
Untargeted Analysis of Lemna minor Metabolites: Workflow and Prioritization Strategy Comparing Highly Confident Features between Different Mass Spectrometers

 , ,
, ,  ,
,  ,
, 
Abstract
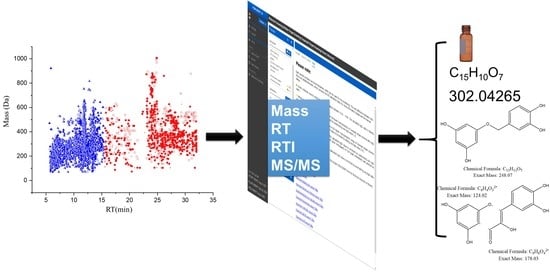
1. Introduction
- (a)
- A comparison study of metabolome samples was performed with an untargeted data handling workflow in two different labs with two mass spectrometers (TOF and QTOF) using the same plant material type;
- (b)
- Further, the metabolomics data from different mass spectrometers were analyzed and compared with predictive methodology orthogonal partial least squares—discriminant analysis (OPLS-DA). The discrimination method has been adapted to validate the features that were extracted with the workflow. Consequently, the standard statistical methods of metabolomics data investigation were used in the identification of relevant variables (i.e., conditional attributes to each solvent), which related to the discrimination analysis. Three different extracts were systematically analyzed with this workflow;
- (c)
- Furthermore, the plant metabolites identification workflow was described from the theoretical predictions to the final analyses in Lemna metabolic profile using reference materials.
2. Results and Discussion
