1. Introduction
Reliable statistical analysis is essential in many areas of biomolecular sciences, including bioinformatics [
1], biomedical diagnostics [
2], and bioprocess engineering [
3]. Researchers in these fields often work with complex datasets that are small in size, contain outliers, or deviate from normal (Gaussian) distributions [
4]. These characteristics can make conventional statistical approaches, such as the arithmetic mean or least squares fitting, less reliable or misleading.
The most frequent value (MFV) method is a robust alternative that estimates the central value of a dataset based on its densest region. This makes the proposed method highly resistant to outliers and better suited for datasets with irregular structures or measurement noise. Because it preserves more of the original information in the data, the MFV is particularly valuable in biomolecular contexts, where measurements are often costly or variable, and data points cannot be easily discarded.
In bioinformatics, MFVs can improve the analysis of high-dimensional datasets, such as gene expression profiles, protein folding simulations, and pathway activity models [
5]. These analyses frequently involve biological replicates with different levels of noise, and the MFV is a stable way to determine representative values that are not overly influenced by outliers. For instance, RNA-seq or proteomics data often contain both biological and technical variability [
6], and the MFV can help extract meaningful trends under such conditions.
In biomedical diagnostics, sensor readings, imaging data, and molecular assays can be affected by noise, sampling inconsistencies, or measurement anomalies. The MFV allows these values to be processed more reliably. When combined with bootstrapping—a method that estimates statistical confidence intervals by repeatedly resampling the dataset—the MFV approach provides robust estimates of variability without assuming a specific data distribution [
7,
8]. This combination is particularly useful when working with small or irregularly sampled datasets, which often occur in clinical research.
In bioprocess engineering, where biological production systems are optimized and monitored, variability in feedstock, growth rates, and process parameters can complicate the analysis of production yields or reaction efficiencies [
9,
10]. The MFV method can help identify representative performance metrics in the presence of such variations, whereas bootstrapping provides reliable uncertainty estimates to support process decisions and quality control.
Bootstrapping is especially useful when the data distribution is unknown or non-Gaussian. Traditional confidence interval (CI) estimation methods [
11] may not perform well under these conditions. Bootstrapping addresses this by generating distributions of the statistic of interest from the resampled datasets, thereby making it highly flexible. When used with the MFV, this technique supports statistically sound conclusions even in the presence of extreme values or limited sample sizes.
This study presents a practical approach for estimating confidence intervals by integrating the MFV with both traditional and hybrid parametric bootstrapping. The proposed method is designed to be broadly applicable, particularly in cases where datasets are small, variable, or contain outliers. Although the method is demonstrated using a dataset from nuclear physics—specifically, activation cross-section measurements—the statistical issues addressed here are directly relevant to biomolecular sciences. These include challenges encountered in protein–ligand binding assays, enzymatic rate measurements, and molecular biomarker evaluations, such as high-sensitivity C-reactive protein measurements in liver disease studies [
12], where population variability, sex-based differences, and limited measurement precision can introduce noise and uncertainty into the analysis.
Historically, before the 1960s, the concept of the most frequent value was known but was rarely used because of computational constraints. The arithmetic mean and Gaussian-based least squares methods were more common even though many real-world datasets did not meet the assumptions required by these methods.
A shift began in the 1970s and 1980s, when researchers such as Steiner, Csernyák, and Hajagos formalized the MFV method and demonstrated its practical advantages. The key contributions from this period include the following:
Csernyák and Steiner (1980) [
13] introduced a practical way to compute the MFV’s scale parameter, known as dihesion.
Steiner (1980) [
14] demonstrated that the MFV offers greater resistance to outliers than traditional least squares fitting.
Csernyák, Hajagos, and Steiner (1981) [
15] established mathematical foundations for the convergence of MFV estimates.
Hajagos (1982) [
16] demonstrated that the proposed method minimizes information loss when estimating central values.
These developments were compiled in Steiner’s 1988 monograph, Most Frequent Value Procedures [
17], which helped expand the use of the MFV beyond geophysics and into other scientific domains.
This study builds on that foundation by showing how the MFV and bootstrapping can be combined to improve data analysis in biomolecular research. Together, they provide a statistically robust framework for analyzing datasets that are small, noisy, or include extreme values—features commonly found in molecular biology, bioassays, and clinical studies. The proposed method enhances confidence in statistical inferences without compromising the integrity of the original data.
Artificial datasets have been used in past studies to demonstrate the performance of the MFV algorithm. For instance, Golovko et al. (2023) [
18] compared the mode statistic with the MFV statistic using an artificial dataset, and Golovko (2025) [
19] introduced the MFV–hybrid parametric bootstrapping framework with a small four-element dataset that had varied uncertainties. However, in our study, we chose real-world nuclear physics data. We selected this dataset due to its natural variability and tendency to contain outliers, which make it an excellent choice for testing the robustness and applicability of the proposed framework. Using real data not only proves the method’s effectiveness but also showcases its potential usefulness across different scientific fields.
2. Methodology
This study emphasizes the application of robust statistical methods, particularly the most frequent value approach [
20], as an alternative to traditional averaging techniques based on the least squares principle [
21]. The MFV method addresses the key limitations inherent in standard methods such as the arithmetic mean, which assumes that the underlying data follow a Gaussian (normal) distribution. In many real-world scenarios, error distributions significantly deviate from Gaussian assumptions, rendering traditional methods inefficient and prone to inaccuracies.
Traditional methods, such as the arithmetic mean, are optimal only when the data follow a Gaussian distribution. However, non-Gaussian distributions require substantially more data to achieve a similar level of accuracy compared to robust alternatives [
17]. In addition, least squares techniques are highly sensitive to outliers—data points that deviate significantly from the main data cluster. These outliers can disproportionately influence the resulting estimates, leading to skewed or misleading results.
The MFV approach overcomes these limitations by identifying the densest cluster of data points [
22], effectively reducing the influence of outliers. Unlike traditional averaging methods, the MFV is designed to handle non-Gaussian error distributions [
23] and provides more reliable central tendency estimates for datasets with irregular or skewed distributions.
The MFV method offers several notable advantages over traditional averaging techniques such as the arithmetic mean. A key benefit of an MFV is its robustness to outliers [
24]. Unlike traditional methods, which can be heavily influenced by extreme data points, the MFV is based on the concept of minimizing information loss [
25], ensuring that the central estimate accurately reflects the majority of the data. This makes it particularly effective in scenarios where datasets contain irregular or extreme values [
26]. In addition, the MFV applies to non-Gaussian distributions, which are frequently encountered in many practical fields. Traditional methods often assume Gaussian error distributions, limiting their effectiveness when this assumption is not met. The MFV, on the other hand, is well suited for datasets with non-standard distributions [
27].
Another significant advantage of the MFV is its efficiency. By concentrating on the densest cluster of data [
28], the MFV provides accurate estimates with fewer data points, thereby reducing the need for extensive sampling. Furthermore, the proposed method improves accuracy by avoiding biases introduced by extreme values, thereby producing results that are closer to the true characteristics of the data. These features make the proposed MFV a significant improvement over traditional least squares techniques, particularly in applications where data variability and non-standard distributions are common [
29]. The MFV is a robust, efficient, and reliable alternative for statistical analysis, making it an essential tool for modern data analysis.
Although the MFV method and its scale parameter (also referred to as “dihesion”) were originally developed by Steiner and have been discussed in various papers [
30] and books [
31,
32], many of these resources are written for readers already familiar with the approach. As a result, they often skip the step-by-step derivation of the key equations used to calculate the central value and spread. This can make it difficult for researchers new to the MFV method to fully understand how it works or how to apply it effectively.
