Author Contributions
Conceptualization, H.K.; methodology, C.H.; software, H.K.; validation, C.H., H.K. and T.L.; formal analysis, C.H.; investigation, C.H.; resources, H.L.; data curation, C.H. and H.L.; writing—original draft preparation, H.K.; writing—review and editing, C.H.; visualization, C.H. and H.K.; supervision, T.L.; project administration, T.L.; funding acquisition, T.L. All authors have read and agreed to the published version of the manuscript.
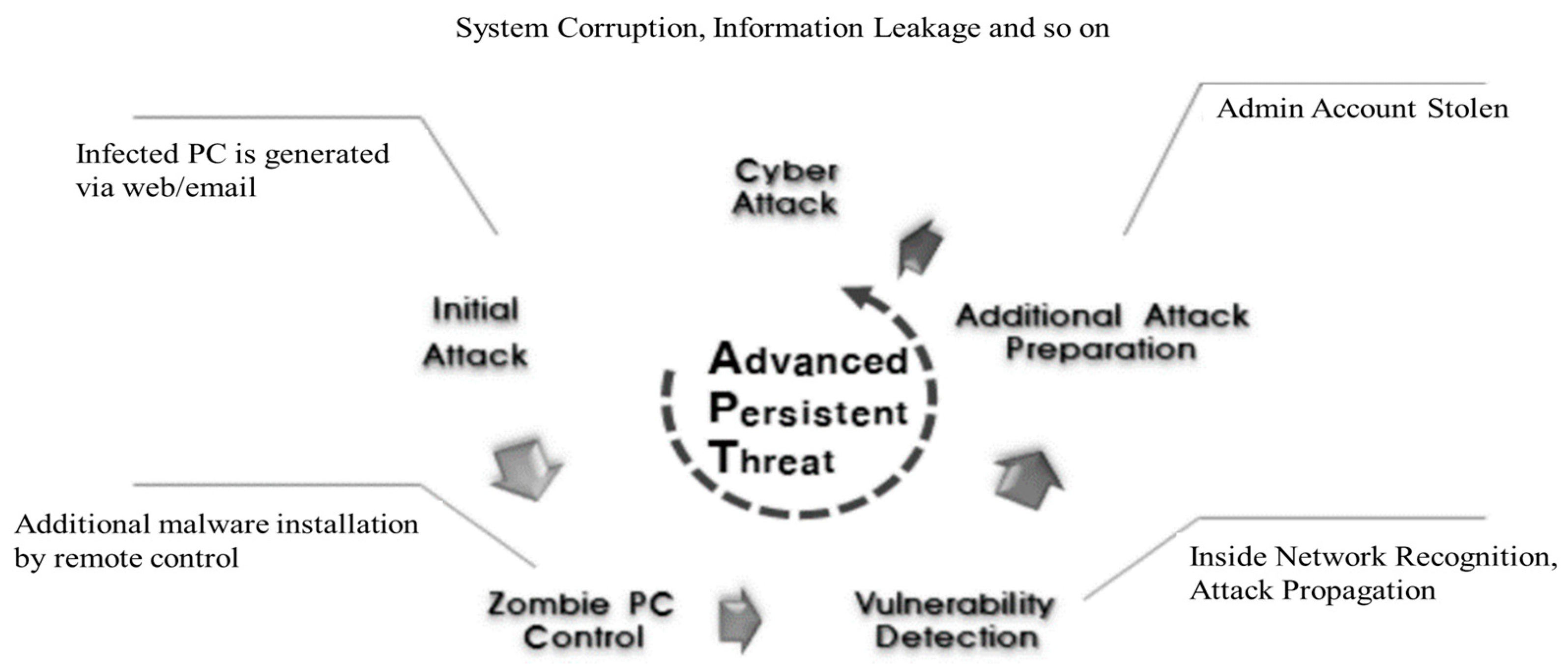
Figure 1.
Advanced persistent threat (APT) attack cycle.
Figure 1.
Advanced persistent threat (APT) attack cycle.
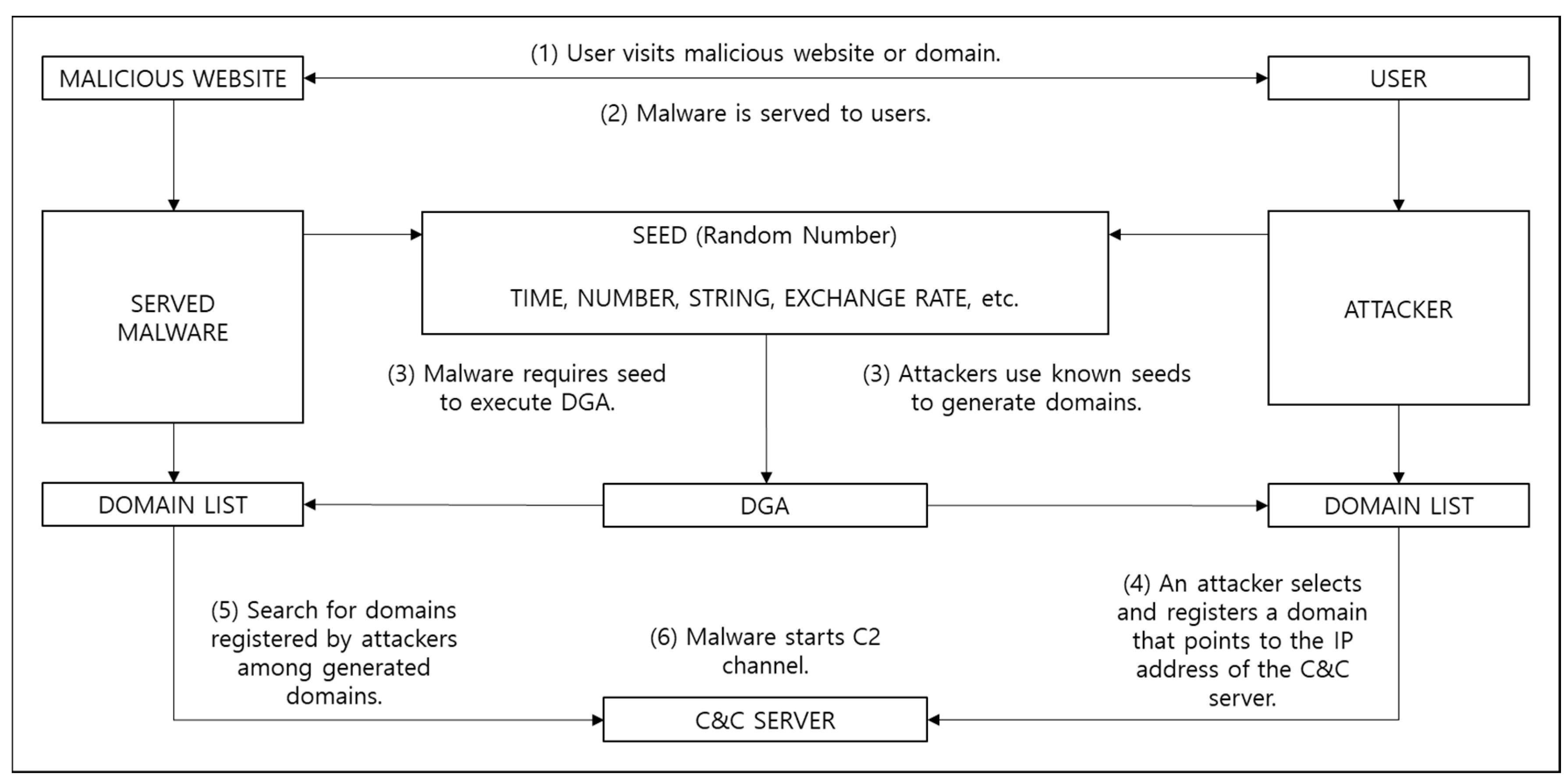
Figure 2.
