1. Introduction
Alzheimer’s disease is a progressive neurodegenerative disease in which patients experience symptoms such as impairment of behavioral and cognitive functions such as memory, comprehension, language, attention, reasoning, and judgment [
1]. Alzheimer’s is the most common form of dementia [
1]. There are three types of Alzheimer’s disease: early onset, late onset, and familial Alzheimer’s disease (FAD) [
2]. While FAD only accounts for about 25% of Alzheimer’s cases, it can provide valuable insight in the alterations in Aβ function [
3]. Alzheimer’s is currently the sixth leading cause of death in the United States. Furthermore, there was a sharp increase in the number of Alzheimer’s cases over the last two decades, emphasizing the need for an effective treatment for Alzheimer’s disease. The current treatments available only address the symptoms of Alzheimer’s but not the underlying cause.
Small aggregates of Aβ called oligomers are cytotoxic and are thought to play a role in neurodegeneration in Alzheimer’s disease [
4]. The oligomers can form protofibrils. Aβ protofibrils aggregate together to form plaques which disrupt the neuronal connections in the brain. Many studies have explored drug interventions to prevent Aβ aggregation [
4,
5]. However, clinical trials of anti-aggregations drugs have thus far mostly failed suggesting that researchers might consider targeting other mechanisms to treat Alzheimer’s disease [
5]. Five drugs that target Aβ to treat Alzheimer’s disease are currently in clinical trials (or have recently completed clinical trials): gantenerumab, crenezumab, solanezumab, donanemab, and lecanemab [
6]. Aducanumab very recently received accelerated FDA approval on 7 June 2021 [
7]. Donanemab has shown to improve the composite score for cognition and the ability to perform daily activities in clinical trials and has awarded FDA Breakthrough Therapy designation in June 2021 [
8,
9].
Previous studies have analyzed the relation between Aβ and Alzheimer’s to understand how the Aβ peptides aggregate and form plaques and how a drug can inhibit aggregation [
3,
10,
11,
12]. Other studies evaluate the different mutations of Aβ through different methods to generate a ranking of the different mutations based on their rate of aggregation. According to Tabaton et al., Aβ also plays a large signaling role for the BACE1 receptor. The signaling domain refers to Residues 1–8. There is a gap with the literature available in terms of the relation between aggregation and the signaling domain. This molecular simulation creates the opportunity to analyze these residues and evaluate the impact of the signaling domain on aggregation. No other molecular simulation provides the ability to specifically analyze the signaling domain. This means that this research is a novel approach to determine the importance of the signaling domain on aggregation.
This research evaluates both familial Alzheimer’s disease (FAD) and cerebral amyloid-angiopathy (CAA). These two are the diseases analyzed along with wildtype (WT) for the purposes of this research. There were also several different mutations that were analyzed that correspond to the diseases. These are A21G (Flemish), A42T (C-terminal), D7N (Tottori), D23N (Iowa), E22G (Arctic), E22K(Italian), E22Q (Dutch), L34V (Piedmont mutation), and WT (wildtype). These mutations were analyzed in the methods below. There were three main methods used to derive the conclusions. These methods all analyzed the residues of Aβ and tried to identify the important regions determined.
This research applies machine learning to the ensembles of conformations of Aβ variants to identify which specific amino acid residues undergo structural changes that can be related to disease severity and Aβ aggregation. These structural changes were accounted for in the data set shown by variance in the angles. By analyzing the changes and the corresponding result of the mutations and thus diseases, an overall conclusion can be derived about the region of Aβ that needs to be targeted for more research. To complete the research, the machine learning algorithm helped rank angles and determine the important residues.
