Fine-Mapping of the Human Blood Plasma N-Glycome onto Its Proteome

 ,
,  , , ,
, , ,
Abstract
:1. Introduction
2. Results
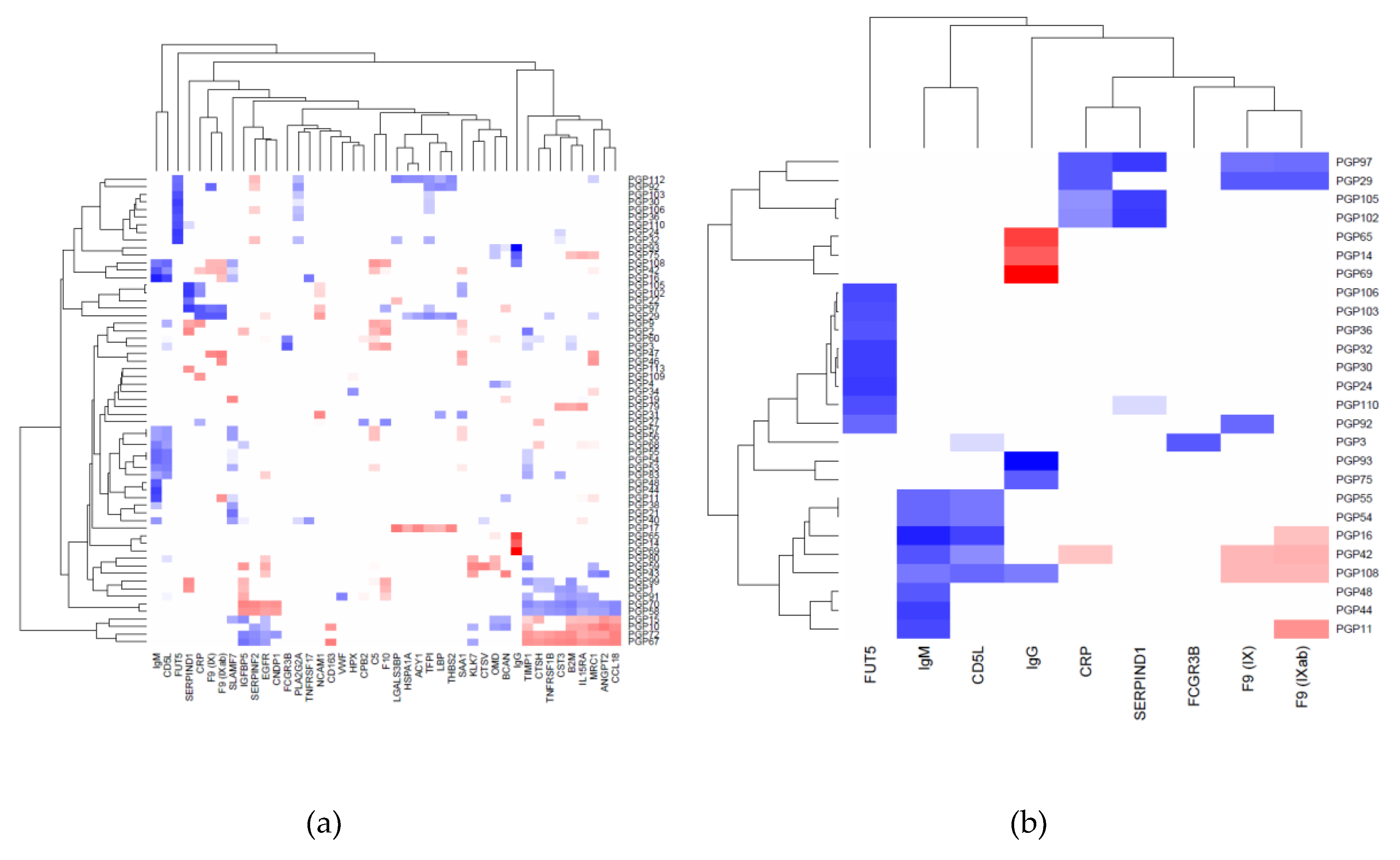
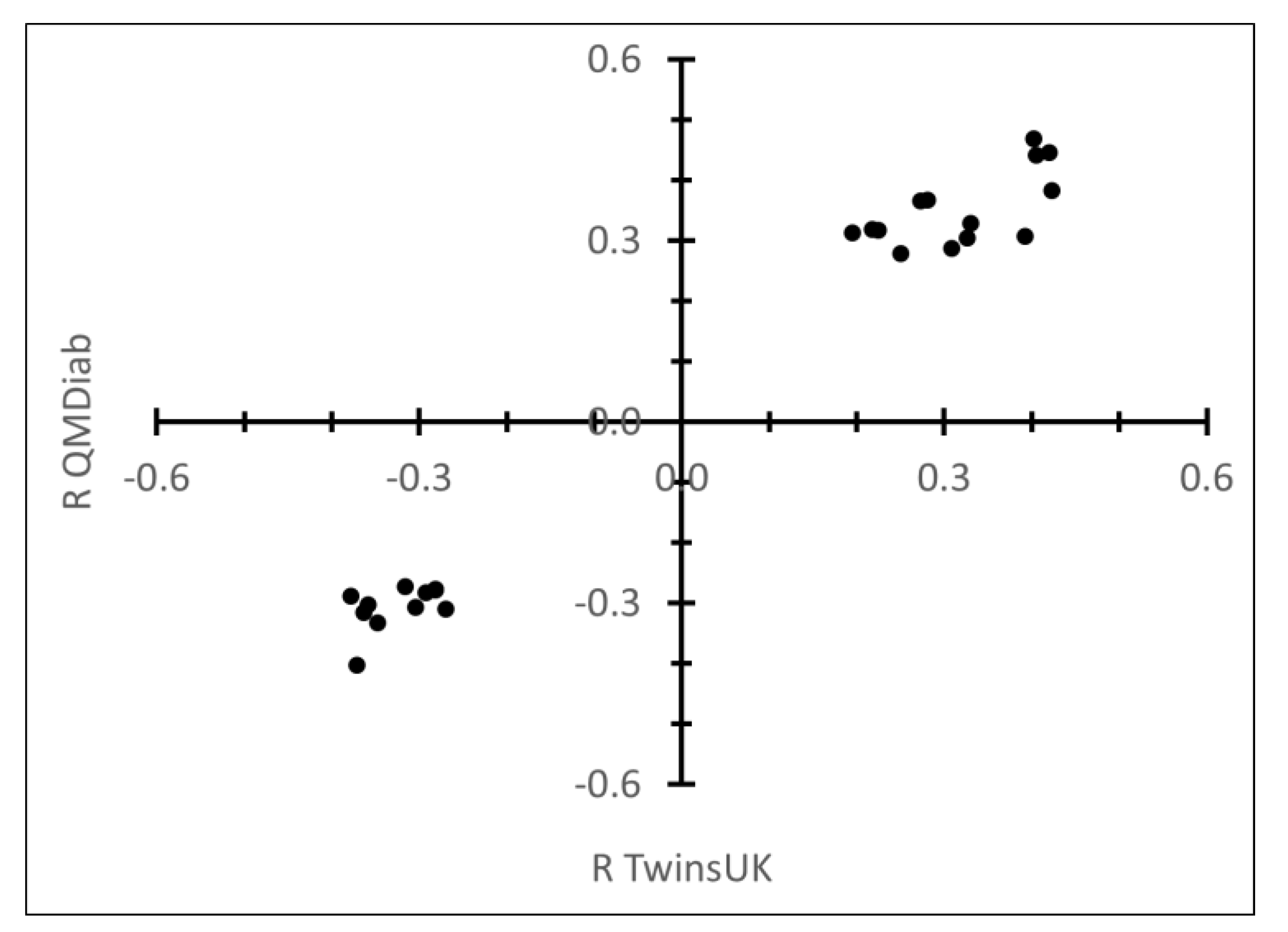
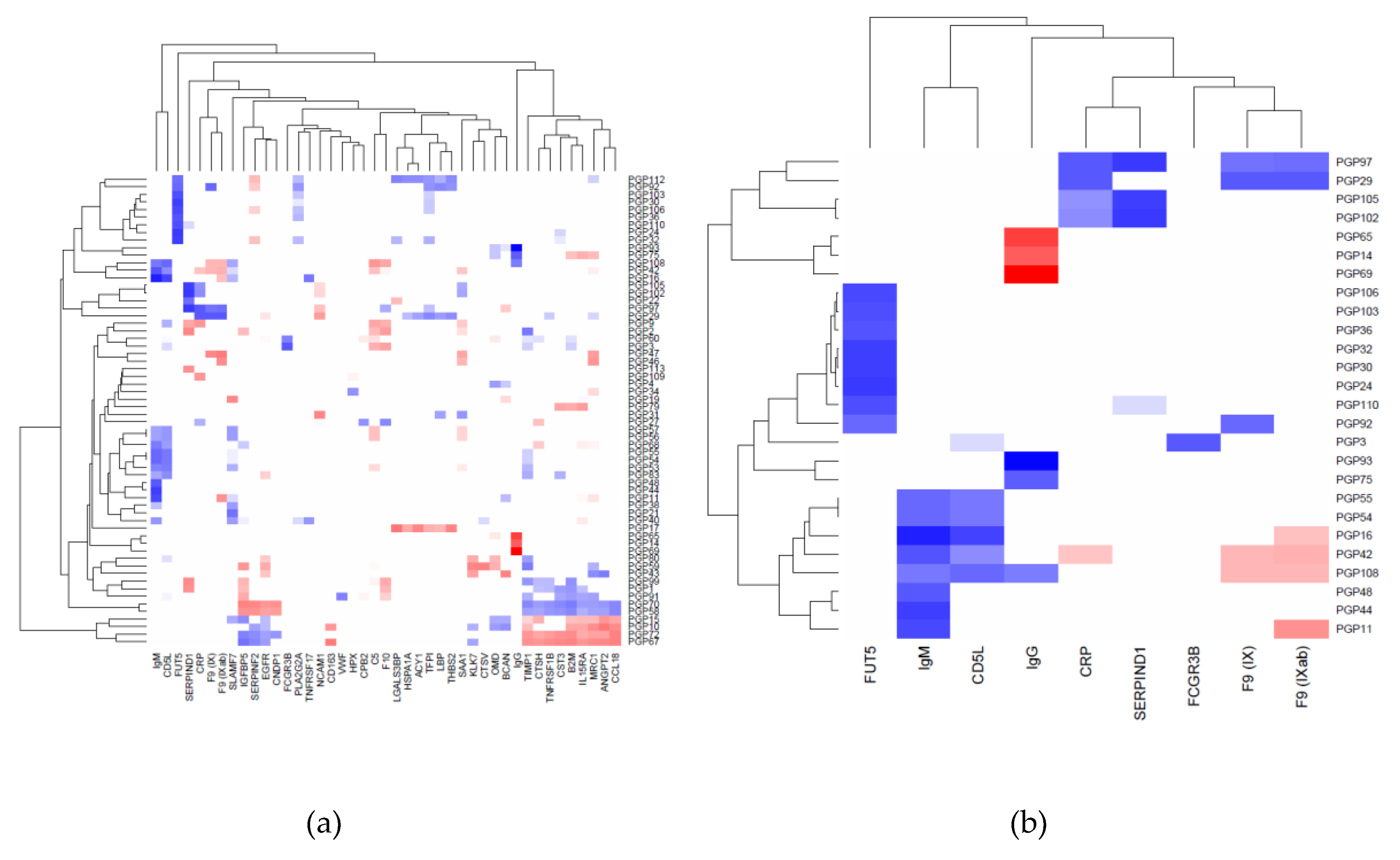
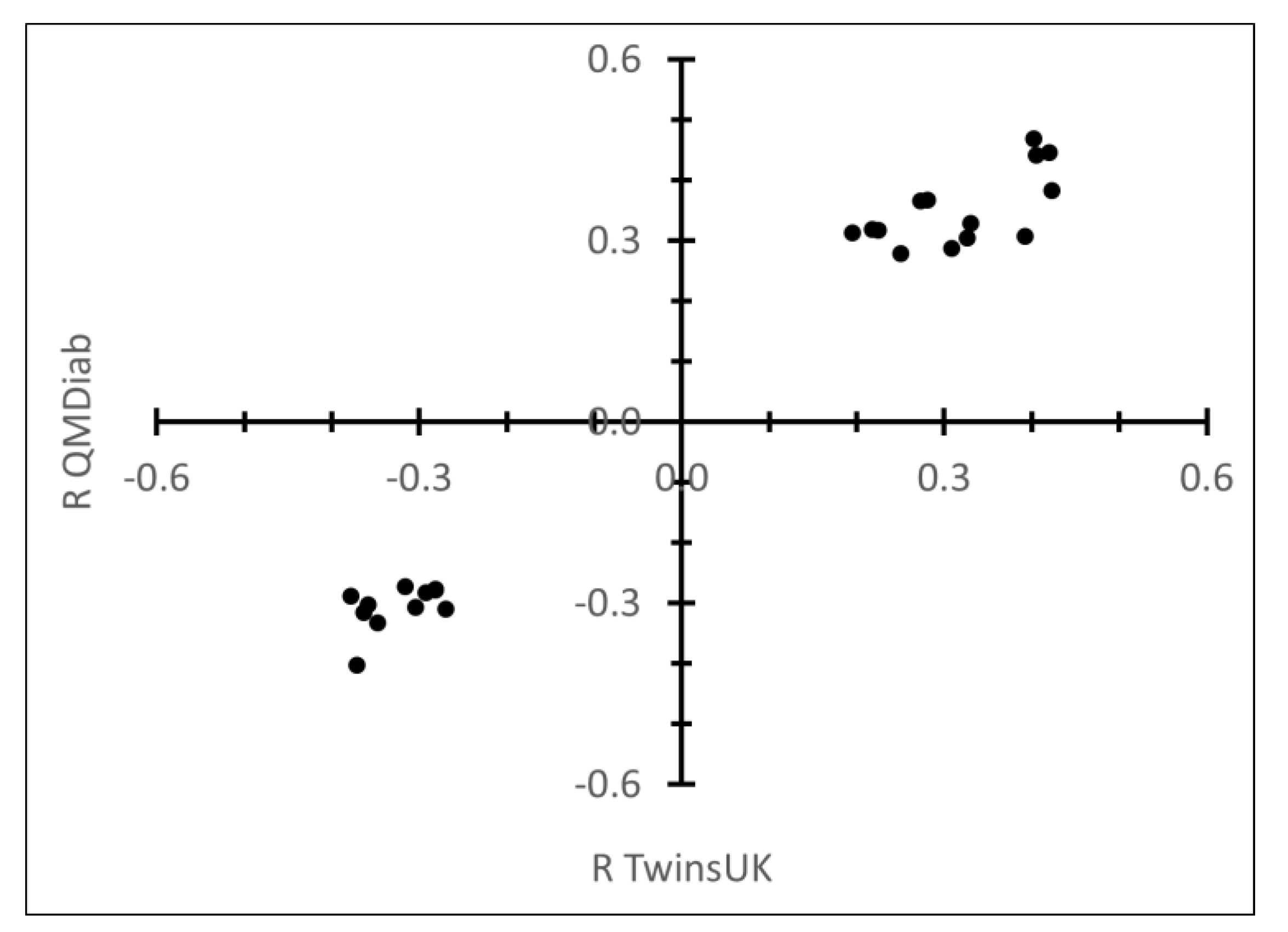
2.1. Correlation between Plasma N-Glycans and Blood Circulating Protein Levels
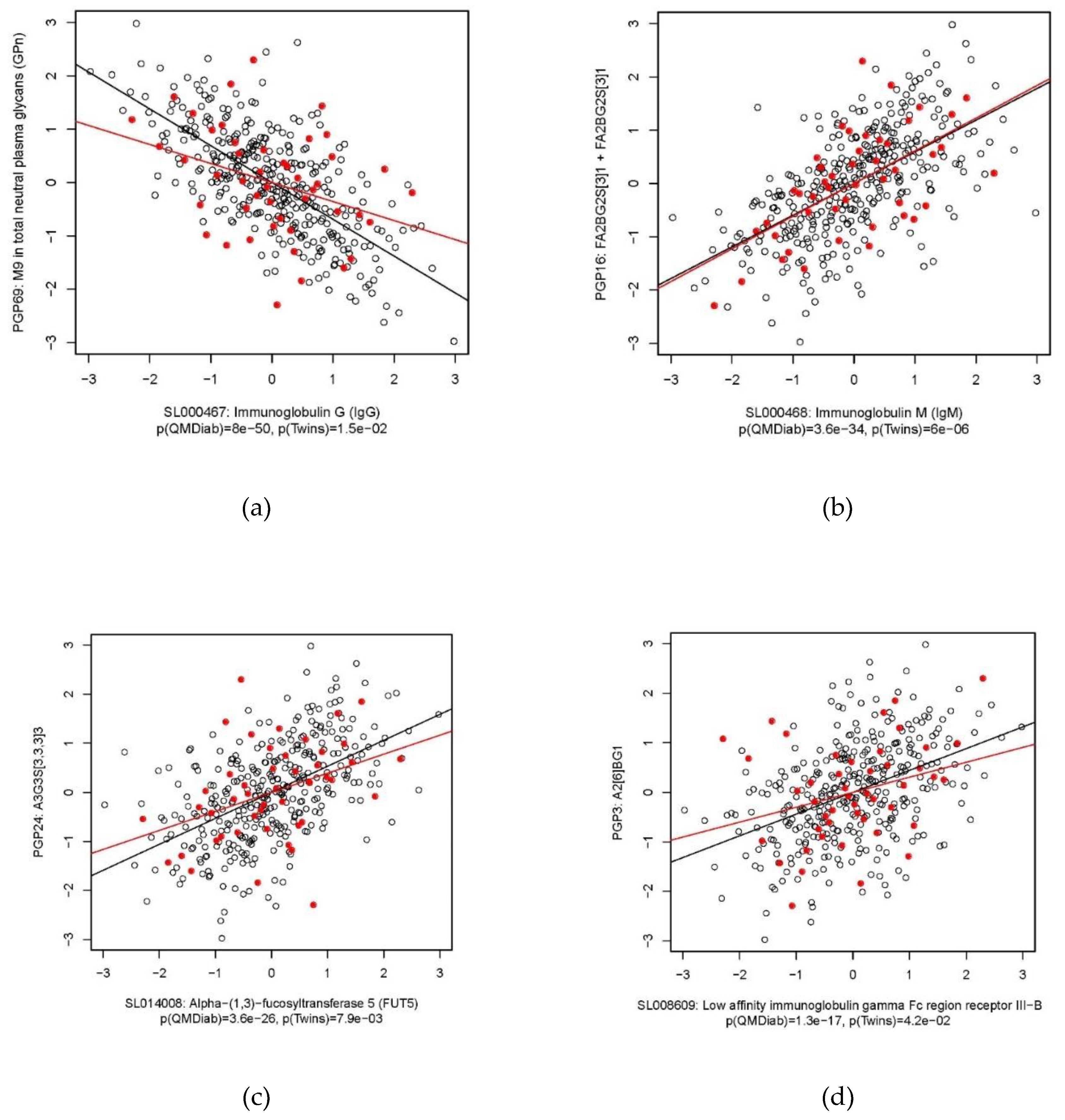
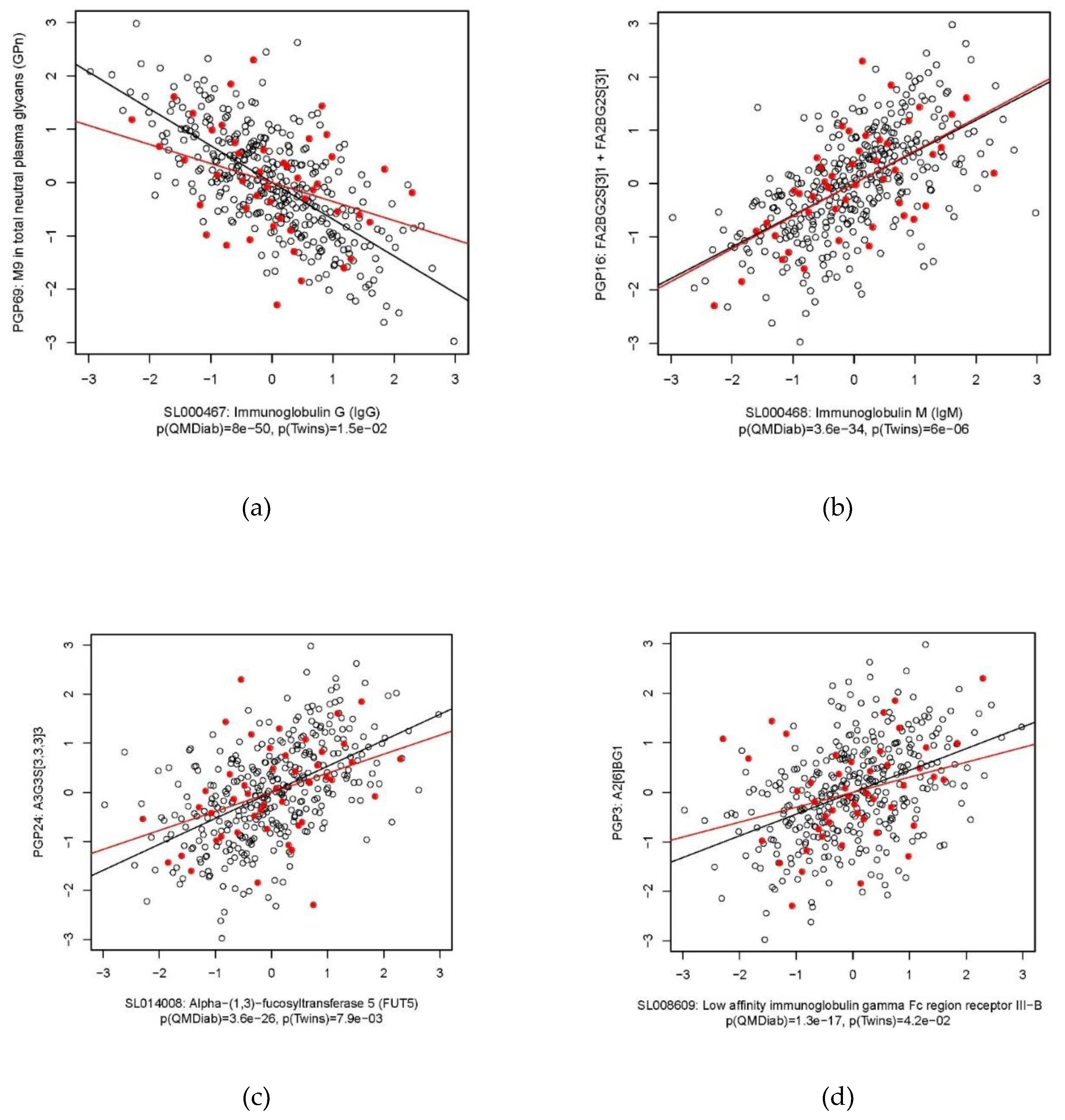
2.2. Immunoglobulin G
2.3. Immunoglobulin M
2.4. Heparin Cofactor 2
2.5. Alpha-(1,3)-Fucosyltransferase 5
2.6. C-Reactive Protein
2.7. Other Proteins
3. Discussion
4. Materials and Methods
4.1. Study Populations
4.2. Sample Collection
4.3. Proteomics Measurements
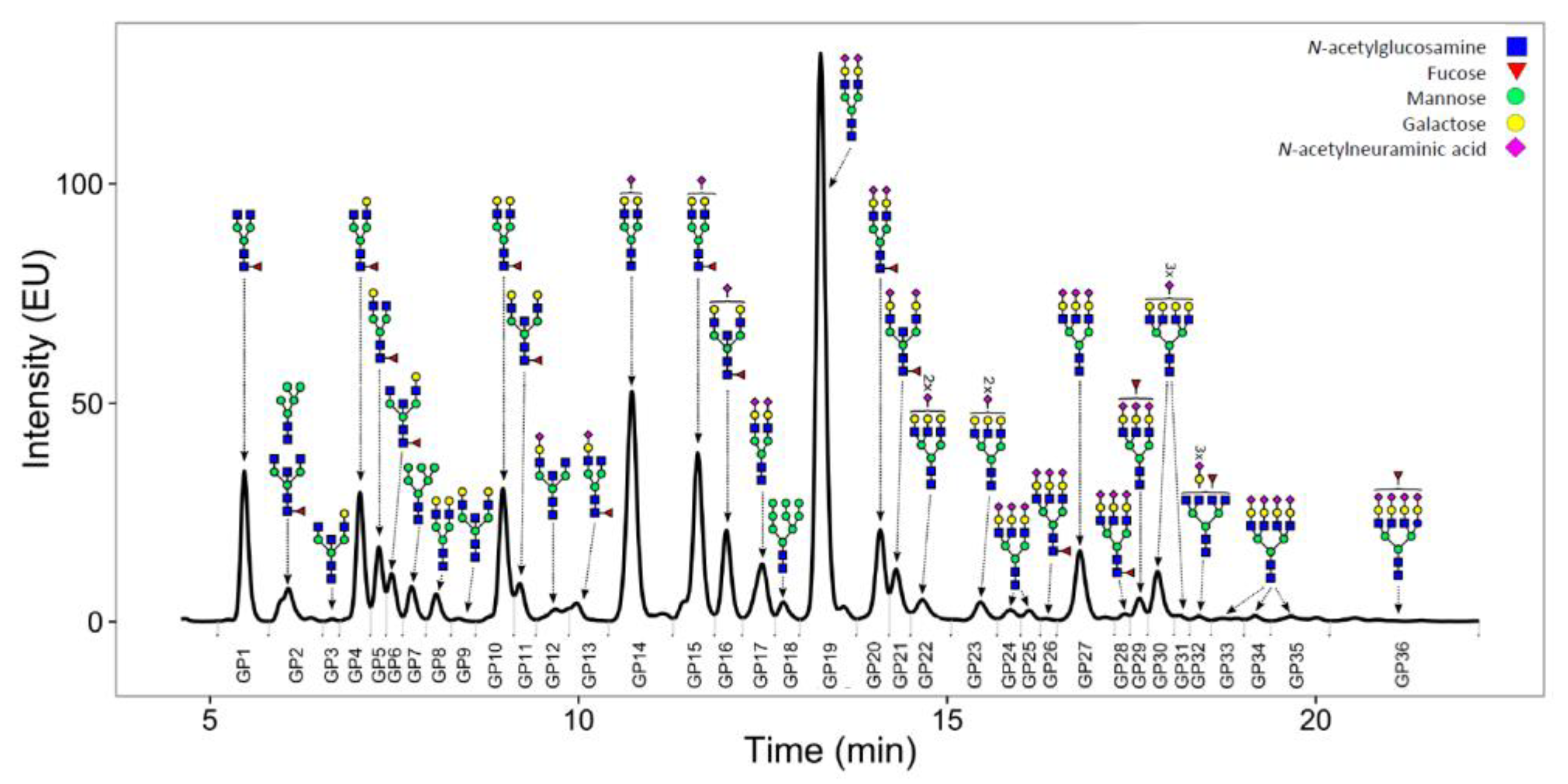
4.4. Total Plasma N-Glycosylation Measurements
4.5. Statistical Analyses
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lauc, G.; Pezer, M.; Rudan, I.; Campbell, H. Mechanisms of disease: The human N-glycome. Biochim. Biophys. Acta 2016, 1860, 1574–1582. [Google Scholar] [CrossRef] [PubMed]
- National Research Council (US) Committee on Assessing the Importance and Impact of Glycomics and Glycosciences. Transforming Glycoscience: A Roadmap for the Future; National Academies Press: Washington, DC, USA, 2012. [Google Scholar]
- Zierer, J.; Pallister, T.; Tsai, P.-C.; Krumsiek, J.; Bell, J.; Lauc, G.; Spector, T.; Menni, C.; Kastenmüller, G. Exploring the molecular basis of age-related disease comorbidities using a multi-omics graphical model. Sci. Rep. 2016, 6, 37646. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bartel, J.; Krumsiek, J.; Schramm, K.; Adamski, J.; Gieger, C.; Herder, C.; Carstensen, M.; Peters, A.; Rathmann, W.; Roden, M.; et al. The Human Blood Metabolome-Transcriptome Interface. PLoS Genet. 2015, 11, e1005274. [Google Scholar] [CrossRef] [PubMed]
