Abstract
This paper explores the problem of automated robot program generation from limited historical data when neither accurate geometric environmental models nor online vision feedback are available. The Program Reuse Framework (PRF) is developed, which uses expert-defined motion classes, a novel data structure introduced in this work, to learn affordances, workspaces, and skills from historical data. Historical data comprise raw robot joint trajectories and descriptions of the robot task being completed. Given new tasks, motion classes are then used again to formulate an optimization problem capable of generating new open-loop, skill-based programs to complete the tasks. To cope with a lack of geometric models, a technique to learn safe workspaces from demonstrations is developed, allowing the risk of new programs to be estimated before execution. A new learnable motion primitive for redundant manipulators is introduced, called a redundancy dynamical movement primitive, which enables new end-effector goals to be reached while mimicking the whole-arm behavior of a demonstration. A mobile manipulator part transportation task is used throughout to illustrate each step of the framework.
1. Introduction
Most industrial robots in operation today are programmed to complete repetitive tasks in highly structured environments, such as material handling, painting, and welding, through a combination of manual online and offline programming methods [1]. Meanwhile, manufacturing is moving towards a paradigm of increased agility and rapid reconfiguration to cope with changing demands under Industry 4.0, rendering traditional brittle programming methods excessively time-consuming and labor-intensive, and emphasizing the need for more automated programming solutions.
Most industrial robot tasks are composed of sequences of simple behaviors, often broadly called skills. This insight has led to great interest in the area of skill-based programming, in which skills are leveraged to accelerate manual programming through human–machine interfaces [2,3,4] or sequenced automatically [5,6,7,8]. In the latter case, vision sensing, precise environmental models, or both are required, which may not be realistic in practice. The industry has been slow to adopt this widespread vision, partly due to worker privacy concerns [9,10], but also because most industrial robots still operate in structured environments. Additionally, suitable environmental models may not be available in practice, especially in smaller enterprises in which online, pendant-based programming is the norm.
Recent deep learning approaches have successfully solved a variety of robotic tasks by effectively leveraging rich datasets [11,12,13,14,15]. However, in practice, historical data currently collected from industrial robots rarely go beyond joint trajectories, which are largely repetitive and thus not sufficiently diverse for deep learning methods. In contrast, learning from demonstration (LfD) methods, originally developed to generalize human demonstrations, are far more data-efficient [16,17]. LfD skills are likewise more suitable for generalizing the most common industrial robot tasks, in which a task variation that a robot may experience is limited to arrangements of manipulated objects. However, LfD skills typically encode only the motion of a skill, with limited learning of the affordance selection (such as grasp targets) and task constraints (such as workspace bounds). This work develops a method to simultaneously learn affordances, workspaces, and skills from demonstrations.
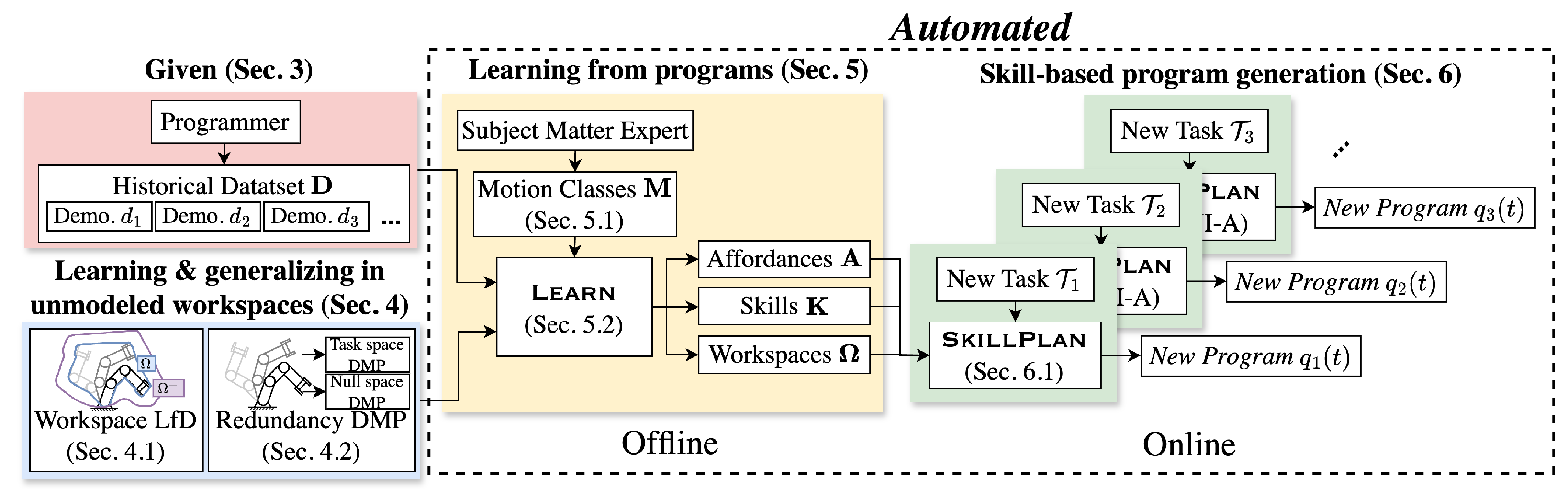
To enable automated, skill-based robot programming with minimal environmental knowledge and limited data, the Program Reuse Framework (PRF) is proposed (Figure 1). At the core of the framework is a set of motion classes: expert-designed templates, each defining the learning and reuse of a distinct behavior. A historical dataset of demonstrations, containing robot programs and task metadata such as object poses, is assumed to be given. An offline module learns affordances, workspaces, and skills from the historical dataset. Then, when a new task is specified, an online skill planning module uses the motion class set and the learned affordances, workspaces, and skills to generate a new program to accomplish the task. The primary contributions of this work are as follows:
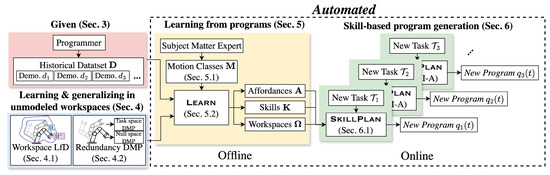
Figure 1.
Schematic of the Program Reuse Framework. Sections of the paper are indicated in the title of each module, e.g., “Sec. 3” correponding to Section 3. programmer generates programs to complete tasks offline, using a ground truth knowledge base available only to the programmer; as a result, a historical dataset of programs is generated. To apply the PRF, an SME designs a motion class set , which is used to learn from to generate sets of affordances , skills , and safe workspaces , forming a learned knowledge base. When a new task specification is given , SkillPlan uses the learned knowledge base to generate a new program to complete .
- An approach to workspace learning from demonstration, in which learned volumetric workspace constraints are used for program safety quantification in the absence of environmental models;
- The development of the redundancy dynamical movement primitive, a learnable motion generator for redundant manipulator skills that encodes and generalizes whole-arm motion to new task space goals;
- The introduction of motion classes, which are expert-designed templates for learning from historical data demonstrations and generating new skill-based programs.
An example mobile manipulator part transportation task is used throughout this work to illustrate an application of each component of the framework. The remainder of this paper is organized as follows. A review of related work is given in Section 2, followed by preliminaries, a formal problem statement, and the illustrative example definition in Section 3. Section 4 introduces both learnable workspaces and redundancy DMPs, and provides an experimental comparison in terms of generalization safety. In Section 5, the offline learning approach is detailed. Section 6 formulates the risk-minimizing, skill-based program generation approach; results of the full framework’s generalization performance are also included. Finally, a discussion is provided in Section 7 and concluding remarks are given in Section 8.
2. Related Work
2.1. Skill-Based Programming
Constraint-based programming approaches focus on the generation of robot motion based on careful definitions of task constraints. The Task Frame Formalism [18] provided an early framework for mapping simple task constraints to force and position control commands using user-provided templates. Later work like iTASC [19] and eTaSL [20] introduced more detailed, formal languages to specify complex tasks and available sensor streams, from which feedback controllers are automatically synthesized for sensor-based execution. Other work recontextualized constraint-based programming in terms of skills: user-defined, semantically meaningful actions with associated motion generators [21,22]. Other skill-based approaches generally consist of expert-defined skills with a variety of approaches to compose them [5,6,7,23]. Many skill-based programming approaches are designed for non-experts to design new programs in a modular way with intuitive graphical user interfaces [2] or even mixed reality [4]. Recent work has emphasized the correctness verification of skill-based programs [24] and automatic synthesis of sensor-based skill sequences suitable for execution in Robot Operating System (ROS) 2 [8]. A skill-based programming approach that emphasizes open-loop execution without vision feedback is presented in [25]; a Unified Programming Framework is introduced that enables a user to flexibly alternate between offline programming with a preexisting skill library and online programming by demonstration. In [26], an augmented reality-based programming interface is developed, with an emphasis on intuitive programming with sensor-based skills. In each approach, accurate world models, runtime perception, or manual design are required for program generation. The focus has been on programming with preexisting skills rather than how skills are learned or encoded.
The most similar work to our approach is [5], in which tasks are defined as desired world states and skills are carefully designed for intuitive use by both non-experts and automated planners. However, skills are realized at runtime by motion planners, which require precise world models and vision. In contrast, the presented work focuses on leveraging a historical dataset to solve a more constrained problem, in which neither explicit environmental models nor vision sensors are available during learning or at runtime. Moreover, we introduce motion classes as expert-designed templates for robot motion, similar to other skill templates that contain symbolic and/or physical constraints [18,19,20,27]. Motion classes enable both structured learning from demonstrations as well as the construction of new programs.
2.2. Skill Learning
While skill-based programming architectures often operate on existing skill libraries, the ability to learn skills expands a robot’s capabilities while reducing programming effort. Deep learning has been widely adopted to enable automated acquisition of a variety of complex skills, encoded as neural networks, including cable insertion [12], bin picking [11], rapid robot rehoming [15], deformable object manipulation [14], and even general manipulation from natural language commands [13]. Deep learning algorithms are commonly implemented with mature open-source Python libraries like Meta’s Pytorch [28] or Google’s TensorFlow [29]. However, deep learning methods can be challenging for non-experts to successfully deploy in practice [30] and are generally sample-inefficient [31]. As such, many deep learning-based approaches rely on simulation for the majority of training [11,12,14], or otherwise require expensive data collection in the real world [13].
