
Extraction and Visualization of Tourist Attraction Semantics from Travel Blogs


Abstract
1. Introduction
- (1)
- What kind of information would a blog reader be potentially interested in the massive unstructured text and how do we organize those distinct information chunks in a POI graph to facilitate travel planning?
- (2)
- How do we extract the most representative semantic features related to a POI that would not only improve frequency-based treatment of blog texts but also enhance visualization from an end user’s perspective?
2. Background
2.1. Travel Blogs and Tourists’ Movement Patterns
2.2. Semantic Information Extraction and Representation
3. Methodology
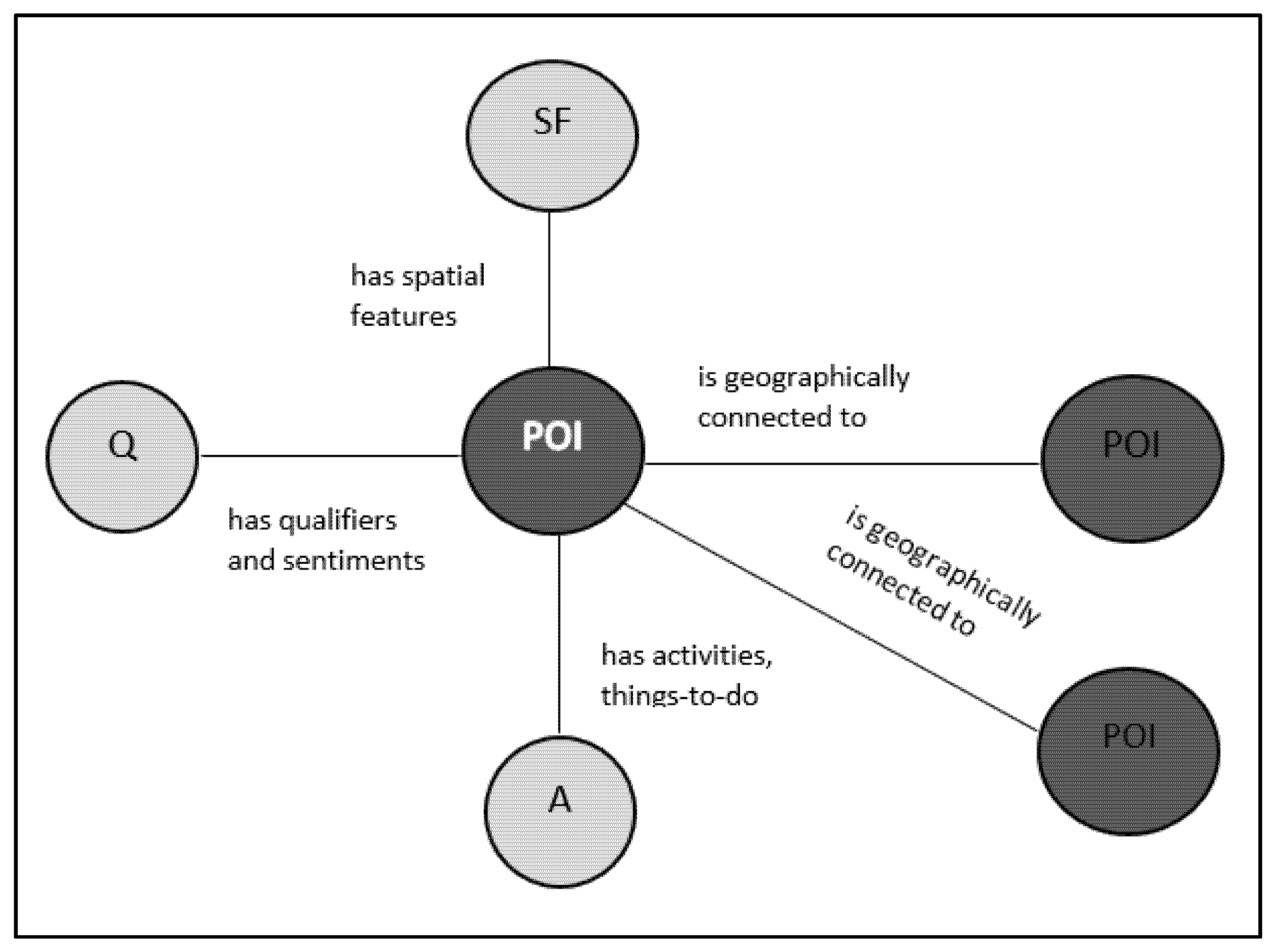
3.1. Semantic Model of a POI
3.2. Sem_POI: Proposed Method for Place Semantics Extraction
3.2.1. Content Analysis for Frequency-Based Weighting
Travel Blog Data Preprocessing
Keyword Co-Word Analysis
MDS Representation
3.2.2. Dependency Parsing for Semantics Extraction
- i.
- Nominal subject (nsubj)
- ii.
- Direct object (dobj)
- iii.
- Negation (neg)
- iv.
- Modifiers
- v.
