
Massively Parallel Discovery of Loosely Moving Congestion Patterns from Trajectory Data

Abstract
:1. Introduction
- We introduce the concept of a new moving group pattern with similar movement tendency and loose consistency moving of vehicles, which we call the loosely moving congestion pattern (LMCP). Different from the previous group patterns, which were basically used to detect moving object clusters instead of traffic congestion, our proposed LMCP can exhibit the actual traffic situation like high density, direction and duration, and take into account the characteristics of group pattern and congestion together.
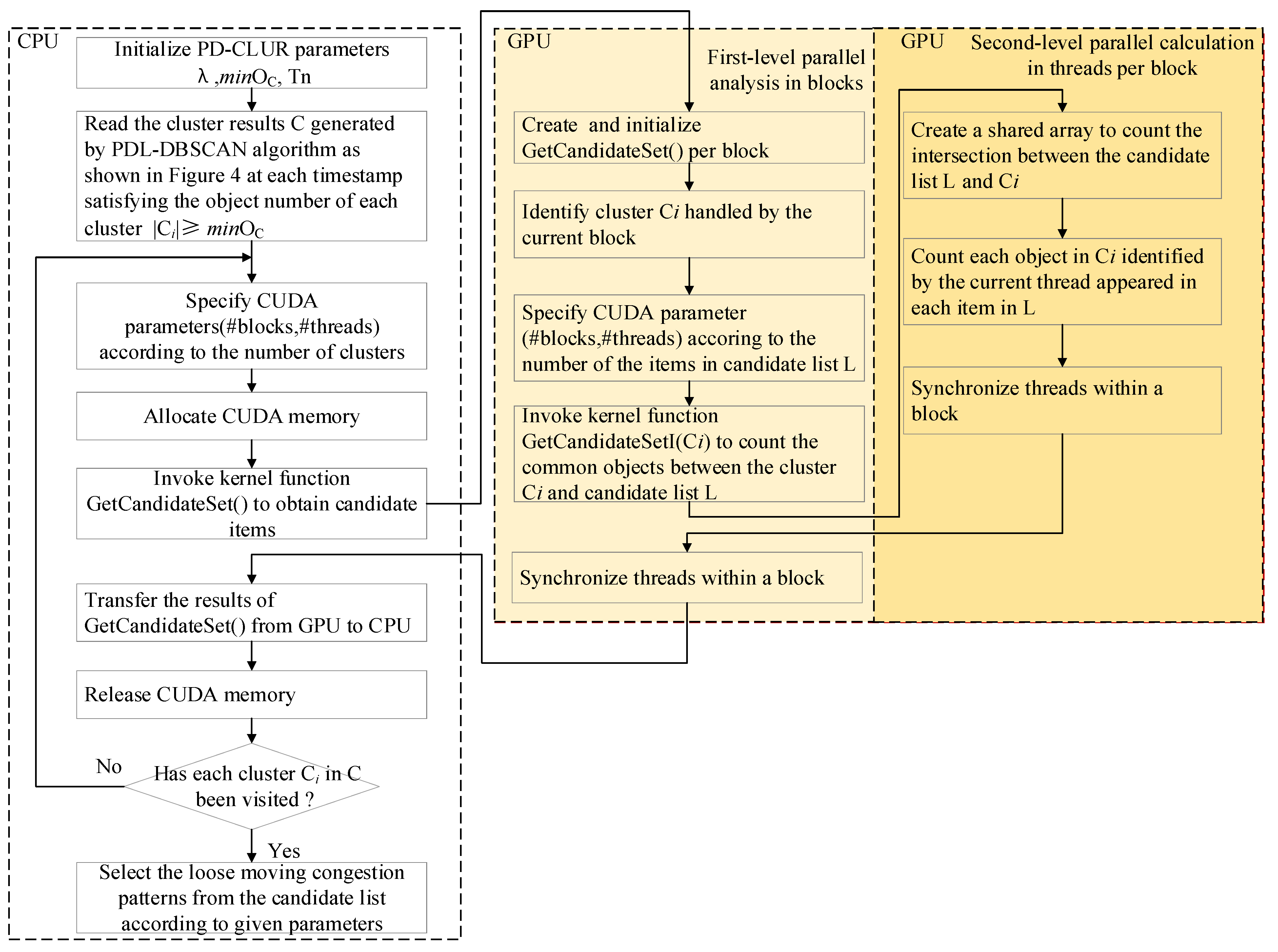
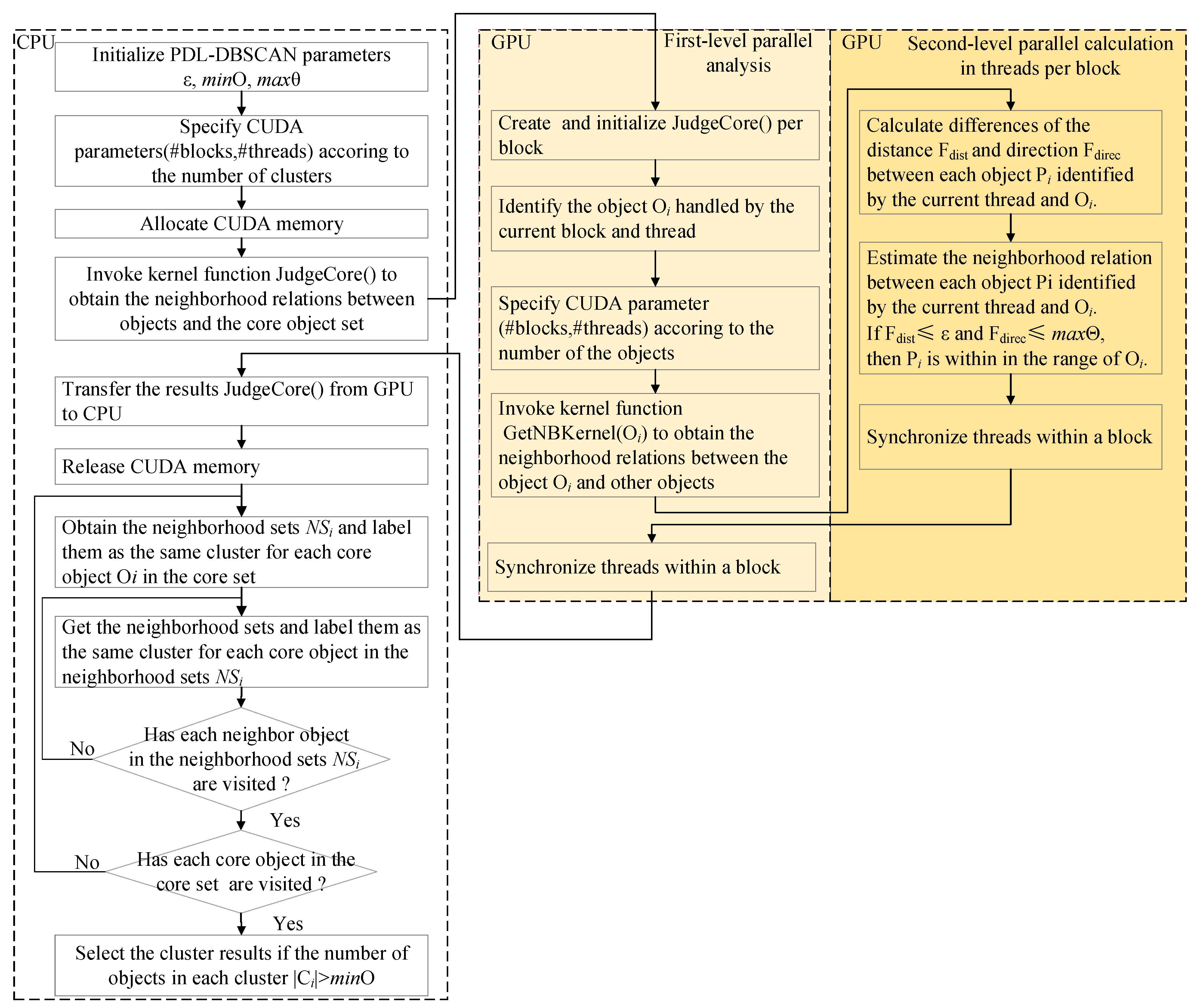
- We propose an algorithm to discover loosely moving congestion patterns based on the characteristics of LMCP and the cluster-recombinant (CLUR) algorithm [10]. In order to achieve the high performance of the algorithm, we also designed a GPU-enabled parallel algorithm named PDCLUR based on the proposed discovery algorithm for handling the massive trajectory data.
