
Hybrid LDA-CNN Framework for Robust End-to-End Myoelectric Hand Gesture Recognition Under Dynamic Conditions




Abstract
1. Introduction
- Highlighting the robustness of Fisher’s representation for sEMG gesture recognition under dynamic conditions (multi-limb positions and contraction forces);
- Highlighting the problem of overfitting in regard to deep CNNs trained with cross-entropy on a limited dataset;
- Improving sEMG hand gesture recognition under dynamic conditions through the knowledge distillation of manual sEMG features in Fisher’s discriminative subspace as deep convolutional weights;
- Applying gradient-based optimization of the CNN optimization framework to address the numerical instability of LDA Rayleigh–Ritz quotient for large feature sets;
- Ensuring the system’s real-time robustness to avoid perceptible user delays by utilizing fast GPU computation.
2. Materials and Methods
2.1. Benchmark Datasets
2.1.1. Multiple Limb Position Hand Gesture Dataset
2.1.2. Amputee sEMG Multi-Contraction Forces Dataset
2.2. sEMG Feature Extraction
- Our proposed extended 23 sEMG feature set (Ext-23): Mean Frequency (mnf), Cepstrum Coefficient (cc), Power Spectrum Ratio (psr), Marginal of Discrete Wavelet Transform (mdwt), Slope Sign Change (ssc), Auto-Regressive Coefficient (ar), and time-domain power spectral moments (TD-PSR), mean absolute value slope (mavs), Histogram of EMG (hemg), mean absolute value (mav), Zero Crossing (zc), Waveform Length (wl), Root Mean Square (rms), Integral Absolute Value (iav), Difference Absolute Standard Deviation Value (dasdv), Average Amplitude Change (aac), Log Detector (log), Willison Amplitude (wamp), Myopulse Percentage Rate (myop), V-Order (v), variance (var), Log variance (logvar), and Maximum Fractal Length (mfl).
- Atzori’s feature set: rms, mdwt, hemg, mav, wl, ssc, and zc;
- Du’s feature set: iav, var, wamp, wl, ssc, and zc;
- Hudgins’ feature set: mav, wl, ssc, and zc;
- Time-domain power spectral moments (TD-PSR): a set of features that are robust to changes in arm position and contraction force frequency domain features extracted directly from the time domain;
- Phinyomark’s feature set: mav, wl, wamp, zc, mavs, ar, mnf, and psr;
- Robust Time-Domain 8 (TD8) [25]: aac, dasdv, mfl, myop, ssc, wamp, wl, and zc;
- Robust Time-Domain 8 with Autoregressive Coefficients (TD8-ARs) [25]: aac, dasdv, mfl, myop, ssc, wamp, wl, zc, and ar.
2.3. Linear Discriminant Analysis and Fisher’s Representation
2.4. Hybrid CNN-LDA Framework for End-to-End sEMG-Based Hand Gesture Recognition
- Cross-entropy CNN (CNN-CE, ), where the CNN parameters are learned by minimizing the .
- Fusion CNN-LDA (CNN-CEMSE, ), which simultaneously optimizes both the and during training.
