A Combination Strategy of Feature Selection Based on an Integrated Optimization Algorithm and Weighted K-Nearest Neighbor to Improve the Performance of Network Intrusion Detection


 , and
, and
Abstract
1. Introduction
1.1. Background
1.2. Related Work
1.3. Main Aim
2. Feature Selection Based on an Integrated Optimization Algorithm
2.1. Moth-Flame Optimization (MFO) Algorithm
2.2. Particle Swarm Optimization (PSO) Algorithm
2.3. An Integrated Optimization Algorithm
2.4. Binary Conversion Method for Feature Selection
- Population initializationIn a binary algorithm, the value of particle feature can only be 0 or 1, in which 1 means the feature is selected, and 0 means not selected. Generally, 50% probability of feature selection is a common method of population initialization. The initialization function of selected particles is as follow.
- Binary conversionIn order to solve the position updating problem of the algorithm above in binary space [47], this paper uses sigmoid function to map the updated real value of moth to [0, 1] to realize the 0 and 1 conversion of moth position. The binary conversion formula is as follows:where is the updated position of moth, and is the random number between [0, 1].
3. A Combination Strategy to Improve the Performance of Network Intrusion Detection
3.1. Classification Algorithms for Network Intrusion Detection
3.1.1. K-Nearest Neighbor (KNN)
3.1.2. Support Vector Machine (SVM)
- When the samples are linearly separable, SVM can be learned by the method of maximum hard interval.
- When the samples are approximately linearly separable, SVM can be learned by the method of maximum soft interval.
- When the samples are not separable linearly, SVM can be learned by the method of maximum core technology and soft interval.
3.1.3. Naive Bayes
- In the stage of preparing for classification, naive Bayes relies on attributes to distinguish categories, so this stage is a necessary stage for naive Bayes. Its main task is to determine the characteristics of attributes according to specific data sets, integrate the samples of the data sets to be classified by people, and integrate the data sets into training sets. This stage will have a crucial impact on the following classifier classification.
- In the training stage, the main purpose is to generate a classifier, calculate the frequency of data appearing in the training set and the probability evaluation of each tag by the classification of feature attributes, and then record the calculation. This stage is a mechanical stage, which can be completed by the program.
