
Prediction of Groundwater Level Variations in a Changing Climate: A Danish Case Study



Abstract
:1. Introduction
1.1. Machine Learning for Groundwater Prediction
1.2. Study Objectives and Problem Statement
- How will the water table be affected by climate change in the future based on different socio-economic pathways (SSPs)?
- Do ML models perform well enough in predicting changes of the groundwater in Denmark? If so, which ML model outperforms for forecasting these changes?
2. Data and Materials
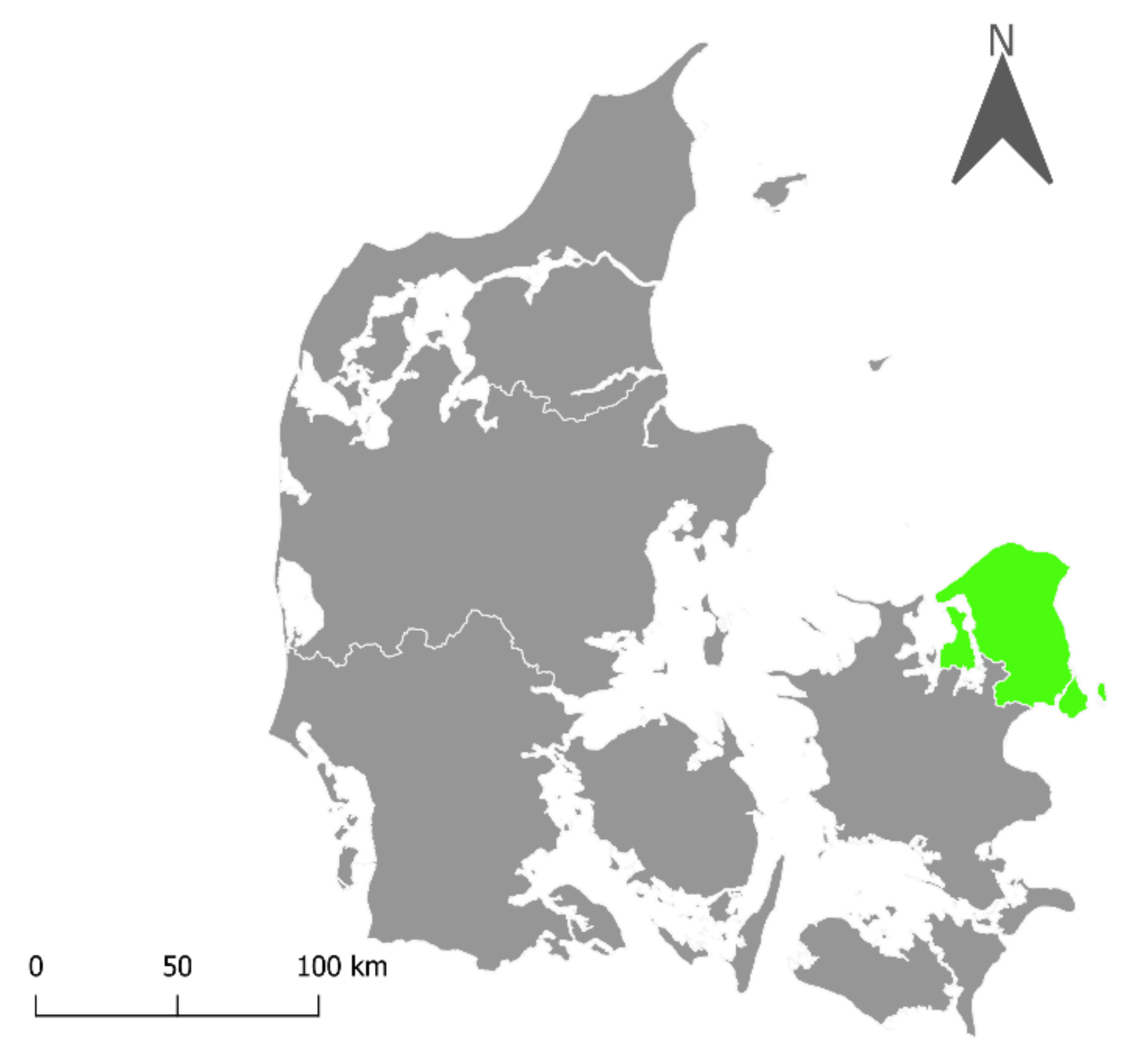
2.1. Study Area
2.2. Dependent Variable: Jupiter Database
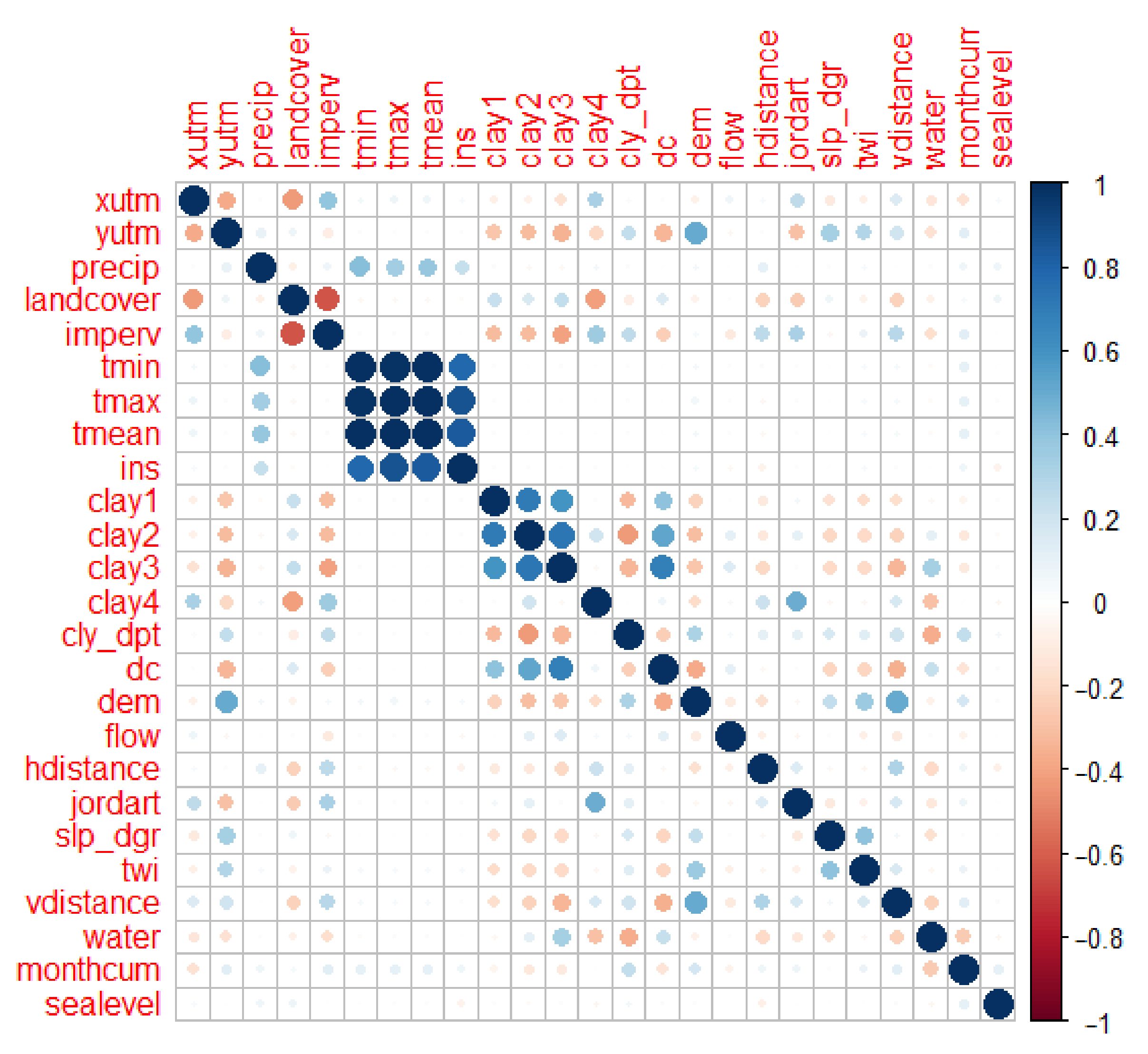
2.3. Independent Variables
3. Methods
3.1. Machine Learning Algorithms
3.1.1. Random Forest
3.1.2. Artificial Neural Networks
3.1.3. Support Vector Machines
3.2. Implementation
4. Results
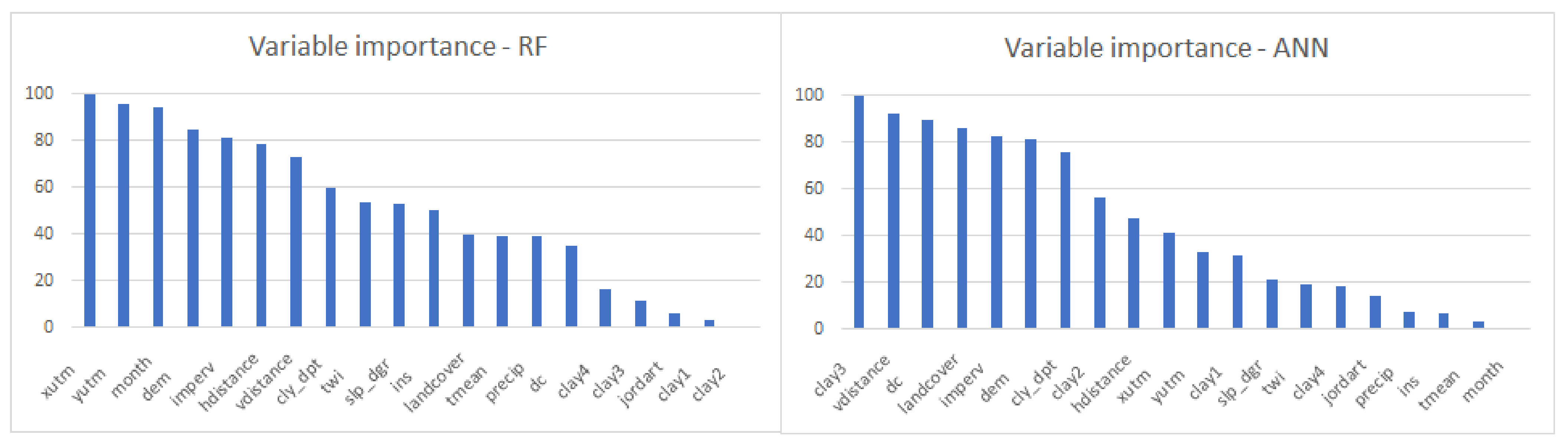
4.1. Comparison of the Models
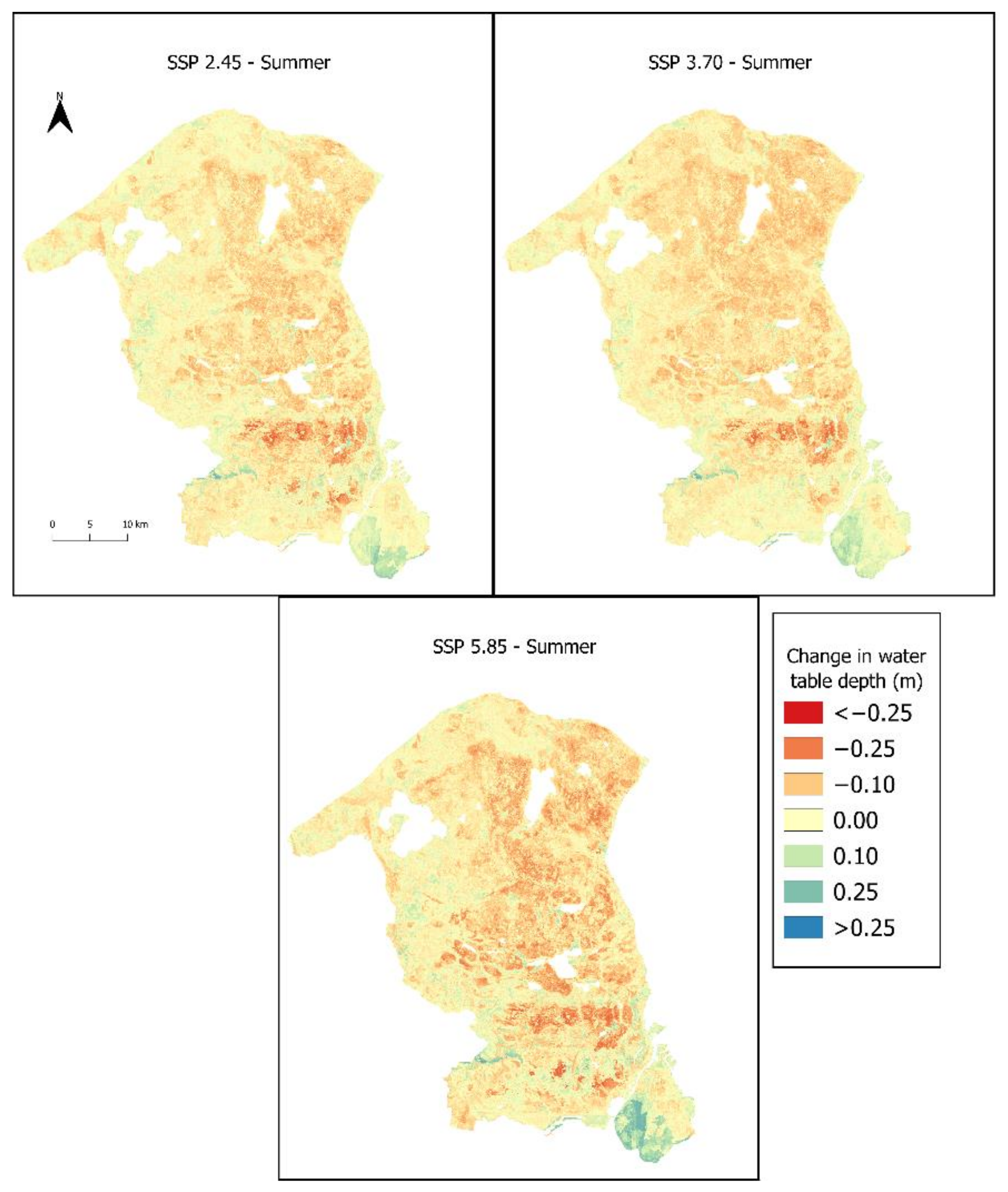
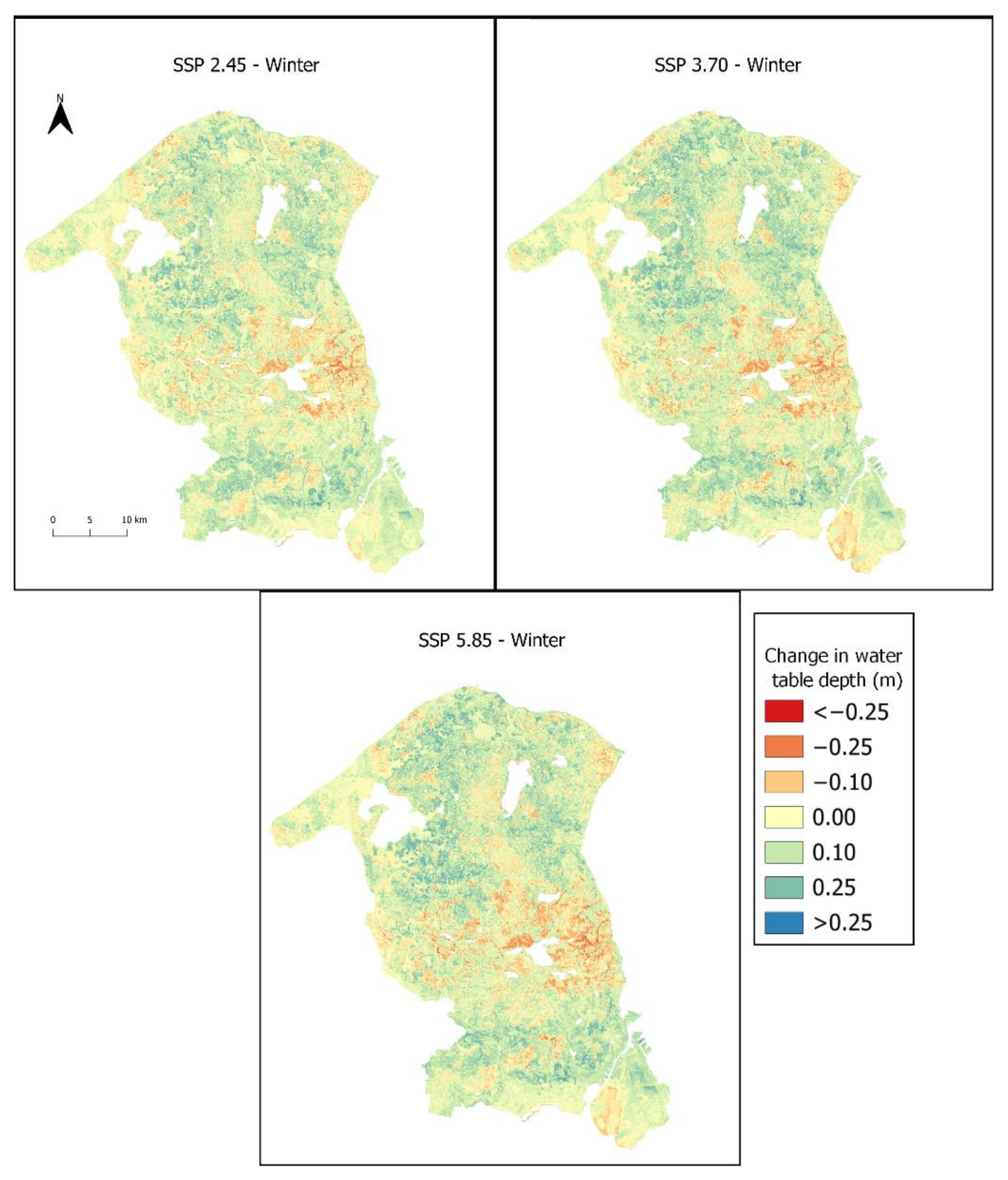