3. Results
We analyze the contributions of different amino acid residues to measures of functional changes and disease for the different variants. These were performed using several machine learning methods to find the phi and psi angles that correlated with the different measures. These measures included Aβ aggregation, prediction of pathology, drugs targeting Aβ, and average age of onset. The results are shown with a table showing the rank and information gained for each angle. With this, plots were generated depicting the rank of the angles corresponding the residues they target. This allows for the visual understanding of the general location of the residues. Finally, a confusion matrix was generated to test for sensitivity and accuracy. This allows for a final understanding of the angles’ ability to characterize the disease. This allows us to determine whether the final angles generated can effectively characterize amyloid-beta mutations and Alzheimer’s disease. This helps check the work to check if the results make sense.
3.1. Prediction Amyloid β Aggregation
The first set of data mining analyses ranked the phi and psi angles of the ensemble of structures based on their ability to characterize measures of Aβ aggregation in the different variants. This research used the data set developed in our previous work as explained in the Methods Section titled “Molecular Simulations” for all the data mining results generated in the prediction of Aβ aggregation [
13]. The variants studied both in vitro and in vivo experimentally by Hatami et al. were separated into two classes, variants that displayed increased aggregation (E22G, L34V, D7N, E22K, A2V, and H6R) and variants that displayed decreased aggregation (A21G and E22Q) [
18]. The three variants that aggregated the most (E22G, L34V, and D7N) were used for the rankings. The “rank” learning module was used for developing a ranking of phi and psi angles involved in aggregation.
First, the ranking of angles in the variants that cause increased aggregation was compiled. These rankings are shown in
Table 1 and in
Figure S1 as a plot with the rank and residue as the axis. These results show how the eight of the residues in the top fifteen were part of the signaling domain (Residues 1–8) which is important for interactions with other molecules.
Table 1 has the ranking of the angles with their information generated.
Similarly, Yang et al., observed in vitro that variants E22G, D23N, and E22Q aggregated faster than variants E22K, A21G, and WT [
19]. Both papers are similar in that they both find mutations that aggregate faster, but the mutations they study differ. The research from Yang et al. evaluated the mutations that aggregated much faster than the ones that did not. From this paper, it was determined that similar to the last method, this method only ranks the mutations for both increased and decreased aggregation. This analysis also uses the data from the molecular simulations coupled with the “rank” module.
Figure S2 and
Table 1 show the results of the method developed based on this paper. Again, many of the angles ranking high were part of the signaling domain. Based on this method, five of the top fifteen ranking angles were in the signaling domain.
Table 1 shows the ranking of the angles along with the information gained from each angle.
3.2. Prediction of Pathology
To determine significant residues associated with pathology an alternative analysis generates a classification tree using the “tree” and “test and score” module. The classification tree is a machine learning algorithm that works by dividing the data into subsets. It then predicts the results of the angles in figuring out the target variable with a percent score. The molecular simulation data used were the same data used above. The angles that could separate the WT from the non-WT points by >0 percent were compiled to form a
Table 2 of angles that are able to predict variants of Alzheimer’s (FAD, familial Alzheimer’s disease and CAA, cerebral amyloid angiopathy) from wild type. These are only the angles that can separate WT from the FAD and CAA variants, but not FAD from CAA. These angles indicate a structural change in the Aβ peptide which might result in some functional change that is associated with disease.
Table 3 was then used to rank the entire data set by disease to determine the most useful angles that are the best at characterizing disease.
Figure S3 is the result of the ranking of the entire data set by variant of disease based on the angles that could separate disease first. These are the angles that were best able to characterize the data as FAD, CAA, or WT. For the ranking of disease, the fifteen angles that ranked the best were angles phi6, phi8,
Table 3 has the angles and their information gained generated from this method.
One more method was also applied for this research to predict Aβ pathology. This set of data mining analyses ranked the ensemble of phi and psi angles based on their ability to characterize the entire data set based on mutation and disease. These angles may be significant since they are the most capable in classifying the mutation or disease. This research characterizes both mutations and diseases to ensure that the angles that are the most useful in predicting the important residues are considered.
Figure S4 and
Table 4 are the result of the ranking of the entire data set by variant of disease. These are the angles that were best able to characterize the data as FAD, CAA, or WT.
Figure S4 has five angles that are ranked as part of the top fifteen in the signaling domain. These angles include phi2, phi4, phi7, phi5, and psi3.
