Model-Agnostic Method for Thoracic Wall Segmentation in Fetal Ultrasound Videos

 , ,
, ,  , , , , , , and
, , , , , , and 
Abstract
1. Introduction
1.1. Related Research
1.2. Our Contributions
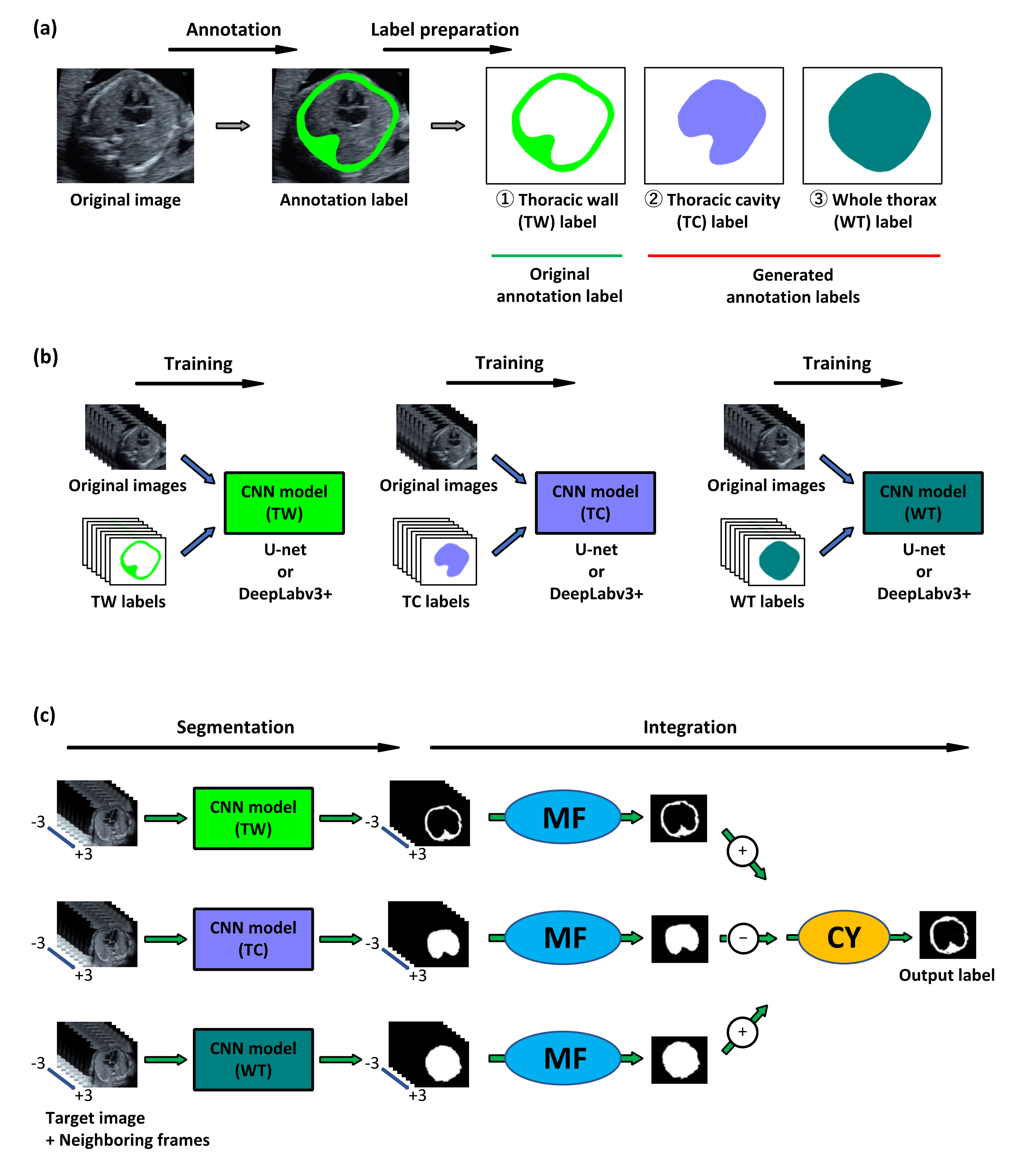
- MF was designed to integrate the prediction labels, corresponding to each target image and its neighboring frames in the video, into a single prediction label. It takes advantage of the similarity between neighboring frames within the set of sequential time-series images that comprise a high frame-rate ultrasound video. As even slight cross-sectional variations between neighboring ultrasound images can affect the appearance of structures substantially. Thanks to this difference in appearance, it is possible to complement the thoracic wall area, which could not be recognized by a single segmentation if the area was recognized by the other segmentation. Collectively, the integration of multiple prediction labels of sequential images belonging to the same video complements the information with each other.
