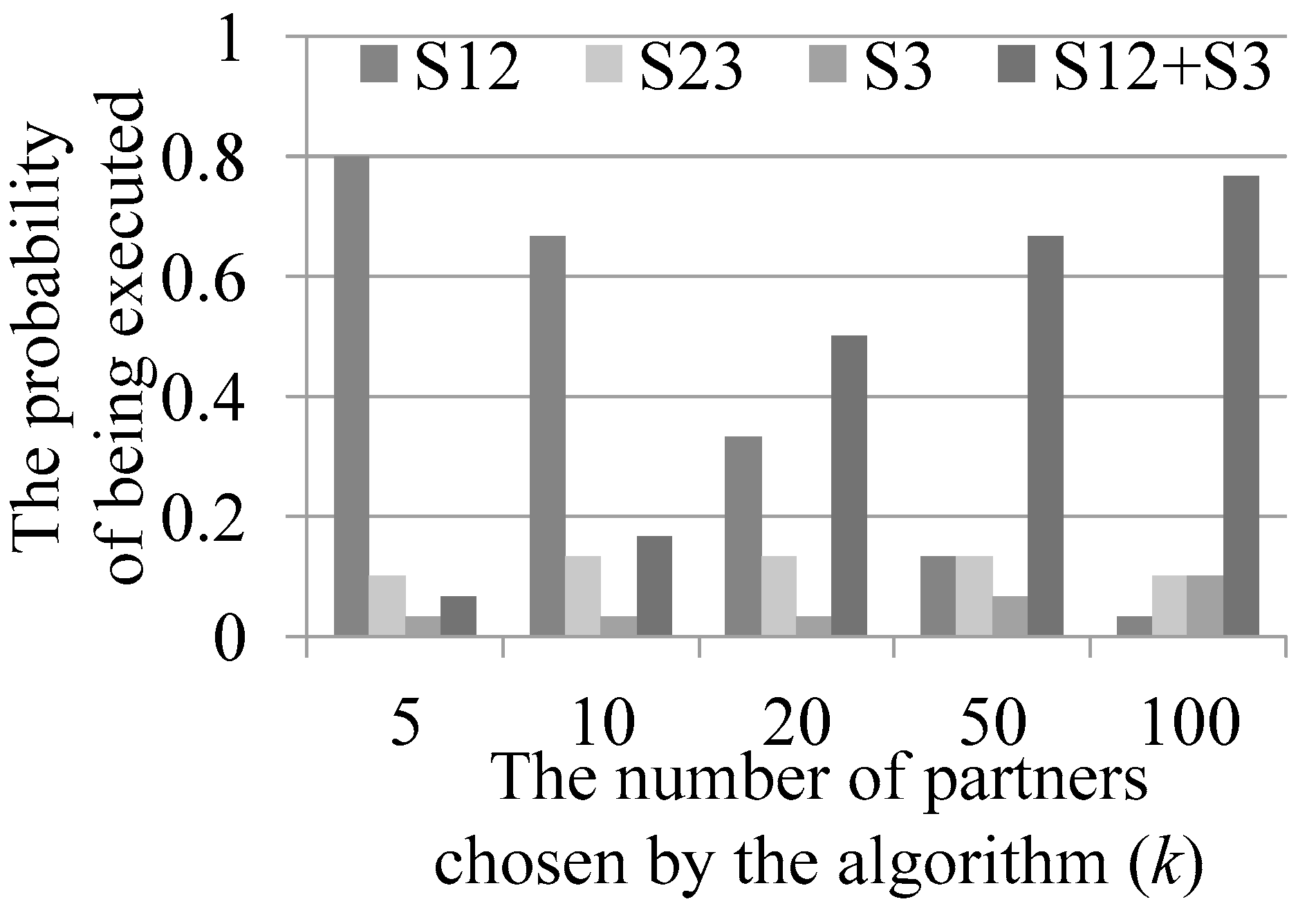
5.2.2. Probability of Each Strategy Combination Being Executed During Queries
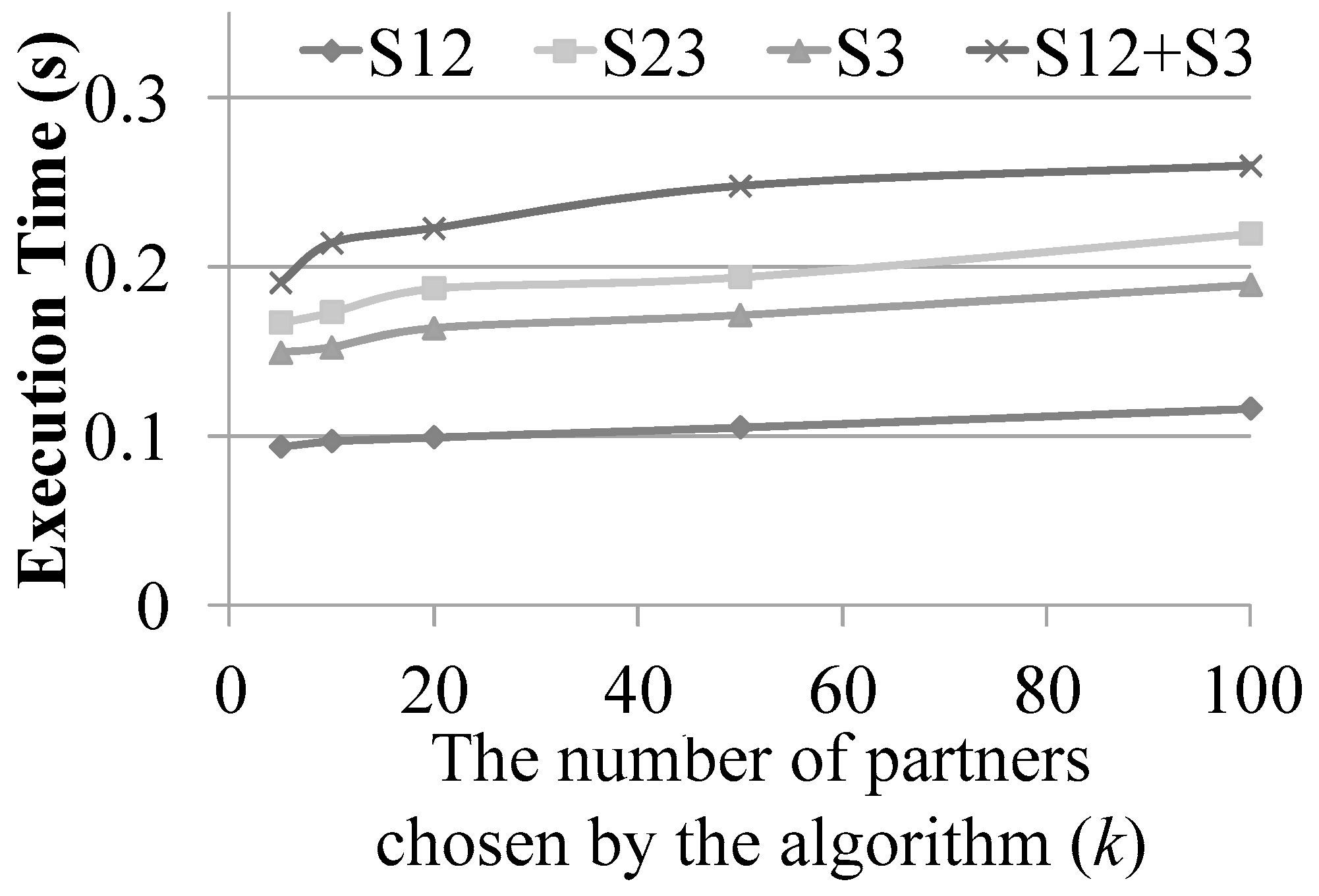
5.2.3. Execution Time of Algorithm Using Various Strategy Combinations
5.3. Performance Comparison with Baseline Algorithm and Other Relevant Algorithms
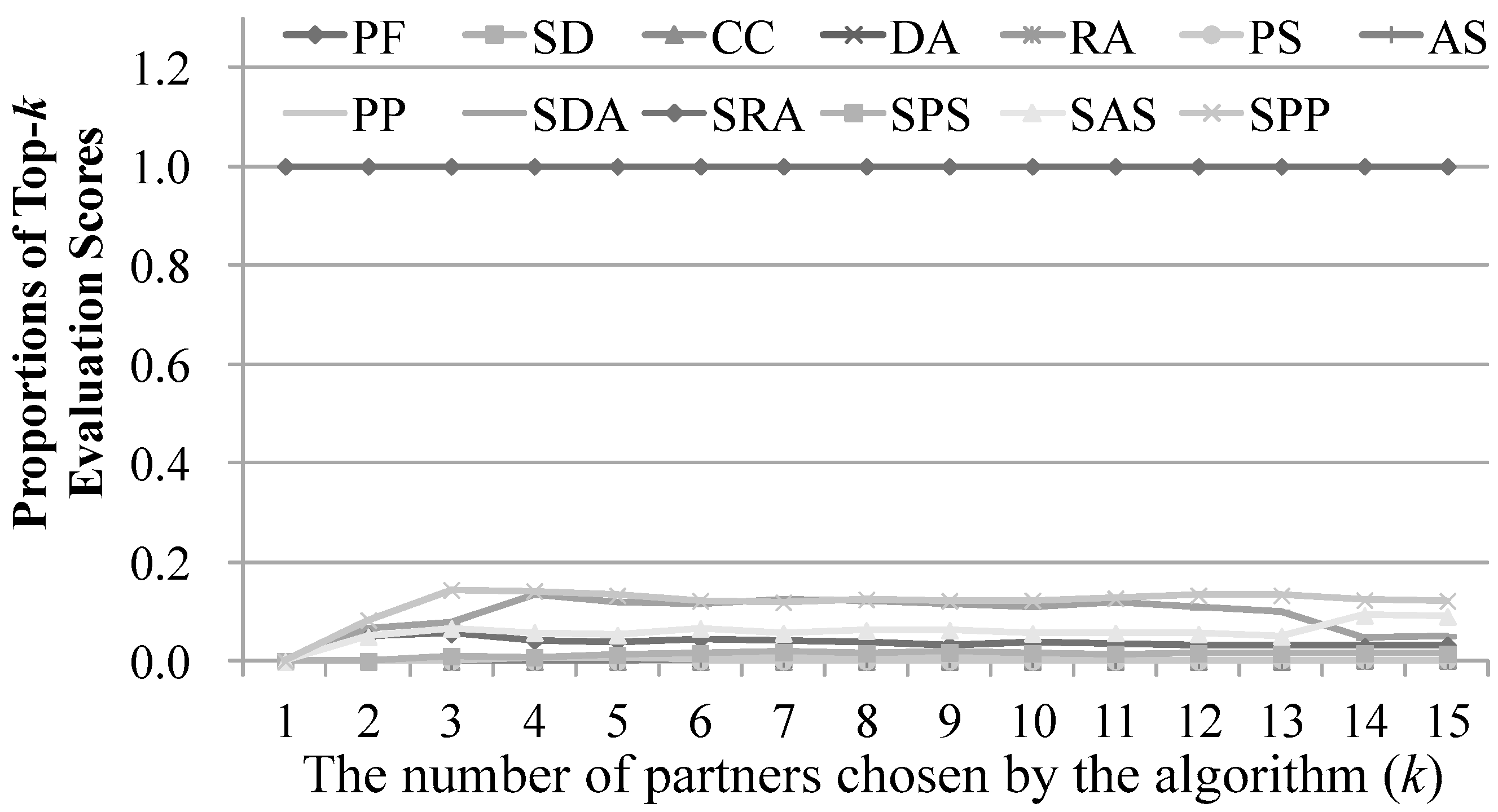
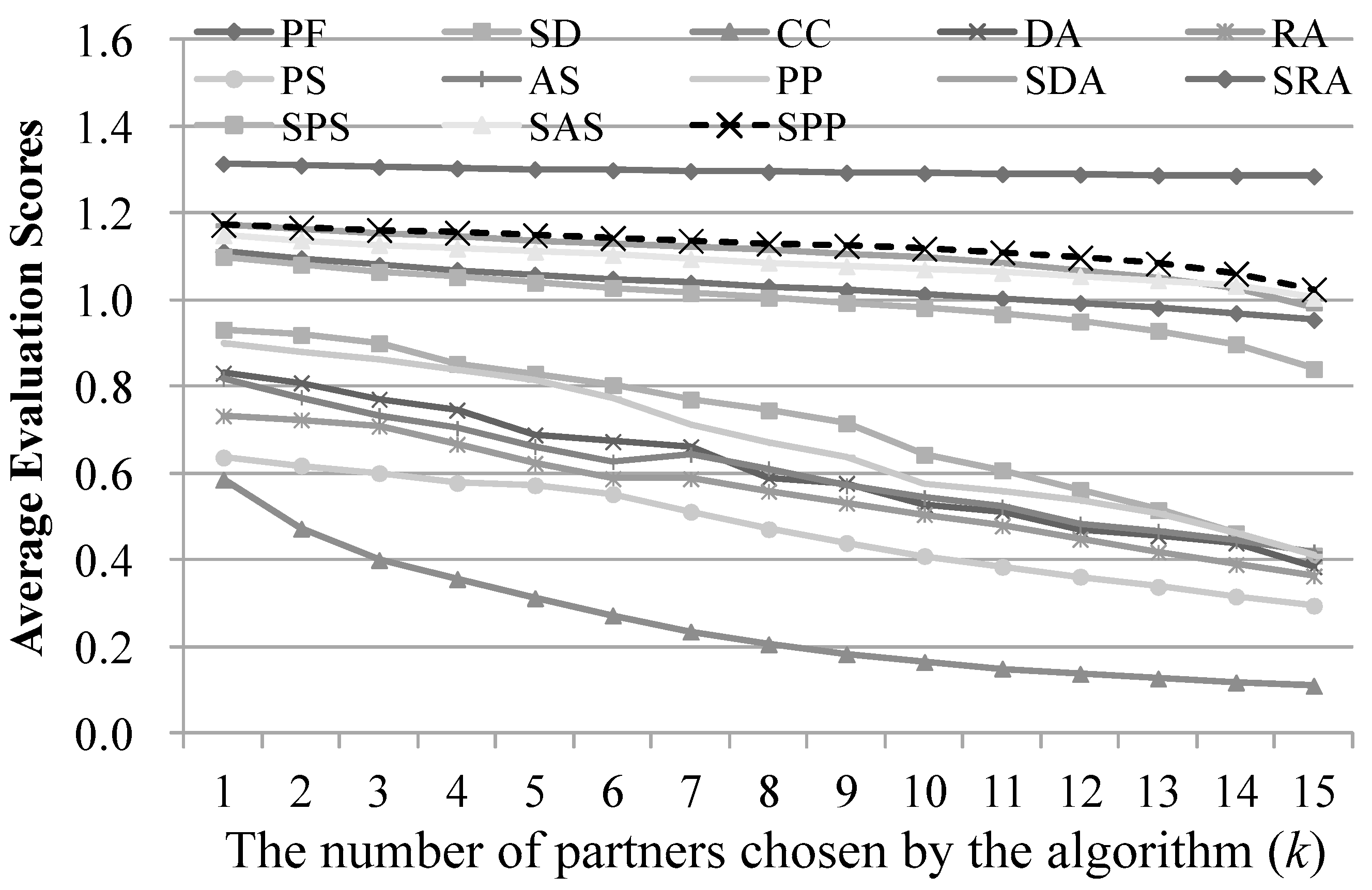
5.3.1. Relevance of Results to Query POI q
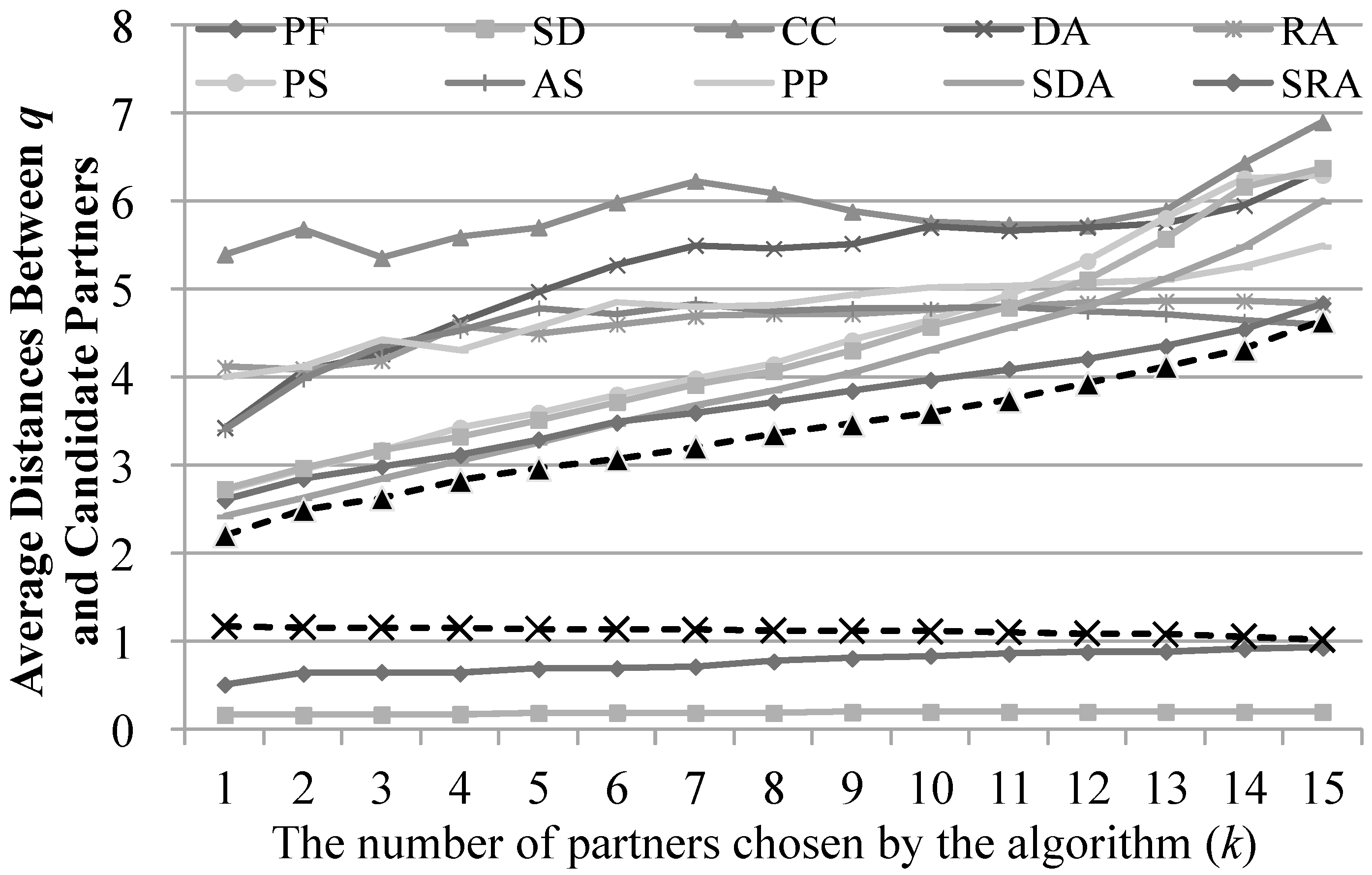
5.3.2. Average Distance between q and Identified Partners
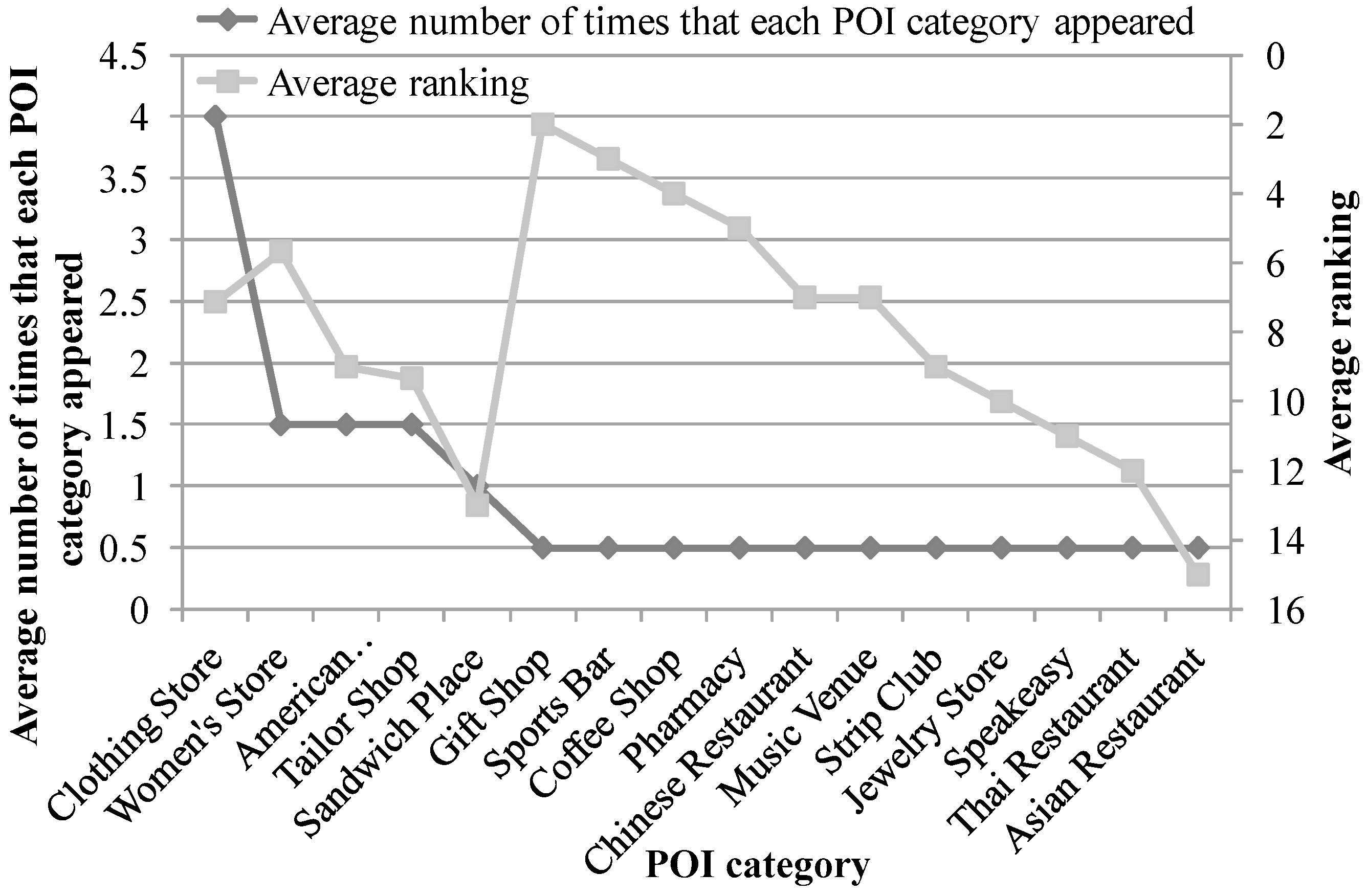
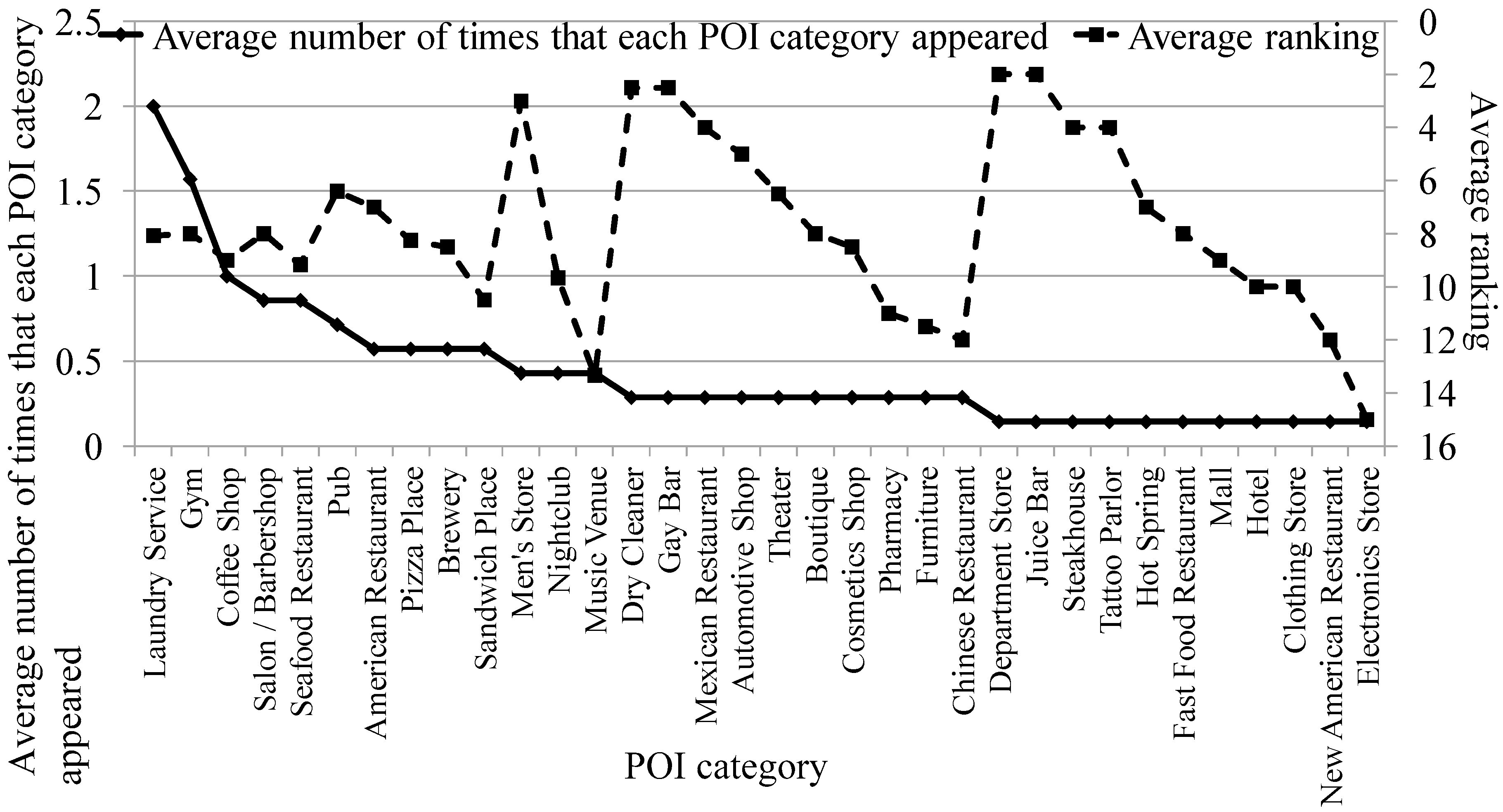
5.4. Case Study to Verify Accuracy of Our Algorithm
5.5. Discussion of Experiment Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hartnett, R. Small Business, Big Opportunity: Winning the Right Customers through Smart Marketing and Advertising, 2nd ed.; Sensis: Melbourne, Australia, 2008. [Google Scholar]