- Petersen, A.K.A.-K.; Zeilinger, S.; Kastenmüller, G.; Werner, R.-M.R.M.; Brugger, M.; Peters, A.; Meisinger, C.; Strauch, K.; Hengstenberg, C.; Pagel, P.; et al. Epigenetics meets metabolomics: An epigenome-wide association study with blood serum metabolic traits. Hum. Mol. Genet. 2014, 23, 534–545. [Google Scholar] [CrossRef] [PubMed]
- Suhre, K.; Arnold, M.; Bhagwat, A.M.; Cotton, R.J.; Engelke, R.; Raffler, J.; Sarwath, H.; Thareja, G.; Wahl, A.; Delisle, R.K.; et al. Connecting genetic risk to disease end points through the human blood plasma proteome. Nat. Commun. 2017, 8, 14357. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Suhre, K.; Shin, S.-Y.; Petersen, A.-K.A.-K.; Mohney, R.P.R.P.; Meredith, D.; Wägele, B.; Altmaier, E.; CARDIoGRAM; Deloukas, P.; Erdmann, J.; et al. Human metabolic individuality in biomedical and pharmaceutical research. Nature 2011, 477, 54–60. [Google Scholar] [CrossRef]
- Gold, L.; Ayers, D.; Bertino, J.; Bock, C.; Bock, A.; Brody, E.N.; Carter, J.; Dalby, A.B.; Eaton, B.E.; Fitzwater, T.; et al. Aptamer-based multiplexed proteomic technology for biomarker discovery. PLoS ONE 2010, 5, e0015004. [Google Scholar] [CrossRef]
- Sattlecker, M.; Kiddle, S.J.; Newhouse, S.; Proitsi, P.; Nelson, S.; Williams, S.; Johnston, C.; Killick, R.; Simmons, A.; Westman, E.; et al. Alzheimer’s disease biomarker discovery using SOMAscan multiplexed protein technology. Alzheimer’s Dement. 2014, 10, 724–734. [Google Scholar] [CrossRef]
- Sattlecker, M.; Khondoker, M.; Proitsi, P.; Williams, S.; Soininen, H.; Koszewska, I.; Mecocci, P.; Tsolaki, M.; Vellas, B.; Lovestone, S.; et al. Longitudinal protein changes in blood plasma associated with the rate of cognitive decline in Alzheimer’s disease. J. Alzheimer’s Dis. 2015, 49, 1105–1114. [Google Scholar] [CrossRef]
- Hathout, Y.; Brody, E.; Clemens, P.R.; Cripe, L.; DeLisle, R.K.; Furlong, P.; Gordish-Dressman, H.; Hache, L.; Henricson, E.; Hoffman, E.P.; et al. Large-scale serum protein biomarker discovery in Duchenne muscular dystrophy. Proc. Natl. Acad. Sci. USA 2015, 112, 7153–7158. [Google Scholar] [CrossRef] [Green Version]
