A Security Monitoring Framework for Mobile Devices




Abstract
:1. Introduction
2. State-of-the-Art
2.1. Mobile Device Security Management and Monitoring
- Android for Work/Android Enterprise is a platform that builds on several management and profile isolation features that are already part of the Android OS. Supported features include managed profiles, remote provisioning of certificates and configurations, and remote device control. Profile isolation implies separating the user’s personal data from the user’s business data through the use of containers. It allows the configuration and enforcement of VPN usage on work profiles, protecting work-related data communications over public/external networks.
- Apple’s Business Manager platform is built on top of the Device Enrollment Program, which provides the device management features. It is primarily targeted at provisioning and configuring devices for work purposes. It does not support BYOD models, as it was conceived to only support corporate-owned devices, managing settings, applications, and services that the employees can use. It automatically configures the devices as they are switched on for the first time and there is no need for interaction from the user or any kind of enrollment afterwards.
- Flyve MDM provides several features already present in Android for Work, also providing monitoring capabilities. It is an open-source solution that can be customized to the specific need of an enterprise. Its noteworthy features include the establishment of device groups, secure enrollment, device file deployment, remote control of mobile device features (e.g., Bluetooth, camera, GPS, Wi-Fi), geolocation device logging, and partial or total deletion of data from the device in case of loss or theft.
- Microsoft Intune is not focused on a single mobile OS platform, offering its services for both Android and iOS mobile devices. Its feature scope is limited to the Microsoft 365 and Microsoft Azure app ecosystem, offering customizable security policies that are defined and enforced for each user, device, app, or groups of any of the prior subsets. It also allows for personal and corporate profile isolation within the same device, as well as exclusively storing data in the cloud.
- Samsung KNOX is a vendor-specific solution from Samsung, leveraging multiple technologies to enable the BYOD paradigm. It makes use of security containers, which are employed to enable enterprise applications to run in an isolated environment, managed by means of the MDM APIs. It assures trust by supporting secure boot mechanisms and relying on runtime protections that are compliant with ARM (Advanced RISC Machines) TrustZone and SELinux.
2.2. Event Processing in the Scope of Mobile Device Security
3. Proposed Framework
- Each covered mobile device features a device agent, an application that is responsible for the local monitoring, processing and reporting of relevant device indicators.
- Mobile devices/agents are organized in clusters. According to the circumstances, these clusters may reflect administrative domains, geographic domains or simply be used for sake of scalability or reliability.
- Agents collect data regardless of the device state (stand-by or active).
- Each cluster is integrated by means of a message broker that relays the data published by each device agent to the central aggregator.
- The central aggregator persists the data sent by the device agents in a database, which feeds the anomaly detection tools.
- The central aggregator creates visual representations of the data received from the device agents, as well as the output from the analysis component, to be shown in a monitoring and management dashboard.
3.1. Device Agent
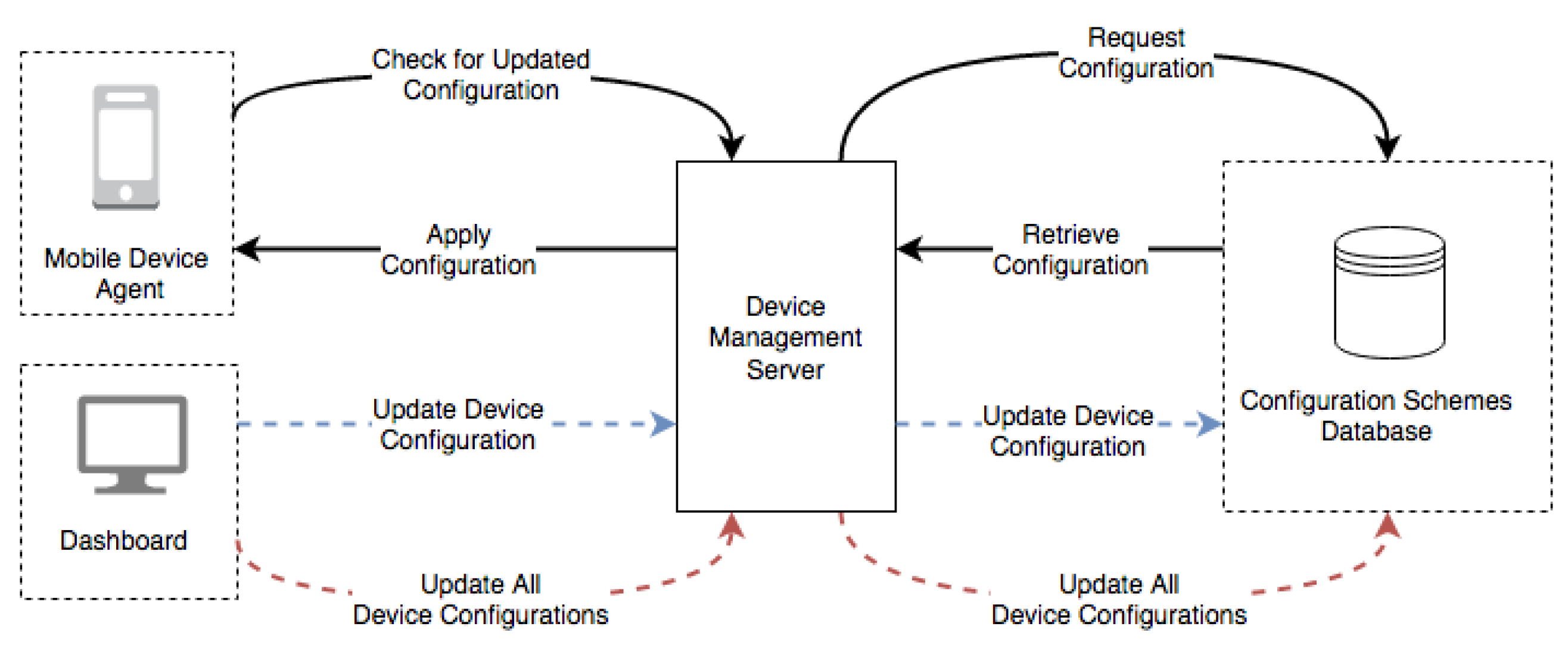
3.2. Device/Agent Management
- Device agents check for configurations changes in the Device Management Server.
- The Device management server is able to query the configurations for a particular device agent.
- The device management server may push new configurations to a specific device agent.
- Via the dashboard UI, the platform administrator may alter the configurations for a specific device, via the device management server.
- The administrator can perform bulk configuration updates for all devices.
4. Implementation
4.1. Device Agent
4.1.1. Collection
- Application Level: Install/update/remove, RAM, CPU, permission list.
- Device Level: Base station association status, GPS (optional), RAM and CPU usage, charging state, battery, connected network (WiFi/cellular data), data traffic (optional), open ports.
- Periodic: CPU, RAM, CPU usage, RAM usage, GPS, battery, open ports, data traffic.
- Eventful: Base station connection/disconnection, charging state, time and timezone changes, network (WiFi/3G) connectivity status, power on/off.
- One Time: Application permissions list, application install/removal/update.
