1. Introduction
Legged robots have always been a focus of robotics research. Rapid progress over the last several years has led to the first instances of mass production of legged robots, as well as to the first cases of their practical use [
1]. This in turn opens new questions, such as the reliability and robustness of legged robots and their control systems. In particular, one may pose the following questions: is it possible to design a control system for a legged robot that would be robust with respect to external disturbances, and is it possible to prove this property? In this paper, we aim to give a particular answer to these questions.
The progress achieved in legged robotics has been partially due to a successful adaptation of well-known control methods, such as Model-Predictive Control (MPC) [
2,
3], Proportional-Differential (PD) control, Extended Kalman Filters (EKFs) [
4], and others. These methods in their standard formulations are directly applicable to systems like industrial robot arms; however, they require modifications to be used for legged robots. Legged robots acquire and break mechanical contact with the supporting surface as a part of their motion, leading to discontinuities in their models. Between discontinuous events (acquisition or breaking of contact), the dynamics of legged robots are well described via differential-algebraic equations (DAEs), where the mechanical constraints are explicitly stated. From the point of view of state estimation, it presents a qualitative difference from models with smooth dynamics described via ordinary differential equations (ODEs).
There are well-known robust control design methods: disturbance observer, adaptive control, quadratic stability, s-procedure-based robust control, etc. [
5,
6,
7,
8].
control is an especially promising type of robust control, as can be seen in recent advancements in the area [
9,
10,
11,
12]. In this work, we focus on
control. Effective
control design methods require the plant to be modeled as a system of linear ODEs, while legged robots are modeled with nonlinear DAEs.
Numerous methods can be used to transform a legged robot model into an ODE; these methods usually rely on differentiating constraint equations and introducing a change of variables [
13,
14,
15]. Among these is the orthogonal decomposition method, which consists of projecting dynamics onto the null space of the constraints equations, while decomposing the state variables into the sets of static and independent states. This results in a system of independent ODEs with independent variables. In this paper, we discuss how this process can be combined with linearization to produce an accurate linear model. The resulting linear model can be used to derive
control.
For practical legged robots, the full-state information is not available (some of the floating base states are usually not measured), requiring the use of observers or equivalent constructions. In this paper, we use the Luenberger state observer, adapting it to the model produced by the orthogonal decomposition method. To tune the controller and observer gains and ensure
gain properties, we derive and solve a linear matrix inequality (LMI) condition. The systems where the controller and observer are tuned simultaneously produce bi-linear matrix inequalities (BMIs); to transform these into an LMI, we use Young’s relation, following an earlier example proposed in [
5].
In this paper, we propose a control design method for constrained mechanical systems, finding the optimal gains for a linear controller and Luenberger observer in terms of the norm of the system, minimizing the system’s reaction to an external disturbance in terms of its norm. To our knowledge, this is the first control method designed to handle constrained mechanical systems with unmeasured static states. We present an LMI condition that guarantees the upper bound on the gain and that can be used directly in the optimal control design formulated as a semidefinite program (SDP). Our method allows us to account for additive terms in the model, related to the uncertainty in the constraints (or equivalently, the uncertainty in our knowledge about the environment in which the robot operates). To this end, we give a comprehensive description of a linearization method for dynamical systems with mechanical constraints, producing a linear model in the tangent space to the constraint manifold. We verify the results via numerical experiments on an underactuated three-link robot with a constrained end-effector and a flat quadruped model.
The remainder of the paper is organized as follows. In
Section 2, we review the state of the art and discuss closely related works.
Section 3 introduces the proposed linearization method for constrained systems. In
Section 4, we provide definitions and formulas useful in the remaining sections. The mathematical formulation of the problem solved in this paper is given in
Section 5, and in
Section 6, we describe and prove the proposed solution to that problem. The last section provides a description of numeric experiments verifying the method.
2. State of the Art
The control system of a modern walking robot usually consists of multiple layers. The configuration and type of these layers vary significantly. A typical example would include a high-level trajectory and step planner, an MPC that runs over the pre-determined foothold positions, a QP-based feedback controller, and an array of motor-level PID controllers. This is augmented with an EKF-based state estimator and a simultaneous localization and mapping (SLAM) algorithm [
2,
16].
The control systems of the type described above use several simplified dynamical models of the robot. These include a point-mass model, a single rigid body (SRB) model (often with additional assumptions and simplifications), and a linear model that relates generalized accelerations to reaction forces and control inputs (but not the state) based on the full dynamical model evaluated at a single moment in time. The first of these is often used in the design of MPC, the second in EKF, and the last in QP-based feedback controllers [
4,
17].