- Menni, C.; Kiddle, S.J.; Mangino, M.; Viñuela, A.; Psatha, M.; Steves, C.; Sattlecker, M.; Buil, A.; Newhouse, S.; Nelson, S.; et al. Circulating proteomic signatures of chronological age. J. Gerontol. - Ser. A Biol. Sci. Med. Sci. 2014, 70, 809–816. [Google Scholar] [CrossRef] [PubMed]
- Qiao, Z.; Pan, X.; Parlayan, C.; Ojima, H.; Kondo, T. Proteomic Study of Hepatocellular Carcinoma Using a Novel Modified Aptamer-Based Array (SOMAscanTM) Platform. Biochim. Biophys. Acta - Proteins Proteom. 2017, 1865, 434–443. [Google Scholar] [CrossRef] [PubMed]
- Webber Stones, T.C.; Katilius, E.; Smith, B.C.; Gordon, B.; Mason, M.D.; Tabi, Z.; Brewis, I.A.; Clayton, A.J.; Webber, J.; Stone, T.C.; et al. Proteomics Analysis of Cancer Exosomes Using a Novel Modified Aptamer-based Array (SOMAscanTM) Platform. Mol. Cell. Proteom. 2014, 13, 1050–1064. [Google Scholar] [CrossRef] [PubMed]
- Ngo, D.; Sinha, S.; Shen, D.; Kuhn, E.W.; Keyes, M.J.; Shi, X.; Benson, M.D.; O’Sullivan, J.F.; Keshishian, H.; Farrell, L.A.; et al. Aptamer-Based Proteomic Profiling Reveals Novel Candidate Biomarkers and Pathways in Cardiovascular Disease. Circulation 2016, 134, 270–285. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Billing, A.M.; Ben Hamidane, H.; Bhagwat, A.M.; Cotton, R.J.; Dib, S.; Kumar, P.; Hayat, S.; Goswami, N.; Suhre, K.; Rafii, A.; et al. Complementarity of SOMAscan to LC-MS/MS and RNA-seq for quantitative profiling of human embryonic and mesenchymal stem cells. J. Proteom. 2017, 150, 86–97. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Skropeta, D. The effect of individual N-glycans on enzyme activity. Bioorganic Med. Chem. 2009, 17, 2645–2653. [Google Scholar] [CrossRef]
- Opdenakker, G.; Rudd, P.M.; Ponting, C.P.; Dwek, R.A. Concepts and principles of glycobiology. Faseb J. 1993, 7, 1330–1337. [Google Scholar] [CrossRef]