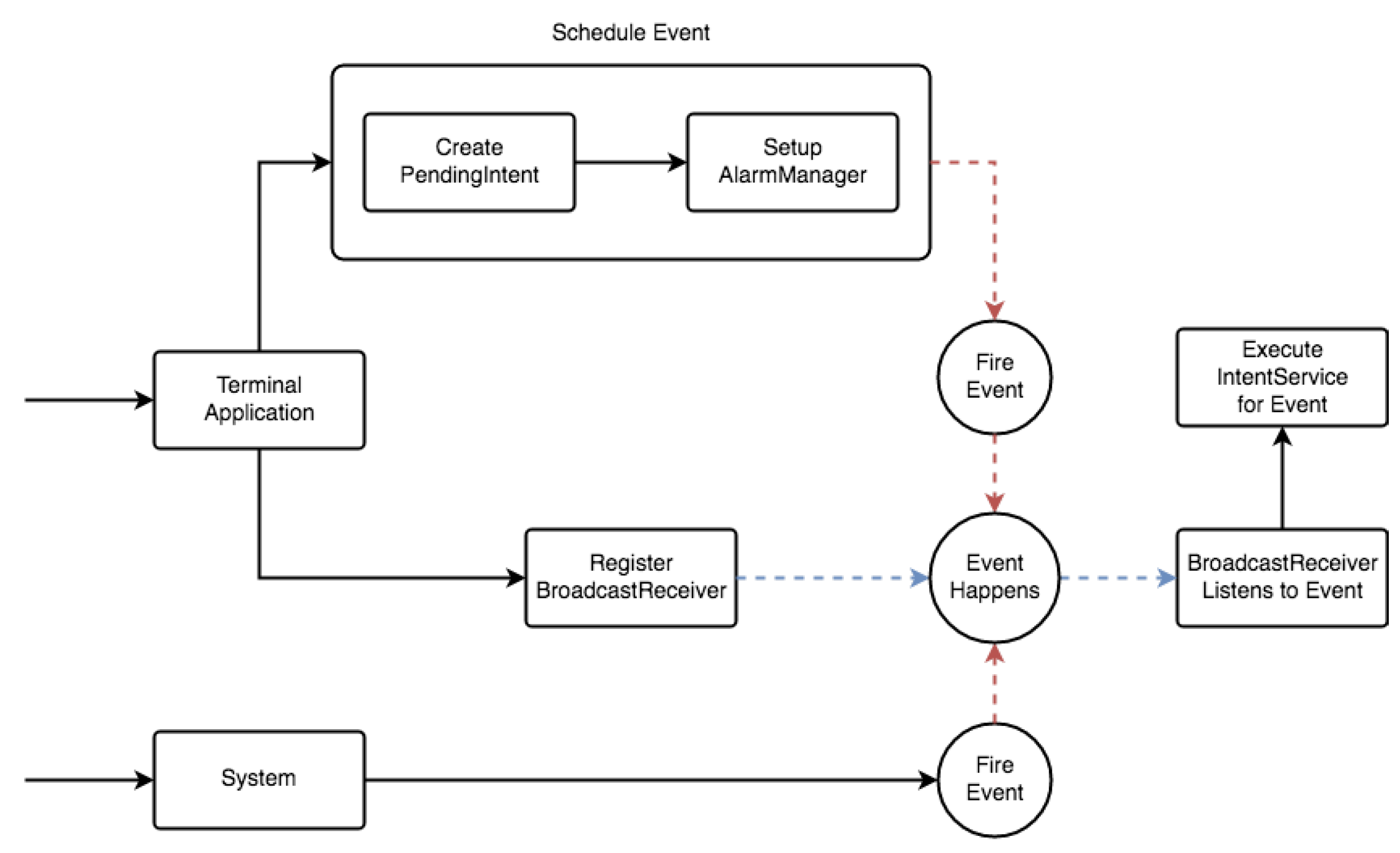
4.1.2. Event Management
- Service—adequate for short, single-threaded tasks not requiring interaction with an activity.
- IntentService—adequate for tasks that are more resource-demanding (threads, time, etc.) than regular services, not requiring interaction with UI elements.
- Handler—these enable sending and processing Message and Runnable objects associated with a thread’s MessageQueue, being capable of managing UI elements in the background.
- AsyncTask—Asynctasks provide a convenient abstraction for Handler objects, while providing tight coupling with an Activity’s UI thread. Asynctasks are able to interact/update UI components before, after or during task execution.
- Register a BroadcastReceiver for the event type.
- Listen for type-specific events.
- Handle the event instance by executing the appropriate IntentService for it.
- For an event is produced by the device agent:
- Create a PendingIntent (the event), which will later be triggered and caught by the adequate BroadcastReceiver.
- Schedule an AlarmManager instance to execute the PendingIntent after an elapsed interval of time.
- In case the event is system-generated, the system itself takes care of dispatching an Intent, to be received by any BroadcastReceivers registerd for events of its kind.
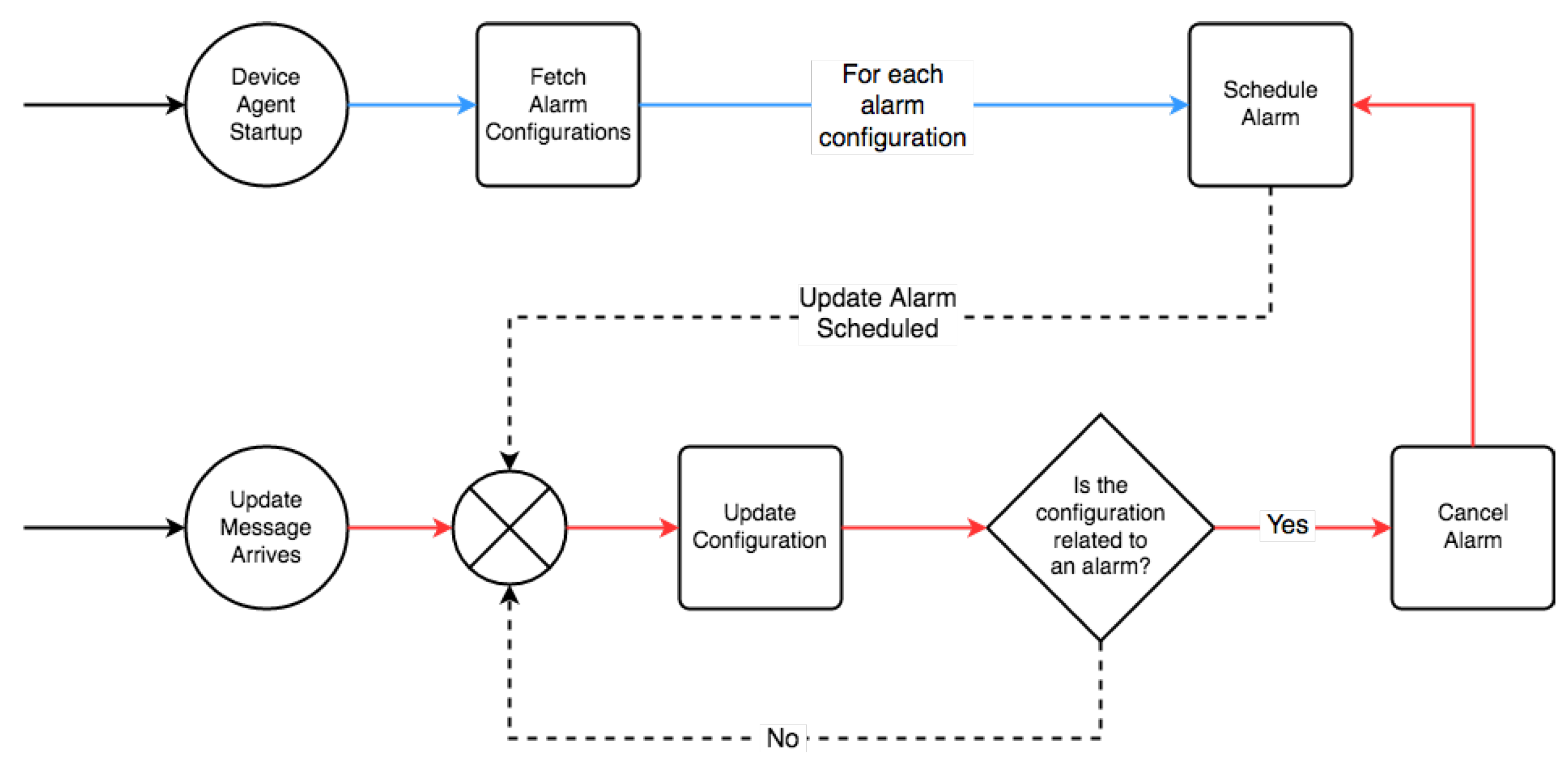
4.1.3. Device Agent Configuration Management within MQTT
Device Agent Configurations: Periodic Collection Actions (Configuration Name (ACTION_), Default Value (s), Description)
- RAM, 60 (s), Measure RAM usage
- CPU, 60 (s), Measure CPU usage
- GPS, 60 (s), Query GPS location data
- CPU_USAGE, 10 (s), Measure application CPU usage
- RAM_USAGE, 10 (s), Measure application RAM usage
- BATTERY, 300 (s), Measure battery level
- OPEN_PORTS, 60 (s), Gather which ports are open for communications
- OPEN_DATA_TRAFFIC, 300 (s), Measure total amount of data received and sent by device (in bytes)
Device Agent Configurations: Other Actions (Configuration Name (ACTION_), Default Value (s), Description)
- AGGREGATE_PERIODIC_DATA, 1800 (s), Aggregate the collected periodic data
- AGGREGATE_EVENTFUL_DATA, 1800 (s), Aggregate the collected eventful data
- PUBLISH_DATA, 3600 (s), Send the collected data to the MQTT server
- UPDATE_CONFIGURATIONS, 3600 (s), Check for updated configurations sent from the MQTT server
Device Agent Configurations: Messaging (Configuration Name (MESSAGING_), Default Value, Description)
- MQTT_TIMEOUT, 10 (s), Timeout value for a network connection to the MQTT server to be established
- MQTT_KEEP_ALIVE, 10 (s), The maximum interval for periodic MQTT keepalive messages, sent or received
- SERVER_PROTOCOL, tcp, Protocol used to communicate with the MQTT server
- SERVER_URI, MQTT server’s URI or IP address
- SERVER_PORT, MQTT server TCP port
- SERVER_BASE_PUBLISH_TOPIC, “OryxInput”, MQTT topic used to publish the data collected from a device
- SERVER_BASE_UPDATE_TOPIC, “Configurations”, subscribed MQTT topic for device agent configuration updates
- SERVER_PASSWORD, MQTT server password
4.1.4. Aggregation
- Median—corresponds to the value separating the higher from the lower half, in a series of observations.
