
Harnessing the Power of Large Language Models for Automated Code Generation and Verification


Abstract
1. Introduction
1.1. Problem Statement
1.2. Research Objectives
2. Background
2.1. Finite State Machines in Robotics
Flexbotics
2.2. Large Language Models (LLMs)
2.3. Guaranteeing the Safety and Quality of Automatically Generated Code
2.4. Proposed Approach
2.4.1. Human-Programmed and Carefully Curated “Software Blocks”
2.4.2. Use of a Second LLM to Verify Results from a First One
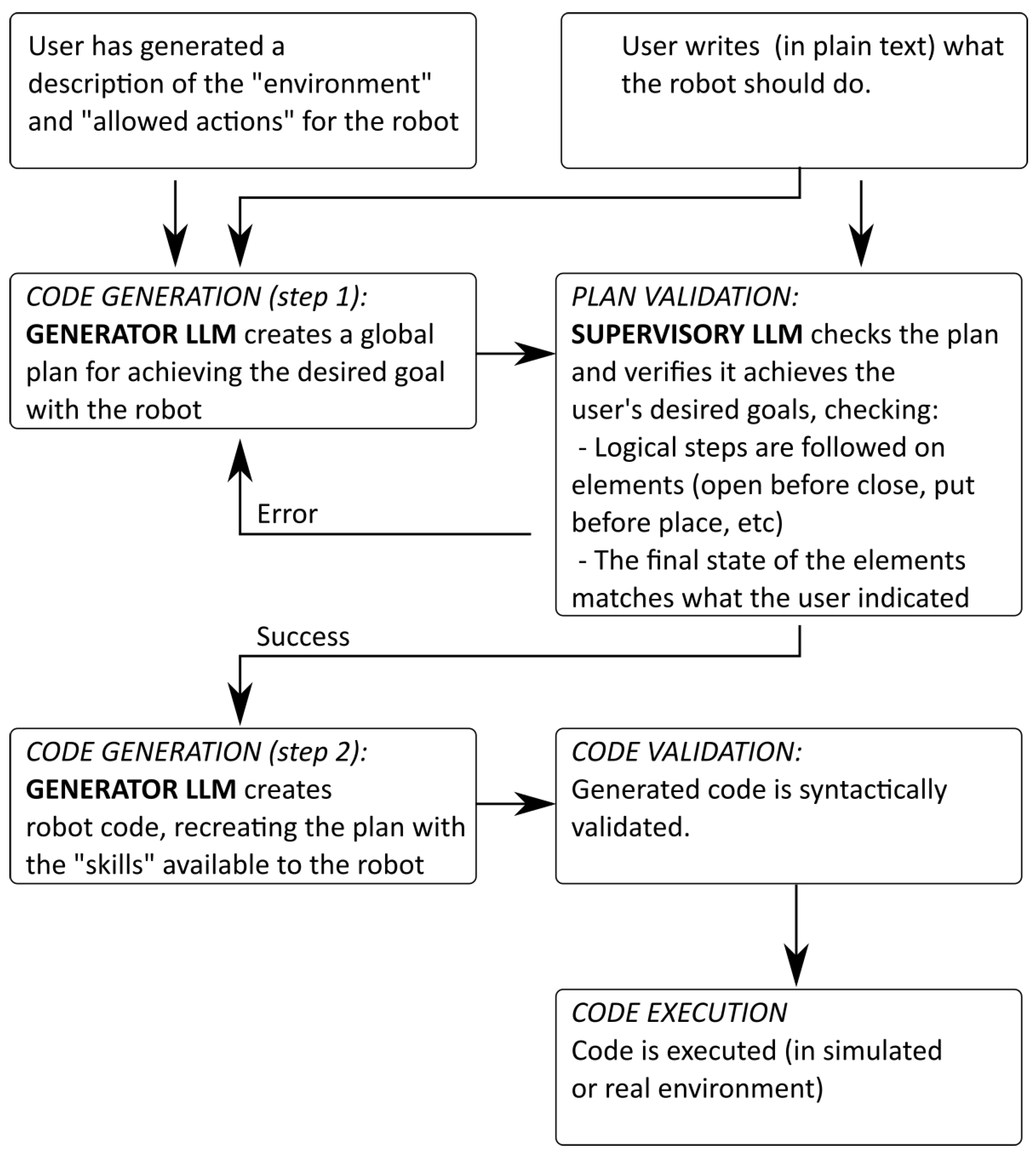
3. Architecture
3.1. Prepare Context Information
3.2. Code Generation—Step 1: Automatically Generates a Plan from the Specification Provided by the User
3.3. Plan Validation: Evaluate Plan and Used Elements
- Actions should follow a certain logical order (for example: an object has to be picked up before it is put somewhere, something has to be opened before it can be closed, ...).
