
A Comprehensive Survey of Visual SLAM Algorithms


Abstract
:1. Introduction
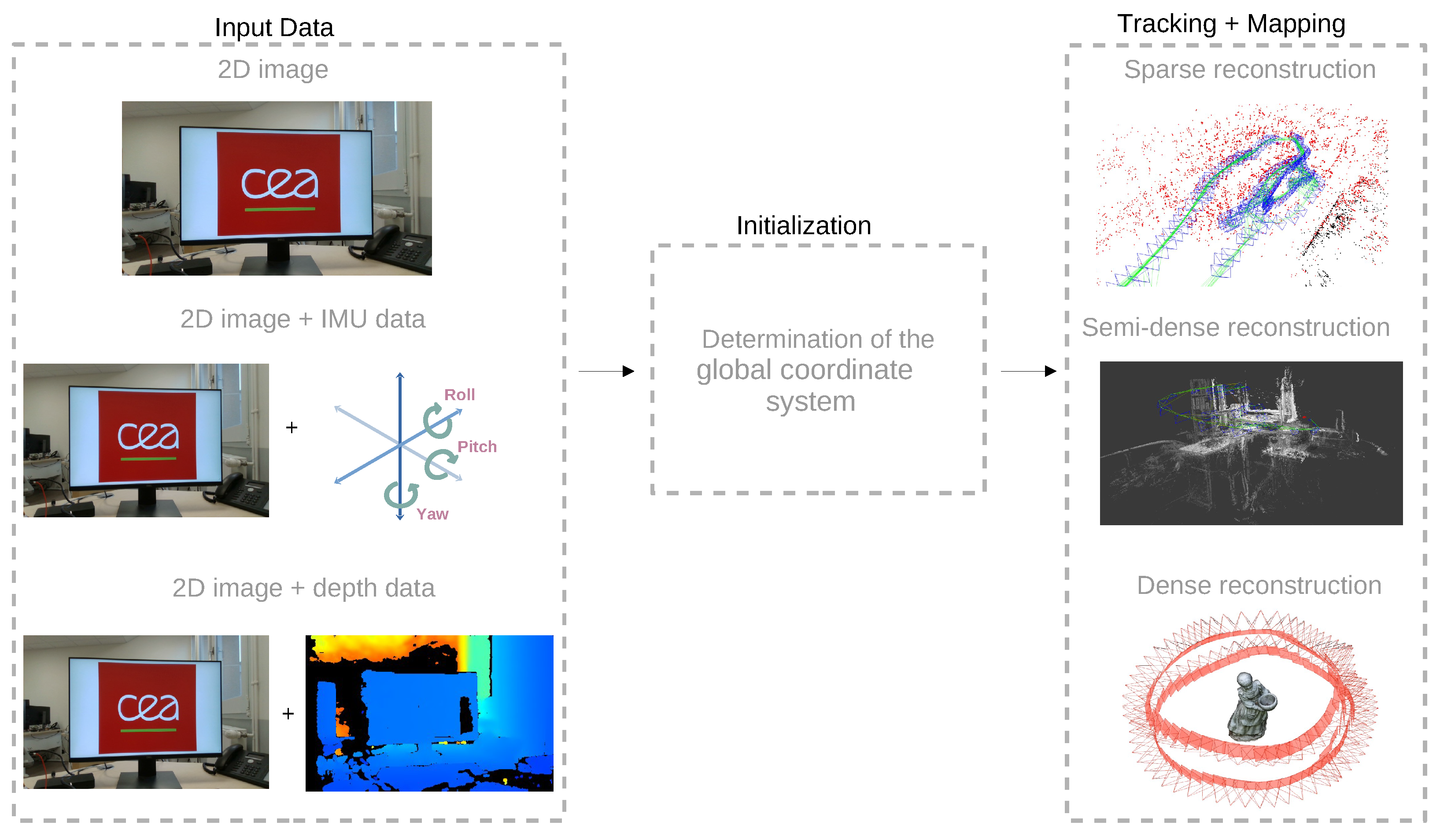
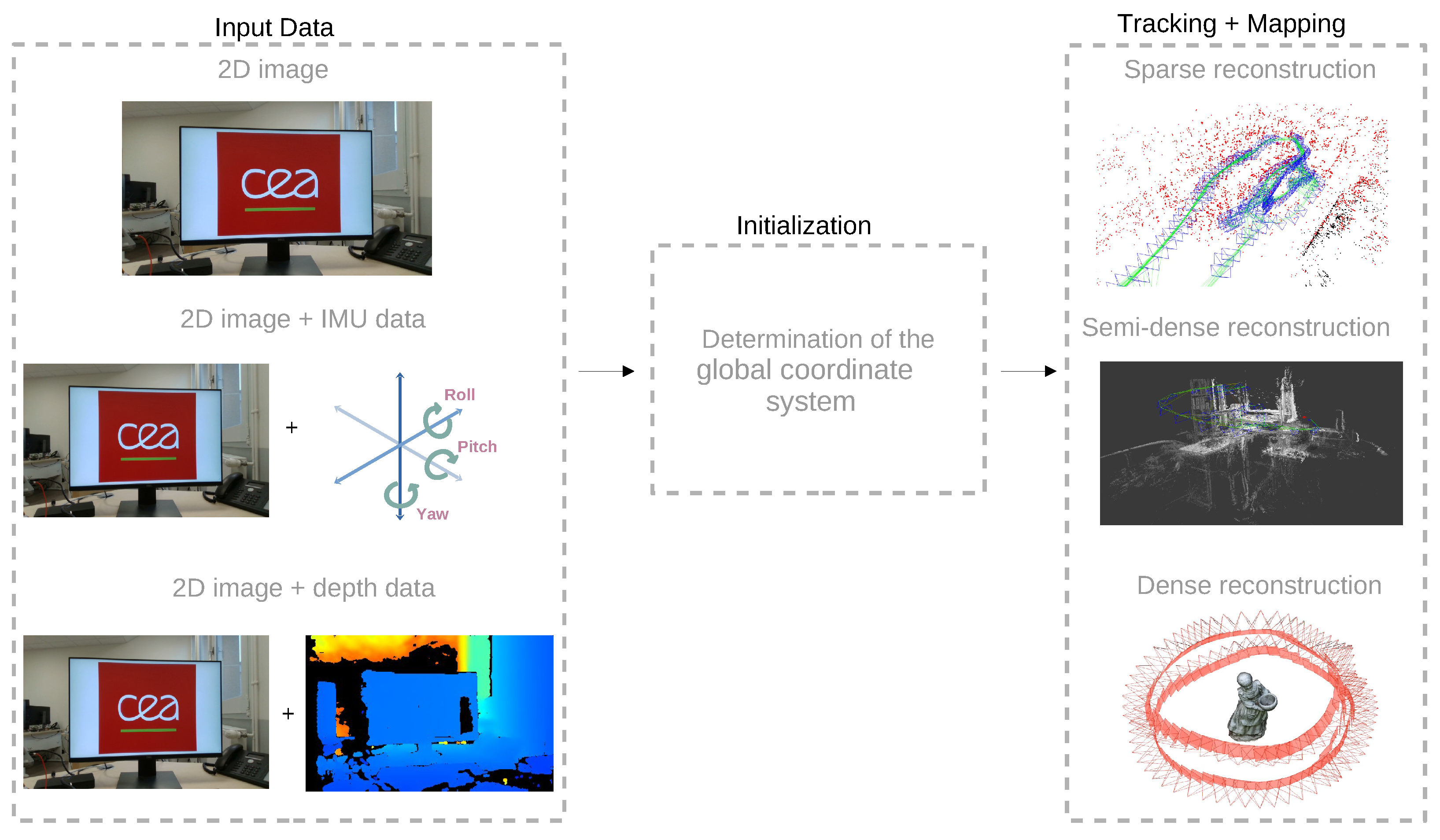
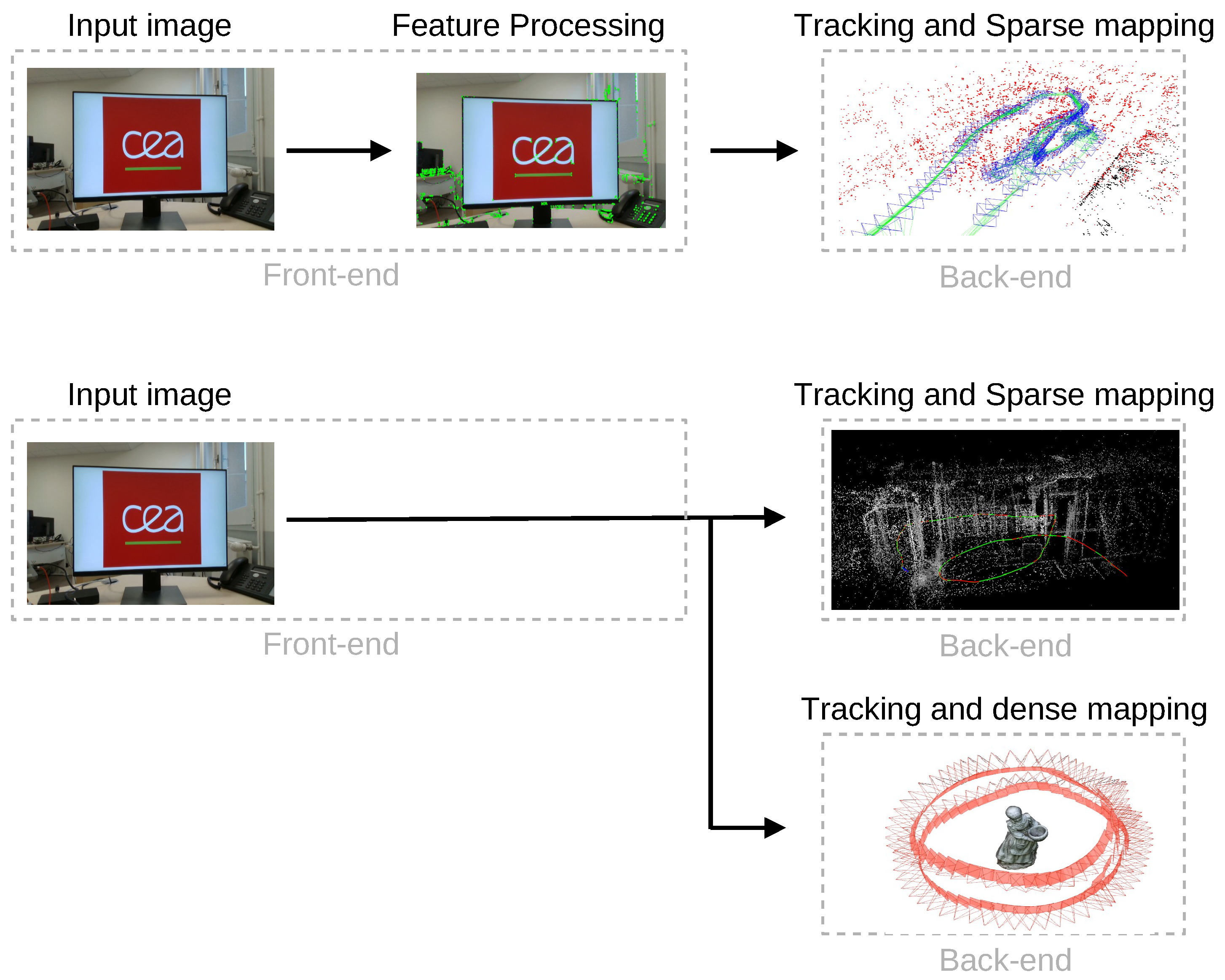
2. Visual-Based SLAM Concepts
2.1. Visual-Only SLAM
2.1.1. Feature-Based Methods
2.1.2. Direct Methods
2.2. Visual-Inertial SLAM
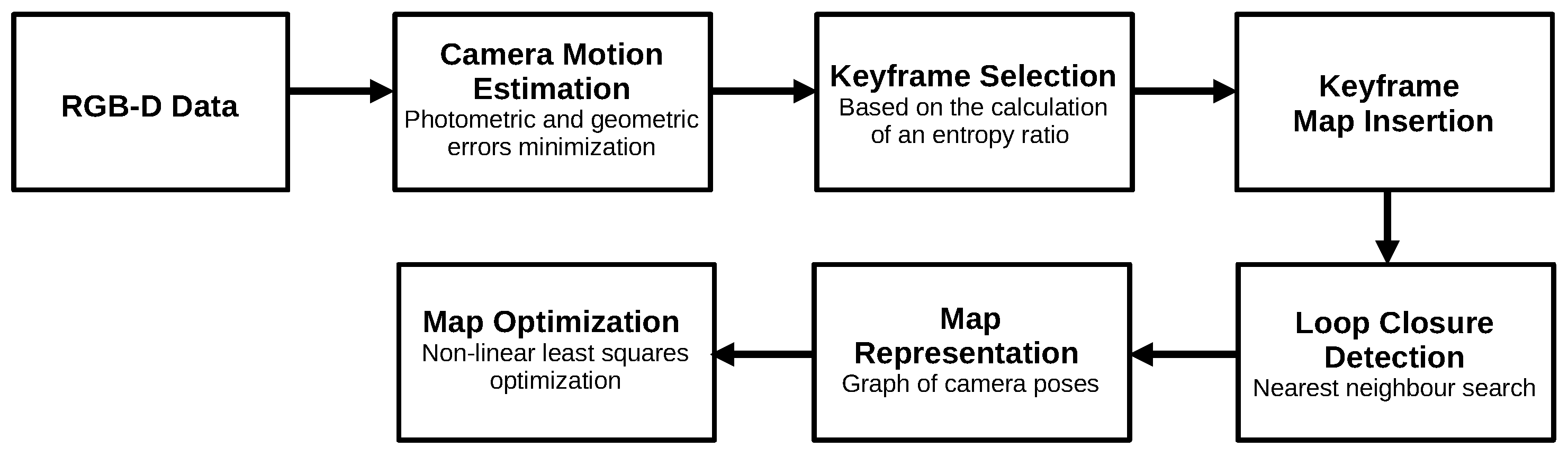
2.3. RGB-D SLAM
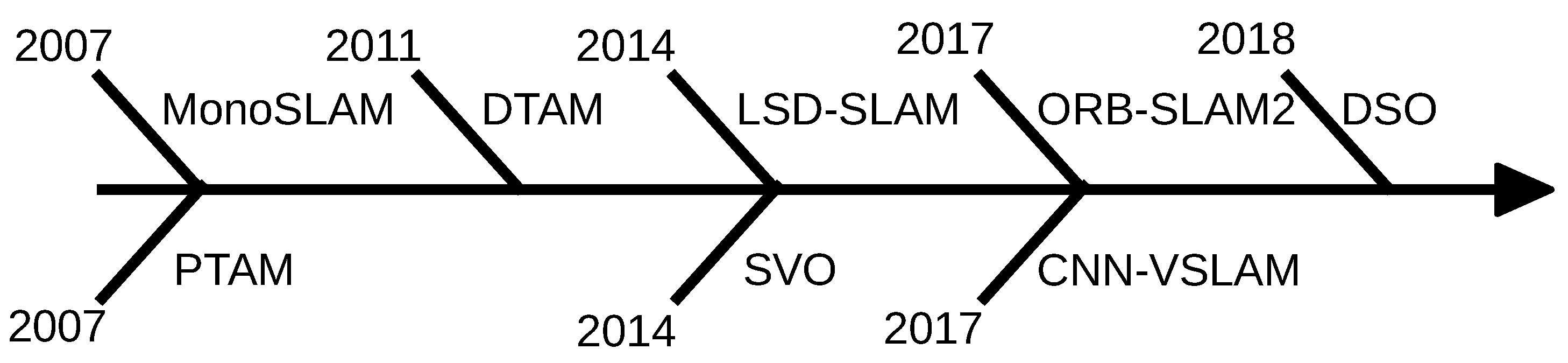
3. Visual-SLAM Algorithms
- Algorithm type: this criterion indicates the methodology adopted by the algorithm. For the visual-only algorithms, we divide them into feature-based, hybrid, and direct methods. Considering the visual-inertial algorithms, they must be filtering-based or optimization-based methods. Lastly, the RGB-D approach can be divided concerning their tracking method, which can be direct, hybrid, or feature-based.