- CY integrates three prediction labels-thoracic wall, thoracic cavity, and whole thorax-for the thoracic wall segmentation. The three prediction labels are obtained from the three independent models trained by each annotation label. CY utilizes the prior knowledge that the thoracic wall is always cylindrical. Namely, the thoracic wall label could be obtained by hollowing out the thoracic cavity label from the whole thorax label. The output prediction label of the thoracic wall obtained by CY more firmly delineates the outer boundary by the whole thorax label and the inner boundary by the thoracic cavity label. Collectively, the three prediction labels from the three independent models can also complement the information with each other.
- MFCY, which is a combination of the two aforementioned methods, is a model-agnostic method. It functions by employing the predictions obtained from any CNN model. Therefore, it can be applied to any state-of-the-art deep learning technology, regardless of whether they are modified or not; it notes that there is no need to make modifications to the state-of-the-art deep learning technology to fit MFCY.
2. Materials and Methods
2.1. Outline of This Study
2.2. MF and CY
2.3. Network Architecture
2.4. Preparation of the Images and Labels
2.5. Evaluation Metrics and Cross-Validation
2.6. Configurations Used in Experiments
3. Results
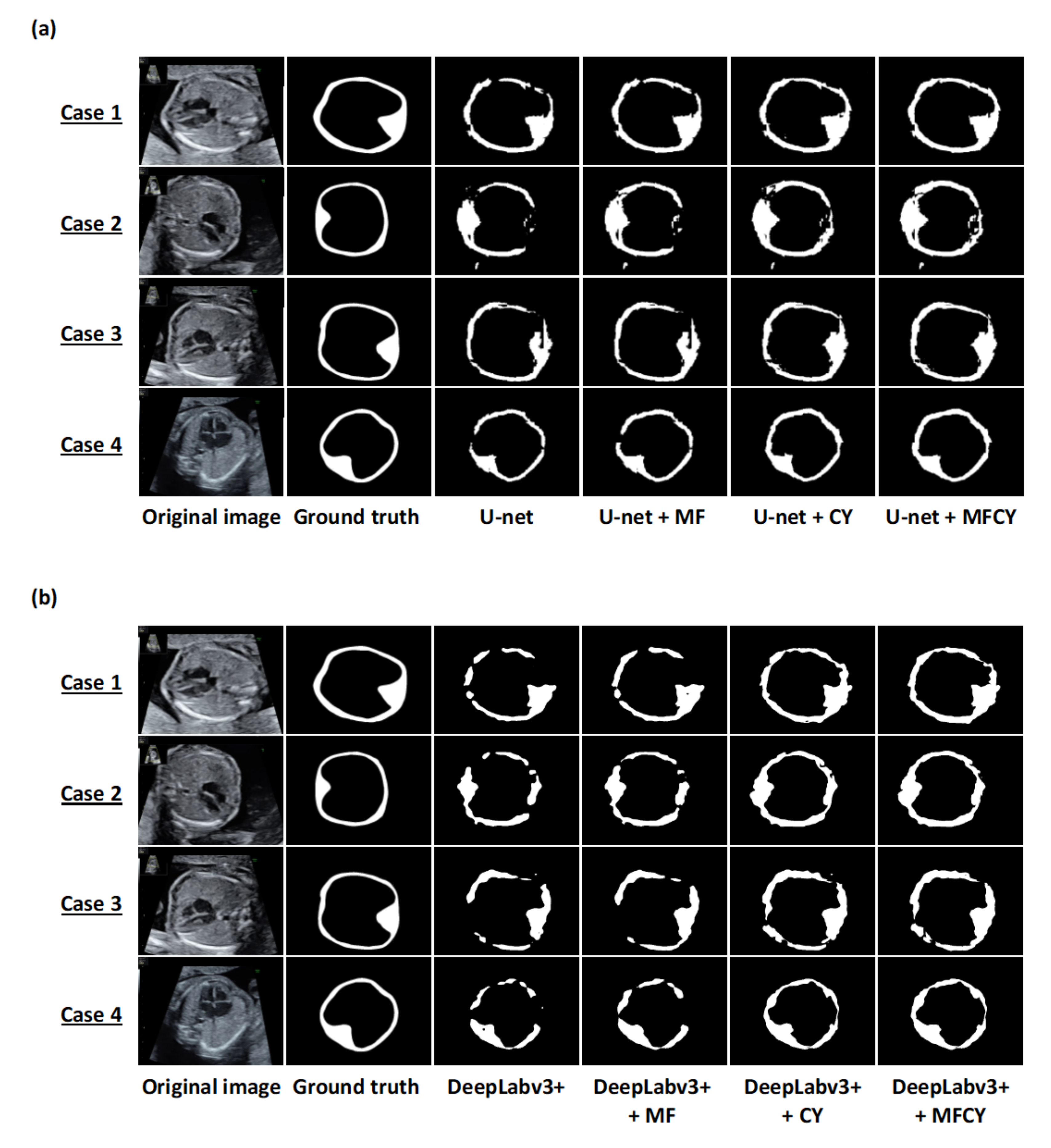
3.1. Comparison between the Performances of the Existing Models and Our Methods
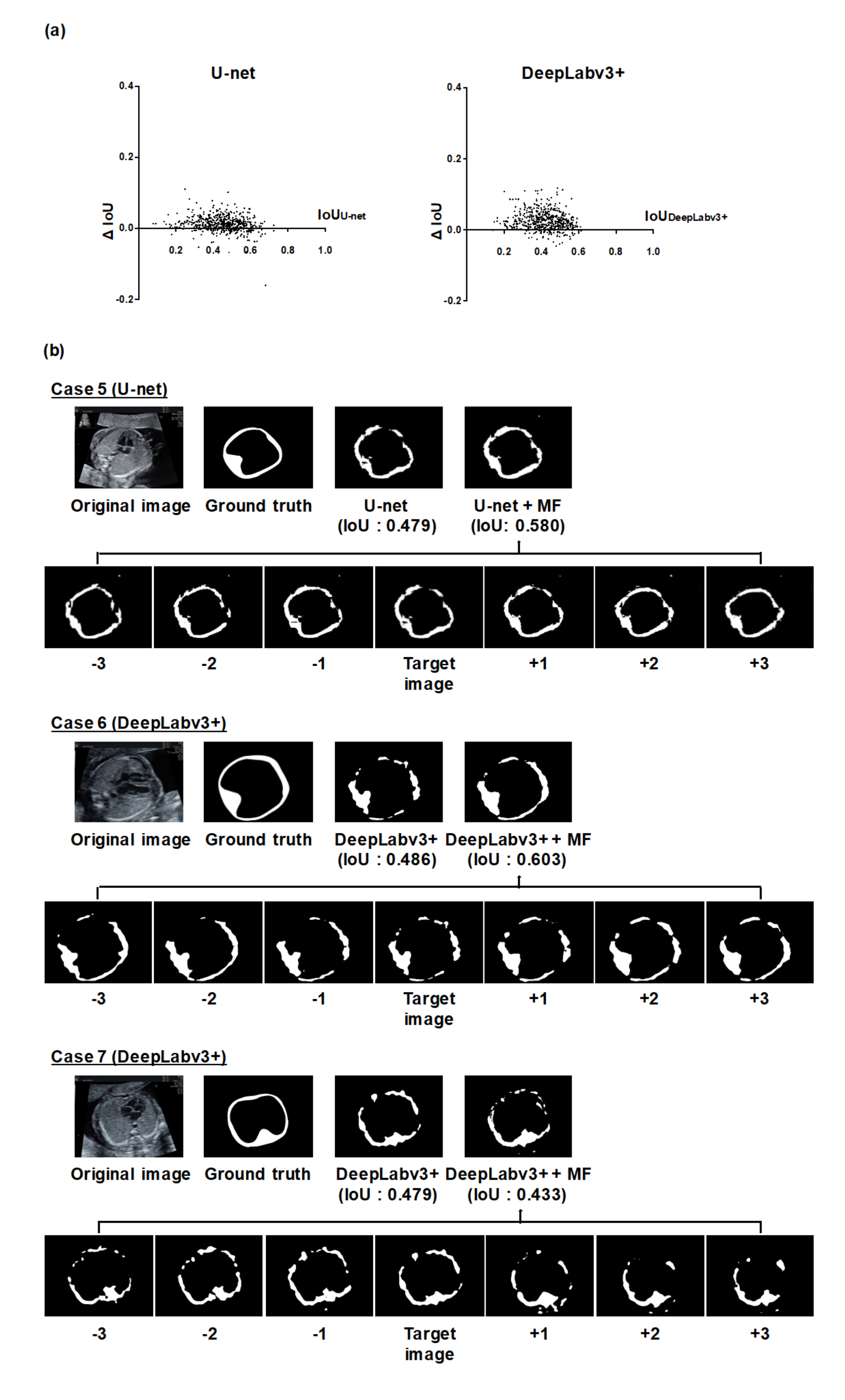
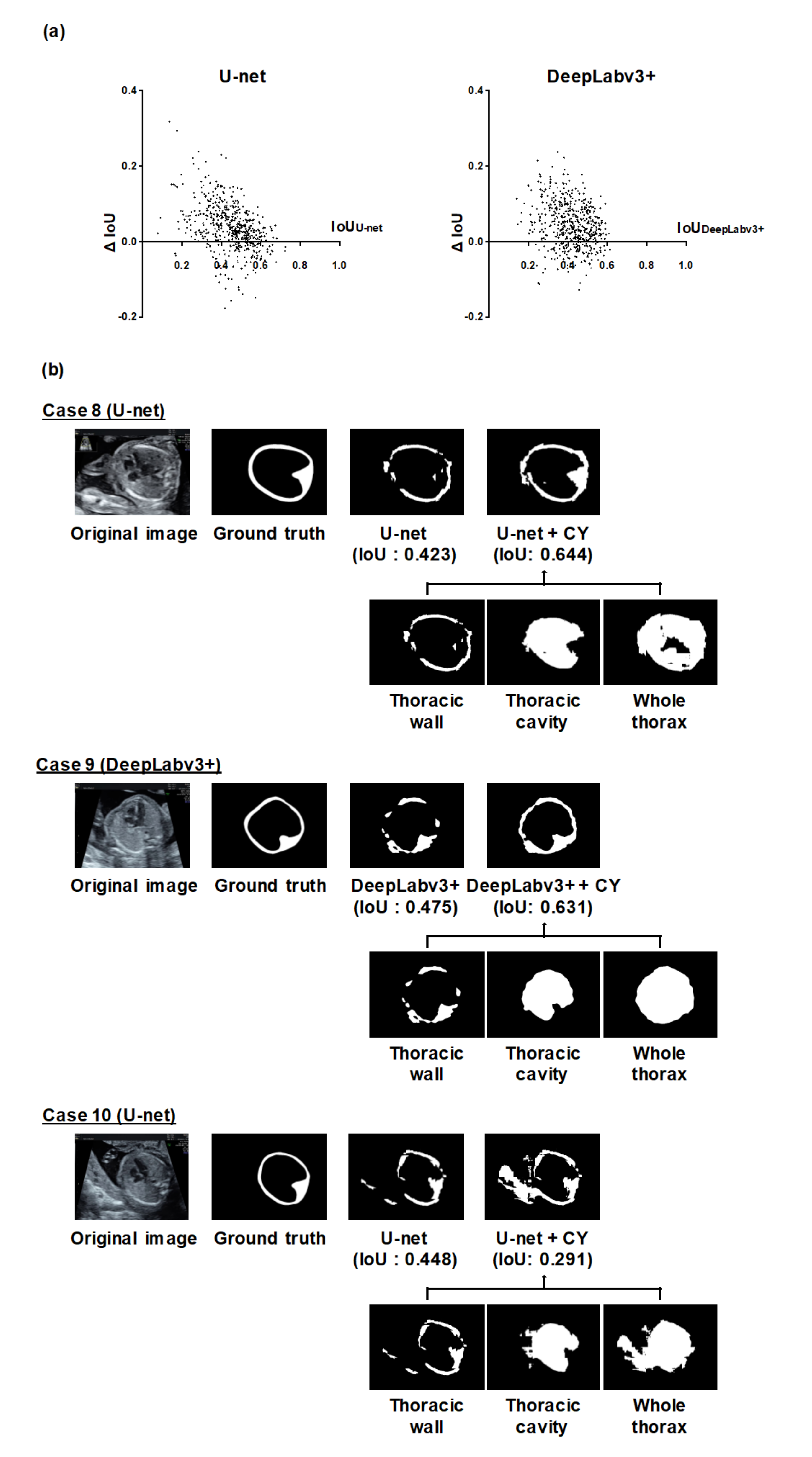
3.2. Analysis of Individual Effectiveness of MF and CY
4. Discussion
Limitations
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CNN | Structure | mIoU | mDice | mPrecision | mRecall | ||||