- Geometric mean—often used when comparing different items—finding a single “figure of merit” for these items—when each item has multiple properties that have different numeric ranges
- Arithmetic mean—it corresponds to the sum of a number list divided by the number of elements in that list.
- Harmonic mean—it strongly tends toward the least elements of a number list. It has the benefit of (unlike the arithmetic mean) mitigating the effect of large outliers, at the expense of aggravating the effect of small ones.
- Generalized mean or power mean—a generalized formulation for which the previous alternatives are particular cases. In its generic form it constitutes a non-linear moving average which is shifted towards small or big values depending on its parameter p.
4.2. Message Brokers
4.2.1. Why MQTT
- The use of a REST/HTTPS API would only cover data exchanges. Message ordering, persistence and queue semantics would have to be managed by a separate entitiy: a broker, or enterprise service bus component;
- Several companies successfully use MQTT for Big Data-related projects involving millions of devices;
- MQTT allows to adopt one of the several existing open-source MQTT brokers, some of which have adequate scalability characteristics;
- MQTT is less resource-intensive than a similar service built on HTTPS;
- The max payload size for MQTT messages is 256 MB, with 65 KB for a topic message, which is perfectly adequate for the purposes of this framework;
4.2.2. Encryption and Security
- Network level—one solution might be to resort to a physically secure network or Virtual Private Network (VPN) to protect clients-broker communication, providing a secure and trustworthy connection. This could be feasible for scenarios where devices are being used on a remote LAN that is bridged to the broker, over a VPN gateway.
- Transport level—When the goal is to provide confidentiality, TLS/SSL can be used to provide transport encryption. This approach constitutes a secure and proven way protect communications, which can be reinforced by using certificate-based authentication.
- Application level—apart from transport-level protection (which is covered by the previous items), the MQTT protocol supports a client identifier and username/password credentials, that can also be used implement application level authentication (however, ACL-style controls are dependent on the specific broker implementation). Moreover, the use of payload encryption on the application level could also be used, providing message confidentiality guarantees, even without full fledged transport encryption.
4.3. Aggregator
4.4. Machine Learning (ML)
- Pre-processing—Before any form of heavy processing or machine learning is used, it might be desirable to sanitize or alter the used data using techniques such as outlier removal, normalization or missing value interpolation. Extra caution is required in this step because, since this is a binary classification problem (anomalous vs. normal), certain unique samples may be crucial for the classification step.
- Feature selection—Before any form of classification is performed it is important to identify and select which features are relevant, resorting to summary statistics, correlation matrix or average value functions.
- Feature reduction—The fact that some dataset dimensions may not be relevant for the classification step can hinder the performance of the classifier. As such, principal component analysis (PCA) is used to reduce the number of relevant features used for analysis, using the Kaiser criteria and Scree test to identify the number of considered factors.
- Classification—Malware strains and other anomalies are constantly changing, posing a serious challenge for signature-based detection methods. For this reason, it makes sense to resort to an unsupervised classification toolbox, using suitable clustering methods such as K-means. After some data has been collected it can be labeled using unsupervised classification and fed through supervised classification methods such as decision trees, SVM, K-Nearest Neighbours or neural network. For this last step, a Triple Modular Redundancy approach will be employed, with the final classification being calculated as the rounded median value of three distinct classification techniques, minimizing misclassification errors.
4.5. Data Visualization
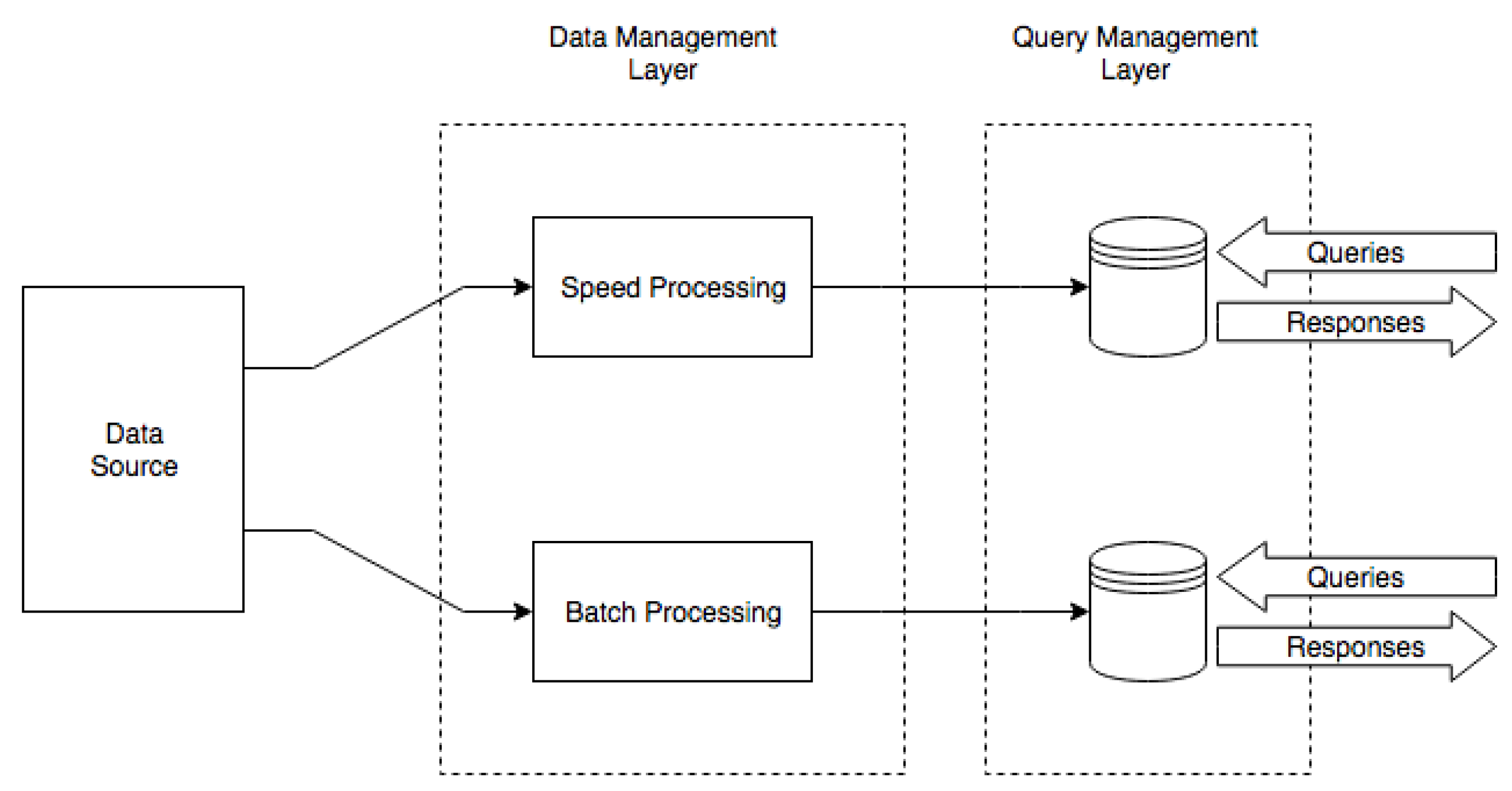
- Large-scale data collection of device measurements.