- Ogata, S.; Shimizu, C.; Franco, A.; Touma, R.; Kanegaye, J.T.; Choudhury, B.P.; Naidu, N.N.; Kanda, Y.; Hoang, L.T.; Hibberd, M.L.; et al. Treatment response in Kawasaki disease is associated with sialylation levels of endogenous but not therapeutic intravenous immunoglobulin G. PLoS ONE 2013, 8, 1–16. [Google Scholar] [CrossRef]
- Krištić, J.; Vučković, F.; Menni, C.; Klarić, L.; Keser, T.; Beceheli, I.; Pučić-Baković, M.; Novokmet, M.; Mangino, M.; Thaqi, K.; et al. Glycans are a novel biomarker of chronological and biological ages. J. Gerontol. - Ser. A Biol. Sci. Med. Sci. 2014, 69, 779–789. [Google Scholar]
- Russell, A.C.; Mirna, Š.; Garcia, M.T.; Novokmet, M.; Wang, Y.; Rudan, I.; Campbell, H.; Lauc, G.; Thomas, M.G.; Wang, W. The N -glycosylation of immunoglobulin G as a novel biomarker of Parkinson’s disease. Front. Neurosci. 2017, 27, 501–510. [Google Scholar] [CrossRef]
- Barrios, C.; Zierer, J.; Gudelj, I.; Stambuk, J.; Ugrina, I.; Rodriguez, E.; Soler, M.J.; Pavic, T.; Simurina, M.; Keser, T.; et al. Glycosylation Profile of IgG in Moderate Kidney Dysfunction. J. Am. Soc. Nephrol. 2016, 27, 933–941. [Google Scholar] [CrossRef] [PubMed]
- Lauc, G.; Krištić, J.; Zoldoš, V. Glycans - the third revolution in evolution. Front. Genet. 2014, 5, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Gruppen, E.G.; Riphagen, I.J.; Connelly, M.A.; Otvos, J.D.; Bakker, S.J.L.; Dullaart, R.P.F. GlycA, a pro-inflammatory glycoprotein biomarker, and incident cardiovascular disease: Relationship with C-reactive protein and renal function. PLoS ONE 2015, 10, e0139057. [Google Scholar] [CrossRef] [PubMed]
- Mook-Kanamori, D.O.; El-Din Selim, M.M.; Takiddin, A.H.; Al-Homsi, H.; Al-Mahmoud, K.A.S.S.; Al-Obaidli, A.; Zirie, M.A.; Rowe, J.; Yousri, N.A.; Karoly, E.D.; et al. 1,5-Anhydroglucitol in saliva is a noninvasive marker of short-term glycemic control. J. Clin. Endocrinol. Metab. 2014, 99, 757–767. [Google Scholar] [CrossRef] [PubMed]