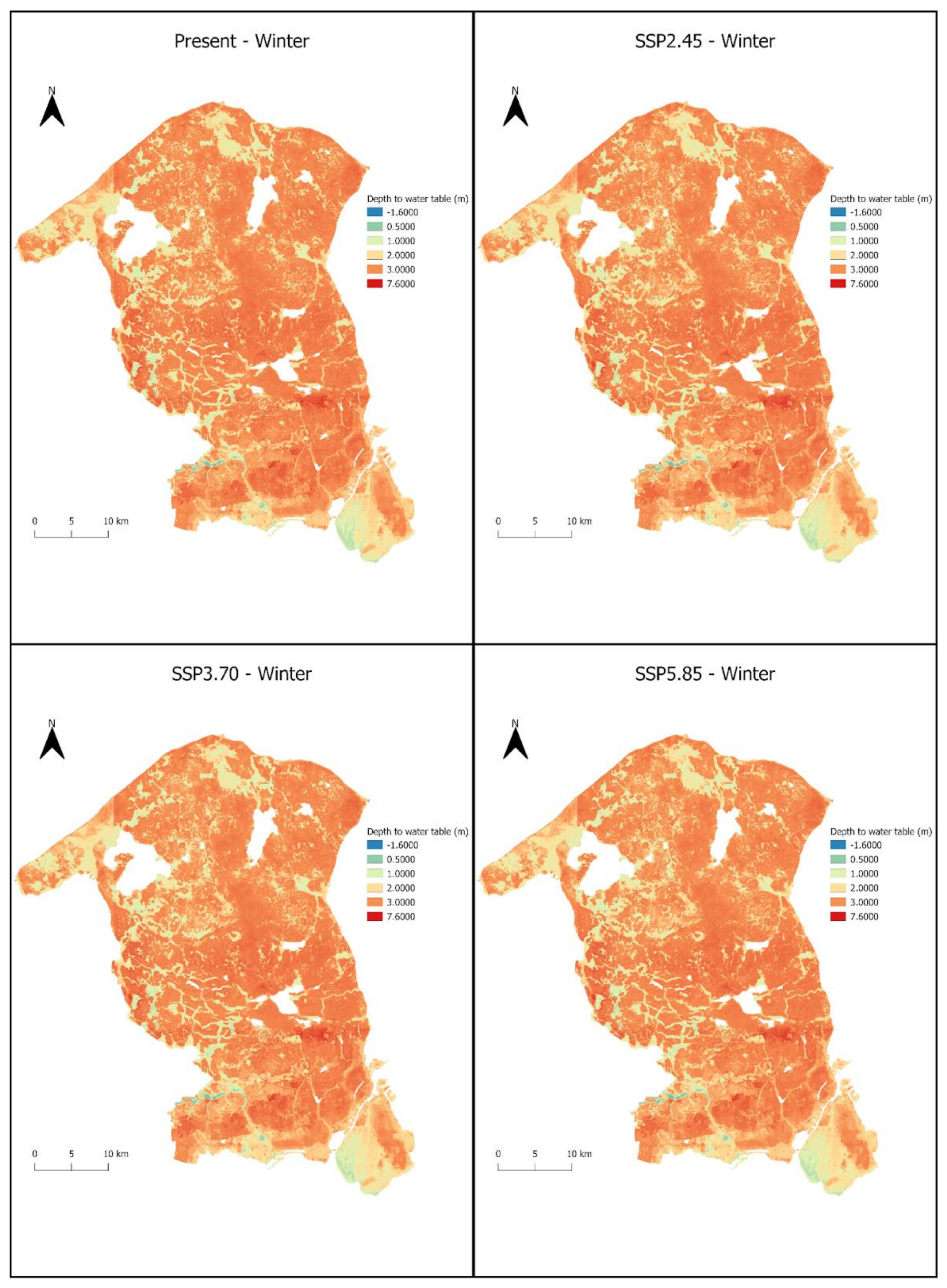
4.2. Future Predictions
5. Discussion
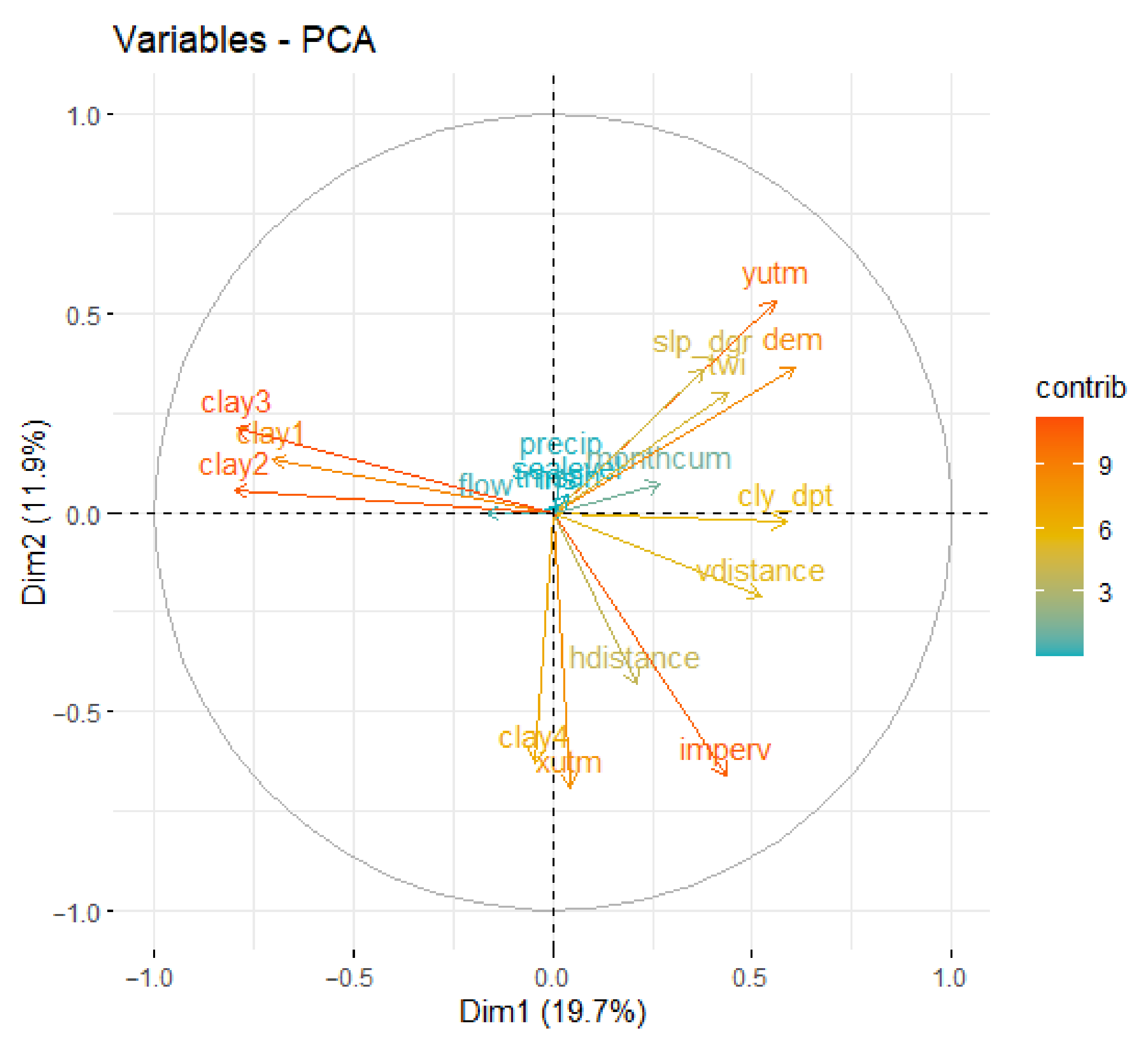
5.1. Comparison of the Models
5.2. Future Predictions
5.3. Limitations of the Model
5.4. Limitations of the Data
5.5. Implications to Society and Decision Makers
6. Conclusions
7. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A



References
- Gleeson, T.; Befus, K.M.; Jasechko, S.; Luijendijk, E.; Cardenas, M.B. The global volume and distribution of modern groundwater. Nat. Geosci. 2016, 9, 161–167. [Google Scholar] [CrossRef]
- European Commission. Groundwater; Environment. 2021. Available online: https://ec.europa.eu/environment/water/water-framework/groundwater/resource.htm (accessed on 20 May 2021).
- Kahlown, M.A.; Ashraf, M. Effect of shallow groundwater table on crop water requirements and crop yields. Agric. Water Manag. 2005, 76, 24–35. [Google Scholar] [CrossRef]
