
Fully Automated Pose Estimation of Historical Images in the Context of 4D Geographic Information Systems Utilizing Machine Learning Methods


Abstract
:1. Introduction
2. Related Work
2.1. Image Retrieval
2.2. Feature Detection and Matching
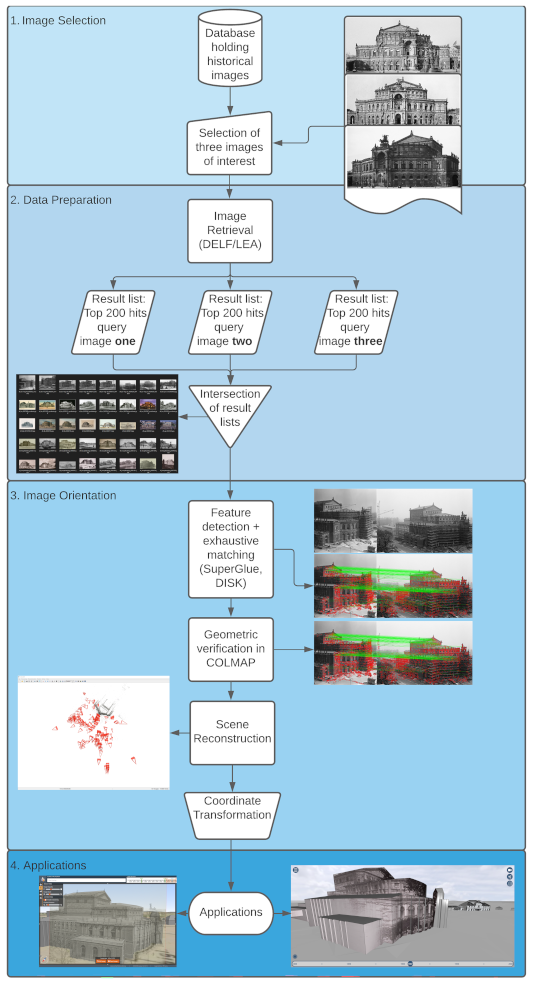
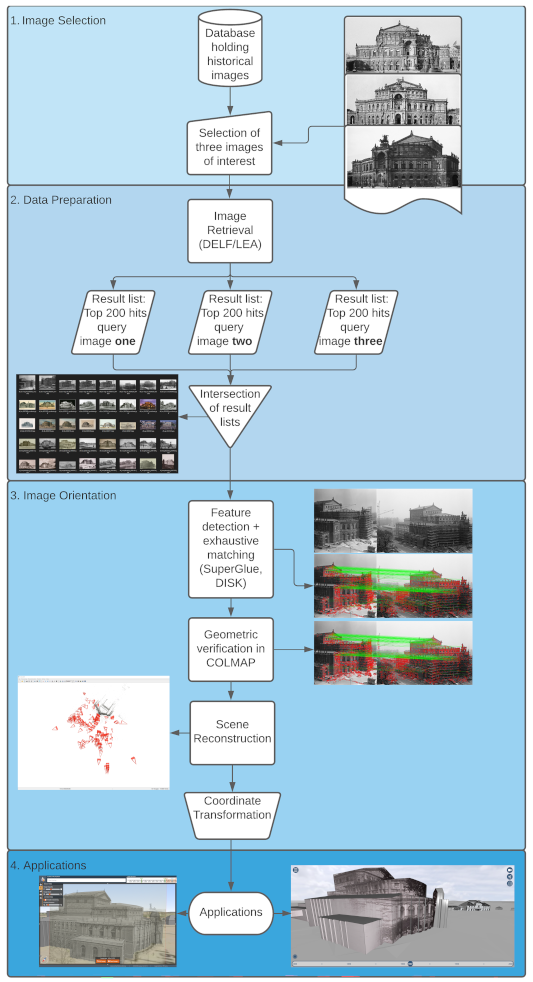
3. Data Preparation: Image Retrieval
3.1. Experiment and Data
- 1.
