
Multi-Omics Investigation into Acute Myocardial Infarction: An Integrative Method Revealing Interconnections amongst the Metabolome, Lipidome, Glycome, and Metallome

 , , , and
, , , and 
Abstract
1. Introduction
2. Materials and Methods
2.1. Biospecimens from Clinical Studies
2.2. Untargeted Metabolomics and Lipidomics Analysis and Data Acquisition
2.2.1. Reagents and Chemicals
2.2.2. Sample Extraction and Preparation
2.2.3. LC-QTOF Analysis
2.2.4. Identification of Highly Contributing Features and Pathway Analysis
2.3. Glycomics and Metallomics Analysis and Data Acquisition
2.4. Data Processing
2.5. Statistical Analysis and Multi-Omics Integrative Analysis
3. Results and Discussion
3.1. Demographic Information and Baseline Characteristics
3.2. Analytical Validation for Untargeted Metabolomics and Lipidomics Analysis
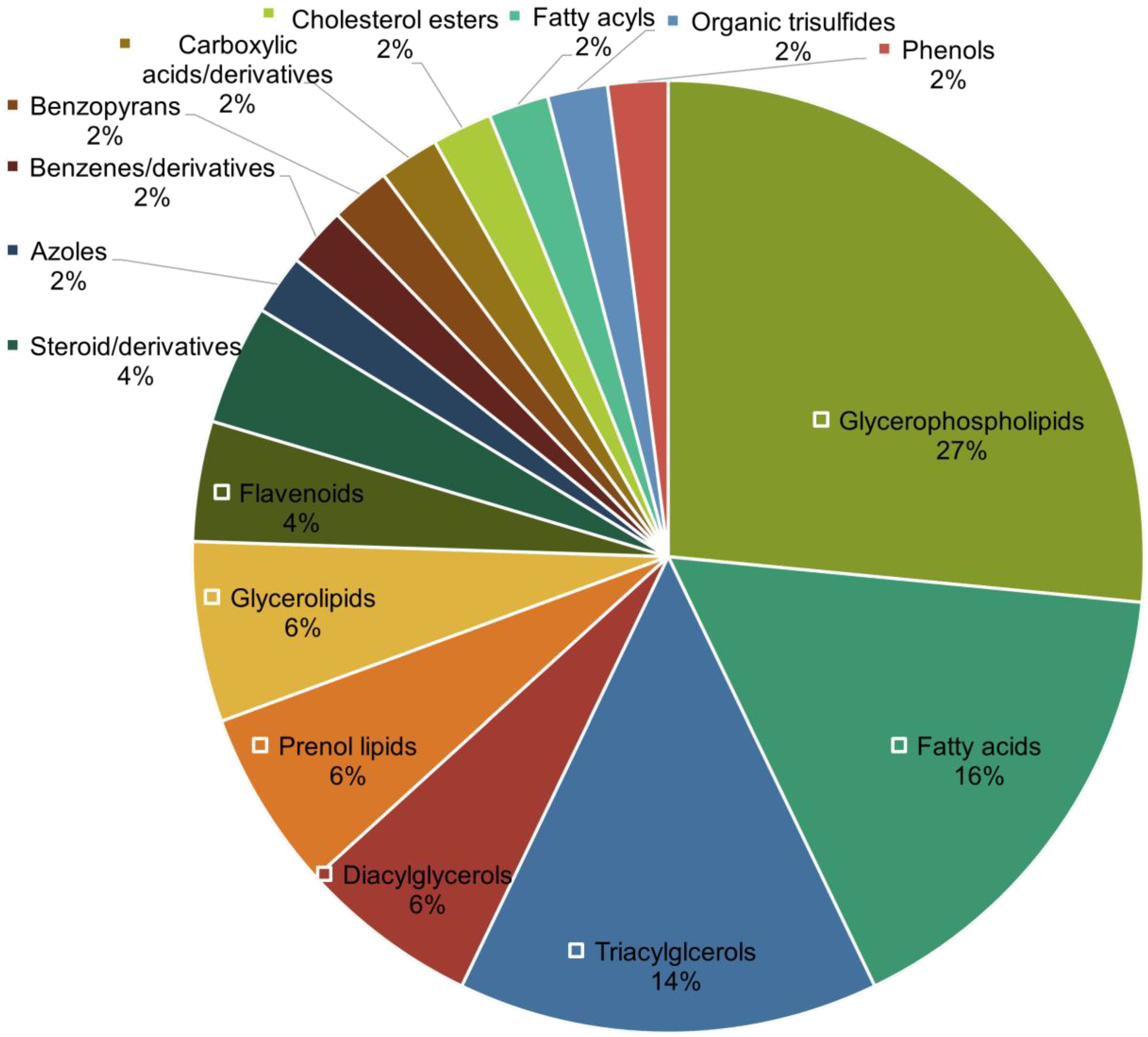
3.3. Generation of Untargeted Lipidomics and Metabolomics Datasets and Identification of Significant Features
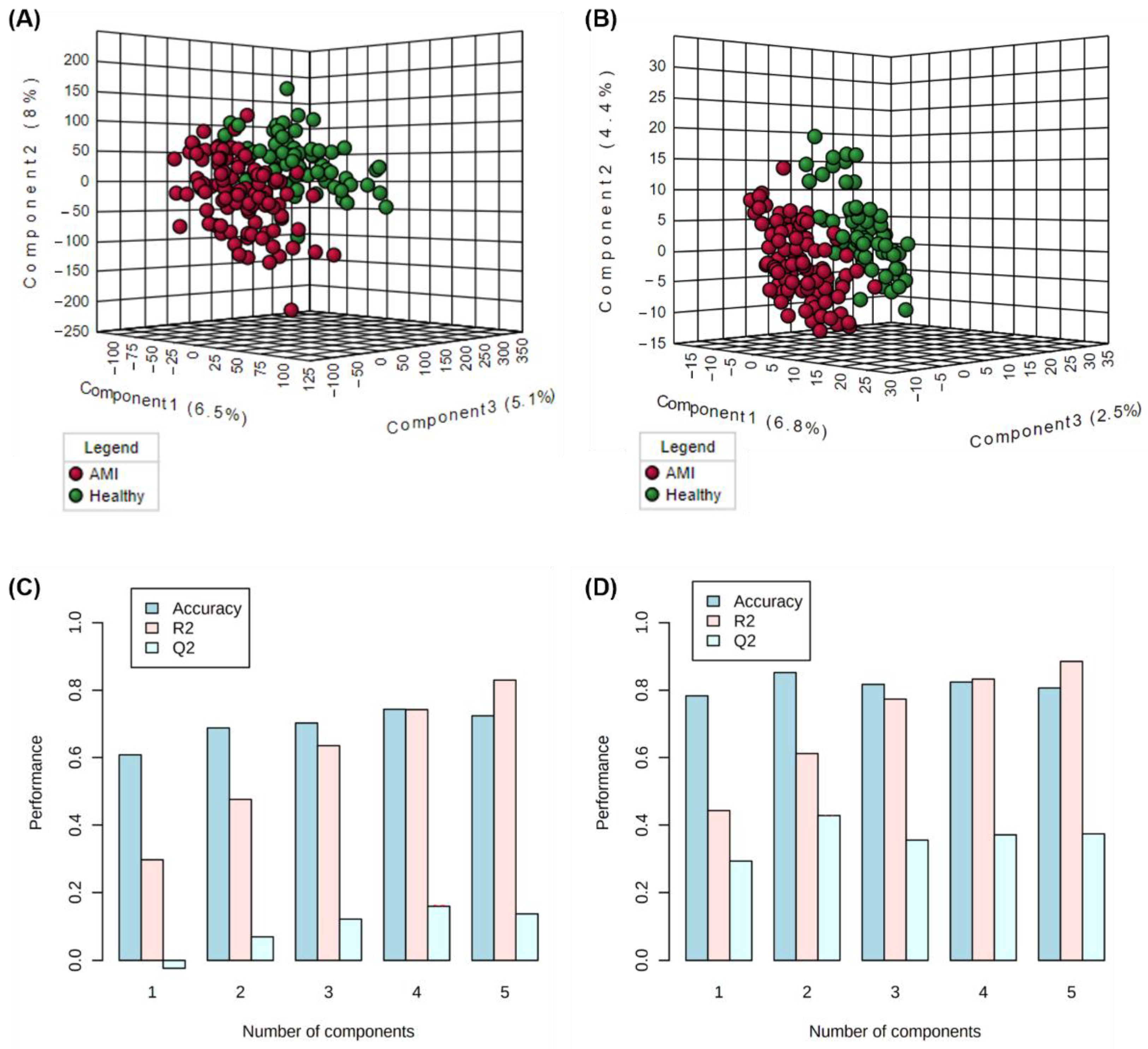
3.4. Single-Omics Evaluation of Metabolomics and Lipidomics Datasets
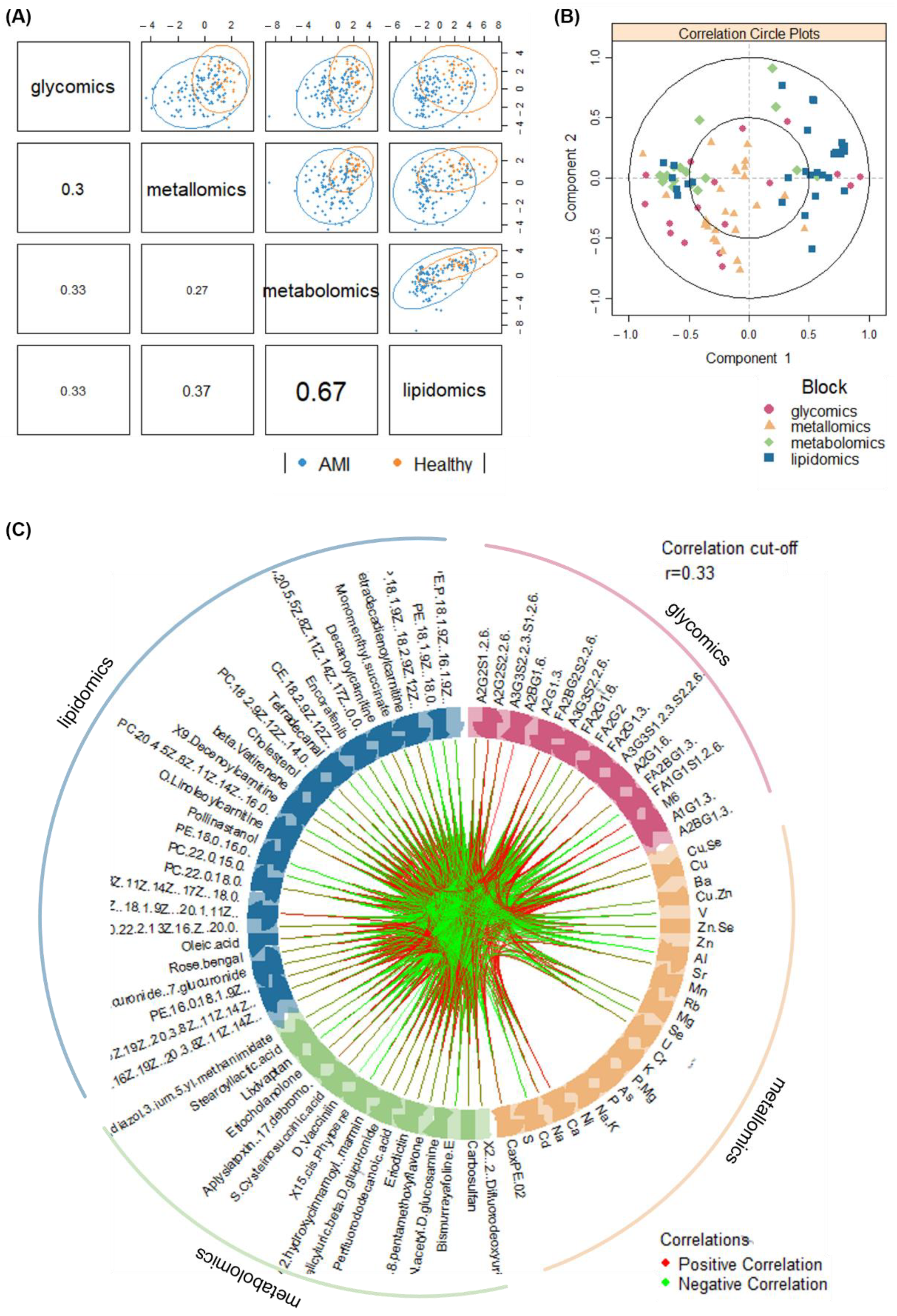
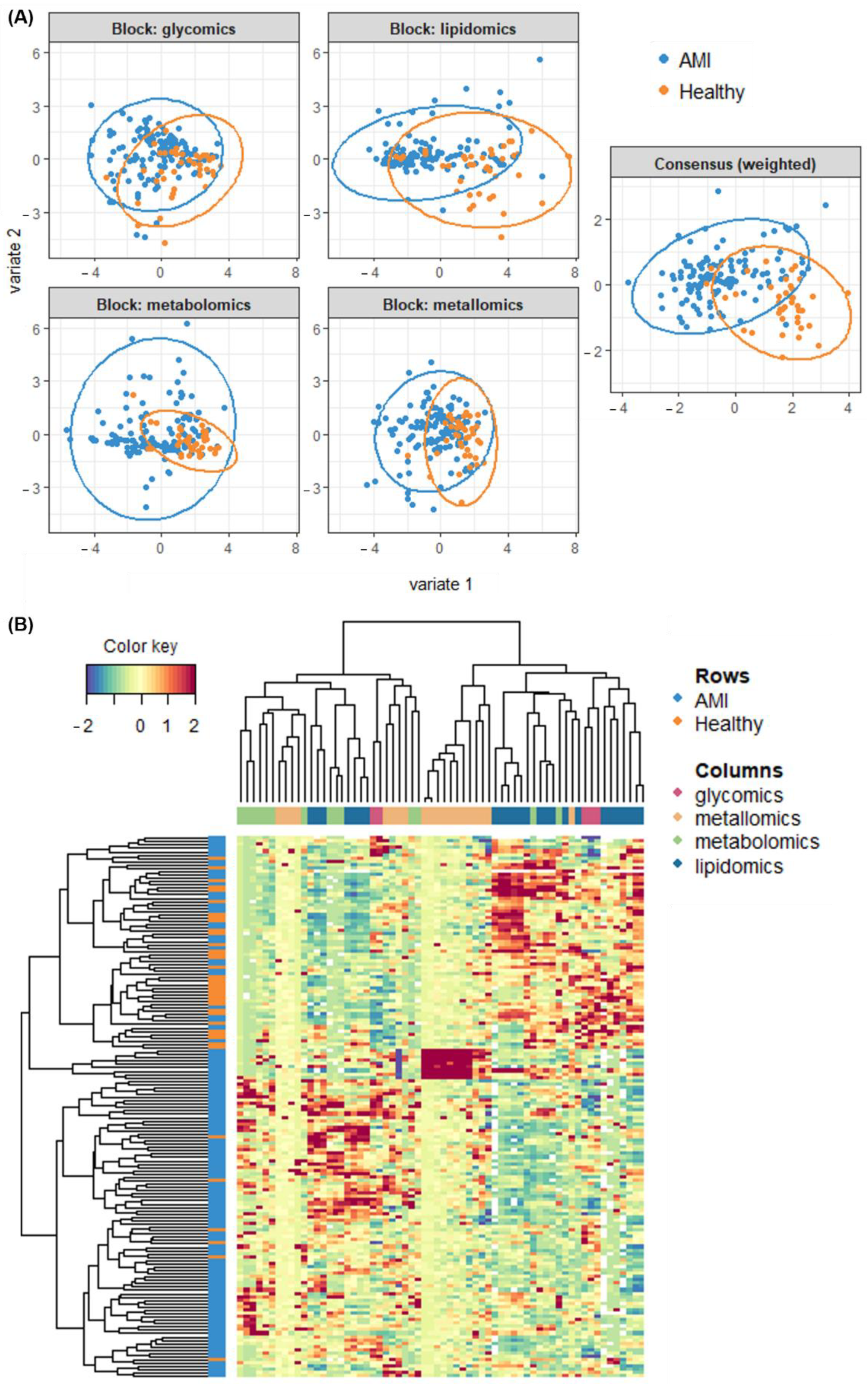
3.5. Multi-Omics Integration and Analysis of Cross-Omics Relationships
3.6. Classification Modelling and Performance of the Multi-Omics Model
3.7. Limitations and Further Work
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Aydin, S.; Ugur, K.; Aydin, S.; Sahin, I.; Yardim, M. Biomarkers in acute myocardial infarction: Current perspectives. Vasc. Health Risk Manag. 2019, 15, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Barron, H.V.; Harr, S.D.; Radford, M.; Wang, Y.; Krumholz, H.M. The association between white blood cell count and acute myocardial infarction mortality in patients ≥65 years of age: Findings from the cooperative cardiovascular project. J. Am. Coll. Cardiol. 2001, 38, 1654–1661. [Google Scholar] [CrossRef]
- Engstrom, G.; Melander, O.; Hedblad, B. Leukocyte count and incidence of hospitalizations due to heart failure. Circ. Heart Fail. 2009, 2, 217–222. [Google Scholar] [CrossRef] [PubMed]
- Lim, S.Y.; Selvaraji, S.; Lau, H.; Li, S.F.Y. Application of omics beyond the central dogma in coronary heart disease research: A bibliometric study and literature review. Comput. Biol. Med. 2021, 140, 105069. [Google Scholar] [CrossRef] [PubMed]
- Sheikh, M.O.; Tayyari, F.; Zhang, S.; Judge, M.T.; Weatherly, D.B.; Ponce, F.V.; Wells, L.; Edison, A.S. Correlations Between LC-MS/MS-Detected Glycomics and NMR-Detected Metabolomics in Caenorhabditis elegans Development. Front. Mol. Biosci. 2019, 6, 49. [Google Scholar] [CrossRef]
- Zhou, L.; Xu, J.-D.; Zhou, S.-S.; Mao, Q.; Kong, M.; Shen, H.; Li, X.Y.; Duan, S.M.; Xu, J.; Li, S.L. Integrating targeted glycomics and untargeted metabolomics to investigate the processing chemistry of herbal medicines, a case study on Rehmanniae Radix. J. Chromatogr. A 2016, 1472, 74–87. [Google Scholar] [CrossRef]
- Igl, W.; Polašek, O.; Gornik, O.; Knežević, A.; Pučić, M.; Novokmet, M.; Huffman, J.; Gnewuch, C.; Liebisch, G.; Rudd, P.M.; et al. Glycomics meets lipidomics—Associations of N-glycans with classical lipids, glycerophospholipids, and sphingolipids in three European populations. Mol. BioSyst. 2011, 7, 1852. [Google Scholar] [CrossRef]
- Wang, M.; Yu, G.; Ressom, H.W. Integrative Analysis of Proteomic, Glycomic, and Metabolomic Data for Biomarker Discovery. IEEE J. Biomed. Health Inform. 2016, 20, 1225–1231. [Google Scholar] [CrossRef]
- Lucio, M.; Willkommen, D.; Schroeter, M.; Sigaroudi, A.; Schmitt-Kopplin, P.; Michalke, B. Integrative Metabolomic and Metallomic Analysis in a Case-Control Cohort with Parkinson’s Disease. Front. Aging Neurosci. 2019, 11, 331. [Google Scholar] [CrossRef]