- Frequent and intensive ingestion of collected data.
- Identification of anomalies based on the acquired data.
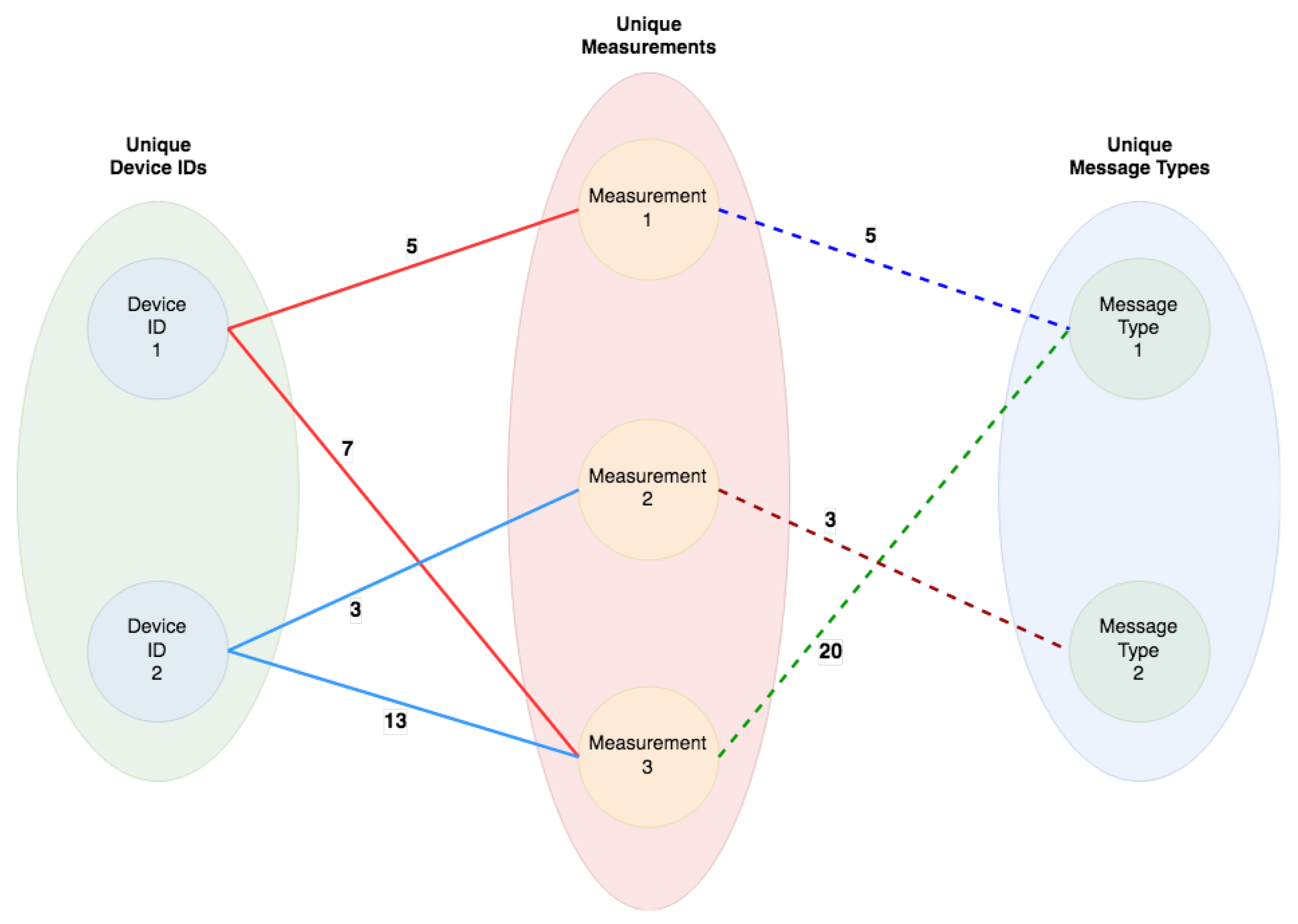
- There are three node groups, each encompassing a variable number of nodes
- Each node on the left node group represents a device agent by means of it’s unique device ID
- Each node on the middle node group represents a unique measurement
- Each node on the right node group represents a type of message
- A device agent belonging to the left group is connected to each one of the unique measurements it generated, in the middle group
- A unique measurement in the middle group is connected to the corresponding category in the right group
- Each edge between the left and middle node groups has a weight which is equal to the number of measurements recorded for the specific Device ID node
- Each edge between the middle and right node groups has a weight which is equal to the number of times that specific measurement has been collected in the system
- The least frequent measurement
- The total amount of measurements
- The most frequent measurement
- The amount of measurements by type/category
- The least frequent type of measurement
- The most frequent type of measurement
- The amount of measurements collected by each device agent
- The device agent with the most amount of measurements collected
- The device agent with the least amount of measurements collected
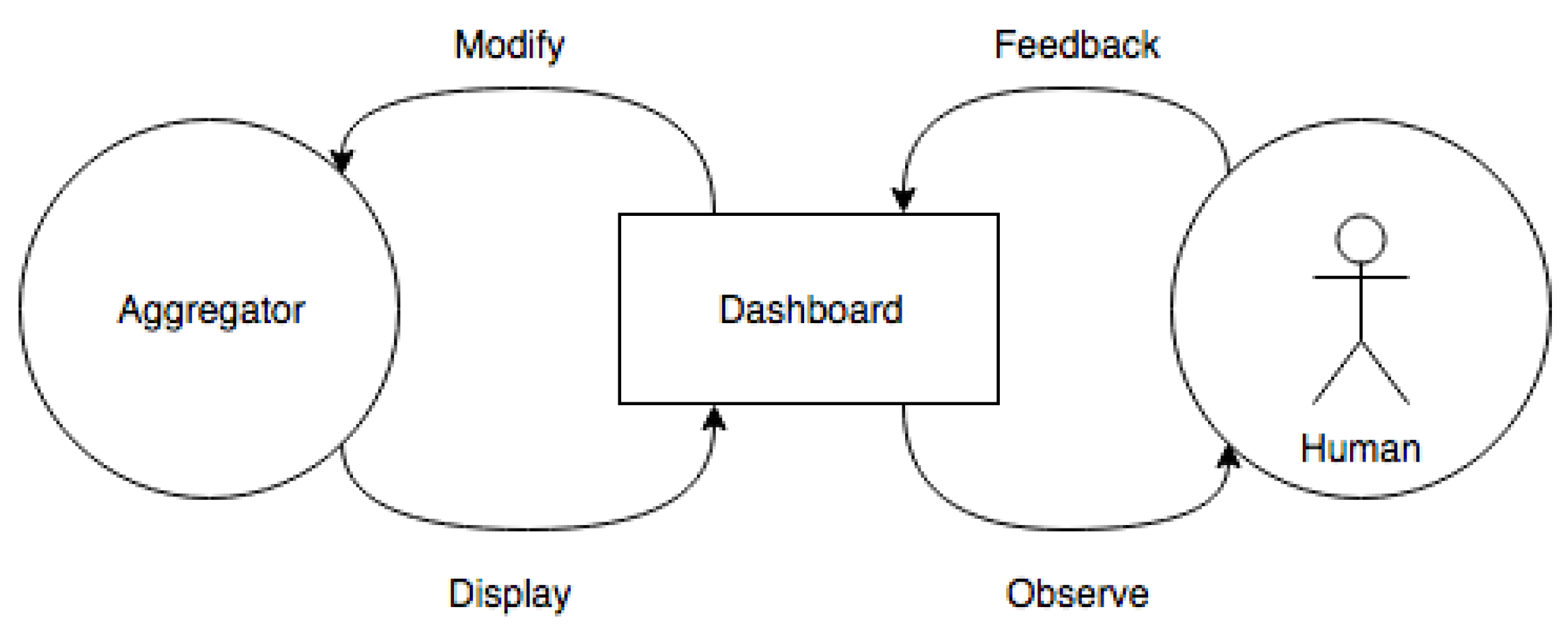
4.6. Dashboard
5. Testing and Validation
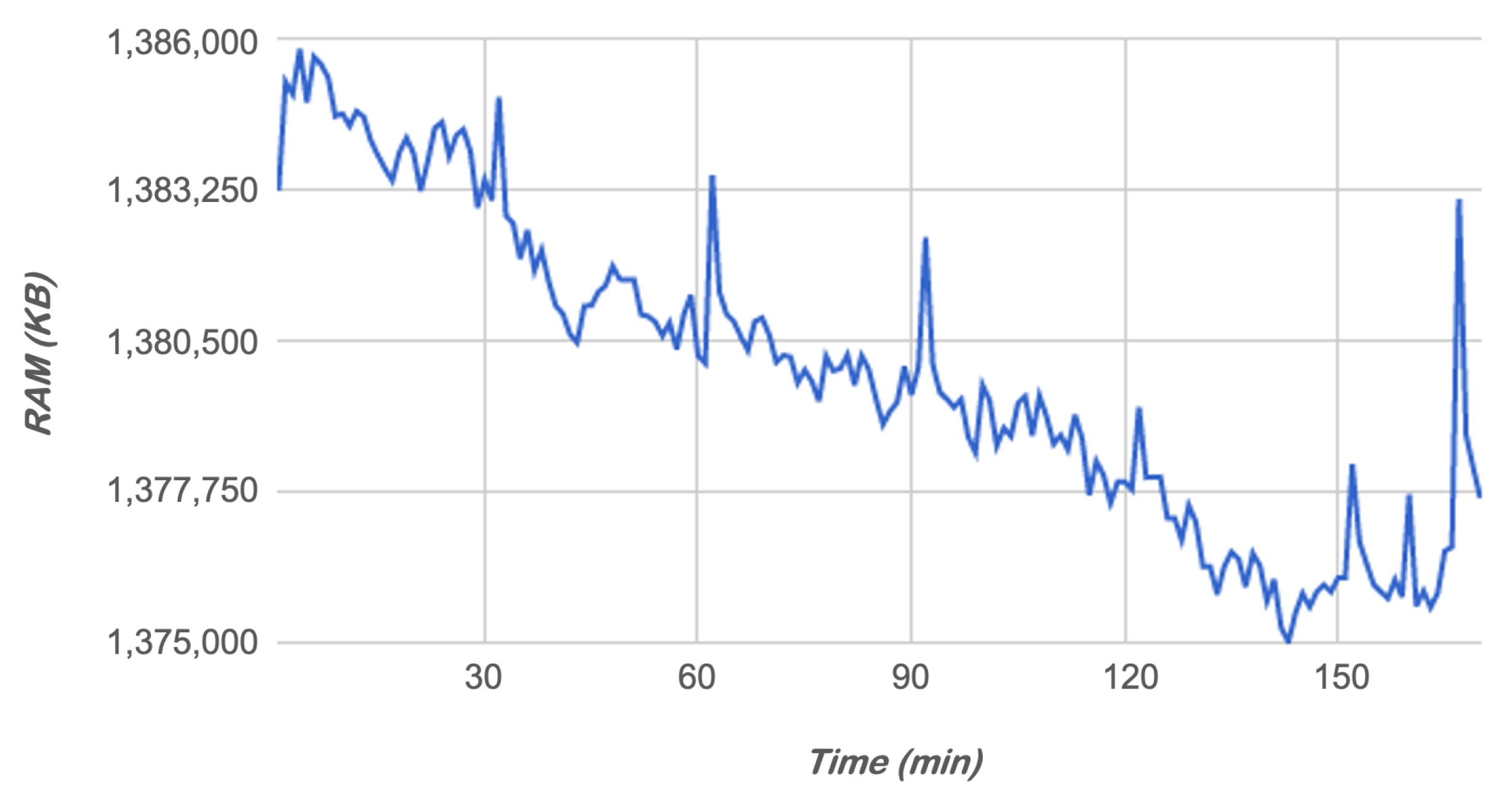
