Incorporating External Knowledge into Unsupervised Graph Model for Document Summarization


Abstract
:1. Introduction
- (1)
- We improve the performance of traditional unsupervised learning models by modifying the Textrank algorithm and combining the output of Textrank and K-means. Our model takes the relative position of sentences into account and improves the diversity of the generated abstracts.
- (2)
- We innovatively incorporate external knowledge from knowledge graphs to our unsupervised model to improve the performance on summarization. A different embedding method based on entity linking is proposed in this paper. Our model runs the improved Textrank algorithm twice to incorporate the external knowledge from Wikipedia into our model.
- (3)
- Experiments are conducted on the New York Times data set. The experimental results show that our knowledge-enhanced model outperforms other mainstream unsupervised models.
2. Related Work
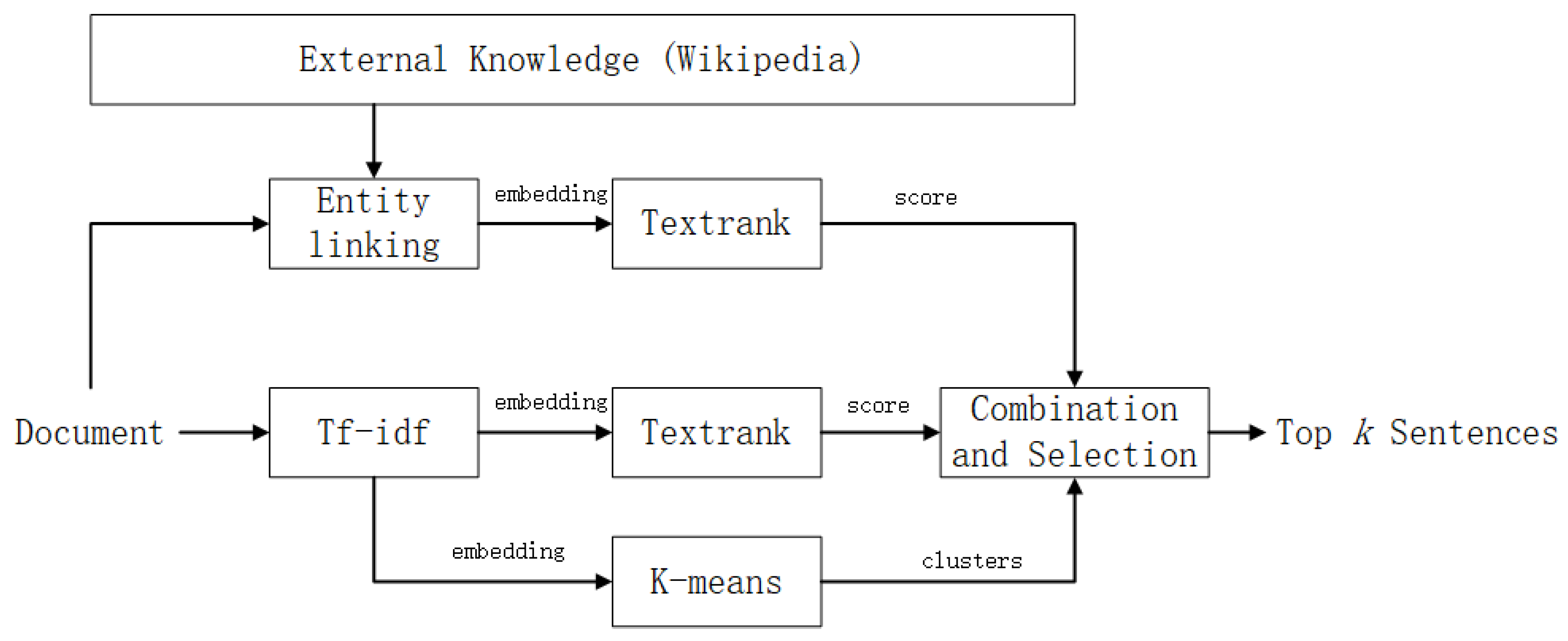
3. Method
3.1. Graph-Sorting Algorithm Based on Textrank
3.1.1. Sentence Embedding
3.1.2. Improved Graph-Sorting Algorithm
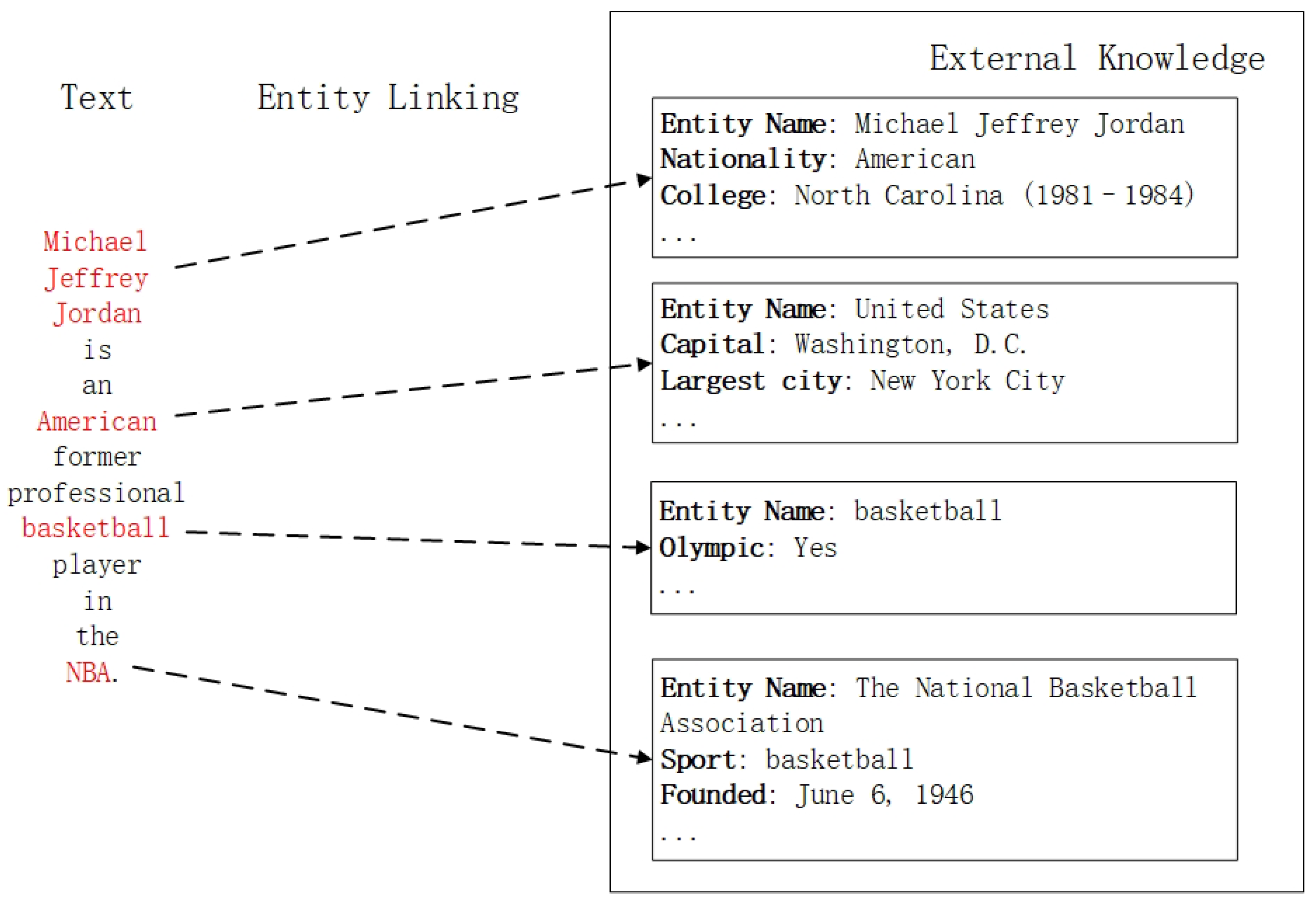
3.2. Incorporation of External Knowledge
3.3. Combining the Scores and Selecting the Top Sentences
4. Experiments
4.1. Data Set
4.2. Experiments Settings
4.3. Baselines and Evaluation Metrics
5. Results and Analysis
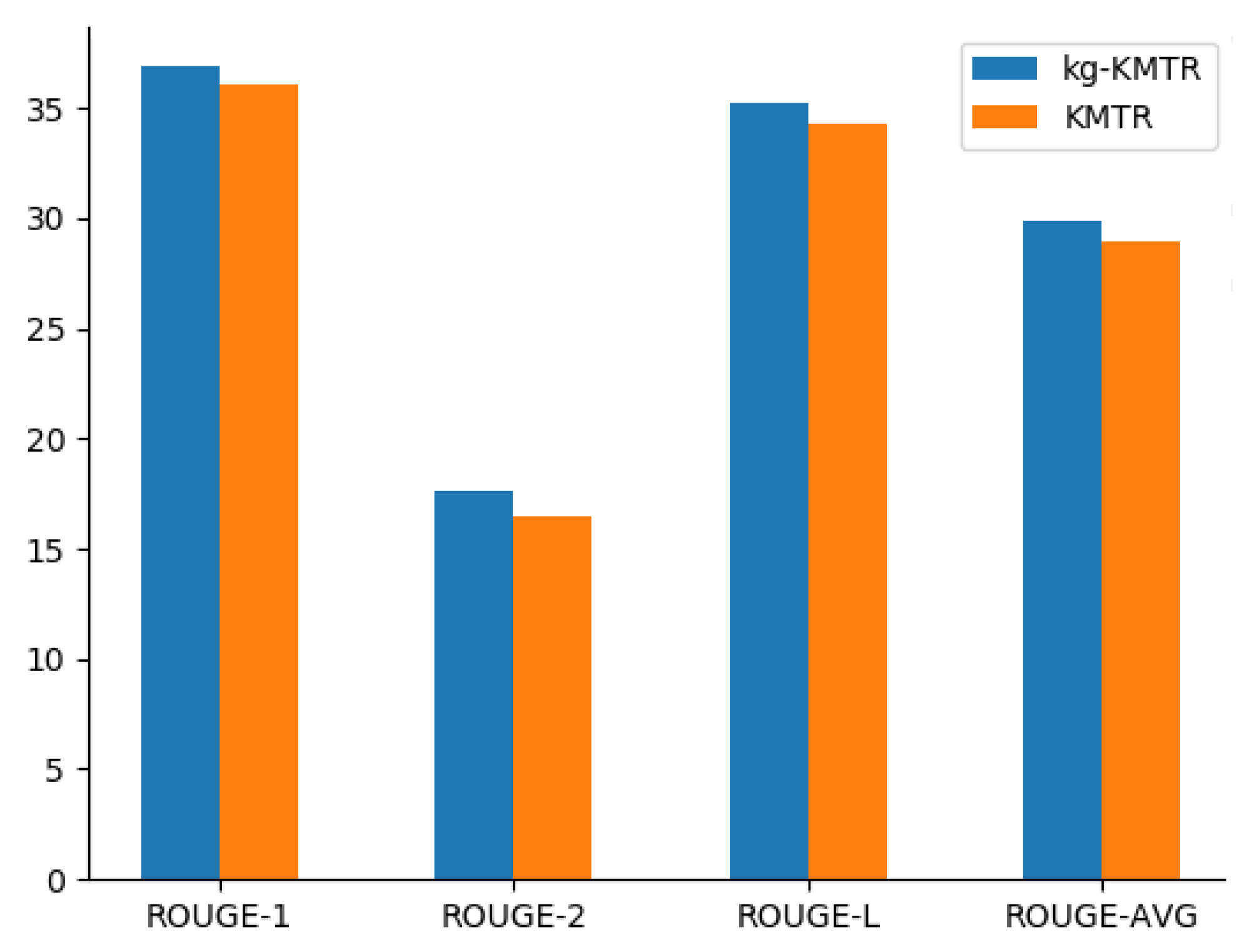
5.1. Experimental Results and Analysis
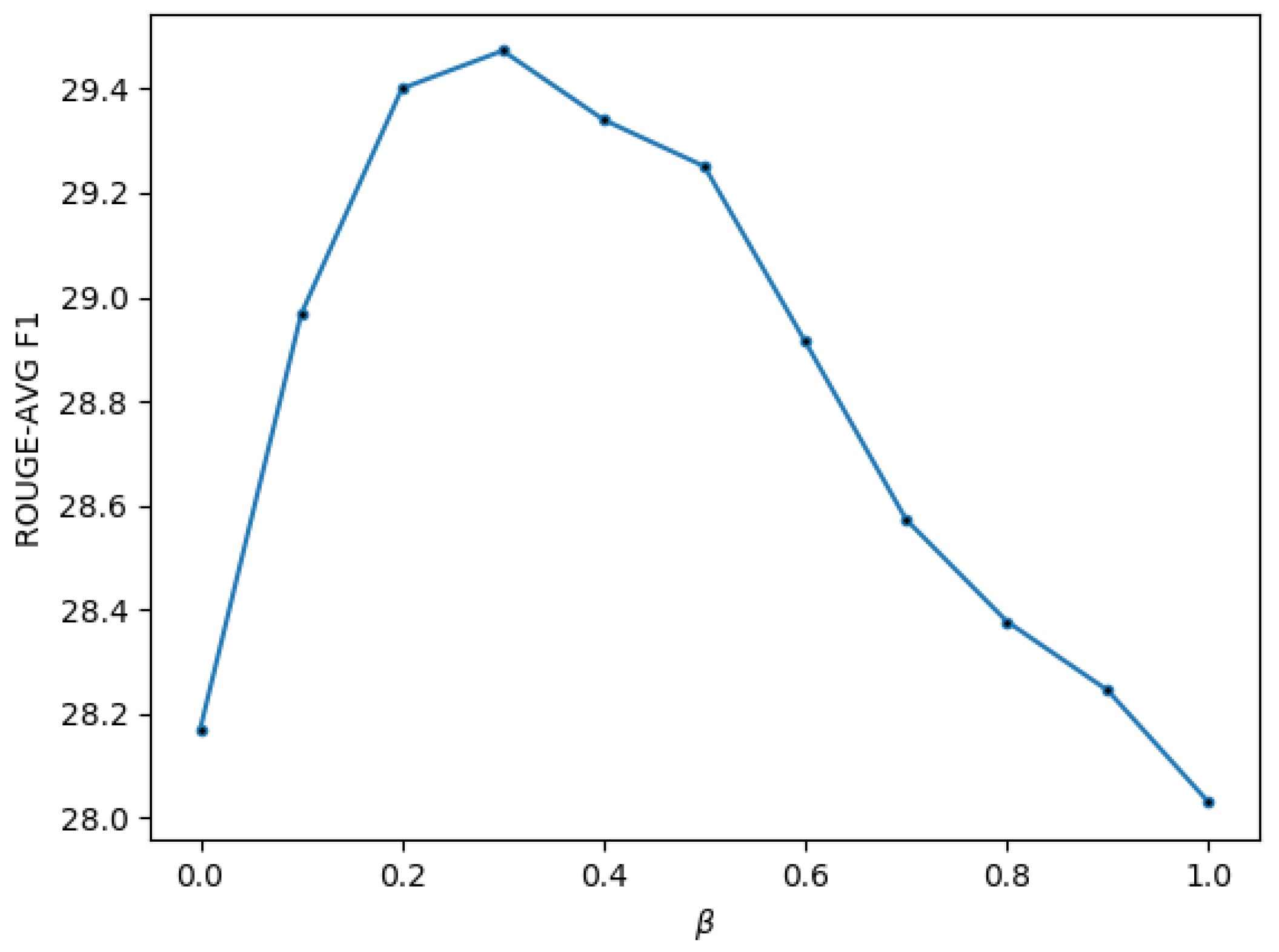
5.2. Ablation Study and Case Study