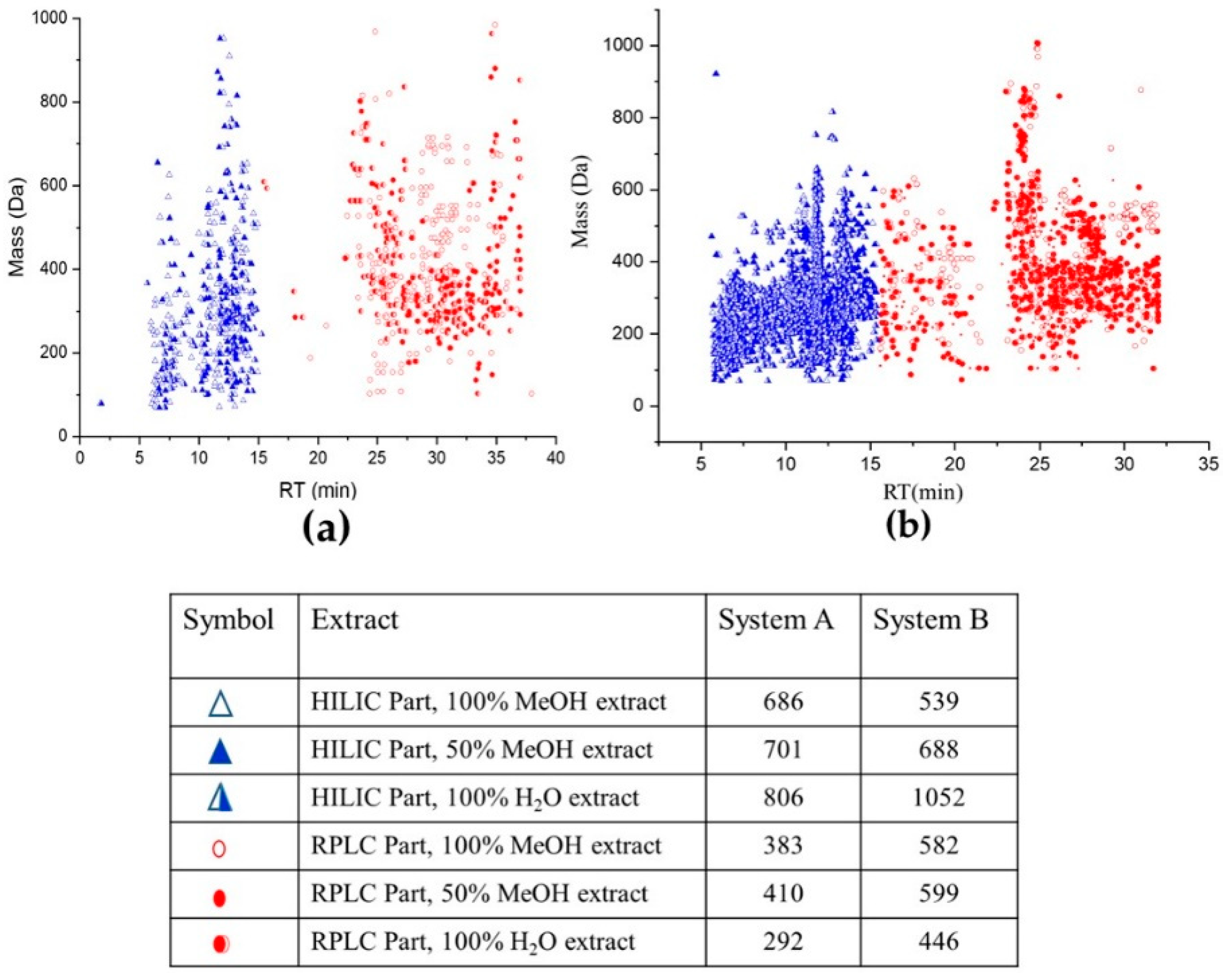
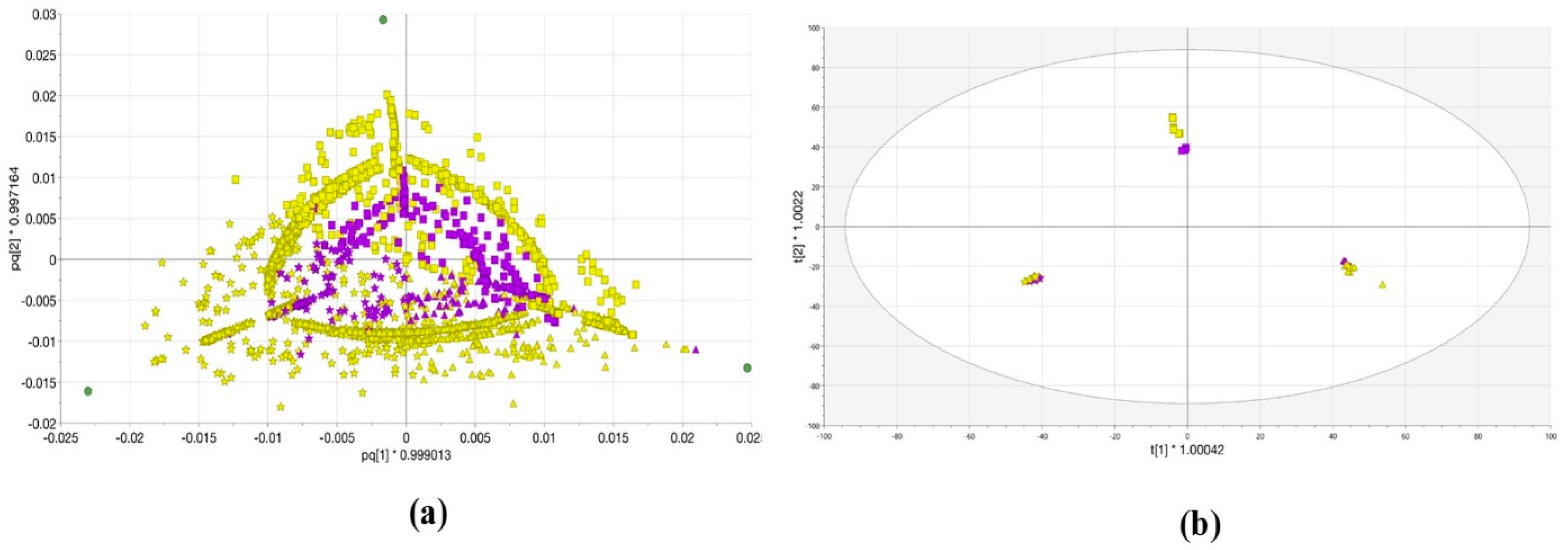
2.1. Lemna minor Extracts Untargeted Analysis Using Systems A and B
2.2. OPLS-DA Analysis of Lemna minor Metabolic Profiles Obtained with Systems A and B
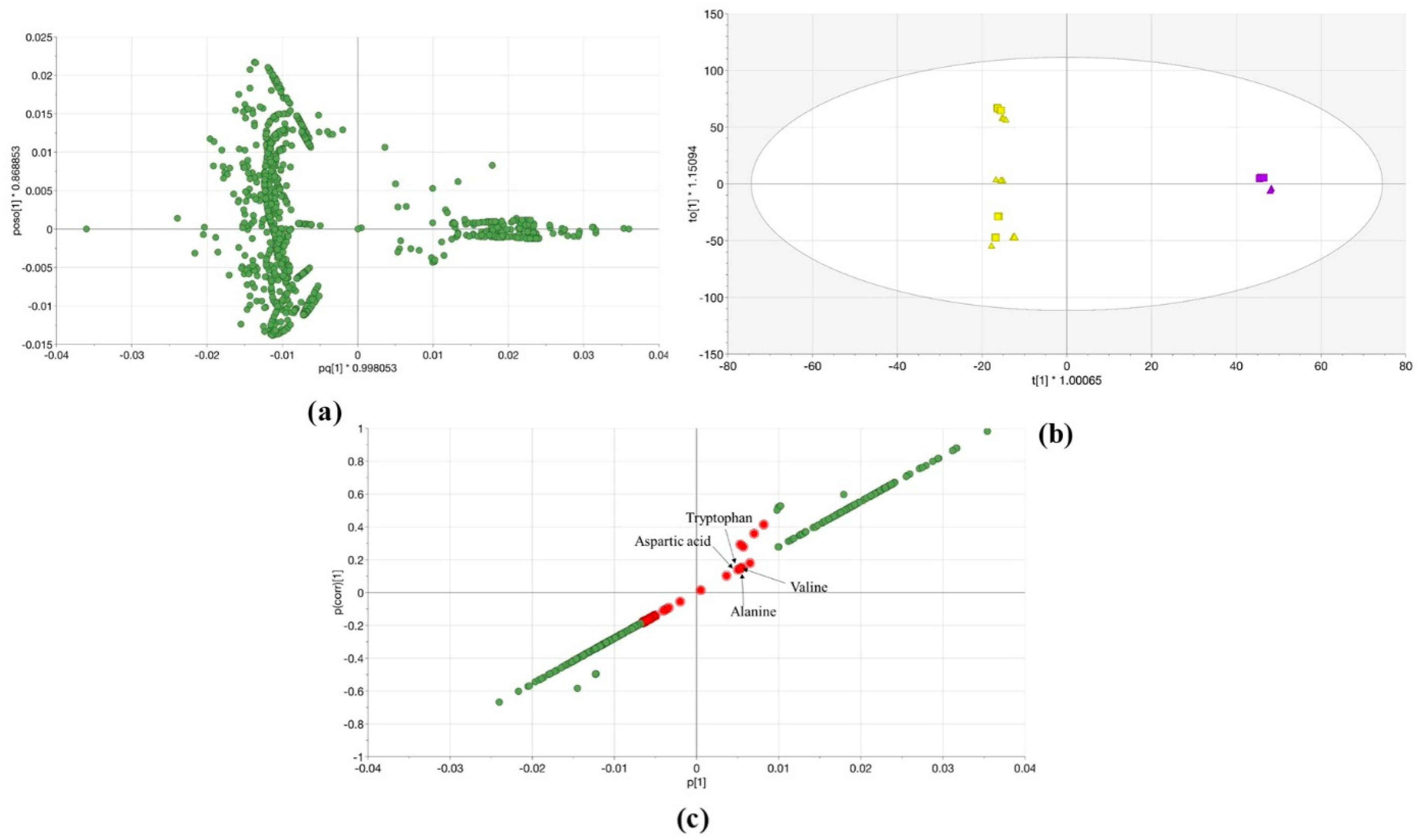
2.3. OPLS-DA Analysis of Lemna minor 100% MeOH and 100% H2O Extracts
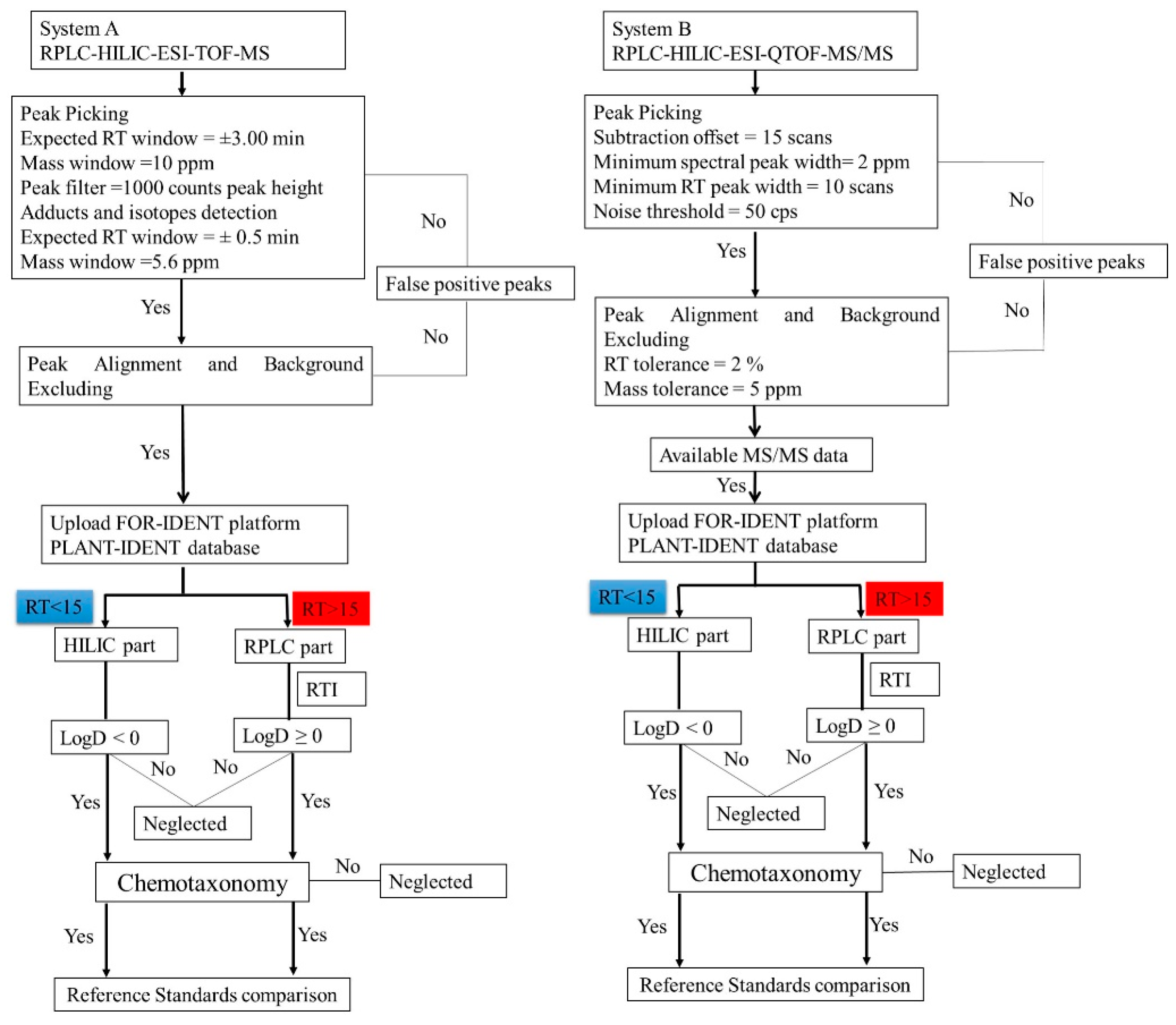
2.4. The Strategy of Lemna minor Metabolites Identification Based on the PLANT-IDENT Database (Using System B)
2.4.1. PLANT-IDENT Batch Searching and Scoring
- (a)
- First, the features eluted from the HILIC column with RT ˂ 15 min were uploaded into the FI platform using the PI database (Figure S1a). The search was scored according to the mass screening, and MS/MS, each with a 50% score. Subsequently, 239 candidates were suggested according to a successive elimination approach. First, the matching features with the highest score and labeled as ‘look at’ in the platform, according to mass matching screening, and MS/MS results were considered. Then, the results were filtered and features with LogD > 0 were eliminated. After that, the chemotaxonomic filter was applied. the results were accepted, which were found in the Lemnaceae. In the end, the results with priority were considered and standards reference organized and injected for confirmation (Figure S1a). The filtred parameters decreased the number of the results from 239 to 41 potential candidates. Those metabolites were annotated and classified in the second classification level [22,23]. They could be classified to level one by confirmation with standards reference injections (see Section 2.4.2);
- (b)
- Secondly, the RP part with RT > 15 min, thus the second part of each dataset, was uploaded. Additionally, the retention times of the reference standard mixture were uploaded to normalize the RT (Table S3 and Figure S1b). Here, the scoring of suspected compounds depends on the same parameters in addition to RTI screening [24] Each is 33% of the total score (mass screening, RTI screening, and MS/MS). One hundred and eighty-eight features were suggested as a matching candidate with the highest score and labeled as ‘look at’ in the platform. After, the adjusted logD > 0 and chemotaxonomic filter exclusively 42 candidates were considered. Those metabolites were annotated and classified in the second classification level. They could be classified to level one (i.e., an identification) by confirmation with standards reference injections (see Section 2.4.2).