- We demonstrate the effectiveness and performance of the proposed algorithm as applied to an actual scenario. Compared with other group patterns like swarm, the discovery of LMCPs enables a better identification of congestion. Our results demonstrate certain significant congesting patterns pointing to the locations and timings of when the most congested patterns appear. Further, the proposed parallelized algorithm performs satisfactorily on handling large-scale datasets.
2. Related Works
3. Methods
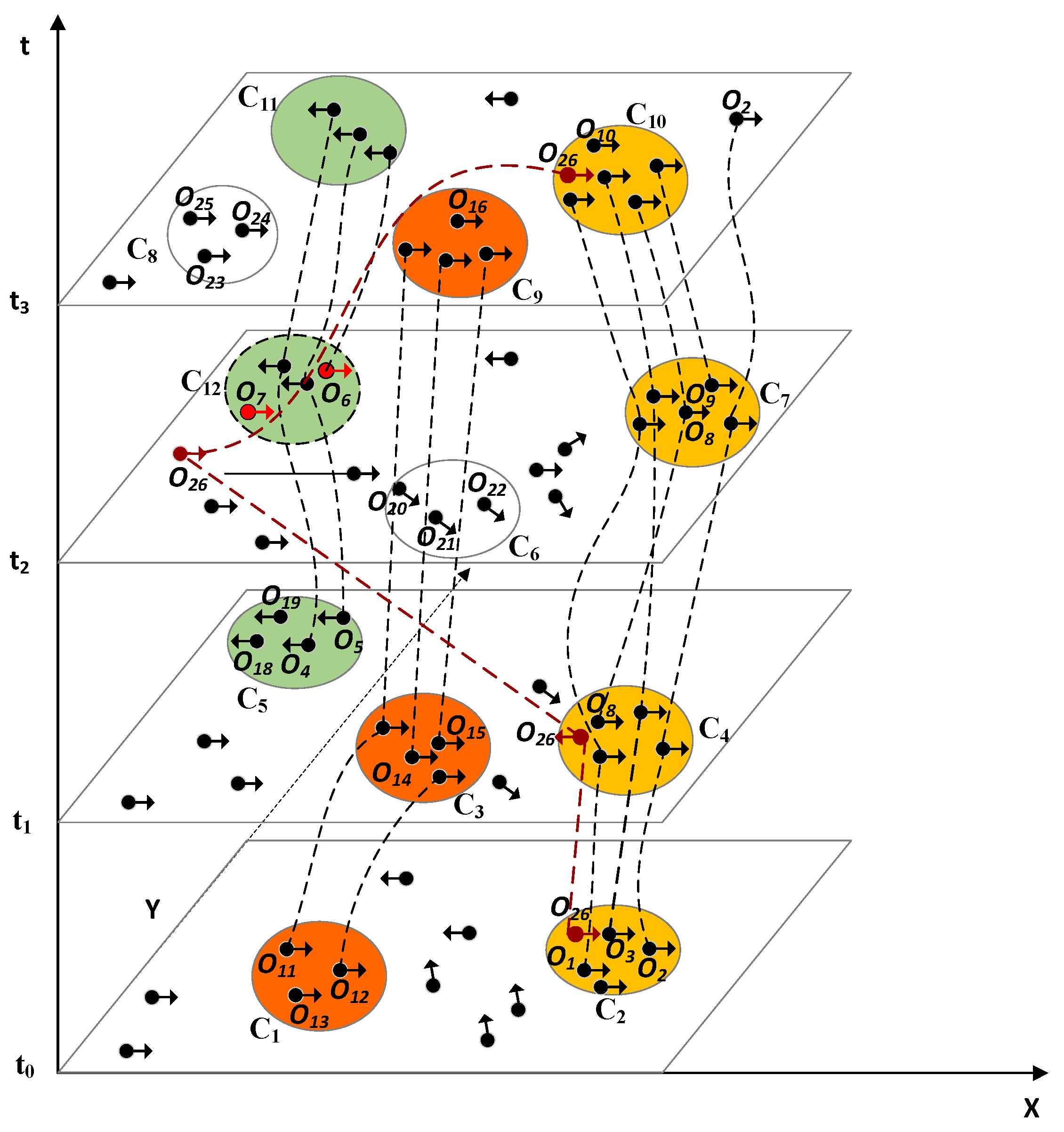
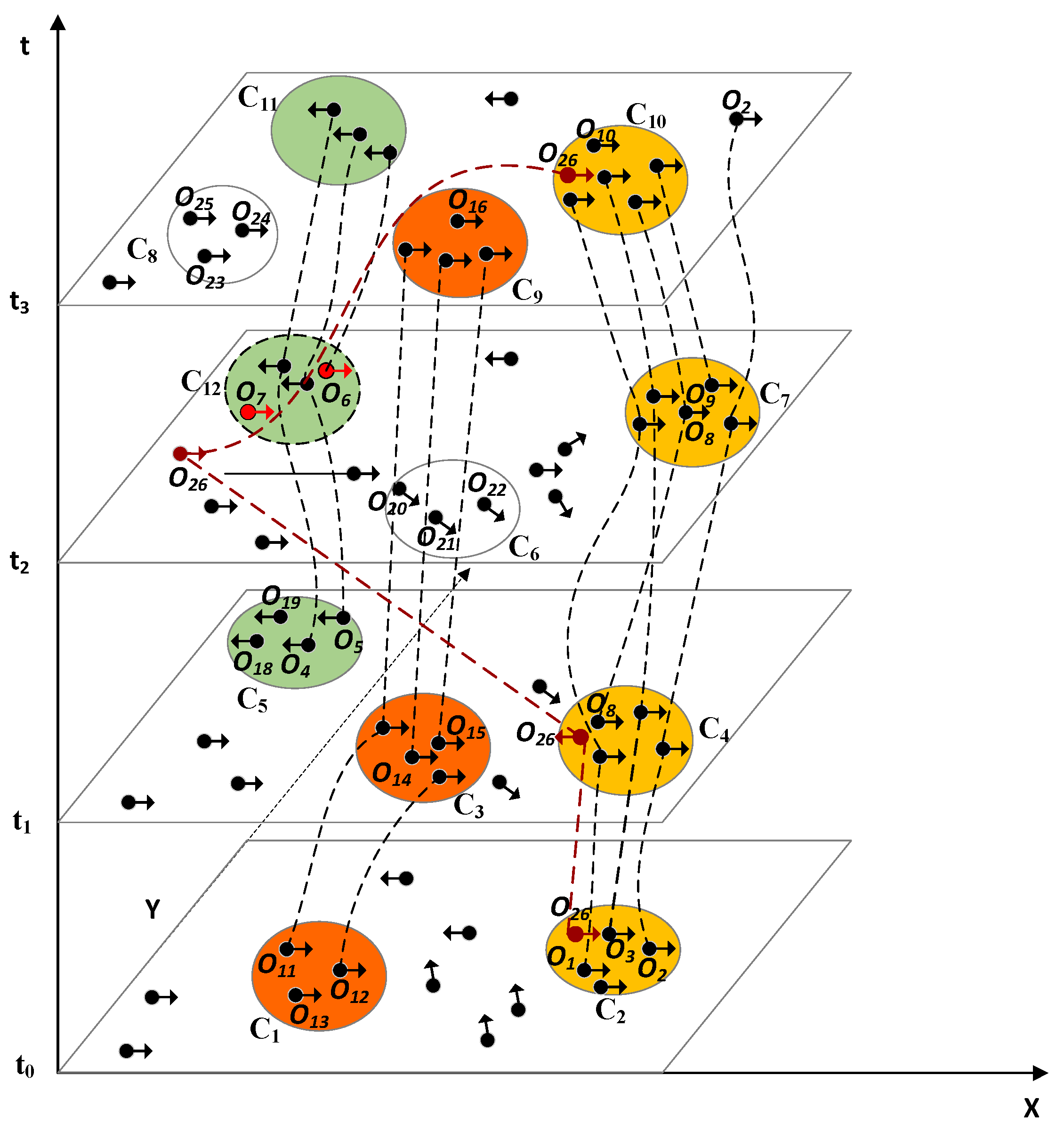
3.1. Concept and Definition
- each Ctij C represents an equidirectional spatial snapshot cluster at timestamp ti for each i (1 ≤ i < s),
- spatial cluster Cti+1k at timestamp ti+1 is formed after Ctij at timestamp ti for each i (1 ≤ i < s),
- there are at least two equidirectional spatial snapshot clusters Ctij and Cti+1k in C satisfying |Cti j ∩ Cti+1k | ≥ λ (the common object number between two consecutive equidirectional spatial snapshot clusters), where λ denotes an integer >2 during T,
- there are totally Tn time points satisfying |Ctij| ≥ minOC for each i (1 ≤ i < s) during time period T, where minOC denotes an integer >2 during T, and
- all equidirectional spatial snapshot clusters exhibit approximately the same moving direction D in a LMCP.
3.2. Pattern Discovery Algorithm
| Algorithm 1. Discovering LMCPs |
 |
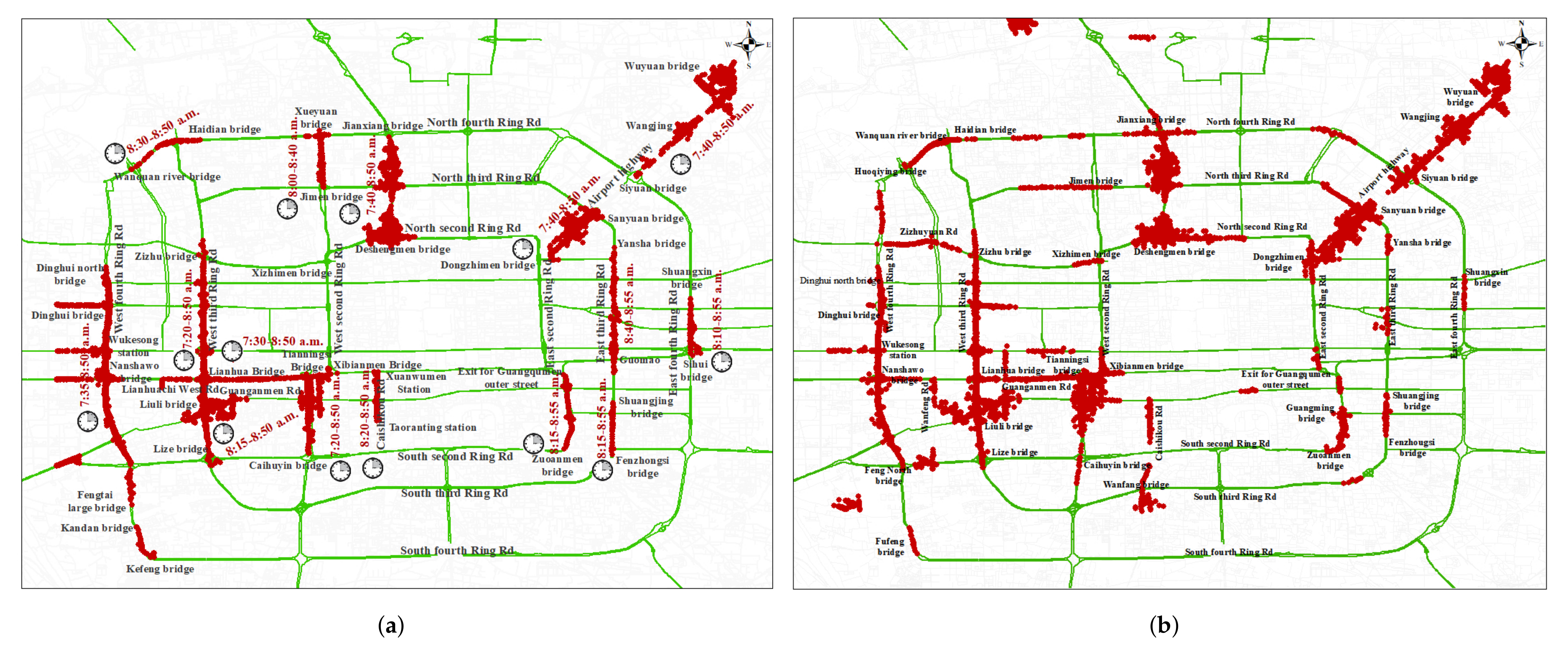
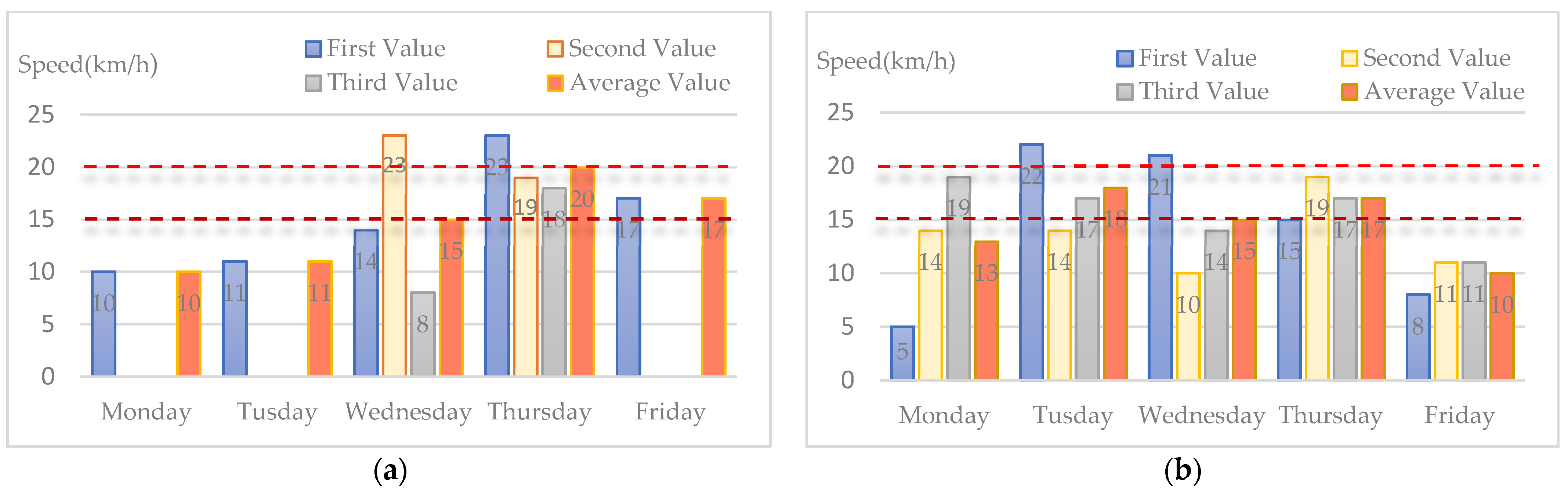
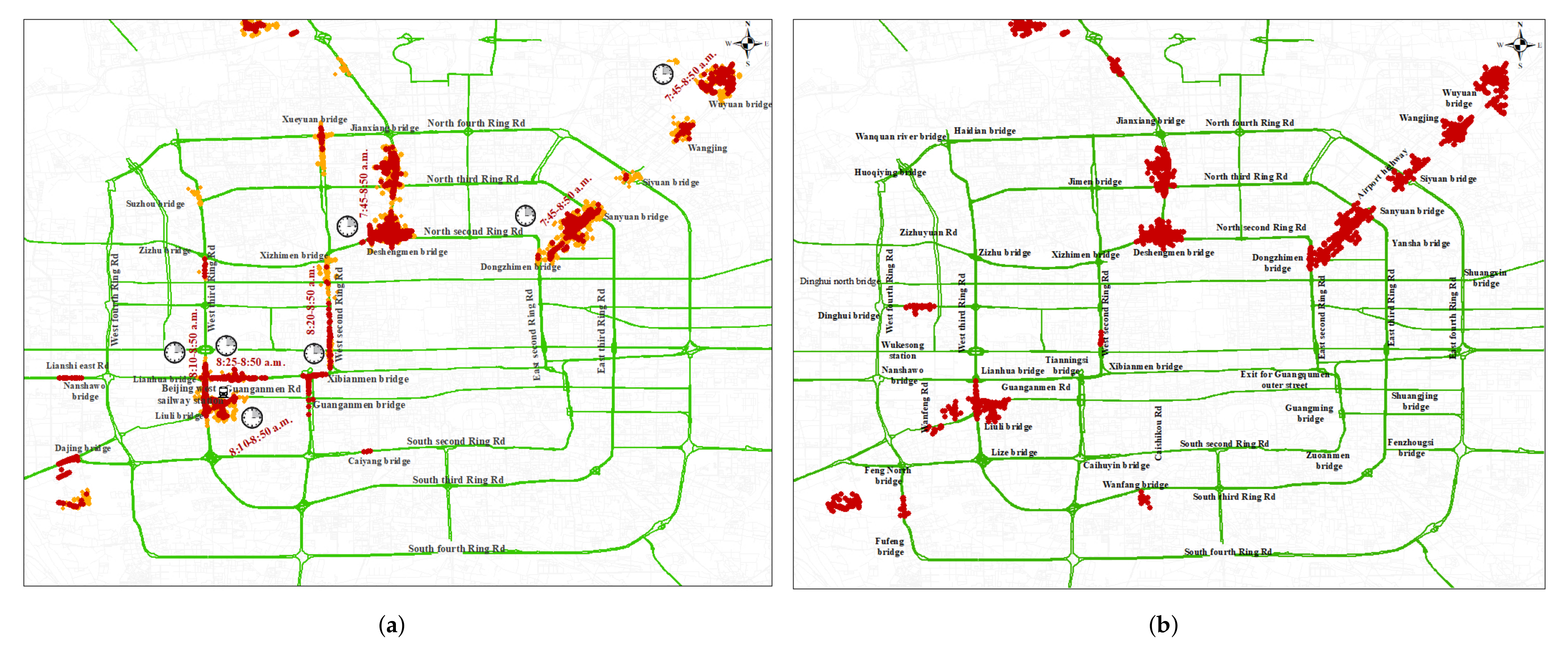
