1. Introduction
The domain of automatic control involving robots equipped with flexible links has emerged as a field of profound significance within control engineering and robotics, as documented in [
1]. The integration of flexible links poses considerable challenges due to vibrations induced during the transitional phases of controlling a robotic arm’s position, which undermines the system’s performance and precision [
2]. These vibrations can lead to positioning errors, component wear, and in some cases, system failures. This issue calls for advanced control strategies to mitigate the adverse effects and enhance the reliability and accuracy of robotic systems.
Passive reduction methods in dynamic robotic environments utilize the system’s inherent dynamics to achieve stability and control, as demonstrated in studies on passive dynamic systems [
3,
4,
5]. In contrast, active control methods employ external forces or control inputs to actively stabilize and manipulate the system, as seen in research on vibration isolation and reduction devices [
5,
6]. Passive methods leverage the system’s natural dynamics and energy for control, while active methods require continuous monitoring and adjustment through external inputs to maintain stability and performance. The primary distinction lies in the autonomy and self-regulation of passive systems versus the intervention and real-time control of active systems, each presenting unique advantages and challenges in dynamic robotic environments [
5].
Effective vibration control in robotics is essential for enhancing human–robot collaboration (HRC) in industrial settings [
7]. Techniques for vibration suppression play a crucial role in enhancing task performance and minimizing unwanted oscillations induced by various sources, including handheld tools and external disturbances [
7,
8,
9]. Advanced control methodologies, such as the bandlimited multiple Fourier linear combiner (BMFLC) algorithm and disturbance observer (DOB)-based control, have been developed to actively mitigate vibrations, ensuring smoother robotic operation while maintaining task efficiency [
7,
9]. Moreover, integrating feedforward force control and variable impedance learning enables robots to effectively counteract vibrational disturbances while preserving compliance, thus optimizing human–robot collaboration (HRC) and overall system performance [
7]. Additionally, innovative approaches such as dynamic simulation and trajectory optimization provide predictive capabilities for vibration suppression, facilitating the development of lighter and more cost-effective robotic systems [
8].
Robotic systems incorporating flexible links offer several advantages, including reduced structural weight, improved energy efficiency, and enhanced operational safety. These attributes make them particularly attractive alternatives to conventional rigid robots across various industrial and research applications [
10,
11]. Flexible link manipulators, by optimizing the payload-to-mass ratio, contribute to the development of more efficient and capable robotic systems [
10]. However, the inherent compliance of flexible joints can result in increased impact forces, necessitating higher input torques for effective manipulation. This underscores the importance of precise control strategies to minimize positioning errors an especially critical consideration when managing substantial payloads [
11]. Addressing these challenges through state-of-the-art design and control methodologies is essential for fully harnessing the potential of flexible link manipulators in robotic applications.
Recent research has increasingly bridged reinforcement learning (RL) with control theory, revealing a wide spectrum of possibilities for robotic applications, particularly in enhancing system stability and control performance. For instance, Ref. [
12] introduces a reinforcement-learning-based controller that integrates a robust integral of the sign of the error (RISE) methodology with an actor–critic framework to address these challenges. This convergence of machine-learning techniques with traditional control strategies highlights a promising avenue for advancing robotic autonomy and adaptability in dynamic environments. This approach ensures asymptotic stability and enhances control performance.
Particularly, Ref. [
13] highlights a hybrid control strategy that merges model-based learning with model-free learning to enhance learning capabilities in robotic systems. This hybrid approach significantly improves the efficiency of sampling and motor skill learning performance, as evidenced in control tasks through simulations and hardware manipulation. Similarly, Raoufi and Delavari have developed an optimal model-free controller for flexible link manipulators using a combination of feedback and reinforcement-learning methods [
14].
Rahimi, Ziaei, and Esfanjani explore a reinforcement learning-based control solution for nonlinear tracking problems, considering adversarial attacks in [
15], utilizing the deep deterministic policy gradient (DDPG) algorithm. Moreover, Annaswamy discusses the integration of adaptive control and reinforcement-learning approaches in [
16], suggesting their combined application to leverage their complementary strengths in real-time control solutions.
Focusing on robotics control, Ref. [
17] presents a method based on reinforcement learning to teach robots continuous control actions in object manipulation tasks through simulations. This method allows robots to adapt to new situations and object geometries with minimal additional training. Further deepening research in system control, Ref. [
18] addresses trajectory tracking for a robotic manipulator and a mobile robot using deep-reinforcement-learning-based methods. However, in [
19], an approach based on reinforcement learning is proposed to control a continuous planar three section robot using the DDPG algorithm, thereby enriching research and blending classic and modern control strategies with reinforcement learning, as seen in [
20]. Here, a predictive control scheme based on reinforcement learning (RLMPC) for discrete systems integrates model predictive control (MPC) and RL, where RLMPC demonstrates performance comparable to traditional MPC in linear systems and surpasses it in nonlinear systems.
In our specific field of research, the control of vibrations in flexible links has seen advancements as in [
21], where a reinforcement-learning controller (RL) is presented for vibration suppression in a two-link flexible manipulator system while maintaining trajectory tracking. Experimental results demonstrate the practical applicability of the RL controller. Lastly, a DRLC-DDPG control for flexible link manipulators using an ARX model and an adaptive Kalman filter (AKF) is presented in [
22].
The twin delayed deep deterministic policy gradient (TD3) algorithm has demonstrated superior control performance across various applications, including aero-engine systems, missile autopilots, hybrid electric vehicle (HEV) energy management, and microgrid frequency regulation [
23,
24,
25,
26].
However, TD3 faces challenges in robotic applications, such as slow convergence rates and high collision risks in complex path planning [
27]. Additionally, TD3 often converges to boundary actions, leading to suboptimal strategies and overfitting [
28]. To mitigate these issues, researchers have proposed enhancements like the deep dense dueling twin delayed deep deterministic (D3-TD3) architecture, which improves convergence speed and reduces collisions [
27]. Other advancements, such as adaptively weighted reverse Kullback–Leibler divergence, enhance TD3’s performance in offline reinforcement learning [
29].
Despite these improvements, TD3 still faces limitations related to training time and computational demands. To address these, guided reinforcement learning (GRL) has been proposed to accelerate convergence by integrating prior knowledge [
30]. Hybrid approaches combining RL with classical control methods, such as using a linear quadratic regulator (LQR) to initialize TD3 agents, enhance training stability while reducing computational costs [
31,
32]. These innovations contribute to making TD3 a more efficient solution for robotic control and continuous motion tasks.
Controlling a rotary flexible-link system demands both high-performance tracking and active vibration damping, which single-method controllers often struggle to achieve. We propose a hybrid control framework that simultaneously integrates a model-free deep-reinforcement-learning agent (twin delayed deep deterministic policy gradient, TD3) with a model-based linear quadratic regulator (LQR) and experimental system identification. This approach leverages the strengths of each component: the LQR provides an optimal baseline derived from a linearized model for immediate stability and performance, while the TD3 agent learns to compensate for unmodeled nonlinearities and uncertainties, fine-tuning control signals beyond the LQR’s fixed gains [
33].
Experimental system identification is used to obtain an accurate dynamic model of the flexible link, which not only informs the LQR design but also serves as a high-fidelity simulator for training the TD3 agent [
34,
35]. The inclusion of LQR in the loop also accelerates RL training by guiding the agent with a reasonable control policy from the start, thus reducing exploration of unsafe actions. This synergy between optimal control and learning ensures that the flexible link remains stabilized during learning while the TD3 gradually learns to outperform the LQR’s baseline in terms of damping and tracking optimality [
33].