Overall domain generation algorithm (DGA) operation process.
Figure 2.
Overall domain generation algorithm (DGA) operation process.
Figure 3.
Comparison of TextCNN and autoencoder classification results.
Figure 3.
Comparison of TextCNN and autoencoder classification results.
Figure 4.
Example of n-gram creation (n = 5).
Figure 4.
Example of n-gram creation (n = 5).
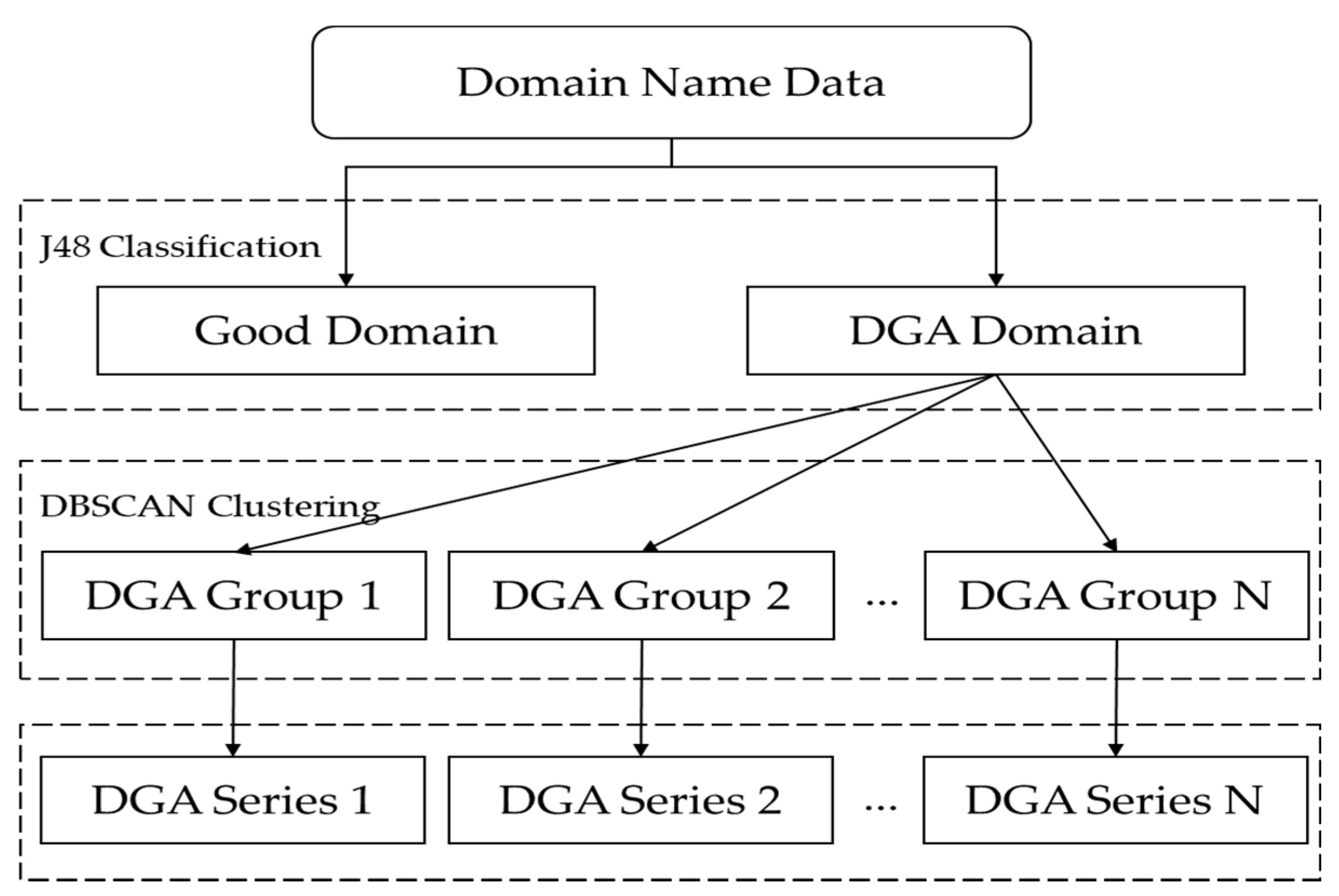
Figure 5.
Model of DGA classification and clustering.
Figure 5.
Model of DGA classification and clustering.