- Adjective and clausal complement (xcomp)
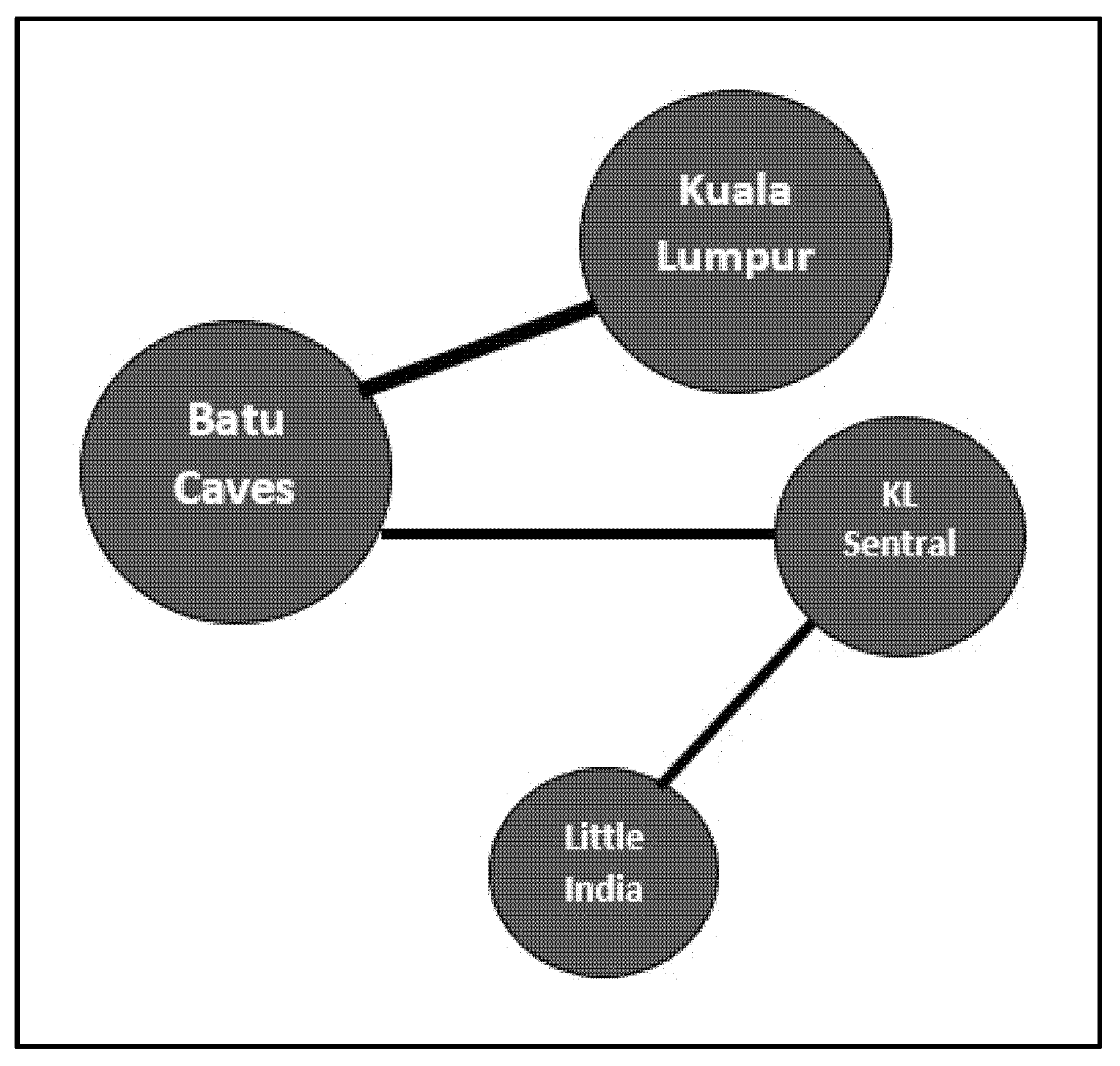
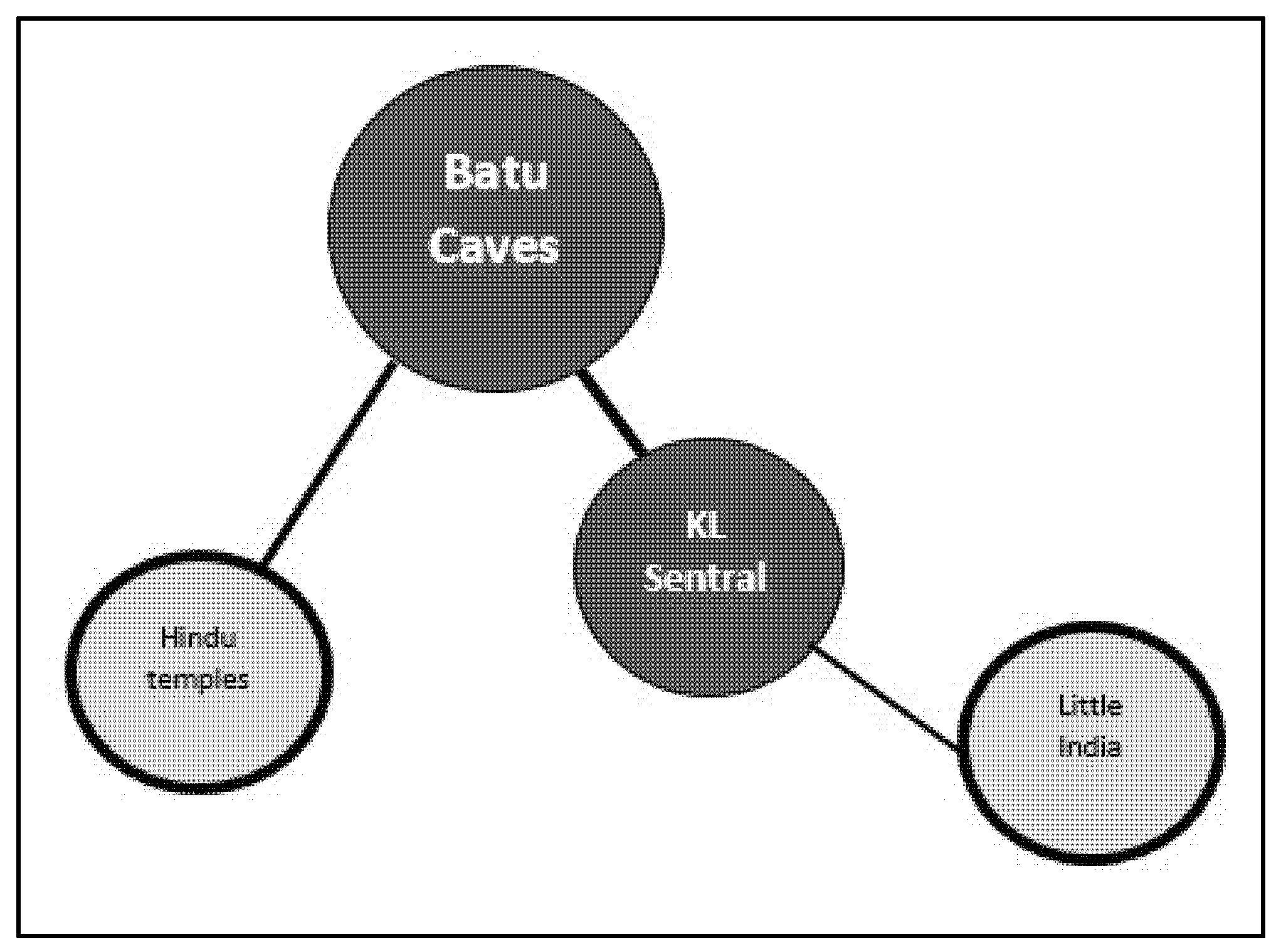
3.3. POI Graph and Geographic Feature Association
3.4. Weighted-Sum Equation Model for Multi-Criteria Weight Computation
- 1)
- , Wnode = R_count, B_rate}
- The function value ranges from 0 to 100, where the first two factors will be assigned 50 points and the succeeding two will be assigned the rest of the 50 points.
- The first two factors are to be computed using travel blog data, while the other two are to be retrieved from social media.
- Each factor is to be separately assigned a unique weight to further distribute the 50 points.
- First, wDegree and wpolarity are assigned values of 20 and 30, respectively. Here, we want more influence of sentiment analysis than frequency-based popularity, which is why wpolarity has a higher value than wDegree.
- Second, wRating and wReview are equally assigned a value of 10 because a greater value would not return a score in the range of 50.
- Since the rating parameter can have a value from 1 to 5 stars, the minimum value this factor can return now is 0 and the maximum value is 40. The review ratio parameter is normalized based on the description of Yahi et al. [79] and it can return a maximum of score of 10.
- The greater the value of , the more popular the POI.
- 2)
- E, Wedge =
- This function value also ranges from 0 to 100, where WCorrelation and WSI are assigned values of 50 and 25, respectively.
- The values are decided so that both factors could contribute half of the points out of 100.
- The attribute SpatialInformation can range from 0 to 2 based on the presence or absence of spatial indicators for a route; hence, in order to have the maximum value of 50, WSI has to be equal to 25.
- The greater the value of , the more popular the route.
4. Experiments and Results
4.1. Performance Comparison Case Study
4.2. Multi-Criteria-Weighted POI Graph
4.3. Comparative Results for Other POIs
5. Discussion and Implications
5.1. Semantics Extraction
5.2. Graph Visualization
5.3. Tourism Research and Practice
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gretzel, U.; Zhong, L.; Koo, C. Application of smart tourism to cities. Int. J. Tour. Cities 2016, 2. [Google Scholar] [CrossRef]
- Pesonen, J.; Neidhardt, J. Special issue: Perspectives on eTourism. Inf. Technol. Tour. 2020, 22, 1–3. [Google Scholar] [CrossRef]
- Bizirgianni, I.; Dionysopoulou, P. The influence of tourist trends of youth tourism through social media (SM) & information and communication technologies (ICTs). Procedia-Soc. Behav. Sci. 2013, 73, 652–660. [Google Scholar]
- Xiang, Z.; Wang, D.; O’Leary, J.T.; Fesenmaier, D.R. Adapting to the Internet: Trends in travelers’ use of the Web for trip planning. J. Inf. Sci. 2014, 54, 511–527. [Google Scholar] [CrossRef]
- Wu, M.Y.; Pearce, P.L. Tourism blogging motivations: Why do Chinese tourists create little “Lonely Planets”? J. Travel Res. 2016, 55, 537–549. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, M.; Li, D. From stay to play–A travel planning tool based on crowdsourcing user-generated contents. Appl. Geogr. 2017, 78, 1–11. [Google Scholar] [CrossRef]
- Ukpabi, D.C.; Karjaluoto, H. What drives travelers’ adoption of user-generated content? A literature review. Tour. Manag. Perspect. 2018, 28, 251–273. [Google Scholar] [CrossRef]
- Leung, R.; Vu, H.Q.; Rong, J. Understanding tourists’ photo sharing and visit pattern at non-first tier attractions via geotagged photos. Inf. Technol. Tour. 2017, 17, 55–74. [Google Scholar] [CrossRef]
- Liu, Y.; Sui, Z.; Kang, C.; Gao, Y. Uncovering patterns of inter-urban trip and spatial interaction from social media check-in data. PLoS ONE 2014, 9, e86026. [Google Scholar] [CrossRef] [PubMed]
