Dynamic OverCloud: Realizing Microservices-Based IoT-Cloud Service Composition over Multiple Clouds


Abstract
1. Introduction
- First, we define the concept of the Dynamic OverCloud approach, which is an additional layer located between the service and resource layers. Dynamic OverCloud provides a consistent overlay layer in a cloud-agnostic way. We design its components such as Interface Proxy, Dev+Ops Post, Cloud-native Clusters, Assembled DataLake, and Visibility Fabric to enable an inter-operable and visibility-supported environment for MSA-based service composition over multiple clouds. And, we also design a software framework that dynamically builds Dynamic OverCloud.
- Second, to make concrete our proposed concept, we implement the software framework by adopting a workflow scheme to specify its order of realization. The workflow scheme is a set of dependent or independent tasks represented in the form of a Directed Acyclic Graph (DAG), where the nodes represent the tasks and a directed edge denotes the dependency between the corresponding tasks to achieve the automated, flexible provisioning [11,12]. The implemented software framework facilitates automated and effective Dynamic OverCloud provisioning by describing well-defined tasks with the workflow.
- Third, to verify the feasibility of Dynamic OverCloud, we suggest an operation lifecycle with the implemented software framework to guide IoT-Cloud service composition using Dynamic OverCloud. Then, we apply a use case of smart energy IoT-Cloud service by following the operation lifecycle. We appear that the instance of Dynamic OverCloud is dynamically deployed with the software framework in an automated and efficient way. We also confirm that Dynamic OverCloud provides users with functionalities such as multi-layer visibility and persistent storage that assist inter-operable service composition.
2. Related Work
3. Dynamic OverCloud: Design
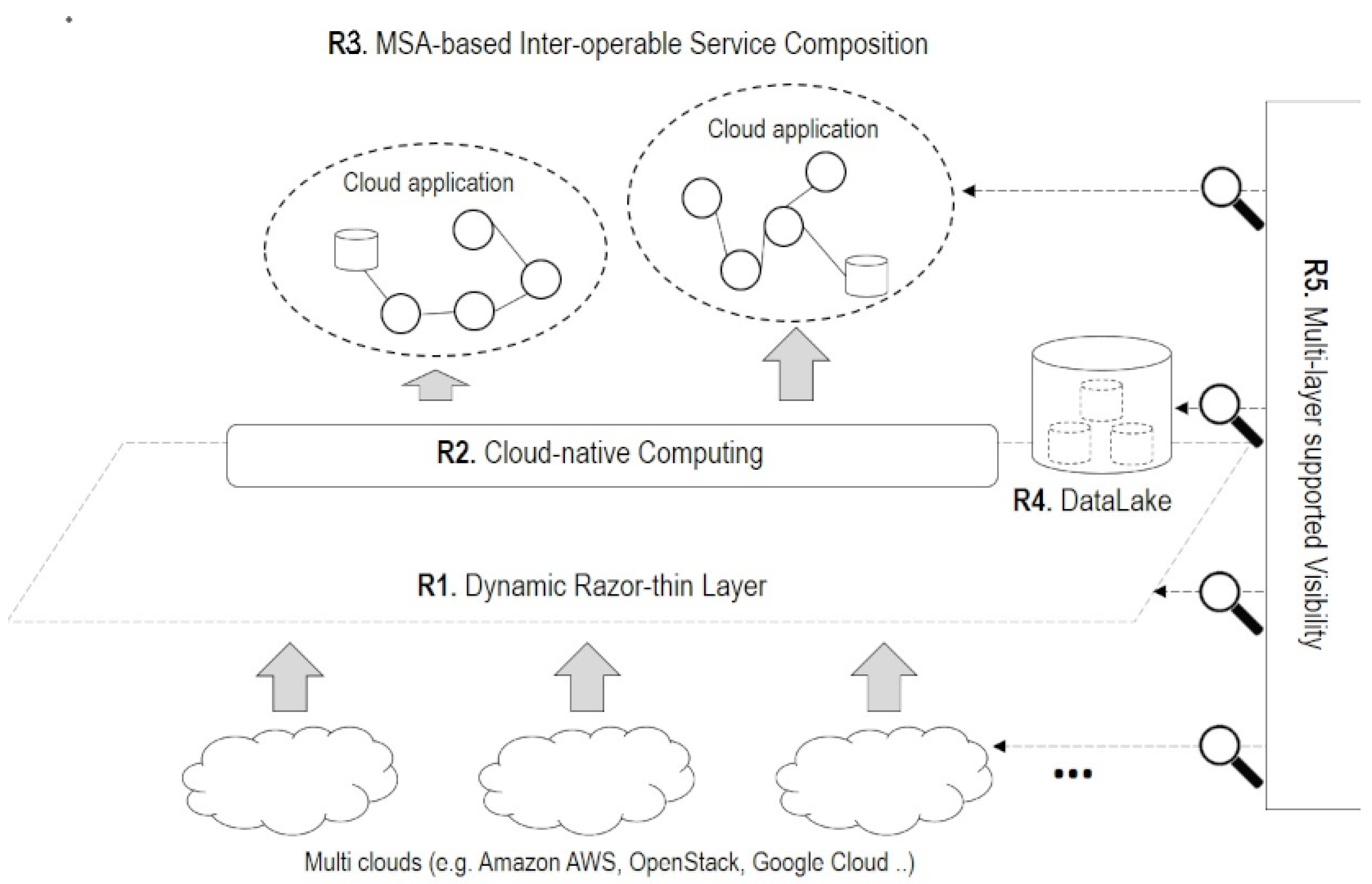
3.1. Requirements
- R1. Dynamic Razor-thin Layer: Cloud interoperability is a critical mission to provide developers with flexible and powerful resources by avoiding vendor lock-in problem. The IoT-Cloud services are recommended to dynamically utilize near-by resources among multi-clouds for low-latency and high-throughput connectivity. Building an additional razor-thin layer that can be dynamically configured over multiple clouds is a simple way to meet requirements that satisfy these characteristics of the IoT-Cloud service. In particular, the additional layer should be lightweight and require less overhead. It also should work smoothly on any clouds.
- R2. Cloud-native Computing: Developers want to quickly and easily develop and validate cloud applications regardless of the underlying infrastructure. Cloud-native computing has changed the way we deploy our services into the infrastructure since containerization enables developers to make lightweight isolation that can easily and quickly deploy their codes to realize services. Cloud-native computing mainly provides computing/networking/storage resources over the underlying infrastructure on top of Kubernetes orchestration. With the features of Container Networking Interface (CNI) and Container Storage Interface (CSI), containers that have stateless properties can be flexibly connected with the persistent storage in a standard way of cloud-native computing defined by CNCF(Cloud Native Computing Foundation).
- R3. MSA-based Inter-operable Service Composition: For performing IoT-Cloud services on cloud-native computing, We need service composition in the form of microservices architectures. Thus, service composition should remove the risk of any friction or conflict between dependency problems by taking advantage of containers. Besides, considering the mobility and geographical characteristics of IoT-Cloud services, scalability and fault-tolerance should also be considered for inter-operable service compositions.
