
Deep Learning for Toponym Resolution: Geocoding Based on Pairs of Toponyms



Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
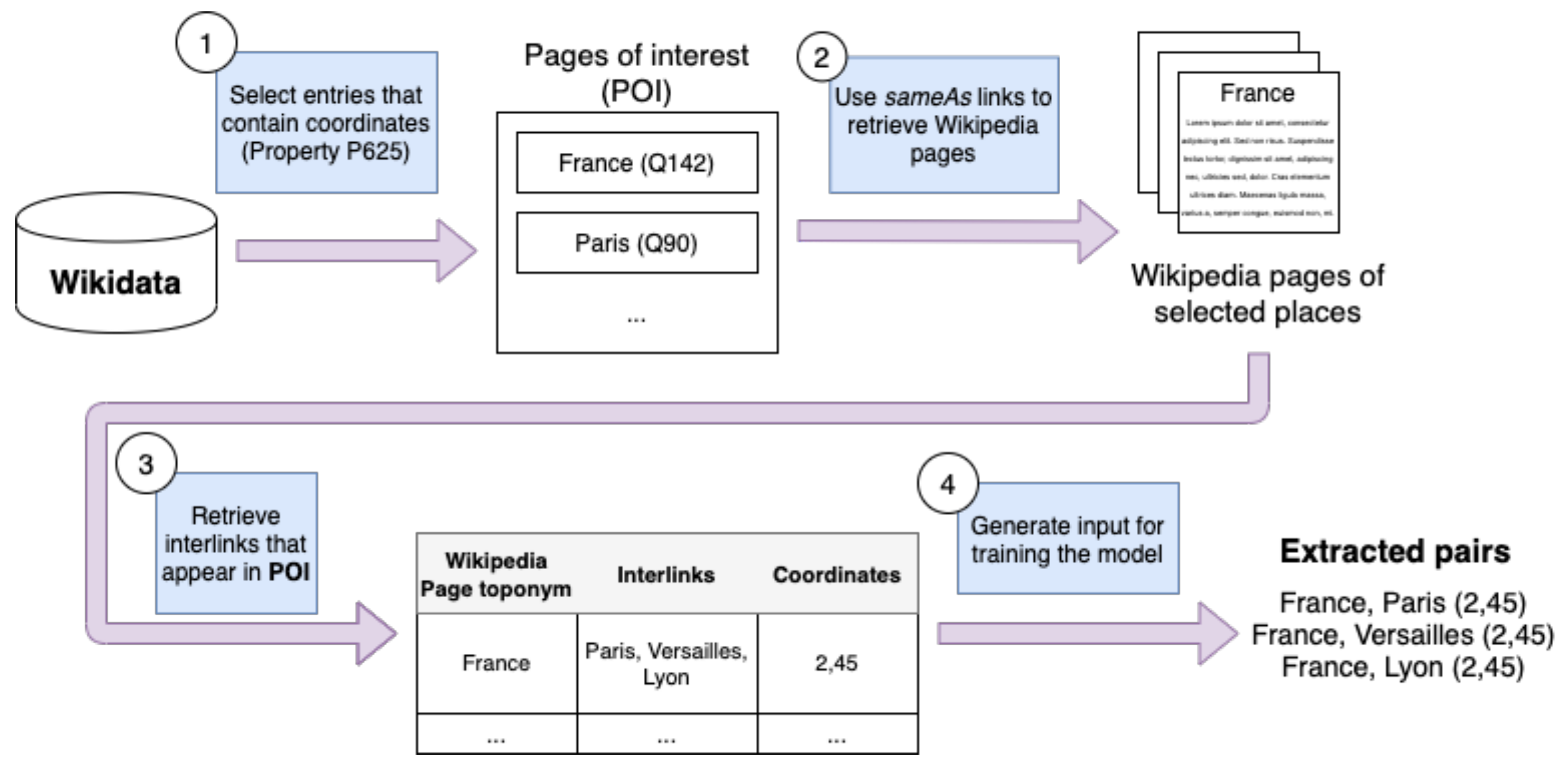
3.1. Process Overview
3.2. Generating Pairs of Toponyms for Training
3.2.1. Textual Context
3.2.2. Spatial Context
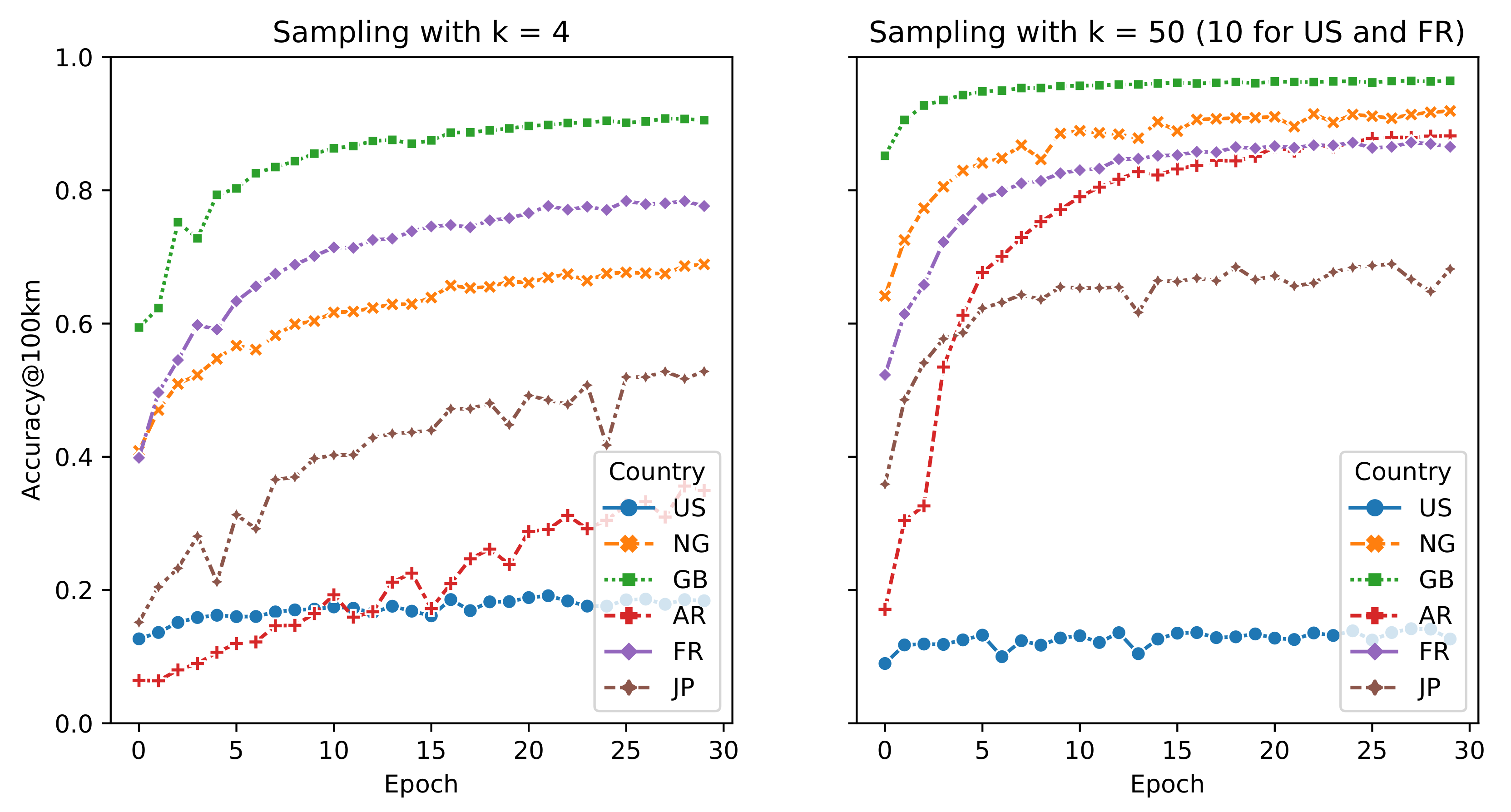
3.2.3. Sampling
3.3. Training/Validation Dataset Generation
4. Model Evaluation
4.1. Datasets
4.2. Evaluation Metrics
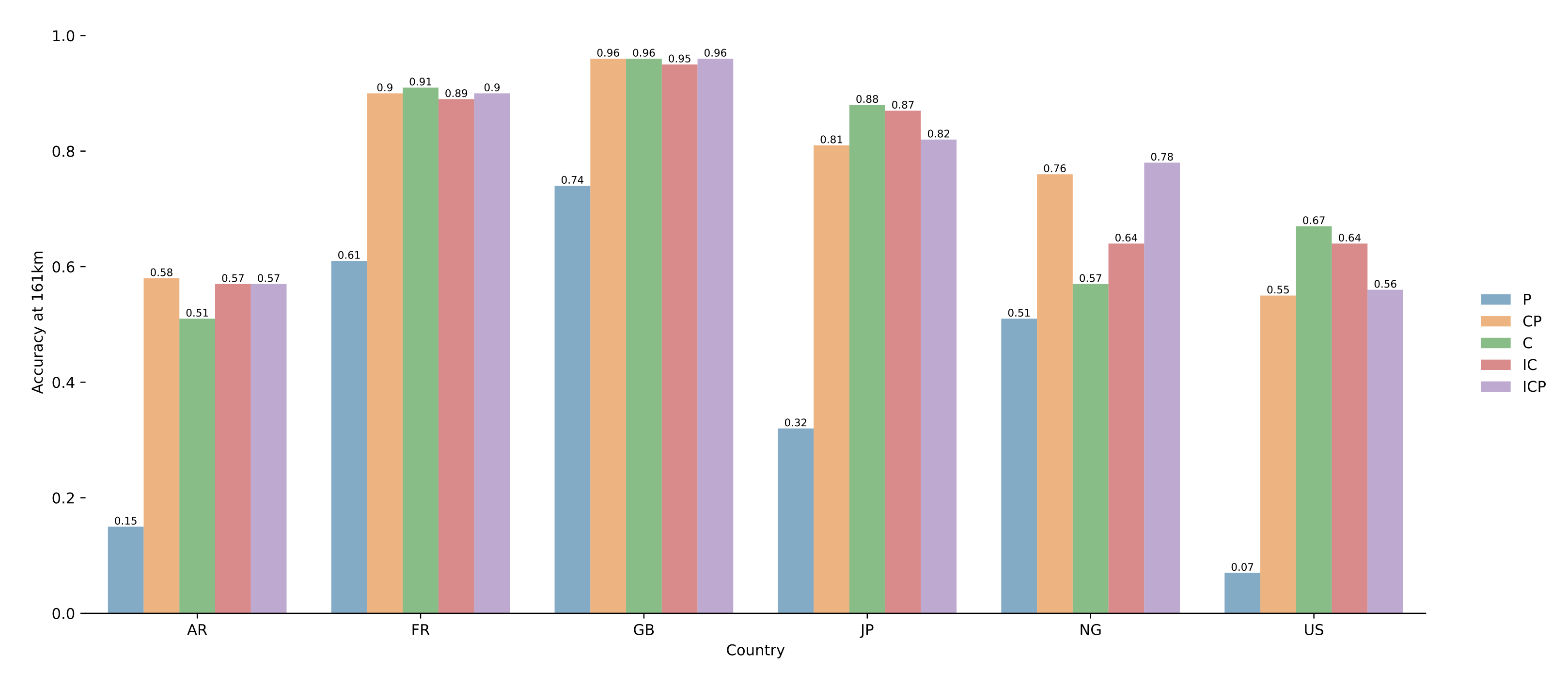
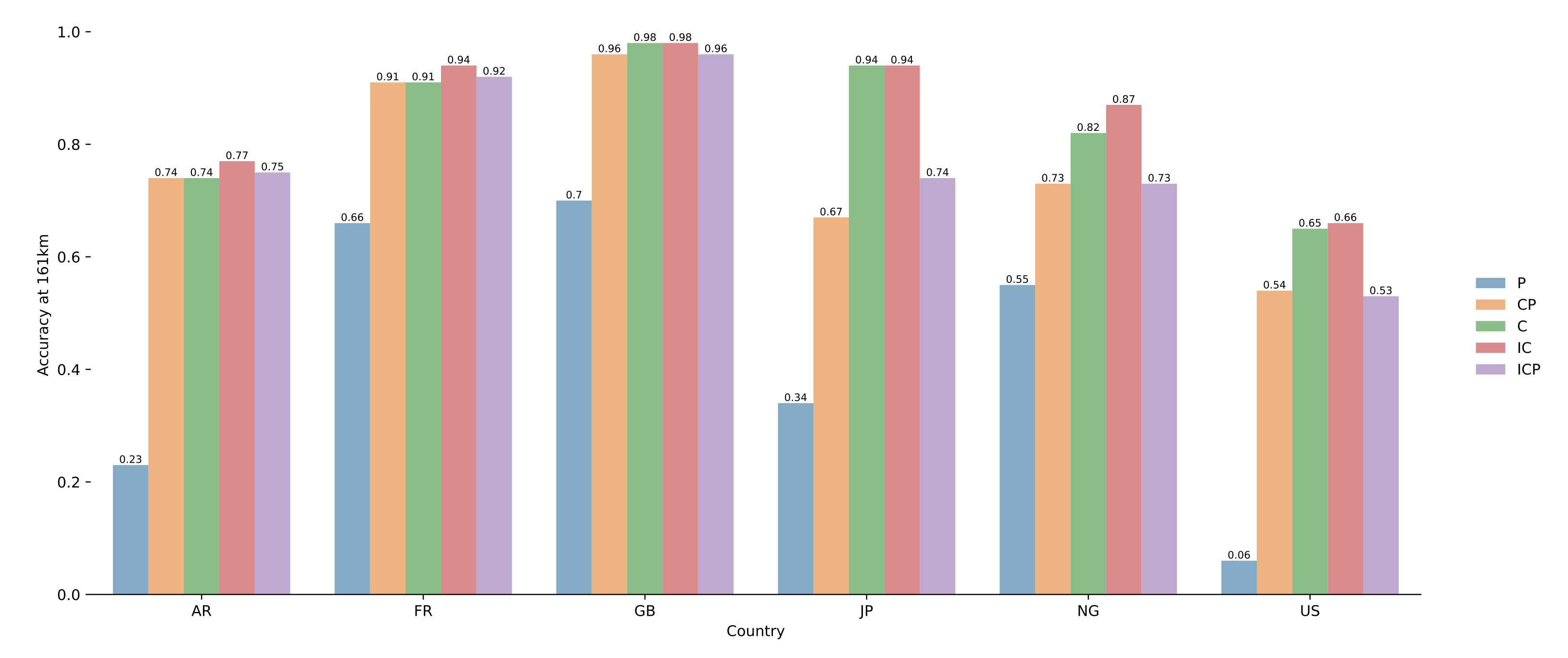
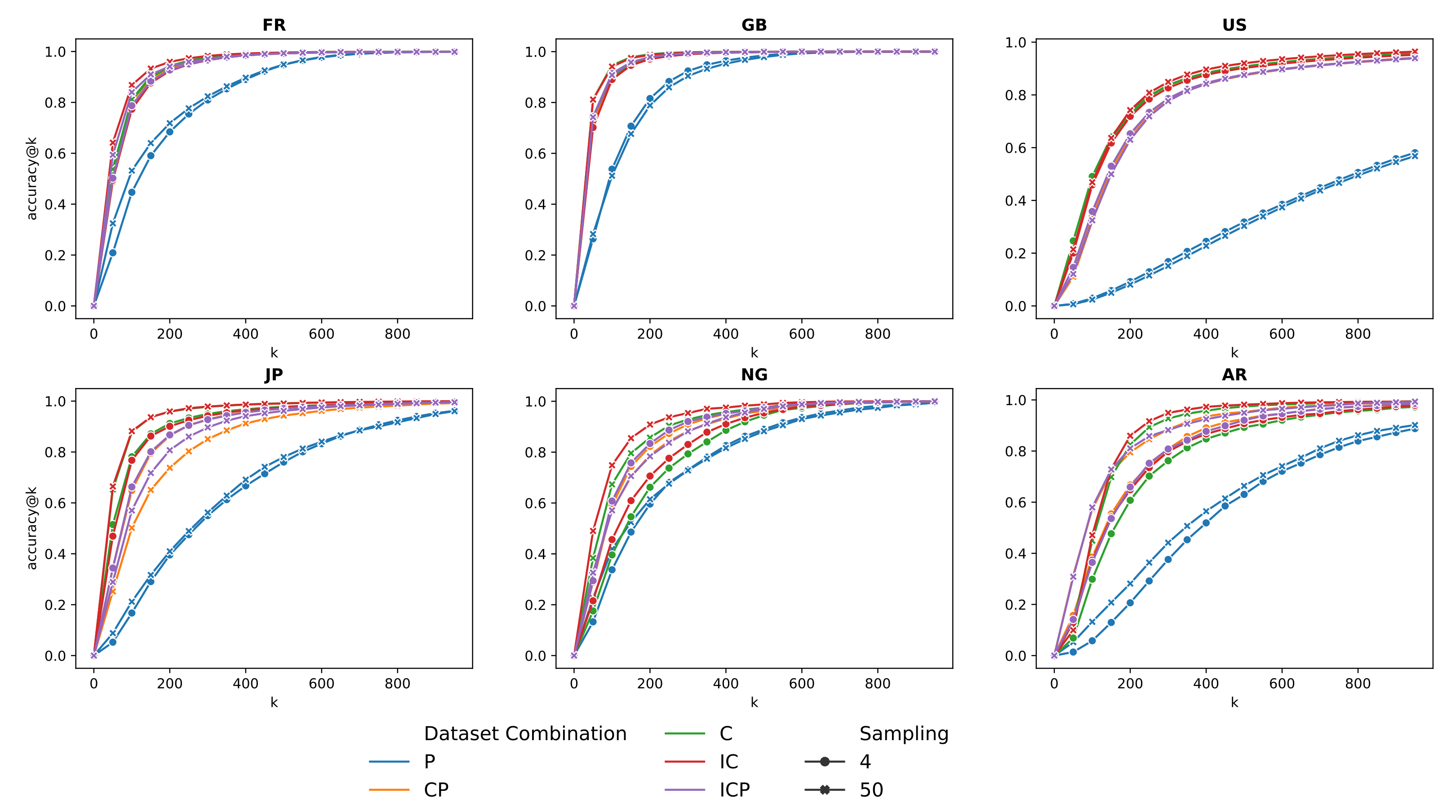
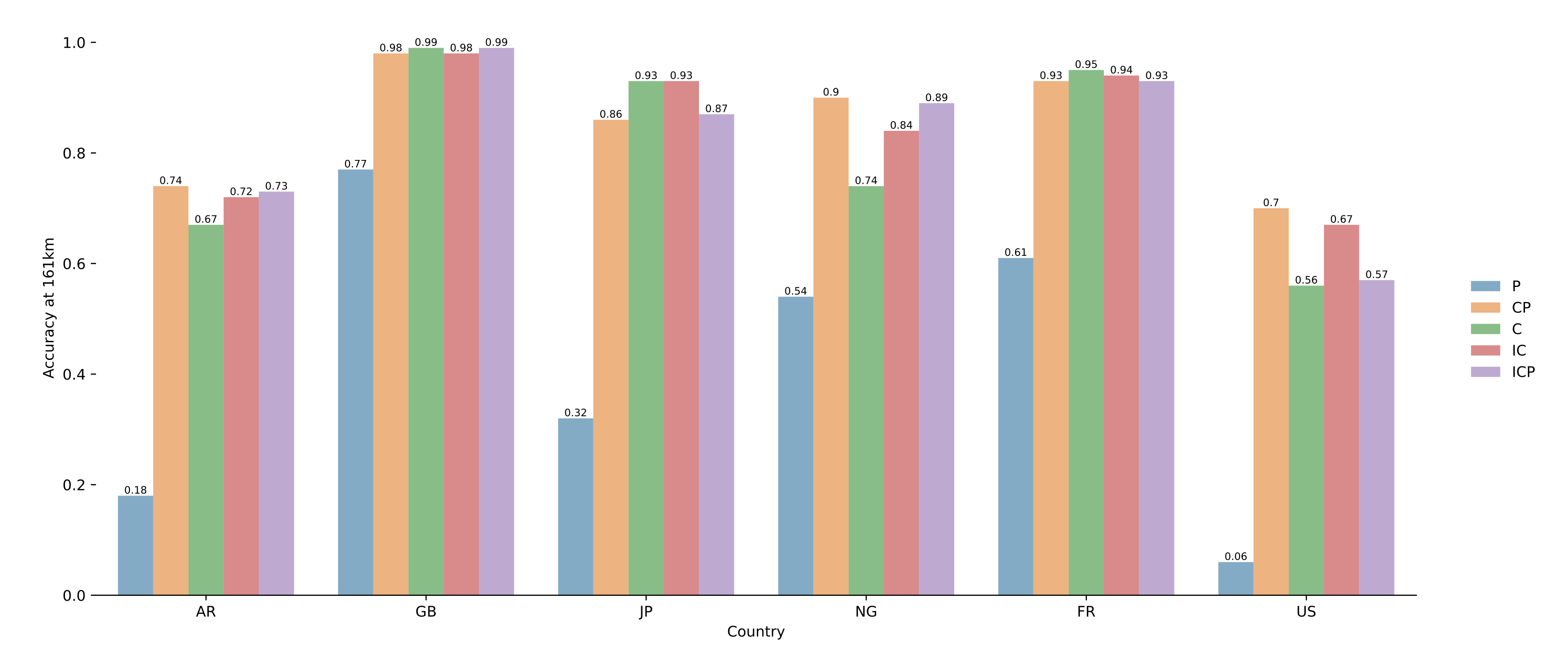
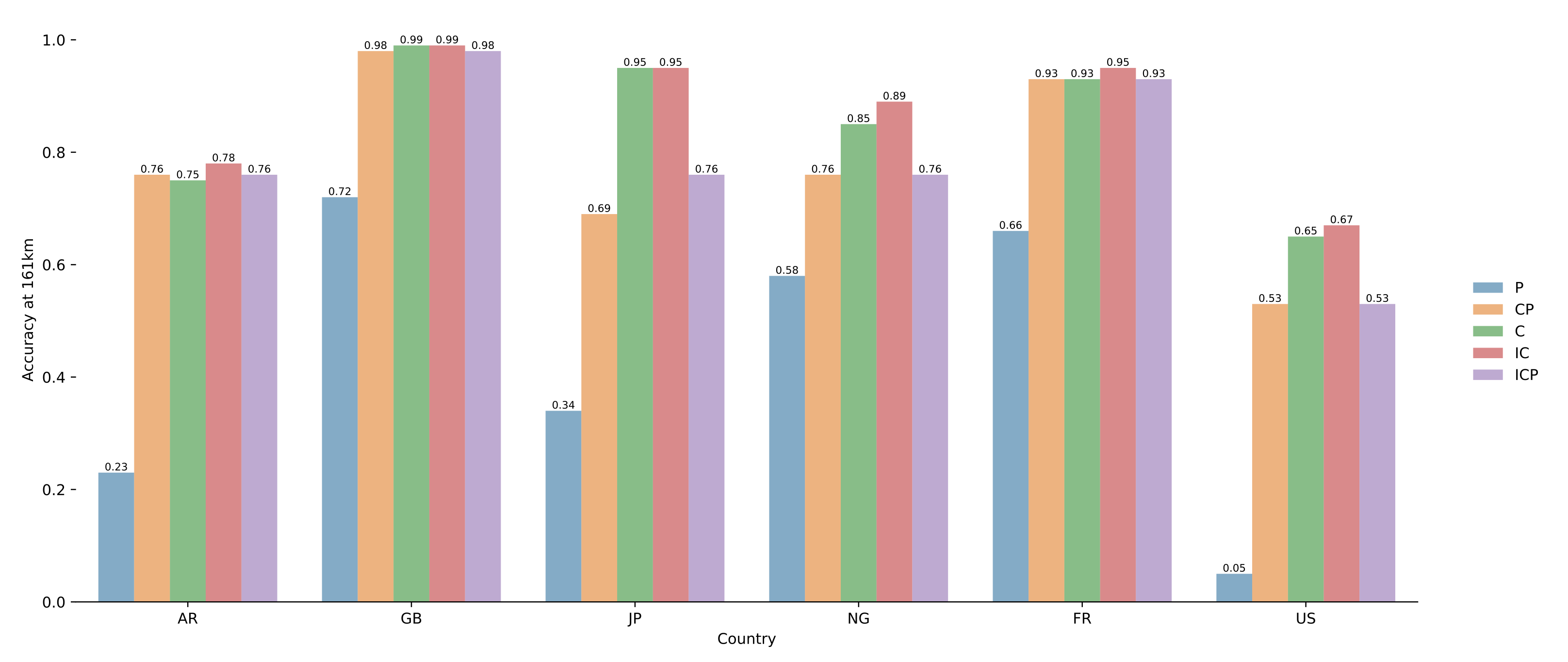
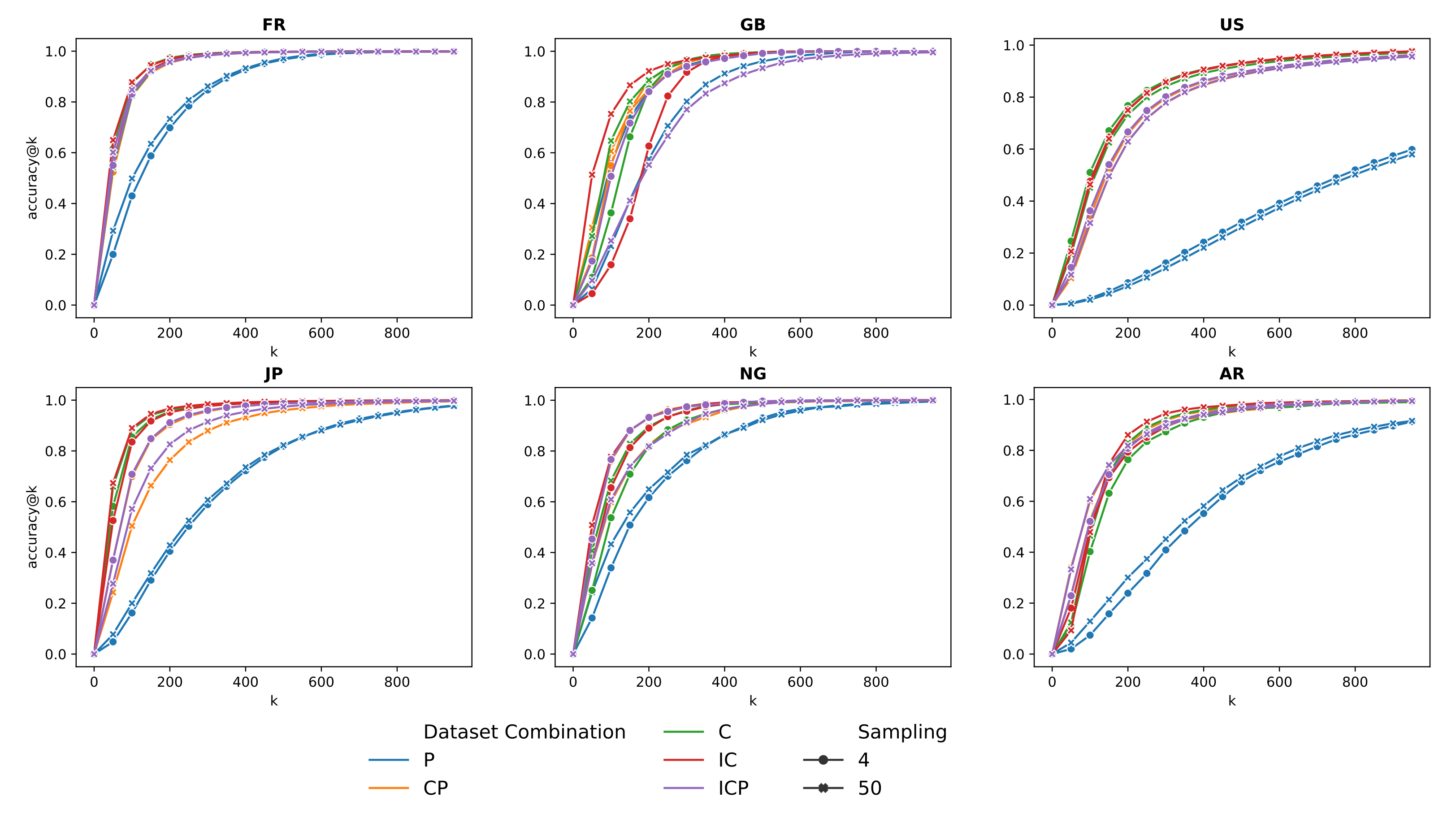
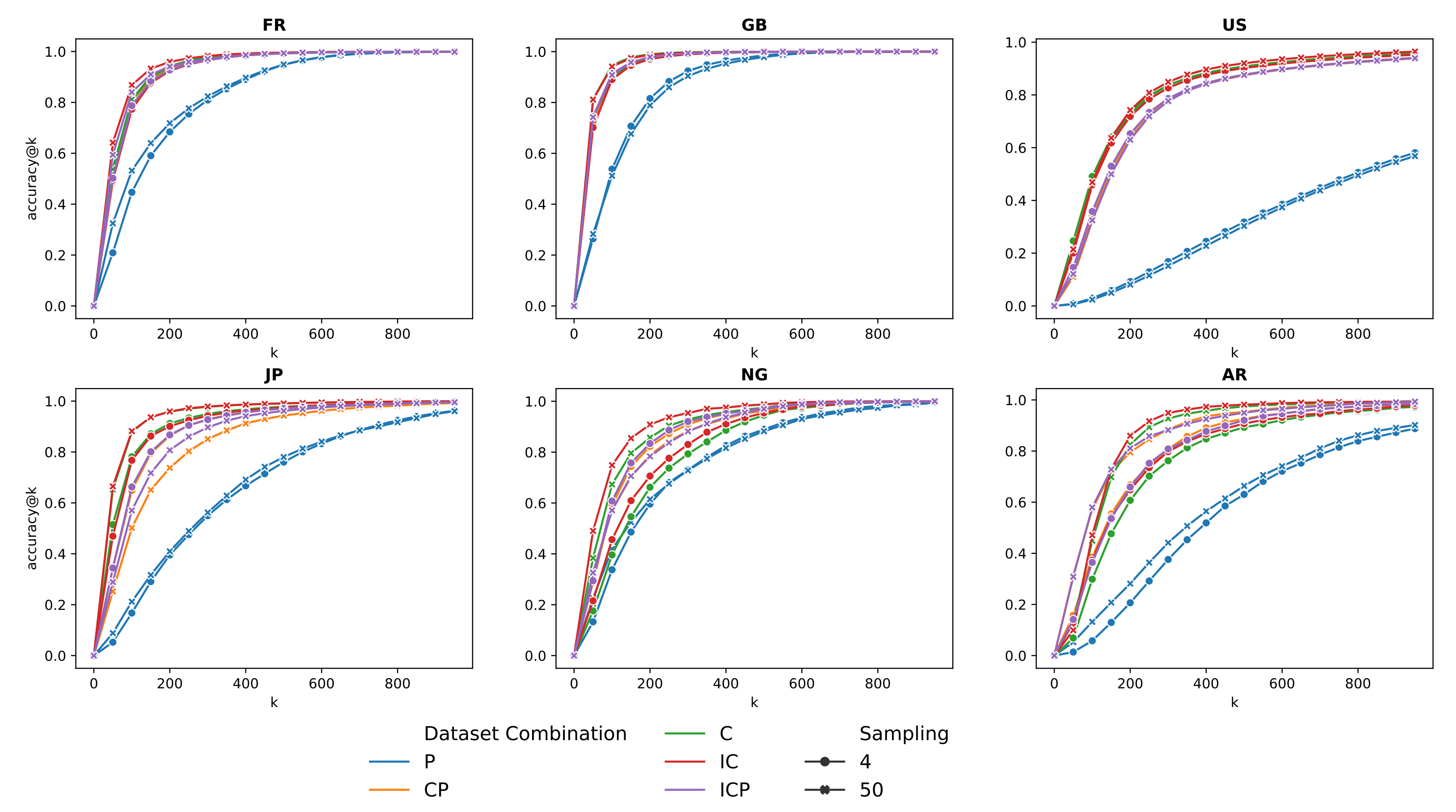
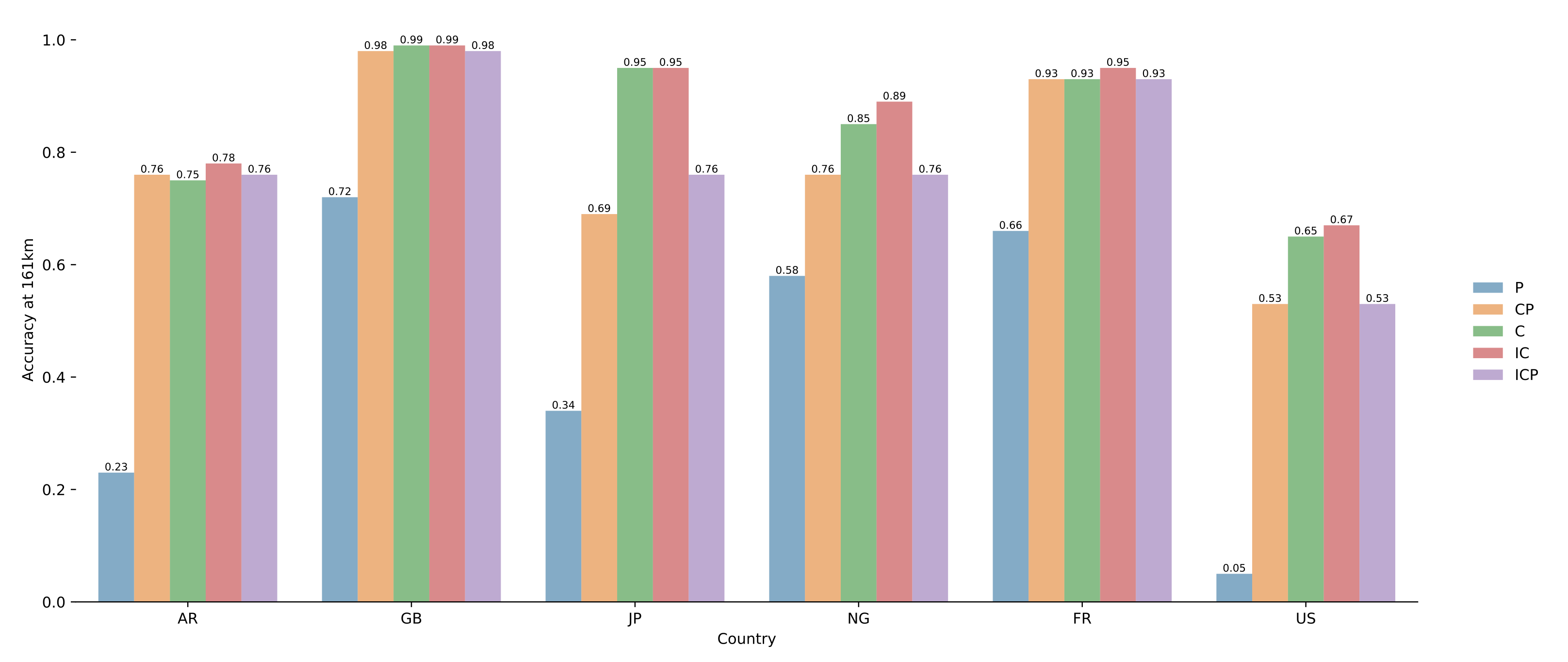
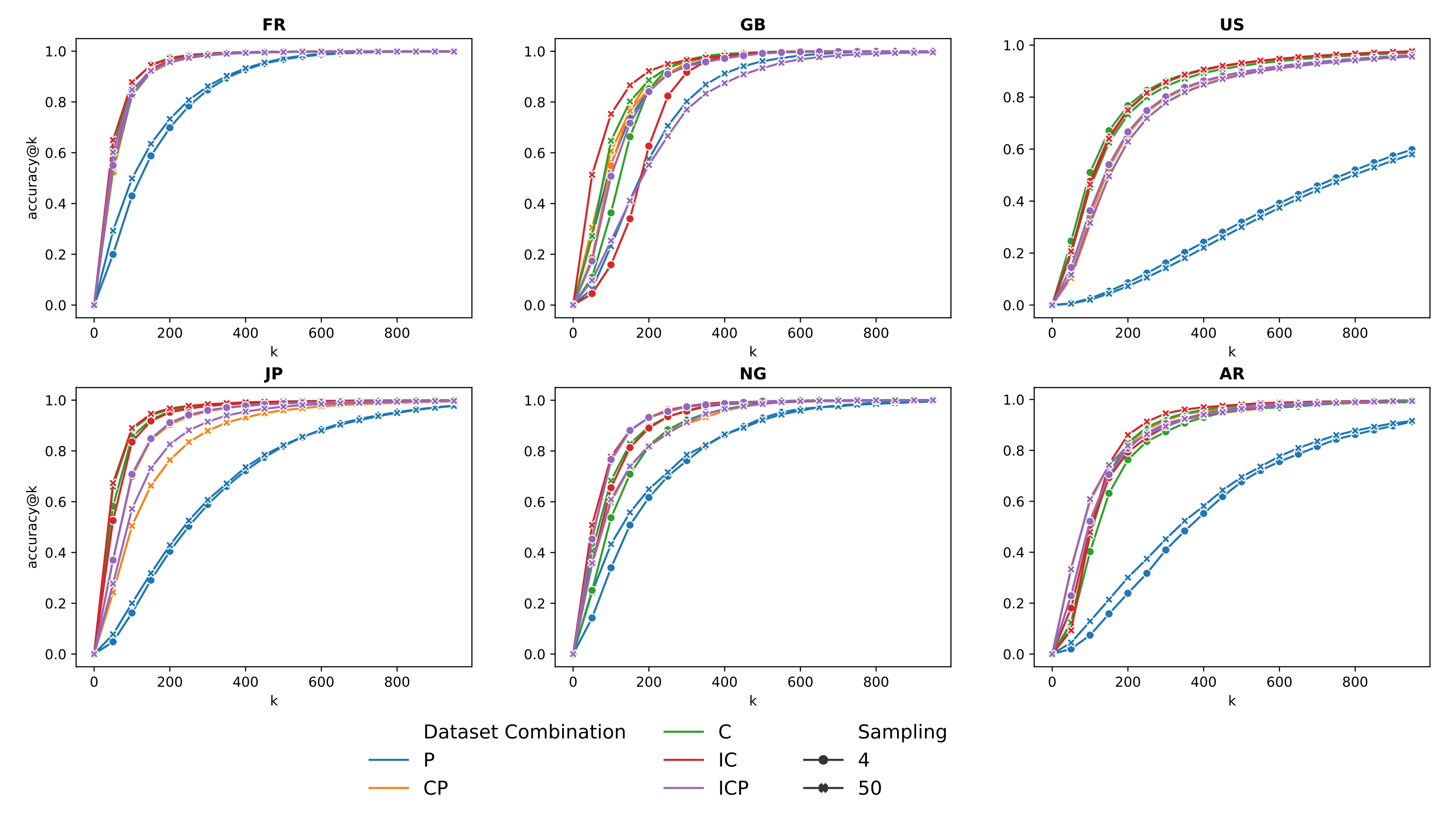
4.3. Results on Pairs of Toponyms
4.4. Geocoding Wikipages
4.5. Geocoding Results with Standard Corpora
5. Discussion
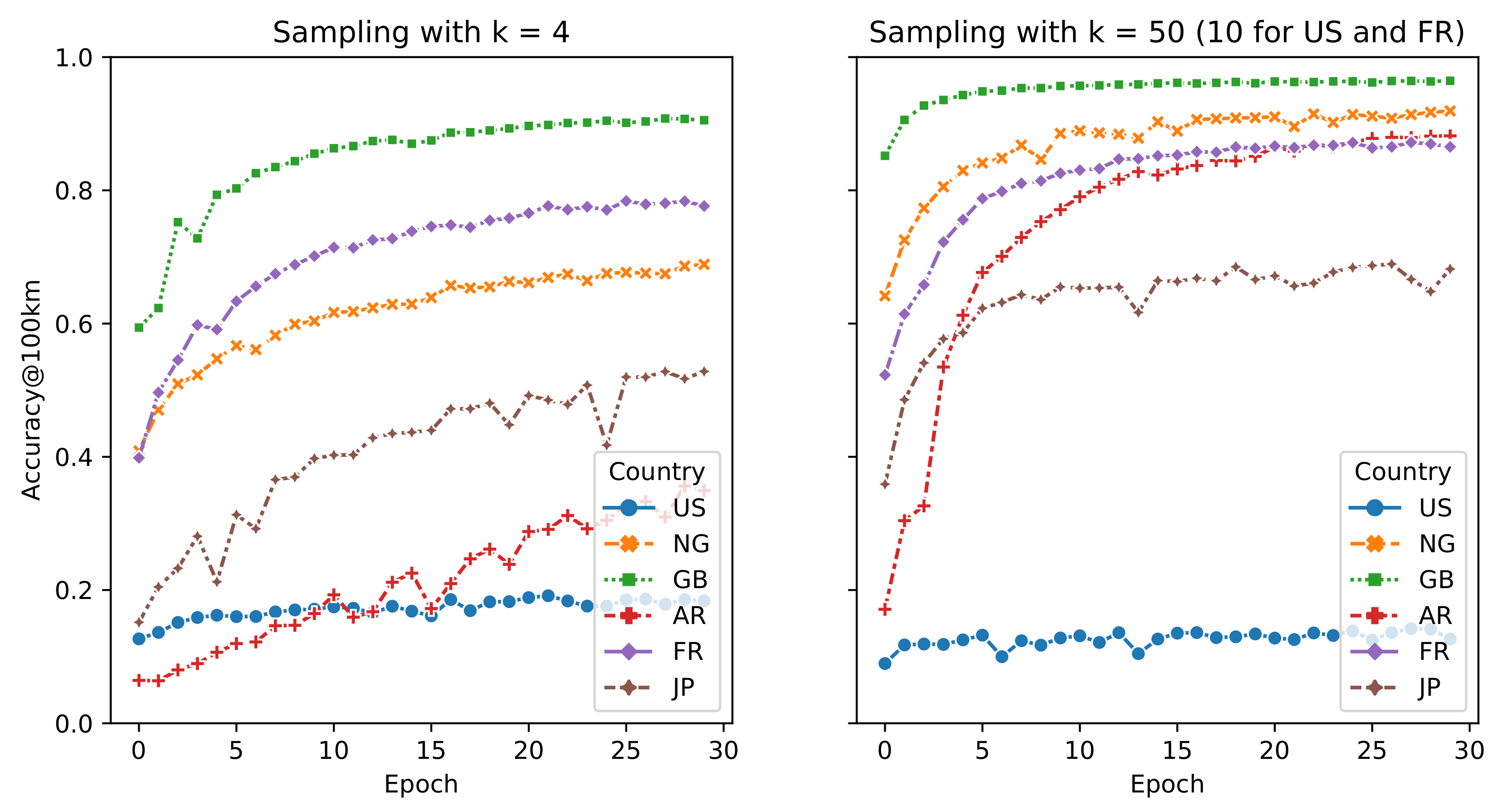
5.1. Scalability
5.2. Selection of Model Parameters
5.3. Impact of Sampling
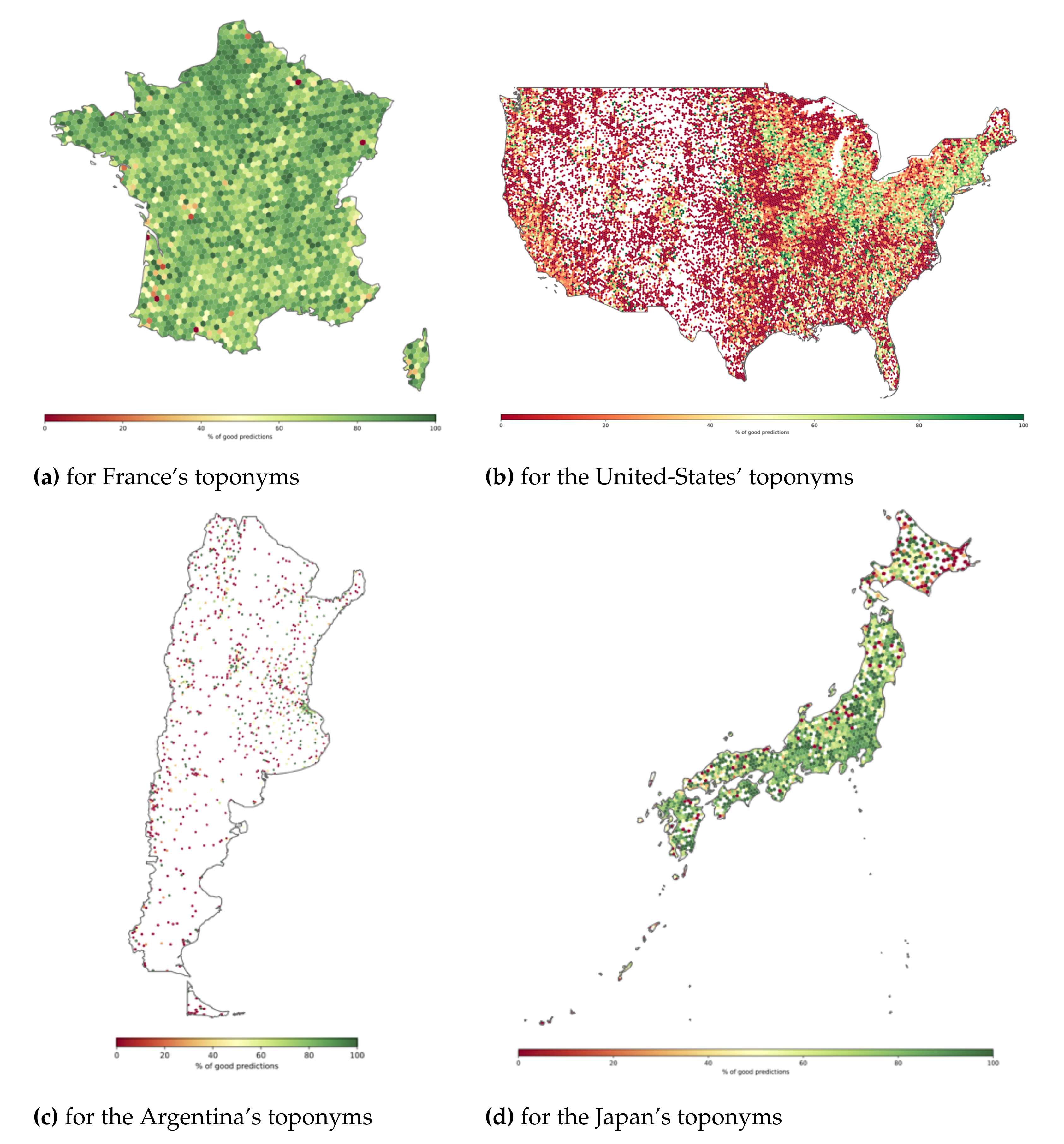
5.4. Why It Does Not Work for the US?
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Smith, D.A.; Crane, G. Disambiguating geographic names in a historical digital library. In Proceedings of the International Conference on Theory and Practice of Digital Libraries, Darmstadt, Germany, 4–9 September 2001; pp. 127–136. [Google Scholar]