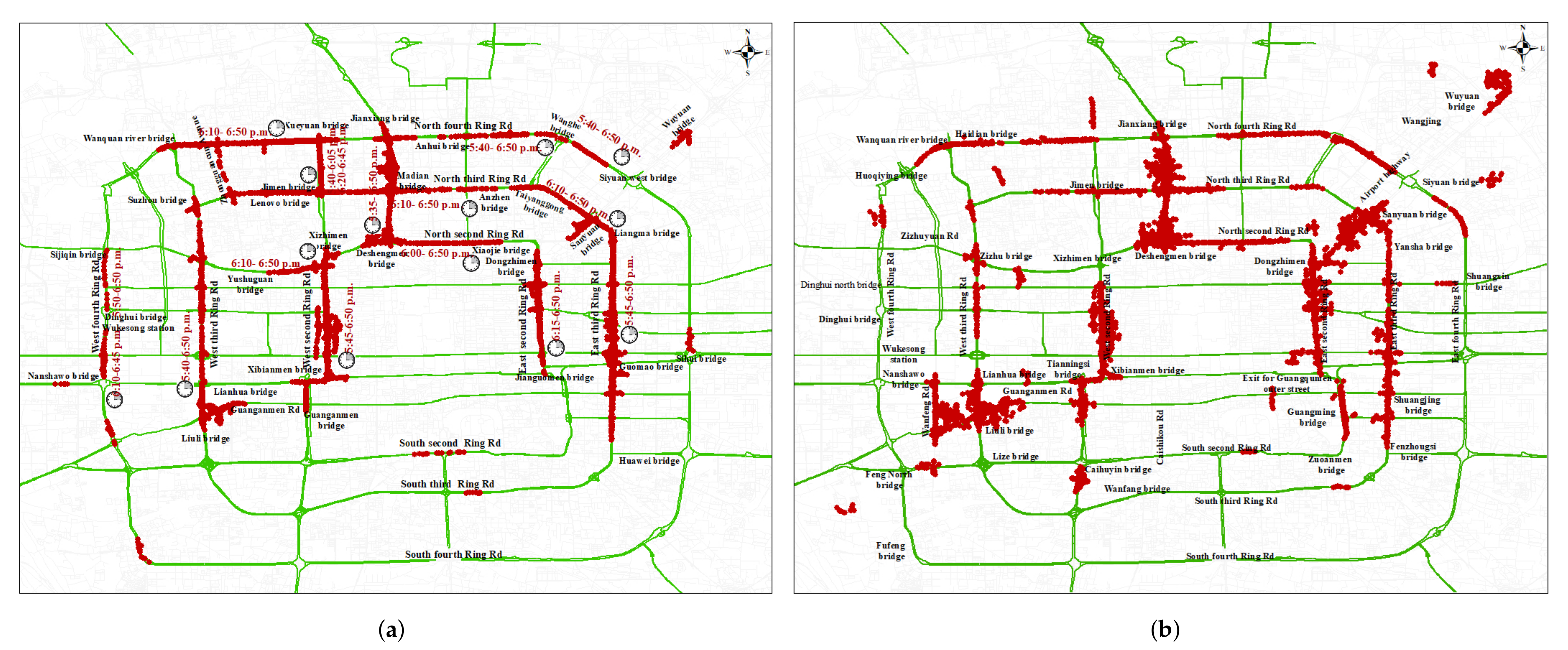
4. Case Study
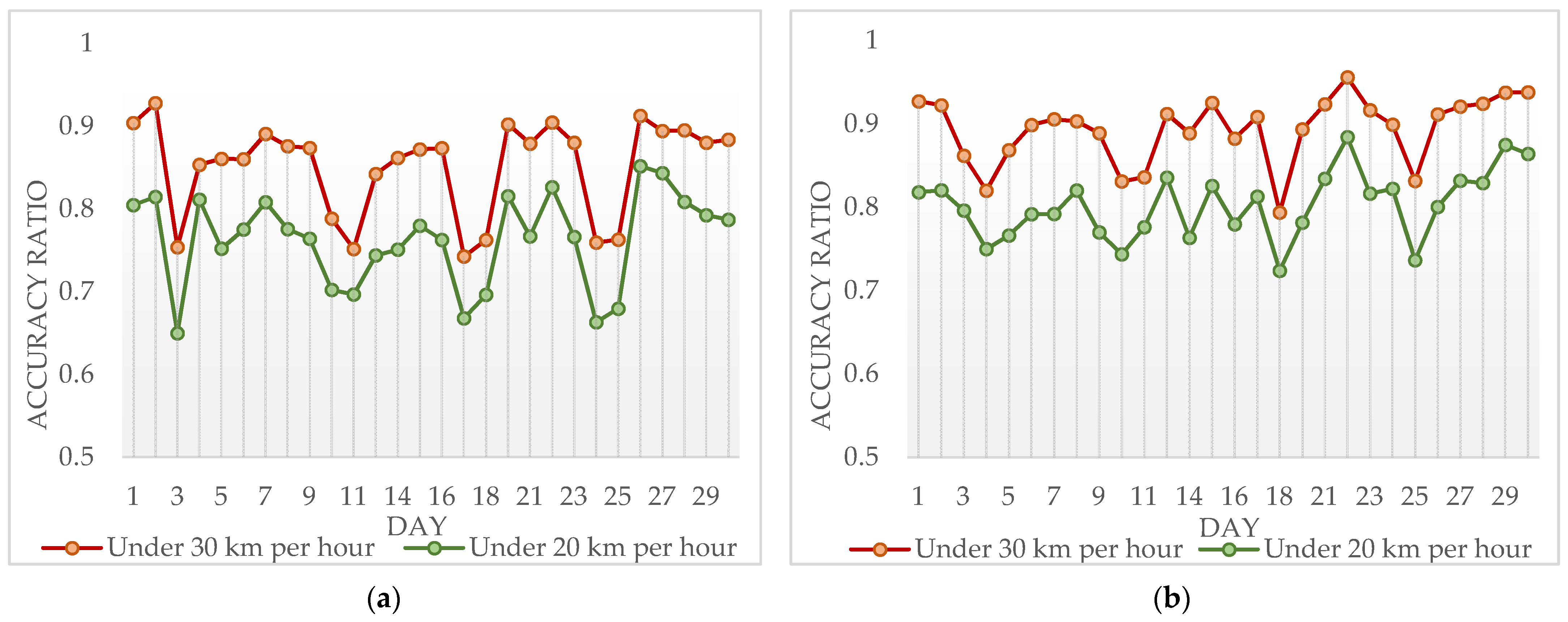
4.1. Algorithm Effectiveness Analysis and Discussion
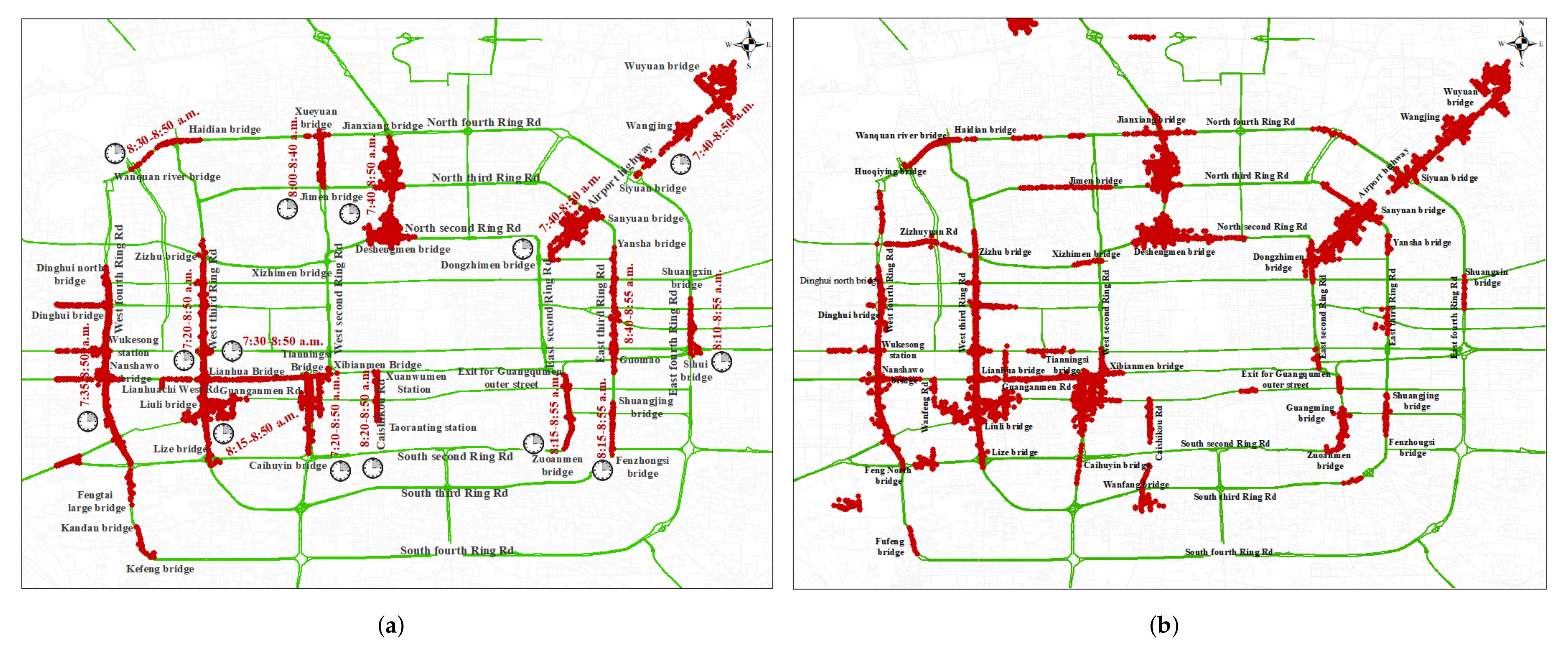
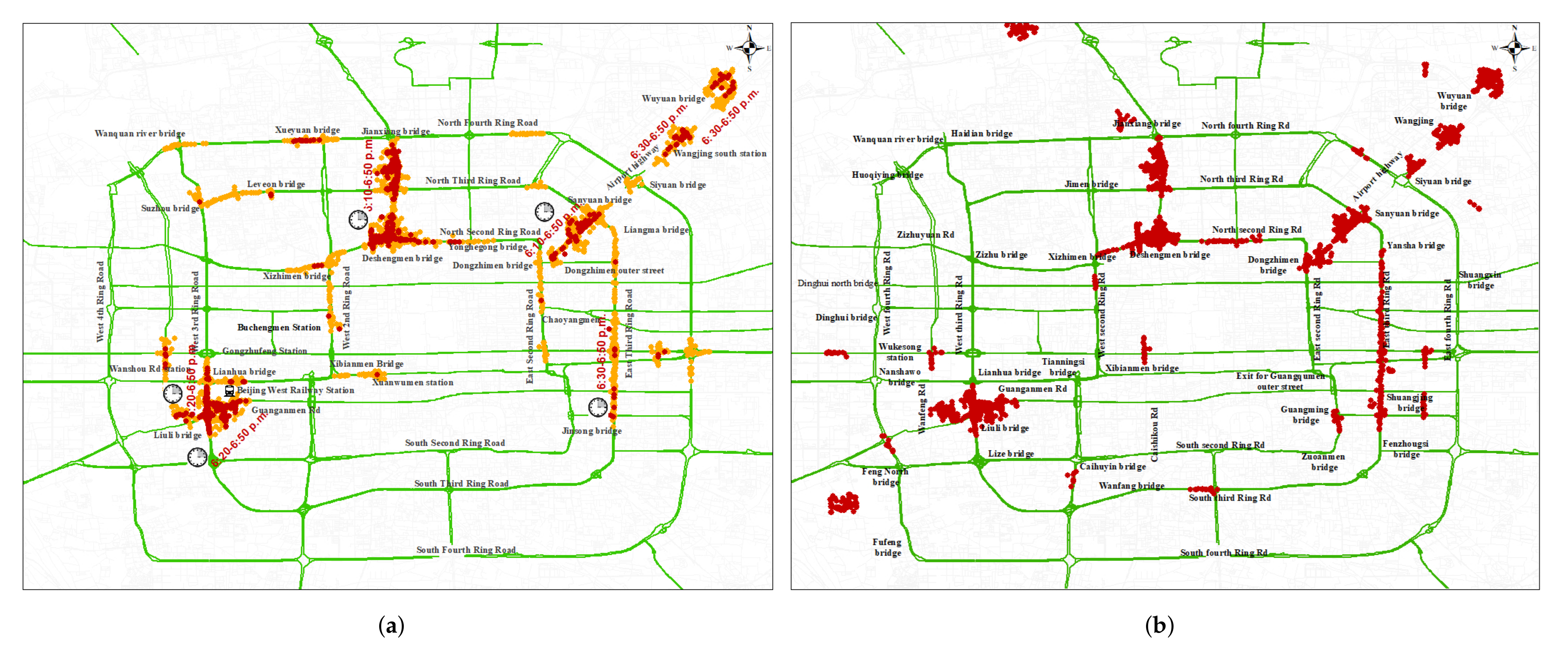
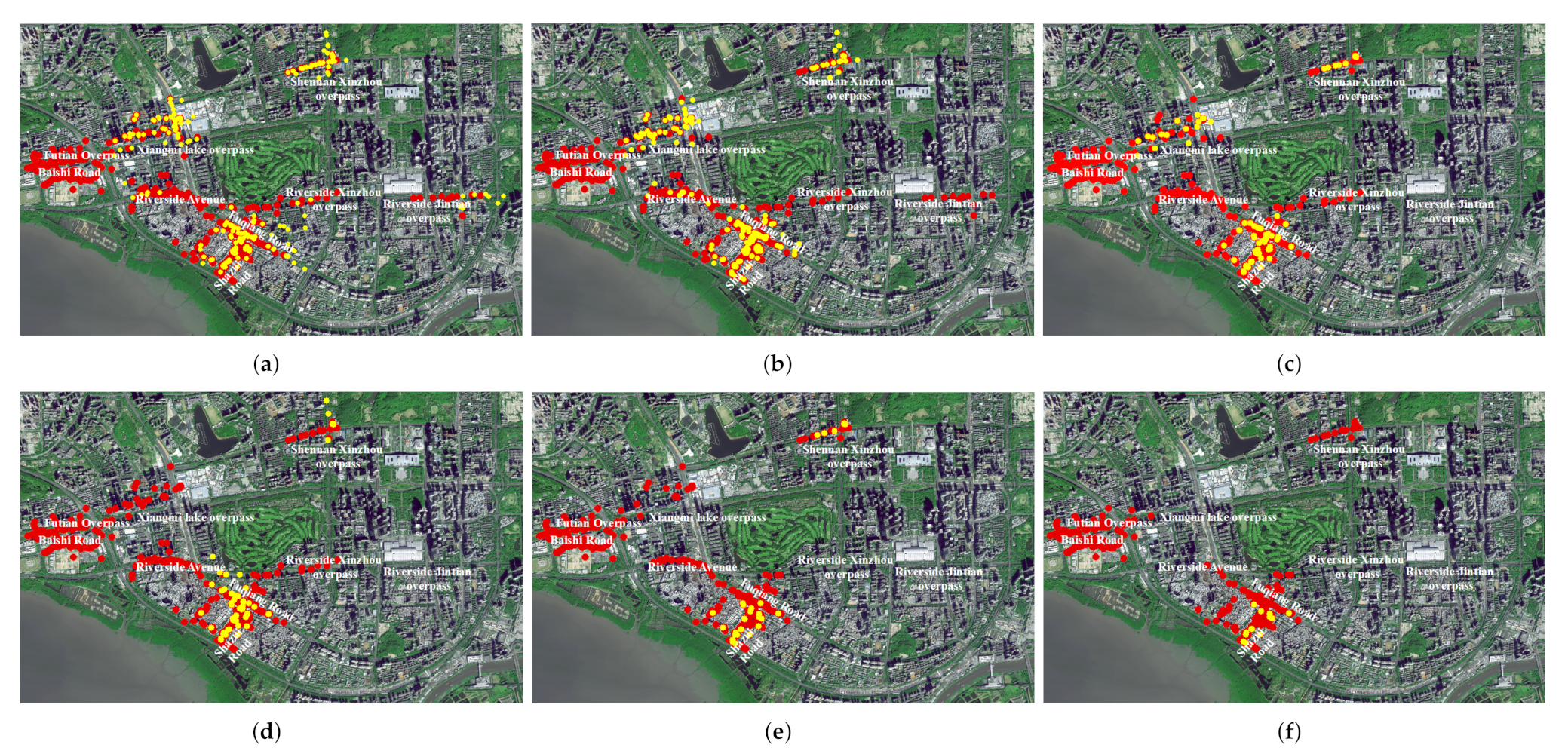
4.1.1. Effectiveness of LMCP Discovery Algorithm for Shenzhen Samples Dataset
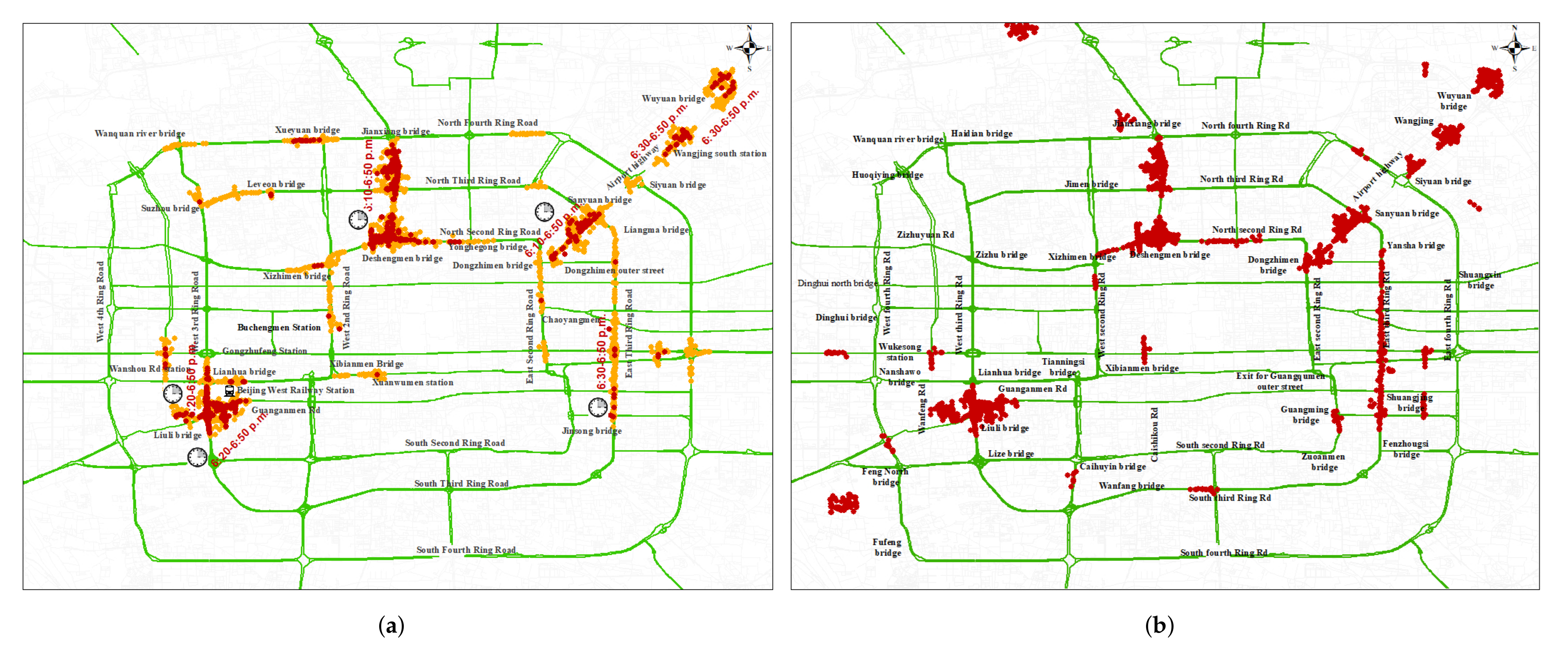
4.1.2. Effectiveness of LMCP Discovery Algorithm for Beijing Samples Dataset
4.2. Algorithm Performance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, Y.; Seah, H.S. Points of interest recommendation from GPS trajectories. Int. J. Geogr. Inf. Sci. 2015, 29, 953–979. [Google Scholar] [CrossRef]
- Li, H.; Kulik, L.; Ramamohanarao, K. Robust inferences of travel paths from GPS trajectories. Int. J. Geogr. Inf. Sci. 2015, 29, 2194–2222. [Google Scholar] [CrossRef]
- Wang, J.; Rui, X.; Song, X.; Tan, X.; Wang, C.; Raghavan, V. A novel approach for generating routable road maps from vehicle GPS traces. Int. J. Geogr. Inf. Sci. 2015, 29, 69–91. [Google Scholar] [CrossRef]
- Hazan, I.; Shabtai, A. Dynamic radius and confidence prediction in grid-based location prediction algorithms. Pervasive Mob. Comput. 2017, 42, 265–284. [Google Scholar] [CrossRef]
- Li, B.; Zhang, D.; Sun, L.; Chen, C.; Li, S.; Qi, G.; Yang, Q. Hunting or waiting? Discovering passenger-finding strategies from a large-scale real-world taxi dataset. In Proceedings of the 9th IEEE International Conference on Pervasive Computing and Communications Workshops, Seattle, WA, USA, 21–25 March 2011; IEEE Computer Society: Washington, DC, USA, 2011; pp. 63–68. [Google Scholar]