- Wallgrün, J.O.; Klippel, A.; Baldwin, T. Building a corpus of spatial relational expressions extracted from web documents. In Proceedings of the 8th Workshop on Geographic Information Retrieval, Dallas, TX, USA, 4–7 November 2014. [Google Scholar]
- Kuzey, E.; Weikum, G. Extraction of temporal facts and events from Wikipedia. In Proceedings of the 2nd ACM Temporal Web Analytics Workshop, Lyon, France, 17 April 2012; pp. 25–32. [Google Scholar]
- Toral, S.L.; Martínez-Torres, M.R.; Gonzalez-Rodriguez, M.R. Identification of the unique attributes of tourist destinations from online reviews. J. Travel Res. 2018, 57, 908–919. [Google Scholar] [CrossRef]
- Kasper, W.; Vela, M. Sentiment analysis for hotel reviews. In Proceedings of the Computational Linguistics-Applications Conference, Jachranka, Poland, 17–19 October 2011; pp. 45–52. [Google Scholar]
- Garcia-Pablos, A.; Cuadros, M.; Linaza, M.T. Automatic analysis of textual hotel reviews. Inf. Technol. Tour. 2016, 16, 45–69. [Google Scholar] [CrossRef]
- Guo, Y.; Barnes, S.J.; Jia, Q. Mining meaning from online ratings and reviews: Tourist satisfaction analysis using latent Dirichlet allocation. Tour. Manag. 2017, 59, 467–483. [Google Scholar] [CrossRef]
- Marine-Roig, E.; Soto, M.T.R.; Clavé, S. Cognitive city maps through user-generated content. In Proceedings of the 5th Interdisciplinary Tourism Research Conference, Cartagena, Spain, 6–11 June 2017; pp. 483–488. [Google Scholar]
- Hou, Z.; Cui, F.; Meng, Y.; Lian, T.; Yu, C. Opinion mining from online travel reviews: A comparative analysis of Chinese major OTAs using semantic association analysis. Tour. Manag. 2019, 74, 276–289. [Google Scholar] [CrossRef]
- Mena, R.A.; Ornelas, E.L. Geo information extraction and processing from travel narratives. In Proceedings of the 14th International Conference on Electronic Publishing, Helsinki, Finland, 16–18 June 2010; pp. 363–373. [Google Scholar]
- Bosangit, C.; Hibbert, S.; McCabe, S. If I was going to die I should at least be having fun: Travel blogs, meaning and tourist experience. Ann. Tour. Res. 2015, 55, 1–14. [Google Scholar] [CrossRef]
- Yuan, H.; Xu, H.; Qian, Y.; Li, Y. Make your travel smarter: Summarizing urban tourism information from massive blog data. Int. J. Inf. Manag. 2016, 36, 1316–1319. [Google Scholar] [CrossRef]
- Puhringer, S.; Taylor, A. A practitioner’s report on blogs as potential sources for destination marketing intelligence. J. Vacat. Mark. 2008, 14, 177–187. [Google Scholar] [CrossRef]
- Nanba, H.; Taguma, H.; Ozaki, T.; Kobayashi, D.; Ishino, A.; Takezawa, T. Automatic compilation of travel information from automatically identified travel blogs. In Proceedings of the ACL-IJCNLP Conference Short Papers, Singapore, 4 August 2009; pp. 205–208. [Google Scholar]
- Blaschke, T.; Merschdorf, H.; Cabrera-Barona, P.; Gao, S.; Papadakis, E.; Kovacs-Györi, A. Place versus space: From points, lines and polygons in GIS to place-based representations reflecting language and culture. ISPRS Int. J. Geo-Inf. 2018, 7, 452. [Google Scholar] [CrossRef]
- Purves, R.; Edwardes, A.; Wood, J. Describing place through user generated content. First Monday 2011, 16. [Google Scholar] [CrossRef]
- Hobel, H.; Fogliaroni, P. Extracting semantics of places from user generated content. In Proceedings of the 19th AGILE International Conference on Geographic Information Science, Helsinki, Finland, 14–17 June 2016. [Google Scholar]
- Hu, Y. Geospatial semantics. In Comprehensive Geographic Information Systems; Huang, B., Cova, T.-J., Tsou, M.-H., Eds.; Elsevier: Oxford, UK, 2017. [Google Scholar]