Importantly, the proposed framework is portable to other flexible-link mechanisms with different physical properties and operating conditions. Because the methodology is model-based and model-free, it generalizes well: one can re-identify the dynamics of a new flexible-link device (e.g., with different link stiffness or inertia), derive an updated LQR for that model, and then re-train or fine-tune the TD3 agent in simulation using the identified model [
35]. This modular process can be applied to custom-built or open-source testbeds just as readily as to the Quanser system, requiring only a system identification phase to calibrate the simulator to the new hardware [
34].
In practice, even significant variations in dynamics can be handled by the RL agent through retraining or robust training (e.g., with domain randomization), allowing the controller to adapt to parameter changes and unmodeled effects in the new platform [
33,
35]. Our research focuses on a cantilever beam coupled to a DC motor, whose state-space dynamic model was developed and validated using real experimental data through the QUARC platform and Simulink
® [
36]. We propose a simulated controller based on guided reinforcement learning (GRL), where a linear quadratic regulator (LQR) guides the training of the twin delayed deep deterministic policy gradient (TD3) algorithm. This hybrid approach significantly reduces training time and improves convergence stability, optimizing trajectory tracking accuracy and minimizing vibrations. Simulation results, compared with conventional methods (LQR, GA-LQR, and fuzzy control), demonstrate its potential for practical applications in flexible systems and collaborative robotics. As a next step, we suggest experimental validation and the exploration of adaptive techniques to enhance control robustness against real-world disturbances.
2. System Description
2.1. Identification of the Rotary Flexible Link System
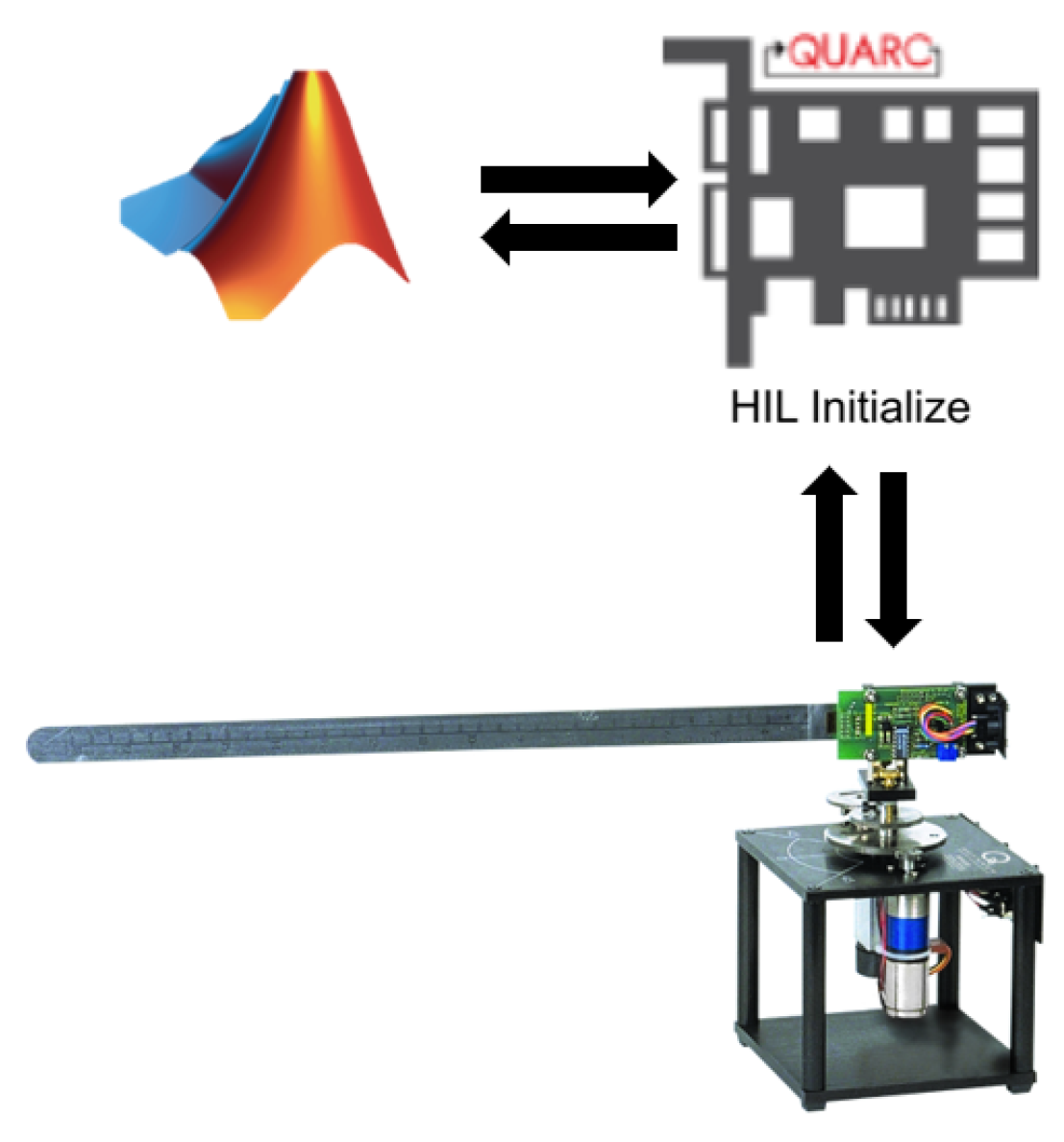
The rotary flexible link (RFL) system consists of a rotary servo motor coupled with a flexible steel link, serving as a model for lightweight robotic manipulators and cantilever beam structures. The servo angle (
) is measured through an incremental encoder, while a strain gauge captures the link deflection (
). Data acquisition and communication are conducted via Simulink
®, version R2022B and the QUARC interface, version 2.15, as depicted in
Figure 1 [
37] and
Figure 2.
The system identification process involves applying a square wave voltage to the motor and capturing the corresponding responses of and . Key parameters considered include the time vector (t), motor voltage (u), servo angle (), and link deflection (). The controller is designed to ensure precise reference trajectory tracking while minimizing vibrations, maintaining operation within voltage constraints of V and a deflection range of .
2.2. Experimental Setup
All experiments in this study were conducted using the QLabs Virtual Rotary Flexible Link platform, a high-fidelity digital twin of the physical Quanser Rotary Flexible Link hardware [
38]. According to Quanser, the virtual platform is dynamically accurate and replicates the behavior of the physical hardware, making it suitable for rigorous experimentation in vibration suppression, system identification, and optimal control [
39,
40]. It allows full instrumentation and control through MATLAB/Simulink, version R2022B and provides the same model-based lab experience as the real-world system, except for the presence of physical sensor noise and cable disturbances, which are inherently absent in the virtual environment [
38].
Table 1 summarizes the physical parameters of the flexible beam emulated by the virtual model. These parameters are used in both modeling and control stages and represent the mechanical configuration of the hardware platform used in typical experimental labs.
The system used in this study is the
QLabs Virtual Rotary Flexible Link; it consists of a rotary base driven by a servo motor, a flexible stainless-steel link, and calibrated sensors capable of accurately measuring the base angle and the tip deflection. To evaluate control performance, a full-state linear quadratic regulator (LQR) was implemented based on a four-state state-space model identified from virtual system data.
Table 2 details the simulation and implementation setup.
2.3. State Definition and Identification Procedure
The rotary flexible link system is modeled as a linear state-space system with four states, one input, and two outputs. The input is the motor voltage , and the measured outputs are the servo angle and the relative deflection angle of the flexible link .