- R4. DataLake: Collecting and Managing data is the most valuable thing for developing and validating services. Many kinds of data, such as service domain data (e.g., machine temperature, the humidity of a room, and so on), are generated by service composition. Also, operation data (e.g., resource utilization, path, links, logs and, etc.) to understand the situation of both services and infrastructures are generated. Raw data is also needed to perform specific functionalities. These data should be systemically stored and managed to get new insights at any time. In other words, we need integrated storage that leverages existing storage or configures new storage to keep their valuable data.
- R5. Multi-layer supported Visibility: Multi-layer visibility across resource, flow, workload layers is required for both developers and operators. From an operator’s point of view, visibility measurement, collection, and associated visualization are essential for the continued operation of their infrastructure, so that operators can gain timely insights into the operational status of resources and associated flows [27]. The developer’s point of view is that they also need a visibility solution to understand the situation of their services and enable better workload placement and optimized resource utilization for better service compositions.
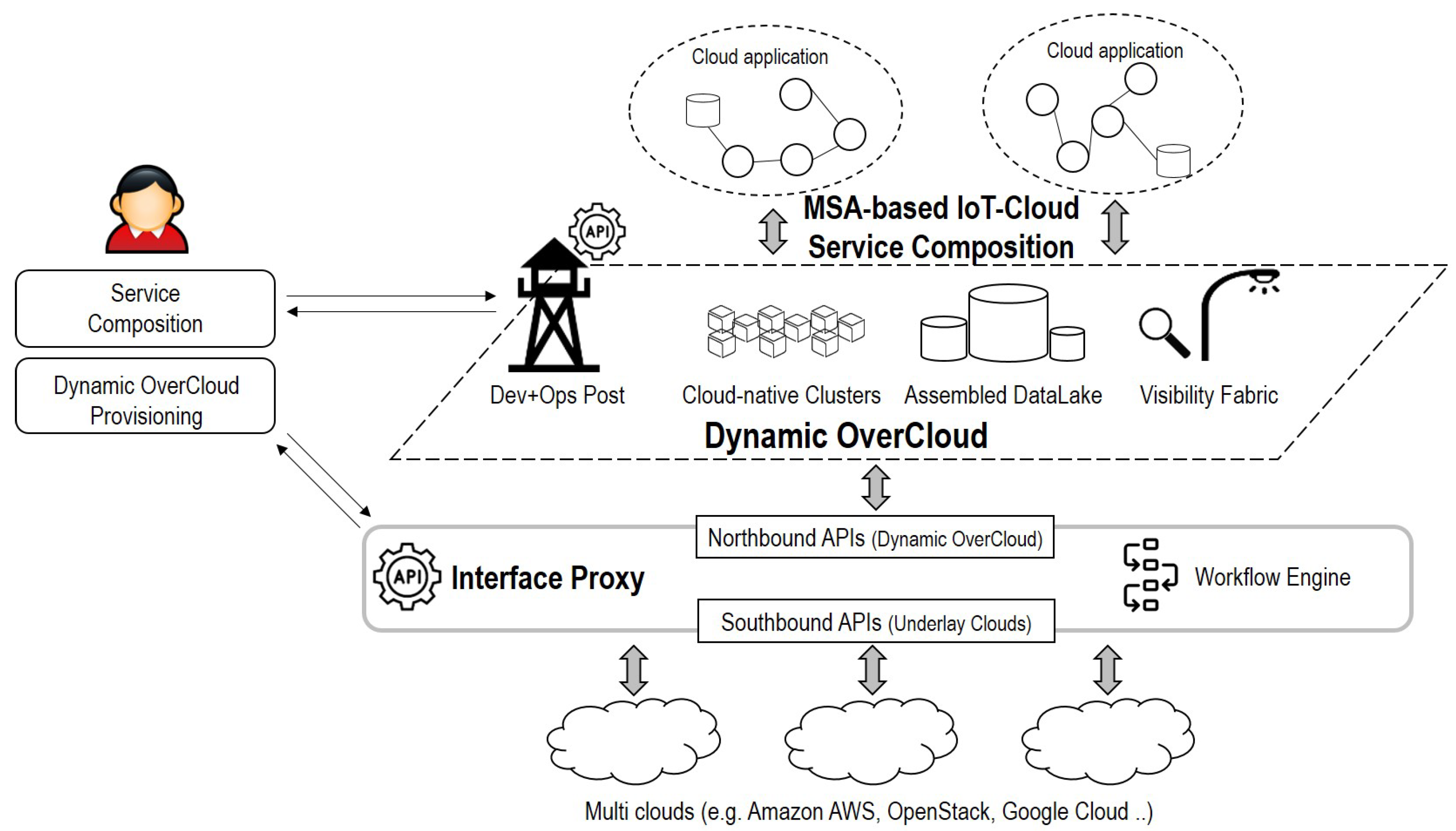
3.2. Overall Design of Dynamic OverCloud
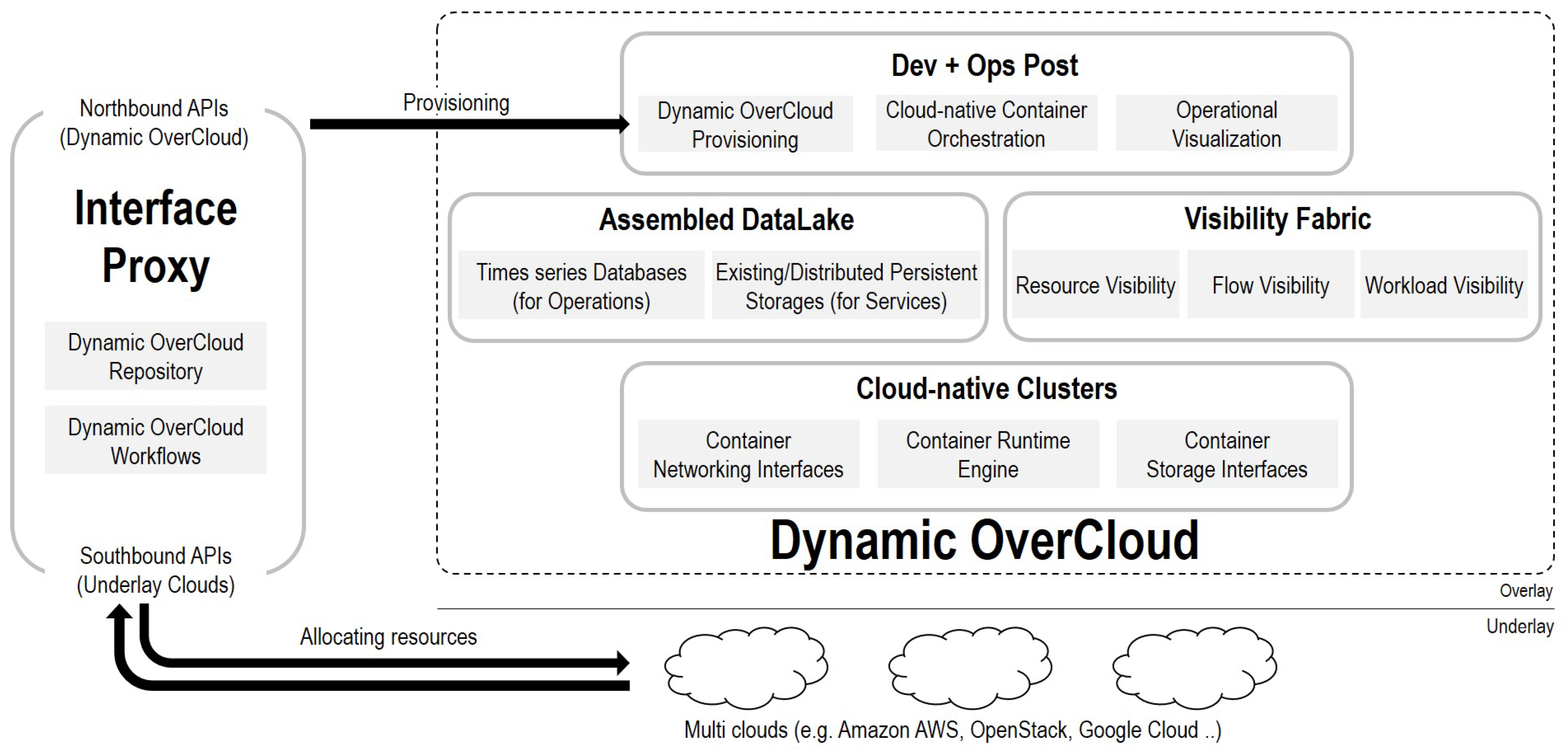
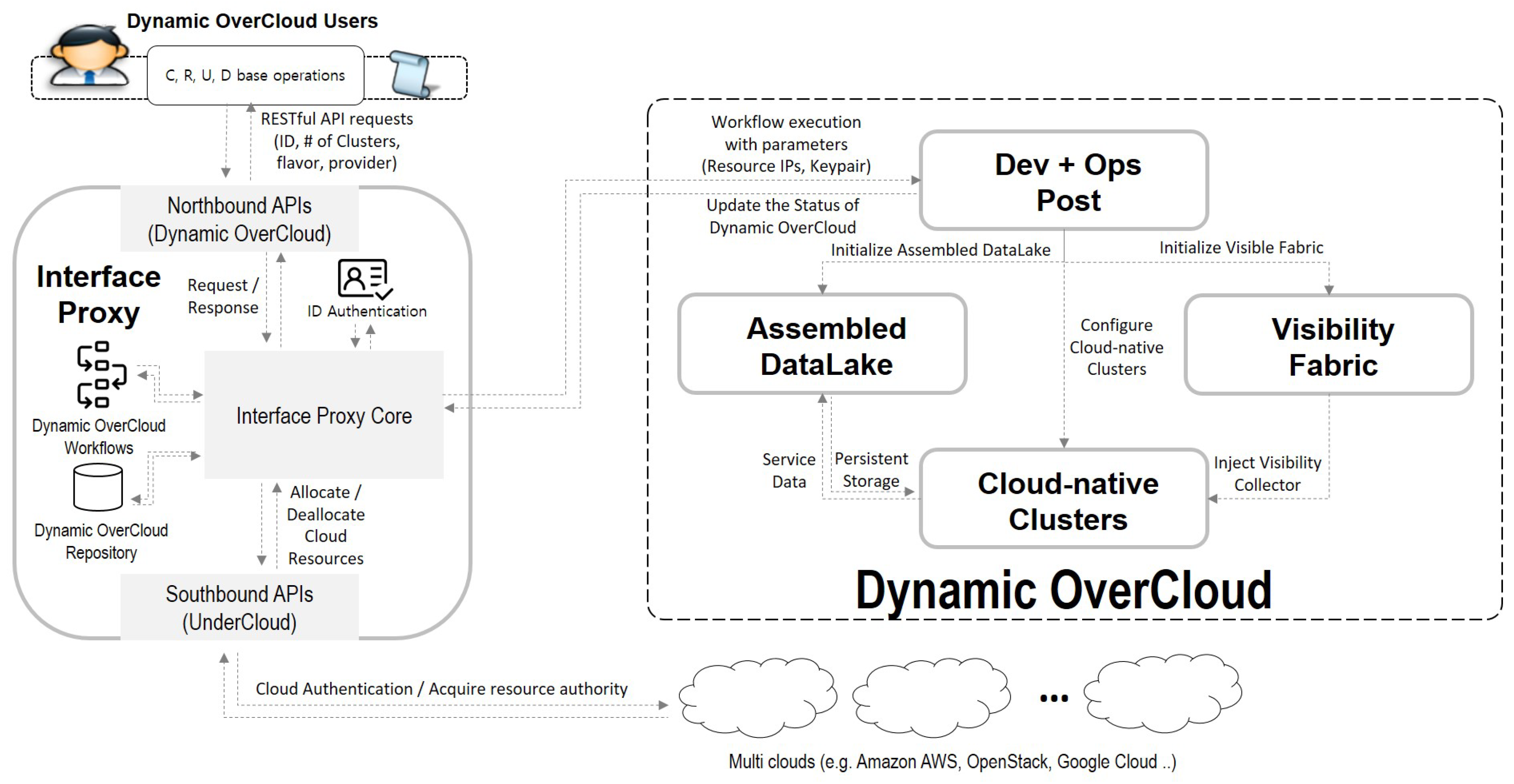
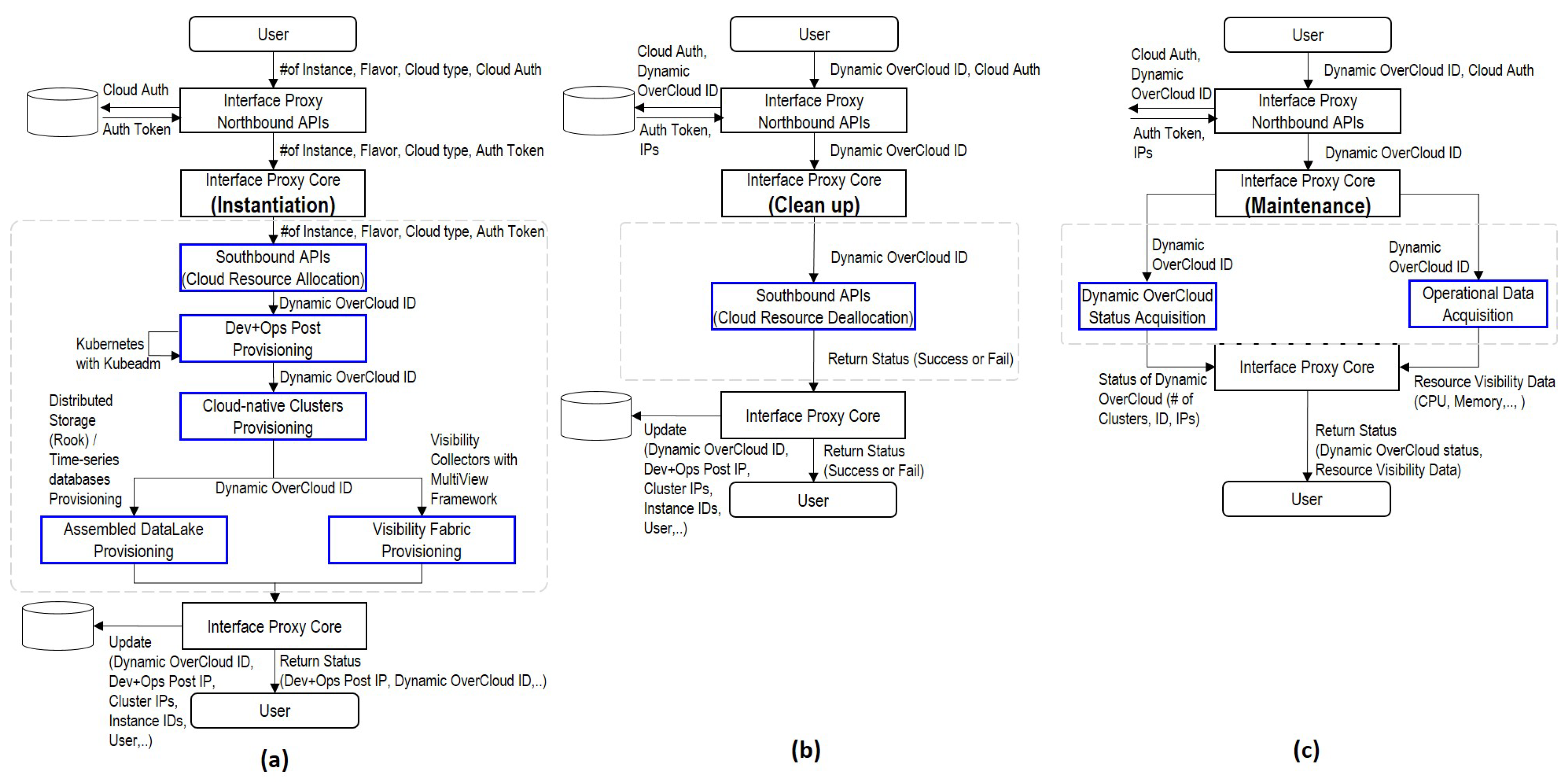
- Interface Proxy: Interface Proxy is a communication channel between users and underlay clouds. Northbound APIs interpret the user’s requirement and generate information to forward them to Interface Core. Southbound APIs acquire cloud resources of underlay clouds based on the generated data. Note