1. Introduction
An Artificial Neural Network (ANN) consists of a large group of nodes, each of which is assigned a value or synaptic weight to act as an artificial neuron. Calculation of the weight for each neuron for learning and the weighted function value of the input vectors for classification requires large computing power; thus, massively parallel processing can be beneficial. Many-core CPUs and GPUs can be employed in a server for the acceleration of neural network computation to exploit the inherent parallelism of the ANN. Currently, GPUs are the most widely used hardware accelerator of artificial intelligence because GPUs are specialized in performing the same operations on many data instances simultaneously, which is inherently required in the ANN. However, CPUs and GPUs are power-hungry devices, and the energy-intensive computation of the ANN is one of the critical problems that make it difficult for the ANN to be used for power-limited embedded systems.
To make the neural network less power-hungry, the use of specially designed hardware dedicated to neural network performance has been studied. The use of Field-Programmable Gate Arrays (FPGAs) is one such effort; FPGAs consume less energy and can be configured as a custom neural-network-specific hardware [
1,
2]. A study comparing energy efficiency between an FPGA and GPU in [
3] found that simple and parallel computations were performed well on the GPU, but the FPGA outperformed the GPU in terms of energy efficiency as the complexity of the computational pipeline grew. FPGAs and GPUs offer suitability depending on the application specifications [
4]. Thus, the hybrid use of both FPGAs and GPUs [
5] has been researched as an efficient implementation of neural networks, especially on embedded systems that require both performance and energy efficiency [
6].
Another approach to accelerate the neural network is the ASIC (Application-Specific Integrated Circuit) implementation of neural network models. In particular, neuromorphic chips have been developed to implement brain-like computation to overcome the memory bottleneck problem in parallel processing with von Neumann architecture processors. There are commercial neuromorphic chips available on the market, such as Intel’s Loihi and General Vision’s NeuroMem. ZISC (Zero Instruction Set Computer) is a hardware implementation of the ANN (Artificial Neural Network) commercialized by IBM, allowing massively parallel processing of digital data [
7]. Its feed-forward network provides a nonlinear classifier, which can be used for unknown and uncertainty detection. Based on ZISC technology, General Vision developed the CM1K chip, which consists of 1,024 neurons that can store and process 256-byte length vectors [
8,
9]. The CM1K chip has been applied to face recognition [
9], a fish inspection system [
10], and an authentication system by face and speech recognition [
8]. The NM500 chip is a successor of CM1K and consists of 576 neurons [
11]. Neurons of NM500 have exactly the same behavior as those of CM1K, but it is operated at a higher clock rate and consumes less power. The possibility of adopting the NM500 chip for an ADAS (Advanced Driver Assistance System) has been discussed in [
12].
While much research has been done to compare the performance and the energy efficiency of FPGAs and GPUs, little work can be found on neuromorphic chips. IBM’s TrueNorth chip is reported as highly energy efficient in [
13], and NM500′s power consumption is available in the hardware manual. In [
14], the authors studied the energy efficiency of a neuromorphic computing system using ReRAM (Resistive RAM). Others compared the performance of neuromorphic computing systems by simulation [
15]. However, most research has focused on the neuromorphic chip’s performance and power consumption. When it is used as an accelerator in a system, other factors such as data transfer from the host system and control subsystem for interconnection should be considered because the energy cost of data movement is much higher than that of computation [
16]. Examining the benefits and the problems of the neuromorphic hardware accelerator for a real-world application needs to include an evaluation of the performance with a real target system.
In this paper, we study the performance and the energy efficiency of a neuromorphic chip employed in an embedded system using a currently available commercial neuromorphic chip, NM500, by comparing its performance and power consumption with those of CPU and GPU cores. To this end, a pedestrian image detection system was implemented and tested on a real target equipped with NM500 chips. The number of neurons in the tested neural network ranges from 576 to 4032 due to the hardware restriction of the evaluation board containing the neuromorphic chips. For these three different configurations (neuromorphic chips, GPUs, and CPUs) of embedded systems, the processing time and power consumption for learning and classification are measured, and the energy efficiency for processing a data instance is calculated and compared.
