

Survey for Computer-Aided Tools and Databases in Metabolomics


Abstract
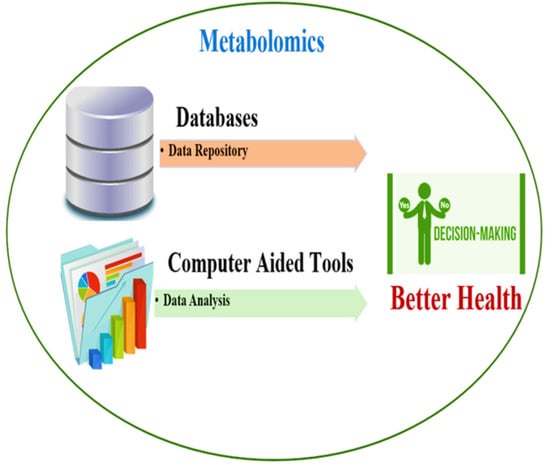
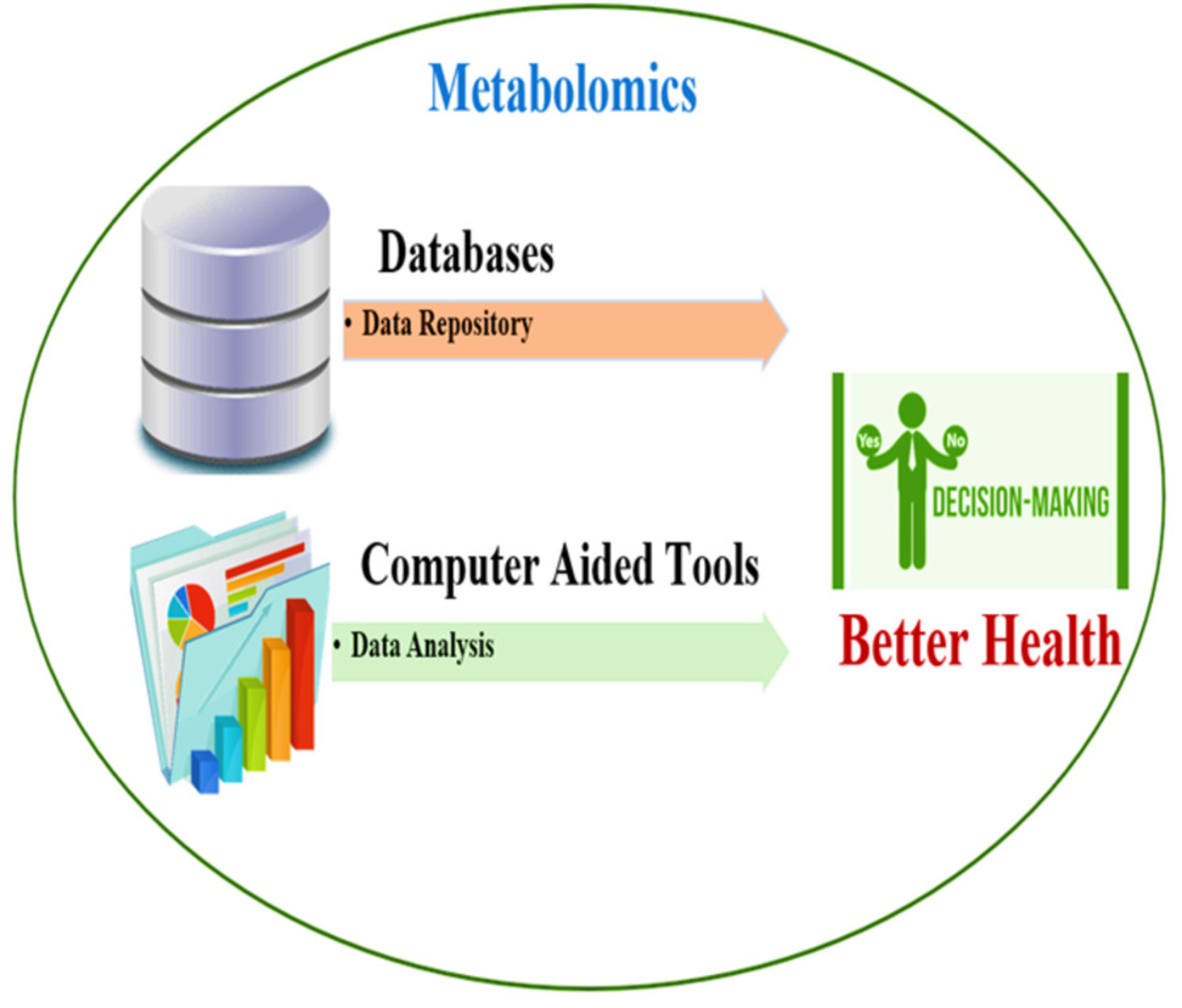
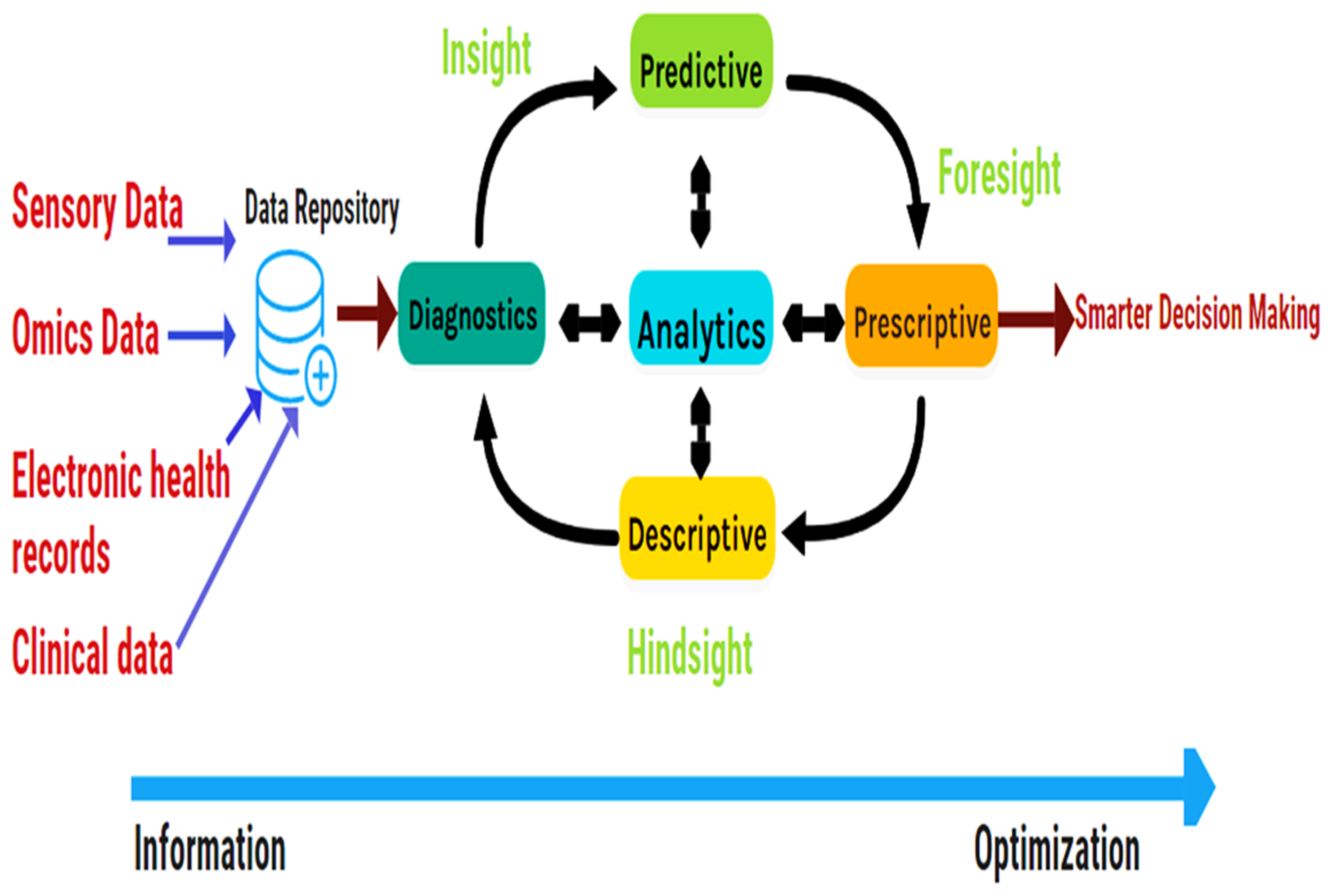
1. Introduction
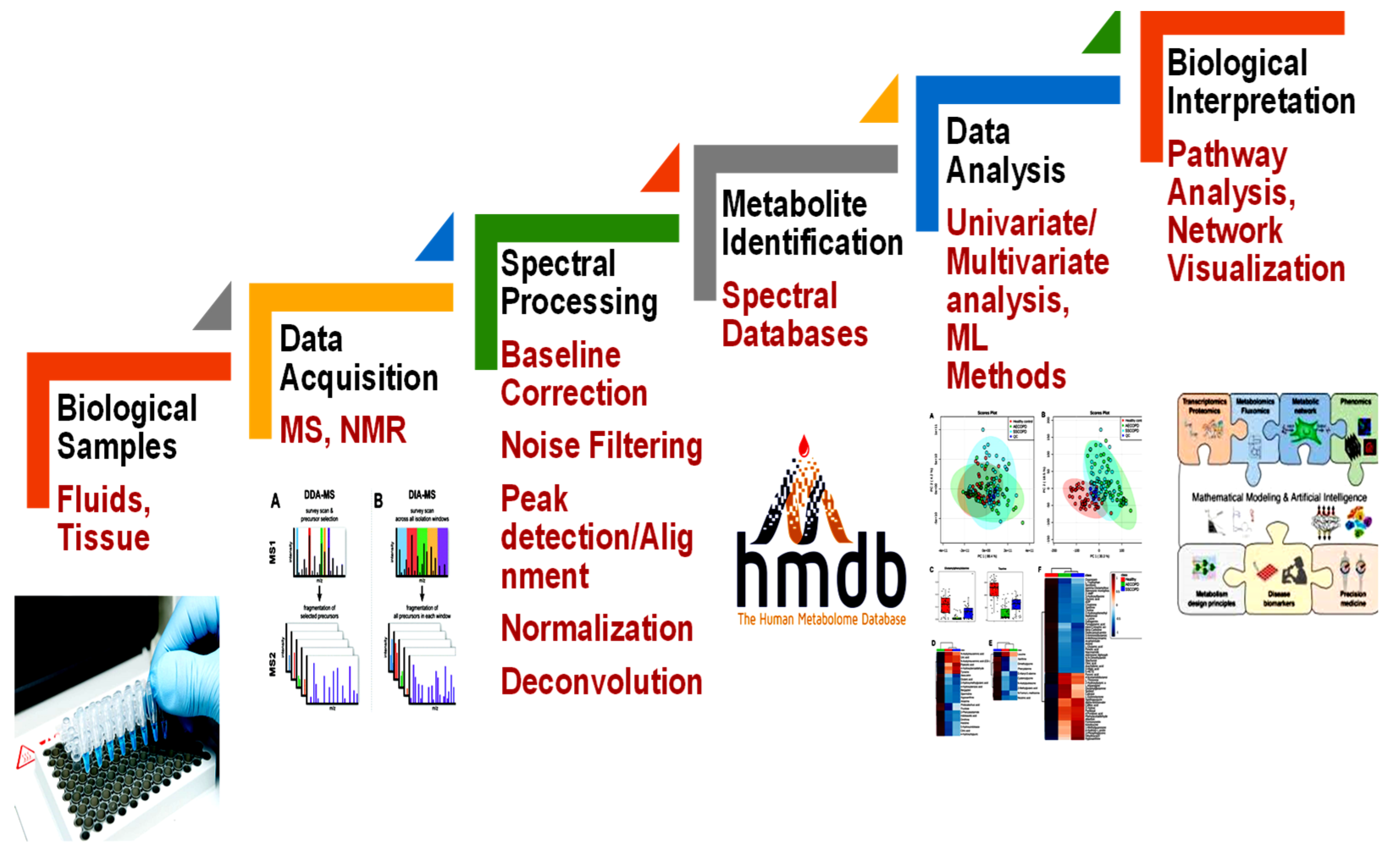
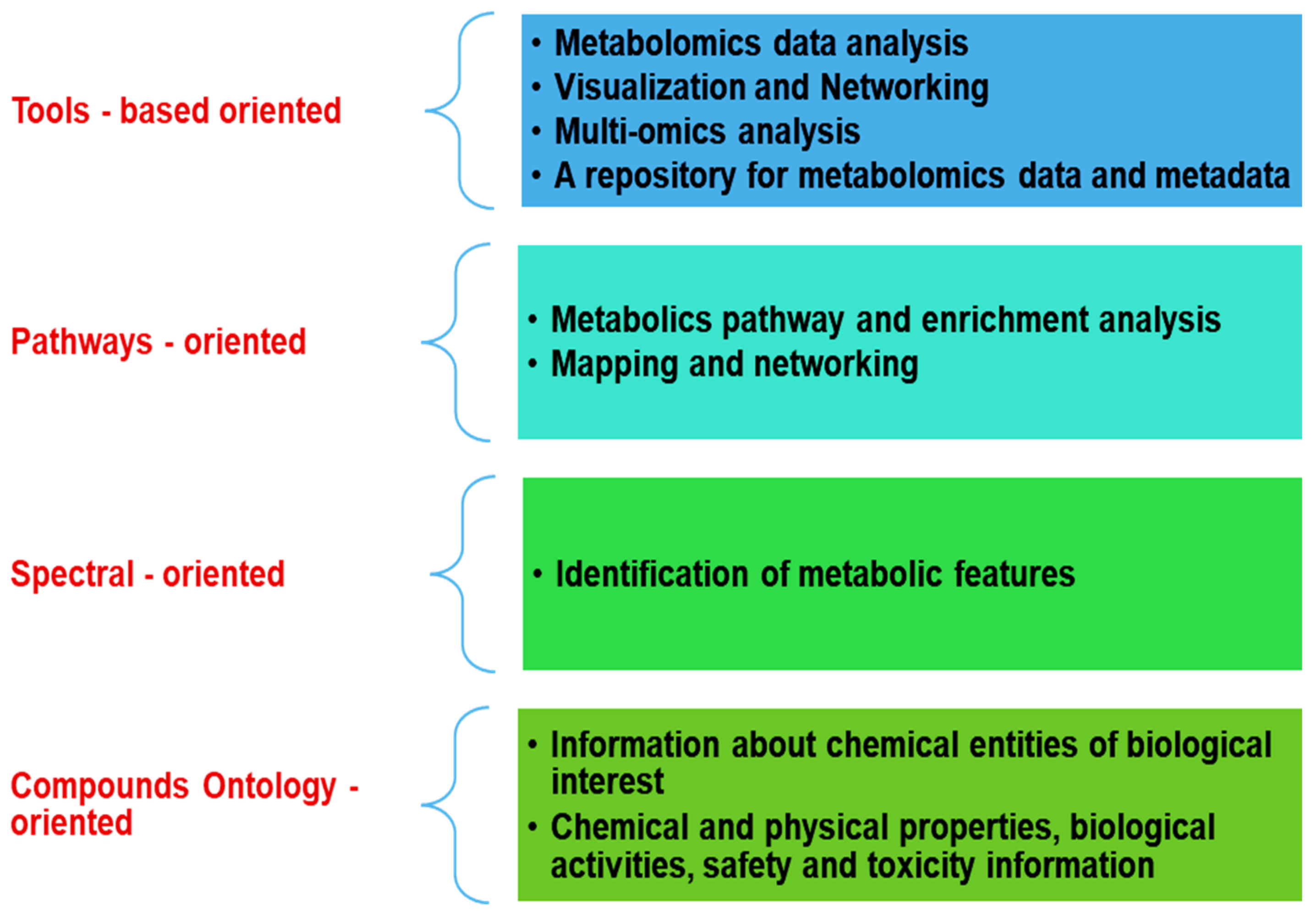
2. Metabolomics Databases
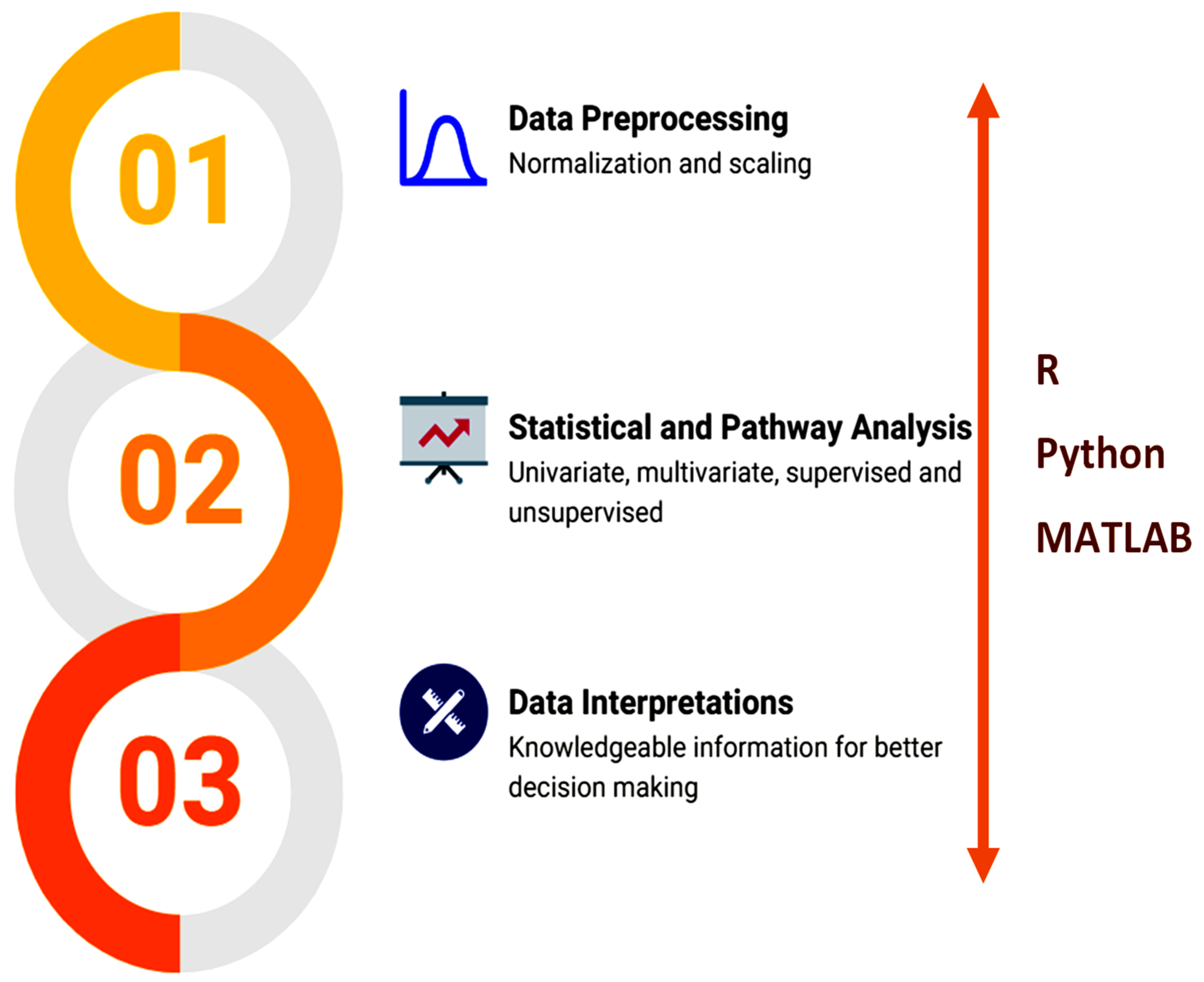
3. Metabolomics Computer-Aided Tools
4. Discussion and Concluding Remarks
Author Contributions
Funding
Conflicts of Interest
References
- Weinstein, J.N. ‘Omic’and hypothesis-driven research in the molecular pharmacology of cancer. Curr. Opin. Pharmacol. 2002, 2, 361–365. [Google Scholar] [CrossRef]
- Ge, H.; Walhout, A.J.M.; Vidal, M. Integrating ‘omic’information: A bridge between genomics and systems biology. TRENDS Genet. 2003, 19, 551–560. [Google Scholar] [CrossRef]
- Mi, K.; Jiang, Y.; Chen, J.; Lv, D.; Qian, Z.; Sun, H.; Shang, D. Construction and Analysis of Human Diseases and Metabolites Network. Front. Bioeng. Biotechnol. 2020, 8, 398. (In English) [Google Scholar] [CrossRef]
- Schneider, M.V.; Orchard, S. Omics technologies, data and bioinformatics principles. In Bioinformatics for Omics Data; Springer: Berlin/Heidelberg, Germany, 2011; pp. 3–30. [Google Scholar]
- Izonin, I.; Shakhovska, N. Informatics & data-driven medicine. Math. Biosci. Eng. 2021, 18, 6430–6433. [Google Scholar] [PubMed]
- van der Kleij, R.M.; Kasteleyn, M.J.; Meijer, E.; Bonten, T.N.; Houwink, E.J.; Teichert, M.; van Luenen, S.; Vedanthan, R.; Evers, A.; Car, J.; et al. SERIES: eHealth in primary care. Part 1: Concepts, conditions and challenges. Eur. J. Gen. Pract. 2019, 25, 179–189. [Google Scholar] [CrossRef] [PubMed]
- Marcolino, M.S.; Oliveira, J.A.Q.; D’Agostino, M.; Ribeiro, A.L.; Alkmim, M.B.M.; Novillo-Ortiz, D. The impact of mHealth interventions: Systematic review of systematic reviews. JMIR Mhealth Uhealth 2018, 6, e8873. [Google Scholar] [CrossRef] [PubMed]
- Mathews, S.C.; McShea, M.J.; Hanley, C.L.; Ravitz, A.; Labrique, A.B.; Cohen, A.B. Digital health: A path to validation. NPJ Digit. Med. 2019, 2, 38. [Google Scholar] [CrossRef]
- Patel, D.T. Big Data Analytics in Bioinformatics. In Biotechnology: Concepts, Methodologies, Tools, and Applications; IGI Global: Pennsylvania, PA, USA, 2019; pp. 1967–1984. [Google Scholar]
- Dash, S.; Shakyawar, S.K.; Sharma, M.; Kaushik, S. Big data in healthcare: Management, analysis and future prospects. J. Big Data 2019, 6, 54. [Google Scholar]
- Gillespie, M.; Jassal, B.; Stephan, R.; Milacic, M.; Rothfels, K.; Senff-Ribeiro, A.; Griss, J.; Sevilla, C.; Matthews, L.; Gong, C. The reactome pathway knowledgebase 2022. Nucleic Acids Res. 2021, 50, D687–D692. [Google Scholar] [CrossRef]
- Karp, P.D.; Billington, R.; Caspi, R.; Fulcher, C.A.; Latendresse, M.; Kothari, A.; Keseler, I.M.; Krummenacker, M.; Midford, P.E.; Ong, Q.; et al. The BioCyc collection of microbial genomes and metabolic pathways. Brief. Bioinform. 2019, 20, 1085–1093. [Google Scholar] [CrossRef]