Table 4 has the ranking of the angles and information gained for this method.
Table 5 and
Figure S5 are the result of the ranking of the entire data set by variant of mutation. These are the angles that were best able to characterize the data as the specific mutation that causes the disease. This ranking result shows five angles that were part of the signaling domain that ranked extremely well. These angles in the signaling domain are phi2, phi4, phi7, phi5, and psi3.
Table 5 and
Figure S5 show the angles that rank the entire data set by mutation and the information gained. In this ranking, eight of the fifteen angles that ranked best are part of the signaling domain. These angles are phi2, phi6, phi8, psi5, phi7, psi2, phi4, and psi1.
3.3. Average Age of Onset
The final method looks at the average age of onset for the mutations of Aβ mutations. With this, there are some mutations that have a significantly faster average age of onset compared to others. This may be related to the aggregation of Alzheimer’s disease as mutations with a lower age aggregate faster. Using this, the mutations that have an average age of onset of less than 60 were analyzed and the 84 angles were ranked based on their ability to influence these mutations. This is important as these angles might be important in the aggregation of Aβ. These angles were then analyzed to determine the important residues in characterizing mutations with a large average age of onset.
This research tests to see the angles that are significant in characterizing mutations with an average age of onset that are less than 60 years old. The mutations and their average age of onset was found through the paper McCoy et al. [
13]. This method applied the “rank” module again to test the angles.
Table 6 refers to the average age of onset along with the mutation. In this, we can see four of the mutations causing FAD and four of them causing CAA. Four of the mutations have an average age of less than 60 years old.
The results are shown in
Table 7 and