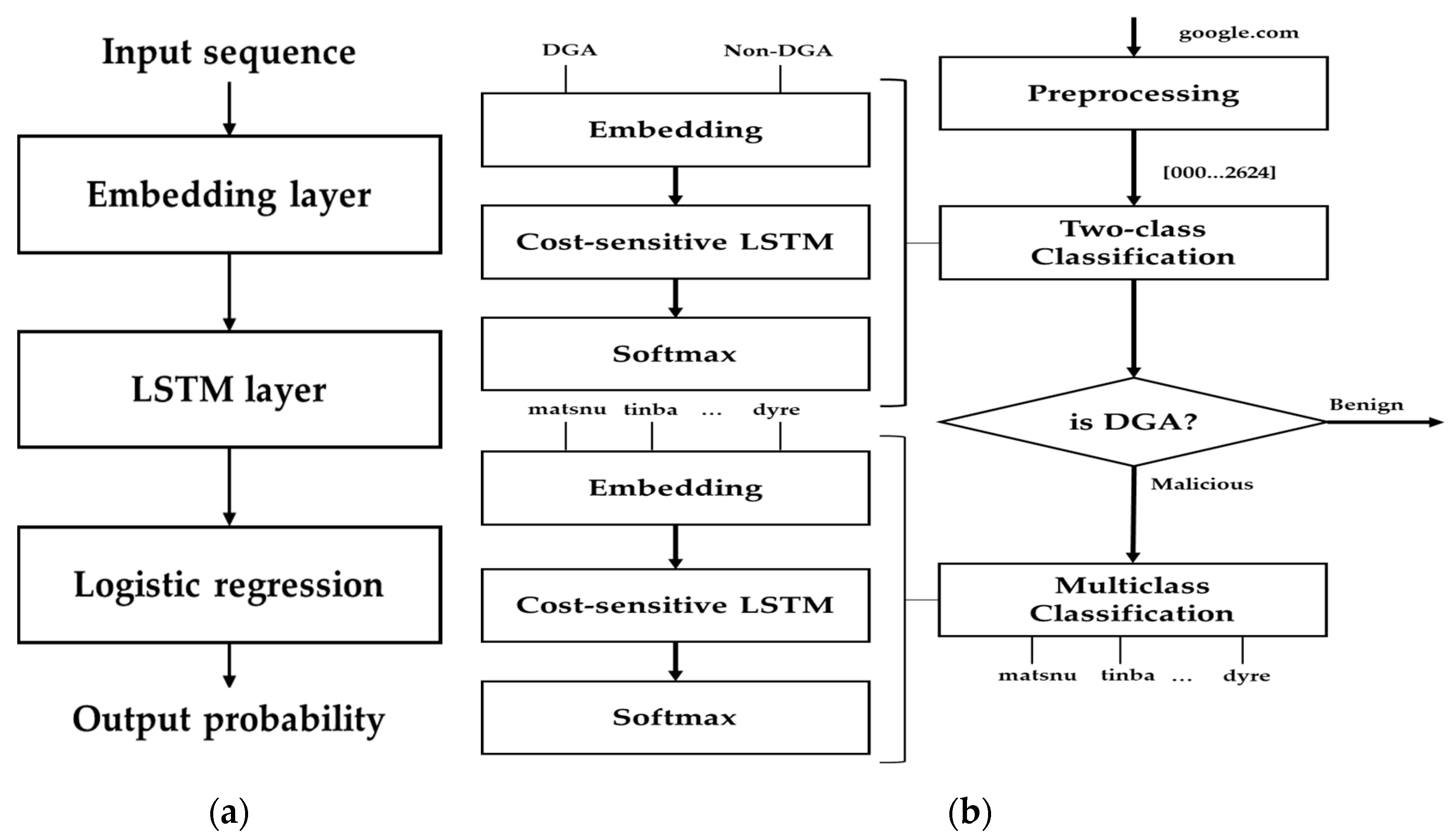
Figure 6.
DGA classification model using long short-term memory (LSTM): (a) LSTM-based DGA classifier without contextual information or manually created features; (b) DGA classifier based on LSTM.MI algorithm.
Figure 6.
DGA classification model using long short-term memory (LSTM): (a) LSTM-based DGA classifier without contextual information or manually created features; (b) DGA classifier based on LSTM.MI algorithm.
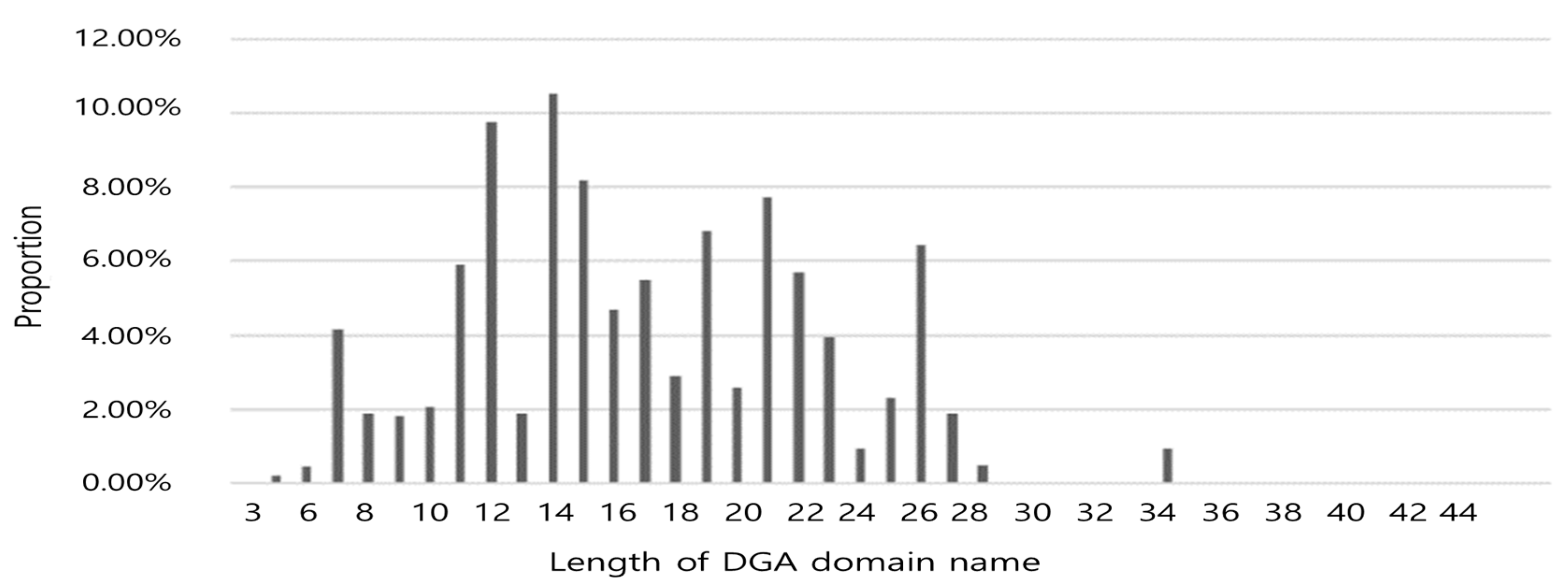
Figure 7.
