1. Introduction
Evolutionary robotics [
1,
2] is an established technique for synthesizing robots’ behaviors that are difficult to derive analytically. The large majority of works carried in this area to date, however, focused on development of a single behavior only.
The capacity to exhibit multiple behaviors constitutes a key aspect of animal behavior and can play a similar important role for autonomous robots. Indeed, all organisms display a broad repertoire of behaviors. More precisely, in most of the cases the behavior of natural organism is organized in functionally specialized subunits governed by switch and decision points [
3].
In this paper we investigate how standard evolutionary robotics methods can be extended to support the evolution of multiple behaviors.
The evolution of multiple behavior presents difficulties and opportunities. The difficulties originate from the fact that the processes that lead to the development of multiple behaviors can interfere among themselves. More specifically, the variations that are adaptive with respect to one behavior can be counter-adaptive with respect to another behavior. Consequentially, the retention of variations that are adaptive with respect to one behavior can reduce the ability to perform another required behavior. The opportunities originate from the fact that traits supporting the production of a given behavior can be reused to produce another required behavior [
4] and consequently can facilitate the development of the latter behavior.
A possible way to reduce the problem caused by interferences consists in reducing the level of pleiotropy by fostering modular solutions. The term pleiotropy refers to traits that are responsible for multiple functions and or multiple behaviors. The hypothesis behind this approach is that the level of pleiotropy can be reduced by dividing the neural network controllers in modules responsible for the production of different behaviors since the variation affecting a module will tend to alter only the corresponding behavior [
5,
6,
7,
8]. Clearly, however, the reduction of pleiotropy also reduces the opportunities that can be gained from the possibility to re-use traits evolved for one behavior for the production of another required behavior [
4]. In addition, neural modularity does not necessarily reduce pleiotropy (see for example Calabretta et al. [
5]). This can be explained by considering that the behavior of the robot is not simply a product of the brain of the robot. The behavior of a robot is a dynamical process that originate from the continuous interaction between the robot and the environment mediated by the characteristics of the brain and of the body of the robot. Consequently, there is not necessarily a one-to-one correspondence between neural modules and functional sub-units of the robot’s behavior.
Several other studies investigate the role of modularity in classification and regression problems [
9,
10,
11] and in the context of genetic regulatory networks [
12,
13]. However, the results obtained in these domains do not necessarily generalize to the evolution of embodied agents for the reasons described above.
A second possible strategy that can be used to reduce the problem caused by the interferences consists in using an incremental approach in which the robot is first encouraged to develop a first behavior and only later to develop additional behaviors, one at a time [
14,
15,
16]. Eventually, the traits supporting the production of the first behaviors can be frozen during the development of successive behaviors, to avoid interferences. However, also this strategy reduces the opportunity for traits reuse. Indeed, the traits supporting the production of behaviors acquired during later stages cannot be reused for the production of behavior acquired earlier. Another weakness of this strategy is that it requires the intervention of the experimenter for the design and implementation of the incremental training process.
In this paper we explore a third strategy that consists in fostering the retention of variations that are adaptive with respect to all relevant behaviors. We evaluate this strategy in the context of standard evolutionary algorithms, that operate on the basis of selective reproduction and variation, and in the context of modern evolutionary strategies [
17]. The latter algorithms operate by estimating the gradient of the expected fitness on the basis of the fitness collected and the variations received by individuals and by moving the population in the direction of the gradient. In the former case we foster the selection of variations adaptive to all behaviors by treating the performance on each behavior as separate objectives optimized through a multi-objective optimization algorithm [
18,
19]. In the latter case, we foster the selection of variations adaptive to all behaviors by calculating and using multi-objective fitness gradients.
The obtained results demonstrate how the usage of a modern evolutionary strategy combined with multi-objectives gradients permits to achieve very good results on state-of-the-art benchmark problems.