Our goal is to propose a control system that guarantees robustness with respect to bounded-energy exogenous inputs. This motivates the decision to use the linearization of the full dynamics of the robot as our model and to simultaneously design both the controller and the observer, guaranteeing that the system’s gain is below the desired threshold. The linear model used to tune the proposed controller is required to be the optimal local linear approximation of the robot dynamics on the tangent space to the constraint manifold.
Previously, successful attempts to design optimal controllers and observers for systems with explicit contact constraints have been made [
13,
18,
19]; we describe these works in the next subsection. However, the question of robustness to exogenous inputs has not been raised in those papers. In the area of optimal control, a similar (but more general) class of linear systems has been considered—descriptor systems [
20]. For these systems, several robust control methods have been proposed [
7]; we review them in
Section 2.2.
2.1. Orthogonal Projection and Decomposition Methods
Orthogonal projection and decomposition (OPD) methods can be seen as an attempt to re-model the dynamics of systems with explicit constraints (presented as a DAE) into a form suitable for control design, using orthogonal projections and decomposition of the state variables.
An early example of such work can be found in [
21], where orthogonal projections are used to exclude algebraic variables from equations of dynamics. Same as in most OPD methods, [
21] takes advantage of a projector onto the null space of the constraint Jacobian. One of the key features of the work is the construction of a constraint inertia matrix—an analog to the generalized inertia matrix in Lagrangian mechanics. This approach is applied for solving problems related to simulation, inverse dynamics, and control design [
21,
22,
23].
A parallel series of works proposed using QR decomposition of the constraint Jacobian and introduced a QR decomposition-based projector matrix [
14,
24,
25,
26]. They showed the equivalence of several independently developed OPD methods for inverse dynamics [
25].
The works we have cited so far used an orthogonal projection of the dynamics equations to find a better representation of the relations between the generalized accelerations, control inputs, and reaction forces; as such, they were dealing with nonlinear second-order ODEs. A new class of methods originated in [
13,
18], where (1) a projection of the state variables (rather than the generalized accelerations) onto the tangent space of the constraint manifold was proposed and (2) a locally linearized model of the robot dynamics was considered. This allowed for the implementation of an LQR control for a walking robot.
In the paper [
19], a decomposition of the state variables into active (lying on the tangent space to the constraint manifold) and static (orthogonal to the active ones) states was used to allow simultaneous controller and observer design, including a disturbance observer estimating the value of static state variables. This paper used the same linearized model as [
18]. In [
27,
28], orthogonal decomposition was used to facilitate a simulation-based reinforcement learning algorithm on a constraint manifold.
While orthogonal projection and decomposition methods have successfully covered problems such as controller and observer design, as well as forward and inverse dynamics, there are still numerous control-related problems that have not been solved within this framework. One of them is the problem of designing a control law robust to an energy-bound exogenous input, which would guarantee a bounded output. This motivates the aim of the present paper: to design an controller–observer pair for the systems with explicit mechanical constraints, which can be represented by a linearized model in the tangent space to the constraint manifold. Additionally, we present a detailed treatment of the question of constructing linearized models, mentioned above, which has not been performed previously in OPD-related papers.
2.2. Linear Models for Constrained Systems
A descriptor system is a state-space model that expresses the relation between state variables and their derivatives in a general form, allowing the system to be described as a mix of differential and algebraic equations. The generality of such a description allows the systems with explicit mechanical constraints to be presented as descriptor systems. Descriptor systems have been extensively studied, and several important results have been achieved in the development of stability criteria as well as control and observer design methods [
29]. The problem of designing an
controller for a descriptor system was considered in [
7,
30], where a version of the Bounded Real Lemma was proposed, and in [
31], where the Riccati equation was used to design an
controller.
While these results are of significant interest, it has not been shown that a mechanical system with changing contact, such as a walking robot, can be successfully controlled using these methods. The class of descriptor systems is very general and includes far more than only systems with mechanical constraints; control methods designed for a smaller class of systems, such as OPD methods, can take advantage of the specific dynamic properties of the individual systems. For example, in [
19], an OPD controller–observer design method allowed an unobservable system to be reduced to an observable one without the loss of information relevant to the control task.
Aside from the descriptor models, one can attempt the linearization of systems with explicit mechanical constraints based on Taylor expansion. The end result can be a model, linear with respect to the full state of the original nonlinear system, control actions, and reaction forces; we can call it an explicit form of a linear model with mechanical constraints. Alternatively, a model can be linearized on the tangent plane to the constraint manifold, producing a model with no reaction forces and a state vector of fewer dimensions; we can call it an implicit model. In papers [
18,
19], the transformation of an explicit model to an implicit one is discussed. In [
13], the construction of a full-state implicit linear model is considered, while in [
32], a linear model for floating-base coordinates (the position and orientation of the robot’s body and corresponding velocities) is constructed using an orthogonal projection of the nonlinear equations. In this paper, we extend and elaborate on this method, presenting a finite difference-based linearization scheme that produces models equivalent to the type required by OPD methods such as those proposed in [
18].