To address this gap, we have included a detailed explanation of how these equations are derived. The following section describes the process based on the principle of minimizing information loss between the observed dataset and a substituting analytical distribution. Our goal is to make the MFV method more accessible and transparent and easier to apply in modern statistical analysis, especially when working with small datasets or those containing outliers.
The MFV method, as a robust statistical estimate [
18], is particularly powerful when paired with bootstrapping techniques to estimate confidence intervals (CIs) with high reliability. This combination ensures that the CI is unaffected by the presence of outliers in the dataset. Unlike the mean statistic, which is not robust and can be significantly distorted by extreme values, the MFV minimizes the influence of outliers by focusing on the densest cluster of data. This makes bootstrapping the MFV-based CI a useful approach for datasets with irregular distributions or outliers. By leveraging this robustness, the MFV method provides more reliable and accurate statistical inferences, making it an effective alternative to traditional mean-based methods for estimating CIs.
2.1. The Most Frequent Value
The Cauchy distribution [
33] used in this section is referred to by various names, especially in physics, such as the Lorentz distribution [
34], the Cauchy–Lorentz distribution, the Lorentzian function, or the Breit–Wigner distribution [
35]. The importance of the Cauchy function lies in its role in most frequent value calculations. It allows for the preservation of information accuracy by substituting an unknown probability distribution with a known one. This practice is based on the principles of information theory and is specifically centered around the idea of Kullback–Leibler divergence [
36]. This divergence measures information loss when a theoretical or analytical distribution approximates the true (but unknown) distribution.
The Cauchy distribution provides several advantages as the substituting distribution in this framework. One significant advantage of the proposed method is its ability to be applied to a broad spectrum of possible true distributions, encompassing those with more pronounced tails than the Gaussian distribution. Consider the scenario where we have two statistically independent random variables,
A and
B, with standard Gaussian distributions. When we calculate the ratio of
A to
B, the resulting distribution of this ratio is actually in the Cauchy form, which is a somewhat unexpected outcome [
37]. Unlike the Gaussian distribution, which may lead to infinite divergence for some datasets, the Cauchy distribution ensures finite Kullback–Leibler divergence. This makes it particularly effective for handling non-standard distributions, which are commonly encountered in real-world data.
Minimizing the Kullback–Leibler divergence with the Cauchy distribution results in defining equations for the MFV (as the location parameter) and dihesion (as the scale parameter). The Cauchy distribution also acts as an ideal weight function in these calculations. It assigns higher weights to data points near the central cluster and progressively downweights the influence of outliers, which enhances the robustness of the MFV estimation. This property ensures that the MFV captures the true central tendency of the data without distortion by extreme values.
Although alternative approaches such as the maximum likelihood principle can also be used to derive MFV and dihesion formulas [
17], they rely on the assumption that the true error distribution is known. The Kullback–Leibler divergence method acknowledges the uncertainty inherent in most practical scenarios and focuses on finding the best substituting distribution.
In addition, the Cauchy distribution offers another crucial advantage. Its robustness ensures a finite asymptotic variance for the MFV [
16,
38], even in datasets with significant outliers. This makes MFV calculations based on the Cauchy function a highly reliable and practical choice for estimating central tendencies in diverse datasets.
The concept of minimizing information loss addresses a fundamental challenge in data analysis: approximating an unknown true probability distribution with a known analytical distribution. This approach is especially important in fields of science where the true error distribution is often unknown and deviations from standard distributions such as the Gaussian distribution are common. By quantifying and minimizing information loss, scientists can make more informed decisions and extract reliable results from limited or uncertain datasets.
A key tool in this framework is the Kullback–Leibler (KL) divergence (also called relative information entropy [
39,
40] and I-divergence [
17,
41]), a measure of the difference between the actual distribution
and a substituting distribution
. Mathematically, Kullback–Leibler divergence is expressed as
where
is the true distribution (unknown), and
is the substituting distribution, which depends on parameter
, the location parameter. The goal is to minimize
with respect to
. The Kullback–Leibler divergence shows how different the two functions
and
are by measuring the amount of information lost when
is used to approximate
. While often called statistical “distance”, it is not a true distance because it is not symmetric and does not satisfy triangle inequality.
Let
be the Cauchy distribution [
37,
40]
where
is the scale parameter (also called the half-width at half-maximum), and
represents the location parameter. The conditions for minimizing the quasi-distance between
and
, as measured by the Kullback–Leibler divergence, are fulfilled if the following equations hold:
and
Using the expression for
from Equation (
1), the condition in Equation (
3) becomes
and the second-derivative condition in Equation (
4) requires
Equation (
6) is automatically fulfilled if the second term vanishes. In other words,
and the simultaneous satisfaction of Equations (
5) and (
7) results in values of
that guarantee the minimum Kullback–Leibler divergence.
For the Cauchy distribution, the partial derivative of
with respect to
is given by
Substituting this expression into the integral condition (
5) yields the following:
This integral determines the optimal value of
, ensuring that the substituting distribution
minimizes the Kullback–Leibler divergence relative to the unknown true distribution
. To simplify it, we expand
which leads to
After separating the terms and rearranging them, we isolate
as
This formula calculates a weighted average of the data, where points close to receive larger weights than those farther away. This location parameter, , is commonly referred to as M in the MFV methodology.
The next step involves isolating the scale parameter through minimization of the Kullback–Leibler divergence. We use Equation (
7) for this purpose. Beginning with the first partial derivative given in Equation (
8), the second derivative of
with respect to
becomes
Substituting Equation (
13) into Equation (
7) leads to
which can be rearranged to isolate
as follows:
In the MFV framework, this scale parameter is typically referred to as
in place of
.
For a finite-sample dataset
, the empirical distribution function
is used. Substituting the empirical function into Equations (
12) and (
15) provides the sample-based MFV
and dihesion,
through
and
which define
and
through weighted sums that strongly favor points close to
, effectively suppressing the influence of outliers.
Each equation for
and
depends on the other’s current estimates, so an iterative procedure is required to solve them. Commonly, one starts with
or one can choose the median of the dataset for
if the data contain extreme outliers [
42]. The iterative updates are
until the changes in both
and
become negligible.
The final values, and , provide robust estimates of the central tendency (location) and spread (scale) of the dataset. Unlike traditional means and standard deviations, these quantities are far less affected by outliers or heavy-tailed distributions.
It can be helpful to see why Equations (
17) and (
18) look like weighted averages and how they confer robustness. Minimizing Kullback–Leibler divergence with a Cauchy form imposes a higher weight on data points that lie close to the current location estimate
. The term
in the denominator becomes large for points lying far from
; thus, distant points carry less influence on the estimates. Consequently, outliers do not inflate the location or spread values as strongly as they would in the case of standard arithmetic means or variances.
Intuitively, the most frequent value emerges as the “peak” of a Cauchy curve positioned to match the core mass of the data, with minimal impact from points on the periphery. Similarly, the dihesion quantifies how widely the main cluster of data is spread around , again downlighting extreme values that might otherwise dominate a conventional variance calculation. As a result, these MFV estimates remain stable and representative even when the dataset exhibits strong deviations from Gaussian assumptions or contains significant outliers.
By iteratively updating and until convergence, we obtain final values that minimize information loss under Cauchy substitution. This procedure directly addresses the requirement to handle non-Gaussian errors and ensures that the substitution remains valid for a broad range of real-world data distributions. This robustness makes the MFV a valuable alternative to traditional least squares or mean-based methods, offering more reliable central estimates and spread measurements in diverse applications.