- Fisher’s approximator (CNN-MSE, ). This model is trained to minimize the loss exclusively to obtain a latent representation closely aligned with Fisher’s representation. After the model is trained, the weight of the convolution layers up to linear_6 are frozen, and the remaining layers are retrained with cross-entropy loss.
2.5. Training and Testing Dataset Partitioning
2.6. Statistical Tests
3. Results
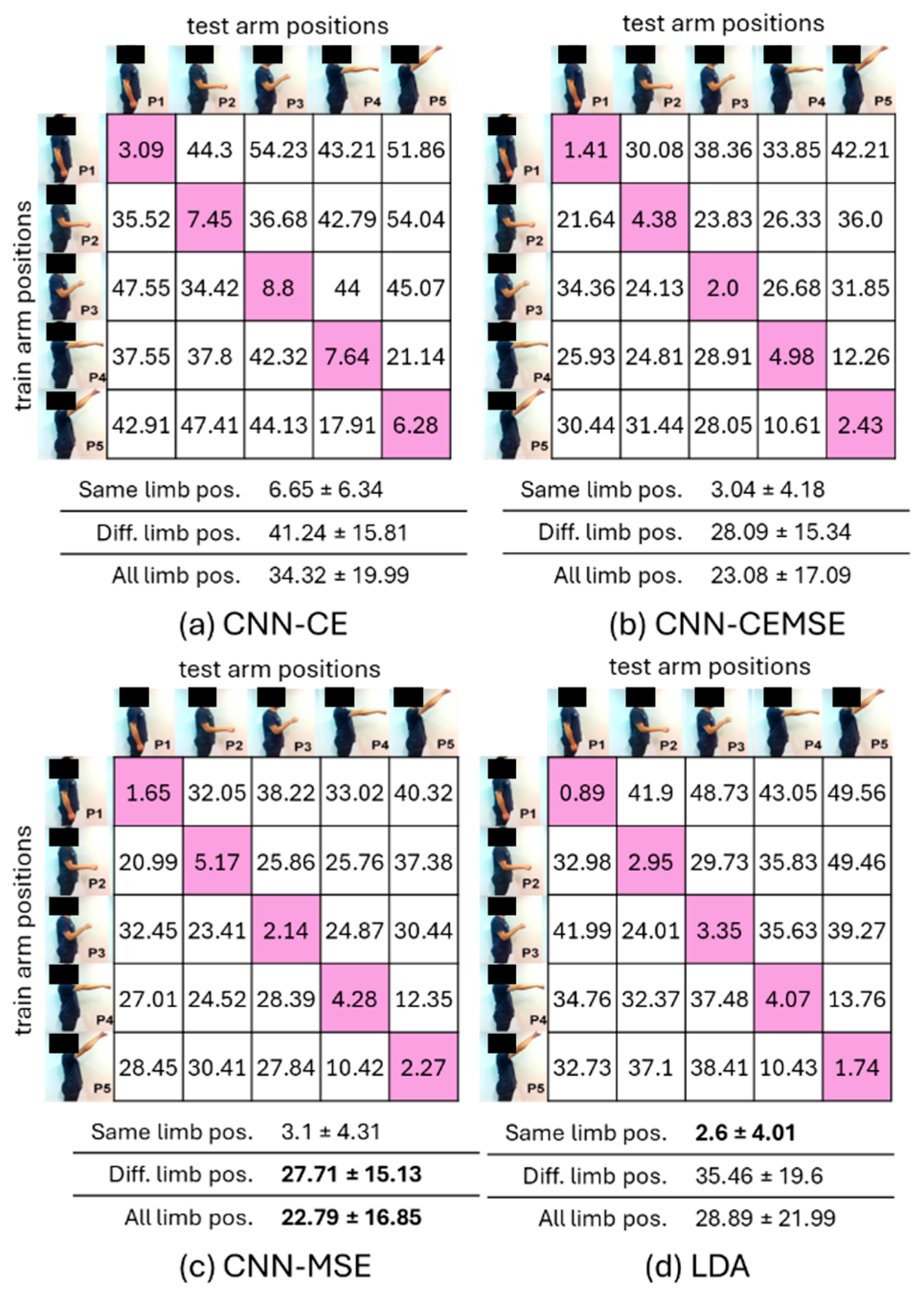
3.1. Robustness of Fisher’s Representation for Hand Gesture Recognition Under Dynamic Conditions Using the TD8-AR Feature Set
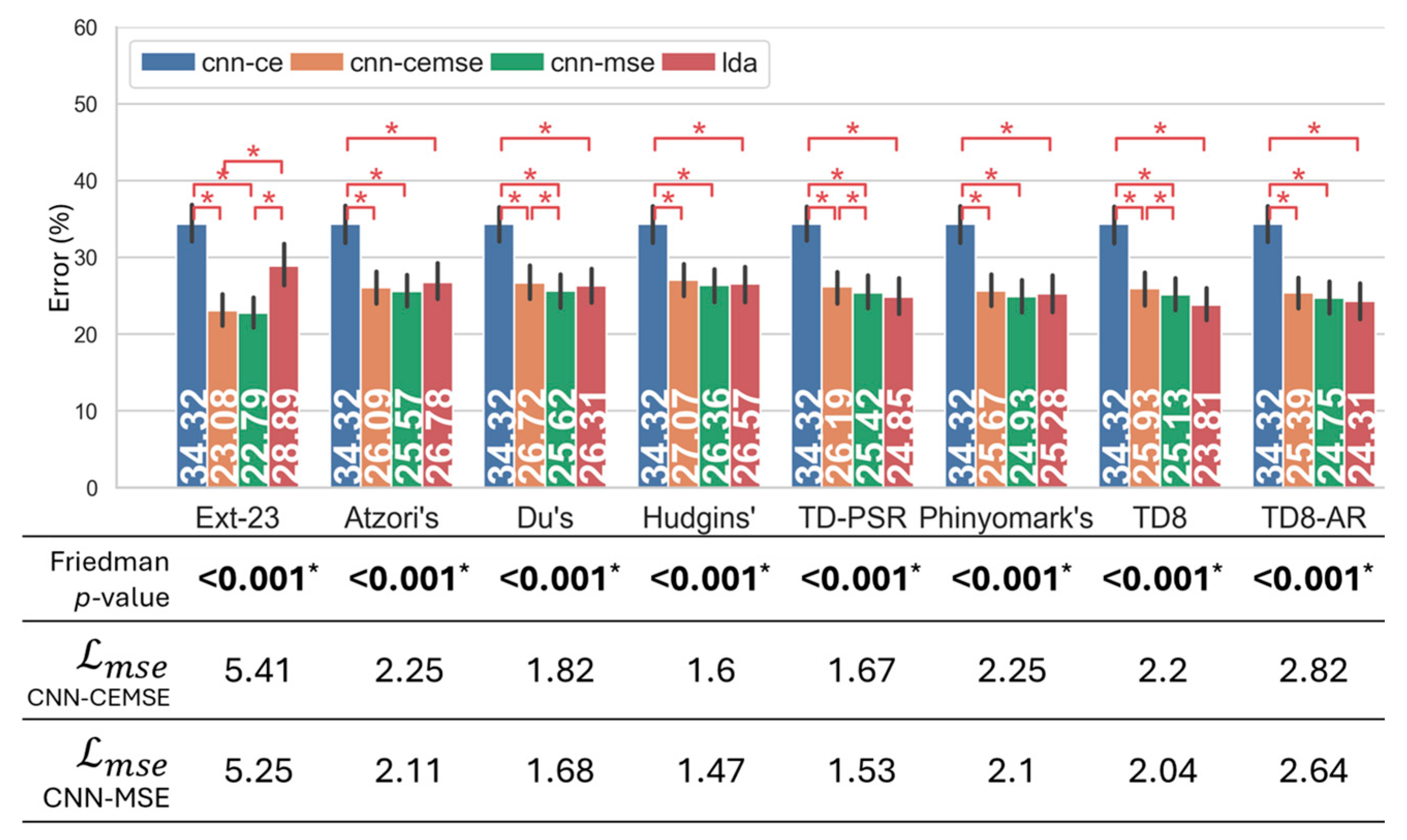
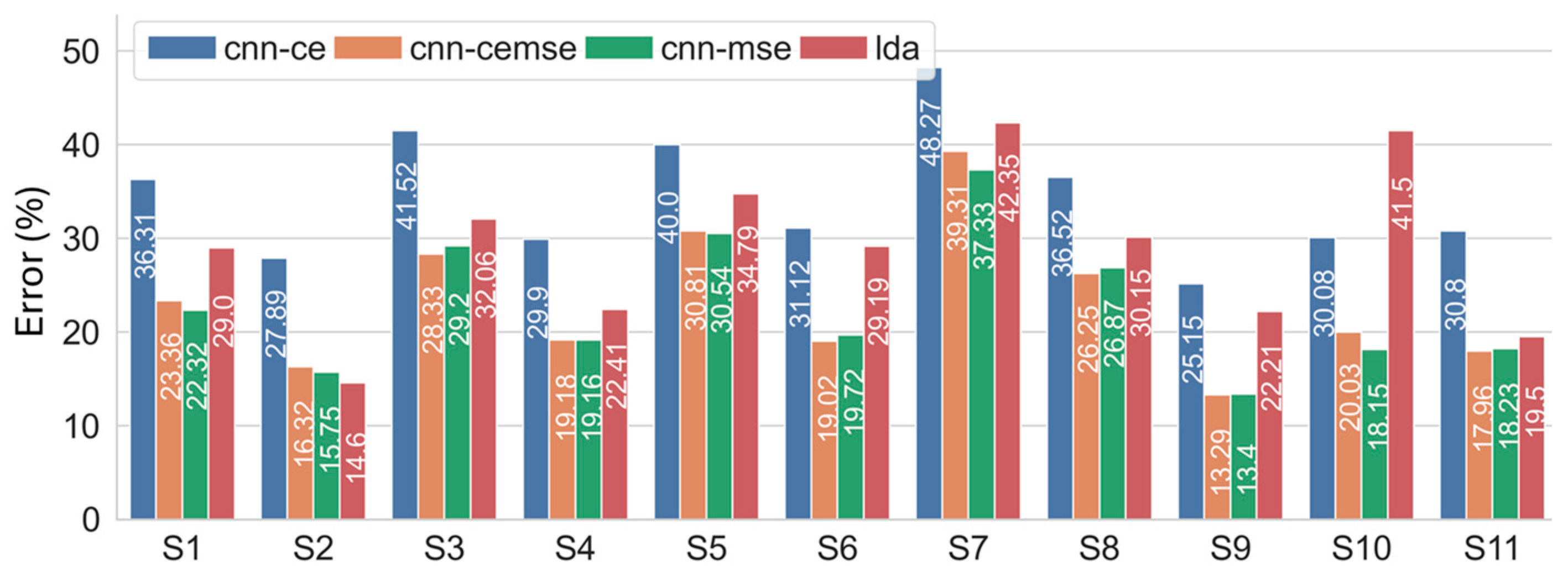
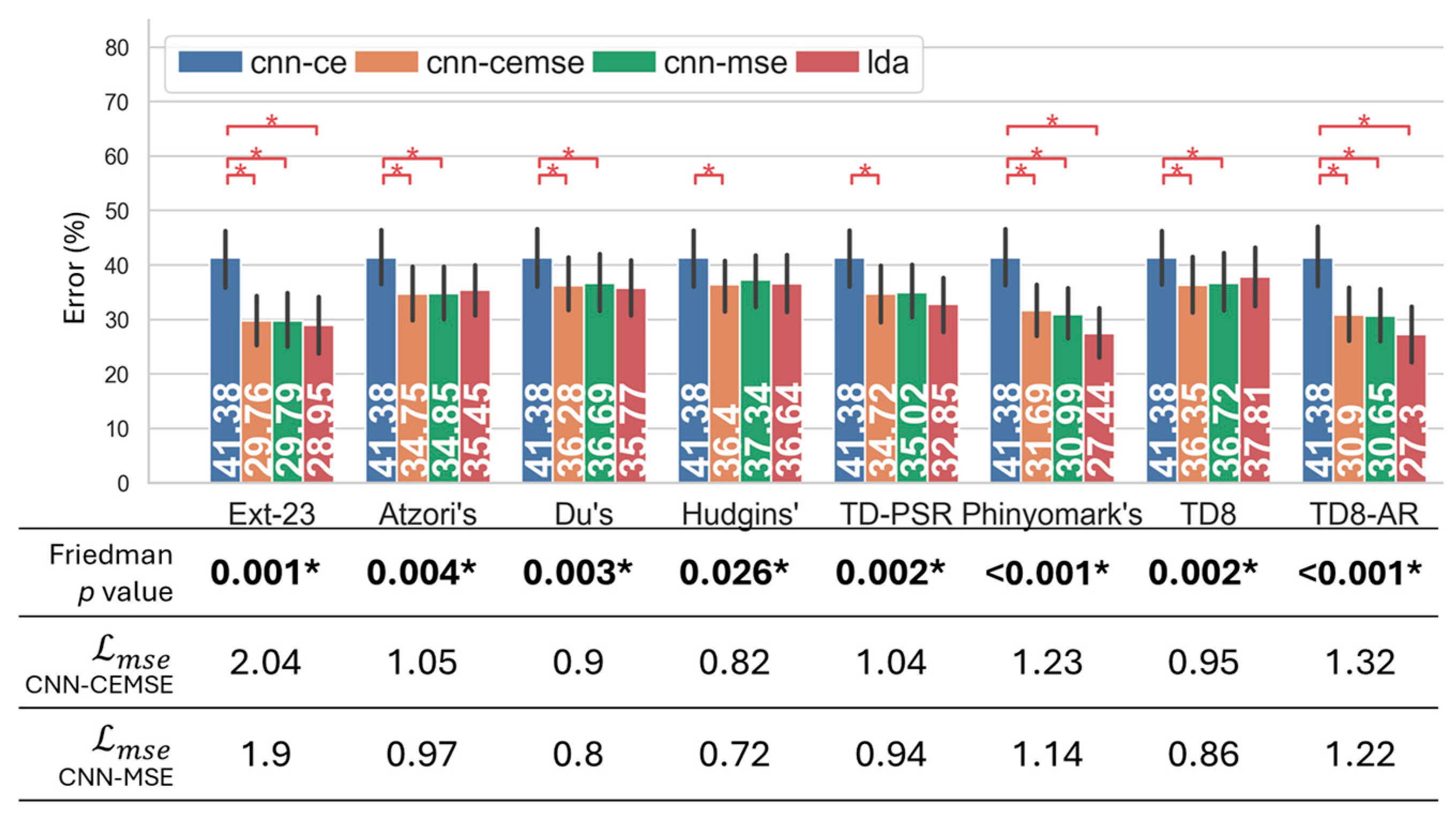
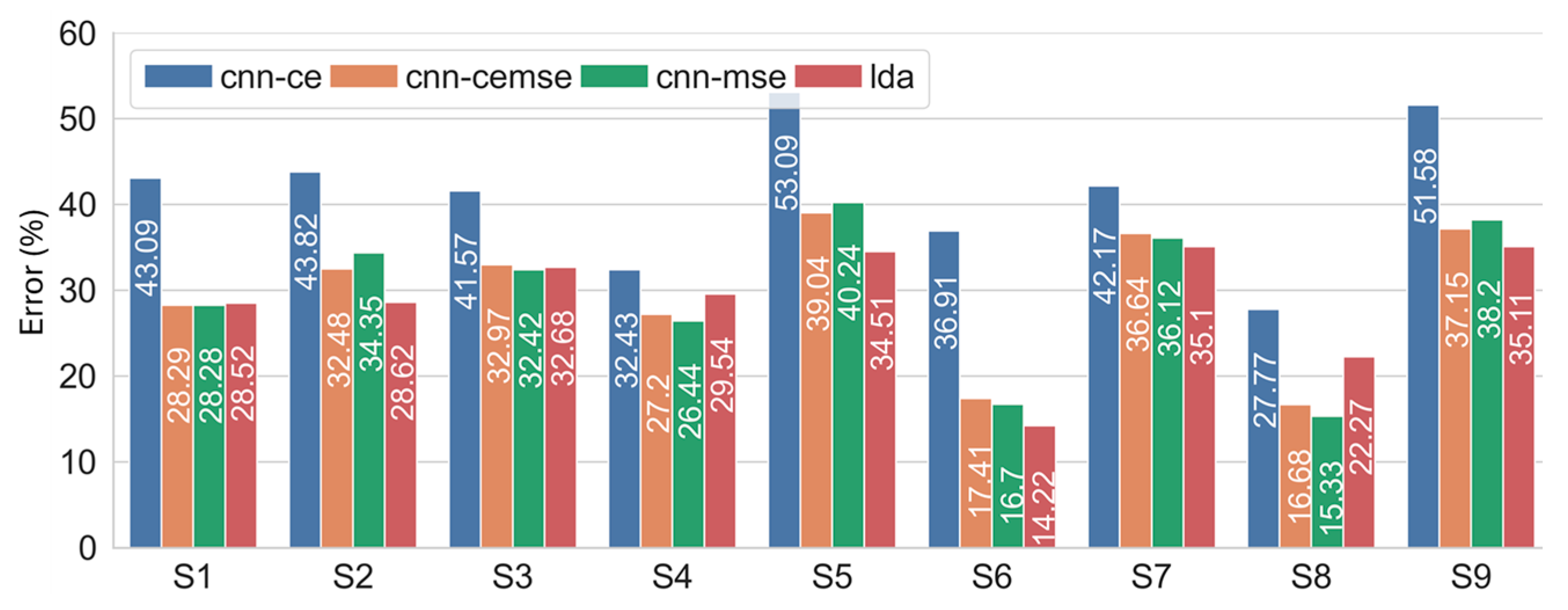
3.2. Recognition Performance of Hybrid Frameworks in Regard to Hand Gesture Recognition Under Dynamic Conditions
3.2.1. Results Based on Limb.Pos. Dataset
3.2.2. Results Based on Amp.Force. Dataset
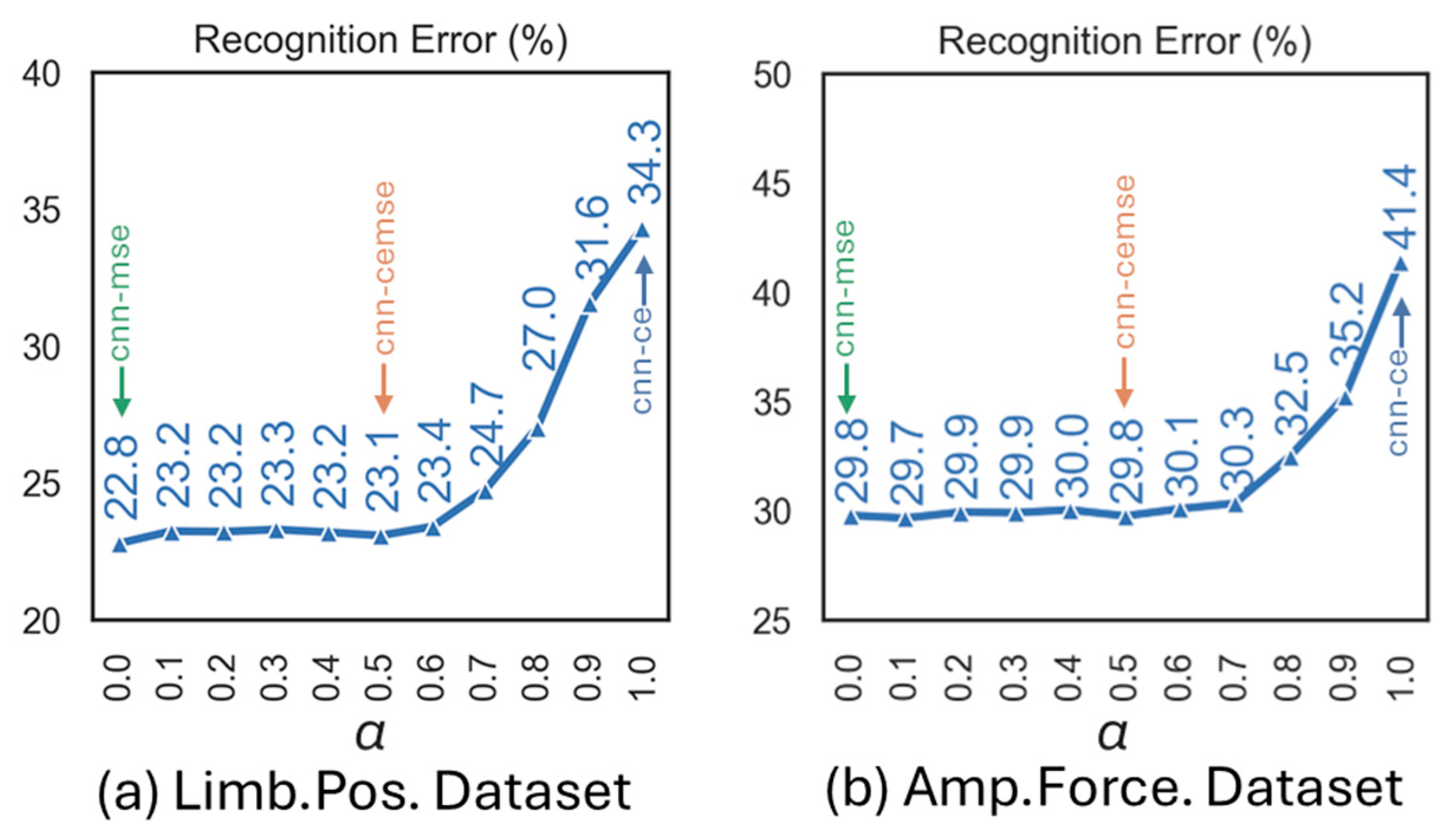
3.3. The Effect of Hyperparameter Balancing MSE and Cross-Entropy Loss
3.4. Evaluation of CNN Training Convergence and Latent Representation
3.5. Comparison of Inference Time
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN-CE | Cross-Entropy CNN (α = 1) |
| CNN-CEMSE | Fusion CNN-LDA (α = 0.5) |
| CNN-MSE | Fisher’s approximator (α = 0) |
| LDA | Linear Discriminant Analysis |
| SVMs | Support Vector Machines |
| QDA | Quadratic Discriminant Analysis |
| kNN | K-nearest neighbor |
| CEN | Nearest centroid |
| LR-quadratic | Logistic Regression with Quadratic Kernel |
| TD8 | Robust Time-Domain 8 |
| TD8-ARs | Robust Time-Domain 8 with Autoregressive Coefficients |
| TD-PSR | Time-domain power spectral moments |
References
- Cordella, F.; Ciancio, A.L.; Sacchetti, R.; Davalli, A.; Cutti, A.G.; Guglielmelli, E.; Zollo, L. Literature review on needs of upper limb prosthesis users. Front. Neurosci. 2016, 10, 209. [Google Scholar] [CrossRef] [PubMed]
- Yang, D.; Gu, Y.; Thakor, N.V.; Liu, H. Improving the functionality, robustness, and adaptability of myoelectric control for dexterous motion restoration. Exp. Brain Res. 2019, 237, 291–311. [Google Scholar] [CrossRef] [PubMed]
- Kyranou, I.; Vijayakumar, S.; Erden, M.S. Causes of performance degradation in electromyographic pattern recognition in upper limb prostheses. Front. Neurorobotics 2018, 12, 58. [Google Scholar] [CrossRef] [PubMed]
- Hargrove, L.J.; Scheme, E.J.; Englehart, K.B.; Hudgins, B.S. Multiple binary classifications via linear discriminant analysis for improved controllability of a powered prosthesis. IEEE Trans. Neural Syst. Rehabil. Eng. 2010, 18, 49–57. [Google Scholar] [CrossRef] [PubMed]