Other methods utilize less data, albeit for more specialized skills. Learning from demonstration (LfD) methods enable encoding demonstrations with low-dimensional, yet highly expressive, models. See [32] for an overview of common models, along with libraries for Python, MATLAB, and C++. Perhaps the most prominent LfD model is the dynamical movement primitive (DMP) [16,33,34], which encodes skills using as few as a single demonstration. DMPs have long served as learnable motion generators for skills [35,36]. When more diverse demonstrations are available, statistical models based on DMPs [37] or Gaussian mixture models (GMMs) [17] can be leveraged for greater generalizability to task variation, such as rearrangements of key objects. Skills may also be acquired through a small number of task iterations in the real world when skill models are sufficiently low-dimensional, including DMPs [38], radial basis functions [21], or reach-avoid controllers [39]. In this work, we interpret existing robot programs in a historical dataset as demonstrations and leverage LfD models to efficiently learn specialized skills from limited, low-diversity data.
In order to effectively deploy learned skills, they must be appropriately parameterized for new tasks, such as end-effector goal selection for picking skills. Task-parameterized DMPs and GMMs [17] build task-conditioned skill parameter distributions from multiple demonstrations, while other methods enable runtime goal selection through multiple task iterations [6,38]. With a rich, multimodal demonstration dataset, as in RT-1 [13], both skills and vision-based goals are jointly learned from vision-based demonstrations, allowing flexible execution at runtime for new object configurations. Our framework learns skills and task-conditioned goals, or affordances, from historical data. In contrast, however, we do not assume the historical dataset was generated with the intention of learning and thus we do not expect sufficiently diverse examples to build statistical models. Moreover, new programs are generated for execution without vision feedback, so iterative methods are not suitable.
2.3. Geometric Constraint Learning
Demonstrations implicitly respect the constraints of a task, although constraints can be encoded in different ways. Prior work has investigated how geometric constraints can be inferred from demonstrations consisting only of state trajectories [40]. Later work focused on the inclusion of vision-based tracking during demonstrations to learn more complex geometric task constraints for multi-step tasks, but did not consider obstacle avoidance at runtime [41]. Other work developed a framework for learning infeasible states by assuming demonstrations are optimal and comparing them to optimal trajectories without constraints [40]. More recent work likewise assumes optimal demonstrations to build probabilistic obstacle models [42]. In practice, robot programs generated manually with traditional methods cannot be assumed to be optimal.
Our work is most similar to [41], which develops a framework to learn geometric constraints from demonstrations, including task space regions (TSRs) [43]. TSRs are volumes in that describe volumetric end-effector constraints. In contrast, we focus on learning volumes in that define safe whole-arm workspaces, which enable the safety quantification of new trajectories generated by learned skills.
3. Preliminaries and Problem Setup
3.1. Automated Planning
Task-level planning can be accomplished by several planning algorithms, such as those described in [44], e.g., GraphPlan [45,46]. A state variable planning domain is a tuple , consisting of a symbolic state space , action space , and state transition function . State variables in a set are symbolic terms of the form where are parameters from a set of symbolic names . A symbolic state is a set of atomic formulas involving state variables in . To form a set of actions , action templates are first introduced, where head is a symbolic expression containing variable arguments, and pre and eff represent the preconditions and effects of in the form of atomic formulas on state variables.
An action is constructed by parameterizing an action template with valid symbolic names, . In this sense, an action a is a concrete version of an action template , and the particular symbolic names in an action are referred to as concrete parameters. The function obeys the preconditions and effects of actions: . Given a state variable planning domain , an initial state , and a goal state , a sequence of actions, or action plan, can be constructed by a planning algorithm if such a plan exists.
3.2. Dynamical Movement Primitives
The dynamical movement primitive (DMP) is a motion model for LfD, encoding demonstrations as dynamical systems. Building upon the original formulation of DMPs [33], later extensions included a proper treatment of rotation trajectories [47]; the latter formulation is briefly summarized next. The purpose of a DMP is to encode the simultaneous motion of multiple robot coordinates as the solution to a forced dynamical system. A canonical system is first introduced for the phase variable , whose exponential decay from 1 to 0 is used to synchronize all other systems without explicit time dependence. The same time constant is used for all systems and is used to scale their convergence. The following system describes stable attraction of a position coordinate to a goal from any initial subject to a forcing term :
Here, z is the scaled time derivative of with . By selecting , the response of (1) is critically damped and exponentially converges to and if .
Equivalently, the following system from [47] describes an attraction to a rotation goal from subject to forcing term :
where for angular velocity . The forcing terms and are commonly defined as follows:
for , where and with and . The same Gaussian bases are used for both forcing terms with centers and widths for all , evenly spacing the bases in phase [48].
By selecting weights and appropriately, the response of (1) and (2) can be shaped as desired, such as to mimic a demonstration in an LfD context. Without loss of generality, consider only position DMPs (1): by substituting values from a demonstration into (1), taking as the duration, and rearranging, can be taken as a target value for regression in (3) for to solve for a matrix of weights . Then, to reach a new goal from a new initial position in a new duration , the new values are substituted into (1) and (3) to generate a new trajectory of duration that is a spatially and temporally scaled version of the demonstration . A locally weighted regression for efficiently solving for is given in [16]. For notational convenience, we introduce the following:
for a generic coordinate y (position or rotation), where Train (4) maps a demonstration to a set of trained DMP weights , and Integrate (5) maps an initial condition , goal g, and a set of DMP weights to a new trajectory . Temporal scaling is not critical to this work and is omitted for clarity.
Train : y(t) → w
Integrate : (0y, g, w) → y(t)
3.3. Problem Statement
In this work, we consider a robot with configuration that has been manually programmed to complete tasks in environments without explicit geometric models. A task description contains only the poses of task-relevant objects, but not their geometric models, representing the minimal data available in a manual programming regime. Each program–task pair is interpreted as a demonstration and stored in a historical dataset .
The present work considers a mobile manipulator performing part transportation tasks. The robot is equipped with a mobile base with (a parameterization of ), a manipulator with , and a gripper with , forming a configuration . The robot is assumed to be equipped with minimal, supplier-provided sensing. A laser scanner is available for the mobile base to navigate safely between work locations. However, the arm operates at each work location without visual feedback, as it is manually programmed. Thus, the safety of new trajectories cannot be guaranteed explicitly. The arm and mobile base have known home configurations and , respectively. We denote the pose of a frame A with respect to B as . When the reference frame is omitted, the world origin frame o is assumed.
A part transportation task (PTT) involves transporting a part p from location to location . Both and represent work locations such as a manufacturing machine, buffer, or other environment in which the arm may operate. The initial part pose is and the goal part pose is . The static locations are at poses and , respectively. Altogether, a PTT is specified with the tuple
Throughout this work, we denote a member of a tuple using a leading superscript, such as or in (6). The poses of the mobile base frame b and end-effector frame e are computed using known forward kinematics, respectively: and . The physical state encodes the configuration of both the robot and the part as , where is a vectorization of a matrix .
The precise problem considered in this work is as follows. Given a historical dataset of task–program pairs and a new task , find a new program to solve while maximizing safety. The following assumptions are made:
- (A1)
- Geometric models of the robot are known, but those of parts and locations are not;
- (A2)
- precisely describes the poses of parts p and locations , .
3.4. Illustrative Example Description
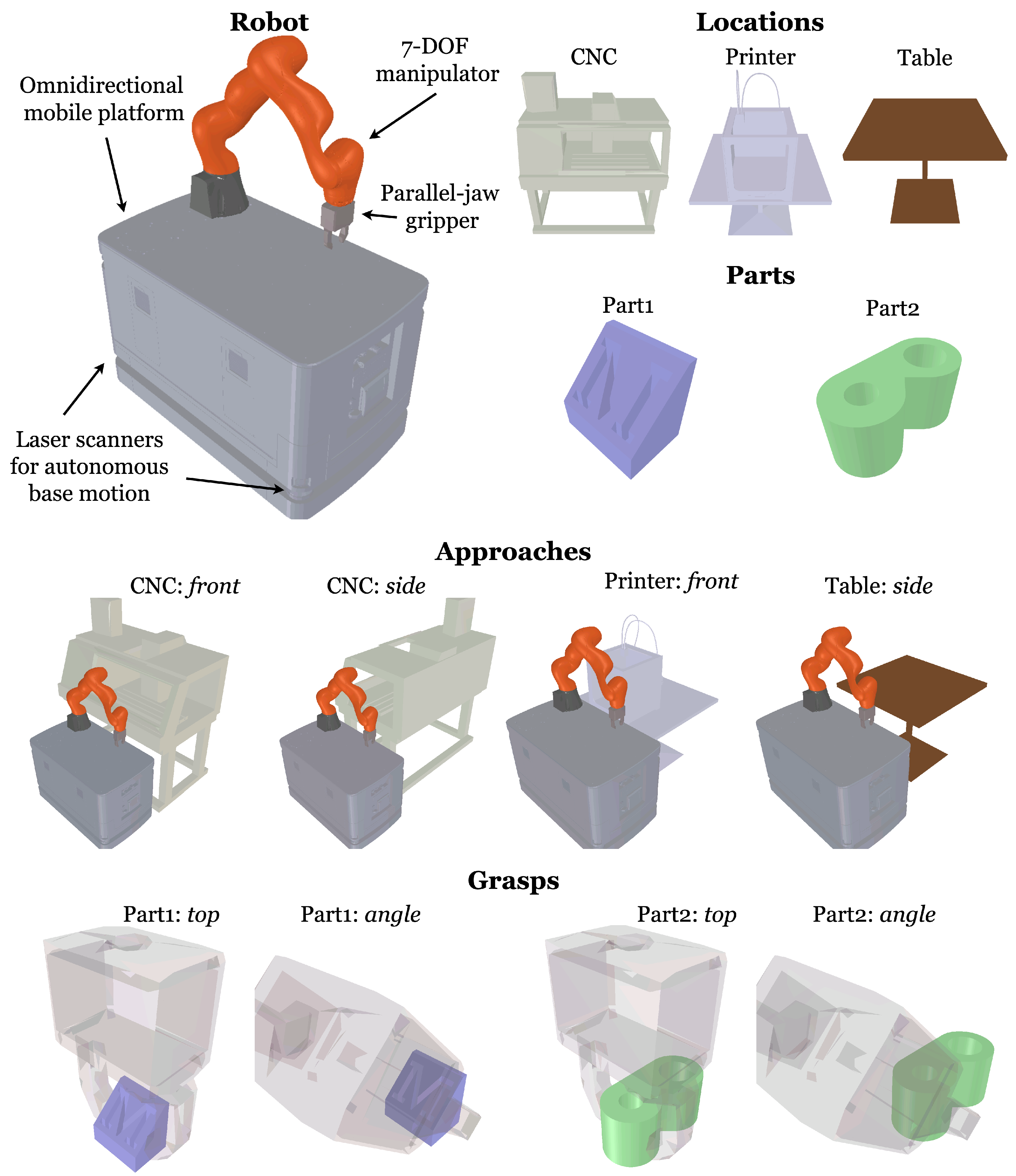
In this section, we introduce a concrete problem domain that will serve as an illustrative example throughout the development of this work (Figure 2). The mobile manipulator under consideration is a Kuka KMR iiwa, composed of an omnidirectional mobile platform, , and a manipulator with axes. The manipulator is redundant, meaning that an end-effector goal can be realized by a non-singleton subset of , enabling greater programming flexibility than a robot with six or fewer axes. Attached to the end of the manipulator is a parallel jaw gripper, , with 0 and 1 indicating an open and closed state, respectively.