- Caspi, R.; Billington, R.; Keseler, I.M.; Kothari, A.; Krummenacker, M.; Midford, P.E.; Ong, W.K.; Paley, S.; Subhraveti, P.; Karp, P.D. The MetaCyc database of metabolic pathways and enzymes-a 2019 update. Nucleic Acids Res. 2020, 48, D445–D453. [Google Scholar] [CrossRef]
- Keseler, I.M.; Gama-Castro, S.; Mackie, A.; Billington, R.; Bonavides-Martínez, C.; Caspi, R.; Kothari, A.; Krummenacker, M.; Midford, P.E.; Muñiz-Rascado, L.; et al. The EcoCyc database in 2021. Front. Microbiol. 2021, 12, 2098. [Google Scholar] [CrossRef] [PubMed]
- Norsigian, C.J.; Pusarla, N.; McConn, J.L.; Yurkovich, J.T.; Dräger, A.; O Palsson, B.; King, Z. BiGG Models 2020: Multi-strain genome-scale models and expansion across the phylogenetic tree. Nucleic Acids Res. 2020, 48, D402–D406. [Google Scholar] [CrossRef] [PubMed]
- Kanehisa, M.; Furumichi, M.; Sato, Y.; Ishiguro-Watanabe, M.; Tanabe, M. KEGG: Integrating viruses and cellular organisms. Nucleic Acids Res. 2021, 49, D545–D551. [Google Scholar] [CrossRef]
- Chang, A.; Jeske, L.; Ulbrich, S.; Hofmann, J.; Koblitz, J.; Schomburg, I.; Neumann-Schaal, M.; Jahn, D.; Schomburg, D. BRENDA, the ELIXIR core data resource in 2021: New developments and updates. Nucleic Acids Res. 2021, 49, D498–D508. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.; Chen, J.; Cheng, T.; Gindulyte, A.; He, J.; He, S.; Li, Q.; Shoemaker, B.A.; Thiessen, P.A.; Yu, B.; et al. PubChem in 2021: New data content and improved web interfaces. Nucleic Acids Res. 2021, 49, D1388–D1395. [Google Scholar] [CrossRef] [PubMed]
- Hastings, J.; Owen, G.; Dekker, A.; Ennis, M.; Kale, N.; Muthukrishnan, V.; Turner, S.; Swainston, N.; Mendes, P.; Steinbeck, C. ChEBI in 2016: Improved services and an expanding collection of metabolites. Nucleic Acids Res. 2016, 44, D1214–D1219. [Google Scholar] [CrossRef]
- Wishart, D.S.; Guo, A.; Oler, E.; Wang, F.; Anjum, A.; Peters, H.; Dizon, R.; Sayeeda, Z.; Tian, S.; Lee, B.L.; et al. HMDB 5.0: The Human Metabolome Database for 2022. Nucleic Acids Res. 2022, 50, D622–D631. [Google Scholar] [CrossRef]
- Pence, H.E.; Williams, A. ChemSpider: An online chemical information resource. J. Chem. Educ. 2010, 87, 1123–1124. [Google Scholar] [CrossRef]
- Haug, K.; Cochrane, K.; Nainala, V.C.; Williams, M.; Chang, J.; Jayaseelan, K.V.; O’Donovan, C. MetaboLights: A resource evolving in response to the needs of its scientific community. Nucleic Acids Res. 2020, 48, D440–D444. [Google Scholar] [CrossRef]
- Sud, M.; Fahy, E.; Cotter, D.; Azam, K.; Vadivelu, I.; Burant, C.; Edison, A.; Fiehn, O.; Higashi, R.; Nair, K.S.; et al. Metabolomics Workbench: An international repository for metabolomics data and metadata, metabolite standards, protocols, tutorials and training, and analysis tools. Nucleic Acids Res. 2016, 44, D463–D470. [Google Scholar] [CrossRef] [PubMed]