|---|---|---|---|---|---|---|---|---|---|
| Mean | SD | Mean | SD | Mean | SD | Mean | SD | ||
| U-net | Heart | 0.686 | 0.042 | 0.798 | 0.036 | 0.849 | 0.028 | 0.784 | 0.069 |
| Lung | 0.712 | 0.015 | 0.828 | 0.011 | 0.832 | 0.020 | 0.832 | 0.014 | |
| Thoracic wall | 0.448 | 0.017 | 0.610 | 0.016 | 0.679 | 0.033 | 0.568 | 0.032 | |
| DeepLabv3+ | Heart | 0.734 | 0.012 | 0.842 | 0.009 | 0.864 | 0.008 | 0.833 | 0.008 |
| Lung | 0.684 | 0.010 | 0.808 | 0.008 | 0.833 | 0.008 | 0.793 | 0.014 | |
| Thoracic wall | 0.417 | 0.007 | 0.582 | 0.007 | 0.675 | 0.009 | 0.525 | 0.013 | |
References
- Jiang, F.; Jiang, Y.; Zhi, H.; Dong, Y.; Li, H.; Ma, S.; Wang, Y.; Dong, Q.; Shen, H.; Wang, Y. Artificial intelligence in healthcare: Past, present and future. Stroke Vasc. Neurol. 2017, 2, 230–243. [Google Scholar] [CrossRef] [PubMed]
- Hamamoto, R.; Komatsu, M.; Takasawa, K.; Asada, K.; Kaneko, S. Epigenetics analysis and integrated analysis of multiomics data, including epigenetic data, using artificial intelligence in the era of precision medicine. Biomolecules 2020, 10, 62. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Liu, Y.; Georgiou, T.; Lew, M.S. A review of semantic segmentation using deep neural networks. Int. J. Multimed. Inf. Retr. 2018, 7, 87–93. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A Review on Deep Learning Techniques Applied to Semantic Segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Martinez-Gonzalez, P.; Garcia-Rodriguez, J. A survey on deep learning techniques for image and video semantic segmentation. Appl. Soft Comput. J. 2018, 70, 41–65. [Google Scholar] [CrossRef]
- Hesamian, M.H.; Jia, W.; He, X.; Kennedy, P. Deep Learning Techniques for Medical Image Segmentation: Achievements and Challenges. J. Digit. Imaging 2019, 32, 582–596. [Google Scholar] [CrossRef]
