Big-But-Biased Data Analytics for Air Quality



Abstract
1. Introduction
1.1. Motivation
1.2. Similar Works
1.3. Content of The Paper
2. Materials and Methods
2.1. Urban Air Quality
2.2. Bias Correction Method
2.3. Bootstrap Algorithm
- The estimated densities and , where and denote the pilot bandwidhts obtained from the rule-of-thumb method, are considered as the true population densities in the bootstrap world.
- Bootstrap resamples, and , of sizes n and N respectively, are obtained from the estimated densities and as follows:
- (a)
- , where is a simple random sample obtained from the empirical distribution computed with the values and , with simulated from the density K (a when considering a Gaussian kernel), for .
- (b)
- , where is a simple random sample obtained from the empirical distribution computed with the values and , with simulated from the density K (a when considering a Gaussian kernel), for .
- The estimator is implemented using the resamples and and considering a very wide range of values for the smoothing parameters h and b.
- Steps 2 and 3 are repeated a large number of times, B, in order to obtain an approximation of the bootstrap mean squared error (MSE) of the estimator,
- The bandwidths and that minimize the function are considered as bootstrap bandwidth selectors.
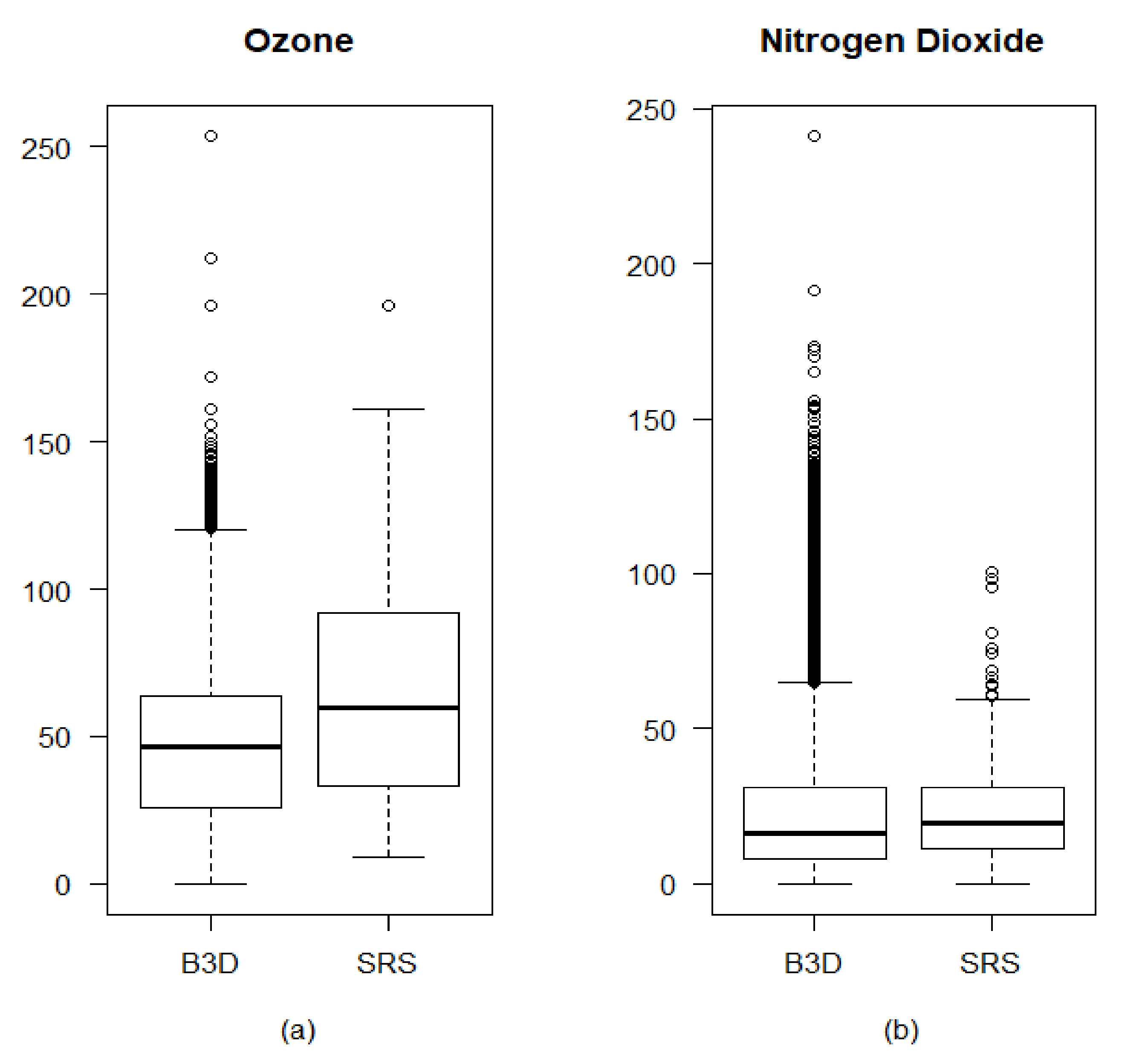
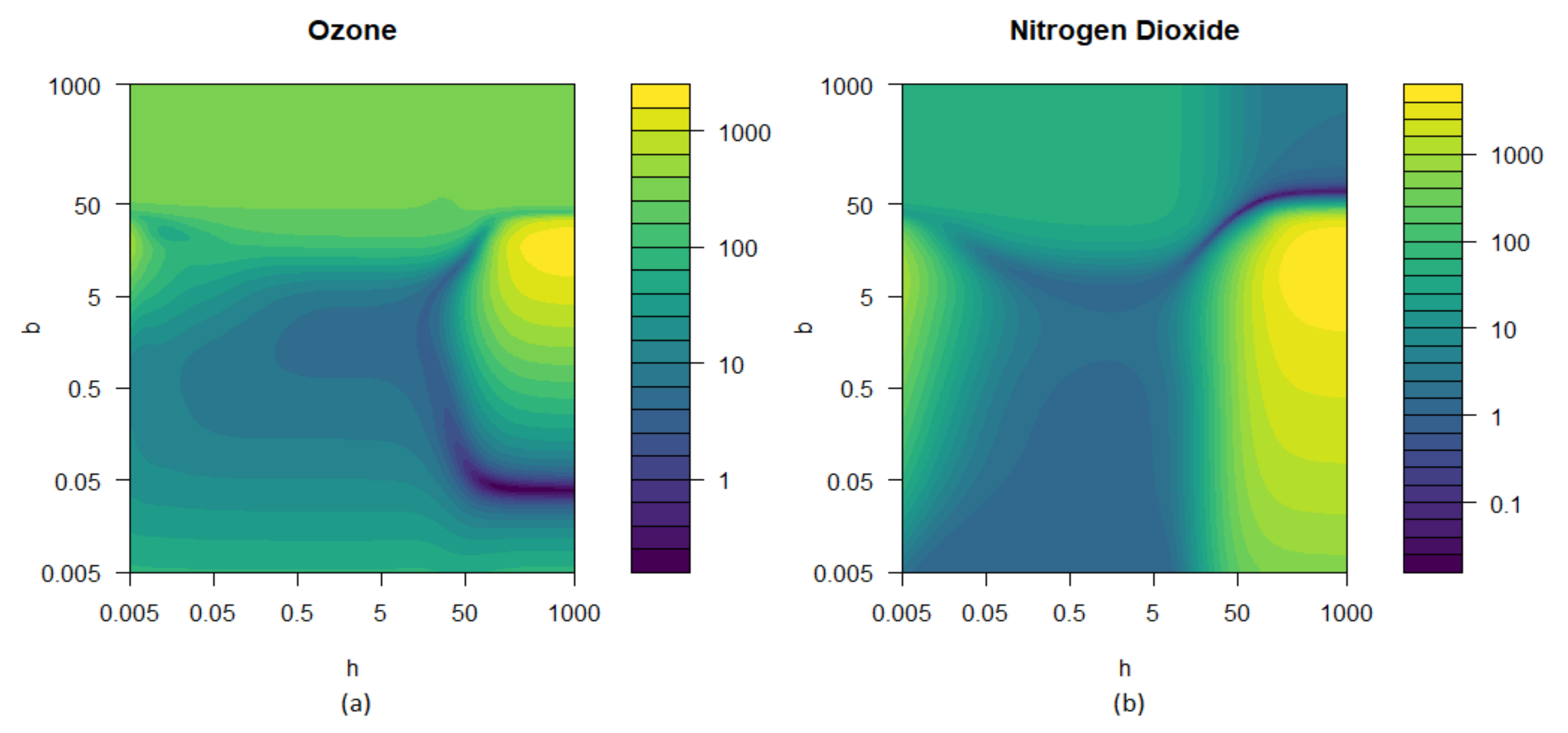
3. Results
4. Discussion and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AQI | Air Quality Index |
| B3D | Big-But-Biased Data |
| CO | Carbon monoxide |
| CH | Benzene |
| MeSE | Bootstrap median squared error |
| MSE | Mean squared error |
| MSE | Bootstrap mean squared error |
| NO | Nitrogen dioxide |
| NOx | Total nitrogen oxides |
| O | Ozone |
| PM10 | Particulate matter smaller than 10 micrometers in diameter |
| PM | Particulate matter smaller than 2.5 micrometers in diameter |
| SO | Sulfure dioxide |
| SRS | Simple random sample |
| TMSE | Bootstrap trimmed mean squared error |
| WHO | World Health Organization |
References
- Chourabi, H.; Nam, T.; Walker, S.; Gil-Garcia, J.R.; Mellouli, S.; Nahon, K.; Pardo, T.A.; Scholl, H.J. Understanding smart cities: An integrative framework. In Proceedings of the 2012 45th Hawaii International Conference on System Sciences, Maui, HI, USA, 4–7 January 2012; pp. 2289–2297. [Google Scholar]