- Map density: in general, dense reconstruction requires more computational resources than a sparse one, having an impact on memory usage and computational cost. On the other hand, it provides a more detailed and accurate reconstruction, which may be a key factor in a SLAM project.
- Global optimization: SLAM algorithms may include global map optimization, which refers to the technique that searches to compensate the accumulative error introduced by the camera movement, considering the consistency of the entire structure.
- Loop closure: the loop closing detection refers to the capability of the SLAM algorithm to identify the images that were previously detected by the algorithm to estimate and correct the drift accumulated during the sensor movement.
- Availability: several SLAM algorithms are open source and made available by the authors or have their implementations made available by third parties, facilitating their usage and reproduction.
- Embedded implementations: the embedded SLAM implementation is an emerging field used in several applications, especially in robotics and automobile domains. This criterion depends on each algorithm’s hardware constraints and specificity, since there must be a trade-off between algorithm architecture in terms of energy consumption, memory, and processing usage. We assembled the main publications we found presenting fully embedded SLAM systems in platforms such as microcontrollers and FPGA boards.
3.1. Visual-Only SLAM
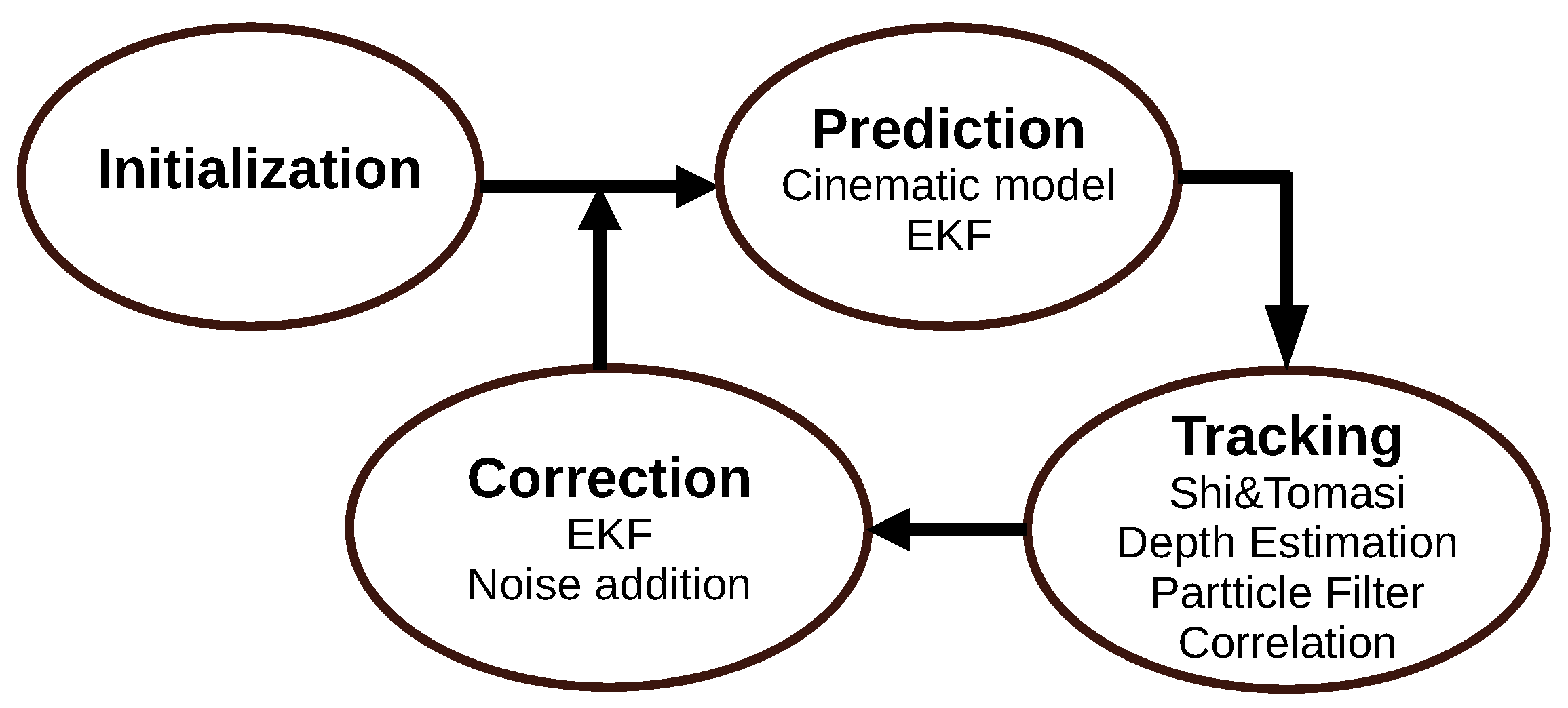
3.1.1. MonoSLAM (2007)
3.1.2. Parallel Tracking and Mapping (2007)
3.1.3. Dense Tracking and Mapping (2011)
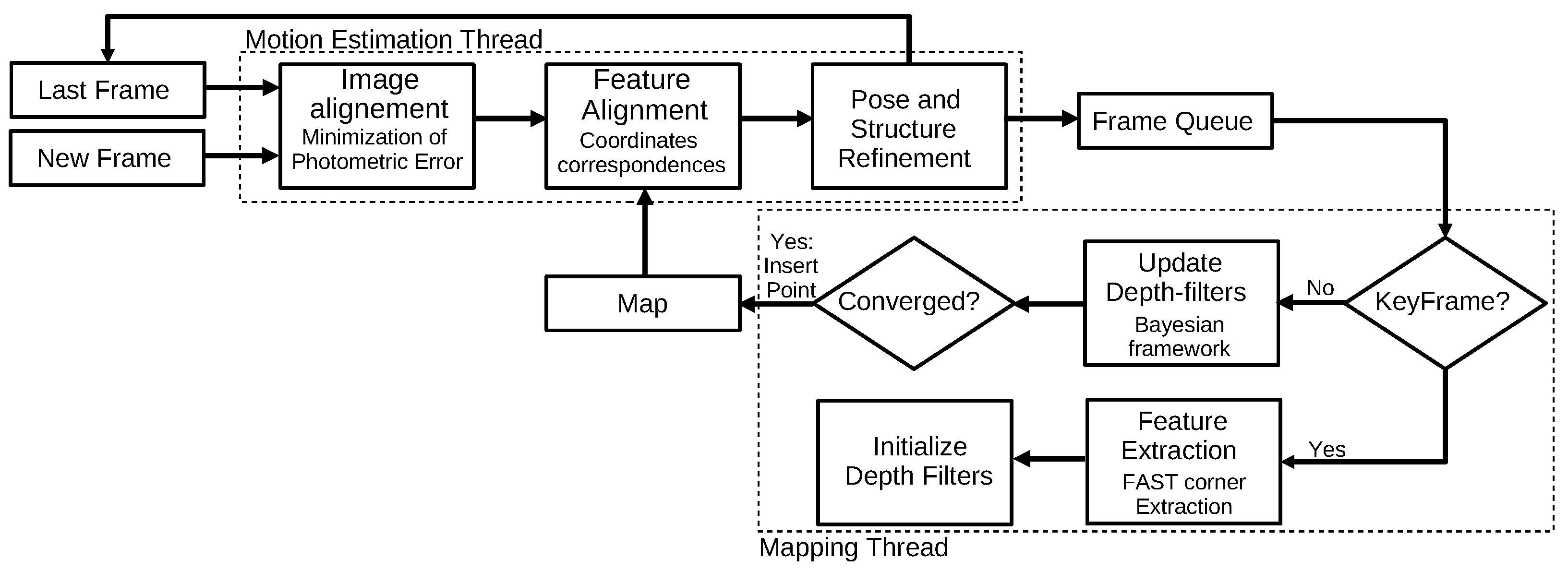
3.1.4. Semi-Direct Visual Odometry (2014)
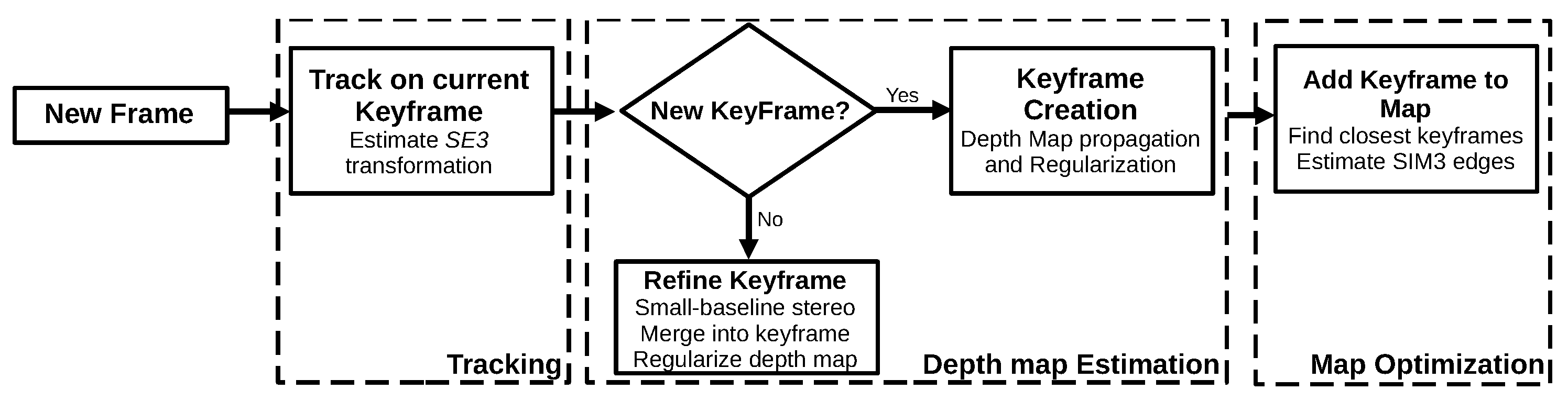
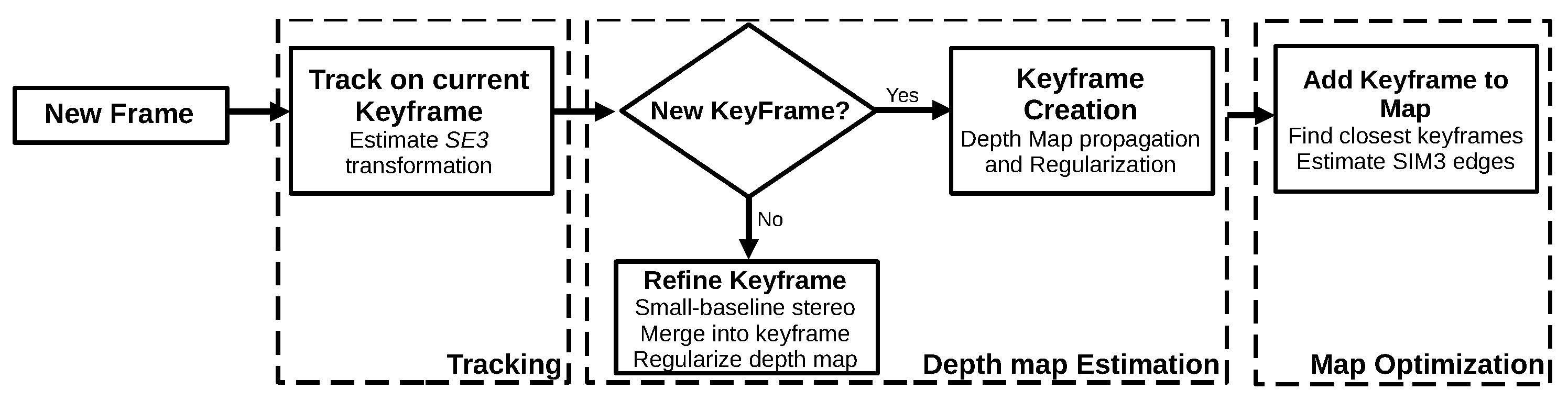
3.1.5. Large-Scale Direct Monocular SLAM (2014)
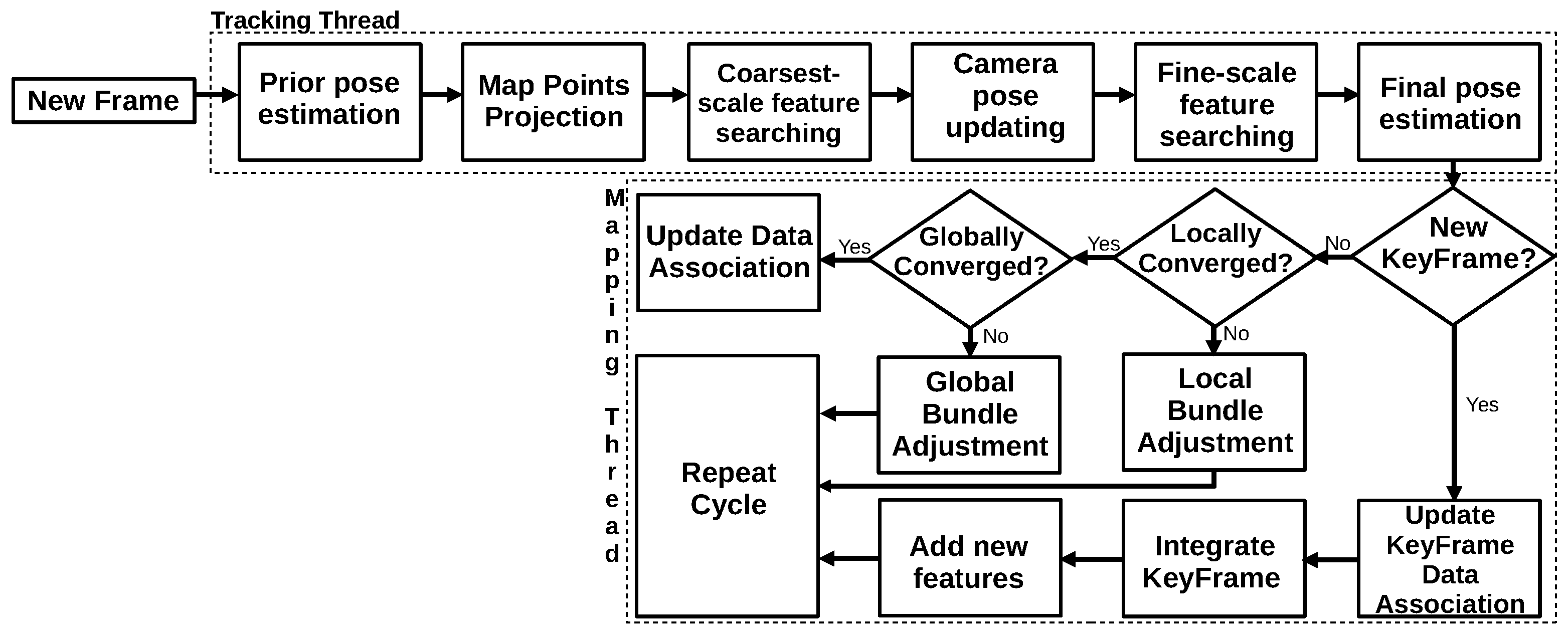
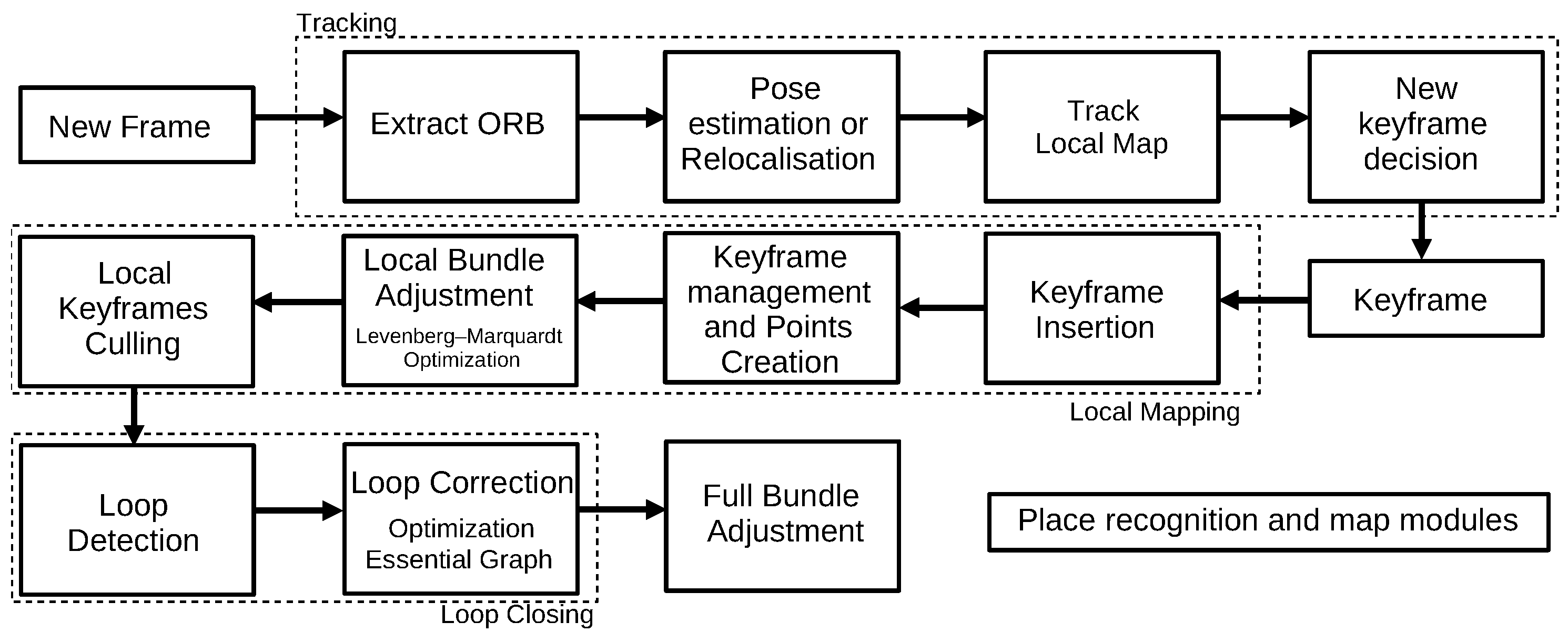
3.1.6. ORB-SLAM 2.0 (2017)
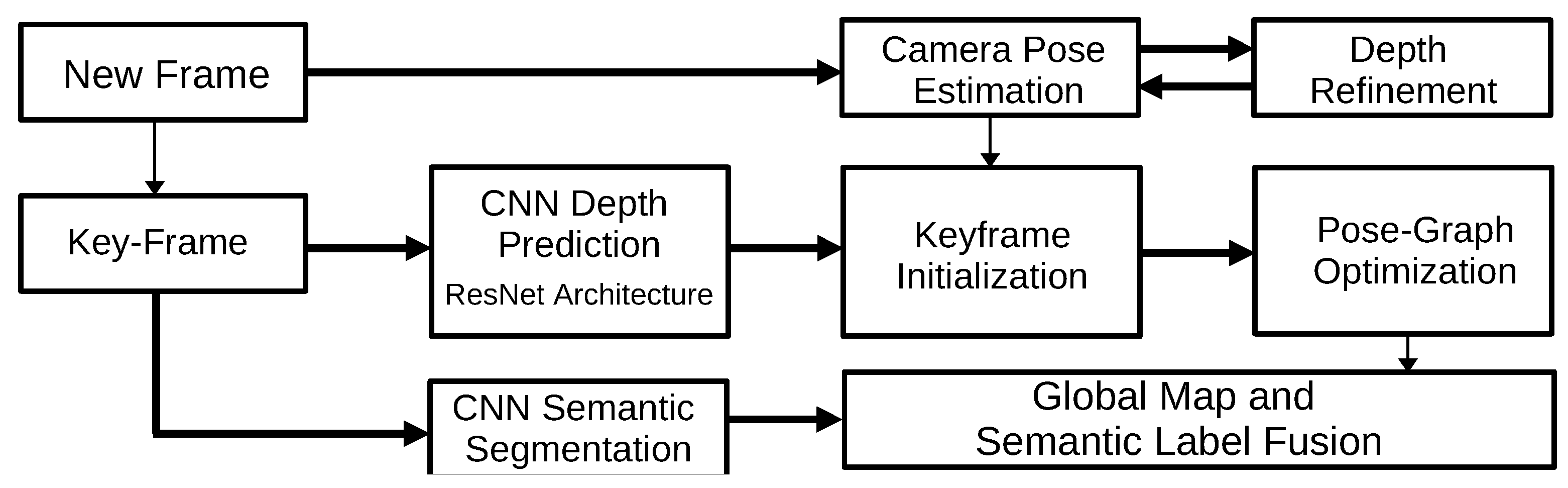
3.1.7. CNN-SLAM (2017)
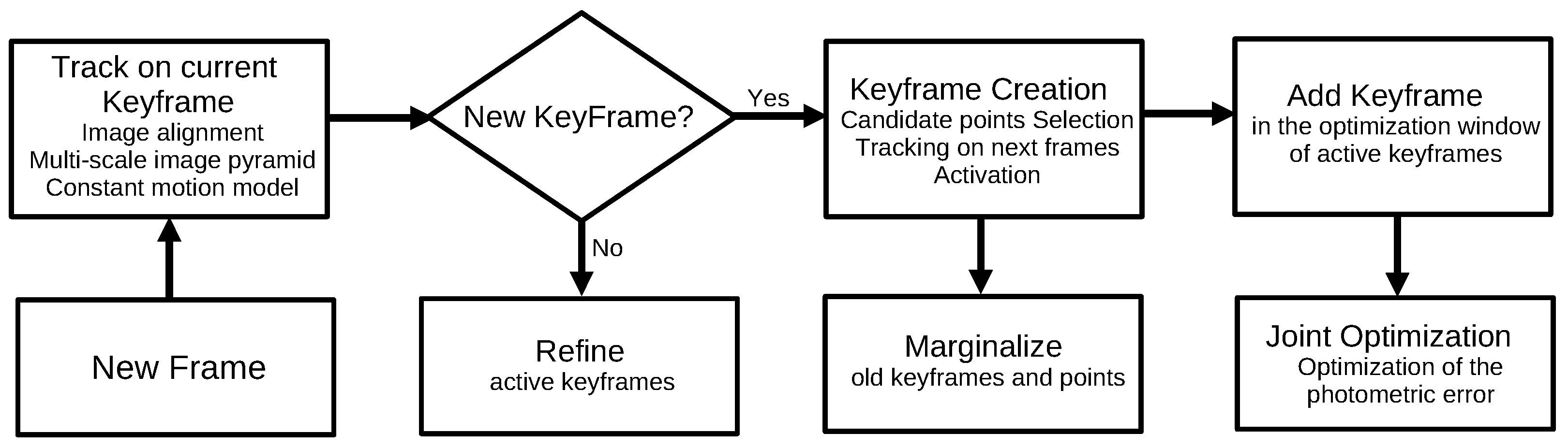
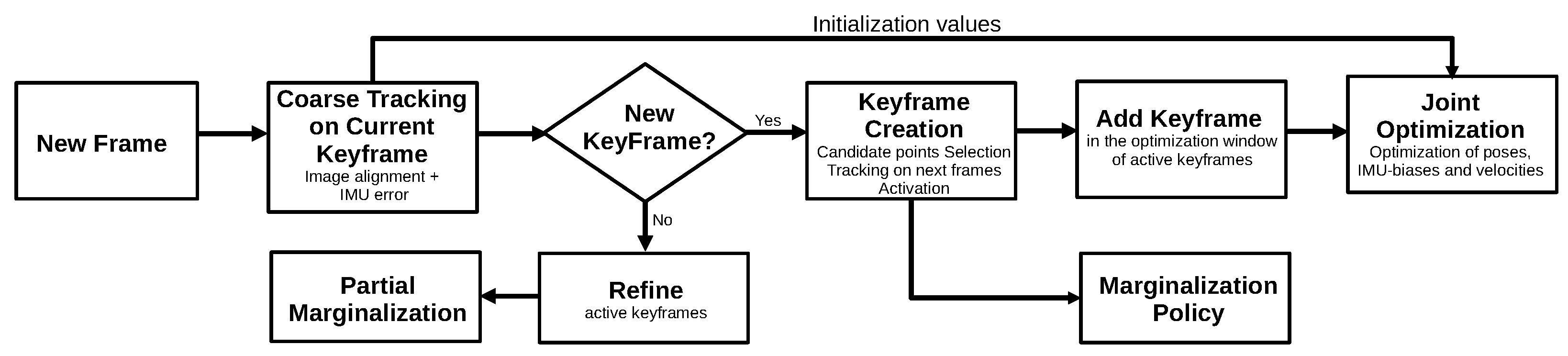
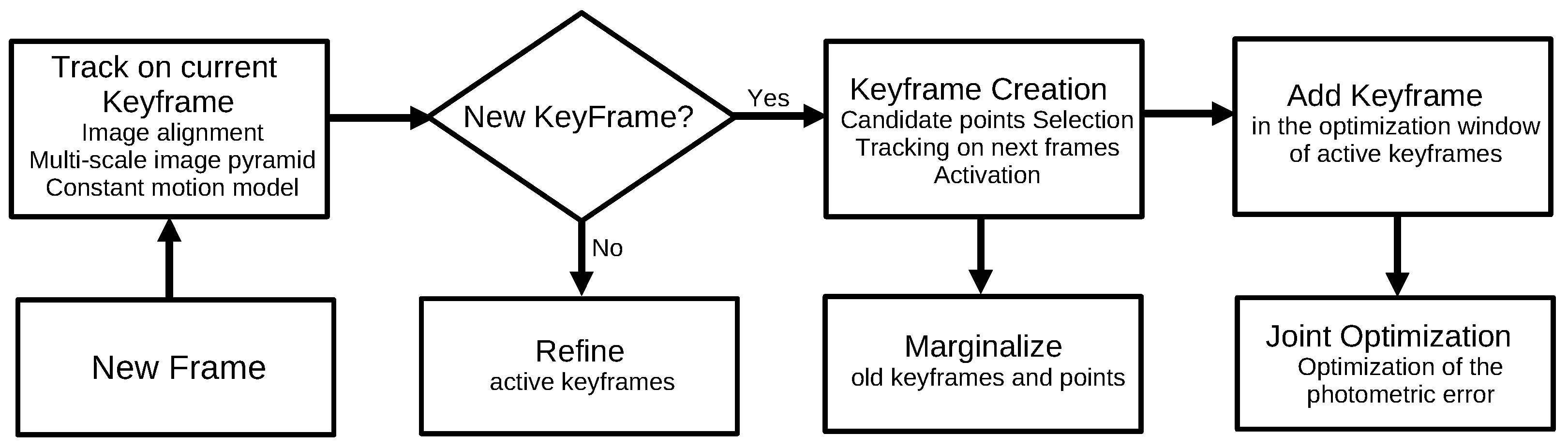
3.1.8. Direct Sparse Odometry (2018)
3.1.9. General Comments
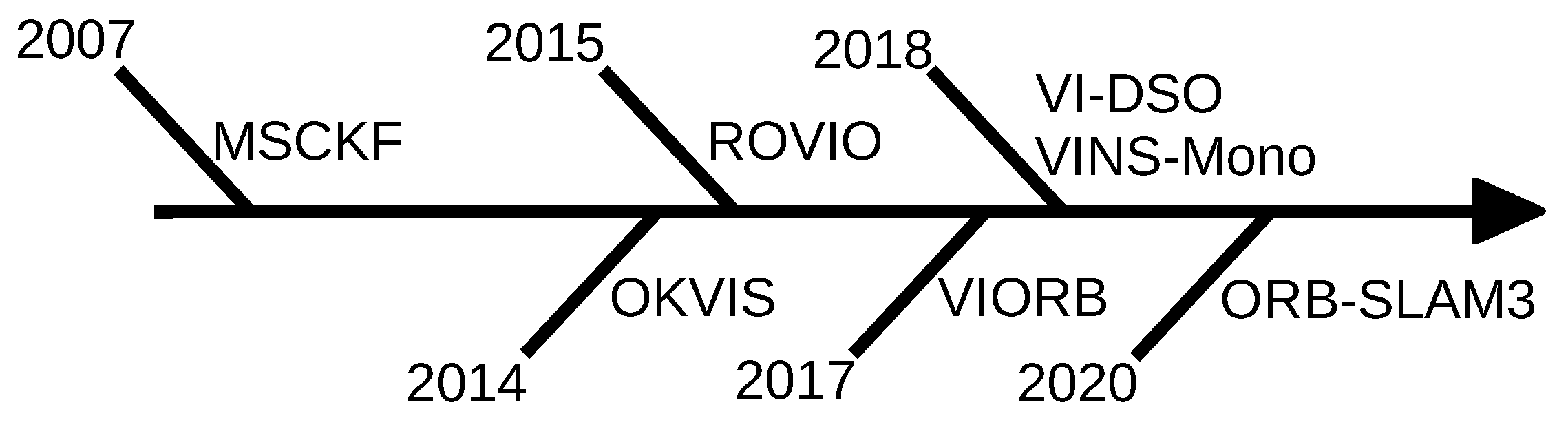
3.2. Visual-Inertial SLAM
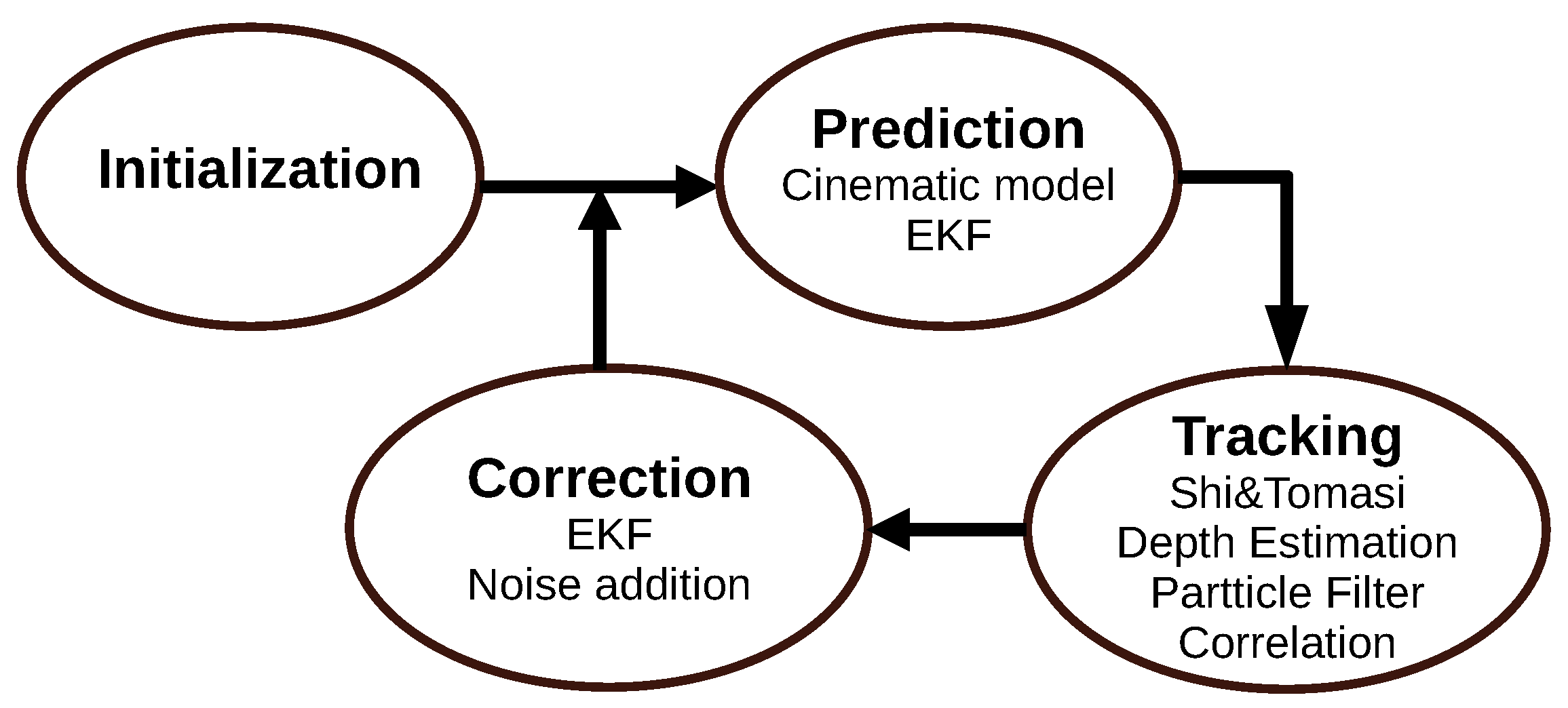
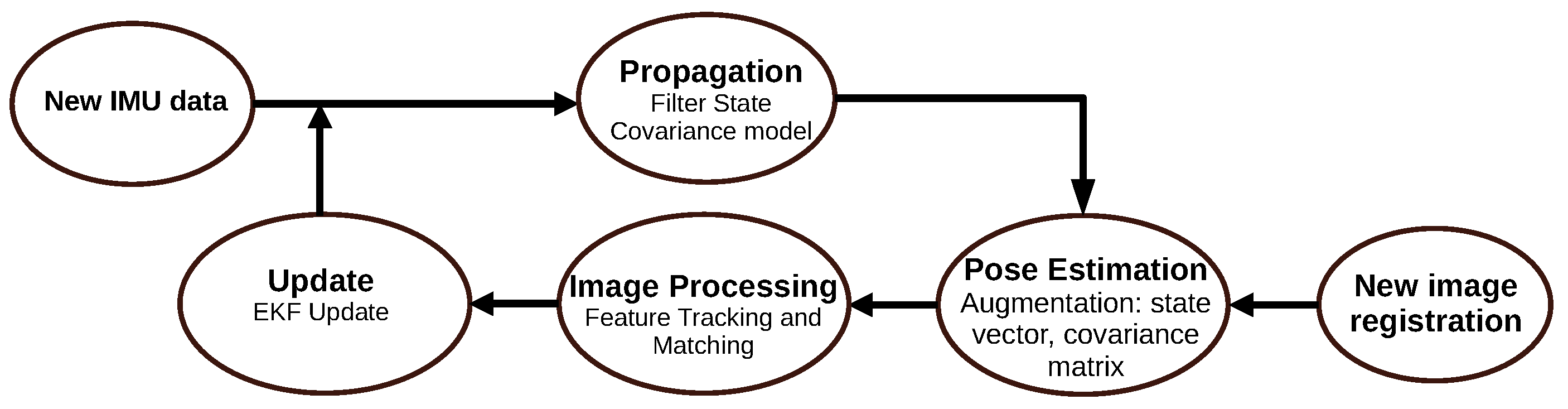
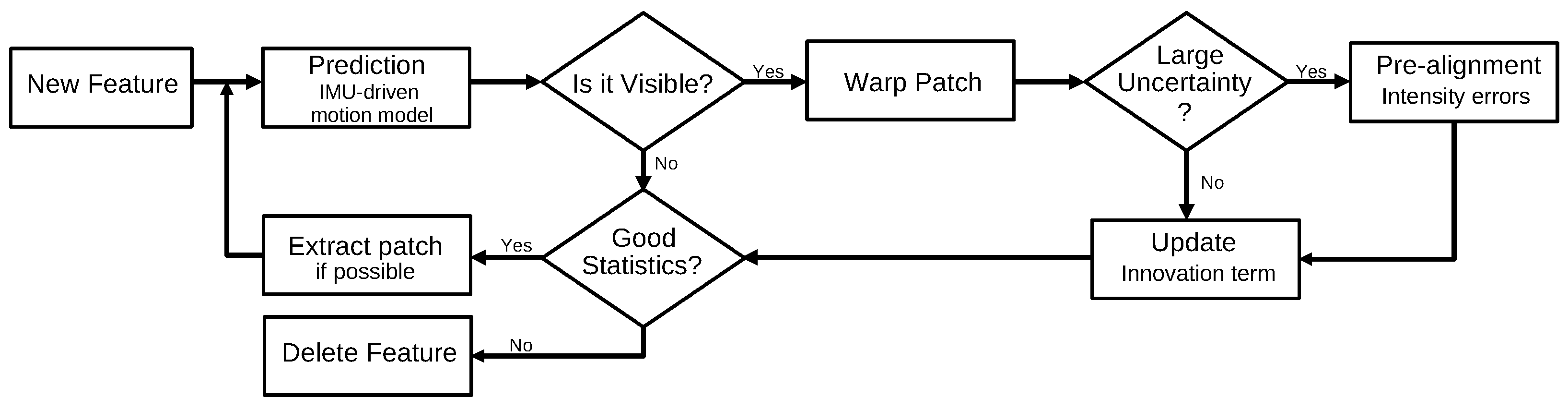
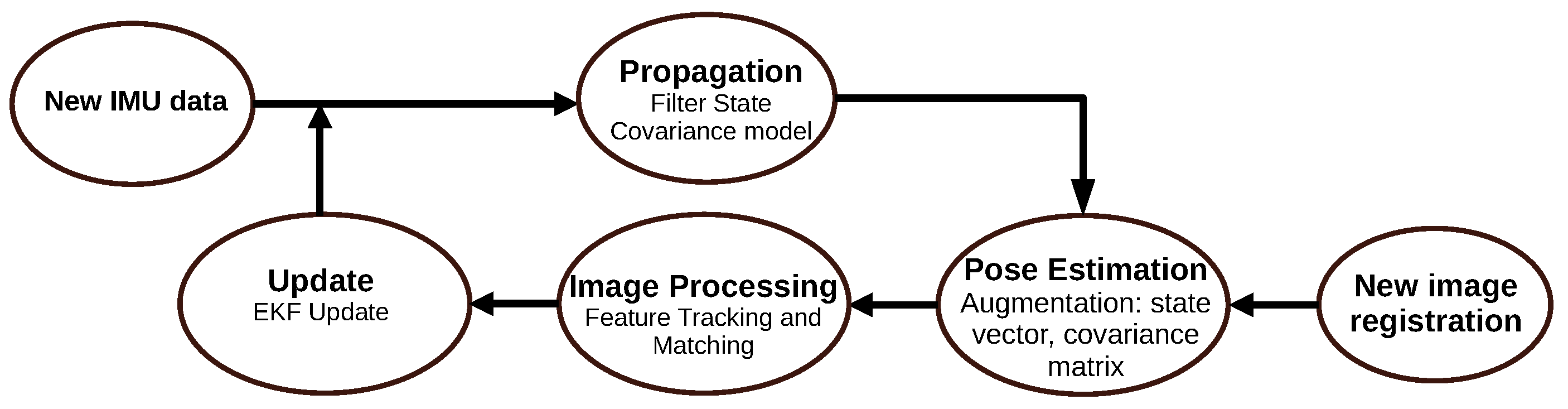
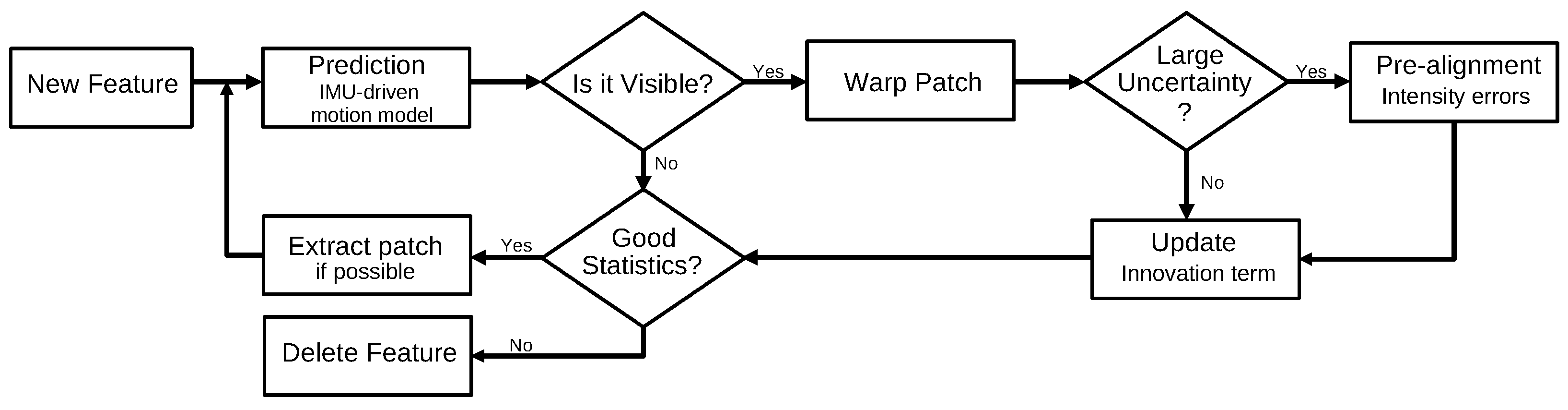
3.2.1. Multi-State Constraint Kalman Filter (2007)
3.2.2. Open Keyframe-Based Visual-Inertial SLAM (2014)
3.2.3. Robust Visual Inertial Odometry (2015)