Figure S6. These are the angles that are best able to characterize the mutations with an average age of onset less than 60 years old. There are six angles that are ranked in the top 15 that are also part of the signaling domain. These angles are phi4, psi3, psi5, psi1, psi4, and phi5.
Table 7 has the information gained and the rank of angles for this process.
3.4. Cumulative Ranking of Residues
Based on the results generated above, for each ranking, the fifteen angles that have the highest rank were given a point value equivalent to their fifteen minus their rank (16-ranking position). For methods where both increased aggregation and decreased aggregation were calculated, only increased aggregation was used for the purposes of this research. This generates seven unique tables with point values.
For the drugs in clinical trials, since residues were not ranked, a new part of the algorithm was utilized. This created a system where every time a residue was included in a clinical trial, it would gain five points. If a residue was targeted more than once, it would gain five times the number of times it was repeated points.
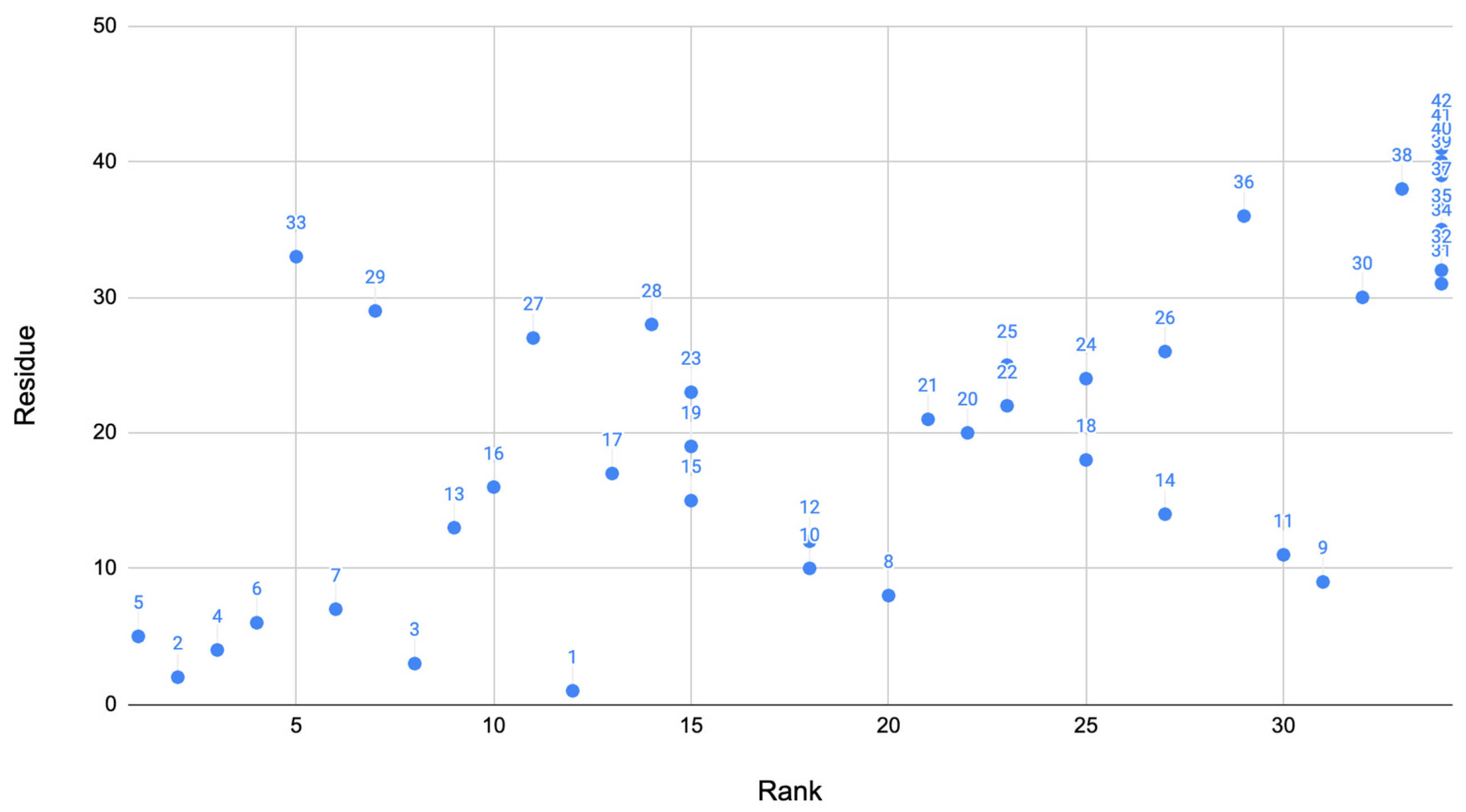
These two methods of the algorithm produce scores for residues that were important for each method. From this, the scores are all added up for the final system where we can determine the most important residues. These scores of the residue were then plotted against the residue as a visual showing the residues scores compared to others. The rank of the residue was also plotted against the residue to show how the residues ranked in comparison to each other (
Figure 1). Based on this algorithm described above, the 10 residues that ranked best are: 2, 3, 4, 5, 6, 7, 13, 16, 29, and 33.
Table 8 shows the ranking of the residues above. This suggests that the residues in the range 2–7, 13, 16, 29, and 33 were the most important in the Alzheimer’s disease phenotype. This graphs clearly shows that many angles found in the signaling domain are highly ranked (bottom left corner of the plot). A few other residues also rank well in other key locations of the protein.