This paper is organized as follows.
Section 2 provides a brief description of the neuromorphic hardware tested in this work.
Section 3 explains the datasets and how they are preprocessed for evaluation. In
Section 4, experimental results on the power consumption and performance in detecting pedestrian images using NM500 hardware are presented and compared with those on a CPU-only system and a GPU system. Finally,
Section 5 discusses applications and possible improvements of the neuromorphic hardware.
2. Neuromorphic Hardware
The neuromorphic chip used in our work to accelerate AI processing in an embedded system is NM500 by Nepes, which is based on the NeuroMem technology of General Vision. An NM500 chip has 576 hardware neurons; a hardware neuron is an identical element that can store and process information simultaneously. They are all interconnected and working in parallel. NM500 makes these hardware components (neurons) collectively behave as a KNN (K-Nearest Network) or RBF (Radial Basis Function) classifier [
11].
Figure 1 shows the interconnection architecture of the NM500. Logically, the network is three-layered: one input layer, one hidden layer, and an output layer. All the neurons in the chip can be considered as nodes in the hidden layer. Each hardware neuron has 256-byte storage, which limits the input size to less than or equal to 256 bytes. The output size is 2 bytes, so the number of candidate class labels for training data is limited to 65,536. Input data and commands are fed to each cell in parallel, and neurons are daisy-chained to signal to the next neuron to accept the input data in training neurons sequentially. Though the layers cannot be made deeper, the hidden layer is extendable by stacking up multiple NM500 chips. The “Neuron interconnect” module shown in
Figure 1 enables the use of multiple chips in parallel to expand the size of the neural network by an increment of 576 neurons.
A neuron has a model and IF (Influence Field) value after its learning process, stored in its volatile memory. When data are provided for classification, each neuron calculates the distance of a data point from its model and fires if the distance is less than the IF value. Each neuron examines the response of others on the parallel bus, and if another neuron reports a smaller distance value, then it withdraws itself [
11].
The NM500′s architecture is not meant to be configured to have a deeper neural network, which may affect accuracy for specific applications. However, because the neural network has only one hidden layer, the classification time of the neuromorphic hardware becomes almost constant. Considering the simplicity of the hardware configuration, it could be suitable for embedded systems whose requirements can be fulfilled by a relatively simple neural network.
3. Benchmark Problem and Data Preprocessing
Because embedded systems have scarce computing resources and power constraints, machine learning problems with a complex model are often infeasible to execute on the system. For example, AlexNet requires about 727 MFLOPS to process a 227 × 227-pixel image, while BCM2835 MCU in Raspberry Pi B development board delivers about 213 MFLOPS at peak operating frequency, which requires 3.4 s to process an image. Thus, we need to select a machine learning problem that can be feasibly executed on embedded systems.
Pedestrian detection is an important problem in computer vision and has broad application prospects, such as video surveillance, robotics, and automotive safety [
17,
18]. As autonomous driving systems emerge, detecting small-size pedestrians in images becomes more important [
19]. Furthermore, pedestrian detection on an embedded system using GPUs has been studied by researchers, including a recent example in [
20]. Thus, because of its practical importance and implementation feasibility, pedestrian detection using the RBF classifier was selected to benchmark the hardware accelerators for embedded systems in our experiments.
For test datasets, the INRIA Person Dataset [
21,
22], which is very popular in pedestrian detection research [
23], was used for our experiments. From the dataset, HOG (Histogram of Oriented Gradient) features with the SVM classifier were extracted to detect a human in [
21]. Normalized images in 128-by-64-pixel format were used in our experiments. A pedestrian data point consists of an image pair in which one is a mirror image of another. Non-pedestrian images were generated by randomly selecting 128-by-64-pixel areas from the original image.
Table 1 summarizes the images used in our experiments.