The four states of the system are defined as follows:
: angular position of the servo (rad);
: relative angular deflection of the flexible link (rad);
: angular velocity of the servo (rad/s);
: angular velocity of the flexible link deflection (rad/s).
These states describe the coupled dynamics of the underactuated rotary base and flexible link mechanism.
The identification process followed these detailed steps:
Experimental Setup:The experiment was conducted using the
QLabs Virtual Rotary Flexible Link platform, which, according to Quanser documentation, faithfully replicates the behavior of the physical hardware [
40,
41]. Proper initial conditions were ensured by starting from a non-vibrating position and avoiding cable interference.
Input Signal: A square wave voltage was applied to the motor to sufficiently excite the dynamics of both the servo and the flexible link.
Data Acquisition: The servo angle was measured using an incremental encoder, and the flexible link deflection was measured using a calibrated strain gauge. The data were recorded with a sampling time of 2 ms and stored in MATLAB variables.
Dataset Preparation: The recorded data were organized into an iddata object.
Model Estimation: A fourth-order state-space model was estimated using the
ssest function from MATLAB’s System Identification Toolbox [
42]. This function employs an iterative prediction error minimization algorithm to fit the model to the measured data.
2.4. Use of the ssest Function in System Identification
The
ssest function, part of MATLAB’s System Identification Toolbox [
43], is a robust and widely validated tool for estimating state-space models using time-domain or frequency-domain data [
42]. It relies on an iterative prediction error minimization algorithm, which fine-tunes model parameters to best represent the dynamic behavior of the system [
44]. Furthermore, the ability to initialize the estimation with known model structures enhances its adaptability to incorporate prior system knowledge [
45].
2.5. System Identification Validation
The validation dataset, sourced from Quanser, corresponds to an RFL plant connected to a data acquisition (DAQ) card. The system features a 10V servo motor equipped with an incremental encoder offering a resolution of 4096 counts per revolution, alongside a strain gauge for deflection measurement. Data acquisition is carried out through the “Quanser Interactive Labs” platform (version 2.15) and processed via QUARC Real-Time Control Software [
41]. This high-fidelity dataset enables the construction of an accurate state-space model, which is validated through open-loop response analysis, comparison of measured and simulated data, residual autocorrelation analysis, cross-correlation, and cross-validation [
46,
47,
48,
49].
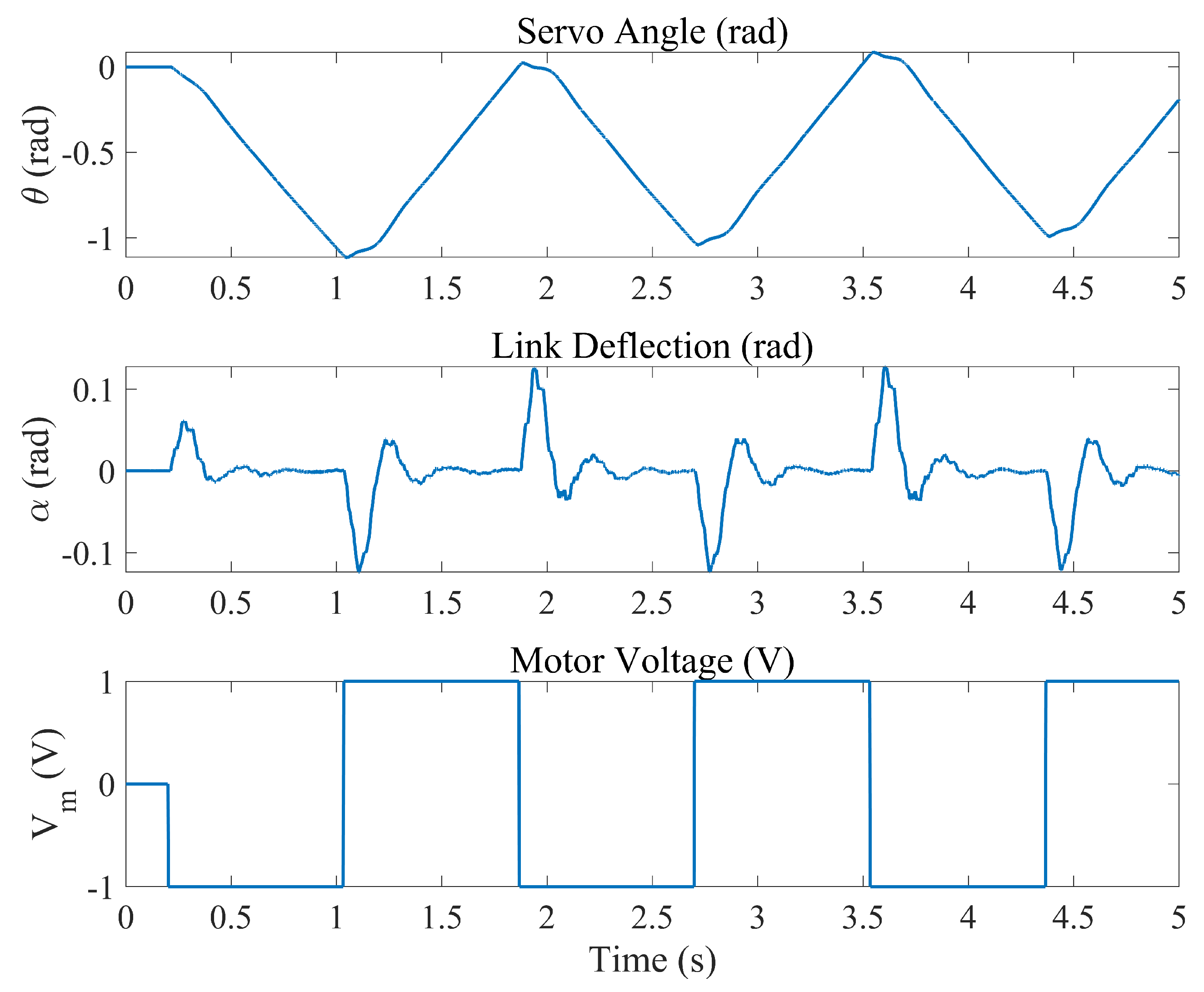
The obtained data are presented in a series of graphs showing the open-loop response of the system.
Figure 3 shows the temporal evolution of the servo angle, link deflection, and the applied motor voltage.
