A Computational Toxicology Approach to Screen the Hepatotoxic Ingredients in Traditional Chinese Medicines: Polygonum multiflorum Thunb as a Case Study

Abstract
1. Introduction
2. Materials and Methods
2.1. Data Set
2.2. Descriptors
2.3. Feature Selection
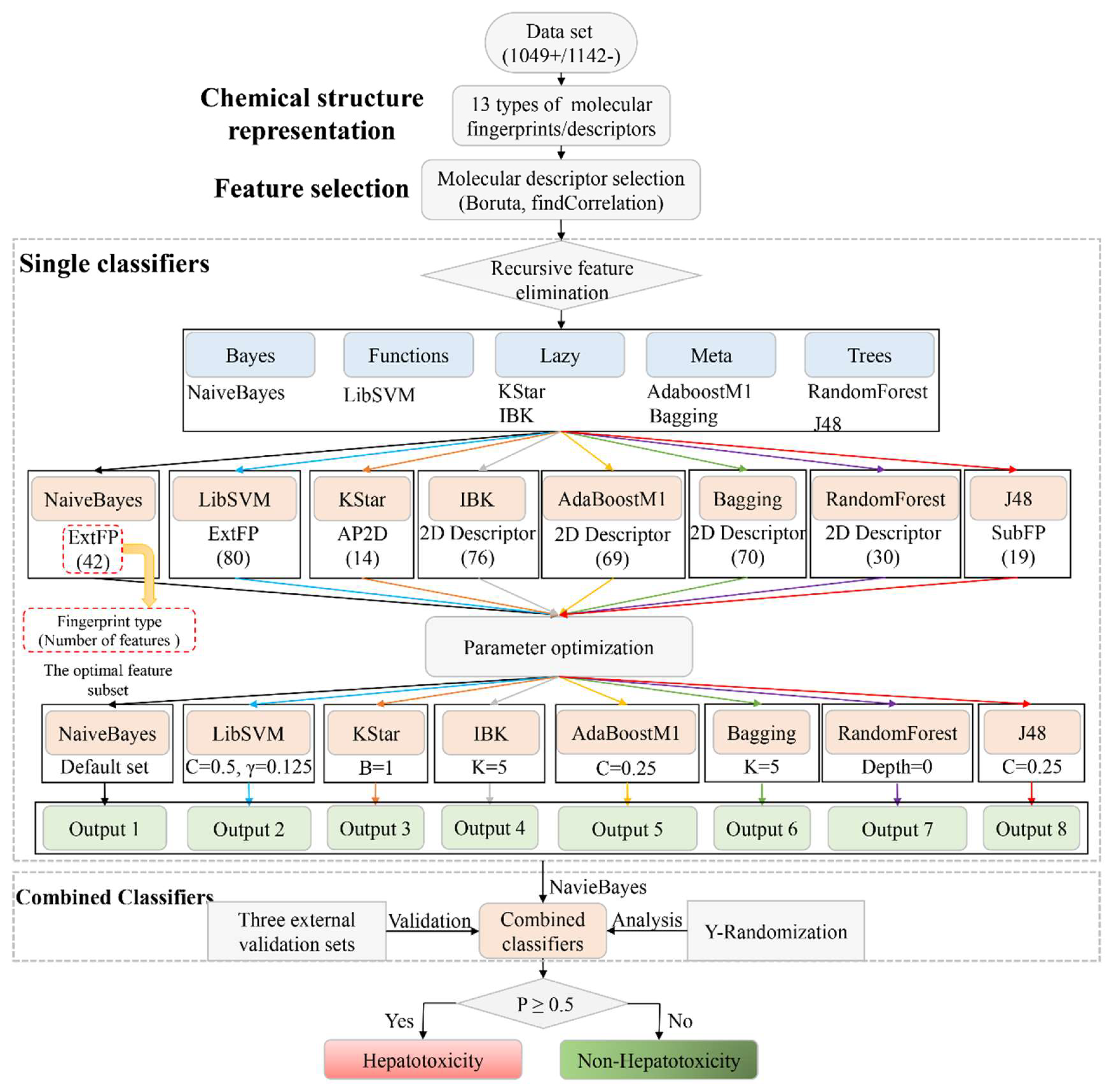
2.4. Machine Learning Models
- (1)
- Single classifiers: For each type of molecular fingerprint/descriptor, the non-redundant features listed in Table 1 were used as input to implement the eight machine learning algorithms selected.Then, RFE was performed to identify the optimal feature subset for each machine learning algorithm. We updated the feature subset of each type of molecular fingerprint/descriptor according to the feature rankings provided by the RFE method. We removed the lowest-ranked feature, and the remaining features were used as input to train the eight machine learning algorithms again. This step was repeated until the number of features was reduced to 1. As a result, a total of 677 models were developed for each machine learning algorithm. Then comparisons among those models were conducted, by which we attempted to identify the optimal feature subset for each machine learning algorithm. For each machine learning algorithm, the feature subset generating the highest average value of area under curve (AUC) and accuracy (ACC) was selected as the optimal feature subset. Of note, herein, all of the machine learning algorithms were implemented with the default parameter settings provided by WEKA. The optimal feature subsets for all of the eight machine learning algorithms are available in Table 3 and are detailed in Supplementary File 1 (Optimal feature subsets).
- (2)
- Parameter optimization: In the development of the single classifiers, CVParameterSelection and GridSearch, two commonly used parameter optimization strategies, were adopted to determine the optimal parameter for each machine learning algorithm. The detailed parameter optimization information is provided in Table 2. All of the parameter optimization methods were implemented against WEKA within 10-fold cross validation.
- (3)
- Combined classifiers: It has been proven that the combined classifiers strategy outperformed many classic classifier-fusion techniques (such as mean, maximum, and majority vote) [55]. In this work, the eight best single classifiers were utilized to predict the training sets. For each compound in the training set, eight predicted results (positive/negative) were provided by the eight best single classifiers. Then, those eight predicted results were defined as new descriptors and used as input to train NaiveBayes algorithm. As a result, a combined classifier focused on predicting DILI was developed.