First, the HOG is used as a feature descriptor for human detection to identify a pedestrian. The HOG descriptor methods have shown high performance in human detection and have been widely used for pedestrian detection [
24,
25]. The image is divided into local regions, where the gradient, direction, and size are computed using the differences in brightness between adjacent pixels. Histograms are generated using the calculated values to make feature vectors.
Because the NM500 chip has a memory of only 256-byte input, the HOG descriptors that are first generated with a high dimension (3780 in our implementation) are not suitable to be used. To reduce the dimension of the features, the PCA (Principal Component Analysis) method was adopted. PCA is a linear transformation feature extraction method that uses less data than the input data while maintaining the most important information of the input data [
25,
26]. Using the PCA method, the HOG features are transformed into 40-dimensional data. Finally, 32-bit floating-point features are quantized to 8-bit data using the vector quantization method in [
27], which results in 160-byte input vectors.
4. Experimental Results
The neuromorphic chips are packaged into a hardware module named NeuroShield. The NeuroShield module is an evaluation board with one NM500 chip containing 576 neurons, on top of which three more extension modules can be stacked at most. The extension module has two NM500 chips and is called NeuroBrick. Thus, a NeuroShield module supports at most 4032 neurons. Because the NeuroShield module has one NM500, and each NeuroBrick module has two NM500 chips, the neuromorphic processing can be done with four different numbers of neurons: 576 with only the NeuroShield module, 1728 with one NeuroBrick on it, 2880 with two NeuroBricks, and 4032 at maximum.
To compare the neuromorphic chip-based system with other systems, the same pedestrian detection neural network was implemented on a CPU-only system and a GPU system. The CPU-only system is an embedded board with the Exynos5422 processor. The Exynos5422 CPU of the embedded board used in our experiments has an 8-core CPU, which consists of 4 fast (big) cores and 4 slow (little) cores. Because little cores are too slow to be used for neural network processing, only big cores were used in the experiments.
As a GPU system for comparison, Nvidia’s Jetson Nano board with 128 GPU cores was used. The neural network on the GPU system was implemented using the Tensorflow-GPU library. The NeuroShield module was connected to the Jetson Nano board using an SPI (Serial Peripheral Interface) connection at 2 MHz. The power consumption of the NeuroShield module was measured separately from the Jetson Nano board.
Table 2 summarizes the hardware configurations of each system test in the experiments. The neuromorphic system (NeuroShield) does not have a CPU or external memory because NM500 is not a Von Neumann architecture.
Figure 2 shows the power consumption of three implementations with different underlying hardware: NM500, GPU, and CPU-only. For the CPU-only system, we measured the power consumption in two cases: using only one core and using all four big cores. The GPU system consumes about 4.85–4.89 Watts on average. The power consumption of the GPU system includes the power consumed by the CPU in the system. For a fair comparison with the neuromorphic hardware, the power consumed only by the GPU cores needs to be measured, which could not be done because the GPU cores are integrated with CPU cores in the Jetson Nano SoC. Therefore, to estimate the power consumption of the GPU cores, the power consumption of the board with GPU cores off at idle state was measured, which is about 1.41 Watts on average. The GPU line in
Figure 2 shows the power consumption of the entire system, while the GPU–idle line shows the power consumption estimated by subtracting the average power consumption of the Jetson Nano board at idle state with the GPU cores off.
The GPU cores cannot be turned off partially; thus, the power consumption remains the same regardless of the number of neurons. The power consumptions of both the CPU-only and GPU systems are barely changed, while that of the NM500 system linearly increases as the number of chips (hardware neurons) employed increases. An additional NM500 chip containing 576 hardware neurons consumes approximately 100mW, so the total power consumption increases by 0.2 W for every additional 1172 neurons. The power consumption of the NeuroShield is a little higher than that of the NeuroBrick because the NeuroShield has an FPGA for interfacing with SPI, I2C, and USB.