- Hu, Y. Geo-text data and data-driven geospatial semantics. Geogr. Compass 2018, 12, e12404. [Google Scholar] [CrossRef]
- Alazzawi, A.; Abdelmoty, A.; Jones, C. What can I do there? Towards the automatic discovery of place-related services and activities. Int. J. Geogr. Inf. Sci. 2012, 26, 345–364. [Google Scholar] [CrossRef]
- Marine-Roig, E. Destination image analytics through traveller-generated content. Sustainability 2019, 11, 3392. [Google Scholar] [CrossRef]
- Park, D.H.; Lee, J. eWOM overload and its effect on consumer behavioral intention depending on consumer involvement. Electron. Commer. Res. Appl. 2008, 7, 386–398. [Google Scholar] [CrossRef]
- Rodriguez, M.G.; Gummadi, K.; Schoelkopf, B. Quantifying information overload in social media and its impact on social contagions. In Proceedings of the Eighth International AAAI Conference on Weblogs and Social Media, Ann Arbor, MI, USA, 1–4 June 2014. [Google Scholar]
- Kim, H.Y.; Yoon, J.-H. Examining national tourism brand image: Content analysis of Lonely Planet Korea. Tour. Rev. 2013, 68, 56–71. [Google Scholar]
- Shao, J.; Chang, X.; Morrison, A.M. How can big data support smart scenic area management? An analysis of travel blogs on Huashan. Sustainability 2017, 9, 2291. [Google Scholar] [CrossRef]
- Kao, A.; Poteet, S.R. Natural Language Processing and Text Mining; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Andrienko, G.; Andrienko, N.; Weibel, R. Geographic data science. IEEE Comput. Graph. Appl. 2017, 37, 15–17. [Google Scholar] [CrossRef][Green Version]
- Zhu, Z.; Shou, L.; Chen, K. Get into the spirit of a location by mining user-generated travelogues. Neurocomputing 2016, 204, 61–69. [Google Scholar] [CrossRef]
- Sigala, M.; Christou, E.; Gretzel, U. Social Media in Travel, Tourism and Hospitality: Theory, Practice and Cases; Ashgate: Farnham, UK, 2012. [Google Scholar]
- Blaer, M.; Frost, W.; Laing, J. The future of travel writing: Interactivity, personal branding and power. Tour. Manag. 2020, 77, 104009. [Google Scholar] [CrossRef]
- Munar, A.M.; Jacobsen, J.K.S. Trust and involvement in tourism social media and web-based travel information sources. Scand. J. Hosp. Tour. 2013, 13, 1–19. [Google Scholar] [CrossRef]
- Tang, Y.; Zhong, M.; Qin, H.; Liu, Y.; Xiang, L. Negative word of mouth about foreign lands: Dimensions of the shared discomforts narrated in travel blogs. J. Glob. Fash. Mark. 2019, 29, 311–329. [Google Scholar] [CrossRef]
- Chandralal, L.; Rindfleish, J.; Valenzuela, F. An application of travel blog narratives to explore memorable tourism experiences. Asia Pac. J. Tour. Res. 2014, 20, 680–693. [Google Scholar] [CrossRef]
- Tseng, C.; Wu, B.; Morrison, A.M.; Zhang, J.; Chen, Y.C. Travel blogs on China as a destination image formation agent: A qualitative analysis using Leximancer. Tour. Manag. 2015, 46, 347–358. [Google Scholar] [CrossRef]
- Banyai, M.; Glover, T.D. Evaluating research methods on travel blogs. J. Travel Res. 2012, 51, 267–277. [Google Scholar] [CrossRef]
- Cohen, S.A.; Prayag, G.; Moital, M. Consumer behaviour in tourism: Concepts, influences and opportunities. Curr. Issues Tour. 2014, 17, 872–909. [Google Scholar] [CrossRef]
- Kori, H.; Hattori, S.; Tezuka, T.; Tanaka, K. Automatic generation of multimedia tour guide from local blogs. In Proceedings of the 13th International Conference on Multimedia Modeling, Singapore, 9–12 January 2007; pp. 690–699. [Google Scholar]
- Xu, H.; Yuan, H.; Ma, B.; Qian, Y. Where to go and what to play: Towards summarizing popular information from massive tourism blogs. J. Inf. Sci. 2015, 41, 830–854. [Google Scholar] [CrossRef]