2.4.2. Confirmation of Lemna minor Metabolites Using the QTOF-MS/MS
2.5. The Strategy of Lemna minor Metabolites Identification Based on the PLANT-IDENT Database (Using Common Data from Both MS Systems)
3. Materials and Methods
3.1. Reagents and Chemicals
3.2. Plant Samples
3.3. Sample Preparation
3.4. Instruments
3.4.1. Chromatographic System for Polarity Extended Separation
3.4.2. Mass Spectrometric Detection System A in Lab 1 (Single TOF-MS)
3.4.3. Mass Spectrometric Detection System B in Lab 2 (QTOF-MS/MS)
3.5. Internal Standards
3.6. Data Collection and Preprocessing
3.6.1. Single TOF-MS (System A)
3.6.2. QTOF-MS/MS (System B)
3.6.3. PI Batch Searching and Scoring of System A Data
3.6.4. Classification Scheme
- 1.
- The identification by the reference standard;
- 2.
- The identification was performed by various criteria such as (retention time behavior, accurate mass (i.e., empirical formula), fragmentation, and chemotaxonomical criteria);
- 3.
- The identification was performed by comparison of accurate mass and fragments from different laboratories;
- 4.
- The identification is done by molecular formula or fragments comparison;
- 5.
- Mass recognition without further information; this classification scheme enhances the identification of plant metabolites in untargeted metabolomics analysis.
3.6.5. Orthogonal Partial Least Square—Discriminant Analysis
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Piovesana, S.; Cavaliere, C.; Cerrato, A.; Montone, C.M.; Laganà, A.; Capriotti, A.L. Developments and pitfalls in the characterization of phenolic compounds in food: From targeted analysis to metabolom-ics-based approaches. TrAC Trends Anal. Chem. 2020, 133, 116083. [Google Scholar] [CrossRef]
- Ikram, M.M.M.; Ridwani, S.; Putri, S.P.; Fukusaki, E. GC-MS based metabolite profiling to monitor ripen-ing-specific metabolites in pineapple (Ananas comosus). Metabolites 2020, 10, 134. [Google Scholar] [CrossRef] [PubMed]
- Aretz, I.; Meierhofer, D. Advantages, and pitfalls of mass spectrometry-based metabolome profiling in sys-tems biology. Int. J. Mol. Sci. 2016, 17, 632. [Google Scholar] [CrossRef] [PubMed]
- Doppler, M.; Bueschl, C.; Kluger, B.; Koutnik, A.; Lemmens, M.; Buerstmayr, H.; Rechthaler, J.; Krska, R.; Adam, G.; Schuhmacher, R. Stable Isotope-assisted plant metabolomics: Combination of global and trac-er-based labeling for enhanced untargeted profiling and compound annotation. Front. Plant Sci. 2019, 10, 1366. [Google Scholar] [CrossRef]
- Yang, Z.; Nakabayashi, R.; Okazaki, Y.; Mori, T.; Takamatsu, S.; Kitanaka, S.; Kikuchi, J.; Saito, K. Toward better annotation in plant metabolomics: Isolation and structure elucidation of 36 specialized metabolites from Oryza sativa (rice) by using MS/MS and NMR analyses. Metabolomics 2014, 10, 543–555. [Google Scholar] [CrossRef]
- Gika, H.G.; Theodoridis, G.A.; Earll, M.; Snyder, R.W.; Sumner, S.J.; Wilson, I.D. Does the mass spectrom-eter define the marker? A comparison of global metabolite profiling data generated simultaneously via UPLC-MS on two different mass spectrometers. Anal. Chem. 2010, 82, 8226–8234. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Sorokina, M.; Steinbeck, C. Review on natural products databases: Where to find data in 2020. J. Cheminform. 2020, 12, 1–51. [Google Scholar] [CrossRef]
- Wahman, R.; Graßmann, J.; Sauvêtre, A.; Schröder, P.; Letzel, T. Lemna minor studies under various storage periods using extended-polarity extraction and metabolite non-target screening analysis. J. Pharm. Biomed. Anal. 2020, 188, 113362. [Google Scholar] [CrossRef] [PubMed]
- Wahman, R.; Sauvêtre, A.; Schröder, P.; Moser, S.; Letzel, T. Untargeted metabolomics studies on drug-incubated phragmites australis Profiles. Metabolites 2020, 11, 2. [Google Scholar] [CrossRef]
- De Vos, R.C.; Schipper, B.; Hall, R.D. High-performance liquid chromatography-mass spectrometry analy-sis of plant metabolites in Brassicaceae. In Plant Metabolomics; Humana Press: Clifton, NJ, USA, 2012; pp. 111–128. [Google Scholar]