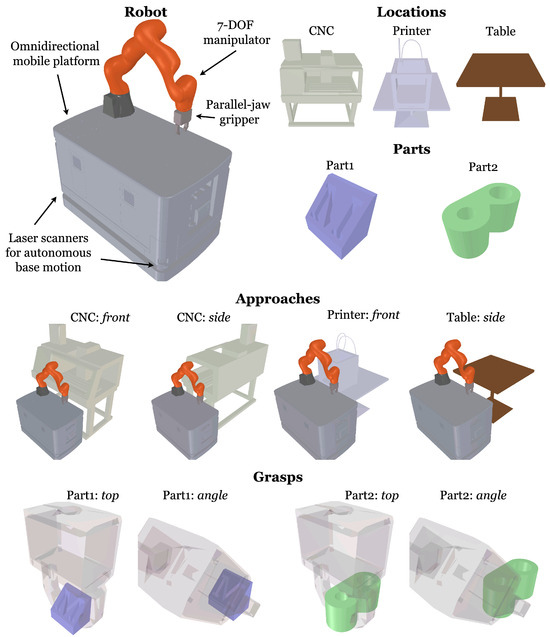
Figure 2.
Specification of an illustrative example: mobile manipulator part transportation. All possible tasks involve three types of locations (CNC, Printer, and Table) and two types of parts (Part1 and Part2). The CNC has two approaches (front and side) while the Printer (front) and Table (side) each have one. Both parts have two grasps (top and angle). Note that each approach or grasp is unique to a particular location or part, and shared names are incidental.
The robot operates at threes types of locations: a computer numerically controlled milling machine (CNC), a 3D printer (Printer), and a simple table (Table). The robot transports two types of parts: and . The robot has a set of manually generated programs for some tasks involving the transport of parts between locations . Note that a task may involve transportation between two instances of the same location, such as between two CNC machines, and , each with the same geometry.
The executions of manual programs to solve tasks form the historical dataset . Within this dataset, affordances in two forms are implicitly encoded: approaches, describing possible base poses with respect to different locations, and grasps, describing possible gripper poses with respect to different parts. Furthermore, the programs provide trajectory examples, from which affordances, workspaces, and skills can be learned. The presented work formalizes a methodology for generalizing a historical program dataset to new tasks by learning feasible affordances, safe workspaces, and skills, which enable the generation of new programs with quantified risk.
4. Learning and Safe Generalization within Unmodeled Workspaces
This section details two parts of our strategy to handle new program generation in unmodeled workspaces. First, a method to learn volumetric workspaces from demonstrations is given in Section 4.1. Then, a novel motion primitive formulation for redundant manipulators is given in Section 4.2. Finally, the performance of the new motion primitive formulation is compared to existing motion primitives in Section 4.3.
4.1. Workspace Learning from Demonstration
While demonstrations are commonly used to train skills capable of generalization, bounds on their generalizability are not commonly considered. In this section, we show how the same demonstration trajectories used for skill learning can be used to build sets capable of certifying the safety of new trajectories.
Consider a robot with links, including end-effectors, mobile platforms, and other attachments. Each link’s volumetric geometries can be expressed as compact sets ∀, where is the set of compact subsets of . The complete volume occupied by the robot at any configuration q, , can then be expressed by the union of all link geometries (we represent link geometries as meshes and use Trimesh [49] for operations like mesh concatenation):
Meanwhile, suppose that a set of control points are sampled from the surface of each link and collected in sets . Then, the full set of control points at a configuration is given by the union of link control points:
To measure the distance between a point and the boundary of a compact set , a signed distance function (we use Pytorch Volumetric for SDF computation between meshes [50]) is used, where and for surface points . From this point-dependent SDF, we introduce a configuration-dependent SDF (C-SDF), similar to [51]:
which finds the minimum clearance between the robot control points and the set .
Now, consider a robot programmed to operate at a location ℓ with static obstacle geometry , resulting in a set of demonstration trajectories which are collision-free, meaning
Gathering all configurations across the trajectory set yields the set of known safe configurations:
The safe configuration set is robot-specific, but we can consider the robot links at each configuration, which sweep through to construct a generic safe Cartesian workspace:
With the safe workspace , we can certify the safety of any trajectory executed at location ℓ without knowledge of . First, since the demonstrations are collision-free, we know that and do not intersect: . Then, we know that the obstacle set must be a subset of the complement of : . Therefore, a sufficient condition for safety of a trajectory at a location ℓ is
In other words, if the robot trajectory does not enter the complement of the safe workspace, it cannot enter the obstacle set.
On its own, (13) does not admit much flexibility in the design of new trajectories, as even the safe demonstrations operate at the boundary of . Instead, we leverage domain knowledge about the construction of the demonstrations to enlarge . Guidelines regarding the minimum clearance between robot trajectories and workspace obstacles are common, specified by enterprise policies and industry standards, such as ISO 10218 2011-2 [52] and ANSI/RIA R15.06 [53]. Suppose that demonstrations used to construct are known to have been generated using a standard, conservative minimum clearance of , so . Further suppose that a less conservative represents the true acceptable clearance. Thus, a dilated safe workspace can be formed:
where is a ball of radius centered at 0, and ⊕ is the Minkowski sum. A planar illustration of the safe workspace and its dilation is given in Figure 1. Following a similar argument as above, we know that the obstacle set is still a disjoint from the dilated safe workspace : . Thus, we have a sufficient condition similar to (13) that is less restrictive:
Note that trajectories that do not satisfy (15) are not necessarily unsafe; their safety is simply uncertain. A reasonable heuristic is to assume that the probability of obstacle collision increases the farther trajectories travel outside of the dilated safe workspace (or, equivalently, how far they travel inside its complement). Therefore, we define the risk of a trajectory as
where is a monotonically increasing function with for . can represent either conservative risk functions, like , or more relaxed ones, like . In all experiments in this paper, we use .
For notational convenience, we hereafter refer to the above procedure of mapping a demonstration trajectory set at a location ℓ to its dilated safe workspace as
LearnWorkspace : {qd(t)} → Ωℓ+.
4.2. Redundancy Dynamical Movement Primitives
Goals for manipulator tasks are most naturally expressed as end-effector goals . DMPs trained in task space allow the straightforward specification of goals in ; however, task space DMPs cannot encode the full motion of redundant robots, resulting in ambiguous joint space solutions. On the other hand, DMPs learned in joint space capture a demonstration’s full motion; however, joint space DMPs do not encode the whole-arm Cartesian behavior. Joint space DMPs also require inverse kinematics for goals to obtain joint space goals , which are ambiguous for redundant robots.
To learn the full motion of a redundant manipulator given new task space goals, the redundancy DMP (RDMP) is introduced. During training, a joint space demonstration trajectory is separated into task space and a compact null space representation , all of which are encoded as individual DMPs. Then, given a new task space goal , both task space and null space DMPs are simultaneously integrated to generate a new trajectory to reach g while preserving both task space and null space characteristics. The details of the compact null space representation are presented next.
4.2.1. Compact Null Space Representation
The manipulator Jacobian maps instantaneous joint space velocities at a particular configuration q to the instantaneous task space twist , composed of linear velocity and angular velocity . The forward and inverse velocity kinematics, respectively, are
where is the Moore–Penrose pseudoinverse of . is the null space projection matrix, which projects any into , generating null space motion, meaning zero task space velocity, as .
For a particular , represents the component of contributing to null space motion, and can be computed by substituting (18) into (19) and rearranging:
Thus, (18)–(20) describe a one-to-one mapping between joint space velocity and . However, since , null space motion describes motion along an -dimensional manifold within . As such, we can represent null space velocity more compactly in dimensions. Let be a matrix whose columns are the orthonormal bases of , obtained from singular value decomposition (SVD). Then, any null space motion can be expressed as
where is a compact null space velocity. Rearranging (21) and substituting (20), the compact null space velocity can be computed from by
Therefore, at a configuration q, a joint velocity can be represented uniquely with . The quantity represents a redundant robot’s speed along its null space manifold given its current configuration q and joint velocity . Note that RDMPs are not suitable for demonstrations that come close to kinematic singularities in , where as the null space computation becomes numerically unstable. However, since singularities pose other challenges, including loss of manipulability, manually generated robot programs are unlikely to contain them.