- (4)
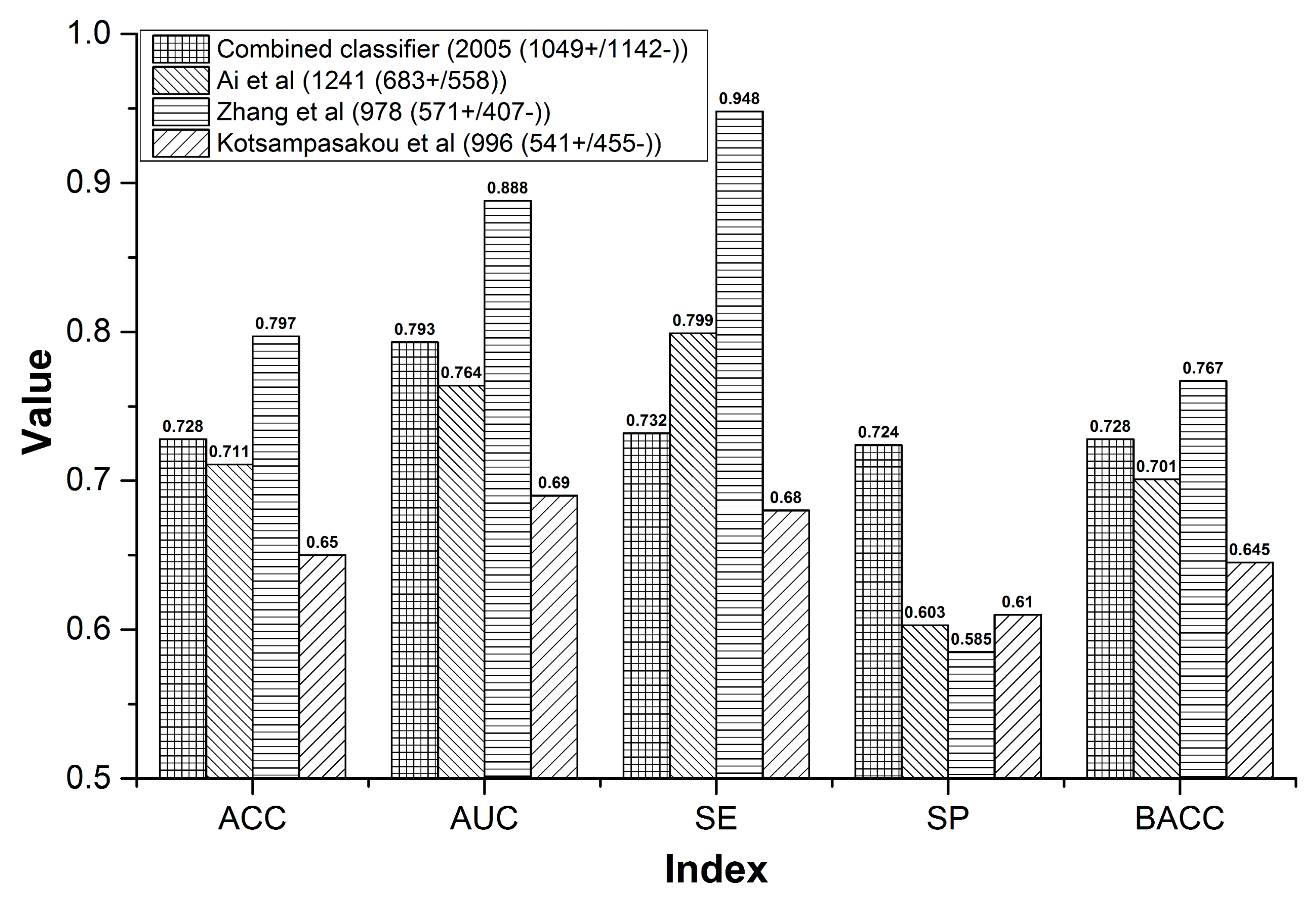
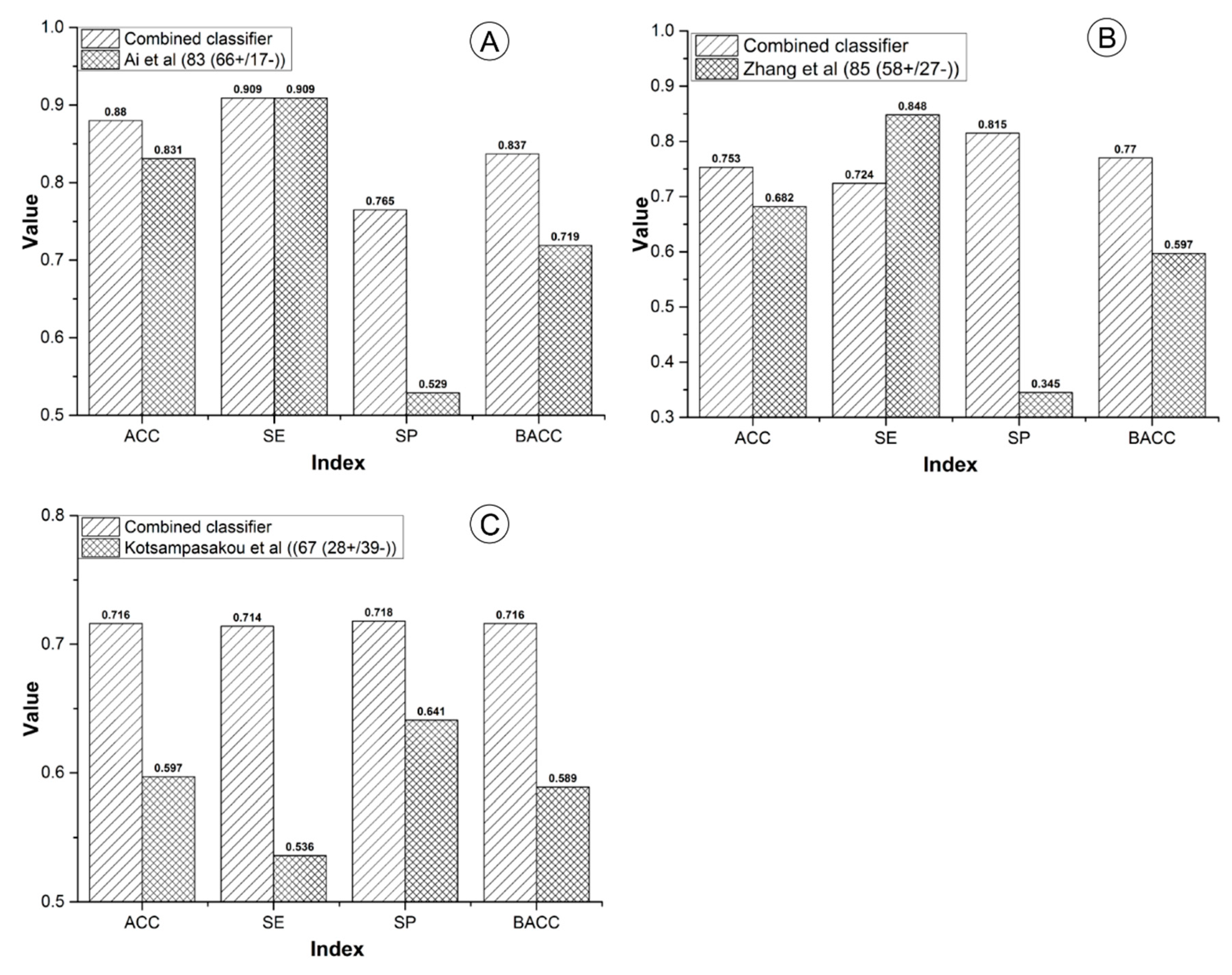
- External Validation: By integrating the three external validation sets collected by Ai et al. [37], Zhang et al. [49], and Kotsampasakou et al. [38], an integrated external validation set was acquired and utilized to test the generalization ability of our model. In addition, to investigate the model’s robustness and statistical significance, Y-randomization analysis was performed [56].
2.5. Performance Metrics
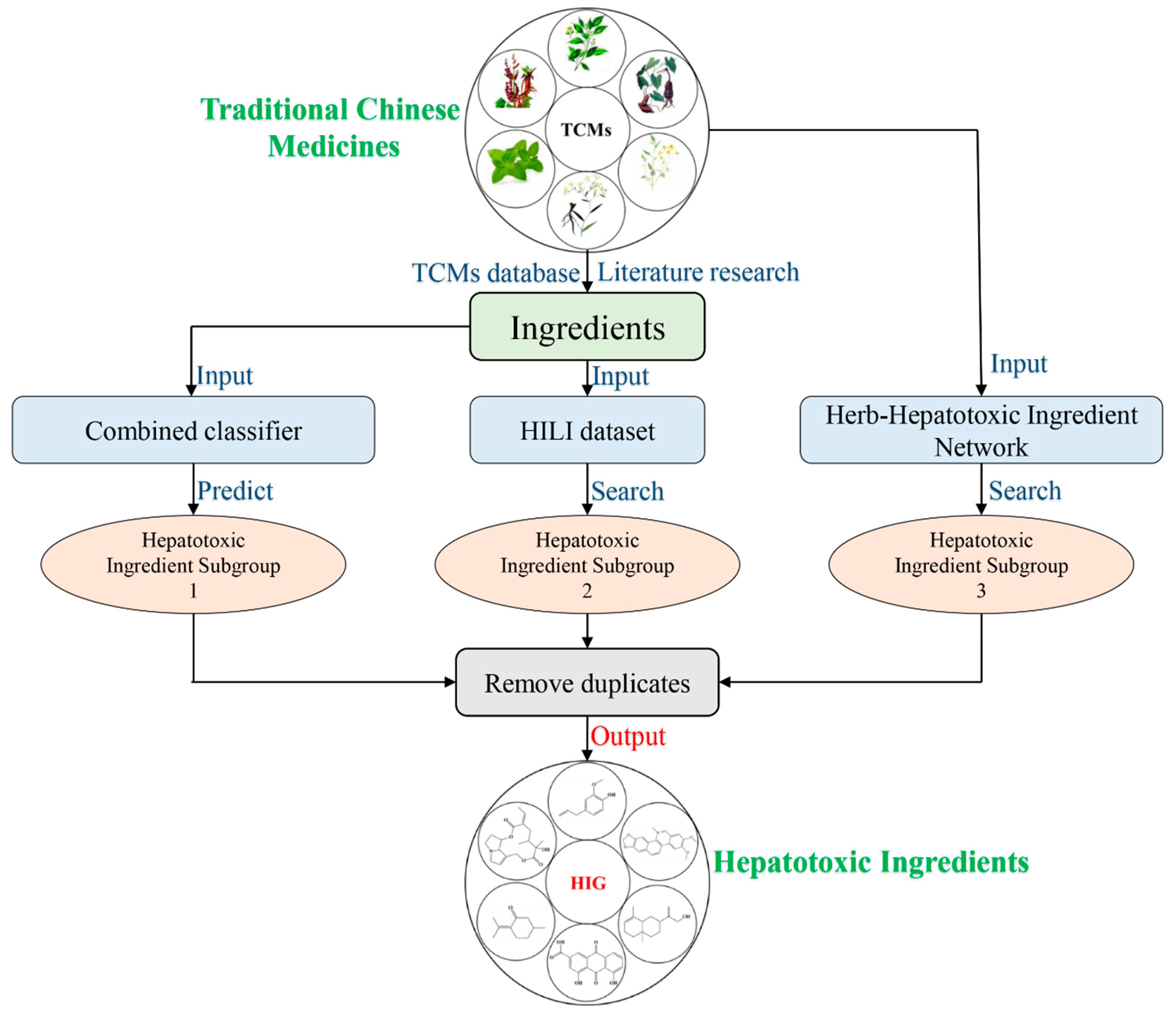
2.6. Herb-Hepatotoxic Ingredient Network
3. Results
3.1. The Construction of In Silico Models for Predicting Drug-Induced Liver Injury
3.1.1. Single Classifiers
3.1.2. Combined Classifier
3.1.3. Comparison to Prior Studies
3.2. A Computational Toxicology Approach to Screening the Hepatotoxic Ingredients in TCMs: Polygonum multiflorum Thunb as a Case
3.2.1. The Computational Toxicology Approach
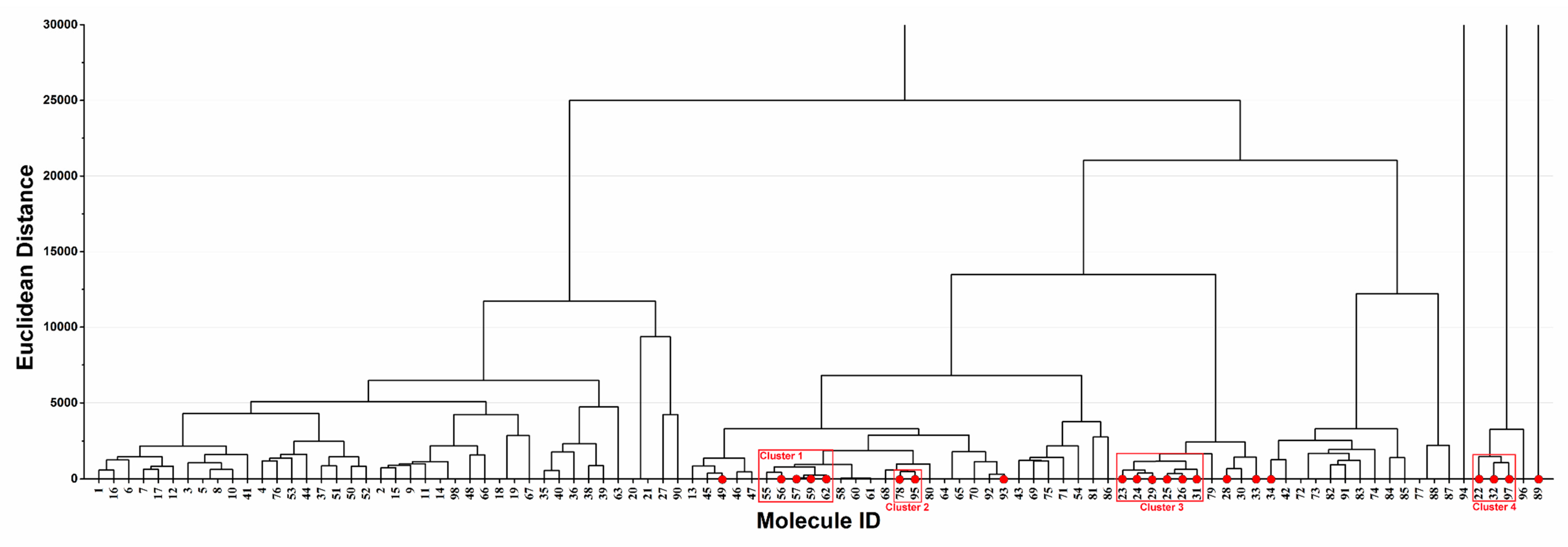
3.2.2. Polygonum multiflorum Thunb as a Case
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| TCMs | Traditional Chinese Medicines |
| DILI | Drug-induced liver injury |
| PmT | Polygonum multiflorum Thunb |
| QSAR | Quantitative structure-activity relationship |
| CTD | Comparative Toxicogenomics Database |
| AUC | Area under curve |
| ACC | Accuracy |
| SE | Sensitivity |
| SP | Specificity |
| BACC | Balanced accuracy |
| HILI | Herb-induced liver injury |
| RFE | Recursive feature elimination |
| WEKA | Waikato Environment for Knowledge Analysis |
References
- Shad, J.A.; Chinn, C.G.; Brann, O.S. Acute hepatitis after ingestion of herbs. South Med. J. 1999, 92, 1095–1097. [Google Scholar] [CrossRef] [PubMed]
- Teschke, R.; Andrade, R.J. Drug, Herb, and Dietary Supplement Hepatotoxicity. Int. J. Mol. Sci. 2016, 17, 1488. [Google Scholar] [CrossRef] [PubMed]
- Allard, T.; Wenner, T.; Greten, H.J.; Efferth, T. Mechanisms of herb-induced nephrotoxicity. Curr. Med. Chem. 2013, 20, 2812–2819. [Google Scholar] [CrossRef] [PubMed]
- Tai, Y.T.; But, P.P.; Young, K.; Lau, C.P. Cardiotoxicity after accidental herb-induced aconite poisoning. Lancet 1992, 340, 1254–1256. [Google Scholar] [CrossRef]
- Zhang, S.N.; Li, X.Z.; Wang, Y.; Zhang, N.; Yang, Z.M.; Liu, S.M.; Lu, F. Neuroprotection or neurotoxicity? new insights into the effects of Acanthopanax senticosus harms on nervous system through cerebral metabolomics analysis. J. Ethnopharmacol. 2014, 156, 290–300. [Google Scholar] [CrossRef] [PubMed]
- Lai, M.Y.; Yang, W.C. Herb-associated carcinogenicity and chronic renal failure in Asian patients with kidney cancer and hypertension. Kidney Int. 2005, 68, 412. [Google Scholar] [CrossRef]
- Abdualmjid, R.J.; Sergi, C. Hepatotoxic botanicals - an evidence-based systematic review. J. Pharm. Pharm. Sci. 2013, 16, 376–404. [Google Scholar] [CrossRef]