3. Preliminaries
We start by recalling a few general results, which will be used in the following derivations.
Schur complement [
33]: Given symmetric matrices
and
and a matrix
, as well as their concatenation
we can make the following equivalent statements:
Here and later, the signs < and ≤ imply negative definiteness and semidefiniteness when applied to the matrices or quadratic forms (equivalently for the opposite sign).
Young’s Relation [
33]: For any symmetric positive definite matrix
, positive scalar
, and
, the following inequality is true:
Gain for Linear Systems [
33]: Given an LTI system:
where
,
, and
are the system state, desired output vector, and the disturbance input, respectively, while
,
,
, and
are the state, control, observation and feed-through matrices, respectively, we define its
gain (which is also its
norm) as:
where
is
norm of the signal, defined as:
and
is defined equivalently. If there exists a function
and the following equation holds for some scalar
:
then the
norm of the system is bounded by
.
4. The Linearization of a Constrained Model
A walking robot can be modeled using a combination of Lagrange and constraint equations:
where
,
,
, and
are the generalized inertia matrix, Coriolis and normal inertial force matrix, generalized gravity force, and constraint Jacobian, while
,
,
, and
are generalized coordinates, reaction forces, joint torques, and an actuation selector matrix. The second equation is obtained by twice-differentiating the constraint equation
.
These equations can be solved to find an explicit formula for the generalized accelerations:
where
is an inertially weighted pseudoinverse. We can describe the dynamics in a state-space form with state variables
,
:
Introducing state variable
and control input
, we re-write the last system as:
4.1. Orthogonal Decomposition of State Coordinates
The state-space model obtained above produces correct state derivatives, given states that correspond to the constraints. We use this model to produce a least-squares-type linearization scheme for the original constrained model. To this end, we need to identify variations
of the state variable
that do not leave the constraint manifold defined by the equation
and its derivative
. We consider the Taylor expansion of both equations around a point
,
:
where higher-order terms (h.o.t.) include quadratic and higher-order terms in variables
and
of the Taylor expansion. Since the linearization point lies on the constraint manifold, we cancel the terms
and
. Introducing variations
and
and dropping the higher-order terms, we obtain a linear system of equations governing the admissible values of variations:
We denote the matrix on the left-hand side of the system as
, obtaining conditions
, with an implication that any admissible
lies in the null space of that matrix.
Let
be an orthonormal basis in the null space of
, and let
be an orthonormal basis in its orthogonal compliment. Any vector
can be represented via its coordinates in the direct sum of the two subspaces:
where
are coordinates in the tangent plane to the constraint manifold, which we will call active states or null space coordinates, and
are coordinates in the linear space that is normal to the manifold, which we will refer to as static states or a static state discrepancy. Since
lies entirely in the null space of
, we can represent it via its null space coordinates
as
.
Note that by differentiating the constraints equation twice, we obtain a condition on the state derivative . Then, any admissible state derivative can be expressed via its null space coordinates: , and equivalently . With that, we can construct linearized dynamics in the tangent plane to the constraint manifold.
Let
be a full-rank matrix and
be its
i-th column. Then, we can find an admissible state variation
; we denote the corresponding state derivative variation as:
Concatenating state derivatives into a matrix
, we obtain an active state matrix
of the linear model by finding the least-squares solution to the following system of equations:
We find the control matrix in a similar way, considering variations in control actions .