- Mao, F.; Ji, M.; Liu, T. Mining spatiotemporal patterns of urban dwellers from taxi trajectory data. Front. Earth Sci. 2016, 10, 205–221. [Google Scholar] [CrossRef]
- Benkert, M.; Gudmundsson, J.; Hübner, F.; Wolle, T. Reporting flock patterns. In Proceedings of the 14th Annual European Symposium on Algorithms, Zurich, Switzerland, 11–13 September 2006; pp. 660–671. [Google Scholar]
- Jeung, H.; Yiu, M.; Zhou, X.; Jensen, C.S.; Shen, H. Discovery of convoys in trajectory databases. Proc. VLDB Endow. 2008, 1, 1068–1080. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Ding, B.; Han, J.; Kays, R. Swarm: Mining relaxed temporal moving object clusters. Proc. VLDB Endow. 2010, 3, 723–734. [Google Scholar] [CrossRef]
- Qi, Y.; Yu, Y.; Kuang, J.; He, J.; Wang, Q. Efficient algorithm for real-time mining swarm patterns. J. Univ. Sci. Technol. Beijing 2012, 34, 37–42. [Google Scholar]
- Agarwal, D.; McGregor, A.; Phillips, J.; Venky, S.; Zhu, Z. Spatial scan statistics: Approximations and performance study. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 24–33. [Google Scholar]
- Lee, J.; Gong, J.; Li, S. Exploring spatiotemporal clusters based on extended kernel estimation methods. Int. J. Geogr. Inf. Sci. 2017, 31, 1154–1177. [Google Scholar]