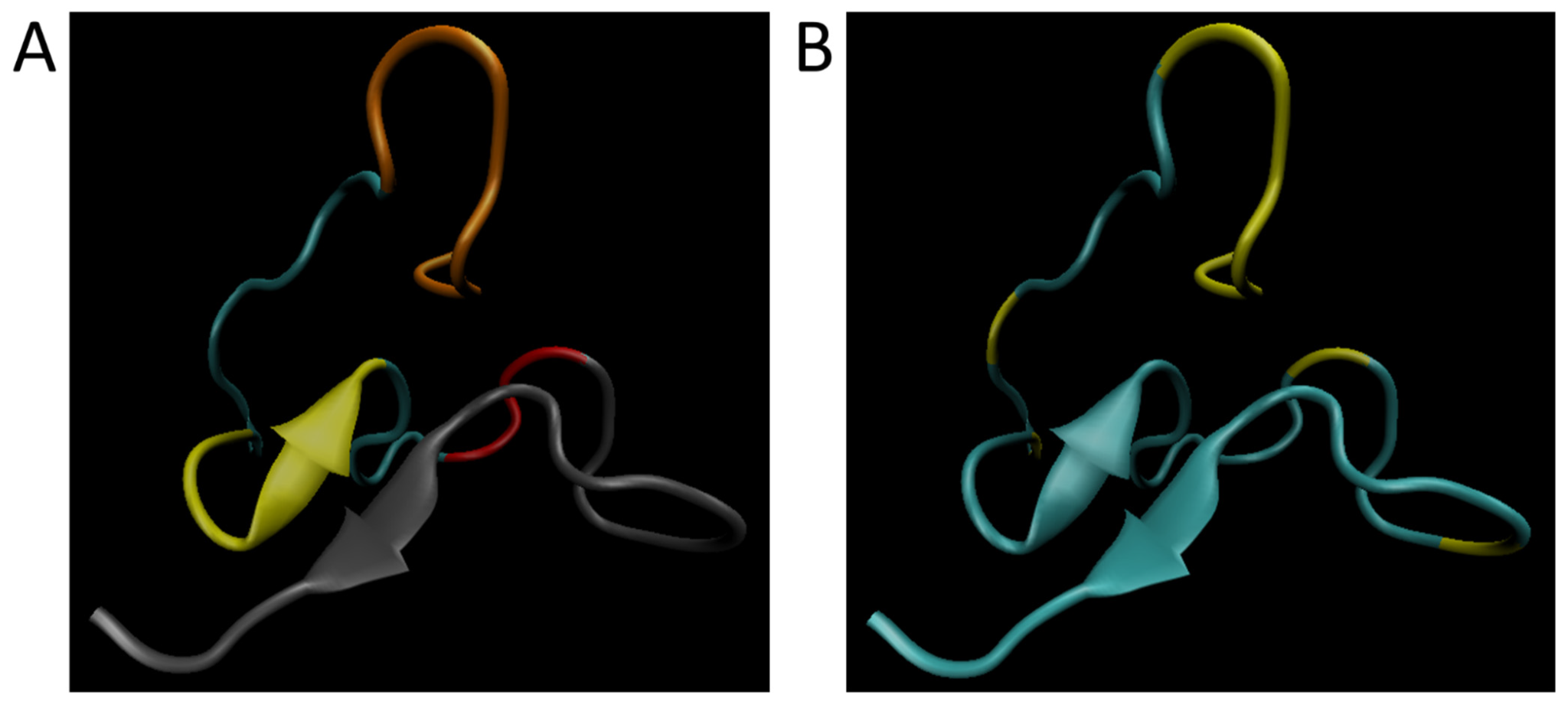
Figure 2A shows the simulated wild-type structure of Aβ with the signaling domain in the N-terminus (Residues 1–8, orange), the hydrophobic cluster (Residues 17–21; yellow), the hairpin turn region (Residues 27–29; red), and the oligomerization domain in the C-terminus (Residues 30–42; gray).
Figure 2B has the simulated wild-type structure showing the significant residues (residues are 2–7, 13, 16, 29, and 33) predicted by this research have been highlighted in yellow. From this it becomes clear that the signaling domain and hairpin turn are well represented in the residues for ranking by cumulative disease phenotype.