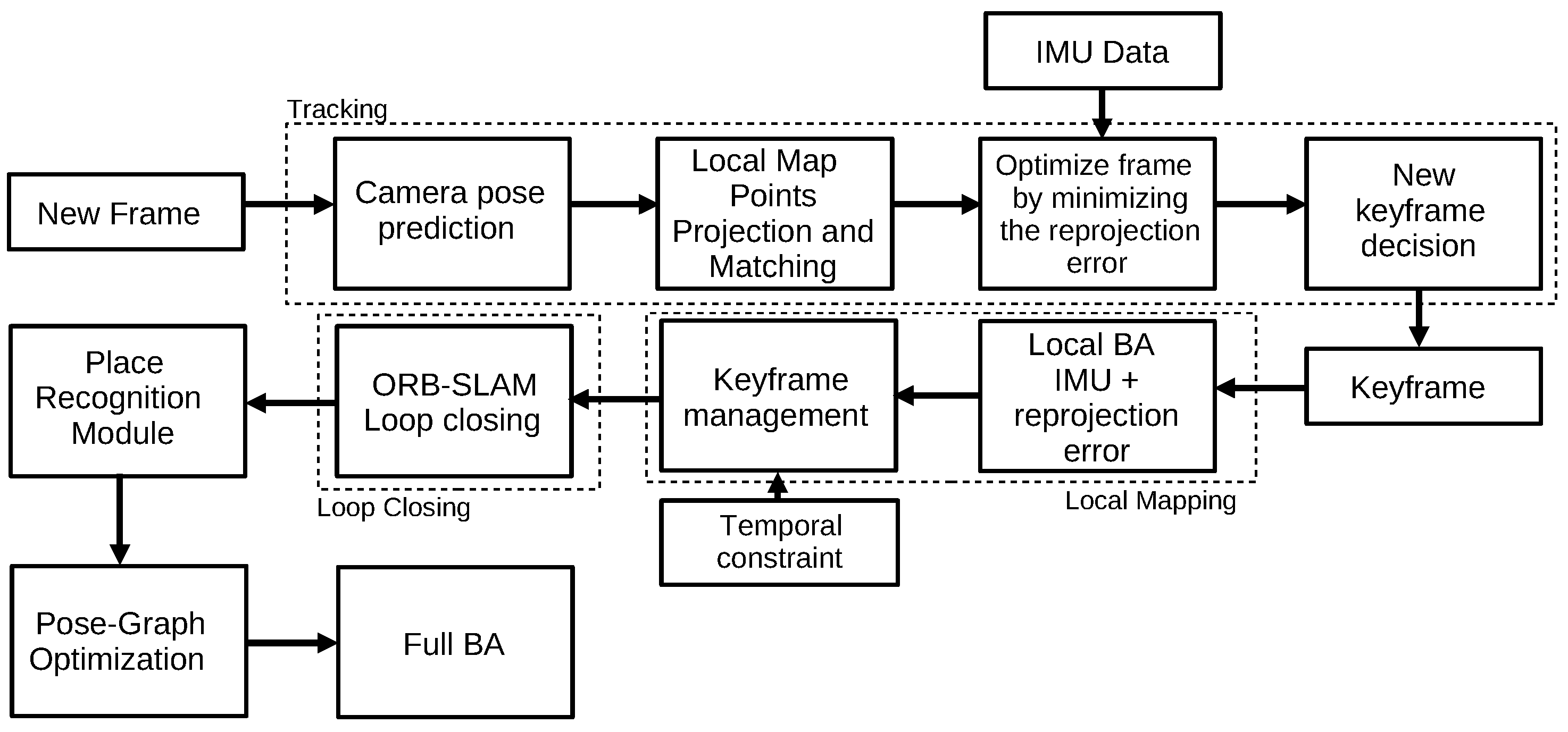
3.2.4. Visual Inertial ORB-SLAM (2017)
3.2.5. Monocular Visual-Inertial System (2018)
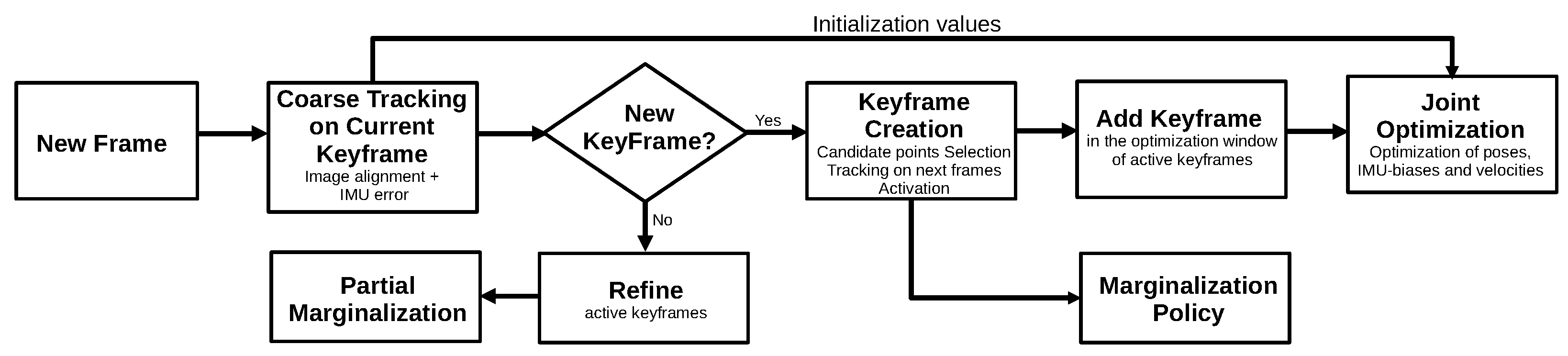
3.2.6. Visual-Inertial Direct Sparse Odometry (2018)
3.2.7. ORB-SLAM3 (2020)
3.2.8. General Comments
3.3. RGB-D SLAM
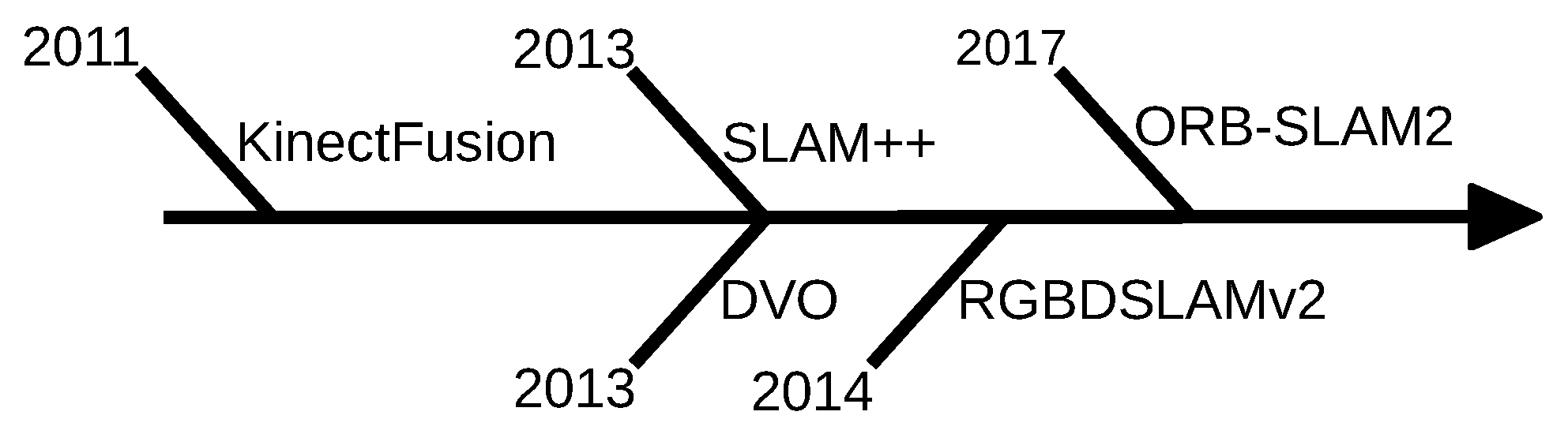
3.3.1. KinectFusion (2011)
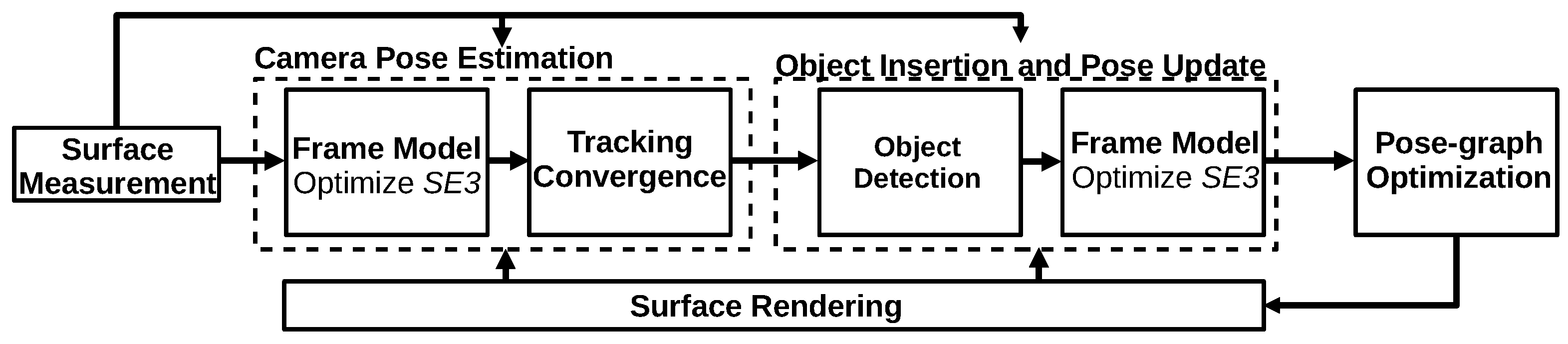
3.3.2. SLAM++ (2013)
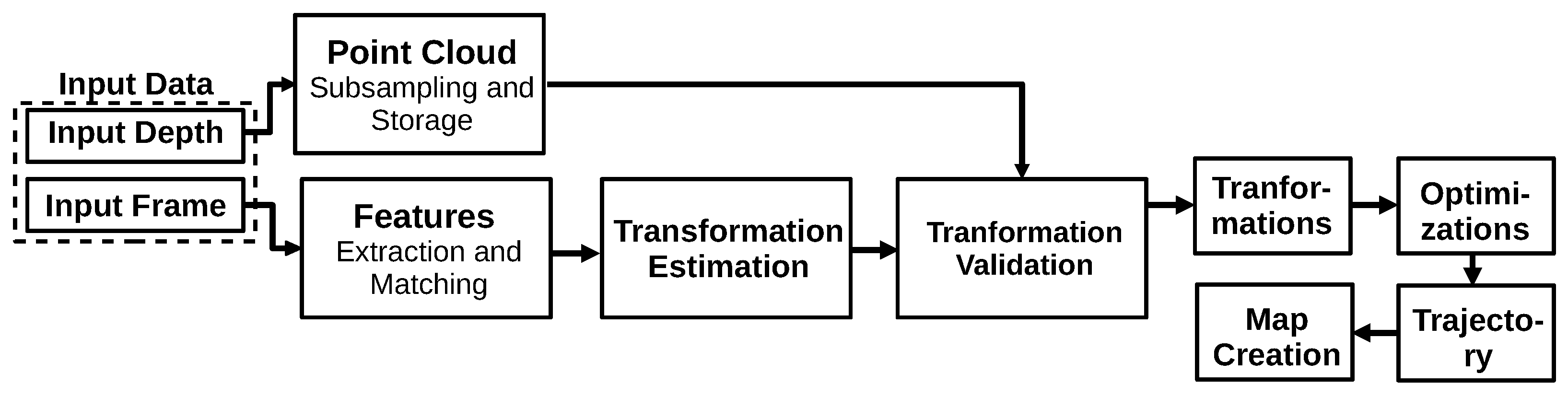
3.3.3. Dense Visual Odometry (2013)
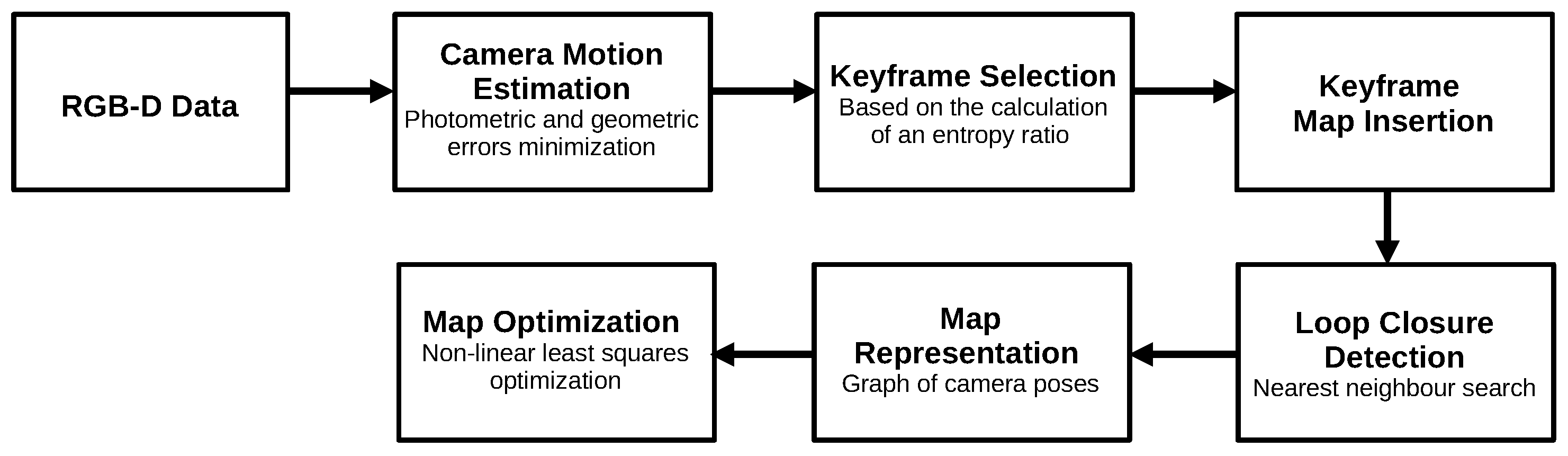
3.3.4. RGBDSLAMv2 (2014)
3.3.5. General Comments
4. Open Problems and Future Directions
4.1. Deep Learning-Based Algorithms
4.2. Semantic-Based Algorithms
4.3. Dynamic SLAM Algorithms
5. Datasets and Benchmarking
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Smith, R.; Cheeseman, P. On the Representation and Estimation of Spatial Uncertainty. Int. J. Robot. Res. 1987, 5, 56–68. [Google Scholar] [CrossRef]
- Jinyu, L.; Bangbang, Y.; Danpeng, C.; Nan, W.; Guofeng, Z.; Hujun, B. Survey and evaluation of monocular visual-inertial SLAM algorithms for augmented reality. Virtual Real. Intell. Hardw. 2019, 1, 386–410. [Google Scholar] [CrossRef]
- Covolan, J.P.; Sementille, A.; Sanches, S. A mapping of visual SLAM algorithms and their applications in augmented reality. In Proceedings of the 2020 22nd Symposium on Virtual and Augmented Reality (SVR), Porto de Galinhas, Brazil, 7–10 November 2020. [Google Scholar] [CrossRef]
- Singandhupe, A.; La, H. A Review of SLAM Techniques and Security in Autonomous Driving. In Proceedings of the 2019 Third IEEE International Conference on Robotic Computing (IRC), Naples, Italy, 25–27 February 2019; pp. 602–607. [Google Scholar] [CrossRef]
- Dworakowski, D.; Thompson, C.; Pham-Hung, M.; Nejat, G. A Robot Architecture Using ContextSLAM to Find Products in Unknown Crowded Retail Environments. Robotics 2021, 10, 110. [Google Scholar] [CrossRef]
- Ruan, K.; Wu, Z.; Xu, Q. Smart Cleaner: A New Autonomous Indoor Disinfection Robot for Combating the COVID-19 Pandemic. Robotics 2021, 10, 87. [Google Scholar] [CrossRef]
- Liu, C.; Zhou, C.; Cao, W.; Li, F.; Jia, P. A Novel Design and Implementation of Autonomous Robotic Car Based on ROS in Indoor Scenario. Robotics 2020, 9, 19. [Google Scholar] [CrossRef] [Green Version]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef] [Green Version]
- Stachniss, C. Robotic Mapping and Exploration; Springer: Berlin/Heidelberg, Germany, 2009; Volume 55. [Google Scholar]
- Taketomi, T.; Uchiyama, H.; Ikeda, S. Visual SLAM algorithms: A survey from 2010 to 2016. IPSJ Trans. Comput. Vis. Appl. 2017, 9, 1–11. [Google Scholar] [CrossRef]