The efficacy of multi-objective optimization algorithms was already investigated in evolutionary robotics experiments involving fitness function with multiple components [
20,
21]. For example, in the case of robots evolved for the ability to navigate in an environment that are rewarded for: (i) the ability to move as fast as possible, (ii) the ability to move as straight as possible, and (iii) the ability to keep the activation of their infrared sensors as low as possible. Rather than computing the fitness on the basis of the sum of these three components, the components can be treated as separate objectives optimized through a multi-objective algorithm. Overall, these studies demonstrate that the usage of multi-objective optimization permits to evolve a more varied set of behaviors and reduce the probability to converge on local minima, in the case of experiments with multicomponent fitness functions. In the case of the first method proposed in this paper, instead, we applied a multi-objective optimization algorithm to the evolution of robots that should produce multiple behaviors. In our case, the objectives to be optimized correspond to the alternative fitness functions that are used in the contexts that require the exhibition of alternative behaviors.
The usage of evolutionary strategies that operate on the basis of multiple gradients was also investigated in previous studies [
20,
21]. This technique has been used to combine a true gradient, that is expensive to compute, with a surrogate gradient that constitute an approximation of the true gradient but that is easier to compute [
21] or to combine the current gradient with historical estimated gradients [
20]. In the case of the second method proposed in this paper, instead, we apply this method to evolution of multiple behaviors. Consequently, we compute and use the gradients calculated with respect to the behaviors to be produced.
2. Method
To investigate the evolution of multiple behaviors we considered simulated neuro-robots evolved for the ability to produce two different behaviors in two different environmental conditions. We assume that the environmental conditions that indicate the opportunity to exhibit the first or the second behaviors are well differentiated. This is realized by including in the observation vector an “affordance” pattern that assume different values during episodes in which the robot should elicit the first or the second behavior. In the following sections we describe the adaptive problems, the neural network of the robots, and the evolutionary algorithms.
2.1. The Adaptive Problems
The problems chosen are an extended version of Pybullet locomotor problems [
22]. These environments represent a free and more realistic implementation of the MuJoCo locomotor problems designed by Todorov, Erez and Tassa [
23] and constitute a widely used benchmark for continuous control domains. We choose these problems since they are challenging and well-studied. The complexity of the problems is important, since the level of interference between the behaviors correlate with the complexity of the control rules that support the production of the required behaviors. Previous works involving situated agents that studied the evolution of multiple behaviors considered the following problems: (i) pill and ghost eating in a pac-man game [