- Cao, X.; Cong, G.; Jensen, C.S. Mining significant semantic locations from GPS data. Proc. VLDB Endow. 2010, 3, 1009–1020. [Google Scholar] [CrossRef] [Green Version]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the 2nd International Conference Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996. [Google Scholar]
- Li, Q.; Zeng, Z.; Zhang, T.; Li, J.; Wu, Z. Path-finding through flexible hierarchical road networks: An experiential approach using taxi trajectory data. Int. J. Appl. Earth Obs. Geoinf. 2011, 13, 110–119. [Google Scholar] [CrossRef]
- Zhao, P.; Qin, K.; Ye, X.; Wang, Y.; Chen, Y. A trajectory clustering approach based on decision graph and data field for detecting hotspots. Int. J. Geogr. Inf. Sci. 2017, 31, 1101–1127. [Google Scholar] [CrossRef]
- Etienne, L.; Devogele, T.; Buchin, M.; McArdle, G. Trajectory Box Plot: A new pattern to summarize movements. Int. J. Geogr. Inf. Sci. 2016, 30, 835–853. [Google Scholar] [CrossRef]
- Zhang, P.; Deng, M.; Shi, Y.; Zhao, L. Detecting hotspots of urban residents’ behaviours based on spatio-temporal clustering techniques. GeoJournal 2017, 82, 923–935. [Google Scholar] [CrossRef]
- Khalid, S.; Shoaib, F.; Qian, T.; Rui, Y.; Bari, A.I.; Sajjad, M.; Shakeel, M.; Wang, J. Network constrained spatio-temporal hotspot mapping of crimes in Faisalabad. Appl. Spat. Anal. Policy 2018, 11, 599–622. [Google Scholar] [CrossRef]
- Kalnis, P.; Mamoulis, N.; Bakira, S. On discovering moving clusters in spatio-temporal data. Lect. Notes Comput. Sci. 2005, 3633, 364–381. [Google Scholar]