- In the application stage, classifiers are used to classify items. This stage is also a mechanical stage, which is completed by the program.
3.2. A Combination Strategy with Weighted KNN
4. Experimental Results
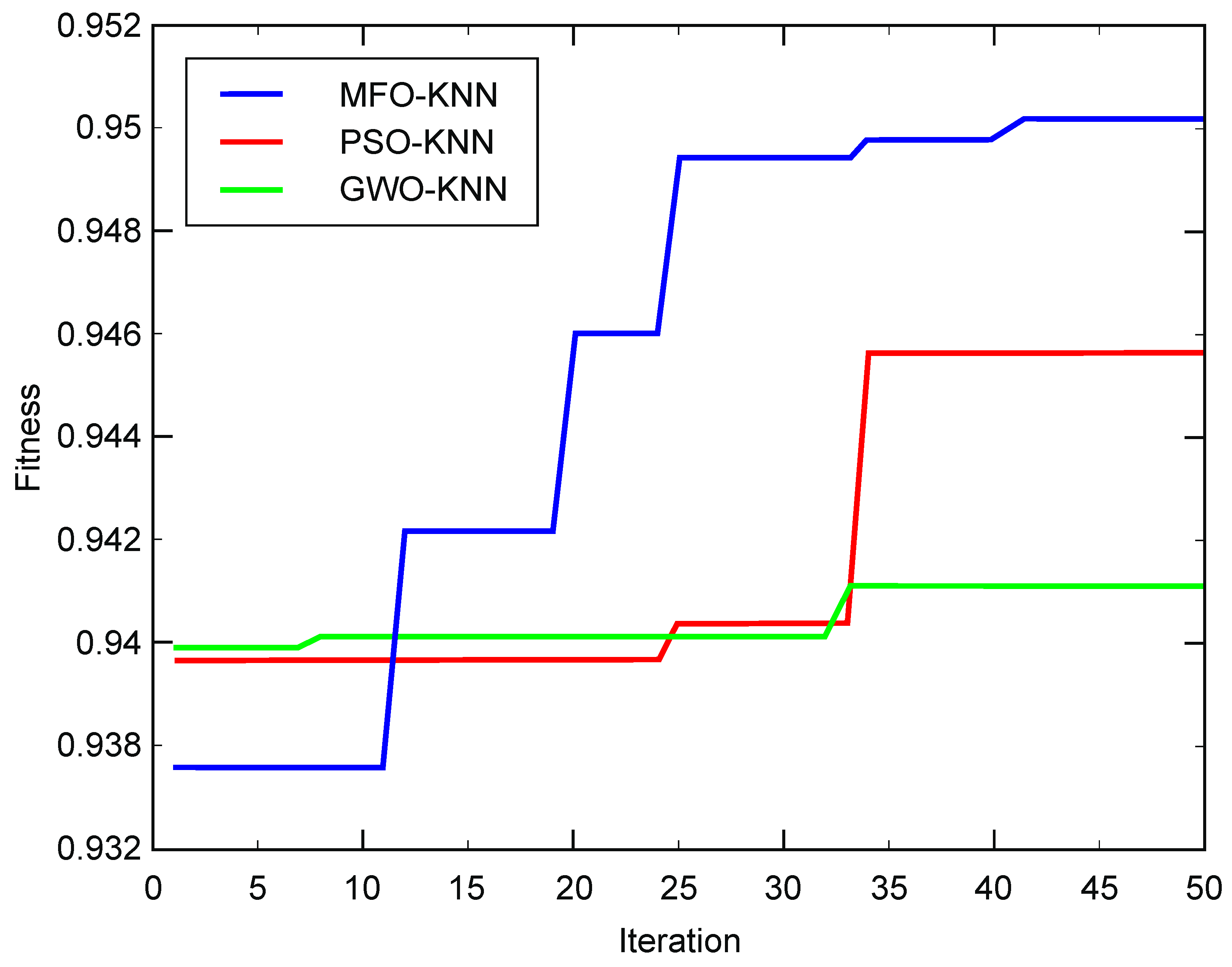
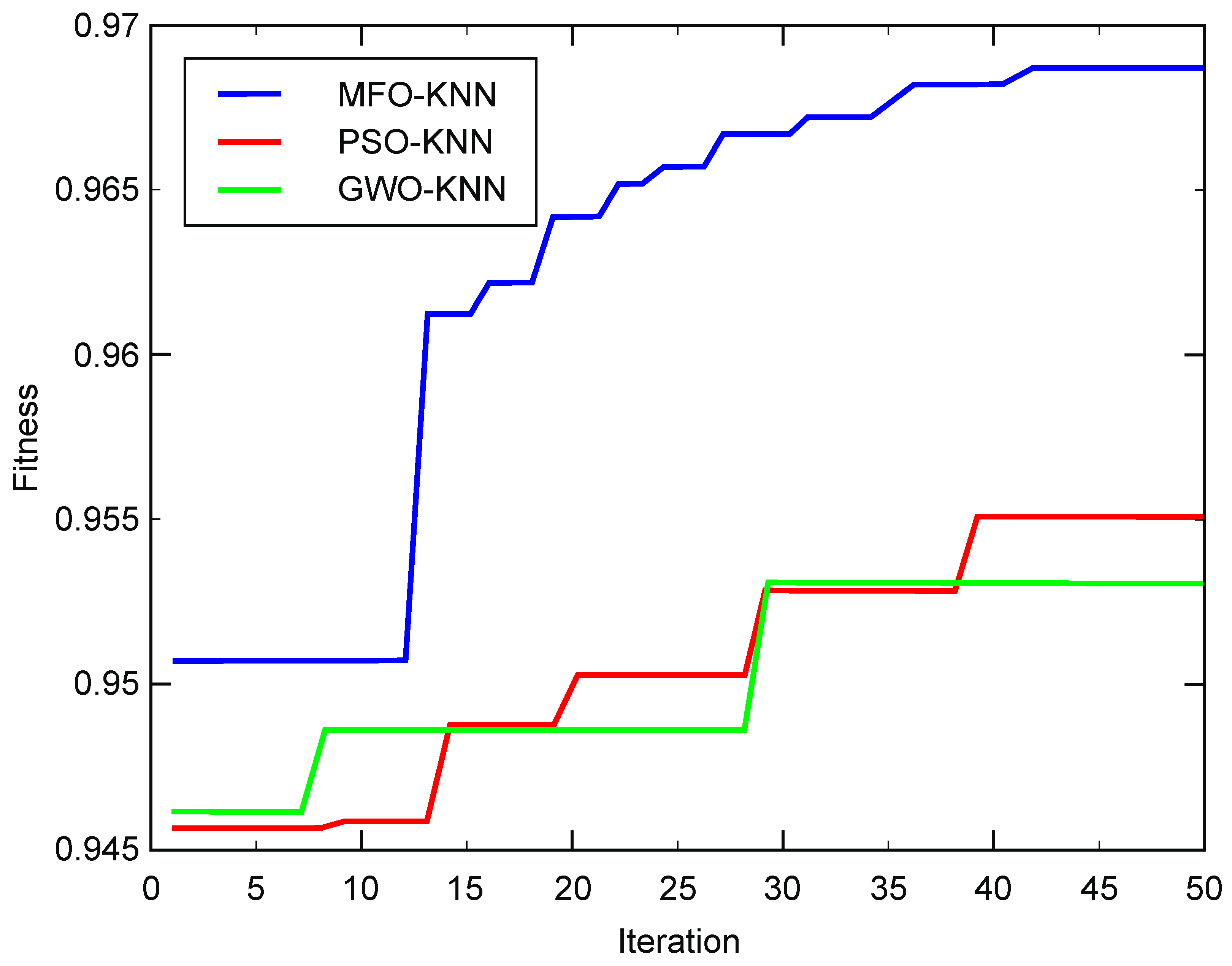
4.1. Method Validation of MFO-Optimized Weighted KNN
4.1.1. Data Sets for Network Intrusion Detection
4.1.2. Experimental Results and Analysis
4.2. Test Functions for the Integrated Optimization Algorithm
4.3. Binary Simulation Experiments for Feature Selection
4.4. Validation of The Combination Strategy
4.4.1. Selection of KNN Weights
4.4.2. Selection of Feature Subsets
4.4.3. Simulation Experiments
- In terms of running time, Group 1 is 9884 ms faster than Group 2, 10,622 ms faster than Group 4, roughly the same as Group 3
- In terms of accuracy, Group 1 is 0.007085 higher than Group 3, Group 2 is 0.02024 higher than Group 4, Group 1 is 0.055884 lower than Group 2, and Group 1 is 0.035644 lower than Group 4.
- In terms of weighted KNN, Group 1 is 0.007085 higher than Group 3, and Group 2 is 0.02024 higher than Group 4.
- In terms of feature selection, Group 1 is 0.055884 lower than Group 2, Group 1 is 0.035644 lower than Group 4, but Group 1 is 9884 ms faster than Group 2, 10,622 ms faster than Group 4.