- Garcia-Canadilla, P.; Sanchez-Martinez, S.; Crispi, F.; Bijnens, B. Machine Learning in Fetal Cardiology: What to Expect. Fetal Diagn. Ther. 2020, 47, 363–372. [Google Scholar] [CrossRef]
- Liu, S.; Wang, Y.; Yang, X.; Lei, B.; Liu, L.; Li, S.X.; Ni, D.; Wang, T. Deep Learning in Medical Ultrasound Analysis: A Review. Engineering 2019, 5, 261–275. [Google Scholar] [CrossRef]
- Salomon, L.J.; Alfirevic, Z.; Berghella, V.; Bilardo, C.; Hernandez-Andrade, E.; Johnsen, S.L.; Kalache, K.; Leung, K.Y.; Malinger, G.; Munoz, H.; et al. Practice guidelines for performance of the routine mid-trimester fetal ultrasound scan. Ultrasound Obstet. Gynecol. 2011, 37, 116–126. [Google Scholar] [CrossRef]
- Roberts, K.P.; Weinhaus, A.J. Anatomy of the Thoracic Wall, Pulmonary Cavities, and Mediastinum. In Handbook of Cardiac Anatomy, Physiology, and Devices; Humana Press: Totowa, NJ, USA, 2005; pp. 25–50. [Google Scholar]
- Bethune, M.; Alibrahim, E.; Davies, B.; Yong, E. A pictorial guide for the second trimester ultrasound. Australas. J. Ultrasound Med. 2013, 16, 98–113. [Google Scholar] [CrossRef]
- The International Society of Ultrasound in Obstetrics ISUOG Practice Guidelines (updated): Sonographic screening examination of the fetal heart. Ultrasound Obstet. Gynecol. 2013, 41, 348–359. [CrossRef] [PubMed]
- Satomi, G. Guidelines for fetal echocardiography. Pediatr. Int. 2015, 57, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. Lect. Notes Comput. Sci. 2015, 9351, 234–241. [Google Scholar] [CrossRef]
- Liu, L.; Cheng, J.; Quan, Q.; Wu, F.X.; Wang, Y.P.; Wang, J. A survey on U-shaped networks in medical image segmentations. Neurocomputing 2020, 409, 244–258. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. Lect. Notes Comput. Sci. 2018, 11211, 833–851. [Google Scholar] [CrossRef]