- Varadarajan, P.R. Joint sales promotion: An emerging marketing tool. Bus. Horiz. 1985, 28, 43–49. [Google Scholar] [CrossRef]
- Varadarajan, P.R. Horizontal Cooperative Sales Promotion: A Framework for Classification and Additional Perspectives. J. Mark. 1986, 50, 61–73. [Google Scholar] [CrossRef]
- Huang, H.C.; Chang, Y.T.; Yeh, C.Y.; Liao, C.W. Promote the price promotion: The effects of price promotions on customer evaluations in coffee chain stores. Int. J. Contemp. Hosp. Manag. 2014, 26, 1065–1082. [Google Scholar] [CrossRef]
- Kim, W.G.; Lee, S.; Lee, H.Y. Co-Branding and Brand Loyalty. J. Qual. Assur. Hosp. Tour. 2007, 8, 1–23. [Google Scholar] [CrossRef]
- Chen, H.L.; Huang, Y. The Establishment of Global Marketing Strategic Alliances by Small and Medium Enterprises. Small Bus. Econ. 2004, 22, 365–377. [Google Scholar] [CrossRef]
- Abowd, G.D.; Atkeson, C.G.; Hong, J.; Long, S.; Kooper, R.; Pinkerton, M. Cyberguide: A mobile context-aware tour guide. Wirel. Netw. 1997, 3, 421–433. [Google Scholar] [CrossRef]