- Stickel, F.; Shouval, D. Hepatotoxicity of herbal and dietary supplements: An update. Arch. Toxicol. 2015, 89, 851–865. [Google Scholar] [CrossRef]
- Teschke, R.; Larrey, D.; Melchart, D.; Danan, G. Traditional Chinese Medicine (TCM) and Herbal Hepatotoxicity: RUCAM and the Role of Novel Diagnostic Biomarkers Such as MicroRNAs. Medicines 2016, 3, 18. [Google Scholar] [CrossRef]
- Zhu, J.; Seo, J.E.; Wang, S.; Ashby, K.; Ballard, R.; Yu, D.; Ning, B.; Agarwal, R.; Borlak, J.; Tong, W.; et al. The Development of a Database for Herbal and Dietary Supplement Induced Liver Toxicity. Int. J. Mol. Sci. 2018, 19, 2955. [Google Scholar] [CrossRef]
- Byeon, J.H.; Kil, J.H.; Ahn, Y.C.; Son, C.G. Systematic review of published data on herb induced liver injury. J. Ethnopharmacol. 2019, 233, 190–196. [Google Scholar] [CrossRef] [PubMed]
- Shen, T.; Liu, Y.; Shang, J.; Xie, Q.; Li, J.; Yan, M.; Xu, J.; Niu, J.; Liu, J.; Watkins, P.B.; et al. Incidence and Etiology of Drug-Induced Liver Injury in Mainland China. Gastroenterology 2019, 156, 2230–2241. [Google Scholar] [CrossRef] [PubMed]
- Hebels, D.G.; Jetten, M.J.; Aerts, H.J.; Herwig, R.; Theunissen, D.H.; Gaj, S.; van Delft, J.H.; Kleinjans, J.C. Evaluation of database-derived pathway development for enabling biomarker discovery for hepatotoxicity. Biomark. Med. 2014, 8, 185–200. [Google Scholar] [CrossRef] [PubMed]
- Luo, J.; Ren, Y.; Gu, H.; Wu, Y.; Wang, Y. dTGS: Method for Effective Components Identification from Traditional Chinese Medicine Formula and Mechanism Analysis. Evid. Based Complement. Altern. Med. 2013, 2013, 840427. [Google Scholar] [CrossRef] [PubMed]
- Li, S. Exploring traditional chinese medicine by a novel therapeutic concept of network target. Chin. J. Integr. Med. 2016, 22, 647–652. [Google Scholar] [CrossRef] [PubMed]
- Huang, C.; Zheng, C.; Li, Y.; Wang, Y.; Lu, A.; Yang, L. Systems pharmacology in drug discovery and therapeutic insight for herbal medicines. Brief Bioinform. 2014, 15, 710–733. [Google Scholar] [CrossRef]
- Tang, H.; He, S.; Zhang, X.; Luo, S.; Zhang, B.; Duan, X.; Zhang, Z.; Wang, W.; Wang, Y.; Sun, Y. A Network Pharmacology Approach to Uncover the Pharmacological Mechanism of XuanHuSuo Powder on Osteoarthritis. Evid. Based Complement. Altern. Med. 2016, 2016, 3246946. [Google Scholar] [CrossRef]
- Zhang, Y.; Bai, M.; Zhang, B.; Liu, C.; Guo, Q.; Sun, Y.; Wang, D.; Wang, C.; Jiang, Y.; Lin, N.; et al. Uncovering pharmacological mechanisms of Wu-tou decoction acting on rheumatoid arthritis through systems approaches: Drug-target prediction, network analysis and experimental validation. Sci. Rep. 2015, 5, 9463. [Google Scholar] [CrossRef]
- Liang, X.; Li, H.; Li, S. A novel network pharmacology approach to analyse traditional herbal formulae: The Liu-Wei-Di-Huang pill as a case study. Mol. Biosyst. 2014, 10, 1014–1022. [Google Scholar] [CrossRef]