DGA domain name length distribution.
Figure 7.
DGA domain name length distribution.
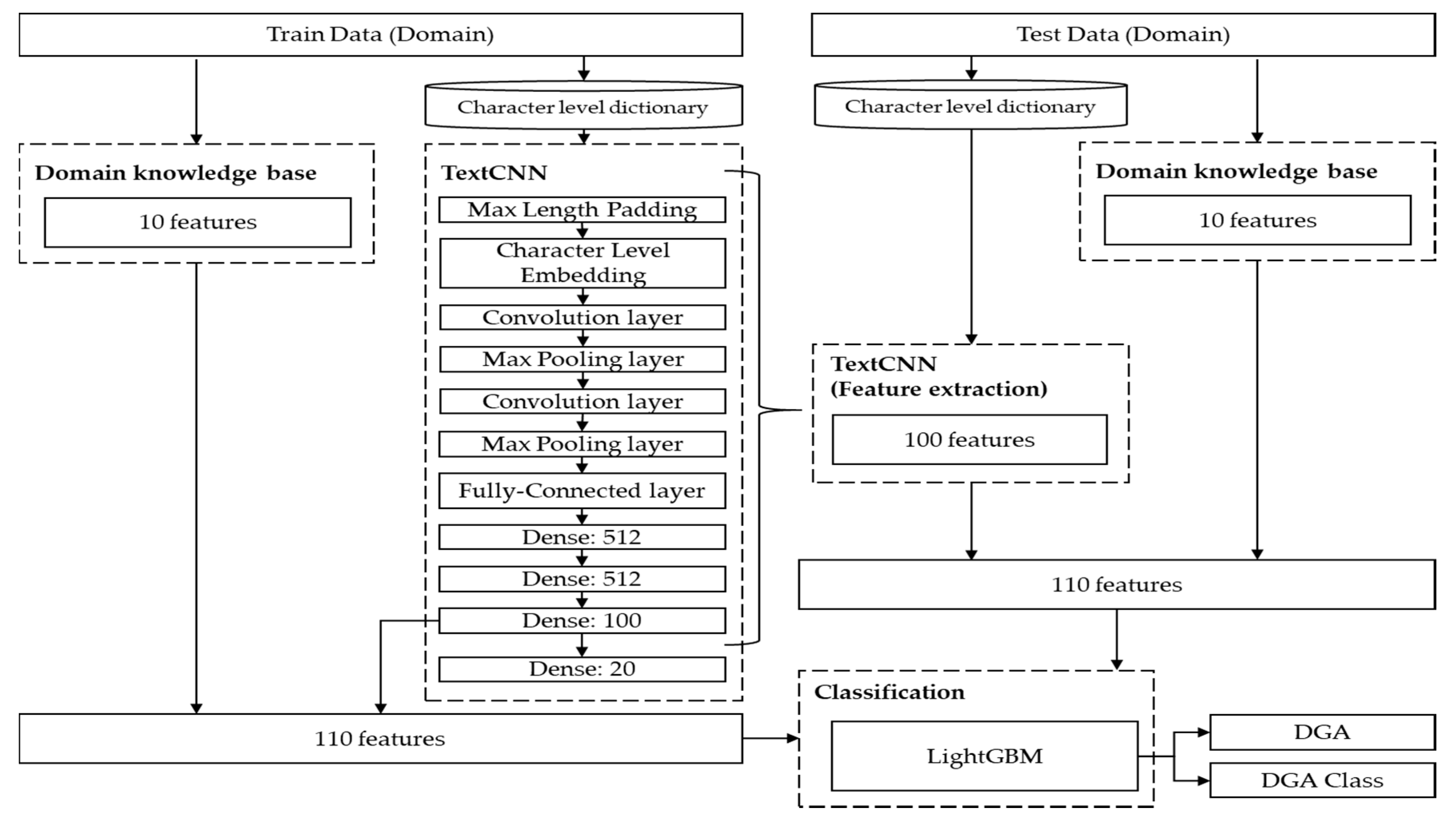
Figure 8.
Effective DGA domain detection and classification model composition diagram combining TextCNN features and domain knowledge features.
Figure 8.
Effective DGA domain detection and classification model composition diagram combining TextCNN features and domain knowledge features.
Figure 9.
Domain length distribution in dataset: (a) training dataset; (b) test dataset.
Figure 9.
Domain length distribution in dataset: (a) training dataset; (b) test dataset.
Figure 10.
Information Entropy calculation pseudo-code.
Figure 10.
Information Entropy calculation pseudo-code.
Figure 11.
Example of distribution for top-level domain (TLD) used by each DGA.
Figure 11.
Example of distribution for top-level domain (TLD) used by each DGA.