- Jewison, T.; Su, Y.; Disfany, F.M.; Liang, Y.; Knox, C.; Maciejewski, A.; Poelzer, J.; Huynh, J.; Zhou, Y.; Arndt, D.; et al. SMPDB 2.0: Big improvements to the Small Molecule Pathway Database. Nucleic Acids Res. 2014, 42, D478–D484. [Google Scholar] [CrossRef] [PubMed]
- Cheng, L.; Yang, H.; Zhao, H.; Pei, X.; Shi, H.; Sun, J.; Zhang, Y.; Wang, Z.; Zhou, M. MetSigDis: A manually curated resource for the metabolic signatures of diseases. Brief. Bioinform. 2019, 20, 203–209. [Google Scholar] [CrossRef]
- Noronha, A.; Modamio, J.; Jarosz, Y.; Guerard, E.; Sompairac, N.; Preciat, G.; Daníelsdóttir, A.D.; Krecke, M.; Merten, D.; Haraldsdóttir, H.S. The Virtual Metabolic Human database: Integrating human and gut microbiome metabolism with nutrition and disease. Nucleic Acids Res. 2019, 47, D614–D624. [Google Scholar] [CrossRef] [PubMed]
- Rodchenkov, I.; Babur, O.; Luna, A.; Aksoy, B.A.; Wong, J.V.; Fong, D.; Franz, M.; Siper, M.C.; Cheung, M.; Wrana, M.; et al. Pathway Commons 2019 Update: Integration, analysis and exploration of pathway data. Nucleic Acids Res. 2020, 48, D489–D497. [Google Scholar] [CrossRef] [PubMed]
- Slenter, D.N.; Kutmon, M.; Hanspers, K.; Riutta, A.; Windsor, J.; Nunes, N.; Mélius, J.; Cirillo, E.; Coort, S.L.; Digles, D.; et al. WikiPathways: A multifaceted pathway database bridging metabolomics to other omics research. Nucleic Acids Res. 2018, 46, D661–D667. [Google Scholar] [CrossRef]
- Zhang, B.; Hu, S.; Baskin, E.; Patt, A.; Siddiqui, J.K.; Mathé, E.A. RaMP: A comprehensive relational database of metabolomics pathways for pathway enrichment analysis of genes and metabolites. Metabolites 2018, 8, 16. [Google Scholar] [CrossRef]
- Pu, J.; Yu, Y.; Liu, Y.; Tian, L.; Gui, S.; Zhong, X.; Fan, C.; Xu, S.; Song, X.; Liu, L.; et al. MENDA: A comprehensive curated resource of metabolic characterization in depression. Brief. Bioinform. 2020, 21, 1455–1464. [Google Scholar] [CrossRef]
- Kaever, A.; Landesfeind, M.; Feussner, K.; Mosblech, A.; Heilmann, I.; Morgenstern, B.; Feussner, I.; Meinicke, P. MarVis-Pathway: Integrative and exploratory pathway analysis of non-targeted metabolomics data. Metabolomics 2015, 11, 764–777. [Google Scholar] [CrossRef]
- Cottret, L.; Frainay, C.; Chazalviel, M.; Cabanettes, F.; Gloaguen, Y.; Camenen, E.; Merlet, B.; Heux, S.; Portais, J.-C.; Poupin, N.; et al. MetExplore: Collaborative edition and exploration of metabolic networks. Nucleic Acids Res. 2018, 46, W495–W502. [Google Scholar] [CrossRef]
- Aggio, R.B.M.; Ruggiero, K.; Villas-Bôas, S.G. Pathway Activity Profiling (PAPi): From the metabolite profile to the metabolic pathway activity. Bioinformatics 2010, 26, 2969–2976. [Google Scholar] [CrossRef] [PubMed]
- López-Ibáñez, J.; Pazos, F.; Chagoyen, M. MBROLE 2.0—Functional enrichment of chemical compounds. Nucleic Acids Res. 2016, 44, W201–W204. [Google Scholar] [CrossRef] [PubMed]