- Zipper, S.C.; Soylu, M.E.; Booth, E.G.; Loheide, S.P. Untangling the effects of shallow groundwater and soil texture as drivers of subfield-scale yield variability. Water Resour. Res. 2015, 51, 6338–6358. [Google Scholar] [CrossRef] [Green Version]
- Jankowfsky, S.; Branger, F.; Braud, I.; Rodriguez, F.; Debionne, S.; Viallet, P. Assessing anthropogenic influence on the hydrology of small peri-urban catchments: Development of the object-oriented PUMMA model by integrating urban and rural hydrological models. J. Hydrol. 2014, 517, 1056–1071. [Google Scholar] [CrossRef]
- Collins, M.; Knutti, R.; Gutowski, W.J., Jr.; Brooks, H.E.; Shindell, D.; Webb, R. Long-Term Climate Change: Projections, Commitments and Irreversibility. In Climate Change 2013: The Physical Science Basis; Contribution of Working Group I to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change; Stocker, T.F., Qin, D., Plattner, G.-K., Tignor, M., Allen, S.K., Boschung, J., Nauels, A., Xia, Y., Bex, V., Midgley, P.M., Eds.; Cambridge University Press: New York, NY, USA, 2013. [Google Scholar]
- Seneviratne, S.I.; Nicholls, N.; Easterling, D.; Goodess, C.; Kanae, S.; Kossin, J.; Luo, Y.; Marengo, J.; Mclnnes, K.; Rahimi, M.; et al. Changes in climate extremes and their impacts on the naturalphysical environment. In Managing the Risks of Extreme Events and Disasters to Advance Climate Change Adaptation; Field, C.B., Barros, V., Stocker, T.F., Qin, D., Dokken, D.J., Ebi, K.L., Mastrandrea, M.D., Mach, K.J., Plattner, G.-K., Allen, S.K., et al., Eds.; Cambridge University Press: Cambridge, UK; New York, NY, USA, 2012; pp. 109–123. [Google Scholar]
- Wuebbles, D.J.; Fahey, D.W.; Hibbard, K.A.; Dokken, D.J.; Stewart, B.C.; Maycock, T.K. Climate Science Special Report: Fourth National Climate Assessment; U.S. Global Change Research Program: Washington, DC, USA, 2017; Volume I. [CrossRef] [Green Version]
- Bates, B.; Kundzewicz, Z.; Wu, S.; Palutikof, J. Climate Change and Water. Intergovernmental Panel on Climate Change; Technical Paper 6; IPCC Secretariat: Geneva, Switzerland, 2008. [Google Scholar]
- Woldeamlak, S.T.; Batelaan, O.; de Smedt, F. Effects of climate change on the groundwater system in the Grote-Nete catchment, Belgium. Hydrogeol. J. 2007, 15, 891–901. [Google Scholar] [CrossRef]
- Danish Nature Agency. Mapping Climate Change—Barriers and Opportunities for Action; Task Force on Climate Change Adaptation: Washington, DC, USA, 2012. [Google Scholar]
- Lakshamanan, V.; Gilleland, E.; McGovern, A.; Tingley, M. Machine Learning and Data Mining Approaches to Climate Science; Springer: New York, NY, USA, 2015. [Google Scholar]
- Rolnick, D.; Donti, P.; Kaack, L.; Kochanski, K.; Lacoste, A.; Sankaran, K.; Ross, A.S.; Milojevic-Dupont, N.; Jaques, N.; Waldman-Brown, A.; et al. Tackling Climate Change with Machine Learning. arXiv 2019, arXiv:abs/1906.05433. [Google Scholar]
- IBM Cloud Education. Machine Learning; IBM: Armonk, NY, USA, 2020; Available online: https://www.ibm.com/cloud/learn/machine-learning (accessed on 7 May 2021).