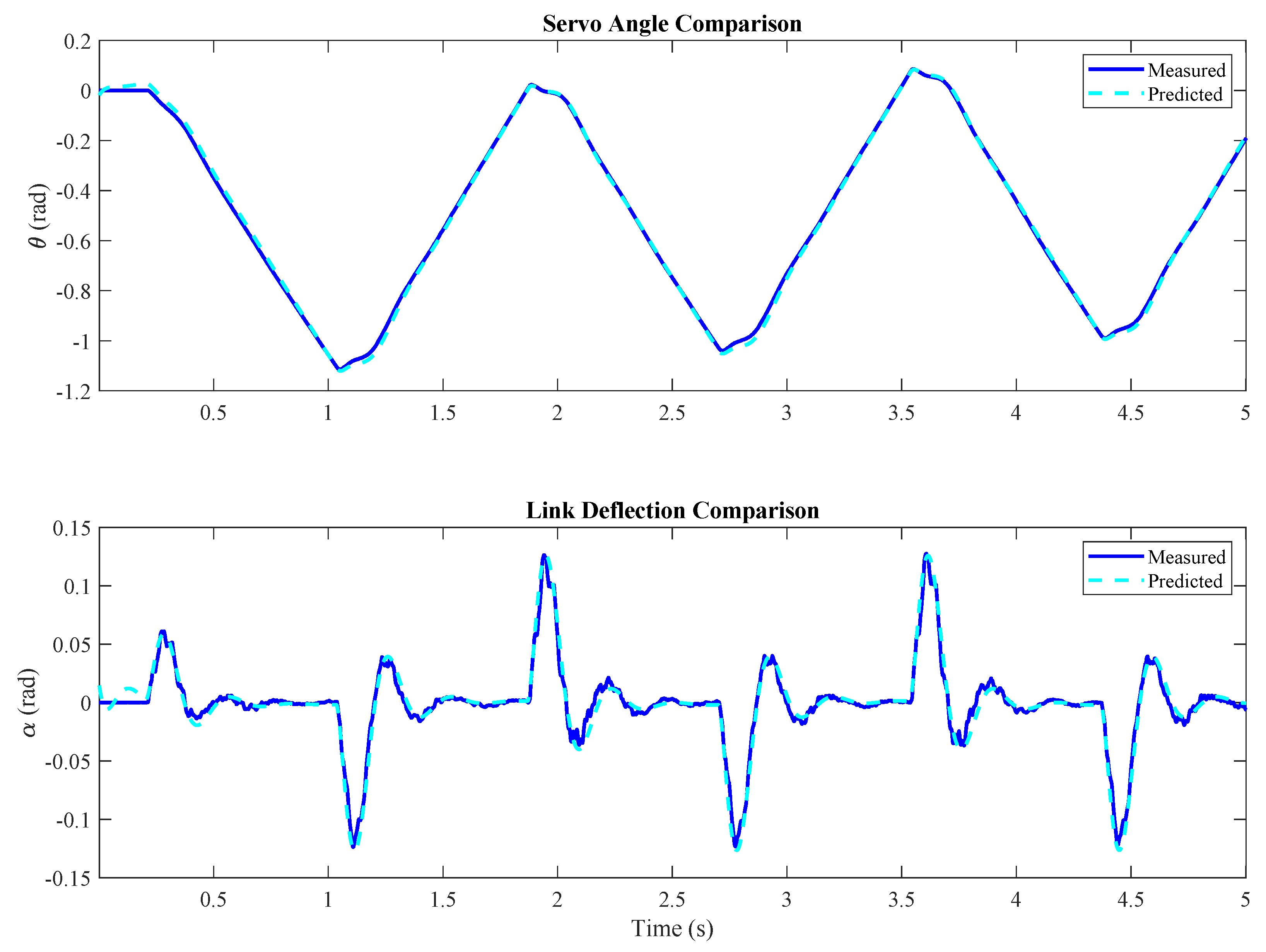
The comparison between the measured results and the simulations provided by the model,
Figure 4, was performed using the
compare command.
The auto-correlation of the residuals was calculated to assess the model’s sufficiency in capturing the system’s dynamics [
50]. While the residuals for the servo angle output showed behavior close to white noise, indicating a good fit, the residuals for the link deflection exhibited some significant auto-correlations, suggesting areas for future model improvements (
Figure 5).
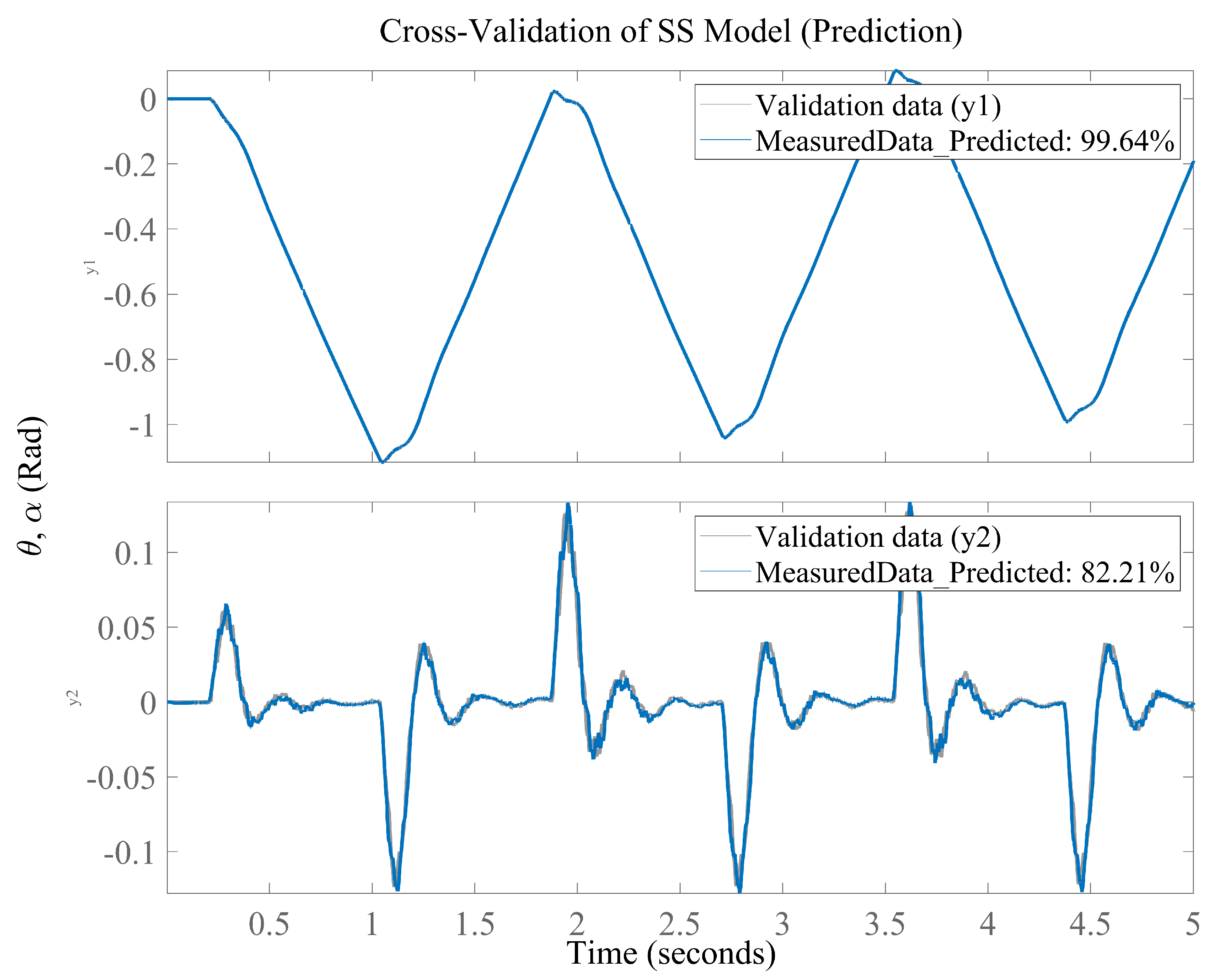
Through cross-validation, the predictions generated by the model are compared with the actual measured data, providing a critical assessment of the model’s ability to generalize to new data not used during the identification process [
51]. The results visualized in
Figure 6 demonstrate a high degree of agreement between the predictions and the real observations, particularly in tracking the servo angle (
), suggesting that the model accurately captures the system’s primary dynamics. However, the figure also reveals areas for improvement, as evidenced by the slight discrepancies observed in the prediction of the link deflection (
).
To assess how well the identified model replicates the experimental system behavior, several standard quantitative metrics have been computed. These metrics are widely accepted in the system identification and control literature for evaluating model accuracy, predictive capability, and response fidelity.
Table 3 summarizes the results and compares them to generally accepted thresholds or desirable ranges for model validation.