- Kabzan, J.; Valls, M.; Reijgwart, V.; Hendrikx, H.; Ehmke, C.; Prajapat, M.; Bühler, A.; Gosala, N.; Gupta, M.; Sivanesan, R.; et al. AMZ Driverless: The Full Autonomous Racing System. J. Field Robot. 2020, 37, 1267–1294. [Google Scholar] [CrossRef]
- Durrant-Whyte, H.; Bailey, T. Simultaneous localization and mapping: Part I. IEEE Robot. Autom. Mag. 2006, 13, 99–110. [Google Scholar] [CrossRef] [Green Version]
- Bailey, T.; Durrant-Whyte, H. Simultaneous localization and mapping (SLAM): Part II. IEEE Robot. Autom. Mag. 2006, 13, 108–117. [Google Scholar] [CrossRef] [Green Version]
- Yousif, K.; Bab-Hadiashar, A.; Hoseinnezhad, R. An Overview to Visual Odometry and Visual SLAM: Applications to Mobile Robotics. Intell. Ind. Syst. 2015, 1, 289–311. [Google Scholar] [CrossRef]
- Fuentes-Pacheco, J.; Ruiz-Ascencio, J.; Rendón-Mancha, J.M. Visual simultaneous localization and mapping: A survey. Artif. Intell. Rev. 2015, 43, 55–81. [Google Scholar] [CrossRef]
- Servières, M.; Renaudin, V.; Dupuis, A.; Antigny, N. Visual and Visual-Inertial SLAM: State of the Art, Classification, and Experimental Benchmarking. J. Sensors 2021, 2021, 2054828. [Google Scholar] [CrossRef]
- Gui, J.; Gu, D.; Wang, S.; Hu, H. A review of visual inertial odometry from filtering and optimisation perspectives. Adv. Robot. 2015, 29, 1–13. [Google Scholar] [CrossRef]
- Chen, C.; Zhu, H.; Li, M.; You, S. A Review of Visual-Inertial Simultaneous Localization and Mapping from Filtering-Based and Optimization-Based Perspectives. Robotics 2018, 7, 45. [Google Scholar] [CrossRef] [Green Version]
- Huang, G. Visual-Inertial Navigation: A Concise Review. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 9572–9582. [Google Scholar] [CrossRef] [Green Version]
- Chen, K.; Lai, Y.; Hu, S. 3D indoor scene modeling from RGB-D data: A survey. Comput. Vis. Media 2015, 1, 267–278. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Zheng, L.; Tao, W. Survey and Evaluation of RGB-D SLAM. IEEE Access 2021, 9, 21367–21387. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.M.; D. Tardós, J. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual–Inertial, and Multimap SLAM. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Burri, M.; Nikolic, J.; Gohl, P.; Schneider, T.; Rehder, J.; Omari, S.; Achtelik, M.; Siegwart, R. The EuRoC micro aerial vehicle datasets. Int. J. Robot. Res. 2016, 35, 1157–1163. [Google Scholar] [CrossRef]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-Scale Direct Monocular SLAM. In Computer Vision–ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 834–849. [Google Scholar]