- Singh, R. Where Deep Learning Meets GIS; ESRI: Redlands, CA, USA, 2014; Available online: https://www.esri.com/about/newsroom/arcwatch/where-deep-learning-meets-gis/ (accessed on 17 May 2021).
- Fahimi, F.; Yaseen, Z.M.; El-shafie, A. Application of soft computing based hybrid models in hydrological variables modeling: A comprehensive review. Theor. Appl. Climatol. 2017, 128, 875–903. [Google Scholar] [CrossRef]
- Bowes, B.D.; Sadler, J.M.; Morsy, M.M.; Behl, M.; Goodall, J.L. Forecasting groundwater table in a flood prone coastal city with long short-term memory and recurrent neural networks. Water 2019, 11, 1098. [Google Scholar] [CrossRef] [Green Version]
- Solomatine, D.P.; Ostfeld, A. Data-driven modelling: Some past experiences and new approaches. J. Hydroinformatics 2008, 10, 3–22. [Google Scholar] [CrossRef] [Green Version]
- Mohanty, S.; Jha, M.K.; Kumar, A.; Panda, D.K. Comparative evaluation of numerical model and artificial neural network for simulating groundwater flow in Kathajodi–Surua Inter-basin of Odisha, India. J. Hydrol. 2013, 495, 38–51. [Google Scholar] [CrossRef]
- Singh, A. Groundwater resources management through the applications of simulation modeling: A review. Sci. Total Environ. 2014, 499, 414–423. [Google Scholar] [CrossRef]
- Markstrom, S.L.; Niswonger, R.G.; Regan, R.S.; Prudic, D.E.; Barlow, P.M. GSFLOW—Coupled Ground-Water and Surface-Water Flow Model Based on the Integration of the Precipitation-Runoff Modeling System (PRMS) and the Modular Ground-Water Flow Model (MODFLOW-2005). In Geological Survey Techniques and Methods 6-D1; United States Geological Survey (USGA): Reston, VA, USA, 2008; p. 240. [Google Scholar]
- Brutsaert, W. Hydrology: An Introduction; Cambridge University Press: New York, NY, USA, 2005. [Google Scholar] [CrossRef]
- Chen, C.; He, W.; Zhou, H.; Xue, Y.; Zhu, M. A comparative study among machine learning and numerical models for simulating groundwater dynamics in the Heihe River Basin, northwestern China. Sci. Rep. 2020, 10, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Solomatine, D.P.; Shrestha, D.L. A novel method to estimate model uncertainty using machine learning techniques. Water Resour. Res. 2009, 45, 12. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 1–41. [Google Scholar] [CrossRef]
- Blanco, C.M.G.; Gomez, V.M.B.; Crespo, P.; Ließ, M. Spatial prediction of soil water retention in a Páramo landscape: Methodological insight into machine learning using random forest. Geoderma 2018, 316, 100–114. [Google Scholar] [CrossRef]
- Guergachi, A.; Boskovic, G. System models or learning machines? Appl. Math. Comput. 2008, 204, 553–567. [Google Scholar] [CrossRef]
- Kenda, K.; Čerin, M.; Bogataj, M.; Senožetnik, M.; Klemen, K.; Pergar, P.; Laspidou, C.; Mladenić, D. Groundwater Modeling with Machine Learning Techniques: Ljubljana polje Aquifer. Proceedings 2018, 2, 697. [Google Scholar] [CrossRef] [Green Version]
- Koch, J.; Berger, H.; Henriksen, H.J.; Sonnenborg, T.O. Modelling of the shallow water table at high spatial resolution using random forests. Hydrol. Earth Syst. Sci. 2019, 23, 4603–4649. [Google Scholar] [CrossRef] [Green Version]
- Maier, H.R.; Dandy, G.C. Neural networks for the prediction and forecasting of water resources variables: A review of modelling issues and applications. Environ. Model. Softw. 2000, 15, 101–124. [Google Scholar] [CrossRef]
- Hussein, E.A.; Thron, C.; Ghaziasgar, M.; Bagula, A.; Vaccari, M. Groundwater Prediction Using Machine-Learning Tools. Algorithms 2020, 13, 300. [Google Scholar] [CrossRef]
- Statistics Denmark. AREALDK: Land by land cover, region and unit. In StatBank Denmark: Geography, Environment and Energy; StatBank Denmark: Copenhagen, Denmark, 2021; Available online: https://www.statbank.dk/statbank5a/default.asp?w=1280 (accessed on 30 April 2021).
- Jørgensen, L.F.; Stockmarr, J. Groundwater monitoring in Denmark: Characteristics, perspectives and comparison with other countries. Hydrogeol. J. 2009, 17, 827–842. [Google Scholar] [CrossRef]
- World Bank. Climate Data: Historical; World Bank: Washington, DC, USA, 2021; Available online: https://climateknowledgeportal.worldbank.org/country/denmark/climate-data-historical (accessed on 4 April 2021).
- OECD. Water and Climate Change Adaptation; OECD Publishing: Paris, France, 2013. [Google Scholar] [CrossRef]
- Kidmose, J.; Refsgaard, J.C.; Troldborg, L.; Seaby, L.P.; Escrivà, M.M. Climate change impact on groundwater levels: Ensemble modelling of extreme values. Hydrol. Earth Syst. Sci. 2013, 17, 1619–1634. [Google Scholar] [CrossRef] [Green Version]
- Henriksen, H.J.; Højberg, A.L.; Seaby, L.P.; van der Keur, P.; Stisen, S.; Troldborg, L.; Sonnenborg, T.O.; Refsgaard, J.C. Klimaeffekter på Hydrologi og Grundvand (Klimagrundvandskort); GEUS: Copenhagen, Denmark, 2012. [Google Scholar]
- Danish Ministry of the Environment. Groundwater Monitoring in Denmark. In The Danish Action Plan for Promotion of Eco-Efficient Technologies; Danish Ministry of the Environment: Copenhagen, Denmark, 2021. [Google Scholar]
- Statistics Denmark. Geography, Environment and Energy: Statistical Yearbook 2017; Statistics Denmark: Copenhagen, Denmark, 2017. [Google Scholar]
- Jebens, M.; Sørensen, C.S.; Piontkowitz, T. Danish risk management plans of the EU Floods Directive. ES3 Web Conf. 2016, 7. [Google Scholar] [CrossRef] [Green Version]
- GEUS. National boringsdatabase (Jupiter). In De Nationale Geologiske Undersøgelser for Danmark og Grønland; GEUS: Copenhagen, Denmark, 2021; Available online: https://www.geus.dk/produkter-ydelser-og-faciliteter/data-og-kort/national-boringsdatabase-jupiter (accessed on 1 April 2021).
