A Parallel Convolutional Neural Network for Pedestrian Detection

Abstract
1. Introduction
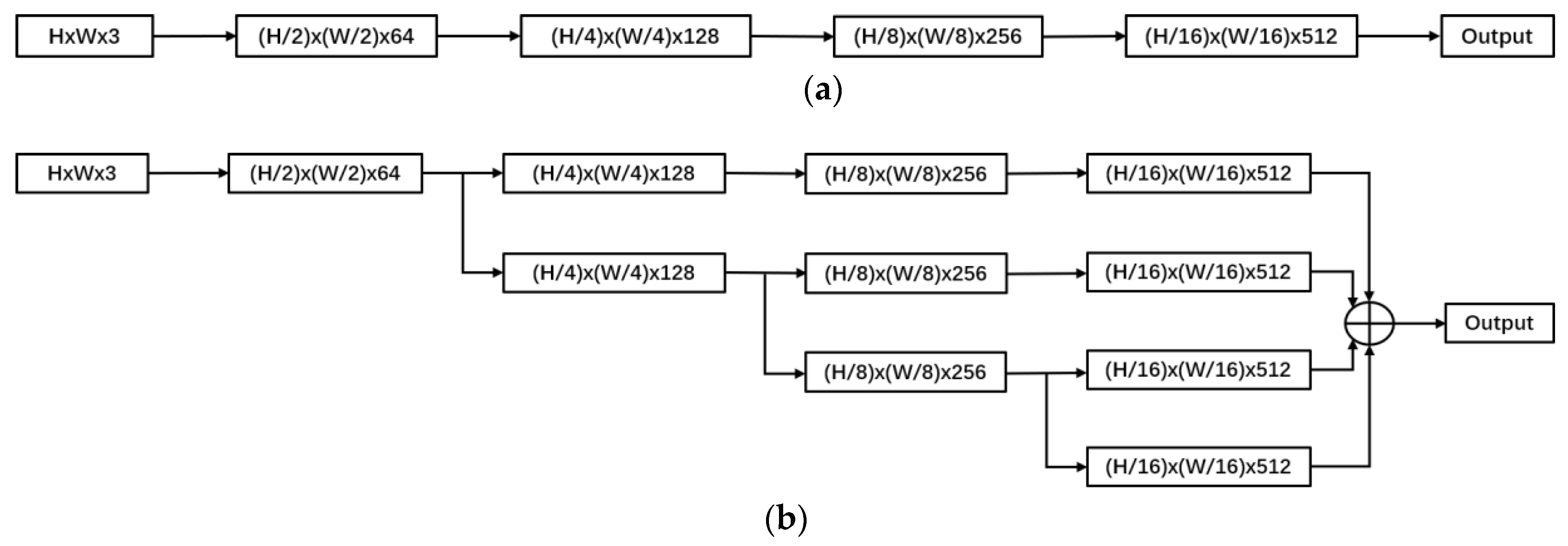
- We design a backbone with a parallel structure, which is called ParallelNet. It aims to improve the robustness of feature representation and detection accuracy.
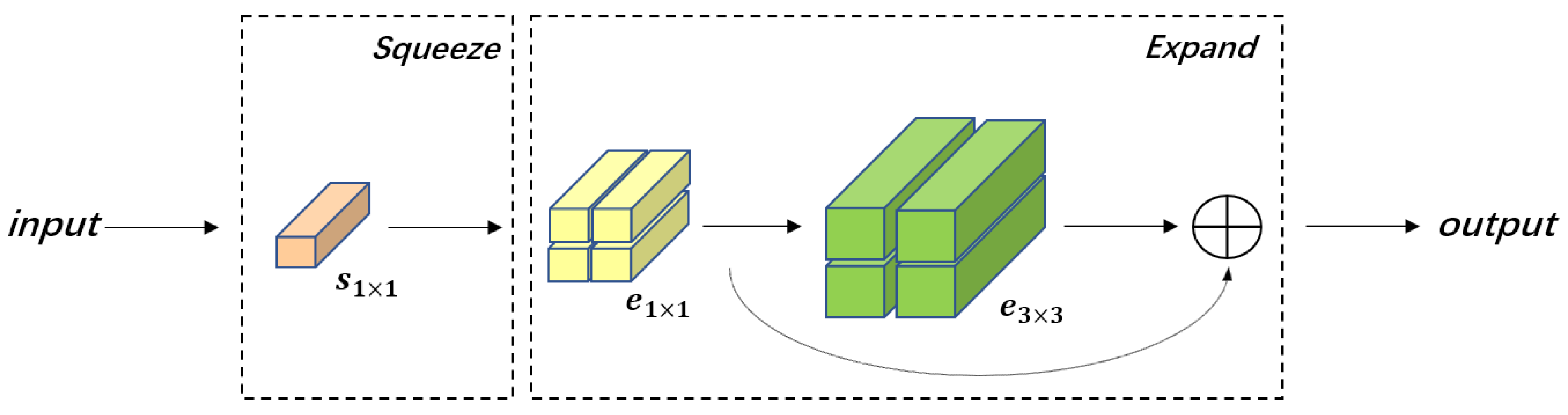
- A large number of Fire modules are employed, aiming to ensure accuracy while reducing the number of model parameters, with subsequent focal loss led into the ParallelNet for end-to-end training.