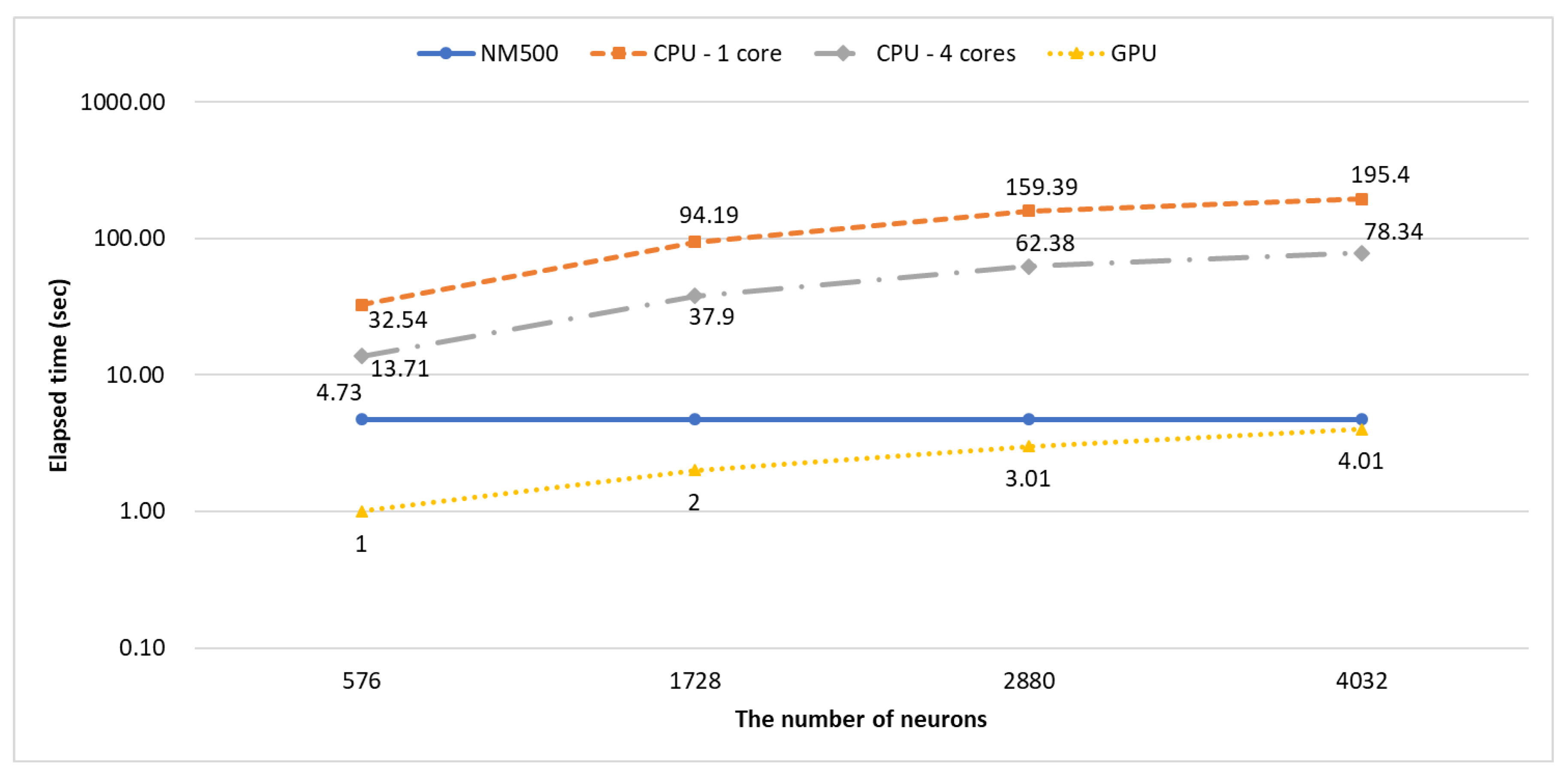
Figure 3 shows the amount of time needed to train a neural network for the three systems. The time in the graph is in a base-10 log scale. Training on the CPU-only system takes much longer than other systems, about 15–185 times longer than the GPU system even though four cores are used. The learning time of the neuromorphic chip-based system is even shorter than that of the GPU system, by about 1300–1500%.