- Bianco, S.; Ciocca, G.; Marelli, D. Evaluating the Performance of Structure from Motion Pipelines. J. Imaging 2018, 4, 98. [Google Scholar] [CrossRef] [Green Version]
- Lepetit, V.; Moreno-Noguer, F.; Fua, P. EPnP: An Accurate O(n) Solution to the PnP Problem. Int. J. Comput. Vis. 2008, 81, 155. [Google Scholar] [CrossRef] [Green Version]
- Davison, A.J.; Reid, I.D.; Molton, N.D.; Stasse, O. MonoSLAM: Real-Time Single Camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Loo, S.Y.; Amiri, A.; Mashohor, S.; Tang, S.; Zhang, H. CNN-SVO: Improving the Mapping in Semi-Direct Visual Odometry Using Single-Image Depth Prediction. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]
- Boikos, K.; Bouganis, C.S. Semi-dense SLAM on an FPGA SoC. In Proceedings of the 2016 26th International Conference on Field Programmable Logic and Applications (FPL), Lausanne, Switzerland, 29 August–2 September 2016; pp. 1–4. [Google Scholar] [CrossRef] [Green Version]
- Engel, J.; Usenko, V.; Cremers, D. A Photometrically Calibrated Benchmark For Monocular Visual Odometry. arXiv 2016, arXiv:1607.02555. [Google Scholar]
- Engel, J.; Koltun, V.; Cremers, D. Direct Sparse Odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 611–625. [Google Scholar] [CrossRef] [PubMed]
- Canovas, B.; Rombaut, M.; Nègre, A.; Pellerin, D.; Olympieff, S. Speed and Memory Efficient Dense RGB-D SLAM in Dynamic Scenes. In Proceedings of the IROS 2020—IEEE/RSJ International Conference on Intelligent Robots and Systems, Las Vegas, NV, USA, 25–29 October 2020; pp. 4996–5001. [Google Scholar] [CrossRef]
- Bresson, G.; Alsayed, Z.; Yu, L.; Glaser, S. Simultaneous Localization and Mapping: A Survey of Current Trends in Autonomous Driving. IEEE Trans. Intell. Veh. 2017, 2, 194–220. [Google Scholar] [CrossRef] [Green Version]
- Vincke, B.; Elouardi, A.; Lambert, A. Design and evaluation of an embedded system based SLAM applications. In Proceedings of the 2010 IEEE/SICE International Symposium on System Integration, Sendai, Japan, 21–22 December 2010; pp. 224–229. [Google Scholar] [CrossRef]
- Vincke, B.; Elouardi, A.; Lambert, A.; Merigot, A. Efficient implementation of EKF-SLAM on a multi-core embedded system. In Proceedings of the IECON 2012—38th Annual Conference on IEEE Industrial Electronics Society, Montreal, QC, Canada, 25–28 October 2012; pp. 3049–3054. [Google Scholar] [CrossRef]
- Klein, G.; Murray, D. Parallel Tracking and Mapping for Small AR Workspaces. In Proceedings of the 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Nara, Japan, 13–16 November 2007; pp. 225–234. [Google Scholar] [CrossRef]