- Chen, L.; Zhong, F.; Zhu, J. Bridging targeted and untargeted mass spectrometry-based metabolomics via hybrid approaches. Metabolites 2020, 10, 348. [Google Scholar] [CrossRef] [PubMed]
- Martins, M.C.M.; Caldana, C.; Wolf, L.D.; de Abreu, L.G.F. The importance of experimental design, quality assurance, and control in plant metabolomics experiments. In Plant Metabolomics; Humana Press: New York, NY, USA, 2018; pp. 3–17. [Google Scholar]
- Want, E.J.; Masson, P.; Michopoulos, F.; Wilson, I.D.; Theodoridis, G.; Plumb, R.S.; Shockcor, J.; Loftus, N.; Holmes, E.; Nicholson, J. Global metabolic profiling of animal and human tissues via UPLC-MS. Nat. Protoc. 2013, 8, 17–32. [Google Scholar] [CrossRef]
- Salem, M.A.; De Souza, L.P.; Serag, A.; Fernie, A.R.; Farag, M.A.; Ezzat, S.M.; Alseekh, S. Metabolomics in the context of plant natural products research: From sample preparation to metabolite analysis. Metabolites 2020, 10, 37. [Google Scholar] [CrossRef]
- Zhang, X.W.; Li, Q.H.; Xu, Z.D.; Dou, J.J. Mass spectrometry-based metabolomics in health and medical science: A systematic review. RSC Adv. 2020, 10, 3092–3104. [Google Scholar] [CrossRef]
- Bedia, C.; Cardoso, P.; Dalmau, N.; Garreta-Lara, E.; Gómez-Canela, C.; Gorrochategui, E.; Navarro-Reig, M.; Ortiz-Villanueva, E.; Puig-Castellví, F.; Tauler, R. Chapter nineteen-applications of metabolomics analysis in environmental research. In Comprehensive Analytical Chemistry; Jaumot, J., Bedia, C., Tauler, R., Eds.; Elsevier B.V.: Amsterdam, The Netherlands; Oxford, UK; Cambridge, MA, USA, 2018; Volume 82, pp. 533–582. [Google Scholar]
- Al-Snafi, A. Lemna minor: Traditional uses, chemical constituents, and pharmacological effects-A review. IOSR J. Pharm. 2019, 9, 6–11. [Google Scholar]
- Jensen, S.R.; Nielsen, B.J. Chemical characters. In The Families of the Monocotyledons: Structure, Evolution, and Taxonomy; Dahlgren, R.M.T., Clifford, H.T., Yeo, P.F., Eds.; Springer: Berlin/Heidelberg, Germany, 1985; pp. 17–22. [Google Scholar]
- Kotowska, U.; Piotrowska, A.; Isidorova, A.G.; Bajguz, A.; Isidorov, V.A. Gas chromatographic-mass spectrometric investigation of the chemical composition of the aquatic plant Wolffia arrhiza (Lemnaceae). Oceanol. Hydrobiol. Stud. 2013, 42, 181–187. [Google Scholar] [CrossRef]
- Wahman, R.; Cruzeiro, C.; Graßmann, J.; Schröder, P.; Letzel, T. The changes in Lemna minor metabolomic profile: A response to diclofenac incubation. Chemosphere 2022, 287, 132078. [Google Scholar] [CrossRef]
- Zhao, X.; Zeng, Z.; Chen, A.; Lu, X.; Zhao, C.; Hu, C.; Zhou, L.; Liu, X.; Wang, X.; Hou, X.; et al. Com-prehensive strategy to construct an in-house database for accurate and batch identification of small molec-ular metabolites. Anal. Chem. 2018, 90, 7635–7643. [Google Scholar] [CrossRef]
- Letzel, T.; Lucke, T.; Schulz, W.; Sengl, M.; Letzel, M. In a class of its own–OMI (Organic Molecule Identi-fication) in water using LC-MS(/MS): Steps from “unknown” to “identified”: A contribution to the discus-sion. Lab More Int. 2014, 4, 24–28. [Google Scholar]
- Schymanski, E.L.; Jeon, J.; Gulde, R.; Fenner, K.; Ruff, M.; Singer, H.P.; Hollender, J. Identifying small mol-ecules via high-resolution mass spectrometry: Communicating confidence. Environ. Sci. Technol. 2014, 48, 2097–2098. [Google Scholar] [CrossRef] [PubMed]
- Grosse, S.; Letzel, T. User Manual for FOR-IDENT Database; TUM: Munich, Germany, 2017; pp. 1–35. [Google Scholar]
- Waridel, P.; Wolfender, J.L.; Ndjoko, K.; Hobby, K.R.; Major, H.J.; Hostettmann, K. Evaluation of quadru-pole time-of-flight tandem mass spectrometry and ion-trap multiple-stage mass spectrometry for the dif-ferentiation of C-glycosidic flavonoid isomers. J. Chromatogr. A 2001, 926, 29–41. [Google Scholar] [CrossRef]
- Ndolo, V.U.; Fulcher, R.G.; Beta, T. Application of LC-MS-MS to identify niacin in aleurone layers of yel-low corn, barley, and wheat kernels. J. Cereal Sci. 2015, 65, 88–95. [Google Scholar] [CrossRef]