To determine the classification performance, 1132 pedestrian images and 453 non-pedestrian images were tested. The processing time of the neuromorphic-based system is unchanged even though the number of neurons used in the system is increased, as shown in
Figure 4, because all hardware neurons are in the same layer and execute in parallel. On the other hand, the processing times of the CPU-only system and the GPU system increase as the number of neurons increase. Nevertheless, the GPU system is the fastest among the systems to process all the test images. We could not test with more neurons because the current NeuroShield does not support more than three NeuroBricks on it.
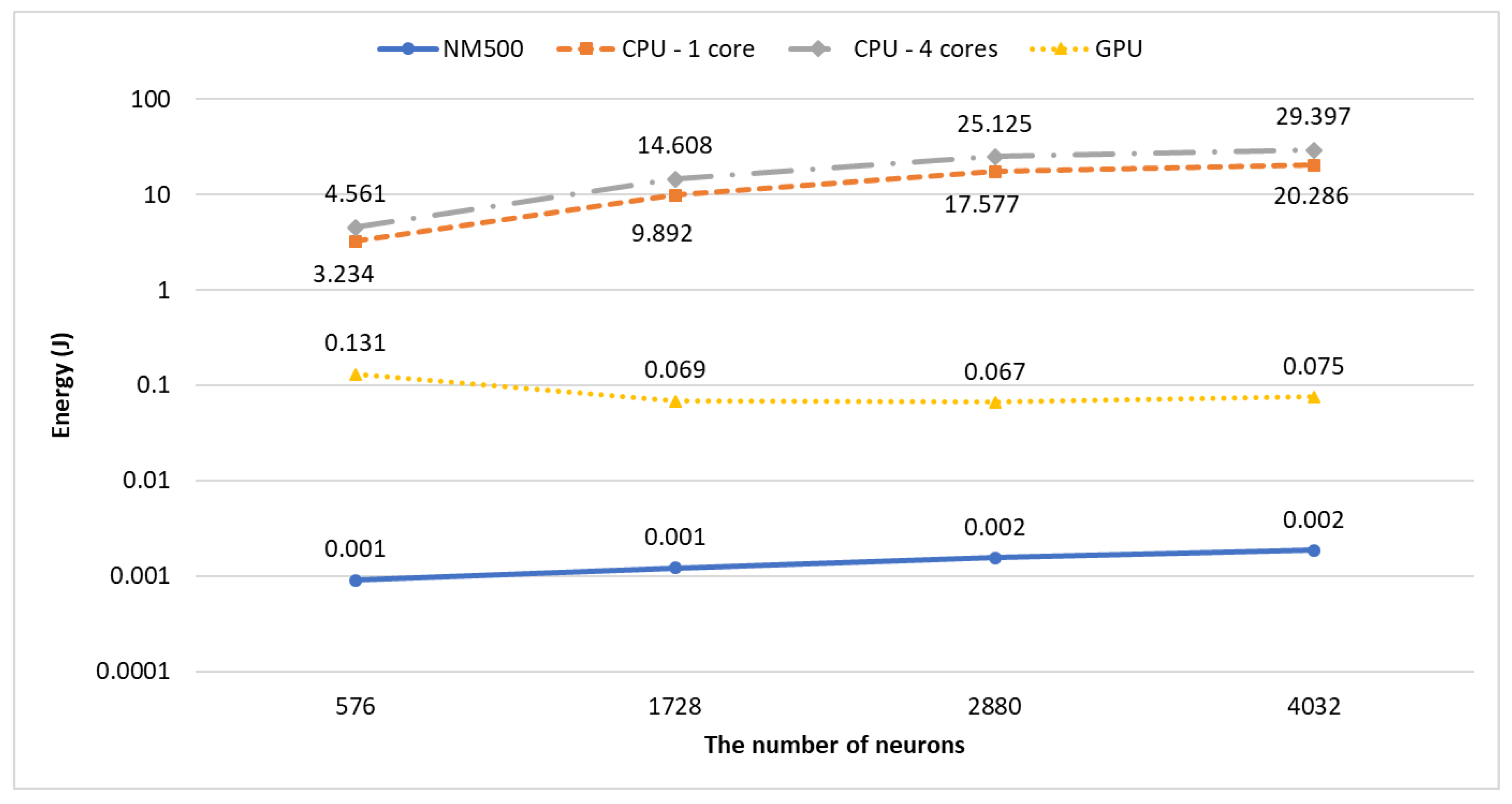
To determine the energy efficiency of the neuromorphic hardware, we calculated the amount of energy needed to process an image when each system is learning or classifying. The consumed energy for learning is shown in
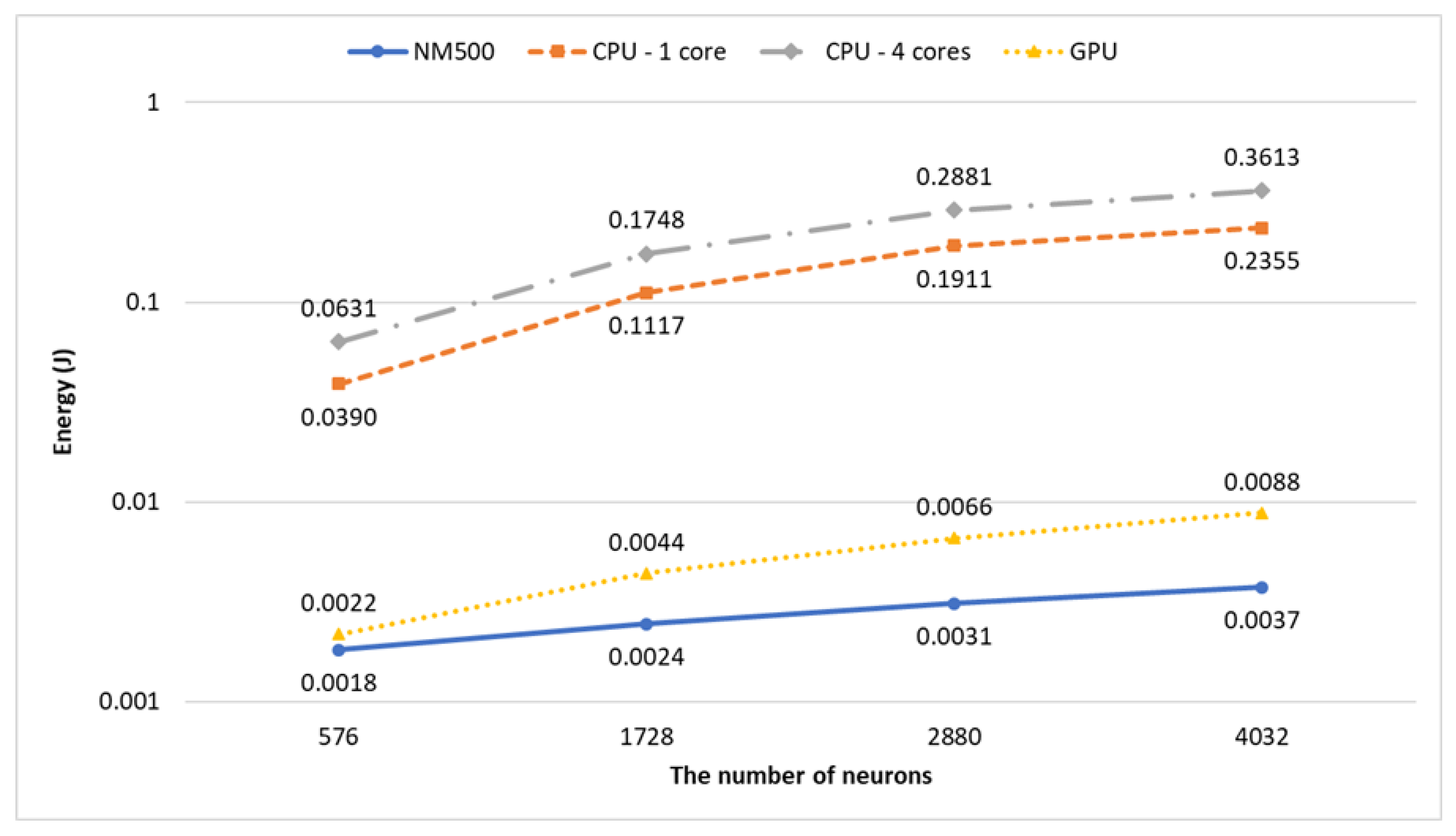
Figure 5, while the energy for image detection is shown in
Figure 6.