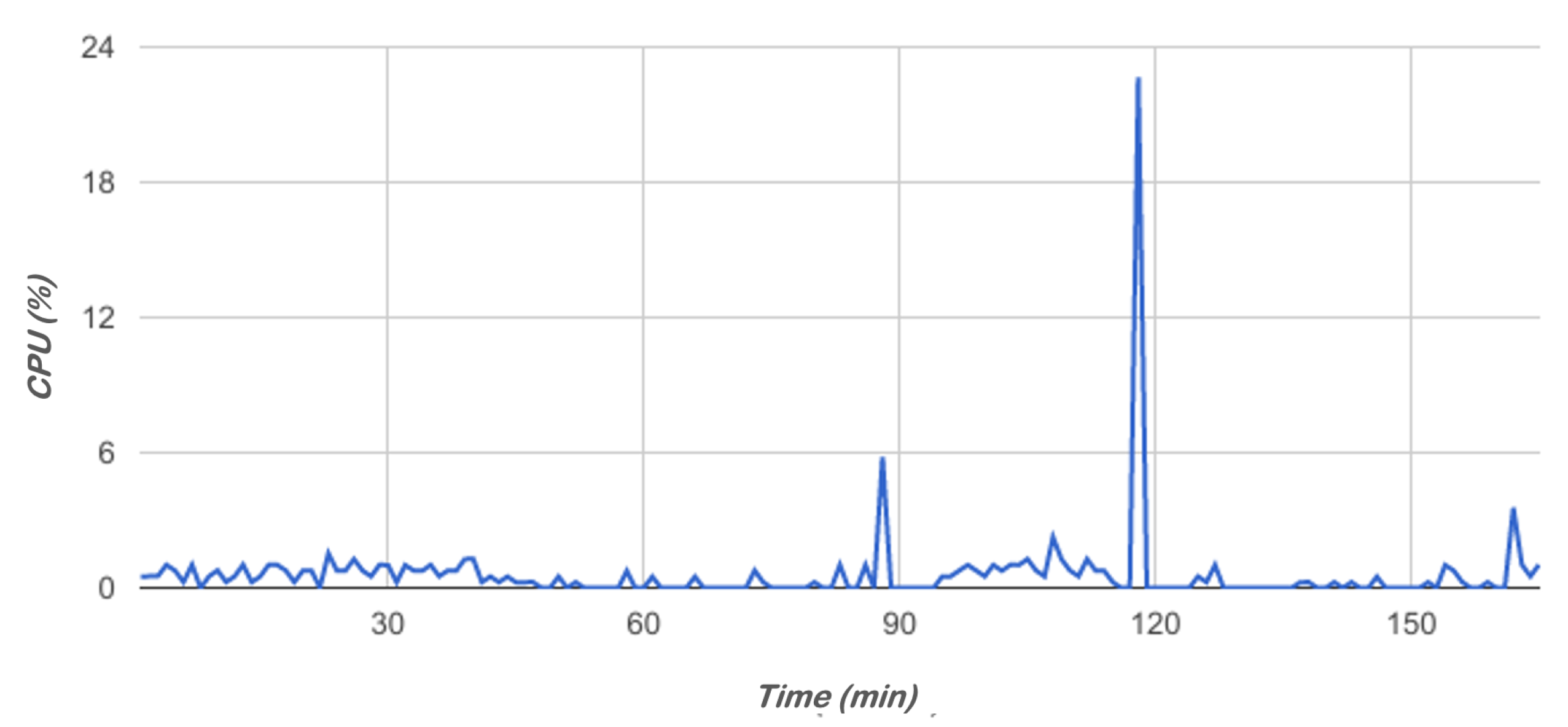
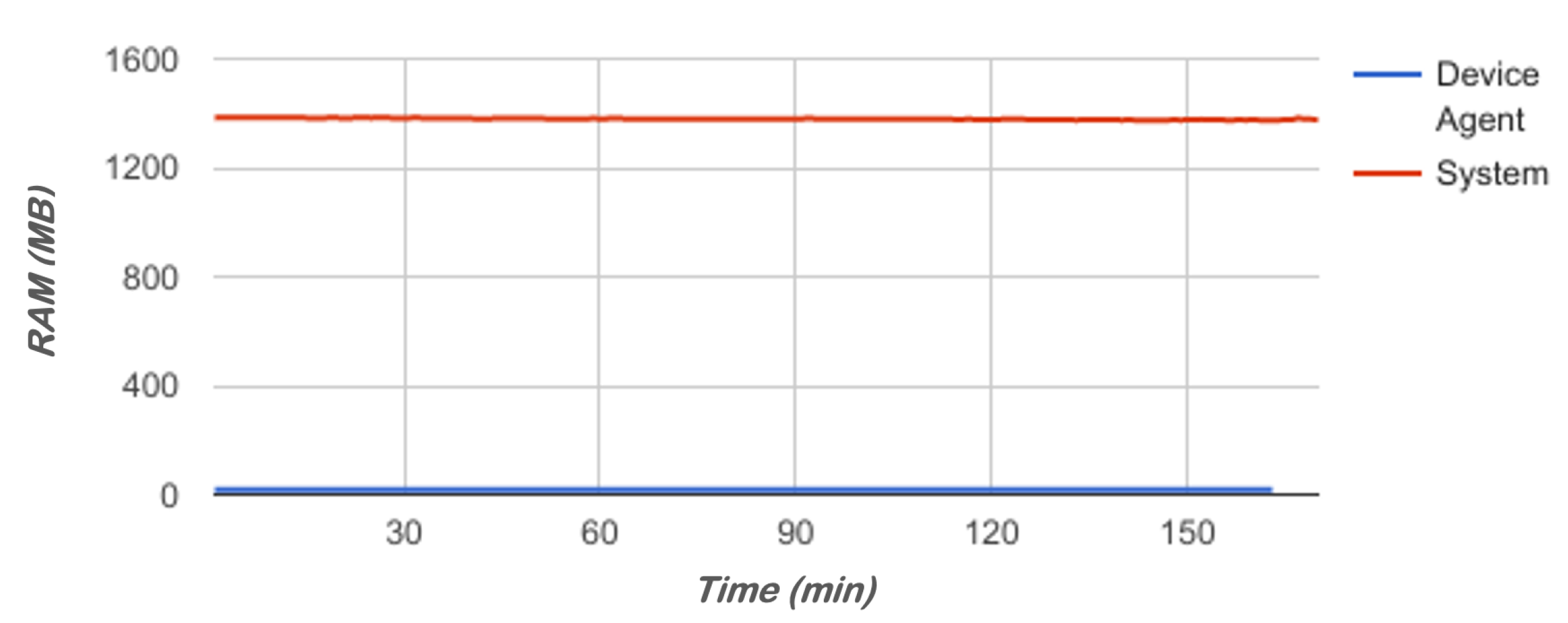
5.1. Impact of the Agent in the Mobile Device
5.2. Impact on the Network
5.2.1. Individual Message Analysis
5.2.2. Empirical Device-Level Network Traffic Overhead Analysis
- ADNT—Average Device Network Traffic
- DMJSO—Device Message JSON Size Overhead
- —Average Number of Device Messages of type m per day
- —Average Size of Content in Device Messages of type m
- CJSO—Content’s JSON string representation Size Overhead
- Message Type—|EM|OM|
- Set of Periodic Messages—RAM, CPU, GPS, CPU Usage, RAM Usage, Battery, Open Ports, Data Traffic}
- Set of Eventful Messages—Time Change, Charging Change, Connection Change, Screen Change, Pwr Change}
- Set of One Time Messages—Package Change}
- Set of Aggregated Messages—Aggregated Periodic, Aggregated Eventful}
5.2.3. Aggregated Network Traffic Overhead Analysis
- ANT—Average Network Traffic
- ADNT—Average Device Network Traffic
- NSDN—Number of Managed Devices in Network
6. Conclusions and Ongoing Work
Author Contributions
Funding
Conflicts of Interest
References
- Lennon, R. Changing user attitudes to security in bring your own device (BYOD) & the cloud. In Proceedings of the 5th Romania Tier 2 Federation Grid, Cloud & High Performance Computing Science (RQLCG), Cluj-Napoca, Romania, 13 June 2012; pp. 49–52. [Google Scholar]
- Lebek, B.; Degirmenci, K.; Breitner, M.H. Investigating the Influence of Security, Privacy, and Legal Concerns on Employees’ Intention to Use BYOD Mobile Devices. In Proceedings of the Nineteenth Americas Conference on Information Systems, Toronto, ON, Canada, 15–17 August 2008; pp. 1–8. [Google Scholar]