4.2. Constraint Uncertainty and the Static States
Assume that equation
and its derivative are augmented with a small additive term, which is uncertain. Then, expanding both equations around the point
,
exactly as was performed in the above section, we arrive at a new system of equations:
where
represents the uncertain term. For a walking robot climbing stairs, it can represent an error related to an incorrect estimation of the height of the stairs. Equation (
15) has a particular solution
; this value represents a distance between the point of expansion
and a point on the constraint manifold. Since
lies in the row space of
, we can re-write it in terms of the earlier proposed static state discrepancy coordinates:
We can find how the value of the discrepancy
influences the active state derivative. Let
be a full-rank matrix and
be its
j-th column. Then, we can find the discrepancy-related state variation as
; we denote the corresponding state derivative variation as:
Concatenating the state derivatives into a matrix
, we obtain the static state matrix
of the linear model by finding the least-squares solution to the following linear system:
4.3. External Disturbance
Consider an additive external disturbance
added to the model Equation (
9):
where
is a function that maps the disturbance
to the state derivatives. The sources of external disturbances for walking robots range from collisions to high-speed wind. We find the linearization of this model as performed previously. Let
be a full-rank matrix and
be its
i-th column. Then, we can find a disturbance variation
; we denote the corresponding state derivative variation as:
Concatenating the state derivatives into a matrix
, we obtain the disturbance matrix
of the linear model by finding the least-squares solution to the following linear system:
Remark 1. We linearized the model around the point . If , or if and , then the previous derivation of the matrices , , and remains unaffected. Otherwise, when computing the state derivative variations in Equations (13) and (17), we need to use rather than only . Together, this gives us a linear model that depends on both the active states and the discrepancy:
where
represents the distance from the linearization point and
represents the state discrepancy related to uncertainty in the constraint equations. For robots moving over static environments,
, motivating its description as a static state.
Finally, we observe that the size of the matrices , , , and (as measured by their spectral norm) determines the accuracy of the linearization, similar to how the step size determines the accuracy of a regular finite-difference method.
5. Problem Statement
In this section, we introduce the problem of
control with a Luenberger observer for a linear system with constraints. Let us consider the linear system (
22) and the measurement equation with sensor disturbances:
where
is the measurement matrix,
,
are the process and sensor disturbance matrices, and
is the disturbance. The state of the system can be expressed as
, and the measurement is modeled as
, giving us the second equation of the system. To facilitate the observer design, we re-write the dynamics in the form:
We introduce the Luenberger observer as follows:
Defining estimation error as
and introducing the variables
,
, and
, we write error dynamics as:
5.1. Feedback State Controller
Using the observer state
,
, we can introduce the control law as follows:
where
and
are control gains related to the active and static states. Defining concatenated control gains
, we write the closed-loop dynamics for the system (
23) as:
We propose the following choice of the control gain
:
As long as columns of
lie in the column space of
, this control law negates the effect of
on the dynamics, at the cost of having less freedom of choice when tuning the controller gains to shape the state observer error dynamics. With the aforementioned assumption, the equation of dynamics takes the form:
Combining the last equation with the error dynamics (
26), we have the closed-loop system with a linear controller, which we need to tune to attain the desired
properties.
5.2. Control Problem
Consider the desired output defined as:
where
is the disturbance feed-through matrix for the output. Noting that
, we combine the error dynamics (
26) and the state dynamics (
30), presenting the system we intend to control:
In the next section, we present a method of tuning the controller and observer gains and for this system, minimizing its gain.
6. Proposed LMI Method
In this section, we propose LMI conditions sufficient both to prove an upper limit of the gain of the closed-loop system and to recover the controller and observer gains of this system. These conditions are given by the following theorem:
Theorem 1. The system:with observer (25) has an norm less than if there exist positive-definite matrices , , matrices , and a constant such that the following LMI is satisfied:whereand the controller and observer gains are given by , , and , while the control law is defined as . Proof. Rewriting the first and second equations from (
33) as in (
24) and applying the observer dynamics equation (
25), we obtain the state estimation error dynamics (
26). Using the feedback control (
27) and selecting the gain
as in (
29), we can express the first equation of (
33) as in (
30). By combining this with the estimation error dynamics (
26) and the desired output equation for
, we arrive at Equation (
32).
We introduce a variable
and write a Lyapunov candidate function:
The
norm of the system will be less than
if the following condition holds:
. We can expand the terms of this condition:
and using (
32), we have:
We can re-write the condition as follows:
where
and
Using the Schur complement on (
44), we have:
Conjugating (
47) by a block-diagonal matrix
, where
, we find:
where
. Let us re-write (
48) as:
Now, we use Young’s relation to convert (
49) to an LMI [
5]. Introducing variables:
and using Young’s relation (
1), we have:
Substituting (
51) into (
49), we have:
where
Expressions quadratic in decision variables appear in the first and second diagonal blocks of the matrix. Using the Schur complement separately on each block, we find a new condition:
Since
,
we can transform the block:
We substitute into (
54):
where
and
are defined as expressions (
35) and (
36).