- Hashem, I.A.T.; Chang, V.; Anuar, N.B.; Adewole, K.; Yaqoob, I.; Gani, A.; Ahmed, E.; Chiroma, H. The role of big data in smart city. Int. J. Inf. Manag. 2016, 36, 748–758. [Google Scholar] [CrossRef]
- Osman, A.M.S. A novel big data analytics framework for smart cities. Future Gener. Comput. Syst. 2019, 91, 620–633. [Google Scholar] [CrossRef]
- Al Nuaimi, E.; Al Neyadi, H.; Mohamed, N.; Al-Jaroodi, J. Applications of big data to smart cities. J. Internet Serv. Appl. 2015, 6, 25. [Google Scholar] [CrossRef]
- Lim, C.; Kim, K.J.; Maglio, P.P. Smart cities with big data: Reference models, challenges, and considerations. Cities 2018, 82, 86–99. [Google Scholar] [CrossRef]
- Cao, R. Inferencia estadística con datos de gran volumen. Gac. Real Soc. Mat. Espa Nola 2015, 18, 393–417. [Google Scholar]
- Cao, R.; Borrajo, L. Nonparametric mean estimation for big-but-biased data. In The Mathematics of the Uncertain; Springer: Berlin/Heidelberg, Germany, 2018; pp. 55–65. [Google Scholar]
- Borrajo, L.; Cao, R. Nonparametric Estimation for Big-But-Biased Data. 2020, Unpublished Manuscript. Available online: http://dm.udc.es/modes/es/node/52 (accessed on 15 August 2020).