- Vidovic, M.M.-C.; Hwang, H.-J.; Amsüss, S.; Hahne, J.M.; Farina, D.; Müller, K.-R. Improving the robustness of myoelectric pattern recognition for upper limb prostheses by covariate shift adaptation. IEEE Trans. Neural Syst. Rehabil. Eng. 2015, 24, 961–970. [Google Scholar] [CrossRef]
- Al-Timemy, A.H.; Khushaba, R.N.; Bugmann, G.; Escudero, J. Improving the performance against force variation of EMG controlled multifunctional upper-limb prostheses for transradial amputees. IEEE Trans. Neural Syst. Rehabil. Eng. 2015, 24, 650–661. [Google Scholar] [CrossRef]
- Khushaba, R.N.; Takruri, M.; Miro, J.V.; Kodagoda, S. Towards limb position invariant myoelectric pattern recognition using time-dependent spectral features. Neural Netw. 2014, 55, 42–58. [Google Scholar] [CrossRef]
- Smith, L.H.; Hargrove, L.J.; Lock, B.A.; Kuiken, T.A. Determining the optimal window length for pattern recognition-based myoelectric control: Balancing the competing effects of classification error and controller delay. IEEE Trans. Neural Syst. Rehabil. Eng. 2010, 19, 186–192. [Google Scholar] [CrossRef]
- Le, H.; Spinks, G.M.; in Het Panhuis, M.; Alici, G. Cross-day myoelectric gesture recognition with hybrid multistream CNN-bidirectional LSTM. In Proceedings of the 2025 IEEE International Conference on Mechatronics (ICM’25), Wollongong, Australia, 28 February–2 March 2025. [Google Scholar]
- Atzori, M.; Cognolato, M.; Müller, H. Deep learning with convolutional neural networks applied to electromyography data: A resource for the classification of movements for prosthetic hands. Front. Neurorobotics 2016, 10, 9. [Google Scholar] [CrossRef]
- Wu, Y.; Zheng, B.; Zhao, Y. Dynamic gesture recognition based on LSTM-CNN. In Proceedings of the 2018 Chinese Automation Congress (CAC), Xi’an, China, 30 November–2 December 2018; pp. 2446–2450. [Google Scholar]
- Wei, W.; Wong, Y.; Du, Y.; Hu, Y.; Kankanhalli, M.; Geng, W. A multi-stream convolutional neural network for sEMG-based gesture recognition in muscle-computer interface. Pattern Recognit. Lett. 2019, 119, 131–138. [Google Scholar] [CrossRef]
- Zabihi, S.; Rahimian, E.; Asif, A.; Mohammadi, A. Light-weight CNN-attention based architecture for hand gesture recognition via electromyography. In Proceedings of the ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Zabihi, S.; Rahimian, E.; Asif, A.; Mohammadi, A. Trahgr: Transformer for hand gesture recognition via electromyography. IEEE Trans. Neural Syst. Rehabil. Eng. 2023, 31, 4211–4224. [Google Scholar] [CrossRef] [PubMed]