- Monteiro, B.R.; Davis, C.A., Jr.; Fonseca, F. A survey on the geographic scope of textual documents. Comput. Geosci. 2016, 96, 23–34. [Google Scholar] [CrossRef]
- Buscaldi, D. Approaches to Disambiguating Toponyms. Sigspatial Spec. 2011, 3, 16–19. [Google Scholar] [CrossRef] [Green Version]
- DeLozier, G.; Baldridge, J.; London, L. Gazetteer-Independent Toponym Resolution Using Geographic Word Profiles. In Proceedings of the 29th AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Ardanuy, M.C.; Sporleder, C. Toponym disambiguation in historical documents using semantic and geographic features. In Proceedings of the 2nd International Conference on Digital Access to Textual Cultural Heritage, Göttingen, Germany, 1–2 June 2017; pp. 175–180. [Google Scholar]
- Moncla, L.; McDonough, K.; Vigier, D.; Joliveau, T.; Brenon, A. Toponym disambiguation in historical documents using network analysis of qualitative relationships. In Proceedings of the 3rd ACM SIGSPATIAL International Workshop on Geospatial Humanities, Chicago, IL, USA, 5 November 2019; pp. 1–4. [Google Scholar]
- Leidner, J.L. Toponym resolution in text: Annotation, evaluation and applications of spatial grounding. In ACM SIGIR Forum; ACM: New York, NY, USA, 2007; Volume 41, pp. 124–126. [Google Scholar]
- Buscaldi, D.; Rosso, P. A conceptual density-based approach for the disambiguation of toponyms. Int. J. Geogr. Inf. Sci. 2008, 22, 301–313. [Google Scholar] [CrossRef]