4.2.2. Training and Integrating RDMPs
In this section, we explain the RDMP implementations of Train (4) and Integrate (5). First, consider TrainRDMP (Algorithm 1). Given a joint space demonstration , corresponding task space Cartesian trajectories and are computed from forward kinematics and trained to weights and , respectively. Compact null space motion is computed using (22) and integrated over time with to form a demonstration which is treated as a position DMP (1) and trained to . Additionally, the integrated has no obvious physical meaning and thus new values cannot sensibly be chosen when the DMP is later integrated for reuse, so the original goal is likewise recorded. Altogether, the RDMP weight vector is
Then, given an initial configuration and goal pose , the task space and null space DMPs are simultaneously integrated to generate a new trajectory , shown in IntegrateRDMP (Algorithm 2). In Section 4.3, RDMPs are compared to traditional DMPs in terms of generating lower-risk trajectories during generalization.
| Algorithm 1 TrainRDMP |
|
| Algorithm 2 IntegrateRDMP |
|
4.3. Illustrative Example: DMP and RDMP Risk during Generalization
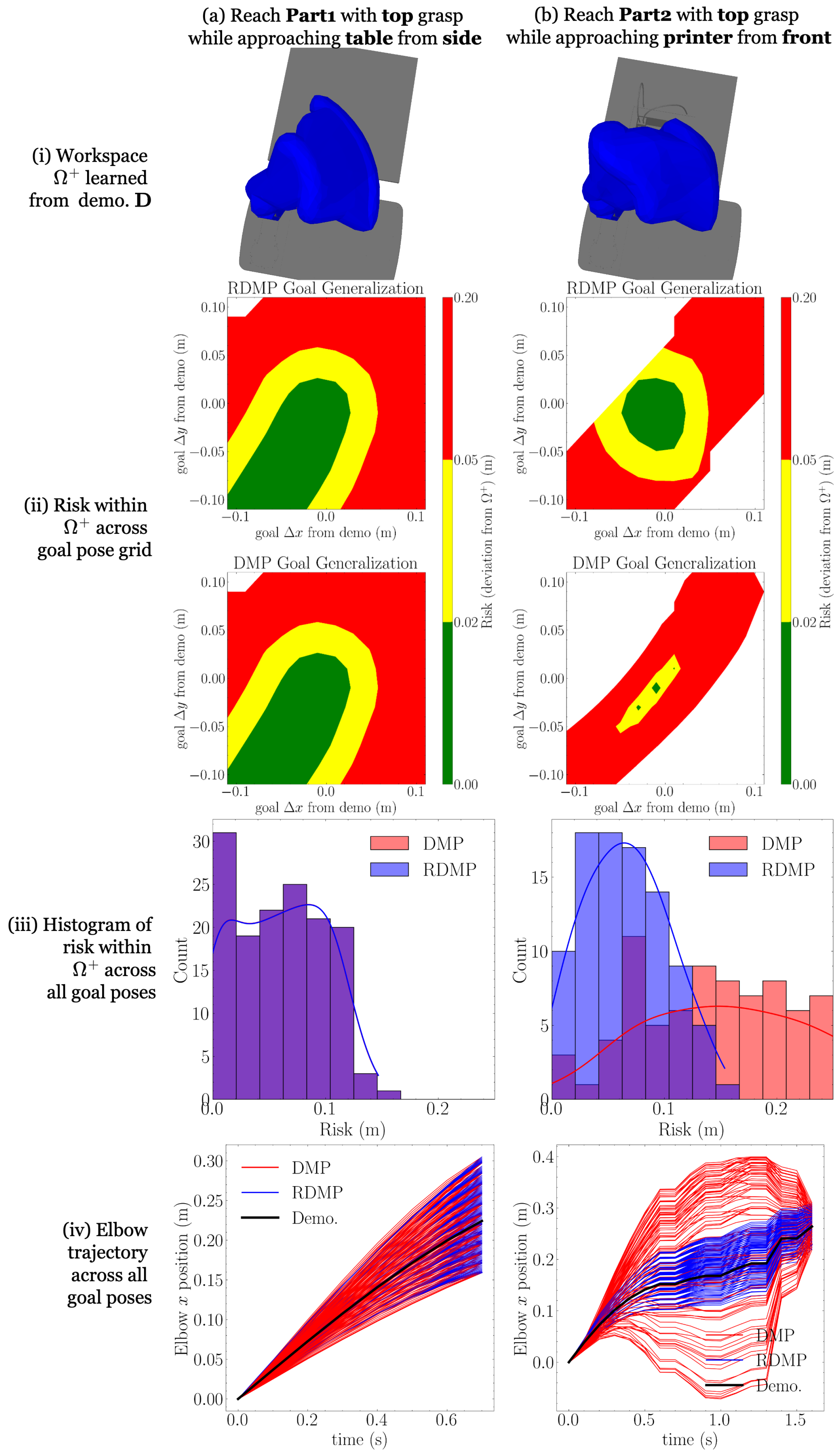
To compare the performance of DMPs and RDMPs in the context of the PRF, we compare the risk (16) of DMP- and RDMP-generated trajectories with the same initial conditions and goal, where the risk’s workspace, DMP, and RDMP are trained on the same demonstrations. To generate example demonstrations, we consider the four location approaches outlined in Section 3.4. Results for all examples are shown in Figure 3i–iv and Figure 4i–iv corresponding to comparison metrics.
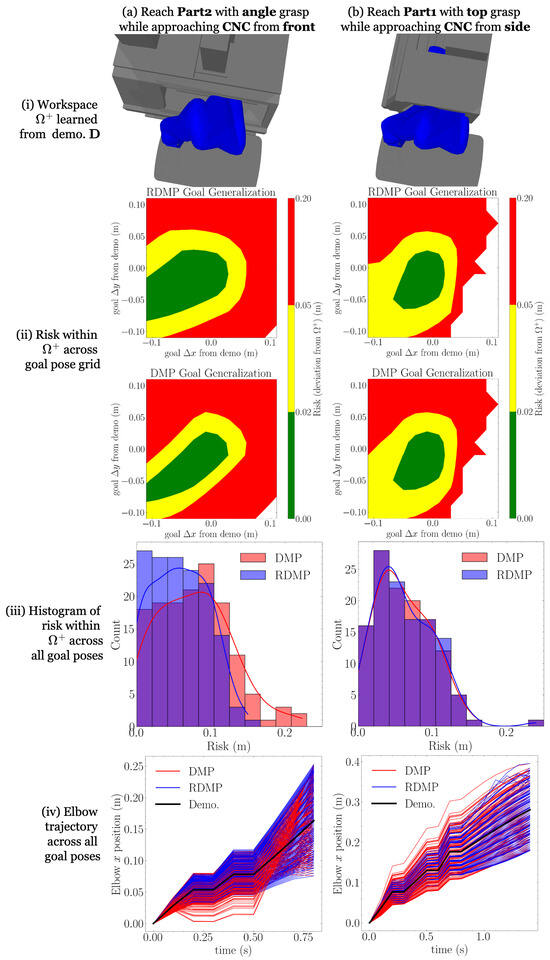
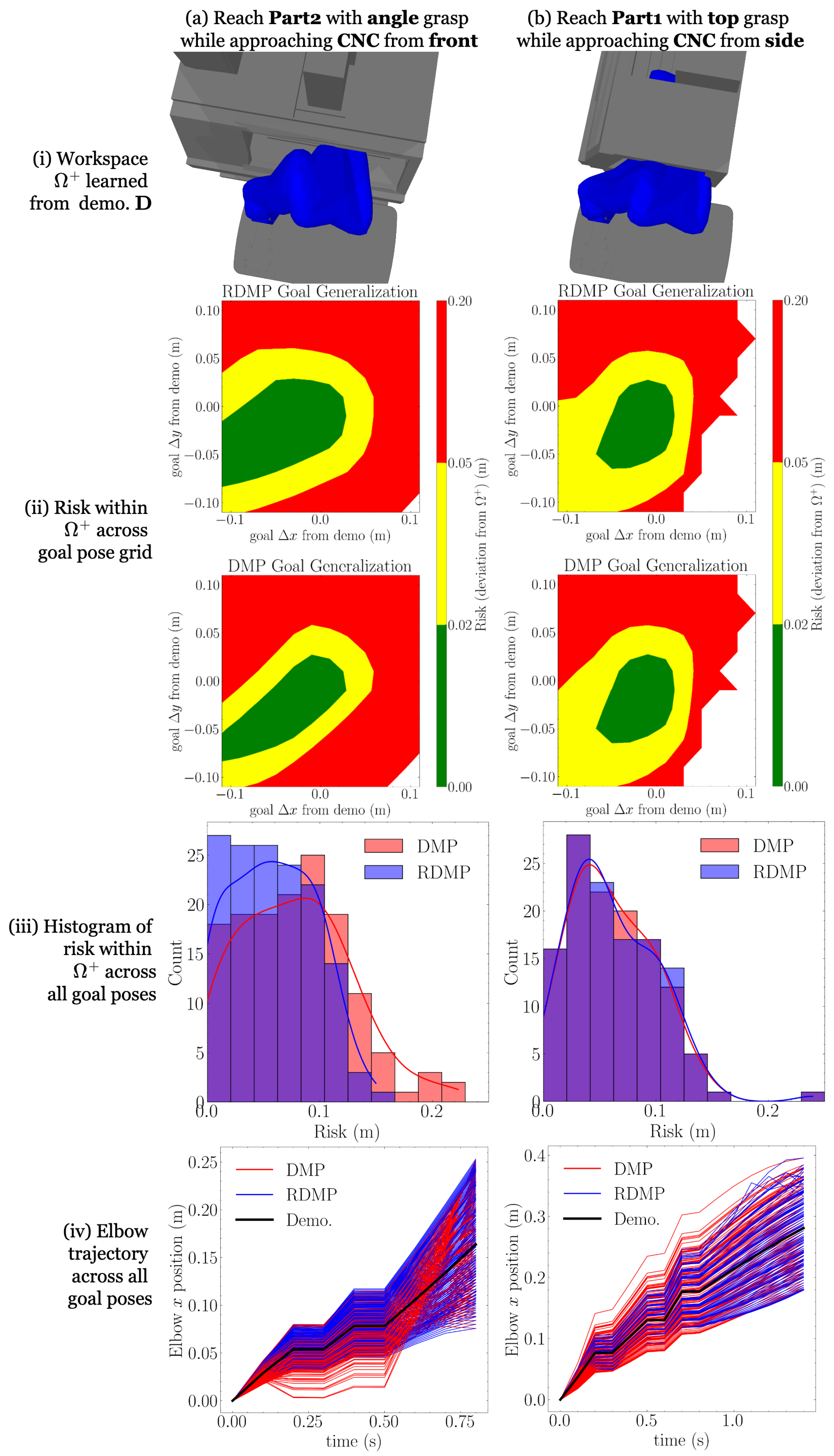
Figure 3.
RDMP and DMP risk-based generalization comparison, part 1; see the continuation in Figure 4. For four examples (two here and two in Figure 4), we take a nominal demonstration and learn a workspace (i), DMP, and RDMP. Then, generalizing over a grid of new goals, we compute risk for both the DMP and RDMP (ii,iii). We observe that the RDMP enables either similar or superior (lower-risk) generalization. To capture the trajectory-level differences, we also consider the position trajectory of the robot’s elbow joint in (iv) and see that the RDMP remains closer to the demonstration, explaining its lower risk. Note that in iii, the appearance of violet is the intersection of the red DMP and blue RDMP histograms.