- Guo, L.; Li, Z.; Sun, W. Understanding travel destinations from structured tourism blogs. In Proceedings of the 14th Wuhan International Conference on e-Business, Hubei, China, 19–21 June 2015; p. 80. [Google Scholar]
- Haris, E.; Gan, K.H.; Tan, T.-P. Spatial information extraction from travel narratives: Analyzing the notion of cooccurrence indicating closeness of tourist places. J. Inf. Sci. 2020, 46, 581–599. [Google Scholar] [CrossRef]
- Gabrilovich, E.; Markovitch, S. Feature generation for text categorization using world knowledge. In Proceedings of the 19th International Joint Conference on Artificial Intelligence, Edinburgh, UK, 30 July–5 August 2005; pp. 1048–1053. [Google Scholar]
- Li, Q.; Li, S.; Zhang, S.; Hu, J.; Hu, J. A review of text corpus-based tourism big data mining. Appl. Sci. 2019, 9, 3300. [Google Scholar] [CrossRef]
- Kumar, M.; Vig, R. Term-frequency inverse-document frequency definition semantic (TIDS) based focused web crawler. In Global Trends in Information Systems and Software Applications. ObCom 2011. Communications in Computer and Information Science; Krishna, P.V., Babu, M.R., Ariwa, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; Volume 270. [Google Scholar]
- Murakami, K.H.; Kawamura, H.; Suzuki, K. Earthquake’s influence on inbound tourism: Voices from the travel blogs. Sustain. Tour. V WIT Trans. Ecol. Environ. 2012, 161, 43–53. [Google Scholar]
- Li, Y.R.; Lin, Y.C.; Tsai, P.H.; Wang, Y.Y. Traveller-Generated Contents for destination image formation: Mainland China travellers to Taiwan as a case study. J. Travel Tour. Mark. 2015, 32, 518–533. [Google Scholar] [CrossRef]
- Pons-Porrata, A.; Berlanga-Llavori, R.; Ruiz-shulcloper, J. Topic discovery based on text mining techniques. Inf. Process. Manag. 2007, 43, 752–768. [Google Scholar] [CrossRef]
- Fournier-Viger, P.; Lin, J.C.-W.; Kiran, R.U.; Koh, Y.S.; Thomas, R. A survey of sequential pattern mining. Data Sci. Pattern Recognit. 2017, 1, 54–77. [Google Scholar]
- Kurashima, T.; Tezuka, T.; Tanaka, K. Blog map of experiences: Extracting and geographically mapping visitor experiences from urban blogs. In Proceedings of the 6th International Conference on Web Information Systems Engineering, New York, NY, USA, 20–22 November 2005; pp. 496–503. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Hao, Q.; Cai, R.; Wang, C.; Xiao, R.; Yang, J.M.; Pang, Y.; Zhang, L. Equip tourists with knowledge mined from travelogues. In Proceedings of the 19th International World Wide Web Conference, Raleigh, NC, USA, 26–30 April 2010; pp. 40–410. [Google Scholar]
- Wang, C.; Wang, J.; Xie, X.; Ma, W.Y. Mining geographic knowledge using location aware topic model. In Proceedings of the 4th ACM Workshop on Geographic Information Retrieval, Lisbon, Portugal, 9 November 2007; pp. 65–70. [Google Scholar]
- Adams, B.; McKenzie, G. Inferring thematic places from spatially referenced natural language descriptions. In Crowdsourcing Geographic Knowledge: Volunteered Geographic Information (VGI) in Theory and Practice; Sui, D., Elwood, S., Goodchild, M., Eds.; Springer: Dordrecht, The Netherlands, 2013; pp. 201–221. [Google Scholar]
- Schuster, S.; Manning, C.D. Enhanced English universal dependencies: An improved representation for natural language understanding tasks. In Proceedings of the Tenth International Conference on Language Resources and Evaluation, Portorož, Slovenia, 23–28 May 2016. [Google Scholar]
- Nakatoh, T.; Yin, C.; Hirokawa, S. Extraction and disambiguation of name of place from tourism blogs. In Proceedings of the First ACIS International Symposium on Software and Network Engineering, Seoul, Korea, 19–20 December 2011; pp. 73–78. [Google Scholar]
