
HA-MPPNet: Height Aware-Multi Path Parallel Network for High Spatial Resolution Remote Sensing Image Semantic Seg-Mentation


Abstract
:1. Introduction
2. Related Work
2.1. Semantic Segmentation
2.2. Multi-Level Feature Fusion
2.3. Height Estimation for Remote Sensing Image
3. Methods
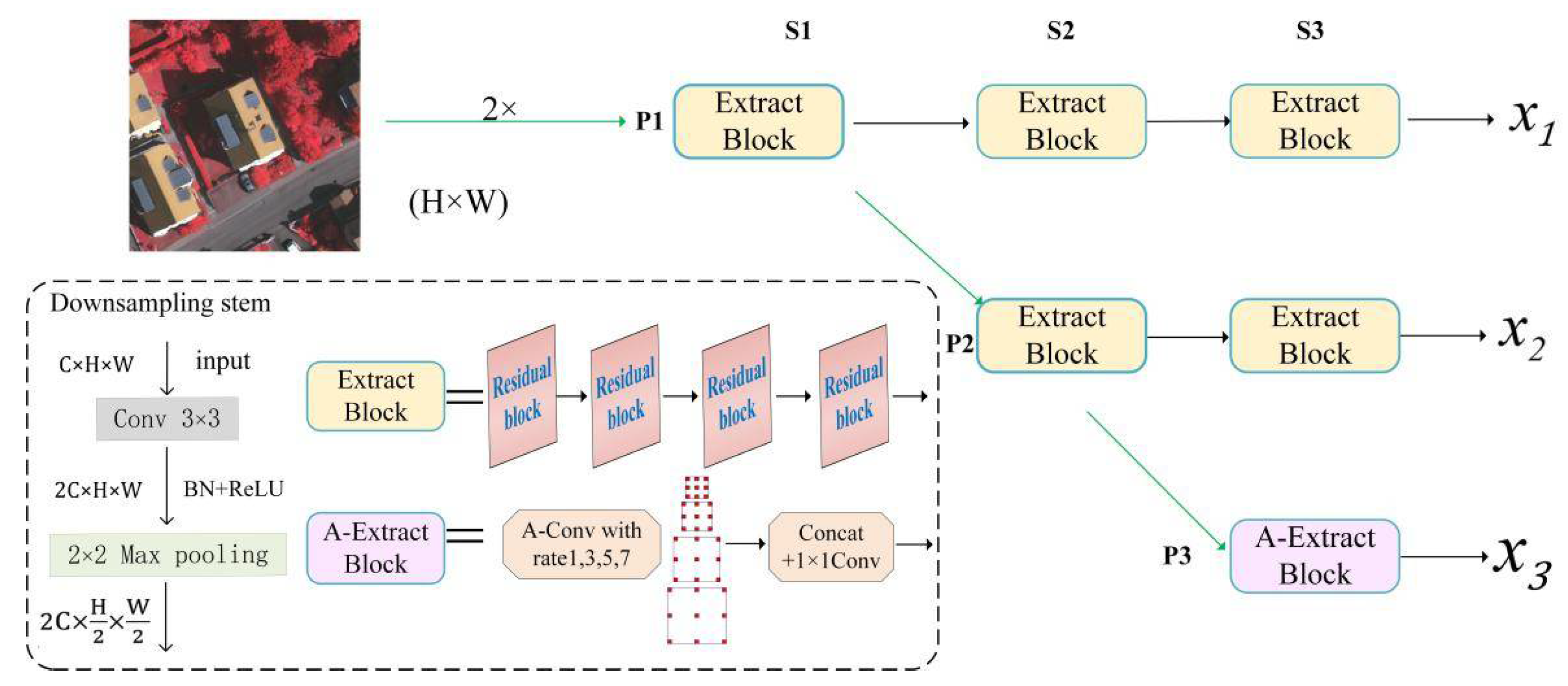
3.1. Multi Path Parallel Network
3.2. Gated High-Low Level Feature Fusion
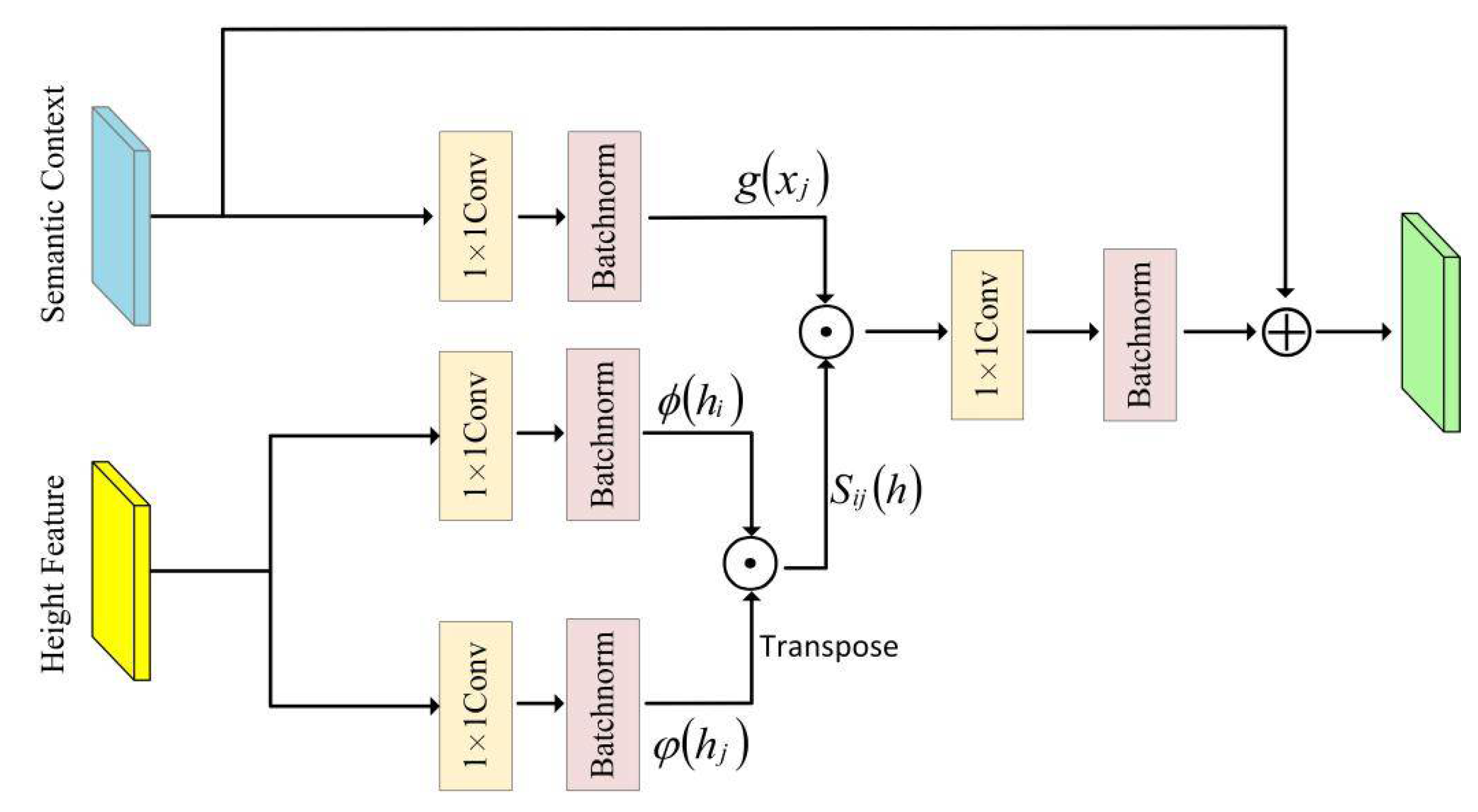
3.3. Height Aware Context Module
3.4. Multi-Task Loss Function
4. Experiment
4.1. Dataset and Metric
4.2. Implement Details and Experimental Setup
4.2.1. Implement Details
4.2.2. Experimental Setup
4.3. Comparison with State-of-the-Art Methods
4.3.1. Results on Vaihingen Dataset
4.3.2. Results on the Postam Dataset
4.4. Ablation Study
4.5. Visualization Results
4.6. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hu, B.; Xu, Y.; Huang, X.; Cheng, Q.; Ding, Q.; Bai, L.; Li, Y. Improving Urban Land Cover Classification with Combined Use of Sentinel-2 and Sentinel-1 Imagery. ISPRS Int. J. Geo-Inf. 2021, 10, 533. [Google Scholar] [CrossRef]
- Kampffmeyer, M.C.; Salberg, A.; Jenssen, R. Semantic Segmentation of Small Objects and Modeling of Uncertainty in Urban Remote Sensing Images Using Deep Convolutional Neural Networks. Paper presented at the 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar] [CrossRef]
- Damos, M.A.; Zhu, J.; Li, W.; Hassan, A.; Khalifa, E. A Novel Urban Tourism Path Planning Approach Based on a Multiobjective Genetic Algorithm. ISPRS Int. J. Geo-Inf. 2021, 10, 530. [Google Scholar] [CrossRef]
- Ding, C.; Weng, L.; Xia, M.; Lin, H. Non-Local Feature Search Network for Building and Road Segmentation of Remote Sensing Image. ISPRS Int. J. Geo-Inf. 2021, 10, 245. [Google Scholar] [CrossRef]
- Liu, S.; Tang, J. Modified Deep Reinforcement Learning with Efficient Convolution Feature for Small Target Detection in VHR Remote Sensing Imagery. ISPRS Int. J. Geo-Inf. 2021, 10, 170. [Google Scholar] [CrossRef]
- Xie, F.; Hu, D.; Li, F.; Yang, J.; Liu, D. Semi-Supervised Classification for Hyperspectral Images Based on Multiple Classifiers and Relaxation Strategy. ISPRS Int. J. Geo-Inf. 2018, 7, 284. [Google Scholar] [CrossRef] [Green Version]