- Betthauser, J.L.; Hunt, C.L.; Osborn, L.E.; Masters, M.R.; Levay, G.; Kaliki, R.R.; Thakor, N.V. Limb position tolerant pattern recognition for myoelectric prosthesis control with adaptive sparse representations from extreme learning. IEEE Trans. Biomed. Eng. 2017, 65, 770–778. [Google Scholar] [CrossRef] [PubMed]
- Tchantchane, R.; Zhou, H.; Zhang, S.; Alici, G. A review of hand gesture recognition systems based on noninvasive wearable sensors. Adv. Intell. Syst. 2023, 5, 2300207. [Google Scholar] [CrossRef]
- Zhang, S.; Zhou, H.; Tchantchane, R.; Alici, G. Hand gesture recognition across various limb positions using a multi-modal sensing system based on self-adaptive data-fusion and convolutional neural networks (CNNs). IEEE Sens. J. 2024, 24, 18633–18645. [Google Scholar] [CrossRef]
- Deshmukh, S.; Khatik, V.; Saxena, A. Robust Fusion Model for Handling EMG and Computer Vision Data in Prosthetic Hand Control. IEEE Sens. Lett. 2023, 7, 6004804. [Google Scholar] [CrossRef]
- Cirelli, G.; Tamantini, C.; Cordella, L.P.; Cordella, F. A Semiautonomous Control Strategy Based on Computer Vision for a Hand–Wrist Prosthesis. Robotics 2023, 12, 152. [Google Scholar] [CrossRef]
- Castro, M.N.; Dosen, S. Continuous semi-autonomous prosthesis control using a depth sensor on the hand. Front. Neurorobotics 2022, 16, 814973. [Google Scholar] [CrossRef]
- Khushaba, R.N.; Al-Timemy, A.; Kodagoda, S.; Nazarpour, K. Combined influence of forearm orientation and muscular contraction on EMG pattern recognition. Expert. Syst. Appl. 2016, 61, 154–161. [Google Scholar] [CrossRef]
- Phinyomark, A.; Quaine, F.; Charbonnier, S.; Serviere, C.; Tarpin-Bernard, F.; Laurillau, Y. EMG feature evaluation for improving myoelectric pattern recognition robustness. Expert. Syst. Appl. 2013, 40, 4832–4840. [Google Scholar] [CrossRef]
- Lorrain, T.; Jiang, N.; Farina, D. Influence of the training set on the accuracy of surface EMG classification in dynamic contractions for the control of multifunction prostheses. J. Neuroeng. Rehabil. 2011, 8, 25. [Google Scholar] [CrossRef]
- Franzke, A.W.; Kristoffersen, M.B.; Bongers, R.M.; Murgia, A.; Pobatschnig, B.; Unglaube, F.; van der Sluis, C.K. Users’ and therapists’ perceptions of myoelectric multi-function upper limb prostheses with conventional and pattern recognition control. PLoS ONE 2019, 14, e0220899. [Google Scholar] [CrossRef] [PubMed]
- Le, H.; Spinks, G.M.; in Het Panhuis, M.; Alici, G. Feature significance and generalizability of myoelectric hand gesture recognition under varying limb positions. In Proceedings of the 2025 IEEE International Conference on Mechatronics (ICM’25), Wollongong, Australia, 28 February–2 March 2025. [Google Scholar]
- Akkad, G.; Mansour, A.; Inaty, E. Embedded deep learning accelerators: A survey on recent advances. IEEE Trans. Artif. Intell. 2023, 5, 1954–1972. [Google Scholar] [CrossRef]