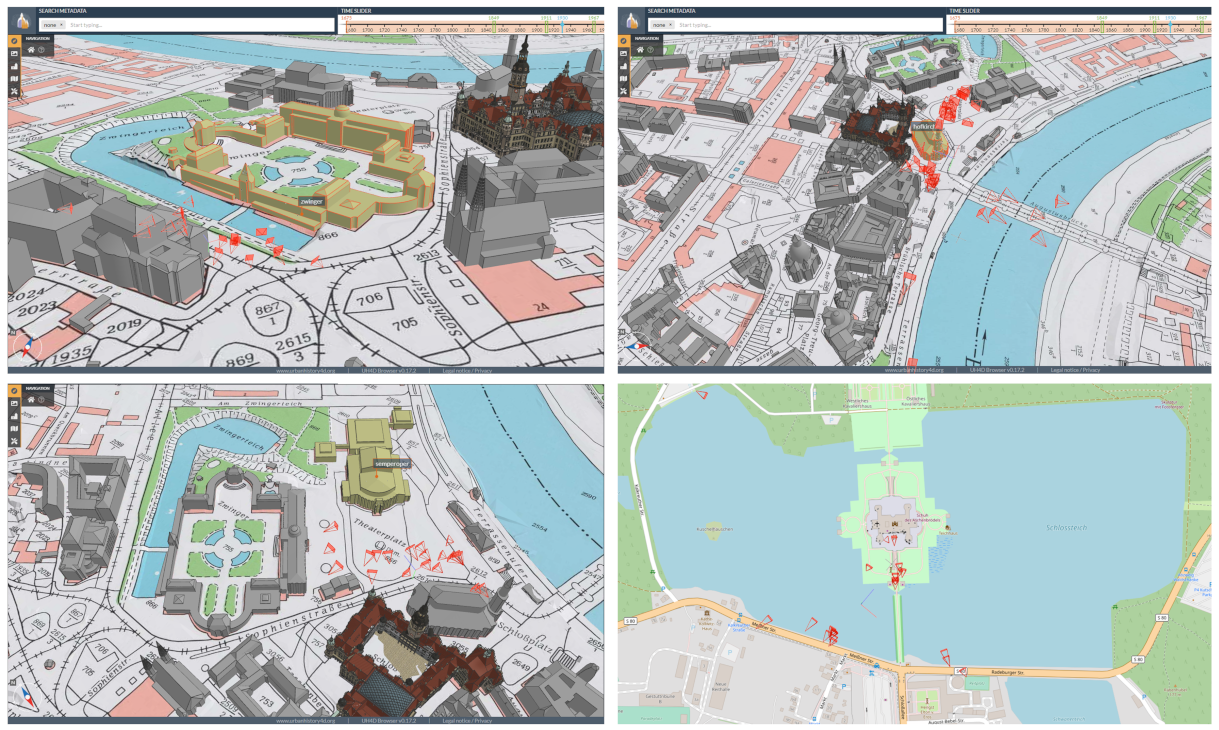
- A fixed number of OoI in the vicinity of Dresden, Germany is defined: Frauenkirche, Hofkirche, Moritzburg, Semperoper, Sophienkirche, Stallhof, Crowngate
- 2.
- For each OoI, a MD search is performed returning a list of results. Note that each of these result lists contains a different number of images across the different OoI.
- 3.
- The result list from step 2. is sorted by two criteria: by name and recording date (ascending and descending each). As an outcome, there is a total of four result lists from the MD search for every single OoI.
- 4.
- To perform IR, for each OoI three query images are defined. Based on each query image, both IR approaches (LEA, DELF) are applied to the result list of every OoI from step 2. The outcome here is one result list per query image with the most similar images at the top.
- 5.
- All result lists from step 3. and step 4. are evaluated for the top-200 positions (more details on evaluation in Section 3.3).
3.2. Methods
3.2.1. Layer Extraction Approach (LEA)
- 1.
- kernel size with stride 0, leading to resulting feature maps of size each (i.e., maximum reduction); flattened to vector of size
- 2.
- kernel size with stride 3, leading to resulting feature maps of size each; flattened to vector of size
3.2.2. Attentive Deep Local Features (DELF) Approach
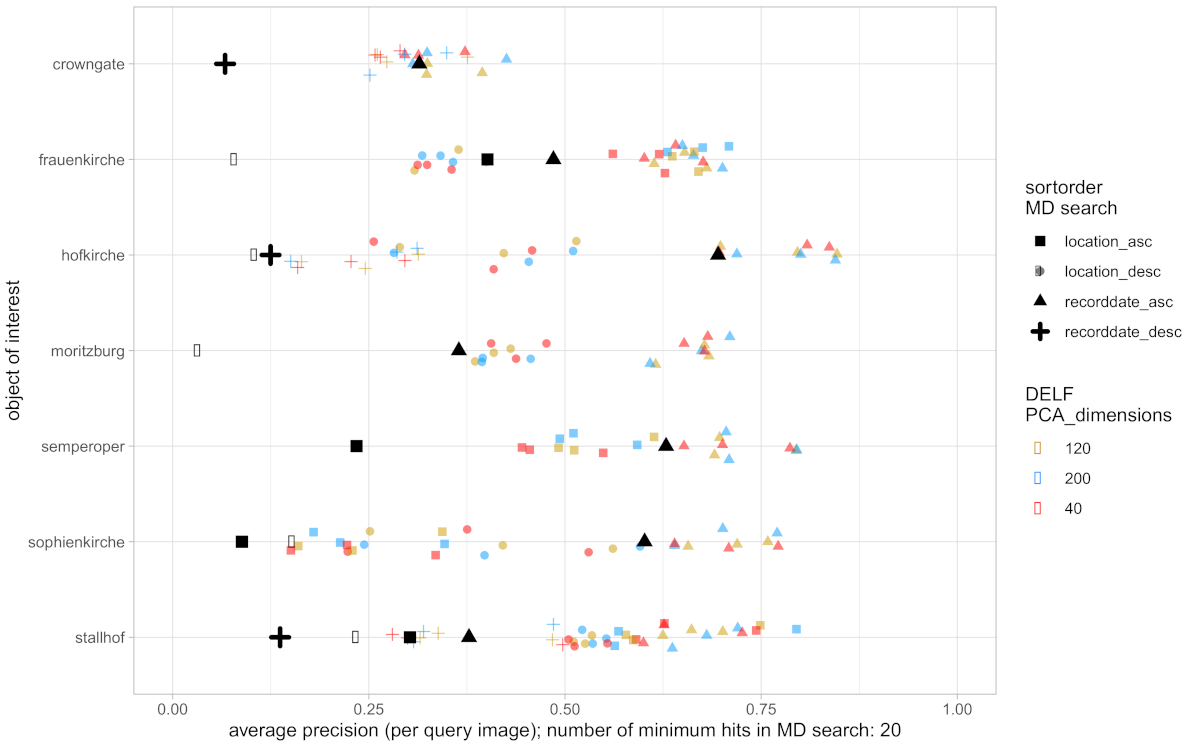
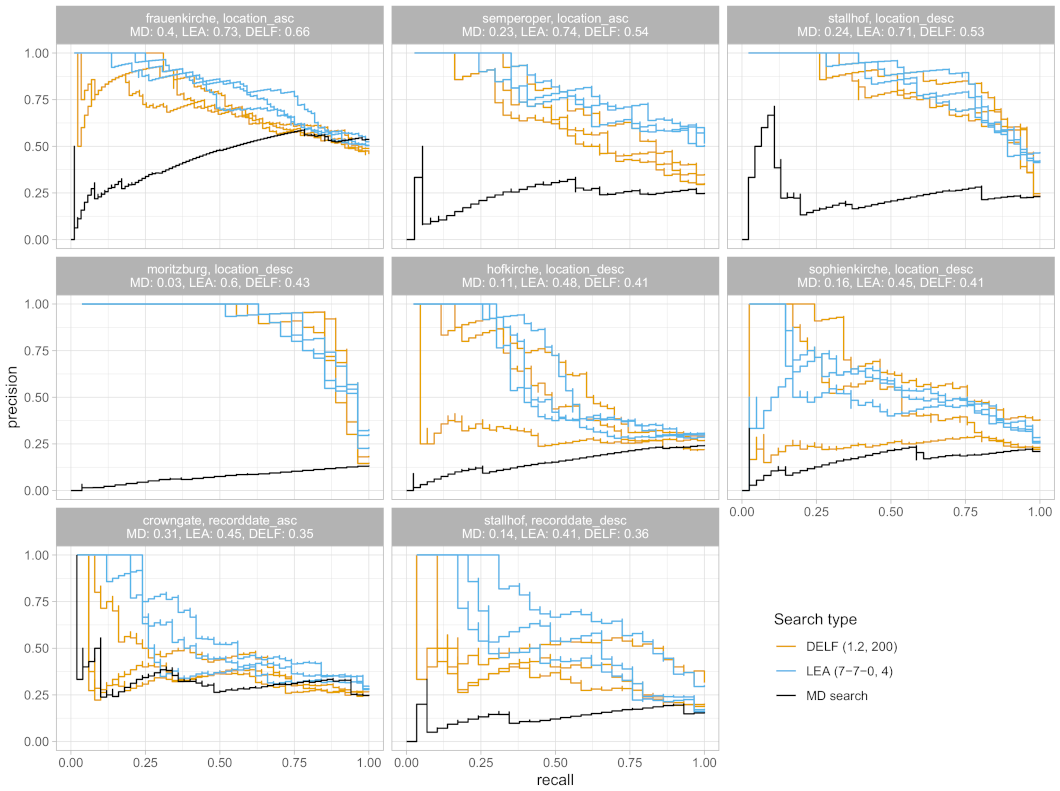