- Lieberman, M.D.; Samet, H.; Sankaranarayanan, J. Geotagging with local lexicons to build indexes for textually-specified spatial data. In Proceedings of the 26th International Conference on Data Engineering (ICDE), Long Beach, CA, USA, 1–6 March 2010; pp. 201–212. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining KDD’96, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Moncla, L.; Renteria-Agualimpia, W.; Nogueras-Iso, J.; Gaio, M. Geocoding for texts with fine-grain toponyms: An experiment on a geoparsed hiking descriptions corpus. In Proceedings of the 22nd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Dallas, TX, USA, 4 November 2014; pp. 183–192. [Google Scholar]
- Amitay, E.; Har’El, N.; Sivan, R.; Soffer, A. Web-a-where: Geotagging web content. In Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Sheffield, UK, 25–29 July 2004; pp. 273–280. [Google Scholar]
- Overell, S.; Rüger, S. Using co-occurrence models for placename disambiguation. Int. J. Geogr. Inf. Sci. 2008, 22, 265–287. [Google Scholar] [CrossRef]
- Batista, D.S.; Ferreira, J.D.; Couto, F.M.; Silva, M.J. Toponym disambiguation using ontology-based semantic similarity. In Proceedings of the International Conference on Computational Processing of the Portuguese Language, Coimbra, Portugal, 17–20 April 2012; pp. 179–185. [Google Scholar]
- Hu, Y.H.; Ge, L. A Supervised Machine Learning Approach to Toponym Disambiguation. In The Geospatial Web: How Geobrowsers, Social Software and the Web 2.0 Are Shaping the Network Society; Scharl, A., Tochtermann, K., Eds.; Springer: London, UK, 2007; pp. 117–128. [Google Scholar]