that Interface Proxy is not a dynamically generated entity each time, but it is a shared entity for multiple users. Dynamic OverCloud APIs run automatically basic operations of Dynamic OverCloud based on the Dynamic OverCloud workflows description. All of the transactions of Dynamic OverCloud APIs are stored in the Dynamic OverCloud Repository. For example, when a user deploys Dynamic OverCloud, the related data such as Dynamic OverCloud ID, specifications of Cloud-native Clusters, Assembled DataLake, and Visibility Fabric are stored to the Dynamic OverCloud repository.
- Dev+Ops Post: Dev+Ops Post is provisioning and orchestration entities in conjunction with other components. It automatically provisions other components following requirements. Orchestration tools in Dev+Ops Post support container orchestration with visibility and persistent storage capabilities in a cloud-native way. It also coordinates Cloud-native Clusters as primary resources in Dynamic OverCloud. Based on the operational data in the Assembled DataLake, Operational Visualization gives users a visual representation to grasp the overall situation of their services.
- Cloud-native Clusters: Cloud-native clusters provide users with pre-prepared resources for the container-based service composition, unlike cloud resources offered by underlay clouds. It can be any containers using container runtime engines that are compatible with the standard of CNCF. It also leverages CNI and CSI to provide users with complete ICT resources (Computing, Networking, and Storage). In the user’s point of view, Cloud-native Clusters are a logical pool of resources supporting containers supervised by container orchestration.