- Lima, A. Analysis and Detection of Anomalies in Mobile Devices. Master’s Thesis, Universidade de Coimbra, Coimbra, Portugal, 2017. Available online: https://estudogeral.sib.uc.pt/handle/10316/83277 (accessed on 20 January 2020).
- Lima, A.; Sousa, B.; Cruz, T.; Simões, P. Security for Mobile Device Assets: A Survey. In Mobile Apps Engineering; CRC Press: Boca Raton, FL, USA, 2018; Volume 1, pp. 1–34. ISBN 9781138054356. [Google Scholar]
- Samsung KNOX. Available online: https://www.samsungknox.com/en (accessed on 22 September 2019).
- Apple Business Manager. Available online: https://business.apple.com (accessed on 22 September 2019).
- Android Enterprise. Available online: https://www.an-droid.com/enterprise/ (accessed on 22 September 2019).
- Microsoft Intune. Available online: https://docs.microsoft.com/en-us/mem/intune/fundamentals/what-is-intune (accessed on 2 July 2020).
- Flyve Open-Source Device Management. Available online: https://www.flyve-mdm.com (accessed on 22 September 2019).
- Google Analytics for Firebase. Available online: https://firebase.google.com/products/analytics (accessed on 22 May 2020).
- Yahoo Flurry Analytics. Available online: https://www.flurry.com (accessed on 22 May 2020).
- Microsoft App Center Analytics. Available online: https://docs.microsoft.com/en-us/appcenter/analytics/ (accessed on 22 May 2020).
- Firebase Crashlytics. Available online: https://firebase.google.com/docs/crashlytics (accessed on 22 May 2020).