- Wang, Y.Y.; Li, J.; Wu, Z.R.; Zhang, B.; Yang, H.B.; Wang, Q.; Cai, Y.C.; Liu, G.X.; Li, W.H.; Tang, Y. Insights into the molecular mechanisms of Polygonum multiflorum Thunb-induced liver injury: A computational systems toxicology approach. Acta Pharmacol. Sin. 2017, 38, 719–732. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, Y.; Liu, Y.; Chen, C.; Xu, W.; Xiao, H. Emodin induces liver injury by inhibiting the key enzymes of FADH/NADPH transport in rat liver. Toxicol. Res. 2018, 7, 888–896. [Google Scholar] [CrossRef] [PubMed]
- Wu, L.; Chen, Y.; Liu, H.; Zhan, Z.; Liang, Z.; Zhang, T.; Cai, Z.; Ye, L.; Liu, M.; Zhao, J.; et al. Emodin-induced hepatotoxicity was exacerbated by probenecid through inhibiting UGTs and MRP2. Toxicol. Appl. Pharmacol. 2018, 359, 91–101. [Google Scholar] [CrossRef] [PubMed]
- Jiang, L.L.; Jiang, Y.; Zhao, D.S.; Fan, Y.X.; Yu, Q.; Li, P.; Li, H.J. CYP3A Activation and Glutathione Depletion Aggravate Emodin-Induced Liver Injury. Chem. Res. Toxicol. 2018, 31, 1052–1060. [Google Scholar] [CrossRef] [PubMed]
- Dong, X.; Ni, B.; Fu, J.; Yin, X.; You, L.; Leng, X.; Liang, X.; Ni, J. Emodin induces apoptosis in human hepatocellular carcinoma HepaRG cells via the mitochondrial caspasedependent pathway. Oncol. Rep. 2018, 40, 1985–1993. [Google Scholar]
- Dong, X.; Fu, J.; Yin, X.; Cao, S.; Li, X.; Lin, L.; Ni, J. Emodin: A Review of its Pharmacology, Toxicity and Pharmacokinetics. Phytother. Res. 2016, 30, 1207–1218. [Google Scholar] [CrossRef] [PubMed]
- Shi, F.; Zhao, P.; Li, X.; Pan, H.; Ma, S.; Ding, L. Cytotoxicity of luteolin in primary rat hepatocytes: The role of CYP3A-mediated ortho-benzoquinone metabolite formation and glutathione depletion. J. Appl. Toxicol. 2015, 35, 1372–1380. [Google Scholar] [CrossRef]
- Choi, Y.J.; Yoon, Y.; Choi, H.S.; Park, S.; Oh, S.; Jeong, S.M.; Suh, H.R.; Lee, B.H. Effects of Medicinal herb Extracts and their Components on Steatogenic Hepatotoxicity in Sk-hep1 Cells. Toxicol. Res. 2011, 27, 211–216. [Google Scholar] [CrossRef]
- Miltonprabu, S.; Tomczyk, M.; Skalicka-Wozniak, K.; Rastrelli, L.; Daglia, M.; Nabavi, S.F.; Alavian, S.M.; Nabavi, S.M. Hepatoprotective effect of quercetin: From chemistry to medicine. Food Chem. Toxicol. 2017, 108, 365–374. [Google Scholar] [CrossRef]
- Zhou, R.J.; Ye, H.; Wang, F.; Wang, J.L.; Xie, M.L. Apigenin inhibits d-galactosamine/LPS-induced liver injury through upregulation of hepatic Nrf-2 and PPARgamma expressions in mice. Biochem. Biophys. Res. Commun. 2017, 493, 625–630. [Google Scholar] [CrossRef]
- Faghihzadeh, F.; Hekmatdoost, A.; Adibi, P. Resveratrol and liver: A systematic review. J. Res. Med. Sci. 2015, 20, 797–810. [Google Scholar]