- Lim, S.Y.; Hendra, C.; Yeo, X.H.; Tan, X.Y.; Ng, B.H.; Laserna, A.K.C.; Tan, S.H.; Chan, M.Y.; Khan, S.H.; Chen, S.M.; et al. N-glycan profiles of acute myocardial infarction patients reveal potential biomarkers for diagnosis, severity assessment and treatment monitoring. Glycobiology 2022, 32, 469–482. [Google Scholar] [CrossRef]
- Lim, S.Y.; Dayal, H.; Seah, S.J.; Tan, R.P.W.; Low, Z.E.; Laserna, A.K.; Tan, S.H.; Chan, M.Y.; Li, S.F.Y. Plasma metallomics reveals potential biomarkers and insights into the ambivalent associations of elements with acute myocardial infarction. medRxiv 2022. [Google Scholar] [CrossRef]
- Matyash, V.; Liebisch, G.; Kurzchalia, T.V.; Shevchenko, A.; Schwudke, D. Lipid extraction by methyl-tert-butyl ether for high-throughput lipidomics. J. Lipid Res. 2008, 49, 1137–1146. [Google Scholar] [CrossRef] [PubMed]
- Patterson, R.E.; Ducrocq, A.J.; McDougall, D.J.; Garrett, T.J.; Yost, R.A. Comparison of blood plasma sample preparation methods for combined LC–MS lipidomics and metabolomics. J. Chromatogr. B 2015, 1002, 260–266. [Google Scholar] [CrossRef] [PubMed]
- Sostare, J.; Di Guida, R.; Kirwan, J.; Chalal, K.; Palmer, E.; Dunn, W.B.; Viant, M.R. Comparison of modified Matyash method to conventional solvent systems for polar metabolite and lipid extractions. Anal. Chim. Acta 2018, 1037, 301–315. [Google Scholar] [CrossRef]
- Dihazi, H.; Asif, A.R.; Beißbarth, T.; Bohrer, R.; Feussner, K.; Feussner, I.; Jahn, O.; Lenz, C.; Majcherczyk, A.; Schmidt, B.; et al. Integrative omics—From data to biology. Expert Rev. Proteom. 2018, 15, 463–466. [Google Scholar] [CrossRef]
- Ebrahim, A.; Brunk, E.; Tan, J.; O’Brien, E.J.; Kim, D.; Szubin, R.; Lerman, J.A.; Lechner, A.; Sastry, A.; Bordbar, A.; et al. Multi-omic data integration enables discovery of hidden biological regularities. Nat. Commun. 2016, 7, 13091. [Google Scholar] [CrossRef]
- Yan, J.; Risacher, S.L.; Shen, L.; Saykin, A.J. Network approaches to systems biology analysis of complex disease: Integrative methods for multi-omics data. Brief. Bioinform. 2018, 19, 1370–1381. [Google Scholar] [CrossRef]
- Yugi, K.; Kubota, H.; Hatano, A.; Kuroda, S. Trans-Omics: How to Reconstruct Biochemical Networks Across Multiple ‘Omic’ Layers. Trends Biotechnol. 2016, 34, 276–290. [Google Scholar] [CrossRef]
- Konjevod, M.; Tudor, L.; Strac, D.S.; Erjavec, G.N.; Barbas, C.; Zarkovic, N.; Nikolac Perkovic, M.; Uzun, S.; Kozumplik, O.; Lauc, G.; et al. Metabolomic and glycomic findings in posttraumatic stress disorder. Prog. Neuropsychopharmacol. Biol. Psychiatry 2019, 88, 181–193. [Google Scholar] [CrossRef]
- Kessner, D.; Chambers, M.; Burke, R.; Agus, D.; Mallick, P. ProteoWizard: Open source software for rapid proteomics tools development. Bioinformatics 2008, 24, 2534–2536. [Google Scholar] [CrossRef]
- Salek, R.M.; Steinbeck, C.; Viant, M.R.; Goodacre, R.; Dunn, W.B. The role of reporting standards for metabolite annotation and identification in metabolomic studies. GigaScience 2013, 2, 13. [Google Scholar] [CrossRef] [PubMed]
- Dunn, W.B.; Broadhurst, D.; Begley, P.; Zelena, E.; Francis-McIntyre, S.; Anderson, N.; Brown, M.; Knowles, J.D.; Halsall, A.; Haselden, J.N.; et al. Procedures for large-scale metabolic profiling of serum and plasma using gas chromatography and liquid chromatography coupled to mass spectrometry. Nat. Protoc. 2011, 6, 1060–1083. [Google Scholar] [CrossRef] [PubMed]
- Robin, X.; Turck, N.; Hainard, A.; Tiberti, N.; Lisacek, F.; Sanchez, J.-C.; Müller, M. pROC: An open-source package for R and S+ to analyze and compare ROC curves. BMC Bioinform. 2011, 12, 77. [Google Scholar] [CrossRef] [PubMed]