- Wu, H.-R.; Yeh, M.-Y.; Chen, M.-S. Profiling moving objects by dividing and clustering trajectories spatiotemporally. IEEE Trans. Knowl. Data Eng. 2013, 25, 2615–2628. [Google Scholar] [CrossRef]
- Patel, D. On discovery of spatiotemporal influence-based moving clusters. ACM Trans. Intell. Syst. Technol. 2015, 6, 2631926. [Google Scholar] [CrossRef]
- Amornbunchornvej, C.; Berger-Wolf, T.Y. Mining and modeling complex leadership-followership dynamics of movement data. Soc. Netw. Anal. Min. 2019, 9, 58. [Google Scholar] [CrossRef]
- Bermingham, L.; Lee, I. Mining place-matching patterns from spatio-temporal trajectories using complex real-world places. Exp. Syst. Appl. 2019, 122, 334–350. [Google Scholar] [CrossRef]
- Zheng, K.; Zheng, Y.; Yuan, N.J.; Shang, S.; Zhou, X. Online discovery of gathering patterns over trajectories. IEEE Trans. Knowl. Data Eng. 2014, 26, 1974–1988. [Google Scholar] [CrossRef]
- Zhang, J.; Li, J.; Liu, Z.; Yuan, Q.; Yang, F. Moving objects gathering patterns retrieving based on spatio-temporal graph. Int. J. Web Serv. Res. 2016, 13, 88–107. [Google Scholar] [CrossRef] [Green Version]
- Loglisci, C. Using interactions and dynamics for mining groups of moving objects from trajectory data. Int. J. Geogr. Inf. Sci. 2018, 32, 1436–1468. [Google Scholar] [CrossRef]
- Zhao, B.; Liu, X.T.; Jia, J.P.; Ji, G.L.; Tan, S.X.; Yu, Z.Y. A framework for group converging pattern mining using spatiotemporal trajectories. Geoinformatica 2020, 24, 745–776. [Google Scholar] [CrossRef]
- Zhao, P.; Hu, H. Geographical patterns of traffic congestion in growing megacities: Big data analytics from Beijing. Cities 2019, 92, 164–174. [Google Scholar] [CrossRef]