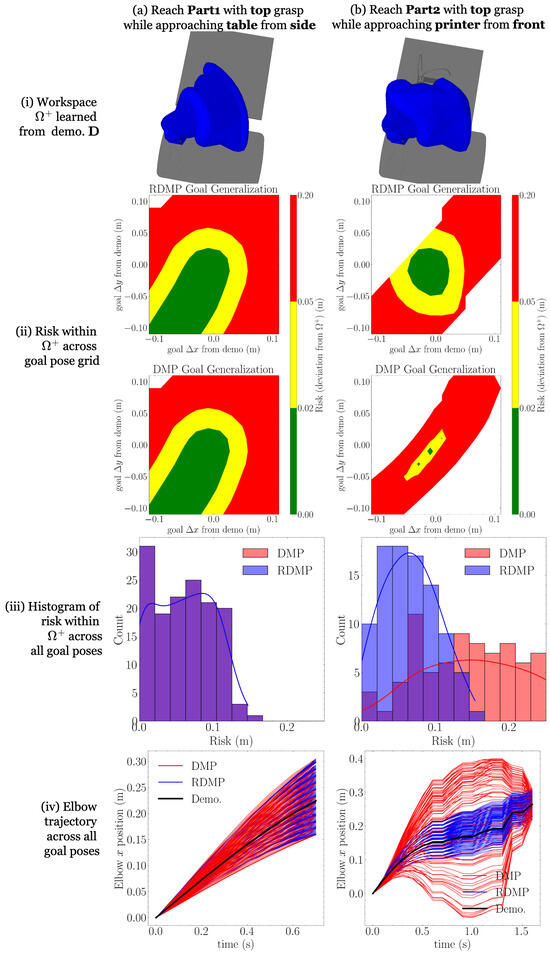
Figure 4.
RDMP and DMP-risk-based generalization comparison, part 2; see the the first part and complete explanation in Figure 3.
4.3.1. Approach
The following procedure is followed for each example to generate the comparison metrics. A part is located at a fixed, nominal pose near the center of each location. One of the part’s grasps is chosen and used to define an end-effector goal pose . A collision-free demonstration trajectory is generated from an initial configuration using a standard (we use RRT-connect [54], implemented in [55], for demonstration trajectory generation) motion planner. A workspace is constructed, LearnWorkspace, where (17) and a demonstration relaxation of m is used for workspace dilation (14); workspaces are illustrated in Figure 3i and Figure 4i.
Next, both a DMP and an RDMP are trained on : Train (4) and TrainRDMP (Algorithm 1). Then, new goals are selected along a uniform horizontal grid centered at . For each new goal , an RDMP trajectory is generated from IntegrateRDMP (Algorithm 2). Using the final RDMP configuration as the DMP goal, a DMP trajectory is likewise generated from Integrate (5). From the RDMP and DMP trajectories for each goal , the corresponding risks are computed (16): and . The corresponding risks are displayed as contour plots in Figure 3ii and Figure 4ii. Note that missing values correspond to kinematically unreachable goals. Then, for each primitive, the risks are aggregated across all goals and displayed as histograms in Figure 3iii and Figure 4iii.
Finally, to help explain the differences in risk during generalization, we need to understand how DMPs and RDMPs differ in their reproduction of whole-arm motion. As a low-dimensional encoding of whole-arm motion, we select the fourth link, or elbow, of the robot (Figure 2). From the demonstration and all generalized trajectories and , the x coordinate trajectory of the elbow link is computed and plotted in Figure 3iv and Figure 4iv.
4.3.2. Analysis
From the risk contours in Figure 3ii and Figure 4ii, we observe that the risk of the RDMP trajectories is the same or lower than that of DMP trajectories for the same goals. In examples (b) and (c), we see similar behavior between the RDMPs and DMPs, while the differences are more drastic in (a) and (d). From the risk histograms in Figure 3iii and Figure 4iii, we observe the same phenomenon without spatial dimensions: the RDMP histograms are similar or have a lower mean compared to the DMP histograms.
To explain the risk, we examine the elbow trajectories (Figure 3iv and Figure 4iv), which represent one dimension of whole-arm motion. In each case, we observe that RDMP trajectories remain closer to the demonstration than DMP trajectories, despite reaching the same joint configuration goals. The most dramatic deviations are in the examples in Figure 3a and Figure 4b, which correspond to the greater difference in risks seen in Figure 3ii–iii and Figure 4ii–iii. As the elbow deviates farther from the demonstration, the whole robot arm is moving farther outside of the safe workspace, so this relationship is sensible. When true workspace geometry is unmodeled and deviations from safe workspaces should be minimized, RDMPs appear to enable safer adaptation to a wider range of goals.
5. Learning from Programs
5.1. Motion Classes and Skills
This section details the specification of motion classes (MCs), a data structure that allows a subject-matter expert (SME) to define distinct behaviors that are salient for a particular class of tasks. A motion class serves as a bridge from the semantic description of a behavior to concrete methods of extracting examples of the behavior from demonstrations and generating new instances of the behavior.
To describe general functions that generate robot trajectories given endpoint constraints, we first define a motion generator as
which maps an initial condition and goal g to a trajectory . Motion generators with learnable parameters are denoted as (e.g., DMP integration (5)). is used to denote an empty motion generator, which is learnable but whose parameters have not yet been learned, thus serving as a template. A motion generator without learnable parameters, such as a motion planner, is considered fixed and denoted as .
A motion class (MC) is defined as
where
m = (fr, fa, fw, fo, SEGMENT, α, π, 𝕐, 𝔾, Φx) ∈ M,
- , , , and define the robot, affordance, workspace, and origin reference frames of a motion class m;
- segment identifies all instances of m in a demonstration , consisting of a robot trajectory segment and reference frame poses during each instance;
- is an action template, describing m symbolically;
- is a sequence of fixed or empty motion generators describing m physically, parameterized by a single pair ;
- and define the admissible initial conditions and goals g as functions of physical state , task , and symbolic names ;
- is a state transition function defining the discrete evolution of the physical state as a result of m with goal .
Items , , , , and segment are used during the learning of affordances, workspaces, and skills from (Section 5.2), while items , , , , and are used to formulate constraints and generate motion during the generation of new programs (Section 6.1). All SME-defined motion classes are collected in the set . Concrete examples of motion classes for mobile manipulator part transportation are given in Section 5.3: , , and .
Next, a skill is defined as
where is a motion generator sequence comprising fixed or learned motion generators . As such, a skill is semantically defined by and can generate motion with . Skill learning is covered in Section 5.2, in which a skill library is constructed from using .
Given an initial condition and goal g, a parameterized skill is denoted as , analogous to an action defined as a parameterized action template, . A parameterized skill generates a trajectory by concatenating the trajectories yielded by its motion generators:
where the operator ← is used to indicate the execution of the parameterized skill k and the union operator ∪ is overloaded in this context to indicate trajectory concatenation. Planning with skills is covered in Section 6.1.
Finally, an SME may define how related skills can share a subset of their motion generators. For example, the motion classes and defined in Section 5.3 are differentiated only by gripper action. Thus, skills learned from can be used to generate skills, and vice versa. The SME-defined function share encodes these relationships and enables the construction of an expanded skill set .
5.2. Learning from Programs as Demonstrations
The process for applying a motion class set to a historical dataset of demonstrations to learn a set of affordances , skills , and workspaces is detailed in Learn (Algorithm 3). For each demonstration d, msegment extracts learning-relevant data from d (line 7), which is computed in the following ways.
First, on line 9, the affordance pose (e.g., end-effector frame and part frame for grasps) is computed and added to the affordance set .
Next, on line 11, the workspace in the origin frame is computed using LearnWorkspace (17) and then transformed into the workspace frame (e.g., the frame of a machine ℓ to which the workspace belongs) using , and then added to the workspace set .
Then, on lines 13–16, a skill is built and added to the skill set . If m contains a learnable motion generator , then the extracted trajectory segment is used to Train a DMP with (4). The resulting weights form a new motion generator which replaces in and the new skill is formed . Otherwise, if m contains only fixed motion generators, then is built directly. Note that since is a set, duplicate skills are not stored.
Finally, affordance, workspace, and skill sets are built. The skill set is expanded by sharing motion generators among compatible skills, as defined in share. The final sets are then returned by Learn. In the next section, these learned sets are used to synthesize new programs.
| Algorithm 3 Learn) |
|
5.3. Illustrative Example: Motion Class Design
In this section, the process of specifying a set of motion classes is illustrated using the example described in Section 3.4.
5.3.1. Motion Generators
The mobile manipulator described in Section 3.4 is capable of safely planning and executing base trajectories using a built-in laser scanner for localization and obstacle avoidance. A fixed motion generator is introduced to represent this capability, for an initial and final base pose .
Moreover, the robot’s gripper is force-controlled with boolean commands. To represent this capability, a fixed motion generator is introduced, where with 0 and 1 corresponding to “open” and “close,” respectively.
Finally, the robot’s redundant manipulator is manually programmed to pick and place parts in a variety of workspace locations safely. For new tasks, we want to generalize the safe workspace trajectories contained in . As such, a learnable motion generator for arm motion is introduced:
where and .
5.3.2. Planning Domain
To describe the symbolic constraints of motion classes in the form of preconditions and effects, a planning domain must be specified. Primarily, the symbolic state representation of a part transportation task must describe the proximity of the robot, part, and locations between which the part can be transported. As such, state variables are introduced, . Additionally, to enable states to be defined as atomic formulae on state variables, a set of symbolic names are defined as .
5.3.3. Motion Classes
The expected behaviors in a part transportation task are , , and . Using the motion generators and planning domain specified above, the motion classes are specified next. Note that the physical state here is with a configuration as introduced in Section 3.3.