- Hamamoto, R.; Suvarna, K.; Yamada, M.; Kobayashi, K.; Shinkai, N.; Miyake, M.; Takahashi, M.; Jinnai, S.; Shimoyama, R.; Sakai, A.; et al. Application of artificial intelligence technology in oncology: Towards the establishment of precision medicine. Cancers 2020, 12, 3532. [Google Scholar] [CrossRef]
- Liu, X.; Deng, Z.; Yang, Y. Recent progress in semantic image segmentation. Artif. Intell. Rev. 2019, 52, 1089–1106. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. 2016, 2016, 3213–3223. [Google Scholar] [CrossRef]
- Anwar, S.M.; Majid, M.; Qayyum, A.; Awais, M.; Alnowami, M.; Khan, M.K. Medical Image Analysis using Convolutional Neural Networks: A Review. J. Med. Syst. 2018, 42, 226. [Google Scholar] [CrossRef]
- Van Den Heuvel, T.L.A.; De Bruijn, D.; De Korte, C.L.; Van Ginneken, B. Automated measurement of fetal head circumference. PLoS ONE 2018, 4, 1–20. [Google Scholar] [CrossRef]
- Arnaout, R.; Curran, L.; Zhao, Y.; Levine, J.; Chinn, E.; Moon-Grady, A. Expert-level prenatal detection of complex congenital heart disease from screening ultrasound using deep learning. medRxiv 2020. [Google Scholar] [CrossRef]
- Burgos-Artizzu, X.P.; Perez-Moreno, Á.; Coronado-Gutierrez, D.; Gratacos, E.; Palacio, M. Evaluation of an improved tool for non-invasive prediction of neonatal respiratory morbidity based on fully automated fetal lung ultrasound analysis. Sci. Rep. 2019, 9, 1–7. [Google Scholar] [CrossRef]