- Feng, R.B.; Wang, Y.; He, C.; Yang, Y.; Wan, J.B. Gallic acid, a natural polyphenol, protects against tert-butyl hydroperoxide- induced hepatotoxicity by activating ERK-Nrf2-Keap1-mediated antioxidative response. Food Chem. Toxicol. 2018, 119, 479–488. [Google Scholar] [CrossRef] [PubMed]
- Tsai, M.S.; Wang, Y.H.; Lai, Y.Y.; Tsou, H.K.; Liou, G.G.; Ko, J.L.; Wang, S.H. Kaempferol protects against propacetamol-induced acute liver injury through CYP2E1 inactivation, UGT1A1 activation, and attenuation of oxidative stress, inflammation and apoptosis in mice. Toxicol. Lett. 2018, 290, 97–109. [Google Scholar] [CrossRef] [PubMed]
- Hong, M.; Li, S.; Tan, H.Y.; Cheung, F.; Wang, N.; Huang, J.; Feng, Y. A Network-Based Pharmacology Study of the Herb-Induced Liver Injury Potential of Traditional Hepatoprotective Chinese Herbal Medicines. Molecules 2017, 22, 632. [Google Scholar] [CrossRef] [PubMed]
- Geyikoglu, F.; Yilmaz, E.G.; Erol, H.S.; Koc, K.; Cerig, S.; Ozek, N.S.; Aysin, F. Hepatoprotective Role of Thymol in Drug-Induced Gastric Ulcer Model. Ann. Hepatol. 2018, 17, 980–991. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.; Wu, M.B.; Lin, J.P.; Yang, L.R. Quantitative structure-activity relationship: Promising advances in drug discovery platforms. Expert. Opin. Drug Discov. 2015, 10, 1283–1300. [Google Scholar] [CrossRef] [PubMed]
- Yang, H.; Lou, C.; Sun, L.; Li, J.; Cai, Y.; Wang, Z.; Li, W.; Liu, G.; Tang, Y. admetSAR 2.0: Web-service for prediction and optimization of chemical ADMET properties. Bioinformatics 2019, 35, 1067–1069. [Google Scholar] [CrossRef] [PubMed]
- Ai, H.; Chen, W.; Zhang, L.; Huang, L.; Yin, Z.; Hu, H.; Zhao, Q.; Zhao, J.; Liu, H. Predicting Drug-Induced Liver Injury Using Ensemble Learning Methods and Molecular Fingerprints. Toxicol. Sci. 2018, 165, 100–107. [Google Scholar] [CrossRef] [PubMed]
- Kotsampasakou, E.; Montanari, F.; Ecker, G.F. Predicting drug-induced liver injury: The importance of data curation. Toxicology 2017, 389, 139–145. [Google Scholar] [CrossRef]
- Huang, S.H.; Tung, C.W.; Fulop, F.; Li, J.H. Developing a QSAR model for hepatotoxicity screening of the active compounds in traditional Chinese medicines. Food Chem. Toxicol. 2015, 78, 71–77. [Google Scholar] [CrossRef]
- Shi, S.Z.; Wang, Q. Validation of two predictive softwares for the toxicity prediction of chemical ingredients in traditional Chinese medicine. Chin. J. New Drugs 2016, 25, 2647–2652. [Google Scholar]
- Liu, Y. Incorporation of absorption and metabolism into liver toxicity prediction for phytochemicals: A tiered in silico QSAR approach. Food Chem. Toxicol. 2018, 118, 409–415. [Google Scholar] [CrossRef] [PubMed]
- Wu, Q.; Cai, C.; Guo, P.; Chen, M.; Wu, X.; Zhou, J.; Luo, Y.; Zou, Y.; Liu, A.L.; Wang, Q.; et al. In silico Identification and Mechanism Exploration of Hepatotoxic Ingredients in Traditional Chinese Medicine. Front. Pharmacol. 2019, 10, 458. [Google Scholar] [CrossRef] [PubMed]