- Rohart, F.; Gautier, B.; Singh, A.; Lê Cao, K.-A. mixOmics: An R package for ‘omics feature selection and multiple data integration. PLoS Comput. Biol. 2017, 13, e1005752. [Google Scholar] [CrossRef] [PubMed]
- Naz, S.; Vallejo, M.; García, A.; Barbas, C. Method validation strategies involved in non-targeted metabolomics. J. Chromatogr. A 2014, 1353, 99–105. [Google Scholar] [CrossRef]
- Chin, W.W. The partial least squares approach for structural equation modeling. In Modern Methods for Business Research; Lawrence Erlbaum Associates Publishers: Mahwah, NJ, USA, 1998; pp. 295–336. [Google Scholar]
- Meikle, P.J.; Wong, G.; Tsorotes, D.; Barlow, C.K.; Weir, J.M.; Christopher, M.J.; Macintosh, G.L.; Goudey, B.; Stern, L.; Kowalczyk, A.; et al. Plasma Lipidomic Analysis of Stable and Unstable Coronary Artery Disease. Arterioscler. Thromb. Vasc. Biol. 2011, 31, 2723–2732. [Google Scholar] [CrossRef]
- Shah, S.H.; Sun, J.-L.; Stevens, R.D.; Bain, J.R.; Muehlbauer, M.J.; Pieper, K.S.; Haynes, C.; Hauser, E.R.; Kraus, W.E.; Granger, C.B.; et al. Baseline metabolomic profiles predict cardiovascular events in patients at risk for coronary artery disease. Am. Heart J. 2012, 163, 844–850.e1. [Google Scholar] [CrossRef]
- Vaarhorst, A.A.; Verhoeven, A.; Weller, C.M.; Böhringer, S.; Göraler, S.; Meissner, A.; Deelder, A.M.; Henneman, P.; Gorgels, A.P.M.; Van Den Brandt, P.A.; et al. A metabolomic profile is associated with the risk of incident coronary heart disease. Am. Heart J. 2014, 168, 45–52.e7. [Google Scholar] [CrossRef]
- Basak, T.; Varshney, S.; Hamid, Z.; Ghosh, S.; Seth, S.; Sengupta, S. Identification of metabolic markers in coronary artery disease using an untargeted LC-MS based metabolomic approach. J. Proteom. 2015, 127, 169–177. [Google Scholar] [CrossRef]
- Fan, Y.; Li, Y.; Chen, Y.; Zhao, Y.-J.; Liu, L.-W.; Li, J.; Wang, S.-L.; Alolga, R.N.; Yin, Y.; Wang, X.-M.; et al. Comprehensive Metabolomic Characterization of Coronary Artery Diseases. J. Am. Coll. Cardiol. 2016, 68, 1281–1293. [Google Scholar] [CrossRef]
- Li, R.; Li, F.; Feng, Q.; Liu, Z.; Jie, Z.; Wen, B.; Xu, X.; Zhong, S.; Li, G.; He, K. An LC-MS based untargeted metabolomics study identified novel biomarkers for coronary heart disease. Mol. BioSyst. 2016, 12, 3425–3434. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.; Gao, B.; Guan, Q.; Zhang, D.; Ye, X.; Zhou, L.; Tong, G.; Li, H.; Zhang, L.; Tian, J.; et al. Metabolomic profile for the early detection of coronary artery disease by using UPLC-QTOF/MS. J. Pharm. Biomed. Anal. 2016, 129, 34–42. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.-Z.; Zheng, S.-X.; Hou, Y.-M. A Non-Targeted Liquid Chromatographic-Mass Spectrometric Metabolomics Approach for Association with Coronary Artery Disease: An Identification of Biomarkers for Depiction of Underlying Biological Mechanisms. Med. Sci. Monit. 2017, 23, 613–622. [Google Scholar] [CrossRef] [PubMed]
- Feng, L.; Yang, J.; Liu, W.; Wang, Q.; Wang, H.; Shi, L.; Fu, L.; Xu, Q.; Wang, B.; Li, T. Lipid Biomarkers in Acute Myocardial Infarction Before and After Percutaneous Coronary Intervention by Lipidomics Analysis. Med. Sci. Monit. 2018, 24, 4175–4182. [Google Scholar] [CrossRef]
- Huang, L.; Zhang, L.; Li, T.; Liu, Y.-W.; Wang, Y.; Liu, B.-J. Human Plasma Metabolomics Implicates Modified 9-cis-Retinoic Acid in the Phenotype of Left Main Artery Lesions in Acute ST-Segment Elevated Myocardial Infarction. Sci. Rep. 2018, 8, 12958. [Google Scholar] [CrossRef]
- Kohlhauer, M.; Dawkins, S.; Costa, A.S.H.; Lee, R.; Young, T.; Pell, V.R.; Choudhury, R.P.; Banning, A.P.; Kharbanda, R.K.; Saeb-Parsy, K.; et al. Metabolomic Profiling in Acute ST-Segment–Elevation Myocardial Infarction Identifies Succinate as an Early Marker of Human Ischemia–Reperfusion Injury. J. Am. Heart Assoc. 2018, 7, e007546. [Google Scholar] [CrossRef]