- Jiang, J.; Lyu, C.; Liu, S.; He, Y.; Hao, X. RWSNet: A semantic segmentation network based on SegNet combined with random walk for remote sensing. Remote Sens. 2019, 41, 487–505. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 39, 640–651. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. Paper presented at the International Conference on Medical image computing and computer-assisted intervention, Munich, Germany, 5–9 October 2015. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Tao, A.; Sapra, K.; Catanzaro, B. Hierarchical Multi-Scale Attention for Semantic Segmentation. arXiv 2020, arXiv:2005.10821. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 99, 3349–3364. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. Paper presented at the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. DenseASPP for Semantic Segmentation in Street Scenes. Paper presented at the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. Paper presented at the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.; Zhang, Y.; Liu, S.; Shi, J.; Loy, C.; Lin, D.; Jia, J. PSANet: Point-wise Spatial Attention Network for Scene Parsing. Paper presented at the 2018 European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar] [CrossRef]
- Wurm, M.; Droin, A.; Stark, T.; Geiß, C.; Sulzer, W.; Taubenböck, H. Deep Learning-Based Generation of Building Stock Data from Remote Sensing for Urban Heat Demand Modeling. ISPRS Int. J. Geo-Inf. 2021, 10, 23. [Google Scholar] [CrossRef]
- Ghamisi, P.; Yokoya, N. IMG2DSM: Height simulation from single imagery using conditional generative adversarial net. Remote Sens. 2018, 15, 794–798. [Google Scholar] [CrossRef]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks. ISPRS-J. Photogramm. Remote Sens 2018, 140, 20–32. [Google Scholar] [CrossRef] [Green Version]
- Lichao, M.; Zhu, X.X. IM2HEIGHT: Height estimation from single monocular imagery via fully residual convolutional-deconvolutional network. arXiv 2018, arXiv:1802.10249. [Google Scholar]
- Srivastava, S.; Volpi, M.; Tuia, D. Joint height estimation and semantic labeling of monocular aerial images with CNNs. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; 2017; pp. 5173–5176. [Google Scholar] [CrossRef]
- Volpi, M.; Tuia, D. Deep multi-task learning for a geographically-regularized semantic segmentation of aerial images. ISPRS-J. Photogramm. Remote Sens. 2018, 144, 48–60. [Google Scholar] [CrossRef] [Green Version]