- Lieberman, M.D.; Samet, H. Adaptive Context Features for Toponym Resolution in Streaming News. In Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval, Portland, OR, USA, 12–16 August 2012; pp. 731–740. [Google Scholar]
- Molina-Villegas, A.; Muñiz-Sanchez, V.; Arreola-Trapala, J.; Alcántara, F. Geographic Named Entity Recognition and Disambiguation in Mexican News using word embeddings. Expert Syst. Appl. 2021, 176, 114855. [Google Scholar] [CrossRef]
- Santos, J.; Anastácio, I.; Martins, B. Using machine learning methods for disambiguating place references in textual documents. GeoJournal 2015, 80, 375–392. [Google Scholar] [CrossRef]
- Goldberg, Y. Neural network methods for natural language processing. Synth. Lect. Hum. Lang. Technol. 2017, 10, 1–309. [Google Scholar] [CrossRef]
- Kamalloo, E.; Rafiei, D. A coherent unsupervised model for toponym resolution. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1287–1296. [Google Scholar]
- Speriosu, M.; Baldridge, J. Text-driven toponym resolution using indirect supervision. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Sofia, Bulgaria, 4–9 August 2013; pp. 1466–1476. [Google Scholar]
- Gritta, M.; Pilehvar, M.T.; Limsopatham, N.; Collier, N. What is missing in geographical parsing? Lang. Resour. Eval. 2018, 52, 603–623. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cardoso, A.B.; Martins, B.; Estima, J. Using Recurrent Neural Networks for Toponym Resolution in Text. In Proceedings of the EPIA Conference on Artificial Intelligence, Vila Real, Portugal, 3–6 September 2019; pp. 769–780. [Google Scholar]