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Jun, S.; Przystupa, K.; Beshley, M.; Kochan, O.; Beshley, H.; Klymash, M.; Wang, J.; Pieniak, D. A Cost-Efficient Software Based Router and Traffic Generator for Simulation and Testing of IP Network. Electronics 2020, 9, 40. [Google Scholar] [CrossRef]
- Song, W.; Beshley, M.; Przystupa, K.; Beshley, H.; Kochan, O.; Pryslupskyi, A.; Pieniak, D.; Su, J. A Software Deep Packet Inspection System for Network Traffic Analysis and Anomaly Detection. Sensors 2020, 20, 1637. [Google Scholar] [CrossRef] [PubMed]
- Liao, H.J.; Lin, C.H.R.; Lin, Y.C. Intrusion detection system: A comprehensive review. J. Netw. Comput. Appl. 2013, 36, 16–24. [Google Scholar] [CrossRef]
- Binbusayyis, A.; Vaiyapuri, T. Comprehensive analysis and recommendation of feature evaluation measures for intrusion detection. Heliyon 2020, 6, e04262. [Google Scholar] [CrossRef] [PubMed]
- Thakkar, A.; Lohiya, R. Role of swarm and evolutionary algorithms for intrusion detection system: A survey. Swarm Evol. Comput. 2020, 53, 100631. [Google Scholar] [CrossRef]
- Bouzgou, H.; Gueymard, C.A. Fast Short-Term Global Solar Irradiance Forecasting with Wrapper Mutual Information. Renew. Energy 2018, 133, 1055–1065. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the IEEE International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]
- Nayak, J.; Vakula, K.; Dinesh, P.; Naik, B. Significance of particle swarm optimization in intrusion detection: Crossing a decade. In Proceedings of the Applications of Robotics in Industry Using Advanced Mechanisms, Bhubaneswar, India, 16–17 August 2019; pp. 187–202. [Google Scholar]
- Peterson, L. K-nearest neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- Saunders, C.; Stitson, M.O.; Weston, J.; Holloway, R.; Bottou, L.; Scholkopf, B. Support Vector Machine. Comput. Sci. 2002, 1, 1–28. [Google Scholar]
- Kononenko, I. Semi-naive bayesian classifier. Lect. Notes Comput. Sci. 1991, 482, 206–219. [Google Scholar]
- Mirjalili, S. Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm. Knowl. Based Syst. 2015, 89, 228–249. [Google Scholar] [CrossRef]
- Savsani, V.; Tawhid, M.A. Non-dominated sorting moth flame optimization (NS-MFO) for multi-objective problems. Eng. Appl. Artif. Intell. 2017, 63, 20–32. [Google Scholar] [CrossRef]
- Apinantanakon, W.; Sunat, K. OMFO: A New Opposition-Based Moth-Flame Optimization Algorithm for Solving Unconstrained Optimization Problems. Recent Advances in Information and Communication Technology 2017. IC2IT 2017. Adv. Intell. Syst. Comput. 2017, 566. [Google Scholar] [CrossRef]
- Zhang, S.; Zhou, Y.Q.; Luo, Q.F. A Complex-Valued Encoding Moth-Flame Optimization Algorithm for Global Optimization. Evol. Syst. 2019, 11643, 1–15. [Google Scholar] [CrossRef]
- Xu, Y.; Chen, H.; Heidari, A.A. An efficient chaotic mutative moth-flame-inspired optimizer for global optimization tasks. Expert Syst. Appl. 2019, 129, 135–155. [Google Scholar] [CrossRef]
- Xu, Y.; Chen, H.; Luo, J. Enhanced Moth-flame optimizer with mutation strategy for global optimization. Inf. Sci. 2019, 492, 181–203. [Google Scholar] [CrossRef]