- Rämö, J.; Ripatti, P.; Tabassum, R.; Söderlund, S.; Matikainen, N.; Gerl, M.; Klose, C.; Surma, M.A.; Stitziel, N.O.; Havulinna, A.S.; et al. Coronary Artery Disease Risk and Lipidomic Profiles Are Similar in Hyperlipidemias with Family History and Population-Ascertained Hyperlipidemias. J. Am. Heart Assoc. 2019, 8, e012415. [Google Scholar] [CrossRef]
- Barchuk, M.; Dutour, A.; Ancel, P.; Svilar, L.; Miksztowicz, V.; Lopez, G.; Rubio, M.; Schreier, L.; Nogueira, J.P.; Valéro, R.; et al. Untargeted Lipidomics Reveals a Specific Enrichment in Plasmalogens in Epicardial Adipose Tissue and a Specific Signature in Coronary Artery Disease. Arterioscler. Thromb. Vasc. Biol. 2020, 40, 986–1000. [Google Scholar] [CrossRef]
- Gundogdu, G.; Senol, O.; Miloglu, F.D.; Koza, Y.; Gundogdu, F.; Hacımüftüoğlu, A.; Abd El-Aty, A.M. Serum metabolite profiling of ST-segment elevation myocardial infarction using liquid chromatography quadrupole time-of-flight mass spectrometry. Biomed. Chromatogr. 2020, 34, e4738. [Google Scholar] [CrossRef]
- Mehta, A.; Liu, C.; Nayak, A.; Tahhan, A.S.; Ko, Y.-A.; Dhindsa, D.S.; Kim, J.H.; Hayek, S.S.; Sperling, L.S.; Mehta, P.K.; et al. Untargeted high-resolution plasma metabolomic profiling predicts outcomes in patients with coronary artery disease. PLoS ONE 2020, 15, e0237579. [Google Scholar] [CrossRef]
- Deidda, M.; Noto, A.; Dessalvi, C.C.; Andreini, D.; Andreotti, F.; Ferrannini, E.; Latini, R.; Maggioni, A.P.; Magnoni, M.; Maseri, A.; et al. Metabolomic correlates of coronary atherosclerosis, cardiovascular risk, both or neither. Results of the 2 × 2 phenotypic CAPIRE study. Int. J. Cardiol. 2021, 336, 14–21. [Google Scholar] [CrossRef] [PubMed]
- Ottosson, F.; Khoonsari, P.E.; Gerl, M.J.; Simons, K.; Melander, O.; Fernandez, C. A plasma lipid signature predicts incident coronary artery disease. Int. J. Cardiol. 2021, 331, 249–254. [Google Scholar] [CrossRef] [PubMed]
- Huang, M.; Jiao, J.; Zhuang, P.; Chen, X.; Wang, J.; Zhang, Y. Serum polyfluoroalkyl chemicals are associated with risk of cardiovascular diseases in national US population. Environ. Int. 2018, 119, 37–46. [Google Scholar] [CrossRef]
- Zago, A.M.; Faria, N.M.X.; Fávero, J.L.; Meucci, R.D.; Woskie, S.; Fassa, A.G. Pesticide exposure and risk of cardiovascular disease: A systematic review. Glob. Public Health 2020, 1–23. [Google Scholar] [CrossRef] [PubMed]
- Fahy, E.; Subramaniam, S.; Brown, H.A.; Glass, C.K.; Merrill, A.H., Jr.; Murphy, R.C.; Raetz, C.R.H.; Russell, D.W.; Seyama, Y.; Shaw, W.; et al. A comprehensive classification system for lipids. J. Lipid Res. 2005, 46, 839–861. [Google Scholar] [CrossRef]
- Chen, H.; Wang, Z.; Qin, M.; Zhang, B.; Lin, L.; Ma, Q.; Liu, C.; Chen, X.; Li, H.; Lai, W.; et al. Comprehensive Metabolomics Identified the Prominent Role of Glycerophospholipid Metabolism in Coronary Artery Disease Progression. Front. Mol. Biosci. 2021, 8, 632950. [Google Scholar] [CrossRef]
- Ford, D.A. Lipid oxidation by hypochlorous acid: Chlorinated lipids in atherosclerosis and myocardial ischemia. Clin. Lipidol. 2010, 5, 835–852. [Google Scholar] [CrossRef]
- Leßig, J.; Fuchs, B. Plasmalogens in Biological Systems: Their Role in Oxidative Processes in Biological Membranes, their Contribution to Pathological Processes and Aging and Plasmalogen Analysis. Curr. Med. Chem. 2009, 16, 2021–2041. [Google Scholar] [CrossRef]
- Zhu, Q.; Wu, Y.; Mai, J.; Guo, G.; Meng, J.; Fang, X.; Chen, X.; Liu, C.; Zhong, S. Comprehensive Metabolic Profiling of Inflammation Indicated Key Roles of Glycerophospholipid and Arginine Metabolism in Coronary Artery Disease. Front. Immunol. 2022, 13, 829425. [Google Scholar] [CrossRef]