- Actions do not overflow the robot’s capabilities (for example: picking up more than one element at the same time).
- A validation to check that the robot’s actions will create a final state of the system that matches the final state indicated by the user (for example: validating that ‘all door should be closed’).
3.4. Code Generation—Step 2: Convert the Plan into a Sequence of Allowed Actions (“Skills” That the Robot Can Execute)
- Step 1) Move to the fridge location.
- Step 2) Open the fridge.
- Step 3) Pick up the egg.
- Step 4) Close the fridge.
4. Experimental Setup and Validation
- A synthetic setup based on the iTHOR environment [33]. iTHOR is an environment within the AI2-THOR framework, which includes a set of interactive objects and more than 120 scenes and provides accurate modeling of the physics of the world. The AI2-THOR framework is a popular simulated environment for embodied AI research, providing a set of realistic and interactive scenarios for testing and training AI systems.
- A physical setup based on a dual-arm robot that performs pick-and-place operations on a factory assembly line.
4.1. Synthetic Setup
- Translating high-level action commands from the Flexbotics system into low-level motor control commands that can be executed in the iTHOR environment.
- Converting sensor data from the AI2-THOR environment into a format that can be processed by the Flexbotics system.
- Handling communication between the Flexbotics system and the iTHOR environment, ensuring that actions are executed correctly and that the system receives accurate feedback.
- Fridge: Is an appliance that is initially closed. Initially, it contains an egg and a head of lettuce.
- Egg: a pickable food located initially inside the fridge.
- Lettuce: a pickable food located initially inside the fridge.
- Stove: is an appliance for cooking.
- StoveBurner: the burner of the stove appliance.
- Pan: a frying pan is a tool used for cooking.
- Plate: an empty plate container located on top of the countertop.
- Countertop: there are two countertops: one aligned with the fridge and a kitchen island countertop.
- Basin: a kitchen sink.
- Toaster: Is an appliance on the countertop. Can be switched on and off.
- Knife: is a slicing tool inside a drawer.
- Tomato: located on the kitchen island countertop.
- Bread: a bread loaf on the kitchen island countertop.
- Drawer: a drawer that contains a knife.
- Environment and elements in it: which elements can be found in the synthetic setup around the robot (the ones in the simulated kitchen shown above) and their initial state.
- Allowed robot actions (basic actions that can later be translated to Flexbotics skills):
- –
- moving around.
- –
- picking up and using tools.
- –
- act on elements (to switch on/off, open/close, slice food, etc.).
- –
- moving elements around.
- Translation of robot actions into Flexbotics skills: describing how to generate a valid JSON from a high-level plan.
Synthetic Setup: Experimental Results
- USER REQUEST 1: “Put the tomato in the fridge. Make sure that in the end the fridge is closed.”
- Total number of tokens used by Generator LLM: 1047.
- S1: a junior user with no prior experience generating JSON files.
- S2: a junior user with some previous experience generating JSON files.
- S3: a senior programmer with experience generating JSON files.