- Yeromenko, V.; Kochan, O. The conditional least squares method for thermocouples error modeling. In Proceedings of the 2013 IEEE 7th International Conference on Intelligent Data Acquisition and Advanced Computing Systems IDAACS-2013, Berlin, Germany, 12–14 September 2013; pp. 157–162. [Google Scholar]
- Singh, P.; Prakash, S. Optical network unit placement in Fiber-Wireless (FiWi) access network by Moth-Flame optimization algorithm. Opt. Fiber Technol. 2017, 36, 403–411. [Google Scholar] [CrossRef]
- Kotary, D.K.; Nanda, S.J. Distributed robust data clustering in wireless sensor networks using diffusion moth flame optimization. Eng. Appl. Artif. Intell. 2020, 87, 103342. [Google Scholar] [CrossRef]
- Yıldız, B.S.; Yıldız, A.R. Moth-flame optimization algorithm to determine optimal machining parameters in manufacturing processes. Materialprufung 2017, 59, 425–429. [Google Scholar] [CrossRef]
- Fayyaz, S.; Ahmad, A.; Singh, V.K.; Bhoi, A.K. Solution of Economic Load Dispatch Problems through Moth Flame Optimization Algorithm. Lect. Notes Electr. Eng. 2019, 462, 287–294. [Google Scholar]
- Przystupa, K. Selected methods for improving power reliability. Przegląd Elektrotechniczny 2018, 94, 270–273. [Google Scholar]
- Kozieł, J.; Przystupa, K. Using the FTA method to analyze the quality of an uninterruptible power supply unitreparation UPS. Przegląd Elektrotechniczny 2019, 95, 77–80. [Google Scholar] [CrossRef]
- Acharyulu, B.V.S.; Mohanty, B.; Hota, P.K. Comparative Performance Analysis of PID Controller with Filter for Automatic Generation Control with Moth-Flame Optimization Algorithm. Appl. Artif. Intell. Tech. Eng. 2019, 698, 509–518. [Google Scholar]
- Nowdeh, S.A.; Moghaddam, M.J.H.; Nasri, S.; Abdelaziz, A.Y.; Ghanbari, M.; Faraji, I. A New Hybrid Moth Flame Optimizer-Perturb and Observe Method for Maximum Power Point Tracking in Photovoltaic Energy System. Appl. Artif. Intell. Tech. Eng. 2020, 401–420. [Google Scholar] [CrossRef]
- Jain, P.; Saxena, A. An opposition theory enabled moth flame optimizer for strategic bidding in uniform spot energy market. Eng. Sci. Technol. Int. J. 2019, 22, 1047–1067. [Google Scholar] [CrossRef]
- Bouakkaz, M.S.; Boukadoum, A.; Boudebbouz, O. Dynamic performance evaluation and improvement of PV energy generation systems using Moth Flame Optimization with combined fractional order PID and sliding mode controller. Sol. Energy 2020, 199, 411–424. [Google Scholar] [CrossRef]
- Hraiba, A.; Touil, A.; Mousrij, A. An Enhanced Moth-Flame Optimizer for Reliability Analysis. Embed. Syst. Artif. Intell. 2020, 1076, 741–751. [Google Scholar]
- Przystupa, K.; Ambrożkiewicz, B.; Litak, G. Diagnostics of Transient States in Hydraulic Pump System with Short Time Fourier Transform. Advances in Science and Technology. Res. J. 2020, 14, 178–183. [Google Scholar]
- Przystupa, K. Planning repair strategies with the application of modified FMEA method. In Proceedings of the XV Konferencja Naukowo-Techniczna Techniki Komputerowe w Inżynierii TKI 2018, Mikołajki, Poland, 16–19 October 2018. [Google Scholar]
- Jalali, S.M.J.; Hedjam, R.; Khosravi, A.; Heidari, A.A.; Mirjalili, S.; Nahavandi, S. Autonomous Robot Navigation Using Moth-Flame-Based Neuroevolution. Evol. Mach. Learn. Tech. 2020, 67–83. [Google Scholar] [CrossRef]