- Wetzel, S.; Schuffenhauer, A.; Roggo, S.; Ertl, P.; Waldmann, H. Cheminformatic Analysis of Natural Products and their Chemical Space. CHIMIA Int. J. Chem. 2007, 61, 355–360. [Google Scholar] [CrossRef]
- Stratton, C.F.; Newman, D.J.; Tan, D.S. Cheminformatic comparison of approved drugs from natural product versus synthetic origins. Bioorg. Med. Chem. Lett. 2015, 25, 4802–4807. [Google Scholar] [CrossRef] [PubMed]
- Zhao, P.; Liu, B.; Wang, C. Hepatotoxicity evaluation of traditional Chinese medicines using a computational molecular model. Clin. Toxicol. 2017, 55, 996–1000. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.E.; Wang, X.Z.; Zhu, Y.L.; Jin, R.M.; Zu-Guang, Y.E.; Yao, G.T.; Liu, J.G.; Qian, X.P. Predicting Hepatotoxicity of Compounds from Traditional Chinese Medicines Using Tree Models. Chin. Pharm. J. 2014, 49, 1583–1588. [Google Scholar]
- He, S.; Ye, T.; Wang, R.; Zhang, C.; Zhang, X.; Sun, G.; Sun, X. An In Silico Model for Predicting Drug-Induced Hepatotoxicity. Int. J. Mol. Sci. 2019, 20, 1897. [Google Scholar] [CrossRef]
- He, S.; Zhang, C.; Zhou, P.; Zhang, X.; Ye, T.; Wang, R.; Sun, G.; Sun, X. Herb-Induced Liver Injury: Phylogenetic Relationship, Structure-Toxicity Relationship, and Herb-Ingredient Network Analysis. Int. J. Mol. Sci. 2019, 20, 3633. [Google Scholar] [CrossRef]
- Zhang, C.; Cheng, F.; Li, W.; Liu, G.; Lee, P.W.; Tang, Y. In silico Prediction of Drug Induced Liver Toxicity Using Substructure Pattern Recognition Method. Mol. Inform. 2016, 35, 136–144. [Google Scholar] [CrossRef]
- Davis, A.P.; Grondin, C.J.; Johnson, R.J.; Sciaky, D.; McMorran, R.; Wiegers, J.; Wiegers, T.C.; Mattingly, C.J. The Comparative Toxicogenomics Database: Update 2019. Nucleic Acids Res. 2019, 47, D948–D954. [Google Scholar] [CrossRef]
- Yap, C.W. PaDEL-descriptor: An open source software to calculate molecular descriptors and fingerprints. J. Comput. Chem. 2011, 32, 1466–1474. [Google Scholar] [CrossRef] [PubMed]
- Kursa, M.B.; Rudnicki, W.R. Feature Selection with the Boruta Package. J. Stat. Softw. 2010, 36, 1–13. [Google Scholar] [CrossRef]
- Frank, E.; Hall, M.; Trigg, L.; Holmes, G.; Witten, I.H. Data mining in bioinformatics using Weka. Bioinformatics 2004, 20, 2479–2481. [Google Scholar] [CrossRef] [PubMed]
- He, S.; Li, M.; Ye, X.; Wang, H.; Yu, W.; He, W.; Wang, Y.; Qiao, Y. Site of metabolism prediction for oxidation reactions mediated by oxidoreductases based on chemical bond. Bioinformatics 2017, 33, 363–372. [Google Scholar] [CrossRef] [PubMed]
- Cai, C.; Fang, J.; Guo, P.; Wang, Q.; Hong, H.; Moslehi, J.; Cheng, F. In Silico Pharmacoepidemiologic Evaluation of Drug-Induced Cardiovascular Complications Using Combined Classifiers. J. Chem. Inf. Model. 2018, 58, 943–956. [Google Scholar] [CrossRef] [PubMed]