- Pucic, M.; Knezevic, A.; Vidic, J.; Adamczyk, B.; Novokmet, M.; Polasek, O.; Gornik, O.; Supraha-Goreta, S.; Wormald, M.R.; Redzic, I.; et al. High throughput isolation and glycosylation analysis of IgG-variability and heritability of the IgG glycome in three isolated human populations. Mol. Cell Proteom. 2011, 10, M111. [Google Scholar] [CrossRef] [PubMed]
- Bondt, A.; Rombouts, Y.; Selman, M.H.J.; Hensbergen, P.J.; Reiding, K.R.; Hazes, J.M.W.; Dolhain, R.J.E.M.; Wuhrer, M. Immunoglobulin G (IgG) Fab Glycosylation Analysis Using a New Mass Spectrometric High-throughput Profiling Method Reveals Pregnancy-associated Changes. Mol. Cell Proteom. 2014, 13, 3029–3039. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Harazono, A.; Kawasaki, N.; Kawanishi, T.; Hayakawa, T. Site-specific glycosylation analysis of human apolipoprotein B100 using LC/ESI MS/MS. Glycobiology 2005, 15, 447–462. [Google Scholar] [CrossRef] [PubMed]
- Clerc, F.; Reiding, K.R.; Jansen, B.C.; Kammeijer, G.S.M.; Bondt, A.; Wuhrer, M. Human plasma protein N-glycosylation. Glycoconj. J. 2016, 33, 309–343. [Google Scholar] [CrossRef] [PubMed]
- Arnold, J.N.; Wormald, M.R.; Suter, D.M.; Radcliffe, C.M.; Harvey, D.J.; Dwek, R.A.; Rudd, P.M.; Sim, R.B. Human serum IgM glycosylation: Identification of glycoforms that can bind to Mannan-binding lectin. J. Biol. Chem. 2005, 280, 29080–29087. [Google Scholar] [CrossRef]
- Tissot, J.-D.; Sanchez, J.-C.; Vuadens, F.; Scherl, A.; Schifferli, J.A.; Hochstrasser, D.F.; Schneider, P.; Duchosal, M.A. IgM are associated to Sp alpha (CD5 antigen-like). Electrophoresis 2002, 23, 1203–1206. [Google Scholar] [CrossRef]
- Böhme, C.; Nimtz, M.; Grabenhorst, E.; Conradt, H.S.; Strathmann, A.; Ragg, H. Tyrosine sulfation and N-glycosylation of human heparin cofactor II from plasma and recombinant Chinese hamster ovary cells and their effects on heparin binding. Eur. J. Biochem. 2002, 269, 977–988. [Google Scholar] [CrossRef] [PubMed]