2.6. State-Space Model
The state-space model used in this work is defined as:
where the state vector is given by:
The matrices obtained via experimental identification are:
Equations (
1) and (
2) represent the standard form of the state-space system. In this case:
the matrix A defines the internal dynamics of the system;
the matrix B describes how the input (motor voltage) affects the states;
the matrix C defines the relationship between the states and the measured outputs (servo position and tip deflection);
the matrix D is null, which is typical when there is no direct feedthrough between input and output.
The matrices
A,
B,
C, and
D were obtained through the experimental identification process using the
ssest function of the MATLAB System Identification Toolbox, based on measured data in the Quanser Virtual Flexible Link environment. This process is documented in the technical manuals of Quanser [
40], and in the methodology applied in this study following [
39].
The analysis of
Table 4 reveals that a free-form parameterization with 36 coefficients and no feedthrough component was used, estimating disturbances from measured data. Specific tools (
idssdata,
getpvec,
getcov) and the
SSEST method were employed, achieving a highly accurate fit (ranging from 96.95% to 99.85%) with exceptionally low errors (FPE and MSE).
2.7. Theoretical Model
The complete theoretical derivation of the rotary flexible link system’s dynamic model, including the formulation based on Euler–Bernoulli beam theory, the application of Hamilton’s principle, the use of generalized coordinates, and the modal decomposition into a state-space representation, has been thoroughly developed in our previous work [
52].
That article presents both the mechatronic modeling of the system and the analysis of its natural and forced vibration modes, laying the foundational framework for the design and evaluation of robust and tracking control strategies. The resulting model captures the kinetic energy contributions from both the motor and the flexible link, the bending potential energy, and the dynamic relationship between the applied motor torque and the angular response of the system. Additionally, it identifies the experimentally relevant vibrational modes for control applications.
For the sake of continuity, only the essential equations required to link the previous theoretical development with the experimental identification and controller validation proposed in this study are presented here. For full derivations involving boundary conditions, Laplace transforms, motion equations, and the final state-space model, the reader is referred to [
52].
The experimental modal parameters that characterize the vibrational response of the system have also been previously identified.
Table 5 summarizes the open-loop vibration frequencies, emphasizing the dominant modes relevant to controller design. These values support the validity of a reduced order single degree of freedom approximation under controlled conditions and are consistent with the findings reported in [
52].
The vibrational response of the rotary flexible link system is characterized by the presence of both rigid-body motion and flexible link deformation. In open-loop conditions, the system exhibits distinct resonance modes, primarily dominated by the first two vibrational frequencies, as reported in
Table 5. These modes correspond to the elastic dynamics of the flexible link and are critical for control design, as they determine the system’s tendency to oscillate in response to external torques. The first vibrational mode, around 5.42 Hz, represents the fundamental elastic deformation of the link, while the second mode at 3.79 Hz suggests a higher-order interaction potentially influenced by boundary effects and damping. The identification and characterization of these frequencies allow for targeted suppression strategies using state-feedback control.
The proposed GRL-LQR control methodology combines the reliability of optimal control with the adaptability of deep reinforcement learning. Initially, a LQR controller is used to provide structured reference signals, guiding the learning process and accelerating convergence. As training progresses, control authority gradually shifts from the LQR to the TD3 agent, allowing the policy to autonomously refine its behavior while preserving stability.
2.8. Using an Internal LQR Controller for the Initial Training Phase
To guide the agent’s learning in the early stages of training, an LQR controller was implemented in the system’s inner loop. This controller acted as a “behavioral baseline”, allowing the agent to observe a controlled response in terms of stability and accuracy across both output variables, even though it did not fully meet the desired control objectives. The LQR served as a preliminary stabilization mechanism to reduce initial oscillations and prevent extreme actions that could interfere with learning in the initial iterations. This initial “assisted learning” approach enabled the agent to begin adjusting its policy based on a relatively stable dynamic, decreasing the risk of instability during early exploration.
2.9. Internal Mechanisms of TD3 for Flexible-Link Control
The agent used in this study incorporates three key mechanisms, such as flexible-link mechanisms: (i) a twin critic architecture that mitigates overestimation bias by taking the minimum of two Q-value estimates; (ii) delayed policy updates, which enhance training stability by updating the actor less frequently than the critics; and (iii) target policy smoothing through Gaussian noise, which regularizes learning and improves generalization. Additionally, the LQR-guided training process imposes a stabilizing structure on the learned policy.
2.10. Reward Function
The reward function is designed to achieve two simultaneous objectives: accurate tracking of the base angle and minimization of tip oscillations. It is defined as:
Here, denotes the initial reference (before the step), and the final reference (after the step). The step reference is applied at time , and is a weight that penalizes tracking error before the step is applied.
For , the reward is composed of two components:
The tracking error is defined as:
If the tracking error is within a predefined settling band
, a positive reward proportional to the remaining margin is given:
Otherwise, a penalty is applied:
- 2.
Oscillation penalty :
Tip oscillation is defined by:
where
corresponds to the tip angular deflection. If
exceeds a defined tolerance
, the agent is penalized:
Otherwise, a small bonus is given to encourage stability:
Here,
is the penalty weight for excessive oscillation, and
is a smaller bonus weight for low oscillations.
Thus, the complete reward after
is:
This formulation differentiates between the pre-reference activation phase () and the post-activation phase (), penalizing anticipatory deviations from the initial reference and, once the reference changes to , emphasizing accurate tracking of the new target while suppressing excessive tip oscillations. The parameters , , , , and can be tuned to reflect the desired control objectives.
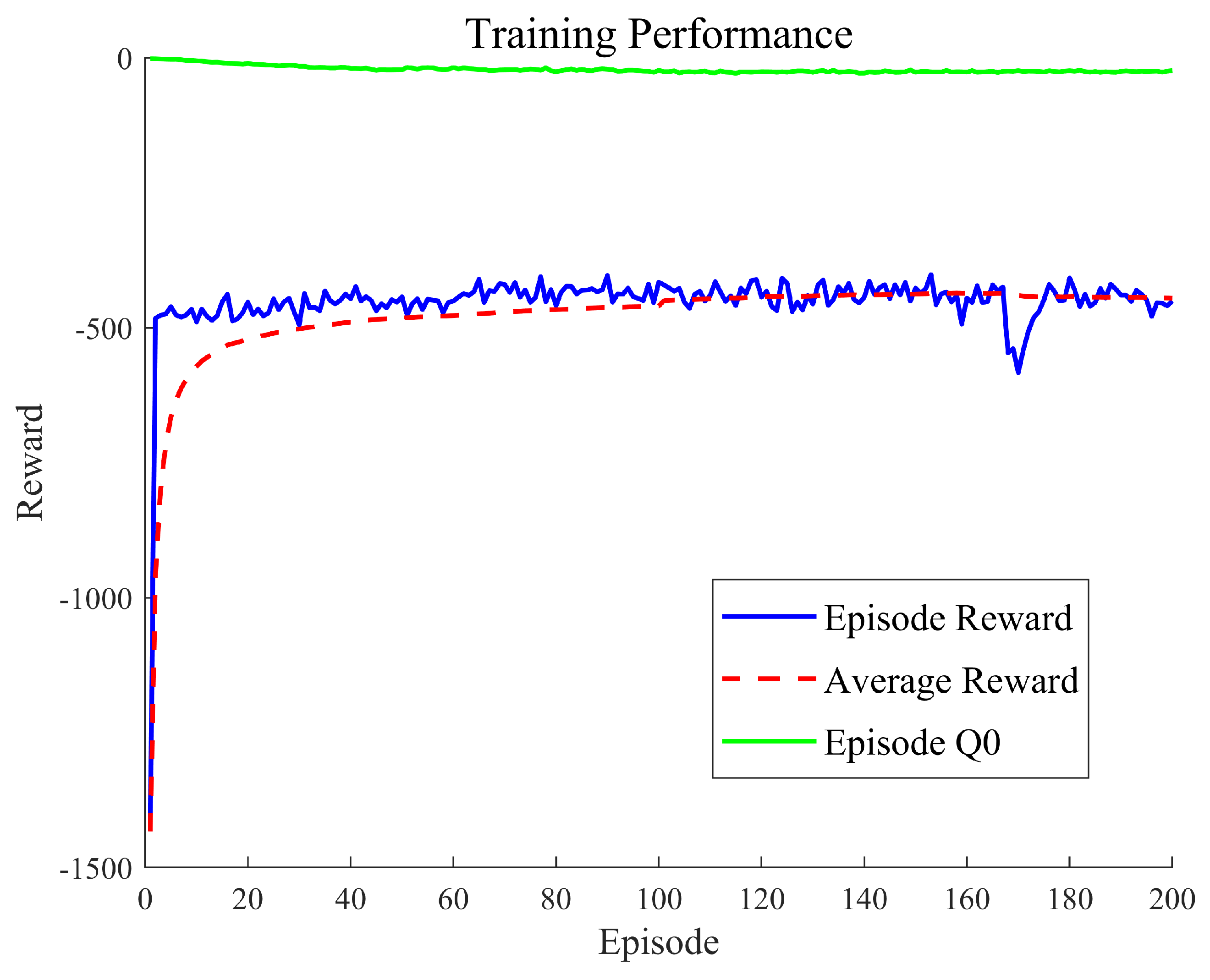
2.11. System Architecture and Network Design
Table 6 summarizes the configuration parameters used in training the reinforcement learning agent using the twin delayed deep deterministic policy gradient (TD3) algorithm. The discount factor (
) prioritizes long-term performance, while the mini-batch size of 256 provides a stable gradient estimation during updates. The training proceeds over a maximum of 200 episodes, each with a fixed step budget defined by the total simulation time
and the sample time
. Training stops early when the average reward over the last 100 episodes surpasses a threshold of 200, reflecting satisfactory performance.