- Pang, Z.; Chong, J.; Zhou, G.; de Lima Morais, D.A.; Chang, L.; Barrette, M.; Gauthier, C.; Jacques, P.-É.; Li, S.; Xia, J. MetaboAnalyst 5.0: Narrowing the gap between raw spectra and functional insights. Nucleic Acids Res. 2021, 49, W388–W396. [Google Scholar] [CrossRef]
- Kankainen, M.; Gopalacharyulu, P.; Holm, L.; Orešič, M. MPEA—Metabolite pathway enrichment analysis. Bioinformatics 2011, 27, 1878–1879. [Google Scholar] [CrossRef] [PubMed]
- Hernández-de-Diego, R.; Tarazona, S.; Martínez-Mira, C.; Balzano-Nogueira, L.; Furió-Tarí, P.; Pappas, G.J., Jr.; Conesa, A. PaintOmics 3: A web resource for the pathway analysis and visualization of multi-omics data. Nucleic Acids Res. 2018, 46, W503–W509. [Google Scholar] [CrossRef] [PubMed]
- Kamburov, A.; Cavill, R.; Ebbels, T.M.D.; Herwig, R.; Keun, H.C. Integrated pathway-level analysis of transcriptomics and metabolomics data with IMPaLA. Bioinformatics 2011, 27, 2917–2918. [Google Scholar] [CrossRef]
- Grapov, D.; Wanichthanarak, K.; Fiehn, O. MetaMapR: Pathway independent metabolomic network analysis incorporating unknowns. Bioinformatics 2015, 31, 2757–2760. [Google Scholar] [CrossRef]
- Danna, V.; Mitchell, H.; Anderson, L.; Godinez, I.; Gosline, S.J.C.; Teeguarden, J.; McDermott, J.E. leapR: An R Package for Multiomic Pathway Analysis. J. Proteome Res. 2021, 20, 2116–2121. [Google Scholar] [CrossRef]
- Palombo, V.; Milanesi, M.; Sferra, G.; Capomaccio, S.; Sgorlon, S.; D’Andrea, M. PANEV: An R package for a pathway-based network visualization. BMC Bioinform. 2020, 21, 46. [Google Scholar] [CrossRef]
- Ulgen, E.; Ozisik, O.; Sezerman, O.U. pathfindR: An R package for comprehensive identification of enriched pathways in omics data through active subnetworks. Front. Genet. 2019, 10, 858. [Google Scholar] [CrossRef]
- Krämer, A.; Green, J.; Pollard, J., Jr.; Tugendreich, S. Causal analysis approaches in ingenuity pathway analysis. Bioinformatics 2014, 30, 523–530. [Google Scholar] [CrossRef] [PubMed]
- Darzi, Y.; Letunic, I.; Bork, P.; Yamada, T. iPath3. 0: Interactive pathways explorer v3. Nucleic Acids Res. 2018, 46, W510–W513. [Google Scholar] [CrossRef] [PubMed]
- Yu, G.; He, Q.-Y. ReactomePA: An R/Bioconductor package for reactome pathway analysis and visualization. Mol. BioSystems 2016, 12, 477–479. [Google Scholar] [CrossRef] [PubMed]
- Chazalviel, M.; Frainay, C.; Poupin, N.; Vinson, F.; Merlet, B.; Gloaguen, Y.; Cottret, L.; Jourdan, F. MetExploreViz: Web component for interactive metabolic network visualization. Bioinformatics 2018, 34, 312–313. [Google Scholar] [CrossRef] [PubMed]
- Brunk, E.; Sahoo, S.; Zielinski, D.C.; Altunkaya, A.; Dräger, A.; Mih, N.; Gatto, F.; Nilsson, A.; Preciat Gonzalez, G.A.; Aurich, M.K.; et al. Recon3D enables a three-dimensional view of gene variation in human metabolism. Nat. Biotechnol. 2018, 36, 272–281. [Google Scholar] [CrossRef]