- We validate ParallelNet on the Caltech–Zhang and KITTI dataset, and compare the results with VGG16, ResNet50, ResNet101, SqueezeNet and SqueezeNet+. An ablation study was designed to verify the feasibility of the ParalleNet. In addition, to prevent the network from overfitting, we adopted data augmentation techniques, including random cropping and horizontal flipping.
2. Related Works
2.1. Pedestrian Detection with Hand-Crafted Features
2.2. Pedestrian Detection with CNNs
2.3. Pedestrian Detection Benchmarks
3. Architecture
3.1. Architecture Design
3.1.1. Strategy 1: Parallel
3.1.2. Strategy 2: Fire Model
3.2. Detection Head
3.2.1. Bounding Box Loss
- Sliding the window to get the coordinate of the anchor, denoted as . Here, , , . the ground truth is known, denoted as .
- Calculating the offset, denoted as , by encoding Equation (1). After a period of training and optimization, the offset convergences to the threshold, which means that the predicted bounding box is close to the ground truth.
- Calculating the coordinate of the predicted bounding box, denoted as , by decoding Equation (2).
3.2.2. Classification Loss
3.2.3. Confidence Score Loss
4. Experimental Results
4.1. Experiment Settings
4.1.1. Datasets
4.1.2. Training Details
4.2. Experiments
4.2.1. Comparative Experiments
4.2.2. Ablation Study
4.3. Results
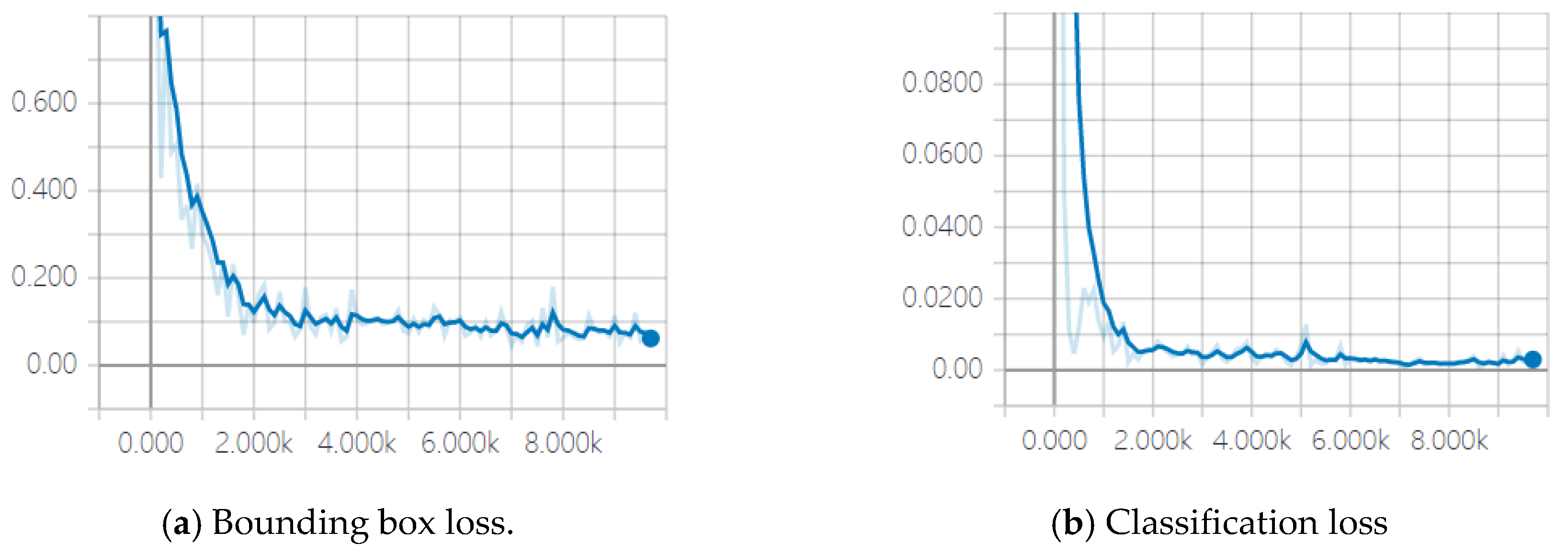
4.3.1. Training Results
4.3.2. Testing Results
4.3.3. Tricks
- In order to prevent the network from overfitting, an L2 loss is added to the total loss function. In addition, data augmentation techniques are used, including random cropping and horizontal flipping. Figure 9 shows some detection examples after data augmentation.
- As mentioned above, our ParallelNet will output four feature maps of equal size, which need to be merged into one feature map when inputting the detection head. There are several alternative fusion methods, including concatenating by channel, add by pixel, average by pixel and maximum by pixel. Through experiments, the detection accuracy of several methods is similar, but the calculation of the pixel-by-pixel method is less, so the method of adding by pixel is finally selected.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hasan, I.; Liao, S.; Li, J.; Akram, S.U.; Shao, L. Pedestrian Detection: The Elephant In The Room. arXiv 2020, arXiv:2003.08799. [Google Scholar]
- Lee, J.H.; Choi, J.-S.; Jeon, E.S.; Kim, Y.G.; Le, T.T.; Shin, K.Y.; Lee, H.C.; Park, K.R. Robust pedestrian detection by combining visible and thermal infrared cameras. Sensors 2015, 15, 10580–10615. [Google Scholar] [CrossRef] [PubMed]
- Martínez, M.A.; Martínez, J.L.; Morales, J. Motion detection from mobile robots with fuzzy threshold selection in consecutive 2D Laser scans. Electronics 2015, 4, 82–93. [Google Scholar] [CrossRef]