- Le, H.; in Het Panhuis, M.; Spinks, G.M.; Alici, G. The effect of dataset size on EMG gesture recognition under diverse limb positions. In Proceedings of the 2024 10th IEEE RAS/EMBS International Conference for Biomedical Robotics and Biomechatronics (BioRob), Heidelberg, Germany, 1–4 September 2024; pp. 303–308. [Google Scholar]
- Moslemi, A.; Briskina, A.; Dang, Z.; Li, J. A Survey on Knowledge Distillation: Recent Advancements. Mach. Learn. Appl. 2024, 18, 100605. [Google Scholar] [CrossRef]
- Zeng, J.; Sheng, Y.; Yang, Y.; Zhou, Z.; Liu, H. Cross modality knowledge distillation between A-mode ultrasound and surface electromyography. IEEE Trans. Instrum. Meas. 2022, 71, 1–9. [Google Scholar] [CrossRef]
- Wei, W.; Ren, L.; Zhou, M.; Ma, Z.; Zhao, K.; Xu, X. Improving unimodal sEMG-based pattern recognition through multimodal generative adversarial learning. IEEE Trans. Instrum. Meas. 2025, 74, 2523520. [Google Scholar] [CrossRef]
- Ghojogh, B.; Karray, F.; Crowley, M. Fisher and kernel fisher discriminant analysis: Tutorial. arXiv 2019, arXiv:1906.09436. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Drapała, J.; Brzostowski, K.; Szpala, A.; Rutkowska-Kucharska, A. Two stage EMG onset detection method. Arch. Control Sci. 2012, 22, 427–440. [Google Scholar] [CrossRef]
- Jiang, N.; Englehart, K.B.; Parker, P.A. Extracting simultaneous and proportional neural control information for multiple-DOF prostheses from the surface electromyographic signal. IEEE Trans. Biomed. Eng. 2008, 56, 1070–1080. [Google Scholar] [CrossRef]
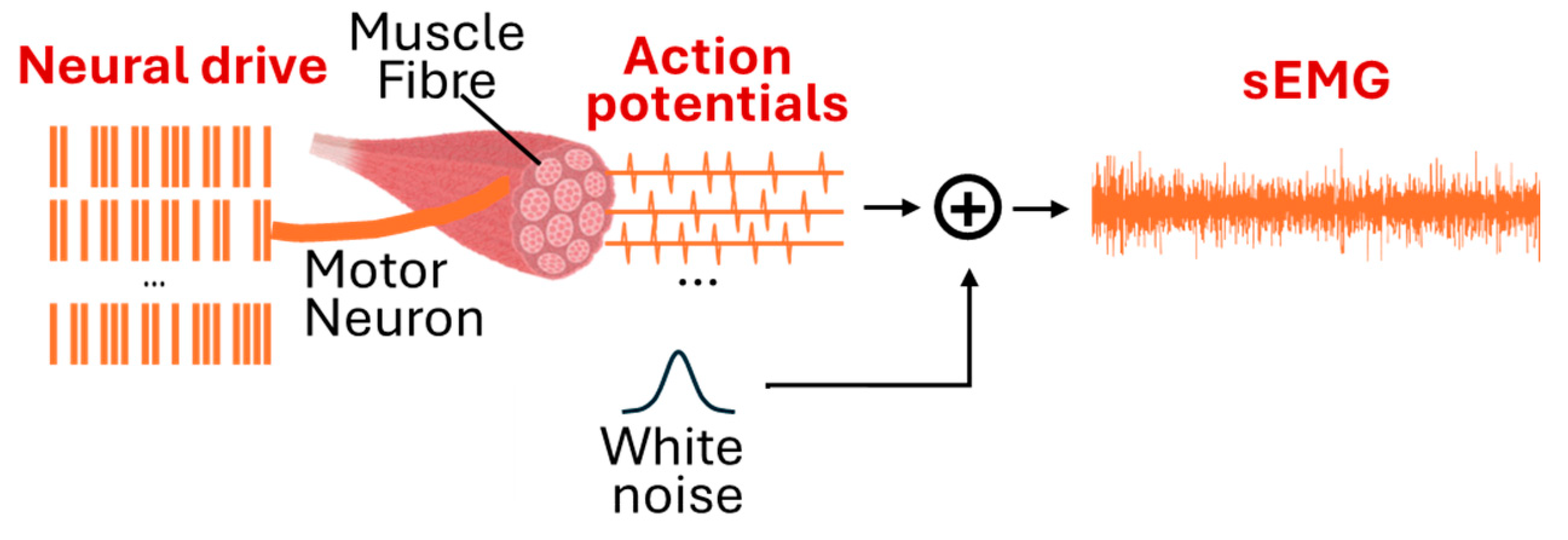
- Fuglevand, A.J.; Winter, D.A.; Patla, A.E.; Stashuk, D. Detection of motor unit action potentials with surface electrodes: Influence of electrode size and spacing. Biol. Cybern. 1992, 67, 143–153. [Google Scholar] [CrossRef]
- Farina, D.; Merletti, R.; Stegeman, D. Biophysics of the generation of EMG signals. In Electromyography: Physiology, Engineering, and Noninvasive Applications; Wiley: Hoboken, NJ, USA, 2004; pp. 81–105. [Google Scholar] [CrossRef]
- Fuglevand, A.J.; Winter, D.A.; Patla, A.E. Models of recruitment and rate coding organization in motor-unit pools. J. Neurophysiol. 1993, 70, 2470–2488. [Google Scholar] [CrossRef]
- Kim, H.; Lee, J.; Kim, J. Electromyography-signal-based muscle fatigue assessment for knee rehabilitation monitoring systems. Biomed. Eng. Lett. 2018, 8, 345–353. [Google Scholar] [CrossRef] [PubMed]
- He, J.; Zhang, D.; Sheng, X.; Li, S.; Zhu, X. Invariant surface EMG feature against varying contraction level for myoelectric control based on muscle coordination. IEEE J. Biomed. Health Inform. 2014, 19, 874–882. [Google Scholar] [CrossRef] [PubMed]