- S4: a senior with experience programming robots and generating JSON files.
- USER REQUEST 2: “I want the robot to slice some tomato and then put it on a plate.”
- Total number of tokens used by Generator LLM: 1107.
- USER REQUEST 3: “Prepare a toast of sliced bread, and put it on the plate with a slice of tomato on top of it. ”
- Total number of tokens used by Generator LLM: 1427.
4.2. Physical Robot
- A dual-arm Kawada Nextage robot
- A stereo camera.
- A set of vitro-ceramic electric cooker components that must be assembled by the robot.
4.3. Results after Validation on Synthetic and Physical Setups
- User Request: the mission requested by the user.
- Actions in JSON: the number of sequential actions created in the generated JSON.
- Total Tokens: the total number of tokens evaluated by the Generator LLM in the first step of code generation (as a measure of the complexity of the user request).
- Verification Loops: the number of times the Supervisory LLM requested a change in the plan.
- Successful Simulation: indicates if the mission was fully executed in the simulation and the goals indicated by the user were achieved.
4.4. Scalability
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- IFR Secretariat Blog—AI in Robotics. 2022. Available online: https://ifr.org/post/ai-in-robotics-blog (accessed on 4 September 2024).
- Ogheneovo, E. On the Relationship between Software Complexity and Maintenance Costs. J. Comput. Commun. 2014, 2, 51631. [Google Scholar] [CrossRef]
- Ben-Ari, M. Finite state machines. In Elements of Robotics; Springer: Berlin/Heidelberg, Germany, 2018; pp. 55–61. [Google Scholar] [CrossRef]
- Balogh, R.; Obdržálek, D. Using Finite State Machines in Introductory Robotics: Methods and Applications for Teaching and Learning. In Using Finite State Machines in Introductory Robotics: Methods and Applications for Teaching and Learning; Springer: Berlin/Heidelberg, Germany, 2019; pp. 85–91. [Google Scholar] [CrossRef]
- Zhou, H.; Min, H.; Lin, Y.; Zhang, S. A Robot Architecture of Hierarchical Finite State Machine for Autonomous Mobile Manipulator. In A Robot Architecture of Hierarchical Finite State Machine for Autonomous Mobile Manipulator; Springer: Berlin/Heidelberg, Germany, 2017; pp. 425–436. [Google Scholar] [CrossRef]
- Foukarakis, M.; Leonidis, A.; Antona, M.; Stephanidis, C. Combining Finite State Machine and Decision-Making Tools for Adaptable Robot Behavior. In Proceedings of the Universal Access in Human-Computer Interaction—Aging and Assistive Environments: 8th International Conference, UAHCI 2014, Heraklion, Crete, Greece, 22–27 June 2014. [Google Scholar]
- Herrero, H.; Outón, J.L.; Puerto, M.; Sallé, D.; López de Ipiña, K. Enhanced Flexibility and Reusability through State Machine-Based Architectures for Multisensor Intelligent Robotics. Sensors 2017, 17, 1249. [Google Scholar] [CrossRef] [PubMed]
- Herrero, H.; Outón, J.L.; Esnaola, U.; Sallé, D.; López de Ipiña, K. Development and evaluation of a Skill Based Architecture for applied industrial robotics. In Proceedings of the 2015 4th International Work Conference on Bioinspired Intelligence (IWOBI), San Sebastian, Spain, 10–12 June 2015; pp. 191–196. [Google Scholar] [CrossRef]
- Diab, M.; Pomarlan, M.; Beßler, D.; Akbari, A.; Rosell, J.; Bateman, J.; Beetz, M. SkillMaN—A skill-based robotic manipulation framework based on perception and reasoning. Robot. Auton. Syst. 2020, 134, 103653. [Google Scholar] [CrossRef]
- Quigley, M.; Conley, K.; Gerkey, B.; Faust, J.; Foote, T.; Leibs, J.; Wheeler, R.; Ng, A. ROS: An Open-Source Robot Operating System. In Proceedings of the ICRA Workshop on Open Source Software, Kobe, Japan, 12–17 May 2009; Volume 3. [Google Scholar]
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. A Survey of Large Language Models. arXiv 2023, arXiv:2303.18223. [Google Scholar] [CrossRef]
- META. Meta-LLama-3-70B-Instruct. 2024. Available online: https://huggingface.co/meta-llama/Meta-Llama-3-70B (accessed on 4 September 2024).