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Cheng, J.; Lapata, M. Neural summarization by extracting sentences and words. arXiv 2016, arXiv:1603.07252. [Google Scholar]
- Narayan, S.; Papasarantopoulos, N.; Cohen, S.B.; Lapata, M. Neural extractive summarization with side information. arXiv 2017, arXiv:1704.04530. [Google Scholar]
- See, A.; Liu, P.J.; Manning, C.D. Get to the point: Summarization with pointer-generator networks. arXiv 2017, arXiv:1704.04368. [Google Scholar]
- Paulus, R.; Xiong, C.; Socher, R. A deep reinforced model for abstractive summarization. arXiv 2017, arXiv:1705.04304. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Bouscarrat, L.; Bonnefoy, A.; Peel, T.; Pereira, C. STRASS: A Light and Effective Method for Extractive Summarization Based on Sentence Embeddings. arXiv 2019, arXiv:1907.07323. [Google Scholar]
- Liu, Y. Fine-tune BERT for extractive summarization. arXiv 2019, arXiv:1903.10318. [Google Scholar]
- Mihalcea, R.; Tarau, P. Textrank: Bringing order into text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004; pp. 404–411. [Google Scholar]
- Radev, D.R.; Jing, H.; Styś, M.; Tam, D. Centroid-based summarization of multiple documents. Inf. Process. Manag. 2004, 40, 919–938. [Google Scholar] [CrossRef]
- Ramos, J. Using tf-idf to determine word relevance in document queries. In Proceedings of the First Instructional Conference on Machine Learning, New Jersey, NJ, USA, 21–24 August 2003; Volume 242, pp. 133–142. [Google Scholar]