- Phinyomark, A.; Phukpattaranont, P.; Limsakul, C. Feature reduction and selection for EMG signal classification. Expert. Syst. Appl. 2012, 39, 7420–7431. [Google Scholar] [CrossRef]
- Wei, W.; Dai, Q.; Wong, Y.; Hu, Y.; Kankanhalli, M.; Geng, W. Surface-electromyography-based gesture recognition by multi-view deep learning. IEEE Trans. Biomed. Eng. 2019, 66, 2964–2973. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin/Heidelberg, Germany, 2009; Volume 2. [Google Scholar]
- Ghojogh, B.; Crowley, M. Linear and quadratic discriminant analysis: Tutorial. arXiv 2019, arXiv:1906.02590. [Google Scholar] [CrossRef]
- Dorfer, M.; Kelz, R.; Widmer, G. Deep linear discriminant analysis. arXiv 2015, arXiv:1511.04707. [Google Scholar] [CrossRef]
- Frénay, B.; Verleysen, M. Classification in the presence of label noise: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2013, 25, 845–869. [Google Scholar] [CrossRef]
- Hahne, J.M.; Biessmann, F.; Jiang, N.; Rehbaum, H.; Farina, D.; Meinecke, F.C.; Müller, K.-R.; Parra, L.C. Linear and nonlinear regression techniques for simultaneous and proportional myoelectric control. IEEE Trans. Neural Syst. Rehabil. Eng. 2014, 22, 269–279. [Google Scholar] [CrossRef]
- Jiang, N.; Vujaklija, I.; Rehbaum, H.; Graimann, B.; Farina, D. Is accurate mapping of EMG signals on kinematics needed for precise online myoelectric control? IEEE Trans. Neural Syst. Rehabil. Eng. 2013, 22, 549–558. [Google Scholar] [CrossRef]
- Bunderson, N.E.; Kuiken, T.A. Quantification of feature space changes with experience during electromyogram pattern recognition control. IEEE Trans. Neural Syst. Rehabil. Eng. 2012, 20, 239–246. [Google Scholar] [CrossRef]
- Stuttaford, S.A.; Dyson, M.; Nazarpour, K.; Dupan, S.S. Reducing motor variability enhances myoelectric control robustness across untrained limb positions. IEEE Trans. Neural Syst. Rehabil. Eng. 2023, 32, 23–32. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Zhang, D.; Sheng, X.; Zhu, X. Quantification and solutions of arm movements effect on sEMG pattern recognition. Biomed. Signal Process. Control 2014, 13, 189–197. [Google Scholar] [CrossRef]
- Radmand, A.; Scheme, E.; Englehart, K. A characterization of the effect of limb position on EMG features to guide the development of effective prosthetic control schemes. In Proceedings of the 2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Chicago, IL, USA, 26–30 August 2014; pp. 662–667. [Google Scholar]
- Vinjamuri, R.; Patel, V.; Powell, M.; Mao, Z.-H.; Crone, N. Candidates for synergies: Linear discriminants versus principal components. Comput. Intell. Neurosci. 2014, 2014, 373957. [Google Scholar] [CrossRef] [PubMed]