- Rucker, C.; Rucker, G.; Meringer, M. y-Randomization and its variants in QSPR/QSAR. J. Chem. Inf. Model. 2007, 47, 2345–2357. [Google Scholar] [CrossRef]
- Linden, A. Measuring diagnostic and predictive accuracy in disease management: An introduction to receiver operating characteristic (ROC) analysis. J. Eval. Clin. Pract. 2006, 12, 132–139. [Google Scholar] [CrossRef]
- Lin, L.; Ni, B.; Lin, H.; Zhang, M.; Li, X.; Yin, X.; Qu, C.; Ni, J. Traditional usages, botany, phytochemistry, pharmacology and toxicology of Polygonum multiflorum Thunb.: A review. J. Ethnopharmacol. 2015, 159, 158–183. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Type | Number of Features | ||
|---|---|---|---|---|
| PaDEL-Descriptor | Boruta | Find Correlation | ||
| 1 | FP | 1024 | 117 | 117 |
| 2 | ExtFP | 1024 | 111 | 111 |
| 3 | EStateFP | 79 | 13 | 12 |
| 4 | GraphFP | 1024 | 83 | 73 |
| 5 | MACCSFP | 166 | 59 | 52 |
| 6 | PubchemFP | 881 | 77 | 58 |
| 7 | SubFP | 307 | 25 | 22 |
| 8 | SubFPC | 307 | 18 | 15 |
| 9 | KRFP | 4860 | 61 | 49 |
| 10 | KRFPC | 4860 | 38 | 26 |
| 11 | AP2D | 780 | 38 | 34 |
| 12 | APC2D | 780 | 33 | 17 |
| 13 | 2D Descriptor | 1444 | 138 | 91 |
| Algorithm | Parameter | Parameter Optimization Method |
|---|---|---|
| RandomForest | Depth: The maximum depth of the tree | CVParameterSelection |
| Bagging | K: The number of neighbors to use | CVParameterSelection |
| AdaBoostM1 | C: The confidence factor used for pruning | CVParameterSelection |
| IBk | K: The number of neighbors to use | CVParameterSelection |
| LibSVM | C: Penalty parameter, γ: The radial basis function kernel parameter | GridSearch |
| KStar | B: The parameter for global blending | CVParameterSelection |
| J48 | C: The confidence factor used for pruning | CVParameterSelection |
| Classifiers | Type (Feature Number) | Parameter | ACC | AUC | SE | SP | BACC |
|---|---|---|---|---|---|---|---|
| RandomForest | 2D Descriptor (30) | Depth = 0 | 72.250 | 0.794 | 0.725 | 0.720 | 0.723 |
| Bagging | 2D Descriptor (70) | K = 5 | 69.557 | 0.762 | 0.663 | 0.726 | 0.695 |
| AdaBoostM1 | 2D Descriptor (69) | C = 0.25 | 68.736 | 0.743 | 0.651 | 0.721 | 0.686 |
| IBk | 2D Descriptor (76) | K = 5 | 70.196 | 0.758 | 0.673 | 0.729 | 0.701 |
| LibSVM | ExtFP (80) | C = 0.5, γ = 0.125 | 69.786 | 0.699 | 0.718 | 0.680 | 0.699 |
| KStar | AP2D (14) | B = 1 | 66.819 | 0.704 | 0.691 | 0.647 | 0.669 |
| J48 | SubFP (19) | C = 0.25 | 68.188 | 0.712 | 0.694 | 0.671 | 0.683 |
| NaiveBayes | ExtFP (42) | Default set | 64.993 | 0.704 | 0.677 | 0.625 | 0.651 |
| Classifier | ACC | AUC | SE | SP | BACC |
|---|---|---|---|---|---|
| RandomForest | 76.961 | 0.810 | 0.789 | 0.737 | 0.763 |
| Bagging | 69.118 | 0.764 | 0.711 | 0.658 | 0.685 |
| AdaBoostM1 | 67.647 | 0.713 | 0.672 | 0.684 | 0.678 |
| IBk | 68.137 | 0.752 | 0.711 | 0.711 | 0.711 |
| LibSVM | 78.431 | 0.756 | 0.867 | 0.645 | 0.756 |