- Kiros, R.; Zhu, Y.; Salakhutdinov, R.R.; Zemel, R.; Urtasun, R.; Torralba, A.; Fidler, S. Skip-thought vectors. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 3294–3302. [Google Scholar]
- Page, L.; Brin, S.; Motwani, R.; Winograd, T. The PageRank Citation Ranking: Bringing Order to the Web; Technical Report; Stanford InfoLab: Stanford, CA, USA, 1999. [Google Scholar]
- Sun, F.; Jiang, P.; Sun, H.; Pei, C.; Ou, W.; Wang, X. Multi-source pointer network for product title summarization. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Turin, Italy, 22–26 October 2018; pp. 7–16. [Google Scholar]
- Huang, L.; Wu, L.; Wang, L. Knowledge Graph-Augmented Abstractive Summarization with Semantic-Driven Cloze Reward. arXiv 2020, arXiv:2005.01159. [Google Scholar]
- Erkan, G.; Radev, D.R. Lexrank: Graph-based lexical centrality as salience in text summarization. J. Artif. Intell. Res. 2004, 22, 457–479. [Google Scholar] [CrossRef]
- Mallick, C.; Das, A.K.; Dutta, M.; Das, A.K.; Sarkar, A. Graph-based text summarization using modified TextRank. In Soft Computing in Data Analytics; Springer: Heidelberg, Germany, 2019; pp. 137–146. [Google Scholar]
- Akter, S.; Asa, A.S.; Uddin, M.P.; Hossain, M.D.; Roy, S.K.; Afjal, M.I. An extractive text summarization technique for Bengali document (s) using K-means clustering algorithm. In Proceedings of the 2017 IEEE International Conference on Imaging, Vision & Pattern Recognition (icIVPR), Dhaka, Bangladesh, 13–14 February 2017; pp. 1–6. [Google Scholar]