- Looney, P.; Stevenson, G.N.; Nicolaides, K.H.; Plasencia, W.; Molloholli, M.; Natsis, S.; Collins, S.L. Fully automated, real-time 3D ultrasound segmentation to estimate first trimester placental volume using deep learning. JCI Insight 2018, 3, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Xu, R.; Ohya, J.; Iwata, H. Automatic fetal body and amniotic fluid segmentation from fetal ultrasound images by encoder-decoder network with inner layers. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Jeju Island, Korea, 11–15 July 2017; pp. 1485–1488. [Google Scholar] [CrossRef]
- Dozen, A.; Komatsu, M.; Sakai, A.; Komatsu, R.; Shozu, K.; Machino, H.; Yasutomi, S.; Arakaki, T.; Asada, K.; Kaneko, S.; et al. Image Segmentation of the Ventricular Septum in Fetal Cardiac Ultrasound Videos Based on Deep Learning Using Time-Series Information. Biomolecules 2020, 10, 1526. [Google Scholar] [CrossRef]
- Yu, L.; Guo, Y.; Wang, Y.; Yu, J.; Chen, P. Segmentation of fetal left ventricle in echocardiographic sequences based on dynamic convolutional neural networks. IEEE Trans. Biomed. Eng. 2017, 64, 1886–1895. [Google Scholar] [CrossRef] [PubMed]
- Sagi, O.; Rokach, L. Ensemble learning: A survey. WIREs Data Min. Knowl. Discov. 2018, 8, 1–18. [Google Scholar] [CrossRef]
- Kusunose, K.; Abe, T.; Haga, A.; Fukuda, D.; Yamada, H.; Harada, M.; Sata, M. A deep learning approach for assessment of regional wall motion abnormality from echocardiographic images. JACC Cardiovasc. Imaging 2020, 13, 374–381. [Google Scholar] [CrossRef] [PubMed]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Cai, S.; Tian, Y.; Lui, H.; Zeng, H.; Wu, Y.; Chen, G. Dense-UNet: A novel multiphoton in vivo cellular image segmentation model based on a convolutional neural network. Quant. Imaging Med. Surg. 2020, 10, 1275–1285. [Google Scholar] [CrossRef]