- Zilong, H.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. CCNet: Criss-Cross Attention for Semantic Segmentation. Paper presented at the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef] [Green Version]
- Woo, S.; Park, J.; Lee, J.; Kweon, I.S. CBAM: Convolutional Block Attention Module. Paper presented at the 2018 European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar] [CrossRef] [Green Version]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. ”Paper presented at the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef] [Green Version]
- Guo, R.; Liu, J.; Li, N.; Liu, S.; Chen, F.; Cheng, B.; Ma, C. Pixel-wise classification method for high resolution remote sensing imagery using deep neural networks. ISPRS Int. J. Geo-Inf. 2018, 7, 110. [Google Scholar] [CrossRef] [Green Version]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Shen, L.; Qiao, W.; Dai, Y.; Li, Z. Deep Feature Fusion with Integration of Residual Connection and Attention Model for Classification of VHR Remote Sensing Images. Remote Sens. 2019, 11, 1617. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. Paper presented at the 2016 IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef] [Green Version]
- Marmanis, D.; Schindler, K.J.; Wegner, D.; Galliani, S.; Datcu, M.; Stilla, U. Classifification with an edge: Improving semantic image segmentation with boundary detection. ISPRS J. Photogramm. Remote Sens. 2018, 135, 158–172. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Qiu, K.; Li, C.; Mei, X.; Hong, L.; Tao, C. SCAttNet: Semantic segmentation network with spatial and channel attention mechanism for high-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2020. [Google Scholar]
- Niu, R.; Sun, X.; Tian, Y.; Diao, W.; Chen, K.; Fu, K. Hybrid Multiple Attention Network for Semantic Segmentation in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2021, 99, 1–8. [Google Scholar] [CrossRef]