- Ye, M.; Yin, P.; Lee, W.C.; Lee, D.L. Exploiting geographical influence for collaborative point-of-interest recommendation. In Proceedings of the International Conference on Research and Development in Information Retrieval (SIGIR), Beijing, China, 24–28 July 2011; pp. 325–334. [Google Scholar]
- Bao, J.; Zheng, Y.; Mokbel, M.F. Location-based and preference-aware recommendation using sparse geo-social networking data. In Proceedings of the International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 6–9 November 2012; pp. 199–208. [Google Scholar]
- Logesh, R.; Subramaniyaswamy, V.; Vijayakumar, V.; Li, X. Efficient user profiling based intelligent travel recommender system for individual and group of users. Mob. Netw. Appl. 2019, 24, 1018–1033. [Google Scholar] [CrossRef]
- Huang, H.H.; Chiu, S.M.; Chen, Y.C.; Lee, C. Group trip recommendation systems. Adv. Intell. Syst. Comput. 2019, 886, 391–412. [Google Scholar]
- Zheng, Y.; Zhang, L.; Xie, X.; A, W.Y.M. Mining interesting locations and travel sequences from gps trajectories. In Proceedings of the International Conference on World Wide Web, Madrid, Spain, 13–14 January 2009; pp. 791–800. [Google Scholar]
- DeScioli, P.; Kurzban, R.; Koch, E.N.; Liben-Nowell, D. Best friends: Alliances, friend ranking, and the myspace social network. Perspect. Psychol. Sci. 2011, 6, 6–8. [Google Scholar] [CrossRef]
- Zhu, J.; Wang, C.; Guo, X.; Ming, Q.; Li, J.; Liu, Y. Friend and POI recommendation based on social trust cluster in location-based social networks. EURASIP J. Wirel. Commun. Netw. 2019, 1, 89. [Google Scholar] [CrossRef]
- Chen, Y.C.; Li, C.T. Finding potential propagators and customers in location-based social networks: An embedding-based approach. Appl. Sci. 2020, 10, 8003. [Google Scholar] [CrossRef]
- Kumar, M.S.; Narayana, M.S. A Study on Habits and Preferences of Customers towards Shopping at Modern Retail Stores. Glob. J. Commer. Manag. Perspect. 2018, 7, 7–14. [Google Scholar]
- Aaker, D.A.; Keller, K.L. Consumer Evaluations of Brand Extensions. J. Mark. 1990, 54, 27–41. [Google Scholar] [CrossRef]
- Yin, D.; Mitra, S.; Zhang, H. Research Note—When Do Consumers Value Positive vs. Negative Reviews? An Empirical Investigation of Confirmation Bias in Online Word of Mouth. Inf. Syst. Res. 2016, 27, 131–144. [Google Scholar] [CrossRef]
- Goldsmith, R.; Flynn, L.; Kim, D. Status Consumption and Price Sensitivity. J. Mark. Theory Pract. 2010, 18, 323–338. [Google Scholar] [CrossRef]
- Hakim, T.; Almahdi, H.K. Impact of Proximity Marketing Devices on Buying Decision-strategical Approach by Small and Medium Size Retail Entrepreneurs. J. Manag. Inf. Decis. Sci. 2020, 23, 187–198. [Google Scholar]
- Narasimhan, C. Competitive Promotional Strategies. J. Bus. 1988, 61, 427–449. [Google Scholar] [CrossRef]
- Instagram. Available online: https://www.instagram.com/ (accessed on 29 October 2020).