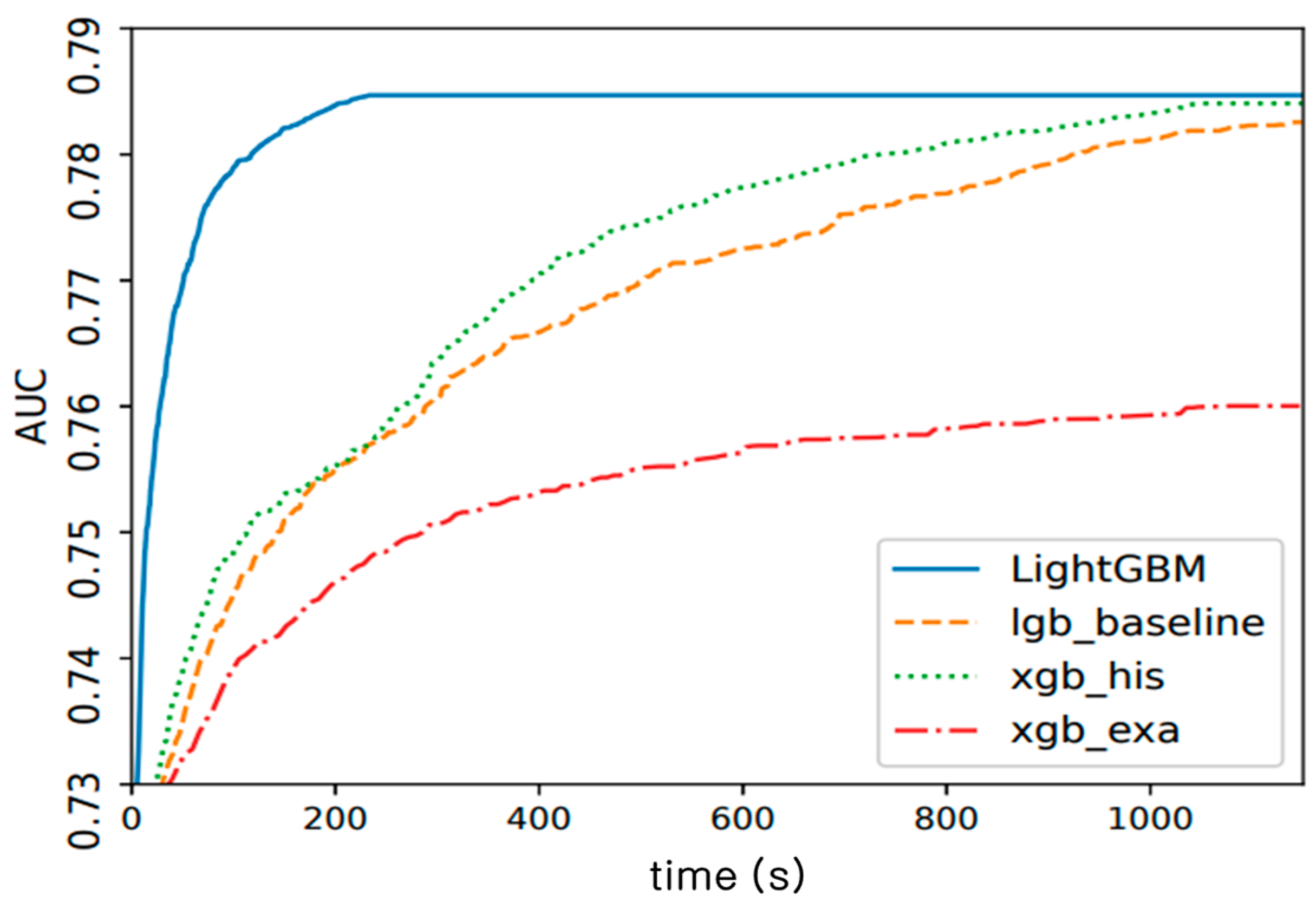
Figure 12.
LightGBM performance comparison graph.
Figure 12.
LightGBM performance comparison graph.
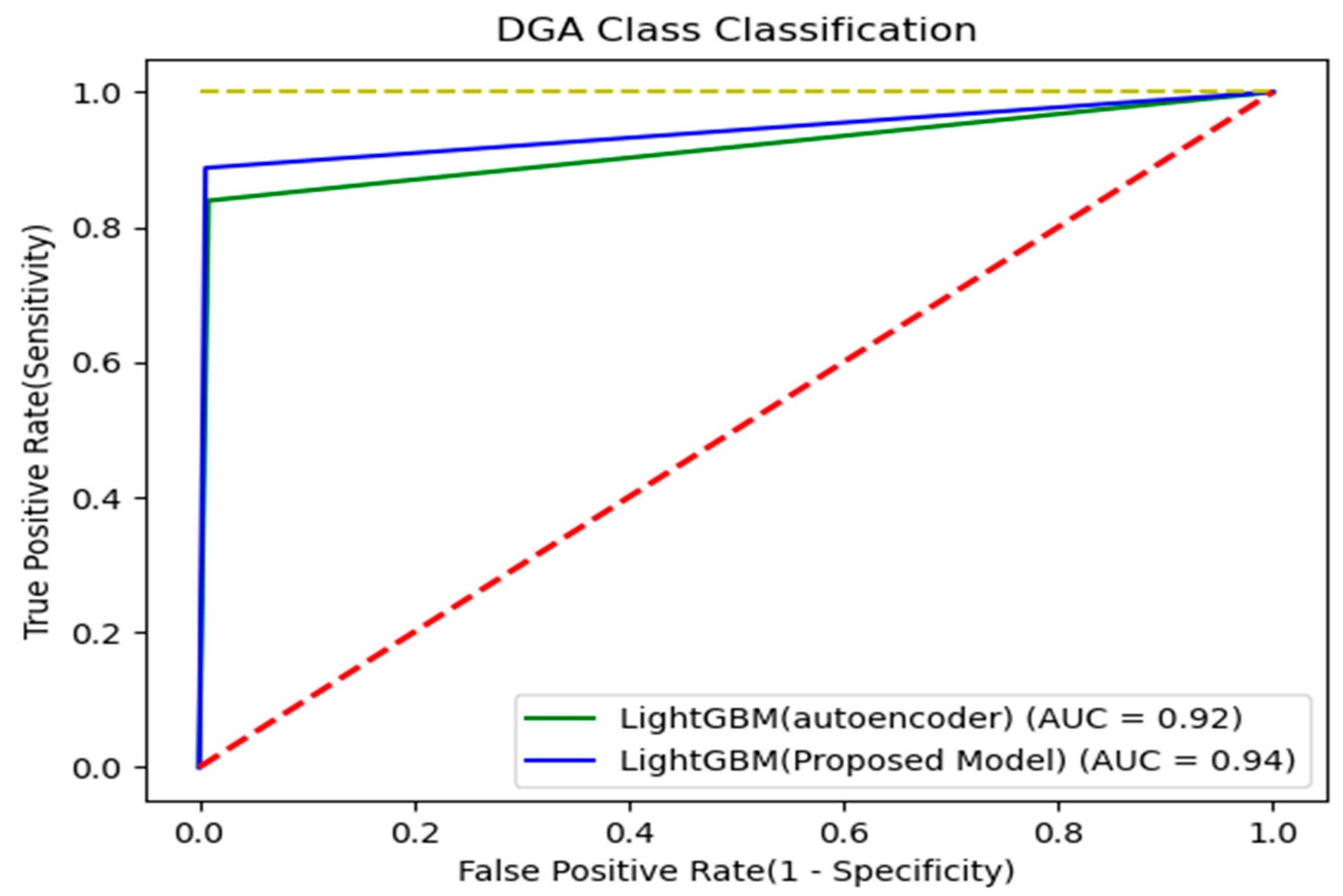
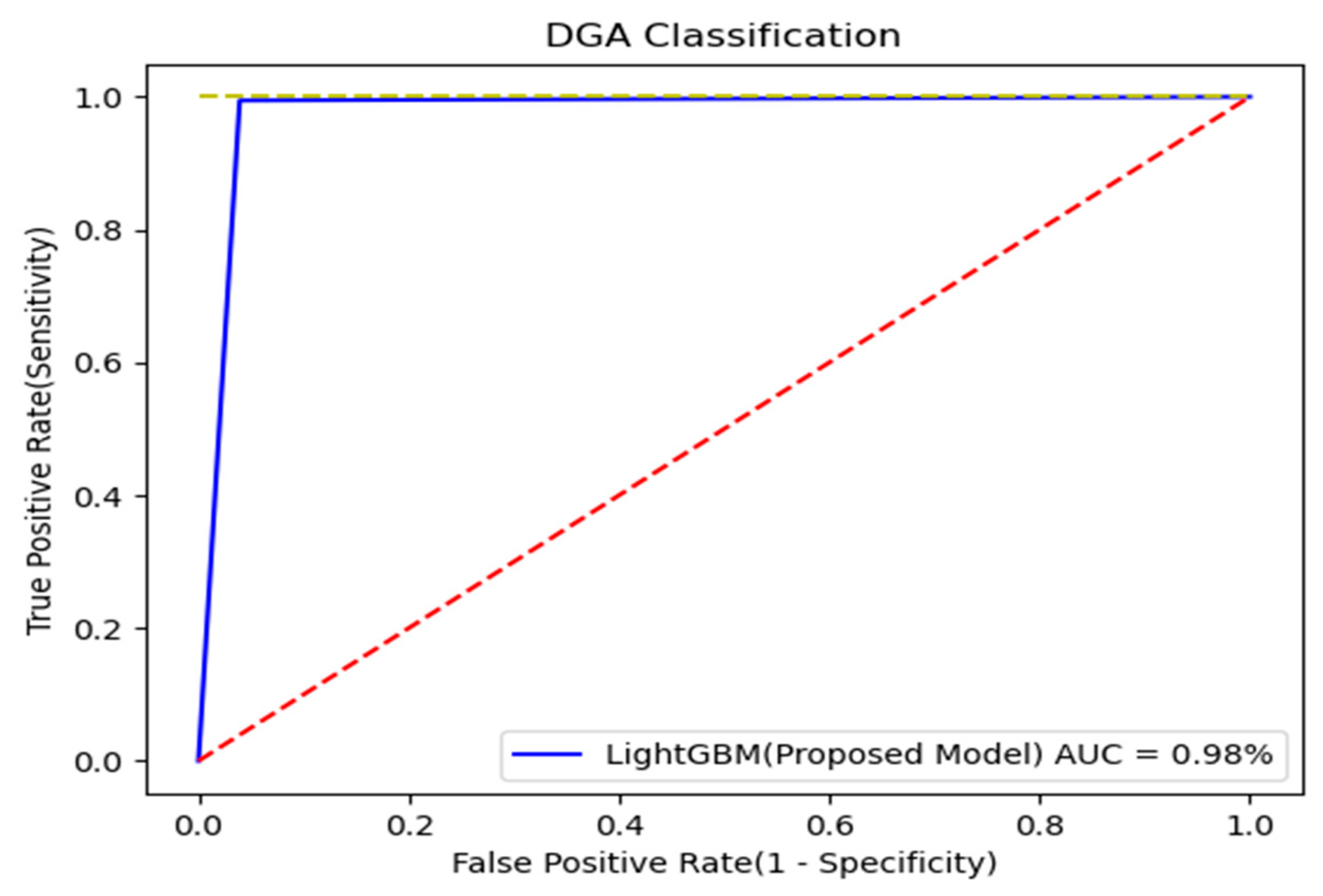
Figure 13.