When training the neural network, the system with NM500 requires the least amount of energy to process an image data instance. The GPU system’s energy efficiency is much better than that of the CPU-only system, but the efficiency of the neuromorphic chip-based system is over an order of magnitude higher than that of the GPU system in terms of per-data energy consumption. This is because both the power consumption and the processing time of the NM500 are much lower than those of the GPU system.
For classification, the required amount of energy consumed for a data instance by the GPU system is more than that of the neuromorphic system but is not very high (<2.5 times). Though the power consumption of the GPU system is higher than that of the NM500 system, the processing time of the GPU system is shorter than that of the NM500 system. The energy consumption of the GPU system in classification is much lower than that in training because less computation is needed in classification. However, the NM500 system consumes about 80% more energy for classification than learning.
5. Conclusions
In this work, we compared the performance and the energy efficiency of a commercially available neuromorphic chip with those of GPU and CPU cores on embedded devices. The processing time and power consumption were measured while increasing the number of neurons in the neural network. The experimental results show that the time required for the neuromorphic chips to learn the same amount of data is about 13–15 times shorter than that required for the embedded system with 128 GPU cores. On the other hand, the time required to classify a dataset remains almost constant for the neuromorphic processor due to its neural network architecture with only one hidden layer. In classification, the GPU processes data faster than the neuromorphic chip, but the processing time tends to increase as the number of neurons increases. Thus, it is expected that the neuromorphic chips can outperform the GPU system with a larger number of neurons, but this could not be tested due to the restriction in the expandability of the evaluation board for the neuromorphic chips.
As most embedded systems depend on limited power supply such as batteries, energy efficiency is a critical factor in designing a system. In our experiments, the energy required for NM500 chips to process an input data instance is less than 1/35 of that required by the GPU accelerated embedded system in training the neural network, while the energy consumption of the GPU system in classification is only 1.22–2.37 times higher than that of NM500 chips. Because the neural network of NM500 has only one hidden layer, the processing time for classifying the given dataset remains almost the same even though the number of neurons increases, while the power consumption increases linearly. On the contrary, the classification time of the GPU system is almost linearly proportional to the number of neurons, while the power consumption remains unchanged. Therefore, the energy for the neuromorphic chips to classify data is expected to be close to 50% of that for the GPU system as the number of chips increases. It is interesting to note that the neuromorphic chips are especially energy efficient in training the neural network in comparison with the GPU system.
However, despite the high energy efficiency of the neuromorphic chip, it still needs to be improved. First of all, NM500′s architecture can support only one hidden layer, which may restrict the possible benefit of deeper neural networks. Second, the lack of the ability to dynamically switch on and off a partial group of chips makes it difficult to manage power consumption. Finally, if high-speed interconnection such as AMBA or other high-speed bus protocols is supported, the processing time can be reduced further. The current SPI connection of the NM500 requires about 10 us to write a byte, a total 1660 us for learning a 160-byte data instance, which is done in about 2045 us. Therefore, communication via SPI interconnection accounts for about 82% of the total processing time. Integration of the neuromorphic chips into an SoC could be considered to improve the performance and the energy efficiency of machine learning on embedded systems using the neuromorphic hardware.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}