- Teng, Z.; Xu, G.; Liang, R.; Li, M.; Zhang, S. Evaluation of synergy-based hand gesture recognition method against force variation for robust myoelectric control. IEEE Trans. Neural Syst. Rehabil. Eng. 2021, 29, 2345–2354. [Google Scholar] [CrossRef]
- Al-Timemy, A.H.; Bugmann, G.; Outram, N.; Escudero, J. Single channel-based myoelectric control of hand movements with Empirical Mode Decomposition. In Proceedings of the 2011 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Boston, MA, USA, 30 August–3 September 2011; pp. 6059–6062. [Google Scholar]
- Zhang, Z.; Sabuncu, M. Generalized cross entropy loss for training deep neural networks with noisy labels. arXiv 2018, arXiv:1805.07836. [Google Scholar] [CrossRef]
- Feng, L.; Shu, S.; Lin, Z.; Lv, F.; Li, L.; An, B. Can cross entropy loss be robust to label noise? In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 2206–2212. [Google Scholar]
- Zhou, H.; Le, H.T.; Zhang, S.; Phung, S.L.; Alici, G. Hand gesture recognition from surface electromyography signals with graph convolutional network and attention mechanisms. IEEE Sens. J. 2025, 25, 9081–9092. [Google Scholar] [CrossRef]
- Oyemakinde, T.T.; Kulwa, F.; Peng, X.; Liu, Y.; Cao, J.; Deng, X.; Wang, M.; Li, G.; Samuel, O.W.; Fang, P. A novel sEMG-FMG combined sensor fusion approach based on an attention-driven CNN for dynamic hand gesture recognition. IEEE Trans. Instrum. Meas. 2025, 747, 2533413. [Google Scholar] [CrossRef]
- Samuel, O.W.; Li, X.; Geng, Y.; Asogbon, M.G.; Fang, P.; Huang, Z.; Li, G. Resolving the adverse impact of mobility on myoelectric pattern recognition in upper-limb multifunctional prostheses. Comput. Biol. Med. 2017, 90, 76–87. [Google Scholar] [CrossRef]
- Scheme, E.; Fougner, A.; Stavdahl, Ø.; Chan, A.D.; Englehart, K. Examining the adverse effects of limb position on pattern recognition based myoelectric control. In Proceedings of the 2010 Annual International Conference of the IEEE Engineering in Medicine and Biology, Buenos Aires, Argentina, 31 August–4 September 2010; pp. 6337–6340. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature extraction | conv_1 k = 3, ch = 20 | norm_1 | relu_1 | pool_1 k = 3, strd = 3 |
| conv_2 k = 3, ch = 20 | norm_2 | relu_2 | pool_2 k = 3, strd = 3 | |
| conv_3 k = 3, ch = 20 | norm_3 | relu_3 | pool_3 k = 3, strd = 3 | |
| conv_4 k = 3, ch = 20 | norm_4 | relu_4 | pool_4 k = 3, strd = 3 | |
| flatten | ||||
| Fisher’s approx. | linear_5 out = 100 | norm_5 | relu_5 | dropout_5 prob = 0.2 |
| linear_6 out = | ||||
| clf. | linear_7 out = 100 | norm_7 | relu_7 | softmax out = |
| Methods | Same Limb Pos. Error (%) | Diff. Limb Pos Error (%) | All Limb Pos. Error (%) |