- Balabantaray, R.C.; Sarma, C.; Jha, M. Document clustering using k-means and k-medoids. arXiv 2015, arXiv:1502.07938. [Google Scholar]
- Chen, Y.C.; Bansal, M. Fast abstractive summarization with reinforce-selected sentence rewriting. arXiv 2018, arXiv:1805.11080. [Google Scholar]
- Narayan, S.; Cohen, S.B.; Lapata, M. Ranking sentences for extractive summarization with reinforcement learning. arXiv 2018, arXiv:1802.08636. [Google Scholar]
- Wang, Q.; Liu, P.; Zhu, Z.; Yin, H.; Zhang, Q.; Zhang, L. A Text Abstraction Summary Model Based on BERT Word Embedding and Reinforcement Learning. Appl. Sci. 2019, 9, 4701. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Zheng, H.; Lapata, M. Sentence centrality revisited for unsupervised summarization. arXiv 2019, arXiv:1906.03508. [Google Scholar]
- Wang, K.; Quan, X.; Wang, R. Biset: Bi-directional selective encoding with template for abstractive summarization. arXiv 2019, arXiv:1906.05012. [Google Scholar]
- Zhou, Q.; Yang, N.; Wei, F.; Tan, C.; Bao, H.; Zhou, M. Neural question generation from text: A preliminary study. In National CCF Conference on Natural Language Processing and Chinese Computing; Springer: Heidelberg, Germany, 2017; pp. 662–671. [Google Scholar]
- Li, X.; Shen, Y.D.; Du, L.; Xiong, C.Y. Exploiting novelty, coverage and balance for topic-focused multi-document summarization. In Proceedings of the 19th ACM International Conference on Information and Knowledge Management, Toronto, ON, Canada, 26 October 2010; pp. 1765–1768. [Google Scholar]