It is important to emphasize that the function represents the unknown “true” distribution of the real-world data. In practice, this distribution can be arbitrary and does not need to follow any standard or symmetric shapes, such as Gaussian shapes. The MFV approach addresses this general case by substituting an unknown distribution with a Cauchy distribution in a way that minimizes Kullback–Leibler divergence. This ensures that the estimated location (and scale) parameters remain robust even when the data are drawn from a heavy-tailed or skewed distribution.
2.2. Bootstrapping for Robust Confidence Interval Estimation
Bootstrapping is a non-parametric resampling technique used to estimate the variability and confidence intervals of a statistical measure without making strong assumptions about the underlying data distribution [
43,
44]. This approach is particularly useful when working with the MFV because it allows for robust confidence interval estimation while minimizing sensitivity to outliers and small sample sizes.
The procedure generates multiple resampled datasets (termed “bootstrap samples”) by randomly sampling the original dataset with replacement. For each bootstrap sample, the statistic of interest, such as the MFV, is recalculated. This results in an empirical distribution of the statistic from which confidence intervals can be derived using the percentile method [
45,
46]. The confidence interval (CI) is obtained by identifying the appropriate quantiles of the bootstrap distribution. For instance, a 95.45% CI is defined as follows:
where
represents the
-th quantile of the bootstrap distribution. Similarly, a 68.27% CI uses the 15.87th and 84.13th percentiles.
This approach offers several advantages. First, it is highly robust [
47] against outliers, particularly when combined with a robust statistic such as the MFV. By incorporating resampling techniques, bootstrapping accounts for data variability while reducing the influence of extreme values on the confidence interval estimation. Second, bootstrapping is flexible and does not require assumptions about the underlying distribution of data. This makes it a valuable tool in real-world applications where the data structure is complex or unknown.
For small datasets that include measurement uncertainties, the hybrid parametric bootstrap (HPB) method offers a powerful way to estimate confidence intervals [
48,
49]. This approach combines two statistical techniques—non-parametric resampling and parametric simulation—to account for both the natural variability in the data and the uncertainties reported with each measurement.
The HPB process begins with a non-parametric bootstrap step. From the original dataset of N measurements, a new synthetic dataset is created by randomly sampling with replacement. This means that some measurements may appear more than once, while others may not be selected at all. This resampling mimics the uncertainty about which data points best represent the underlying distribution.
Next, each resampled data point is used to generate a simulated value through a parametric step. For each selected point, a new value is randomly drawn from a normal (Gaussian) distribution centered on the original measurement, with the corresponding reported uncertainty used as the standard deviation. If a simulated value is physically impossible—such as a negative cross-section or half-life—it is discarded and redrawn. This ensures all values remain physically meaningful.
After both steps are completed, the most frequent value is calculated for the simulated dataset. This entire two-step process is repeated many times, generating a distribution of MFV estimates. Confidence intervals, such as the 68.27% range (equivalent to 1-sigma in Gaussian statistics), are then calculated using the percentile method [
45,
46].
By combining realistic uncertainty modeling with repeated resampling, the HPB method provides a statistically robust and physically meaningful way to quantify uncertainty in central estimates, even when working with small or irregular datasets.
The integration of the MFV with bootstrapping provides a powerful framework for analyzing small datasets, which are costly to obtain or are prone to outliers. This is especially beneficial in fields such as environmental monitoring and radiation measurement, where robust statistical methods are essential for accurate analysis. By iteratively resampling and recalculating the MFV, the derived confidence intervals become more reliable and representative of the underlying data. This methodology ensures minimal information loss, making it a practical and effective approach for applications requiring high-precision statistical inference.
3. Description of the Methods and Results
Nuclear physics cross-sectional datasets provide compelling cases for applying robust statistical methods such as the MFV approach and bootstrapping. These datasets often contain inconsistencies, outliers, and non-Gaussian distributions stemming from experimental challenges, including fluctuations in neutron energy, difficulties with sample preparation, and uncertainties in detection methods. As a result, different laboratories may report varying cross-sectional values for the same nuclear reaction due to differences in equipment calibration, experimental procedures, and data processing methodologies. This variability exposes the limitations of conventional statistical tools, especially those that rely on the arithmetic mean, which can be significantly skewed by outliers.
The MFV method offers a more resilient measure of central tendency by identifying the most densely populated data region. When combined with bootstrapping to estimate confidence intervals, this approach yields robust and interpretable results, particularly for datasets with limited sample sizes. The use of advanced statistical techniques in nuclear physics improves the reliability of data analysis and enhances the precision of outcomes in critical applications, such as nuclear reactor design, isotope production, and radiation shielding.
As part of this work, a benchmark dataset based on neutron lifetime measurements [
25] was used to further validate the MFV method. These measurements provided an independent check that the MFV approach yields consistent results. In fact, the same MFV value for neutron lifetime was obtained as reported in the original study [
25], confirming the method’s accuracy and reproducibility.
The dataset of
109Ag(n, 2n)
108mAg cross-sections in
Table 1 served as a practical example for applying the MFV method and bootstrapping. The experimental setup introduced significant uncertainties and inconsistencies, reflecting its complexity. The MFV method mitigated the influence of outliers, and bootstrapping provided insight into the variability and confidence intervals of the data.
Measuring the 109Ag(n, 2n)108mAg cross-section remains challenging due to experimental difficulties, technical constraints, and limited resources. Generating and controlling fast neutrons is particularly problematic. Neutron sources, whether reactors or generators, can be difficult to monitor precisely in terms of flux and energy. Often, neutron energies are inferred from the cross-section ratios of other reactions, introducing additional uncertainty.
Because the cross-section is highly dependent on neutron energy, we restricted our analysis to measurements within the 14.7 ± 0.2 MeV range, specifically, between 14.5 and 14.9 MeV (see
Table 1). This filtering ensured uniformity and reduced variability under different experimental energy conditions.
Sample preparation also affects the measurement quality. High-purity silver samples with well-defined geometry minimize bias [
61]. Cadmium shielding is typically employed to suppress low-energy neutron capture on
107Ag, although some residual contributions remain [
61]. Gamma-ray spectrometry adds further uncertainty due to factors such as detector efficiency, counting statistics, and self-absorption corrections.
The half-life of
108mAg has undergone significant revision over the past decades, which has also contributed to variations in the reported cross-section values for reactions producing this isomer. Early theoretical studies suggested a minimum half-life of 5 years [
62], which was subsequently refined by a series of experimental investigations: from
years [
63] to
years [
64] to
years [
65], and, most recently, to
years [
66].
A landmark early experimental determination was reported in 1969 by Vonach et al., who estimated the half-life to be
years [
50]. Their approach relied on evaluating the absolute activity of a sample containing a known quantity of
108mAg, and estimating the half-life using the cross-section of the
109Ag(n, 2n)
108mAg reaction, for which they adopted a value of
. Although this measurement carried a large uncertainty, it was based on a methodology distinct from later decay-spectroscopy-based measurements. As such, it provided valuable complementary information rooted in different experimental systematics. This makes the 1969 result a critical reference point for validating updated half-life determinations through modern statistical reanalysis.