This is an LMI in variables , , , . □
Using Theorem 1, we can formulate a semidefinite program, solving which we obtain the controller gain that guarantees the
gains of the system below
:
This optimization problem can be efficiently solved using an SDP solver. We will refer to it as the optimal control problem (OCP) in the rest of the paper. It contains
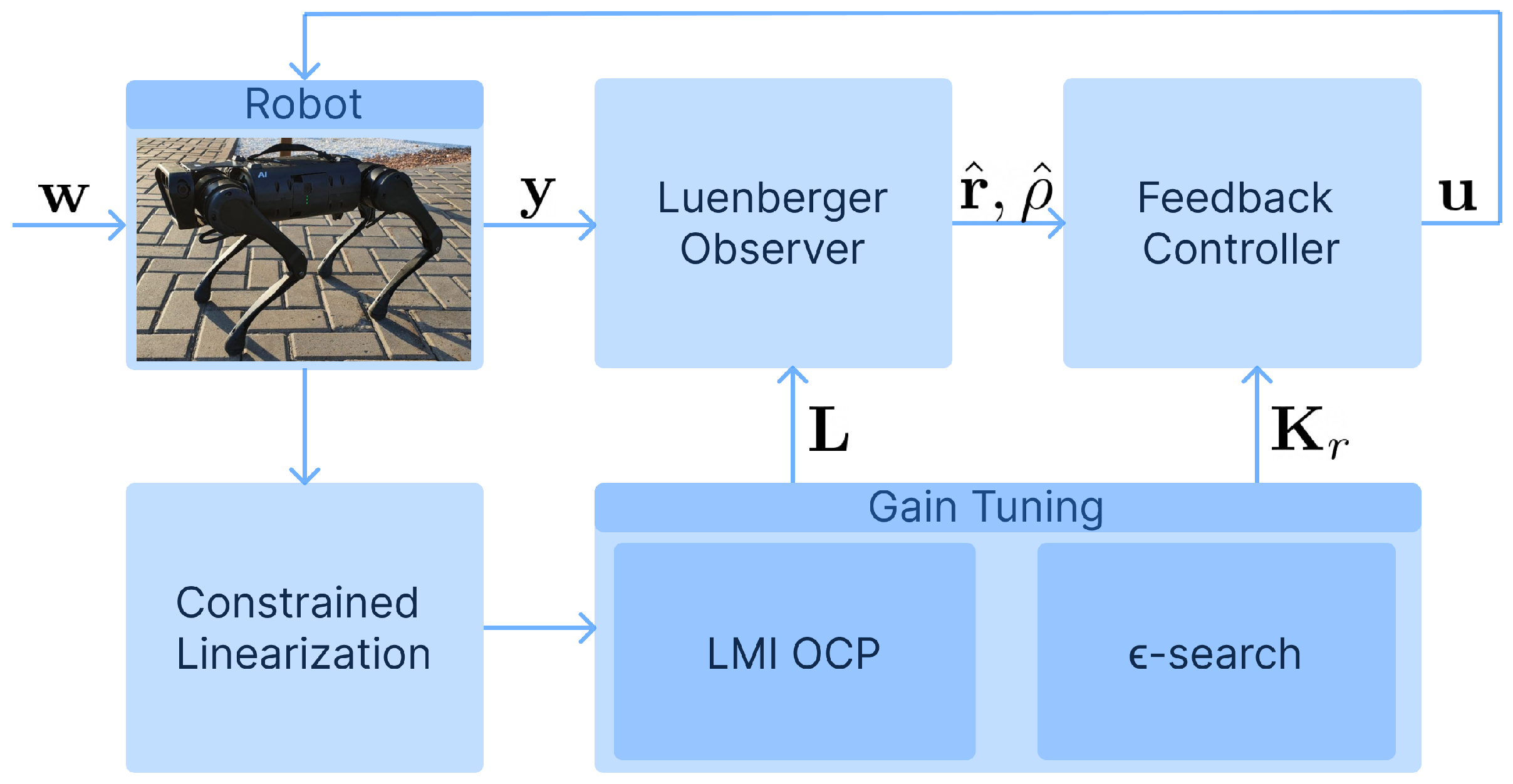
as a parameter. The resulting closed-loop control system is illustrated in the
Figure 1.
Remark 2. The scalar is chosen ahead of solving the problem (57). To overcome the difficulty of choosing the proper ϵ, we use a gridding method, searching over a range of values of ϵ to find the one that provides the best γ. Let ; hence, . Since , it follows that . We divide the interval evenly, find ϵ associated with each value of κ on that interval, and solve the OCP for that ϵ value. Among multiple OCP solutions, we choose the one that demonstrates the smallest gain γ. This method was introduced in [8]. 7. Numerical Simulations and Discussion
To verify the proposed method, we apply it to the design of control for two mechanical systems: an underactuated three-link robot with a fixed end-effector and a flat quadruped robot model.