- Assembled DataLake: Assembled DataLake consists of time-series databases and distributed persistent storage for operation/service data. Time-series databases primarily store operational data that includes visibility and log data from Visibility Fabric to catch the status of Dynamic OverCloud. Service-domain data that is generated by running applications are stored in distributed persistent storage. Since, running application on Dynamic OverCloud is in the form of containers, distributed persistent storage should be compatible with containers. In the case of the existing storage that can be compatible with Kubernetes orchestration, it can be used as a persistent volume of containers.
- Visibility Fabric: Visibility Fabric provides resource, flow, and workload layer visibility to understand the overall situation of Dynamic OverCloud with the help of visibility solutions. For that, it injects visibility data collectors into Cloud-native Clusters in the form of a lightweight agent. Visibility Fabric supports dynamic resource-centric visibility rather than fixed topology due to the nature of Dynamic OverCloud. It also covers the view of workloads that understand the relations of functions for performed services, as well as the view of resources and flow that checks the status of resources and networking in Dynamic OverCloud.
3.3. Software Framework Design of Dynamic OverCloud
4. Dynamic OverCloud: Implementation
4.1. Software Framework Components’ Implementation
4.2. Dynamic OverCloud Workflows Implementation with the Software Framework
5. Dynamic OverCloud: Feasibility Verification with Operation Lifecycle
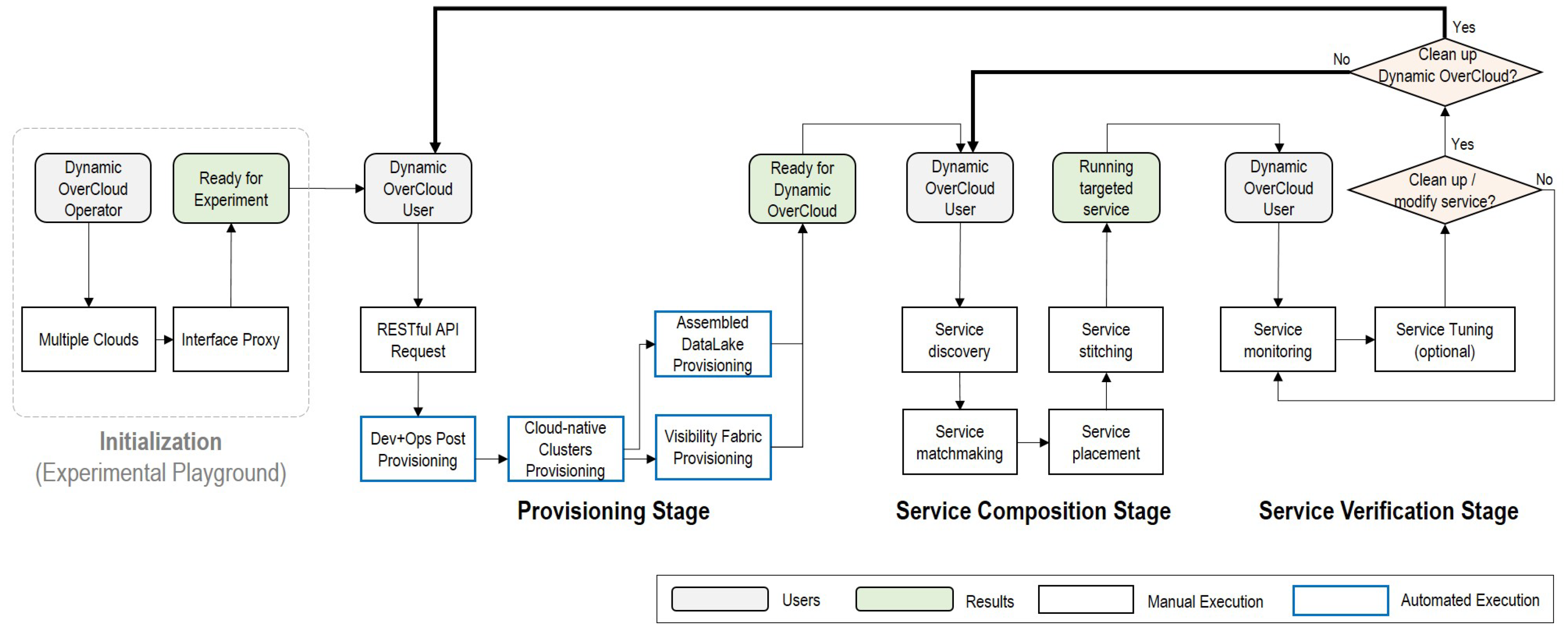
5.1. Operation Lifecycle on Dynamic OverCloud
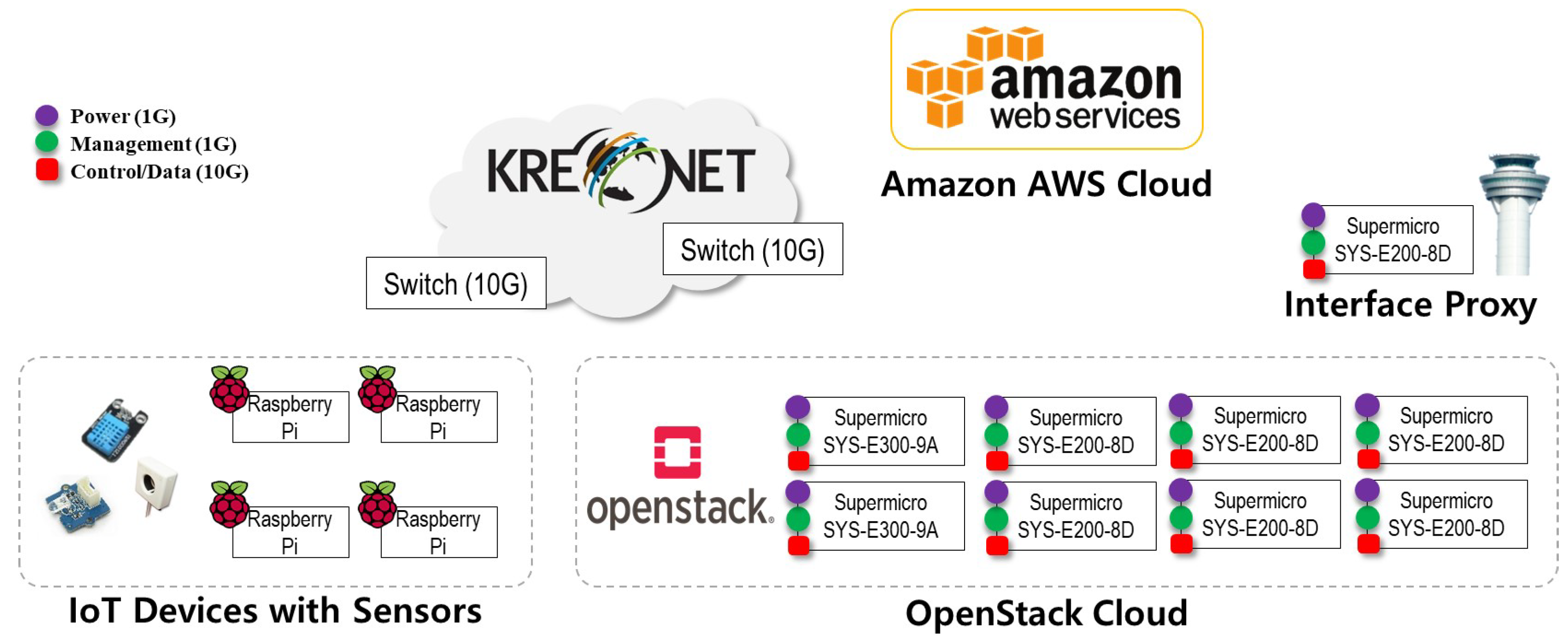
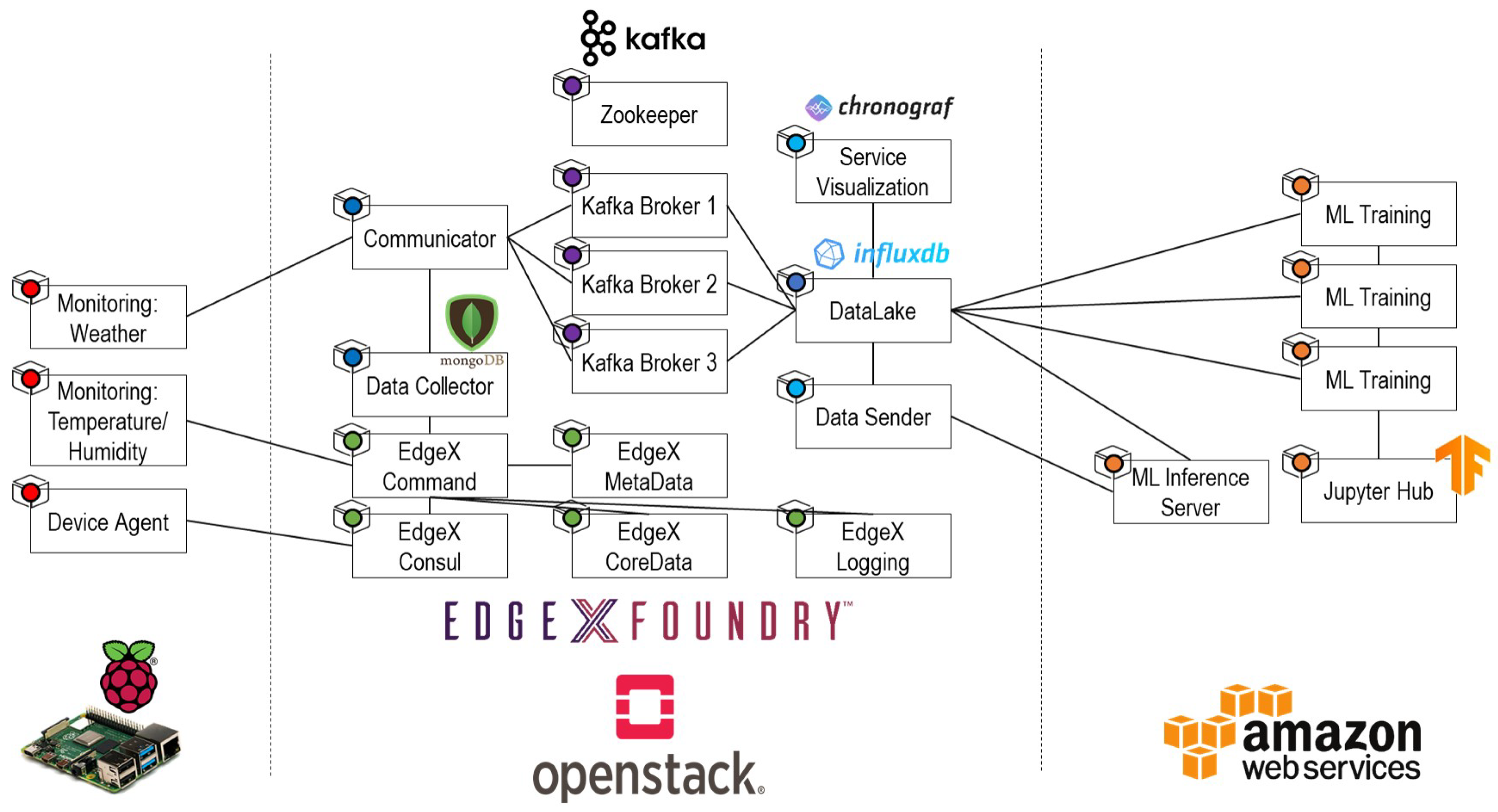
5.2. IoT-Cloud Service Realization with Operation Lifecycle
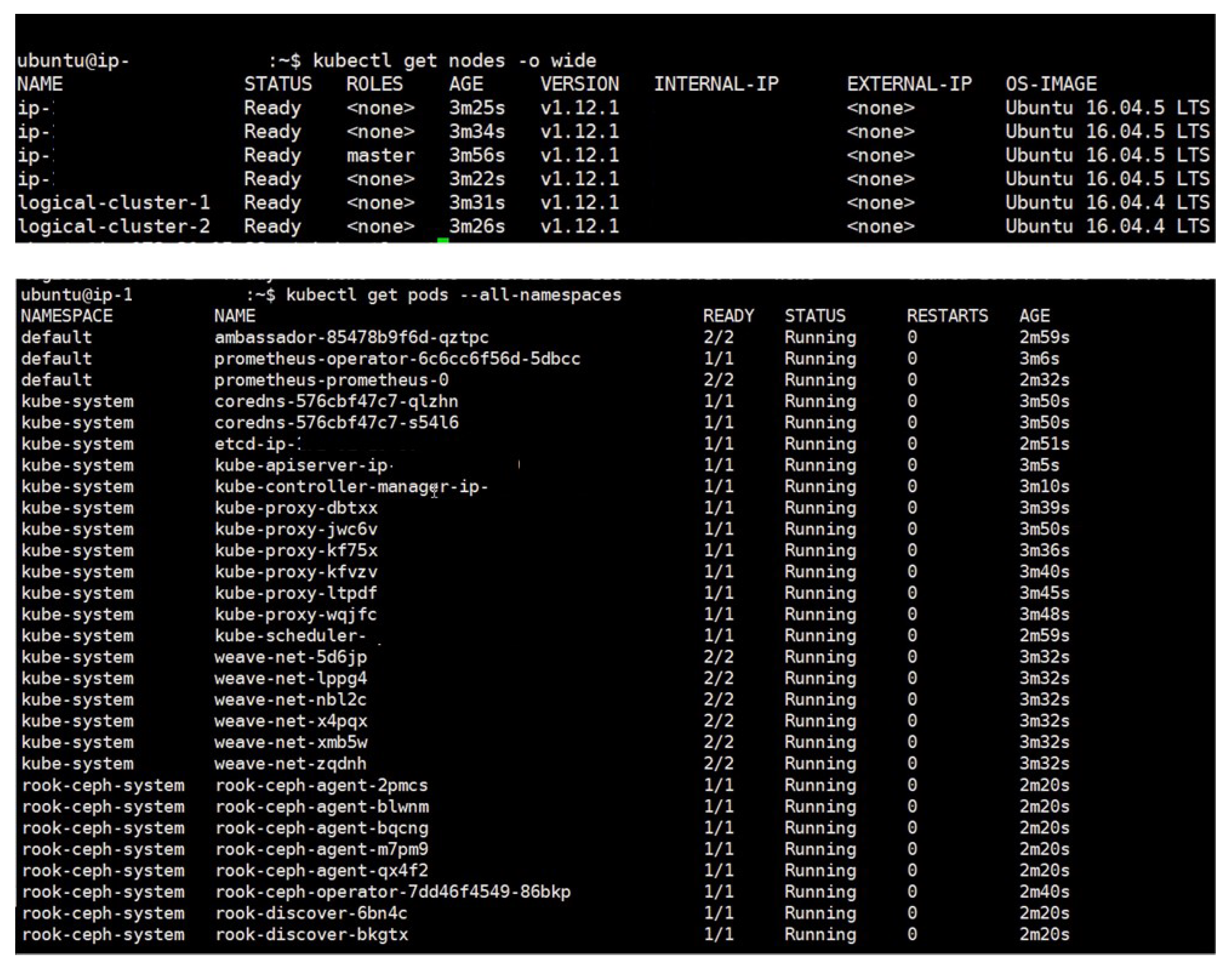
5.2.1. Provisioning Stage