- Kulkarni, S.; Jain, S.; Hosseini, M.; Baldridge, J.; Le, E.; Zhang, L. Multi-Level Gazetteer-Free Geocoding. In Proceedings of the International Combined Workshop on Spatial Language Understanding and Grounded Communication for Robotics, Bangkok, Thailand, 6 August 2021; pp. 79–88. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), New Orleans, LA, USA, 1–6 June 2018. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. In Proceedings of the 1st International Conference on Learning Representations, ICLR Workshop Track Proceedings, Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Akbik, A.; Bergmann, T.; Vollgraf, R. Pooled Contextualized Embeddings for Named Entity Recognition. In Proceedings of the 2019 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), Minneapolis, MN, USA, 3–5 June 2019; pp. 724–728. [Google Scholar]
- Agarap, A.F. Deep learning using rectified linear units (relu). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Vrandečić, D.; Krötzsch, M. Wikidata: A Free Collaborative Knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef]
- Gorski, K.M.; Hivon, E.; Banday, A.J.; Wandelt, B.D.; Hansen, F.K.; Reinecke, M.; Bartelmann, M. HEALPix: A Framework for High-Resolution Discretization and Fast Analysis of Data Distributed on the Sphere. Astrophys. J. 2005, 622, 759–771. [Google Scholar] [CrossRef]