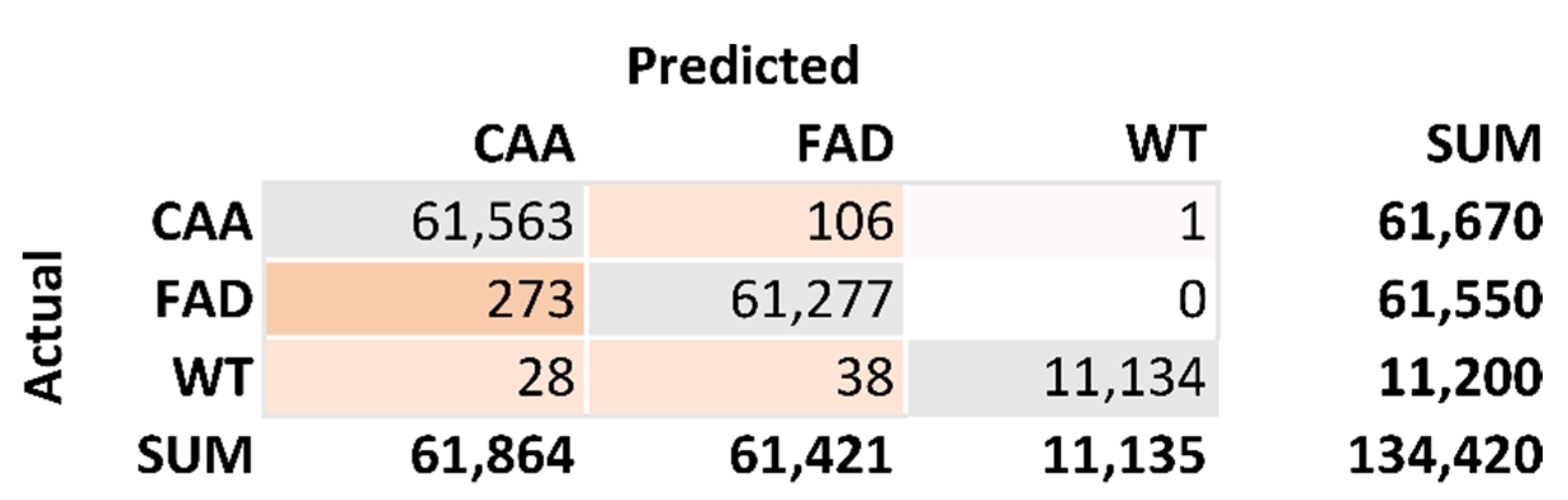
From these models, a confusion matrix was developed to check the accuracy of the model.
Figure 3 is the confusion matrix generated from the 10 top-ranking residues. The total number of correct predictions is 134,064. The total number of incorrect predictions is 446. This results in an accuracy calculation of 99.67%. The sensitivity calculation for FAD is 0.9983. The sensitivity calculation for CAA is 0.9966. The sensitivity calculation for WT is 0.9941. The specificity calculation for CAA is 0.9958. The specificity calculation for FAD is 0.9980. The specificity calculation for WT is 1.0000.
4. Discussion
4.1. Novelty of Method
Machine learning is a relatively new idea for predicting torsion angles. Machine learning has been used to predict torsion angles since 2012 [
20]. The torsion angles have also been able to predict the folding of different proteins before [
21]. For Aβ specifically, torsion angles have been used to predict gene severity [
13]. The methods used here are still very unique as currently no methods produced have been able to use torsion angles to predict the significant residues of different proteins. This is a unique method for Aβ prediction to discover new targets for different drugs.
4.2. Residues Involved in Aggregation
Evaluating the changes in the phi/psi angles is important in understanding locations where functional change may occur. The use of machine learning to find these functional loci presents a novel approach to identify important sites with applications such as the identification to which effective drugs can be targeted. This research evaluates the phi/psi angles that are best correlated with aggregation as well as those correlated with the signaling domain.
Based on our research, regions of Aβ such as the hairpin turn region (Residues 27–29) and the signaling domain (Residues 1–8) seem rank highly in separating the aggregation data of Hatami and Yang [
18,
19]. In general, the central hydrophobic cluster (17–21) and C-terminus (29–42) are believed important for aggregation [
22,
23,
24]. For example, Residues 41 and 42 drastically speed up aggregation compared to Aβ1-40 [
11]. Our analysis suggests that Residues 16–21 and 29–42 are less highly ranked as other possible loci where interactions between Aβ might occur during oligomerization. It might be that the highly ranked residues might help position the residues involved in oligomerization. Furthermore, other regions such N terminus (Residues 1–15) which are thought to interact with small, charged molecules have other functional implications [
25,
26]. It seems likely that cell signaling helps set up the cellular conditions to promote Aβ aggregation. This is important to analyze to figure out where all the main interactions are and what they can lead to. NMR structures also show that the changes in the C-terminus increases the chances of aggregation.