6], (ii) reaching a target position with a 2D three-segments arm [
8,
14] (iii) an inverted pendulum, a cart-pole balancing, and a single legged waling task [
4], (iv) walking and navigation in simple multi-segments robots [
15], (v) wheeled robot vacuum-cleaning an indoor environment [
7], and (vi) wheeled robots provided with a 2 DOFs gripper able to find, pick-up and release cylinders [
5].
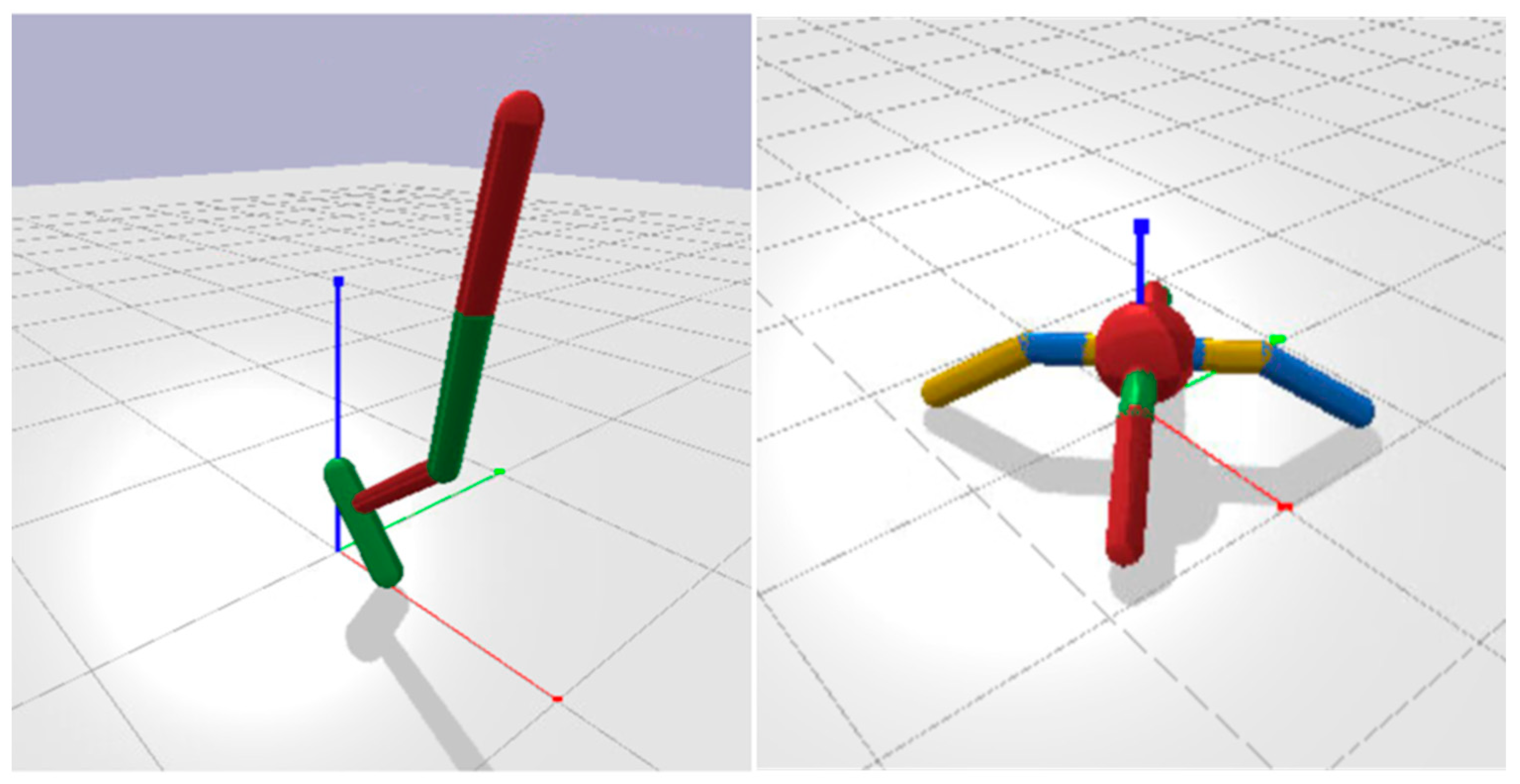
The locomotors involve simulated robots composed by several cylindrical body parts connected through actuated hinge joints that can be trained for the ability to jump or walk toward a target destination as fast as possible. In particular, we selected the Hopper and the Ant problems. The Hopper robot has a single leg formed by a femur, a tibia and a foot that can jump (
Figure 1, left). The Ant robot has a spherical torso and four evenly spaced legs formed by a femur and a tibia (
Figure 1, right).
In our extended version, the hopper is trained for jumping toward the target as fast as possible or for jumping vertically as high as possible while remaining in the same position. The Ant is trained for the ability to walk 45 degrees left or right with respect to its frontal orientation.
In the case of the Hopper, this is realized by using the following fitness functions:
where
fitness1 and
fitness2 are the fitness functions used during the evaluation episode in which the agent should exhibit the first or the second behavior, respectively,
d is the distance with respect to the target,
h is the height of the torso with respect to the ground, and
t is time.
In the case of Ant, we use the following fitness functions:
where fitness
1 and fitness
2 are the fitness functions used during the evaluation episode in which the agent should exhibit the first or the second behavior, Δ
p is the Euclidean distance between the position of the torso on the plane at time
t and
t-1, α is the angular offset between the frontal orientation of the Ant and the angle of movement during the current step,
gl is the number of joint currently located on a limit, and
a is the action vector (i.e., the activation of the motor neurons, see the next section). The bonus of 0.01 and the costs for the number of joints at their limits and for the square of the output torque are secondary fitness components that facilitates the evolution of walking behaviors (see Pagliuca, Milano and Nolfi [
17]).
2.2. The Neural Network
The controller of the robot is constituted by a feedforward neural network with 17 and 30 sensory neurons (in the case of the Hopper and the Ant, respectively), 50 internal neurons, and 3 and 8 motor neurons (in the case of the Hopper and the Ant, respectively). The sensory neurons encode the orientation and the velocity of the robot, the relative orientation of the target destination, the position and the velocity of the joints, the contact sensors situated on the foot of the Hopper and on the terminal part of the four legs of the Ant, and the affordance vector. The affordance vector is set to [0.0 0.5] and to [0.5 0.0] during evaluation episodes in which the robots are rewarded with the first or the second fitness function illustrated above, respectively. The motor neurons encode the intensity and the direction of the torque applied by motors controlling the 3 and 8 actuated joints of the Hopper and of the Ant, respectively.