- Cheng, Z.; Caverlee, J.; Lee, K. You are where you tweet: A content-based approach to geo-locating twitter users. In Proceedings of the 19th ACM International Conference on INFORMATION and Knowledge Management, Toronto, ON, Canada, 26–30 October 2010; pp. 759–768. [Google Scholar]
- Jurgens, D.; Finethy, T.; McCorriston, J.; Xu, Y.T.; Ruths, D. Geolocation prediction in twitter using social networks: A critical analysis and review of current practice. In Proceedings of the Ninth International AAAI Conference on Web and Social Media, Oxford, UK, 26–29 May 2015. [Google Scholar]
- Mani, I.; Hitzeman, J.; Richer, J.; Harris, D.; Quimby, R.; Wellner, B. SpatialML: Annotation Scheme, Corpora, and Tools. In Proceedings of the Sixth International Conference on Language Resources and Evaluation (LREC'08), Marrakech, Morocco, 28–30 May 2008. [Google Scholar]
- Leidner, J.L. Toponym Resolution in Text: Annotation, Evaluation and Applications of Spatial Grounding of Place Names. Ph.D. Thesis, University of Edinburgh, Edinburgh, UK, 2007. [Google Scholar]
- Rayson, P.; Reinhold, A.; Butler, J.; Donaldson, C.; Gregory, I.; Taylor, J. A deeply annotated testbed for geographical text analysis: The corpus of lake district writing. In Proceedings of the 1st ACM SIGSPATIAL Workshop on Geospatial Humanities, Redondo Beach, CA, USA, 7–10 November 2017; pp. 9–15. [Google Scholar]