- Liu, K.; Wang, W.; Wang, J. Pedestrian detection with LiDAR point clouds based on single template matching. Electronics 2019, 8, 780. [Google Scholar] [CrossRef]
- Ball, J.E.; Tang, B. Machine Learning and Embedded Computing in Advanced Driver Assistance Systems (ADAS). Electronics 2019, 8, 748. [Google Scholar] [CrossRef]
- Barba-Guaman, L.; Eugenio Naranjo, J.; Ortiz, A. Deep Learning Framework for Vehicle and Pedestrian Detection in Rural Roads on an Embedded GPU. Electronics 2020, 9, 589. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Dollár, P.; Tu, Z.; Perona, P.; Belongie, S. Integral channel features. In Proceedings of the British Machine Vision Conference, London, UK, 7–10 September 2009. [Google Scholar]
- Felzenszwalb, P.; McAllester, D.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Sun, T.; Fang, W.; Chen, W.; Yao, Y.; Bi, F.; Wu, B. High-Resolution Image Inpainting Based on Multi-Scale Neural Network. Electronics 2019, 8, 1370. [Google Scholar] [CrossRef]
- Wang, X.; Hua, X.; Xiao, F.; Li, Y.; Hu, X.; Sun, P. Multi-object detection in traffic scenes based on improved SSD. Electronics 2018, 7, 302. [Google Scholar] [CrossRef]
- Xu, D.; Wu, Y. Improved YOLO-V3 with DenseNet for Multi-Scale Remote Sensing Target Detection. Sensors 2020, 20, 4276. [Google Scholar] [CrossRef]
- Zhao, L.; Li, S. Object Detection Algorithm Based on Improved YOLOv3. Electronics 2020, 9, 537. [Google Scholar] [CrossRef]
- Wei, H.; Kehtarnavaz, N. Semi-supervised faster RCNN-based person detection and load classification for far field video surveillance. Mach. Learn. Knowl. Extr. 2019, 1, 756–767. [Google Scholar] [CrossRef]
- Nguyen, K.; Huynh, N.T.; Nguyen, P.C.; Nguyen, K.-D.; Vo, N.D.; Nguyen, T.V. Detecting Objects from Space: An Evaluation of Deep-Learning Modern Approaches. Electronics 2020, 9, 583. [Google Scholar] [CrossRef]
- Liu, W.; Liao, S.; Ren, W.; Hu, W.; Yu, Y. High-level semantic feature detection: A new perspective for pedestrian detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5187–5196. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9627–9636. [Google Scholar]
- Zhu, C.; He, Y.; Savvides, M. Feature selective anchor-free module for single-shot object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 840–849. [Google Scholar]
- Viola, P.; Jones, M.J.; Snow, D. Detecting pedestrians using patterns of motion and appearance. Int. J. Comput. Vis. 2005, 63, 153–161. [Google Scholar] [CrossRef]
- Dollár, P.; Appel, R.; Belongie, S.; Perona, P. Fast feature pyramids for object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1532–1545. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Benenson, R.; Schiele, B. Filtered channel features for pedestrian detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; p. 4. [Google Scholar]
- Kwon, S.; Park, T. Channel-Based Network for Fast Object Detection of 3D LiDAR. Electronics 2020, 9, 1122. [Google Scholar] [CrossRef]