- Serrata, A.A.J.; Yang, S.; Li, R. An intelligible implementation of FastSLAM2.0 on a low-power embedded architecture. EURASIP J. Embed. Syst. 2017, 2017, 27. [Google Scholar]
- Newcombe, R.A.; Lovegrove, S.J.; Davison, A.J. DTAM: Dense tracking and mapping in real-time. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2320–2327. [Google Scholar]
- Ondrúška, P.; Kohli, P.; Izadi, S. MobileFusion: Real-Time Volumetric Surface Reconstruction and Dense Tracking on Mobile Phones. IEEE Trans. Vis. Comput. Graph. 2015, 21, 1251–1258. [Google Scholar] [CrossRef]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 15–22. [Google Scholar] [CrossRef] [Green Version]
- Mur-Artal, R.; Montiel, J.; Tardos, J. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef] [Green Version]
- Forster, C.; Zhang, Z.; Gassner, M.; Werlberger, M.; Scaramuzza, D. SVO: Semidirect Visual Odometry for Monocular and Multicamera Systems. IEEE Trans. Robot. 2017, 33, 249–265. [Google Scholar] [CrossRef] [Green Version]
- Boikos, K.; Bouganis, C.S. A high-performance system-on-chip architecture for direct tracking for SLAM. In Proceedings of the 2017 27th International Conference on Field Programmable Logic and Applications (FPL), Gent, Belgium, 4–6 September 2017; pp. 1–7. [Google Scholar] [CrossRef] [Green Version]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef] [Green Version]
- Zhan, Z.; Jian, W.; Li, Y.; Yue, Y. A SLAM Map Restoration Algorithm Based on Submaps and an Undirected Connected Graph. IEEE Access 2021, 9, 12657–12674. [Google Scholar] [CrossRef]
- Abouzahir, M.; Elouardi, A.; Latif, R.; Bouaziz, S.; Tajer, A. Embedding SLAM algorithms: Has it come of age? Robot. Auton. Syst. 2018, 100, 14–26. [Google Scholar] [CrossRef]
- Yu, J.; Gao, F.; Cao, J.; Yu, C.; Zhang, Z.; Huang, Z.; Wang, Y.; Yang, H. CNN-based Monocular Decentralized SLAM on embedded FPGA. In Proceedings of the 2020 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), New Orleans, LA, USA, 18–22 May 2020; pp. 66–73. [Google Scholar] [CrossRef]
- Tateno, K.; Tombari, F.; Laina, I.; Navab, N. CNN-SLAM: Real-Time Dense Monocular SLAM with Learned Depth Prediction. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6565–6574. [Google Scholar] [CrossRef] [Green Version]
- Gao, X.; Wang, R.; Demmel, N.; Cremers, D. LDSO: Direct Sparse Odometry with Loop Closure. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018. [Google Scholar]
- Davison, A.J. SceneLib 1.0. 2006. Available online: https://www.doc.ic.ac.uk/~ajd/Scene/index.html (accessed on 21 January 2022).