- DeLozier, G.; Wing, B.; Baldridge, J.; Nesbit, S. Creating a Novel Geolocation Corpus from Historical Texts. In Proceedings of the 10th Linguistic Annotation Workshop held in conjunction with ACL 2016 (LAW-X 2016), Berlin, Germany, 11 August 2016; pp. 188–198. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Type | Proximity | Cooccurrences | Inclusion | |||
|---|---|---|---|---|---|---|
| Sampling | 4 | 50 | 4 | 50 | ⌀ | |
| Country | FR | 394,036 | 4,925,450 | 376,088 | 714,974 | 36,476 |
| US | 995,760 | 12,447,000 | 795,750 | 1,550,502 | 52,401 | |
| GB | 123,240 | 1,540,500 | 295,133 | 668,501 | 12,496 | |
| JP | 219,820 | 2,747,750 | 56,147 | 101,269 | 8341 | |
| AR | 30,712 | 383,900 | 8512 | 13,830 | 759 | |
| NG | 244,160 | 3,052,000 | 5639 | 9378 | 3786 | |
| Dataset | Country | A@161 | A@100 | A@50 | MDE | AUC |
|---|---|---|---|---|---|---|
| SpatialML | FR | 0.36 | 0.33 | 0.33 | 304.86 | 0.77 |
| US | - | - | - | - | - | |
| JP | 0.49 | 0.41 | 0.27 | 164.34 | 0.85 | |
| AR | - | - | - | - | - | |
| NG | 0.46 | 0.31 | 0.08 | 232.20 | 0.75 | |
| GB | 1.00 | 1.00 | 0.95 | 16.49 | 0.96 | |
| TR-CONLL | FR | 0.28 | 0.28 | 0.23 | 317.17 | 0.72 |
| US | 0.15 | 0.13 | 0.08 | 859.28 | 0.30 | |
| JP | 0.37 | 0.30 | 0.16 | 192.18 | 0.83 | |
| AR | 1.00 | 0.46 | 0.00 | 116.99 | 0.88 | |
| NG | 0.92 | 0.15 | 0.00 | 146.53 | 0.81 | |
| GB | 0.92 | 0.74 | 0.66 | 24.05 | 0.92 | |
| Lake District Corpus | GB | 0.80 | 0.66 | 0.42 | 65.46 | 0.84 |