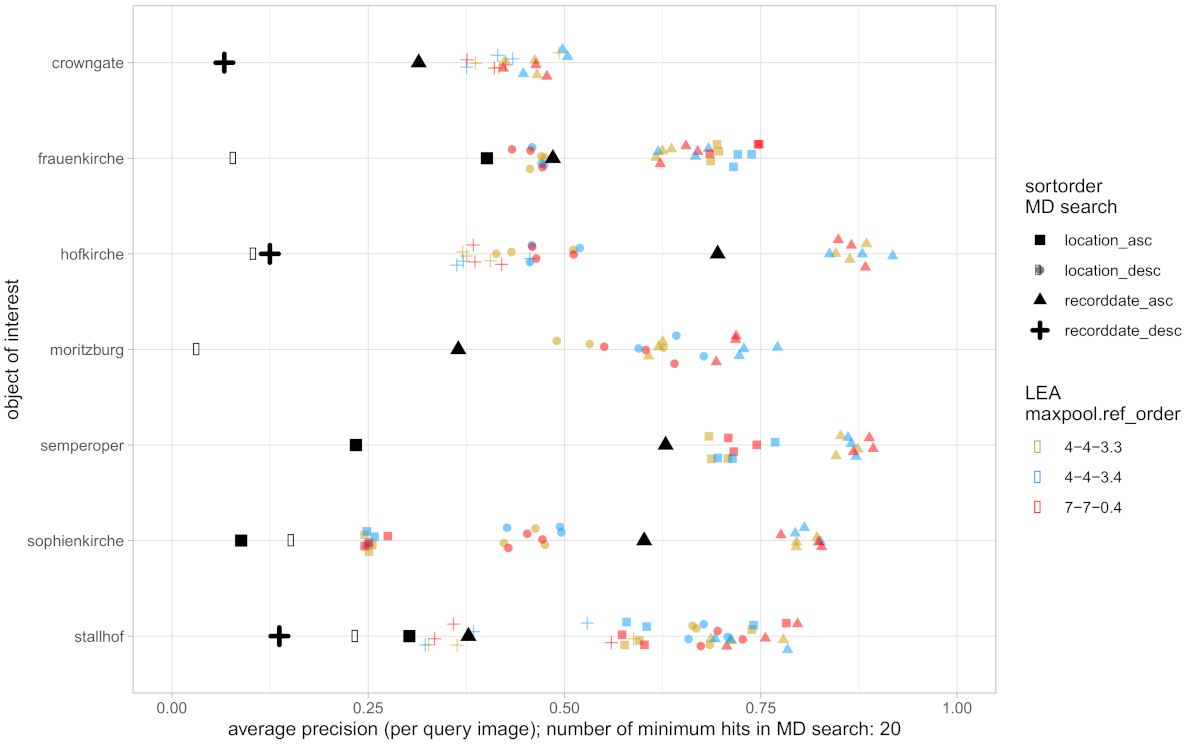
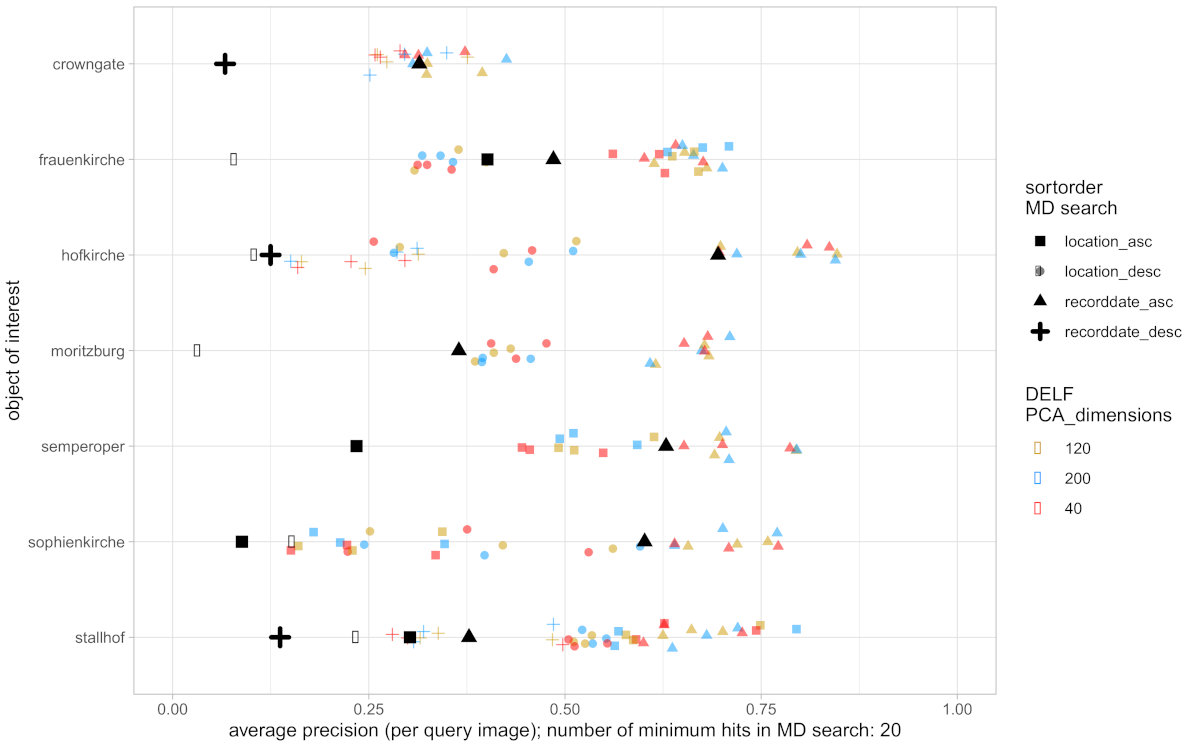
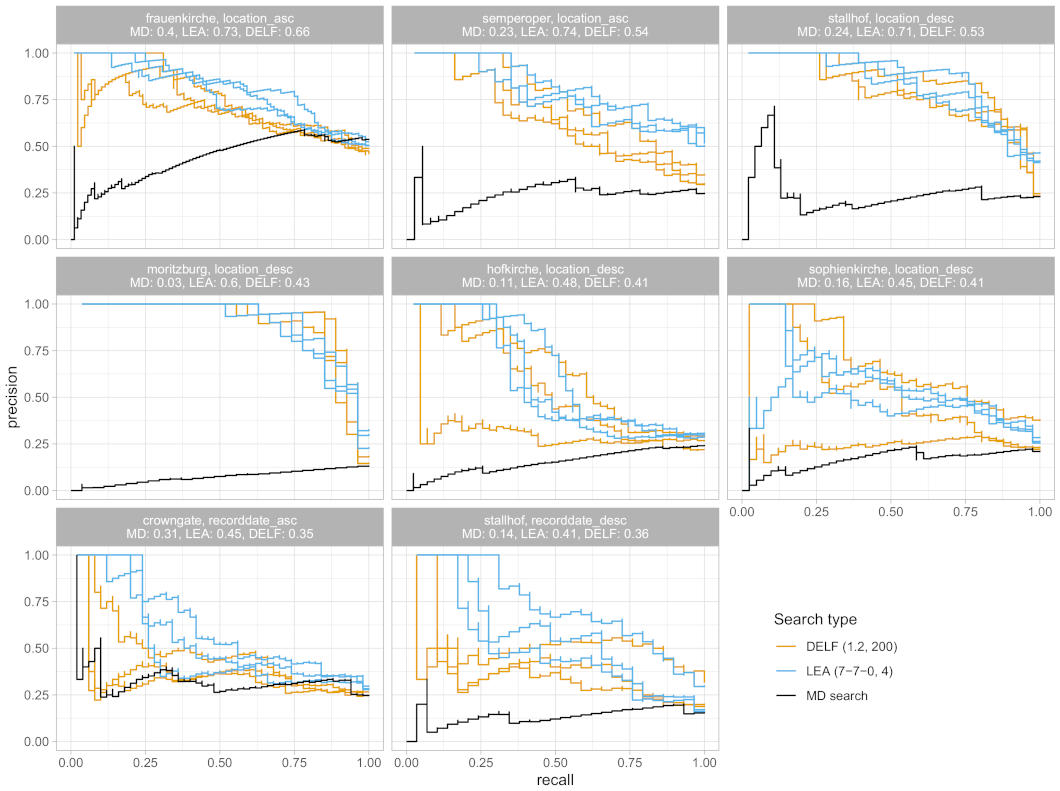
3.3. Results and Evaluation
- MD search: sorted by recording date and location, in ascending and descending order, respectively
- LEA, DELF: sorted by distance measure depending on the approach (top ranked positions have small distances to query image)
- relevant image before or at the considered position is a true positive (TP or a hit)
- irrelevant image that occurs before or at the considered position is a false positive (FP or a miss)
- For each OoI, the AP of the MD search is marked with a large black symbol (square, circle, etc.) as a reference value.