First, is introduced below. The moving robot frame is the end-effector e with respect to the robot base frame b as it approaches a part p at a workspace ℓ (line 1). Before picking part p from location ℓ, the robot and p must both be at ℓ and the robot must be holding nothing (line 2). After picking the part, p is no longer at ℓ, and the robot now holds p (line 3). segment identifies within temporally proximal arm motions between which the gripper closes, which it identifies as instances of (line 4). The motion generator sequence encodes an arm motion, followed by gripper closing, following by a reversal of the same arm motion, indicated by the notation ¬ (line 5). A is assumed to always begin from a home configuration (line 6), while the goal is confined to a known grasp in (line 7). Finally, the application of results in a new physical state with an unchanged base pose and arm configuration; however, the gripper is closed and the part pose is defined by the selected goal g and the end-effector pose (line 8).
|
Next, the motion class is defined in a similar way to . Preconditions and effects are reversed (lines 2–3). Instead of closing, the segment function looks for the gripper opening (line 4), and likewise in the motion generator sequence (line 5). The initial condition is the same (line 6), but the goal is constrained by the part goal pose rather than affordances (line 7). After a , the next physical state has the same base pose and arm configuration; however, the gripper opens and the part pose is defined by the goal selection (line 8).
|
Finally, the motion class describes the motion of the robot base frame b with respect to the origin o as it approaches in a workspace likewise defined at the origin o (line 1). The preconditions and effects describe the robot moving from to (lines 2–3). segment identifies all periods of base motion in as instances of . The motion generator sequence comprises a single (line 5). The initial condition is the initial base pose (line 6) while the goal is confined to a known stance defined in (line 7). After a , the next physical state has a base pose coincident with the goal, unchanged arm and gripper configurations, and a conditional part pose. If the gripper is open (), then the part pose is unchanged; otherwise, the part is assumed to be rigidly attached to the robot during base motion (line 8).
|
With the motion class set , applying Learn (Algorithm 3) to yields an affordance set , workspace set , and skill set . Since the only learnable motion generators are instances of , we know that has a single element, while and contain as many elements as instances of and , respectively, with each containing with a unique . Note that and are only physically differentiated by gripper action. Therefore, the share function can be simply defined as duplicating all skills , replacing terms with , adding them to , and doing the reverse for all .
6. Skill-Based Program Generation
6.1. Program Generation from Skill-Based Planning
This section presents an approach to generating a new program that drives the robot to complete a task . Our skill-based planning approach involves two steps: task planning followed by skill planning.
In the first step, an action plan is constructed to solve symbolically. In specifying a motion class set and the action templates therein, an expert implicitly defines a planning domain . From a task description , the initial and goal symbolic states can be constructed. Then, an automated task planner [44] constructs an action plan to solve .
In the second step, each action is physically realized by a parameterized skill to form a skill plan . Then, the new program trajectory is constructed by the concatenation of individual skill trajectories :
The skills must be selected from the known skill set along with initial conditions and goals in a way that is safe and feasible. Recall that an action is an action template parameterized by concrete symbolic arguments, . Thus, the action plan can be rewritten as a motion class sequence and symbolic name sequence .
For each step i, the motion class provides constraints on initial conditions and goals , which constrain goal selection based on learned affordances to ensure physical feasibility, such as mobile base stances and part grasps. Motion classes also encode discrete state transitions , enabling a state estimate to be available for other constraints in each step i. Note that the initial and final states and are available directly from . For risk calculation (16), allows selection of the relevant workspace . Altogether, skill planning is formulated as the following optimization problem, SkillPlan:
The problem (30) can only be formulated if the task is symbolically feasible with respect to , , , and , meaning
- The affordance sets are nonempty;
- The skill sets , are nonempty;
- The workspaces are nonempty.
If a task is symbolically feasible, then the problem (30) can be formulated. If (30) has a local minimizer with acceptable risk, then the task is also physically feasible and (30) yields a skill plan that physically solves .
As (30) involves simultaneous optimization of a nonlinear objective over discrete variables and continuous variables like and , it is a mixed-integer nonlinear program, which is NP-hard. However, (30) can be greatly simplified for particular motion class sets, as shown in Section 6.2.
6.2. Illustrative Example: Skill Planning
While SkillPlan (30) is, in general, a mixed-integer nonlinear program, it can be simplified by considering a specific motion class set. Given the motion class set defined in Section 5.3, a minimum-length action plan is
Since can safely move between locations, its execution and resulting risk computation can be neglected from the planning loop. Moreover, while and are continuous decision variables in general in (30), the sets and defined in each describe discrete sets. Therefore, SkillPlan (30) can be reduced to a grid search on base stances and , grasp poses , and skills and , which is given in SkillPlan-PTT (Algorithm 4). The algorithm loops over all pick and place skills as well as all possible end-effector goal poses, as defined by affordances, and finds the combination with the lowest risk.
| Algorithm 4 SkillPlan-PTT) |
|
6.3. Illustrative Example: End-to-End Learning and Planning Performance
In this section, we evaluate the end-to-end performance of the PRF by estimating the number of solvable tasks for a given number of demonstrations. Since there are an uncountable number of possible tasks and demonstrations, we restrict part poses and location poses to fixed, nominal values for tractability. To aid analysis, we introduce a final structure, the afforded task :
which appends a set of specific affordances (approaches and and grasp ) to a given task .
The objective of this study is to take a demonstration set , learn from it using Learn, and then apply the outputs to SkillPlan-PTT to count how many tasks are solvable.
6.3.1. Approach
For the illustrative example outlined in Section 3.4, there are a total of 18 unique tasks, assuming nominal part and location poses. There are also 64 unique afforded tasks, as there are multiple ways to perform each task considering the various approaches and grasps. Each afforded task can be realized by an infinite variation in demonstrations, but for tractability, we generate exactly one demonstration for each afforded task. Thus, for our complete demonstration set , its size is . Following the same procedure as in Section 4.3.1, demonstrations are generated using motion planners that have access to the true geometric models of the robot’s environment, ensuring that the historical datasets are safe and feasible.
Since contains demonstrations of every possible task, it is also capable of solving all tasks. Here, we adopt a Monte Carlo approach, in which we simulate multiple episodes of learning, with each episode representing a random sequence in which demonstrations are learned, checking the number of feasible tasks in each episode step.
Starting each episode i at step with an empty demonstration set , we randomly select a demonstration from to append to . Then, we learn from the current set: Learn. After learning, we iterate over all 18 tasks and attempt to solve each with SkillPlan-PTT. We store all feasible tasks (and corresponding afforded tasks from the inner loop of SkillPlan-PTT) and advance to the next episode step .
During each episode step, we count three types of feasible tasks: physically feasible tasks, physically feasible afforded tasks, and symbolically feasible afforded tasks. As in Section 6.1, physical feasibility indicates an acceptable risk, computed by (16) using learned workspaces . Meanwhile, symbolic feasibility merely indicates any return value from the planner. These three counts are collected since they represent different levels of abstraction. For a task or afforded task to be physically feasible, it depends strongly on the nature of the demonstrations and specifics of the environment in which the demonstration was performed. On the other hand, symbolic feasibility captures the most basic rate of learning, abstracted from the demonstrations or environments themselves.
6.3.2. Analysis
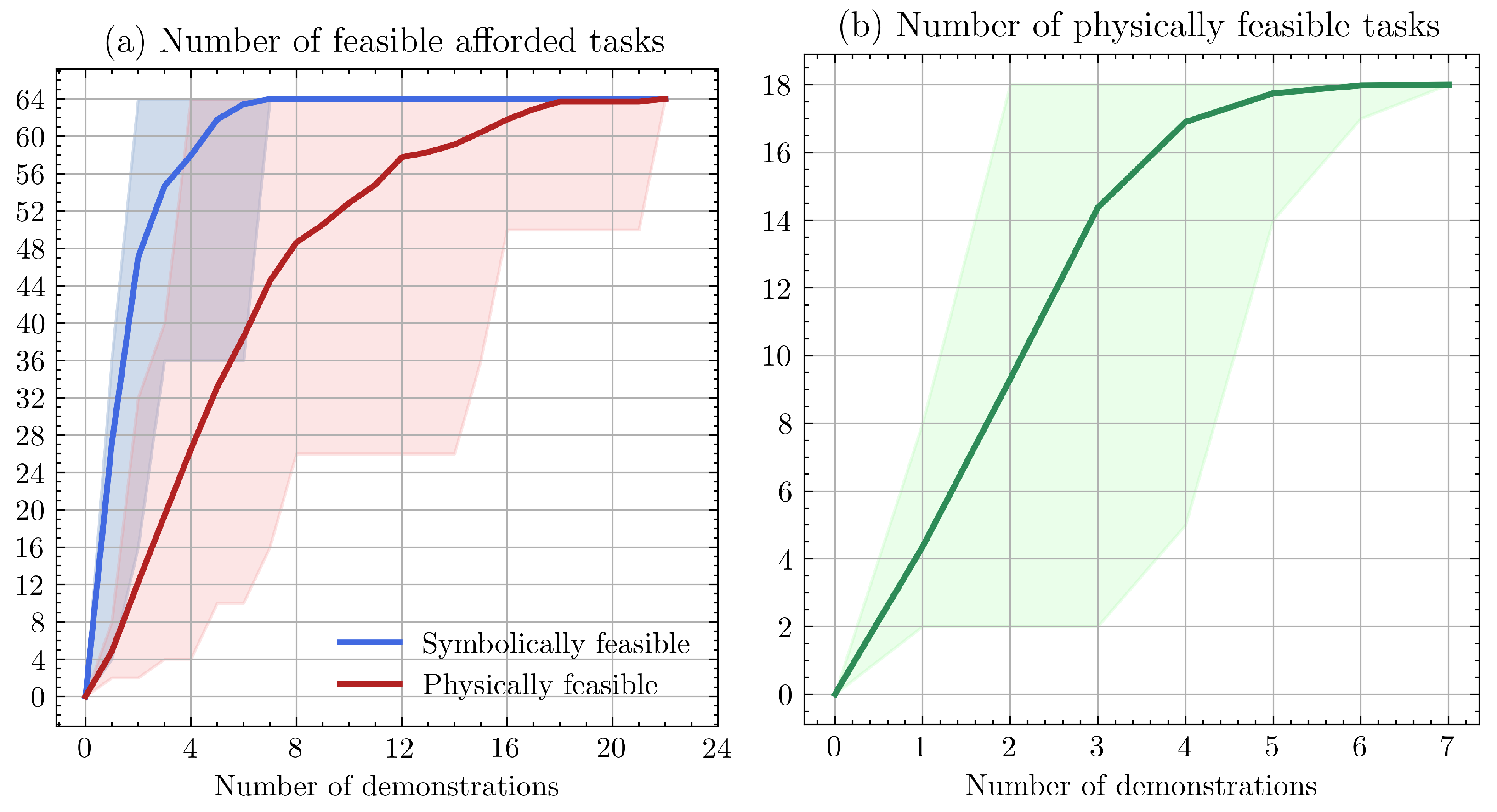
Figure 5 captures the results of the Monte Carlo simulation with 50 episodes. The shaded regions represent the range over the episodes while the dark lines represent the mean across episodes in each step. We observe that all episodes eventually converge to solving all (afforded) tasks, and do so with fewer than half the total number of demonstrations even in the worst scenario.