- Yang, B.; Yan, J.; Lei, Z.; Li, S.Z. Aggregate channel features for multi-view face detection. In Proceedings of the IEEE International Joint Conference on Biometrics, Clearwater, FL, USA, 29 September–2 October 2014; pp. 1–8. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 10–16 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Lin, L.; Liang, X.; He, K. Is faster R-CNN doing well for pedestrian detection? In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 443–457. [Google Scholar]
- Li, J.; Liang, X.; Shen, S.; Xu, T.; Feng, J.; Yan, S. Scale-aware fast R-CNN for pedestrian detection. IEEE Trans. Multimed. 2017, 20, 985–996. [Google Scholar] [CrossRef]
- Mao, J.; Xiao, T.; Jiang, Y.; Cao, Z. What can help pedestrian detection? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 October 2017; pp. 3127–3136. [Google Scholar]
- Zhang, S.; Benenson, R.; Omran, M.; Hosang, J.; Schiele, B. Towards reaching human performance in pedestrian detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 973–986. [Google Scholar] [CrossRef]
- Zhang, S.; Yang, J.; Schiele, B. Occluded pedestrian detection through guided attention in cnns. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6995–7003. [Google Scholar]
- Wang, X.; Xiao, T.; Jiang, Y.; Shao, S.; Sun, J.; Shen, C. Repulsion loss: Detecting pedestrians in a crowd. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7774–7783. [Google Scholar]
- Shao, S.; Zhao, Z.; Li, B.; Xiao, T.; Yu, G.; Zhang, X.; Sun, J. Crowdhuman: A benchmark for detecting human in a crowd. arXiv 2018, arXiv:1805.00123. [Google Scholar]
- Zhang, X.; Cheng, L.; Li, B.; Hu, H.-M. Too far to see? Not really!—Pedestrian detection with scale-aware localization policy. IEEE Trans. Image Process. 2018, 27, 3703–3715. [Google Scholar] [CrossRef]
- Song, T.; Sun, L.; Xie, D.; Sun, H.; Pu, S. Small-scale pedestrian detection based on topological line localization and temporal feature aggregation. In Proceedings of the European Conference on Computer Vision, Munich, Bavaria, Germany, 8–14 September 2018; pp. 536–551. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 1–9. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Kim, W.; Jung, W.-S.; Choi, H.K. Lightweight driver monitoring system based on multi-task mobilenets. Sensors 2019, 19, 3200. [Google Scholar] [CrossRef] [PubMed]
- Lee, D.-H. Fully Convolutional Single-Crop Siamese Networks for Real-Time Visual Object Tracking. Electronics 2019, 8, 1084. [Google Scholar] [CrossRef]
- Liu, B.; Zou, D.; Feng, L.; Feng, S.; Fu, P.; Li, J. An fpga-based cnn accelerator integrating depthwise separable convolution. Electronics 2019, 8, 281. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and < 0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Wu, B.; Iandola, F.; Jin, P.H.; Keutzer, K. Squeezedet: Unified, small, low power fully convolutional neural networks for real-time object detection for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 129–137. [Google Scholar]