The actor and critic networks are trained using learning rates of and , respectively. These values reflect the necessity for conservative policy updates (actor) and faster value estimation convergence (critic). The exploration model incorporates Gaussian noise with a standard deviation of 0.9, which decays at a rate of until a minimum threshold of 0.91 is reached, ensuring continued exploration while avoiding excessive variability in the control policy.
6. Parameter Uncertainty Analysis and Robustness Evaluation
Reinforcement learning (RL) has shown promising advancements in control applications; however, given that a general theory of stability and performance in the RL domain has not yet been established, it is essential to conduct exhaustive and rigorous testing of the controller prior to implementation. This ensures that potential instabilities and performance degradation are identified before deployment [
58].
In order to evaluate the robustness of the GRL–TD3 control system, a parameter uncertainty analysis was performed by applying
offsets to the nominal gains of the LQR controller. This approach simulates variations in the plant model and allows for an assessment of the closed-loop system’s sensitivity to parameter deviations. The uncertainties are visualized using polar plots, the nominal gain for each channel is represented as a reference orbit (highlighted in red), with the perturbed gains distributed around it (see
Figure 12). Although the angular coordinates in these plots do not carry direct physical significance, they serve as a convenient means to illustrate the magnitude and directional bias of the variations. This methodology is well supported by robust control theory [
59] and multivariable feedback control principles [
60], both of which advocate the inclusion of parametric uncertainties in controller design to ensure robust performance. Moreover, recent studies in reinforcement learning for control have demonstrated that guided exploration using an expert controller such as the LQR to steer the learning process can accelerate convergence and enhance robustness, thereby justifying the GRL–TD3 framework.
6.1. Experimental Setup and Performance Metrics