ROC curve for model evaluation.
Figure 13.
ROC curve for model evaluation.
Figure 14.
Confusion matrix for model evaluation.
Figure 14.
Confusion matrix for model evaluation.
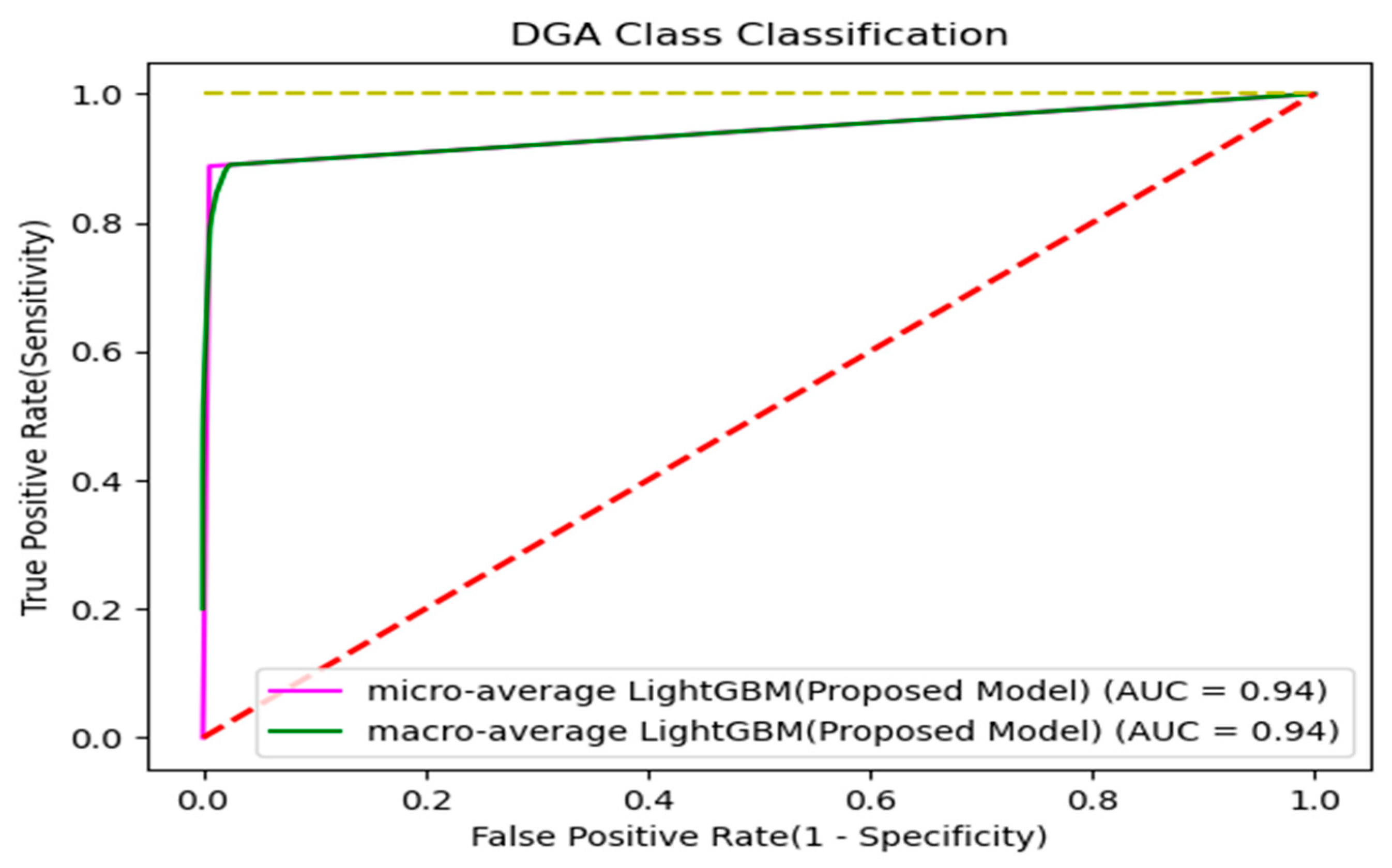
Figure 15.