- Klein, G.; Murray, D. Parallel Tracking and Mapping on a camera phone. In Proceedings of the 2009 8th IEEE International Symposium on Mixed and Augmented Reality, Orlando, FL, USA, 19–22 October 2009; pp. 83–86. [Google Scholar]
- Oxford-PTAM. Available online: https://github.com/Oxford-PTAM/PTAM-GPL (accessed on 21 January 2022).
- OpenDTAM. Available online: https://github.com/anuranbaka/OpenDTAM (accessed on 21 January 2022).
- SVO. Available online: https://github.com/uzh-rpg/rpg_svo (accessed on 21 January 2022).
- LSD-SLAM: Large-Scale Direct Monocular SLAM. Available online: https://github.com/tum-vision/lsd_slam (accessed on 21 January 2022).
- ORB-SLAM2. Available online: https://github.com/raulmur/ORB_SLAM2 (accessed on 21 January 2022).
- CNN SLAM. Available online: https://github.com/iitmcvg/CNN_SLAM (accessed on 21 January 2022).
- DSO: Direct Sparse Odometry. Available online: https://github.com/JakobEngel/dso (accessed on 21 January 2022).
- Piat, J.; Fillatreau, P.; Tortei, D.; Brenot, F.; Devy, M. HW/SW co-design of a visual SLAM application. J.-Real-Time Image Process. 2018. [Google Scholar] [CrossRef] [Green Version]
- DPU for Convolutional Neural Network. Available online: https://www.xilinx.com/products/intellectual-property/dpu.html#overview (accessed on 21 January 2022).
- Xu, Z.; Yu, J.; Yu, C.; Shen, H.; Wang, Y.; Yang, H. CNN-based Feature-point Extraction for Real-time Visual SLAM on Embedded FPGA. In Proceedings of the 2020 IEEE 28th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Fayetteville, AR, USA, 3–6 May 2020; pp. 33–37. [Google Scholar]
- Mourikis, A.I.; Roumeliotis, S.I. A Multi-State Constraint Kalman Filter for Vision-aided Inertial Navigation. In Proceedings of the 2007 IEEE International Conference on Robotics and Automation, Roma, Italy, 10–14 April 2007; pp. 3565–3572. [Google Scholar]
- Sun, K.; Mohta, K.; Pfrommer, B.; Watterson, M.; Liu, S.; Mulgaonkar, Y.; Taylor, C.J.; Kumar, V. Robust Stereo Visual Inertial Odometry for Fast Autonomous Flight. IEEE Robot. Autom. Lett. 2018, 3, 965–972. [Google Scholar] [CrossRef] [Green Version]
- Li, S.P.; Zhang, T.; Gao, X.; Wang, D.; Xian, Y. Semi-direct monocular visual and visual-inertial SLAM with loop closure detection. Robot. Auton. Syst. 2019, 112, 201–210. [Google Scholar] [CrossRef]
- Delmerico, J.; Scaramuzza, D. A Benchmark Comparison of Monocular Visual-Inertial Odometry Algorithms for Flying Robots. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 2502–2509. [Google Scholar] [CrossRef]
- Li, M.; Mourikis, A.I. Improving the accuracy of EKF-based visual-inertial odometry. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MI, USA, 14–18 May 2012; pp. 828–835. [Google Scholar]
- Leutenegger, S.; Lynen, S.; Bosse, M.; Siegwart, R.; Furgale, P. Keyframe-Based Visual-Inertial Odometry Using Nonlinear Optimization. Int. J. Robot. Res. 2014, 34, 314–334. [Google Scholar] [CrossRef] [Green Version]
- Nikolic, J.; Rehder, J.; Burri, M.; Gohl, P.; Leutenegger, S.; Furgale, P.T.; Siegwart, R. A synchronized visual-inertial sensor system with FPGA pre-processing for accurate real-time SLAM. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 431–437. [Google Scholar] [CrossRef] [Green Version]
- Bloesch, M.; Omari, S.; Hutter, M.; Siegwart, R. Robust visual inertial odometry using a direct EKF-based approach. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; pp. 298–304. [Google Scholar] [CrossRef] [Green Version]
- Von Stumberg, L.; Usenko, V.; Cremers, D. Direct Sparse Visual-Inertial Odometry Using Dynamic Marginalization. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 2510–2517. [Google Scholar] [CrossRef] [Green Version]
- Mur-Artal, R.; Tardós, J.D. Visual-Inertial Monocular SLAM With Map Reuse. IEEE Robot. Autom. Lett. 2017, 2, 796–803. [Google Scholar] [CrossRef] [Green Version]
- Silveira, O.C.B.; de Melo, J.G.O.C.; Moreira, L.A.S.; Pinto, J.B.N.G.; Rodrigues, L.R.L.; Rosa, P.F.F. Evaluating a Visual Simultaneous Localization and Mapping Solution on Embedded Platforms. In Proceedings of the 2020 IEEE 29th International Symposium on Industrial Electronics (ISIE), Delft, The Netherlands, 17–19 June 2020; pp. 530–535. [Google Scholar] [CrossRef]
- Qin, T.; Li, P.; Shen, S. VINS-Mono: A Robust and Versatile Monocular Visual-Inertial State Estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef] [Green Version]
- Paul, M.K.; Wu, K.; Hesch, J.A.; Nerurkar, E.D.; Roumeliotis, S.I. A comparative analysis of tightly-coupled monocular, binocular, and stereo VINS. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 165–172. [Google Scholar] [CrossRef]
- Campos, C.; Montiel, J.M.; Tardós, J.D. Inertial-Only Optimization for Visual-Inertial Initialization. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 51–57. [Google Scholar] [CrossRef]
- Seiskari, O.; Rantalankila, P.; Kannala, J.; Ylilammi, J.; Rahtu, E.; Solin, A. HybVIO: Pushing the Limits of Real-Time Visual-Inertial Odometry. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 4–8 January 2022; pp. 701–710. [Google Scholar]
- Merzlyakov, A.; Macenski, S. A Comparison of Modern General-Purpose Visual SLAM Approaches. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 9190–9197. [Google Scholar] [CrossRef]
- dvo. Available online: https://github.com/daniilidis-group/msckf_mono (accessed on 21 January 2022).
- msckf_vio. Available online: https://github.com/KumarRobotics/msckf_vio (accessed on 21 January 2022).
- OKVIS. Available online: https://github.com/ethz-asl/okvis (accessed on 21 January 2022).
- ROVIO. Available online: https://github.com/ethz-asl/rovio (accessed on 21 January 2022).
- VINS-Mono. Available online: https://github.com/HKUST-Aerial-Robotics/VINS-Mono (accessed on 21 January 2022).
- VI-Stereo-DSO. Available online: https://github.com/RonaldSun/VI-Stereo-DSO (accessed on 21 January 2022).
- ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual-Inertial and Multi-Map SLAM. Available online: https://github.com/UZ-SLAMLab/ORB_SLAM3 (accessed on 21 January 2022).
- Aslam, M.S.; Aziz, M.I.; Naveed, K.; uz Zaman, U.K. An RPLiDAR based SLAM equipped with IMU for Autonomous Navigation of Wheeled Mobile Robot. In Proceedings of the 2020 IEEE 23rd International Multitopic Conference (INMIC), Bahawalpur, Pakistan, 5–7 November 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Nguyen, T.M.; Yuan, S.; Cao, M.; Nguyen, T.H.; Xie, L. VIRAL SLAM: Tightly Coupled Camera-IMU-UWB-Lidar SLAM. arXiv 2021, arXiv:2105.03296. [Google Scholar]
- Chang, L.; Niu, X.; Liu, T. GNSS/IMU/ODO/LiDAR-SLAM Integrated Navigation System Using IMU/ODO Pre-Integration. Sensors 2020, 20, 4702. [Google Scholar] [CrossRef]
- Zuñiga-Noël, D.; Moreno, F.A.; Gonzalez-Jimenez, J. An Analytical Solution to the IMU Initialization Problem for Visual-Inertial Systems. IEEE Robot. Autom. Lett. 2021, 6, 6116–6122. [Google Scholar] [CrossRef]
- Petit, B.; Guillemard, R.; Gay-Bellile, V. Time Shifted IMU Preintegration for Temporal Calibration in Incremental Visual-Inertial Initialization. In Proceedings of the 2020 International Conference on 3D Vision (3DV), Fukuoka, Japan, 25–28 November 2020; pp. 171–179. [Google Scholar] [CrossRef]
- Newcombe, R.A.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Kim, D.; Davison, A.J.; Kohi, P.; Shotton, J.; Hodges, S.; Fitzgibbon, A. KinectFusion: Real-time dense surface mapping and tracking. In Proceedings of the 2011 10th IEEE International Symposium on Mixed and Augmented Reality, Basel, Switzerland, 26–29 October 2011; pp. 127–136. [Google Scholar]
- Jin, Q.; Liu, Y.; Man, Y.; Li, F. Visual SLAM with RGB-D Cameras. In Proceedings of the 2019 Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 4072–4077. [Google Scholar] [CrossRef]
- Nardi, L.; Bodin, B.; Zia, M.Z.; Mawer, J.; Nisbet, A.; Kelly, P.H.J.; Davison, A.J.; Luján, M.; O’Boyle, M.F.P.; Riley, G.D.; et al. Introducing SLAMBench, a performance and accuracy benchmarking methodology for SLAM. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 5783–5790. [Google Scholar]
- Bodin, B.; Nardi, L.; Zia, M.Z.; Wagstaff, H.; Shenoy, G.S.; Emani, M.; Mawer, J.; Kotselidis, C.; Nisbet, A.; Lujan, M.; et al. Integrating algorithmic parameters into benchmarking and design space exploration in 3D scene understanding. In Proceedings of the 2016 International Conference on Parallel Architecture and Compilation Techniques (PACT), Haifa, Israel, 11–15 September 2016; pp. 57–69. [Google Scholar] [CrossRef] [Green Version]
- Salas-Moreno, R.F.; Newcombe, R.A.; Strasdat, H.; Kelly, P.H.; Davison, A.J. SLAM++: Simultaneous Localisation and Mapping at the Level of Objects. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1352–1359. [Google Scholar] [CrossRef] [Green Version]
- Kerl, C.; Sturm, J.; Cremers, D. Dense visual SLAM for RGB-D cameras. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 2100–2106. [Google Scholar]
- Endres, F.; Hess, J.; Sturm, J.; Cremers, D.; Burgard, W. 3-D Mapping With an RGB-D Camera. IEEE Trans. Robot. 2014, 30, 177–187. [Google Scholar] [CrossRef]
- KinectFusion. Available online: https://github.com/ParikaGoel/KinectFusion (accessed on 21 January 2022).