- Kohan, M.; Ale, J.M. Discovering traffic congestion through traffic flow patterns generated by moving object trajectories. Comput. Environ. Urban Syst. 2020, 80, 101426. [Google Scholar] [CrossRef]
- Wang, G.; Chen, X.; Zhang, F.; Wang, Y.; Zhang, D. Experience: Understanding long-term evolving patterns of shared electric vehicle networks. In Proceedings of the 25th Annual International Conference on Mobile Computing and Networking (MobiCom), Los Cabos, Mexico, 21–25 October 2019; ACM: New York, NY, USA, 2019. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| t0 | t1 | ||||||
| O | C | T | D | O | C | T | D |
| O1, O2, O3, O26 | C2 | t0 | 0 | O1, O2, O3, O8 | C2, C4 | t0, t1 | 0 |
| O11, O12, O13 | C1 | t0 | 0 | O11, O12, O14, O15 | C1, C3 | t0, t1 | 0 |
| O4, O5, O18, O19 | C5 | t1 | π | ||||
| t2 | t3 | ||||||
| O | C | T | D | O | C | T | D |
| O1, O2, O3, O8, O9 | C2, C4, C7 | t0, t1, t2 | 0 | O1, O2, O3, O8, O9, O10 | C2, C4, C7, C10 | t0, t1, t2, t3 | 0 |
| O4, O5, O18, O19 | C5, C12 | t1, t2 | π | O11, O12, O14, O15, O16 | C1, C3, C9 | t0, t1, t3 | 0 |
| O20, O21, O22 | C6 | t2 | 1.75π | O4, O5, O18, O19 | C5, C12, C11 | t1, t2, t3 | π |
| O11, O12, O14, O15 | C1, C3 | t0, t1 | 0 | O20, O21, O22 | C6 | t2 | 1.75π |
| Days | Number of Points | Time Taken Using Algorithm 1 (s) | Time Taken Using PDCLUR (s) | Acceleration Ratio |
|---|---|---|---|---|
| 1 | 166,758 | 950 | 13 | 73.08 |
| 5 | 735,726 | 4112 | 57 | 72.14 |