- Warfel, J.D.; Bermudez, E.M.; Mendoza, T.M.; Ghosh, S.; Zhang, J.; Elks, C.M.; Mynatt, R.; Vandanmagsar, B. Mitochondrial fat oxidation is essential for lipid-induced inflammation in skeletal muscle in mice. Sci. Rep. 2016, 6, 37941. [Google Scholar] [CrossRef]
- Chiu, H.-C.; Kovacs, A.; Ford, D.A.; Hsu, F.-F.; Garcia, R.; Herrero, P.; Saffitz, J.E.; Schaffer, J.E. A novel mouse model of lipotoxic cardiomyopathy. J. Clin. Investig. 2001, 107, 813–822. [Google Scholar] [CrossRef] [PubMed]
- Schulze, P.C.; Drosatos, K.; Goldberg, I.J. Lipid Use and Misuse by the Heart. Circ. Res. 2016, 118, 1736–1751. [Google Scholar] [CrossRef] [PubMed]
- Singh, A.; Shannon, C.P.; Gautier, B.; Rohart, F.; Vacher, M.; Tebbutt, S.J.; Lê Cao, K.-A. DIABLO: An integrative approach for identifying key molecular drivers from multi-omics assays. Bioinformatics 2019, 35, 3055–3062. [Google Scholar] [CrossRef]
- Zhang, P.; Woen, S.; Wang, T.; Liau, B.; Zhao, S.; Chen, C.; Yang, Y.; Song, Z.; Wormald, M.R.; Yu, C.; et al. Challenges of glycosylation analysis and control: An integrated approach to producing optimal and consistent therapeutic drugs. Drug Discov. Today 2016, 21, 740–765. [Google Scholar] [CrossRef] [PubMed]
- Bournazos, S.; Ravetch, J.V. Diversification of IgG effector functions. Int. Immunol. 2017, 29, 303–310. [Google Scholar] [CrossRef] [PubMed]
- Bournazos, S.; Gupta, A.; Ravetch, J.V. The role of IgG Fc receptors in antibody-dependent enhancement. Nat. Rev. Immunol. 2020, 20, 633–643. [Google Scholar] [CrossRef]
- Kara, S.; Amon, L.; Lühr, J.J.; Nimmerjahn, F.; Dudziak, D.; Lux, A. Impact of Plasma Membrane Domains on IgG Fc Receptor Function. Front. Immunol. 2020, 11, 1320. [Google Scholar] [CrossRef]
- Salvatore, G.; Bernoud-Hubac, N.; Bissay, N.; Debard, C.; Daira, P.; Meugnier, E.; Proamer, F.; Hanau, D.; Vidal, H.; Aricò, M.; et al. Human monocyte-derived dendritic cells turn into foamy dendritic cells with IL-17A. J. Lipid Res. 2015, 56, 1110–1122. [Google Scholar] [CrossRef]
- Gurbanov, R.; Bilgin, M.; Severcan, F. Restoring effect of selenium on the molecular content, structure and fluidity of diabetic rat kidney brush border cell membrane. Biochim. Biophys. Acta Biomembr. 2016, 1858, 845–854. [Google Scholar] [CrossRef]
- Huang, Z.; Rose, A.H.; Hoffmann, P.R. The Role of Selenium in Inflammation and Immunity: From Molecular Mechanisms to Therapeutic Opportunities. Antioxid. Redox Signal. 2012, 16, 705–743. [Google Scholar] [CrossRef]
- Melcrová, A.; Pokorna, S.; Pullanchery, S.; Kohagen, M.; Jurkiewicz, P.; Hof, M.; Jungwirth, P.; Cremer, P.S.; Cwiklik, L. The complex nature of calcium cation interactions with phospholipid bilayers. Sci. Rep. 2016, 6, 38035. [Google Scholar] [CrossRef] [PubMed]
- Hunter, G.W.; Negash, S.; Squier, T.C. Phosphatidylethanolamine Modulates Ca-ATPase Function and Dynamics. Biochemistry 1999, 38, 1356–1364. [Google Scholar] [CrossRef] [PubMed]
- Ottolia, M.; Torres, N.; Bridge, J.H.B.; Philipson, K.D.; Goldhaber, J.I. Na/Ca exchange and contraction of the heart. J. Mol. Cell. Cardiol. 2013, 61, 28–33. [Google Scholar] [CrossRef] [PubMed]
- Eisner, D.; Caldwell, J.; Trafford, A. Sarcoplasmic reticulum Ca-ATPase and heart failure 20 years later. Circ. Res. 2013, 113, 958–961. [Google Scholar] [CrossRef] [PubMed]
- Kawase, Y.; Hajjar, R.J. The cardiac sarcoplasmic/endoplasmic reticulum calcium ATPase: A potent target for cardiovascular diseases. Nat. Clin. Pract. Cardiovasc. Med. 2008, 5, 554–565. [Google Scholar] [CrossRef] [PubMed]
- Poyton, M.F.; Sendecki, A.M.; Cong, X.; Cremer, P.S. Cu2+ Binds to Phosphatidylethanolamine and Increases Oxidation in Lipid Membranes. J. Am. Chem. Soc. 2016, 138, 1584–1590. [Google Scholar] [CrossRef]