- Krishna, K.; Srinivasan, B.V. Generating topic-oriented summaries using neural attention. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; pp. 1697–1705. [Google Scholar]
- Kim, S.E.; Kaibalina, N.; Park, S.B. A Topical Category-Aware Neural Text Summarizer. Appl. Sci. 2020, 10, 5422. [Google Scholar] [CrossRef]
- Kavuluru, R.; Han, S.; Harris, D. Unsupervised extraction of diagnosis codes from EMRs using knowledge-based and extractive text summarization techniques. In Canadian Conference on Artificial Intelligence; Springer: Heidelberg, Germany, 2013; pp. 77–88. [Google Scholar]
- Hou, S.; Lu, R. Knowledge-guided unsupervised rhetorical parsing for text summarization. Inf. Syst. 2020, 94, 101615. [Google Scholar] [CrossRef]
- Sandhaus, E. The new york times annotated corpus. Linguist. Data Consort. Phila. 2008, 6, e26752. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Text Summarization Branches Out; Association for Computational Linguistics: Barcelona, Spain, 2004; pp. 74–81. [Google Scholar]
- Nallapati, R.; Zhou, B.; Gulcehre, C.; Xiang, B.; dos Santos, C.N. Abstractive text summarization using sequence-to-sequence rnns and beyond. arXiv 2016, arXiv:1602.06023. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| embedding size | 128 |
| hidden size | 768 |
| initializer range | 0.02 |
| intermediate size | 3072 |
| max position embeddings | 512 |
| attention heads | 12 |
| hidden layers | 12 |
| vocab size | 30,000 |
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L | ROUGE-AVG |
|---|---|---|---|---|
| Lead-3 | 34.64 | 16.22 | 33.18 | 28.01 |