- The 4 different symbol shapes (square, circle, triangle, cross) refer to the considered sorting order for the MD search.
- Within each OoI there might be less than 4 symbol shapes due to the requirement of at least 20 hits from the MD search.
- Besides the black symbols, the other colors refer to different parameter settings of the IR approach under consideration. Since the IR is based on 3 query images, there are 3 symbols of the same shape and color within each line for each IR setting.
- Finally, symbols of the same shape belong together within each line, but can be compared across the lines for comparing different OoI as well.
- 1.
- Most sorting criteria for MD search provide poor result lists with AP below 30%. This magnitude quantifies the trouble of practitioners (see Section 1) while searching images of relevance in databases and repositories.
- 2.
- There are differences across the OoI referring to the IR quality and its deviation. Thereby, LEA performs slightly better and with less deviation than DELF.
- 3.
- IR improves the quality of every MD search result list. More precisely, the improvement factor () for LEA is around in 50% of the cases (factor , 75% of the cases). The improvement factor () for the DELF approach is around in 50% of the cases (factor , 75% of the cases).
- 4.
- Within the parameter settings illustrated there is no clear dependency on IR quality, i.e., no setting is preferred.
4. Camera Pose Estimation of Historical Images Using Photogrammetric Methods
4.1. Data
4.1.1. Benchmark Datasets
4.1.2. Retrieval Datasets
4.2. Methods
4.2.1. Feature Detection and Matching
D2-Net (Single-Scale and Multiscale)
R2D2
SuperGlue
DISK
4.2.2. Geometric Verification and Camera Pose Estimation
4.3. Results and Evaluation
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| 4D | four-dimensional |
| CNN | convolutional neural networks |
| VR | Virtual Reality |
| GIS | geographic information system |
| 3D | three-dimensional |
| 6-DoF | six degrees-of-freedom |
| SfM | Structure-from-Motion |
| OoI | Object of Interest |
| LEA | layer extraction approach |
| MD | metadata |
| IR | image retrieval |
| SLUB | Saxon State and University Library Dresden |
| PCA | principal component analysis |
| RANSAC | Random Sample Consensus |
| LORANSAC | locally optimized RANSAC |
| TP | true positive |
| FP | false positive |
| PR curve | precision recall curve |
| AP | average precision |
| mAP | mean average precision |
| RMS | root mean square |
| GPU | Graphics Processing Unit |
Appendix A

References
- Niebling, F.; Bruschke, J.; Messemer, H.; Wacker, M.; von Mammen, S. Analyzing Spatial Distribution of Photographs in Cultural Heritage Applications. In Visual Computing for Cultural Heritage; Springer International Publishing: Cham, Switzerland, 2020; pp. 391–408. [Google Scholar] [CrossRef]
- Evens, T.; Hauttekeete, L. Challenges of digital preservation for cultural heritage institutions. J. Librariansh. Inf. Sci. 2011, 43, 157–165. [Google Scholar] [CrossRef]
- Münster, S.; Kamposiori, C.; Friedrichs, K.; Kröber, C. Image libraries and their scholarly use in the field of art and architectural history. Int. J. Digit. Libr. 2018, 19, 367–383. [Google Scholar] [CrossRef]
- Maiwald, F.; Vietze, T.; Schneider, D.; Henze, F.; Münster, S.; Niebling, F. Photogrammetric analysis of historical image repositories for virtual reconstruction in the field of digital humanities. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 447. [Google Scholar] [CrossRef] [Green Version]
- Bevilacqua, M.G.; Caroti, G.; Piemonte, A.; Ulivieri, D. Reconstruction of lost Architectural Volumes by Integration of Photogrammetry from Archive Imagery with 3-D Models of the Status Quo. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-2/W9, 119–125. [Google Scholar] [CrossRef] [Green Version]
- Condorelli, F.; Rinaudo, F. Cultural Heritage Reconstruction From Historical Photographs And Videos. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, XLII-2, 259–265. [Google Scholar] [CrossRef] [Green Version]
- Kalinowski, P.; Both, F.; Luhmann, T.; Warnke, U. Data Fusion of Historical Photographs with Modern 3D Data for an Archaeological Excavation—Concept and First Results. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2021, XLIII-B2-2021, 571–576. [Google Scholar] [CrossRef]
- Maiwald, F.; Maas, H.G. An automatic workflow for orientation of historical images with large radiometric and geometric differences. Photogramm. Rec. 2021, 36, 77–103. [Google Scholar] [CrossRef]