- Sharma, R.; Saha, A. Fermat Spiral-Based Moth-Flame Optimization Algorithm for Object-Oriented Testing. Adv. Comput. Intell. Syst. 2020, 19–34. [Google Scholar] [CrossRef]
- Zhang, H.L.; Ali, A.H.; Wang, M.J.; Zhang, L.J.; Chen, H.L.; Li, C.Y. Orthogonal Nelder-Mead moth flame method for parameters identification of photovoltaic modules. Energy Convers. Manag. 2020, 211, 112764. [Google Scholar] [CrossRef]
- Majhi, S.K. How Effective Is the Moth-Flame Optimization in Diabetes Data Classification. Recent Dev. Mach. Learn. Data Anal. 2019, 470, 79–87. [Google Scholar]
- Debendra, M.; Ratnakar, D.; Banshidhar, M. Automated breast cancer detection in digital mammograms: A moth flame optimization based ELM approach. Biomed. Signal Process. Control 2020, 59, 101912. [Google Scholar]
- Lei, X.; Fang, M.; Fujita, H. Moth–flame optimization-based algorithm with synthetic dynamic PPI networks for discovering protein complexes. Knowl. Based Syst. 2019, 172, 76–85. [Google Scholar] [CrossRef]
- Xu, L.; Li, Y.; Li, K. Enhanced Moth-flame Optimization Based on Cultural Learning and Gaussian Mutation. J. Bionic Eng. 2018, 15, 751–763. [Google Scholar] [CrossRef]
- Pelusi, D.; Mascella, R.; Tallini, L.G. An Improved Moth-Flame Optimization algorithm with hybrid search phase. Knowl. Based Syst. 2020, 191, 105277. [Google Scholar] [CrossRef]
- Bhesdadiya, R.H.; Trivedi, I.N.; Jangir, P.; Kumar, A.; Jangir, N.; Totlani, R. A Novel Hybrid Approach Particle Swarm Optimizer with Moth-Flame Optimizer Algorithm. Adv. Comput. Comput. Sci. 2017, 553, 569–577. [Google Scholar]
- Majhi, S.K.; Mahapatra, P. Classification of Phishing Websites Using Moth-Flame Optimized Neural Network. Emerg. Technol. Data Min. Inf. Secur. 2019, 755, 39–48. [Google Scholar]
- Yu, C.Y.; Ali, A.H.; Chen, H.L. A Quantum-behaved Simulated Annealing Enhanced Moth-flame Optimization Method. Appl. Math. Model. 2020, 87, 1–19. [Google Scholar] [CrossRef]
- Gupta, D.; Ahlawat, A.K.; Sharma, A. Feature selection and evaluation for software usability model using modified moth-flame optimization. Computing 2020. [Google Scholar] [CrossRef]
- Elaziz, M.A.; Ewees, A.A.; Ibrahim, R.A. Opposition-based moth-flame optimization improved by differential evolution for feature selection. Math. Comput. Simul. 2020, 168, 48–75. [Google Scholar] [CrossRef]
- Pankaja, K.; Suma, V. Mango Leaves Recognition Using Deep Belief Network with Moth-Flame Optimization and Multi-feature Fusion. Smart Intell. Comput. Appl. 2020, 159, 23–31. [Google Scholar]
- Chaithanya, P.S.; Raman, M.R.G.; Nivethitha, S.; Seshan, K.S.; Sriram, V.S. An Efficient Intrusion Detection Approach Using Enhanced Random Forest and Moth-Flame Optimization Technique. Comput. Intell. Pattern Recognit. 2020, 999, 877–884. [Google Scholar]
- Kumar, V.; Kumar, D. Binary Whale Optimization Algorithm and Its Application to Unit Commitment Problem. Neural Comput. Appl. 2018, 32, 2095–2123. [Google Scholar]
- KDD Cup 99 Data Set. Available online: kdd.ics.uci.edu/databases/kddcup99/kddcup99.html (accessed on 17 May 2020).