- Ruano, R.; Molho, M.; Roume, J.; Ville, Y. Prenatal diagnosis of fetal skeletal dysplasias by combining two-dimensional and three-dimensional ultrasound and intrauterine three-dimensional helical computer tomography. Ultrasound Obstet. Gynecol. 2004, 24, 134–140. [Google Scholar] [CrossRef] [PubMed]
- Çetin, C.; Büyükkurt, S.; Sucu, M.; Özsürmeli, M.; Demir, C. Prenatal diagnosis of pectus excavatum. Turkish J. Obstet. Gynecol. 2016, 13, 158–160. [Google Scholar] [CrossRef] [PubMed]
- Paladini, D.; Chita, S.K.; Allan, L.D. Prenatal measurement of cardiothoracic ratio in evaluation of heart disease. Arch. Dis. Child. 1990, 65, 20–23. [Google Scholar] [CrossRef]
- Awadh, A.M.A.; Prefumo, F.; Bland, J.M.; Carvalho, J.S. Assessment of the intraobserver variability in the measurement of fetal cardiothoracic ratio using ellipse and diameter methods. Ultrasound Obstet. Gynecol. 2006, 28, 53–56. [Google Scholar] [CrossRef] [PubMed]
- Usui, N.; Kitano, Y.; Okuyama, H.; Saito, M.; Morikawa, N.; Takayasu, H.; Nakamura, T.; Hayashi, S.; Kawataki, M.; Ishikawa, H.; et al. Reliability of the lung to thorax transverse area ratio as a predictive parameter in fetuses with congenital diaphragmatic hernia. Pediatr. Surg. Int. 2011, 27, 39–45. [Google Scholar] [CrossRef] [PubMed]
- Hidaka, N.; Murata, M.; Sasahara, J.; Ishii, K.; Mitsuda, N. Correlation between lung to thorax transverse area ratio and observed/expected lung area to head circumference ratio in fetuses with left-sided diaphragmatic hernia. Congenit. Anom. 2015, 55, 81–84. [Google Scholar] [CrossRef] [PubMed]




| CNN | MF | CY | mIoU | mDice | mPrecision | mRecall | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| Mean | SD | Mean | SD | Mean | SD | Mean | SD | |||
| U-net | 0.448 | 0.017 | 0.610 | 0.016 | 0.679 | 0.033 | 0.568 | 0.032 | ||