- $ curl –X POST –H “Content-Type: application/json” –d ‘{“provider”: “heterogeneous”, “OpenStack”: {“number”: “2”, “size”: “m1.logical”, “post”: “no”}, “Amazon”: {“number”: “3”, “size”: “c5d.2xlarge”, “post”: yes”}}’ http://Interface_Proxy_IP:6125/overclouds
- $ { “devops_post”: “IP”, “ssh”: “PRIVATE_KEY”, “logical_cluster”: [ “IP1”, “IP2”, “IP3”, “IP4”, “IP5”], “overcloud_ID”: “ID”, “Prometheus_url”: “URL”, “rook_url”: “URL”, “chronograf_url”: “URL”, “weave_url”: “URL”, “smartx-multiview”: “URL”}
5.2.2. Service Composition Stage
5.2.3. Service Verification Stage
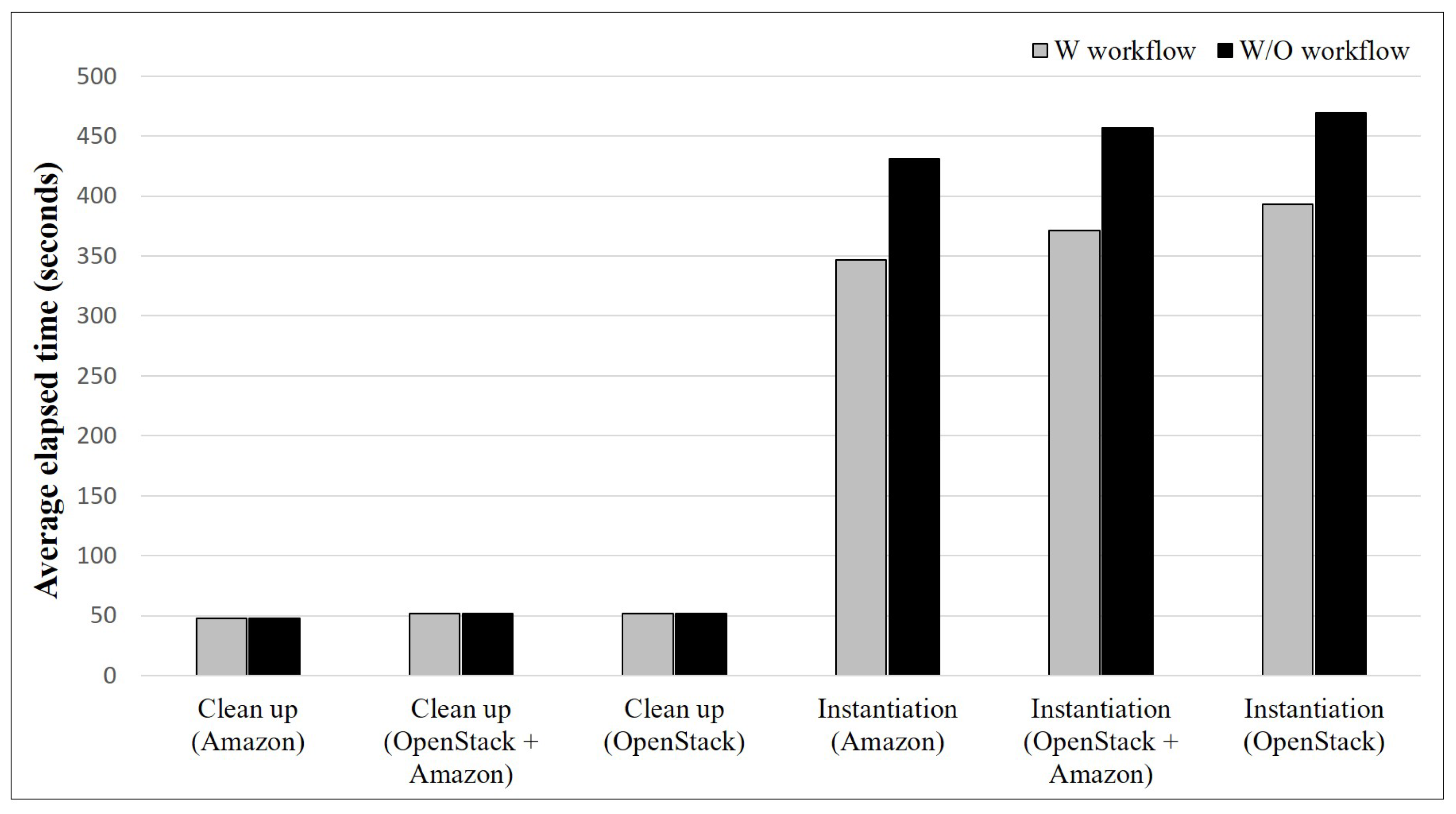
5.3. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Han, J.; Kim, J. Analytics-leveraged Box Visibility for Resource-aware Orchestration of SmartX Multi-site Cloud. In Proceedings of the 30th International Conference on Information Networking (ICOIN 2016), Kota Kinabalu, Malaysia, 13–15 January 2016. [Google Scholar]
- Hwang, M.; Lee, K.; Yoon, S. Software Development Methodology for SaaS Cloud Service. J. Inst. Internet Broadcast. Commun. 2014, 14, 61–67. [Google Scholar] [CrossRef]
- Hasselbring, W. Microservices for scalability: Keynote talk abstract. In Proceedings of the 7th ACM/SPEC on International Conference on Performance Engineering, Delft, The Netherlands, 12–18 March 2016. [Google Scholar]
- Balalaie, A.; Heydarnoori, A.; Jamshidi, P. Migrating to cloud-native architectures using microservices: An experience report. In Proceedings of the European Conference on Service-Oriented and Cloud Computing, Taormina, Italy, 15–17 September 2015. [Google Scholar]
- Josep, A.D.; Katz, R.; Konwinski, A.; Gunho, L.E.E.; Patterson, D.; Rabkin, A. A view of cloud computing. Commun. ACM 2010, 54, 50–58. [Google Scholar]
- Opera-Martins, J.; Sahandi, R.; Tian, F. Critical analysis of vendor lock-in and its impact on cloud computing migration: A business perspective. J. Cloud Comput. 2016, 5, 4. [Google Scholar] [CrossRef]