- Crawford, K. The hidden biases in big data. Harv. Bus. Rev. 2013, 1, 814. [Google Scholar]
- Zheng, Y.; Liu, F.; Hsieh, H.P. U-air: When urban air quality inference meets big data. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 1436–1444. [Google Scholar]
- Martínez-España, R.; Bueno-Crespo, A.; Timon-Perez, I.M.; Soto, J.A.; Ortega, A.M.; Cecilia, J.M. Air-Pollution Prediction in Smart Cities through Machine Learning Methods: A Case of Study in Murcia, Spain. J. UCS 2018, 24, 261–276. [Google Scholar]
- Ameer, S.; Shah, M.A.; Khan, A.; Song, H.; Maple, C.; Islam, S.U.; Asghar, M.N. Comparative analysis of machine learning techniques for predicting air quality in smart cities. IEEE Access 2019, 7, 128325–128338. [Google Scholar] [CrossRef]
- Kök, İ.; Şimşek, M.U.; Özdemir, S. A deep learning model for air quality prediction in smart cities. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 1983–1990. [Google Scholar]
- Ramos, F.; Trilles, S.; Muñoz, A.; Huerta, J. Promoting pollution-free routes in smart cities using air quality sensor networks. Sensors 2018, 18, 2507. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization (WHO). Air Pollution. Available online: http://www.who.int/airpollution/en/ (accessed on 12 August 2020).
- Ayuntamiento de A Coruña, Spain. Coruña Sostenible. Available online: http://coruna.es/infoambiental/ (accessed on 10 August 2020).
- Parzen, E. On estimation of a probability density function and mode. Ann. Math. Stat. 1962, 33, 1065–1076. [Google Scholar] [CrossRef]
- Rosenblatt, M. Remarks on some nonparametric estimates of a density function. Ann. Math. Stat. 1956, 27, 832–837. [Google Scholar] [CrossRef]
- Cardelino, C.; Chameides, W. Natural hydrocarbons, urbanization, and urban ozone. J. Geophys. Res. Atmos. 1990, 95, 13971–13979. [Google Scholar] [CrossRef]
- Jhun, I.; Fann, N.; Zanobetti, A.; Hubbell, B. Effect modification of ozone-related mortality risks by temperature in 97 US cities. Environ. Int. 2014, 73, 128–134. [Google Scholar] [CrossRef]
- Meleux, F.; Solmon, F.; Giorgi, F. Increase in summer European ozone amounts due to climate change. Atmos. Environ. 2007, 41, 7577–7587. [Google Scholar] [CrossRef]
- Kolmogorov, A. Sulla determinazione empirica di una legge di distribuzione. Inst. Ital. Attuari Giorn. 1933, 4, 83–91. [Google Scholar]
- Smirnov, N.V. Estimate of deviation between empirical distribution functions in two independent samples. Bull. Mosc. Univ. 1939, 2, 3–16. [Google Scholar]
- Bickel, P.J.; Rosenblatt, M. On some global measures of the deviations of density function estimates. Ann. Stat. 1973, 1, 1071–1095. [Google Scholar] [CrossRef]
- Li, Q.; Racine, J. Nonparametric estimation of distributions with categorical and continuous data. J. Multivar. Anal. 2003, 86, 266–292. [Google Scholar] [CrossRef]
Sample Availability: Data used in this paper and the script in R are available at http://dm.udc.es/modes/es/node/52. |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | K–S test | t-test | ||
|---|---|---|---|---|
| Ozone | <2.2 | 64.44 | 45.35 | <2.2 |
| Nitrogen dioxide | 0.001064 | 23.88 | 22.28 | 0.1411 |
| Variable | |||||
|---|---|---|---|---|---|
| Ozone | 64.44 | 45.35 | 199.05 | 0.0397 | 67.94 |
| Nitrogen dioxide | 23.88 | 22.28 | 79.24 | 50 | 23.90 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Borrajo, L.; Cao, R. Big-But-Biased Data Analytics for Air Quality. Electronics 2020, 9, 1551. https://doi.org/10.3390/electronics9091551
Borrajo L, Cao R. Big-But-Biased Data Analytics for Air Quality. Electronics. 2020; 9(9):1551. https://doi.org/10.3390/electronics9091551
Chicago/Turabian StyleBorrajo, Laura, and Ricardo Cao. 2020. "Big-But-Biased Data Analytics for Air Quality" Electronics 9, no. 9: 1551. https://doi.org/10.3390/electronics9091551
APA StyleBorrajo, L., & Cao, R. (2020). Big-But-Biased Data Analytics for Air Quality. Electronics, 9(9), 1551. https://doi.org/10.3390/electronics9091551