|---|---|---|---|
| 1D-CNN [9] (CNN-CE equivalent) | 6.65 | 41.24 | 34.32 |
| 2D-CNN [9,10] | 6.27 | 38.36 | 31.94 |
| LSTM-CNN [11] | 3.75 | 34.70 | 28.51 |
| Multi-stream 1D-CNN [9,12] | 3.9 | 33.32 | 27.44 |
| Multi-stream 1D-CNN-LSTM [9] | 3.82 | 31.85 | 26.24 |
| Transformer TC-HGR [13] | 17.8 | 50.89 | 44.27 |
| Transformer Tra-HGR [14] | 12.2 | 43.19 | 36.99 |
| Transformer Tra-HGR-Fnet [14] | 15.47 | 43.16 | 37.62 |
| Transformer Tra-HGR-Tnet [14] | 23.29 | 62.44 | 54.61 |
| Our Hybrid CNN-LDA (CNN-MSE and Ext-23 feature set) | 3.1 | 27.71 | 22.79 |
| Methods | Same Force Error (%) | Diff. Force Error (%) | All Force Error (%) |
|---|---|---|---|
| 1D-CNN [9] (CNN-CE equivalent) | 16.98 | 53.58 | 41.38 |
| 2D-CNN [9,10] | 14.11 | 48.89 | 37.30 |
| LSTM-CNN [11] | 11.42 | 47.15 | 35.24 |
| Multi-stream 1D-CNN [9,12] | 10.53 | 47.89 | 35.44 |
| Multi-stream 1D-CNN-LSTM [9] | 11.57 | 48.75 | 36.36 |
| Transformer TC-HGR [13] | 28.48 | 59.19 | 48.95 |
| Transformer Tra-HGR [14] | 29.21 | 54.93 | 46.36 |
| Transformer Tra-HGR-Fnet [14] | 31.49 | 56.98 | 48.48 |
| Transformer Tra-HGR-Tnet [14] | 51.70 | 69.35 | 63.47 |
| Our Hybrid CNN-LDA (CNN-MSE and Ext-23 feature set) | 8.19 | 40.59 | 29.79 |
| Ext-23 | Atzori’s | Du’s | Hudgin’s | TD-PSR | Phinyo-mark’s | TD8 | TD8-AR | CNN * | |
|---|---|---|---|---|---|---|---|---|---|
| Feature Dimension | 528 | 272 | 48 | 32 | 48 | 120 | 64 | 120 | - |
| Feat. Extraction (ms/frame) | 16.95 | 5.02 | 0.83 | 0.55 | 0.49 | 6.80 | 1.07 | 2.25 | - |
| Classification (ms/frame) | 0.19 | 0.19 | 0.19 | 0.19 | 0.19 | 0.19 | 0.19 | 0.19 | - |
| Total (ms/frame) | 17.14 | 5.21 | 1.02 | 0.74 | 0.68 | 6.99 | 1.26 | 2.44 | 1.72 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Le, H.; Panhuis, M.i.h.; Spinks, G.M.; Alici, G. Hybrid LDA-CNN Framework for Robust End-to-End Myoelectric Hand Gesture Recognition Under Dynamic Conditions. Robotics 2025, 14, 83. https://doi.org/10.3390/robotics14060083
Le H, Panhuis Mih, Spinks GM, Alici G. Hybrid LDA-CNN Framework for Robust End-to-End Myoelectric Hand Gesture Recognition Under Dynamic Conditions. Robotics. 2025; 14(6):83. https://doi.org/10.3390/robotics14060083
Chicago/Turabian StyleLe, Hongquan, Marc in het Panhuis, Geoffrey M. Spinks, and Gursel Alici. 2025. "Hybrid LDA-CNN Framework for Robust End-to-End Myoelectric Hand Gesture Recognition Under Dynamic Conditions" Robotics 14, no. 6: 83. https://doi.org/10.3390/robotics14060083
APA StyleLe, H., Panhuis, M. i. h., Spinks, G. M., & Alici, G. (2025). Hybrid LDA-CNN Framework for Robust End-to-End Myoelectric Hand Gesture Recognition Under Dynamic Conditions. Robotics, 14(6), 83. https://doi.org/10.3390/robotics14060083