- Sitaram, D.; Manjunath, G. Moving to the Cloud: Developing Apps in the New World of Cloud Computing; Elsevier: Burlington, VT, USA, 2011. [Google Scholar]
- Rodero-Merino, L.; Vaquero, L.M.; Gil, V.; Galán, F.; Fontán, J.; Montero, R.S.; Llorente, I.M. From infrastructure delivery to service management in clouds. Future Gener. Comput. Syst. 2010, 26, 1226–1240. [Google Scholar] [CrossRef]
- Pahl, C.; Lee, B. Containers and clusters for edge cloud architectures—A technology review. In Proceedings of the 3rd International Conference on Future Internet of Things and Cloud, Rome, Italy, 24–26 August 2015. [Google Scholar]
- Han, J.; Kim, J. Design of SaaS OverCloud for 3-tier SaaS compatibility over cloud-based multiple boxes. In Proceedings of the 12th International Conference on Future Internet Technologies, Fukuoka, Japan, 14–16 June 2017. [Google Scholar]
- Georgakopoulos, D.; Hornick, M.; Sheth, A. An overview of workflow management: From process modeling to workflow automation infrastructure. Distrib. Parallel Databases 1995, 3, 119–153. [Google Scholar] [CrossRef]
- Singh, V.; Gupta, I.; Jana, P.K. A novel cost-efficient approach for deadline-constrained workflow scheduling by dynamic provisioning of resources. Future Gener. Comput. Syst. 2018, 79, 95–110. [Google Scholar] [CrossRef]
- Opara-Martins, J.; Sahandi, R.; Tian, F. Critical review of vendor lock-in and its impact on adoption of cloud computing. In Proceedings of the International Conference on Information Society (i-Society 2014), London, UK, 10–12 November 2014. [Google Scholar]
- Miranda, J.; Murillo, J.M.; Guillén, J.; Canal, C. Identifying adaptation needs to avoid the vendor lock-in effect in the deployment of cloud SBAs. In Proceedings of the 2nd International Workshop on Adaptive Services for the Future Internet and 6th International Workshop on Web APIs and Service Mashups, Bertinoro, Italy, 19 September 2012. [Google Scholar]