- Twitter. Available online: https://twitter.com/ (accessed on 29 October 2020).
- Facebook. Available online: https://www.facebook.com/ (accessed on 29 October 2020).
- Flickr. Available online: https://www.flickr.com/ (accessed on 29 October 2020).
- Dataset Information of Gowalla. Available online: https://snap.stanford.edu/data/loc-gowalla.html// (accessed on 29 October 2020).
- Foursquare. Available online: https://foursquare.com/ (accessed on 29 October 2020).
- Gan, M.; Gao, L. Discovering memory-based preferences for POI recommendation in location-based social networks. ISPRS Int. J. Geo-Inf. 2019, 8, 279. [Google Scholar] [CrossRef]
- Naserian, E.; Wang, X.; Dahal, K.; Alcaraz-Calero, J.M.; Gao, H. A partition-based partial personalized model for points of interest recommendations. IEEE Trans. Comput. Soc. Syst. 2020, Accepted. [Google Scholar]
- Cao, K.; Guo, J.; Meng, G.; Liu, H.; Liu, Y.; Li, G. Points-of-interest recommendation algorithm based on LSBN in edge computing environment. IEEE Access 2020, 8, 47973–47983. [Google Scholar] [CrossRef]
- Jiao, X.; Xiao, Y.; Zheng, W.; Wang, H.; Hsu, C.H. A novel next new point-of-interest recommendation system based on simulated user travel decision-making process. Future Gener. Comput. Syst. 2019, 100, 982–993. [Google Scholar] [CrossRef]
- Kang, L.; Liu, S.; Gong, D.; Tang, M. A personalized point-of-interest recommendation system for O2O commerce. Electron. Mark. 2020, Accepted. [Google Scholar] [CrossRef]
- Wei, H.; Zhang, H. Research on hybrid recommendation algorithm for integrating consumption habits in LSBN. In Proceedings of the International Conference on Machine Learning and Computing, Shenzhen, China, 15–17 February 2020; pp. 188–192. [Google Scholar]
- Pan, H.; Zhang, Z. Research on context-awareness mobile tourism e-commerce personalized recommendation model. J. Signal Process. Syst. 2019. [Google Scholar] [CrossRef]
- Bian, L.; Holtzman, H. Online friend recommendation through personality matching and collaborative filtering. In Proceedings of the International Conference on Mobile Ubiquitous Computing, Systems, Services and Technologies, Lisbon, Portugal, 20–25 November 2011; pp. 230–235. [Google Scholar]
- Chen, W.; Fong, S. Social network collaborative filtering framework and online trust factors: A case study on Facebook. Int. J. Web Appl. 2011, 3, 17–28. [Google Scholar]
- Clements, M.; Serdyukov, P.; de Vries, A.P.; Reinders, M.J.T. Using flickr geotags to predict user travel behavior. In Proceedings of the International Conference on ACM SIGIR on Research and Development in Information Retrieval, Geneva, Switzerland, 19–23 July 2010; pp. 851–852. [Google Scholar]
- Singh, T.; Nayyar, A.; Solanki, A. Multilingual opinion mining movie recommendation system using RNN. In Proceedings of the International Conference on Computing, Communications, and Cyber-Security (IC4S), Chandigarh, India, 12–13 October 2019; pp. 589–605. [Google Scholar]
- Vesdapunt, N.; Garcia-Molina, H. Identifying users in social networks with limited information. In Proceedings of the 2015 IEEE 31st International Conference on Data Engineering, Seoul, South Korea, 13–17 April 2015. [Google Scholar] [CrossRef]
- Vicente, M.; Batista, F.; Carvalho, J.P. Gender detection of twitter users based on multiple information sources. Stud. Comput. Intell. 2018, 794, 39–54. [Google Scholar]
- Vesdapunt, N. Entity Resolution and Tracking on Social Networks. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2016. [Google Scholar]
- Asukai, S.; Yamamoto, K. A recommendation system regarding meeting places for groups during events. ISPRS Int. J. Geo-Inf. 2018, 7, 296. [Google Scholar] [CrossRef]
- Carta, S.; Podda, A.S.; Recupero, D.R.; Saia, R.; Usai, G. Popularity prediction of instagram posts. Information 2020, 11, 453. [Google Scholar] [CrossRef]
- Guo, D.; Xu, J.; Zhang, J.; Xu, M.; Cuia, Y.; He, X. User relationship strength modeling for friend recommendation on Instagram. Neurocomputing 2017, 239, 9–18. [Google Scholar] [CrossRef]
- Tiwari, P.; Pandey, H.M.; Khamparia, A.; Kumar, S. Twitter-based opinion mining for flight service utilizing machine learning. Informatica 2019, 43, 381–386. [Google Scholar] [CrossRef]
- Bao, J.; Zheng, Y.; Wilkie, D.; Mokbel, M. Recommendations in location-based social networks: A survey. GeoInformatica 2015, 19, 525–565. [Google Scholar] [CrossRef]
- Horozov, T.; Narasimhan, N.; Vasudevan, V. Using location for personalized POI recommendations in mobile environments. In Proceedings of the International Symposium on Applications and the Internet (SAINT), Phoenix, AZ, USA, 23–27 January 2006; pp. 124–129. [Google Scholar]
- Salter, J.; Antonopoulos, N. CinemaScreen Recommender Agent: Combining Collaborative and Content-Based Filtering. IEEE Trans. Intell. Syst. 2006, 21, 35–41. [Google Scholar] [CrossRef]
- Barranco, M.J.; Martínez, L. A method for weighting multi-valued features in content-based ltering. In Proceedings of the International Conference on Industrial Engineering and Other Applications of Applied Intelligent Systems, Córdoba, Spain, 1–4 June 2010; pp. 409–418. [Google Scholar]
- Arase, Y.; Xie, X.; Hara, T.; Nishio, S. Mining people’s trips from large scale geo-tagged photos. In Proceedings of the International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 133–142. [Google Scholar]
- Ying, J.J.C.; Lu, E.H.C.; Kuo, W.N.; Tseng, V.S. Urban point-of-interest recommendation by mining user check-in behaviors. In Proceedings of the International Workshop on Urban Computing, Beijing, China, 12 August 2012; pp. 63–70. [Google Scholar]