- Gimenez, M.S.; Oliveros, L.B.; Gomez, N.N. Nutritional Deficiencies and Phospholipid Metabolism. Int. J. Mol. Sci. 2011, 12, 2408–2433. [Google Scholar] [CrossRef]
- Zavareh, R.B.; Lau, K.S.; Hurren, R.; Datti, A.; Ashline, D.J.; Gronda, M.; Cheung, P.; Simpson, C.D.; Liu, W.; Wasylishen, A.R.; et al. Inhibition of the Sodium/Potassium ATPase Impairs N-Glycan Expression and Function. Cancer Res. 2008, 68, 6688–6697. [Google Scholar] [CrossRef]
- Tokhtaeva, E.; Munson, K.; Sachs, G.; Vagin, O. N-glycan-dependent quality control of the Na,K-ATPase beta(2) subunit. Biochemistry 2010, 49, 3116–3128. [Google Scholar] [CrossRef][Green Version]
- Psychogios, N.; Hau, D.D.; Peng, J.; Guo, A.C.; Mandal, R.; Bouatra, S.; Sinelnikov, I.; Krishnamurthy, R.; Eisner, R.; Gautam, B.; et al. The Human Serum Metabolome. PLoS ONE 2011, 6, e16957. [Google Scholar] [CrossRef]
- Naser, F.J.; Mahieu, N.G.; Wang, L.; Spalding, J.L.; Johnson, S.L.; Patti, G.J. Two complementary reversed-phase separations for comprehensive coverage of the semipolar and nonpolar metabolome. Anal. Bioanal. Chem. 2018, 410, 1287–1297. [Google Scholar] [CrossRef] [PubMed]
- Ortmayr, K.; Causon, T.J.; Hann, S.; Koellensperger, G. Increasing selectivity and coverage in LC-MS based metabolome analysis. TrAC Trends Anal. Chem. 2016, 82, 358–366. [Google Scholar] [CrossRef]
- Lim, S.Y.; Ng, B.H.; Vermulapalli, D.; Lau, H.; Laserna, A.K.C.; Yang, X.; Tan, S.H.; Chan, M.Y.; Li, S.F.Y. Simultaneous Polar Metabolite and N-Glycan Extraction Workflow for Joint-Omics Analysis: A Synergistic Approach for Novel Insights into Diseases. J. Proteome Res. 2022, 21, 643–653. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic | AMI (n = 101) | Control (n = 66) | p-Value |
|---|---|---|---|
| Demographic variables | |||
| Age (Median (Min–Max)) | 57 (33–81) | 54.5 (40–71) | 2.7 × 10−1 |
| Gender (Female) (%) | 12.9 | 40.9 | 6.3 × 10−4 |
| Smoking status (%) | |||
| Non | 37.6 | 90.9 | |
| Current | 35.6 | 3.0 | |
| Ex | 26.7 | 6.1 | |
| Race (%) | 1.0 × 10−14 | ||
| Chinese | 27.7 | 60.6 | |
| Malay | 21.8 | 9.1 | |
| Indian | 6.9 | 30.3 | |
| Others | 43.6 | 0.0 | |
| Cardiovascular risk factors based on medical history | |||
| Prior MI (%) | 4.0 | 0.0 | 1.5 × 10−1 |
| FH of CHD (%) | 20.8 | 10.6 | 9.4 × 10−2 |
| Diabetes (%) | 20.8 | 12.1 | 2.1 × 10−1 |
| Hypertension (%) | 43.6 | 28.8 | 7.2 × 10−2 |
| Dyslipidemia (%) | 42.6 | 77.3 | 3.3 × 10−5 |
| Other cardiovascular risk factors, predictors of AMI and adverse events (Median [Min–Max]) | |||
| DBP, mm Hg | 83.50 (39–138) | 74 (53–107) | 1.6 × 10−4 |
| SBP, mm Hg | 140 (74–241) | 127 (97–175) | 8.2 × 10−6 |
| Triglyceride, mmol/L | 1.50 (0.35–5.58) | 1.38 (0.37–4.37) | 5.1 × 10−1 |
| Cholesterol, mmol/L | 5.01 (3.20–7.40) | 5.32 (4.05–7.37) | 1.5 × 10−3 |
| HDL-C, mmol/L | 1.03 (0.67–9.40) | 1.34 (0.80–2.31) | 6.6 × 10−10 |
| LDL-C, mmol/L | 3.20 (1.60–5.51) | 3.27 (2.19–5.25) | 1.1 × 10−1 |
| WBC, ×109/L | 10.85 (4.40–25.90) | 5.50 (2.60–9.0) | 1.5 × 10−20 |
| Platelet, ×109/L | 250.5 (134–649) | 258 (165–599) | 3.8 × 10−1 |
| Creatinine, mmol/L | 88.5 (51–142) | 69 (42–97) | 3.9 × 10−13 |
| hsTnT, pg/mL | 1726 (62–9819) | 6 (3–18) | 8.8 × 10−28 |
| NTproBNP, pg/mL | 718 (68–6819) | 36 (7–150) | 3.0 × 10−27 |
| Compound Class | Compound Name | RT|m/z | Regulation (Up/Down) a | Fold-Change b | p-Value c |
|---|---|---|---|---|---|
| 2-Arylbenzofuran flavonoids | Lixivaptan | 6.83|472.29 | DOWN | 0.39 | 6.0 × 10−5 |
| Alkyl halides | Perfluorododecanoic acid | 6.41|613.36 | UP | 1.85 | 7.6 × 10−9 |
| Benzene & substituted derivatives | 1-Piperazinecarboxylic acid, 4-((3,4-dichlorophenyl)acetyl)-3-(1-pyrrolidinylmethyl)-, methyl ester, (3R)- | 10.18|413.33 | DOWN | 0.64 | 2.1 × 10−6 |