In 2024, Song et al. [
61] re-evaluated several fast-neutron activation cross-sections using an updated half-life for
108mAg of 438 years, as shown in
Table 2. Their adjustments significantly shifted the data distribution toward higher values. The original low-value cluster between 200 and 300 mb was absent in the re-evaluated set; instead, it clustered tightly between 600 and 800 mb, as shown in
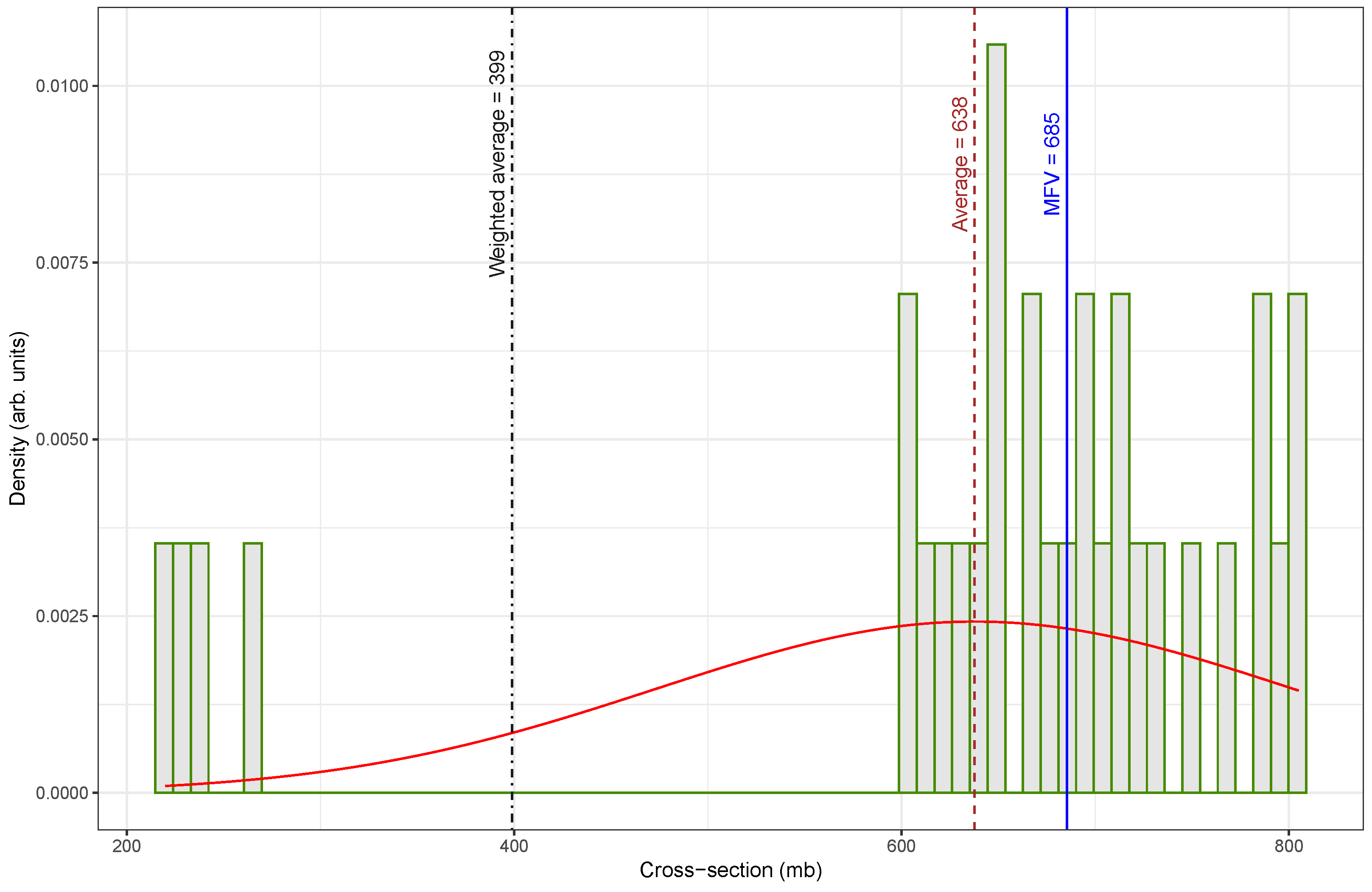
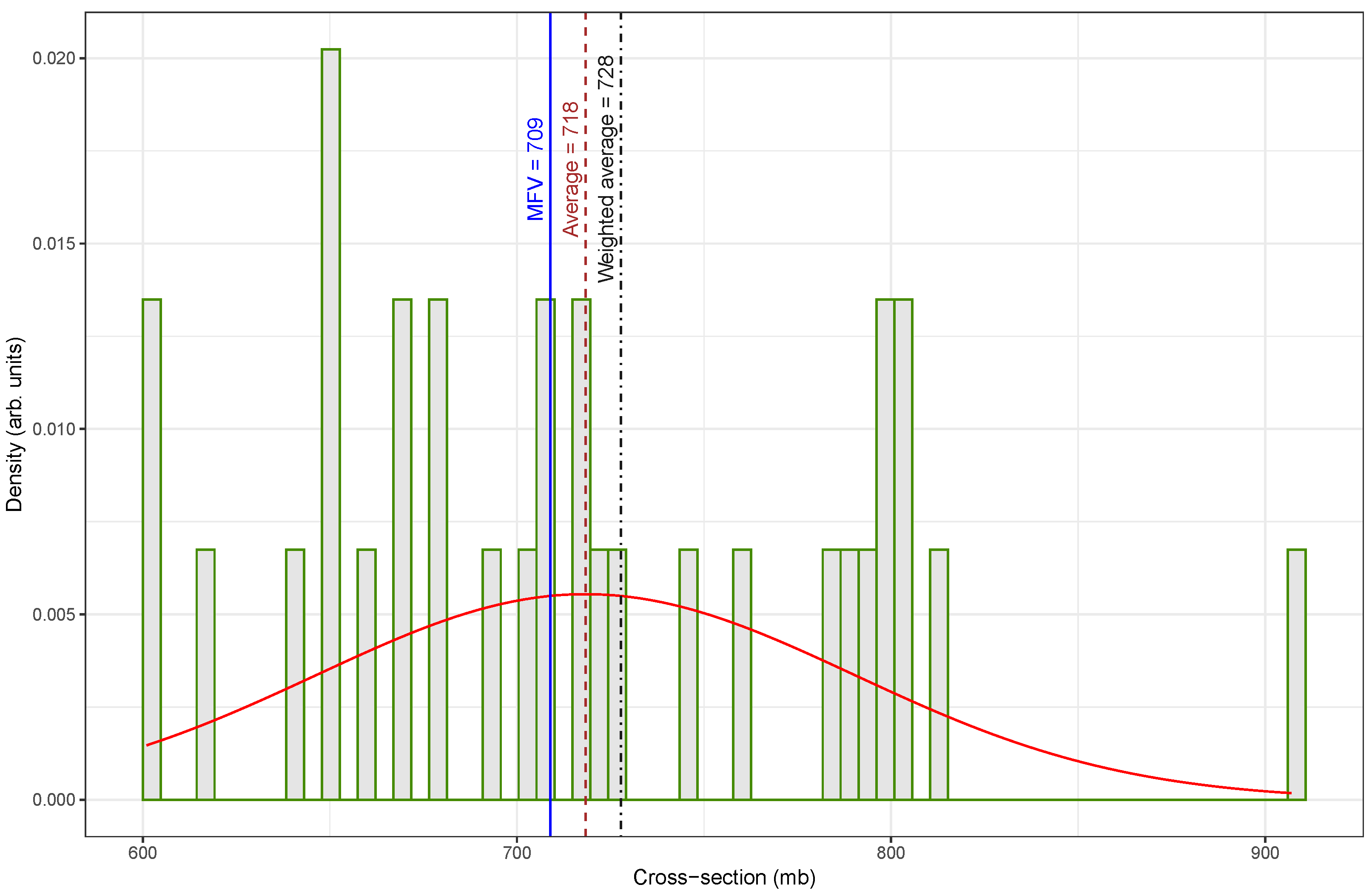
Figure 1.