- Stadler, R.; Jenny, T.A.; Fay, L.B. Tandem mass spectrometric accurate mass performance of time-of-flight and Fourier transform ion cyclotron resonance mass spectrometry: A case study with pyridine derivatives. Rapid Commun. Mass Spectrom. 2001, 15, 1840–1848. [Google Scholar] [CrossRef]
- Wang, X.; Zhong, X.J.; Zhou, N.; Cai, N.; Xu, J.H.; Wang, Q.B.; Li, J.J.; Liu, Q.; Lin, P.C.; Shang, X.Y. Rapid characterization of chemical constituents of the tubers of Gymnadenia conopsea by UPLC-Orbitrap-MS/MS analysis. Molecules 2020, 25, 898. [Google Scholar] [CrossRef]
- Sakalem, M.E.; Negri, G.; Tabach, R. Chemical composition of hydroethanolic extracts from five species of the Passiflora genus. Rev. Bras. Farm. 2012, 22, 1219–1232. [Google Scholar] [CrossRef]
- Simirgiotis, M.J.; Schmeda-Hirschmann, G.; Bórquez, J.; Kennelly, E.J. The Passiflora tripartita (Banana Passion) Fruit: A source of bioactive flavonoid C-Glycosides isolated by HSCCC and characterized by HPLC–DAD–ESI/MS/MS. Molecules 2013, 18, 1672–1692. [Google Scholar] [CrossRef]
- Akhtar, T.A.; Lees, H.A.; Lampi, M.A.; Enstone, D.; Brain, R.A.; Greenberg, B.M. Photosynthetic redox imbalance influences flavonoid biosynthesis in Lemna gibba. Plant Cell Environ. 2010, 33, 1205–1219. [Google Scholar] [CrossRef] [PubMed]
- Pereira, C.; Yariwake, J.; McCullagh, M. Distinction of the C-glycosylfavone isomer pairs orien-tin/isoorientin and vitexin/isovitexin using HPLC-MS exact mass measurement and in-source CID. Phytochem. Anal. Int. J. Plant Chem. Biochem. Tech. 2005, 16, 295–301. [Google Scholar] [CrossRef] [PubMed]
- Gao, X.; Sun, W.; Fu, Q.; Niu, X. Ultra-performance liquid chromatography coupled with electrospray ioni-zation/quadrupole time-of-flight mass spectrometry for the rapid analysis of constituents in the traditional Chinese medical formula Danggui San. J. Sep. Sci. 2014, 37, 53–60. [Google Scholar] [CrossRef]
- Jang, G.H.; Kim, H.W.; Lee, M.K.; Jeong, S.Y.; Bak, A.R.; Lee, D.J.; Kim, J.B. Characterization and quanti-fication of flavonoid glycosides in the Prunus genus by UPLC-DAD-QTOF/MS. Saudi J. Biol. Sci. 2018, 25, 1622–1631. [Google Scholar] [CrossRef]
- Crow, F.W.; Tomer, K.B.; Looker, J.H.; Gross, M.L. Fast atom bombardment and tandem mass spectrome-try for structure determination of steroid and flavonoid glycosides. Anal. Biochem. 1986, 155, 286–307. [Google Scholar] [CrossRef]
- Tsimogiannis, D.; Samiotaki, M.; Panayotou, G.; Oreopoulou, V. Characterization of flavonoid subgroups and hydroxy substitution by HPLC-MS/MS. Molecules 2007, 12, 593–606. [Google Scholar] [CrossRef] [PubMed]
- Le Gall, G.; DuPont, M.S.; Mellon, F.A.; Davis, A.L.; Collins, G.J.; Verhoeyen, M.E.; Colquhoun, I.J. Char-acterization and content of flavonoid glycosides in genetically modified tomato (Lycopersicon esculentum) fruits. J. Agric. Food Chem. 2003, 51, 2438–2446. [Google Scholar] [CrossRef] [PubMed]
- Ma, Y.L.; Li, Q.M.; Van den Heuvel, H.; Claeys, M. Characterization of flavone and flavonol aglycones by collision-induced dissociation tandem mass spectrometry. Rapid Commun. Mass Spectrom. 1997, 11, 1357–1364. [Google Scholar] [CrossRef]
- Xu, L.L.; Xu, J.J.; Zhong, K.R.; Shang, Z.P.; Wang, F.; Wang, R.F.; Zhang, L.; Zhang, J.Y.; Liu, B. Analysis of non-volatile chemical constituents of Menthae haplocalycis herba by ultra-high performance liquid chroma-tography-high resolution mass spectrometry. Molecules 2017, 22, 1756. [Google Scholar] [CrossRef]
- Hughes, R.J.; Croley, T.R.; Metcalfe, C.D.; March, E.R. A tandem mass spectrometric study of selected characteristic flavonoids. Int. J. Mass Spectrom. 2001, 210, 371–385. [Google Scholar] [CrossRef]
- Wahman, R.; Grassmann, J.; Schröder, P.; Letzel, T. Plant metabolomic workflows using reversed-phase LC and HILIC with ESI-TOF-MS. LCGC N. Am. 2019, 37, 8–15. [Google Scholar]