| D-Vacciniin | 4.57|283.08 | UP | 1.86 | 1.3 × 10−5 | |
| Carboxylic acids & derivatives | S-Cysteinosuccinic acid | 4.92|236.09 | UP | 1.84 | 8.3 × 10−10 |
| N-Acetyl-L-phenylalanine | 4.60|208.13 | UP | 0.51 | 5.9 × 10−6 | |
| Diisodityrosine | 5.07|716.85 | UP | 2.06 | 3.1 × 10−7 | |
| Coumarans | Carbosulfan | 4.84|379.16 | UP | 4.00 | 2.5 × 10−9 |
| Fatty Acyls | 15-Palmitoylsolamin | 4.33|801.42 | UP | 2.63 | 2.7 × 10−4 |
| Stearoyllactic acid | 9.41|355.29 | DOWN | 0.59 | 3.5 × 10−7 | |
| 4,7,10,13-Hexadecatetraenoate | 10.72|251.20 | UP | 0.60 | 4.1 × 10−5 | |
| Flavonoids | Eriodictin | 5.70|433.21 | UP | 4.81 | 5.2 × 10−11 |
| 7-Chloro-3,4′,5,6,8-pentamethoxyflavone | 5.24|405.18 | UP | 4.58 | 5.3 × 10−10 | |
| Indoles & derivatives | Bismurrayafoline E | 4.59|723.37 | UP | 1.99 | 5.4 × 10−7 |
| Indolepyruvate | 4.84|204.10 | UP | 1.62 | 8.5 × 10−4 | |
| Organooxygen compounds | Salicyluric beta-D-glucuronide | 3.90|370.08 | UP | 9.00 | 1.1 × 10−15 |
| Aldehydo-N-acetyl-D-glucosamine | 5.38|219.95 | UP | 5.37 | 3.8 × 10−10 | |
| N-Acetylgalactosamine 4-sulphate | 4.99|302.20 | UP | 0.64 | 2.9 × 10−4 | |
| alpha-Furyl methyl diketone | 5.38|137.02 | UP | 7.18 | 3.2 × 10−10 | |
| Oxazinanes | Molsidomine | 8.02|241.18 | DOWN | 0.53 | 3.9 × 10−10 |
| Prenol lipids | 15-cis-Phytoene | 5.34|543.28 | UP | 2.18 | 6.1 × 10−10 |
| ′-6′-O-(4-Geranyloxy-2-hydroxycinnamoyl)-marmin | 5.08|631.35 | UP | 1.54 | 9.4 × 10−5 | |
| Pyrimidine nucleoside’ | 2′,2′-Difluorodeoxyuridine | 4.66|264.01 | UP | 5.39 | 6.0 × 10−13 |
| Pyrroles | O-Hydroxyatorvastatin | 7.45|573.24 | UP | 2.98 | 1.6 × 10−12 |
| Steroids & steroid derivatives | Etiocholanolone | 10.39|241.18 | UP | 0.57 | 1.6 × 10−5 |
| Tetrapyrroles & derivatives | L-Urobilin | 5.73|593.34 | UP | 3.39 | 5.0 × 10−4 |
| Class | Compound Name | RT|m/z | Regulation (Up/Down) a | Fold-Change b | p-Value c |
|---|---|---|---|---|---|
| Carboxylic acids & derivatives | Pentasine | 11.02|654.6 | UP | 1.51 | 4.7 × 10−6 |
| Cholesteryl esters | CE(18:2(9Z,12Z)) | 14.7|666.62 | DOWN | 0.53 | 5.6 × 10−6 |
| Diacylglycerols | DG(18:0/18:1(9Z)/0: 0) | 15.39|605.55 | UP | 1.69 | 1.8 × 10−6 |
| DG(20:0/20:5(5Z,8Z,11Z,14Z,17Z)/0:0) | 14.68|671.57 | DOWN | 0.39 | 9.9 × 10−7 | |
| DG(24:1(15Z)/14:1(9Z)/0:0) | 15.34|631.57 | UP | 1.89 | 1.4 × 10−4 | |
| Fatty acids & acylcarnitines | Decanoylcarnitine | 1.12|316.25 | DOWN | 0.58 | 9.4 × 10−7 |
| Tetradecanal | 1.54|230.25 | DOWN | 0.45 | 6.5 × 10−7 | |
| Docosatrienoic acid | 14.69|299.27 | DOWN | 0.36 | 4.1 × 10−6 | |
| Oleic acid | 2.51|302.3 | DOWN | 0.32 | 9.5 × 10−10 | |
| Palmitic acid | 10.64|615.5 | UP | 1.66 | 2.8 × 10−6 | |
| 9-Decenoylcarnitine | 1|314.23 | DOWN | 0.61 | 3.0 × 10−6 | |
| Dodecanoylcarnitine | 1.68|344.28 | DOWN | 0.64 | 8.2 × 10−6 | |
| (5Z,8Z)- Tetradecadienoylcarnitine | 1.58|368.28 | DOWN | 0.58 | 3.9 × 10−7 | |
| O-Linoleoylcarnitine | 4.06|424.34 | DOWN | 0.60 | 6.7 × 10−9 | |
| Fatty acyls | Cohibin D | 10.99|577.52 | UP | 1.51 | 1.9 × 10−5 |
| Flavonoids | Apigenin 4′-[p-coumaroyl-(->2)-glucuronyl-(1->2)-glucuronide] 7-glucuronide | 14.66|944.87 | UP | 1.53 | 1.2 × 10−6 |
| Malvidin 3-(6″-p-coumarylglucoside) | 11.48|640.59 | UP | 1.57 | 2.5 × 10−5 | |
| Glycerolipids | MG(18:1(11Z)/0:0/0: 0) | 11.02|339.29 | UP | 1.66 | 6.5 × 10−5 |
| MG(20:4(5Z,8Z,11Z, 14Z)/0:0/0:0) | 2.44|396.31 | DOWN | 0.53 | 8.9 × 10−7 | |
| Glycero-phospholipids | PE(P-18:1(9Z)/18:2(9Z,12Z)) | 9.88|746.51 | DOWN | 0.64 | 3.8 × 10−8 |
| PE(P-18:1(9Z)/16:1(9Z)) | 10.16|698.51 | DOWN | 0.55 | 1.3 × 10−9 | |
| PS(22:6(4Z,7Z,10Z,1 3Z,16Z,19Z)/20:3(8Z,11Z,14Z)) | 10.27|902.51 | UP | 1.54 | 1.7 × 10−9 | |