Figure 2, which presents the re-evaluated fast-neutron activation cross-section data for the
109Ag(n, 2n)
108mAg reaction at
, shows a marked improvement in data consistency compared to the original dataset displayed in
Figure 1.
In
Figure 1, the distribution of the cross-section values is notably irregular and skewed, with a broad spread of measurements ranging from low to high values. This dataset includes several low-valued outliers that significantly influence the statistical estimates. As a result, the weighted average is much lower (
) than both the arithmetic mean (
) and the MFV (
). The mismatch between these indicators of central tendency highlights the presence of inconsistencies and the potential impact of outliers on the overall estimation.
In contrast,
Figure 2 shows a more symmetrical and concentrated distribution, with most cross-section values clustered between approximately 640 and
. The re-evaluated dataset appears to reduce or eliminate the influence of earlier outliers. Consequently, the statistical measures are in close agreement. The weighted average is
, the arithmetic mean is
, and the MFV is
. The improved alignment among these values indicates that the dataset is more internally consistent and statistically robust.
A comparison of central tendency measures between the original and re-evaluated datasets reveals substantial differences, particularly in how each estimator responded to outliers. The arithmetic mean increased from
in
Figure 1 to
in
Figure 2, representing a percentage difference of approximately 12.5%. In contrast, the weighted mean underwent a dramatic increase from
to
, corresponding to an 82.5% difference. This large change indicates that the original dataset contained low-valued outliers that significantly influenced the weighted average, and their impact was effectively mitigated in the updated dataset. The MFV showed only a small change, rising from
to
, with a percent difference of about 3.5%. The relatively small change observed in the MFV between the two datasets suggests that this estimator is more forgiving with respect to data quality, exhibiting robustness against the presence of outliers or inconsistencies that significantly affect other estimators, such as the mean or weighted average.
This comparison highlights the value of re-evaluating nuclear data using updated nuclear parameters. This study also demonstrates the importance of selecting appropriate statistical estimators—especially the MFV—for achieving reliable analysis. By correcting problematic measurements, the updated dataset shown in
Figure 2 allowed for a more accurate estimation of central tendency and supported stronger confidence in the subsequent statistical analysis.
Furthermore, we aimed to evaluate the concept of calculating confidence intervals using a robust MFV estimator within the HPB framework. The HPB method explicitly incorporates the uncertainty associated with each individual data point. Our goal was to evaluate how sensitive the estimated confidence intervals were to the presence of outliers in the dataset. This comparison helped us to assess the robustness of different estimation approaches under different data quality conditions.
To do this, we estimated the confidence intervals using the HPB method based on the data in
Table 1 (see
Figure 1). We then repeated the analysis using the re-evaluated data from Song et al. [
61], shown in
Table 2. We matched rows between the two tables using neutron energy, original cross-sectional values, and associated uncertainties. The matching entries were then updated with the re-evaluated values. This ensured that the final dataset shown in
Figure 2 incorporated the most current and accurate nuclear information, providing a solid foundation for robust confidence interval estimation.
The HPB method, originally proposed in [
48] and fully described in [
19], has been successfully applied in nuclear safety evaluations and environmental monitoring [
49], where data quality varies and outliers are common. In this case, its application is particularly appropriate given the limited dataset and the presence of variable uncertainty levels.
4. Discussion
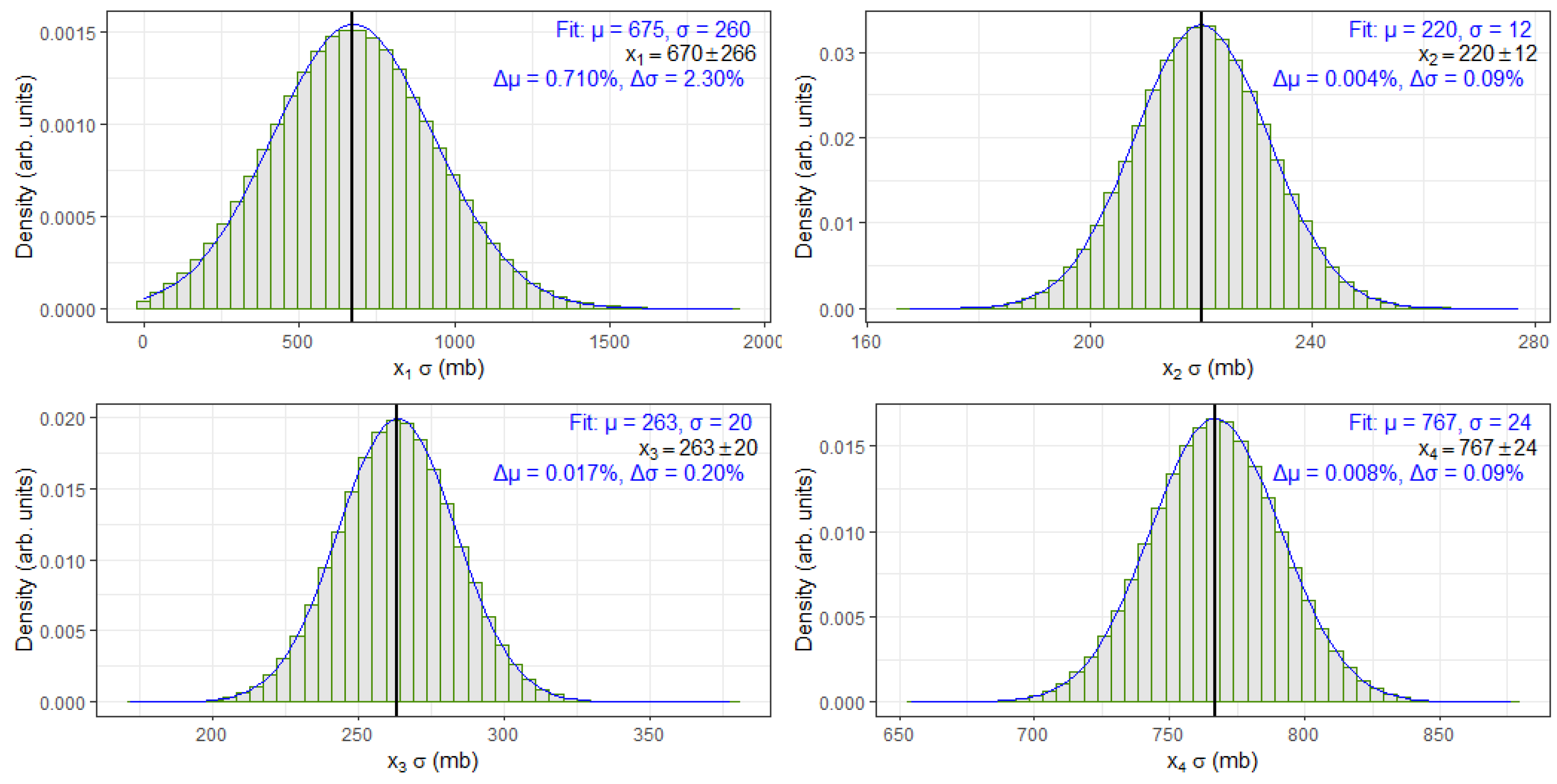
To validate the correctness and consistency of the randomized bootstrap sample values used in the MFV-HPB statistical framework, we analyzed a subset of four cross-section entries from
Table 1, specifically,
,
,
, and
. These values were randomly sampled using a Gaussian distribution based on their reported central values and uncertainties.