To evaluate the robustness of the GRL–TD3 control system, an experimental campaign was conducted comprising 16 simulations. In each simulation, a unique offset was added to the nominal gain vector of the LQR controller, resulting in a modified gain matrix expressed as
where each element of
was perturbed by up to
of its nominal value. The objective was to assess the system’s robustness to parametric uncertainty by observing the closed-loop response to both a step reference and a periodic reference with variable amplitude. Performance was evaluated using metrics such as the
relative error (%) which quantifies the deviation between the actual response and the desired reference and a
performance index that summarizes the overall behavior of the system. In the polar plots (see
Figure 12), the parameter variations are clearly observed, represented by the gain values in the
K matrix.
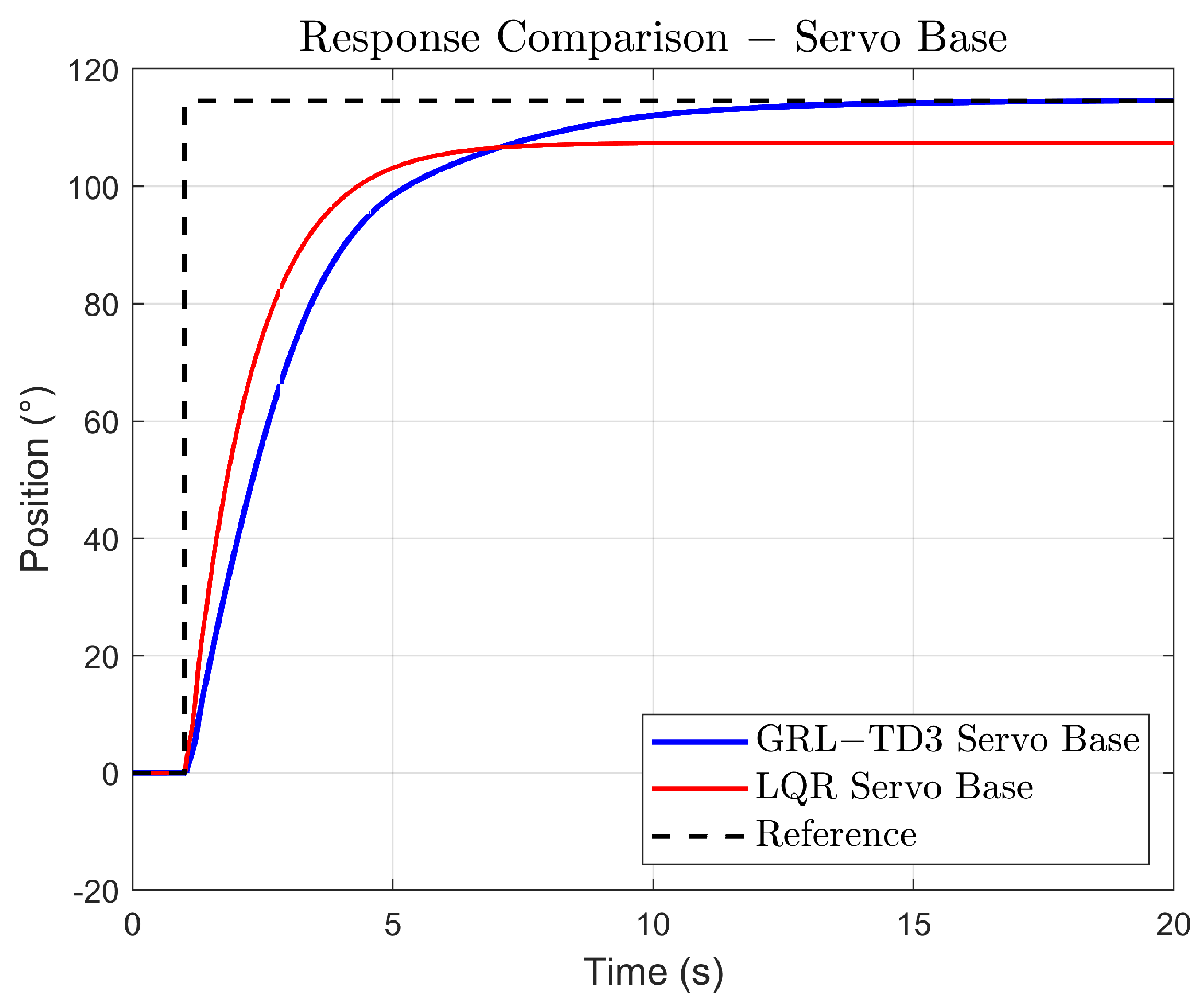
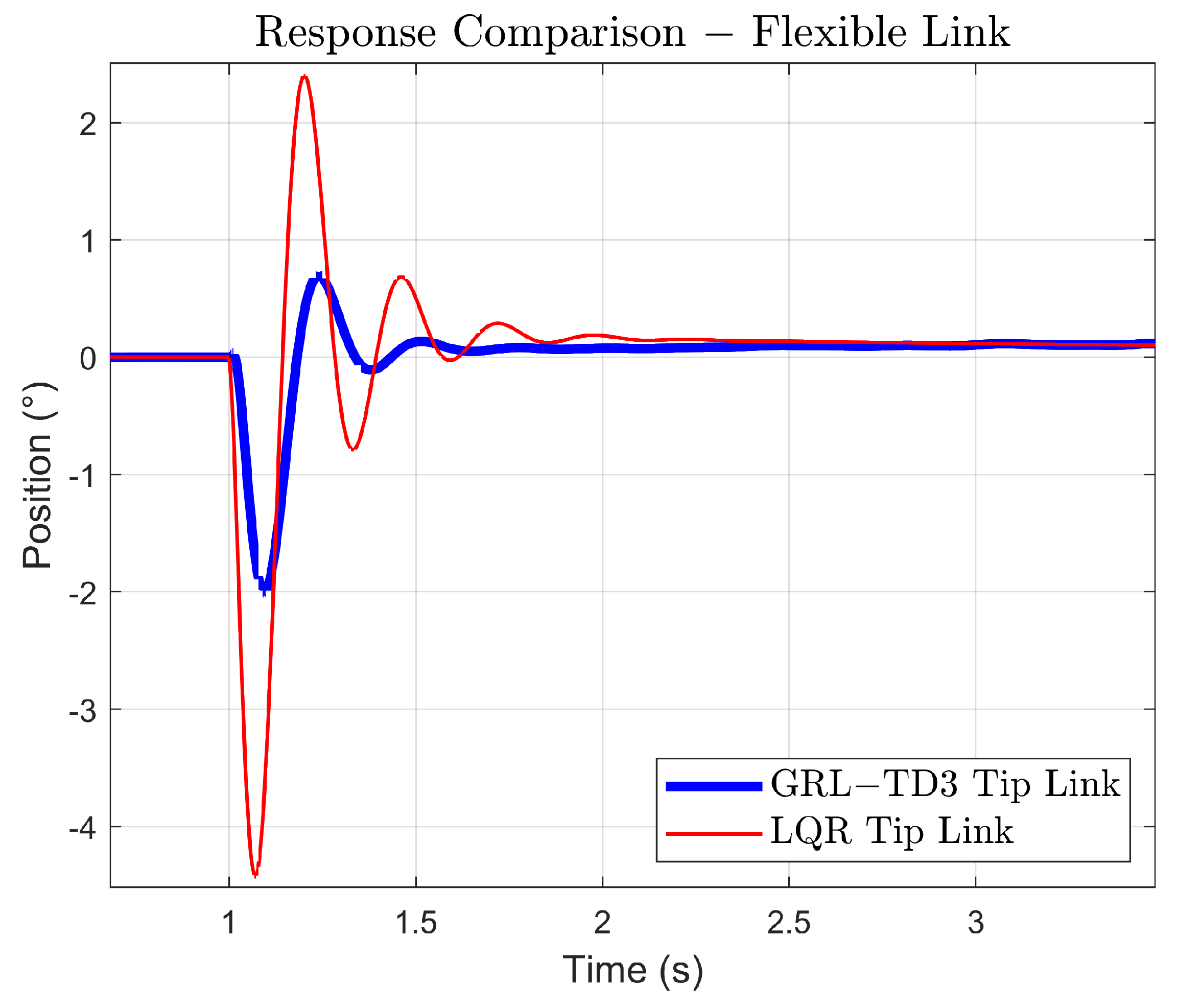
Figure 13 shows the simulation results for the LQR controller. Although the controller maintains closed-loop stability across all 16 simulations, its robustness, measured by performance, is not consistently achieved. Specifically, while the tip response is attenuated, the base response fails to reliably track the reference signal under the evaluated parametric uncertainties. This disparity suggests that, despite the LQR’s ability to stabilize the system, its performance deteriorates under significant gain variations, highlighting a gap between mere stability and robust performance.
In
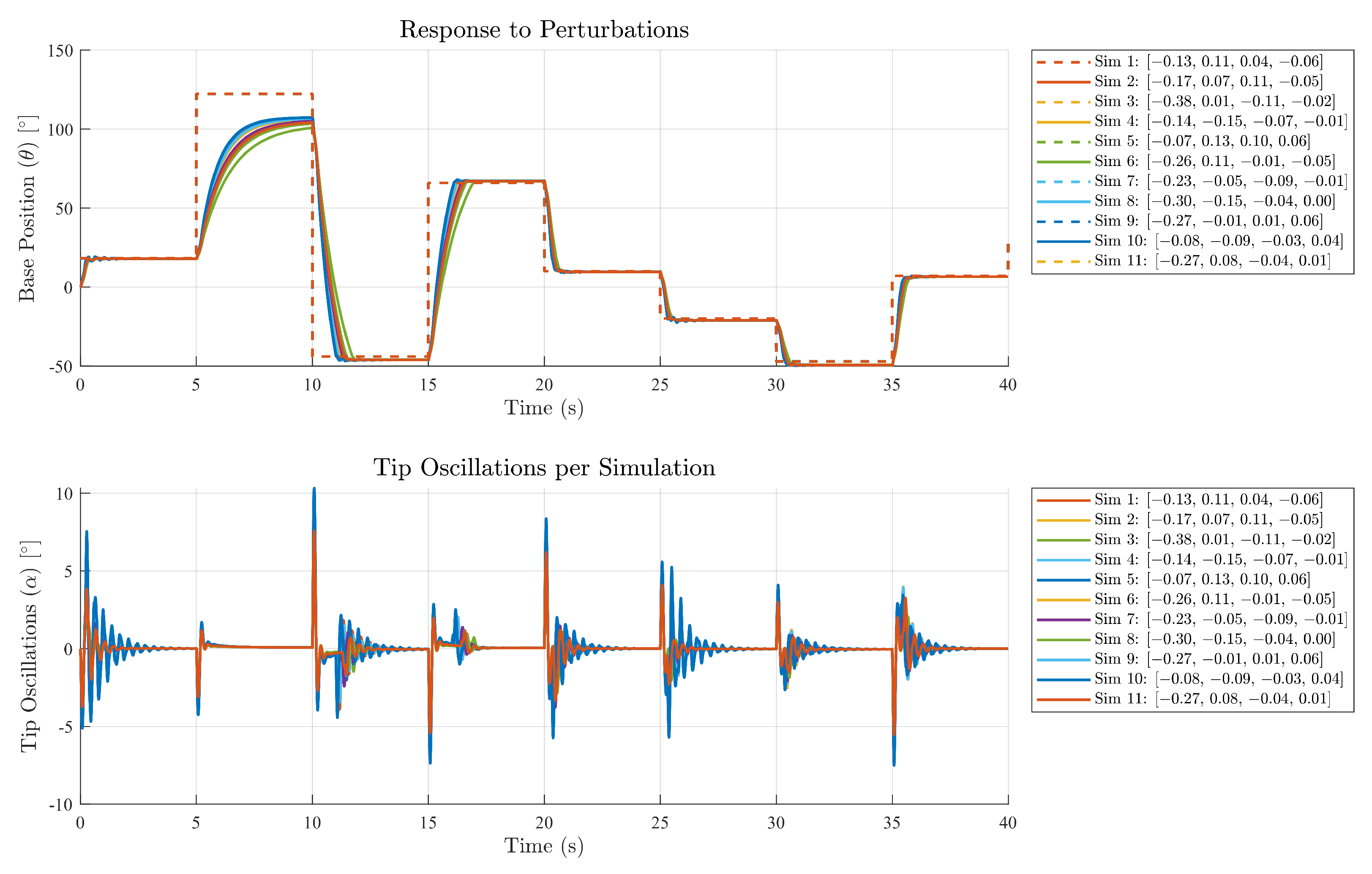
Figure 14, the simulation results for the GRL–TD3 controller are illustrated. The base position trajectories converge very closely to the reference signal, exhibiting only a minor steady-state error, which indicates effective tracking performance. Concurrently, the tip of the flexible link displays controlled oscillations, which are a direct consequence of the reward function designed to balance the performance between base tracking and tip regulation. Compared to the conventional LQR controller, the GRL–TD3 approach not only achieves a more uniform clustering of the base responses in steady state but also realizes a slight reduction in the maximum tip oscillations. This demonstrates that the guided reinforcement-learning strategy successfully enhances overall robustness by mitigating excessive tip movement while maintaining precise base control.