- Snavely, N.; Seitz, S.M.; Szeliski, R. Photo tourism: Exploring photo collections in 3D. ACM Trans. Graph. 2006, 25, 835–846. [Google Scholar] [CrossRef]
- Schindler, G.; Dellaert, F. 4D Cities: Analyzing, Visualizing, and Interacting with Historical Urban Photo Collections. J. Multimed. 2012, 7, 124–131. [Google Scholar] [CrossRef] [Green Version]
- Datta, R.; Joshi, D.; Li, J.; Wang, J.Z. Image Retrieval: Ideas, Influences, and Trends of the New Age. ACM Comput. Surv. 2008, 40, 1–60. [Google Scholar] [CrossRef]
- Sharif Razavian, A.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN Features Off-the-Shelf: An Astounding Baseline for Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Wan, J.; Wang, D.; Hoi, S.C.H.; Wu, P.; Zhu, J.; Zhang, Y.; Li, J. Deep learning for content-based image retrieval: A comprehensive study. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 157–166. [Google Scholar] [CrossRef]
- Zheng, L.; Yang, Y.; Tian, Q. SIFT Meets CNN: A Decade Survey of Instance Retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1224–1244. [Google Scholar] [CrossRef] [Green Version]
- Razavian, A.S.; Sullivan, J.; Carlsson, S.; Maki, A. Visual instance retrieval with deep convolutional networks. ITE Trans. Media Technol. Appl. 2016, 4, 251–258. [Google Scholar] [CrossRef] [Green Version]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar] [CrossRef] [Green Version]
- Maiwald, F.; Bruschke, J.; Lehmann, C.; Niebling, F. A 4D information system for the exploration of multitemporal images and maps using photogrammetry, web technologies and VR/AR. Virtual Archaeol. Rev. 2019, 10, 1–13. [Google Scholar] [CrossRef]
- Münster, S.; Lehmann, C.; Lazariv, T.; Maiwald, F.; Karsten, S. Toward an Automated Pipeline for a Browser-Based, City-Scale Mobile 4D VR Application Based on Historical Images; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar] [CrossRef]
- Noh, H.; Araujo, A.; Sim, J.; Weyand, T.; Han, B. Large-scale image retrieval with attentive deep local features. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3456–3465. [Google Scholar] [CrossRef] [Green Version]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Winder, S.A.J.; Brown, M. Learning Local Image Descriptors. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar] [CrossRef]
- Sattler, T.; Weyand, T.; Leibe, B.; Kobbelt, L. Image Retrieval for Image-Based Localization Revisited. In Proceedings of the British Machine Vision Conference, Surrey, UK, 3–7 September 2012; Volume 1, p. 4. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Balntas, V.; Lenc, K.; Vedaldi, A.; Mikolajczyk, K. HPatches: A Benchmark and Evaluation of Handcrafted and Learned Local Descriptors. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Schönberger, J.L.; Hardmeier, H.; Sattler, T.; Pollefeys, M. Comparative Evaluation of Hand-Crafted and Learned Local Features. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Csurka, G.; Dance, C.R.; Humenberger, M. From handcrafted to deep local features. arXiv 2018, arXiv:1807.10254. [Google Scholar]
- Jin, Y.; Mishkin, D.; Mishchuk, A.; Matas, J.; Fua, P.; Yi, K.M.; Trulls, E. Image Matching Across Wide Baselines: From Paper to Practice. Int. J. Comput. Vis. 2020, 129, 517–547. [Google Scholar] [CrossRef]
- Sarlin, P.E.; Unagar, A.; Larsson, M.; Germain, H.; Toft, C.; Larsson, V.; Pollefeys, M.; Lepetit, V.; Hammarstrand, L.; Kahl, F.; et al. Back to the Feature: Learning Robust Camera Localization from Pixels to Pose. In Proceedings of the CVPR, Virtual, 19–25 June 2021. [Google Scholar]
- Jahrer, M.; Grabner, M.; Bischof, H. Learned local descriptors for recognition and matching. In Proceedings of the Computer Vision Winter Workshop, Moravske Toplice, Slovenia, 4–6 February 2008; Volume 2, pp. 39–46. [Google Scholar]
- Simo-Serra, E.; Trulls, E.; Ferraz, L.; Kokkinos, I.; Fua, P.; Moreno-Noguer, F. Discriminative Learning of Deep Convolutional Feature Point Descriptors. In Proceedings of the International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar] [CrossRef] [Green Version]
- Tian, Y.; Fan, B.; Wu, F. L2-Net: Deep Learning of Discriminative Patch Descriptor in Euclidean Space. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperPoint: Self-Supervised Interest Point Detection and Description. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–23 June 2018; pp. 337–33712. [Google Scholar] [CrossRef] [Green Version]