| 10 | 1,535,117 | 8571 | 119 | 72.03 |
| 14 | 2,150,514 | 11,961 | 175 | 68.35 |
| 18 | 2,747,272 | 15,204 | 223 | 68.18 |
| 23 | 3,534,680 | 19,619 | 281 | 69.82 |
| 28 | 4,339,689 | 24,056 | 352 | 68.34 |
| Days | Number of Points | Time Taken Using Algorithm 1 (s) | Time Taken Using PDCLUR (s) | Acceleration Ratio |
|---|---|---|---|---|
| 1 | 205,289 | 1143 | 15 | 76.2 |
| 5 | 901,220 | 5008 | 69 | 72.58 |
| 10 | 1,901,502 | 10,627 | 146 | 72.79 |
| 14 | 2,589,308 | 14,464 | 193 | 74.94 |
| 18 | 3,378,266 | 18,710 | 263 | 71.14 |
| 23 | 4,412,752 | 24,639 | 375 | 65.7 |
| 28 | 5,452,006 | 30,634 | 458 | 66.91 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, C.; Chen, S. Massively Parallel Discovery of Loosely Moving Congestion Patterns from Trajectory Data. ISPRS Int. J. Geo-Inf. 2021, 10, 787. https://doi.org/10.3390/ijgi10110787
Hu C, Chen S. Massively Parallel Discovery of Loosely Moving Congestion Patterns from Trajectory Data. ISPRS International Journal of Geo-Information. 2021; 10(11):787. https://doi.org/10.3390/ijgi10110787
Chicago/Turabian StyleHu, Chunchun, and Si Chen. 2021. "Massively Parallel Discovery of Loosely Moving Congestion Patterns from Trajectory Data" ISPRS International Journal of Geo-Information 10, no. 11: 787. https://doi.org/10.3390/ijgi10110787
APA StyleHu, C., & Chen, S. (2021). Massively Parallel Discovery of Loosely Moving Congestion Patterns from Trajectory Data. ISPRS International Journal of Geo-Information, 10(11), 787. https://doi.org/10.3390/ijgi10110787