| KStar | 65.686 | 0.673 | 0.703 | 0.579 | 0.641 |
| J48 | 64.216 | 0.632 | 0.711 | 0.526 | 0.619 |
| NaiveBayes | 61.275 | 0.603 | 0.719 | 0.434 | 0.577 |
| Combined classifier | 78.922 | 0.826 | 0.813 | 0.750 | 0.782 |
| ID | Ingredient | Liver Toxicity | Source | ||
|---|---|---|---|---|---|
| Subgroup 1 | Subgroup 2 | Subgroup 3 | |||
| 1 | Emodin | [21] | + | + | + |
| 2 | Chrysophanol | [43] | + | + | + |
| 3 | Chrysarobin | [41] | none | none | + |
| 4 | Rhein | [44] | + | + | + |
| 5 | Danthron | [45] | + | none | + |
| 6 | Polygonumnolide C2 | [41] | none | none | + |
| 7 | Emodin dianthrone | [41] | none | none | + |
| 8 | Aloe emodin | [46] | + | + | none |
| 9 | Luteolin | [26] | - | + | none |
| 10 | Physcion | [43] | + | + | none |
| 11 | Apigenin | [27] | + | none | none |
| 12 | Emodin-8-methyl ether | No report | + | none | none |
| 13 | Citreorosein | No report | + | none | none |
| 14 | Emodin-3-methyl ether | No report | + | none | none |
| 15 | Fallacinol | No report | + | none | none |
| 16 | 2-Acetylemodin | No report | + | none | none |
| 17 | Hexadecanoic acid methyl ester | No report | + | none | none |
| 18 | Octadecanoic acid methyl ester | No report | + | none | none |
| 19 | Docosanoic acid methyl ester | No report | + | none | none |
| 20 | 4-Hydroxybenzaldehyde | No report | + | none | none |
| 21 | 2,5-dimethyl-7-hydroxychromone | No report | + | none | none |
| 22 | Hydroxymaltol | No report | + | none | none |
| 23 | Butanedioic acid | No report | + | none | none |
| 24 | Emodin-6,8-dimethylether | No report | + | none | none |
| 25 | Hexanoic acid | No report | + | none | none |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, S.; Zhang, X.; Lu, S.; Zhu, T.; Sun, G.; Sun, X. A Computational Toxicology Approach to Screen the Hepatotoxic Ingredients in Traditional Chinese Medicines: Polygonum multiflorum Thunb as a Case Study. Biomolecules 2019, 9, 577. https://doi.org/10.3390/biom9100577
He S, Zhang X, Lu S, Zhu T, Sun G, Sun X. A Computational Toxicology Approach to Screen the Hepatotoxic Ingredients in Traditional Chinese Medicines: Polygonum multiflorum Thunb as a Case Study. Biomolecules. 2019; 9(10):577. https://doi.org/10.3390/biom9100577
Chicago/Turabian StyleHe, Shuaibing, Xuelian Zhang, Shan Lu, Ting Zhu, Guibo Sun, and Xiaobo Sun. 2019. "A Computational Toxicology Approach to Screen the Hepatotoxic Ingredients in Traditional Chinese Medicines: Polygonum multiflorum Thunb as a Case Study" Biomolecules 9, no. 10: 577. https://doi.org/10.3390/biom9100577
APA StyleHe, S., Zhang, X., Lu, S., Zhu, T., Sun, G., & Sun, X. (2019). A Computational Toxicology Approach to Screen the Hepatotoxic Ingredients in Traditional Chinese Medicines: Polygonum multiflorum Thunb as a Case Study. Biomolecules, 9(10), 577. https://doi.org/10.3390/biom9100577