- DEEPINFRA. Meta-LLama-3-70B-Instruct. 2024. Available online: https://deepinfra.com/meta-llama/Meta-Llama-3-70B-Instruct (accessed on 4 September 2024).
- Naveed, H.; Khan, A.U.; Qiu, S.; Saqib, M.; Anwar, S.; Usman, M.; Akhtar, N.; Barnes, N.; Mian, A. A Comprehensive Overview of Large Language Models. arXiv 2024, arXiv:2307.06435. [Google Scholar] [CrossRef]
- Will Henshall. TIME: 4 Charts That Show Why AI Progress Is Unlikely to Slow Down. 2023. Available online: https://time.com/6300942/ai-progress-charts/ (accessed on 4 September 2024).
- Schäfer, M.; Nadi, S.; Eghbali, A.; Tip, F. An Empirical Evaluation of Using Large Language Models for Automated Unit Test Generation. arXiv 2023, arXiv:2302.06527. [Google Scholar] [CrossRef]
- D’Silva, V.; Kroening, D.; Weissenbacher, G. A Survey of Automated Techniques for Formal Software Verification. Trans. Comp.-Aided Des. Integ. Cir. Sys. 2008, 27, 1165–1178. [Google Scholar] [CrossRef]
- Floridi, L.; Chiriatti, M. GPT-3: Its Nature, Scope, Limits, and Consequences. Minds Mach. 2020, 30, 681–694. [Google Scholar] [CrossRef]
- Ye, W.; Ou, M.; Li, T.; Chen, Y.; Ma, X.; Yanggong, Y.; Wu, S.; Fu, J.; Chen, G.; Wang, H.; et al. Assessing Hidden Risks of LLMs: An Empirical Study on Robustness, Consistency, and Credibility. arXiv 2023, arXiv:2305.10235. [Google Scholar] [CrossRef]
- Bisk, Y.; Zellers, R.; Bras, R.L.; Gao, J.; Choi, Y. PIQA: Reasoning about Physical Commonsense in Natural Language. arXiv 2019, arXiv:1911.11641. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar] [CrossRef]
- Kocoń, J.; Cichecki, I.; Kaszyca, O.; Kochanek, M.; Szydło, D.; Baran, J.; Bielaniewicz, J.; Gruza, M.; Janz, A.; Kanclerz, K.; et al. ChatGPT: Jack of all trades, master of none. Inf. Fusion 2023, 99, 101861. [Google Scholar] [CrossRef]
- Yang, X.; Li, Y.; Zhang, X.; Chen, H.; Cheng, W. Exploring the Limits ChatGPT for Query or Aspect-based Text Summarization. arXiv 2023, arXiv:2302.08081. [Google Scholar] [CrossRef]
- De Wynter, A.; Wang, X.; Sokolov, A.; Gu, Q.; Chen, S.Q. An evaluation on large language model outputs: Discourse and memorization. Nat. Lang. Process. J. 2023, 4, 100024. [Google Scholar] [CrossRef]
- Delobelle, P.; Tokpo, E.; Calders, T.; Berendt, B. Measuring Fairness with Biased Rulers: A Comparative Study on Bias Metrics for Pre-trained Language Models. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, WA, USA, 15 July 2022; Carpuat, M., de Marneffe, M.C., Meza Ruiz, I.V., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 1693–1706. [Google Scholar] [CrossRef]
- Domnich, A.; Anbarjafari, G. Responsible AI: Gender bias assessment in emotion recognition. arXiv 2021, arXiv:2103.11436. [Google Scholar] [CrossRef]
- ESA. Guide to Software Verification and Validation; ESA PSS-05-10 Issue 1, Revision 1, March 1995; ESA: Paris, France, 1995. [Google Scholar]