- Hong, D.; Yokoya, N.; Chanussot, J.; Xu, J. Joint and Progressive Subspace Analysis (JPSA) With Spatial–Spectral Manifold Alignment for Semisupervised Hyperspectral Dimensionality Reduction. IEEE Trans. Cybern. 2020, 51, 3602–3615. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Zhang, X.; Peng, C.; Xue, X.; Sun, J. Exfuse: Enhancing feature fusion for semantic segmentation. Paper presented at the 2018 European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.; Dollár, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. Paper presented at the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Yann, D.; Fan, A.; Auli, M.; Grangier, D. Language Modeling with Gated Convolutional Networks. Paper presented at the 34th International Conference on Machine Learning (ICML) 2017, Sydney, NSW, Australia, 6–11 August 2017. [Google Scholar]
- Towaki, T.; Acuna, D.; Jampani, V.; Fidler, S. Gated-SCNN: Gated Shape CNNs for Semantic Segmentation. Paper presented at the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Kore, 27 October–2 November 2019. [Google Scholar] [CrossRef] [Green Version]
- Xiangtai, L.; Zhao, H.; Han, L.; Tong, Y.; Tan, S.; Yang, K. Gated Fully Fusion for Semantic Segmentation. Paper presented at the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–20 February 2020. [Google Scholar] [CrossRef]
- Peng, Y.; Sun, S.; Wang, Z.; Pan, Y.; Li, R. Robust Semantic Segmentation by Dense Fusion Network on Blurred VHR Remote Sensing Images. Paper presented at the 2020 6th International Conference on Big Data and Information Analytics (BigDIA), ShenZhen, China, 4–6 December 2020. [Google Scholar] [CrossRef]
- Sun, S.; Yang, L.; Liu, W.; Li, R. Feature Fusion Through Multitask CNN for Large-scale Remote Sensing Image Segmentation. In Proceedings of the 2018 10th IAPR Workshop on Pattern Recognition in Remote Sensing (PRRS), Beijing, China, 19–20 August 2018. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Shen, X.; Cohen, S.; Price, B.; Yuille, A. Towards unified depth and semantic prediction from a single image. Paper presented at the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Input | Imp. Surf | Building | Low. Veg | Tree | Car | OA (%) | mIoU(%) |
|---|---|---|---|---|---|---|---|---|
| U-Net | IRRG | 76.59 | 78.46 | 71.82 | 72.94 | 62.69 | 84.35 | 72.50 |
| PSPNet | IRRG | 77.45 | 79.51 | 73.04 | 75.01 | 64.58 | 86.07 | 73.92 |
| HMANet | IRRG | 78.34 | 80.21 | 78.18 | 78.57 | 64.12 | 87.19 | 75.88 |
| HRNet | IRRG | 79.23 | 84.35 | 75.86 | 77.42 | 67.62 | 87.96 | 76.90 |
| V-FuseNet | IRRG+DSM | 82.57 | 82.86 | 83.94 | 82.45 | 73.32 | 90.12 | 81.02 |