Figure 3 presents the histograms of these samples along with fitted Gaussian curves.
To evaluate how closely the randomized bootstrap samples matched the original measurements, each histogram was fitted with a Gaussian distribution. The resulting mean (
) and standard deviation (
) from the fit were then compared to the corresponding reference values from
Table 1. For each case, the absolute percent difference was calculated to quantify the deviation between the fitted and tabulated values:
Here,
and
are the parameters obtained from the fit, while
and
are the original values from the table. These percent differences are shown on each panel of
Figure 3 and provide a simple measure of consistency between the fit results and the expected values. All differences were found to be small, indicating that the Gaussian randomization process preserved the statistical characteristics of the original data.
It is worth noting that, for the
dataset, the reported uncertainty in
Table 1 is comparable in magnitude to the cross-section value itself. This presents a potential challenge when generating randomized bootstrap values using a Gaussian distribution, as the sampling process could yield negative values. Since negative cross-sections have no physical meaning, any such values encountered during the bootstrap process were discarded, and a new random sample was drawn in their place to preserve physical consistency. This correction mechanism can slightly distort the expected shape of the resulting distribution. Consequently, the fitted Gaussian parameters for
show a modest deviation from the reference value. However, this discrepancy remains much smaller than the associated uncertainty, and, as such, does not compromise the reliability or conclusions drawn from the MFV-HPB analysis.
Overall, the excellent agreement between the Gaussian fits and the original cross-section values affirms that the randomized samples preserve the statistical characteristics of the source data. This outcome confirms the reliability of the bootstrapped datasets as valid inputs for robust estimation using the MFV-HPB framework.
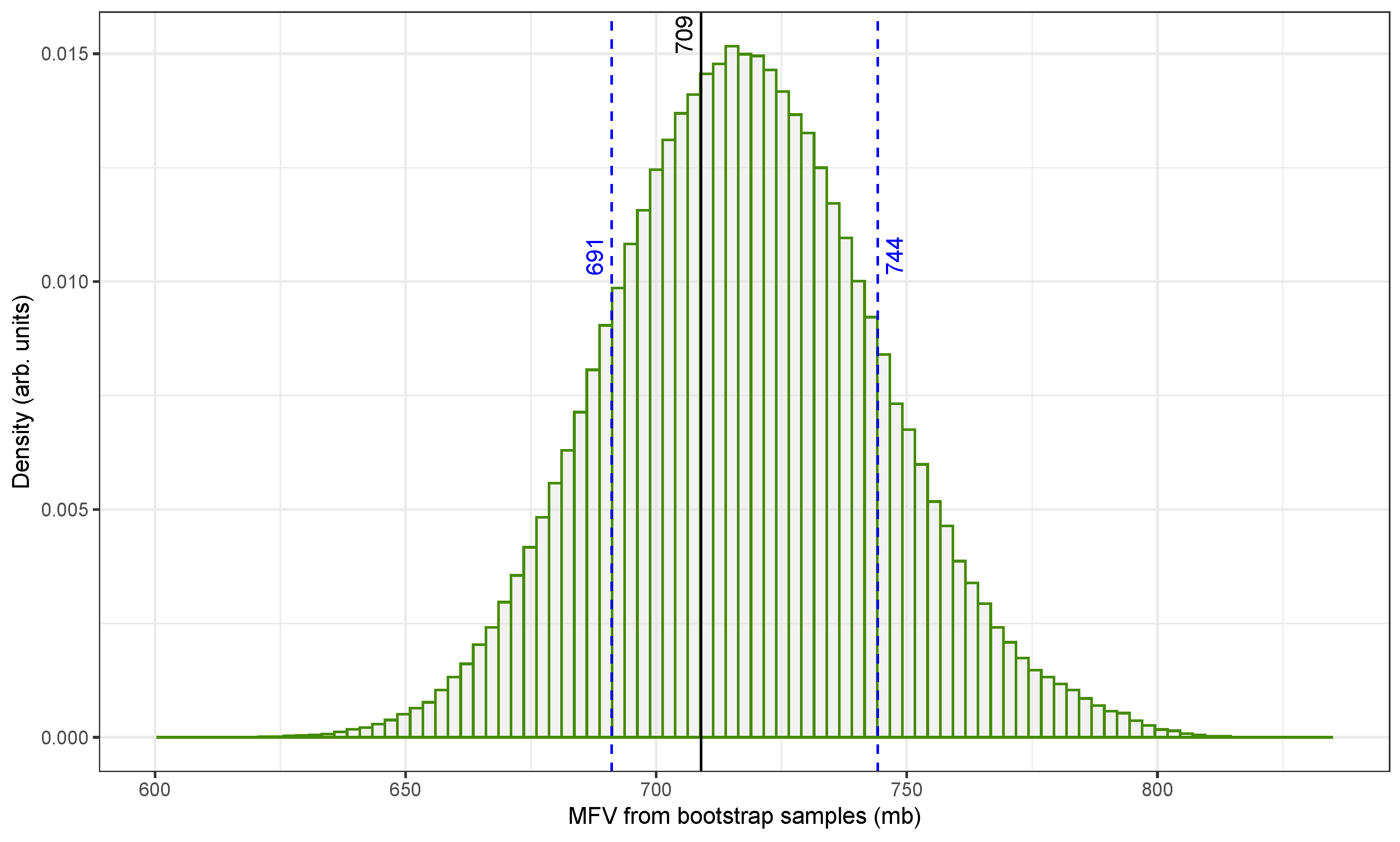
Figure 4 illustrates the distribution of MFV estimates for the
109Ag(n, 2n)
108mAg reaction using the original fast-neutron cross-section dataset from
Table 1. These estimates were generated using HPB, a method that incorporates both measurement uncertainties and sampling variability [
49].
The x-axis shows the MFV values obtained from individual bootstrap samples, expressed in millibarns (mb), while the y-axis represents the normalized density. The distribution is centered around the original dataset’s MFV of , as indicated by a solid vertical line. The 68.27% confidence interval (marked by dashed blue lines) ranges from approximately to . Although not shown in the figure, a broader 2-sigma interval was also calculated to extend from about to . The intervals were determined using the percentile method.
To ensure statistical reliability, 500,000 bootstrap replicates were generated. This large sample size helped us to reduce the influence of random fluctuations and improved the precision of the resulting confidence intervals. Additionally, only physically meaningful, positive-valued cross-sectional data were used in the analysis, especially in light of the large uncertainties associated with some older measurements, such as the 1969 value of
[
50].
The resulting histogram is narrow and symmetric with minimal skew. This confirms that the MFV is a stable and reliable central estimate even when applied to a dataset that includes variable uncertainties and possible outliers. The narrow confidence interval further demonstrates that the combined MFV and HPB approach [
48] provides a robust framework for summarizing central tendency and uncertainty in nuclear cross-sectional data.
Figure 5 presents a similar analysis applied to the re-evaluated dataset with the updated cross-sectional values from
Table 2. This dataset incorporates updated nuclear information, including a revised half-life for
108mAg, and yields an MFV centered at approximately
. The histogram again displays the distribution of MFV values derived from HPB resampling.
The shape of the distribution in
Figure 5 is slightly right skewed, with the 68.27% confidence interval spanning from
to
. The corresponding 2-sigma interval ranges from
to
. Compared with the original data in
Figure 4, the revised dataset produced slightly higher MFV estimates while maintaining a similar spread. This shift reflects a higher concentration of consistent values in the upper cross-section range, as seen in the re-evaluated measurements (see
Figure 2).