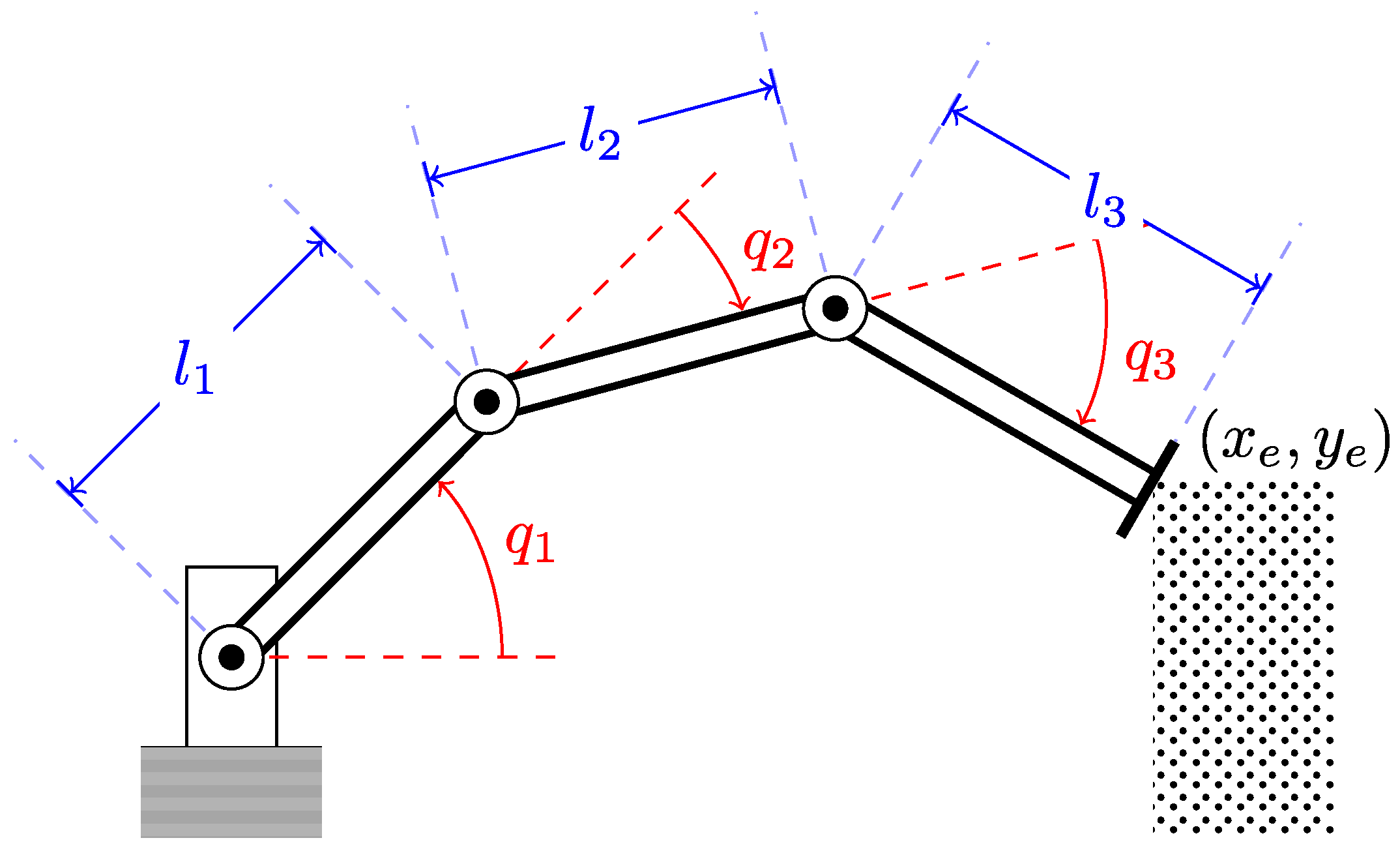
7.1. Constrained Underactuated Three-Link Robot
In this subsection, we design a control law for a serial mechanism consisting of three links connected via rotary joints. Each link has length
m, mass
kg, and inertia 0.2083 kg·m
2. Let
,
, and
be joint angles; then, the state of the robot is formed by the joint angles and their derivatives. The end-effector of the robot is fixed, providing two mechanical constraints and leaving the robot with one mechanical degree of freedom, or equivalently, two active states (using terminology proposed in
Section 4). A scheme of the robot is shown in
Figure 2.