- Sharapov, S.; Tsepilov, Y.; Klaric, L.; Mangino, M.; Thareja, G.; Simurina, M.; Dagostino, C.; Dmitrieva, J.; Vilaj, M.; Vuckovic, F.; et al. Defining the genetic control of human blood plasma N-glycome using genome-wide association study. bioRxiv 2018. [Google Scholar] [CrossRef] [PubMed]
- Lauc, G.; Essafi, A.; Huffman, J.E.; Hayward, C.; Knežević, A.; Kattla, J.J.; Polašek, O.; Gornik, O.; Vitart, V.; Abrahams, J.L.; et al. Genomics meets glycomics-the first gwas study of human N-glycome identifies HNF1A as a master regulator of plasma protein fucosylation. PLoS Genet. 2010, 6, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Hirschfield, G.M.; Pepys, M.B. C-reactive protein: A critical update. J. Clin. Investig. 2003, 111, 1805–1812. [Google Scholar]
- Moayyeri, A.; Hammond, C.J.; Hart, D.J.; Spector, T.D. The UK Adult Twin Registry (TwinsUK Resource). Twin Res. Hum. Genet. 2013, 16, 144–149. [Google Scholar] [CrossRef]
- Trbojević Akmačić, I.; Ugrina, I.; Štambuk, J.; Gudelj, I.; Vučković, F.; Lauc, G.; Pučić Baković, M. High Throughput Glycomics: Optimization of Sample Preparation. Biochemistry 2015, 80, 934–942. [Google Scholar] [CrossRef] [PubMed]
- Saldova, R.; Asadi Shehni, A.; Haakensen, V.D.; Steinfeld, I.; Hilliard, M.; Kifer, I.; Helland, Å.; Yakhini, Z.; Børresen-Dale, A.L.; Rudd, P.M. Association of N-glycosylation with breast carcinoma and systemic features using high-resolution quantitative UPLC. J. Proteome Res. 2014, 13, 2314–2327. [Google Scholar] [CrossRef]
- R Core Team. R: A language and environment for statistical computing. Available online: https://www.gbif.org/en/tool/81287/r-a-language-and-environment-for-statistical-computing (accessed on 10 February 2015).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Protein | Glycan Trait | R QMDiab | R TwinsUK | p-Value QMDiab | p-Value TwinsUK |
|---|---|---|---|---|---|
| IgG | PGP69: M9 in total neutral plasma glycans (GPn) | −0.69 | −0.36 | 8.0 × 10−50 | 1.5 × 10−2 |
| IgG | PGP93: core fucosylated structures | 0.68 | 0.31 | 3.7 × 10−47 | 3.7 × 10−2 |