The stability of the MFV across both the original and re-evaluated datasets underscores the strength of the proposed method. While conventional metrics like the mean or weighted average are easily distorted by extreme values or skewed uncertainties, the MFV remains centered within the most densely populated region of the data. By combining the MFV with HPB, we can generate confidence intervals that are not only statistically rigorous but also not sensitive to the quality and distribution of the original measurements.
These findings highlight the advantages of MFV-based analysis of nuclear data, particularly in the presence of heterogeneous uncertainty and limited experimental repetition. The proposed method reduces the bias introduced by outliers and leverages resampling to quantify uncertainty without assuming a specific underlying distribution. Although computationally intensive, the MFV and HPB approaches are well suited for nuclear datasets where precision matters and data collection is costly.
Together,
Figure 4 and
Figure 5 demonstrate that combining the MFV estimator with hybrid bootstrapping results in a consistent and interpretable analysis framework. This methodology offers a promising direction for future nuclear data evaluation efforts, especially when dealing with incomplete, conflicting, or high-uncertainty datasets.
For datasets containing more than 10 elements, the use of non-parametric bootstrapping is generally considered appropriate for estimating statistical confidence intervals [
67]. Singh et al. [
68] recommend this guideline. In this study, we used a dataset of 31 values, which would normally allow for such non-parametric bootstrapping. However, we chose the hybrid parametric bootstrap method instead. Unlike traditional resampling, HPB accounts for the measurement uncertainty of each data point and incorporates it directly into the resampling process. As a result, it produces confidence intervals that are more representative of real-world conditions. In applications such as nuclear cross-section calculations, it is also essential to ensure that generated values remain physically valid. For example, cross-sections must be strictly positive. The HPB method allows such constraints to be imposed as part of its core procedure.
To evaluate the robustness of the MFV-HPB method when applied to small datasets, we analyzed five published half-life values for
108mAg, each reporting a central estimate and associated uncertainty. These values span nearly five decades of research, ranging from Vonach et al.’s 1969 result to the latest measurements in 2018. The earliest estimate,
years [
50], relied on neutron activation and cross-section-based modeling, whereas subsequent values were derived from decay spectroscopy with progressively improved precision.
Using all five values, the MFV analysis produced a half-life of , with a 68.27% confidence interval (1-sigma) of and a 95.45% interval (2-sigma) of . These broad intervals reflect both the limited sample size and the large uncertainty associated with the 1969 measurement.
To test whether the earlier, less precise estimate significantly influenced the result, we repeated the MFV-HPB analysis using only the three most recent and precise values from 1992, 2004, and 2018. This yielded an MFV of with narrower confidence intervals: for 1-sigma and for 2-sigma.
The difference between the two MFV results was modest—less than
—and well within the respective uncertainty ranges. Notably, the second analysis excluded not only the earliest measurement by Vonach et al. [
50] (
), but also the 1970 value of
[
63], which is significantly lower than later estimates and based on earlier-generation measurement techniques. Despite removing these two lower and more uncertain values, the resulting MFV changed only slightly.
The bootstrap values for the hybrid parametric bootstrap analysis, focusing on the three latest half-life measurements of
108mAg, are shown in
Figure 6. A summary of these values is also provided in
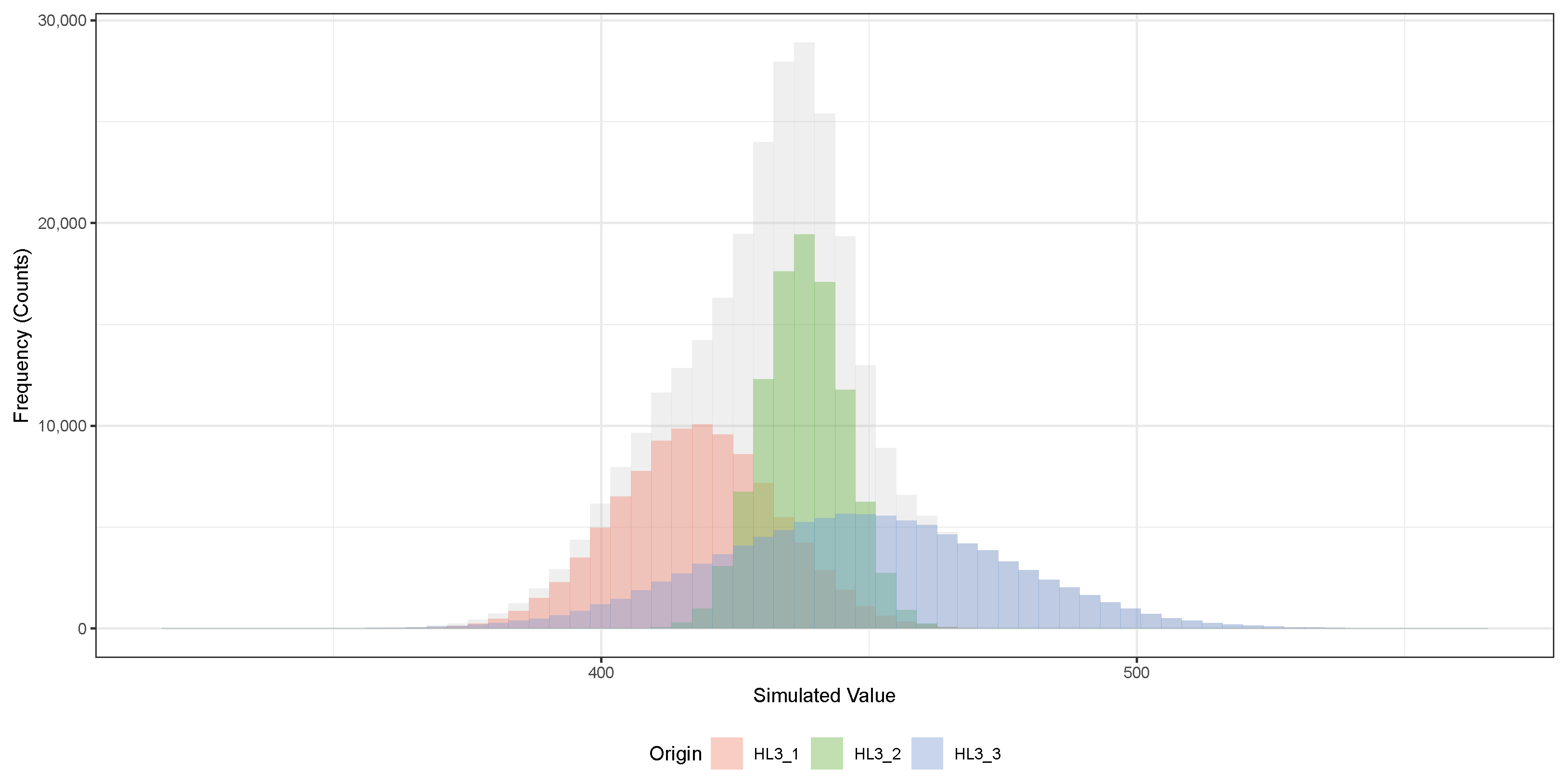
Table 3. Each colored distribution in
Figure 6 corresponds to the set of simulated half-life values for one of the original measurements:
years (HL3_1),
years (HL3_2), and
years (HL3_3). For each dataset, 100,000 bootstrap replicates were generated by randomly sampling according to the reported measurement uncertainties, assuming Gaussian distributions. The gray histogram in the background shows the combined distribution of all simulated values. The plotted histograms illustrate the spread and central tendency of the simulated half-lives, with clear separation between the peaks corresponding to each original measurement.