- rgbdslam. Available online: http://ros.org/wiki/rgbdslam (accessed on 21 January 2022).
- dvo. Available online: https://github.com/tum-vision/dvo (accessed on 21 January 2022).
- Belshaw, M.S.; Greenspan, M.A. A high speed iterative closest point tracker on an FPGA platform. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 1449–1456. [Google Scholar] [CrossRef] [Green Version]
- Williams, B. Evaluation of a SoC for Real-time 3D SLAM. Doctoral Dissertation, Iowa State University, Ames, IA, USA, 2017. [Google Scholar]
- Gautier, Q.; Shearer, A.; Matai, J.; Richmond, D.; Meng, P.; Kastner, R. Real-time 3D reconstruction for FPGAs: A case study for evaluating the performance, area, and programmability trade-offs of the Altera OpenCL SDK. In Proceedings of the 2014 International Conference on Field-Programmable Technology (FPT), Shanghai, China, 10–12 December 2014; pp. 326–329. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, H.; Li, Y.; Nakamura, Y.; Zhang, L. FlowFusion: Dynamic Dense RGB-D SLAM Based on Optical Flow. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 7322–7328. [Google Scholar] [CrossRef]
- Dai, W.; Zhang, Y.; Li, P.; Fang, Z.; Scherer, S. RGB-D SLAM in Dynamic Environments Using Point Correlations. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 373–389. [Google Scholar] [CrossRef]
- Ai, Y.; Rui, T.; Lu, M.; Fu, L.; Liu, S.; Wang, S. DDL-SLAM: A Robust RGB-D SLAM in Dynamic Environments Combined With Deep Learning. IEEE Access 2020, 8, 162335–162342. [Google Scholar] [CrossRef]
- Deng, X.; Zhang, Z.; Sintov, A.; Huang, J.; Bretl, T. Feature-constrained Active Visual SLAM for Mobile Robot Navigation. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 7233–7238. [Google Scholar] [CrossRef]
- Jaenal, A.; Zuñiga-Nöel, D.; Gomez-Ojeda, R.; Gonzalez-Jimenez, J. Improving Visual SLAM in Car-Navigated Urban Environments with Appearance Maps. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 4679–4685. [Google Scholar] [CrossRef]
- Li, D.; Shi, X.; Long, Q.; Liu, S.; Yang, W.; Wang, F.; Wei, Q.; Qiao, F. DXSLAM: A Robust and Efficient Visual SLAM System with Deep Features. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 4958–4965. [Google Scholar] [CrossRef]
- Xu, Q.; Kuang, H.; Kneip, L.; Schwertfeger, S. Rethinking the Fourier-Mellin Transform: Multiple Depths in the Camera’s View. Remote Sens. 2021, 13, 1000. [Google Scholar] [CrossRef]
- Xu, Q.; Chavez, A.G.; Bülow, H.; Birk, A.; Schwertfeger, S. Improved Fourier Mellin Invariant for Robust Rotation Estimation with Omni-Cameras. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 320–324. [Google Scholar] [CrossRef] [Green Version]
- Scona, R.; Jaimez, M.; Petillot, Y.R.; Fallon, M.; Cremers, D. StaticFusion: Background Reconstruction for Dense RGB-D SLAM in Dynamic Environments. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 3849–3856. [Google Scholar] [CrossRef]
- Soares, J.C.V.; Gattass, M.; Meggiolaro, M.A. Visual SLAM in Human Populated Environments: Exploring the Trade-off between Accuracy and Speed of YOLO and Mask R-CNN. In Proceedings of the 2019 19th International Conference on Advanced Robotics (ICAR), Horizonte, Brazil, 2–6 December 2019; pp. 135–140. [Google Scholar] [CrossRef]
- Soares, J.C.V.; Gattass, M.; Meggiolaro, M.A. Crowd-SLAM: Visual SLAM Towards Crowded Environments using Object Detection. J. Intell. Robot. Syst. 2021, 102, 50. [Google Scholar] [CrossRef]
- Van Opdenbosch, D.; Aykut, T.; Alt, N.; Steinbach, E. Efficient Map Compression for Collaborative Visual SLAM. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 992–1000. [Google Scholar] [CrossRef]
- Wan, Z.; Yu, B.; Li, T.; Tang, J.; Wang, Y.; Raychowdhury, A.; Liu, S. A Survey of FPGA-Based Robotic Computing. IEEE Circuits Syst. Mag. 2021, 21, 48–74. [Google Scholar] [CrossRef]
- Li, R.; Wang, S.; Long, Z.; Gu, D. UnDeepVO: Monocular Visual Odometry Through Unsupervised Deep Learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 7286–7291. [Google Scholar] [CrossRef] [Green Version]
- Li, R.; Wang, S.; Gu, D. DeepSLAM: A Robust Monocular SLAM System With Unsupervised Deep Learning. IEEE Trans. Ind. Electron. 2021, 68, 3577–3587. [Google Scholar] [CrossRef]
- Kang, R.; Shi, J.; Li, X.; Liu, Y.; Liu, X. DF-SLAM: A Deep-Learning Enhanced Visual SLAM System based on Deep Local Features. arXiv 2019, arXiv:1901.07223. [Google Scholar]
- Zhao, C.; Sun, Q.; Zhang, C.; Tang, Y.; Qian, F. Monocular depth estimation based on deep learning: An overview. Sci. China Technol. Sci. 2020, 63, 1612–1627. [Google Scholar] [CrossRef]
- Xiaogang, R.; Wenjing, Y.; Jing, H.; Peiyuan, G.; Wei, G. Monocular Depth Estimation Based on Deep Learning: A Survey. In Proceedings of the 2020 Chinese Automation Congress (CAC), Shanghai, China, 6–8 November 2020; pp. 2436–2440. [Google Scholar] [CrossRef]
- Ming, Y.; Meng, X.; Fan, C.; Yu, H. Deep learning for monocular depth estimation: A review. Neurocomputing 2021, 438, 14–33. [Google Scholar] [CrossRef]
- Doherty, K.; Fourie, D.; Leonard, J. Multimodal Semantic SLAM with Probabilistic Data Association. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 2419–2425. [Google Scholar] [CrossRef]
- Cao, Y.; Hu, L.; Kneip, L. Representations and Benchmarking of Modern Visual SLAM Systems. Sensors 2020, 20, 2572. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; Liu, M.; Meng, M.Q.H. Improving RGB-D SLAM in dynamic environments: A motion removal approach. Robot. Auton. Syst. 2017, 89, 110–122. [Google Scholar] [CrossRef]
- Sun, Y.; Liu, M.; Meng, M.Q.H. Motion removal for reliable RGB-D SLAM in dynamic environments. Robot. Auton. Syst. 2018, 108, 115–128. [Google Scholar] [CrossRef]
- Xiao, L.; Wang, J.; Qiu, X.; Rong, Z.; Zou, X. Dynamic-SLAM: Semantic monocular visual localization and mapping based on deep learning in dynamic environment. Robot. Auton. Syst. 2019, 117, 1–16. [Google Scholar] [CrossRef]
- Bescos, B.; Campos, C.; Tardós, J.D.; Neira, J. DynaSLAM II: Tightly-Coupled Multi-Object Tracking and SLAM. IEEE Robot. Autom. Lett. 2021, 6, 5191–5198. [Google Scholar] [CrossRef]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Algarve, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar] [CrossRef] [Green Version]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Handa, A.; Whelan, T.; McDonald, J.; Davison, A.J. A benchmark for RGB-D visual odometry, 3D reconstruction and SLAM. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 1524–1531. [Google Scholar] [CrossRef] [Green Version]
- Whelan, T.; Kaess, M.; Johannsson, H.; Fallon, M.; Leonard, J.J.; McDonald, J. Real-time large-scale dense RGB-D SLAM with volumetric fusion. Int. J. Robot. Res. 2015, 34, 598–626. [Google Scholar] [CrossRef] [Green Version]
- Schubert, D.; Goll, T.; Demmel, N.; Usenko, V.; Stückler, J.; Cremers, D. The TUM VI Benchmark for Evaluating Visual-Inertial Odometry. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1680–1687. [Google Scholar] [CrossRef] [Green Version]
- RGB-D SLAM Dataset and Benchmark. Available online: https://vision.in.tum.de/data/datasets/rgbd-dataset (accessed on 21 January 2022).
- KITTI-360. Available online: http://www.cvlibs.net/datasets/kitti/ (accessed on 21 January 2022).
- ICL-NUIM. Available online: https://www.doc.ic.ac.uk/~ahanda/VaFRIC/iclnuim.html (accessed on 21 January 2022).
- The EuRoC MAV Dataset. Available online: https://projects.asl.ethz.ch/datasets/doku.php?id=kmavvisualinertialdatasets (accessed on 21 January 2022).
- Monocular Visual Odometry Dataset. Available online: http://vision.in.tum.de/mono-dataset (accessed on 21 January 2022).
- Visual-Inertial Dataset. Available online: https://vision.in.tum.de/data/datasets/visual-inertial-dataset (accessed on 21 January 2022).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Type | Map Density | Global Optim. * | Loop Closure | Embed. Implem. ** | Availability |
|---|---|---|---|---|---|---|
| MonoSLAM | Feature-based | Sparse | No | No | [34,35] | [50] |
| PTAM | Feature-based | Sparse | Yes | No | [51] | [52] |
| DTAM | Direct | Dense | No | No | [39] | [53] |
| SVO | Hybrid | Sparse | No | No | [40] | [54] |
| LSD | Direct | Semi-dense | Yes | Yes | [29,43] | [55] |
| ORB-SLAM | Feature-based | Sparse | Yes | Yes | [46,47] | [56] |
| CNN-SLAM | Direct | Semi-dense | Yes | Yes | - | [57] |
| DSO | Direct | Sparse | No | No | - | [58] |
| Method | Type | Map Density | Global Optim. * | Loop Closure | Embed. Implem. ** | Availability |
|---|---|---|---|---|---|---|
| MSCKF | Filtering-based | Sparse | No | No | [65] | [78,79] |
| OKVIS | Optimization-based | Sparse | No | No | [65,68] | [80] |
| ROVIO | Filtering-based | Sparse | No | No | [65] | [81] |
| VINS | Optimization-based | Sparse | Yes | Yes | [65,74] | [82] |
| VIORB | Optimization-based | Sparse | Yes | Yes | - | - |
| VI-DSO | Optimization-based | Sparse | No | No | - | [83] |
| ORB-SLAM3 | Optimization-based | Sparse | Yes | Yes | - | [84] |
| Method | Tracking Method | Map Density | Loop Closure | Embed. Implem. * | Availability |
|---|---|---|---|---|---|
| KinectFusion | Direct | Dense | No | [92,93] | [97] |
| SLAM++ | Hybrid | Dense | Yes | - | - |
| RGBDSLAMv2 | Feature-based | Dense | Yes | - | [98] |
| DVO | Direct | Dense | Yes | - | [99] |
| ORB-SLAM 2.0 | Feature-based | Dense | Yes | - | [56] |
| Dataset | Year | Env. * | Platform | Sensor System | Ground-truth | Availability |
|---|---|---|---|---|---|---|
| TUM RGB-D | 2012 | Indoor | Robot/Handheld | RGB-D camera | Motion capture | [133] |
| KITTI | 2013 | Outdoor | Car | Stereo-cameras | INS/GPS | [134] |
| 3D laser scanner | ||||||
| ICL-NUIM | 2014 | Indoor | Handheld | RGB-D camera | 3D surface model | [135] |
| SLAM estimation | ||||||
| EuRoC | 2016 | Indoor | MAV | Stereo-cameras | Total Station | [136] |
| IMU | Motion capture | |||||
| TUM MonoVO | 2016 | Indoor/Outdoor | Handheld | Non-stereo cameras | - | [137] |
| TUM VI | 2018 | Indoor/Outdoor | Handheld | Stereo-camera | Motion capture | [138] |
| IMU | (partially) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Macario Barros, A.; Michel, M.; Moline, Y.; Corre, G.; Carrel, F. A Comprehensive Survey of Visual SLAM Algorithms. Robotics 2022, 11, 24. https://doi.org/10.3390/robotics11010024
Macario Barros A, Michel M, Moline Y, Corre G, Carrel F. A Comprehensive Survey of Visual SLAM Algorithms. Robotics. 2022; 11(1):24. https://doi.org/10.3390/robotics11010024
Chicago/Turabian StyleMacario Barros, Andréa, Maugan Michel, Yoann Moline, Gwenolé Corre, and Frédérick Carrel. 2022. "A Comprehensive Survey of Visual SLAM Algorithms" Robotics 11, no. 1: 24. https://doi.org/10.3390/robotics11010024
APA StyleMacario Barros, A., Michel, M., Moline, Y., Corre, G., & Carrel, F. (2022). A Comprehensive Survey of Visual SLAM Algorithms. Robotics, 11(1), 24. https://doi.org/10.3390/robotics11010024