6.2. Performance Evaluation of the LQR Under a Periodic Input of Variable Amplitude
Figure 15 illustrates the response of the system, controlled using an LQR, to a periodic input with variable amplitude. The graph reveals that, in most experiments, the base response does not reach the desired reference, indicating a lack of robustness in the LQR controller. Moreover, during abrupt or large changes in the reference signal, the resulting oscillations can reach up to 10 degrees.
6.3. Response of the GRL–TD3 Controlled System
In
Figure 16, the simulation results using the GRL–TD3 controller are shown. In this case, the system successfully reaches the desired reference, demonstrating that the control strategy not only meets the tracking requirements but is also capable of significantly reducing oscillations, even in the presence of the complex flexible dynamics of the link. Although some oscillations are observed at the tip, they remain at very low levels since the controller prioritizes precise tracking of the base position. This behavior is crucial in real-world applications, where minimizing tip oscillations is essential to ensure system stability and accuracy.
6.4. Analysis of Excluded Simulations and Robustness of the GRL–TD3 Controller
Out of the 16 simulations performed, five (specifically, simulations 1, 4, 7, 9, and 14) were excluded due to instability issues. This instability arises because the uncertainty parameters, particularly the offset applied to , are around the critical value of 1. In the polar plot, these simulations cluster around the orbit with a radius of 1, indicating that values near this threshold lead to closed-loop instability or critical stability of the system. This behavior demonstrates that, within a defined robustness margin, the GRL–TD3 controller can effectively track the base reference even under substantial disturbances.
It is noteworthy that, as a reinforcement-learning-based control system, the GRL–TD3 controller has learned to prioritize accurate tracking of the base position, even if that entails permitting slightly larger oscillations at the tip. This approach is consistent with the designed reward function, which heavily penalizes both oscillations and tracking errors of the base. In scenarios where the parameter variations are excessive, it may be necessary to adjust or redesign the reward function to achieve a more balanced trade-off between reducing oscillations and maintaining precise reference tracking.
6.5. Comparative Analysis of LQR and GRL–TD3 Controllers Under Parametric Uncertainty
Table 11 presents the outcomes of the system controlled by a conventional LQR approach under varying parametric offsets. Each simulation corresponds to a different offset applied to the baseline gains (
), reflecting the plant’s sensitivity to uncertain dynamics. Notably, while the LQR controller ensures nominal stability in most cases, the
relative error percent (RE) and
performance score (PS) vary considerably. The more substantial RE values (e.g., simulations 6, 8, and 12) highlight the limitations of relying solely on an LQR scheme for robust performance. This underscores the need for advanced control or learning-based techniques when the plant experiences significant parameter fluctuations, especially in highly flexible or underactuated systems.
Table 12 illustrates how the guided reinforcement-learning (GRL–TD3) controller, specifically the GRL–TD3 approach, adapts to the same set of parametric variations used in the LQR tests. Despite facing the same uncertain conditions, the
relative error percent is generally lower, and the
performance score is consistently higher or comparable across most simulations These results validate the premise that a learning-based controller, guided by an expert policy (LQR in this case), can effectively mitigate performance degradation induced by model uncertainty.
The comparative table (
Table 13) quantifies the
relative error (RE) and
performance score (PS) improvements achieved by the GRL-based controller over the classical LQR approach. A positive
RE improvement reflects a reduction in tracking error, and a positive
PS improvement denotes enhanced overall performance. Most simulations (e.g., 2, 3, 4, 7, 8) show substantial gains, frequently exceeding 50% in
RE improvement, underlining the robustness of the learned controller in coping with uncertain parameters. Nonetheless, a few simulations (e.g., 13, 16) demonstrate negative improvement, revealing that while GRL generally outperforms LQR, certain parameter offsets can challenge the controller’s learned policy. These findings highlight the importance of thorough parameter studies, reward function refinement, and potentially hybrid robust-learning designs to consistently ensure performance across a broad range of operational scenarios.
7. Discussion and Future Work
This study demonstrated that integrating a linear quadratic regulator (LQR) with a twin delayed deep deterministic policy gradient (TD3) agent via guided reinforcement learning (GRL–TD3) enhances control performance and robustness in rotary flexible link systems. The LQR component ensures initial stability and accelerates convergence, while TD3 adapts to dynamic variations and learns effective control strategies. Despite these benefits, the methodology remains sensitive to reward design, hyperparameter tuning, and lacks interpretability posing challenges for certification and safety-critical deployment.
The analysis adopted an empirical BIBO–based criterion to evaluate external stability, given that classical model-based approaches are not directly applicable to learned policies. Monitoring the output trajectory confirmed that the GRL–TD3 controller produced bounded responses across all test scenarios. Nonetheless, the absence of formal guarantees highlights the need for further research into theoretical stability analysis and certification frameworks for reinforcement-learning-based controllers.
As the approach has only been validated in a simulation environment, future work should focus on real-world implementation. Practical deployment may involve unmodeled phenomena such as friction, backlash, and sensor delays, which could affect performance. Experimental validation on physical platforms is necessary to assess robustness under these conditions and confirm the applicability of the controller in real settings.
The lightweight architecture of the trained policy makes it suitable for embedded real-time applications. Prior research has shown that deep RL policies can be executed efficiently on microcontrollers using techniques such as quantization and hardware acceleration [
61,
62,
63]. Deploying the trained actor on embedded systems while offloading training to external platforms offers a feasible path for industrial implementation.
A further research direction involves evaluating the controller’s robustness to structural variations (e.g., link stiffness, damping), which were not explored here due to the fixed configuration of the experimental platform. This would extend the current framework toward transferable or adaptive policies applicable across families of flexible mechanisms.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}