The internal and output neurons are updated by using tanh and linear activation functions, respectively. The state of the motor neurons is perturbed each step with the addition of Gaussian noise with mean 0.0 and standard deviation 0.01. The connection weights of the neural networks are encoded in free parameters and evolved. The number of connection weights is 1053 and 1958, in the case of the Hopper and of the Ant, respectively.
2.3. The Evolutionary Algorithms
We evolved the agents by using two state-of-the-art methods selected among standard evolutionary algorithms, that operate on the basis of selective reproduction and variation, and modern evolutionary algorithms, that estimated the gradient of the expected fitness on the basis of the fitness collected and the variations received by individuals and move the population in the direction of the gradient. Moreover, we designed and tested a variant of each algorithm designed to enable the retention of variations producing progress with respect to all target behaviors.
The first method is the steady state algorithm (SSA) described in Pagliuca, Milano and Nolfi [
24], see the pseudocode below (left). The procedure starts by creating a population of vectors that encode the parameters of a corresponding population of neural networks (line 1). Then, for a certain number of generations, the algorithm evaluates the fitness of the individuals forming the population (line 3), ranks the individual of the population on the basis of the average fitness obtained during two episodes evaluated with the two fitness functions (line 5), and replaces the parameters of the worse half individuals with varied copies of the best half individuals (lines 7–9). In 80% of the cases, the parameters of the new individuals are generated by crossing over each best individual with a second individuals selected randomly among the best half. The crossover is realized by cutting the vectors of parameters in two randomly selected points. In the remaining 20% of the cases, the parameters of the new individual are simply a copy of the parameter of the corresponding best individuals. (line 7). The parameters are then varied by adding a random Gaussian vector with mean 0.0 and variance 0.02 (line 8).
The variant Algorithm 1 designed for the evolution of multiple behaviors is the multi-objective steady state algorithm (MO-SSA), see the pseudocode below (right). In this case the ranking is made by ranking the individuals on the basis of the Pareto fronts to which they belong. The Pareto fronts are computed on the basis of the fitness obtained during the production of behavior 1 and 2 (line 5). The MO-SSS algorithm thus retain in the population the individuals that achieve the best performance with respect to behavior 1 or 2. This implies that the best individuals with respect to one behavior are retained even if they perform very poorly on the other behavior.
| Algorithm 1: designed for the evolution of multiple behaviors is the multi-objective steady state algorithm (MO-SSA). |
| SSA | MO-SSA |
| σ = 0.02: mutation variance | σ = 0.02: mutation variance |
| μ = 0.8: crossover rate | μ = 0.8: crossover rate |
| λ = 40: population size | λ = 40: population size |
| : population | : population |
| fn(): fitness function for behavior n | fn(): fitness function for behavior n |
| | |
| 1 initialize : | 1 initialize : |
| 2forg = 1, 2, … do | 2forg = 1, 2, … do |
| 3 for j = 1, 2, … do | 3 for j = 1, 2, … do |
| 4 evaluate score: ← f12( ) | 4 evaluate score: ← f12( ) |
| 5 rank individuals by average fitness: u = ranks(s) | 5 rank individuals by pareto fronts: u = ranks(s) |
| 6 for l = 1, 2, … do | 6 for l = 1, 2, … do |
| 7 Φ = crossover( or Φ= | 7 Φ = crossover( or Φ= |
| 8 sample mutation vector: ε ~ Ν(0, I) ∗ σ | 8 sample mutation vector: ε ~ Ν(0, I) ∗ σ |
| 9
| 9
|
The second method is the natural evolutionary strategy method (ES) proposed by Salimans et al. [
25], see the pseudocode below (left). The algorithm evolves a distribution over policy parameters centered on a single parent θ composed of λ2 individuals. At each generation, the algorithm generates the gaussian vectors ε that are used to perturb the parameters (line 4), and evaluate the offspring (lines 4, 5). To improve the accuracy of the fitness estimation the algorithm generates mirrored samples [
26], i.e., generates λ couples of offspring receiving opposite perturbations (lines 4, 5). The offspring are evaluated for two episodes for the ability to produce the two different behaviors (lines 5, 6). The average fitness values obtained during the two episodes are then ranked and normalized in the range [−0.5, 0.5] (line 7). This normalization makes the algorithm invariant to the distribution of fitness values and reduce the effect of outliers. The estimated gradient g is then computed by summing the dot product of the samples ε and of the normalized fitness values (line 8). Finally, the gradient is used to update the parameters of the parent through the Adam [
27] stochastic optimizer (line 9).