- Toivonen, M. Cloud Provider Interoperability and Customer Clock-In. In Proceedings of the Seminar (No. 58312107), Helsinki, Finland, 5 August 2013. [Google Scholar]
- Badidi, E. A cloud service broker for SLA-based SaaS provisioning. In Proceedings of the International Conference on Information Society (i-Society 2013), Toronto, ON, Canada, 24–26 June 2013. [Google Scholar]
- Karim, B.; Tan, Q.; Villar, J.; de la Cal, E. Resource brokerage ontology for vendor-independent Cloud Service management. In Proceedings of the IEEE 2nd International Conference on Cloud Computing and Big Data Analysis (ICCCBDA), Chengdu, China, 28–30 April 2017. [Google Scholar]
- Kritikos, K.; Zeginis, C.; Politaki, E.; Plexousakis, D. Towards the Modelling of Adaptation Rules and Histories for Multi-Cloud Applications. In Proceedings of the CLOSER, Heraklion, Greece, 2–4 May 2019. [Google Scholar]
- Ferry, N.; Chauvel, F.; Song, H.; Rossini, A.; Lushpenko, M.; Solberg, A. CloudMF: Model-driven management of multi-cloud applications. ACM Trans. Internet Technol. 2018, 18, 1–24. [Google Scholar] [CrossRef]
- Merle, P.; Barais, O.; Parpaillon, J.; Plouzeau, N.; Tata, S. A precise metamodel for open cloud computing interface. In Proceedings of the 2015 IEEE 8th International Conference on Cloud Computing, New York, NY, USA, 27 June–2 July 2015. [Google Scholar]
- Sandobalin, J.; Insfran, E.; Abrahao, S. Towards Model-Driven Infrastructure Provisioning for Multiple Clouds. In Advances in Information Systems Development; Springer: Cham, Switzerland, 2019; pp. 207–225. [Google Scholar]
- OpenStack TripleO. Available online: https://docs.openstack.org/tripleo-docs/latest/install/introduction/architecture.html/ (accessed on 3 May 2020).