- Nakatoh, T.; Yin, C.; Hirokawa, S. Analysis and visualization of tourism blog. In Proceedings of the IIAI International Symposium on Applied Informatics, Fukuoka, Japan, 20–22 September 2012; pp. 26–27. [Google Scholar]
- Haris, E.; Gan, K.H. Framework of blog data based multi-criteria weighted points of interest graph for trip planning. Intell. Decis. Technol. 2018, 12, 1–10. [Google Scholar] [CrossRef]
- Scheider, S.; Janowicz, K. Place reference systems. Appl. Ontol. 2014, 9, 97–127. [Google Scholar] [CrossRef]
- Lancia, F. T-LAB Tools for Text Analysis. 2017. Available online: http://tlab.it/en/presentation.php (accessed on 5 May 2018).
- Benites-Lazaro, L.L.; de MelloThéry, N.A.; Lahsen, M. Business storytelling in energy and climate change: The case of Brazil’s ethanol industry. Energy Res. Soc. Sci. 2017, 31, 77–85. [Google Scholar] [CrossRef]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.J.; McClosky, D. The Stanford CoreNLP natural language processing toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 23–24 June 2014; pp. 55–60. [Google Scholar]
- Zhao, W.; Mao, J.; Lu, K. Ranking themes on co-word networks: Exploring the relationships among different metrics. Inf. Process. Manag. 2018, 54, 203–218. [Google Scholar] [CrossRef]
- Khasseh, A.A.; Soheili, F.; Moghaddam, H.S.; Chelak, A.M. Intellectual structure of knowledge in iMetrics. Inf. Process. Manag. 2017, 53, 705–720. [Google Scholar] [CrossRef]
- Haris, E.; Gan, K.H. Kuala Lumpur Travel Blogs Dataset; V1. Mendeley Data: London, UK, 2018. [Google Scholar] [CrossRef]
- Shafie, A.S.; Sharef, N.M.; Murad MA, A.; Azman, A. Aspect extraction performance with POS tag pattern of dependency relation in aspect-based sentiment analysis. In Proceedings of the IEEE Fourth International Conference on Information Retrieval and Knowledge Management, Kota Kinabalu, Malaysia, 26–28 March 2018. [Google Scholar]
- Poria, S.; Ofek, N.; Gelbukh, A.; Hussain, A.; Rokach, L. Dependency tree based rules for concept-level aspect-based sentiment analysis. In Semantic Web Evaluation Challenge. SemWebEval 2014. Communications in Computer and Information Science; Presutti, V., Stankovic, M., Cambria, E., Cantador, I., di Iorio, A., di Noia, T., Lange, C., Recupero, D.R., Tordai, A., Eds.; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Poria, S.; Hussain, A.; Cambria, E. Concept extraction from natural text for concept level text analysis. In Multimodal Sentiment Analysis; Springer: Cham, Switzerland, 2018; pp. 79–84. [Google Scholar]
- Kang, Y.; Zhou, L. RubE: Rule-based Methods for Extracting Product Features from Online Consumer Reviews. Inf. Manag. 2017, 54, 166–176. [Google Scholar] [CrossRef]
- Baccianella, S.; Esuli, A.; Sebastiani, F. SentiWordNet 3.0: An enhanced lexical resource for sentiment analysis and opinion mining. In Proceedings of the Seventh International Conference on Language Resources and Evaluation, Valletta, Malta, 17–23 May 2010; pp. 2200–2204. [Google Scholar]
- Hazelrigg, G.A. A note on the weighted sum method. J. Mech. Des. 2019, 141, 100301. [Google Scholar] [CrossRef]
- Dhanisetty, V.S.V.; Verhagen, W.J.C.; Curran, R. Multicriteria weighted decision making for operational maintenance processes. J. Air Transp. Manag. 2018, 68, 152–164. [Google Scholar] [CrossRef]
- Yahi, A.; Chassang, A.; Raynaud, L.; Duthil, H.; Chau, D.H. Aurigo: An interactive tour planner for personalized itineraries. In Proceedings of the 20th International Conference on Intelligent User Interfaces, Atlanta, GA, USA, 29 March–1 April 2015; pp. 275–285. [Google Scholar]
- TripAdvisor. Batu Caves. 2018. Available online: https://www.tripadvisor.com.my/Attraction_Review-g3198092-d317520-Reviews-Batu_Caves-Batu_Caves_Selangor.html (accessed on 10 April 2018).