- Levandoski, J.J.; Sarwat, M.; Eldawy, A.; Mokbel, M.F. Lars: A location-aware recommender system. In Proceedings of the International Conference on Data Engineering (ICDE), Arlington, VA, USA, 1–5 April 2012; pp. 450–461. [Google Scholar]
- Liu, Q.; Chen, E.; Xiong, H.; Ge, Y.; Li, Z.; Wu, X. A cocktail approach for travel package recommendation. IEEE. Trans. Knowl. Data Eng. 2014, 26, 278–293. [Google Scholar] [CrossRef]
- Xie, M.; Lakshmanan, L.V.; Wood, P.T. ComPrec-Trip: A composite recommendation system for travel planning. In Proceedings of the International Conference on Data Engineering, Hannover, Germany, 11–16 April 2011; pp. 1352–1355. [Google Scholar]
- Hsieh, H.P.; Li, C.T.; Lin, S.D. TripRec: Recommending trip routes from large scale check-in data. In Proceedings of the International Conference on World Wide Web, Lyon France, 16–20 April 2012; pp. 529–530. [Google Scholar]
- Sang, J.; Mei, T.; Sun, J.T.; Xu, C.; Li, S. Probabilistic sequential pois recommendation via check-in data. In Proceedings of the International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 6–9 November 2012; pp. 402–405. [Google Scholar]
- Lu, E.H.C.; Chen, C.Y.; Tseng, V.S. Personalized trip recommendation with multiple constraints by mining user check-in behaviors. In Proceedings of the International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 6–9 November 2012; pp. 209–218. [Google Scholar]
- Chiang, H.S.; Huang, T.C. User-adapted travel planning system for personalized schedule recommendation. Inf. Fusion 2015, 21, 3–17. [Google Scholar] [CrossRef]
- Hosseini, S.; Li, L.T. Point-Of-Interest Recommendation Using Temporal Orientations of Users and Locations. In Proceedings of the International Conference on Database Systems for Advanced Applications (DASFAA), Dallas, TX, USA, 16–19 April 2016; pp. 330–347. [Google Scholar]
- Hosseini, S.; Yin, H.; Zhou, X.; Sadiq, S.; R, M.; Kangavari, M.R.; Cheung, N.M. Leveraging multi-aspect time-related influence in location recommendation. World Wide Web 2019, 22, 1001–1028. [Google Scholar] [CrossRef]
- Meng, S.; Wang, H.; Li, Q.; Luo, Y.; Dou, W.; Wan, S. Spatial-Temporal Aware Intelligent Service Recommendation Method Based on Distributed Tensor factorization for Big Data Applications. IEEE Access 2018, 6, 59462–59474. [Google Scholar] [CrossRef]
- Cai, L.; Xu, J.; Liu, J.; Pei, T. Integrating spatial and temporal contexts into a factorization model for POI recommendation. Int. J. Geogr. Inf. Sci. 2018, 32, 524–546. [Google Scholar] [CrossRef]
- Ying, Y.; Chen, L.; Chen, G. A temporal-aware POI recommendation system using context-aware tensor decomposition and weighted HITS. Neurocomputing 2017, 242, 195–205. [Google Scholar] [CrossRef]
- Zheng, X.; Luo, Y.; Sun, L.; Zhang, J.; Chen, F. A tourism destination recommender system using users’ sentiment and temporal dynamics. J. Intell. Inf. Syst. 2018, 51, 557–578. [Google Scholar] [CrossRef]
- Mukasa, Y.; Yamamoto, K. A sightseeing spot recommendation system for urban smart tourism based on users’ priority conditions. J. Civ. Eng. Archit. 2019, 13, 622–640. [Google Scholar] [CrossRef]
- Su, C.; Chen, Y.; Xie, X. Location recommendation with privacy protection. In Proceedings of the International Conference on Intelligent Systems, Metaheuristics & Swarm Intelligence, Male, Maldives, 23–24 March 2019; pp. 83–91. [Google Scholar]
- Huo, Y.; Chenad, B.; Tang, J.; Zeng, Y. Privacy-preserving point-of-interest recommendation based on geographical and social influence. Inf. Sci. 2021, 543, 202–218. [Google Scholar] [CrossRef]
- Li, W.; Liu, X.; Yan, C.; Ding, G.; Sun, Y.; Zhang, J. STS: Spatial–temporal–semantic personalized location recommendation. ISPRS Int. J. Geo-Inf. 2020, 9, 538. [Google Scholar] [CrossRef]
- Wang, W.; Chen, J.; Wang, J.; Chen, J.; Liu, J.; Gong, Z. Trust-enhanced collaborative filtering for personalized point of interests recommendation. IEEE Trans. Ind. Inform. 2019, 16, 6124–6132. [Google Scholar] [CrossRef]
- Mehmood, F.; Ahmad, S.; Kim, D.H. Design and development of a real-time optimal route recommendation system using big data for tourists in jeju island. Electronics 2019, 8, 506. [Google Scholar] [CrossRef]
- Guo, Q. Graph-based point-of-interest recommendation on location-based social networks. Ph.D. Thesis, Nanyang Technological University, Singapore, 2019. [Google Scholar]
- Bin, C.; Gu, T.; Sun, Y.; Chang, L. A personalized POI route recommendation system based on heterogeneous tourism data and sequential pattern mining. Multimed. Tools Appl. 2019, 78, 35135–35156. [Google Scholar] [CrossRef]
- Yang, Y.; Pan, X.; Yao, X.; Wang, S.; Han, L. PHR: A personalized hidden route recommendation system based on hidden markov model. In Proceedings of the Asia-Pacific Web and Web-Age Information Management Joint International Conference on Web and Big Data, Tianjin, China, 12–14 August 2020; pp. 535–539. [Google Scholar]
- Gao, Y.; Duan, Z.; Shi, W.; Feng, J.; Chiang, Y.Y. Personalized recommendation method of POI based on deep neural network. In Proceedings of the International Conference on Behavioral, Economic and Socio-Cultural Computing, Beijing, China, 28–30 October 2019; pp. 1–6. [Google Scholar]
- Zhang, C.; Li, T.; Gou, Y.; Yang, M. KEAN: Knowledge embedded and attention-based network for POI recommendation. In Proceedings of the IEEE International Conference on Artificial Intelligence and Computer Applications, Dalian, China, 27–29 June 2020. [Google Scholar]