- Kratzke, N. Lightweight virtualization cluster how to overcome cloud vendor lock-in. J. Comput. Commun. 2014, 2, 1. [Google Scholar] [CrossRef]
- Hadley, J.; Elkhatib, Y.; Blair, G.; Roedig, U. Multibox: Lightweight containers for vendor-independent multi-cloud deployments. In Proceedings of the Workshop on Embracing Global Computing in Emerging Economies, Almaty, Kazakhstan, 26–28 February 2015. [Google Scholar]
- Afgan, E.; Lonie, A.; Taylor, J.; Goonasekera, N. CloudLaunch: Discover and deploy cloud applications. Future Gener. Comput. Syst. 2019, 94, 802–810. [Google Scholar] [CrossRef]
- Terraform. Available online: https://www.terraform.io/ (accessed on 3 May 2020).
- Usman, M.; Risdianto, A.C.; Han, J.; Kim, J. Inter-correlation of Resource-/Flow-Level Visibility for APM Over OF@ TEIN SDN-Enabled Multi-site Cloud. In Proceedings of the International Conference on Heterogeneous Networking for Quality, Reliability, Security and Robustness, Seoul, Korea, 7–8 July 2016. [Google Scholar]
- Li, Q.; Wang, Z.; Li, W.H.; Li, J.; Wang, C.; Du, R.Y. Applications integration in a hybrid cloud computing environment: Modelling and platform. Enterp. Inf. Syst. 2013, 7, 237–271. [Google Scholar] [CrossRef]
- Kubernetes. Available online: https://kubernetes.io/ (accessed on 3 May 2020).
- Grafana. Available online: https://grafana.com/ (accessed on 3 May 2020).
- Prometheus. Available online: http://prometheus.io/ (accessed on 3 May 2020).
- Rook. Available online: http://rook.io/ (accessed on 3 May 2020).
- Kubernetes Storageclass. Available online: https://kubernetes.cn/docs/concepts/storage/storage-classes/ (accessed on 3 May 2020).
- Usman, M.; Risdianto, A.C.; Han, J.; Kim, J. Interactive visualization of SDN-enabled multisite cloud playgrounds leveraging smartx multiview visibility framework. Comput. J. 2019, 62, 838–854. [Google Scholar] [CrossRef]
- Envoy. Available online: http://envoyproxy.io/ (accessed on 3 May 2020).
- Weave Scope. Available online: https://github.com/weaveworks/scope/ (accessed on 3 May 2020).
- Lee, S.; Han, J.; Kwon, J.; Kim, J. Relocatable Service Composition based on Microservice Architecture for Cloud-Native IoT-Cloud Services. In Proceedings of the Asia-Pacific Advanced Network, Putrajaya, Malaysia, 22–26 July 2019. [Google Scholar]
- Kim, S.; Kim, J. Designing smart energy IoT-Cloud services for mini-scale data centers. In Proceedings of the KICS 2017 Winter Conference, Jeongseon, Korea, 18–21 January 2017. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Research Work | Interoperability | Multiple Clouds | MSA-Based Service Composition | Open-Source |
|---|---|---|---|---|
| [17] | Yes | Yes | No | No |
| [18] | Yes | Yes | No | No |
| [19] | Yes | Yes | No | Yes |
| [20] | Yes | Yes | No | Yes |
| [21] | Yes | Yes | No | No |
| [22] | Yes | No | No | Yes |
| [23] | Yes | No | Partially yes | Yes |
| [24] | Yes | Yes | Partially yes | No |
| [25] | Yes | Yes | Partially yes | Yes |
| [26] | Yes | Yes | Yes | Partially yes |
| Dynamic OverCloud | Yes | Yes | Yes | Yes |
| Parameter | Description |
|---|---|
| Provider | Cloud type (OpenStack, Amazon, heterogeneous) |
| Number | The number of cloud-native clusters |
| Size | Instance flavor |
| OpenStack.number | The number of cloud-native clusters (heterogeneous) |
| OpenStack.size | Flavor (heterogeneous) |
| OpenStack.post | Dev+Ops Post location (yes, no) |
| Amazon.number | The number of cloud-native clusters (heterogeneous) |
| Amazon.size | Flavor (heterogeneous) |
| Amazon.post | Dev+Ops Post location (yes, no) |
| Initial Parameters | |
|---|---|
| Database | MySQL host, password |
| OpenStack | OpenStack ID, password, Keystone url |
| Amazon AWS | Amazon AWS access key, secret access key |
| Workflow engine | OpenStack Mistral host, ID, password |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, J.; Park, S.; Kim, J. Dynamic OverCloud: Realizing Microservices-Based IoT-Cloud Service Composition over Multiple Clouds. Electronics 2020, 9, 969. https://doi.org/10.3390/electronics9060969
Han J, Park S, Kim J. Dynamic OverCloud: Realizing Microservices-Based IoT-Cloud Service Composition over Multiple Clouds. Electronics. 2020; 9(6):969. https://doi.org/10.3390/electronics9060969
Chicago/Turabian StyleHan, Jungsu, Sun Park, and JongWon Kim. 2020. "Dynamic OverCloud: Realizing Microservices-Based IoT-Cloud Service Composition over Multiple Clouds" Electronics 9, no. 6: 969. https://doi.org/10.3390/electronics9060969
APA StyleHan, J., Park, S., & Kim, J. (2020). Dynamic OverCloud: Realizing Microservices-Based IoT-Cloud Service Composition over Multiple Clouds. Electronics, 9(6), 969. https://doi.org/10.3390/electronics9060969