ROC curve for classification model evaluation.
Figure 15.
ROC curve for classification model evaluation.
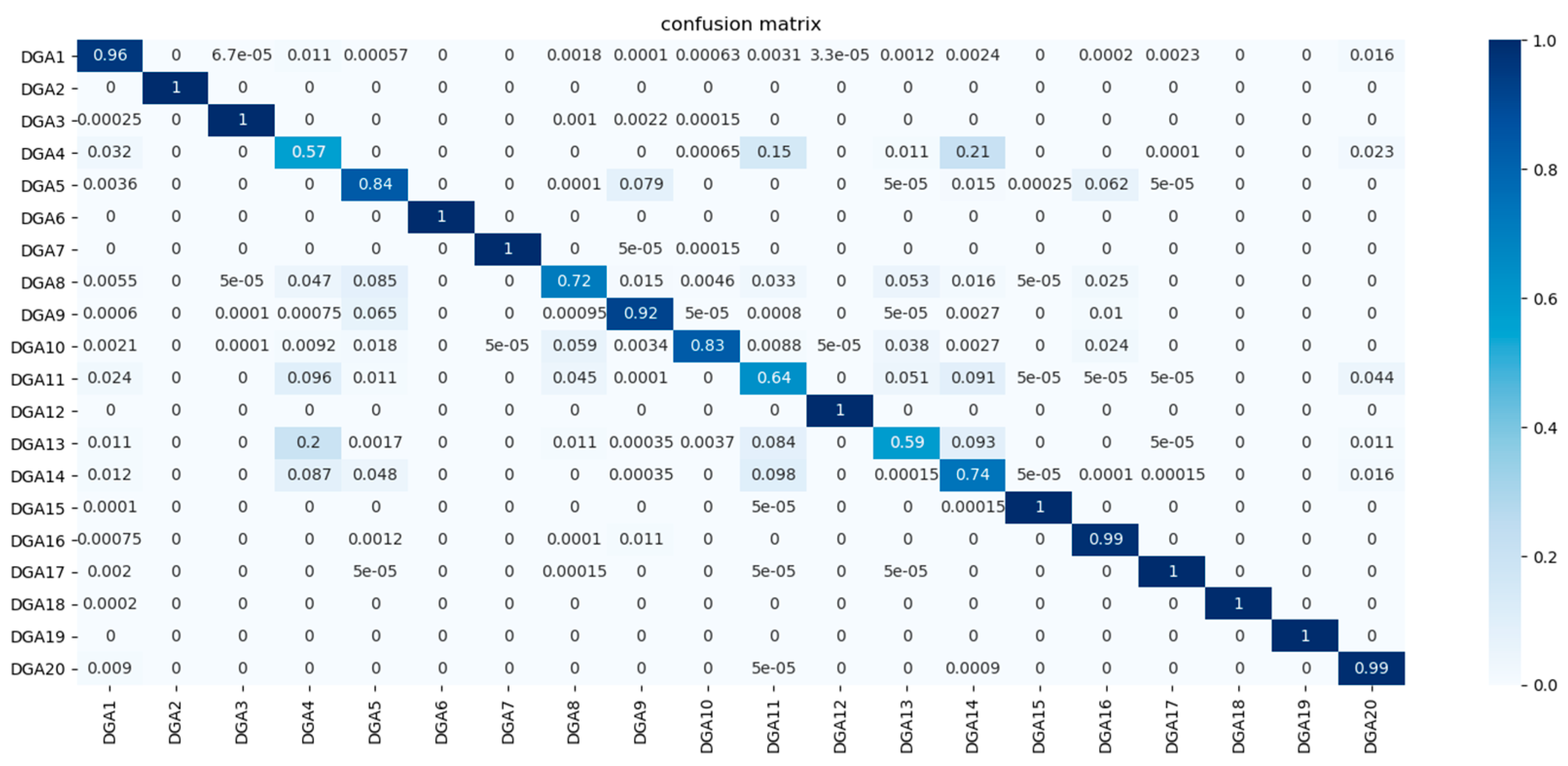
Figure 16.
Confusion matrix for classification model evaluation.
Figure 16.
Confusion matrix for classification model evaluation.
Figure 17.
Top 10 important features in the proposed model.
Figure 17.
Top 10 important features in the proposed model.
Table 1.
Summary of Existing DGA Techniques and Examples.
Table 1.
Summary of Existing DGA Techniques and Examples.
| DGA. | DGA techniques | Example Domain Names |
|---|
| Zeus | MD5 of the year, month, day, and a sequence number between 0 and 999 | krhafeobleyhiy-trwuduzlbucutwt, vsmfabubenvib-wolvgilhirvmz |
| Conficker | GMT data as the seed of the random number generator | fabdpdri, sfqzqigzs, whakxpvb |
| Kraken | a random string of 6 to 11 characters | rhxqccwdhwg, huwoyvagozu, gmkxtm |
| Srizbi | data transformation using XOR operations | wqpyygsq, tqdaourf, aqforugp |
| Torpig | current date and number 8 as the seed of the random number generator | 16ah4a9ax0apra, 12ah4a6abx5apra, 3ah0a16ax0apra |
| Kwyjibo | Markov process on English syllables | overloadable, refillingman, multible |
Table 2.
Examples of features used for DGA classification.
Table 2.