- Han, X.; Leung, T.; Jia, Y.; Sukthankar, R.; Berg, A.C. MatchNet: Unifying feature and metric learning for patch-based matching. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef] [Green Version]
- Zagoruyko, S.; Komodakis, N. Deep compare: A study on using convolutional neural networks to compare image patches. Comput. Vis. Image Underst. 2017, 164, 38–55. [Google Scholar] [CrossRef]
- Yi, K.M.; Trulls, E.; Lepetit, V.; Fua, P. LIFT: Learned Invariant Feature Transform. In Proceedings of the Computer Vision—ECCV, Amsterdam, The Netherlands, 11–14 October 2016; pp. 467–483. [Google Scholar] [CrossRef] [Green Version]
- Mishchuk, A.; Mishkin, D.; Radenović, F.; Matas, J. Working hard to know your neighbor’s margins: Local descriptor learning loss. In Proceedings of the NIPS, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Ono, Y.; Trulls, E.; Fua, P.; Yi, K.M. LF-Net: Learning Local Features from Images. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Curran Associates Inc.: Red Hook, NY, USA, 2018; pp. 6237–6247. [Google Scholar]
- Dusmanu, M.; Rocco, I.; Pajdla, T.; Pollefeys, M.; Sivic, J.; Torii, A.; Sattler, T. D2-Net: A Trainable CNN for Joint Detection and Description of Local Features. arXiv 2019, arXiv:1905.03561. [Google Scholar]
- Revaud, J.; Weinzaepfel, P.; Souza, C.D.; Pion, N.; Csurka, G.; Cabon, Y.; Humenberger, M. R2D2: Repeatable and Reliable Detector and Descriptor. arXiv 2019, arXiv:1906.06195v2. [Google Scholar]
- Sarlin, P.E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperGlue: Learning Feature Matching with Graph Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 4938–4947. [Google Scholar]
- Tyszkiewicz, M.J.; Fua, P.; Trulls, E. DISK: Learning local features with policy gradient. arXiv 2020, arXiv:2006.13566. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Chollet, F. Deep Learning with Python; Manning Publications: Shelter Island, NY, USA, 2018. [Google Scholar]
- Jégou, H.; Chum, O. Negative evidences and co-occurences in image retrieval: The benefit of PCA and whitening. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 774–787. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Weyand, T.; Araujo, A.; Cao, B.; Sim, J. Google landmarks dataset v2-a large-scale benchmark for instance-level recognition and retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 2575–2584. [Google Scholar]
- Ting, K.M. Precision and Recall. In Encyclopedia of Machine Learning and Data Mining; Sammut, C., Webb, G.I., Eds.; Springer US: Boston, MA, USA, 2016; p. 781. [Google Scholar] [CrossRef]
- Schönberger, J.L.; Frahm, J.M. Structure-from-Motion Revisited. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar] [CrossRef]
- Marx, H. Matthäus Daniel Pöppelmann: Der Architekt des Dresdner Zwingers; VEB E.A. Seemann: Leipzig, Germany, 1989. [Google Scholar]
- Remondino, F.; Nocerino, E.; Toschi, I.; Menna, F. A Critical Review of Automated Photogrammetric Processing of Large Datasets. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, XLII-2/W5, 591–599. [Google Scholar] [CrossRef] [Green Version]
- OpenStreetMap Contributors. Planet Dump Retrieved from https://planet.osm.org. 2017. Available online: https://www.openstreetmap.org (accessed on 20 September 2021).
- Li, Z.; Snavely, N. MegaDepth: Learning Single-View Depth Prediction from Internet Photos. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2041–2050. [Google Scholar] [CrossRef] [Green Version]
- Sarlin, P.E.; Cadena, C.; Siegwart, R.; Dymczyk, M. From Coarse to Fine: Robust Hierarchical Localization at Large Scale. In Proceedings of the CVPR, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Chum, O.; Matas, J.; Kittler, J. Locally Optimized RANSAC. In Pattern Recognition; Michaelis, B., Krell, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 236–243. [Google Scholar] [CrossRef]
- Sattler, T.; Maddern, W.; Toft, C.; Torii, A.; Hammarstrand, L.; Stenborg, E.; Safari, D.; Okutomi, M.; Pollefeys, M.; Sivic, J.; et al. Benchmarking 6DOF Outdoor Visual Localization in Changing Conditions. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Ling, H. On the Robustness of Multi-View Rotation Averaging. arXiv 2021, arXiv:2102.05454. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Size | Landmark | Time Span | Characteristics |
|---|---|---|---|---|
| 1 | 20 | Crowngate | 1880–1994 | repetitive patterns, symmetry |