| War of the Rebellion | US | 0.11 | 0.05 | 0.02 | 603.17 | 0.38 |
| Parameter | LSTM | n-Gram | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 2 | 3 | 4 | 5 | 6 | WL | WP | ||
| Accuracy | @100 km | 0.87 | 0.75 | 0.32 | 0.66 | 0.87 | 0.89 | 0.89 | 0.08 | 0.11 |
| @50 km | 0.58 | 0.47 | 0.16 | 0.36 | 0.58 | 0.65 | 0.69 | 0.03 | 0.04 | |
| @20 km | 0.17 | 0.16 | 0.05 | 0.10 | 0.17 | 0.22 | 0.26 | 0.00 | 0.01 | |
| Country | Average Number of Duplicates |
|---|---|
| FR | 1.461936 |
| GB | 1.246243 |
| AR | 1.410444 |
| NG | 1.291725 |
| US | 1.640997 |
| JP | 1.286867 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fize, J.; Moncla, L.; Martins, B. Deep Learning for Toponym Resolution: Geocoding Based on Pairs of Toponyms. ISPRS Int. J. Geo-Inf. 2021, 10, 818. https://doi.org/10.3390/ijgi10120818
Fize J, Moncla L, Martins B. Deep Learning for Toponym Resolution: Geocoding Based on Pairs of Toponyms. ISPRS International Journal of Geo-Information. 2021; 10(12):818. https://doi.org/10.3390/ijgi10120818
Chicago/Turabian StyleFize, Jacques, Ludovic Moncla, and Bruno Martins. 2021. "Deep Learning for Toponym Resolution: Geocoding Based on Pairs of Toponyms" ISPRS International Journal of Geo-Information 10, no. 12: 818. https://doi.org/10.3390/ijgi10120818
APA StyleFize, J., Moncla, L., & Martins, B. (2021). Deep Learning for Toponym Resolution: Geocoding Based on Pairs of Toponyms. ISPRS International Journal of Geo-Information, 10(12), 818. https://doi.org/10.3390/ijgi10120818