- Tsolmon, B.; Fang, Y.; Yang, T.; Guo, L.; He, K.; Li, G.-Y.; Zhao, H. Structural identification and UPLC-ESI-QTOF-MS2 analysis of flavonoids in the aquatic plant Landoltia punctata and their in vitro and in vivo antioxidant activities. Food Chem. 2020, 343, 128392. [Google Scholar] [CrossRef]
- Obermeier, M.; Schröder, C.A.; Helmreich, B.; Schröder, P. The enzymatic and antioxidative stress response of Lemna minor to copper and a chloroacetamide herbicide. Environ. Sci. Pollut. Res. 2015, 22, 18495–18507. [Google Scholar] [CrossRef] [PubMed]
- Bieber, S.; Greco, G.; Grosse, S.; Letzel, T. RPLC-HILIC and SFC with mass spectrometry: Polarity-extended organic molecule screening in environmental (water) samples. Anal. Chem. 2017, 89, 7907–7914. [Google Scholar] [CrossRef]
- Greco, G.; Grosse, S.; Letzel, T. Serial coupling of reversed-phase and zwitterionic hydrophilic interaction LC/MS for the analysis of polar and nonpolar phenols in wine. J. Sep. Sci. 2013, 36, 1379–1388. [Google Scholar] [CrossRef] [PubMed]
- Nürenberg, G.; Schulz, M.; Kunkel, U.; Ternes, T.A. Development and validation of a generic nontarget method based on liquid chromatography–high resolution mass spectrometry analysis for the evaluation of different wastewater treatment options. J. Chromatogr. A 2015, 1426, 77–90. [Google Scholar] [CrossRef]
- Ruttkies, C.; Schymanski, E.L.; Wolf, S.; Hollender, J.; Neumann, S. MetFrag relaunched: Incorporating strategies beyond in silico fragmentation. J. Cheminform. 2016, 8, 3. [Google Scholar] [CrossRef]
- Blasco, H.; Błaszczyński, J.; Billaut, J.; Nadal-Desbarats, L.; Pradat, P.; Devos, D.; Moreau, C.; Andres, C.; Emond, P.; Corcia, P.; et al. Comparative analysis of targeted metabolomics: Dominance-based rough set approach versus orthogonal partial least square-discriminant analysis. J. Biomed. Inform. 2015, 53, 291–299. [Google Scholar] [CrossRef]
- Löfstedt, T.; Trygg, J. OnPLS-a novel multiblock method for the modelling of predictive and orthogonal variation. J. Chemom. 2011, 25, 441–455. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Compound Name | RT (S) [Min] | RT (M) [Min] | ΔRT [Min] | Mass (S) [Da] | Mass (M) [Da] | Δppm | MSMS Fragments | References |
|---|---|---|---|---|---|---|---|---|
| Vitexin | 7.5 | 7.3 | 0.2 | 433.1133 | 433.1129 | 0.8 | 433;415;397;379;337;313; 283 | [25] |
| Niacin * | 7.6 | 7.8 | −0.2 | 124.0394 | 124.0393 | 0.7 | 124;96;80;78 | [26] |
| Nicotinamide | 7.8 | 7.6 | 0.1 | 123.0554 | 123.0553 | 0.8 | 123;106;80;78 | [27] |
| Phenylalanine * | 11.0 | 11.1 | −0.1 | 166.0866 | 166.08627 | 2.0 | 120;103;77 | MassBank of North America (MoNA) |
| Leucine/Isoleucine * | 11.2 | 11.2 | −0.1 | 132.1018 | 132.1020 | −2.0 | 86;69;44;30 | (MoNA) |
| Tryptophan * | 11.7 | 11.7 | 0.0 | 205.0973 | 205.0970 | 1.8 | 188;146;144 | (MoNA) |
| Valine * | 12.1 | 11.9 | 0.1 | 118.0863 | 118.0862 | 0.8 | 72;71;55 | (MoNA) |
| Tyrosine * | 12.3 | 12.2 | 0.1 | 182.0811 | 182.0810 | 1.9 | 136;123;119 | (MoNA) |
| Proline * | 12.4 | 12.4 | 0.0 | 116.0705 | 116.0707 | 0.3 | 70;68;43 | (MoNA) |
| Glutamic acid * | 12.5 | 12.6 | −0.1 | 147.0434 | 147.0430 | 3.0 | 130;102;84 | (MoNA) |
| Aspartic acid * | 12.7 | 12.7 | 0.0 | 134.0447 | 134.0447 | −0.0 | 134;115 | (MoNA) |
| Di-L-Alanine | 12.7 | 12.8 | −0.1 | 161.0928 | 161.0920 | 4.9 | 161;115;90 | (MoNA) |
| 4-Methoxy cinnamic acid | 13.4 | 13.1 | 0.3 | 179.0706 | 179.0708 | −0.9 | 147;137 | [28] |
| Alanine* | 13.4 | 13.2 | 0.2 | 90.0550 | 90.0548 | 2.1 | 44;28 | (MoNA) |
| Threonine* | 13.6 | 13.4 | 0.2 | 120.0656 | 120.0653 | 2.8 | 73;56 | (MoNA) |
| Serine * | 14.0 | 13.8 | 0.2 | 106.0500 | 116.0499 | 0.9 | 60;42;43 | (MoNA) |
| Apigenin-6,8-di-C-glucopyranoside * | 15.8 | 15.7 | 0.1 | 595.1659 | 595.1658 | 0.2 | 595; 383 | [29] |
| Robinetin | 15.8 | 15.9 | −0.1 | 303.0494 | 303.0493 | 0.3 | 285;267;147 | (MoNA) |
| Apigenin-6-C-arabopyranoside-8- C-glucopyranose | 23.4 | 23.3 | 0.2 | 565.1550 | 565.1557 | −1.2 | 565;547;379;337;325;295;121 | [30] |
| Luteolin-3′,7-di-O-glucoside | 23.8 | 23.6 | 0.3 | 611.1640 | 611.1622 | 2.8 | 611;449;287 | (MoNA) |