| PS(22:6(4Z,7Z,10Z,13Z,16Z,19Z)/20:3(8Z,11Z,14Z)) | 10.27|852.5 | UP | 1.80 | 3.5 × 10−13 | |
| PE(18:0/16:0) | 10.49|700.52 | DOWN | 0.49 | 2.1 × 10−5 | |
| PE(18:1(9Z)/18:0) | 10.57|726.54 | DOWN | 0.61 | 3.1 × 10−10 | |
| PC(22:0/15:0) | 9.49|804.55 | DOWN | 0.62 | 4.4 × 10−9 | |
| PC(22:0/18:0) | 9.19|846.6 | DOWN | 0.57 | 5.2 × 10−5 | |
| PE(20:4(8Z,11Z,14Z, 17Z)/18:0) | 10.16|750.54 | DOWN | 0.55 | 1.0 × 10−4 | |
| PE(16:0/18:1(9Z)) | 10.36|718.54 | UP | 1.97 | 5.9 × 10−8 | |
| PC(18:4(6Z,9Z,12Z,15Z)/15:0) | 11.66|740.53 | DOWN | 0.47 | 1.1 × 10−5 | |
| PC(18:2(9Z,12Z)/14:0) | 9.35|730.54 | DOWN | 0.65 | 5.9 × 10−7 | |
| PC(20:4(5Z,8Z,11Z,14Z)s/16:0) | 9.49|782.57 | DOWN | 0.65 | 4.6 × 10−9 | |
| Organic trisulfides | Pollinastanol | 7.64|401.34 | DOWN | 0.42 | 1.0 × 10−3 |
| Phenols | Betaxolol | 1.46|308.12 | DOWN | 0.35 | 4.5 × 10−2 |
| Prenol lipids | beta-Vatirenene | 14.69|203.18 | DOWN | 0.53 | 1.8 × 10−4 |
| Monomenthyl succinate | 14.7|257.23 | DOWN | 0.60 | 8.2 × 10−5 | |
| Ubiquinone-4 | 3.79|472.34 | DOWN | 0.49 | 8.7 × 10−6 | |
| Steroids & steroid derivatives | Cholesterol | 14.69|369.35 | DOWN | 0.60 | 8.2 × 10−6 |
| 8-Dehydrocholesterol | 14.1|367.34 | DOWN | 0.61 | 1.1 × 10−3 | |
| Triacylglycerols | TG(16:1(9Z)/18:0/20:1(11Z)) | 15.37|904.83 | UP | 1.58 | 8.0 × 10−9 |
| TG(17:0/18:1(9Z)/18:1(9Z)) | 15.07|890.82 | UP | 1.65 | 2.0 × 10−5 | |
| TG(18:0/18:0/18:1(9 Z)) | 16.03|906.85 | UP | 1.64 | 9.2 × 10−5 | |
| TG(18:0/18:0/20:4(5 Z,8Z,11Z,14Z)) | 16.02|911.81 | UP | 1.54 | 3.2 × 10−5 | |
| TG(15:0/22:2(13Z,16 Z)/20:0) | 15.33|946.88 | UP | 1.58 | 6.7 × 10−9 | |
| TG(18:1(9Z)/18:1(9Z)/20:1(11Z)) | 15.33|930.85 | UP | 1.63 | 5.8 × 10−8 | |
| TG(18:0/18:1(9Z)/20:0) | 16.63|934.88 | UP | 1.76 | 2.7 × 10−4 |
| Classifier | No. of Features Used | AUCROC | CI |
|---|---|---|---|
| Glycomics | 37 | 0.786 | 0.688–0.883 |
| Metallomics | 30 | 0.851 | 0.782–0.904 |
| Metabolomics | 27 | 0.836 | 0.744–0.930 |
| Lipidomics | 48 | 0.822 | 0.724–0.905 |
| Multi-omics | Top 100 out of 142 | 0.953 | 0.911–0.987 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lim, S.Y.; Lim, F.L.S.; Criado-Navarro, I.; Yeo, X.H.; Dayal, H.; Vemulapalli, S.D.; Seah, S.J.; Laserna, A.K.C.; Yang, X.; Tan, S.H.; et al. Multi-Omics Investigation into Acute Myocardial Infarction: An Integrative Method Revealing Interconnections amongst the Metabolome, Lipidome, Glycome, and Metallome. Metabolites 2022, 12, 1080. https://doi.org/10.3390/metabo12111080
Lim SY, Lim FLS, Criado-Navarro I, Yeo XH, Dayal H, Vemulapalli SD, Seah SJ, Laserna AKC, Yang X, Tan SH, et al. Multi-Omics Investigation into Acute Myocardial Infarction: An Integrative Method Revealing Interconnections amongst the Metabolome, Lipidome, Glycome, and Metallome. Metabolites. 2022; 12(11):1080. https://doi.org/10.3390/metabo12111080
Chicago/Turabian StyleLim, Si Ying, Felicia Li Shea Lim, Inmaculada Criado-Navarro, Xin Hao Yeo, Hiranya Dayal, Sri Dhruti Vemulapalli, Song Jie Seah, Anna Karen Carrasco Laserna, Xiaoxun Yang, Sock Hwee Tan, and et al. 2022. "Multi-Omics Investigation into Acute Myocardial Infarction: An Integrative Method Revealing Interconnections amongst the Metabolome, Lipidome, Glycome, and Metallome" Metabolites 12, no. 11: 1080. https://doi.org/10.3390/metabo12111080
APA StyleLim, S. Y., Lim, F. L. S., Criado-Navarro, I., Yeo, X. H., Dayal, H., Vemulapalli, S. D., Seah, S. J., Laserna, A. K. C., Yang, X., Tan, S. H., Chan, M. Y., & Li, S. F. Y. (2022). Multi-Omics Investigation into Acute Myocardial Infarction: An Integrative Method Revealing Interconnections amongst the Metabolome, Lipidome, Glycome, and Metallome. Metabolites, 12(11), 1080. https://doi.org/10.3390/metabo12111080