It is important to comment on the plausible mechanistic relationship between monomeric conformational ensembles and aggregation propensities. It has been shown that monomeric structures of Aβ species displaying different aggregation propensities are distinct. For example, Sgourakis et al. have studied Aβ1–40 and Aβ1–42 conformational ensembles by NMR and microsecond REMD [
15]. Aβ1–42 aggregates orders of magnitude faster than Aβ1–40 and, consequently, they found clear differences in the C-terminus conformations manifested by more rigid structure in Aβ1–42 species. Thus, the “signals” differentiating aggregation propensities might be discerned even in monomeric conformational propensities. In our study, we have demonstrated that certain sequence positions strongly contribute for discriminating aggregation rates of Aβ mutants by serving as possible nucleation centers. It is then natural to expect that when these “important” amino acids are altered by mutations aggregation pathways are affected. However, mutations also affect monomeric conformational preferences, which are detected by our analysis and linked to aggregation rates. These arguments make up the premise of our approach.
4.3. Implications for Drug Targeting
There are many implications for future drug targeting. As the phi and psi angles involved in drug action that aims to reduce the aggregation of Aβ were analyzed. These drugs are all currently in clinical trials to test if they are effective. This research only looked at the residues for drugs that were in clinical trials since at least 2018. This is to ensure that the research only looks at recent drugs. This is important because this will result in the highest level of accuracy. This is because they use the most up to date research. Furthermore, they have not been proven to fail yet as the other drugs have.
Analysis of these drugs is critical as it allows us to understand research that is not available. The drugs would only target the residues if past researchers found that there may be some significance at those regions. This must mean that previous research found that these residues were significant. This is because the drugs would not target these locations unless they felt that changing something at these residues would decrease the aggregation. This means that these residues may provide some functional change at the locations. This is important to ensure that the residues are important in figuring out the significant locations.
These are the drugs that aimed at reducing the aggregation of Aβ that made it to clinical trials. For the purposes of this research, we looked at the drugs that are still in clinical trials. This refers to aducanumab, gantenerumab, crenezumab, solanezumab, donanemab, and lecanemab. These drugs will have their residues analyzed for these models. The residues targeted were found from past literature available for Aβ.
This method essentially analyzes all the residues that are targeted by drugs in clinical trials. These residues were then scored based on frequency.
Table 9 lists the drugs in clinical trials and the residues they target. This was used to identify important locations and domains. The drugs in clinical trials target Residues 3–11 and 13–27. Drugs that failed clinical trials were also analyzed based on their function and their result. In some cases, the exact residues targeted by these drugs are not publicly available. The drugs that failed, mechanism class, and results have been compiled into
Table 10. The anti-tau antibodies and secretase inhibitor drugs shown in
Table 1 have not successfully completed clinical trials. This table can be used to further evaluate the residues if the knowledge becomes public [
27].
Based on the cumulative ranking of important resides presented here, drugs that target Residues 27–29 and/or 2–8 will be effective in reducing symptoms of Alzheimer’s. Based on this, aducanumab, donanemab, and gantenerumab seem to be the drugs that will be most effective in reducing aggregation. This prediction is supported by the FDA approval of aducanumab and favorable findings in current trials for gantenerumab [
7,
28]. Recent reports indicated that Alzheimer’s patients taking donanemab showed improvement over those taking placebo [
8,
9]. This analysis suggests that the reason that the drugs targeting Aβ in clinical trials have failed and will fail in the future is because the drugs are not targeting the regions of Aβ that have the largest effect on disease phenotype.






{kind=link}
{kind=link}
{kind=link}