- Barupal, D.K.; Fiehn, O. Chemical Similarity Enrichment Analysis (ChemRICH) as alternative to biochemical pathway mapping for metabolomic datasets. Sci. Rep. 2017, 7, 14567. [Google Scholar] [CrossRef]
- Tenenbaum, D.; Runit, S.; Maintainer, M.B.P.; Carlson, M.; ThirdPartyClient. Package ‘KEGGREST’; R Foundation for Statistical Computing: Vienna, Austria, 2019. [Google Scholar]
- Wen, B.; Mei, Z.; Zeng, C.; Liu, S. metaX: A flexible and comprehensive software for processing metabolomics data. BMC Bioinform. 2017, 18, 183. [Google Scholar] [CrossRef]
- Leclercq, M.; Vittrant, B.; Martin-Magniette, M.L.; Boyer, M.P.S.; Perin, O.; Bergeron, A.; Fradet, Y.; Droit, A. Large-scale automatic feature selection for biomarker discovery in high-dimensional OMICs data. Front. Genet. 2019, 10, 452. [Google Scholar] [CrossRef]
- Kuo, T.-C.; Tian, T.-F.; Tseng, Y.J. 3Omics: A web-based systems biology tool for analysis, integration and visualization of human transcriptomic, proteomic and metabolomic data. BMC Syst. Biol. 2013, 7, 64. [Google Scholar] [CrossRef]
- Kessler, N.; Neuweger, H.; Bonte, A.; Langenkämper, G.; Niehaus, K.; Nattkemper, T.W.; Goesmann, A. MeltDB 2.0–advances of the metabolomics software system. Bioinformatics 2013, 29, 2452–2459. [Google Scholar] [CrossRef]
- Wägele, B.; Witting, M.; Schmitt-Kopplin, P.; Suhre, K. MassTRIX reloaded: Combined analysis and visualization of transcriptome and metabolome data. PLoS ONE 2012, 7, e39860. [Google Scholar] [CrossRef] [PubMed]
- Kastenmüller, G.; Römisch-Margl, W.; Wägele, B.; Altmaier, E.; Suhre, K. metaP-server: A web-based metabolomics data analysis tool. J. Biomed. Biotechnol. 2011, 2011, 839862. [Google Scholar] [CrossRef] [PubMed]
- Leader, D.P.; Burgess, K.; Creek, D.; Barrett, M.P. Pathos: A web facility that uses metabolic maps to display experimental changes in metabolites identified by mass spectrometry. Rapid Commun. Mass Spectrom. 2011, 25, 3422–3426. [Google Scholar] [CrossRef] [PubMed]
- Romero, P.; Wagg, J.; Green, M.L.; Kaiser, D.; Krummenacker, M.; Karp, P.D. Computational prediction of human metabolic pathways from the complete human genome. Genome Biol. 2005, 6, R2. [Google Scholar] [CrossRef] [PubMed]
- Ulrich, E.L.; Akutsu, H.; Doreleijers, J.F.; Harano, Y.; Ioannidis, Y.E.; Lin, J. BioMagResBank. Nucleic Acids Res. 2008, 36, D402–D408. [Google Scholar] [CrossRef] [PubMed]
- Kopka, J.; Schauer, N.; Krueger, S.; Birkemeyer, C.; Usadel, B.; Bergmuller, E.; Dormann, P.; Weckwerth, W.; Gibon, Y.; Stitt, M.; et al. GMD@ CSB. DB: The Golm metabolome database. Bioinformatics 2005, 21, 1635–1638. [Google Scholar] [CrossRef]
- Prendeville, S.; Sanders, C.; Sherry, J.; Costa, F. NIST Standard Reference Database 1A; Standard Reference Data; NIST: Gaithersburg, MD, USA, 2014. Available online: https://www.nist.gov/srd/nist-standard-referencedatabase-1a (accessed on 1 April 2022).