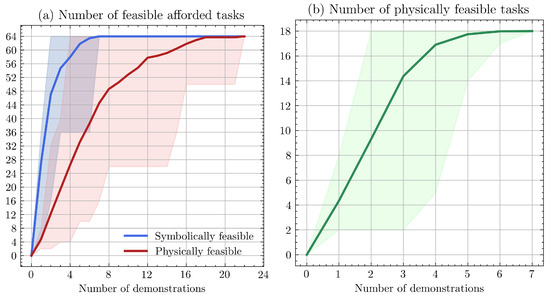
Figure 5.
PRF generalization performance over 50 randomized traces. In (a), blue values correspond to symbolically feasible afforded tasks while the red lines correspond to physically feasible afforded tasks. In (b), the green line corresponds physically feasible tasks. In each plot, the transparent area indicates the range of values across the random samples, while the solid line indicates the mean value.
In the afforded task simulations (Figure 5a), we see that all afforded tasks become symbolically feasible far earlier than physically feasible. This gap is the result of the geometry of the available demonstrations; more circuitous demonstrations result in larger safe workspaces (permitting more task variation) while more direct demonstrations result in smaller workspaces. In the physical task simulations (Figure 5b), we observe that all 18 tasks become physically feasible with between two and seven demonstrations. This indicates that some sequences of demonstrations are more informative than others. The case with two demonstrations encodes workspaces and affordances for all locations and parts, enabling a significant multiplication of 18 tasks from only two demonstrations.
7. Discussion
7.1. Applicability
The PRF is designed to automate the programming of new tasks given a historical dataset of existing robot programs. The PRF is well suited for situations in which robots are manually programmed to complete repetitive tasks that do not require online vision feedback, do not have accurate CAD models of the environment, and are occasionally reconfigured to operate at different locations and with different parts. The PRF uses historical data across all tasks for which a robot has been programmed and generates programs for new tasks that result from reconfigurations. The PRF trades the labor of robot programming for the labor of motion class design, allowing an SME to embed knowledge of robot behaviors that are both task-relevant and known to be present in the historical dataset. As shown in Section 6.3, the PRF is capable of solving a large number of new tasks with a modest historical dataset by leveraging a set of well-designed motion classes.
However, the PRF is not suitable in all situations. Generalization is only possible for new tasks that are reconfigurations of tasks covered in the historical dataset. It also must be possible for new tasks to be completed with behaviors contained in the historical dataset, and those behaviors must be appropriately encoded as motion classes. For instance, the robot in our illustrative example (Section 3.4) is used for part transportation; the PRF would not be capable of generalizing the historical data from this robot for a machining task. Additionally, generalization depends on the diversity of the historical data. From Figure 5b, we see that a historical dataset with two demonstrations can generalize to between 2 and 18 tasks. If the two demonstrations are very similar, they cannot generalize significantly. For example, the demonstration tasks may be (1) transport Part1 between one CNC and another CNC and (2) transport Part2 between one CNC and another CNC; as a result, no tasks involving a Printer or Table are feasible. On the other hand, if the two demonstration tasks are diverse—(1) transport Part1 from a CNC to a Printer and (2) transport Part2 from a Printer to a Table—then all 18 tasks become feasible.
7.2. Study Limitations
Although we demonstrate the application of the PRF for a part transportation task, our study does not cover the entire range of situations for which the PRF may be used nor does it include hardware implementation. Our emphasis on learning manipulator motion skills was motivated by the ubiquity of such behavior across industrial robots, but does not capture behavior involving forceful environmental interaction, such as machining. Furthermore, one would expect the hardware implementation of the PRF to include other practical considerations. For one, the robot’s geometric model must accurately capture the real robot’s geometry, including any end-of-arm tooling that may not be included in the robot’s standard manufacturer-provided model, as the geometry is critical for both workspace construction and safety verification. Additionally, real robot control systems are imperfect: controllers for both robot arms and mobile bases track reference trajectories with some error. Future studies should focus on both a wider range of robot tasks as well as experimental validation on real robots.
8. Conclusions
This paper considers the problem of automatically generating robot programs for new tasks when neither geometric environmental models nor vision feedback are available. The Program Reuse Framework (PRF) is defined for generating programs to solve new tasks through structured learning from a historical dataset of programs for similar tasks, which are interpreted as demonstrations. The PRF aims to maximize the utility of data collected from the existing industry to solve similar tasks without traditional manual programming.
To cope with unmodeled environments, an approach to learning safe workspaces from demonstrations is given. The approach leverages link geometries and assumptions on minimum clearance to construct safe workspace sets, from which a risk metric is defined. Workspaces are currently learned from demonstrations alone, limiting generalization, so the safe, active exploration of unknown or partially known workspaces will be explored. Additionally, the problem of on-demand sensing introduced in [39] will be developed further and integrated with the PRF to handle new tasks that deviate significantly from the historical dataset without relying on continuous sensing.
A novel dynamical movement primitive variant tailored to redundant manipulators is developed, called the RDMP, which generalizes to new end-effector goals while maintaining whole-arm motion characteristics. RDMPs were found to outperform DMPs in most cases in terms of minimizing risk while generalizing to new goals, more effectively constraining arm motion to within learned workspaces. Presently, RDMPs simply replay learned null space trajectories during integration, limiting generalization to new goals and environments. In practice, this means that RDMPs are only valid near their demonstration goal. Further development will consider how the null space goal can be modulated given new end-effector goals with the objective of increasing the range of generalization goals.
To enable structured learning of affordances, workspaces, and skills from a limited historical dataset, expert-designed motion classes are defined. Moreover, to enable the generation of new programs, motion classes also define a set of constraints suitable for formulation of a risk-minimizing plan optimization. Presently, new tasks are only feasible within the PRF if programs in the historical dataset contain explicit reference to the parts and locations involved in new tasks. Future work will consider how task infeasibility can prompt users for additional information, such as part or location models, from which affordances and workspaces can be inferred.
Author Contributions
Conceptualization, T.T., D.M.T. and K.B.; data curation, T.T.; formal analysis, T.T.; funding acquisition, T.T., D.M.T. and K.B.; investigation, T.T.; methodology, T.T.; project administration, D.M.T. and K.B.; resources, T.T., D.M.T. and K.B.; software, T.T.; supervision, D.M.T. and K.B.; validation, T.T.; visualization, T.T.; writing—original draft preparation, T.T.; writing—review and editing, T.T., D.M.T. and K.B. All authors have read and agreed to the published version of the manuscript.
Funding
This material is based upon work supported by the National Science Foundation Graduate Research Fellowship under Grant No. DGE1841052. Any opinion, findings, and conclusions or recommendations expressed in this material are those of the authors(s) and do not necessarily reflect the views of the National Science Foundation. This research was also sponsored by the Combat Capabilities Development Command Army Research Laboratory and was accomplished under Cooperative Agreement Number W911NF-20-2-0163. The views and conclusions contained in this document are those of the authors, and should not be interpreted as representing the official policies, either expressed or implied, of the Combat Capabilities Development Command Army Research Laboratory or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for Government purposes notwithstanding any copyright notation herein.
Data Availability Statement
The original contributions presented in the study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Hägele, M.; Nilsson, K.; Pires, J.N.; Bischoff, R. Industrial Robotics. In Springer Handbook of Robotics; Siciliano, B., Khatib, O., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 1385–1422. [Google Scholar] [CrossRef]
- Stenmark, M.; Haage, M.; Topp, E.A. Simplified Programming of Re-Usable Skills on a Safe Industrial Robot: Prototype and Evaluation. In Proceedings of the 2017 ACM/IEEE International Conference on Human-Robot Interaction, HRI’17, Vienna, Austria, 6–9 March 2017; pp. 463–472. [Google Scholar] [CrossRef]
- Steinmetz, F.; Nitsch, V.; Stulp, F. Intuitive Task-Level Programming by Demonstration Through Semantic Skill Recognition. IEEE Robot. Autom. Lett. 2019, 4, 3742–3749. [Google Scholar] [CrossRef]
- Krieglstein, J.; Held, G.; Bálint, B.A.; Nägele, F.; Kraus, W. Skill-based Robot Programming in Mixed Reality with Ad-hoc Validation Using a Force-enabled Digital Twin. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 11612–11618. [Google Scholar] [CrossRef]
- Pedersen, M.R.; Nalpantidis, L.; Andersen, R.S.; Schou, C.; Bøgh, S.; Krüger, V.; Madsen, O. Robot skills for manufacturing: From concept to industrial deployment. Robot. -Comput. -Integr. Manuf. 2016, 37, 282–291. [Google Scholar] [CrossRef]
- Krüger, N.; Geib, C.; Piater, J.; Petrick, R.; Steedman, M.; Wörgötter, F.; Ude, A.; Asfour, T.; Kraft, D.; Omrčen, D.; et al. Object–Action Complexes: Grounded abstractions of sensory–motor processes. Robot. Auton. Syst. 2011, 59, 740–757. [Google Scholar] [CrossRef]