| Textrank | 29.96 | 9.74 | 27.33 | 22.34 |
| Lexrank | 22.05 | 4.45 | 19.31 | 15.27 |
| K-means | 31.69 | 12.02 | 29.34 | 24.35 |
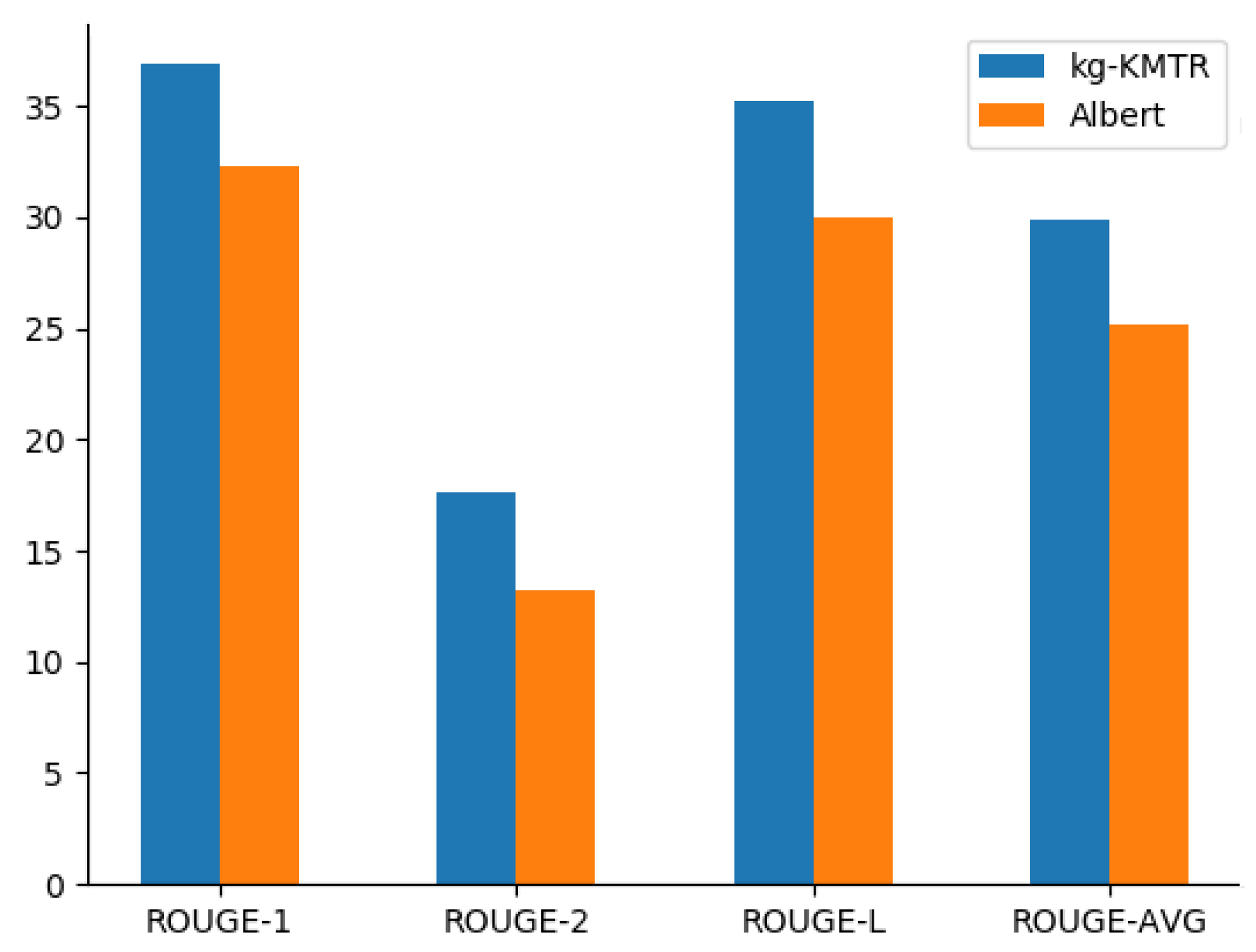
| kg-KMTR (ours) | 36.89 | 17.66 | 35.27 | 29.94 |
| Reference: |
|---|
| paul j lim article holds that four-year-old bull market can continue to rage on given enough economic growth, |
| corporate profits and cheap capital. |
| average general domestic stock fund gained 12.8 percent in 2006, representing surprising improvement |
| over 2005. |
| investors reap rewards for risks taken during year. |
| Textrank: |
| the average diversified emerging-market stock fund, for example, soared 17.4 percent in the quarter and |
| finished the year up 32.6 percent, according to morningstar. |
| despite predictions that this would be the year when large-cap domestic stock funds returned to dominance, |
| small-cap stock funds again led the domestic markets among general domestic stock funds. |
| according to morningstar, the average small-cap growth fund advanced 11.1 percent last year, versus |
| 7.3 percent for the average large-cap growth portfolio. |
| KMTR: |
| emboldened by an economy that proved resilient in the face of federal reserve interest-rate increases, high |
| oil prices and a cooling housing market, the average general domestic stock fund gained 12.8 percent last year. |
| but it was a surprising improvement from 2005, when domestic stock funds gained 7.7 percent, on average, |
| and looked to be tiring. |