- Garba, A.B.; Armarego, J.; Murray, D.; Kenworthy, W. Review of the information security and privacy challenges in Bring Your Own Device (BYOD) environments. J. Inf. Priv. Secur. 2015, 11, 38–54. [Google Scholar] [CrossRef]
- Hou, S.; Ye, Y.; Song, Y.; Abdulhayoglu, M. Hindroid: An intelligent android malware detection system based on structured heterogeneous information network. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1507–1515. [Google Scholar]
- Memon, L.U.; Bawany, N.Z.; Shamsi, J.A. A comparison of machine learning techniques for android malware detection using apache spark. J. Eng. Sci. Technol. 2019, 14, 1572–1586. [Google Scholar]
- Zhu, H.J.; You, Z.H.; Zhu, Z.X.; Shi, W.L.; Chen, X.; Cheng, L. DroidDet: Effective and robust detection of android malware using static analysis along with rotation forest model. Neurocomputing 2018, 272, 638–646. [Google Scholar] [CrossRef]
- Abawajy, J.H.; Kelarev, A. Iterative Classifier Fusion System for the Detection of Android Malware. IEEE Trans. Big Data 2019, 5, 282–292. [Google Scholar] [CrossRef]
- DeLoach, J.; Caragea, D.; Ou, X. Android malware detection with weak ground truth data. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 3457–3464. [Google Scholar]
- Tong, F.; Yan, Z. A hybrid approach of mobile malware detection in Android. J. Parallel Distrib. Comput. 2017, 103, 22–31. [Google Scholar] [CrossRef]
- Google Brain Team. TensorFlow Lite: Deploy Machine Learning Models on Mobile and IoT Devices. Available online: https://www.tensorflow.org/lite (accessed on 21 July 2020).
- Feng, R.; Chen, S.; Xie, X.; Ma, L.; Meng, G.; Liu, Y.; Lin, S. MobiDroid: A Performance-Sensitive Malware Detection System on Mobile Platform. In Proceedings of the 2019 24th International Conference on Engineering of Complex Computer Systems (ICECCS), Hong Kong, China, 10–13 November 2019; pp. 61–70. [Google Scholar]
- Takawale, H.C.; Thakur, A. Talos App: On-Device Machine Learning Using TensorFlow to Detect Android Malware. In Proceedings of the 2018 Fifth International Conference on Internet of Things: Systems, Management and Security, Valencia, Spain, 15–18 October 2018; pp. 250–255. [Google Scholar]
- Barmpatsalou, K.; Cruz, T.; Monteiro, E.; Simoes, P. Current and Future Trends in Mobile Device Forensics: A Survey. ACM Comput. Surv. 2018, 51. [Google Scholar] [CrossRef]
- Marz, N.; Warren, J. Big Data: Principles and Best Practices of Scalable Real-Time Data Systems; Manning Publications Co.: New York, NY, USA, 2015. [Google Scholar]
- Kreps, J. Questioning the Lambda Architecture. July 2014. Available online: https://www.oreilly.com/radar/questioning-the-lambda-architecture/ (accessed on 21 July 2020).
- Forgeat, J. Data Processing Architectures—Lambda and Kappa; Ericsson: Stockholm, Sweden, 2015. [Google Scholar]
- Feick, M.; Kleer, N.; Kohn, M. Fundamentals of Real-Time Data Processing Architectures Lambda and Kappa. In Proceedings of the SKILL 2018—Studierendenkonferenz Informatik, Berlin, Germany, 26–27 September 2018; pp. 55–66. [Google Scholar]
- Databricks. Delta Architecture, a Step Beyond Lambda Architecture. Available online: https://pt.slideshare.net/JuanPauloGutierrez/delta-architecture (accessed on 23 July 2020).
- Linux Foundation. Delta Lake—Reliable Data Lakes at Scale. Available online: https://delta.io/ (accessed on 23 July 2020).
- Zahid, H.; Mahmood, T.; Morshed, A.; Sellis, T. Big data analytics in telecommunications: Literature review and architecture recommendations. IEEE/CAA J. Autom. Sin. 2019, 7, 18–38. [Google Scholar] [CrossRef]
- Liu, X.; Iftikhar, N.; Nielsen, P.S.; Heller, A. Online anomaly energy consumption detection using lambda architecture. In International Conference on Big Data Analytics and Knowledge Discovery; Springer: Cham, Switzerland, 2016; pp. 193–209. [Google Scholar]
- Seyvet, N.; Viela, I.M. Applying the Kappa Architecture in the Telco Industry. 2016. Available online: https://www.oreilly.com/content/applying-the-kappa-architecture-in-the-telco-industry/ (accessed on 21 July 2020).
- Carvalho, O.; Roloff, E.; Navaux, P.O. A Distributed Stream Processing Based Architecture for IoT Smart Grids Monitoring. In Proceedings of the UCC ’17 Companion 10th International Conference on Utility and Cloud Computing, Austin, TX, USA, 5–8 December 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 9–14. [Google Scholar] [CrossRef]
- Estrada, R. Fast Data Processing Systems with SMACK Stack; Packt Publishing Ltd.: Birmingham, UK, 2016. [Google Scholar]
- Dizdarević, J.; Carpio, F.; Jukan, A.; Masip-Bruin, X. A Survey of Communication Protocols for Internet of Things and Related Challenges of Fog and Cloud Computing Integration. ACM Comput. Surv. 2019, 51, 1–29. [Google Scholar] [CrossRef]
- Apache Spark (2017b) Spark Overview. Available online: https://spark.apache.org/docs/1.0.1/index.html (accessed on 22 September 2019).
- Acar, A.; Aksu, H.; Selcuk, A.; Conti, M. A Survey on Homomorphic Encryption Schemes: Theory and Implementation. ACM Comput. Surv. 2018, 51, 1–35. [Google Scholar] [CrossRef]
- Halevi, S.; Shoup, V. HElib: An Implementation of Homomorphic Encryption. Available online: https://github.com/shaih/HElib (accessed on 31 December 2014).
- Apache Hadoop Project. Available online: http://hadoop.apache.org (accessed on 22 September 2019).
- Dean, J.; Ghemawat, S. MapReduce: Simplified Data Processing on Large Clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Shvachko, K.; Kuang, H.; Radia, S.; Chansler, R. The Hadoop Distributed File System. In Proceedings of the 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), Incline Village, NV, USA, 3–7 May 2010; pp. 1–10. [Google Scholar] [CrossRef]
- Bertran, P.F. Lambda Architecture: A State-of-the-Art. 2014. Available online: http://www.datasalt.com/2014/01/lambda-architecture-a-state-of-the-art/ (accessed on 20 January 2017).
- Bijnens, N.; Hausenblas, M. Lambda Architecture: A State-of-the-Art. 2016. Available online: http://lambda-architecture.net/ (accessed on 20 January 2017).
- Nierbeck, A. IoT Analytics Platform. 2016. Available online: https://blog.codecentric.de/en/2016/07/iot-analytics-platform/ (accessed on 20 January 2017).
- Bertran, P.F. An Example “Lambda Architecture” for Real-Time Analysis of Hashtags Using Trident, Hadoop and Splout SQL. 2013. Available online: http://www.datasalt.com/2013/01/an-example-lambda-architecture-using-trident-hadoop-and-splout-sql (accessed on 22 September 2019).
- Apache Spark (2017a) Machine Learning Library (MLlib). Available online: https://spark.apache.org/docs/1.0.1/mllib-guide.html (accessed on 22 September 2019).