The variant Algorithm 2 designed for the evolution of multiple behaviors is the multi-objective evolutionary strategy (MO-ES), see the pseudocode below (right). In this case the algorithm compute two gradients (lines 3 and 9) by first evaluating the offspring for the ability to produce the behavior 1 and then behavior 2 (lines 6–7). The parameters of the parent are then updated by using the sum of the two gradients (line 10). The MO-ES algorithm thus moves the population in the directions that maximize the performance on both behavior 1 and 2, independently from the relative gain in performance that is obtained with respect to each behavior.
| Algorithm 2: The variant designed for the evolution of multiple behaviors is the multi-objective evolutionary strategy (MO-ES). |
| ES | MO-ES |
| σ = 0.02: mutation variance | σ = 0.02: mutation variance |
| λ = 20: half population size (total population size = 40) | λ = 20: half population size (total population size = 40) |
| θ: policy parameters | θ: policy parameters |
| fn(): fitness function for behavior n | fn(): fitness function for behavior n |
| optimizer = Adam | optimizer = Adam |
| | |
| 1 initialize θ0 | 1 initialize θ0 |
| 2forg = 1, 2, … do | 2forg = 1, 2, … do |
| | 3 for b = 1, 2 |
| 3 fori = 1, 2, … λ do | 4 fori = 1, 2, … λ do |
| 4 sample noise vector: εi ~ Ν(0, I) | 5 sample noise vector: εi ~ Ν(0, I) |
| 5 evaluate score: ← f12(θt−1 + σ ∗ εi) | 6 evaluate score: ← fb(θt−1 + σ ∗ εi) |
| 6 evaluate score: ← f12(θt−1 − σ ∗ εi) | 7 evaluate score: ← fb(θt−1 − σ ∗ εi) |
| 7 compute normalized ranks: u = ranks(s), ui ∈ [−0.5,0.5] | 8 compute normalized ranks: u = ranks(s), ui ∈ [−0.5,0.5] |
| 8 estimate gradient: gt ← | 9 estimate gradient: gb ← |
| 9 θg= θg−1 + optimizer(g) | 10 θg= θg−1 + optimizer(g1 + g2) |
The evolutionary process is continued until total of 107 evaluation steps are performed. The episodes last up to 500 steps and are terminated prematurely if the agents fall down. The initial posture of the agents is varied randomly at the beginning of each evaluation episode. The evolutionary process of each experimental condition is replicated 16 times.
The state of the actuators is perturbed with the addition of stochastic random noise with standard deviation 0.01 and average 0.0. The addition of noise makes the simulation more realistic and facilitates the transfer of solutions evolved in simulation in the real environment. The new methods proposed in this article do not alter the way in which the robots are evaluated with respect to standard method. Consequently, they do not alter the chance that the results obtained in simulation can be transferred in the real environment.
3. Results
Figure 2 and
Figure 3 display the average performance of the best agents evolved with the SSA and MO-SSA algorithms in the case of the Hopper and Ant problems, respectively (see the left side of the Figures). The video displaying the representative replications of the experiments are available online (see
Section 5). As can be seen, the performance of the evolved robots is relatively good in the case of the Hopper (
Figure 2) but rather poor in the case of the Ant (
Figure 3). The performance obtained with the standard and multi-objective version of the algorithms, does not differ statistically, both in the case of the Hopper and in the case of the Ant (Mann–Whitney U test,
p-value > 0.05).
To measure the fraction of agents capable to achieve sufficiently good performance during the exhibition of both behavior we post-evaluated the best evolved agents for 5 episodes on each behavior and we counted the fraction of agents that exceed a minimum threshold on both behaviors. The evolved Hopper robots exceed a minimum threshold of 700 in 5/16 and 2/16 replications in the case of the SSA and MO-SSA algorithms, respectively (see
Table 1). The evolved Ant robots exceed a minimum threshold of 400 in 0/16 and 0/16 replications in the case of the SSA and MO-SSA algorithms, respectively (see
Table 2).