- Zhou, W.; Ying, Y.; Xie, L. Spectral database systems: A review. Appl. Spectrosc. Rev. 2012, 47, 654–670. [Google Scholar] [CrossRef]
- Bader, G.D.; Cary, M.P.; Sander, C. Pathguide: A pathway resource list. Nucleic Acids Res. 2006, 34, D504–D506. [Google Scholar] [CrossRef]
- Kumar, A.; Suthers, P.F.; Maranas, C.D. MetRxn: A knowledgebase of metabolites and reactions spanning metabolic models and databases. BMC Bioinform. 2012, 13, 6. [Google Scholar] [CrossRef]
- Alcántara, R.; Axelsen, K.; Morgat, A.; Belda, E.; Coudert, E.; Bridge, A.; Cao, H.; De Matos, P.; Ennis, M.; Turner, S.; et al. Rhea—A manually curated resource of biochemical reactions. Nucleic Acids Res. 2012, 40, D754–D760. [Google Scholar] [CrossRef]
- Fahy, E.; Subramaniam, S. RefMet: A reference nomenclature for metabolomics. Nat. Methods 2020, 17, 1173–1174. [Google Scholar] [CrossRef] [PubMed]
- Wieder, C.; Frainay, C.; Poupin, N.; Rodríguez-Mier, P.; Vinson, F.; Cooke, J.; Lai, R.P.; Bundy, J.G.; Jourdan, F.; Ebbels, T. Pathway analysis in metabolomics: Recommendations for the use of over-representation analysis. PLoS Comput. Biol. 2021, 17, e1009105. [Google Scholar] [CrossRef] [PubMed]
- Van Rossum, G. Python Reference Manual; Department of Computer Science [CS]; CWI: Amsterdam, The Netherlands, 1995. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Barupal, D.K.; Fan, S.; Fiehn, O. Integrating bioinformatics approaches for a comprehensive interpretation of metabolomics datasets. Curr. Opin. Biotechnol. 2018, 54, 1–9. [Google Scholar] [CrossRef]
- Lefort, G.; Liaubet, L.; Canlet, C.; Tardivel, P.; Père, M.-C.; Quesnel, H.; Paris, A.; Iannuccelli, N.; Vialaneix, N.; Servien, R. ASICS: An R package for a whole analysis workflow of 1D 1H NMR spectra. Bioinformatics 2019, 35, 4356–4363. [Google Scholar] [CrossRef] [PubMed]
- O’Shea, K.; Misra, B.B. Software tools, databases and resources in metabolomics: Updates from 2018 to 2019. Metabolomics 2020, 16, 36. [Google Scholar] [CrossRef] [PubMed]
- Misra, B.B. New software tools, databases, and resources in metabolomics: Updates from 2020. Metabolomics 2021, 17, 49. [Google Scholar] [CrossRef] [PubMed]
- Booth, S.C.; Weljie, A.M.; Turner, R.J. Computational tools for the secondary analysis of metabolomics experiments. Comput. Struct. Biotechnol. J. 2013, 4, e201301003. [Google Scholar] [CrossRef]
- Kamburov, A.; Wierling, C.; Lehrach, H.; Herwig, R. ConsensusPathDB—A database for integrating human functional interaction networks. Nucleic Acids Res. 2009, 37, D623–D628. [Google Scholar] [CrossRef]
- Domingo-Fernández, D.; Mubeen, S.; Marín-Llaó, J.; Hoyt, C.T.; Hofmann-Apitius, M. PathMe: Merging and exploring mechanistic pathway knowledge. BMC Bioinform. 2019, 20, 243. [Google Scholar] [CrossRef]
- Wanichthanarak, K.; Fan, S.; Grapov, D.; Barupal, D.K.; Fiehn, O. Metabox: A toolbox for metabolomic data analysis, interpretation and integrative exploration. PLoS ONE 2017, 12, e0171046. [Google Scholar] [CrossRef]
- Kutmon, M.; van Iersel, M.; Bohler, A.; Kelder, T.; Nunes, N.; Pico, A.; Evelo, C.T. PathVisio 3: An extendable pathway analysis toolbox. PLoS Comput. Biol. 2015, 11, e1004085. [Google Scholar] [CrossRef] [PubMed]
- Banimfreg, B.H. Biomarker Discovery Utilizing Big Data: The Case of Diabetes in United Arab Emirates. Doctoral Dissertation, American University of Sharjah, Sharjah, United Arab Emirates, 2022. [Google Scholar]
- Banimfreg, B.H.; Shamayleh, A.; Alshraideh, H.; Semreen, M.H.; Soares, N.C. Untargeted approach to investigating the metabolomics profile of type 2 diabetes emiratis. J. Proteom. 2022, 269, 104718. [Google Scholar] [CrossRef] [PubMed]
- Banimfreg, B.H.; Alshraideh, H.; Shamayleh, A.; Guella, A.; Semreen, M.H.; Al Bataineh, M.T.; Soares, N.C. Untargeted Metabolomic Plasma Profiling of Emirati Dialysis Patients with Diabetes versus Non-Diabetic: A Pilot Study. Biomolecules 2022, 12, 962. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | Organisms | Database Descriptions | Coverage | Accessibility | Link | Y.O.R | Ref. |
|---|---|---|---|---|---|---|---|
| Reactome Knowledgebase | Homo-sapiens | It contains visualization, interpretation, and analysis of pathway knowledge. Available tools: SkyPainter, PathFinder, BioMart, Reactome Gene Set Analysis (ReactomeGSA) and Reactome IDG Portal. | Human Pathways:2546 Reactions:13890 Proteins:1020 Small Molecules:1940 Drugs:507 | Free | Reactome.org (accessed on 1 April 2022) | 2005 | [11] |
| BioCyc | Eukaryotes Bacteria and Archaea. | A comprehensive reference containing listed data from 130,000 publications—available tools: Pathologic, Genome browser, Pathway Tools, BLAST search, and SmartTables. | Pathway/Genome Databases (PGDBs): 19,494 Archaea: 465 databases Bacteria: 18,956 databases Eukaryota: 37 databases MetaCyc: Metabolic Encyclopedia | EcoCyc and MetaCyc databases: free access. Others: Paid subscription | Biocyc.org (accessed on 1 April 2022) | 1997 | [12] |
| MetaCyc | Eukaryotes Bacteria and Archaea. | Serves as a comprehensive reference to metabolic pathways and enzymes. Available tools: Pathologic, Genome browser, BLAST search, Pathways Tools, Google™. | Multi-organisms: 3295 Metabolic pathways:2937 Enzymatic reactions:17,310 | Free | MetaCyc.org (accessed on 1 April 2022) | 1999 | [13] |
| EcoCyc | Bacterial organism: Escherichia coli K-12 MG1655 | Contains Metabolic Network Explorer, Circular Genome Viewer | Genes:4518 Enzymes:1682 Metabolic reactions:2151 | Free | EcoCyc.org (accessed on 1 April 2022) | 1995 | [14] |