- Miljøstyrelsen. Indberetning og godkendelse af vandforsyningsdata (Jupitervejledningen). Miljøministeriet, 2020. Available online: https://mst.dk/service/nyheder/nyhedsarkiv/2020/maj/indberetning-og-godkendelse-af-vandforsyningsdata-jupitervejledningen/ (accessed on 19 May 2021).
- GEUS. Dokumentation af PCJupiterXL tabeller og koder. de Nationale Geologiske Undersøgelser for Danmark og Grønland; GEUS: Copenhagen, Denmark, 2021; Available online: https://data.geus.dk/tabellerkoder/index.html?tablename=WATLEVEL (accessed on 1 April 2021).
- GEUS. Download PCJupiter. De Nationale Geologiske Undersøgelser for Danmark og Grønland. 2021. Available online: https://data.geus.dk/JupiterWWW/downloadpcjupiter.jsp?xl=1 (accessed on 1 April 2021).
- Hedley, C.B.; Roudier, P.; Yule, I.J.; Ekanayake, J.; Bradbury, S. Soil water status and water table depth modelling using electromagnetic surveys for precision irrigation scheduling. Geoderma 2013, 199, 22–29. [Google Scholar] [CrossRef]
- Hengl, T.; Nussbaum, M.; Wright, M.N. Random Forest for Spatial Data. GeoMLA. 2018. Available online: https://github.com/thengl/GeoMLA/blob/master/README.md (accessed on 30 April 2021).
- Meyer, H. Introduction to Cast. R-Project. 2018. Available online: https://cran.r-project.org/web/packages/CAST/vignettes/CAST-intro.html (accessed on 3 May 2021).
- Adhikari, K.; Kheir, R.B.; Greve, M.B.; Bøcher, P.K.; Malone, B.P.; Minasny, B.; McBratney, A.B.; Greve, M.H. High-Resolution 3-D Mapping of Soil Texture in Denmark. Soil Sci. Soc. Am. J. 2013, 77, 860–876. [Google Scholar] [CrossRef]
- Møller, A.B.; Iversen, B.v.; Beucher, A.; Greve, M.H. Prediction of soil drainage classes in Denmark by means of decision tree classification. Geoderma 2019, 352, 314–329. [Google Scholar] [CrossRef]
- GEUS. Download jordartskort. De Nationale Geologiske Undersøgelser for Danmark og Grønland. 2021. Available online: https://www.geus.dk/produkter-ydelser-og-faciliteter/data-og-kort/danske-kort/download-jordartskort (accessed on 1 April 2021).
- Copernicus. EU-DEM v1.0. Copernicus Programme. 2021. Available online: https://land.copernicus.eu/imagery-in-situ/eu-dem/eu-dem-v1-0-and-derived-products/eu-dem-v1.0 (accessed on 1 April 2021).
- NOAA. Relative Sea Level Trend. National Oceanic and Atmospheric Administration. 2021. Available online: https://tidesandcurrents.noaa.gov/sltrends/sltrends_station.shtml?id=130-021 (accessed on 1 April 2021).
- Copernicus. CORINE Land Cover. Copernicus Programme. 2021. Available online: https://land.copernicus.eu/pan-european/corine-land-cover (accessed on 1 April 2021).
- Copernicus. Copernicus Land Monitoring Service-High Resolution Layers—Imperviousness. European Environment Information and Observation Network. 2021. Available online: https://www.eea.europa.eu/data-and-maps/data/copernicus-land-monitoring-service-imperviousness-2 (accessed on 1 April 2021).
- Harris, I.; Jones, P.D.; Osborn, T.J.; Lister, D.H. Updated high-resolution grids of monthly climatic—The CRU TS3.10 Dataset. Int. J. Climatol. 2014, 34, 11593–11610. [Google Scholar] [CrossRef] [Green Version]
- Fick, S.E.; Hijmans, R.J. WorldClim 2: New 1-km spatial resolution climate surfaces for global land areas. Int. J. Climatol. 2017, 37, 4302–4315. [Google Scholar] [CrossRef]
- Kuhn, M. The Caret Package 2019. Available online: https://topepo.github.io/caret/index.html (accessed on 23 May 2021).
- STHDA. Regression Analysis Essentials for Machine Learning. Statistical Tools for High-Throughput Data Analysis, 2021. Available online: http://www.sthda.com/english/wiki/regression-analysis-essentials-for-machine-learning (accessed on 15 May 2021).
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Brownlee, J. Random Forest for Time Series Forecasting. Machine Learning Mastery. 2020. Available online: https://machinelearningmastery.com/random-forest-for-time-series-forecasting/ (accessed on 6 May 2021).
- Catani, F.; Lagomarsino, D.; Segoni, S.; Tofani, V. Landslide susceptibility estimation by random forests technique: Sensitivity and scaling issues. Nat. Hazards Earth Syst. Sci. 2013, 13, 2815–2831. [Google Scholar] [CrossRef] [Green Version]
- Frankenfield, J. Artificial Neural Network (ANN). Investopedia, 2020. Available online: https://www.investopedia.com/terms/a/artificial-neural-networks-ann.asp (accessed on 17 May 2021).
- Zhou, V. Machine Learning for Beginners: An Introduction to Neural Networks. Towards Data Science, 2019. Available online: https://towardsdatascience.com/machine-learning-for-beginners-an-introductionto-Neural-networks-d49f22d238f9 (accessed on 18 May 2021).
- Sayad, S. An Introduction to Data Science; Saedsayad: Toronto, ON, Canada, 2021; Available online: https://www.saedsayad.com/data_mining_map.htm (accessed on 5 May 2021).
- Hijmans, R.J. Package ‘Raster’. The Comprehensive R Archive Network. 2020. Available online: https://cran.rproject.org/web/packages/raster/raster.pdf (accessed on 23 May 2021).