- Peleska, J.; Haxthausen, A.; Schnieder, E.; Tarnai, G. Object Code Verification for Safety-Critical Railway Control Systems. In Proceedings of the Formal Methods for Automation and Safety in Railway and Automotive Systems (FORMS/FORMAT 2007), Braunschweig, Germany, 25–26 January 2007; pp. 184–199. [Google Scholar]
- Iyyer, M.; Wieting, J.; Gimpel, K.; Zettlemoyer, L. Adversarial Example Generation with Syntactically Controlled Paraphrase Networks. arXiv 2018, arXiv:1804.06059. [Google Scholar] [CrossRef]
- Alzantot, M.; Sharma, Y.; Elgohary, A.; Ho, B.J.; Srivastava, M.; Chang, K.W. Generating Natural Language Adversarial Examples. arXiv 2018, arXiv:1804.07998. [Google Scholar] [CrossRef]
- Gao, J.; Lanchantin, J.; Soffa, M.L.; Qi, Y. Black-box Generation of Adversarial Text Sequences to Evade Deep Learning Classifiers. arXiv 2018, arXiv:1801.04354. [Google Scholar] [CrossRef]
- Zhao, Z.; Dua, D.; Singh, S. Generating Natural Adversarial Examples. arXiv 2018, arXiv:1710.11342. [Google Scholar] [CrossRef]
- Kolve, E.; Mottaghi, R.; Han, W.; VanderBilt, E.; Weihs, L.; Herrasti, A.; Deitke, M.; Ehsani, K.; Gordon, D.; Zhu, Y.; et al. AI2-THOR: An Interactive 3D Environment for Visual AI. arXiv 2022, arXiv:1712.05474. [Google Scholar] [CrossRef]
- Zhang, H.; Li, L.H.; Meng, T.; Chang, K.W.; den Broeck, G.V. On the Paradox of Learning to Reason from Data. arXiv 2022, arXiv:2205.11502. [Google Scholar] [CrossRef]
- Wu, Z.; Qiu, L.; Ross, A.; Akyürek, E.; Chen, B.; Wang, B.; Kim, N.; Andreas, J.; Kim, Y. Reasoning or Reciting? Exploring the Capabilities and Limitations of Language Models Through Counterfactual Tasks. arXiv 2024, arXiv:2307.02477. [Google Scholar] [CrossRef]
- Wu, Z.; Bai, H.; Zhang, A.; Gu, J.; Vydiswaran, V.V.; Jaitly, N.; Zhang, Y. Divide-or-Conquer? Which Part Should You Distill Your LLM? arXiv 2024, arXiv:2402.15000. [Google Scholar] [CrossRef]
- Plaat, A.; Wong, A.; Verberne, S.; Broekens, J.; van Stein, N.; Back, T. Reasoning with Large Language Models, a Survey. arXiv 2024, arXiv:2407.11511. [Google Scholar] [CrossRef]
- Huang, J.; Chang, K.C.C. Towards Reasoning in Large Language Models: A Survey. arXiv 2023, arXiv:2212.10403. [Google Scholar] [CrossRef]
- Qiao, S.; Ou, Y.; Zhang, N.; Chen, X.; Yao, Y.; Deng, S.; Tan, C.; Huang, F.; Chen, H. Reasoning with Language Model Prompting: A Survey. arXiv 2023, arXiv:2212.09597. [Google Scholar] [CrossRef]
- Levy, M.; Jacoby, A.; Goldberg, Y. Same Task, More Tokens: The Impact of Input Length on the Reasoning Performance of Large Language Models. arXiv 2024, arXiv:2402.14848. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Synthetic | S1 | S2 | S3 | S4 | User Mean | LLM | LLM Adv. |
|---|---|---|---|---|---|---|---|
| Generation | 14 m 2 s | 6 m 52 s | 4 m 27 s | 3 m 54 s | 7 m 18 s | 14 s | 97% |
| Check | 1 m 16 s | 1 m 6 s | 56 s | 28 s | 26 s | 12 s | 78% |