| Saponarin | 23.8 | 24.0 | −0.2 | 595.1638 | 595.1663 | −4.2 | 433;415;397;367;337;283;271 | [31] |
| Isoorientin | 23.8 | 23.6 | 0.2 | 449.1085 | 449.1095 | −2.1 | 449;329;299;165 | [32] |
| Isovitexin | 24.1 | 23.9 | 0.2 | 433.1125 | 433.1134 | −2.0 | 313;295;284;283;267 | [25] |
| Norwogonin | 24.2 | 24.0 | 0.2 | 271.0604 | 271.0599 | 1.8 | 271;253;241;225 | [33] |
| Quercetin-3-O-glucoside | 24.2 | 24.3 | −0.1 | 465.1018 | 465.1022 | −0.7 | 465; 303 | [34] |
| Apiin | 24.6 | 23.8 | 0.9 | 565.1566 | 565.1559 | 1.3 | 433;313 | [35] |
| Umbelliferone | 24.7 | 24.4 | 0.2 | 163.0396 | 163.0391 | 2.9 | 135;107 | [28] |
| Quercetin | 24.8 | 24.9 | −0.1 | 303.0549 | 303.0544 | 1.7 | 303;285;257;229;165 | [36] |
| Luteolin | 24.8 | 24.6 | 0.2 | 287.0562 | 287.0557 | 1.6 | 287;269;241;153 | [36] |
| Naringenin-7-O-glucoside | 25.0 | 24.1 | 0.9 | 435.1298 | 435.1285 | 2.9 | 435;273 | [37] |
| Myricetin | 25.1 | 25.1 | 0.0 | 319.0440 | 319.0453 | 4.0 | 301;283;265;111 | [38] |
| Orientin | 25.1 | 25.2 | −0.1 | 449.1123 | 449.1134 | −2.6 | 449; 329 | [29] |
| Peonidin | 25.6 | 25.2 | 0.4 | 302.0785 | 302.0792 | −2.4 | 302;283;197 | (MoNA) |
| Chrysoeriol | 26.9 | 26.8 | 0.1 | 301.0731 | 301.0722 | 2.9 | 286;121 | [39] |
| Tricin | 26.8 | 26.3 | 0.6 | 331.0811 | 331.0796 | 4.7 | 331;315 | [5] |
| Apigenin | 26.8 | 26.7 | 0.1 | 271.0603 | 271.0604 | −0.6 | 271;253;153 | [36] |
| Acacetin | 28.8 | 29.1 | −0.3 | 285.0759 | 285.0760 | −0.4 | 285;242;153 | [39] |
| Kaempferol | 29.0 | 29.1 | −0.1 | 287.0531 | 287.0540 | −3.1 | 287;269;231;165;153;133 | [36] |
| Galangin | 29.4 | 29.4 | −0.1 | 271.0602 | 271.0608 | 2.3 | 271;253 | [40] |
| Flavone (2-Phenylchromone) | 29.9 | 29.6 | 0.2 | 223.0756 | 223.0748 | 3.6 | 223;178;152;121 | (MoNA) |
| 6-Methoxyflavone | 30.4 | 30.6 | −0.2 | 253.0879 | 253.0881 | −0.7 | 253; 238; 210 | NIST |
| 5-Hydroxy-6-Methoxyflavone | 31.3 | 31.1 | 0.1 | 269.0823 | 269.0819 | 1.3 | 269;254;104 | (MoNA) |
| Binary Pump 1 | Binary Pump 2 | ||||||
|---|---|---|---|---|---|---|---|
| Time (min) | Flow Rate (mL/min) | A% | B% | Time (min) | Flow Rate (mL/min) | C% | D% |
| 1 | 0.05 | 100 | 0 | 0 | 0.4 | 100 | 0 |
| 7 | 0.05 | 100 | 0 | 6 | 0.4 | 100 | 0 |
| 12 | 0.05 | 50 | 50 | 13 | 0.4 | 60 | 40 |
| 13 | 0.1 | 50 | 50 | 32 | 0.4 | 60 | 40 |
| 22 | 0.1 | 0 | 100 | 33 | 0.8 | 100 | 0 |
| 32 | 0.1 | 0 | 100 | 53 | 0.8 | 100 | 0 |
| 33 | 0.1 | 100 | 0 | 54 | 0.4 | 100 | 0 |
| 53 | 0.1 | 100 | 0 | 58 | 0.4 | 100 | 0 |
| 54 | 0.05 | 100 | 0 | ||||
| 58 | 0.05 | 100 | 0 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wahman, R.; Moser, S.; Bieber, S.; Cruzeiro, C.; Schröder, P.; Gilg, A.; Lesske, F.; Letzel, T. Untargeted Analysis of Lemna minor Metabolites: Workflow and Prioritization Strategy Comparing Highly Confident Features between Different Mass Spectrometers. Metabolites 2021, 11, 832. https://doi.org/10.3390/metabo11120832
Wahman R, Moser S, Bieber S, Cruzeiro C, Schröder P, Gilg A, Lesske F, Letzel T. Untargeted Analysis of Lemna minor Metabolites: Workflow and Prioritization Strategy Comparing Highly Confident Features between Different Mass Spectrometers. Metabolites. 2021; 11(12):832. https://doi.org/10.3390/metabo11120832
Chicago/Turabian StyleWahman, Rofida, Stefan Moser, Stefan Bieber, Catarina Cruzeiro, Peter Schröder, August Gilg, Frank Lesske, and Thomas Letzel. 2021. "Untargeted Analysis of Lemna minor Metabolites: Workflow and Prioritization Strategy Comparing Highly Confident Features between Different Mass Spectrometers" Metabolites 11, no. 12: 832. https://doi.org/10.3390/metabo11120832
APA StyleWahman, R., Moser, S., Bieber, S., Cruzeiro, C., Schröder, P., Gilg, A., Lesske, F., & Letzel, T. (2021). Untargeted Analysis of Lemna minor Metabolites: Workflow and Prioritization Strategy Comparing Highly Confident Features between Different Mass Spectrometers. Metabolites, 11(12), 832. https://doi.org/10.3390/metabo11120832