The variation of performance during the evolutionary process is shown in
Figure 4 and
Figure 5 (top Figures).
The videos displaying a representative replication of the experiments are available online (see
Section 5). As can be seen, the performance of the evolved robots is quite good both in the case of the Hopper (
Figure 2) and the Ant (
Figure 3), and is significantly better than the performance obtained with the SSA and MO-SSA algorithms (Mann-Whitney U test with Bonferrori correction,
p-value < 0.05). The MO-ES algorithm is significantly better than the ES method (Mann-Whitney U test,
p-value < 0.05).
The evolved Hopper robots exceed a minimum threshold of 700 in 10/16 and 11/16 replications in the case of the ES and MO-ES algorithms, respectively (see
Table 1). The evolved Ant robots exceed a minimum threshold of 400 in 1/16 and 10/16 replications in the case of the ES and MO-ES algorithms, respectively (see
Table 2).
The variation of performance during the evolutionary process is shown in
Figure 4 and
Figure 5 (bottom side). As can be seen, in the case of the Hopper the MO-ES algorithm outperform the ES algorithm from the beginning of the evolutionary process. In the case of the Ant, instead, the MO-ES algorithm outperform the ES algorithm during in the second half of the evolutionary process.
4. Discussion
We investigated how standard evolutionary robotics methods can be extended to support the evolution of multiple behaviors. More specifically we investigated whether forcing the retention of variations that are adaptive with respect to all required behaviors facilitate the concurrent development of multiple behavioral skills.
We considered both standard evolutionary algorithms, in which the population is formed by varied copies of selected individuals, and modern evolutionary strategies, in which the population is distributed around a single parent and in which the parameters of the parent are moved in the direction of the gradient of the expected fitness. The retention of variations adaptive with respect to all behaviors should be realized in a different way depending on the algorithm used. In the case of standard evolutionary algorithms, it can be realized by using a multi-objective optimization technique, i.e., by selecting the individuals located in the first Pareto fronts of the multidimensional space of the fitness of multiple behaviors. In the case of modern evolutionary strategies, it can be realized by computing multiple gradients and by moving the center of the population in the directions corresponding to the vector sum of the gradients. This method to pursue multi-objective optimization in evolutionary strategies is original, as far as we know.
We evaluated the efficacy of the two methods on two extended versions of the Hopper and Ant Pybullet locomotor problems in which the Hopper is evolved for the ability to jump toward a target destination as fast as possible or to jump on the place as high as possible and in which the Ant is evolved for the ability to walk 45 degrees left or right with respect to its current orientation.
The obtained results indicate that Salimans et al. [
25] evolutionary strategy extended with multiple gradients calculation permits to obtain close to optimal performance for both problems. The performance obtained are statistically better than the control condition that rely on a single gradient and statistically better than the results obtained with the other algorithm considered. Moreover, the analysis of the evolved robots demonstrate that they manage to display sufficiently good performance on both behaviors in most of the replications.
In the case of the standard algorithm, instead, the selection of the individuals located on the first Pareto fronts does not produce better performance with respect to the control condition in which the robots are selected on the basis of the average performance obtained during the production of the two behaviors. The analysis of the evolved robots indicate that they are able to achieve sufficiently good performance on both behaviors only in a minority of the replications in the base of the Hopper and in none of the replications in the case of the Ant.
5. Conclusions
We introduced a variation of a state-of-the-art evolutionary strategy [
25] that support the evolution of multiple behaviors in evolving robots. The new MO-ES algorithm moves the population by using the vector sum of the gradients of the expected fitness computed with respect to each behavior. The obtained results demonstrated that the method is effective and produce significantly better results than the standard ES algorithm. This new method also outperforms significantly the other two algorithms considered: a standard steady state algorithm (SSA) and a multi-objective steady state algorithm (MO-SSA) that operates by selecting the individuals located on the first pareto-fronts of the objectives of the behaviors.
The relative efficacy of the algorithm proposed with respect to alternative methods remain to be investigated in future works. Carrying out a quantitative comparison can result difficult, due to the specificity of the requirements imposed by each method, but can provide valuable insights.
A second aspects that deserves future investigation is the scalability of the method proposed with respect to the number of behaviors and to the complexity of the behaviors.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}