- Elaoud, S.; Loukil, T.; Teghem, J. The Pareto fitness genetic algorithm: Test function study. Eur. J. Oper. Res. 2007, 177, 1703–1719. [Google Scholar]
- Sakai, H.; Liu, C.; Nakata, M. Information Dilution: Granule-Based Information Hiding in Table Data—A Case of Lenses Data Set in UCI Machine Learning Repository. In Proceedings of the Third International Conference on Computing Measurement Control & Sensor Network, Matsue, Japan, 20–22 May 2016. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Parameter Setting |
|---|---|
| MFO-KNN | b = 1; K = 10 |
| PSO-KNN | = 2; Vmax = 1; Vmin = −1; K = 10 |
| GWO-KNN | K = 10 |
| KNN | K = 10 |
| SVM | Gamma = 1.0 |
| Naïve Bayes | None |
| Average Fitness | Running Time (s) | Standard Deviation | |
|---|---|---|---|
| MFO-KNN | 0.940397 | 81.455 | 0.002536 |
| PSO-KNN | 0.923469 | 135.918 | 0.005140 |
| GWO-KNN | 0.939882 | 133.491 | 0.003167 |
| KNN | 0.925067 | 0.764 | - |
| SVM | 0.919361 | 0.594 | - |
| Naïve Bayes | 0.608596 | 0.109 | - |
| Average Fitness | Running Time (s) | Standard Deviation | |
|---|---|---|---|
| MFO-KNN | 0.968548 | 362.971 | 0.002122 |
| PSO-KNN | 0.958741 | 607.764 | 0.002986 |
| GWO-KNN | 0.955524 | 616.583 | 0.002622 |
| KNN | 0.937934 | 1.821 | - |
| SVM | 0.939921 | 1.439 | - |
| Naïve Bayes | 0.654419 | 0.204 | - |
| Algorithm | Parameter Setting |
|---|---|
| PMFO | C1, C2 = 2; b = 1; Vmax = 1; Vmin = −1 |
| MFO | b = 1 |
| Test Function | Dimension | Definition Domain | Minimum Value |
|---|---|---|---|
| 20 | (−100, 100) | 0 | |
| 20 | (−10, 10) | 0 | |
| 20 | (−100, 100) | 0 | |
| 20 | (−10, 10) | 0 |
| Test Function | Algorithm | Average Value | Variance |
|---|---|---|---|
| PMFO | 2.3425 | 1.2319 | |
| MFO | 3.6716 | 5.9147 | |
| PMFO | 5.1893 | 3.0818 | |
| MFO | 7.8062 | 9.2393 | |
| PMFO | 0.082636 | 0.209585 | |
| MFO | 0.038062 | 0.043858 | |
| PMFO | 0.090248 | 0.050483 | |
| MFO | 0.108808 | 0.044769 |
| Test Function | Dimension | Definition Domain | Min. Value |
|---|---|---|---|
| 20 | (−100, 100) | 0 | |
| 20 | (−500, 500) | 0 | |
| 20 | (−50, 50) | 0 | |
| 20 | (−50, 50) | 0 |
| Test Function | Algorithm | Average Value | Variance |
|---|---|---|---|
| PMFO | 0.1543 | 3.176 | |
| MFO | 7.7671 | 6.176 | |
| PMFO | 8.6771 | 5.7615 | |
| MFO | 2.0415 | 1.7511 | |
| PMFO | 0.009523 | 0.208581 | |
| MFO | 0.077749 | 0.171080 | |
| PMFO | 0.001649 | 0.005124 | |
| MFO | 0.004395 | 0.002523 |
| Data Set | Number of Data | Number of Categories | Number of Features |
|---|---|---|---|
| Glass | 214 | 6 | 9 |
| Breast | 699 | 2 | 11 |
| Abalone | 4177 | 29 | 8 |
| Wine | 178 | 3 | 13 |
| Iris | 150 | 3 | 4 |
| Ecoli | 336 | 8 | 8 |
| Algorithm | Parameter Setting |
|---|---|
| BPMFO | = 2; b = 1; Vmax = 1; Vmin = −1 |
| BMFO | b = 1 |
| Data Set | Algorithm | Before Feature Selection | After Feature Selection | Fitness Value |
|---|---|---|---|---|
| Glass | BPMFO | 9 | 2 | 0.797978 |
| BMFO | 9 | 4 | 0.782778 | |
| Breast | BPMFO | 11 | 4 | 0.966704 |
| BMFO | 11 | 2 | 0.924271 | |
| Abalone | BPMFO | 8 | 3 | 0.265281 |
| BMFO | 8 | 3 | 0.262053 | |