| BIGG Models | Eukaryotes, Prokaryotes, and Photosynthetic Eukaryotes. | Provides pathway visualization with Escher. It also offers standardized identifiers for metabolites, reactions, and genes. | It contains more than 75 high-quality manually-curated genome-scale metabolic models. | Free | BIGG.ucsd.edu (accessed on 1 April 2022) | 2007 | [15] |
| KEGG | Eukaryotes Bacteria and Archaea. | PATHWAY database, KEGG NETWORK database, KO annotation and taxonomy, drug information, and virus-cell interaction. Available tools: KEGG Atlas, KegHier, KegArray, KegDraw, KegTools, KEGG2, KEGG API. | KEGG organisms: 7760 (Eukaryotes: 695, Bacteria:6694, Archaea:371). KEGG modules: 456 Reaction modules:46 | Free | www.kegg.jp/ (accessed on 1 April 2022) | 1995 | [16] |
| BRENDA | Eukaryotes Bacteria and Archaea. | Comprises disease-related data, protein sequences, 3D structures, genome annotations, ligand information, taxonomic, bibliographic, and kinetic data. | Number of different enzymes: 8197 | Free | www.brenda-enzymes.org (accessed on 1 April 2022) | 1987 | [17] |
| PubChem | Eukaryotes Bacteria and Archaea | Provides chemical and physical properties, biological activities, safety and toxicity information, patents, literature citations, and more. Available tools: PubChem Structure Editor, Entrez, PubChem3D, PubChem Download Facility, ToxNet. | Compounds:110 million, Substances:277 million, Bioactivities:293 million. | Free | PubChem.ncbi.nlm.nih.gov (accessed on 1 April 2022) | 2004 | [18] |
| ChEBI | Eukaryotes Bacteria and Archaea | A database and ontology containing information about chemical entities of biological interest. | Annotated compounds: 59,708 | Free | www.ebi.ac.uk/chebi (accessed on 1 April 2022) | 2010 | [19] |
| HMDB | Homo-sapiens | A human metabolomics database. It has spectral and pathway visualization tools. Available tools: Data Extractor, ChemSketch, BLAST search, MetaboCard, MS and NMR spectral search utility, MetaboLIMS. | Annotated metabolite entries: 217,920 | Free | https://hmdb.ca (accessed on 1 April 2022) | 2007 | [20] |
| ChemSpider | Eukaryotes Bacteria and Archaea | A chemical structure database. | Chemical entities:114 Million | Free | chemspider.com (accessed on 1 April 2022) | 2007 | [21] |
| MetaboLights | Eukaryotes Bacteria and Archaea | An open-access database repository for cross-platform and cross-species metabolomics research. | Different organisms: 6510 Reference compounds:27,475 Metabolite annotation features:2016,457 | Free | https://www.ebi.ac.uk/metabolights (accessed on 1 April 2022) | 2012 | [22] |
| Metabolomics Workbench | Eukaryotes Bacteria and Archaea | A repository for metabolomics data and metadata and provides analysis tools and access to metabolite standards, protocols, tutorials, training, and more. | Discrete structures:136,000 Genes:7300 Proteins:15,500 | Free | metabolomicsworkbench.org (accessed on 1 April 2022) | 2016 | [23] |
| SMPDB | Eukaryotes Bacteria and Archaea | A pathway database for different model organisms such as humans, mice, E. coli, yeast, and Arabidopsis thaliana. | Pathways Number: 48,690 Metabolites Number (non-redundant): 55,700 | Free | https://smpdb.ca/ (accessed on 1 April 2022) | 2009 | [24] |
| MetSigDis | Homo-sapiens, Rat, Mouse, Drosophila melanogaster, Triatomine, Mice, Pig, and Mus musculus. | A manually curated resource that aims to provide a comprehensive resource of metabolite alterations in various disease. | Curated relationships:6849 Metabolites:2420 Diseases:129 Species: 8 | Free | http://www.bio-annotation.cn/MetSigDis/ (accessed on 1 April 2022) | 2017 | [25] |
| Virtual Metabolic Human | Homo-sapiens | Captures human and gut microbial metabolism information and links it to hundreds of diseases and nutritional data. | Reactions:19,313 Metabolites:5607 Human genes:3695 Diseases:255 Foodstuff:8790 | Free | www.vmh.life (accessed on 1 April 2022) | 2018 | [26] |
| Pathway Commons | Eukaryotes Bacteria and Archaea | Aims to collect and disseminate biological pathway and interaction data | Pathways:5772 Interactions:2,424,055 Databases:22 | Free | https://www.pathwaycommons.org (accessed on 1 April 2022) | [27] | |
| WikiPathways | Eukaryotes Bacteria and Archaea | A public, collaborative platform devoted to the curation of biological pathways | Human genes: 11,532 Number of pathways: 3013 | Free | wikipathways.org (accessed on 1 April 2022) | 2008 | [28] |
| RaMP | Eukaryotes Bacteria and Archaea | A multi-database integration approach for gene/metabolite enrichment analysis providing interactive tables of query results, interactive tables of pathway analysis results, and clustering of enriched pathways by pathway similarity | Pathways: 51,526 (from KEGG, Reactome, SMPDB, and WikiPathways) Genes: 23,077 Metabolites: 113,725 | Free | https://github.com/mathelab/RaMP-DB/orhttps://github.com/mathelab/RaMP-DB/inst/extdata/ (accessed on 1 April 2022) | [29] | |
| MENDA | Organisms include: Human, Rat, Mouse, and Non-human primates. | A comprehensive metabolic characterization database for depression. | Differential expressed metabolites: 5675. (Humans:1347 Rat:3127 Mouse:1105 Non-human primates:96) | Free | Menda.cqmu.edu.cn:8080/index.php\ (accessed on 1 April 2022) | 2020 | [30] |
| Tool Name | Description | Input | Implementation | Accessibility | Databases Used | Link | Ref |
|---|---|---|---|---|---|---|---|
| MarVis-Suite | Metabolic pathways analysis and visualization | MS, microarray, or RNA-seq experiments | Web-based | Free | KEGG and BioCyc | http://marvis.gobics.de (accessed on 1 April 2022) | [31] |
| MetExplore | Metabolic network and OMICs data analysis | Any | Web-based | Free | BioCyc- related | https://metexplore.toulouse.inra.fr/metexplore2/ (accessed on 1 April 2022) | [32] |