| IgG | PGP65: A2G2 in total neutral plasma glycans (GPn) | −0.51 | −0.35 | 3.8 × 10−24 | 1.6 × 10−2 |
| IgG | PGP75: fucosylation of digalactosylated structures in total neutral plasma glycans | 0.44 | 0.35 | 1.3 × 10−17 | 1.9 × 10−2 |
| IgG | PGP14: A2G2S(6)1 + A2G2S(3)1 | −0.44 | −0.30 | 1.4 × 10−17 | 4.3 × 10−2 |
| IgM | PGP16: FA2BG2S(3)1 + FA2BG2S(6)1 | 0.59 | 0.61 | 3.6 × 10−34 | 6.0 × 10−6 |
| IgM | PGP44: monosialylation of core-fucosylated digalactosylated structures with bisecting GlcNAc | 0.51 | 0.48 | 2.5 × 10−24 | 8.0 × 10−4 |
| IgM | PGP11: FA2BG2 | 0.48 | 0.32 | 1.3 × 10−21 | 2.9 × 10−2 |
| IgM | PGP42: monosialylation of core-fucosylated digalactosylated structures without bisecting GlcNAc | 0.46 | 0.41 | 4.6 × 10−19 | 4.1 × 10−3 |
| IgM | PGP48: ratio of fucosylated monosialylated and disialylated structures (with bisecting GlcNAc) | 0.45 | 0.38 | 1.7 × 10−18 | 8.3 × 10−3 |
| IgM | PGP54: ratio of fucosylated monosialylated structures with and without bisecting GlcNAc | 0.40 | 0.56 | 1.1 × 10−14 | 4.4 × 10−5 |
| IgM | PGP55: the incidence of bisecting GlcNAc in all fucosylated monosialylated structures | 0.40 | 0.56 | 1.1 × 10−14 | 4.4 × 10−5 |
| SERPIND1 | PGP97: trisialylated structures | 0.53 | 0.29 | 8.0 × 10−27 | 4.9 × 10−2 |
| SERPIND1 | PGP102: trigalactosylated structures | 0.53 | 0.35 | 8.7 × 10−26 | 1.7 × 10−2 |
| SERPIND1 | PGP105: triantennary structures | 0.52 | 0.34 | 7.0 × 10−25 | 2.0 × 10−2 |
| FUT5 | PGP24: A3G3S(3,3,3)3 | 0.53 | 0.39 | 3.6 × 10−26 | 7.9 × 10−3 |
| FUT5 | PGP30: A4G4S(3,3,3)3 | 0.51 | 0.50 | 3.8 × 10−24 | 3.8 × 10−4 |
| FUT5 | PGP32: A4F1G3S(3,3,3)3 + A4F1G3S(3,3,6)3 + A4F1G3S(3,6,6)3 | 0.51 | 0.43 | 4.4 × 10−24 | 3.1 × 10−3 |
| FUT5 | PGP106: tetraantennary structures | 0.48 | 0.46 | 1.9 × 10−21 | 1.4 × 10−3 |
| FUT5 | PGP110: ratio of trisialylated and tetrasialylated tetragalactosylated structures | 0.47 | 0.48 | 9.4 × 10−21 | 8.3 × 10−4 |
| FUT5 | PGP103: tetragalactosylated structures | 0.47 | 0.45 | 2.4 × 10−20 | 1.5 × 10−3 |