- Schwenkel, L.; Guo, M.; Bürger, M. Optimizing Sequences of Probabilistic Manipulation Skills Learned from Demonstration. Proc. Mach. Learn. Res. 2020, 100, 273–282. [Google Scholar]
- Mayr, M.; Rovida, F.; Krueger, V. SkiROS2: A Skill-Based Robot Control Platform for ROS. In Proceedings of the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 1–5 October 2023; pp. 6273–6280. [Google Scholar] [CrossRef]
- Terziyan, V.; Malyk, D.; Golovianko, M.; Branytskyi, V. Encryption and Generation of Images for Privacy-Preserving Machine Learning in Smart Manufacturing. Procedia Comput. Sci. 2023, 217, 91–101. [Google Scholar] [CrossRef]
- Paneru, S.; Jeelani, I. Computer vision applications in construction: Current state, opportunities & challenges. Autom. Constr. 2021, 132, 103940. [Google Scholar] [CrossRef]
- Feldman, Z.; Ziesche, H.; Vien, N.A.; Castro, D.D. A Hybrid Approach for Learning to Shift and Grasp with Elaborate Motion Primitives. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 6365–6371. [Google Scholar] [CrossRef]
- Zhao, T.Z.; Luo, J.; Sushkov, O.; Pevceviciute, R.; Heess, N.; Scholz, J.; Schaal, S.; Levine, S. Offline Meta-Reinforcement Learning for Industrial Insertion. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 6386–6393. [Google Scholar] [CrossRef]
- Brohan, A.; Brown, N.; Carbajal, J.; Chebotar, Y.; Dabis, J.; Finn, C.; Gopalakrishnan, K.; Hausman, K.; Herzog, A.; Hsu, J.; et al. RT-1: Robotics transformer for real-world control at scale. arXiv 2022, arXiv:2212.06817. [Google Scholar]
- Wang, C.; Zhang, Y.; Zhang, X.; Wu, Z.; Zhu, X.; Jin, S.; Tang, T.; Tomizuka, M. Offline-Online Learning of Deformation Model for Cable Manipulation With Graph Neural Networks. IEEE Robot. Autom. Lett. 2022, 7, 5544–5551. [Google Scholar] [CrossRef]
- Karigiannis, J.N.; Laurin, P.; Liu, S.; Holovashchenko, V.; Lizotte, A.; Roux, V.; Boulet, P. Reinforcement Learning Enabled Self-Homing of Industrial Robotic Manipulators in Manufacturing. Manuf. Lett. 2022, 33, 909–918. [Google Scholar] [CrossRef]
- Ijspeert, A.J.; Nakanishi, J.; Hoffmann, H.; Pastor, P.; Schaal, S. Dynamical Movement Primitives: Learning Attractor Models for Motor Behaviors. Neural Comput. 2013, 25, 328–373. [Google Scholar] [CrossRef]
- Calinon, S. A tutorial on task-parameterized movement learning and retrieval. Intell. Serv. Robot. 2016, 9, 1–29. [Google Scholar] [CrossRef]
- Bruyninckx, H.; De Schutter, J. Specification of force-controlled actions in the “task frame formalism”—A synthesis. IEEE Trans. Robot. Autom. 1996, 12, 581–589. [Google Scholar] [CrossRef]
- Smits, R.; De Laet, T.; Claes, K.; Bruyninckx, H.; De Schutter, J. iTASC: A tool for multi-sensor integration in robot manipulation. In Proceedings of the 2008 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems, Seoul, Republic of Korea, 20–22 August 2008; pp. 426–433. [Google Scholar] [CrossRef]
- Aertbeliën, E.; De Schutter, J. eTaSL/eTC: A constraint-based task specification language and robot controller using expression graphs. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 1540–1546. [Google Scholar] [CrossRef]
- Pane, Y.; Aertbeliën, E.; Schutter, J.D.; Decré, W. Skill-based Programming Framework for Composable Reactive Robot Behaviors. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 7087–7094. [Google Scholar] [CrossRef]
- Pane, Y.; Mokhtari, V.; Aertbeliën, E.; De Schutter, J.; Decré, W. Autonomous Runtime Composition of Sensor-Based Skills Using Concurrent Task Planning. IEEE Robot. Autom. Lett. 2021, 6, 6481–6488. [Google Scholar] [CrossRef]
- Stenmark, M.; Topp, E.A. From demonstrations to skills for high-level programming of industrial robots. In Proceedings of the 2016 AAAI Fall Symposium Series, Arlington, VA, USA, 17–19 November 2016. [Google Scholar]
- Albore, A.; Doose, D.; Grand, C.; Guiochet, J.; Lesire, C.; Manecy, A. Skill-based design of dependable robotic architectures. Robot. Auton. Syst. 2023, 160, 104318. [Google Scholar] [CrossRef]
- Eiband, T.; Lay, F.; Nottensteiner, K.; Lee, D. Unifying Skill-Based Programming and Programming by Demonstration through Ontologies. Procedia Comput. Sci. 2024, 232, 595–605. [Google Scholar] [CrossRef]
- Yin, Y.; Zheng, P.; Li, C.; Wan, K. Enhancing Human-Guided Robotic Assembly: AR-assisted DT for Skill-Based and Low-Code Programming. J. Manuf. Syst. 2024, 74, 676–689. [Google Scholar] [CrossRef]
- Kroemer, O.; Niekum, S.; Konidaris, G. A Review of Robot Learning for Manipulation: Challenges, Representations, and Algorithms. J. Mach. Learn. Res. 2021, 22, 1–82. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for Large-Scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Toner, T.; Saez, M.; Tilbury, D.M.; Barton, K. Opportunities and challenges in applying reinforcement learning to robotic manipulation: An industrial case study. Manuf. Lett. 2023, 35, 1019–1030. [Google Scholar] [CrossRef]
- Recht, B. A Tour of Reinforcement Learning: The View from Continuous Control. Annu. Rev. Control. Robot. Auton. Syst. 2019, 2, 253–279. [Google Scholar] [CrossRef]
- Calinon, S.; Lee, D. Learning Control. In Humanoid Robotics: A Reference; Goswami, A., Vadakkepat, P., Eds.; Springer: Dordrecht, The Netherlands, 2017; pp. 1–52. [Google Scholar] [CrossRef]
- Ijspeert, A.; Nakanishi, J.; Schaal, S. Learning Attractor Landscapes for Learning Motor Primitives. In Proceedings of the Advances in Neural Information Processing Systems; Becker, S., Thrun, S., Obermayer, K., Eds.; MIT Press: Cambridge, MA, USA, 2002; Volume 15. [Google Scholar]
- Saveriano, M.; Abu-Dakka, F.J.; Kramberger, A.; Peternel, L. Dynamic movement primitives in robotics: A tutorial survey. Int. J. Robot. Res. 2023, 42, 1133–1184. [Google Scholar] [CrossRef]
- Niekum, S.; Osentoski, S.; Konidaris, G.; Barto, A.G. Learning and generalization of complex tasks from unstructured demonstrations. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 5239–5246. [Google Scholar] [CrossRef]
- Kong, L.H.; He, W.; Chen, W.S.; Zhang, H.; Wang, Y.N. Dynamic Movement Primitives Based Robot Skills Learning. Mach. Intell. Res. 2023, 20, 396–407. [Google Scholar] [CrossRef]
- Pervez, A.; Lee, D. Learning task-parameterized dynamic movement primitives using mixture of GMMs. Intell. Serv. Robot. 2018, 11, 61–78. [Google Scholar] [CrossRef]
- Stulp, F.; Theodorou, E.A.; Schaal, S. Reinforcement Learning with Sequences of Motion Primitives for Robust Manipulation. IEEE Trans. Robot. 2012, 28, 1360–1370. [Google Scholar] [CrossRef]
- Toner, T.; Tilbury, D.M.; Barton, K. Probabilistically Safe Mobile Manipulation in an Unmodeled Environment with Automated Feedback Tuning. In Proceedings of the 2022 American Control Conference (ACC), Atlanta, GA, USA, 8–10 June 2022; pp. 1214–1221. [Google Scholar] [CrossRef]
- Chou, G.; Berenson, D.; Ozay, N. Learning Constraints from Demonstrations. In Proceedings of the Algorithmic Foundations of Robotics XIII; Springer Proceedings in Advanced Robotics; Springer: Cham, Switzerland, 2020; Volume 14, pp. 228–245. [Google Scholar] [CrossRef]
- Perez-D’Arpino, C.; Shah, J.A. C-LEARN: Learning geometric constraints from demonstrations for multi-step manipulation in shared autonomy. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4058–4065. [Google Scholar] [CrossRef]
- Knuth, C.; Chou, G.; Ozay, N.; Berenson, D. Inferring Obstacles and Path Validity from Visibility-Constrained Demonstrations. In Algorithmic Foundations of Robotics XIV; Springer Proceedings in Advanced Robotics; Springer: Cham, Switzerland, 2021; Volume 17, pp. 18–36. [Google Scholar] [CrossRef]
- Berenson, D.; Srinivasa, S.; Kuffner, J. Task Space Regions: A framework for pose-constrained manipulation planning. Int. J. Robot. Res. 2011, 30, 1435–1460. [Google Scholar] [CrossRef]
- Ghallab, M.; Nau, D.; Traverso, P. Automated Planning and Acting; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar] [CrossRef]
- Akbari, A.; Muhayyuddin; Rosell, J. Task and motion planning using physics-based reasoning. In Proceedings of the 2015 IEEE 20th Conference on Emerging Technologies & Factory Automation (ETFA), Luxembourg, 8–11 September 2015; pp. 1–7. [Google Scholar] [CrossRef]
- Blum, A.L.; Furst, M.L. Fast planning through planning graph analysis. Artif. Intell. 1997, 90, 281–300. [Google Scholar] [CrossRef]
- Ude, A.; Nemec, B.; Petrić, T.; Morimoto, J. Orientation in Cartesian space dynamic movement primitives. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 2997–3004. [Google Scholar] [CrossRef]
- Ude, A.; Gams, A.; Asfour, T.; Morimoto, J. Task-specific generalization of discrete and periodic dynamic movement primitives. IEEE Trans. Robot. 2010, 26, 800–815. [Google Scholar] [CrossRef]
- Dawson-Haggerty, M. Trimesh. 2019. Available online: https://trimesh.org/ (accessed on 29 July 2024).
- Zhong, S.; Power, T. PyTorch Volumetric. 2023. Available online: https://github.com/UM-ARM-Lab/pytorch_volumetric (accessed on 29 July 2024).
- Vasilopoulos, V.; Garg, S.; Piacenza, P.; Huh, J.; Isler, V. RAMP: Hierarchical Reactive Motion Planning for Manipulation Tasks Using Implicit Signed Distance Functions. In Proceedings of the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 1–5 October 2023; pp. 10551–10558. [Google Scholar] [CrossRef]
- ISO Standard No. 10218-2:2011; Robots and Robotic Devices—Part 2: Robot Systems and Integration. International Organization for Standardization: Geneva, Switzerland, 2011.
- ANSI/RIA Standard R15.06; Industrial Robots and Robot Systems—Safety Requirements. American National Standards Institute/Robotic Industries Association: Washington, DC, USA, 2012.
- Kuffner, J.; LaValle, S. RRT-connect: An efficient approach to single-query path planning. In Proceedings of the 2000 ICRA. Millennium Conference. IEEE International Conference on Robotics and Automation. Symposia Proceedings (Cat. No.00CH37065), San Francisco, CA, USA, 24–28 April 2000; Volume 2, pp. 995–1001. [Google Scholar] [CrossRef]
- Garrett, C.R. Motion Planners. 2017. Available online: https://github.com/caelan/motion-planners (accessed on 30 July 2024).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).