| Wine | BPMFO | 13 | 5 | 0.943396 |
| BMFO | 13 | 6 | 0.934579 | |
| Iris | BPMFO | 4 | 1 | 0.941945 |
| BMFO | 4 | 1 | 0.941945 | |
| Ecoli | BPMFO | 8 | 4 | 0.893901 |
| BMFO | 8 | 6 | 0.893589 |
| Feature | Weight | Feature | Weight |
|---|---|---|---|
| 1 | 5.619589 | 21 | 3.658905 |
| 2 | 9.650791 | 22 | 4.694852 |
| 3 | 4.282662 | 23 | 7.443937 |
| 4 | 6.494251 | 24 | 2.886449 |
| 5 | 8.390892 | 25 | 2.702098 |
| 6 | 7.107178 | 26 | 6.152995 |
| 7 | 5.752698 | 27 | 2.928758 |
| 8 | 3.011028 | 28 | 7.309848 |
| 9 | 2.883600 | 29 | 5.841692 |
| 10 | 2.733738 | 30 | 9.088569 |
| 11 | 4.100507 | 31 | 5.612757 |
| 12 | 5.615577 | 32 | 4.074626 |
| 13 | 6.363829 | 33 | 2.119303 |
| 14 | 3.248322 | 34 | 4.254331 |
| 15 | 4.471637 | 35 | 5.930137 |
| 16 | 5.707215 | 36 | 2.171261 |
| 17 | 5.514407 | 37 | 5.624371 |
| 18 | 5.487701 | 38 | 6.962610 |
| 19 | 4.147335 | 39 | 7.559233 |
| 20 | 4.782790 | 40 | 4.223209 |
| Feature Number | 5 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| Occurrence Time | 1 | 3 | 4 | 7 | 14 | 11 | 5 | 3 | 1 |
| Feature | Frequency | Feature | Frequency |
|---|---|---|---|
| 1 | 9 | 21 | 6 |
| 2 | 37 | 22 | 28 |
| 3 | 17 | 23 | 29 |
| 4 | 8 | 24 | 11 |
| 5 | 10 | 25 | 10 |
| 6 | 8 | 26 | 8 |
| 7 | 10 | 27 | 12 |
| 8 | 5 | 28 | 14 |
| 9 | 17 | 29 | 8 |
| 10 | 11 | 30 | 14 |
| 11 | 9 | 31 | 19 |
| 12 | 9 | 32 | 12 |
| 13 | 13 | 33 | 15 |
| 14 | 9 | 34 | 17 |
| 15 | 9 | 35 | 42 |
| 16 | 6 | 36 | 5 |
| 17 | 6 | 37 | 14 |
| 18 | 10 | 38 | 9 |
| 19 | 5 | 39 | 13 |
| 20 | 5 | 40 | 7 |
| Group 1 | Group 2 | Group 3 | Group 4 | |
|---|---|---|---|---|
| Average fitness value | 0.920181 | 0.976065 | 0.913096 | 0.955825 |
| Average running time (ms) | 8228 | 18,212 | 8154 | 18,150 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, H.; Przystupa, K.; Fang, C.; Marciniak, A.; Kochan, O.; Beshley, M. A Combination Strategy of Feature Selection Based on an Integrated Optimization Algorithm and Weighted K-Nearest Neighbor to Improve the Performance of Network Intrusion Detection. Electronics 2020, 9, 1206. https://doi.org/10.3390/electronics9081206
Xu H, Przystupa K, Fang C, Marciniak A, Kochan O, Beshley M. A Combination Strategy of Feature Selection Based on an Integrated Optimization Algorithm and Weighted K-Nearest Neighbor to Improve the Performance of Network Intrusion Detection. Electronics. 2020; 9(8):1206. https://doi.org/10.3390/electronics9081206
Chicago/Turabian StyleXu, Hui, Krzysztof Przystupa, Ce Fang, Andrzej Marciniak, Orest Kochan, and Mykola Beshley. 2020. "A Combination Strategy of Feature Selection Based on an Integrated Optimization Algorithm and Weighted K-Nearest Neighbor to Improve the Performance of Network Intrusion Detection" Electronics 9, no. 8: 1206. https://doi.org/10.3390/electronics9081206
APA StyleXu, H., Przystupa, K., Fang, C., Marciniak, A., Kochan, O., & Beshley, M. (2020). A Combination Strategy of Feature Selection Based on an Integrated Optimization Algorithm and Weighted K-Nearest Neighbor to Improve the Performance of Network Intrusion Detection. Electronics, 9(8), 1206. https://doi.org/10.3390/electronics9081206