- TripAdvisor. Changes to the TripAdvisor Popularity Ranking Algorithm. 2016. Available online: https://www.tripadvisor.com/TripAdvisorInsights/n2701/changes-tripadvisorpopularity-ranking-algorithms (accessed on 2 May 2016).
- TripAdvisor. Petronas Towers. 2020. Available online: https://www.tripadvisor.com/Attraction_Review-g298570-d317521-Reviews-Petronas_Twin_Towers-Kuala_Lumpur_Wilayah_Persekutuan.html (accessed on 1 November 2020).
- TripAdvisor. Kuala Lumpur Bird Park. 2020. Available online: https://www.tripadvisor.com/Attraction_Review-g298570-d455105-Reviews-Kuala_Lumpur_Bird_Park-Kuala_Lumpur_Wilayah_Persekutuan.html (accessed on 1 November 2020).
- Vazirgiannis, M. Graph of Words: Boosting text mining tasks with graphs. In Proceedings of the 26th International Conference on World Wide Web Companion, Perth, Australia, 3–7 April 2017; p. 1181. [Google Scholar]
- Pang, Y.; Hao, Q.; Yuan, Y.; Hu, T.; Cai, R.; Zhang, L. Summarizing tourist destinations by mining user-generated travelogues and photos. Comput. Vis. Image Underst. 2011, 115, 352–363. [Google Scholar] [CrossRef]
- Kim, E.; Ihm, H.; Myaeng, S.H. Topic-based place semantics discovered from microblogging text messages. In Proceedings of the 23rd International World Wide Web Conference, Seoul, Korea, 7–11 April 2014; pp. 561–562. [Google Scholar]
- Liu, K.; Qiu, P.; Gao, S.; Lu, F.; Jiang, J.; Yin, L. Investigating urban metro stations as cognitive places in cities using points of interest. Cities 2020, 97, 102561. [Google Scholar] [CrossRef]
- Hu, T.; Marchiori, E.; Kalbaska, N.; Cantoni, L. Online representation of Switzerland as a tourism destination: An exploratory research on a Chinese microblogging platform. Stud. Commun. Sci. 2014, 14, 136–143. [Google Scholar] [CrossRef]
- Andrade, J.; Sobata, M.F. Most important contents in travel blogs: A perspective from Brazilian tourists. In Advances in Tourism, Technology and Smart Systems. Smart Innovation, Systems and Technologies; Rocha, Á., Abreu, A., de Carvalho, J.V., Liberato, D., González, E., Liberato, P., Eds.; Springer: Singapore, 2020. [Google Scholar]
- Litvin, S.W.; Goldsmith, R.E.; Pan, B. Electronic word-of-mouth in hospitality and tourism management. Tour. Manag. 2008, 29, 458–468. [Google Scholar] [CrossRef]
- McKercher, B.; Lau, G. Movement patterns of tourists within a destination. Tour. Geogr. 2008, 10, 355–374. [Google Scholar] [CrossRef]
- Hu, F.; Li, Z.; Yang, C.; Jiang, Y. A graph-based approach to detecting tourist movement patterns using social media data. Cartogr. Geogr. Inf. Sci. 2019, 46, 368–382. [Google Scholar] [CrossRef]
- Vega, R.R.S. Special Issue: Smart Tourism: A GIS-Based Approach. 2020. Available online: https://www.mdpi.com/journal/ijgi/special_issues/smart_tourism (accessed on 27 February 2020).