| FUT5 | PGP36: A4F1G4S(3,3,3,6)4 | 0.45 | 0.30 | 6.3 × 10−19 | 4.0 × 10−2 |
| FUT5 | PGP92: antennary fucosylated structures | 0.40 | 0.37 | 6.6 × 10−15 | 1.1 × 10−2 |
| CD5L | PGP16: FA2BG2S(3)1 + FA2BG2S(6)1 | 0.51 | 0.40 | 6.3 × 10−24 | 5.7 × 10−3 |
| CD5L | PGP108: glycan structures with bisecting GlcNAc | 0.40 | 0.41 | 6.7 × 10−15 | 4.9 × 10−3 |
| CRP | PGP97: trisialylated structures | 0.45 | 0.38 | 3.3 × 10−18 | 8.8 × 10−3 |
| CRP | PGP29: A3F1G3S(3,3,3)3 + A3F1G3S(3,3,6)3 | 0.44 | 0.39 | 7.1 × 10−18 | 7.1 × 10−3 |
| F9 (IX) | PGP29: A3F1G3S(3,3,3)3 + A3F1G3S(3,3,6)3 | 0.44 | 0.38 | 6.9 × 10−18 | 9.7 × 10−3 |
| F9 (IXab) | PGP29: A3F1G3S(3,3,3)3 + A3F1G3S(3,3,6)3 | 0.44 | 0.38 | 7.1 × 10−18 | 9.3 × 10−3 |
| F9 (IX) | PGP92: antennary fucosylated structures | 0.41 | 0.31 | 4.5 × 10−15 | 3.5 × 10−2 |
| FCGR3B | PGP3: A2(6)BG1 | 0.44 | 0.30 | 1.3 × 10−17 | 4.2 × 10−2 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Suhre, K.; Trbojević-Akmačić, I.; Ugrina, I.; Mook-Kanamori, D.O.; Spector, T.; Graumann, J.; Lauc, G.; Falchi, M. Fine-Mapping of the Human Blood Plasma N-Glycome onto Its Proteome. Metabolites 2019, 9, 122. https://doi.org/10.3390/metabo9070122
Suhre K, Trbojević-Akmačić I, Ugrina I, Mook-Kanamori DO, Spector T, Graumann J, Lauc G, Falchi M. Fine-Mapping of the Human Blood Plasma N-Glycome onto Its Proteome. Metabolites. 2019; 9(7):122. https://doi.org/10.3390/metabo9070122
Chicago/Turabian StyleSuhre, Karsten, Irena Trbojević-Akmačić, Ivo Ugrina, Dennis O. Mook-Kanamori, Tim Spector, Johannes Graumann, Gordan Lauc, and Mario Falchi. 2019. "Fine-Mapping of the Human Blood Plasma N-Glycome onto Its Proteome" Metabolites 9, no. 7: 122. https://doi.org/10.3390/metabo9070122
APA StyleSuhre, K., Trbojević-Akmačić, I., Ugrina, I., Mook-Kanamori, D. O., Spector, T., Graumann, J., Lauc, G., & Falchi, M. (2019). Fine-Mapping of the Human Blood Plasma N-Glycome onto Its Proteome. Metabolites, 9(7), 122. https://doi.org/10.3390/metabo9070122