| PAPi | Compare activity of metabolic pathway between sample types. | Any | R package | Free | KEGG | http://www.4shared.com/file/s0uIYWIg/PAPi_10.html (accessed on 1 April 2022) | [33] |
| MBROLE | Enrichment analysis of metabolites annotations. | Any | Web-based | Free | KEGG, HMDB, PubChem, ChEBI, SMILES, YMDB, ECMDB, BioCyc-related, Rhea, UniPathway, LMSD, CTD, MeSH, MATADOR, DrugBank. | http://csbg.cnb.csic.es/mbrole2 (accessed on 1 April 2022) | [34] |
| MetaboAnalyst 5.0 | Metabolomics analysis platform, tutorials, and report analysis. | LC, GC raw spectra, MS, NMR peak list, and spectral bins. | Web-based, R package | Free | KEGG, HMDB, PubChem, ChEBI, RefMet and LIPID MAPS. | https://www.metaboanalyst.ca (accessed on 1 April 2022) | [35] |
| MPEA | Pathway enrichment analysis. | Pre-annotated compounds or GC-MS-based MSTs | Web-based | Free | KEGG, SMPDB and GMD. | http://ekhidna.biocenter.helsinki.fi/poxo/mpea/ (accessed on 1 April 2022) | [36] |
| PaintOmics 3 | Compound mapping | Any | Web-based | Free | KEGG | www.paintomics.org (accessed on 1 April 2022) | [37] |
| IMPaLA | Enrichment analysis. | Any | Web-based | Free | Reactome, KEGG, Wikipathways, HMDB, CAS, ChEBI, PubChem, SMPDB, NetPath, BIOCART, BioCyc. | http://impala.molgen.mpg.de (accessed on 1 April 2022) | [38] |
| MetaMapR | Metabolic network mapping. | LC and GC raw spectra, MS and NMR peak list, and spectral bins. | Web-based or desktop software. | Free | KEGG and PubChem | http://dgrapov.github.io/MetaMapR/ (accessed on 1 April 2022) | [39] |
| LeapR | Enrichment analysis. | Any | R package | Free | https://github.com/biodataganache/leapR (accessed on 1 April 2022) | [40] | |
| PANEV | Gene/pathway-based network visualization | Any | R package | Free | KEGG | https://github.com/vpalombo/PANEV (accessed on 1 April 2022) | [41] |
| PathfindR | Enrichment analysis. | Any | R package | Free | KEGG, Biogrid, v, IntAct, | https://cran.r-project.org/package=pathfindR (accessed on 1 April 2022) | [42] |
| Ingenuity Pathway Analysis | Metabolic network mapping. | Any | Web-based, software | Paid | GO, KEGG, BIND | IPA, http://www.ingenuity.com (accessed on 1 April 2022) | [43] |
| iPath3.0 | Metabolic network mapping. | Compound IDs | Web-based | Free | KEGG, Uniprot, STRING, protein IDs, COGs, eggNOGs, NCBI gene identifiers, ChEBI and PubChem. | http://pathways.embl.de (accessed on 1 April 2022) | [44] |
| ReactomePA | Enrichment analysis. | Any | R-package | Free | REACTOME | http://www.bioconductor.org/packages/ReactomePA (accessed on 1 April 2022) | [45] |
| MetExploreViz | Metabolic network mapping. | Any | Web-based | Free | KEGG | http://metexplore.toulouse.inra.fr/metexploreViz/doc/ (accessed on 1 April 2022) | [46] |
| Recon3D | Network reconstruction | Any | Web-based | Free | KEGG, PDB, CHEBI, PharmGKB, UniProt | http://vmh.life (accessed on 1 April 2022) | [47] |
| ChemRICH | Web-based and R-package | Free | NCBI BioSystems, PubChem, KEGG, BioCyc, Reactome, GO, and Wikipathways | www.chemrich.fiehnlab.ucdavis.edu) and www.github.Com/barupal/chemrich (accessed on 1 April 2022) | [48] | ||
| KEGGREST | A package providing a client interface to the KEGG REST server. | Compound IDs | R package | Free | KEGG | https://bioconductor.org/packages/release/bioc/html/KEGGREST.html (accessed on 1 April 2022) | [49] |
| MetaX | Flexible and comprehensive Software for processing metabolomics data | Raw peak intensity data | Web-based and R-package | Free | HMDB, KEGG, MassBank, Pub-Chem, LIPID MAPS, MetaCyc, and PlantCyc | http://metax.genomics.cn). (accessed on 1 April 2022) | [50] |
| BioDiscML | Biomarker discovery software that supports classification and regression problems. | Any | Stand-alone program | Free | https://github.com/mickaelleclercq/BioDiscML. (accessed on 1 April 2022) | [51] | |
| 3Omics | Web tool visualization of multi-omics data (transcriptomics, proteomics, and metabolomics) | Any | Web-based | Free | iHOP, KEGG, HumanCyc, DAVID, Entrez Gene, OMIM and UniProt | http://3omics.cmdm.tw (accessed on 1 April 2022) | [52] |
| MeltDB 2.0 | Web-based tool for statistical analysis and sets for enrichment analysis. | Raw GC/LC-MS spectra, processed spectra, compound IDs, and abundances. | Web-based, login required | Free | KEGG, ChEBI, GMD and CAS. | https://meltdb.cebitec.uni-bielefeld.de (accessed on 1 April 2022) | [53] |
| MassTRIX | Compound mapping | MS spectra | Web-based | Free | KEGG, HMDB and LipidMaps. | www.masstrix.org (accessed on 1 April 2022) | [54] |
| MetaP-server | Global statistical analysis | Compound IDs and sample metadata. | Web-based | Free | KEGG, HMDB, LIPID MAPS, PubChem and CAS. | http://metabolomics.helmholtz-muenchen.de/metap2/) (accessed on 1 April 2022) | [55] |
| Pathos | Compound mapping | MS-spectra (raw m/z) and compound IDs (KEGG or MetaCyc IDs) | Web-based | Free | KEGG | http://motif.gla.ac.uk/Pathos/) (accessed on 1 April 2022) | [56] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Banimfreg, B.H.; Shamayleh, A.; Alshraideh, H. Survey for Computer-Aided Tools and Databases in Metabolomics. Metabolites 2022, 12, 1002. https://doi.org/10.3390/metabo12101002
Banimfreg BH, Shamayleh A, Alshraideh H. Survey for Computer-Aided Tools and Databases in Metabolomics. Metabolites. 2022; 12(10):1002. https://doi.org/10.3390/metabo12101002
Chicago/Turabian StyleBanimfreg, Bayan Hassan, Abdulrahim Shamayleh, and Hussam Alshraideh. 2022. "Survey for Computer-Aided Tools and Databases in Metabolomics" Metabolites 12, no. 10: 1002. https://doi.org/10.3390/metabo12101002
APA StyleBanimfreg, B. H., Shamayleh, A., & Alshraideh, H. (2022). Survey for Computer-Aided Tools and Databases in Metabolomics. Metabolites, 12(10), 1002. https://doi.org/10.3390/metabo12101002