- Dormann, C.F.; Elith, J.; Bacher, S.; Buchmann, C.; Carl, G.; Carré, G.; García Marquéz, J.R.; Gruber, B.; Lafourcade, B.; Leitão, P.J.; et al. Collinearity: A review of methods to deal with it and a simulation study evaluating their performance. Ecography 2013, 36, 27–46. [Google Scholar] [CrossRef]
- Meyer, H.; Reudenbach, C.; Hengl, T.; Katurji, M.; Nauss, T. Improving performance of spatio-temporal machine learning models using forward feature selection and target-oriented validation. Environ. Model. Softw. 2018, 101, 1–9. [Google Scholar] [CrossRef]
- Levin, G. Dynamics of Danish agricultural landscape and role of organic farming. Agric. Ecosyst. Environ. 2007, 120, 330–344. [Google Scholar] [CrossRef]
- Danish Agriculture & Food Council. Denmark—A Food and Farming Country; Danish Agriculture & Food Council: Copenhagen, Denmark, 2019. [Google Scholar]
- Robbach, P. Neural Networks vs. Random Forest—Does It always Have to Be Deep Learning? Frankfurt School of Finance and Management. 2018. Available online: https://blog.frankfurt-school.de/neural-networks-vs-random-forests-does-it-always-have-to-be-deep-learning/ (accessed on 16 May 2021).
- Henriksen, H.J.; Troldborg, L.; Nyegaard, P.; Sonnenborg, T.O.; Refsgaard, J.C.; Madsen, B. Methodology for construction, calibration and validation of a national hydrological model for Denmark. J. Hydrol. 2003, 280, 52–71. [Google Scholar] [CrossRef]
- GEUS. Groundwater Monitoring 1989–2017—Summary; GEUS: Copenhagen, Denmark, 2017. [Google Scholar]
- Miljø Metropolen. Copenhagen Climate Adaptation Plan; Miljø Metropolen: Copenhagen, Denmark, 2011. [Google Scholar]
- Fung, A.; Babcock, R. A Flow-Calibrated Method to Project Groundwater Infiltration into Coastal Sewers Affected by Sea Level Rise. Water 2020, 12, 1934. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type/Group | Variable | Type | Resolution | Source |
|---|---|---|---|---|
| Geology | Clay content (1–4) | Continuous | 30 m | Adhikari et al. [48] |
| Depth to clay occurence | Continuous | 30 m | - | |
| Soil drainage class | Categorical | 30 m | Møller et al. [49] | |
| Soil type | Categorical | N/A | GEUS [50] | |
| Topography | DEM | Continuous | 25 m | Copernicus [51] |
| Topographic wetness index | Continuous | 25 m | - | |
| Flow accumulation | Continuous | 25 m | - | |
| Slope | Continuous | 25 m | - | |
| Incoming solar radiation | Continuous | 25 m | - | |
| Water | Horizontal distance to nearest waterbody | Continuous | 25 m | - |
| Vertical distance to nearest water body | Continuous | 25 m | - | |
| Water bodies (lakes, streams, etc.) | Categorical | Koch et al. [29] | ||
| Sea level | Continuous | N/A | NOAA [52] | |
| Land cover | Corine | Categorical | 100 m | Copernicus [53] |
| Imperviousness | Continuous | 20 m | Copernicus [54] | |
| Bioclimatic variables (monthly historical data) | Precipitation | Continuous | 4.5 km | Harris et al. [55] |
| Minimum temperature | Continuous | 4.5 km | ||
| Maximum temperature | Continuous | 4.5 km | ||
| Average temperature | Continuous | 4.5 km | ||
| Coordinates | xytm | Continuous | 25 m | - |
| yutm | Continuous | 25 m | - | |
| Bioclimatic variables–Future projections | Precipitation | Continuous | 4.5 km | Fick & Hijmans [56] |
| Average temperature | Continuous | 4.5 km |
| ML Model | R2 | RMSE (m) | MAE (m) |
|---|---|---|---|
| RF | 0.75 | 0.98 | 0.61 |
| ANN | 0.63 | 1.19 | 0.85 |
| SVM | 0.65 | 1.15 | 0.75 |
| Land Cover Type | R2 | MAE (m) |
|---|---|---|
| Urban | 0.70 | 0.63 |
| Agricultural | 0.65 | 0.69 |
| Nature | 0.86 | 0.38 |
| Scenario | Winter (%) | Summer (%) |
|---|---|---|
| 2018 | 1.40 | 1.26 |
| 2.4–5 | 1.40 | 1.25 |
| 3.7–0 | 1.43 | 1.29 |
| 5.8–5 | 1.43 | 1.41 |
| Winter | Summer | |||||
|---|---|---|---|---|---|---|
| Scenario | SSP 2.4-5 | SSP 3.7-0 | SSP 5.8-5 | SSP 2.4-5 | SSP 3.7-0 | SSP 5.8-5 |
| Max. rise (m) | +0.67 | +0.83 | +0.82 | +0.70 | +0.70 | +0.71 |
| Max. fall (m) | −0.52 | −0.47 | −0.49 | −0.52 | −0.49 | −0.52 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gonzalez, R.Q.; Arsanjani, J.J. Prediction of Groundwater Level Variations in a Changing Climate: A Danish Case Study. ISPRS Int. J. Geo-Inf. 2021, 10, 792. https://doi.org/10.3390/ijgi10110792
Gonzalez RQ, Arsanjani JJ. Prediction of Groundwater Level Variations in a Changing Climate: A Danish Case Study. ISPRS International Journal of Geo-Information. 2021; 10(11):792. https://doi.org/10.3390/ijgi10110792
Chicago/Turabian StyleGonzalez, Rebeca Quintero, and Jamal Jokar Arsanjani. 2021. "Prediction of Groundwater Level Variations in a Changing Climate: A Danish Case Study" ISPRS International Journal of Geo-Information 10, no. 11: 792. https://doi.org/10.3390/ijgi10110792
APA StyleGonzalez, R. Q., & Arsanjani, J. J. (2021). Prediction of Groundwater Level Variations in a Changing Climate: A Danish Case Study. ISPRS International Journal of Geo-Information, 10(11), 792. https://doi.org/10.3390/ijgi10110792