| Total | 15 m 8 s | 8 m 8 s | 5 m 23 s | 4 m 20 s | 8 m 14 s | 26 s | 95% |
| Physical | S1 | S2 | S3 | S4 | User Mean | LLM | LLM Adv. |
|---|---|---|---|---|---|---|---|
| Generate FSM | 4 m 5 s | 2 m 2 s | 1 m 20 s | 54 s | 2 m 5 s | 15 s | 88% |
| Check FSM | 57 s | 52 s | 49 s | 22 s | 45 s | 13 s | 71% |
| Total | 5 m 2 s | 2 m 54 s | 2 m 9 s | 1 m 16 s | 2 m 50 s | 14 s | 92% |
| User Request | Actions in JSON | Total Tokens | Verification Loops | Successful Simulation |
|---|---|---|---|---|
| Open the fridge | 2 | 851 | 0 | Yes |
| Pick up the egg from the fridge | 5 | 948 | 0 | Yes |
| Put the tomato in the fridge. Make sure that in the end, the fridge is closed | 7 | 1047 | 0 | Yes |
| I want the robot to slice some tomato and then put it on a plate | 12 | 1107 | 1 | Yes |
| Slice the bread and make toast | 19 | 1237 | 1 | Yes |
| Prepare toast from the sliced bread and put that on a plate with a slice of the tomato on top of it | 24 | 1427 | 2 | Yes |
| Put the egg on the plate. Slice the tomato and put it onto the plate. Put the pan in the basin. Pick up the bread and put it onto the countertop | 23 | 1454 | 0 | Yes |
| Put the frying pan in the basin. Slice and toast some bread and put that on the plate with an egg. When you are finished with the knife, leave it in the basin | 26 | 1507 | 1 | Yes |
| Pick up the knife and slice the bread and the tomato. Then, toast the bread and put it onto the plate. Then, cook the tomato slice in the pan and put it onto the plate | 21 | 1820 | 2 | No |
| Pick up the knife and slice the bread and the tomato. Then, toast the bread, fry it, and put it onto the plate. Then, cook the tomato slice in the pan and put it onto the plate | 41 | 1677 | 2 | No |
| Prepare a fried egg using the pan and the stove, and then prepare toast from the sliced bread and put that (together with the egg and some sliced lettuce) on a plate | 30 | 1961 | 4 | No |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Antero, U.; Blanco, F.; Oñativia, J.; Sallé, D.; Sierra, B. Harnessing the Power of Large Language Models for Automated Code Generation and Verification. Robotics 2024, 13, 137. https://doi.org/10.3390/robotics13090137
Antero U, Blanco F, Oñativia J, Sallé D, Sierra B. Harnessing the Power of Large Language Models for Automated Code Generation and Verification. Robotics. 2024; 13(9):137. https://doi.org/10.3390/robotics13090137
Chicago/Turabian StyleAntero, Unai, Francisco Blanco, Jon Oñativia, Damien Sallé, and Basilio Sierra. 2024. "Harnessing the Power of Large Language Models for Automated Code Generation and Verification" Robotics 13, no. 9: 137. https://doi.org/10.3390/robotics13090137
APA StyleAntero, U., Blanco, F., Oñativia, J., Sallé, D., & Sierra, B. (2024). Harnessing the Power of Large Language Models for Automated Code Generation and Verification. Robotics, 13(9), 137. https://doi.org/10.3390/robotics13090137