In this experiment, the coordinates at which the end-effector is fixed are
,
. The mechanical constraints related to the fixed end-effector have the following form:
Choosing the configuration
,
, and
as the linearization point, we use the method discussed in
Section 4 to produce the following linear approximation of the robot model:
where the state, control, and constraint matrices
,
,
,
attain the following values:
Matrix
, providing a basis in the null space of the constraint equation, is given as:
The external force is assumed to act on the center of mass of the second link in the vertical direction. The corresponding
is found to be:
We consider the case where the rank of the measurement matrix is 4; additionally, we assume that there is a feed-through from the external disturbance to the measurement. Thus, the measurement matrix
and the input matrix
take the form:
The desired output matrices
and
have the form:
For brevity, we do not discuss units of the model matrices here; however, we note that the units are chosen in such a way that the input and output signals
,
are both unitless. We use the static control law (
29) to find the following control gain:
Solving a semidefinite program with the conditions given by (
34), minimizing
, and choosing the
that gives the lowest value for
using Remark 2, we find the optimal controller and observer gains:
In our case, the optimal value of was found to be , achieved with . It was easy to verify that the closed-loop system was stable. We tested the system’s response to signal , whose norm was . The ratio between the input and the output signals in that experiment was . The time required to solve a single OCP was 0.127 s, while the time for grinding search was 4.967 s with a fixed step of size 0.001 for over the interval (0,1), as outlined in Remark 2. The gridding is terminated for as the solver fails for larger values.
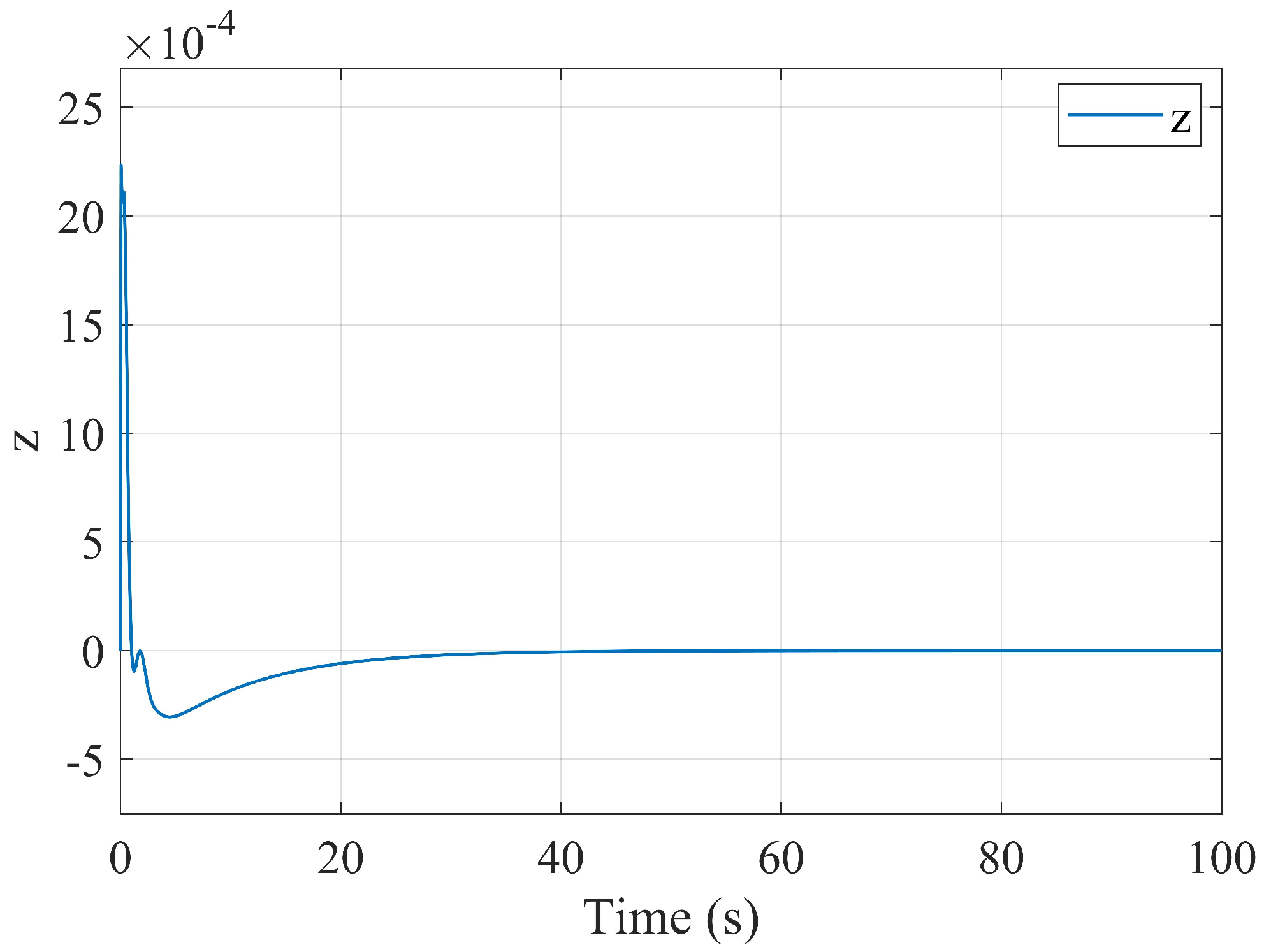
Figure 3 shows the output signal
for this experiment;
Figure 4 shows the same signal plotted together with the input signal
using logarithmic scale. We observe that the output signal quickly decays to zero. As the input signal vanishes, so does the output. This is the desired behavior of the controller. Let us note that the time horizon of the graph in
Figure 3 was chosen with the aim to demonstrate the shape of the signal; however, the primary way of analyzing the signal is linked to its
norm, rather than the speed of its decay.