| ✓ | 0.461 | 0.017 | 0.623 | 0.016 | 0.659 | 0.035 | 0.606 | 0.032 | ||
| ✓ | 0.486 | 0.006 | 0.647 | 0.005 | 0.599 | 0.014 | 0.718 | 0.025 | ||
| ✓ | ✓ | 0.493 | 0.006 | 0.654 | 0.005 | 0.596 | 0.016 | 0.738 | 0.023 | |
| DeepLabv3+ | 0.417 | 0.007 | 0.582 | 0.007 | 0.675 | 0.009 | 0.525 | 0.013 | ||
| ✓ | 0.443 | 0.006 | 0.608 | 0.006 | 0.663 | 0.009 | 0.575 | 0.014 | ||
| ✓ | 0.462 | 0.005 | 0.626 | 0.005 | 0.567 | 0.004 | 0.709 | 0.012 | ||
| ✓ | ✓ | 0.470 | 0.004 | 0.633 | 0.004 | 0.566 | 0.007 | 0.729 | 0.010 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shozu, K.; Komatsu, M.; Sakai, A.; Komatsu, R.; Dozen, A.; Machino, H.; Yasutomi, S.; Arakaki, T.; Asada, K.; Kaneko, S.; et al. Model-Agnostic Method for Thoracic Wall Segmentation in Fetal Ultrasound Videos. Biomolecules 2020, 10, 1691. https://doi.org/10.3390/biom10121691
Shozu K, Komatsu M, Sakai A, Komatsu R, Dozen A, Machino H, Yasutomi S, Arakaki T, Asada K, Kaneko S, et al. Model-Agnostic Method for Thoracic Wall Segmentation in Fetal Ultrasound Videos. Biomolecules. 2020; 10(12):1691. https://doi.org/10.3390/biom10121691
Chicago/Turabian StyleShozu, Kanto, Masaaki Komatsu, Akira Sakai, Reina Komatsu, Ai Dozen, Hidenori Machino, Suguru Yasutomi, Tatsuya Arakaki, Ken Asada, Syuzo Kaneko, and et al. 2020. "Model-Agnostic Method for Thoracic Wall Segmentation in Fetal Ultrasound Videos" Biomolecules 10, no. 12: 1691. https://doi.org/10.3390/biom10121691
APA StyleShozu, K., Komatsu, M., Sakai, A., Komatsu, R., Dozen, A., Machino, H., Yasutomi, S., Arakaki, T., Asada, K., Kaneko, S., Matsuoka, R., Nakashima, A., Sekizawa, A., & Hamamoto, R. (2020). Model-Agnostic Method for Thoracic Wall Segmentation in Fetal Ultrasound Videos. Biomolecules, 10(12), 1691. https://doi.org/10.3390/biom10121691