Table 3 provides a quantitative comparison between the fitted Gaussian parameters extracted from the simulated datasets and the original measured values. For each origin, the mean (
) and standard deviation (
) obtained from the bootstrap simulations are compared to the original published values. The absolute percent differences (
and
) are extremely small, all below
, indicating excellent agreement between the simulations and the experimental data. This validates that the bootstrap sampling process accurately preserved the statistical properties of the original measurements without introducing additional bias or systematic deviation.
The close agreement between the MFV values derived from the five-element and three-element datasets demonstrates that the central estimate remains stable even when early, high-uncertainty, or outlier data are excluded. It further underscores the MFV-HPB method’s ability to yield reliable central values from small, heterogeneous, and historically diverse datasets. This reinforces its usefulness in validating or reinterpreting legacy nuclear measurements using modern statistical approaches.
In both cases, the confidence intervals were estimated using the percentile method, which extracts quantiles from the empirical bootstrap distribution. To improve statistical accuracy and reduce variability, the MFV was computed for each of 100,000 bootstrap samples. This large number of resamples ensured precise estimation of the confidence bounds even with limited source data and considered the uncertainty associated with each element in the dataset (see
Table 3). In addition, a large bootstrap sample size was selected to minimize the introduction of additional statistical errors due to the inherent randomness of the HPB technique. To validate this, we performed a Gaussian fit for each individual data point generated during resampling and confirmed that both the mean and standard deviation of the fitted distribution matched the original source values. This step confirmed that the HPB procedure truly preserved the original data structure and uncertainty, thereby ensuring the reliability of the resulting MFV-based confidence intervals.
An important observation from this analysis is that the confidence intervals derived using the MFV-HPB method were not necessarily symmetric around the central value. This contrasts with intervals based on the arithmetic mean, which typically assume normally distributed data and produce symmetric intervals. The asymmetry observed in the MFV-HPB results more accurately reflects the underlying distribution of the data and highlights the method’s suitability for non-Gaussian datasets.
Despite its strengths, the MFV-HPB framework is not without limitations. Like other statistical methods, it performs best when most data are concentrated near the true value. If erroneous or biased values overwhelm a dataset, even the MFV-HPB approach can yield misleading results. This limitation is not unique to MFV; it represents a general challenge in statistical inference that underscores the importance of high-quality data.
In addition, the HPB method is computationally intensive, especially when large numbers of bootstrap samples are required or when applied to larger datasets. Nonetheless, this approach remains highly effective in situations in which measurement uncertainty is significant and traditional statistical assumptions do not hold. The flexibility and reliability of the proposed method make it a valuable tool not only in nuclear data analysis but also in other fields, such as biophysics and medical diagnostics, where datasets are often small, noisy, and irregularly distributed.
The MFV-HPB framework is a method developed to provide strong estimates of central values and their confidence intervals in datasets with variability and potential outliers. This framework faces specific challenges when dealing with datasets with multimodal distributions, which are common in areas like molecular dynamics and the microscale mechanical mapping of cancer cells, where bimodal or multimodal systems often occur [
69,
70]. The MFV-HPB procedure can be performed in a “mode-by-mode” approach. By isolating each peak and recalculating the MFV with a confidence interval using a hybrid bootstrap method, this approach usually offers more precise confidence intervals for each mode. The MFV step reduces the impact of extreme data points within each subgroup, leading to MFV-HPB confidence intervals that are systematically narrower than those from traditional methods, thus providing more insightful summaries of multimodal datasets.
In this study, the dataset represents a single physical parameter: the cross-section value of a particular nuclear reaction at a specific neutron energy. Ideally, the data should converge to a value that accurately reflects this parameter. However, multiple peaks or modes can appear in the data. These multimodal features often result from differences in methods, inconsistent measurement techniques, or hidden systematic errors rather than actual physical variations.
In the analysis of neutron lifetime data [
25], different experimental methods produced several groups of values. Although these groups varied, there should be one true central value for the neutron lifetime because it is a fundamental physical constant. The MFV approach helped us to find a reliable central value that considered all data points and reduced the effects of clusters caused by specific measurement techniques.
Similarly, this study initially observed a bimodal pattern in the cross-section data for the reaction
109Ag(n, 2n)
108mAg (see
Figure 1). This pattern mainly arose from differences in the reported half-life of
108mAg. Some values relied on older half-life estimates, whereas others used updated measurements. Adjusting the dataset to correct these systematic differences reduced the bimodal effect (see
Figure 2), supporting the conclusion that a single value can accurately describe the cross-section.
The MFV-HPB framework considers the uncertainties of each data point, thereby providing a more complete estimate of the central value and its confidence intervals. In contrast, PDG uses a weighted mean method, which also considers uncertainties but tends to bias the central value toward data points with the smallest uncertainties [
19]. This bias can become an issue when the smallest uncertainty does not truly reflect better measurement accuracy but instead arises from unrecognized systematic errors or possible mistakes in data reporting [
24].
5. Conclusions
In this study, we presented a robust statistical approach that combines Steiner’s most frequent value method with a hybrid bootstrap procedure to estimate central tendency and confidence intervals for datasets affected by variability, outliers, or limited sample size. We applied this method to fast-neutron activation cross-section measurements of the 109Ag(n, 2n)108mAg reaction at , a dataset characterized by significant uncertainties and inconsistencies.
Our findings show that the MFV provides a stable and reliable central estimate, even when traditional metrics like the arithmetic or weighted mean are distorted by outliers. Combined with the hybrid bootstrap procedure, which models both measurement uncertainty and sampling variability, the method produced interpretable and well-constrained confidence intervals. For the cross-section data, the MFV was determined to be , with a 68.27% confidence interval of and a 95.45% confidence interval of , based on 500,000 hybrid bootstrap replicates.
To further demonstrate the method’s flexibility, we applied the MFV-HPB framework to estimate the half-life of the 108mAg isotope using a small dataset of published measurements. When analyzing five available values (excluding the earliest lower-limit estimate from 1960), the MFV was found to be , with a 68.27% confidence interval of and a 95.45% interval of . A secondary analysis, considering only the three most recent and precise measurements, yielded an MFV of with narrower confidence intervals. The close agreement between these results confirmed that the method maintains stability even when earlier, higher-uncertainty data are excluded.
Importantly, the MFV-HPB method does not assume any particular shape for the underlying data distribution. As observed in the half-life analysis, the resulting confidence intervals can be asymmetric, providing a more accurate reflection of the real uncertainty structure compared to traditional Gaussian-based methods.
The hybrid bootstrap method used in this study combines non-parametric resampling of the original data entries with parametric simulation based on their individual uncertainties. Unlike a purely parametric bootstrap, where each original data point contributes exactly one simulated value per replicate, our approach first resamples the data points with replacement. This adds an extra layer of variability, capturing uncertainty about which measurements are most representative. Especially in small datasets or when uncertainties are heterogeneous—as in early half-life measurements—this strategy produces slightly wider and more conservative confidence intervals, better representing the true uncertainty.
Although this work focused on nuclear physics examples, the statistical challenges addressed here—such as data sparsity, measurement uncertainty, and non-Gaussian behavior—are common across many fields, including biomolecular research, environmental monitoring, and diagnostics. As a result, the MFV-HPB framework provides a generalizable and reliable tool for extracting trustworthy insights from real-world data.
We hope that this study will encourage broader adoption of the MFV-HPB methodology in scientific data analysis, particularly in situations where robustness and interpretability are critical. Future efforts could expand its application to additional scientific domains and help formalize its integration into standard evaluation practices. Ultimately, the MFV-HPB approach offers a statistically rigorous and adaptable pathway for addressing uncertainty in complex datasets.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}