- Gao, Y.; Ye, C.; Zhong, X.; Wu, L.; Liu, Y. Extracting spatial patterns of intercity tourist movements from online travel blogs. Sustainability 2019, 11, 3526. [Google Scholar] [CrossRef]
- Crooks, A.; Pfoser, D.; Jenkins, A.; Croitoru, A.; Stefanidis, A.; Smith, D.; Karagiorgou, S.; Efentakis, A.; Lamprianidis, G. Crowdsourcing urban form and function. Int. J. Geogr. Inf. Sci. 2015, 29, 720–741. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Texts | 60 |
| Contexts | 1536 |
| Words | 7893 |
| Lemma | 6341 |
| Occurrences (Tokens) | 72,967 |
| Threshold | 10 |
| Dependency Type | Grammatical Triples | |
|---|---|---|
| compound | compound (temples-5, Hindu-4) compound (Caves-8, Batu-7) compound (north-4, km-3) compound (Caves-10, Batu-9) | compound (outcrop-4, limestone-3) compound (temples-12, cave-11) compound (temple-12, cave-11) |
| dobj | dobj (Visit-1, temples-5) dobj (Located-1, north-4) | dobj (houses-5, series-7) dobj (climb-4, steps-7) |
| nsubj | nsubj (place-14, Caves-10) | nsubj (houses-5, outcrop-4) |
| amod | amod (place-14, intriguing-13) amod (outcrop-4, massive-2) | amod (temples-5, historic-3) amod (temple-12, main-10) |
| nmod | nmod (Visit-1, Caves-8) nmod (north-4, KL-6) | nmod (series-7, caves-9) nmod (climb-4, temple-1) |
| Parameter | Value |
|---|---|
| Texts | 70 |
| Contexts | 68 |
| Words | 999 |
| Lemmas | 887 |
| Occurrences | 3296 |
| Threshold | 4 |
| Extracted | Not Extracted | |
|---|---|---|
| Semantic features related to a POI | true positive (tp) | false negative (fn) |
| Semantic features not related to a POI | false positive (fp) | true negative (tn) |
| Method | Extracted Top Semantic Features for Batu Caves | Precision | Recall | |
|---|---|---|---|---|
| Term frequency (TF) | cave temple India hindu top site | minute hindu god dedicate steps world | 0.54 | 0.6 |
| Term frequency–inverse document frequency (TF–IDF) | temple top site minute dedicate hindu god | hindu shrines impressive lord Murugan famous feature | 0.63 | 0.53 |
| Frequent item-set mining | cave limestone kl north India visit | hindu temple train minute steps | 0.54 | 0.5 |
| Topic model | kuala lumpur city train day visit petronas | monkeys air things hindu towers | 0.27 | 0.3 |
| Sem_POI | hindu temples popular shrines golden statue limestone hill train ride wild monkeys | lord Murugan climb steps kl Sentral ride minute main cave | 0.81 | 0.75 |
| Popular POI | Degree Ratio | Polarity | Rating | Review Ratio | Multi-Criteria Weight |
|---|---|---|---|---|---|
| Batu Caves | 0.5 | 0.875 | 4 | 1 | 76 |
| POIs Sequence (n = 2) | Correlation Weight | Spatial Indictor(s) | Spatial Information | Multi-Criteria Weight |
|---|---|---|---|---|
| {Batu Caves, Kuala Lumpur} | 0.9 | 13 km north | 2 | 95 |
| {Batu Caves, KL Sentral} | 0.8 | 30 min | 1 | 65 |
| Method | Extracted Top Semantic Features for Petronas Towers | Precision | Recall | |
|---|---|---|---|---|
| TF | twin lumpur kuala city world | ticket visit klcc bridge night | 0.4 | 0.4 |
| TF–IDF | klcc lumpur kuala tallest ticket | skyline bridge malaysia mall deck | 0.6 | 0.5 |
| Frequent item-set mining | city world ticket klcc sky | lumpur kuala bridge things walk | 0.4 | 0.36 |
| Topic model | world waiting highest hour malaysia | light entire visually petrosains hotel | 0.3 | 0.23 |
| Sem_POI | twin towers skybridge floor observation deck night view park towers | impressive towers klcc park tickets Petronas shopping mall skyline city | 0.8 | 0.67 |
| Method | Extracted Top Semantic Features for KL Bird Park | Precision | Recall | |
|---|---|---|---|---|
| TF | birds park kl garden aviary | world free-flight lumpur kuala largest | 0.3 | 0.27 |
| TF–IDF | kl free-flight aviary parrot botanical | lumpur kuala Perdana walk-in garden | 0.4 | 0.33 |
| Frequent item-set mining | birds aviary largest world free | garden lumpur kuala visit flight | 0.3 | 0.27 |
| Topic model | park bird birds kl world | free gardens aviary flight largest | 0.3 | 0.27 |
| Sem_POI | free flight aviary walk largest aviary birds hornbill aviary flight | lake gardens botanical garden bird species home park bird shows | 0.7 | 0.538 |
| Graph Representation | Methodology | Spatial Information | Semantic Information |
|---|---|---|---|
| POI graph [45] | FSPM | × | Route context |
| POI and Things of Interest (ToI) graph [46] | FSPM, correlation analysis | × | POI services |
| POI and ToI graph [47] | Frequent pattern mining, compact pattern mining | × | Things-to-do |
| Word network [20] | FSPM, word correlation analysis | Geographically close POIs | Local features |
| Multi-criteria-weighted POI graph (Proposed Model) | Keywords co-word analysis, dependency parsing | Geographically close POIs with precise spatial information | Geo-features, activities, sentiments |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Haris, E.; Gan, K.H. Extraction and Visualization of Tourist Attraction Semantics from Travel Blogs. ISPRS Int. J. Geo-Inf. 2021, 10, 710. https://doi.org/10.3390/ijgi10100710
Haris E, Gan KH. Extraction and Visualization of Tourist Attraction Semantics from Travel Blogs. ISPRS International Journal of Geo-Information. 2021; 10(10):710. https://doi.org/10.3390/ijgi10100710
Chicago/Turabian StyleHaris, Erum, and Keng Hoon Gan. 2021. "Extraction and Visualization of Tourist Attraction Semantics from Travel Blogs" ISPRS International Journal of Geo-Information 10, no. 10: 710. https://doi.org/10.3390/ijgi10100710
APA StyleHaris, E., & Gan, K. H. (2021). Extraction and Visualization of Tourist Attraction Semantics from Travel Blogs. ISPRS International Journal of Geo-Information, 10(10), 710. https://doi.org/10.3390/ijgi10100710