- Lima, A. Network Traffic Spreadsheet. 2017. Available online: https://goo.gl/BHn2oZ (accessed on 21 July 2020).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Samsung KNOX | Android for Work | Flyve MDM | Microsoft Intune | Apple DEP | |
|---|---|---|---|---|---|
| Secure Boot | • | ||||
| Profile Isolation | • | • | • | ||
| Deployment of Security Policies | • | • | • | • | • |
| Deployment of Apps | • | • | • | • | • |
| Dedicated Apps | • | • | • | ||
| Device Monitoring | • | • | |||
| Remote data Wipe | • | • | • | • | |
| Secure Execution | • | ||||
| Supported OSs | Android | Android | Android | Android, iOS | iOS |
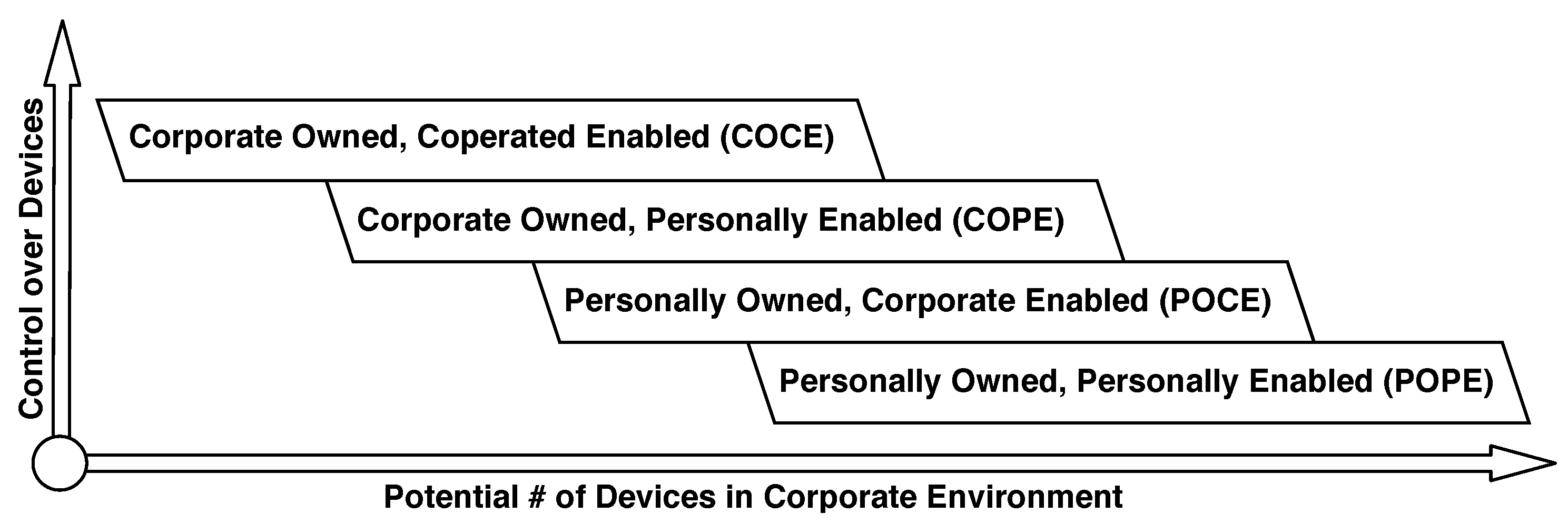
| BYOD Scheme | Device Control | # Devices in Corporation |
|---|---|---|
| Corporate Owned Corporate Enabled (COCE) | ++++ | + |
| Corporate Owned Personally Enabled (COPE) | +++ | ++ |
| Personally Owned Corporate Enabled (POCE) | ++ | +++ |
| Personally Owned Personally Enabled (POPE) | + | ++++ |
| # | Min | Avg | Max | ||
|---|---|---|---|---|---|
| Application RAM (MB) | 467 | 17,756 | 18,773 | 544 | 23,521 |
| Available System RAM (MB) | 493 | 1,365,270 | 1,383,270 | 6361 | 1,395,916 |
| Available System CPU (%) | 476 | 0 | 0.8 | 1.6 | 22.6(6) |
| Min | Avg | Max | ||
|---|---|---|---|---|
| Application CPU (%) | 0 | 0.007 | 0.368 | 26 |
| Application Threads (#) | 14 | 17.87 | 0.823 | 22 |
| Aprox. Size (bytes) | ||||
|---|---|---|---|---|
| Configuration Message Type | Min | Avg | Limit | Stdev |
| Data Generation | ||||
| RAM | 1 | 5 | 10 | 0.82 |
| CPU | 1 | 5 | 10 | 0.23 |
| GPS | 1 | 5 | 10 | 0.13 |
| CPU_USAGE | 1 | 5 | 10 | 0.62 |
| RAM_USAGE | 1 | 5 | 10 | 1.21 |
| BATTERY | 1 | 6 | 10 | 0.11 |
| OPEN_PORTS | 1 | 5 | 10 | 1.13 |
| DATA_TRAFFIC | 1 | 6 | 10 | 3.84 |
| AGGREGATE_PERIODIC_DATA | 1 | 7 | 10 | 1.88 |
| AGGREGATE_EVENTFUL_DATA | 1 | 7 | 10 | 2.62 |
| Aprox. Size (bytes) | |||
|---|---|---|---|
| Configuration Message Type | Min | Avg | Limit |
| Message Management | |||
| PUBLISH_DATA | 1 | 7 | 10 |
| UPDATE_CONFIGURATIONS | 1 | 7 | 10 |
| MQTT_TIMEOUT | 1 | 2 | 10 |
| MQTT_KEEP_ALIVE | 1 | 2 | 10 |
| SERVER_PROTOCOL | 3 | 3 | 4 |
| SERVER_URI | 1 | 15 | 23 |
| SERVER_PORT | 1 | 4 | 10 |
| SERVER_BASE_PUBLISH_TOPIC | 1 | 9 | 65,536 |
| SERVER_BASE_UPDATE_TOPIC | 1 | 14 | 65,536 |
| SERVER_PASSWORD | 0 | 16 | 65,535 |
| Message Type (m) | ANDM (#) | ASDM (bytes) | Stdev |
|---|---|---|---|
| Periodic | |||
| RAM | 1440 | 37 | 4.7 |
| CPU | 1440 | 21 | 4.1 |
| GPS | 1440 | 35 | 6.1 |
| CPU Usage | 8640 | 44 | 2.8 |
| RAM Usage | 8640 | 72 | 5.5 |
| Battery | 288 | 13 | 1.8 |
| Open Ports | 1440 | 155 | 1.7 |
| Data Traffic | 288 | 84 | 12.1 |
| Eventful | |||
| Time Change | 0 | 65 | N/C |
| Charging Change | 1 | 70 | N/C |
| Connection Change | 1 | 63 | N/C |
| Cell Location Change | 1 | 100 | N/C |
| Screen Change | 50 | 70 | 1.8 |
| Power Change | 0 | 70 | N/C |
| One Time | |||
| Package Change | 0 | 150 | N/C |
| Aggregated | |||
| Aggregated Periodic | 2880 | 120 | 6.1 |
| Aggregated Eventful | 2880 | 90 | 4.7 |
| Total | 29,429 | 1259 | — |
| (#) | Aprox. (bytes) |
|---|---|
| 1 | 4 MB |
| 10 | 40 MB |
| 100 | 400 MB |
| 1 K | 4 GB |
| 10 K | 40 GB |
| 100 K | 400 GB |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lima, A.; Rosa, L.; Cruz, T.; Simões, P. A Security Monitoring Framework for Mobile Devices. Electronics 2020, 9, 1197. https://doi.org/10.3390/electronics9081197
Lima A, Rosa L, Cruz T, Simões P. A Security Monitoring Framework for Mobile Devices. Electronics. 2020; 9(8):1197. https://doi.org/10.3390/electronics9081197
Chicago/Turabian StyleLima, António, Luis Rosa, Tiago Cruz, and Paulo Simões. 2020. "A Security Monitoring Framework for Mobile Devices" Electronics 9, no. 8: 1197. https://doi.org/10.3390/electronics9081197
APA StyleLima, A., Rosa, L., Cruz, T., & Simões, P. (2020). A Security Monitoring Framework for Mobile Devices. Electronics, 9(8), 1197. https://doi.org/10.3390/electronics9081197