| and the average gain for equities during these years has been 18 percent. |
| kg-KMTR: |
| given enough of a dose of economic growth, corporate profits and cheap capital, a bull market that ’s more |
| than four years old – as this one is – can still rage on like a young buck. |
| emboldened by an economy that proved resilient in the face of federal reserve interest-rate increases, high oil |
| prices and a coolinghousing market, the average general domestic stock fund gained 12.8 percent last year. |
| but it was a surprising improvement from 2005, when domestic stock funds gained 7.7 percent, on average, |
| and looked to be tiring. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, T.; Yuan, T.; Tang, X.; Chen, D. Incorporating External Knowledge into Unsupervised Graph Model for Document Summarization. Electronics 2020, 9, 1520. https://doi.org/10.3390/electronics9091520
Tang T, Yuan T, Tang X, Chen D. Incorporating External Knowledge into Unsupervised Graph Model for Document Summarization. Electronics. 2020; 9(9):1520. https://doi.org/10.3390/electronics9091520
Chicago/Turabian StyleTang, Tiancheng, Tianyi Yuan, Xinhuai Tang, and Delai Chen. 2020. "Incorporating External Knowledge into Unsupervised Graph Model for Document Summarization" Electronics 9, no. 9: 1520. https://doi.org/10.3390/electronics9091520
APA StyleTang, T., Yuan, T., Tang, X., & Chen, D. (2020). Incorporating External Knowledge into Unsupervised Graph Model for Document Summarization. Electronics, 9(9), 1520. https://doi.org/10.3390/electronics9091520