- Li, C.; Wei, X.; Yu, H.; Guo, J.; Tang, X.; Zhang, Y. An Enhanced SqueezeNet Based Network for Real-Time Road-Object Segmentation. In Proceedings of the 2019 IEEE Symposium Series on Computational Intelligence (SSCI), Xiamen, China, 6–9 December 2019; pp. 1214–1218. [Google Scholar]
- Sun, W.; Zhang, Z.; Huang, J. RobNet: Real-time road-object 3D point cloud segmentation based on SqueezeNet and cyclic CRF. Soft Comput. 2019, 24, 5805–5818. [Google Scholar] [CrossRef]
- Flohr, F.; Gavrila, D. Daimler Pedestrian Segmentation Benchmark Dataset. In Proceedings of the British Machine Vision Conference, Bristol, UK, 9–13 September 2013. [Google Scholar]
- Ess, A.; Leibe, B.; Van Gool, L. Depth and appearance for mobile scene analysis. In Proceedings of the IEEE International Conference on Computer Vision, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Dominguez-Sanchez, A.; Cazorla, M.; Orts-Escolano, S. A new dataset and performance evaluation of a region-based cnn for urban object detection. Electronics 2018, 7, 301. [Google Scholar] [CrossRef]
- Dollár, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: A benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami Beach, FL, USA, 20–25 June 2009; pp. 304–311. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Zhang, S.; Benenson, R.; Schiele, B. Citypersons: A diverse dataset for pedestrian detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3213–3221. [Google Scholar]
- Zhang, S.; Benenson, R.; Omran, M.; Hosang, J.; Schiele, B. How far are we from solving pedestrian detection? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016; pp. 1259–1267. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) | |||||
| Layer Name | Output Size | Size/Stride | |||
| input | 480 × 640 × 3 | - | - | - | - |
| conv | 240 × 320 × 64 | 3 × 3 × 64/2 | - | - | - |
| pool1 | 120 × 160 × 64 | 3 × 3/2 | - | - | - |
| fire1/fire2 | 120 × 160 × 64 | - | 16 | 64 | 64 |
| pool2 | 60 × 80 × 64 | 3 × 3/2 | - | - | - |
| fire3/fire4 | 60 × 80 × 128 | - | 32 | 128 | 128 |
| pool3 | 30 × 40 × 128 | 3 × 3/2 | - | - | - |
| fire5/fire6 | 30 × 40 × 192 | - | 48 | 192 | 192 |
| fire7/fire8 | 30 × 40 × 256 | - | 64 | 256 | 256 |
| pool4 | 15 × 20 × 256 | 3 × 3/2 | - | - | - |
| fire9/fire10 | 15 × 20 × 384 | - | 96 | 384 | 384 |
| fire11/fire12 | 15 × 20 × 512 | - | 128 | 512 | 512 |
| feature map1 | 15 × 20 × 63 | 3 × 3 × 63/1 | - | - | - |
| (b) | |||||
| Layer Name | Output Size | Size/Stride | |||
| conv | 120 × 160 × 128 | 3 × 3 × 128/2 | - | - | - |
| pool1 | 60 × 80x128 | 3 × 3/2 | - | - | - |
| fire1/fire2 | 60 × 80 × 128 | - | 32 | 128 | 128 |
| pool2 | 30 × 40 × 128 | 3 × 3/2 | - | - | - |