7.2. Flat Quadruped Robot Model
In this subsection, we apply the proposed method to a flat quadruped robot model, as shown in
Figure 5. The robot consists of two legs attached to the body via a rotary joint; each leg consists of two links connected via a rotary joint. All joints are actuated, and the feet of the robot remain on the ground throughout the experiment, experiencing constraints associated with unilateral mechanical contact. The lengths of the links are
m, and the length of the body is
m. The mass of each link is 2kg, and the mass of the body is 10 kg. The inertia of each link is 0.0750 kg·m
2, and the inertia of the body is 0.2083 kg·m
2. The state of the robot includes the position and orientation of the robot’s body, the robot’s joint angles
, and the derivatives of all these quantities. We linearize the model around the configuration
,
,
, and
, while the robot’s body is horizontal. The external force is assumed to act on the center of mass of the robot’s body in the horizontal direction.
Performing grid search, we find the optimal , while the optimal upper estimate of the gain of the system is . We test the system with an exponential input , finding that the ratio of norms of the input and the output signals (the latter is chosen as the sum of robot states and observer error states) is . The time required to solve a single OCP is 0.507 s, while the total time for gridding search is 28.207 s. The gridding is terminated for as the solver fails for larger values.
Figure 6 shows the output signal
for this experiment;
Figure 7 shows the same signal plotted together with the input signal
on a logarithmic scale. As we can see, the output signal is orders of magnitude below the input signal; as the input signal vanishes, so does the output. Like in the previous experiment, what we observe is the desired behavior of the controller.
7.3. Limitations
When analyzing the practicality of the proposed method, it is important to consider its computational cost. Computationally expensive control may lead to demanding hardware requirements or a lower-frequency control loop, both of which are undesirable. The proposed
control method presents two sources of computational expense. The first is the linear controller and observer, which are updated on each control loop iteration. They pose a negligible computational expense related to vector addition and matrix–vector multiplication. The second is related to solving OCP (
57) multiple times during the gridding, as explained in Remark 2. This is a computationally expensive process: solving the OCP a single time requires 0.127 s for a three-link robot arm and 0.507 s for a quadruped. Gridding pushes these numbers to 4.967 s and 28.207 s, respectively. However, these computations do not need to be performed during the operation of the robot. If the controller and observer gains are tuned before the robot starts its operation, this source of computational expense will not affect the performance of the control system.
The OCP (
57) is an SDP problem and thus requires an SDP solver. The computational expense of a semidefinite program grows with the size of its LMI. In the case of problem (
57), the size of the LMI (
34) grows quadratically (in terms of the number of elements on the LMI matrix) with the increase in the number of state variables describing the robot. Additionally, the SDP solver may fail to solve a large-scale problem even if a solution exists. Other considerations, such as the structure and sparsity of the matrices and the solver settings, also affect the computation time and accuracy [
34].
Like other model-based methods, the proposed controller assumes that the system can be modeled by (
23) within a reasonable degree of accuracy. This assumption can be violated for several reasons: if the linearization point is too far from the current operational point, if there is significant parametric uncertainty or unmodeled dynamics, if the system undergoes a hybrid transition (e.g., impact or collision), or for other reasons. Given an accurate nonlinear model, it is possible to use nonlinear control tools to ascertain the stability of the nonlinear system controlled by a linear feedback law [
35]. Methods such as sum-of-squares programming (SOS) allow us to estimate the region of attraction in the state space where the control law guarantees the stability of the system [
36]. Estimating the region where the
norm of the nonlinear system is below a given threshold remains a problem to be solved and poses an interesting direction for further research.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}