| HA-MPPNet | IRRG+DSM(S) | 83.46 | 83.85 | 83.27 | 84.68 | 78.79 | 91.54 | 82.81 |
| Model | Input | Imp. Surf | Building | Low. Veg | Tree | Car | OA (%) | mIoU(%) |
|---|---|---|---|---|---|---|---|---|
| U-Net | IRRGB | 75.68 | 77.59 | 70.76 | 72.49 | 61.93 | 83.82 | 71.69 |
| PSPNet | IRRGB | 77.05 | 78.32 | 72.83 | 74.41 | 64.05 | 85.24 | 73.33 |
| HMANet | IRRGB | 78.04 | 79.28 | 76.56 | 78.85 | 65.39 | 86.56 | 75.62 |
| HRNet | IRRGB | 78.75 | 83.89 | 75.20 | 76.54 | 66.23 | 87.43 | 76.12 |
| V-FuseNet | IRRGB+DSM | 81.38 | 82.96 | 81.96 | 81.25 | 69.56 | 89.79 | 79.42 |
| HA-MPPNet | IRRGB+DSM(S) | 82.85 | 83.43 | 81.63 | 83.13 | 71.52 | 90.21 | 80.51 |
| Module | OA (%) | mIoU(%) | ||||
|---|---|---|---|---|---|---|
| Baseline | MPPNet | GHLF | HFD | HFGP | ||
| √ | 85.73 | 73.64 | ||||
| √ | √ | 87.86 | 77.52 | |||
| √ | √ | √ | 88.95 | 78.85 | ||
| √ | √ | √ | √ | 90.28 | 81.67 | |
| √ | √ | √ | √ | √ | 91.54 | 82.81 |
| Module | mIo U(%) | Memory (MB) | Params (M) |
|---|---|---|---|
| MPPNet + Addition | 77.68 | 256 | 33.1 |
| MPPNet + Contact | 77.52 | 238 | 32.8 |
| MPPNet + GHLF | 78.85 | 185 | 29.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Wu, C.; Mukherjee, M.; Zheng, Y. HA-MPPNet: Height Aware-Multi Path Parallel Network for High Spatial Resolution Remote Sensing Image Semantic Seg-Mentation. ISPRS Int. J. Geo-Inf. 2021, 10, 672. https://doi.org/10.3390/ijgi10100672
Chen S, Wu C, Mukherjee M, Zheng Y. HA-MPPNet: Height Aware-Multi Path Parallel Network for High Spatial Resolution Remote Sensing Image Semantic Seg-Mentation. ISPRS International Journal of Geo-Information. 2021; 10(10):672. https://doi.org/10.3390/ijgi10100672
Chicago/Turabian StyleChen, Suting, Chaoqun Wu, Mithun Mukherjee, and Yujie Zheng. 2021. "HA-MPPNet: Height Aware-Multi Path Parallel Network for High Spatial Resolution Remote Sensing Image Semantic Seg-Mentation" ISPRS International Journal of Geo-Information 10, no. 10: 672. https://doi.org/10.3390/ijgi10100672
APA StyleChen, S., Wu, C., Mukherjee, M., & Zheng, Y. (2021). HA-MPPNet: Height Aware-Multi Path Parallel Network for High Spatial Resolution Remote Sensing Image Semantic Seg-Mentation. ISPRS International Journal of Geo-Information, 10(10), 672. https://doi.org/10.3390/ijgi10100672