| 2 | 33 | Hofkirche | 1883–1992 | wide baselines, radiometric differences |
| 3 | 24 | Moritzburg | 1884–1998 | building symmetry |
| 4 | 20 | Semperoper | 1869–1992 | terrestrial and oblique aerial images |
| 5 | 188 | Crowngate | ∼1860–2010 | ∼1000 keyword hits |
| 6 | 176 | Hofkirche | ∼1860–2010 | ∼3000 keyword hits |
| 7 | 200 | Moritzburg | ∼1884–2010 | ∼2700 keyword hits |
| 8 | 197 | Semperoper | ∼1869–2010 | ∼2100 keyword hits |
| Dataset | Size | Landmark | Selected Features | Reprojection Error (px) | (px) |
|---|---|---|---|---|---|
| 1 | 20 | Crowngate | 419 | 0.84 | 1.68 |
| 2 | 33 | Hofkirche | 1108 | 1.23 | 2.10 |
| 3 | 23 | Moritzburg | 947 | 1.15 | 1.73 |
| 4 | 20 | Semperoper | 540 | 1.13 | 1.86 |
| Dataset and Parameters | D2-Net-ss | D2-Net-ms | R2D2 | SuperGlue | DISK | |
|---|---|---|---|---|---|---|
| Crowngate (20 images) | Oriented images | 17 | 18 | 12 | 19 | 18 |
| Reproj. error | 1.1 | 1.2 | 0.9 | 1.3 | 0.9 | |
| Pose error (mean) | 8245.1 | 5.5 | 0.9 | 0.8 | 11.7 | |
| Angle error (mean) | 173.3 | 169.9 | 12.5 | 4.3 | 172.8 | |
| Angle error (median) | 174.1 | 173.3 | 10.7 | 4.0 | 172.6 | |
| Hofkirche (33 images) | Oriented images | 27 | 28 | NA | 30 | 25 |
| Reproj. error | 1.0 | 1.0 | NA | 1.3 | 0.8 | |
| Pose error (mean) | 4.8 | 4.6 | NA | 5.0 | 5.1 | |
| Angle error (mean) | 93.1 | 106.5 | NA | 88.5 | 92.2 | |
| Angle error (median) | 80.7 | 102.6 | NA | 108.6 | 153.3 | |
| Moritzburg (23 images) | Oriented images | 20 | 13 | 14 | 23 | 20 |
| Reproj. error | 1.1 | 1.1 | 0.8 | 1.2 | 0.8 | |
| Pose error (mean) | 3.4 | 6.2 | 2.9 | 1.7 | 0.7 | |
| Angle error (mean) | 33.0 | 159.3 | 43.7 | 5.8 | 7.2 | |
| Angle error (median) | 30.1 | 159.6 | 42.9 | 0.8 | 2.6 | |
| Semperoper (20 images) | Oriented images | 19 | 19 | 14 | 20 | 19 |
| Reproj. error | 1.0 | 1.1 | 0.8 | 1.2 | 0.8 | |
| Pose error (mean) | 16,042.5 | 0.9 | 2.2 | 0.3 | 0.3 | |
| Angle error (mean) | 7.8 | 7.3 | 7.1 | 3.0 | 2.1 | |
| Angle error (median) | 3.1 | 3.2 | 7.6 | 3.0 | 2.1 | |
| Crowngate (188 images, 12 in common) | Oriented images | 175 | 178 | 178 | 184 | 183 |
| Reproj. error | 1.3 | 1.4 | 1.1 | 1.4 | 1.1 | |
| Pose error (mean) | 3.6 | 1.1 | 1.2 | 1.2 | 0.8 | |
| Angle error (mean) | 164.0 | 65.6 | 176.9 | 169.4 | 10.2 | |
| Angle error (median) | 164.8 | 65.6 | 177.4 | 169.1 | 10.7 | |
| Hofkirche (176 images, 15 in common) | Oriented images | 155 | 160 | 166 | 157 | 150 |
| Reproj. error | 1.3 | 1.3 | 1.0 | 1.4 | 1.1 | |
| Pose error (mean) | 2.9 | 2.6 | 2.6 | 2.1 | 3.8 | |
| Angle error (mean) | 76.1 | 74.5 | 73.4 | 70.7 | 71.3 | |
| Angle error (median) | 7.4 | 6.0 | 4.0 | 5.7 | 2.6 | |
| Moritzburg (200 images, 15 in common) | Oriented images | 129 | 151 | NA | 176 | 155 |
| Reproj. error | 1.4 | 1.4 | NA | 1.3 | 1.0 | |
| Pose error (mean) | 0.7 | 2.2 | NA | 0.5 | 0.3 | |
| Angle error (mean) | 5.2 | 66.3 | NA | 4.2 | 2.0 | |
| Angle error (median) | 4.7 | 66.2 | NA | 4.1 | 1.8 | |
| Semperoper (197 images, 10 in common) | Oriented images | 135 | 135 | 150 | 167 | 148 |
| Reproj. error | 1.2 | 1.2 | 0.9 | 1.3 | 0.9 | |
| Euclidean distance | 1.9 | 0.8 | 0.4 | 0.3 | 0.3 | |
| Angle error (mean) | 111.2 | 6.1 | 2.5 | 2.6 | 2.8 | |
| Angle error (median) | 110.8 | 6.1 | 2.3 | 2.5 | 2.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maiwald, F.; Lehmann, C.; Lazariv, T. Fully Automated Pose Estimation of Historical Images in the Context of 4D Geographic Information Systems Utilizing Machine Learning Methods. ISPRS Int. J. Geo-Inf. 2021, 10, 748. https://doi.org/10.3390/ijgi10110748
Maiwald F, Lehmann C, Lazariv T. Fully Automated Pose Estimation of Historical Images in the Context of 4D Geographic Information Systems Utilizing Machine Learning Methods. ISPRS International Journal of Geo-Information. 2021; 10(11):748. https://doi.org/10.3390/ijgi10110748
Chicago/Turabian StyleMaiwald, Ferdinand, Christoph Lehmann, and Taras Lazariv. 2021. "Fully Automated Pose Estimation of Historical Images in the Context of 4D Geographic Information Systems Utilizing Machine Learning Methods" ISPRS International Journal of Geo-Information 10, no. 11: 748. https://doi.org/10.3390/ijgi10110748
APA StyleMaiwald, F., Lehmann, C., & Lazariv, T. (2021). Fully Automated Pose Estimation of Historical Images in the Context of 4D Geographic Information Systems Utilizing Machine Learning Methods. ISPRS International Journal of Geo-Information, 10(11), 748. https://doi.org/10.3390/ijgi10110748