| fire3/fire4 | 30 × 40 × 192 | - | 48 | 192 | 192 |
| fire5/fire6 | 30 × 40 × 256 | - | 64 | 256 | 256 |
| pool3 | 15 × 20 × 256 | 3 × 3/2 | - | - | - |
| fire7/fire8 | 15 × 20 × 384 | - | 96 | 384 | 384 |
| fire9/fire10 | 15 × 20 × 512 | - | 128 | 512 | 512 |
| feature map2 | 15 × 20 × 63 | 3 × 3 × 63/1 | - | - | - |
| (c) | |||||
| Layer Name | Output Size | Size/Stride | |||
| conv | 60 × 80 × 128 | 3 × 3 × 128/2 | - | - | - |
| pool1 | 30 × 40 × 128 | 3 × 3/2 | - | - | - |
| fire1 | 30 × 40 × 192 | - | 48 | 192 | 192 |
| fire2 | 30 × 40 × 192 | - | 48 | 192 | 192 |
| fire3 | 30 × 40 × 256 | - | 64 | 256 | 256 |
| fire4 | 30 × 40 × 256 | - | 64 | 256 | 256 |
| pool2 | 15 × 20 × 256 | 3 × 3/2 | - | - | - |
| fire1/fire2 | 15 × 20 × 384 | - | 96 | 384 | 384 |
| fire3/fire4 | 15 × 20 × 512 | - | 128 | 512 | 512 |
| feature map3 | 15 × 20 × 63 | 3 × 3 × 63/1 | - | - | - |
| (d) | |||||
| Layer Name | Output Size | Size/Stride | |||
| conv | 30 × 40 × 256 | 3 × 3 × 256/2 | - | - | - |
| pool1 | 15 × 20 × 256 | 3 × 3/2 | - | - | - |
| fire1/fire2 | 15 × 20 × 384 | - | 96 | 384 | 384 |
| fire3/fire4 | 15 × 20 × 512 | - | 128 | 512 | 512 |
| feature map4 | 15 × 20 × 63 | 3 × 3 × 63/1 | - | - | - |
| (a) | ||||
| Backbone | AP (%) | FPS | # Param (MB) | GFLOPs |
| VGG16 | 51.39 | 21.11 | 17.91 | 75.44 |
| ResNet50 | 52.54 | 27.78 | 9.11 | 39.63 |
| ResNet101 | 53.22 | 24.31 | 15.48 | 70.86 |
| SqueezeNet | 48.90 | 43.48 | 2.02 | 6.68 |
| SqueezeNet+ | 53.44 | 30.30 | 6.98 | 50.42 |
| PrallelNet | 54.61 | 35.71 | 7.54 | 17.73 |
| (b) | ||||
| Backbone | AP (%) | FPS | # Param (MB) | GFLOPs |
| VGG16 | 72.89 | 18.65 | 17.91 | 117.69 |
| ResNet50 | 73.05 | 25.00 | 9.11 | 60.97 |
| ResNet101 | 74.19 | 22.50 | 15.48 | 107.71 |
| SqueezeNet | 68.66 | 37.04 | 2.02 | 10.34 |
| SqueezeNet+ | 73.90 | 29.41 | 6.98 | 77.11 |
| PrallelNet | 77.90 | 32.26 | 7.54 | 27.35 |
| Backbone | AP (%) | FPS | # Param (MB) | GFLOPs |
|---|---|---|---|---|
| 1-branch | 48.90 | 43.48 | 2.02 | 6.68 |
| 2-branches | 50.08 | 43.55 | 3.65 | 10.05 |
| 3-branches | 52.03 | 37.02 | 5.41 | 14.85 |
| 4-branches | 54.61 | 35.71 | 7.54 | 17.73 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, M.; Wu, Y. A Parallel Convolutional Neural Network for Pedestrian Detection. Electronics 2020, 9, 1478. https://doi.org/10.3390/electronics9091478
Zhu M, Wu Y. A Parallel Convolutional Neural Network for Pedestrian Detection. Electronics. 2020; 9(9):1478. https://doi.org/10.3390/electronics9091478
Chicago/Turabian StyleZhu, Mengya, and Yiquan Wu. 2020. "A Parallel Convolutional Neural Network for Pedestrian Detection" Electronics 9, no. 9: 1478. https://doi.org/10.3390/electronics9091478
APA StyleZhu, M., & Wu, Y. (2020). A Parallel Convolutional Neural Network for Pedestrian Detection. Electronics, 9(9), 1478. https://doi.org/10.3390/electronics9091478