- Liu, C.; Liu, J.; Xu, S.; Wang, J.; Liu, C.; Chen, T.; Jiang, T. A spatiotemporal dilated convolutional generative network for point-of-interest recommendation. ISPRS Int. J. Geo-Inf. 2020, 9, 113. [Google Scholar] [CrossRef]
- Ying, J.J.C.; Lee, W.; Ye, M.; Chen, C.; Tseng, V. User association analysis of locales on location based social networks. In Proceedings of the International Conference on ACM SIGSPATIAL International Workshop on Location-Based Social Networks, Chicago, IL, USA, 1–4 November 2011; pp. 69–76. [Google Scholar]
- Pan, X.; Hu, R.; Li, D. Social-IFD: Personalized influential friends discovery based on semantics in LBSN. In Proceedings of the International Conference on Communications, Dublin, Ireland, 7–11 June 2020. [Google Scholar]
- Xin, M.; Wu, L. Using multi-features to partition users for friends recommendation in location based social network. Inf. Process. Manag. 2020, 57, 102125. [Google Scholar] [CrossRef]
- Luo, C.; Lou, J.G.; Lin, Q.; Fu, Q.; Ding, R.; Zhang, D.; Wang, Z. Correlating events with time series for incident diagnosis. In Proceedings of the International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 1583–1592. [Google Scholar]
- Sarwat, M.; Eldawy, A.; Mokbel, M.F.; Riedl, J. Plutus: Leveraging location-based social networks to recommend potential customers to venues. In Proceedings of the IEEE International Conference on Mobile Data Management (MDM), Milan, Italy, 3–6 June 2013; pp. 26–35. [Google Scholar]
- Deza, M.M.; Deza, E. Dictionary of Distances; Elsevier Science: London, UK, 2006. [Google Scholar]
- Mullin, R. Sales Promotion: How to Create, Implement and Integrate Campaigns That Really Work; Kogan Page Publishers: London, UK, 2010. [Google Scholar]
- Jørgensen, S.; Sigué, S.P. Defensive, offensive, and generic advertising in a lanchester model with market growth. Dyn. Games Appl. 2015, 5, 523–539. [Google Scholar] [CrossRef]
- Lanchester, F.W. Aircraft in Warfare: The Dawn of the Fourth Arm; Constable and company limited: London, UK, 1916. [Google Scholar]
- Pearson, D. The 20 Ps of Marketing: A Complete Guide to Marketing Strategy; Kogan Page Publishers: London, UK, 2013. [Google Scholar]
- Boar, B.H. Constructing Blueprints for Enterprise IT Architectures; John Wiley & Sons, Inc.: New York, NY, USA, 1998. [Google Scholar]
- Sarwat, M.; Levandoski, J.J.; Eldawy, A.; Mokbel, M.F. Lars*: An efficient and scalable location-aware recommender system. IEEE Trans. Knowl. Data Eng. 2014, 26, 1384–1399. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attributes\POIs | o1 | o2 | o3 | |
|---|---|---|---|---|
| Gender | Male | 0.3 | 0.8 | 0.4 |
| Female | 0.7 | 0.2 | 0.6 | |
| Rating | 4(0.8) | 3.5(0.7) | 4.2(0.84) | |
| Total check-in count (unique customers) | 5000(0.25) | 150(0.0075) | 4000(0.2) | |
| Price | 5(0.01) | 500(1) | 3.5(0.007) | |
| Star rating | 0(0) | 5(1) | 0(0) | |
| c v.s. oj\c v.s. oi | Don’t Like oi, [0, 0.33) | Don’t Rule Out oi, [0.33, 0.67) | Like oi, [0.67, 1] |
|---|---|---|---|
| Like oj [0.67, 1] | (1) ≈0% | (2) ≈75% | (3) ≈100% |
| Don’t rule out oj, [0.33, 0.67) | (4) ≈0% | (5) ≈50% | (6) ≈75% |
| Don’t like oj, [0, 0.33) | (7) ≈0% | (8) ≈0% | (9) ≈0% |
| o1 | o2 | o3 | ... | Total | |
|---|---|---|---|---|---|
| c1 | 10 | 0 | 1 | … | 20 |
| c5 | 30 | 3 | 10 | … | 60 |
| c14 | 25 | 5 | 25 | … | 60 |
| c19 | 12 | 0 | 0 | … | 15 |
| Customer ID | Time | Location |
|---|---|---|
| 0005 | 2015/05/06/09:00 | o1 |
| 0421 | 2015/05/06/14:15 | o3 |
| 0005 | 2015/05/06/15:30 | o2 |
| 0005 | 2015/05/06/19:00 | o15 |
| … | … | … |
| 0158 | 2015/06/11 19:00 | o9 |
| Description | Dataset | Description | Dataset |
|---|---|---|---|
| Number of POI check-ins | 155,637 | Time period | 2011/12/08–2012/04/23 |
| Number of paths | 12,574 | Number of categories | 425 |
| Number of users | 81,685 | Distance threshold dt | 20.24 |
| Number of users’ rating | 166,585 | Number of POIs | 7691 |
| Category of Query | Category of Partner | Reference |
|---|---|---|
| Dry Cleaner | Tailor Shop | [1] p. 37 |
| Tailor Shop | Dry Cleaner | [1] p. 37 |
| Nail Salon | Salon/Barbershop | [1] p. 37 |
| Salon/Barbershop | Nail Salon | [1] p. 37 |
| Cosmetics Shop | Nail Salon | [83] p. 238 |
| Nail Salon | Cosmetics Shop | [83] p. 238 |
| Bakery | Coffee shop, Cafe | [83] p. 186 |
| Coffee shop, Cafe | Bakery | [83] p. 186 |
| Coffee shop, Cafe | Dessert Shop, Snack Place | [83] p. 186 |
| Dessert Shop, Snack Place | Coffee shop, Cafe | [83] p. 186 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.-C.; Huang, H.-H.; Chiu, S.-M.; Lee, C. Joint Promotion Partner Recommendation Systems Using Data from Location-Based Social Networks. ISPRS Int. J. Geo-Inf. 2021, 10, 57. https://doi.org/10.3390/ijgi10020057
Chen Y-C, Huang H-H, Chiu S-M, Lee C. Joint Promotion Partner Recommendation Systems Using Data from Location-Based Social Networks. ISPRS International Journal of Geo-Information. 2021; 10(2):57. https://doi.org/10.3390/ijgi10020057
Chicago/Turabian StyleChen, Yi-Chung, Hsi-Ho Huang, Sheng-Min Chiu, and Chiang Lee. 2021. "Joint Promotion Partner Recommendation Systems Using Data from Location-Based Social Networks" ISPRS International Journal of Geo-Information 10, no. 2: 57. https://doi.org/10.3390/ijgi10020057
APA StyleChen, Y.-C., Huang, H.-H., Chiu, S.-M., & Lee, C. (2021). Joint Promotion Partner Recommendation Systems Using Data from Location-Based Social Networks. ISPRS International Journal of Geo-Information, 10(2), 57. https://doi.org/10.3390/ijgi10020057