Examples of features used for DGA classification.
| Features | Description |
|---|
| Length | It is simply the length of a domain name. |
| Meaningful Word Ratio | Measures the proportion of meaningful words in a domain name. |
| Pronounceability Score | Selects the substring length n (2 or 3) and counts the number of occurrences in the n-gram frequency text. |
| Percentage of Numerical Characters | Measures the percentage of numbers in a string. |
| Percentage of the Length of LMS | Measures the length of the longest meaningful string in the domain name. |
| Levenshtein Edit Distance | Measures the minimum number of single character edits between domains. |
Table 3.
Example of features that can be extracted from the domain format.
Table 3.
Example of features that can be extracted from the domain format.
| Features | Description |
|---|
| symbol character ratio | The number of characters that do not exist in the English alphabet divided by the string length. |
| hex character ratio | The number of hexadecimal characters (A–F) divided by the string length. |
| vowel character ratio | The number of vowels divided by the string length. |
| TLD hash | A hash value is computed for each potential TLD and normalized to the range 0 to 1. |
| first character digit | A flag for whether the first character is or is not a numerical digit. |
| Length | The length of the string taken as the domain name. |
Table 4.
Comparison results on test data [
23]. Accuracy, true positive rate (TPR), and false positive rate (FPR) are thresholds that give an FPR of 0.001 on the validation data.
Table 4.
Comparison results on test data [
23]. Accuracy, true positive rate (TPR), and false positive rate (FPR) are thresholds that give an FPR of 0.001 on the validation data.
| Model | Architecture | Acc | TPR | FPR | AUC@1% |
|---|
| RF | Lexical features | 91.51% | 83.15% | 0.00128 | 84.77% |
| MLP | Lexical features | 73.74% | 47.61% | 0.00091 | 58.81% |
| Embedding | | | 84.29% | 68.69% | 0.00108 | 80.88% |
| | LSTM | CNN | | | | |
| Endgame | O | | 98.72% | 97.55% | 0.00102 | 98.03% |
| Invincea | | O | 98.95% | 98.01% | 0.00109 | 97.47% |
| CMU | O | | 98.54% | 97.18% | 0.00108 | 98.25% |
| MIT | O | O | 98.70% | 97.49% | 0.00099 | 97.55% |
| NYU | | O | 98.58% | 97.27% | 0.00116 | 97.93% |
Table 5.
Character-level embedding approach in the proposed model. (a) Character dictionary; (b) one-hot vector dictionary.
Table 5.
Character-level embedding approach in the proposed model. (a) Character dictionary; (b) one-hot vector dictionary.
| (a) |
| Char | Index | Char | Index |
| a | 1 | … | … |
| b | 2 | [ | 65 |
| c | 3 | ] | 66 |
| d | 4 | { | 67 |
| e | 5 | } | 68 |
| … | … | UNK | 69 |
| (b) |
| Index | One-Hot Vector |
| 0 | [0, 0, 0, 0, …, 0, 0, 0, 0] |
| 1 | [1, 0, 0, 0, …, 0, 0, 0, 0] |
| 2 | [0, 1, 0, 0, …, 0, 0, 0, 0] |
| … | … |
| 68 | [0, 0, 0, 0, …, 0, 0, 1, 0] |
| 69 | [0, 0, 0, 0, …, 0, 0, 0, 1] |
Table 6.
TextCNN’s feature extraction process.
Table 6.
TextCNN’s feature extraction process.
| Layer | Output |
|---|
| Input | [None, 100] |
| Embedding | [None, 100, 69] |
| Convolution1 | [None, 96, 256] |
| Max Pooling1 | [None, 48, 256] |
| Convolution2 | [None, 46, 256] |
| Max Pooling2 | [None, 23, 256] |
| Flatten | [None, 5888] |
| Dense1 | [None, 512] |
| Dense2 | [None, 512] |
| Dense3 | [None, 100] |
| Output | [None, 20] |
Table 7.
Average of extracted feature values.
Table 7.
Average of extracted feature values.
| Feature No. | Contents | DGA Domain | Normal Domain |
|---|
| 1 | Whether letters and numbers are mixed | 0.1671 | 0.3333 |
| 2 | Number Count | 0.2395 | 3.6437 |
| 3 | Number of DOTs | 1.319 | 1.0446 |
| 4 | Length | 11.3472 | 15.8952 |
| 5 | Number of vowels | 0.3487 | 0.2041 |
| 6 | Vowel ratio | 3.9829 | 2.8458 |
| 7 | Information entropy | 2.7387 | 3.2068 |
Table 8.
(a) Dataset contents examples; (b) dataset configurations.
Table 8.
(a) Dataset contents examples; (b) dataset configurations.
| (a) |
| Domain | DGA | Class |
| fbcfdlcnlaaakffb.info | 1 | 11 |
| firstbike.kr | 0 | 0 |
| foreignsmell.ru | 1 | 16 |
| booklog.kyobobook.co.kr | 0 | 0 |
| (b) |
| | DGA Domain | Normal Domain |
| Train Data | 2,670,000 | 930,000 |
| Test Data | 370,000 | 30,000 |
Table 9.
Running time of the proposed model.
Table 9.
Running time of the proposed model.
| Unit (Second) | TextCNN | Knowledge | LightGBM | Analysis per Domain (Second) | Analysis per Second (Domain Count) |
|---|
| Training | 2289 | 242 | 1796 | 0.0012019 | 832 |
| Test | 254 | 29 | 24 | 0.0007675 | 1303 |
Table 10.
Comparison result of evaluating the proposed model.
Table 10.
Comparison result of evaluating the proposed model.
| Type | Precision | Recall | F1-Score | Accuracy |
|---|
| TextCNN | 98.719 | 99.0 | 99.36 | 98.82 |
| TextCNN(100 Feature) + LightGBM | 99.744 | 99.035 | 99.388 | 98.872 |
| Domain knowledge(10 Feature) + LightGBM | 99.253 | 95.988 | 97.593 | 95.621 |
| Proposed Model | 99.681 | 99.445 | 99.563 | 99.192 |
Table 11.
Comparison result of evaluating the proposed classification model.
Table 11.
Comparison result of evaluating the proposed classification model.
| Type | Precision | Recall | F1-Score | Accuracy |
|---|
| TextCNN | 88.532 | 87.935 | 87.683 | 87.935 |
| TextCNN (100 Feature) + LightGBM | 88.61 | 88.392 | 88.219 | 88.392 |
| Domain knowledge (10 Feature) + LightGBM | 82.664 | 81.833 | 81.219 | 81.833 |
| Proposed Model | 89.01 | 88.77 | 88.695 | 88.77 |









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}